Daftar Isi v
Penerbit
Gunadarma
Dody Pernadi
2018
M
o
d
u
l
K
u
li
a
h
P
e
n
g
a
n
t
a
r
T
e
k
n
o
l
o
g
i
I
n
f
o
r
m
a
s
i
TOPOLOGI
JARINGAN
Pengertian
Topologi
Jaringan
Topologi
jaringan
dalam
telekomunikasi
adalah
suatu
cara
menghubungkan
perangkat
telekomunikasi
yang
satu
dengan
yang
lainnya
sehingga
membentuk
jaringan.
Dalam
suatu
jaringan telekomunikasi, jenis topologi yang dipilih akan mempengaruhi kecepatan komunikasi.
Untuk itu maka perlu dicermati kelebihan/keuntungan dan kekurangan/kerugian dari masing ‐
masing topologi berdasarkan karakteristiknya.
Jenis
Topologi
1.
Topologi BUS
2.
Topologi Star
3.
Topologi Ring
4.
Topologi Mesh
Topologi
BUS
Karakteristik
Topologi
BUS
•
Node
–
node
dihubungkan
secara
serial
sepanjang
kabel,
dan
pada
kedua
ujung
kabel
ditutup dengan terminator.
•
Sangat sederhana dalam instalasi
•
Sangat ekonomis dalam biaya.
•
Paket‐paket data saling bersimpangan pada suatu kabel
•
Tidak
diperlukan hub,
yang banyak diperlukan adalah
Tconnector pada
setiap
ethernet
card.
•
Problem
yang
sering
terjadi
adalah
jika
salah
satu
node
rusak,
maka
jaringan
keseluruhan
dapat
down,
sehingga
seluruh
node
tidak
bisa
berkomunikasi
dalam
jaringan tersebut.
Keuntungan
Topologi
BUS
•
Topologi yang sederhana
•
Kabel
yang
digunakan
sedikit
untuk
menghubungkan
komputer‐komputer
atau
peralatan‐peralatan yang lain
•
Biayanya lebih murah dibandingkan dengan susunan pengkabelan yang lain.
•
Cukup mudah apabila kita ingin memperluas jaringan pada topologi bus.
Kerugian
Topologi
BUS
•
Traffic (lalu lintas) yang padat akan sangat memperlambat bus.
•
Setiap
barrel
connector
yang
digunakan
sebagai
penghubung
memperlemah
sinyal
elektrik yang dikirimkan, dan kebanyakan akan menghalangi sinyal untuk dapat diterima
dengan benar.
•
Sangat sulit untuk melakukan troubleshoot pada bus.
•
Lebih lambat dibandingkan dengan topologi yang lain.
Topologi
STAR
Karakteristik
Topologi
STAR
•
Setiap node berkomunikasi langsung dengan konsentrator (HUB)
•
Bila
setiap
paket
data
yang
masuk
ke
consentrator
(HUB)
kemudian
di
broadcast
keseluruh
node yang
terhubung sangat banyak (misalnya
memakai
hub
32 port), maka
kinerja jaringan akan semakin turun.
•
Jika
salah
satu
ethernet
card
rusak,
atau
salah
satu
kabel
pada
terminal
putus,
maka
keseluruhhan
jaringan
masih
tetap
bisa
berkomunikasi
atau
tidak
terjadi
down
pada
jaringan keseluruhan tersebut.
•
Tipe kabel yang digunakan biasanya jenis UTP.
Keuntungan
Topologi
STAR
•
Cukup
mudah
untuk
mengubah
dan
menambah
komputer
ke
dalam
jaringan
yang
menggunakan
topologi
star
tanpa
mengganggu
aktvitas
jaringan
yang
sedang
berlangsung.
•
Apabila
satu
komputer
yang
mengalami
kerusakan
dalam
jaringan
maka
computer
tersebut tidak akan membuat mati seluruh jaringan star.
•
Kita dapat menggunakan beberapa tipe kabel
di dalam jaringan yang sama dengan
hub
yang dapat mengakomodasi tipe kabel yang berbeda.
Kerugian
Topologi
STAR
•
Memiliki
satu
titik
kesalahan,
terletak
pada
hub.
Jika
hub
pusat
mengalami
kegagalan,
maka seluruh jaringan akan gagal untuk beroperasi.
•
Membutuhkan
lebih
banyak
kabel
karena
semua
kabel
jaringan
harus
ditarik
ke
satu
central
point,
jadi
lebih
banyak
membutuhkan
lebih
banyak
kabel
daripada
topologi
jaringan yang lain.
•
Jumlah terminal terbatas, tergantung dari port yang ada pada hub.
•
Lalulintas data yang padat dapat menyebabkan jaringan bekerja lebih lambat.
Topologi
RING
Karaktristik
Topologi
RING
•
Node‐node
dihubungkan
secara
serial
di
sepanjang
kabel,
dengan
bentuk
jaringan
seperti lingkaran.
•
Sangat sederhana dalam layout seperti jenis topologi bus.
•
Paket‐paket
data
dapat
mengalir
dalam
satu
arah
(kekiri
atau
kekanan)
sehingga
collision dapat dihindarkan.
•
Problem
yang
dihadapi
sama
dengan
topologi
bus,
yaitu:
jika
salah
satu
node
rusak
maka seluruh node tidak bisa berkomunikasi dalam jaringan tersebut.
•
Tipe kabel yang digunakan biasanya kabel UTP atau Patch Cable (IBM tipe 6).
Keuntungan
Topologi
RING
•
Data mengalir dalam satu arah sehingga terjadinya collision dapat dihindarkan.
•
Aliran
data
mengalir
lebih
cepat
karena
dapat
melayani
data
dari
kiri
atau
kanan
dari
server.
•
Dapat melayani aliran lalulintas data yang padat, karena data dapat bergerak kekiri atau
kekanan.
•
Waktu untuk mengakses data lebih optimal.
Kerugian
Topologi
RING
•
Apabila ada satu komputer
dalam ring yang gagal berfungsi, maka akan mempengaruhi
keseluruhan jaringan.
•
Menambah atau mengurangi computer akan mengacaukan jaringan.
•
Sulit untuk melakukan konfigurasi ulang.
Topologi
MESH
Karakteristik
Topologi
MESH
•
Topologi
mesh
memiliki
hubungan
yang
berlebihan
antara
peralatan‐peralatan
yang
ada.
•
Susunannya
pada
setiap
peralatan
yang
ada
didalam
jaringan
saling
terhubung
satu
sama lain.
•
jika
jumlah
peralatan
yang
terhubung
sangat
banyak,
tentunya
ini
akan
sangat
sulit
sekali untuk dikendalikan dibandingkan hanya sedikit peralatan saja yang terhubung.
Keuntungan
Topologi
MESH
•
Keuntungan utama dari penggunaan topologi mesh adalah fault tolerance.
•
Terjaminnya kapasitas channel komunikasi, karena memiliki hubungan yang berlebih.
•
Relatif lebih mudah untuk dilakukan troubleshoot.
Kerugian
Topologi
MESH
•
Sulitnya
pada
saat
melakukan
instalasi
dan
melakukan
konfigurasi
ulang
saat
jumlah
komputer dan peralatan‐peralatan yang terhubung semakin meningkat jumlahnya.
•
Biaya yang besar untuk memelihara hubungan yang berlebih.
1
JENIS KOMPUTER
Pembagian Komputer
Komputer digolongkan dalam beberapa sudut pandang, yaitu berdasarkan :
1. Data yang diolah atau cara kerjanya
2. Penggunaannya
3. Ukuran atau kapasitas
1. Data yang diolah atau cara kerjanya
Berdasarkan data yang diolah atau cara kerjanya, komputer digolongkan
kedalam tiga jenis, yaitu : analog komputer, digital komputer dan hybrid
komputer.
a. Analog komputer
Komputer analog digunakan untuk data yang sifatnya kontinyu dan bukan data
yang berbentuk angka, tetapi dalam bentuk phisik, seperti misalnya arus listrik
atau temperatur.
Output dari komputer analog umumnya adalah untuk pengaturan atau
pengontrolan suatu mesin. Komputer analog biasanya banyak digunakan pada
proses pengontrolan pada pabrik kimia, pembangkit tenaga listrik, dsb.
Keuntungan dari komputer analog adalah kemampuannya untuk menerima data
dalam besaran phisik dan langsung mengukur data tersebut tanpa harus
dikonversikan terlebih dahulu, sehingga proses dari komputer analog lebih cepat.
2
Kerugian komputer analog adalah terletak pada faktor ketepatannya, komputer
digital lebih tepat dibandingkan komputer analog.
b. Digital komputer
Data yang diterima pada komputer digital dalam bentuk angka atau huruf.
Komputer digital biasanya digunakan pada aplikasi bisnis dan aplikasi teknik.
Keunggulan dari komputer digital adalah :
1. Memproses data lebih tepat dibandingkan dengan komputer analog.
2. Dapat menyimpan data selama masih dibutuhkan oleh proses.
3. Dapat melakukan operasi logika, yaitu membandingkan dua nilai dan
menentukan hasilnya, yaitu membandingkan elemen nilai yang satu lebih
kecil atau sama dengan, atau lebih kecil sama dengan, atau tidak sama
dengan elemen nilai yang kedua.
4. Data yang telah dimasukkan dapat dikoreksi atau dihapus.
5. Output dari komputer digital dapat berupa angka, huruf, grafik maupun
gambar.
c. Hybrid komputer
Didalam aplikasi yang khusus dibutuhkan suatu komputer yang mampu
menyelesaikan permasalahan lebih cepat dari komputer digital dan lebih cepat
dari komputer analog. Komputer hybrid adalah kombinasi dari komputer analog
dan komputer digital. Data yang diterima dalam bentuk angka atau huruf dan
phisik.
3
2. Penggunaannya
Berdasarkan penggunaannya, komputer digolongkan kedalam komputer untuk
penggunaan khusus (
special purpose komputer
), dan komputer untuk
penggunaan umum (
general purpose komputer
).
a. Komputer untuk penggunaan khusus (
special purpose komputer
)
Komputer ini dirancang untuk menyelesaikan suatu masalah yang khusus, yang
biasanya hanya berupa satu masalah saja. Program komputer sudah tertentu
dan sudah tersimpan di dalam komputernya. Komputer ini dapat berupa
komputer digital maupun komputer analog, dan umumnya komputer analog
adalah
special purpose komputer
.
Special purpose komputer
banyak dikembangkan untuk pengontrolan yang
otomatis pada proses-proses industri dan untuk tujuan militer, untuk
memecahkan masalah navigasi di kapal selam atau kapal terbang.
Sekali
special purpose komputer
sudah diprogram untuk masalah yang khusus
maka tidak dapat digunakan untuk masalah yang lainnya, tanpa adanya
perubahan-perubahan yang dilakukan di dalam komputer.
b. Komputer untuk penggunaan umum (
general purpose komputer
)
Komputer ini dirancang untuk menyelesaikan bermacam-macam masalah, dapat
mempergunakan program yang bermacam-macam untuk menyelesaikan jenis
permasalahan-permasalahan yang berbeda. Karena komputer jenis ini tidak
dirancang untuk masalah yang khusus, maka dibandingkan dengan
special
purpose komputer
, kecepatannya lebih rendah.
4
General purpose komputer
dapat digunakan untuk menyelesaikan
masalah-masalah yang berbeda, misalnya aplikasi bisnis, teknik, pendidikan, pengolahan
data, permaianan, dsb.
General purpose komputer
dapat merupakan komputer digital maupun komputer
analog, tetapi umumnya komputer digital adalah
general purpose komputer
.
3.
Ukuran
a. Super Komputer
computer ini merupakan computer paling bertenaga. Aplikasi yang
digunakan biasanya lebih cenderung untuk penelitian ilmiah. Computer ini
biasanya memiliki beberapa prosesor sekaligus untuk menjalankan tugasnya.
Super computer biasanya unggul dalam kecepatan dari computer biasa
dengan menggunakan desain inovatif yang membuat mereka dapat
melakukan banyak tugas secara parallel, dan juga detail sipil yang rumit.
Computer ini biasanya mespesialisasikan untuk perhitungan tertentu,
biasanya perhitungan angka, dan dalam tugas umumnya tidak bagus
hasilnya.
Supercomputer
digunakan
untuk
tugas
penghitungan-intensif
seperti
prakiraan cuaca, riset iklim (termasuk riset pemanasan global, pemodelan
molekul, simulasi fisik seperti simulasi kapal terbang dalam terowongan
angin, simulasi peledakan senjata nuklir, dan riset fusi nuklir), dll. Militer dan
agensi sains salah satu pengguna utama supercomputer.
b. Mainframe
pada tahap awal mulainya era komputerisasi, mainframe merupakan
satu-satunya computer yang ada pada waktu itu. Mainframe ini dapat melayani
ratusan penggunanya pada saat yang bersamaan. Computer ini mirip dengan
5
minicomputer namun lebih besar dan lebih mahal. Penggunaannya umumnya
untuk pengolahan data dari suatu divisi atau perusahaan besar yang
membutuhkan pengolahan yang cukup berat.
c. Minicomputer
computer mainframe sangat mahal dan hanya perusahaan besar yang
mampu menggunakannya. Untuk membuat komputasi lebih tersedia dibuat
jenis computer yang lebih kecil dari mainframe yang disebut dengan
minicomputer yang dikembangkan sejak tahun 60-an. Computer jenis ini
digunakan lebih luas daripada mainframe, karena alas an untuk mendapatkan
yang tidak lebih mahal dari mainframe tapi lebih mudah dalam pengoperasian
dan pemeliharaan. Sekarang ini istilah minicomputer disamakan dengan
server, karena peran utamanya adalah mengkoordinasi suatu jaringan
computer.
d. Personal Computer (PC)
personal Computer (PC) adalah suatu perangkat computer yang ditujukan
untuk satu pengguna. Perangkatnya terdiri atas CPU, keyboard, monitor, dan
mouse. Perangkat
– perangkat tersebut dapat diringkas dalam satu meja,
tidak terlalu banyak membutuhkan tempat. Computer jenis ini paling banyak
digunakan di berbagai tempat seperti rumah, sekolah, kantor, dan
sebagainya.
KOMPRESI DATA
BAGIAN I : KONSEP DASAR
A. PENDAHULUAN
Teknik kompresi data ada dua yaitu :
(1)
lossy data-compression
dan;
(2)
lossless data-compression
.
Lossy data-compression masih memperbolehkan adanya kesalahan dalam
proses kompresi atau dekompresi, selama kesalahan proses tersebut tidak terlalu
mengubah pola pokok dari data yang dikompres. Teknik kompresi ini biasanya
digunakan untuk kompresi data gambar dan suara.
Lossless data-compression digunakan jika kesalahan tidak boleh terjadi
sama sekali. Artinya data sebelum dikompres harus sama dengan data hasil
dekompresi. Teknik ini biasanya digunakan untuk rekaman database, file-file word
prosessing dan data-data lain yang memerlukan proses kompresi dan dekompresi
akurasi tinggi.
Kompresi data merupakan penerapan Teori Informasi yang merupakan
cabang ilmu matematika. Teori ini muncul pada akhir 1940 dan dikembangkan
pertama kali oleh Claude Shannon di Laboratorium Bell. Dorongan pengembangan
ilmu ini adalah berdasarkan beberapa pertanyaan tentang apa itu informasi ,
termasuk bagaimana cara penyimpanan dan pengiriman pesan (informasi).
Dalam Teori Informasi digunakan istilah “
entropy
” yang diambil dari
istilah Ilmu Thermodinamika. Makna dari entropy sebetulnya menunjukkan
ketidakteraturan sesuatu (dalam hal ini informasi). Semakin tinggi nilai entropy
sebuah
message
(informasi) berarti semakin banyak simbul yang muncul dalam
informasi tersebut. Dengan demikian nilai entropy berkaitan dengan probabilitas
simbul dari sebuah informasi.
Nilai entropy dari sebuah simbul didefinisikan dengan logaritma negatif
dari probabilitasnya. Untuk menentukan banyaknya bit dari simbul yang digunakan
dalam informasi tersebut dapat dinyatakan dengan logaristma berbasis 2 yaitu :
Sedangkan entropy keseluruhan informasi merupakan jumlah entropy dari
masing-masing simbul.
Sebagai gambaran misalkan dalam sebuah tulisan, probabilitas huruf “e”
adalah 1/16. Maka jumlah bit untuk kode huruf tersebut adalah 4 bit. Sedangkan
kalau menggunakan kode ASCII jumlah bit yang digunakan adalah 8-bit.
Dalam perhitungan entropy untuk kompresi data berbeda dengan
perhitungan entropy dalam thermodinamika. Untuk kompresi data kita
menggunakan bilangan yang tidak absolut, artinya tergantung cara memandang
dalam memperoleh nilai probabilitas sebuah simbul.Untuk orde-0 kita
mengabaikan simbul-simbul yang telah muncul sebelumnya. Atau dengan kata lain
setiap simbul yang akan muncul memiliki nilai probabilitas yang sama. Model ini
disebut dengan
zero-memory source
(sumber tanpa memori). Nilai entropy untuk
zero-memory source yang menhasilkan
S
buah simbul dapat dihitung dengan
persamaan :
H S P Si P Si S ( ) ( ) log ( ) =∑
2 1dimana
P(Si)
adalah probabilitas setiap simbul.
B. PEMODELAN DAN PENGKODEAN DALAM KOMPRESI DATA
Pada umumnya proses kompresi data meliputi pembacaan simbul,
mengubah kode untuk tiap-tiap simbul kemudian menuliskan simbul-simbul
dengan kode yang baru. Jika proses kompresi berjalan efektif, maka hasil file yang
diperoleh dapat lebih kecil dari file aslinya. Efektif tidaknya sistem kompresi data
tergantung dari pemodelan dan pengkodean yang digunakan. Model dan Kode
yang digunakan dalam kompresi data dibentuk berdasarkan nilai probabilitas
tiap-tiap simbul.
Gambar-1. Model Statistik dengan Huffman Encoder
C. ALGORITMA PENGKODEAN HUFFMAN
Algoritma pengkodean Huffman sebetulnya hampir sama dengan algoritma
pengkodean Shannon-Fano. Yaitu simbul yang mempunyai probabilitas paling
besar diberi kode paling pendek (jumlah bit kode sedikit) dan simbul dengan
probabilitas paling kecil akan memperoleh kode paling panjang (jumlah bit kode
banyak). Kode tersebut diperoleh dengan cara memyusun sebuah pohon Huffman
untuk masing-masing simbul berdasarkan nilai probabilitasnya. Simbul yang
memiliki probabilitas terbesar akan dekat dengan root (sehingga memiliki kode
terpendek) dan simbul yang memiliki probabilitas terkecil akan terletak jauh dari
root (sehingga memiliki kode terpanjang).
Pohon Huffman merupakan pohon-biner (
binary tree
). Sedangkan
Algoritma penyusunan pohon beserta pengkodeannya adalah sebagai berikut :
•
Berdasarkan daftar simbul dan probabilitas, buat dua buah node dengan
frekuensi paling kecil.
•
Buat node parent dari node tersebut dengan bobot parent merupakan jumlah
dari probabilitas kedua node anak tersebut.
•
Masukkan node parent tersebut beserta bobotnya ke dalam daftar, dan
kemudian kedua node anak beserta probabilitasnya dihapus dari daftar.
•
Salah satu node anak dijadikan jalur (dilihat dari node parent) untuk
pengkodean 0 sedangkan lainnya digunakan untuk jalur pengkodean 1.
Gambar-2. Langkah-langkah Pembentukan Pohon Huffman
Gambar-3. Pohon Huffman yang terbentuk beserta kode simbul
•
Langkah-langkah di atas diulang sampai hanya tinggal satu node bebas yang
tersisa dalam daftar (dengan bobot 1) dan digunakan sebagai akar pohon
tersebut.
Suatu contoh dalam daftar terdiri dari 5 huruf beserta frekuensinya (dapat
dilihat pada
Gambar-2a
.). Nilai frekuensi tiap-tiap simbul dapat juga dinyatakan
dalam nilai probabilitas, dengan cara membagi masing-masing nilai frekuensi
dengan jumlah seluruh simbul yang muncul dalam pesan (bilangan yang terdapat
dalam akar pohon).
Hasil algoritma
pertama, kedua
dan
ketiga
seperti ditunjukkan
Gambar-2b
. Dalam
membuat dua buah node untuk algoritma pertama, node dengan frekuensi terkecil
selalu diletakkan di sebelah kiri. Algoritma
keempat
(penentuan jalur untuk kode 0
dan 1) diperlihatkan pada
Gambar-2b
atau
Gambar-2c
. Sedangkan pohon Huffman
yang terbentuk ditunjukkan pada
Gambar-3
.
D. ALGORITMA PENGKODEAN ELIAS
Algoritma Elias Encoder menggunakan rumus logaritma berbasis 2
terhadap nomor urut simbul dalam membuat kodenya. Nomor urut ini dibentuk
berdasarkan probabilitas simbul. Simbul yang memiliki propabilitas terbesar akan
memiliki nomor urut terkecil dan simbul yang memiliki probabilitas terkecil akan
memiliki nomor urut terbesar. Dengan demikian simbul yang memiliki nomor urut
terkecil akan diberi kode pendek dan simbul yang memiliki nomor urut terbesar
akan diberi kode panjang sesuai dengan nilai logaritmanya.
Kode Elias terdiri dari dua bagian yaitu
prefix
yang terdiri dari sejumlah
deretan bit ‘0’ diikuti dengan sejumlah deretan bit akhiran. Aturan pembuatan kode
untuk sebuah integer
n
dari nomor simbul adalah :
•
Banyaknya bit ‘0’ dalam prefix dihitung dengan persamaan
log (2 n+ 1) •Deretan bit akhiran merupakan bilangan biner dari
n
+ 1.
Contoh :
Nomor
Kode
0
1
1
010
2
011
3
00100
4
00101
5
00110
6
00111
7
0001000
Dalam algoritma Elias Encoder ini proses pertama yang dilakukan untuk
keperluan pembuatan kode adalah mencari probabilitas masing-masing simbul
kemudian mengurutkan simbul-simbul tersebut berdasarkan probabilitasnya.
Sehingga diperoleh simbul yang memiliki probabilitas terbesar menempati nomor
paling kecil dan simbul yang memiliki probabilitas paling kecil menempati nomor
paling besar.
BAGIAN II : REALISASI PROGRAM
A. ALGORITMA POHON HUFFMAN
Program kompresi data menggunakan Pohon Huffman ini dibuat dengan
bahasa Turbo Pascal 7.0. Untuk keperluan penyusunan pohon digunakan stuktur
data pointer (struktur data dinamis) karena dirasa lebih menguntungkan. Untuk
lebih meningkatkan efisiensi pengunaan pointer maka setiap pointer harus
memiliki 3 medan pointer selain 2 medan untuk data (karakter dan probabilitas).
Fungsi ketiga medan pointer ini adalah satu medan digunakan untuk menunjuk
pointer berikutnya dalam pembuatan senarai berantai, sedangkan dua medan
lainnya digunakan untuk menunjuk cabang kiri dan kanan setelah menjadi bentuk
pohon.
Bentuk komponen pointer tersebut dapat digambarkan sebagai berikut :
Gambar-4. Struktur komponen pointer untuk pohon Huffman
Dalam struktur di atas, medan
DTKAR
sebagai tempat data simbul
sedangkan
DTPROB
sebagai tempat data probabilits dari simbul tersebut. Medan
KIRI
adlah pointer yang akan menunjuk cabang kiri, medan
KANAN
adalah pointer
yang akan menunjuk cabang kanan, dan medan
NEXT
adalah pointer yang
digunakan untuk menggandeng komponen dalam bentuk senarai berantai (sebelum
pembuatan pohon Huffman).
Deklarasi type berdasarkan struktur komponen di atas adalah:
type Node = ^Simpul; Simpul = record dtkar : char; dtprob : real; Kiri, Kanan, Next : Node end;
PROGRAM KOMPRESI
Program kompresi dibagi menjadi 3 bagian utama yaitu :
•
Proses Membaca Berkas.
•
Proses Pengkodean Huffman Tree.
•
Proses Penulisan Hasil Kompresi.
1. Proses Membaca File.
Proses ini dilakukan oleh procedure BACA_FILE. Dalam proses ini
dilakukan pencarian simbul-simbul yang muncul beserta probabilitasnya.
Masing-masing simbul dibaca dalam bentuk byte, kemudian ditransfer kedalam
bentuk nilai ASCII dan disimpan dalam sebuah array data karakter dengan indek
0..255. Sedangkan nilai probabilitasnya disimpan dalam sebuah array bilangan
dengan indek karakter yang bersangkutan.
Pembacaan file dalam procedure BACA-FILE dilakukan setiap 1 kbyte
(1024 byte).Sedangkan algoritma yang digunakan adalah sebagai berikut :
1. Buka berkas yang akan dibaca.
2. (Inisialisasi): pencacah simbul=0;
3. Untuk I=0 sampai 1024 (1 Kbyte) lakukan langkah 4;
4. Lakukan pengetesan apakah posisi berkas = eof; jika “Ya” keluar dari
procedure; jika “Tidak” lakukan langkah 5 sampai 8
5.
Baca satu byte dari berkas, masukkan ke
dt[I]
;
6. Naikkan pencacah jumlah simbul;
7.
Untuk
J=0
sampai
255
cari simbul yang sesuai untuk
dt[I];
jika
dt[I]=j
8.
Ulangi langkah 3 (untuk 1 Kbyte berikutnya) selama posisi berkas <>
eof
.
9. Tutup berkas;
10. Selesai.
Realisasi program procedure BACA_FILE dapat dilihat pada Lampiran
A.1. Jika program ini dijalankan dengan file coba.dat sebagai file inputnya maka
akan ditampilkan simbul-simbul dalam file tersebut beserta probabilitasnya.
a = 0.40 b = 0.04 c = 0.30 d = 0.10 e = 0.06 f = 0.10
2. Proses Pembuatan Pohon Huffman.
Fungsi prosedur ini adalah untuk menyusun pohon Huffman berdasarkan
probabilitas simbul, kemudian membuat kode berdasarkan pohon tersebut.
Procedure pohon Huffman terdiri dari beberapa procedure yaitu:
1. BUAT_LIST_PELUANG
2. CARI_PELUANG_TERKECIL
3. SUSUN_POHON
4. ENCRYPT (Pembuatan Kode).
2.1 Algoritma Procedure BUAT_LIST_PELUANG
Prosedur ini digunakan untuk membuat senarai berantai (linked-list)
dari tabel simbul beserta probabilitasnya yang telah disediakan oleh prosedur
BACA_FILE. Masukan prosedur ini adalah variabel
Kal
(array probabilitas
dengan indeks karakter) dan keluarannya adalah pointer yang menunjuk
pada simpul kepala dari senarai berantai
H
.
Sebelum menjalankan prosedur BUAT_LIST_PELUANG, prosedur
HUFFMAN memanggil prosedur DUMMY(Kepala) yang artinya membuat
pointer boneka dengan nama Kepala. Pointer ini selanjutnya akan digunakan
proses.
Algoritma BUAT_LIST_PELUANG adalah :
2.
Untuk
I=0sampai
255kerjakan langkah 3;
3.(Uji probabilitas setiap karakter:
Tes : Apakah
Kal[chr(I)] <>0?
Jika “Ya” kerjakan langkah 4 sampai langkah 6;
Jika “Tidak” ulangi langkah 3 untuk I berikutnya;
4.
Panggil procedure
DUMMY
dengan argumen
Bantu^.Next;
5.(Mengisi simpul) :
Tentukan :
Bantu^.Next.dtkar = chr(I);Bantu^.Next.dtprob = Kal[chr(I)] ;
6.
Tentukan
Bantu = Bantu^.Next;
Selesai.
Dari algoritma tersebut maka karakter yang probabilitasnya sama dengan nol
(berarti simbul tersebut tidak muncul) maka tidak akan dimasukkan ke
dalam tabel. Sehingga akan menghemat tabel karakter dan probabilitasnya.
Setelah semua data karakter dan peluangnya dimasukkan ke dalam senarai
berantai oleh prosedur BUAT_LIST_PELUANG, maka kemudian dilakukan
pencarian peluang terkecil dengan prosedur CARI_PELUANG_TERKECIL.
2.2 Prosedur CARI_PELUANG_TERKECIL
Prosedur ini digunakan untuk mencari dua simpul yang berisi
peluang terkecil. Masukannya adalah pointer yang menunjuk ke simpul
kepala,
H
. Keluaran adalah pointer yang menunjuk ke simpul dengan
frekuensi terkecil kedua,
Dua
.
Algoritma mencari dua peluang terkecil adalah sebagai berikut :
1. (Mencari peluang terkecil pertama).
Tentukan :
Satu = H^.Next, Bantu = Satu^.Next;
2.Kerjakan langkah 3 dan 4 selama
Bantu <> Nil;
3.Tes: apakah
Satu^.dtprob > Bantu^.dtprob?
Jika “Ya”, tentukan
Satu = Bantu;
4.Tentukan :
Bantu = Bantu ^.Next;
5. (Mencari peluang terkecil kedua).
Tes: apakah
Satu = H^.Next?
Jika “Ya” tentukan
Dua = Satu^.Next;
Jika “Tidak” tentukan
Dua = H^.Next;
6.Tentukan
Bantu = Dua^.Next;
7.
Kerjakan langkah 8 dan 9 selama
Bantu <> Nil;
8.
Tes apakah
(Dua^.dtprob > Bantu^.dtprob)dan
(
Bantu <> Satu)?
Jika “Ya” tentukan
Dua = Bantu;
9.
Tentukan
Bantu = Bantu^.Next;
2.3 Prosedur SUSUN_POHON
Dalam algoritma SUSUN_POHON ini selain pointer
Satu,
yang
menunjuk ke simpul peluang terkecil pertama,
Dua
yang menunjuk ke
simpul peluang terkecil kedua, digunakan pointer
B
dan
B1
. Pointer
B
digunakan untuk menunjuk ke simpul sebelum yang ditunjuk oleh simpul
Satu
, pointer
B1
digunakan untuk menunjuk ke simpul sebelum simpul yang
ditunjuk oleh simpul
Dua
. Untuk lebih jelasnya dapat dilihat pada
Gambar-5
.
Dalam program penentuan letak pointer B dan B1 diimplementasikan
dalam fungsi
SAMBUNGAN.
Berdasarkan
Gambar-5,
ada dua titik kritis yang dapat menyebabkan
kesalahan. Titik kritis yang pertama apabila pointer
Dua
terletak persis
sesudah pointer
Satu
, sehingga pointer
B1
akan menunjuk pointer ke simpul
yang sama seperti halnya pointer
Satu
. Titik kritis kedua, apabila pointer
Dua
terletak persis sebelum pointer
Satu
, sehingga pointer
B
menunjuk
simpul yang sama seperti halnya pointer
Dua
.
Dengan memperhatikan titik kritis tersebut, maka sebelum proses
pembentukan pohon Huffman dilanjutkan harus dilakukan pengetesan
terlebih dahulu apakah kita sedang dihadapkan dari salah satu titik kritis
tersebut atau tidak. Algoritma penyusunan pohon Huffman adalah sebagai
berikut :
Gambar-5. Ilustrasi pembentukan Pohon Huffman
1.(Menentukan letak pointer
Bdan
B1);
Tentukan:
B = SAMBUNGAN(H,SATU),
dan
B1=SAMBUNGAN(H,Dua);
2. (Alokasi tempat untuk menjumlah dua peluang).
Panggil prosedur DUMMY dengan parameter
B2.
3. (Menyambung cabang kiri dan kanan).
Tentukan:
B2^.dtprob = Satu^.dtprob + Dua^.dtprob, B2^.Kiri = Satu,dan
B2^.Kanan = Dua.
4. (Tes titik kritis pertama).
Tes : apakah
B^.Next[^.Next = Dua?
Jika “Ya” tentukan
B^.Next = Dua^.Next;5. (Tes titik kritis kedua).
Tes: apakah
B1^.Next^.Next = Satu?
Jika “Ya” tentukan
B1^.Next = Satu^.Next;
Jika “Tidak” tentukan
B1^.Next = Dua^.Next.
6. (Memindahkan letak simpul yang ditunjuk oleh B2)
Tentukan:
B2^.Next = H^.Next, danH^.Next = B2.
7. Selesai.
2.4 Prosedur ENCRYPT.
Prosedur Encrypt bersama-sama dengan prosedur Prefiks berfungsi
untuk membuat kode Huffman berdasarkan pohon Huffman yang telah
dibuat. Kode Huffman tersebut diujudkan dalam bentuk string dari ‘0’ dan
‘1’ dan diartikan sebagai bilangan biner, meskipun pada saat penulisan file
hasil kompresi kode tersebut diubah dari bentuk bilangan biner menjadi
bilangan bertype byte.
Pembuatan kode Huffman adalah dengan membuat daftar simbul
seperti yang dihasilkan pada saat mencari probabilitas simbul kemudian
dilakukan penelusuran simbul dalam pohon Huffman. Penelusuran selalu
dimulai dari ujung akar. Langkah dalam penelusuran untuk cabang kiri dan
kanan itulah yang akan menentukan kode Huffman. Jika mengujungi cabang
kiri diartikan ‘0’ dan mengunjungi cabang kanan diartikan ‘1’.
3. Prosedur Penulisan Hasil Kompresi
Prosedur ini menyediakan dua fungsi utama yang berkaitan dengan
penulisan file hasil kompresi. Yaitu penulisan header dan badan file.
3.1 Header
Header file hasil kompresi terdiri dari empat bagian yaitu :
•
informasi jumlah byte file asli
•
informasi banyak simbul yang terdapat dalam file asli
•
informasi simbul-simbul yang dalam file asli
Informasi besarnya file asal
digunakan sebagai ukuran pencacah
pada saat dilakukan proses dekompresi file hasil kompresi tersebut. Dengan
adanya informasi ini maka program akan mudah dalam menentukan kapan
harus menyelesaikan pembacaan data untuk dekompresi file hasil kompresi.
Informasi jumlah simbul
digunakan untuk menentukan pencacah
yang berhubungan dengan daftar simbul dan daftar probabilitas agar tidak
terjadi kesalahan akses data dari file hasil kompresi. Atau dengan kata lain
informasi tersebut digunakan untuk menentukan besarnya array/pointer yang
mencacat simbul dan probabilitasnya.
Informasi simbul
dan
informasi probabilitas
simbul digunakan
pembuatan pohon Huffman kembali dalam proses dekompresi.
3.2 Badan File
Badan file terdiri dari data byte hasil kompresi berdasarkan kode
Huffman yang dibuat. Setiap byte dalam badan file ini merupakan potongan
(karena diujudkan dalam byte berarti sebanyak 8 bit) dari deretan simbul file
asal yang telah diubah menjadi deretan kode. Karena setiap kode dari
masing-masing simbul tidak sama panjangnya maka perlu dilakukan kerja
keras dan hati-hati pada saat melakukan proses dekompresi.
Dalam melakukan proses penulisan hasil kompresi ini maka
algoritma yang digunakan adalah :
1. Siapkan informasi-informasi header file dan tulis ke dalam file hasil
kompresi;
2. Baca file asal byte demi byte dan cari kode yang cocok dari tabel kode
Huffman yang terlah dibuat (berdasarkan prosedur Encrypt);
3. Apabila deretan kode sudah mencapai 8-bit maka dilakukan penulisan
data 8-bit tersebut, jika tidak lakukan langkah 2;
4. Ulangi proses 2 sampai 3 hingga file asal telah terbaca semua.
Dalam penulisan file hasil kompresi ini agar proses dapat berlangsung
dengan cepat maka pembacaan file asal dan penulisan file hasil dilakukan secara
blok.
PROGRAM DEKOMPRESI
•
Proses Membaca Berkas.
•
Proses Pembuatan Pohon Huffman.
•
Proses Penulisan Hasil Dekompresi.
1. Proses Membaca Berkas
Proses membaca berkas/file pada program dekomprefsi ini berbeda
dengan proses pembacaan berkas/file pada program kompresi sebelumnya.
Pembacaan berkas/file hasil kompresi dalam program dekompresi ini harus
mengikuti aturan yang digunakan dalam proses penulisan file hasil kompresi
pada program kompresi di atas.
Karena berkas/file hasil kompresi terdiri dari header dan badan file maka
pembacaannya juga disesuaikan. Yaitu pertama-tama membaca header untuk
memperoleh informasi besar file asli, informasi banyaknya simbul, informasi
simbul dan informasi probabilitas tiap-tiap simbul. Berdasarkan hasil
pembacaan tersebut maka baru dapat dilakukan proses selanjutnya.
2. Proses Pembuatan Pohon Huffman
Berdasarkan informasi-informasi yang diperoleh pada proses pembacaan
berkas, maka dapat disusun Pohon Huffman untuk keperluan dekompresi.
Prosedur-prosedur yang digunakan sama dengan proses pembuatan pohon
Huffman pada Program Kompresi. Yaitu :
1. BUAT_LIST_PELUANG
2. CARI_PELUANG_TERKECIL
3. SUSUN_POHON
Dalam proses pembuatan pohon Huffman ini tidak ada prosedur Decrypt
sebagai lawan dari prosedur Encrypt dari program kompresi. Hal ini disebabkan
prosedur Decrypt akan langsung digunakan dalam prosedur dekompresi nanti.
Jadi ada sedikit perbedaan dalam proses pembuatan pohon Huffman dalam
program kompresi dengan program dekompresi.
3. Proses Penulisan Hasil Dekompresi
Setelah selesai melakukan proses pertama dan kedua (baca header dan
membuat pohon Huffman) maka dilakukan proses berikutnya yaitu proses
dekompresi dan penulisan hasilnya.
Dalam proses dekompresi dan penulisan hasilnya ini akan selalu
memanggil prosedur Decrypt untuk mencari simbul yang sesuai dengan aliran
bit-bit dari pembacaan file hasil kompresi. Bit-bit tersebut akan digunakan
sebagai petunjuk dalam mengunjungi pohon Huffman sampai ditemukan sebuah
simbul.
Seperi dalam proses pembuatan kode Huffman yaitu kunjungan kekiri
akan menghasil kode ‘0’ dan kunjungan ke kanan akan menghasilkan kode ‘1’,
maka dalam proses Decrypt ini juga sama. Yaitu jika memperoleh bit ‘0’ maka
harus mengunjungi cabang kiri dan jika diperoleh bit ‘1’ akan mengunjungi
cabang kanan Kunjungan akan berakhir pada saat tidak ada cabang kiri ataupun
cabang kanan, yang berarti telah ditemui sebuah simbul. Simbul tersebut
kemudian ditampung dalam array terlebih dahulu. Hal ini dimaksudkan untuk
mempercepat proses, karena penulisan file dilakukan secara blok.
Algoritma yang digunakan dalam proses Decrypt ini adalah :
1. Inisialisai pencacah besar file;
2. Baca file hasil kompresi byte demi byte;
3. Berdasarkan bit-bit dalam byte tersebut kunjungi pohon Huffman dengan
prosedur Decrypt, sampai tidak ada cabang kiri maupun cabang kanan.
Tulis simbul yang diperoleh dan naikkan pencacah besar file dengan 1;
4. Lakukan langkah 1 dan 2 sampai blok penulisan file terpenuhi, lakukan
penulisan file hasil dekompresi;
5. Ulangi langkah 1 sampai 4 hingga pencacah besar file menunjukkan angka
sama dengan informasi besar file.
6. Selesai
B. ALGORITMA ELIAS ENCODER
Seperti telah dijelaskan pada Bagian I, bahwa pengkodean Elias
menggunakan rumus logaritma terhadap nomor urut suatu simbul. Sehingga
perbedaan yang nyata dari program kompresi dan dekompresi dengan algoritma
Elias Encoder ini adalah proses sorting simbul berdasarkan probabilitasnya dan
cara pembuatan kode untuk tiap-tiap simbul. Proses lainnya seperti : membaca file
untuk mengetahui macam simbul dan probabilitasnya (dari file yang akan
dikompres) serta proses penulisan hasil kompresi menjadi file terkompres tidak
berbeda dengan prosedur-prosedur yang digunakan dalam program kompresi
dengan algoritma pohon Huffman.
Suatu hal penting yang perlu diperhatikan dalam program ini adalah :
Karena dalam bahasa pemrograman Pascal hanya memiliki fungsi aritmatika
logaritma natural, sedangkan fungsi logaritma yang diperlukan dalam pengkodean
Elias menggunakan logaritma berbasis 2 maka perlu dibuatkan fungsi baru untuk
keperluan tersebut. Fungsi yang dimaksud diujudkan dalam program fungsi :
function log(x:integer):string;
Fungsi tersebut akan mengolah data integer (nomor urut dari simbul) menjadi
deretan bit ‘0’ sebagai prefiks sekaligus menambahkan sufiks pengkodean Elias.
PROGRAM KOMPRESI
Secara garis besar proses kompresi dibagi menjadi empat bagian proses
yaitu :
•
Proses Membaca Berkas
•
Proses Mengurutkan Simbul Berdasarkan Probabilitasnya
•
Proses Membuat Kode Elias
•
Proses Penulisan Hasil Kompresi
1. Proses Membaca Berkas/File
Algoritma proses pertama dan proses keempat hampir sama dengan
algoritma yang digunakan pada program kompresi Pohon Huffman. Untuk
proses pertama perbedaan hanya terletak pada struktur data yang digunakan.
Karena pointer yang digunakan hanya untuk membentuk senarai berantai linear
(tidak berbentuk pohon) maka bentuk pointernya adalah sebagai berikut :
Setelah melakukan pendataan macam simbul dan probabilitasnya maka
dilakukan proses optimasi tabel yaitu dengan menggunakan prosedur
SELEKSI_SIMBUL. Prosedur ini akan menghapus karakter yang
probabilitasnya sama dengan nol dari tabel simbul dan probabilitas.
Untuk keperluan proses sorting, maka simbul dan probabilitas
dimasukkan dalam struktur data pointer dengan memanggil prosedur
MASUK_HEAP.
2. Proses Mengurutkan Simbul Berdasarkan Probabilitasnya
Proses ini berfungsi untuk mengurutkan simbul berdasarkan
probabilitasnya sehingga simbul yang memiliki probabilitas besar akan memiliki
nomor urut paling kecil sedangkan simbul dengan probabilitas paling kecil akan
memiliki nomor urut paling besar.
Banyak algoritma sorting yang dapat digunakan dalam pengurutan
simbul ini. Dalam program ini digunakan algoritma Chain Record Sort yang
memiliki kecepatan tinggi dalam melakukan sorting meskipun memori yang
dipakai menjadi lebih besar. Dengan metode Chain Record Sort ini
masing-masing elemen yang akan diurutkan tetap pada posisinya masing-masing-masing-masing (tidak
akan dipindahkan). Dengan pointer yang ada maka cukup merubah arah
penunjuk sesuai dengan peringkat elemen yang kita bandingkan. Dengan
demikian letak masing-masing elemen tidak berubah. Proses sorting ini
dilakukan dengan memanggil prosedur URUTKAN. Berdasarkan senarai
berantai yang telah dibentuk oleh prosedur MASUK_HEAP maka alogritma
sorting adalah sebagai berikut :
1. Inisialisasi :
Tentukan
Akhir :=Awal;
2. Tentukan pointer Kepala disebelah kanan pointer Akhir :
Nama pointerSebelum Sesudah dtkar
Kepala := Awal^.Sesudah
;
3.
Tentukani :
Awal^.Sesudah := Nil;
4. Jika Kepala sama dengan Nil maka proses SELESAI, jika tidak sama
dengan Nil maka lakukan langkah berikut ini:
5.
Tentukan
I:=Kepala^.Sesudah;
6.
Jika
Kepala^.dtprob <= Akhir^.dtprobmaka lakukan langkah 7, jika tidak lakukan
langkah 8 dan selanjutnya;
7. Letakkan letakkan pointer Kepala disebelah kanan pointer Akhir dan ;
- jadikan pointer Akhir tadi menjadi pointer Awal;
- jadikan pointer Kepala menjadi pointer Akhir;
- Ulangi langkah 2 sampai 6.
8. J:= Akhir^.sebelum;
- Selama
Kepala^.dtprob >= J^.dtprobdan
J <> Nilmaka tentukan:
J:=J^.Sebelum;
9.Jika
J = Nilmaka Kepala merupakan pointer awal paling kiri;
10.
Jika
J <> Nilmaka letakkan J disebelah kiri Kepala;
11. Ulangi langkah 4 sampai dengan langkah 11.
Setelah dilakukan sorting maka bentuk senarai berantai menjadi urut
dimana simbul dengan probabilitas paling besar akan ditunjuk paling awal dan
simbul dengan probabilitas paling kecil akan ditunjuk paling akhir dalam senarai
tersebut. Dengan demikian dapat kita buat sebuah array yang berisi urutan hasil
sorting tersebut. Nomor array inilah yang akan kita gunakan sebagai bahan
pembuatan kode Elias.
3. Proses Pembuatan Kode Elias
Proses pengkodean Elias dilakukan dengan memanggil prosedur ELIAS
dimana terdapat fungsi log yang dapat melakukan operasi aritmatik logaritma
berbasis dua dari sebuah nilai integer sekaligus mengubah nilai integer tersebut
menjadi kode elias. Algoritma untuk pengkodean Elias adalah :
1. Tentukan x:= nomor simbul pertama;
2.
Buat Prefiks berupa deretan bit ‘0’ sebanyak log
2(x+1), tampung ke
variabel
awal;
3.
Buat Sufiks yang merupakan bilangan biner dari (x+1), tampung dalam
variabel
akhir;
4. Gabungkan menjadi kode Elias :
5. Kode[x] := awal + akhir;
6.
Ulangi langkah 2 sampai 5 untuk nilai x berikutnya sebanyak
jumlah_simbul;
7. Selesai.
Setelah proses ini selesai maka dilakukan pembacaan file yang akan
dikompres byte demi byte dan diubah simbulnya sesuai dengan kode yang sudah
dibuat.
4. Proses Penulisan Hasil Kompresi.
Prosedur ini menyediakan dua fungsi utama yang berkaitan dengan
penulisan file hasil kompresi. Yaitu penulisan header dan badan file.
4.1 Header
Header file hasil kompresi terdiri dari empat bagian yaitu :
•
informasi jumlah byte file asli
•
informasi banyak simbul yang terdapat dalam file asli
•
informasi simbul-simbul yang dalam file asli
Informasi besarnya file asal
digunakan sebagai ukuran pencacah
pada saat dilakukan proses dekompresi file hasil kompresi tersebut. Dengan
adanya informasi ini maka program akan mudah dalam menentukan kapan
harus menyelesaikan pembacaan data untuk dekompresi file hasil kompresi.
Informasi jumlah simbul
digunakan untuk menentukan pencacah
yang berhubungan dengan daftar simbul dan daftar probabilitas agar tidak
terjadi kesalahan akses data dari file hasil kompresi. Atau dengan kata lain
informasi tersebut digunakan untuk menentukan besarnya array/pointer yang
mencacat simbul.
Informasi simbul
digunakan pembuatan kode Elias kembali dalam
proses dekompresi.
Dalam header file kompresi Elias ini tidak perlu mencantumkan
informasi peluang tiap simbul, karena urutan simbul tersebut sudah dapat
digunakan untuk membuat kode Elias dalam proses Dekompresi nantinya.
4.2 Badan File
Badan file ini sama dengan badan file program kompresi Huffman.
Yaitu menyimpan byte demi byte hasil pengkodean tiap simbul. Setiap byte
dalam file ini merupakan potongan (karena diujudkan dalam byte berarti
sebanyak 8 bit) dari deretan simbul file asal yang telah diubah menjadi
deretan kode. Karena setiap kode dari masing-masing simbul tidak sama
panjangnya maka perlu dilakukan kerja keras dan hati-hati pada saat
melakukan proses dekompresi.
Dalam melakukan proses penulisan hasil kompresi ini maka
algoritma yang digunakan adalah :
1. Siapkan informasi-informasi header file dan tulis ke dalam file hasil
kompresi;
2. Baca file asal byte demi byte dan cari kode yang cocok dari tabel kode
Elias yang terlah dibuat (berdasarkan prosedur Elias);
3. Apabila deretan kode sudah mencapai 8-bit maka dilakukan penulisan
data 8-bit tersebut, jika tidak lakukan langkah 2;
4. Ulangi proses 2 sampai 3 hingga file asal telah terbaca semua.
Dalam penulisan file hasil kompresi ini agar proses dapat berlangsung
dengan cepat maka pembacaan file asal dan penulisan file hasil dilakukan secara
blok.
PROGRAM DEKOMPRESI
Dalam program dekompresi ini proses dibagi menjadi tiga bagian :
•
Proses Membaca Berkas.
•
Proses Pembuatan Kode Elias.
•
Proses Penulisan Hasil Dekompresi.
1. Proses Membaca Berkas
Proses membaca berkas/file pada program dekomprefsi Elias ini hampir
sama dengan program Huffman dimana pembacaan harus mengikuti aturan
sesuai dengan bentuk file yang diproses pada saat penulisan hasil kompresi
sebelumnya. Yaitu pertama-tama membaca header untuk memperoleh informasi
besar file asli, informasi banyaknya simbul dan informasi simbul. Berdasarkan
hasil pembacaan tersebut maka baru dapat dilakukan proses selanjutnya.
2. Proses Pembuatan Kode Elias
Berdasarkan informasi-informasi yang diperoleh pada proses pembacaan
berkas, maka dapat disusun kode Elias seperti pada program kompresi. Karena
simbul-simbul yang disimpan sudah urut dari probabilitas terbesar sampai
probabilitas terkecil, maka nomor urutan tersebut langsung dapat dipakai untuk
membuat kode Eliasnya.
3. Proses Penulisan Hasil Dekompresi
Setelah selesai melakukan proses pertama dan kedua (baca header dan
membuat kode Elias) maka dilakukan proses berikutnya yaitu proses
dekompresi dan penulisan hasilnya.
Dalam proses dekompresi proses pencarian kode yang cocok dengan
pembacaan byte demi byte dari badan file akan lebih mudah dilakukan, karena
kode tersebut sebenarnya dapat ditebak berdasarkan prefiknya dan nilai prefiks
ini akan menentukan panjangnya deretan sufik dari kode tersebut. Sehingga
proses perulangan (loop) menjadi lebih sedikit.
Simbul-simbul yang diperoleh dari hasil dekode tersebut kemudian
ditampung dalam array terlebih dahulu. Hal ini dimaksudkan untuk
mempercepat proses, karena penulisan file dilakukan secara blok.
C. PELENGKAP PROGRAM
Baik program Kompresi/Dekompresi Huffman maupun Elias dilengkapi
prosedur tambahan seperti peringatan bahwa nama file yang akan dikompres tidak
ada dan nama file yang akan dikompres ternyata sama dengan nama file hasil
kompresi yang semuanya dikemas dalam prosedur Header yang juga merupakan
tempat komunikasi dengan pemakai.
BAGIAN III : KESIMPULAN
Dalam tugas ini telah berhasil dibuat program kompresi dengan algoritma
Pengkodean Pohon Huffman dan algoritma Elias Encoder. Hasil yang diperoleh
terhadap kinerja dan sifat-sifat kedua program tersebut adalah :
1. Kedua program kompresi tersebut hampir memiliki prosesntase kompresi yang
sama.
2. Algoritma Elias Encoder memiliki kelebihan dibanding algoritma Pohon Huffman
yaitu konfigurasi header file hasil kompresi lebih sederhana (tidak mencantumkan
probabilitas tiap simbul); sederhana dalam pengkodean dan dalam proses
pencarian simbul berdasarkan kode dapat ditebak secara cepat sehingga
mempercepat proseas dekompresi.
3. Program kompresi dengan algoritma Pohon Huffman kadang-kadang dalam
membuat kode tidak efektif yaitu menghasilkan kode terpendek lebih dari 2 atau 3
bit, sedangkan untuk algoritma Elias pasti ada kode yang panjangnya satu bit.
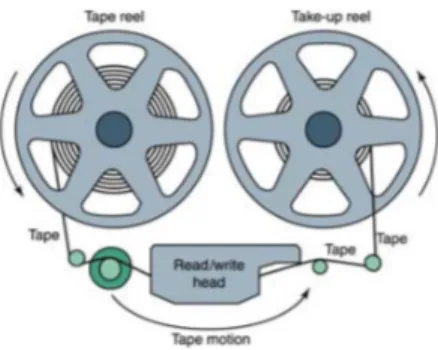
Gambar 5.1 Alat penyimpanan
5.1 JENIS MEMORI DALAM KOMPUTER
Ada tiga macam memori yang dipergunakan di dalam sistem komputer, yaitu:
1. Register, digunakan untuk menyimpan instruksi dan data yang sedang diproses. 2. Main memory, dipergunakan untuk menyimpan instruksi dan data yang akan diproses
dan hasil pengolahan.
3. Secondary storage, dipergunakan untuk menyimpan program dan data secara permanen.
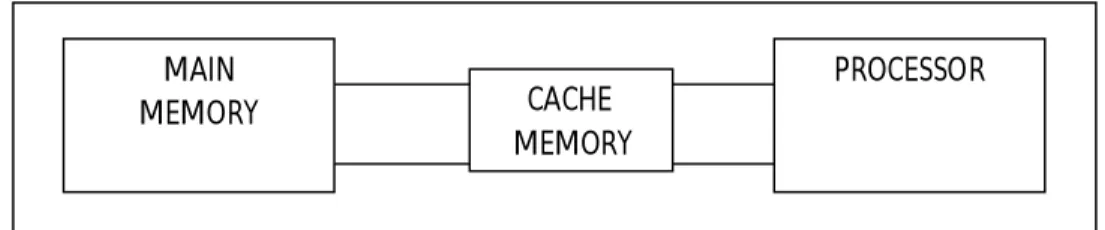
5.1.1Memori Utama (Main Memory)
Merupakan elemen yang penting dari suatu komputer yang digunakan untuk menyimpan data dan instruksi program untuk digunakan oleh prosesor. Fasilitas Penyimpanan Utama adalah :
BAB V
MEMORI DAN MEDIA PENYIMPANAN
Pengantar Teknologi Informasi _________________________________________________
55
1. Operasinya secara keseluruhan bersifat elektronis, operasi sangat cepat dan handal.
2. Data hampir bisa diakses secara sekaligus dari memori utama karena operasinya
elektronis dan proksimitasnya mendekati prosesor.
3. Data harus ditransfer ke penyimpanan utama sebelum dapat diproses oleh prosesor
Penyimpan utama digunakan untuk meyimpan semua data yang memerlukan pemrosessan guna mencapai kecepatan pemrosesan yang maksimum ini disebut memori jangka pendek. Penyimpanan utama dapat menyimpan :
1. Instruksi yang menunggu diproses.
2. Instruksi yang saat itu sedang dipproses. 3. Data yang saat itu sedang diproses.
4. Data yang menunggu pemrosesan.
5. Data yang sedang menunggu dikeluarkan (output).
Proses menjemput data dari lokasi dalam penyimpanan utama dengan urutan acak dan lama waktu yang diperlukan tidak tergantung pada posisi dari lokasi tersebut . Lihat gambar berikut:
Gambar 5.2 Lokasi dalam Penyimpanan Utama
Satuan Unit Data
1. Word adalah lokasi dalam penyimpanan utama atau penyangga unit data. Pembagian
word dapat berdasarkan Fixed Word-length computer (word machine) dan Variabel word – length computer. Pada Fixed Word-length computer (word machine) dimana satu word adalah satu lokasi dalam penyimpanan utama, yakni data ditransfer ke satu lokasi dalam penyimpanan utama setiap kali, word length adalah jumlah bit dalam setiap lokasi (word). Pada Variabel word – length computer satu word memiliki panjang satu lokasi atau beberapa lokasi dan di set (ditetapkan panjangnya) menurut panjang yang diperlukan pada setiap transfer data. Jenis word lengtha adalah byte dan
1 2 3 4 5
Etc. 0
_______________________________________________ Memori dan Media Penyimpanan
56
character machine, dimana dalam byte setiap lokasi mempunyai 8 bit dan pada character machine setiap lokasi mempunyai panjang 16 bit.
2. Byte adalah unit-unit yang lebih kecil dari word
RAM ( Random Access Memory)
Semua data dan program yang dimasukkan lewat alat input akan disimpan terlebih dahulu di main memory, khususnya di RAM (Random Access Memory). RAM merupakan memori yang dapat diakses yaitu dapat diisi dan diambil isinya oleh programmer.
Struktur dari RAM dibagi menjadi 4 bagian,yaitu sebagai berikut ini :
a. Input storage, digunakan untuk menampung input yang dimasukkan lewat alat
input.
b. Program storage, digunakan untuk menyimpan semua instruksi-instruksi program
yang akan diproses.
c. Working storage, digunakan untuk menyimpan data yang akan diolah dan hasil
dari pengolahan.
d. Output storage, digunakan untuk menampung hasil akhir dari pengolahan data
yang akan ditampilkan ke alat output.
Input yang dimasukkan lewat dari alat input, pertama kali ditampung terlebih dahulu di
input storage, bila input tersebut terbentuk program, maka dipindahkan ke program
storage dan bila berbentuk data, akan dipindahkan ke working storage. Hasil dari
pengolahan juga ditampung di working storage dan hasil yang akan ditampilkan ke alat output dipindahkan ke output storage.
RAM mempunyai kemampuan untuk melakukan pengecekan dari data yang disimpannya, yang disebut dengan istilah parity check. Bila data hilang atau rusak, dapat diketahui dari sebuah bit tambahan yang disebut dengan parity bit atau check bit. Misalnya 1 byte memory di RAM terdiri dari 8-bit, sebagai parity bit digunakan sebuah bit tambahan,sehingga menjadi 9 bit.
Pengantar Teknologi Informasi _________________________________________________
57
Tabel 5.1 Beberapa teknologi RAM
TEKNOLOGI KETERANGAN
DRAM Konvensional
Merupakan DRAM kuno dan tidak dipergunakan lagi dalam system komputer masa kini.
Fast Page Mode (FPM) DRAM
Lebih cepat dari DRAM biasa, pemakaiannya tidak memerlukan kompatibilitas teknologi.
Extended Data Out (EDO) DRAM
Lebih cepat dari FDM, biasanya dipakai pada Pentium dan beberapa system 486.
Burst Extended Data Out (BEDO) RAM
Merupakan perbaikan dari EDO RAM, memungkinkan penggunaan bus dengan kecepatan yang lebih tnggi dari EDO.
Synchronous DRAM (SDRAM)
Terikat pada pulsa detak system, mendukung penggunaan bus.
RAMbus RAM (RDRAM) Dikembangkan oleh intel sebagai system memori PC masa depan.
Double Data Rate RAM (DDR RAM)
DDR SDRAM adalah tipe memori generasi penerus DRAM, yang memiliki kemampuan dua kali lebih cepat dari SDRAM.
Video RAM (VRAM) Merupakan memori khusus yang digunakan untuk keperluan video monitor.
ROM (Read Only Memory)
ROM (Read Only Memory), dari namanya memori ini hanya dapat dibaca saja, programmer tidak bisa mengisi sesuatu ke dalam ROM. Isi ROM sudah diisi oleh pabrik pembuatnya, berupa sistem operasi (Operating System) yang terdiri dari program-program pokok yang diperlukan oleh sistem komputer, seperti misalnya program untuk mengatur
penampilan karakter di layar, pengisian tombol kunci di keyboard untuk keperluan kontrol
tertentu dan bootstrap program. Beberapa komputer, misalnya komputer mikro Apple dan
IBM PC, ROM juga diisi dengan program interpreter BASIC.
Bootstrap program diperlukan pada waktu pertama kali sistem komputer diaktifkan, yang
proses ini disebut dengan istilah booting dapat berupa cold booting dan warm booting.
Cold booting merupakan proses mengaktifkan sistem komputer pertama kali untuk
mengambil bootstrap program dari keadaan listrik komputer mati (off) dengan cara
menghidupkannya, sedang warm booting merupakan proses pengulangan pengambilan
bootstrap program dalam keadaan komputer masih hidup (on) dengan cara menekan tombol-tombol Ctrl, Alt dan Del (Ketiga tombol Ctrl+Alt+Del tersebut ditekan bersamaan). Warm booting biasanya dilakukan bila sistem komputer macet, dari pada
_______________________________________________ Memori dan Media Penyimpanan
58
harus mematikan aliran listrik komputer dan menghidupkannya kembali (lebih lama dan
membuat komputer cepat rusak),lebih baik dilakukan warm booting.
Isi dari ROM tidak boleh hilang atau rusak, bila terjadi demikian, maka sistem komputer tidak akan bisa berfungsi. Oleh karena itu, untuk mencegahnya pabrik komputer merancang ROM sedemikian rupa sehingga hanya bisa dibaca saja, tidak dapat diisi programmer supaya tidak terganti oleh isi yang lain yang menyebabkan isi ROM rusak. Selain itu ROM sifatnya adalah non volatile, supaya isinya tidak hilang bila listrik komputer dimatikan. Atau dengan kata lain, untuk menyimpan data dan program dalam kurun waktu yang tertentu.
ROM yang bisa diprogram berbentuk chip yang ditempatkan pada rumahnya yang mempunyai jendela diatasnya. ROM yang dapat diprogram kembali adalah PROM (Programmable Read Only Memory), yang dapat diprogram sekali saja oleh programmer yang selanjutnya tidak dapat diubah kembali. Jenis lain adalah EPROM (Erasable Programmable Read Only Memory) yang dapat dihapus dengan sinar ultra violet (dapat dijemur di sinar matahari) serta dapat diprogram kembali berulang-ulang. EEPROM (Electrically Erasable Programmable Read Only Memory), dapat dihapus secara elektronik dan dapat diprogram kembali.
Tabel 5.2 Beberapa jenis ROM
TEKNOLOGI KETERANGAN
ROM Digunakan untuk program yang bersifat static (jarang berubah) dan diproduksi masal
Programmable ROM (PROM)
Dapat diprogram dengan menggunakan peralatan khusus dan dilakukan sekali. Pola datanya tersimpun digabungkan secara permanen ke dalam chip dengan menggunakan “mask”
Erasable PROM Dapat diprogram beberapa kali dengan peralatan khusus. Jika ingin menghapus harus dikeluarkan dari komputer dengan sinar ultra violet.
Electrically Erasable PROM
Dapat diprogram dengan menggunakan perangkat lunak. Dihapus dengan pulsa tegangan listrik. Diguakan untuk menyimpan BIOS Electrically Alterable
ROM
Dapat dibaca, dihapus dan ditulisi kembali tanpa mengeluarkannya dari komputer. Proses penghapusan dan penulisannya kembali sangat lambat bila dibandingkan proses pembacaan yang disebut RMM (Read Mostly Memories)