Fakultas Ilmu Komputer
Universitas Brawijaya 1039
Analisis Sentimen Pada Ulasan Pengguna Aplikasi Mandiri Online Menggunakan Metode Modified Term Frequency Scheme Dan Naïve Bayes
Eka Putri Nirwandani1, Indriati2, Randy Cahya Wihandika3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Layanan distribusi digitalmerupakan wadah untuk berbagai macam aplikasi yang dapat di unduh kapan saja. Selain aplikasi pada layanan distribusi digital juga terdapat ulasan aplikasi yang berisikan komentar dari pengguna aplikasi tertentu. Ulasan tersebut berisikan komentar negatif atau komentar positif dengan jumlah yang sangat banyak. Dikarenakan jumlah ulasan yang sangat banyak maka Layanan distribusi digital membagi ulasan-ulasan tersebut menggunakan pemberian rating dengan isi ulasan yang tidak sesuai. Untuk mengatasi masalah ketidaksesuaian antara isi ulasan dengan rating yang diberikan pengguna maka dibutuhkan sentimen analisis. Penelitian ini menggunakan metode Naïve Bayes dan Modified Term Frequency Scheme. Metode Naïve Bayes dipilih dikarenakan metode ini bekerja cukup baik dalam klasifikasi dokumen dengan memperkirakan parameter yang diperlukan. Digunakan 1.500 data yang terdiri dari 627 ulasan positif dan 873 ulasan negatif. Dilakukan proses preprocessing, pem- bobotan menggunakan Modified Term Frequency Scheme dan klasifikasi dokumen dengan metode Na- ïve Bayes. Pada pengujian dengan 5-fold diperoleh rata-rata dari metode yang digunakan dengan accu- racy 83%, recall 86%, precision 76%, f-measure 77,70% dengan fold ke-3 merupakan fold terbaik dengan accuracy 85%, recall 84,50%, precision 81,34%, f-measure 82,88%.
Kata kunci: analisis sentimen, ulasan aplikasi, komentar, Naïve Bayes, Modified Term Frequency Scheme
Abstract
Digital distribution serviceis a container for various applications that can be downloaded at any time.
In addition to applications on Digital distribution service, there are also application reviews that con- tain comments from certain application users. The review contains a very large number of negative comments or positive comments. Due to the large number of reviews, the digital distribution service shares these reviews using ratings with inappropriate review content. To solve the problem of mismatch between the content of the review and the rating given by the user, a sentiment analysis is needed. This study uses the Naïve Bayes method and the Modified Term Frequency Scheme. Naïve Bayes method was chosen because it works well in document classification by estimating the required parameters. Used 1,500 data consisting of 627 positive reviews and 873 negative reviews. Preprocessing process is car- ried out, weighting using the Modified Term Frequency Scheme and document classification using the Naïve Bayes method. In the 5-fold test, the average of the method used was accuracy 83%, recall 86%, precision 76%, f-measure 77,70% with the 3rd fold being the best fold with accuracy 85%, recall 84,50%, precision 81,34%, f-measure 82,88%.
Keywords: sentiment analysis, reviews, comments, Naïve Bayes, Modified Term Frequency Scheme
1. PENDAHULUAN
Di era digital ini semakin majunya teknologi dan banyaknya masyarakat yang menggunakannya untuk berbagai kepentingan seperti berkomunikasi, berdagang bahkan men- cari informasi yang dapat membantu manusia dalam menyelesaikan masalah, beraktivitas lebih
mudah dan praktis. Namun, hal ini sering dis- alahgunakan oleh pihak yang tidak bertanggung jawab untuk mencari keuntungan bahkan meru- gikan orang lain dengan informasi atau komentar yang tidak relevan untuk suatu aplikasi. Untuk mengatasi masalah tersebut diperlukan pen- yaringan komentar terhadap suatu aplikasi. San- gat banyaknya aplikasi tentunya membutuhkan
suatu wadah untuk menampung, yaitu Layanan distribusi digital. Layanan distribusi digital yang banyak digunakan saat ini adalah Google Play Store dengan jumlah aplikasi sebanyak 2.960.000 Desember 2009-Juni 2020 berbagai aplikasi di Google Play Store.
Ulasan pengguna yang berisikan feedback berupa saran, rating pengguna sangat dibutuh- kan untuk menganalisis, memperbaiki, menge- tahui kebutuhan pengguna guna untuk mening- katkan kinerja aplikasi dan berinvestasi dalam bisnis pembuatan aplikasi. Namun tidak semua ulasan pengguna merepresentasikan kondisi ap- likasi tersebut (tidak relevan), seperti ulasan dan rating jelek disebabkan oleh bug, fitur yang be- lum tersedia. Hal itu tentunya bisa merugikan pihak developer karena pemberian ulasan dan rating yang tidak sesuai menyebabkan menurunnya peminat dari aplikasi tersebut.
Maka dari itu perlu perbaikan akan masalah ter- sebut dengan analisis ulasan pengguna aplikasi dengan kombinasi kelas sentimen negatif dan kelas positif.
Salah satu metode yang dapat digunakan adalah Naïve Bayes. Metode Naïve Bayes identik dengan hukum probabilitas total dengan peluang masuknya sampel dengan karakteristik tertentu, dengan variable label yang merepresentasikan kelas dan karakteristik data yang dibutuhkan un- tuk proses klasifikasi. Untuk meningkatkan pemilihan fitur metode Naïve Bayes, pemilihan fitur menggunakan modified term frequency scheme dengan memasukkan proporsi jumlah to- tal frekuensi istilah dalam semua dokumen koleksi ke jumlah total istilah khusus dalam koleksi yang dapat diklasifikasikan sesuai dengan kelas yang ada. Proporsi panjang doku- men dengan jumlah total istilah khusus dalam koleksi juga digunakan saat proses normalisasi ketika menghitung bobot dalam dokumen (Sabbah, et al., 2017).
Penelitian mengenai penggunaan Naïve Bayes untuk klasifikasi dilakukan oleh Wibowo
& Hartati (2016) tentang penilaian kinerja satpam di PT.Garuda Merah Indonesia menggunakan Naïve Bayes Classifier, diper- lukan sistem untuk klasifikasi dikarenakan penilaian “teman menilai teman” yang tidak aku- rat. Penelitian tersebut menggunakan perhi- tungan numeric 3 variabel dengan 39 data uji dan menghasilkan nilai kebenaran 92,31%, kinerja baik 20,51%, kinerja cukup 71,79%, kinerja bu- ruk 7,69%. Metode Naïve Bayes juga digunakan pada penelitian Musa’adah, et al., (2018) melakukan klasifikasi komentar spam pada
Youtube dengan berbagai metode untuk me- nangkal konten spam pada kolom komentar me- dia sosial dengan hasil precision, recall dan fl- scores Multinomial Naïve Bayes, Bernoulli Na- ïve Bayes, Nu SVC, dan Linear SVC memiliki nilai paling tinggi dibanding metode lainnya.
Penelitian lain yang dilakukan Sari, et al., (2019) mengklasifikasikan ulasan pengguna ap- likasi Mandiri Online menggunakan metode Na- ïve Bayes Classifier dan Information Gain ter- masuk kedalam ulasan positif atau negatif, serta mengklasifikasikan berdasarkan faktor kualitas perangkat lunak ISO/IEC 25010, yang menghasilkan akurasi 91,33% dan f-measure 89.18%. Penelitian metode Naïve Bayes oleh Antaristi & Kurniawan (2017) tentang klasifi- kasi penentuan pengajuan kartu kredit yang sesuai dengan pelanggan dengan mencari pola nasabah yang sudah diterima dalam pengajuan kartu kredit, yang menghasilkan precision 100%, recall 95% dan accuracy 98,67%.
Penelitian klasifikasi teks menggunakan metode Naïve Bayes oleh Indrayuni (2019) dari review produk kosmetik berbahasa indonesia dengan kelas analisis sentimen positif dan negatif, dengan penggunaan N-gram untuk mengurangi selisih antar kelas klasifikasinya menghasilkan nilai akurasi 90,50%, nilai AUC 0,715% untuk n-gram = 2.
Penelitian yang berkaitan dengan penggunaan metode Naïve Bayes untuk klasifi- kasi teks dilakukan oleh Oktaviana, et al. (2019) dengan prediksi rating terhadap teks review produk kosmetik yang terdapat pada website Fe- male Daily, dengan pendekatan machine learn- ing. Menghasilkan klasifikasi rating yang dikelompokkan dalam kelas rating satu, dua, tiga, empat dan lima. Dengan akurasi metode 49,27%, Presision 49,61%, recall 48,19% dan akurasi rata-rata 38,62%. Penelitian tersebut berkaitan dengan Modified Term Frequency Scheme oleh Santhanakuma & Columbus (2016) penetapan bobot yang disesuaikan dengan per- syaratan pengambilan data yang relevan dengan 20 dataset, yang menghasilkan nilai presisi, dengan f-score yang lebih baik untuk memvali- dasi berbagai metode klasifikasi dan penge- lompokkan daripada metode lain. Penggunaan Modified Term Frequency Scheme untuk klasifi- kasi probabilitas kelas positif dan negatif dengan dataset yang memiliki banyak perbedaan akarakteristik sebanyak 21578 dan 20 Grup Berita, serta set data UseNet Korea yang ditulis dalam 2 bahasa yang berbeda. Menghasilkan log tf.TRR mencapai kinerja terbaik untuk semua
Fakultas Ilmu Komputer, Universitas Brawijaya
data set dan pengklasifikasian, hasil makro 90.48 dan hasil mikro 94.90. Kinerja log tf.TRR mengungguli pembobotan tradisional (TF-IDF dan log TF-IDF) (Ko, 2016).
Berdasarkan uraian permasalahan latar belakang di atas beserta penelitian-penelitian yang dilakukan sebelumnya, penelitian ini ber- tujuan mengimplementasikan metode Naïve Bayes dengan pembobotan Term Modified Term Frequency Scheme dalam menganalisa ulasan pengguna mandiri Mobile Banking berdasarkan kelas sentimen (positif dan negatif). Dari penelitian ini diharapkan akan membantu nasa- bah dalam memilah ulasan yang sesuai
2. METODE PENELITIAN
Pada penelitian ini ada beberapa tahapan sebagai berikut.
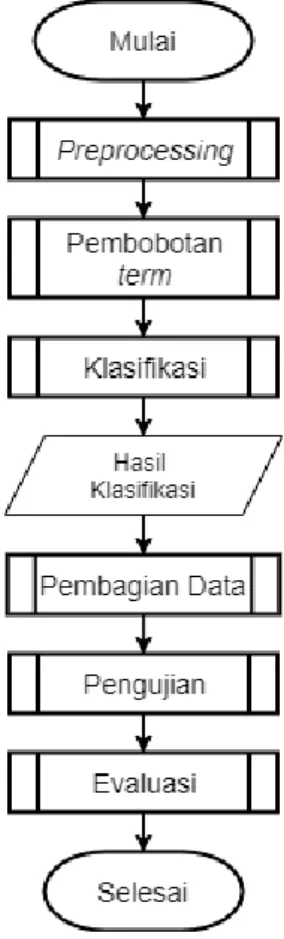
Gambar 1. Diagram Alir Sistem Pada gambar 1 disajikan diagram alirsistem dengan tahapan awal dilakukan preprocessing.
Dilanjutkan dengan pembobotan term dengan menggunakan Modified Term Frequency Scheme. Hasil dari pembobotan akan digunakan untuk proses klasifikasi menggunakan Naïve Bayes dengan ouput berupa hasil pelabelan.
Sebelum melakukan pengujian dilakukan
pembagian data dengan menggunakan k-fold cross validation sebanyak 5 fold. Dilanjutkan ke tapahan pengujian dan mengevaluasi hasil pen- gujian.
2.1. Data
Dataset ulasan yang digunakan berbahasa In- donesia sebanyak 1.500 data. Peneliti mem- peroleh data dengan cara mengujungi situs https://play.google.com/ dengan pilihan aplikasi Mandiri Online menggunakan Google Chrome yang diakses pada 19 Februari 2020. Dataset yang diambil dengan rentang waktu 3 bulan (01 November 2019 – 31 January 2020) menggunakan metode web scraping menggunakan aplikasi Data Miner. Kemudian dilakukan pelabelan data ulasan oleh pakar (responden) sesuai dengan la- bel negatif, label positif dan tidak ada kelas. Data ulasan yang digunakan hanya data yang mem- iliki label positif dan label negatif. Tabel 1 meru- pakan contoh pelabelan data ulasan.
Tabel 1. Contoh Pelabelan Data Ulasan
Ulasan Label
Susah dibuka,stuck di 50 persen Negatif Sangat membantu,thanks...Mandiri Positif Halo, sy mau tanya, sy kan udh bs
pakai mandiri online, klo sy mau ganti hp ke oppo, apakah sy harus daftar ulang lg buat aktifin mandiri online nya? Mohon dijawab.
Tidak ada kelas
Setelah penambangan dataset dilanjutkan dengan proses preprocessing untuk mendapat- kan kumpulan term yang akan digunakan di tahap pembobotan teks (term weighting).
2.2. Text Mining
Teks mining merupakan proses mengumpul- kan data yang digunakan untuk mendapatkan suatu kata atau pola dari kumpulan teks atau dokumen untuk tujuan tertentu. Tujuan umum dari teks mining yaitu untuk memperoleh infor- masi yang penting dari sekumpulan teks atau dokumen Witten (2003). Dalam arti luas Teks mining bisa diartikan sebagai proses penge- tahuan intensif dimana seorang pengguna ber- interaksi dengan koleksi teks atau dokumen dengan bantuan alat bantu analisis dari waktu ke waktu Feldman & Sanger (2007). Kebanyakan teks atau dokumen yang ada bersifat tidak ter- struktur dan kompleks, maka agar teks atau dokumen tersebut menjadi terstruktur perlu dil- akukannya proses preprocessing (Feldman &
Sanger, 2007).
2.2.1. Preprocessing
Pada tahapan preprocessing yaitu melakukan proses tokenizing, filtering dan stemming Feldman & Sanger (2007).
2.2.2. Tokenization/Tokenisasi
Pemotongan string berdasarkan dokumen di setiap kata penyusunnya. Setelah memisahkan setiap kata dari suatu dokumen, dilanjutkan dengan case folding yakni penghilangan angka, tanda baca, emoji dan karakter laiinya yang tidak digunakan selama pemrosesan teks. Hasil case folding harus melewati tahapan cleaning yakni proses menghilangkan komponen seperti tag HTML, link, url, hastag (#), username (@), dan alamat website.
2.2.3. Filtering
Tahap ini dilakukan pemilihan kata dari hasil tokenisasi yang akan digunakan selama proses pemrosesan teks dengan penggunaan algoritma stoplist atau stopword, yakni menghilangkan kata yang tidak penting tujuan pemilihan kata untuk mewakili suatu dokumen.
2.2.4. Stemming
Proses pengubahan bentuk kata menjadi kata dasar dengan mencari root kata dari setiap kata hasil filtering. Untuk setiap kata berimbuhan akan diubah menjadi kata dasar, tujuan dari stemming untuk memaksimalkan dan mengopti- malkan proses pengolahan teks.
2.2.5 Klasifikasi Sentimen
Klasifikasi sentimen tingkat dokumen karena menganggap seluruh dokumen sebagai unit in- formasi dasar dan sebagaian besar mengklasifi- kasikan ulasan online. Untuk kelas sentimen bi- asanya dibagi menjadi 2 kelas yakni positif dan negatif, menggunakan data training dan testing berasal dari ulasan (product reviews). Dalam penelitian ini menggunakan supervised learning, dengan menggunakan online reviews Liu (2012). tahapan ini digunakan untuk memprediksi suatu objek baru termasuk kedalam kategori manakah objek baru tersebut. Menurut Gorunescu (2011) Pada tahapan klasifikasi memiliki 4 komponen dasar utama dalam klasifikasi yaitu :
1.Kelas
suatu variabel dependen (terikat) yang digunakan untuk mengkategorikan dan merepresentasikan “label” pada suatu
objek. Contoh: resiko penyakit jantung, resiko kredit dan jenis gempa.
2.Prediktor
Prediktor merupakan suatu variabel independen yang berupa karakteristik dari (atribut) data. Contoh: merokok, ta- bungan, gaji, aset.
3.Data latih
Data Latih merupakan himpunan (kumpulan) data yang mengandung nilai dari komponen kelas dan prediktor yang digunakan untuk menentukan kelas dari data uji berdasarkan prediktor.
4.Data uji
Data Uji merupakan kumpulan data baru yang akan diklasifikasikan berdasarkan data latih yang telah diperoleh.
2.2. Pembobotan Modified Term Frequency Scheme
Skema pembobotan ini merupakan turunan dari rumus tf, idf dan TF-IDF standar. Hasil modifikasi dari metode TF-IDF dengan memod- ifikasi pembobotan, menambahkan faktor perkalian df. Sehingga metode ini merupakan penggabungan tf*idf*df. Untuk meningkatkan kinerja kategorisasi teks digunakan modifikasi skema pembobotan mTF-IDF dengan mem- perhitungkan bobot term yang ada. Dengan itu statistik uji signifikasi menunjukkan adanya pen- ingkatan yang signifikan dari kinerja klasifikasi berdasarkan hasil modifikasi skema pembobotan serta pendekatan wrapper juga diterapkan untuk domain dimensi yang lebih tinggi (Sabbah, et al., 2017). Untuk perhitungan mTF-IDF dengan Per- samaan 1.
𝑚𝑇𝐹𝑡,𝑑=
𝑡𝑓𝑡,𝑑 × log √𝑇𝑐 𝑇𝑡
𝑙𝑜𝑔 [(∑𝑛𝑡=1𝑡𝑓 𝑡,𝑑²) × (𝑙𝑒𝑛𝑔𝑡ℎ𝑑²
√𝑇𝑐
)]
(1)
Dimana,
𝑇𝑡 = ∑ 𝑡𝑓𝑡,𝑑 𝑛𝑖𝑙𝑎𝑖 𝑡𝑓𝑡,𝑑 > 0
𝐷
𝑑=1
𝑇𝑐 = ∑ ∑ 𝑡𝑓𝑡,𝑑
𝑡 𝐷
𝑑=1
Keterangan:
𝑇𝑡 = Total semua term dalam dokumen.
Fakultas Ilmu Komputer, Universitas Brawijaya
𝑇𝑐 = Total token keseluruhan dari corpus.
𝑚𝑇𝐹𝑡,𝑑 = Modifkasi rumus TF
𝑙𝑒𝑛𝑔𝑡ℎ 𝑑2 = Panjang dokumen (jumlah token khusus di dokumen).
𝑡𝑓𝑡,𝑑 = Kemunculan token t dalam dokumen d.
2.3. Naïve Bayes
Naïve Bayes metode pengelompokan probalistik sederhana berdasarkan penerapan teorema bayes dengan asumsi yang kuat. Dengan mengklasifi- kasikan dokumen sesuai dengan isinya, seperti gelap dan tidak gelap (J. Rennie, 2003).
Menggunakan Naïve Bayes sebagai metode klas- ifikasi karena metode ini bekerja cukup baik da- lam banyak kasus di dunia nyata, seperti klasifi- kasi dokumen dan pemfilteran spam. Meskipun jumlah data pelatihan kecil namun metode ini bisa berfungsi dengan baik dan memperkirakan parameter yang diperlukan. Terdapat teknik klasifikasi dengan metode probabilitas dan statistik oleh Thomas Bayes, dengan mempred- iksi peluang berdasarkan kejadian sehingga munculnya Teorema Bayes. Teorema tersebut terbentuk karena adanya pengabungan atribut data yang saling tidak berhubungan. Pengklasifi- kasian menggunakan Naïve Bayes dilihat dari ciri khas serta adanya hubungan tertentu dari se- buah kelas atau tidak. Untuk perhitungan Naïve Bayes dengan persamaan 2.
𝑃 (𝑐𝑖│𝑑𝑗) = 𝑃 (𝑐𝑖) ∏│𝑇│𝑘=1𝑃 (𝑤𝑘𝑗│𝑐𝑖)
𝑃(𝑑𝑗) (2) Keterangan:
𝑐𝑖 = Peluang kemunculan sebuah kata indeks kata yang dimulai dari 1 hingga kata ke-k.
𝑑𝑗 = Indeks kategori yang di mulai dari 1 hingga kategori ke-n.
𝑃 (𝑐𝑖│𝑑𝑗) = Posterior Probability merupakan peluang kategori i ketika terdapat kemunculan kata j.
𝑃 (𝑤𝑘𝑗│𝑐𝑖) = Conditional Probability merupakan peluang sebuah kata kj masuk ke dalam kategori i.
𝑃 (𝑐𝑖) = Prior merupakan peluang kemuncu lan kategori i.
𝑃 (𝑑𝑗) = Peluang kemunculan sebuah kata.
𝑃 (𝑤𝑘𝑗) = Peluang kemunculan sebuah kata.
Alur perhitungan metode Naïve Bayes sebagai berikut:
1. Data latih yang terdiri dari kelas yang ber- beda (positif dan negatif).
2. Menghitung Probabilitas dari kedua kelas (positif dan negatif).
Kelas positif = jumlah objek kelas positif 𝑡𝑜𝑡𝑎𝑙 𝑗𝑢𝑚𝑙𝑎ℎ 𝑑𝑎𝑡𝑎
Kelas negatif = jumlah objek kelas negatif 𝑡𝑜𝑡𝑎𝑙 𝑗𝑢𝑚𝑙𝑎ℎ 𝑑𝑎𝑡𝑎
3. Menghitung jumlah kata (number of word) setiap frekuensi dari kedua kelas (positif dan negatif) 𝑛𝑖.
𝑛𝑝𝑜𝑠𝑖𝑡𝑖𝑓 = total frekuensi kata kelas positif.
𝑛𝑛𝑒𝑔𝑎𝑡𝑖𝑓 =total frekuensi kata kelas negatif.
4. Menghitung probabilitas bersyarat dengan keyword sesuai dengan kejadian untuk kelas tertentu.
𝑷 (𝒌𝒂𝒕𝒂 𝒏 |𝒌𝒆𝒍𝒂𝒔 … ) =𝒋𝒖𝒎𝒍𝒂𝒉 𝒌𝒂𝒕𝒂 𝒏𝒊 (… ) 5. Pendistribusian harus di lakukan secara
berurutan untuk menghindari masalah frek- uensi nol.
6. Dokumen baru 𝑀 diklasifikasikan berdasar- kan perhitugan probabilitas untuk kelas pos- itif dan negatif
7. menghitung probabilitas (Posterior) untuk kedua kelas (positif dan negatif) dan mem- bandingkan nilai posterior terbesar diantara 2 kelas tersebut, kelas dengan probabilitas lebih tinggi adalah kelas dokumen baru 𝑀.
8. Hasil klasifikasi dapat digunakan untuk pen- gujian selanjutnya.
3. HASIL DAN PEMBAHASAN
Pada penelitian ini melakukan pengujian dari metode Modified term frequency scheme dan Naïve Bayes. Pengujian terdiri dari pengujiank-fold cross validation.
3.1. Pengujian K-fold Cross Validation
Pengujian dengan k-fold cross validation dilakukan dengan tujuan untuk mengetahui pengaruh akurasi metode naïve bayes yang dihasilkan oleh sistem. Diawali dengan
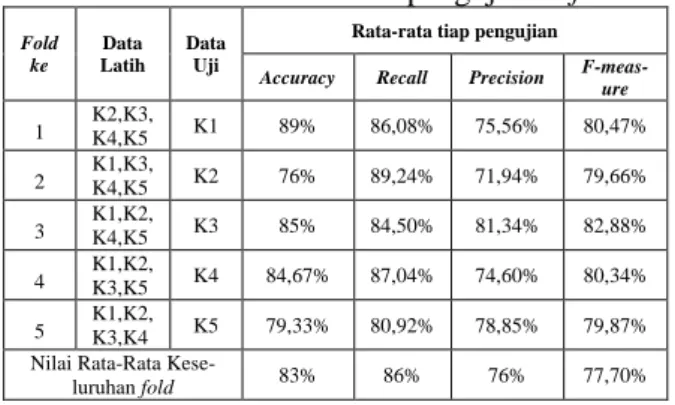
membagi nilai k sebanyak 5 fold, dataset ber- jumlah 1.500 akan dibagi menjadi 5 bagian di- inisialisasi dengan nama K1,K2,K3,K4,K5 dengan masing dataset berisi 300 data untuk se- tiap bagiannya. Pada fold awal akan ada kom- binasi 4 bagian data berbeda yang digabungkan serta digunakan sebagai data latih, untuk sisanya digunakan sebagai data uji. Proses pelatihan dan pengujian dilakukan sampai fold kelima. Hasil pengujian dapat dilihat pada Tabel 7.
Tabel 2. Nilai Rata-rata hasil pengujian 5-fold
Fold ke
Data Latih
Data Uji
Rata-rata tiap pengujian Accuracy Recall Precision F-meas-
ure 1 K2,K3,
K4,K5 K1 89% 86,08% 75,56% 80,47%
2 K1,K3,
K4,K5 K2 76% 89,24% 71,94% 79,66%
3 K1,K2,
K4,K5 K3 85% 84,50% 81,34% 82,88%
4 K1,K2,
K3,K5 K4 84,67% 87,04% 74,60% 80,34%
5 K1,K2,
K3,K4 K5 79,33% 80,92% 78,85% 79,87%
Nilai Rata-Rata Kese-
luruhan fold 83% 86% 76% 77,70%
3.1.1 Fold ke-1
Dari pengujian fold ke-1 dengan menggunakan 300 data uji (data ke 1 sampai data ke- 300) sistem dapat melabeli data ulasan dengan benar sebanyak 68 data ulasan positif dan 199 data negatif, total yang berhasil dila- belin sistem dengan benar sebanyak 267 data ulasan. Ditemukan juga hasil sistem masih gagal dalam melabelin ulasan dengan benar. yakni sis- tem gagal untuk melabelin ulasan yang seha- rusnya berlabel positif namun sistem melabeli sebagai label negatif sebanyak 11 data ulasan, dan sistem gagal dalam melabeli ulasan yang seharusnya berlabel negatif namun sistem mela- beli sebagai label positif sebanyak 22 data ulasan. Didapatkan hasil evaluasi mengenai kesuaian pelabelan pada sistem dengan pela- belan pakar untuk seluruh dokumen tergolong bagus 89% (accuracy), dengan kemampuan sis- tem dalam menemukan semua dokumen yang relevan tergolong bagus 86,08% (recall), untuk tingkat ketepatan inputan antara informasi yang di inputkan dengan hasil klasifikasi sistem tergo- long cukup 75,56% (precision) dan hasil per- badingan rata-rata untuk tingkat ketepatan dan kemampuan sistem dalam menemukan dokumen yang relevan tergolong bagus 80,47% (f-meas- ure).
3.1.2 Fold ke-2
Dari pengujian fold ke-2 dengan menggunakan 300 data uji (data ke 301 sampai data ke- 600) sistem dapat melabeli data ulasan
dengan benar sebanyak 141 data ulasan positif dan 87 data negatif, total yang berhasil dilabelin sistem dengan benar sebanyak 228 data ulasan.
Ditemukan juga hasil sistem masih gagal dalam melabelin ulasan dengan benar. yakni sistem ga- gal untuk melabelin ulasan yang seharusnya be- rada pada label positif namun sistem melabeli ulasan tersebut sebagai label negatif sebanyak 55 data ulasan, dan sistem gagal dalam melabeli ulasan yang seharusnya berada pada negatif na- mun sistem melabeli ulasan tersebut sebagai la- bel positif sebanyak 17 data ulasan. Didapatkan hasil evaluasi kesuaian pelabelan pada sistem dengan pelabelan pakar untuk seluruh dokumen tergolong cukup 76% (accuracy), dengan ke- mampuan sistem dalam menemukan semua dokumen yang relevan tergolong bagus 89,24%
(recall) untuk tingkat ketepatan inputan antara informasi yang di inputkan dengan hasil klasifi- kasi sistem tergolong cukup 71,94% (precision) dan hasil perbadingan rata-rata untuk tingkat ketepatan dan kemampuan sistem dalam menemukan dokumen yang relevan tergolong cukup 79,66% (f-measure).
3.1.3 Fold ke-3
Dari pengujian fold ke-3 dengan menggunakan 300 data uji (data ke 601 sampai data ke 900) sistem dapat melabeli data ulasan dengan benar sebanyak 109 data ulasan positif dan 156 data negatif, total yang berhasil dila- belin sistem dengan benar sebanyak 265 data ulasan. Ditemukan juga hasil sistem masih gagal dalam melabelin ulasan dengan benar. Yakni sis- tem gagal untuk melabelin ulasan yang seha- rusnya berada pada label positif namun sistem melabeli ulasan tersebut sebagai label negatif sebanyak 20 data ulasan, dan sistem gagal dalam melabeli ulasan yang seharusnya berada pada negatif namun sistem melabeli ulasan tersebut sebagai label positif sebanyak 25 data ulasan.
Didapatkan hasil mengenai kesuaian pelabelan pada sistem dengan pelabelan pakar pakar untuk seluruh dokumen tergolong bagus 85% (accu- racy), dengan kemampuan sistem dalam menemukan semua dokumen yang relevan ter- golong bagus 84,50% (recall) untuk tingkat ketepatan inputan antara informasi yang di in- putkan dengan hasil klasifikasi sistem tergolong bagus 81,34% (precision) dan hasil perbadingan rata-rata untuk tingkat ketepatan dan kemam- puan sistem dalam menemukan dokumen yang relevan tergolong bagus 82,88% (f-measure). 3.1.4 Fold ke-4
Fakultas Ilmu Komputer, Universitas Brawijaya
Dari pengujian fold ke-4 dengan menggunakan 300 data uji (data ke 901 sampai data ke 1200) sistem dapat melabeli data ulasan dengan benar sebanyak 94 data ulasan positif dan 160 data negatif, total yang berhasil dila- belin sistem dengan benar sebanyak 254 data ulasan. Ditemukan juga hasil sistem masih gagal dalam melabelin ulasan dengan benar. yakni sis- tem gagal untuk melabelin ulasan yang seha- rusnya berada pada label positif namun sistem melabeli ulasan tersebut sebagai label negatif sebanyak 14 data ulasan, dan sistem gagal dalam melabeli ulasan yang seharusnya berada pada negatif namun sistem melabeli ulasan tersebut sebagai label positif sebanyak 32 data ulasan.
Didapatkan hasil mengenai kesuaian kesuaian pelabelan pada sistem dengan pelabelan pakar untuk seluruh dokumen tergolong bagus 84,67%
(accuracy), dengan kemampuan sistem dalam menemukan semua dokumen yang relevan ter- golong bagus 87,04% (recall) untuk tingkat ketepatan inputan antara informasi yang di in- putkan dengan hasil klasifikasi sistem tergolong cukup 74,06% (precision) dan hasil perbadingan rata-rata untuk tingkat ketepatan dan kemam- puan sistem dalam menemukan dokumen yang relevan tergolong bagus 80,34% (f-measure).
3.1.5 Fold ke-5
Dari pengujian fold ke-5 dengan menggunakan 300 data uji (data ke 1201 sampai data ke 1500) sistem dapat melabeli data ulasan dengan benar sebanyak 123 data ulasan positif dan 115 data negatif, total yang berhasil dila- belin sistem dengan benar sebanyak 238 data ulasan. Ditemukan juga hasil sistem masih gagal dalam melabelin ulasan dengan benar. yakni sis- tem gagal untuk melabelin ulasan yang seha- rusnya berada pada label positif namun sistem melabeli ulasan tersebut sebagai label negatif sebanyak 29 data ulasan, dan sistem gagal dalam melabeli ulasan yang seharusnya berada pada negatif namun sistem melabeli ulasan tersebut sebagai label positif sebanyak 33 data ulasan.
Didapatkan hasil mengenai kesuaian label pada klasifikasi sistem dengan klasifikasi pakar untuk seluruh dokumen tergolong cukup 79,33% (ac- curacy), dengan kemampuan sistem dalam menemukan semua dokumen yang relevan ter- golong bagus 80,92% (recall) untuk tingkat ketepatan inputan antara informasi yang di in- putkan dengan hasil klasifikasi sistem tergolong cukup 78,85% (precision) dan hasil perbadingan rata-rata untuk tingkat ketepatan dan kemam- puan sistem dalam menemukan dokumen yang
relevan tergolong cukup 79,87% (f-measure).
Hasil pengujian yang diperoleh fold terbaik adalah fold ke-3. Sistem dapat melabelin data ulasan negatif positif sebanyak 228 data se- hingga menghasilkan nilai accuracy 85%, recall 84,50%, precision 81,34%, f-measure 82,88%.
Pada pengujian tersebut menghasilkan nilai fold terbaik dapat dilihat dari representasi penggunaan term, seimbangnya penyebaran data dalam dokumen sehingga proses pengklasifika- sian bekerja dengan baik. Dari hasil keseluruhan fold sistem masih tidak tepat dalam melabeli data. Adanya penggunaan data ulasan yang tidak tepat Sehingga ditemukan banyak kemunculan term yang bukan termasuk kategorinya pada data uji yang digunakan.
Seperti contoh data ulasan yang digunakan berlabel negatif terdapat term “bagus” dan pada ulasan berlabel positif terdapat juga term “ba- gus” yang berasal dari kalimat “Bagus… Cuma lagi terblokir nomornya”. Dengan term yang sama pada data ulasan label positif dan label negatif yang menyebabkan kesalahan saat proses klasifikasi. Sehingga data ulasan “Bagus…
Cuma lagi terblokir nomornya”. Hal tersebut menyebabkan sistem salah memberikan label ka- rena sistem mendeteksi awalan kalimat sebagai ulasan positif kemudian diakhir berisikan ka- limat negatif akan diabaikan. Jika penggunaan data ulasan terdapat term yang sama atau adanya ulasan dengan awalan kalimat negatif diakhiri dengan kalimat positif dan awalan kalimat posi- tif diakhiri dengan kalimat negatif dapat me- nyebabkan kinerja sistem kurang maksimal da- lam melabeli data ulasan yang sesuai
3.2. Analisis Pengujian Dengan 5-fold
Hasil pengujian yang diperoleh fold terbaik adalah fold ke-3. Sistem dapat melabelin data ulasan negatif positif sebanyak 228 data se- hingga menghasilkan nilai accuracy 85%, recall 84,50%, precision 81,34%, f-measure 82,88%.
pada pengujian tersebut menghasilkan nilai fold terbaik dapat dilihat dari representasi penggunaan term, seimbangnya penyebaran data dalam dokumen sehingga proses pengklasifika- sian bekerja dengan baik. Dari hasil keseluruhan fold sistem masih tidak tepat dalam melabeli data. adanya penggunaan data ulasan yang tidak tepat Sehingga ditemukan banyak kemunculan term yang bukan termasuk kategorinya pada data uji yang digunakan.
Seperti contoh data ulasan yang digunakan berlabel negatif terdapat term “bagus” dan pada
ulasan berlabel positif terdapat juga term “ba- gus” yang berasal dari kalimat “Bagus… Cuma lagi terblokir nomornya”. Dengan term yang sama pada data ulasan label positif dan label negatif yang menyebabkan kesalahan saat proses klasifikasi. Sehingga data ulasan “Ba- gus… Cuma lagi terblokir nomornya”. Hal ter- sebut menyebabkan sistem salah memberikan label karena sistem mendeteksi awalan kalimat sebagai ulasan positif kemudian diakhir berisi- kan kalimat negatif akan diabaikan. Jika penggunaan data ulasan terdapat term yang sama atau adanya ulasan dengan awalan kalimat negatif diakhiri dengan kalimat positif dan awalan kalimat positif diakhiri dengan kalimat negatif dapat menyebabkan kinerja sistem ku- rang maksimal dalam melabeli data ulasan yang sesuai.
3.3 Analisis Performa Sistem
Pada tahapan ini dilakukan analisa pengujian rata-rata hasil keseluruhan fold dan performa sis- tem dalam mengelolah data.
Performa sistem dalam mengelolah data ulasan netral seperti komentar yang tidak mengandung ulasan negatif atau positif seperti contoh “Halo, sy mau tanya, sy kan udh bs pakai mandiri online, klo sy mau ganti hp ke oppo, apakah sy harus daftar ulang lg buat aktifin mandiri online nya? Mohon dijawab”. Perlakuan sistem terhadap komentar tersebut dengan mendeteksi awalan kalimat dan akhir kalimat dan term penting yang muncul dari ulasan netral tersebut condong ke kelas positif atau negatif.
Jika diawalan kalimat ulasan netral tersebut mengandung unsur ulasan negatif maka sistem akan memberikan label negatif pada ulasan ter- sebut. Dan jika awalan kalimat ulasan netral ter- sebut mengandung unsur ulasan positif maka sis- tem akan meberikan label positif pada ulasan ter- sebut. Apabila ada komentar seperti bertanya, memberikan saran maka sistem akan mencari term yang banyak muncul dari ulasan tersebut untuk dijadikan acuan pemberian label. Semisal isi ulasan bertanya “Kok saya tidak bisa login yah padahal, saya sudah registrasi, mohon pen- cerahannya”. Sistem akan mendeteksi ulasan ter- sebut condong ke ulasan negatif, dikarenakan pada ulasan tersebut ada term “tidak bisa login, mohon pencerahannya” yang berarti pengguna aplikasi tidak bisa menggunakan aplikasi terse- but dengan lancar.
Untuk ulasan yang mengandung saran positif atau negatif, seperti contoh “masih perlu banyak
peningkatan. Conto:1.) mutasi transaksi kurang jelas apalagi transferan masuk. Tidak ada nama bank & nama pengirim transfer. Padahal ini penting sekali, apalagi jika jumlah transaksi transfer yang masuk banyak, akan sulit dicocok- kan tanpa nama. 2.) tidak bisa screenshot layar.
terkadang nasabah butuh simpan catatan saldo/transfer. 3.) resi transfer bisa dicetak, tapi kualitas gambar buruk & buram. aplikasi saya dari bank lain menunjang 3 hal penting di atas”.
Sistem akan memberikan label positif pada ulasan tersebut dikarenakan mengandung ban- yak term ulasan positif. Namun jika saran yang diberikan condong ke arahnegatif maka sistem akan memberikan label negatif untuk ulasan ter- sebut.
Untuk kelebihan penggunaan modified term frequency scheme pada performa sistem. Yakni memasukkan faktor dalam perhitungan bobot istilah yang mewakili istilah yang hilang (token) dari dokumen. Istilah yang hilang didefinisikan sebagai istilah (token) itu muncul di ruang fitur korpus saat tidak ada dokumen tersebut, oleh ka- rena itu, istilah khusus ini diakui sebagai miss- ing. Dapat dilihat setiap fold memberikan hasil yang berbeda. Untuk kekurangan penggunaan modified term frequency scheme yakni jika adanya banyak term yang muncul maka akan di- akumulasikan dan dihitung sehingga menyebab- kan kesalahan pemberian pembobotan. Seperti banyaknya muncul term “Aplikasi” seharusnya jika terlalu sering muncul maka term tesebut merupakan term penting yang merepresentasi- kan kondisi dari aplikasi tersebut. Sehingga perlu penambahan seleksi fitur dan akronim agar pembobotan dilakukan dengan benar oleh sis- tem.
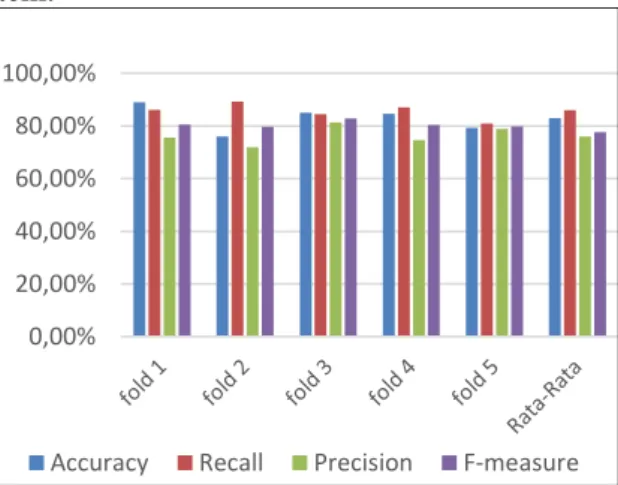
Gambar 2. Hasil Rata-Rata Semua fold Dengan Modified Term Frequency Scheme dan Naïve Bayes didapatkan hasil rata-rata pen- gujian pada Gambar 2 dengan nilai rata-rata pada
0,00%
20,00%
40,00%
60,00%
80,00%
100,00%
Accuracy Recall Precision F-measure
Fakultas Ilmu Komputer, Universitas Brawijaya
semua fold f-measure 77,70%, precision 76%, recall 86%, accuracy 83%.
4. KESIMPULAN
Berdasarkan hasil pengujian dan analisis yang dilakukan, maka dapat disimpulkan pada penelitian yang dilakukan dari 1.500 data yang digunakan sistem sudah cukup baik dalam memberikan pelabelan yang sesuai sebanyak 535 data ulasan positif dan 707 data ulasan negatif. Namun, ada beberapa data yang gagal diolah dan dikenali sistem sehingga diberikan pelabelan yang tidak sesuai seperti data “Bisa di perbaiki gak ini, error terus” data tersebut berlabel negatif namun sistem melabeli ulasan tersebut sebagai label positif sebanyak 167 data ulasan. Begitupun untuk ulasan berlabel positif namun sistem melabeli ulasan tersebut sebagai label negatif seperti data “mantap aplikasi nya...
cepat dan aman sampai saat ini” sebagai label negatif sebanyak 91 data ulasan. Hal tersebut berpengaruh pada hasil accuracy, recall, precision dan f-measure. Pada pengujian dilakukan penyebaran data secara acak dengan menggunakan 5-fold, didapatkan hasil rata-rata dari metode yang digunakan dengan nilai f- measure 77,70%, recall 86%, accuracy 83%, dan precision 76%. Serta untuk fold terbaik adalah fold ke-3 dengan nilai accuracy 85%, recall 84,50%, precision 81,34%, f-measure 82,88%.
5. DAFTAR PUSTAKA
Antaristi, M. & Kurniawan, Y. I., 2017. Aplikasi Klasifikasi Penentuan Pengajuan Kartu Kredit Menggunakan Metode Naive Bayes di Bank BNI Syariah Surabaya.
Jurnal Teknik Elektro, Vol 9, No. 2 (2549 - 1571 / 1411 - 0059), pp. 45 - 52.
B., Musa’adah, Y. & Wihardi, Y., 2018. KLAS- IFIKASI KOMENTAR SPAM PADA
YOUTUBE MENGGUNAKAN
METODE NAÏVE BAYES, SUPPORT VECTOR MACHINE, DAN K-NEAR- EST NEIGHBORS. Jurnal Informatika dan Komputer (JIKO), Vol 3, No.2 (-), pp.
54-59.
Feldman, R. &. S. J., 2007. The Text Mining Handbook: Advanced Approaches in An- alyzing Unstructured Data. In: S. J. Feld- man R, ed. New York: Cambridge Univer- sity Press. New York: s.n.
Gorunescu, F., 2011. Data Mining: Concepts,
Model and Techniques. Berlin, Jerman:
Springer.
Indrayuni, E., 2019. Klasifikasi Text Mining Re- view Produk Kosmetik Untuk Teks Ba- hasa Indonesia Menggunakan Algoritma Naive Bayes. JURNAL KHATU- LISTIWA INFORMATIKA, Vol.VII NO.
1 (p-ISSN: 2339-1928 & e-ISSN: 2579- 633X), pp. 29 - 36.
J. Rennie, L. S. J. T. D. K., 2003. Tackling the poor assumptions of naivebayes text clas- sifiers, Proceedings of the Twentieth In- ternationalConference on Machine Learn- ing (ICML), pp. 616 - 623.
Ko, Y., 2016. A New Term Weighting Scheme for Text Classification using the Odds of Positive and Neagtive Class Probabilities.
Computer Engineering, Dong-A Univer- sity.
Liu, B., 2012. Sentiment Analysis and Opinion Mining. s.l: Morgan & Claypool Publish- ers.
Sabbah, T. et al., 2017. Modified Frequency- Based Term Weighting Schemes For Text Classification. Applied Soft Computing Journal, Volume 58, pp. 193-206.
SANTHANAKUMA, M. & COLUMBUS, C.
C., 2016. A MODIFIED FREQUENCY BASED TERM WEIGHTING AP- PROACH FOR INFORMATION RE- TRIEVAL.sadgurupublications, Vol. 14 No. 1 (0972-768X), pp. 449-457.
Sari, A. E., Widowati, S. & Lhaks, K. M., 2019.
Klasifikasi Ulasan Pengguna Aplikasi Mandiri Online di Google Play Store dengan Menggunakan Metode Infor- mation Gain dan Naive Bayes Classifier.e- Proceeding of Engineering, Vol 6 , No.2(2355-9365), pp. 9143 - 9157.
Wibowo, A. P. & Hartati, S., 2016. Sistem Klas- ifikasi Kinerja Satpam Menggunakan Metode Naїve Bayes Classifier. JURNAL INOVTEK POLBENG - SERI IN- FORMATIKA, vol 1, no 2(2527-9866), pp. 192-201.
Witten, I. H., 2003. Text Mining. University of Wakaito, New Zealand: s.n.