PENINGKATAN AKURASI PADA METODE KLASIFIKASI K-NEAREST NEIGHBOR MENGGUNAKAN LOCAL MEAN BASED DAN
DISTANCE WEIGHT K-NEAREST NEIGHBOR
TESIS
KHAIRUL UMAM SYALIMAN 157038069
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN
2018
TESIS
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Magester Teknik Informatika
KHAIRUL UMAM SYALIMAN 157038069
PROGRAM STUDI S2 TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN
2018
ii
PERSETUJUAN
Judul : PENINGKATAN AKURASI PADA METODE
KLASIFIKASI K-NEAREST NEIGHBOR
MENGGUNAKAN LOCAL MEAN BASED DAN DISTANCE WEIGHT K-NEARESR NEIGHBOR
Kategori : TESIS
Nama : KHAIRUL UMAM SYALIMAN
Nomor Induk Mahasiswa : 157038069
Program Studi : MAGISTER(S2) TEKNIK INFORMATIKA
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Dr. Erna Budhiarti Nababan Prof. Dr. Opim Salim Sitompul
Diketahui/disetujui oleh
Program Studi Magister(S2) Teknik Informatika Ketua,
Prof. Dr. Muhammad Zarlis NIP. 19570701 198601 1 003
PERNYATAAN
PENINGKATAN AKURASI PADA METODE KLASIFIKASI K-NEAREST NEIGHBOR MENGGUNAKAN LOCAL MEAN BASED DAN
DISTANCE WEIGHT K-NEARESR NEIGHBOR
TESIS
Saya mengakui semua tesis ini adalah hasil karya saya sendiri kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 23 Januari 2018
Khairul Umam Syaliman 157038069
iv
PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Sebagai sivitas akademika Universitas Sumatera Utara, saya yang bertanda tangan di bawah ini :
Nama : Khairul Umam Syaliman
NIM : 157038069
Program Studi : Magister(S2) Teknik Informatika Jenis Karya Ilmiah : Tesis
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepadaUniversitas Sumatera Utara Hak Bebas Royalti Non-Eksklusif (Non-Exclusive RoyaltyFree Right) atas tesis saya yang berjudul :
PENINGKATAN AKURASI PADA METODE KLASIFIKASI K-NEAREST NEIGHBOR MENGGUNAKAN LOCAL MEAN BASED DAN
DISTANCE WEIGHT K-NEARESR NEIGHBOR
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non- Eksklusif ini, Universitas Sumatera Utara berhak menyimpan, mengalih media,memformat, mengelola dalam bentuk database, merawat dan mempublikasikan tesissaya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagaipenulis dan sebagai pemegang dan/atau sebagai pemilik hak cipta.
Demikian pernyataan ini dibuat dengan sebenarnya.
Medan, 23 Januari 2018
Khairul Umam Syaliman 157038069
Telah diuji pada
Tanggal : 23 Januari 2018
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Opim Salim Sitompul Anggota : 1. Dr. Erna Budhiarti Nababan
2. Prof. Dr. MuhammadZarlis 3. Prof. Dr. Marwan Ramli
vi
RIWAYAT HIDUP
DATA PRIBADI
Nama Lengkap : KHAIRUL UMAM SYALIMAN
Tempat dan Tanggal Lahir : Perawang, 21Juni 1992
Alamat Rumah : Jl. Hang Nadim Kampung Tualang
Telp/HP : 081277972250
Email : [email protected]
DATA PENDIDIKAN
SD : SD Negeri 006 Tualang TAMAT : 2004 SLTP : SMPSwasta Bina Karya TAMAT : 2007
SLTA : SMA Negeri 4 Siak TAMAT : 2010
S1 : Teknik Informatika UIR TAMAT : 2015 S2 : Teknik Informatika USU TAMAT : 2018
UCAPAN TERIMA KASIH
Alhamdulillahirobil ‘Alamin,tiada kata yang pantas terucap dari pada kalimat syukur atas rasa nikmat yang telah penulis terima dari Sang Pencipta Allah S.W.T dalam setiap sendi kehidupan yang penulis jalani. Tak lupa pula salawat beserta salam untuk nabi junjungan alam Muhammad S.A.W yang telah menjadi tauladan yang baik bagi seluruh umat muslim. Penulis menerima banyak bantuan, dukungan dan semangat selama proses pendikikan sampai dengan penyusunan tesis ini. Oleh karena itu penulis menyampaikan ucapan terima kasih kepada:
1. Bapak Prof. Dr. Runtung Sitepu, S.H.,M.Hum. selaku Rektor Universitas Sumatera Utara.
2. Bapak Prof. Dr. Opim Salim Sitompul selaku Dekan Fakultas Ilmu Komputer dan Teknologi Informasi (Fasilkom-TI)Universitas Sumatera Utara.
3. Bapak Prof. Dr. MuhammadZarlis selaku Ketua Program Studi Magister Teknik InformatikaUniversitas Sumatera Utara.
4. Bapak Syahril Efendi, S.Si.,M.IT selaku Sekretaris Program Studi Teknik Informatika Universitas Sumatera Utara.
5. Bapak Prof. Dr. Opim Salim Sitompul selaku Dosen Pembimbing I yang telah memberikan kritik, saran dan bimbingan kepada penulis untuk memperbaiki kualitas dari tesis ini.
6. Ibu Erna Budhiarti Nababan selaku Dosen Pembimbing II yang telah memberikan kritik, saran dan bimbingan kepada penulis untuk memperbaiki kualitas dari tesis ini.
7. Seluruh tenaga pengajar dan pegawai di Fakultas Ilmu Komputer dan Teknologi Informasi USU.
8. Nabi Muhamaad S.A.W, dan para sahabat-sahabat beliau, terutama Abu bakar r.a,Umar bin khattab r.a, Utsman r.a, Ali r.a, dan Aisyah r.a.
9. Buat kedua orang tua,buat Abang Lung Syukri Abdillah Syaliman bin Lukman, buat adik tercantik Hidayatul Jannah Syaliman binti Lukman, adik kecil ku Zuhdi Fadlullah Syaliman bin Lukman sang rival dalam bermain game,dan Raudhatul Jannah binti Ibnu Arpan beserta keluarga yang selalu memberi warna, dukungan sertasemangatbagi penulis.
viii
10. Buat seluruh keluarga yang tak dapat penulis sebutkan satu persatu, terkhusus buat para hafidz (Yahdi Abdillah bin Saiful Bakri) dan hafidzah (Hasya Dini Aisyah binti Saiful Bakri) yang Allah S.W.T berikan ditengah-tengah keluarga kami.
11. Teman-teman khususnya Edwil Jafri, M. Toha, dan Angga Negara yang telah memberikan bantuan, semangat, dan masukan kepada penulis untuk menyelesaikan tesis ini.
12. Seluruh penghuni sekret hipermaksi terutama Windi Wirawan,. S.T, Andre Kurniawan, dan Taufiq Ridho.
13. Seluruh rekan-rekan seperjuangan mahasiswa Magister Teknik Informatika Kom C 2015, terkhusus untuk A ANababan, R P Fhona, M Z F Nasution, Y Aprilia, M Jannah, R Rahmadani, A B Nasution, S A Sitepu, M P Novelan, M. Syukron dan Martiano.
14. Seluruh pihak yang terlibat langsung dan tidak langsung dalam penulisan tesis ini dan tidak bisa disebutkan satu persatu.
Semoga Allah SWT memberikan rahmat, kasih sayang, dan balasan kepada semua pihak yang telah memberikan bantuan, masukan, dan semangat kepada penulis untuk menyelesaikan tesis ini. Penulis berharap tesis ini dapat bermanfaat kepada penulis dan pembaca.
Medan, 23 Januari 2018
Penulis
ABSTRAK
Pada k-nearesr neighbor (K-NN), dalam penentuan kelas terhadap data baru biasanya menggunakan sistem vote majority yang sederhana, dimana sistem vote majority ini mengabaikan kedekatan antar data, dan pada sistem ini juga memungkinkan terjadinya kelas mayoritas ganda yang dapat meningkatkan kesalahan klasifikasi.
Pada penelitian ini, penulis mengajukan solusi dalam permasalahan sistem vote majority dengan menggunakan pembobotan jarak, dimana untuk melakukan perhitungan bobot dari jarak ini akan menggunkan kombinasi beberapa tahapan dari local mean based k-nearest neighbor (LMKNN) dan distance weight k-nearest neighbor (DWKNN). Hasil akurasi dari metode yang diusulkan akan dibandingkan dengan K-NN konvensional, dimana pengujian dilakukan dengan menggunakan beberapa dataset dari UCI Machine Learning repository, Kaggle and Keel, antara lain ionosphare, iris, voice genre, lower back pain sypmtopms, dan thyroid, selain itu, metode yang diusulkan akan diuji kembali dengan menggunakan data penjurusan siswa SMA di desa Tualang, Indonesia. Hasil penelitian menunjukkan bahwa kombinasi LMKNN dan DWKNN mampu meningkatkan akurasi klasifikasi pada metode K-NN, dimana peningkatan rata-rata nilai akurasi pada seluruh dataset adalah 2.45%, dengan peningkatan akurasi tertinggi 3.71% yang terjadi pada dataset lower back pain sypmtopms, sedangkan pada data penjurusan siswa peningkatan akurasi yang terjadi adalah sebesar 5.16%.
Keywords : Distance Weight K-Nearest Neighbor (DWKNN), K-Nearest Neighbor (K-NN), Kombinasi, Local Mean Based K-Nearest Neighbor (LMKNN), Vote Majority.
x
INCREASING ACCURACY ON K-NEAREST NEIGHBOR CLASSIFICATION METHOD USING LOCAL MEAN
BASED AND DISTANCE WEIGHT K-NEAREST NEIGHBOR
ABSTRACT
In k-nearest neighbor (K-NN), the determination of classes for new data is normally performed by a simple majority vote system, which may ignore the similarities among data, as well as allowing the occurrence of a double majority class that can lead to misclassification. In this research, we propose an approach to resolve the majority vote issues by calculating the distance weight using a combination of local mean based k-nearest neighbor (LMKNN) and distance weight k-nearest neighbor (DWKNN). The accuracy of results is compared to the accuracy acquired from the original k-NN method using several datasets from the UCI Machine Learning repository, Kaggle and Keel, such as ionosphare, iris, voice genre, lower back pain, and thyroid. In addition, the proposed method is also tested using real data from a public senior high school in city of Tualang, Indonesia. Results shows that the combination of LMKNN and DWKNN was able to increase the classification accuracy of kNN, whereby the average accuracy on test data is 2.45% with the highest increase in accuracy of 3.71% occurring on the lower back pain symptoms dataset. For the real data, the increase in accuracy is obtained as high as 5.16%.
Keywords : Combination, Distance Weight K-Nearest Neighbor (DWKNN), K- Nearest Neighbor (K-NN), Local Mean Based K-Nearest Neighbor (LMKNN), Vote Majority.
DAFTAR ISI
Halaman
Persetujuan ii
Pernyataan iii
Persetujuan Publikasi iv
Panitia Penguji Tesis v
Riwayat Hidup vi
Ucapan Terima Kasih vii
Abstrak ix
Abstract x
Daftar Isi xi
Daftar Tabel xiii
Daftar Gambar xiv
Daftar Lampiran xv
Bab 1 Pendahuluan
1.1. Latar Belakang 1
1.2. Rumusan Masalah 3
1.3. Tujuan dan Manfaat Penelitian 3
1.4. Batasan Masalah 3
1.5. Manfaat Penelitian 4
Bab 2 Landasan Teori
2.1. K-Nearest Neighbor (K-NN) 5
2.2. Local Mean Based K-Nearest Neighbor (K-NN) 7 2.3. Distance Weight K-Nearest Neighbor (K-NN) 8
2.4. Model Jarak 9
2.5. Riset-Riset Terkait 10
2.6. Perbedaan Dengan Riset Yang Lainnya 13
Bab 3 Metode Penelitian
3.1. Data Yang Digunakan 14
3.2. Penggabungan Local Mean Based K-Nearest Neighbor (LMKNN) dan Distance Weight K-Nearest Neighbor (DWKNN) 15
3.2.1. Penentuan Tetangg Terdekat 16
3.2.2. Pembobotan Jarak Antar Data 17
3.2.3. Penentuan Kelas Data Baru 18
3.3. Tahapan Analisis Kinerja Metode 18
3.3.1. Penentuan Data Latih dan Data Uji 21
3.3.2. Proses Klasifikasi 22
3.3.2.1. Klasifikasi Dengan Metode Gabungan
LMKNN dan DWKNN 22
3.3.2.2. Klasifikasi Menggunakan K-NN Konvensional 23
xii
3.3.3. Analisis Kinerja Metode 24
3.4. Software dan Tools yang Digunakan 24
Bab 4 Hasil dan Pembahasan
4.1. Hasil 25
4.2. Pengujian 28
4.2.1. Pengujian Terhadap Dataset Ionosphare 29
4.2.2. Pengujian Terhadap Dataset Iris 32
4.2.3. Pengujian Terhadap Dataset Voice Genre 35 4.2.4. Pengujian Terhadap Dataset Lower Back
Pain Symptomps 38
4.2.5. Pengujian Terhadap Dataset New Thyroid 42 4.2.6. Pengujian Terhadap Data Penjurusan Siswa 46
4.3. Pembahasan 49
Bab 5 Kesimpulan dan Saran
5.1. Kesimpulan 51
5.2. Saran 51
Daftar Pustaka 52
Lampiran 55
DAFTAR TABEL
Halaman
Tabel 2.1. Riset-Riset Terkait 11
Tabel 3.1. Rincian Data 21
Tabel 3.2. Jarak Data Uji ke Setiap Data Latih 22
Tabel 3.3. Urutan Jarak Antar Data Uji ke Seluruh Data Latih 22 Tabel 3.4. Urutan Jarak Terdekat Untuk Setiap Kelas Data 22
Tabel 3.5. Bobot Jarak Setiap Kelas 23
Tabel 3.6. Urutan K Tetangga Terdekat 24
Tabel 4.1. Rincian Dataset Yang Digunakan 25
Tabel 4.2. Distribusi Data Ionosphare 26
Tabel 4.3. Rincian Data Ionosphare 26
Tabel 4.4. Jarak Antar Data Pada Dataset Ionosphare 27 Tabel 4.5. Urutan Jarak Terdekat Pada Dataset Ionosphare 27 Tabel 4.6. Perbandingan Akurasi Pada Dataset Ionosphare 28
Tabel 4.7. Distribusi Data Iris 29
Tabel 4.8. Rincian Data Iris Yang Digunakan 30
Tabel 4.9. Jarak Antar Data Pada Dataset Iris 30
Tabel 4.10. Urutan Jarak Terdekat Pada Dataset Iris 30 Tabel 4.11. Perbandingan Akurasi Pada Dataset Iris 31
Tabel 4.12. Distribusi Data Voice Genre 32
Tabel 4.13. Rincian Data Latih Voice Genre 33
Tabel 4.14. Rincian Data Uji Voice Genre 33
Tabel 4.15. Jarak Antar Data Pada Dataset Voice Genre 33 Tabel 4.16. Urutan Jarak Terdekat Pada Dataset Voice Genre 34 Tabel 4.17. Perbandingan Akurasi Pada Dataset Voice Genre 34 Tabel 4.18. Distribusi Dataset Lower Back Pain Symptomps 36 Tabel 4.19. Rincian Data Latih Lower Back Pain Symptomps 36 Tabel 4.20. Rincian Data Uji Lower Back Pain Symptomps 36 Tabel 4.21. Jarak Antar Data Pada Dataset Lower Back Pain Symptomps 37 Tabel 4.22. Urutan Jarak Terdekat Pada Dataset Lower Back Pain Symptomps 37 Tabel 4.23. Perbandingan Akurasi Pada Dataset Lower Back Pain Symptomps 38
Tabel 4.24. Distribusi Dataset New Thyroid 39
Tabel 4.25. Rincian Data Latih New Thyroid 39
Tabel 4.26. Rincian Data Uji New Thyroid 40
Tabel 4.27. Jarak Antar Data Pada Dataset New Thyroid 40 Tabel 4.28. Urutan Jarak Terdekat Pada Dataset New Thyroid 41 Tabel 4.29. Perbandingan Akurasi Pada Dataset New Thyroid 41
Tabel 4.30. Distribusi Data Penjurusan Siswa 43
Tabel 4.31. Rincian Data Latih Penjurusan Siswa 43
Tabel 4.32. Rincian Data Uji Penjurusan Siswa 44
Tabel 4.33. Jarak Antar Data Pada Dataset Penjurusan Siswa 44 Tabel 4.34. Urutan Jarak Terdekat Pada Dataset Penjurusan Siswa 45 Tabel 4.35. Perbandingan Akurasi Pada Dataset Penjurusan Siswa 45
xiv
DAFTAR GAMBAR
Halaman Gambar 2.1. K-NN dengan nilai: (a) K=1, (b) K=2, (c) K=5 (d) K=7 6
Gambar 3.1. Gabungan LMKN dan DWKNN 15
Gambar 3.2. Tahapan Penentuan Tetangga Terdekat 16
Gambar 3.3. Tetangga Terdekat Dari Setiap Kelas 17
Gambar 3.4. Tahapan Pembobotan Jarak Antar Data 17
Gambar 3.5. Details Tahapan Gabungan LMKNN dan DWKNN 18
Gambar 3.6. Prosedure Penyelesaian Masalah 19
Gambar 3.7. Detail Prosedure Penyelesaian Masalah 20 Gambar 4.1. Output Akurasi Pengujian Pada Dataset Ionosphare 25 Gambar 4.2. Output Akurasi Pengujian Pada Dataset Iris 26 Gambar 4.3. Output Akurasi Pengujian Pada Dataset Voice Genre 26 Gambar 4.4. Output Akurasi Pengujian Pada Dataset Lower Back Pain 27 Gambar 4.5. Output Akurasi Pengujian Pada Dataset New Thyroid 27 Gambar 4.6. Output Akurasi Pengujian Pada Data Penjurusan Siswa 28 Gambar 4.7. Grafik Perbandingan Akurasi Pada Dataset Ionosphare 31 Gambar 4.8. Grafik Perbandingan Akurasi Pada Dataset Iris 34 Gambar 4.9. Grafik Perbandingan Akurasi Pada Dataset Voice Genre 38 Gambar 4.10. Grafik Akurasi Pada Dataset Lower Back Pain Symptomps 41 Gambar 4.11. Grafik Perbandingan Akurasi Pada Dataset New Thyroid 45 Gambar 4.12. Grafik Perbandingan Akurasi Pada Data Penjurusan Siswa 49 Gambar 4.13. Grafik Rata-rata Nilai Akurasi Dari Seluruh Data 50
DAFTAR LAMPIRAN
Halaman
Lampiran 1 Rincian Data Latih Penjurusan Siswa 55
Lampiran 2 Rincian Data Uji Penjurusan Siswa 59
Lampiran 3 Listing Program 60
Lampiran 4 Daftar Publikasi Ilmiah Penulis 62
Lampiran 5 Source Code Program dan Link Dataset 62
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Pada beberapa penelitian, nilai akurasi yang dihasilkan oleh K-NN masih tergolong rendah, terlebih lagi jika dibandingkan dengan algoritma klasifikasi lainnya. Salah satunya pada penelitian yang dilakukan oleh Danades, et al. (2016), dimana pada penelitian ini membandingkan nilai akurasi antara Support Vector Machine (SVM) dan K-NN. Hasil dari penelitian ini didapati bahwa rata-rata nilai akurasi yang dihasilkan K-NN hanya sebesar 71.28%, sedangkan SVM sebesar 92.40%.
Penelitian lainnya dilakukan oleh Tamatjita & Mahasta (2016) yang telah membandingkan metode Nearest Centroid Classifier (NCC) dan K-NN dimana hasil dari penelitian ini adalah, NCC mendapati nilai akurasi tertinggi sebesar 96.67% dan terendah sebesar 33.33%, sedangkan metode K-NN hanya mampu menghasilkan nilai akurasi tertinggi sebesar 26.7% dan terendah sebesar 22.5%.
Pada penelitian yang dilakukan oleh Brown (2017) dengan menggunakan metode K-NN dimana data yang digunakan sebanyak 395 records, memiliki 30 attributes, dan 4 kelas. Setengah dari data digunakan untuk data latih dan setengahnya lagi digunakan untuk data tes, hasil terbaik yang didapatkan adalah sebesar 48.78%
saat K bernilai 8.
Rendahnya nilai akurasi dari K-NN konvensional disebabkan oleh beberapa faktor. Salah satunya karena setiap karakterisitik dalam metode ini memilki pengaruh yang sama terhadap penentuan jarak. Solusi dari permasalah ini adalah dengan memberikan bobot pada setiap karakteristik data (Kuhkan. 2016).
Faktor lain yang menyebabkan rendahnya nilai akurasi dari K-NN konvensional adalah penentuan kelas data baru berdasarkan pada sistem vote majority yang sederhana (Lidya, et al. 2015), dimana sistem vote majority mengabaikan
kedekatan antar data (Gou & Xiong. 2011). Tentu saja hal ini tidak rasional ketika jarak setiap tetangga terdekat sangat berbeda terhadap jarak data uji (Pan, et al. 2016).
Masalah lainnya pada K-NN konvensional adalah kemungkinan munculnya kelas mayoritas ganda yang disebabkan sistem penentuan kelas bagi data baru berdasarkan vote majority dan penentuan jumlah tetangga terdekat, dimana jumlah tetangga terdekat dipilih sesuai dengan tingkat keberhasilan yang diinginkan (Ertuğrul
& Tağluk. 2017).
Permasalahan dalam penentuan kelas data baru dengan sistem vote majority yang mengabaikan kedekatan antar data yang mengakibatkan kesalahan klasifikasi dapat diatasi dengan menggunakan Distance Weight (Batista & Silva. 2009). Dengan menggunakan metode distance weight penentuan kelas bagi data baru didasarkan pada bobot yang didapati melalui jarak antar data.
Batista & Silva (2009) mengusulkan sebuah metode yang disebut Distance Weight K-Nearest Neighbor (DWKNN), metode ini menentukan kelas data baru berdasarkan pada nilai bobot yang didapati dari jarak antar data, sehingga kesalahan klasifikasi yang terjadi karena mengabaikan kedekatan antar data (Yan, et al. 2015;
Pan, et al. 2016) dapat diatasi. Metode pembobotan ini memiliki kinerja yang baik karena dapat mengurangi pengaruh outlier, dan distribusi data set yang tidak seimbang (Gou, et al. 2011).
Mitani & Hamamoto (2006) mengusulkan metode Local Mean Based K- Nearest Neighbor (LMKNN) untuk meningkatkan hasil klasifikasi. Pada LMKNN penentuan kelas bagi data baru tidak lagi berdasarkan pada sistem vote majority, akan tetapi untuk menentukan kelas bagi data baru metode LMKNN lebih memilih menggunakan local mean. Sehingga permasalahan kelas mayoritas ganda yang dapat menyebabkan miss klasifikasi tidak akan terjadi karena pada sistem local mean, pemilihan kelas bagi data baru didasarkan pada perhitungan jarak terdekat ke local mean vector dari setiap kelas data (Pan, et al. 2016).
Berdasarkan penelitian terdahulu, rendahnya hasil akurasi dari metode K-NN disebabkan karena penentuan kelas bagi data baru hanya menggunakan sistem vote majority sederhana, dimana sistem ini mengabaikan kemiripan antar data dan juga memungkinkan munculnya kelas mayoritas ganda yang dapat menyebabkan tingginya miss klasifikasi. Untuk mengatasi masalah pada sistem vote majority, penelitian ini akan menggantikan sistem vote majority pada K-Nearest Neighbor (K-NN)
3
Konvensional menggunakan metode Distance Weight, dimana untuk mendapati bobot antar data akan dilakukan dengan cara menggabungkan metode Local Mean Based K- Nearest Neighbor (LMKNN) dan metode Distance Weight K-Nearest Neighbor (DWKNN), diharapkan penggabungan kedua metode ini mampu untuk meningkatkan hasil akurasi dalam proses klasifikasi.
1.2 Rumusan Masalah
Rendahnya akurasi K-NN konvensional disebabkan oleh beberapa faktor, diantaranya setiap karakteristik pada metode K-NN konvensional memiliki pengaruh yang sama terhadap penentuan jarak antar data. Faktor lainnya disebabkan oleh sistem vote majority pada K-NN konvensional, dimana sistem vote majority memungkinkan munculnya kelas mayoritas ganda dan mengabaikan jarak antar data. Hal-hal ini dapat meningkatkan kesalahan dalam proses klasifikasi.
1.3 Tujuan Penelitian
Penelitian ini dilakukan dengan tujuan untuk meningkatkan nilai akurasi dari metode K-Nearest Neighbor (K-NN) konvensional dengan cara menggantikan sistem vote majority pada K-Nearest Neighbor konvensional menggunakan metode Distance Weight. Untuk mendapatkan bobot dari jarak antar data akan dilakukan penggabungan metode Local Mean Based K-Nearest Neighbor (LMKNN) dan metode Distance Weight K-Nearest Neighbor (DWKNN).
1.4 Batasan Masalah
Batasan masalah dalam penelitian ini adalah sebagai berikut :
1. Penelitian ini menggabungkan metode Local Mean Based K-Nearest Neighbor (LMKNN) dan metode Distance Weight K-Nearest Neighbor (DWKNN) untuk mengatasi masalah sistem vote majority pada metode K-Nearest Neighbor (K- NN) Konvensional.
2. Pada penelitian ini menggunakan beberapa data, antara lain 2 dataset dari UCI Machine Learning Repository, yaitu ionosphere dan iris, 2 dataset dari Kaggle, yaitu voice genre dan lower back pain symptoms, 1 dataset thyroid disease (new thyroid) dari Keel Repository, dan 1 set data penjursan siswa di SMAN 2
Tualang, Kecamatan Tualang Kabupaten Siak, Provinsi Riau, yang merupakan hasil studi lapangan secara langsung pada tahun 2013.
3. Kinerja diukur hanya berdasarkan dari tingkat akurasi.
1.5 Manfaat Penelitian
Manfaat yang diharapkan dari penelitian ini adalah sebagai berikut :
1. Mendalami metode tentang klasifikasi terutama metode K-NN yang bersifat distance-based.
2. Memberi kontribusi kepada ilmu pengetahuan dalam bidang klasifikasi, khususnya mengenai data nonparametrik.
BAB 2
LANDASAN TEORI
2.1 K-Nearest Neighbor (K-NN)
Metode K-NN pertama kali diperkenalkan pada awal tahun 1950-an (Han. 2011). K- NN merupakan salah satu metode yang paling banyak digunakan dalam text categorization, pengenalan pola, pengklasifikasian, dan lain-lain (Bhatia & Vandana.
2010; Jabbar, et al. 2013; Rui-Jia & Xing. 2014; Sánchez, et al. 2014; Zheng, et al.
2017). Hal ini dikarenakan K-NN cukup atraktif, mudah diterapkan, intuitif, dapat dieksploitasi di berbagai domain aplikasi, dan sederhana (Wang, et al. 2007; García- Pedrajas & Ortiz-Boyer, 2009; Pan, et al. 2017; Ougiaroglou & Evangelidis, 2012;
Song, et al. 2016; Feng, et al. 2016).
Algoritma K-Nearest Neighbor (K-NN) merupakan algoritma termasuk kedalam kategori distance-based algorithms (Wang, et al. 2007). Distance-Based Algorithms adalah algoritma yang menentukan kemiripan data atau objek berdasarkan pada kedekatan jarak antar data ke suatu kelas atau label atau kelompok data lainnya (Kataria & Singh, 2013; Lei, et al. 2016). Kemiripan antar data pada K-NN ditentukan dengan menggunakan pengukuran model jarak.
K-NN bekerja dengan melihat K tetangga terdekat dari data (Kalaivani &
Shunmuganathan. 2014; Iswarya & Radha. 2015), nilai K pada K-NN merupakan jumlah tetangga terdekat, jika K bernilai 1, maka kelas dari satu data latih yang terdekat akan menjadi kelas bagi data uji yang baru. Jika K bernilai 3, maka akan diambil tiga data latih terdekat yang akan dijadikan kelas bagi data uji yang baru.
Begitu juga jika nilai K 5, 7, 9, dan seterusnya. Pada proses klasifikasi K-NN menggunakan voting terbanyak sebagai kelas prediksi dari data yang baru (Lidya, et al. 2015).
Pemilihan nilai K yang kecil menyebabkan hasil klasifikasi sensitive terhadap noise, jika nilai K terlalu besar kemungkinan jumlah tetangga terdekat dari kelas lain terlalu banyak yang akhirnya dapat menurunkan hasil klasifikasi (Gou, et al. 2014).
b. K=2 Tetangga
d.K=7 a. K=1
c.K=5
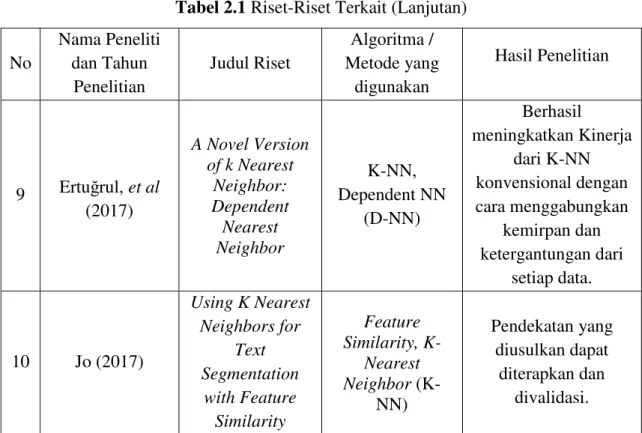
Untuk lebih jelasnya perhatikan gambar 2.1, ada dua kelas sebagai sampel yaitu lingkaran dan bintang, dan oval yang berwarna hitam adalah data baru yang akan diklasifikasikan oleh algoritma K-NN.
Gambar 2.1 K-NN dengan nilai: (a) K=1, (b) K=2, (c) K=5 (d) K=7
Jika K bernilai 1 maka kelas untuk data baru adalah kelas lingkaran (gambar 2.1 bagian a), jika K bernilai 2 maka kelas masih sama dengan K bernilai 1 yaitu lingkaran (gambar 2.1 bagian b), jika K bernilai 5 maka kelas untuk data baru juga lingkaran (gambar 2.1 bagian c), dan gambar 2.1 bagian d memiliki hasil prediksi dengan kelas mayoritas lingkaran.
Salah satu masalah yang dihadapi K-NN adalah dalam pemilihan nilai K yang tepat. Pemilihan nilai K yang besar dapat mengakibatkan distorsi data yang besar pula.
Hal ini dikarenakan setiap tetangga mempunyai bobot yang sama terhadap data uji, sedangkan K yang terlalu kecil bisa menyebabkan algoritma terlalu sensitive terhadap noise.
K-NN merupakan teknik klasifikasi yang sederhana, tetapi mempunyai hasil kerja yang cukup bagus. Beberapa karakter K-NN adalah sebagai berikut :
1. K-NN merupakan algoritma yang menggunakan seluruh atau sebagian data latih untuk melakukan proses klasifikasi. Hal ini mengakibatkan proses prediksi yang sangat lama.
2. K-NN tidak membedakan setiap fitur (attribut) data dengan suatu bobot.
3. Hal yang rumit dari K-NN adalah menentukan nilai K yang paling sesuai.
4. Prinsip K-NN adalah memilih tetangga terdekat dan melakukan klasifikasi dengan voting terbanyak.
7
Karena K-NN konvensional adalah algoritma yang bersifat lazy learner, untuk melakukan klasifikasi K-NN memerlukan seluruh data (Buana, et al. 2012), dan data juga harus sudah disetai dengan kelas atau target, hal ini disebabkan K-NN masuk kedalam kategori terpandu (supervised). Dengan segala kekurangan dan kelebihannya, K-Nearest Neighbor (K-NN) merupakan salah satu dari top ten algoritma data mining dalam proses klasifikasi (Wu & Kumar. 2009).
2.2 Local Mean Based K-Nearest Neighbor (LMKNN)
Local Mean K-Nearest Neighbor yang dikembangkan oleh Mitani, et al. (2006) adalah sebuah klasifikasi nonparametrik sederhana, efektif dan tangguh. LMKNN ini telah terbukti dapat memperbaiki kinerja klasifikasi dan juga mengurangi pengaruh outlier yang ada, terutama dalam ukuran jumlah data yang kecil (Pan, et al. 2016).
Adapun alur kerja dari LMKNN adalah sebagai berikut : Langkah 1 : Tentukan Nilai K
Langkah 2 : Hitung jarak data uji keseluruh data dari masing-masing kelas data dengan menggunakan model jarak Euclidean.
Langkah 3 : Urutkan jarak antar data dari yang terkecil ke yang terbesar sebanyak K dari setiap kelas
Langkah 4 : Hitung local mean vector dari setiap kelas dengan persamaan (Pan, et al. 2016) :
= ∑ = 𝑁𝑁, (2.1)
Langkah 5 : Tentukan kelas data uji dengan cara menghitung jarak terdekat ke local mean vector dari setiap kelas data dengan persamaan :
= 𝑎 𝑔 , , = , , … , 𝑀 (2.2)
Klasifikasi LMKNN sama dengan 1-NN jika nilai K=1 (Mitani, et al. 2006).
Nilai K pada LMKNN sangat berbeda jauh dari K-NN konvensional, dimana pada K- NN konvensional nilai K merupakan jumlah tetangga terdekat yang dipilih dari seluruh data latih, sedangkan pada LMKNN nilai K merupakan jumlah tetangga terdekat yang dipilih dari setiap kelas pada data latih (Pan, et al. 2016).
Dalam Penentuan kelas bagi data uji, LMKNN menggunakan pengukuran jarak terdekat ke masing-masing local mean vector dari setiap kelas data, yang mana cara ini dinilai efektif untuk mengatasi efek negative dari outlier (Pan, et al. 2016).
2.3 Distance Weight K-Nearest Neighbor (DWKNN)
Dalam penentuan kelas bagi data uji, K-NN konvensional menggunakan vote majority (Lidya, et al. 2015), dimana setiap tetangga terdekat memiliki bobot yang sama dalam penentuan kelas. Tentu saja hal ini tidak rasional ketika jarak setiap tetangga terdekat sangat berbeda terhadap jarak data uji, yang dapat mengakibatkan miss klasifikasi (Pan, et al. 2016).
Batista & Silva (2009) memberi solusi dalam penelitiannya dimana jarak antar data diberikan bobot menggunakan persamaan :
= 𝑞, (2.3)
Atau
= − 𝑞, (2.4)
Dimana :
adalah bobot ke-i dari tetangga terdekat.
𝑞, adalah jarak antar data uji dan data latih.
Gou & Xiong (2011) memberikan pilihan lain dalam memberikan bobot terhadap jarak antar data uji dan data latih, pemberian bobot berdasarkan dari tetangga terdekat, dimana jarak yang paling dekat memilki bobot paling tinggi, adapun persamaan dalam pemberian bobot adalah sebagai berikut :
= {
𝑁𝑁− 𝑁𝑁
𝑁𝑁− 1𝑁𝑁× , 𝑁𝑁 ≠ 𝑁𝑁, , 𝑁𝑁 = 𝑁𝑁
(2.5)
Dalam metode DWKNN ini, kelas data uji dipilih berdasarkan jumlah tertinggi dari rata-rata bobot pada setiap kelas. Adapun persamaan yang digunakan adalah sebagai berikut :
𝑚𝑎 = 𝑎 𝑔 𝑎 𝑢 _ (2.6)
Dimana untuk mencari jumlah bobot setiap kelas dapat menggunakan persamaan :
𝑢 _ = ∑=𝑁𝑁 , = 𝑁𝑁 (2.7)
Dimana :
c adalah kelas dari setiap data.
𝑢 _ adalah jumlah bobot untuk setiap kelas.
Alur kerja dari DWKNN adalah sebagai berikut : Langkah 1 : Tentukan nilai K
9
Langkah 2 : Hitung jarak data uji keseluruhan data dengan menggunakan model jarak.
Langkah 3 : Urutkan jarak antar data dari yang terkecil hingga ke yang terbesar sebanyak K.
Langkah 4 : Hitung bobot dari jarak antar data yang telah diurutkan.
Langkah 5 : Tentukan rata-rata bobot untuk setiap kelas data berdasarkan K tetangga terdekat denga persamaan 2.7.
Langkah 6 : Tentukan rata-rata nilai bobot tertinggi untuk setiap kelas dengan menggunakan persamaan 2.6 untuk dijadikan kelas bagi data baru.
Alur kerja dari DWKNN pada dasarnya hampir sama dengan K-NN konvensional, perbedaan terletak pada perhitungan bobot dan penentuan kelas bagi data uji. Pada K-NN konvensional penentuan kelas berdasarkan vote majority sedangkan pada DWKNN menggunkan jumlah tertinggi dari rata-rata nilai bobot, hal ini tentunya dapat menghindari kemungkinan munculnya kelas mayoritas ganda tanpa membatasi nilai K tetangga terdekat hanya pada nilai ganjil positif.
2.4 Model Jarak
Kesamaan kedua objek harus diukur untuk menentukan perbedaan dan kemiripan (Mahyuddin, et al. 2017), salah satu cara untuk menentukan kemiripan data adalah dengan menggunakan model pengukuran jarak.
Terdapat banyak model pengukuran jarak, antara lain Manhattan, Euclidean, Minkowsky, Chebyshev, Harmonic, dan lain sebagainya. Berikut ini adalah beberapa persamaan dari model jarak tersebut :
Pengukuran jarak Manhattan menggunakan formula :
D , = || − || = ∑𝑁= | − | (2.8)
Pengukuran jarak Euclidean menggunakan formula :
D , = || − || = √∑𝑁= | − | (2.9)
Pengukuran jarak Chebyshev menggunakan formula :
D , = || − ||λ = limλ→∞√∑λ 𝑁= | − |λ (2.10)
Pengukuran jarak Minkowsky menggunakan formula :
D , = || − ||λ = √∑λ 𝑁= | − |λ (2.11) Dimana :
D adalah jarak antara data x dan y.
N adalah jumlah fitur (dimensi) data.
λ adalah parameter jarak Minkowsky.
Secara umum Minkowsky adalah generalisasi dari jarak yang ada seperti Euclidean dan Manhattan (Mergio & Casanovas, 2011). Lamda (λ) merupakan parameter penentu dan bernilai bilangan positif dari 1 sampai dengan tak terhingga (∞), jika nilai λ = 1 maka ruang jarak Minkowsky sama dengan Manhattan (Labellapansa, et al.
2016), dan jika λ = 2 ruang jaraknya sama dengan Euclidean (Mergio & Casanovas, 2008), dan jika λ= ∞ sama dengan ruang jarak Chebyshev (Rao, et al. 2012).
Setiap model pengukuran jarak mempunyai kelebihan masing-masing, Euclidean cocok untuk menentukan jarak terdekat (lurus) antara dua data, sedangkan Manhattan sangat teguh untuk mendeteksi outlier pada data.
2.5 Riset-Riset Terkait
Rendahnya nilai akurasi dari K-NN dapat dilihat dari beberapa penelitian yang telah dilakukan, diantaranya penelitian yang dilakukan oleh Al-Shehri, et al (2017), penelitian ini melakukan perbandingan kinerja antara SVM dan K-NN untuk, hasil yang didapati SVM mampu memberikan kinerja yang lebih baik dari K-NN.
Penelitian selanjutnya dilakukan oleh Danades, et al (2016), penelitian ini membandingkan kinerja SVM dan K-NN. Hasil dari penelitian ini SVM mampu mencapai tingkat akurasi sebesar 92.020% sedangkan K-NN hanya mampu mencapai tingkat akurasi sebesar 71.28%.
Namun, para peneliti telah banyak melakukan upaya peningkatan kinerja dari K-NN konvensional. Salah satunya Batista & Silva (2009) menyarankan memberikan bobot pada setiap jarak antara data uji dan data latih, hal yang senada juga disarankan oleh Gou & Xiong (2011), pemberian bobot terhadap jarak ini bertujuan untuk mengurangi pengaruh outlier yang terpilih menjadi K tetangga terdekat. Kedua penelitian ini menghasilkan peningkatan nilai akurasi pada metode K-NN.
Untuk meningkatkan nilai akurasi dari K-NN konvensional para peneliti telah menerapkan banyak metode lainnya, diantaranya penelitian yang dilakukan oleh
11
Ferreira, et al (2015) menerapkan chemometri sebelum mengklasifikasikan menggunakan K-NN, García-Pedrajas, et al (2015) menyaranakan penggunaan Lokal K, Al-Hadidi M.R, et al (2016) menggunakan Back Propagation Neural Network dalam K-NN, Panwar, et al (2016) melakukan attribute checking sebelum melakukan klasifikasi dengan K-NN, Ertuğrul, et al (2017) menyarankan Dependent dari K-NN, dan Jo (2017) menerapkan kemiripan fitur. Metode yang diterapkan dari penelitian- penelitian tersebut mampu meningkatkan akurasi dari K-NN konvensional.
Jadi untuk memperkuat bahwa penelitian ini layak untuk diteliti, maka dibawah ini akan dipaparkan beberapa riset yang berkaitan dengan riset yang akan dilakukan.
Tabel 2.1 Riset-Riset Terkait
No
Nama Peneliti dan Tahun
Penelitian
Judul Riset
Algoritma / Metode yang
digunakan
Hasil Penelitian
1 Danades, et al (2016)
Comparison of Accuracy Level
K-Nearest Neighbor Algorithm and Support Vector
Machine Algorithm in Classification Water Quality
Status
K-Nearest Neighbor (K- NN), Support Vector Machine (SVM), 10 Fold- Cross Validation
SVM menghasilkan nilai akurasi sebesar 92.20% pada kernel linear, sedangkan K- NN hanya mampu
mencapai hasil sebesar 71.28%.
2 Al-Shehri, et al (2017)
Student Performance Prediction Using
Support Vector Machine and K-
Nearest Neighbor
Support Vector Machine (SVM),
K-Nearest Neighbor (K-
NN)
SVM mencapai hasil yang sedikit lebih baik dengan koefisien korelasi sebesar 0.96,
sedangkan K-NN mencapai koefisien korelasi sebesar 0.95.
3 Batista & Silva (2009)
How K-Nearest Neighbor Parameters
Affect it’s Performance
K-NN, DWKNN, Heterogeneous
Euclidean- Overlap Metric,
Heterogeneous
Menganlisa performa dan menyarankan nilai K terbaik pada
klasifikasi menggunakan metode
DWKNN dengan
Tabel 2.1 Riset-Riset Terkait (Lanjutan)
No
Nama Peneliti dan Tahun
Penelitian
Judul Riset
Algoritma / Metode yang
digunakan
Hasil Penelitian Manhattan
Overlap Metric, Heterogeneous Value Diference
Metric
model jarak HEOM, HMOM, dan HVDM.
4 Gou & Xiong (2011)
A Novel Weighte Voting for K-
Nearest Neighbor Rule
K-NN, Weight Voting, Distance
Weight K-NN.
Berhasil mengatasi masalah sensitivitas dari
pemilihan nilai K yang dapat meningkatkan
performa dalam klasifikasi.
5 Ferreira, et al (2015)
The Use of the K-Nearest
Neighbor Method to Classify The Representative
Elements
K-Nearest Neighbor, Chemometrics
Berhasil menerapkan Algoritma K-NN untuk melakukan klasifikasi terhadap element material dan
non material
6 García-Pedrajas, et al (2015)
A Proposal for Local k Values for
k-Nearest Neighbor Rule
K-NN, Local K
Berhasil meningkatkan performa K-NN terhadap kelas data yang tidak seimbang
7 Al-Hadidi, et al (2016)
Breast Cancer Detection using
K-nearest Neighbor Machine Learning Algorithm
K-NN,Back Propagation Neural Network
(BPNN), Logistic Regression (LR)
Dalam hasil klasifikasi LR lebih
baik dari BPNN, namun dalam regresi
240 fitur, BPNN mampu mencapai akurasi sebesar 93%
8 Panwar, et al (2016)
K-Nearest Neighbor Based Methodology for
Accurate Diagnosis of
Diabetes Mellitus
K-Nearest Neighbor (K-
NN), Pattern matching,
Attribute checking
Berhasil
mengimplementasikan K-NN, Pattern
matching, dan attribute checking untuk mendiagnosa
penyakit diabetes, dengan nilai akurasi
100% pada 2 fitur
13
Tabel 2.1 Riset-Riset Terkait (Lanjutan)
No
Nama Peneliti dan Tahun
Penelitian
Judul Riset
Algoritma / Metode yang
digunakan
Hasil Penelitian
9 Ertuğrul, et al (2017)
A Novel Version of k Nearest
Neighbor:
Dependent Nearest Neighbor
K-NN, Dependent NN
(D-NN)
Berhasil meningkatkan Kinerja
dari K-NN konvensional dengan cara menggabungkan
kemirpan dan ketergantungan dari
setiap data.
10 Jo (2017)
Using K Nearest Neighbors for
Text Segmentation
with Feature Similarity
Feature Similarity, K-
Nearest Neighbor (K-
NN)
Pendekatan yang diusulkan dapat
diterapkan dan divalidasi.
2.6 Perbedaan Dengan Riset Yang Lain
Adapun perbedaan riset yang akan dilakukan terletak pada penentuan tetangga terdekat dan pengambilan keputusan dalam pemilihan kelas pada data uji yang baru dimana pada K-NN konvensional menggunakan vote majority, namun dalam penelitian ini penentuan kelas baru pada data uji akan menggunakan sistem pembobotan terhadap jarak (Distance Weight) dari data uji ke seluruh data sampel.
BAB 3
METODOLOGI PENELITIAN
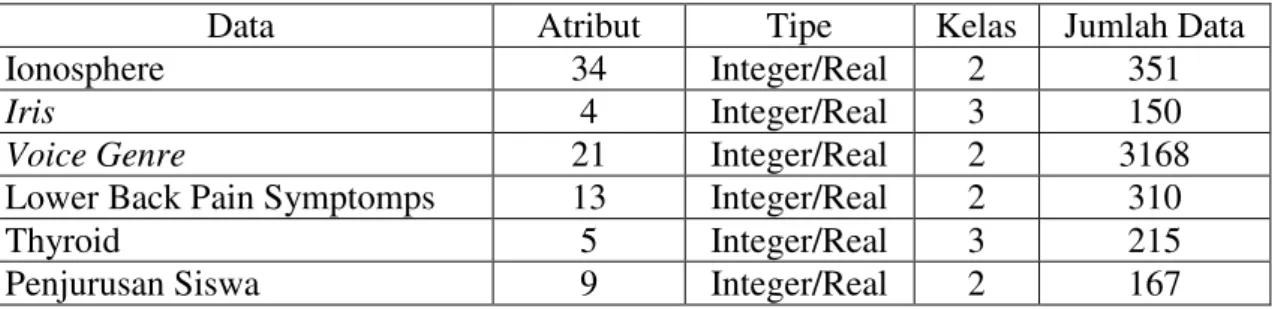
3.1 Data Yang Digunakan
Pada penelitian ini, untuk mengetahui kinerja dari metode yang digunakan maka akan digunakan 5 dataset sebelum akhirnya diterapkan pada data penjurusan siswa di SMAN 2 Tualang, Kecamatan Tualang, Kabupaten Siak, Provinsi Riau. Adapun dataset yang digunakan terdiri dari 2 dataset yang berasal dari UCI Machine Learning Repository, 2 dataset yang bersumber dari Kaggle Repository, dan 1 dataset yang berasal dari Keel Repository.
Dataset yang berasal dari UCI Machine Learning Repository diataranya adalah data ionosphere dan iris. Dataset ionosphere dikumpulkan oleh sebuah sistem di Goose Bay, Labrador, dimana data tersebut merupakan sinyal yang diterima dan diproses menggunakan fungsi autokorelasi. Dataset ionosphere ini berjumlah sebanyak 351 records dengan 34 attributes dan terdiri dari 2 kelas, data ini didonasikan pada tahun 1989 oleh Vince Sigilito.
Iris merupakan salah satu dataset yang populer, dataset ini mungkin merupakan dataset yang paling terkenal dan dapat ditemukan dalam literatur pengenalan pola yang telah disusun oleh Fisher (1988). Dataset ini terdiri dari 150 records dengan 4 attributes dan 3 kelas, dimana setiap kelas data terdiri dari 50 records.
Dataset selanjutnya bersumber dari Kaggle Repository, yaitu dataset voice genre dan Lower back pain symptoms. Dataset voice genre disusun oleh Becker dan terakhir diperbaharui pada tahun 2016. Dataset voice genre dikumpulkan untuk mengidentifikasi suara dari seorang pria atau seorang wanita berdasarkan sifat akustik dari suara dan ucapan, data ini berjumlah sebanyak 3168 records dengan 20 attributes dan 2 (dua) kelas data, yaitu pria (male) dan wanita (female).
Lower back pain symptoms adalah kumpulan data ini ditujukan untuk mengidentifikasi nyeri punggung dengan menggunakan data fisik tulang belakang,
15
data ini terakhir diperbaharui tahun 2016. Data lower back pain symptoms memiliki 12 attributes dengan dua kelas yaitu abnormal dan normal yang berjumlah sebanyak 310 records.
Selanjutnya, data yang digunakan pada penelitian ini adalah dataset thyroid disease (new thyroid) yang digunakan sebagai sampel untuk mendeteksi penyakit tiroid. Data ini berasal dari Keel Repository. Data thyroid disease (new thyroid) terdiri dari 215 records dengan 5 attributes dan 3 kelas data antara lain normal, hyperthyroidism dan hypothyroidism.
Terakhir, data yang digunakan pada penelitian ini adalah data penjurusan siswa SMA Negeri 2 Tualang yang berada di Kecamatan Tualang, Kabupaten Siak, Provinsi Riau. Data ini didapati melalui studi lapangan secara langsung yang dilakukan penulis pada tahun 2013, data penjurusan siswa ini memiliki 9 attributes dan 2 (dua) kelas dengan jumlah 167 records.
3.2 Penggabungan Local Mean Based K-Nearest Neighbor (LMKNN) dan Distance Weight K-Nearest Neighbor (DWKNN)
Pada penelitian ini akan menggantikan sistem vote majority pada K-Nearest Neighbor (K-NN) Konvensional menggunakan metode Distance Weight, dimana untuk mendapati bobot antar data akan dilakukan dengan cara menggabungkan metode Local Mean Based K-Nearest Neighbor (LMKNN) dan metode Distance Weight K- Nearest Neighbor (DWKNN).
Untuk lebih jelas dalam mendeskripsikan gabungan dari metode Local Mean Based K-Nearest Neighbor (LMKNN) dan metode Distance Weight K-Nearest Neighbor (DWKNN) maka akan dijelaskan tahapan demi tahapan dalam sub bab ini.
Adapun tahapan-tahapannya secara garis besar dapat dilihat pada gambar 3.1 :
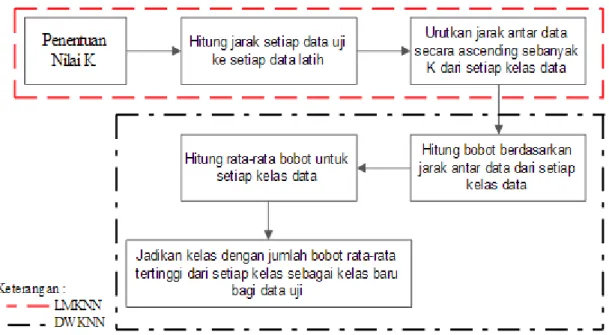
Gambar 3.1 Gabungan Local Mean Based K-Nearest Neighbor (LMKNN) dan Distance Weight K-Nearest Neighbor (DWKNN)
Berdasarkan gambar 3.1 terlihat bahwa metode gabungan Local Mean Based K-Nearest Neighbor (LMKNN) dan Distance Weight K-Nearest Neighbor (DWKNN) memiliki beberapa tahapan, antara lain :
i. Penentuan Tetangga Terdekat, tahapan ini merupakan kontribusi dari Local Mean Based K-Nearest Neighbor (LMKNN).
ii. Pembobotan Berdasarkan Jarak Antar Data, tahapan ini merupakan kontribusi dari Distance Weight K-Nearest Neighbor (DWKNN).
iii. Penentuan Kelas Data Baru, tahapan ini juga merupakan kontribusi dari Distance Weight K-Nearest Neighbor (DWKNN).
3.2.1 Penentuan Tetangga Terdekat
Penentuan tetangga terdekat dalam penelitian ini merupakan kontribusi dari metode Local Mean Based K-Nearest Neighbor (LMKNN), dalam penentuan tetangga harus melewati beberapa tahapan. Adapun tahapan dalam penentuan tetangga terdekat dapat dilihat pada gambar 3.2.
Gambar 3.2 Tahapan Penentuan Tetangga Terdekat
Berdasarkan gambar 3.2 dapat dijelaskan bahwa dalam penentuan tetangga terdekat akan melewati beberapa tahapan, antara lain :
Langkah 1 : Penentuan Nilai K, Hal pertama yang dilakukan dalam penentuan tetangga terdekat adalah penentuan jumlah tetangga terdekat yang diasumsikan dengan nilai K
Langkah 2 : Selanjutnya akan dilakukan perhitungan jarak dari data uji ke seluruh data sampel menggunakan model jarak Euclidean.
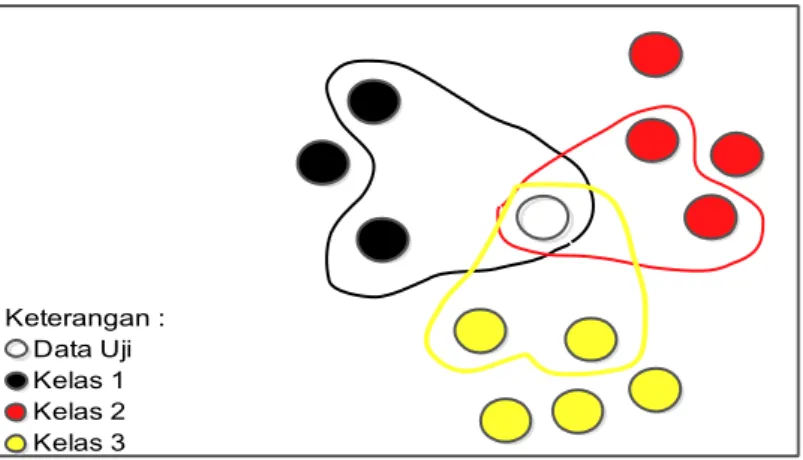
Langkah 3 : Tahapan selanjutnya, dilakukan pengurutan data secara ascending sebanyak K dari setiap kelas data, sehingga didapati K tetangga terdekat untuk setiap kelas, perhatikan gambar 3.3 dibawah ini untuk lebih jelasnya :
17
3.3
Gambar 3.3 Tetangga Terdekat Dari Setiap Kelas
Tahapan ini merupakan kontribusi dari metode LMKNN. Nilai K pada LMKNN sangat berbeda jauh dari nilai K pada K-NN konvensional, dimana pada K- NN konvensional nilai K merupakan jumlah tetangga terdekat dari seluruh data sampel, sedangkan pada LMKNN nilai K merupakan jumlah tetangga terdekat dari setiap kelas data sampel (Pan, et al. 2016).
3.2.2 Pembobotan Berdasarkan Jarak Antar Data
Setelah didapati K tetangga terdekat dari setiap kelas, maka tahapan selanjutnya adalah pembobotan berdasarkan jarak antar data. Untuk memberikan bobot dari jarak antar data dalam penelitian ini akan menggunakan tahapan dari metode DWKN (yaitu langkah 4 sampai dengan langkah 5). Adapun tahpan tersebut dapat dilihat pada gambar 3.4.
Gambar 3.4 Tahapan Pembobotan Jarak Antar Data
Berdasarkan gambar 3.4 terlihat tahapan dalam pemberian bobot berdasarkan jarak antar data antara lain :
Langkah 1 : Hitungan bobot berdasarkan berdasarkan jarak antar data dari setiap kelas data menggunakan persamaan 2.3.
Langkah 2 : Selanjutnya akan hitung rata-rata bobot dari setiap kelas data dengan persamaan 2.7.
Keterangan : Data Uji Kelas 1 Kelas 2 Kelas 3
Tahapan ini merupakan kontribusi dari metode DWKNN, dimana pada tahapan ini jarak antar data akan diberkan suatu bobot. Dengan pemberian bobot tersebut maka pengaruh antar data akan berbeda dalam penentuan kelas bagi data yang baru.
3.2.3 Penentuan Kelas Data Baru
Tahapan terakhir dari gabungan metode Local Mean Based K-Nearest Neighbor (LMKNN) dan Distance Weight K-Nearest Neighbor (DWKNN) adalah penentuan kelas data uji, dimana kelas data uji ditentukan berdasarkan rata-rata nilai bobot tertinggi dari setiap kelas data dengan menggunakan persamaan 2.6, tahapan ini merupakan kontribusi dari metode DWKNN.
Adapun tahapan dari penggabungan metode Local Mean Based K-Nearest Neighbor (LMKNN) dan Distance Weight K-Nearest Neighbor (DWKNN) secara menyeluruh dijelaskan dengan mengunakan gambar 3.5.
Gambar 3.5 Details Tahapan Gabungan Local Mean Based K-Nearest Neighbor (LMKNN) dan Distance Weight K-Nearest Neighbor (DWKNN)
3.3 Tahapan Analisa Kinerja Metode
Pada penelitian ini, untuk meningkatkan hasil akurasi dari metode K-Nearest Neighbor akan menggantikan sistem vote majority pada K-Nearest Neighbor (K-NN) Konvensional dengan metode Distance Weight, dimana untuk mendapati bobot antar data akan dilakukan dengan cara menggabungkan metode Local Mean Based K-
19
Nearest Neighbor (LMKNN) dan metode Distance Weight K-Nearest Neighbor (DWKNN). Untuk melihat apakah penggabungan ini berhasil atau tidak, akan dilakukan analisis kinerja berdasarkan hasil akurasi yang kemudian hasil akurasi tersebut akan dibandingkan dengan hasil akurasi dari metode K-NN konvensional.
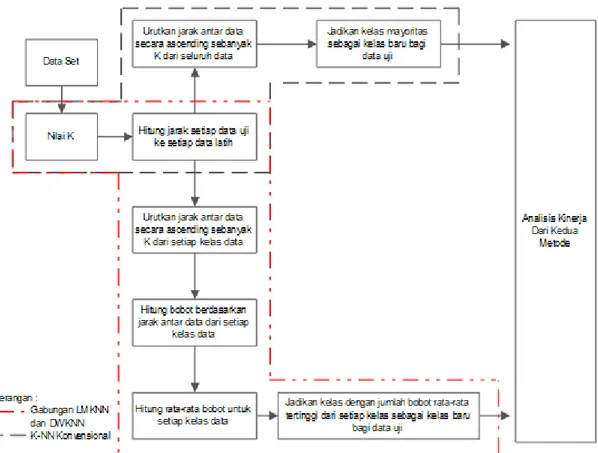
Penelitian ini menggunakan beberapa dataset, diantaranya 2 dataset yang berasal dari UCI Machine Learning Repository, 2 dataset yang didapati dari Kaggle Repository, yaitu voice genre dan lower back pain symptoms, dan 1 dataset thyroid disease (new thyroid) yang didapati dari Keel Repository. Secara garis besar prosedure dari penelitian yang diusulkan dapat dilihat pada gambar 3.3.
Gambar 3.3 Prosedure Penyelesaian Masalah
Berdasarkan Gambar 3.3, dapat dijelaskan alur proses penelitian adalah sebagai berikut :
i) Dataset. Dalam penelitian ini 80% dataset akan dijadikan data latih, dan 20% akan dijadikan data uji.
ii) Data latih tersebut akan digunakan untuk melakukan penentuan kelas terhadap data uji dengan menggunakan K-NN konvensional dan metode yang diusulkan.
iii) Untuk melihat apakah metode yang diusulkan berhasil meningkatkan akurasi atau tidak, maka akan dilakukan analisa kinerja dari kedua metode berdasarkan hasil akurasi dari setiap dataset yang digunakan. Dimana untuk mengukur tingkat akurasi dapat menggunakan persamaan di bawah ini (Han, 2011) :
Akurasi = P+ NP+N × % = J p y p × % (3.1)
Adapun langkah-langkah klasifikasi pada penelitian ini secara lengkap dapat dilihat pada gambar 3.3.
Gambar 3.3 Detail Prosedure Penyelesaian Masalah
Berdasarkan Gambar 3.3, dapat dijelaskan bahwa prosedure penyelesaian masalah dalam penelitian adalah sebagai berikut :
i) Data set yang telah dipilih akan dibagi menjadi 2, sebanyak 80% sebagai data latih dan 20% sebagai data uji.
ii) Lakukan proses klasifikasi dengan metode yang diusulkan, adapun tahapannya adalah :
1. Tentukan Nilai K yang merupakan jumlah tetangga terdekat.
2. Hitung jarak dari setiap data uji ke setiap data latih dengan menggunakan model jarak Euclidean dengan persamaan 2.9.
3. Urutkan jarak antar data secara ascending sebanyak K dari setiap kelas.
4. Hitung bobot menggunakan persamaan 2.3.
5. Hitung Rata-rata bobot untuk setiap kelas data.
21
6. Jadikan kelas dengan jumlah bobot rata-rata tertinggi dari setiap kelas sebagai kelas baru bagi data uji.
iii) Lakukan proses klasifikasi dengan K-NN konvensional, adapun tahapannya adalah :
1. Tentukan nilai K yang merupapkan jumlah tetangga terdekat.
2. Hitung jarak dari setiap data uji ke setiap data latih dengan menggunakan model jarak Euclidean dengan persamaan 2.9.
3. Urutkan jarak antar data secara ascending sebanyak K dari seluruh data.
4. Jadikan kelas mayoritas sebagai kelas baru bagi data uji.
iv) Analisis kinerja metode berdasarkan hasil akurasi yang dicapai dari kedua metode.
Setelah semua dataset dijadikan sebagai data untuk menguji metode manakah yang mampu menghasilkan hasil akurasi terbaik, maka metode tersebut yang nantinya akan digunakan untuk melakukan klasifikasi pada data penjurusan siswa kelas XI di SMAN 2 Tualang Kabupaten Siak, Provinsi Riau.
3.3.1 Penentuan Data Latih dan Data Uji
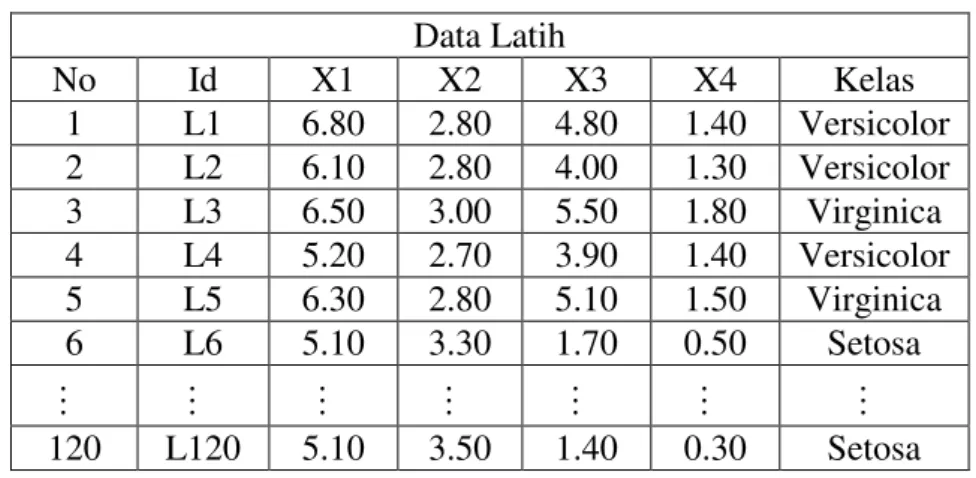
Diasumsikan terdapat sebuah dataset dengan jumlah data sebanyak 11 record, yang mana data tersebut memiliki 5 atribut dan 2 kelas, sebanyak 80% dari data dijadikan sebagai data latih dan 20% dari data dijadikan sebagai data uji, dimana data uji akan ditentukan kelasnya. Adapun paparan dari rincian data dapat dilihat pada tabel 3.1.
Tabel 3.1 Rincian Data
No X1 X2 X3 X4 X5 Kelas Keterangan
1 85 85 85 90 85 1 Data Latih 1
2 87 73 70 71 74 1 Data Latih 2
3 80 71 78 82 80 1 Data Latih 3
4 82 90 90 80 84 1 Data Latih 4
5 77 91 83 90 84 1 Data Latih 5
6 70 70 70 71 76 2 Data Latih 6
7 70 70 70 72 70 2 Data Latih 7
8 75 84 80 81 75 2 Data Latih 8
9 70 70 70 71 70 2 Data Latih 9
10 76 75 71 80 76 2 Data Uji 1
11 75 78 70 80 81 2 Data Uji 2
3.3.2 Proses Klasifikasi
3.3.2.1 Klasifikasi Dengan Metode Gabungan Local Mean Based dan Distance Weight K-Nearest Neighbor
Langkah pertama untuk menentukan kelas dengan menggunakan gabungan metode LMKNN dan DWKNN bagi data uji adalah menentukan nilai K, dimisalkan K bernilai 3, selanjutnya hitung jarak data uji ke seluruh data latih dengan menggunakan model jarak Euclidean.
𝐷 𝐷𝑎 𝑎 𝑈 , 𝐷𝑎 𝑎 𝐿𝑎 ℎ = √ − 2 + − 2 + ⋯ + − 2
𝐷 𝐷𝑎 𝑎 𝑈 , 𝐷𝑎 𝑎 𝐿𝑎 ℎ = .
Lakukan hal yang sama untuk seluruh data latih lainnya, adapun jarak yang didapati dapat dilihat pada tabel 3.2.
Tabel 3.2 Jarak Data Uji ke Setiap Data Latih Jarak Antar
Data Latih 1 Latih 2 Latih 3 Latih 4 Latih 5 Latih 6 … Latih 9 Uji 1 23.62 14.53 10.05 26.19 23.77 11.96 … 13.37 Uji 2 22.14 17.29 11.96 24.54 21.24 13.96 … 17.06
Urutkan jarak secara ascending sebanyak K untuk setiap kelasnya, pada tahapan ini akan diurutkan 3 data latih terdekat terhadap data uji untuk setiap kelasnya. Adapun urutan jarak terdekat antara data uji dan data latih dapat dilihat pada tabel 3.3 dan untuk 3 data latih terdekat dari setiap kelasnya dapat dilihat pada tabel 3.4.
Tabel 3.3 Urutan Jarak Terdekat Antara Data Uji ke Seluruh Data Latih Urutan Jarak Terdekat
1st 2nd 3rd 4th 5th 6th 7th 8th 9th
Data Latih
Uji 1 3 6 7 8 9 2 1 5 4
Uji 2 3 8 6 7 9 2 5 1 4
Tabel 3.4 Urutan Jarak Terdekat Untuk Setiap Kelas Data
Data Kelas Urutan Data Latih
Uji 1 1 Data Latih 3 Data Latih 2 Data Latih 1 2 Data Latih 6 Data Latih 7 Data Latih 8
23
Tabel 3.4 Urutan Jarak Terdekat Untuk Setiap Kelas Data (Lanjutan)
Data Kelas Urutan Data Latih
Uji 2 1 Data Latih 3 Data Latih 2 Data Latih 1 2 Data Latih 8 Data Latih 6 Data Latih 7 Berdasarkan tabel 3.4, 3 tetangga terdekat dari data uji 1 dan data uji 2 adalah sama, dimana untuk kelas 1 adalah data latih 3, 2, dan data latih 1. Untuk kelas 2, yang merupakan 3 tetangg terdekar dari data uji 1 adalah data latih 6, 7, dan data latih 8, sedangkan 3 tetangga terdekat dari data uji 2 adalah data latih 8, 6 dan data latih 7.
Tahapan selanjutnya dilakukan perhitungan bobot jarak (dengan persamaan 2.3) untuk setiap data terdekat pada setiap keleas, kemudian hitung rata-rata bobot jarak dari setiap kelas. Adapun nilai rata-rata bobot jarak dari masing-masing kelas dapat dilihat pada tabel 3.5.
Tabel 3.5 Bobot Jarak Setiap Kelas
Data Kelas Bobot Jarak Rata-rata
Uji 1 1 0.0995 0.0688 0.0423 0.0702
2 0.0836 0.0786 0.0788 0.0800
Uji 2 1 0.0836 0.0578 0.0452 0.0622
2 0.0760 0.0716 0.0604 0.0693
Tahapan dalam penentuan kelas bagi data uji dalam gabungan LMKNN dan DWKNN adalah dengan menjadikan kelas dengan bobot tertinggi sebagi kelas bagi data uji. Berdasarkan tabel 3.5 terlihat bahwa rata-rata bobot jarak tertinggi pada data uji 1 dan 2 didapati oleh kelas 2 (dua), sehingga data uji 1 dan data uji 2 berada pada kelas 2 (dua).
3.3.2.2 Klasifikasi Menggunakan K-Nearest Neighbor Konvensional
Sedangkan pada K-NN konvensional langkah pertama dimulai dengan penentuan nilai K, dimana K telah diasumsikan bernilai 3, tahapan selanjutnya adalah perhitungan jarak antara data uji ke setiap data latih dengan model jarak Euclidean. Adapun perhitungan jarak yang dihasilkan sama dengan perhitungan jarak pada gabungan metode LMKNN dan DWKNN (dapat dilihat pada tabel 3.2). Selanjutnya dilakukan pengurutan tetangga terdekat sebanyak K, adapun urutan data latih terdekat dapat dilihat pada tabel 3.6.
Tabel 3.6 Urutan K Tetangga Terdekat
Data Latih Data Latih
1st 2nd 3rd 1st 2nd 3rd
Data Uji 1 3 6 7 Data Uji 2 3 8 6
Kelas 1 2 2 Kelas 1 2 2
Tahapan terakhir adalah penentuan kelas bagi data uji dengan menggunakan sistem vote majority. Berdasarkan tabel 3.6 terlihat bahwa kelas mayoritas adalah kelas 2 (dua), sehingga data uji 1 dan data uji 2 berada pada kelas 2 (dua).
3.3.3 Analisa Kinerja Metode
Umumnya, pengukuran kinerja klasifikasi dapat dilakukan dengan menggunakan confusion matrix. Akan tetapi pada penelitian ini hanya berfokus kepada tingkat akurasi yang dihasilkan. Dimana untuk mengukur tingkat akurasi dapat menggunakan persamaan 3.1.
𝐴 𝑎 − 𝑣𝑒 𝑠𝑖 𝑎𝑙 = × % = %
𝐴 𝑎 +𝐷𝑊 = × % = %
Berdasarkan sub bab sebelumnya maka nilai akurasi dari K-NN konvensional adalah sebesar 100% dan metode gabungan LMKNN dan DWKNN adalah sebesar 100%. Hal ini dikarenakan kedua metode mampu memprediksi seluruh data uji dengan benar. Maka hasil analisa dari kedua metode adalah sama baiknya.
3.4 Software dan Tools yang digunakan
Untuk mempermudah perhitungan dalam penelitian ini penulis menggunakan bantuan aplikasi MATLAB®. Dimana langkah-langkah dari metode gabungan LMKNN dan DWKNN diimplementasikan secara manual, dan untuk K-NN konvensional penulis menggunakan fungsi yang sudah terdapat di MATLAB®. Pengimplementasian dengan bahasa pemograman matlab ini menggunakan spesifikasi processor Intel Core I3 dan RAM 3 GB serta menggunakan data yang diambil dari UCI Repository, Kaggle Repository, dan Keel Repository.
BAB 4
HASIL DAN PEMBAHASAN
4.1 Hasil
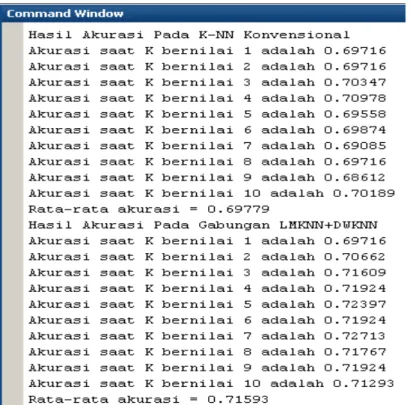
Tahapan-tahapan pada sub bab 3.3 diimplementasi dengan menggunakan bahasa pemograman MATLAB®, dimana semua proses pengimplementasian dilakukan hanya melalui console pada program MATLAB® tersebut.
Pengimplementasian ini bertujuan untuk menpermudah proses perhitungan dalam pengujian terhadap seluruh data yang digunakan dalam penelitian ini. Adapun hasil output dari pengujian terhadap dataset ionosphare dapat dilihat pada gambar 4.1.
Gambar 4.1 Output Akurasi Pengujian Pada Dataset Ionosphare
Adapun hasil output dari pengujian terhadap dataset iris dapat dilihat pada gambar 4.2.
Gambar 4.2 Output Akurasi Pengujian Pada Dataset Iris
Adapun hasil output dari pengujian terhadap dataset voice genre dapat dilihat pada gambar 4.3.
Gambar 4.3 Output Akurasi Pengujian Pada Dataset Voice Genre
27
Adapun hasil output dari pengujian terhadap dataset lower back pain symptomps dapat dilihat pada gambar 4.4.
Gambar 4.4 Output Akurasi Pengujian Pada Dataset Lower Back Pain Symptomps
Adapun hasil output dari pengujian terhadap dataset new thyroid dapat dilihat pada gambar 4.5.
Gambar 4.5 Output Akurasi Pengujian Pada Dataset New Thyroid
Adapun hasil output dari pengujian terhadap data penjurusan siswa dapat dilihat pada gambar 4.6.
Gambar 4.6 Output Akurasi Pengujian Pada Data Penjurusan Siswa
4.2 Pengujian
Pengujian dilakukan dengan menggunakan beberapa data yang didapat dari UCI Repository, Kaggle Repository, Keel Repository dan data yang merupakan hasil studi lapangan secara langsung yang dialaukan oleh penulis.
Pada saat pengujian, sebanyak 80% dari data akan dijadikan sebagai data latih dan sebanyak 20% dari data akan dijadikan data uji yang dilakukan secara random.
Adapun rincian data yang digunakan dapat dilihat pada tabel 4.1.
Tabel 4.1 Rincian Dataset Yang Digunakan
Data Atribut Tipe Kelas Jumlah Data
Ionosphere 34 Integer/Real 2 351
Iris 4 Integer/Real 3 150
Voice Genre 21 Integer/Real 2 3168
Lower Back Pain Symptomps 13 Integer/Real 2 310
Thyroid 5 Integer/Real 3 215
Penjurusan Siswa 9 Integer/Real 2 167
29
Pengujian ini bertujuan untuk melihat kinerja metode Local Mean dan Distance Weight pada K-NN. Pengukuran kinerja dilihat berdasarkan dari hasil akurasi yang didapati dari K-NN yang menggunakan Local Mean dan Distance Weight terhadap K-NN konvensional.
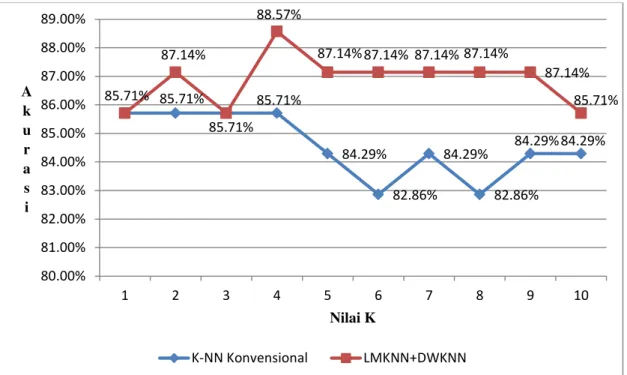
4.1.1 Pengujian Terhadap Dataset Ionosphare
Pengujian pertama dilakukan menggunakan dataset ionosphere, dimana dataset ini berjumlah 351 record dengan 34 atribut dan terdiri dari 2 kelas data. Pada pengujian menggunakan dataset ionosphere ini, data latih berjumlah 281 data, dan data uji berjumlah 70 data. Adapun rincian dari distribusi data ionoshpere dapat dilhat pada tabel 4.2, dan untuk melihat data latih dan data uji yang digunakan dapat dilihat pada tabel 4.3.
Tabel 4.2 Distribusi Data Ionosphare
No Kategori Kelas Jumlah
Data
Bad Good
1 Data Latih 103 178 281
2 Data Uji 23 47 70
Total 126 225 351
Tabel 4.3 Rincian Data Ionosphare Yang digunakan Data Latih
No Id X1 X2 X3 X4 X5 X6 … X34 Kelas
1 L1 1 0 0.44 0.04 0.58 -0.10 … -0.06 Good
2 L2 1 0 0.42 -0.61 0.00 0.00 … 0.00 Bad
3 L3 0 0 1.00 -1.00 -1.00 1.00 … 1.00 Bad
4 L4 1 0 0.83 0.29 0.69 0.48 … -0.35 Good
5 L5 1 0 0.87 -0.07 1.00 -0.02 … -0.44 Good
6 L6 1 0 -1.00 1.00 -1.00 0.15 … 1.00 Bad
… … … …
281 L281 1.00 0 1.00 -1.00 0.00 0.00 … 0 Bad Data Uji
No Id X1 X2 X3 X4 X5 X6 … X34 Kelas
1 U1 1 0 1.00 -0.57 0.99 -0.73 … -0.76 Good
2 U2 0 0 1.00 -1.00 1.00 1.00 … 1.00 Bad
3 U3 1 0 0.92 0.18 0.86 0.36 … 0.05 Good
4 U4 1 0 0.87 0.04 0.80 0.18 … 0.09 Good
5 U5 1 0 0.94 0.39 0.48 0.65 … 0.50 Good
… … … …
70 U70 1 0 0.499 0.018 0.431 0.096 … 0.086 Good
Selanjutnya dilakukan perhitungan jarak antara data latih dan data uji menggunakan model jarak Euclaudien (persamaan 2.10). Adapun jarak yang dihasilkan dapat dilihat pada tabel 4.4. Selanjutnya dilakukan pengurutan jarak antar data secara ascending, adapun urutan jarak terdekat antar data dapat dilihat pada tabel 4.5.
Tabel 4.4 Jarak Antara Data Pada Dataset Ionosphare
Data Uji Data Latih
L1 L2 L3 L4 L5 … L281
U1 3.438 4.297 7.058 5.737 2.953 … 3.976
U2 4.747 5.485 8.062 6.630 4.195 … 5.361
U3 3.789 4.175 6.745 3.420 5.151 … 5.736
U4 2.168 3.537 6.493 4.859 1.062 … 4.806
U5 3.458 4.016 5.736 3.881 4.713 … 5.380
U6 3.898 4.341 5.573 4.642 5.184 … 5.597
U7 4.126 4.062 6.725 3.805 5.458 … 6.031
U8 2.432 3.375 6.233 4.965 1.621 … 4.871
U9 2.425 3.715 6.912 5.235 0.620 … 4.930
U10 2.008 3.498 6.692 4.862 0.558 … 4.606
… … … …
U70 0.847 2.648 6.031 3.857 1.812 … 4.127
Tabel 4.5 Urutan Jarak Terdekat Pada Dataset Ionosphare Data
Uji
Urutan Jarak Terdekat
1st 2nd 3rd 4th 5th … 281th
U1 L14 L42 L219 L129 L207 … L228
U2 L223 L70 L259 L52 L102 … L228
U3 L124 L177 L72 L100 L23 … L30
U4 L91 L102 L77 L182 L253 … L228
U5 L44 L54 L153 L185 L199 … L60
U6 L101 L116 L260 L245 L87 … L188
U7 L135 L177 L72 L124 L23 … L30
U8 L102 L29 L91 L253 L58 … L288
U9 L41 L27 L144 L200 L222 … L38
U10 L8 L144 L253 L222 L118 … L38
… … … …
U70 L156 L81 L109 L34 L216 … L288
Untuk K-NN konvensional akan ditentukan kelas mayoritasnya berdasarkan K tetangga terdekat dan akan menjadian kelas mayoritas sebagai kelas bagi data uji, sedangkan tahap selanjutnya untuk gabungan LMKNN dan DWKNN akan menghitung nilai rata-rata bobot dari jarak sebanyak K tetangga terdekat untuk setiap