PROCEEDING
SEM I N AR N ASI ON AL
T EK N OLOGI I N FORM ASI DAN APLI K ASI N Y A
2 0 1 2
“Aplikasi Teknologi Informasi dalam Menunjang
Pelestarian Budaya Nasional dan Pengembangan Sektor
Pariwisata”
Bali, 9 Oktober 2012
Diselenggarakan Oleh :
Program Studi Teknik Informatika
Jurusan Ilmu Komputer
Universitas Udayana
KATA PENGANTAR
Puji syukur kita panjatkan kehadirat Tuhan Yang Maha Esa, atas terselesainya
penyususnan Proceeding SNATIA 2012 ini. Buku ini memuat naskah hasil penelitian dari
berbagai bidang kajian yang telah direview oleh pakar dibidangnya dan telah
dipresentasikan dalam acara Seminar SNATIA 2012 pada tanggal 9 Oktober 2012 di
Universitas Udayana kampus Bukit Jimbaran, Badung, Bali.
Kegiatan SNATIA 2012 merupakan yang pertama kali diadakan, dan akan menjadi
agenda tahunan Program Studi Teknik Informatika, Jurusan Ilmu Komputer, Universitas
Udayana. SNATIA 2012 mengambil tema “Aplikasi Teknologi Informasi dalam
Menunjang Pelestarian Budaya Nasional dan Pengembangan Sektor Pariwisata”, dengan
pembicara utama seminar yang terdiri dari pakar peneliti dibidang teknologi informasi,
pembicara dari praktisi pariwisata Bali, dan pembicara dari Dinas Kebudayaan Propinsi
Bali.
Meskipun kegiatan seminar dan pendokumentasian naskah dalam proceeding ini telah
dipersiapkan dengan baik, namun kami menyadari masih banyak kekurangannya. Untuk
itu panitia mohon maaf yang sebesar-besarnya, dan juga mengucapkan terimakasih atas
kepercayaan dan kerjasamanya dalam kegiatan ini. Kritik dan saran perbaikan sangat
diharapkan untuk penyempurnaan di masa mendatang, yang dapat dikirimkan melalui
.
Kepada semua pihak yang terlibat, baik langsung maupun tidak langsung dalam
penyelenggaraan seminar, dan penyusunan proceeding SNATIA 2012, panitia
mengucapkan terima kasih.
Denpasar, 9 Oktober 2012
Panitia SNATIA 2012
Ketua Pelaksana
DAFTAR ISI
Kata Pengantar
Daftar Isi
Analisis Dan Implementasi Algoritma Learning Vector Quantization (Lvq) Dalam Pengenalan Ekspresi Wajah
Kadek Dian Trisnadewi, I Wayan Santiyasa, I Made Widiartha ... 1
Analisis Kualitas Voip Pada Jaringan Yang Menggunakan Active Queue Management Random
Early Detection (Red)
I Dewa Made Bayu Atmaja Darmawan ... 6
Analisis Sistem Firewall Pada Jaringan Komputer Menggunakan Iptables Untuk Meningkatkan Keamanan Jaringan ( Studi Kasus : Jaringan Komputer Jurusan Matematika Fakultas Mipa Universitas Udayana)
I Wayan Supriana, I Wayan Santiyasa, Cokorda Rai Adi Pramartha ... 13
Ekstraksi Tepi Dengan Menggunakan Fuzzy Spatial Filtering Dan Slicing Intensity
I Gede Aris Gunadi, Retantyo Wardoyo ... 22
Evaluasi Cluster Menggunakan Metode Prototype-Based Cohesion And Separation Dan Silhouette Coefficient Pada Implementasi Algoritma Som
Gusti Ayu Vida Mastrika Giri, Kadek Cahya Dewi ... 29
Group Decision Support System Dengan Menggunakan Metode Analytical Hierarchy Process (Ahp) Dan Borda Dalam Penentuan Lokasi Bank Dan Pimpinan Cabang Yang Tepat
Desak Made Dwi Utami Putra ... 34
Identifikasi Lagu Menggunakan Algoritma K-Nearestneighbours – Cosine Similarity(KNNCS)
I Gede Suta Lascarya Astawa, Agus Muliantara, Kadek Cahya Dewi... 42
Kompresi Citra Fraktal Dengan Algoritma Genetika Adaptif
Putu Indah Ciptayani1, Zulfahmi Indra2 ... 46
Mobile Information System Untuk Mengidentifikasidefisiensi Unsur Hara Pada Daun
Asti Dwi Irfianti, Endang Sulistyaningsih ... 51
Model Rekayasa Perangkat Lunak Berbasis Komponen (Component-Based Software Engineering)
Herri Setiawan, Edi Winarko... 57
Model Sistem Pendukung Keputusan Kelompok Dengan Metode Multiplicative Exponent Weighting
Muhammad Syaukani, Sri Hartati ... 65
Optimasi Distribusi Pupuk Bersubsidi Dengan Menggunakan Algoritma Genetika (Studi Kasus: Kab. Jombang Jawa Timur)
Perancangan Dan Implementasi Aplikasi Web Service(Studi Kasus : Sim Perpustakaan Dengan Simak F.Mipa Universitas Udayana)
Made Agung Raharja ... 78
Perancangan Dan Implementasi Rekam Medis Berbasis Mobile
Ida Bagus Made Mahendra, Ida Bagus Gede Dwidasmara, Putu Praba Santika ... 88
Pengalokasian Sumber Daya Dalam Sistem Pendukung Keputusan
Rita Wiryasaputra .... ... 95
Perancangan Dan Implementasi Customer Information Gathering Menggunakan Model Ruang Vektor Dan Perluasan Query
Sang Gede Suriadnyana, I Made Widiartha, I Gede Santi Astawa ... 101
Perancangan Dan Implementasi Sistem Pencarian Buku Menggunakan Algoritma Pemetaan Transaksi
Wayan Gede Suka Parwita, Ngurah Agus Sanjaya Er, Luh Gde Astuti ... 107
Pengembangan Cost Driver Model Cocomo Ii Dengan Modifikasi Nilai Atribut Analysis Capability Untuk Estimasi Usaha Perangkat Lunak
Sri Andayani, L. Anang Setiyo ... 111
Prototype Sistem Penyeberangan Jalanbagi Penyandang Tuna Netra Berbasis Rfid( Radio Frequency Identification )
I Made Widhiwirawan ... 119
Review Of Ontology-Based Question Answering System
Eka Karyawati, Azhari S. N. ... 126
Resiko Proyek Teknologi Informasi
Herri Setiawan, Ashari SN ... 134
Sistem Pendukung Keputusan Untuk Pembelian Rumah Menggunakan Analytical Hierarchy Process (Ahp)
Standy Oei, Riah Ukur Ginting ... 140
Vanet Untuk Solusi Komunikasi Data Di Kawasan Pariwisata Bali
I Komang Ari Mogi,Waskitho Wibisono ... 146
Visualisasi Cluster Menggunakan Smoothed Data Histograms (Sdh) Pada Audio Clustering Lagu Daerah Indonesia Menggunakan Self Organizing Map (Som)
PELAKSANA SEMINAR
Pelindung
Rektor Universitas Udayana, Bali
Penanggung Jawab
Dekan Fakultas MIPA Universitas Udayana
Ketua Program Studi Teknik Informatika, Jurusan Ilmu Komputer, FMIPA,
Universitas Udayana
Panitia
I Gede Santi Astawa, S.T., M.Cs.
I Made Widiartha, S.Si., M.Kom.
Agus Muliantara, S.Kom., M.Kom
Ida Bagus Gede Dwidasmara, S.Kom., M.Cs.
Ida Bagus Made Mahendra, S.Kom., M.Kom.
I Ketut Gede Suhartana, S.Kom., M.Kom.
Ngurah Agus Sanjaya Er, S.Kom., M.Kom.
I Made Widi Wirawan, S.Si., M.Cs.
Cokorda Rai Adi Pramartha, S.T., M.M
Made Agus Setiawan
Dra. Luh Gede Astuti, M.Kom.
I Wayan Supriana, S.Si., M.Cs.
Gusti Ayu Vida Mastrika Giri, S.Kom.
Desak Made Dwi Utami Putra, S.Si., M.Cs.
Bayu Bintoro
Made Agung Raharja
I Dewa Made Bayu Atmaja Darmawan, S.Kom.
Kadek Cahya Dewi, S.T., M.Cs.
Putu Wida Gunawan, S.Si., M.Cs.
Proceeding Seminar Nasional Teknologi Informasi & Aplikasinya
2012
101 Jurusan Ilmu Komputer, FMIPA, Universitas Udayana
PERANCANGAN DAN IMPLEMENTASI CUSTOMER INFORMATION GATHERING MENGGUNAKAN MODEL RUANG VEKTOR DAN PERLUASAN QUERY
Sang Gede Suriadnyana, I Made Widiartha, I Gede Santi Astawa
Program Studi Teknik Informatika, Jurusan Ilmu Komputer,, Fakultas MIPA, Universitas Udayana Email : [email protected], [email protected], [email protected]
ABSTRAK
Kritik dan saran customer merupakan salah satu informasi yang penting bagi perusahaan. Dimana dengan adanya kritik dan saran ini, perusahaan dapat meninjau kembali kelemahan atau kekurangan dari produk atau jasa yang mereka tawarkan selama ini. Terkadang kritik dan saran yang diberikan oleh customer kurang mendapat respon dari pihak perusahaan. Meskipun kritik dan saran telah diberikan tetapi untuk waktu yang lama perusahaan tidak secara baik meninjau kritik dan saran tersebut. Hal ini terjadi karena proses yang dilakukan secara manual. Meninjau satu per satu kritik dan saran secara manual akan membutuhkan waktu yang cukup banyak, dan tentu akan berdampak kurang baik bagi kinerja perusahaan. Salah satu solusi untuk mengatasi permasalahan tersebut adalah dengan membangun sistem Customer Information Gathering yang dapat membantu pihak perusahaan untuk dapat mengumpulkan informasi pelanggan berupa kritik dan saran serta memparsing dan mencari informasi pelanggan sesuai dengan bidang-bidang kritik dan saran tertentu. Sistem Customer Information Gathering pada penelitianini dirancang berbasis web dengan menggunakan bahasa pemrograman PHP dan Apache MySQL. Sistem ini diimplementasikan menggunakan metode model ruang vektor dan perluasan query. Dari hasil evaluasi sistem yang dilakukan dengan menggunakan 100 data sampel kritik dan saran dan dengan menerapkan 10 query dalam proses pencarian, rata-rata nilai recall yang diperoleh adalah 91% dan meningkat hingga 95% dengan perluasan query.
Kata kunci: Kritik dan saran, Model ruang vektor, Perluasan query
ABSTRACT
Criticism and advice customer is one of the important information for the company. Where with the criticisms and suggestions, companies can review the weaknesses or shortcomings of the products or services they offer so far. Sometimes criticism and suggestions given by the customer less get a response from the company. Despite criticism and suggestions have been given but for a long time the company did not properly review the criticisms and suggestions. This occurs because the process is done manually. Reviewing one by one manually criticisms and suggestions will require considerable time, and it will certainly impact for the company’s performance. One solution to overcome these problems is to build a system of Customer Information Gathering that can help the company to collect customer information in the form of criticism and suggestions as well as parsing and search for customer information in accordance with field specific criticisms and suggestions. Customer Information Gathering system is designed based on the research web using PHP programming language and Apache MySQL. The system is implemented using the vector space model and query expansion. From the results of the evaluation system is conducted by using 100 data samples criticism and suggestions, and by applying 10 queries in the search process, the average recall value obtained was 91% and increased to 95% with query expansion.
Keywords : Criticism and suggestions, vector space model, query expansion
1. PENDAHULUAN
Salah satu informasi yang penting bagi perusahaan adalah informasi mengenai kelemahan atau kekurangan dari produk maupun pelayanan yang ditawarkan perusahaan tersebut. Dimana kelemahan atau kekurangan ini dapat ditinjau dari kritik dan saran yang diberikan oleh pelanggan atau dalam hal ini adalah user yang menggunakan produk atau jasa dari perusahaan. Terkadang kritik dan saran dari pelanggan atau customer kurang mendapat respon dan tanggapan dari perusahaan. Meskipun kritik dan saran telah diberikan tetapi untuk waktu yang lama perusahaan tidak secara baik meninjau. Hal ini terjadi karena proses yang dilakukan secara manual dan terkadang penggolongan terhadap kritik dan saran sangat sulit untuk diimplementasikan.
Untuk mengatasi persoalan diatas, maka diperlukan suatu sistem informasi yang dapat membantu pihak perusahaan untuk dapat mengumpulkan informasi pelanggan (customer) berupa kritik dan saran serta memparsing dan mencari informasi pelanggan (customer) sesuai dengan bidang-bidang kritik dan saran tertentu sehingga diharapkan perusahaan dapat dengan mudah melakukan evaluasi terhadap segala kekurangan baik dari segi produk maupun pelayanannya berdasarkan kritik dan saran yang diberikan pelanggan (customer).
memberikan hasil yang lebih baik dibandingkan model Boolean. Model ini juga dapat menampilkan hasil temu balik secara terurut (Ranking). Berdasarkan hal tersebut diatas, maka penulis menerapkan metode model ruang vektor pada penelitian ini, namun yang menjadi masalah selanjutnya adalah mengenai query yang di masukkan pengguna, dimana terkadang pengguna tidak mampu merepresentasikan kebutuhan informasi yang diinginkan kedalam bentuk kueri. Untuk itu pada sistem ini juga di rasa perlu diterapkan metode umpan balik relevansi, yaitu metode perluasan query. Query Expansion atau perluasan query adalah proses me-reformulasikan kembali query awal dengan melakukan penambahan beberapa term atau kata pada query untuk meningkatkan perfoma dalam proses information retrieval (Nugroho, 2009). Dengan ini diharapkan pengguna akan mendapatkan dokumen atau informasi yang sesuai.
2. Information Retrieval
Information Retrieval System atau Sistem Temu Balik Informasi merupakan bagian dari bidang ilmu
computer science yaitu membahas tentang pengambilan informasi dari dokumen-dokumen yang didasarkan pada isi dan konteks dari dokumen-dokumen itu sendiri. Menurut (Kowalski and Maybury, 2002) di dalam bukunya “Information Storage and Retrieval Systems Theory and Implementation”, sistem temu balik informasi adalah suatu sistem yang mampu melakukan penyimpanan, pencarian, dan pemeliharaan informasi. Informasi dalam konteks ini dapat terdiri dari teks (termasuk data numeric dan tanggal), gambar, audio, video, dan objek multimedia lainnya.
Menurut (Goker and Davies, 2009) ada tiga proses standard yang harus didukung dalam sistem temu kembali informasi: representasi isi dari dokumen, representasi kebutuhan informasi pengguna, dan membandingkan kedua representasi. Representasi dokumen biasanya disebut dengan proses pengideksan atau
indexing. Proses ini berlangsung secara off-line, yang mana pengguna akhir dari system temu kembali informasi tidak terlibat langsung dalam hal ini. Hasil dari proses pengindeksan merupakan sebuah representasi dari dokumen yang diproses.
2.1 Indexing
Indexing adalah proses yang merepresentasikan koleksi dokumen kedalam bentuk tertentu untuk memudahkan dan mempercepat proses pencarian dan penemuan kembali dokumen yang relevan.
Pembangunan index dari koleksi dokumen merupakan tugas pokok pada tahapan preprocessing di dalam information retrieaval. Hal ini dikarenakan kualitas index mempengaruhi efektifitas dan efisiensi sistem IR. Index dokumen adalah himpunan term yang menunjukkan isi atau topik yang dikandung oleh dokumen. Index akan membedakan suatu dokumen dari dokumen lain yang berada di dalam koleksi. Ukuran index yang kecil dapat memberikan hasil buruk dan mungkin beberapa item yang relevan terabaikan. Index yang besar memungkinkan ditemukan banyak dokumen yang relevan tetapi sekaligus dapat menaikkan jumlah dokumen yang tidak relevan dan menurunkan kecepatan pencarian (searching) (Hyusein and Patel, 2003).
Adapun tahapan dari pengindeksan adalah sebagai berikut (Hasibuan and Andri, 2001) : 1. Parsing Dokumen yaitu proses pengambilan kata-kata dari kumpulan dokumen.
2. stopword removal yaitu proses pembuangan kata yang terdapat pada stoplist (daftar kata buang) seperti: tetapi, yaitu, sedangkan, dan sebagainya.
3. Stemming yaitu proses penghilangan/ pemotongan dari suatu kata menjadi bentuk dasar. Kata “diadaptasikan” atau “beradaptasi” mejadi kata “adaptasi” sebagai istilah.
2.2 Weighting
Term Weighting dan Inverted File yaitu proses pemberian bobot pada istilah. Didalam memberikan bobot pada sebuah istilah, terdapat berbagai macam teknik atau metode antara lain yaitu :
1. Metode pembobotan yang digunakan dalam perancangan similarity Thesaurus. Metode ini ditunjukkan oleh persamaan berikut (Baeza and Ribeiro, 1999) :
, dengan itfj =
Dimana :
• Wij = bobot istilah ki pada dokumeni dj,
• fi,j = frekuensi kemunculan istilah ki pada dokumen dj,
• Maxj (fi,j) = frekuensi maksimal kemunculan istilah di koleksi,
• Itfj = inverse term frekuensi untuk dokumen dj,
• N = jumlah dokumen dalam koleksi,
• t = jumlah istilah dikoleksi,
• tfj = jumlah istilah di dokumen dj.
2. Teknik pembobotan berdasarkan rumus Savoy (Savoy, 1993) yaitu:
Proceeding Seminar Nasional Teknologi Informasi & Aplikasinya
2012
103 Jurusan Ilmu Komputer, FMIPA, Universitas Udayana
Dimana
tfik = , dan idfk =
Dengan :
• Wik adalah bobot istilah k pada dokumeni i.
• tfik merupakan frekuensi dari istilah k dalam dokumen i.
• idfk merupakan ukuran diskriminan kemunculan istilah k dalam koleksi dokumen
• n adalah jumlah dokumen dalam koleksi
• dfk adalah jumlah dokumen yang mengandung istilah k.
• Maxj tfij adalah frekuensi istilah terbesar pada satu dokumen.
Pada teknik pembobotan ini, bobot istilah telah dinormalisasi. Dalam menentukan bobot suatu istilah tidak hanya berdasarkan frekuensi kemunculan istilah di satu dokumen, tetapi juga memperhatikan frekuensi terbesar pada suatu istilah yang dimiliki oleh dokumen bersangkutan. Hal ini untuk menentukan posisi relative bobot dari istilah dibanding dengan istilah-istilah lain di dokumen yang sama. Selain itu teknik ini juga memperhitungkan jumlah dokumen yang mengandung istilah yang bersangkutan dan jumlah keseluruhan dokumen. Hal ini berguna untuk mengetahui posisi relative bobot istilah bersangkutan pada suatu dokumen dibandingkan dengan dokumen-dokumen lain yang memiliki istilah yang sama. Sehingga jika sebuah istilah mempunyai frekuensi kemunculan yang sama pada dua dokumen belum tentu mempunyai bobot yang sama.
3. Model Ruang Vektor
Model ruang vektor adalah salah satu model sistem temu kembali informasi yang mengibaratkan masing-masing query dan dokumen sebagai sebuah vektor n-dimensi. Tiap dimensi pada vektor tersebut diwakili oleh satu term. Term yang digunakan biasanya berpatokan kepada term yang ada pada query, sehingga term yang ada pada dokumen tetapi tidak ada pada query biasanya diabaikan.
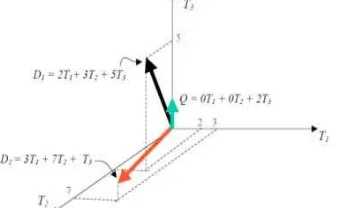
Misalkan terdapat sejumlah n kata yang berbeda. Kata-kata ini akan membentuk ruang vektor yang memiliki dimensi sebesar n. Setiap kata i dalam dokumen atau query diberikan bobot sebesar wi. Baik dokumen maupun query direpresentasikan sebagai vektor berdimensi n. Contoh penggambaran sebuah model ruang vektor dapat dilihat pada Gambar 1.
Gambar 1. Representasi dokumen dan vektor pada ruang vektor (Mandala and Setiawan, 2002)
3.1 Similarity pada Ruang Vektor
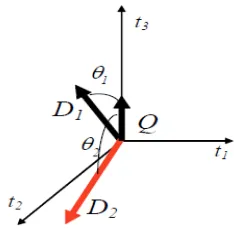
Koleksi dokumen direpresentasikan dalam ruang vektor sebagai matriks kata-dokumen (termsdocuments matrix). Nilai dari elemen matriks wij adalah bobot kata i dalam dokumen j. Misalkan terdapat sekumpulan kata T sejumlah n, yaitu T = (T1, T2, … , Tn) dan sekumpulan dokumen D sejumlah m, yaitu D = (D1, D2, … , Dm) serta wij adalah bobot kata i pada dokumen j. Maka representasi matriks kata-dokumen adalah :
Gambar 2. Sudut yang dibentuk antara dokumen dan vektor pada ruang vektor (Hadhiatma, 2010)
Jika Q adalah vektor query dan D adalah vektor dokumen, yang merupakan dua buah vektor dalam ruang berdimensi-n, dan θ adalah sudut yang dibentuk oleh kedua vektor tersebut. Maka:
Inner product : Q•D= Q Dcosθ
= ∑=
n
i Di
D
1
2 dan
∑ = = n i Qi Q 1 2
Rumus yang digunakan untuk memgukur jarak kedekatan antar vektor adalah sebagai berikut :
= =cos( , ) )
,
(QD QD Sim
D Q
D
Q•
∑
= • = n i Di Qi D Q 1 1
Kedekatan query dan dokumen diindikasikan dengan sudut yang dibentuk. Nilai cosinus yang cenderung besar mengindikasikan bahwa dokumen cenderung sesuai query. Nilai cosinus sama dengan 1 mengindikasikan bahwa dokumen sesuai dengan dengan query (Hadhiatma, 2010).
4. Perluasan Kueri
Query Expansion atau perluasan query adalah proses me-reformulasikan kembali query awal dengan melakukan penambahan beberapa term atau kata pada query untuk meningkatkan perfoma dalam proses information retrieval. Dalam konteks web search engine, hal ini termasuk evaluasi input user dan memperluas query pencarian untuk mendapatkan dokumen yang cocok dengan query.
Menurut (Selberg, 1997) dalam (Paiki, 2006) ekspansi kueri atau perluasan kueri adalah sekumpulan teknik untuk memodifikasi kueri dengan tujuan untuk memenuhi sebuah kebutuhan informasi. Ekspansi kueri dapat berarti penambahan maupun pengurangan kata pada kueri.
Proses ekspansi kueri berdasarkan similarity thesaurus dilakukan melalui tiga tahap, yaitu: 1. Merepresentasikan kueri dalam ruang vektor
2. Menghitung nilai kesamaan antara kueri dengan istilah-istilah yangberkorelasi dengan istilah di dalam kueri
dengan :
sim(q,kv) = nilai kesamaan antara kueri (q) dengan istilah-istilah yang berkorelasi dengan istilah di
dalam kueri (kv)
wu,q = bobot istilah dalam kueri
cu,v = nilai kesamaan antara istilah di kueri (ku) dengan istilah yang berkolerasi dengannya (kv)
3. Melakukan ekspansi kueri dengan mengambil r istilah teratas berdasarkan nilai sim(q,kv). bobot dari
istilah-istilah yang diambil tersebut dihitung kembali dengan persamaan:
dengan :
wv,q : bobot istilah hasil ekspansi baru
sim(q,kv): nilai kesamaan antara kueri (q) dengan istilah-istilah yang berkorelasi dengan istilah di
dalam kueri (kv)
Proceeding Seminar Nasional Teknologi Informasi & Aplikasinya
2012
105 Jurusan Ilmu Komputer, FMIPA, Universitas Udayana
4. Eavaluasi Sistem
Pada tahap ini dilakukan evaluasi sistem yang ditinjau dari pendapat ahli yang sudah terbiasa dalam menangani data kritik dan saran customer yang juga merupakan seorang pemimpin dalam suatu perusahaan. Data yang digunakan dalam evaluasi sistem ini adalah data kritik dan saran customer dari salah satu perusahaan yang bergerak di bidang software development. Jumlah data yang digunakan adalah sebanyak 100 data dengan kueri yang digunakan dalam proses pencarian adalah 10 kueri.
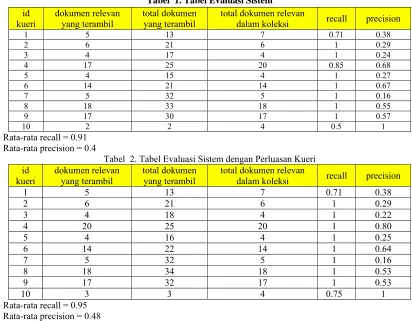
Tabel 1. Tabel Evaluasi Sistem
id kueri dokumen relevan yang terambil total dokumen yang terambil
total dokumen relevan
dalam koleksi recall precision
1 5 13 7 0.71 0.38
2 6 21 6 1 0.29
3 4 17 4 1 0.24
4 17 25 20 0.85 0.68
5 4 15 4 1 0.27
6 14 21 14 1 0.67
7 5 32 5 1 0.16
8 18 33 18 1 0.55
9 17 30 17 1 0.57
10 2 2 4 0.5 1
Rata-rata recall = 0.91 Rata-rata precision = 0.4
Tabel 2. Tabel Evaluasi Sistem dengan Perluasan Kueri id kueri dokumen relevan yang terambil total dokumen yang terambil
total dokumen relevan
dalam koleksi recall precision
1 5 13 7 0.71 0.38
2 6 21 6 1 0.29
3 4 18 4 1 0.22
4 20 25 20 1 0.80
5 4 16 4 1 0.25
6 14 22 14 1 0.64
7 5 32 5 1 0.16
8 18 34 18 1 0.53
9 17 32 17 1 0.53
10 3 3 4 0.75 1
Rata-rata recall = 0.95 Rata-rata precision = 0.48
Dari hasil perhitungan didapatkan rata-rata nilai recall untuk pencarian dokumen kritik dan saran tanpa menggunakan ekspansi kueri adalah 91 % dan rata-rata nilai recall untuk pencarian dengan menggunakan ekspansi kueri adalah 95 %. Sedangkan rata-rata nilai precision untuk kedua pencarian tersebut adalah sama yaitu 48 %. Berdasarkan perhitungan tersebut dapat dilihat bahwa nilai recall mengalami peningkatan sebanyak 4 % pada saat menggunakan ekspansi kueri untuk melakukan proses temu kembali dokumen kritik dan saran. Daftar kueri yang digunakan dalam evaluasi sistem ini dapat dilihat pada tabel 3.
Tabel 3. Daftar Kueri dan Perluasan Kueri
Id Kueri Kueri Perluasan Kueri 1 data tidak tersimpan data simpan pesan field hilang 2 kesalahan currency currency salah ajusment lg editor 3 payment tidak tersimpan payment simpan travel agent cash 4 sistem error error sistem standar edit penambahan 5 tampilan tampil rentan missal daftar
5. Kesimpulan Dan Saran
1. Kesimpulan
Kesimpulan yang dapat diambil dari penelitian yang telah dilakukan adalah sebagai berikut :
1. Penelitian ini telah berhasil merancang dan mengimplementasikan sistem Customer Information Gathering dengan menerapkan metode model ruang vektor dan perluasan query. Jenis perluasan atau ekspansi kueri yang digunakan adalah Automatic Query Expansion yaitu dengan menggunakan analisis global berdasarkan similarity thesaurus.
2. Dengan menggunakan 100 data uji dan 10 kueri, proses temu balik informasi dengan menerapkan perluasan kueri dapat meningkatkan nilai recall sehingga dokumen relevan yang berhasil di temu kembalikan oleh sistem menjadi lebih banyak jika dibandingkan dengan tanpa menggunakan perluasan kueri.
2. Saran
Untuk pengembangan sistem lebih lanjut penulis ingin menyampaikan beberapa saran, antara lain : 1. Gunakan metode stemming lain yang juga dapat memproses kata dalam bahasa inggris.
2. Gunakan koleksi kata dasar yang lebih banyak, sehingga hasil stemming lebih baik dan proses retrieval menjadi lebih baik.
3. Untuk jumlah dokumen yang besar, proses perluasan kueri sedikit lambat, sehingga perlu dilakukan pengembangan lebih lanjut.
4. Penggunaan metode lain untuk ekspansi kueri, misal Local Clustering, Statistical Thesaurus, dll.
Daftar Pustaka
[1] Baeza, Ricardo, and Ribeiro, Berthier. 1999. Modern Information Retrieval. ACM Press. United States of America.
[2] Goker, A., and Davies, J. 2009. Information Retrieval: Searching in the 21st Century. John Wiley and Sons, Ltd., ISBN-13: 978-0470027622.
[3] Hadhiatma, Agung. 2010. Pencarian Dokumen Berdasarkan Kombinasi Antara Model Ruang Vektor Dan Model Domain Ontologi. Jurusan Teknik Informatika, Fakultas Sains dan Teknologi, Universitas Sanata Dharma Yogyakarta.
[4] Hariyono, M.E.A. and Wahyudi. 2005. Customer Information Gathering Menggunakan Metode Temu Kembali Informasi Dengan Model Ruang Vektor. Seminar Nasional Aplikasi Teknologi Informasi. Yogyakarta.
[5] Hasibuan, Z.A., and Andri Yofi. 2001. Penerapan Berbagai Teknik Sistem Temu-Kembali Informasi Berbasis Hiperteks. Universitas Indonesia.
[6] Hyusein, B., and Patel, A. 2003. Web Document Indexing and Retrieval. LNCS 2588 pp. 573-579, Springer Verlag. Berlin. An overview. http://www.springerlink.com/index/3nqtd0xdlgupj5cm.pdf. Diakses 9 maret 2011.
[7] Jaya, Hendra. 2007. Perbandingan Performansi Word Indexing dan Phrase Indexing dalam Sistem Temu Balik Informasi dengan Menggunakan Model Probabilistik. Skripsi Terpublikasi. Bandung: Institut Teknologi Bandung.
[8] Nugroho, Susetyo Adi. 2009. Query Expansion Dengan Menggabungkan Metode Ruang Vektor Dan Wordnet Pada Sistem Information Retrieval. Jurnal Informatika, Volume 5 Nomor 1.
[9] Kowalski, G.J., and Maybury, M.T. 2002. Information Storage And Retrieval Systems Theory and Implementation. 2nd ed. Kluwer Academic Publishers. New York.
[10] Mandala, Rila, and Setiawan, Hendra. 2002. Peningkatan Performansi Sistem Temu-Kembali Informasi dengan Perluasan Query Secara Otomatis. Departemen Teknik Informatika Institut Teknologi Bandung. Bandung.
[11] Paiki, Fridolin F., 2006. “Evaluasi Penggunaan Similarity Thesaurus terhadap Ekspansi Kueri dalam Sistem Temu Kembali Informasi Berbahasa Indonesia”. Skripsi. Departemen Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor. Bogor.