Fakultas Ilmu Komputer
Universitas Brawijaya
4340
Implementasi Algoritme
Modified K-Nearest Neighbor
(MK-NN) Untuk
Diagnosis Penyakit Anjing
Luh Putu Novita Budiarti1, Nurul Hidayat2, Tri Afirianto3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Anjing adalah salah satu hewan yang banyak dijadikan peliharaan. Berinteraksi dengan anjing memiliki banyak manfaat bagi kesehatan seperti membantu menurunkan stres dan membuat pemiliknya memiliki gaya hidup yang lebih aktif. Tetapi, kondisi kesehatan hewan peliharaan itu sendiri harus diperhatikan. Anjing yang terserang penyakit memiliki resiko dapat menularkannya pada hewan peliharaan lainnya atau bahkan pada manusia, Kondisi menjadi sedikit sulit apabila pemilik baru menyadari bahwa anjingnya sedang dalam keadaan tidak sehat pada jam-jam di luar jam kerja. Terbatasnya jumlah klinik hewan yang dapat menangani pasien di luar jam kerja membuat pemilik anjing harus dapat memberikan penanganan awal dengan segera. Untuk menangani masalah tersebut, diperlukan suatu sistem untuk membantu mendiagnosis penyakit anjing dengan memanfaatkan metode klasifikasi Modified K-Nearest
Neighbor (MK-NN) untuk membantu pemilik anjing melakukan deteksi dini penyakit anjing agar dapat
dilakukan penanganan awal dengan segera. Sistem diimplementasikan menggunakan bahasa pemrograman Java. Ada 10 macam penyakit dengan gejala sebanyak 46. Berdasarkan pengujian akurasi yang dilakukan, didapatkan rata-rata akurasi maksimal sebesar 96,6% dengan k=2.
Kata kunci: Modified K-Nearest Neighbor (MK-NN), klasifikasi, penyakit anjing
Abstract
Dog is one of the most favorite pets. Interacting with dogs has its benefit such as lowering stress levels and leading the owners to have a more active lifestyle. However, the dog’s health itself should be taken care of. Dog who suffers from a disease can infect other pets or even humans, so veterinarian help is needed. Things will be difficult if the owners realize that their dogs are sick outside of working hours because there is not much veterinary clinic that open for 24 hours. So the owners should be capable of giving immediate response to their dogs. Therefore, a system is needed to help this problem using Modified K-Nearest Neighbor (MK-NN) algorithm, to help the owner getting their dog diagnosed and giving immediate response. The system is implemented using Java programming language. There are 10 types of the diseases with 46 clinical symptoms. Based on the accuracy test, the maximum average of accuracy obtained is 96.6% with k=2.
Keywords: Modified K-Nearest Neighbor (MK-NN), classification, dog diseases
1. PENDAHULUAN
Salah satu hewan yang banyak dijadikan peliharaan adalah anjing. Salah satu manfaat memiliki hewan peliharaan adalah dapat meningkatkan kesehatan mental manusia. Berdasarkan penelitian, kecil kemungkinan bagi mereka yang memiliki anjing atau kucing untuk mengalami lonjakan denyut jantung dan tekanan darah dalam kondisi stres seperti saat mengerjakan tugas matematika dengan waktu yang terbatas. Denyut jantung dan tekanan darah
mereka dapat kembali normal lebih cepat dibanding mereka yang tidak memiliki anjing atau kucing (Allen et al, 2002). Meskipun memiliki manfaat bagi kesehatan manusia, namun kesehatan anjing itu sendiri harus diperhatikan. Anjing yang terserang penyakit memiliki resiko dapat menularkannya ke anjing lain atau hewan peliharaannya, atau bahkan kepada manusia.
kerja. Terbatasnya jumlah klinik hewan yang dapat menangani pasien di luar jam kerja membuat pemilik anjing harus dapat memberikan penanganan awal dengan segera. Oleh karena itu, diperlukan suatu sistem yang dapat melakukan klasifikasi penyakit anjing untuk membantu pemilik anjing melakukan deteksi dini penyakit anjing sehingga penanganan awal dapat dilakukan dengan segera.
Klasifikasi merupakan salah satu fungsionalitas dari data mining yang digunakan untuk melakukan pengelompokan data atau objek ke dalam kelas-kelas, di mana kelas-kelas tersebut sudah didefinisikan sebelumnya. Pada klasifikasi, data masukan (input) berupa sekumpulan atribut-atribut atau fitur-fitur yang merupakan ciri-ciri dari suatu data atau objek. Terdapat berbagai macam algoritme klasifikasi yang dapat digunakan, salah satunya adalah
Modified K-Nearest Neighbor (MK-NN).
Algoritme MK-NN berasal dari algortime
K-Nearest Neighbor (K-NN) yang dimodifikasi
dengan adanya penambahan proses baru yaitu perhitungan validitas dan weight voting, sehingga seluruh data latih harus divalidasi satu kali terlebih dahulu, yang dihitung sesuai dengan tetangga terdekatnya kemudian melakukan
weight voting menggunakan nilai validasi
tersebut (Parvin, 2010).
Penelitian sebelumnya berkaitan dengan MK-NN salah satunya adalah untuk klasifikasi penyakit demam berdasarkan gejala-gejala klinis, yang memiliki rata-rata akurasi terhadap perubahan nilai k sebesar 88,55%, sedangkan rata-rata akurasi terhadap pengaruh komposisi data latih sebesar 87,89% (Wafiyah et al, 2017). Penelitian lainnya mengenai penentuan status gizi balita menggunakan MK-NN untuk mengklasifikasikan status gizi balita ke dalam 4 kelas yaitu gizi baik, gizi kurang, gizi buruk, dan gizi lebih, memiliki akurasi yang berada pada kisaran 80% (Khotimah, 2015).
Berdasarkan permasalahan dan pemaparan tersebut, maka pada penelitian ini dibangun sebuah sistem menggunakan algoritme MK-NN untuk diagnosis penyakit anjing. Sistem ini diharapkan dapat membantu pemilik anjing melakukan deteksi dini penyakit sehingga penanganan awal dapat dilakukan dengan segera. Tujuan dari penelitian ini adalah menerapkan algoritme MK-NN untuk diagnosis penyakit anjing dan mengetahui tingkat akurasi yang dihasilkan sistem.
2. LANDASAN KEPUSTAKAAN
2.1 Penyakit Anjing
Ada 10 penyakit anjing yang diklasifikasi pada sistem yaitu Demodicosis, Scabiosis, Otitis, Helminthiasis, Canine Parvovirus, Ringworm,
Coccidiosis Ehrlichiosis, Urolithiasis dan
Canine Distemper.
2.2 DataMining
Data mining merupakan suatu proses
menemukan pengetahuan dan pola dari sejumlah data yang berukuran besar yang berasal dari basis data, data warehouse, web dan penyimpanan informasi lainnya. Data mining
mempunyai fungsionalitas-fungsionalitas yang digunakan untuk menentukan pola yang ditemukan dalam tugas data mining. Secara umum, tugas data mining dikategorikan menjadi 2, yaitu deskriptif dan prediktif. Tugas dekriptif adalah untuk menggambarkan properti-properti data dalam data set, sedangkan tugas prediktif adalah untuk membuat prediksi dengan melakukan induksi pada data yang ada (Han, 2012).
2.3 Klasifikasi
Salah satu fungsionalitas data mining adalah klasifikasi. Terdapat 2 langkah dalam klasifikasi yaitu pelatihan (learning) dan klasifikasi (classification). Pelatihan merupakan langkah untuk membuat model klasifikasi, sedangkan klasifikasi adalah langkah untuk menetukan kelas dari data menggunakan model klasifikasi yang telah dibuat (Han, 2012).
Dalam proses pelatihan, suatu set data latih yang kelasnya telah diketahui dianalisis kemudian sebuah model dibangun dari setiap kelas menggunakan algoritme klasifikasi. Karena setiap data latih telah diketahui kelasnya, proses pelatihan pada klasifikasi disebut
supervised learning.
Model yang telah didapatkan menggunakan algoritme klasifikasi merupakan aturan-aturan klasifikasi (classification rules) yang akan diuji menggunakan data uji untuk memperkirakan akurasinya. Data yang digunakan sebagai data uji tidak digunakan dalam proses pelatihan.
2.4 Modified K-Nearest Neighbor (MK-NN)
klasifikasi algoritme MK-NN.
1. Menetukan nilai k tetangga terdekat.
2. Menghitung jarak Euclidean antar data latih menggunakan Persamaan (1).
𝑑(𝑥,𝑦)= √∑ (𝑥𝑛𝑖=1 𝑖− 𝑦𝑖)2 (1)
3. Menghitung nilai validitas data latih. Nilai validitas data latih tergantung pada tetangga terdekatnya, yang digunakan untuk menghitung jumlah titik dengan label yang sama untuk data tersebut. Persamaan (2) merupakan persamaan menghitung nilai validitas.
Fungsi S dalam Persamaan (2) digunakan untuk menghitung kesamaan antara titik x
dan data ke-i tetangga terdekat, yang didefinisikan dalam Persamaan (3).
𝑆(𝑎,𝑏)= {1 𝑎 = 𝑏0 𝑎 ≠ 𝑏 (3)
4. Menghitung jarak Euclidean antara data latih dengan data uji menggunakan Persamaan (1).
5. Menghitung weight voting
Pada variasi metode metode K-NN,
weighted K-NN, bobot setiap tetangganya dihitung dengan Persamaan (4).
𝑊(𝑖)= 𝑑+𝛼1 (4)
Keterangan:
W(i) = bobot-setiap tetangga
d = jarak-Euclidean data uji dengan data latih
α = smoothing regulator, bernilai 0,5 Pembobotan ini kemudian dijumlahkan untuk setiap kelas dan kelas dengan total yang terbesar dipilih. Validitas data latih dikalikan dengan bobot tersebut berdasarkan pada jarak Euclidean, sehingga didapatkan perhitungan weight voting pada MK-NN yang didefinisikan oleh Persamaan (5).
𝑊(𝑖)= 𝑉𝑎𝑙𝑖𝑑𝑖𝑡𝑎𝑠(𝑖)×𝑑+0.51 (5) Keterangan:
W(i) = weight votingi
Validitas(i) = nilai-validitas
d = jarak data uji dengan data
latih
Weight voting pada MK-NN berpengaruh
besar pada data yang memiliki nilai validitas lebih tinggi dan lebih dekat dengan data uji. Perkalian validitas dengan bobot pada Persamaan (5) mampu mengatasi kelemahan dalam hal outlier. Oleh karena itu, MK-NN merupakan algoritme yang lebih kuat dari K-NN yang hanya berdasarkan pada jarak (Parvin, 2010).
6. Menentukan kelas data uji.
Untuk menentukan kelas data uji, diambil nilai weight voting terbesar. Kelas data dari nilai weight voting yang paling besar merupakan kelas data uji.
3. METODOLOGI PENELITIAN
Penelitian ini dilakukan mengikuti tahapan-tahapan yang ditunjukan pada Gambar 1.
3.1.Data Penelitian
Data penelitian didapatkan dari Klinik Hewan Yudisthira, Denpasar, berupa penyakit-penyakit anjing yang berjumlah 10 penyakit-penyakit, gejala-gejala penyakit anjing yang berjumlah 46 gejala beserta bobot masing-masing gejala, dan data rekam medis pasien anjing yang berjumlah 250
data.
4. PERANCANGAN
Perancangan menjelaskan kebutuhan yang diperlukan untuk membangun sistem diagnosis penyakit anjing menggunakan MK-NN.
Gambar 1.Metodologi Penelitian
4.1 Analisis Kebutuhan Proses
Masukan pada sistem berupa nilai k dan gejala-gejala penyakit anjing. Sistem kemudian akan memproses masukan-masukan tersebut
menggunakan MK-NN dan memberikan
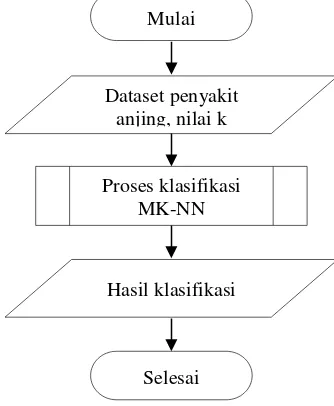
keluaran berupa hasil klasifikasi penyakit anjing. Secara umum, diagram alir sistem ditunjukan pada Gambar 2.
4.2 Perancangan Klasifikasi
Klasifikasi menggunakan MK-NN terdiri dari beberapa tahap yaitu, memasukan data set penyakit anjing dan nilai k, menghitung jarak Euclidean antar data latih, menghitung nilai validitas, menghitung jarak Euclidean antara data
Gambar 2. Diagram alir sistem
latih dengan data uji, menghitung weight voting, dan menentukan kelas data uji. Proses klasifikasi
MK-NN ditunjukan pada Gambar 3.
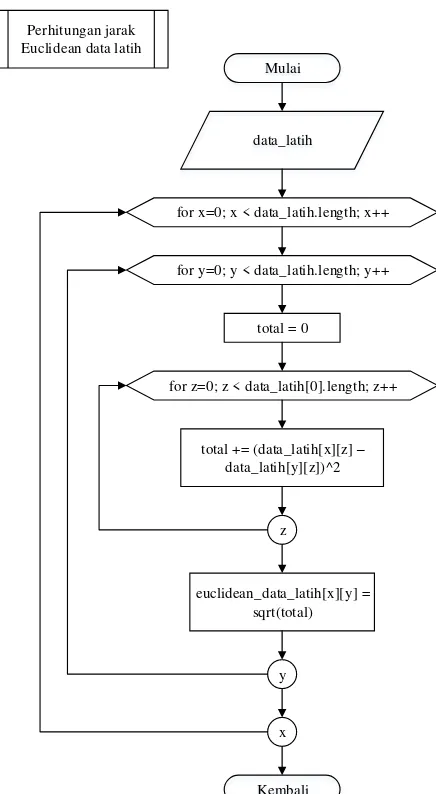
4.2.1 Perhitungan Jarak Data Latih
Setelah memasukan nilai k dan dataset penyakit anjing yang berupa data latih dan data uji, langkah pertama adalah menghitung jarak euclidean antar data latih. Proses perhitungan jarak euclidean antar data latih ditunjukan pada Gambar 4.
4.2.2 Perhitungan Validitas
Setelah jarak antar data latih didapatkan, dilakukan perhitungan validitas. Diambil jarak terdekat sejumlah nilai k, lalu membandingkan kelas data latih dengan kelas tetangga terdekat tersebut. Nilai kesamaan kelas yang didapatkan kemudian dijumlahkan dan hasilnya dibagi dengan nilai k. Proses perhitungan validitas ditunjukan pada Gambar 5.
Proses Klasifikasi MK-NN
Mulai
Dataset penyakit anjing, nilai k
Perhitungan jarak Euclidean data latih
Perhitungan Validitas
Perhitungan jarak Euclidean data latih
dan data uji
Perhitungan weight voting
Klasifikasi penyakit anjing
Selesai Menentukan kelas
data uji
Gambar 3. Diagram alir proses klasifikasi MK-NN Analisis Kebutuhan
Pengumpulan Data
Perancangan Sistem
Implementasi sistem
Pengujian dan Analsis
Kesimpulan dan Saran
Mulai
Dataset penyakit anjing, nilai k
Proses klasifikasi MK-NN
Perhitungan jarak Euclidean data latih
Mulai
data_latih
for x=0; x < data_latih.length; x++
for y=0; y < data_latih.length; y++
total = 0
for z=0; z < data_latih[0].length; z++
total += (data_latih[x][z] –
data_latih[y][z])^2
z
euclidean_data_latih[x][y] = sqrt(total)
y
x
Kembali
Gambar 4. Proses perhitungan jarak antar data latih
4.2.3 Perhitungan Jarak Data Latih dan Uji
Setelah validitas didapatkan, proses selanjutnya adalah menghitung jarak euclidean antara data latih dengan data uji, yang ditunjukan pada Gambar 6.
4.2.4 Perhitungan Weight Voting
Setelah jarak data latih dengan data uji didapatkan, dilakukan perhitungan weight voting
menggunakan nilai validitas dan jarak antara data latih dengan data uji. Proses perhitungan
weight voting ditunjukan pada Gambar 7.
4.2.5 Menentukan Kelas Data Uji
Setelah didapatkan hasil perhitungan weight voting, diambil nilai weight voting yang terbesar. Kelas dari nilai weight voting yang terbesar tersebut merupakan kelas dari data uji. Proses menentukan data uji ditunjukan pada Gambar 8.
Perhitungan Validitas
Mulai
jarak, K, K_euclidean_data_latih,
kelas_data
for x=0; x < K_euclidean_data_latih.length; x++ Urutkan jarak dari yang terkecil
ambil jarak terdekat sebanyak K (K_euclidean_data_latih)
for y=0; y < K_euclidean_data_latih[0].length; y++ validitas[x] = 0
kelas_data[x] == kelas_data[x][y]
validitas[x] +=1
y
validitas[x] = validitas[x]/k
x
Kembali Ya
Tidak
Gambar 5. Proses perhitungan validitas
5. PENGUJIAN DAN ANALISIS
Pengujian yang dilakukan adalah pengujian akurasi untuk mengukur tingkat akurasi sistem yang telah dibangun. Pengujian tingkat akurasi dilakukan dengan melakukan perbandingan hasil keluaran sistem dengan data sebenarnya, yaitu data rekam medis.
Perhitungan jarak Euclidean data latih
dan data uji Mulai
data_latih, data_uji
for x=0; x < data_uji.length; x++
for y=0; y < data_latih.length; y++
total = 0
for z=0; z < data_latih[0].length; z++
total += (data_uji[x][z] –
data_latih[y][z])^2
z
euclidean_data_uji[x][y] = sqrt(total)
y
x
Kembali
Gambar 6. Perhitungan jarak data latih dan data uji
Perhitungan weight
voting
Mulai
euclidean_data_uji, validitas
for x=0; x < euclidean_data_uji.length; x++
for y=0; y < euclidean_data_uji[0].length; y++
weight_voting[x][y] = validitas[y] * (1/(euclidean_data_uji [x][y]+0.5))
y
x
Kembali
Gambar 7. Proses perhitungan weight voting
Mulai
kelas_data_uji, weight_voting
Urutkan weight_voting dari yang terbesar ke terkecil
hasil_klasifikasi = kelas_data_uji.length
for x=0; x < hasil_klasifikasi.length; x++
hasil_klasifikasi[x] = kelas_data_uji[x][0]
x
Kembali Menentukan
kelas data uji
Gambar 8. Proses menentukan kelas data uji
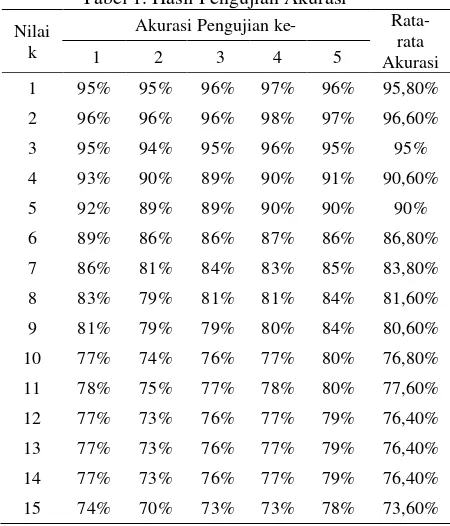
Tabel 1. Hasil Pengujian Akurasi
Nilai k
Akurasi Pengujian ke-
Rata-rata Akurasi
1 2 3 4 5
1 95% 95% 96% 97% 96% 95,80%
2 96% 96% 96% 98% 97% 96,60%
3 95% 94% 95% 96% 95% 95%
4 93% 90% 89% 90% 91% 90,60%
5 92% 89% 89% 90% 90% 90%
6 89% 86% 86% 87% 86% 86,80%
7 86% 81% 84% 83% 85% 83,80%
8 83% 79% 81% 81% 84% 81,60%
9 81% 79% 79% 80% 84% 80,60%
10 77% 74% 76% 77% 80% 76,80%
11 78% 75% 77% 78% 80% 77,60%
12 77% 73% 76% 77% 79% 76,40%
13 77% 73% 76% 77% 79% 76,40%
14 77% 73% 76% 77% 79% 76,40%
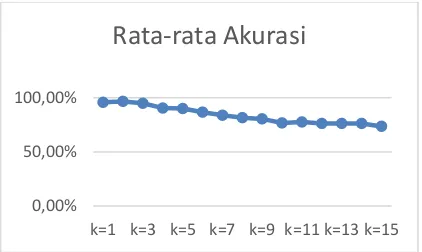
Gambar 9. Grafik rata-rata akurasi pengujian
Berdasarkan Tabel 1, perubahan nilai k mempunyai pengaruh terhadap nilai akurasi pengujian. Nilai akurasi mengalami penurunan dengan bertambahnya nilai k. Hal ini dikarenakan, semakin besar nilai k yang digunakan maka semakin banyak tetangga terdekat yang diambil untuk perhitungan validitas. Tetangga-tetangga terdekat tersebut berkemungkinan memiliki kelas yang berbeda sehingga mempengaruhi nilai kesamaan kelas penyakit yang akan mempengaruhi nilai validitas dan nilai weight voting. Selain itu, hasil klasifikasi juga dipengaruhi oleh komposisi data latih yang tidak seimbang. Pada data latih, terdapat kelas penyakit yang mendominasi. Hal ini membuat hasil klasifikasi menjadi tidak akurat karena data uji akan cenderung diklasifikasikan ke dalam kelas yang dominan tersebut. Berdasarkan Tabel 1, rata-rata akurasi maksimal yang didapatkan sebesar 96,6% dengan k=2. Grafik rata-rata pengujian akurasi ditunjukan pada Gambar 9.
6. KESIMPULAN
Kesimpulan yang didapatkan berdasarkan pengujian yang telah dilakukan adalah sebagai berikut:
1. Algoritme MK-NN dapat diterapkan untuk melakukan diagnosis penyakit anjing dengan beberapa tahapan yaitu menghitung jarak antar data latih, menghitung nilai validitas data latih, menghitung jarak antara data latih dengan data uji, dan menghitung
weight voting. Nilai weight voting terbesar diambil di mana kelas dari nilai weight voting terbesar tersebut merupakan kelas penyakit data uji.
2. Penurunan akurasi dipengaruh oleh penambahan nilai k. Rata-rata akurasi maksimal yang didapatkan adalah sebesar 96,6% dengan k=2. Komposisi data latih yang tidak seimbang juga mempengaruhi hasil klasifikasi dan akurasi di mana terdapat
kelas penyakit yang dominan sehingga data uji akan cenderung diklasifikasikan ke dalam kelas yang dominan tersebut dan membuat hasil klasifikasi menjadi tidak akurat.
7. DAFTAR PUSTAKA
Allen, K., Blascovich, J., Mendes, W.B., 2002, Cardiovascular reactivity and the presence of pets, friends, and spouses: the truth about cats and dogs,
Psychosomatic Medicine, 64(5), p.727-739.
Han, J., Kamber, M., Pei, J., 2012, Data Mining: Concepts and Techniques Third Edition.
Morgan Kaufmann Publisher. United
States of America.
Khotimah, H., 2015, Penentuan Status Gizi Balita menggunakan Metode Modified K-Nearest Neighbor (MK-NN) (Studi Kasus: Kecamatan Kertosono), FILKOM Universitas Brawijaya, Malang.
Parvin, H., Alizadeh, H., Minati, B., 2010, A
Modification on K-Nearest Neighbor Classifier, Global Journal of Computer Science and Technology, 10(14), p.37-41.
Wafiyah, F., Hidayat, N., Perdana, R.S., 2017, Implementasi Algoritma Modified K-Nearest Neighbor (MKNN) untuk Klasifikasi Penyakit Demam, Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer (JPTIIK), 1(10), p.1210-1219.
0,00% 50,00% 100,00%
k=1 k=3 k=5 k=7 k=9 k=11 k=13 k=15