BAB 2
LANDASAN TEORI
Bab ini membahas tentang teori penunjang dan penelitian sebelumnya yang berhubungan dengan penerapan metode Adaptive Neuro Fuzzy Inference System (ANFIS) untuk prediksi harga saham syariah di Indonesia.
2.1 Saham Syariah
Saham syariah merupakan bukti kepemilikan suatu perusahaan yang memenuhi kereteria syariah atau prinsip-prinsip syariah dan tidak termasuk saham preferen. Saham preferen adalah saham memiliki hak-hak istimewa yang bertentangan dengan syariat bagi hasil dimana perusahaan tidak memiliki hak suara tetapi mendapatakan deviden yang sudah pasti (Sholihin, 2010). Saham yang sesuai syariah Islam adalah saham yang setiap pemiliknya memiliki hak yang sama dan proporsional dengan jumlah lembar saham yang dimilikinya (Sholihin, 2010). Prinsip-prinsip dalam transaksi saham syariah adalah sebagai berikut (Kurniawan, 2008):
a. Pembiayaan dan investasi hanya dapat dilakukan pada asset atau kegiatan usaha yang halal.
b. Pembiayaan dan investasi harus pada mata uang yang sama dengan pembukuan kegiatan usaha.
d. Investor dan emiten tidak boleh mengambil resiko melebihi kemampuan (maisyir) dan menimbulkan kerugian yang sebenarnya bisa dihindari.
e. Investor, emiten, bursa efek dan self regulating organization lainnya tidak boleh melakukan hal-hal yang menyebabkan gangguan yang disengaja atas mekanisme pasar, baik dari sisi permintaan maupun penawaran.
Gharar dalam bahasa Arab diterjemahkan resiko atau ketidakpastian. Analisis resiko saham yang memiliki ketidakpastian dapat digolongkan menjadi tiga (Kurniawan, 2008), yaitu:
a. Risk, yaitu analisis yang memiliki preseden historis dan dapat dilakukan estimasi probabilitas untuk tiap hasil yang mungkin muncul.
b. Structural uncertainties, yaitu analisis yang kemungkinan terjadinya suatu hasil bersifat unik, tidak memiliki preseden di masa lalu, tetapi tetap terjadi dalam logika kausalitas.
c. Unknownables, yaitu gharar yang menunjukan kejadian yang secara ekstrim kemunculannya tidak terbayangkan sebelumnya. Dengan demikian kasus gharar akan banyak terjadi pada unknownables.
2.2 Analisis Harga Saham
Analisis harga saham adalah suatu proses memprediksi pergerakan harga suatu saham. Ada dua pendekatan dasar dalam menganalisis atau memilih saham, yaitu analisis fundamental dan analisis teknikal (Sulistiawan, 2008).
Analisis fundamental adalah analisis saham yang menggunakan data-data fundamental dan faktor-faktor eksternal yang berhubungan dengan badan usaha. Data fundamental yang dimaksud adalah data keuangan, data pangsa pasar, siklus bisnis dan lain sebagainya. Data faktor eksternal yang berhubungan dengan badan usaha adalah kebijakan pemerintah, tingkat bunga, inflasi, dan sejenisnya. Di sisi lain, analisis teknikal merupakan upaya untuk memprediksi harga saham dengan mengamati perubahan harga saham tersebut (kondisi pasar) berdasarkan runtun waktu di masa lalu. Berlainan dengan pendekatan fundamental, analisis teknikal tidak memperhatikan faktor-faktor fundamental yang mungkin mempengaruhi harga saham. Pemikiran yang mendasari analisis teknikal adalah pola harga saham yang mencerminkan informasi yang relevan dimana informasi tersebut ditunjukkan oleh perubahan harga saham di waktu yang lalu, dan mempunyai pola tertentu, dan pola tersebut terus berulang (Sulistiawan, 2008).
Analisis teknikal digunakan untuk mencari pola harga saham yang berulang dan dapat diidentifikasi. Salah satu teori analisis terkenal menyatakan bahwa pergerakan harga dari suatu sekuritas mengandung semua informasi mengenai semua sekuritas tersebut. Untuk lebih mendekati pasar, para analis teknikal modern membuat grafik yang dapat menampilkan harga pembukaan, penutupan, tertinggi, dan terendah. Baik analisis teknikal maupun analisis fundamental dapat dikombinasikan dengan metode-metode penelitian lainnya untuk menghasilkan prediksi yang lebih akurat seperti metode rata-rata bergerak (moving averages), Oscillator, dan Stochastic RSI, fuzzy, neural network, algoritma genetic, dan metode hybrid (Sulistiawan, 2007).
a. Level konstan
Pola konstan menunjukkan data bergerak di sekitar nilai rata-rata, dengan variasi
jarak yang terkadang ‘jauh’ dan terkadang ‘dekat’. Akan tetapi secara umum data
tidak menunjukkan adanya perubahan tren, baik meningkat maupun menurun. Salah satu contoh pola konstan ditunjuk oleh Saham United Traktor pada bulan Mei-Juli 2002. Plot tersebut menyatakan pola data yang mempunyai tingkat konstan dengan fluktuasi yang random.
Gambar 2.1 Harga Saham United Traktors Mei-Juni 2002
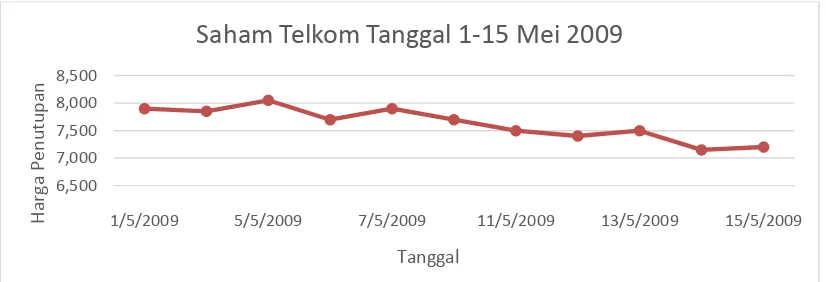
b. Tren Linier
Pola data yang menunjukkan adanya peusahaan rata-rata, tetapi nilai variannya tetap, merupakan karakteristik dari pola tren. Pola harga penutupan saham Telkom tanggal 1-15 Mei 2009 merupakan contoh data runtun waktu yang mempunyai gerakan tren dimana pola tersebut menunjukkan adanya tren yang linier dan fluktuasi random.
Gambar 2.2 Harga Saham Telkom 1-15 Mei 2009
c. Model Kombinasi
Dalam prakteknya, kita sering menjumpai data runtun waktu yang bentuknya tidak seperti salah satu jenis data tersebut. Oleh sebab itu, kita perlu membuat justifikasi perkiraan data yang akan kita analisis. Biasanya, pola data yang ini dapat merupakan kombinasi dari pola-pola tersebut.
2.3 Normalisasi Data
Normalisasi data berfungsi untuk membuat data yang akan diproses berada pada range tertentu sehingga dalam pemrosesan nantinya angka yang diolah tidak terlalu besar sehingga mempercepat proses perhitungan. Pada penelitian ini data pelatihan akan dinormalisasi dalam range 0,1 sampai 0,9. Adapun rumus untuk melakukan normalisasi data pada range 0,1 sampai 0,9 adalah sebagai berikut (Siang, 2005):
𝑦 = 0,8 (𝑥 − 𝑎)𝑏 − 𝑎 + 0,1 (2.1)
dimana: y = nilai normaliasai x = nilai data saham
a = nilai minimum dari data saham b = nilai maximum dari data saham
Setelah data masukan yang telah dinormalisasi diproses dan didapatkan hasil prediksi maka data hasil prediksi tersebut akan didenormalisasi kembali dengan menggunakan persamaan berikut:
𝑥 =(𝑦 − 0,1)(𝑏 − 𝑎) + 0,8𝑎0,8 (2.2)
2.4 Fuzzy System
Sistem fuzzy atau Fuzzy Inference System (FIS) adalah adalah sistem kendali logika fuzzy yang dapat melakukan penalaran dengan prinsip serupa seperti manusia melakukan penalaran dengan nalurinya dan pengetahuannya (Effendi, 2009). Logika fuzzy adalah logika mengandung unsur ketidakpastian. Pada logika biasa atau logika tegas (crisp) hanya terdapat 2 anggota himpunan nilai yakni salah atau benar, 0 atau 1. Sedangkan logika fuzzy mengenal nilai antara benar dan salah. Kebenaran dalam logika fuzzy dapat dinyatakan dalam derajat kebenaran atau fungsi keanggotaan dalam interval 0 hingga 1 (Widodo, 2005).
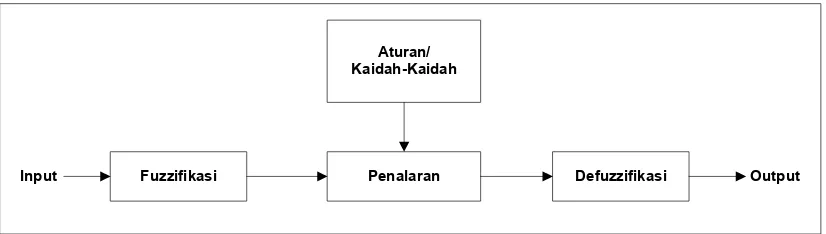
Aturan/ Kaidah-Kaidah
Fuzzifikasi Penalaran Defuzzifikasi Output
Input
Gambar 2.3 Proses Fuzzy Inference System (Effendi, 2009)
Pada Fuzzy Inference System terdapat beberapa proses mulai dari pemasukan data hingga penarikan kesimpulan. Proses tersebut terdiri dari proses fuzzifikasi, inferensi (penalaran) dengan memanfaatkan aturan-aturan fuzzy (fuzzy rule), dan defuzzifikasi. Gambaran umum bagan Fuzzy Inference System dapat dilihat pada Gambar 2.3.
2.4.1 Fuzzifikasi
Fuzzifikasi adalah pemetaan nilai input yang merupakan nilai tegas ke dalam fungsi keanggotaan himpunan fuzzy, untuk kemudian diolah di dalam mesin penalaran (Effendi, 2009). Fungsi keanggotaan (membership function) dari himpunan fuzzy dapat disajikan dengan dua cara yaitu numerik dan fungsional. Secara numerik himpunan fuzzy disajikan dalam bentuk gabungan derajat keanggotaan tiap–tiap elemen pada semesta pembicaraan yang dinyatakan sebagai berikut:
Secara fungsional himpunan fuzzy disajikan dalam bentuk persamaan matematis sehingga untuk mengetahui derajat keanggotaan dari masing-masing elemen dalam semesta pembicaraan memerlukan suatu perhitungan (Suratno, 2011). Pembentukan derajat keanggotaan dapat dilakukan dengan memetakan data secara langsung pada fungsi keanggotaan atau dengan menggunakan data cluster yang kemudian dipetakan pada fungsi keanggotaan.
2.4.1.1 Fungsi keanggotaan
Fungsi keanggotaan digunakan untuk mendapatkan derajat keanggotaan dari suatu data terhadap himpunan semestaya. Adapun Fungsi keanggotaan yang biasa digunakan dalam logika fuzzy adalah sebagai berikut:
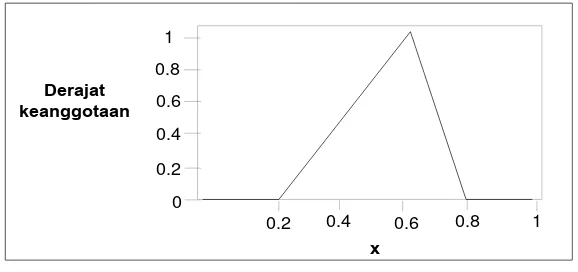
1. Fungsi Keanggotaan Segitiga
Fungsi keanggotaan segitiga memiliki tampilan kurva berbentuk segitiga yang ditunjukkan oleh Gambar 2.4.
0 0.2 0.4 0.6 0.8 1
Derajat keanggotaan
0.2 0.4 0.6 0.8 1
x
Gambar 2.4 Kurva Segitiga (Irawan, 2007)
Fungsi keanggotaan kurva segitiga dapat dinyatakan sebagai berikut:
𝑡𝑟𝑖𝑎𝑛𝑔𝑙𝑒(𝑥; 𝑎, 𝑏, 𝑐) = {(𝑥 − 𝑎)/(𝑏 − 𝑎); 𝑎 ≤ 𝑥 ≤ 𝑏 0; 𝑥 ≤ 𝑎
1; 𝑥 ≥ 𝑏 (2.4)
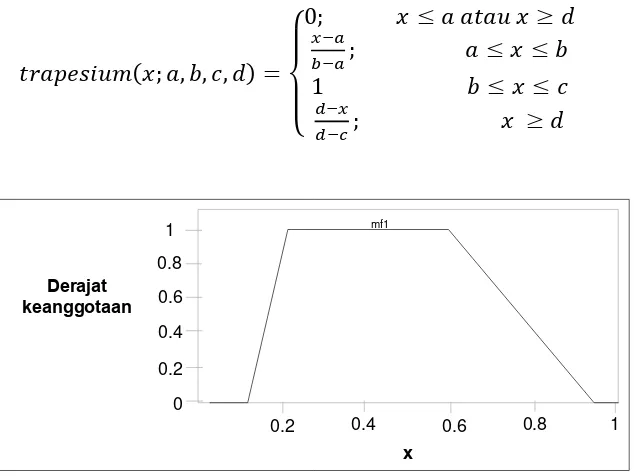
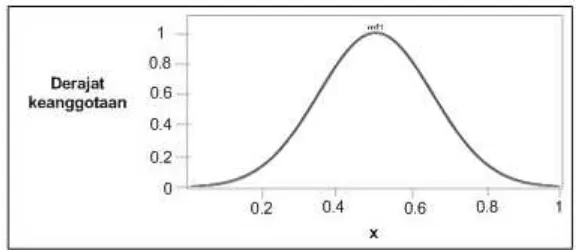
2. Fungsi Keanggotaan Trapesium
𝑡𝑟𝑎𝑝𝑒𝑠𝑖𝑢𝑚(𝑥; 𝑎, 𝑏, 𝑐, 𝑑) =
{
0; 𝑥 ≤ 𝑎 𝑎𝑡𝑎𝑢 𝑥 ≥ 𝑑
𝑥−𝑎
𝑏−𝑎; 𝑎 ≤ 𝑥 ≤ 𝑏
1 𝑏 ≤ 𝑥 ≤ 𝑐
𝑑−𝑥
𝑑−𝑐; 𝑥 ≥ 𝑑
(2.5)
0 0.2 0.4 0.6 0.8 1
Derajat keanggotaan
0.2 0.4 0.6 0.8 1
x
mf1
Gambar 2.5 Kurva Trapesium (Irawan, 2007)
3. Fungsi Keanggotaan Generalized Bell (GBell)
Bentuk dari fungsi keanggotaan generalized bell ditentukan oleh tiga parameter {a,b,c} seperti ditunjukkan pada Gambar 2.6.
Gambar 2.6 Kurva Generalized Bell (Irawan, 2007)
Fungsi keanggotaan Generalized Bell (GBell) dapat dinyatakan sebagai berikut:
𝑏𝑒𝑙𝑙(𝑥; 𝑎, 𝑏, 𝑐) = 1
Keterangan :
𝑏 : nilai bias yang biasanya bernilai positif agar kurva menghadap ke bawah. Jika 𝑏 negatif, maka fungsi keanggotaan akan menjadi upside-down bell. c : nilai mean kurva.
a : standar deviasi yang terbentuk.
4. Fungsi Keanggotaan Gaussian (Gauss)
Bentuk dari fungsi keanggotaan gaussian ditentukan oleh dua parameter {c,} seperti ditunjukkan oleh Gambar 2.7.
Gambar 2.7 Kurva Gaussian (Irawan, 2007)
Fungsi keanggotaan gaussian dapat dinyatakan sebagai berikut:
𝑔𝑎𝑢𝑠𝑠(𝑥;, 𝑐) = 𝑒−(𝑥−𝑐)22𝜎2 (2.7)
Keterangan:
𝑐: merupakan pusat dari fungsi keanggotaan gaussian,
𝜎: menentukan lebar fungsi keanggotaan.
(GBell) dan Gaussian. Fungsi keanggotaan Generalized Bell (GBell) dan Gaussian menyediakan fungsi yang lebih halus dan cocok digunakan oleh sistem pembelajaran seperti neural networks. Fungsi keanggotaan Gbell dan Gaussian juga sering digunakan dalam bidang probabilistik dan statistik (Melin, et al, 2002).
2.4.1.2 Fuzzy clustering
Fuzzy clustering merupakan pengelompokan data atau data cluster yang memiliki karakteristik yang hampir sama secara matematis dalam sebuah kelompok atau kelas tertentu. Membership function yang akan digunakan pada fuzzy clustering dimodelkan dari data-data yang telah ada. Proses pembentukan membership function ini disebut modeling (Fariska, 2010). Metode fuzzy clustering yang biasa digunakan untuk memodelkan data adalah Fuzzy C-Means (FCM) dan Fuzzy Subclustering.
Fuzzy Subclustering merupakan metode pengelompokan data secara tidak terawasi dimana jumlah cluster tidak perlu didefenisikan terlebih dahulu. Berbeda dengan Fuzzy Subclustering, FCM merupakan metode pengelompokan data secara terawasi dimana jumlah cluster harus ditentukan terlebih dahulu sebelum melakukan pengelompokan data.
Konsep dasar FCM pertama kali adalah menentukan pusat cluster pada kondisi awal pusat cluster ini masih belum akurat. Setiap data memiliki derajat keanggotaan untuk tiap cluster dengan cara memperbaiki pusat cluster dan nilai keanggotaan tiap data secara berulang, maka akan dapat dilihat bahwa pusat cluster akan bergerak menuju lokasi yang tepat (Fariska, 2010).
Sen-Chi Yu (2008) dan Rukli (2013) mengemukakan prosedur perhitungan FCM secara lengkap, yakni:
1. Menentukan matriks X berukuran n x m, dengan n = banyak data yang akan di cluster dan m = banyak variabel (kriteria). Penentuan n dan m disesuaikan dengan kondisi data yang digunakan.
3. Tentukan bobot pangkat cluster dimana bobot pangkat bernilai lebih besar 1 (pembobot w > 1).
4. Tentukan maksimum iterasi yang diinginkan.
5. Tentukan kriteria penghentian (ε = nilai positif yang sangat kecil).
6. Bentuklah matriks partisi awal U (derajat keanggotaan dalam cluster) dengan matriks partisi awal biasanya dibuat secara acak.
[
7. Hitung pusat cluster V untuk setiap cluster dengan menggunakan persamaan berikut:
9. Tentukanlah kriteria penghentian iterasi, yaitu perubahan matriks partisi pada iterasi sekarang dan iterasi sebelumnya dimana perubahan tersebut sebesar delta:
Δ≡||Ut - Ut-1||.
10.Apabila Δ<ε maka iterasi dihentikan dan jika tidak lanjutkan menghitung kembali pusat cluster ke-k.
11.Pada akhir proses FCM akan diperoleh suatu pengelompokan data yang terdiri dari nilai center tiap cluster.
Bila fungsi keanggotaan yang digunakan adalah kurva Generalized Bell (GBell), maka standar deviasi setiap cluster harus dihitung terlebih dahulu. Nilai fuzzy membership function pada setiap data dapat diperoleh dengan memasukkan data yang telah dinormalkan, nilai center dan standar deviasi cluster ke dalam persamaan kurva GBell. Informasi cluster ini nantinya akan membantu dalam pembangunan FIS model Sugeno yang bisa memodelkan hubungan data input-output dengan jumlah rule minimum. Definisi sebuah rule diasosiasikan dengan suatu cluster data (Sari, et al, 2012).
2.4.2 Inferensi
Pada tahapan ini sistem menalar nilai masukan (input) untuk menentukan nilai keluaran (output) sebagai bentuk pengambil keputusan. Sistem terdiri dari beberapa aturan dimana kesimpulan diperoleh dari kumpulan dan korelasi antaraturan (Effendi, 2009). Metode inferensi yang sering digunakan yaitu, metode Mamdani, Sugeno dan Sukamoto. Untuk melakukan proses inferensi, terdapat 3 operasi dasar yang umum digunakan yaitu max, min dan not.
2.4.2.1 Operasi himpunan fuzzy
Menurut Sari (2001), operasi dasar himpunan fuzzy adalah sebagai berikut:
1. Operasi “dan”(Intersection)
A “dan” B merupakan himpunan fuzzy dari X, ditunjukkan sebagai derajat keanggotaan dari A B adalah hasil yang diperoleh dengan mengambil nilai keanggotaan terkecil antara elemen-elemen pada himpunan-himpunan yang bersangkutan.
𝜇𝐴∩𝐵 = 𝑚𝑖𝑛[𝜇𝐴(𝑥), 𝜇𝑏(𝑥)], 𝑥 ∈ 𝑋 (2.11)
2. Operasi “atau” (Union)
A “atau” B merupakan himpunan fuzzy dari X, ditunjukkan sebagai derajat keanggotaan dari A B adalah hasil yang diperoleh dengan mengambil nilai keanggotaan terbesar antara elemen-elemen pada himpunan-himpunan yang bersangkutan.
𝜇𝐴∪𝐵 = 𝑚𝑎𝑥[𝜇𝐴(𝑥), 𝜇𝑏(𝑥)], 𝑥 ∈ 𝑋 (2.12)
3. Operasi “Tidak” (Complement)
Operasi “tidak” A merupakan himpunan fuzzy dari X, ditunjukkan sebagai derajat
keanggotaan dari A’ (A komplemen) adalah hasil yang diperoleh dengan mengurangkan nilai keanggotaan elemen pada himpunan yang bersangkutan dari 1.
𝜇𝐴′(𝑥) = 1 − 𝜇𝐴(𝑥) (2.13)
2.4.2.2 Metode inferensi sugeno
1. Model Fuzzy Sugeno Orde-Nol
Secara umum bentuk model fuzzy Sugeno Orde-Nol adalah:
IF (x1 is A1) • (x2 is A2) • (x3 is A3) • ... •(xn is An) THEN z=k
dengan Ai adalah himpunan fuzzy ke-i sebagai anteseden, dan k adalah suatu konstanta (tegas) sebagai consequent.
2. Model Fuzzy Sugeno Orde-Satu
Secara umum bentuk model fuzzy Sugeno Orde-Satu adalah:
IF (x1 is A1) • ... • (xn is An) THEN z = p1*x1 + … + pn*xn + q
dengan Ai adalah himpunan fuzzy ke-i sebagai anteseden, dan pi adalah suatu konstanta (tegas) ke-i dan q juga adalah konstanta dalam consequent.
Metode inferensi Sugeno memformulasikan pendekatan sistematis menggunakan aturan fuzzy dari kumpulan data masukan-keluaran guna membentuk semua operasi dari fungsi keanggotaan menjadi kesimpulan tunggal. Metode inferensi Sugeno memiliki efisiensi komputasi dan bekerja dengan baik dengan teknik linier, teknik optimasi, teknik adaptif, serta cocok untuk analisis matematis. Metode inferensi Sugeno memiliki hasil yang tidak jauh berbeda dengan metode inferensi Mamdani.
2.4.3 Defuzzifikasi
Input dari proses defuzzifikasi adalah suatu himpunan fuzzy yang diperoleh dari komposisi aturan-aturan fuzzy, sedangkan output yang dihasilkan merupakan suatu bilangan pada domain himpunan fuzzy tersebut. Sehingga jika diberikan suatu himpunan fuzzy dalam range tertentu, maka harus dapat diambil suatu nilai crsip tertentu sebagai output (Sari, et al, 2012). Metode defuzzifikasi yang digunakan dalam penelitian ini adalah weight average.
𝑍∗ = ∑𝜇(𝑧).𝑧
𝜇(𝑧) (2.14)
dimana z adalah nilai crisp dan μ(z) adalah derajat keanggotaan dari nilai crisp z.
2.5 Jaringan Saraf Tiruan
Jaringan saraf tiruan (JST) adalah struktur jaringan dimana keseluruhan tingkah laku masukan-keluaran ditentukan oleh sekumpulan parameter yang dimodifikasi. Salah satu struktur jaringan neural adalah multilayer perceptrons (MLP) dimana jenis jaringan ini khusus bertipe lajur maju. MLP telah diterapkan dengan sukses untuk menyelesaikan masalah-masalah yang sulit dan beragam dengan melatihnya menggunakan algoritma propagasi balik dari kesalahan atau Error Backpropagation (EBP) (Fariza,2007).
Untuk meningkatkan kemampuan pembelajaran, jaringan saraf tiruan dapat bekerja dengan sistem fuzzy. Sistem fuzzy menggambarkan suatu sistem dengan pengetahuan linguistik yang mudah dimengerti. Sistem inferensi fuzzy dapat ditalar dengan algoritma propagasi balik berdasarkan pasangan data masukan-keluaran menggunakan arsitektur jaringan neural. Dengan cara ini memungkinkan sistem fuzzy dapat belajar. Gabungan sistem fuzzy dengan jaringan neural ini biasa disebut dengan sistem Neuro Fuzzy (Fariza,2007).
2.6 Prediksi Menggunakan ANFIS
Sistem Neuro Fuzzy berstruktur ANFIS (Adaptive Neuro Fuzzy Inference Sistem atau biasa disebut juga Adaptive Network based Fuzzy Inference Sistem) termasuk dalam kelas jaringan neural namun berdasarkan fungsinya sama dengan Fuzzy Inference System. Pada sistem Neuro Fuzzy, proses belajar pada neural network dengan sejumlah pasangan data yang berguna untuk memperbaharui parameter-parameter Fuzzy Inference System (Fariza, 2007).
RULE 1 : IF x is A1 AND y is B1, THEN f1 = p1x + q1y + r1; RULE 2 : IF x is A2 AND y is B2, THEN f2 = p2x + q2y + r2;
dengan x dan y adalah masukan tegas pada node ke i, Ai dan Bi adalah label linguistik (rendah, sedang, tinggi, dan lain-lain) yang dinyatakan dengan fungsi keanggotaan yang sesuai, sedangkan pi, qi, dan ri adalah parameter consequent (i = 1 atau 2) (Rosyadi, 2011).
Data yang digunakan untuk proses pembelajaran (training) terdiri dari data masukan, parameter ANFIS, dan data test yang berada pada priode training ANFIS yang kemudian dilakukan proses pembelajaran terhadap data-data tersebut sehingga nantinya diproleh output berupa hasil prediksi.
Training dengan ANFIS menggunakan algoritma belajar hybrid, dimana dilakukan penggabungan metode Least-Squares Estimator (LSE) untuk menghitung nilai consequent pada alur maju dan menggunakan Error Backpropagation (EBP) dan gradient descent pada alur mundur untuk menghitung error yang terjadi pada tiap layer (Fariza, 2007).
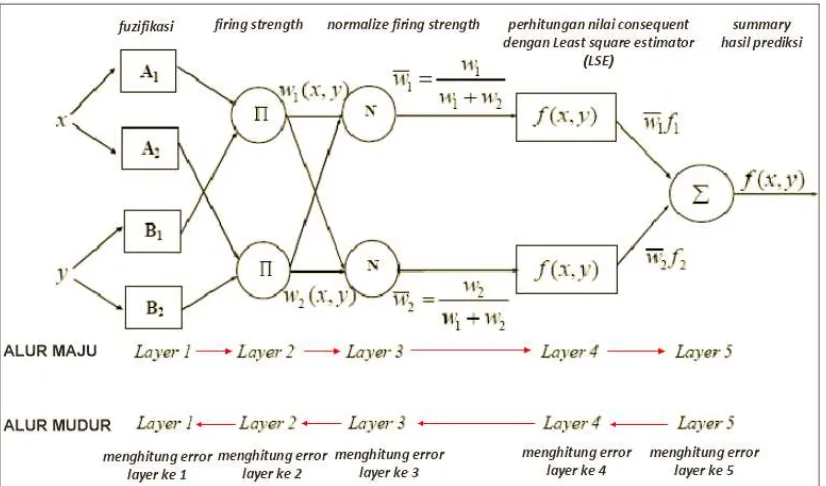
ANFIS terdiri dari lima layer. Pada layer pertama terdiri dari proses fuzzifikasi dimana data masukan dan target dipetakan dalam derajat keanggotaannya. Pada layer kedua dan ketiga dilakukan proses inferensi yang digunakan untuk menentukan rule fuzzy menggunakan inferensi Sugeno dimana hasilnya akan diproses pada perhitungan selanjutnya. Pada layer 4 dilakukan proses pencarian nilai consequent dengan menggunakan LSE. Pada layer 5 dilakukan proses summary dari dua keluaran pada layer 4.
Pada ANFIS, Fuzzy Inference System (FIS) terletak pada layer 1, 2, 3 dan 4 dimana FIS adalah sebagai penentu hidden node yang terdapat pada sistem neural network (Fariza, 2007).
Gambar 2.8 Blok diagram ANFIS (Rosyadi, 2011)
Berikut ini adalah algoritma Adaptive Neuro Fuzzy Inference System yang digunakan untuk memprediksi data runtun waktu (Mordjaoui, et. al, 2011):
1. Melakukan inisialisasi terhadap parameter ANFIS, yaitu laju pembelajaran (lr), momentum (mc), batasan kesalahan (err), dan maksimum iterasi (Max Epoch). 2. Tahap pertama yang dilakukan adalah lajur maju yang berisi beberapa tahap untuk
mencari nilai consequent dari aturan yang dibuat dan melakukan penjumlah terhadap semua masukan pada layer terakhir. Adapun tahapan lajur maju adalah sebagai berikut:
a. Setiap node i pada layer satu merupakan node adaptive dengan fungsi node sebagai berikut:
𝑂1,𝑖 = 𝜇𝐴𝑖(𝑥), 𝑖 = 1, 2 𝑎𝑡𝑎𝑢 𝑂1,𝑖= 𝜇𝐵𝑖−2(𝑥), 𝑖 = 3, 4 (2.15)
dimana:
x atau y : input dari node i
Ai atau Bi : sebuah label linguistik yang terhubung dengan node i.
b. Setiap node i pada layer kedua berupa node tetap yang keluarannya adalah hasil dari masukan. Operator yang digunakan adalah operator AND. Tiap-tiap node merepresentasikan α predikat dari aturan ke-i. Keluaran dari layer ini disebut dengan firing strength.
𝑂2,𝑖= 𝑤𝑖 = 𝜇𝐴𝑖(𝑥)𝜇𝐵𝑖(𝑦), 𝑖 = 1, 2 (2.16)
c. Tiap-tiap node pada layer ketiga berupa node tetap yang merupakan hasil
penghitungan rasio dari α predikat (𝑤̅), dari aturan ke-i terhadap jumlah dari
keseluruhan α predikat. Dimana hasilnya dinamakan dengan normalized firing strength.
𝑂3,𝑖 = 𝑤̅i = 𝑤 𝑤𝑖
1+ 𝑤2, 𝑖 = 1, 2 (2.17)
d. Tiap-tiap node pada layer keempat merupakan node adaptive terhadap suatu keluaran.
𝑂4,𝑖 = 𝑤𝑖𝑓𝑖 = 𝑤𝑖(𝑝𝑖𝑥 + 𝑞𝑖𝑦 + 𝑟𝑖), 𝑖 = 1, 2 (2.18)
Dengan 𝑤̅ adalah normalized firing strength pada layer ketiga dan {pi, qi, ri} adalah parameter-parameter pada node tersebut yang dinamakan consequent parameters.
e. Menentukan consequent parameters dengan menggunakan recursive least-squares estimator (LSE resahamif). Berikut ini adalah langkah untuk menentukan nilai consuquent dengan menggunakan LSE resahamif:
i. Buat matrix A dengan ukuran n x n yang berisi nilai dari keluaran pada layer keempat dan nilai n merupakan jumlah parameter keluaran pada layer keempat.
ii. Buat matrix Y dengan ukuran n x 1 yang berisi nilai dari target prediksi.
𝑃𝑛 = (𝐴𝑛𝑇𝐴𝑛)−1 (2.19)
iii. Melakukan pengulangan dari n+1 sampai data terakhir untuk mendapatkan nilai consequent.
𝑃𝑛+1 = 𝑃𝑛− 𝑃𝑛𝑎𝑛+1𝑎𝑛+1
𝑇 𝑃
𝑛
1 + 𝑎𝑛+1𝑇 𝑃𝑛𝑎𝑛+1 (2.21)
𝜃𝑛+1 = 𝜃𝑛+ 𝑃𝑛+1𝑎𝑛+1(𝑌𝑛+1− 𝑎𝑛+1𝑇 𝜃𝑛) (2.22)
f. Pada layer kelima memiliki sebuah node yang tetap yang mempunyai tugas untuk menjumlahkan nilai dari semua masukan.
𝑂5,𝑖= ∑ 𝑤̅𝑖𝑓𝑖 𝑖
=∑ 𝑤∑ 𝑤𝑖 𝑖𝑓𝑖
𝑖
𝑖 (2.23)
g. Berdasarkan arsitektur ANFIS yang terdapat Gambar 2.8 ketika nilai dari parameter consequent telah ditetapkan, maka nilai output juga dapat ditetapkan sebagai persamaan linear yang merupakan kombinasi dari parameter consequent. Nilai simbul arsitektur dinotasikan dengan f.
𝑓 =𝑤 𝑤1
1+ 𝑤2𝑓1+
𝑤2
𝑤1+ 𝑤2𝑓2
𝑓 = 𝑤̅1(𝑝1𝑥 + 𝑞1𝑦 + 𝑟1) + 𝑤̅2(𝑝1𝑥 + 𝑞1𝑦 + 𝑟1) (2.24)
𝑓 = (𝑤̅1𝑥)𝑝1+ (𝑤̅1𝑦)𝑞1+ (𝑤̅1)𝑟1+ (𝑤̅2𝑥)𝑝1+ (𝑤̅2𝑦)𝑞1+ (𝑤̅2)𝑟2
3. Setelah tahap lajur maju selesai, maka selanjutnya dilakukan tahap laju mundur dengan menggunakan Error Backbropagation (EBP) untuk mengecek setiap error pada setiap layer dan menggunakan gradient descent untuk mengubah nilai parameter masukan pada layer pertama. EBP menggunakan metode ordered derivative untuk mencari error pada setiap layer.
a. Menghitung nilai error pada layer kelima.
ℰ5,𝑖 =𝜕𝑂𝜕𝐸𝑝
5,𝑖 = −2(𝑦𝑝− 𝑦𝑝
dimana:
yp = target prediksi yp* = hasil prediksi
b. Menghitung nilai error pada layer keempat.
ℰ4,𝑗 = (𝜕𝑂𝜕𝐸𝑝
c. Menghitung nilai error pada layer ketiga.
ℰ3,𝑗 = (𝜕𝑂𝜕𝐸𝑝
d. Menghitung nilai error pada layer kedua.
ℰ2,𝑗 = ∑ (𝜕
e. Menghitung nilai error pada layer pertama.
ℰ1,𝑖𝑗 = ∑ (𝜕
f. Mengitung nilai error antara layer pertama dengan parameter masukan.
g. Mengubah nilai parameter masukan pada layer pertama dengan menggunakan gradient descent.
∆𝑎𝑖𝑗 = 𝜂ℰ𝑎,𝑖𝑗𝑥𝑖 (2.32)
∆𝑐𝑖𝑗 = 𝜂ℰ𝑐,𝑖𝑗𝑥𝑖 (2.33)
𝑎𝑖𝑗 = 𝑎𝑖𝑗𝑙𝑎𝑚𝑎+ ∆𝑎𝑖𝑗 (2.34)
𝑐𝑖𝑗 = 𝑐𝑖𝑗𝑙𝑎𝑚𝑎+ ∆𝑐𝑖𝑗 (2.35)
dimana:
a : Mean c : Deviasi
: Laju pembelajaran
4. Menghitung jumlah kuadrat error (SSE) pada layer ke L data ke-p, 1 ≤ p ≤ N.
𝐸𝑝 = ∑(𝑑𝑘𝑝− 𝑋𝐿,𝑘𝑝 )2 𝑁(𝐿)
𝑘=1
(2.36)
5. Ulangi proses iterasi hingga nilai epoch < Max Epoch dan Ep > batasan kesalahan (err).
6. Setelah melakukan training, dilakukan perhitungan kesalahan hasil prediksi dengan menggunakan MAPE (Mean Absolute Percentage Error), berikut adalah formula yang digunakan:
𝐸𝑟𝑟𝑜𝑟 = ∑ (
|𝑎−𝑏| 𝑎 )
𝑛 × 100% (2.37)
dimana:
2.7 Teknik Prediksi Harga Saham Terdahulu
Penelitian mengenai prediksi harga saham di Indonesia telah banyak dilakukan dengan berbagai algoritma guna mendapatkan hasil prediksi yang lebih akurat.
Chairisni, Sutedjo, dan Setiadi (2005) menggunakan Algoritma Hybrid Neural Network untuk memprediksi harga saham. Adapun langkah-angkah prediksi saham menggunakan Algoritma Hybrid Neural Network yang mereka lakukan (Chairisni, et. al, 2005) adalah sebagai berikut:
1. Melakukan penyaringan data dengan menggunakan algoritma Self Organising Maps Kohonen (SOM) ke dalam pola-pola untuk menyederhanakan proses pembelajaran jaringan Backpropagation.
2. SOM memilik 5 neuron yang terhubung ke lapisan output (cluster) yang berjumlah 20 pola neuron. Lima neuron input yang digunakan adalah harga pembukaan, harga tertinggi, harga terendah, harga penutupan dan volume perdagangan. Dari 20 pola output yang terbentukakan dipilih neuron pemenang, yaitu neuron yang paling mendekati vektor input.
3. Dari neuron pemenang tersebut, diambil harga penutupan pada vektor tersebut sebagai harga saham prediksi.
4. Algoritma Backpropagation pada algoritma hybrid, digunakan untuk memberikan keakuratan dalam prediksi harga saham menggunakan faktor pembimbing g(n) yang dihasilkan dari pembelajaran Algoritma SOM.
5. Jumlah neuron pada lapisan input sama dengan yang digunakan pada SOM yaitu sebanyak 5 buah dengan representasi yang sama. Terdapat 15 lapisan neuron dan 1 neuron pada lapisan output. Semua lapisan menggunakan fungsi sigmoid unipolar sebagai fungsi aktivasi.
7. Berdasarkan titik tersebut beberapa data pada masa lampau dipelajari dan dengan menggunakan nilai data yang telah ditentukan (nilai data harga penutupan pada titik tersebut), maka algoritma Backpropagation Network dapat melakukan pembelajaran. Proses pembelajaran tersebut terus berulang dan berhenti sampai dengan batasan yang ditentukan.
Pada tahun 2008, Setiawan melakukan penelitian mengenai prediksi harga saham menggunakan Jaringan Syaraf Tiruan Multilayer Feedforward Network dengan Algoritma Backpropagation. Langkah-langkah yang dilakukan oleh Setiawan dalam penelitiannya adalah sebagai berikut:
1. Inisialisasi nilai bobot dan bias yang dapat diatur dengan sembarang angka (acak) antara -0.5 dan 0.5, dan inisialisasi learning rate, maksimal iterasi dan toleransi error.
2. Lakukan iterasi selama stopping condition masih belum terpenuhi. Untuk menentukan stopping condition. Jika iterasi sudah melebihi maksimal iterasi maka pelatihan dihentikan. Jika menggunakan toleransi error dengan metode MAPE, bila nilai MAPE kurang dari atau sama dengan toleransi error maka pelatihan dihentikan.
3. Setiap unit input menerima sinyal input dan menyebarkannya pada seluruh hidden unit.
4. Setiap hidden unit akan menghitung sinyal-sinyal input dengan bobot dan nilai bias. Hasil perhitunan tersebut kemudian akan diproses dengan menggunakan fungsi aktivasi yang telah ditentukan sebelumnya sehingga diperoleh sinyal output dari hidden unit tersebut.
6. Hitung kesalahan antara target output dengan output hasil menggunakan metode Mean Absolute Persentage Error. Jika masih belum memenuhi syarat, dilakukan penghitungan faktor koreksi error (δk).
7. Setiap hidden unit akan menghitung bobot yang dikirimkan output unit. Kemudian hasilnya dikalikan dengan turunan dari fungsi aktivasi untuk mendapatkan faktor koreksi error.
8. Setiap unit output akan memperbaharui bobotnya dari setiap hidden unit. Demikian pula setiap hidden unit akan memperbaharui bobotnya dari setiap unit input.
9. Memeriksa stopping condition.
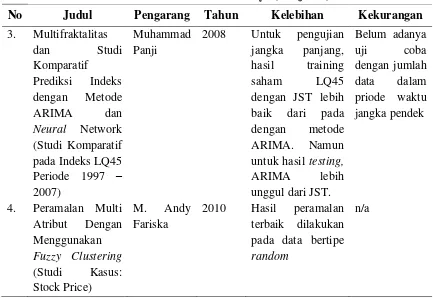
Pada tahun 2008, Panji melakukan penelitian mengenai multifraktalitas dan studi komparatif prediksi indeks dengan metode Arima dan Neural Network (studi komparatif pada indeks LQ45 periode 1997 – 2007). Adapun langkah-langkah metode ARIMA dalam penelitian tersebut sebagai berikut:
1. Melakukan pemeriksaan kestasioneran data dengan menggunakan ADF (augmented dickey-fuller).
2. Melakukan proses differencing (pembedaan) apabila data tidak stasioner.
3. Melakukan penentuan nilai derajat autoregressive (AR), tingkat proses differencing, dan derajat moving average (MA) dalam ARIMA.
4. Melakukan estimasi parameter pada metode ARIMA, lalu melakukan proses prediksi.
5. Menghitung tingkat error dengan mengunakan MAD (Mean Absolute Deviation), MSE (Mean Squared Error), dan MPE (Mean Percentage Error).
1. Menentukan nilai perulangan, derajat, jumlah kelas, fungsi objektif, jumlah baris data, dan jumlah kolom data.
2. Menentukan nilai U awal.
3. Melakukan pengulangan sampai batas nilai pengulangan dan error yang telah ditentukan untuk mencari nilai center dan U baru.
4. Melakukan pengempokkan data berdasarkan hasil U baru yang telah diperoleh pada perulangan sebelumnya.
5. Mencari mean, standar deviasi, dan derajat keanggotaan. 6. Melakukan prediksi menggunakan metode Fuzzy Sugeno.
Adapun beberapa penelitian sebelumnya yang telah dilakukan untuk memprediksi harga saham berdasarkan data masa lalunya dapat dilihat pada Table 2.1.
Tabel 2.1 Penelitian Sebelumnya
No Judul Pengarang Tahun Kelebihan Kekurangan
Tabel 2.1 Penelitian Sebelumnya (Lanjutan)
No Judul Pengarang Tahun Kelebihan Kekurangan