BAB 2
LANDASAN TEORI
2.1 Desain Analisis Algoritma
Kovelamudi (2013) menyatakan algoritma dapat di definisikan sebagai prosedur komputasi yang mengambil beberapa nilai atau set nilai-nilai sebagai output. Ini adalah tahap-tahap komputasi yang akan mengubah input menjadi output. Dan merupakan alat untuk untuk memecahkan berbagai permasalahan di dalam komputer. Algoritma harus memiliki kriteria sebagai berikut :
Input : nilai 0 atau lebih disisipkan.
Output : setidaknya akan menghasilkan satu kuantitas. Kepastian : setiap instruksi jelas dan tidak ambigu.
Finiteness :Jika kita menelusuri petunjuk dari sebuah algoritma, maka untuk semua kasus, algoritma akan berhenti setelah memasuki langkah
terakhir.
Efektivitas : Setiap instruksi harus dimulai dari awal sehingga dapat diproses. Sebuah program adalah ekspresi dari algoritma dalam bahasa pemrograman. Kumpulan dari instruksi, yang mana komputer akan mengikuti instruksi untuk memecahkan sebuah masalah.
Sekali sebuah algoritma diberikan kepada sebuah permasalahan dan dijamin akan memberikan hasil yang diharapkan, maka langkah penting selanjutnya adalah menentukan besar biaya yang diperlukan algoritma tersebut untuk memperoleh hasil itu. Proses inilah yang disebut dengan analisis algoritma (Weiss.M.A, 1996). Maksud dilakukannya analisis algoritma (Horowitz & Sahni, 1978) adalah untuk:
1. Memenuhi aktivitas intelektual.
2. Meramalkan suatu hal yang akan terjadi atau yang akan didapat dari algoritma tersebut.
2.2 Jenis-jenis Algoritma
Jenis-jenis algoritma terdapat beragam klasifikasi algoritma dan setiap klasifikasi mempunyai alasan tersendiri. Salah satu cara untuk melakukan klasifikasi jenis-jenis algoritma adalah dengan memperhatikan paradigma dan metode yang digunakan untuk mendesain algoritma tersebut. Beberapa paradigma yang digunakan dalam menyusun suatu algoritma akan dipaparkan dibagian ini. Masing-masing paradigma dapat digunakan dalam banyak algoritma yang berbeda (Kovelamudi, 2013).
2.2.1 Divide and Conquer
Kovelamudi (2013) paradigma untuk membagi suatu permasalahan besar menjadi permasalahan-permasalahan yang lebih kecil. Pembagian masalah ini dilakukan terus menerus sampai ditemukan bagian masalah kecil yang mudah untuk dipecahkan. Singkatnya menyelesaikan keseluruhan masalah dengan membagi masalah besar dan kemudian memecahkan permasalahan-permasalahan kecil yang terbentuk.
2.2.2 Dynamic Programming
Kovelamudi (2013) paradigma pemrograman dinamik akan sesuai jika digunakan pada suatu masalah yang mengandung sub-struktur yang optimal dan mengandung beberapa bagian permasalahan yang tumpang tindih. Paradigma ini sekilas terlihat mirip dengan paradigma Divide and Conquer, sama-sama mencoba untuk membagi permasalahan menjadi sub permasalahan yang lebih kecil, tapi secara intrinsik ada perbedaan dari karakter permasalahan yang dihadapi
2.2.3 Greedy Algorithm
1. Bahasa Semu (pseudocode).
Yaitu dengan menggunakan bahasa sehari-hari, tetapi harus jelas dan struktur. 2. DiagramAlir/Alur (Flowchart).
Yaitu dengan membuat suatu penulisan atau penyajian algoritma berupa diagram yang menggambarkan susunan alur logika dari suatu permasalahan.
2.3 Algoritma Quicksort
Quicksort adalah algoritma pengurutan yang dikembangkan oleh Tony Hoare. Algoritma
Quicksort melakukan perbandingan sebayak n log n untuk mengurutkan data sebanyak n. kondisi paling buruk dari jumlah perbandingan adalah n2. Secara praktis, Quicksort
beroperasi lebih cepat dibanding algoritma dengan kompleksitas n logn n lainnya. Sareen (2013) menyatakan bahwa keuntungan dari penggunaan algoritma Quicksort
adalah cepat dan efisien, sedangkan kerugian yang dapat dialami adalah menghasilkan performa yang buruk apabila data sudah terurut. Berikut adalah sarat dalam melakukan pengurutan ataupun penyortiran algoritma Quicksort;
1. Semua elemen yang ada disebelah kiri pivot harus lebih kecil atau sama dengan pivot, dan semua elemen disebelah kanan pivot harus lebih besar atau sama dengan pivot.
2. Pivot yang sudah diurutkan disusun berdasarkan urutan dari array/list. 3. Conquer yaitu disusun menjadi 2 sub array secara rekursif.
4. Kemudian digabungkan.
5. Permasalahannya yaitu sorting kunci n pada yang bukan urutan penurunan 6. Inputkan bilangan integer n positive, array dari kunci m yang sudah
diindekskan dari pertama hingga data ke-n.
7. Output, array m yang berisi kunci yang tidak menurun 8. Quicksort(rendah, tinggi)
1. Tinggi> rendah
2. kemudian partisi (rendah, tinggi, pivotIndex) 3. Quicksort (rendah, pivotIndex -1)
4. Quicksort (pivotIndex 1, tinggi)
1. pivotitem = S [rendah] 2. k=low
3. for j = low +1 tinggi
4. lakukan if S [ j ] < pivot item 5. Kemudian k = k + 1
6. Ganti S [ j ] dan m [ k ] 7. pivot = k
8. Ganti S[low] dan S[pivot]
Quicksort adalah algoritma sorting acak berdasarkan paradigma Divide and Conquer
Divide: memilih elemen acak dari x (pivot) dan partisi m ke dalam L elements lebih kecil dari x
E elements sama dengan x G elements lebih besar dari x Recursive: sorting L dan G Conquer: gabungkan L, E dan G
2.3.1 Metode Rekursif dalam Algoritma Quicksort
Quicksort dengan pendekatan rekursif tidak membutuhkan struktur data khusus, seperti
stack, karena setiap kelompok akan berjalan secara rekursif. Robert Sedgewick & Kevin Wayne (2011) menyatakan bahwa terdapat dua bagian pada pendekatan rekursif, yaitu
sort dan partisi. Partisi merupakan bagian yang melakukan tugas untuk mengelompokkan data, sedangkan sort adalah bagian yang melakukan proses rekursif. Semakin besar jumlah data, maka kompleksitas ruang suatu algoritma rekursif akan semakin besar.
kelompok sehingga kelompok lainnya menjadi kosong. Hal ini akan menyebabkan terjadinya banyak pengulangan pada saat pengurutan data. Nilai pivot pada kasus ini biasanya adalah nilai maksimum atau minimum dari kelompok data yang ingin diurutkan. Kompleksitas dari kasus terburuk ini adalah ½ n2. Kondisi yang ketiga adalah kasus rata-rata, yaitu ketika pivot tidak terpilih secara acak dari data. Kompleksitas dari kasus rata-rata sama dengan kasus terbaik adalah 1.39 n log n.
2.3.2 Implementasi Quicksort
Implementasi Quicksort ( Abdul. K, 2012.) Algoritma:
Subrutin Quicksort(L,p,r) Jika p < r MAKA
q partisi (L,p,r)
Quicksort(L,p,q)
Quicksort(L,q+1,r) Akhir-jika
Akhir – subrutin
Untuk mengurutkan isi keseluruhan Larik L, diperlukan pemanggilan seperti berikut:
Quicksort(L,O, jumlah-elemen(L)-1) Subrutin partisi sendiri seperti berikut:
Subrutin partisi(L,p,r) x L[p] i p j r
Ulang selama benar
Ulang selama L[j] > x j j -1
Akhir-ulang Ulang selama L[j] < x i i – 1
// Tukarkan L[i] dengan L[j] tmp L[i]
L[i] L[j] L[j] tmp Sebaliknya
Nilai – balik J Akhir-jika Akhir – ulang Akhir - subrutin
2
Setelah penukaran L[i] dan L[j] dilaksanakan
i j
Setelah i digerakkan ke
kanan sampai L[i] >=6 dan setelah j digerakkan i j Ke kiri sampai L[j]<=6
Setelah penukaran L[i] dan L[j] dilaksanakan Karena i<j tidak berlaku lagi,maka nilai balik berupa j
0 1 2 3 4 5 6 7
7 6 8
L[0..4] L[5..7]
Gambar 2.1 Keadaan setelah pivot didapatkan
3
2.3.3 Kasus terburuk Running Time Quicksort
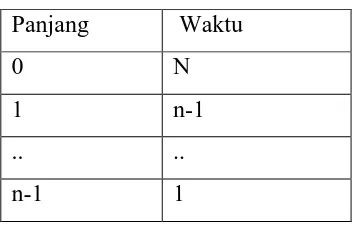
Kovelamudi (2013) kasus terburuk untuk Quicksort dapat terjadi ketika pivot adalah elemen terkecil atau terbesar. Salah satu dari objek L dan G memiliki ukuran n-1 dan yang lain memiliki ukuran 0. Running timenya berdasarkan data yang sudah ada, kemudian dijumlahkan n + (n - 1) + … + 2 + 1, dengan demikian, kasus terburuk running time pada Quicksort adalah O(n2). Berikut tabel running time Quicksort :
Tabel 2.1 Running Time Quicksort
Panjang Waktu
0 N
1 n-1
.. ..
n-1 1
2.3.4 Analisis kasus terburuk Running Time pada Quicksort
Kovelamudi (2013) pivot adalah yang terkecil (ataupun terbesar) dari element T (N) = T (N-1) + cN, N > 1
Telescoping:
T (N-1) = T (N-2) + c (N-1) T (N-2) = T (N-3) + c (N-2) T (N-3) = T (N-4) + c (N-3) …………...
T (2) = T (1) + c.2
T (N) + T (N-1) + T (N-2) + … + T (2) = = T (N-1) + T (N-2) + … + T (2) + T (1) + C (N) + c (N-1) + c (N-2) + … + c.2
T (N) = T (1) + c times (the sum of 2 thru N) = T (1) + c (N (N+1) / 2 -1) = O (N2)
4
Pivot adalah nilai tengah dari array, bagian dari sisi kiri dan kanan memiliki ukuran yang sama. Partisi dari Log N, untuk memperoleh setiap partisi kita harus melakukan perbandingan (dan bukan hanya swap dari N/2 ). Karena itu kompleksitas dari algoritma ini adalah O (N log N).
2.3.5 Kasus terbaik analisis Running Time
T (N) = T (i) + T (N - i -1) + cN
Kovelamudi (2013) waktu untuk menyortir file sama dengan waktu untuk menyortir partisi yang disebelah kiri dengan element i, ditambah dengan waktu untuk menyortir sebelah kanan dengan elemen N-i-1, ditambah dengan waktu untuk membangun partisi.
Kita ambil pivot dari tengah T (N) = 2 T (N/2) + cN
Bagi dengan N: T (N) / N = T (N/2) / (N/2) + c Telescoping:
T (N) / N = T (N/2) / (N/2) + c T (N/2) / (N/2) = T (N/4) / (N/4) + c T (N/4) / (N/4) = T (N/8) / (N/8) + c ……
T (2) / 2 = T (1) / (1) + c Ambil semua persamaan :
T (N) / N + T (N/2) / (N/2) + T (N/4) / (N/4) + …. + T (2) / 2 = = (N/2) / (N/2) + T (N/4) / (N/4) + … + T (1) / (1) + c.logN Setelah penukaran nilai yang sama:
T (N)/N = T (1) + c * LogN
T (N) = N + N * c * LogN = O (NlogN)
2.4 Algoritma Knuth-Morris-Pratt (KMP)
5
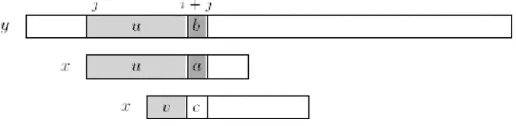
bersamaan pada tahun 1977. Algoritma Knuth-Morris-Pratt melakukan perbandingan karakter teks dan karakter pada pola dari kiri ke kanan. Ide dari algoritma ini adalah bagaimana memanfaatkan karakter-karakter pola yang sudah diketahui ada di dalam teks sampai terjadinya ketidakcocokkan untuk melakukan pergeseran. Seperti pada gambar 2.2 :
Gambar 2.2 Pergeseran dalam Algoritma Pencocokan String
Misalkan, string teks y pada gambar 2 mempunyai panjang n, indeksnya dinyatakan dengan i, serta string pola x, mempunyai panjang m, indeknya dinyatakan dengan j. Jika terjadi ketidakcocokan di x[j] = a dan y[i+j] = b, maka telah diketahui terdapat karakter-karakter pola yang ada pada teks yaitu x[0..j-1] = y[i..j+j-1] = u. karakter-karakter ini dapat dimanfaatkan sehingga dapat dimungkinkan melakukan pergeseran yang lebih jauh.
Secara sistematis, langkah-langkah yang dilakukan algoritma Knuth-Morris-Pratt pada saat mencocokkan string:
1. Algoritma Knuth-Morris-Pratt mulai mencocokkan pattern pada awal teks. 2. Dari kiri ke kanan, algoritma ini akan mencocokkan karakter per karakter
pattern dengan karakter diteks yang bersesuaian, sampai salah satu kondisi berikut dipenuhi:
a. Karakter dipattern dan diteks yang dibandingkan tidak cocok
(mismatch).
b. Semua karakter dipattern cocok. Kemudian algoritma akan memberitahukan penemuan di posisi ini.
6
2.4.1 Kelebihan Algoritma Knuth-Morris Pratt (KMP)
Pada algoritma KMP, kita memelihara informasi yang digunakan untuk melakukan jumlah pergeseran. Algoritma menggunakan informasi tersebut untuk membuat pergeseran yang lebih jauh, tidak hanya satu karakter.
2.4.2 Kekurangan Algoritma Knuth-Morris Pratt (KMP)
Kekurangan yakni efektifitas dari algoritma ini akan berkurang seiring dengan bertambahnya aplikasi yang dibuka ketika menjalankan aplikasi ini.
2.4.3 Fungsi Pinggiran (Border Function) Pada Metode KMP
Fungsi pinggiran b(j) didefinisikan sebagai ukuran awalan terpanjang dari P yang merupakan akhiran dari P[1..j]. Sebagai contoh, tinjau pattern P = ababaa. Nilai F untuk setiap karakter di dalam P adalah sebagai berikut:
Tabel 2.2 Fungsi Pinggiran
J 1 2 3 4 5 6
P[j] A B A B A A
B[j] 0 0 1 2 3 1
2.4.4 Alur Dari Algoritma Knuth-Morris-Pratt (KMP)
masukan:
sebuah array karakter, S (teks yang akan dicari) sebuah array karakter, W (kata yang dicari)
output:
integer (yang berbasis-nol posisi di S di mana W adalah ditemukan) mendefinisikan variabel:
7
selama m + i adalah kurang dari panjang dari S, lakukan: jika W [i] = S [m + i],
jika S sama dengan (panjang dari W) -1, kembali m
i ← i + 1 jika tidak,
m ← m + i - T [i],
jika T [i] adalah lebih besar dari -1, i ← T [i]
lain i ← 0
(Jika kita mencapai di sini, kita telah mencari semua S tidak berhasil) mengembalikan panjang dari S.
Gambar 2.3 Algoritma KMP
2.5 Netbeans
Fatta (2007) netbeans adalah sebuah proyek software OpenSource. Proyek Netbeans
mulai diprakarsai oleh Perusahaan Sun Microsistems sejak bulan Juni 2000 dan terus berkembang hingga saat ini. Netbeans mengacu pada dua hal, yaitu Netbeansplatform
untuk pengembangan aplikasi desktop java dan sebuah Netbeans IDE (Integrated Development Environment). Netbeans dimulai pada tahun 1996 sebagai Xelfi (Delphi), Java IDE proyek mahasiswa di bawah bimbingan Fakultas Matematika dan Fisika di Charles University di Praha. Pada tahun 1997 Staněk Romawi membentuk perusahaan untuk proyek tersebut dan menghasilkan versi komersial Netbeans IDE hingga kemudian dibeli oleh Sun Microsistems pada tahun 1999. IDE Netbeans
memiliki editor untuk file Java yang berbasiskan teks ataupun GUI (Graphical User Interface). Ada bermacam-macam proyek file Java yang dapat dibuat di dalam
Netbeans. Netbeans yang berisi sebuah aplikasi GUI Java yang bertujuan sebagai sarana untuk memperkenalkan fitur editor teks dari IDE Netbeans.
8
Flowchart program adalah sebuah bagan yang mendekripsikan suatu algoritma ataupun alur dalam menyelesaikan suatu masalah algoritma. Flowchart di bagi menjadi dua, yaitu flowchart sistem dan flowchart program. (Sismoro, H. 2005)
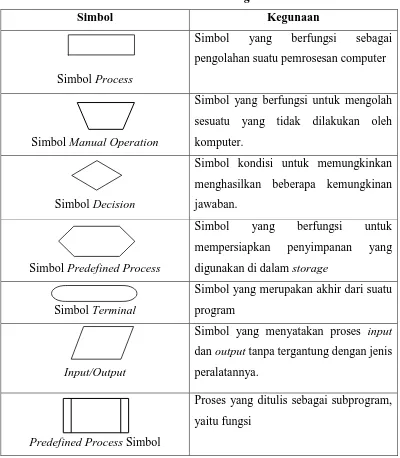
Program flowchart, yaitu simbol-simbol flowchart yang digunakan untuk menggambarkan logic dari pemrosesan terhadap data, berikut adalah simbol-simbol
flowchart (Sismoro, H. 2005)
Tabel 2.3 Flowchart Program
Simbol Kegunaan
Simbol Process
Simbol yang berfungsi sebagai pengolahan suatu pemrosesan computer
Simbol Manual Operation
Simbol yang berfungsi untuk mengolah sesuatu yang tidak dilakukan oleh komputer.
Simbol Decision
Simbol kondisi untuk memungkinkan menghasilkan beberapa kemungkinan jawaban.
Simbol Predefined Process
Simbol yang berfungsi untuk mempersiapkan penyimpanan yang digunakan di dalam storage
Simbol Terminal
Simbol yang merupakan akhir dari suatu program
Input/Output
Simbol yang menyatakan proses input
dan output tanpa tergantung dengan jenis peralatannya.
Predefined Process Simbol
9
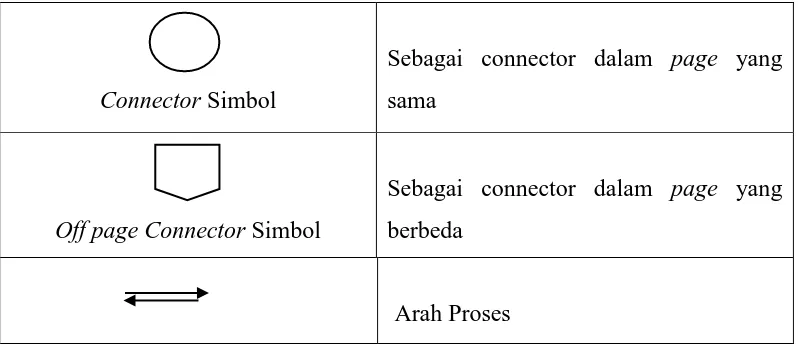
Connector Simbol
Sebagai connector dalam page yang sama
Off page Connector Simbol
Sebagai connector dalam page yang berbeda
Arah Proses
Flowchart sistem yaitu suatu bagan yang berfungsi untuk mendekskripsikan suatu alur dari program pemrosesan suatu file dalam suatu area menjadi area yang lain (Sismoro, H. 2005). Berikut adalah tabel flowchart sistem:
Tabel 2.4 Flowchart Sistem
Simbol Kegunaan
Input/Output
Simbol yang berfungsi sebagai proses
input dan output.
Simbol Punched Card
Simbol yang berfungsi sebagai input
yang berasal dari halaman atau output
yang ditulis ke halaman
Simbol Magnetic Tape unit
Simbol yang menyatakan input yang berasal dari pita magnetik dan output
yang disimpan ke pita magnetik
Simbol Disk and On-Line Storage
Simbol untuk menyatakan input yang berasal dari sebuah hardware disk atau
output disimpan ke disk juga.
Simbol-simbol yang menyatakan input
10
Simbol Document akan dicetak ke kertas.
Simbol Display