PENGEMBANGAN JARINGAN SITASI PADA
REPOSITORI DIGITAL
Adi Wibowo, Resmana Lim, H. Felix H.P.
Jurusan Teknik Informatika, Fakultas Teknologi Industri, Universitas Kristen Petra Jl. Siwalankerto 121 – 131 Surabaya, 0318439040
[email protected], [email protected]
Abstract
Digital repository consists of research papers and journal articles in PDF or DOC format. This study proposes the steps to develop citation network from digital repository. The first and second steps build a citation network by identifying a citation block and extracting citations from the block. The third step tries to parse citation using regex to identify citation’s title, authors’ name, and year of publication. Fourth step build a citation network by linking every citation to an actual paper based on similarity between them. The testing shows that this study is able to identify each citation metadata (title, authors, and year) and build citation network among papers based on authors and titles similarity.
Keywords: repository, citation network
Abstrak
Repositori digital terdiri dari hasil penelitian berupa paper hasil seminar atau jurnal ilmiah dalam format PDF atau DOC. Penelitian ini mengusulkan langkah-langkah dalam membangun jaringan sitasi di atas repositori digital tersebut. Langkah pertama dan kedua dalam membangun jaringan sitasi adalah dengan mengidentifikasi blok sitasi dan mengestrak sitasi dari blok tersebut. Langkah ketiga mencoba melakukan proses parsing menggunakan regex untuk mengidentifikasi judul, penulis, dan tahun publikasi dari sitasi tersebut. Langkah keempat membuat jaringan sitasi dengan menghubungkan tiap sitasi ke paper sesungguhnya didasarkan pada kemiripan antara sitasi dan paper. Pengujian menunjukkan bahwa penelitian dapat mengidentifikasi setiap metadata sitasi (judul, penulis, dan tahun publikasi) dan membangun jaringan sitasi antara paper berdasarkan kemiripan judul dan penulis.
Kata kunci: repositori, jaringan sitasi
1. PENDAHULUAN
Setiap insitusi pendidikan biasanya memiliki jumlah paper terpublikasi dan tidak terpublikasi dalam jumlah yang besar. Paper-paper tersebut disimpan dalam repositori digital. Sebuah mesin pencari (search engine) biasanya dibangun di atas repositori untuk memungkinkan akses publik pada paper-paper tersebut.
Mesin pencari biasanya berjalan dengan prinsip kemiripan antara query dengan dokumen, dan antar dokumen dengan dokumen. Kinerja mesin pencari ini dapat ditingkatkan bila dapat menghubungkan sebuah paper dengan paper lainnya yang memiliki topik yang mirip. Kemiripan topik diasumsikan dapat diwakili oleh kutipan atau sitasi. Setiap paper akan mengutip paper lainnya yang memiliki topik yang berhubungan dengan topik yang sedang dibahas oleh paper tersebut. Dengan membangun jaringan sitasi antar paper, sekelompok paper dengan topik yang sama dapat dihasilkan oleh mesin pencari. Dengan demikian dibutuhkan sebuah jaringan sitasi antar paper dalam sebuah repository digital.
menggunakan nama penulis dan judul dalam sitasi untuk dibandingkan dengan sebuah paper. Sitasi dengan nilai kemiripan tertinggi akan dihubungkan dengan artikel tersebut.
2. METODE PENELITIAN
Penelitian dimulai dengan mengumpulkan contoh dokumen PDF dari Citeseer. Dokumen-dokumen PDF tersebut kemudian diproses menggunakan regular expression untuk mendapatkan blok sitasi dari dokumen, mendapatkan sitasi-sitasi dari blok sitasi tersebut, dan membuat uraian sitasi (judul, penulis, tahun penerbitan) dari tiap sitasi. Regular expression adalah sebuah pola yang menjelaskan satu set string [2]. Dengan menggunakan pola tersebut regular expression dapat digunakan untuk mencari substring atau memisahkan sebuah string menjadi beberapa string. Sintaks regular expression yang digunakan dalam penelitian ini adalah PCRE (Perl Compatible Regular Expression) [3]. PCRE memiliki konsistensi bahwa setiap karakter non alfanumerik harus di-escape untuk membedakannya dengan karakter alfanumerik.
Setelah uraian dari sitasi didapatkan, maka uraian tersebut digunakan untuk membuat jaringan sitasi antar paper dengan mencari paper sebenarnya yang diwakili oleh sitasi tersebut. Untuk menentukan paper sebenarnya yang diwakili oleh sitasi dibuat persamaan matematika sederhana untuk mencari kemiripan antara sitasi dengan paper. Baik regular expression maupun persamaan kemiripan dibuat dengan metode heuristik. 3. HASIL DAN PEMBAHASAN
Terdapat empat langkah yang dibutuhkan untuk membangun repositori berbasis sitasi: 1. Konversi dokumen PDF ke dokumen XML
Langkah ini mengkonversi dokumen-dokumen PDF ke dokumen-dokumen XML. Setiap dokumen XML akan memiliki elemen dan struktur file PDF. Tujuan konversi ke XML adalah karena langkah kedua dan ketiga membutuhkan pengenalan format teks. Format teks yang perlu dikenali adalah bagian mana dari teks dalam bentuk italic, atau memiliki garis bawah, dan juga posisi teks tersebut di dalam dokumen. Dokumen PDF dalam format aslinya tidak cocok dalam menyediakan informasi ini. Hal ini disebabkan dokumen PDF seringkali dibangun dari sekumpulan teks yang dikodekan (encoded) dalam bentuk biner, dan juga sekumpulan obyek biner seperti gambar. Secara garis besar dokumen PDF terlihat seperti sebuah kumpulan obyek yang saling tidak terhubung [4]. Agar dapat menyediakan informasi yang dibutuhkan dokumen PDF perlu dikonversi lebih dulu ke dalam bentuk XML.
2. Identifikasi Blok Sitasi
Langkah kedua berusaha mengidentifikasi elemen-elemen mana dari dokumen XML yang mewakili satu blok sitasi. Blok sitasi biasanya terletak pada bagian bawah dokumen dan didahului oleh kata “references”, “reference”, “daftar pustaka”, atau “referensi”. Langkah ini berusaha menemukan kata-kata tersebut dalam sebuah baris kalimat yang tidak didahului atau diikuti oleh kata lainnya, dan berasumsi bahwa setiap baris setelahnya adalah blok sitasi. Setelah blok sitasi didapatkan maka setiap sitasi akan diambil dari blok dan disimpan ke dalam database.
3. Citation Parser
Bila sebuah blok sitasi didapatkan pada langkah kedua, setiap sitasi akan diuraikan (parsed) menjadi judul, tahun publikasi, dan bagian penulis. Langkah ini diulangi hingga setiap dokumen XML telah diproses. Data judul, tahun, dan penulis setiap sitasi disimpan ke dalam database.
4. Citation Linking
Dengan menggunakan data judul, tahun, dan penulis dari tiap sitasi, langkah ini membangun jaringan sitasi antar paper.
3.1. Citation Parser
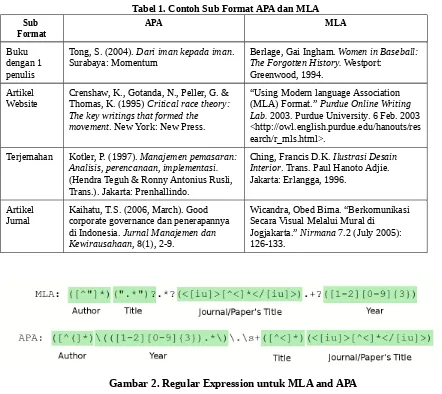
Setiap sitasi yang diambil dari blok sitasi akan diurai untuk mengidentifikasi judul, penulis, dan tahun publikasi. Untuk dapat mengenali bagian-bagian sitasi tersebut, perbedaan antara format sitasi APA dan MLA perlu diketahui. APA dan MLA adalah sekumpulan dari sub format-sub format yang berbeda [5]. Terdapat sub format untuk dokumen serial, bagian dari buku online, online website, buku dengan satu penulis, buku dengan dua hingga lima penulis, dan sub format-sub format untuk berbagai keperluan yang lain. Tabel 1 menunjukkan beberapa contoh sub format dari APA dan MLA.
Berdasarkan perbandingan antara beberapa sub format APA dan MLA tersebut terdapat beberapa perbedaan pada penulis dan tahun sitasi. APA menggunakan nama depan dalam bentuk pendek (singkatan), sedangkan MLA mempertahankan nama depan dalam bentuk panjang. APA menempatkan tahun publikasi di bagian depan sitasi, dan MLA menempatkannya pada bagian akhir sitasi. APA tidak menggunakan tanda kutip ganda (double quote) untuk menunjukkan judul artikel dalam sebuah jurnal atau website, sedangkan MLA menggunakannya.Kesamaan antar keduanya adalah bahwa APA dan MLA menggunakan bentuk italic untuk menunjukkan judul artikel selain jurnal atau website, judul jurnal dan judul website.
Untuk mengidentifikasi format sitasi, lokasi judul perlu diketahui lebih dulu dengan mengidentifikasi bagian mana dari sitasi yang berbentuk italic atau memiliki garis bawah. Setelah lokasi judul diketahui, lokasi tahun publikasi dicari apakah berada sebelum atau sesudah judul. Bila lokasi tahun publikasi sebelum judul, maka format yang digunakan adalah APA, bila setelahnya maka format yang digunakan adalah MLA. Tahun publikasi diidentifikasi dengan adanya empat digit angka yang diawali oleh angka ‘1’ dan ‘2’.
2. Memisahkan judul artikel, judul jurnal, nama penulis, dan tahun publikasi sesuai format sitasi yang telah teridentifikasi. Regular expression yang digunakan ditunjukkan pada gambar 1.
Tabel 1. Contoh Sub Format APA dan MLA
Sub Format
APA MLA
Buku dengan 1 penulis
Tong, S. (2004). Dari iman kepada iman. Surabaya: Momentum
Berlage, Gai Ingham. Women in Baseball: The Forgotten History. Westport: Greenwood, 1994.
Artikel
Website Crenshaw, K., Gotanda, N., Peller, G. & Thomas, K. (1995) Critical race theory: The key writings that formed the movement. New York: New Press.
“Using Modern language Association (MLA) Format.” Purdue Online Writing Lab. 2003. Purdue University. 6 Feb. 2003 <http://owl.english.purdue.edu/hanouts/res earch/r_mls.html>.
Terjemahan Kotler, P. (1997). Manajemen pemasaran: Analisis, perencanaan, implementasi. (Hendra Teguh & Ronny Antonius Rusli, Trans.). Jakarta: Prenhallindo.
Ching, Francis D.K. Ilustrasi Desain Interior. Trans. Paul Hanoto Adjie. Jakarta: Erlangga, 1996.
Artikel
Jurnal Kaihatu, T.S. (2006, March). Good corporate governance dan penerapannya di Indonesia. Jurnal Manajemen dan Kewirausahaan, 8(1), 2-9.
Wicandra, Obed Bima. “Berkomunikasi Secara Visual Melalui Mural di
Jogjakarta.” Nirmana 7.2 (July 2005): 126-133.
Gambar 2. Regular Expression untuk MLA and APA
3. Setiap atribut metadata dari sitasi (judul, penulis, dan tahun) dibersihkan dari karakter-karakter yang tidak diperlukan seperti spasi, titik, koma, atau tag html.
3.2. Citation Linking
Citation linking adalah sebuah proses untuk menghubungkan sitasi yang telah terurai ke paper sebenarnya. Proses ini akan menghasilkan jaringan sitasi antar paper. Karena ada kemungkinan bahwa judul, nama penulis, dan tahun publikasi tidak selalu memiliki kemiripan penuh dengan metadata paper sebenarnya maka algoritma sederhana untuk memeriksa tingkat kemiripannya diperlukan.
Langkah pertama adalah membatasi paper yang memiliki tahun publikasi yang sama dengan tahun publikasi dari sitasi. Langkah ini menggunakan asumsi bahwa ketidakmiripan antara tahun paper dan sitasi akan minimal. Langkah ini diperlukan untuk masalah kinerja pada database sitasi yang besar.
nama depan penulis dari paper perlu dikembangkan untuk meliputi semua kombinasi yang mungkin dari nama depan yang pendek dan panjang.
Persamaan untuk menghitung kemiripan nama penulis ditunjukkan pada persamaan (1).
n LN
LS
AS (0)
AS adalah nilai akhir dari kemiripan penulis antara paper dan sitasi. n adalah jumlah penulis sitasi dikali dengan jumlah semua kombinasi kemungkinan nama penulis paper (kombinasi nama pendek dan panjang). LS adalah jumlah huruf yang sama antara nama penulis sitasi dan penulis paper dimulai dari awal nama penulis sitasi. LN adalah jumlah huruf dari penulis sitasi.
Langkah ketiga adalah menemukan kemiripan antara judul paper dan judul sitasi. Terdapat kemungkinan kesalahan pengetikan dari kata-kata judul, yaitu sebuah kata dapat kehilangan satu huruf atau lebih, atau bahkan sebuah judul dapat kehilangan satu kata. Urutan kata pada judul paper dan sitasi juga penting karena perbedaan urutan kata dapat berarti paper-paper yang sangat berbeda.
x
WS adalah nilai kemiripan antara setiap kata dari judul paper dan kata dari judul sitasi. x dan y adalah index yang menunjukkan posisi kata dari awal setiap judul. x adalah untuk judul sitasi, dan y adalah untuk judul paper.LS adalah jumlah huruf yang sama antara kata dari judul sitasi dan judul paper dari awal dari kata tersebut. LN adalah jumlah huruf dari kata dari judul sitasi.
Bila WS lebih besar dari similarity treshold (penelitian ini menggunakan 0,6) maka WB dan WA dihitung. WB adalah nilai kemiripan antara pasangan kata dari paper dan sitasi yang masing-masing mendahului kata-kata yang sedang dihitung kemiripannya. WA adalah kemiripan pasangan kata yang terletak setelah kata yang sedang dihitung kemiripannya. Penelitian ini berasumsi bahwa bahwa kata yang memiliki pasangan kata yang sama antara paper dan sitasi baik berada sebelum dan sesudah kata tersebut harus memiliki nilai yang lebih tinggi daripada bila memiliki pasangan kata yang sama hanya sebelum atau sesudahnya. n adalah jumlah kata dari judul paper dikali dengan jumlah kata dari judul sitasi. TS adalah nilai total dari kemiripan judul sitasi dan paper.
Nilai kemiripan akhir dihitung sesuai persamaan (4). w adalah variabel bobot untuk memberikan pengaruh yang lebih besar pada kemiripan judul daripada kemiripan penulis. Paper yang memiliki nilai kemiripan tertinggi akan digunakan sebagai paper sebenarnya dari sebuah sitasi.
) (TS w AS
S (4)
3.3. Pengujian
Dalam proses pengujian, penelitian ini menggunakan file-file PDF dan metadatanya yang diambil dari CiteSeerX. Gambar 2 menunjukkan antar muka dari hasil pengujian citation parser. Tabel 2 dan 3 menunjukkan jumlah sitasi yang ditemukan dari format MLA dan APA, dan persentase dari identifikasi yang sukses dari judul, penulis, dan tahun publikasi dari sitasi-sitasi tersebut. Regular expression tidak mampu seratus persen menemukan judul, penulis, dan tahun publikasi dari setiap paper. Hal ini disebabkan adanya variasi-variasi dari format sitasi yang digunakan yang menyebabkan gagalnya menemukan sebagian atau seluruh bagian sitasi.
Gambar 2. Contoh dari Hasil Citation Parser
Table 2. Hasil Pengujian Citation Parser untuk MLA
Proses Jumlah sample yangdigunakan (sitasi) Jumlah hasil yang benar(sitasi) %
Get Year 187 185 98.93%
Get Title 187 165 88.23%
Get Author 187 168 89.83%
Semua 187 164 87.7%
Table 3. Hasil Pengujian Citation Parser untuk APA
Process Jumlah sample yangdigunakan (sitasi) Jumlah hasil yang benar(sitasi) %
Get Year 272 272 100.00%
Get Title 272 247 90.81%
Get Author 272 251 92.28%
Semua 272 245 90.07%
Tabel 4. Hasil Pengujian dari Citation Linking
Proses Jumlah Sitasi
Jumlah paper yang
ditemukan %
CITATION LINKING 102 99 97.06%
4. KESIMPULAN
Penelitian ini mengusulkan penggunaan regular expression untuk menguraikan judul, nama penulis, dan tahun publikasi. Penelitian ini juga mengusulkan proses perbandingan antara judul sitasi dan nama penulis antara paper dan sitasi untuk membangun jaringan sitasi. Proses membangun repositori berbasis sitasi tidak sepenuhnya otomatis karena pemeriksaan manual terhadap hasil citation parser masih diperlukan. DAFTAR PUSTAKA
Giles, C.L., Bollacker, K.D., & Lawrence, S., “CiteSeer: An Automatic Citation Indexing System”, Digital Libraries 98 - Third ACM Conference on Digital Libraries, 89-98, 1998.
The Open Group, “Regular Expressions”, The Single UNIX ® Specification, Version 2, 1997.
Hazel, P., PCRE - Perl Compatible Regular Expressions. Diambil pada Des. 17, 2010, dari http://www.pcre.org/pcre.txt , 2010.
Adobe Systems Incorporated, PDF Reference Sixth Edition, Version 1.7, 2009.