3.1 Waktu dan Lokasi Penelitian
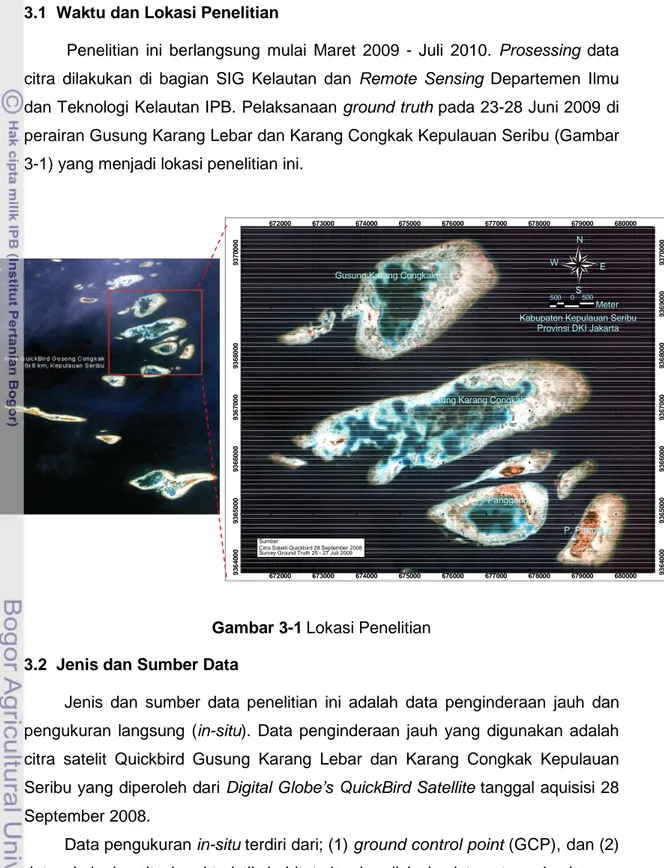
Penelitian ini berlangsung mulai Maret 2009 - Juli 2010. Prosessing data citra dilakukan di bagian SIG Kelautan dan Remote Sensing Departemen Ilmu dan Teknologi Kelautan IPB. Pelaksanaan ground truth pada 23-28 Juni 2009 di perairan Gusung Karang Lebar dan Karang Congkak Kepulauan Seribu (Gambar 3-1) yang menjadi lokasi penelitian ini.
Gambar 3-1 Lokasi Penelitian 3.2 Jenis dan Sumber Data
Jenis dan sumber data penelitian ini adalah data penginderaan jauh dan pengukuran langsung (in-situ). Data penginderaan jauh yang digunakan adalah citra satelit Quickbird Gusung Karang Lebar dan Karang Congkak Kepulauan Seribu yang diperoleh dari Digital Globe’s QuickBird Satellite tanggal aquisisi 28 September 2008.
Data pengukuran in-situ terdiri dari; (1) ground control point (GCP), dan (2) data ekologi, yaitu karakteristik habitat dan kondisi ekosistem terumbu karang (biotik dan abiotik). Sejumlah stasiun pengamatan dalam penelitian ini merupakan deskripsi terkait karakteristik habitat perairan dangkal.
# #### # # # # ############### ## # ## # ### # ## ## # # # ## # ### ## # # # # # 672000 672000 673000 673000 674000 674000 675000 675000 676000 676000 677000 677000 678000 678000 679000 679000 680000 680000 9 3 6 4 0 0 0 9 3 6 4 0 0 0 9 3 6 5 0 0 0 9 3 6 5 0 0 0 9 3 6 6 0 0 0 9 3 6 6 0 0 0 9 3 6 7 0 0 0 9 3 6 7 0 0 0 9 3 6 8 0 0 0 9 3 6 8 0 0 0 9 3 6 9 0 0 0 9 3 7 0 0 0 0 9 3 7 0 0 0 0 N W S E Meter 500 0 500
Citra Satelit Quickbird 28 September 2008 Sumber:
Survey Ground Truth 25 - 27 Juli 2009
Gusung Karang Congkak
Gusung Karang Congkak
P. Panggang
P. Pramuka Kabupaten Kepulauan Seribu
3.3 Metode Pengumpulan Data Citra
Metode pengumpulan data citra in-situ ditentukan dengan teknik sampling data spasial secara stratified random sampling. Teknik ini dilakukan di wilayah Gusung Karang Congkak terhadap 122 titik yang dipilih mewakili klasifikasi habitat perairan dangkal dari keseluruhan daerah penelitian. Data tersebut diperoleh dengan metode survey ground truth posisi menggunakan prinsip Differential Global Positioning System (DGPS) memanfaatkan teknologi GPS. Sedangkan pengumpulan data sekunder ditelusuri dari hasil akuisisi pengetahuan dan penelitian yang relevan. Peralatan dan parameter tersebut disajikan pada Tabel 3-1,
Tabel 3-1 Peralatan dan parameter pengukuran
No Nama Peralatan Parameter
1. Geomatic equipment Koordinat: - ground control point; - ground truth point; - Transect habitat site. 2. Scuba Diving equipment,
Transect quadrate (1 x 1m), Line meter (50 m),
Digital underwater camera,
Transect habitat data
3. Akuisisi pengetahuan dan laporan penelitian
Pengenalan karang dan habitatnya 4. Hardware dan Soft computing untuk
komputasi Image processing system
Pembentukan klasifikasi citra
Survei DGPS bertujuan untuk menentukan posisi kondisi lapangan secara akurat dan memperbaikinya apabila terjadi perubahan atau ketidaksesuaian informasi dari sumber yang beragam, melalui pengecekan silang peta dasar dan peta citra satelit yang ada. Prinsip operasional survei DGPS tersebut dikembangkan sebagai berikut;
Mengatur output dua GPS yang sama tipenya, yaitu Garmin 60 dengan waktu sama (5 detik) dan menghidupkannya secara bersamaan pada saat perekaman data berlangsung, sehingga menghasilkan sejumlah data n GCP. Merekam titik-titik yang dianggap penting sebagai acuan untuk menafsirkan
kenampakan/objek antara kenyataan di lapangan dan peta dasar survey, sehingga memudahkan identifikasi dan analisis spasial peta dan koreksi geometrik,
Merekam lokasi yang memiliki kecenderungan untuk berubah. Titik-titik lokasi GPS dipilih sesuai kebutuhan dan tujuan penggunaan GPS itu sendiri,
Membuat dokumentasi melalui pemotretan objek-objek di lapangan, baik untuk validasi kenampakan objek di peta/citra maupun melengkapi peta dasar survey,
Mencatat dan mengidentifikasi informasi survey. Pemilihan informasi survey untuk titik-titik yang dijadikan pencatatan, tidak seperti halnya survei terestrial, survey GPS tidak memerlukan saling keterlihatan (intervisibility) antara titik-titik pengamat.
Menghitung koreksi posisi lintang dan bujur sebagai posisi yang sebenarnya. 3.4 Analisis Pengolahan Citra ANN
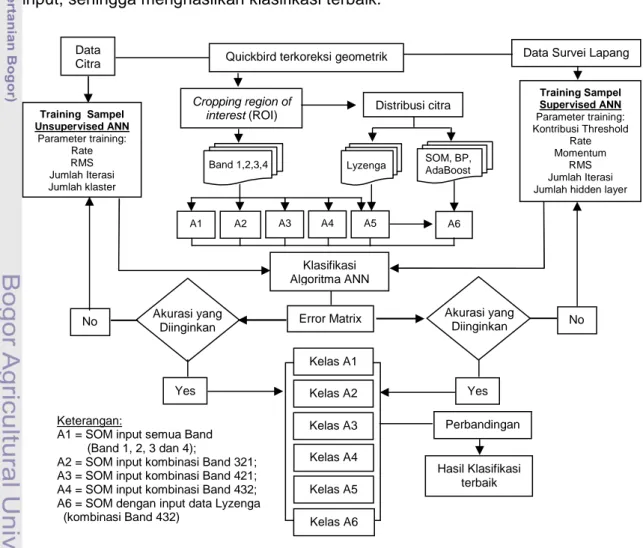
Diagram alir umum analisa citra digital dalam penelitian ini (Gambar 3-2) bermaksud menguji klasifikasi algoritma Artificial Neural Network (ANN). Proses pengolahan citra merupakan eksperimen dari kombinasi Band dari berbagai input, sehingga menghasilkan klasifikasi terbaik.
Gambar 3-2 Metodologi umum training Algoritma ANN Quickbird terkoreksi geometrik
Cropping region of interest (ROI)
Data Survei Lapang
Training Sampel Unsupervised ANN Parameter training: Rate RMS Jumlah Iterasi Jumlah klaster Distribusi citra Klasifikasi Algoritma ANN Akurasi yang
Diinginkan Error Matrix
Yes Training Sampel Supervised ANN Parameter training: Kontribusi Threshold Rate Momentum RMS Jumlah Iterasi Jumlah hidden layer
A2 A1
Data Citra
No Akurasi yang Diinginkan
Yes No Perbandingan Hasil Klasifikasi terbaik A4 A3 A5 SOM, BP, AdaBoost Band 1,2,3,4 Lyzenga A6 Kelas A4 Kelas A6 Kelas A5 Kelas A1 Kelas A3 Kelas A2 Keterangan:
A1 = SOM input semua Band (Band 1, 2, 3 dan 4);
A2 = SOM input kombinasi Band 321; A3 = SOM input kombinasi Band 421; A4 = SOM input kombinasi Band 432; A6 = SOM dengan input data Lyzenga (kombinasi Band 432)
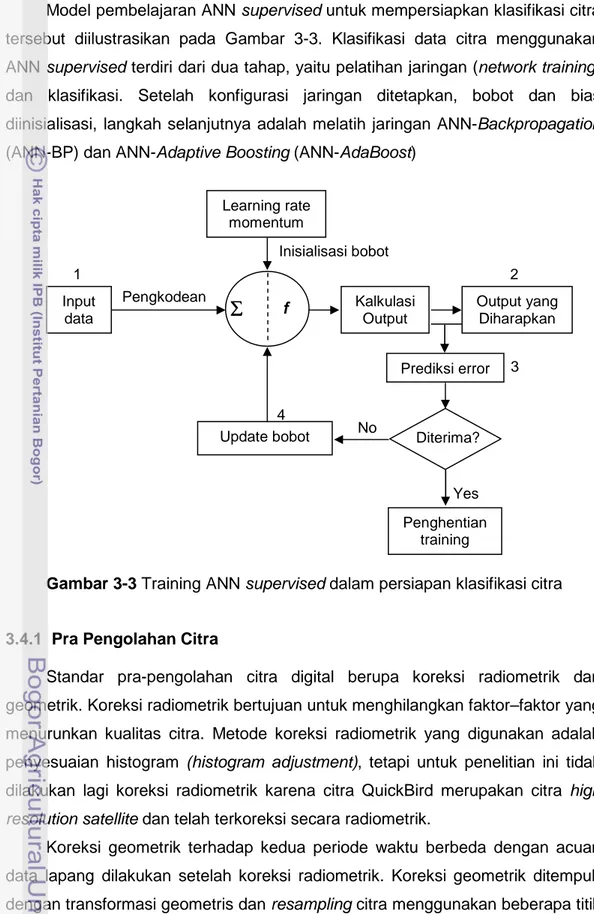
Model pembelajaran ANN supervised untuk mempersiapkan klasifikasi citra tersebut diilustrasikan pada Gambar 3-3. Klasifikasi data citra menggunakan ANN supervised terdiri dari dua tahap, yaitu pelatihan jaringan (network training) dan klasifikasi. Setelah konfigurasi jaringan ditetapkan, bobot dan bias diinisialisasi, langkah selanjutnya adalah melatih jaringan ANN-Backpropagation (ANN-BP) dan ANN-Adaptive Boosting (ANN-AdaBoost)
Gambar 3-3 Training ANN supervised dalam persiapan klasifikasi citra
3.4.1 Pra Pengolahan Citra
Standar pra-pengolahan citra digital berupa koreksi radiometrik dan geometrik. Koreksi radiometrik bertujuan untuk menghilangkan faktor–faktor yang menurunkan kualitas citra. Metode koreksi radiometrik yang digunakan adalah penyesuaian histogram (histogram adjustment), tetapi untuk penelitian ini tidak dilakukan lagi koreksi radiometrik karena citra QuickBird merupakan citra high resolution satellite dan telah terkoreksi secara radiometrik.
Koreksi geometrik terhadap kedua periode waktu berbeda dengan acuan data lapang dilakukan setelah koreksi radiometrik. Koreksi geometrik ditempuh dengan transformasi geometris dan resampling citra menggunakan beberapa titik kontrol bumi (ground control point). Titik-titik tersebut diambil pada tempat berbeda yang tersebar di bagian citra, sehingga diperoleh nilai root mean square
Input data Learning rate momentum Kalkulasi Output Output yang Diharapkan Update bobot Penghentian training Pengkodean ∑ ∑ ∑ ∑ f Inisialisasi bobot Prediksi error Diterima? No Yes 1 2 3 4
(RMS) <0,5. Penentuan nilai RMS menentukan akurasi koreksi geometrik yang diketahui dari formula:
n i i i f x y u a u d 2 2/ )} , ( { − = o ………...……. ...(3-1) n i i i g x y v a v d 2 = o{ − ( , )}2/ ………...………...(3-2)
Dimana; du= standar deviasi pada nomor pixel; dv= standar deviasi pada nomor pixel;
)
,
(
x
iy
i = koordinat peta dari GCP;(
u
i,
v
i)
= koordinat peta dari GCP.Rektifikasi (pembetulan) citra berdasarkan informasi posisi GCP yang ada bertujuan untuk menempatkan pixel citra pada posisi sebenarnya di permukaan bumi. Rektifikasi ini sangat erat kaitannya dengan pengambilan data in-situ, metode penentuan akurasi posisi, dan GPS yang digunakan.
3.4.2 Pengolahan Citra
Distribusi spasial karakteristik habitat dasar perairan dangkal diolah dari citra satelit menggunakan beberapa pendekatan seperti komposit Band dan penajaman citra dengan algoritma depth invariant index. Algoritma ini mengaplikasikan metode koreksi kolom air atau dikenal dengan Algoritma Lyzenga (1981). Metode ini efektif untuk meningkatkan kualitas identifikasi dan klasifikasi habitat dasar perairan dangkal secara tematik. Persamaan algoritma depth invariant index diturunkan sebagai berikut::
Y = Ln B1 – (ki/kj) Ln B2
dimana
Y = indek dasar perairan; B = band yang dipilih; ki/kj= koefisien atenuasi = Variance Band ke i, = Variance Band ke j, = Covar Band ke ij
Pengolahan citra ANN selanjutnya memerlukan ekstraksi ciri parameter input untuk data pembelajaran (learning), dan paramater training masing-masing metode ANN supervised dan unsupervised.
1) Ekstraksi Parameter Input
Penelitian ini menyelidiki kombinasi 6 (enam) parameter input, yaitu A1, A2, A3, A4, A5 dan A6. Ilustrasi kesemuanya disajikan pada Tabel 3-2.
Tabel 3-2 Parameter input klasifikasi
Kode Input Jumlah
Node
Proses/
Metode Output
A1 Band 1, 2, 3 dan 4 (4 Band asli)
4 SOM Klaster citra A2 Komposit Band 1, 2 dan 3
(Band 321)
3 SOM Klaster citra A3 Komposit Band 1, 2 dan 4
(Band 421)
3 SOM Klaster citra A4 Komposit Band 2, 3 dan 4
(Band 432)
3 SOM Klaster citra A5 Band 1, 2, 3 dan 4 (4 Band
asli) dan komposit Band 432
7 Lyzenga Klaster/klasifikasi citra, dan koreksi kolom air
A6 Data A5 (rationing) 3 SOM/BP/ AdaBoost
Klaster/klasifikasi citra, dan koreksi kolom air
2) Parameter Training
Parameter training untuk membangun model pembelajaran ANN unsupervised mengikuti parameter-parameter SOM berikut:
Tabel 3-3 Parameter training ANN unsupervised
Item parameter Nilai
Jumlah input citra 3
Training rate 0.5 – 0.001
Radius ketetanggaan pixel 4 Jumlah Iterasi training 10,000
Sedangkan algoritma ANN supervised untuk membangun model pembelajaran ANN-BP dan AdaBoost mengacu parameter training (Tabel 3-4) dan ROI (Tabel 3-5) sebagai data pembelajaran (learning).
Tabel 3-4 Parameter training ANN supervised
Item parameter Nilai
Training threshold 0.9
Training momentum 0.9
Kriteria RMS 0 - 0.1
Jumlah unit hidden layer*) 2 – 4 Jumlah node hidden layer**) 8
Training rate 0.2
Jumlah Iterasi training 10,000
*) Unit hidden layer berjumlah 2 khusus untuk AdaBoost **) Unit node hidden layer khusus untuk AdaBoost
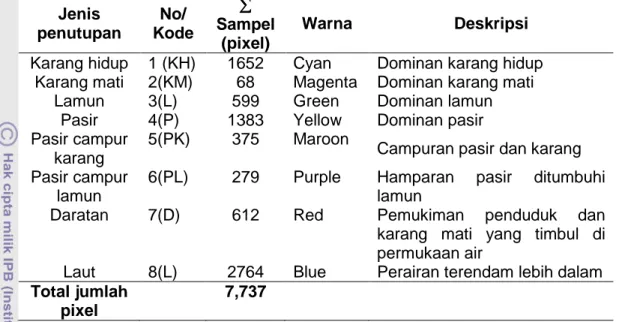
Tabel 3-5 Region of Interest (ROI) training ANN supervised Jenis penutupan No/ Kode ∑ ∑∑ ∑ Sampel (pixel) Warna Deskripsi
Karang hidup 1 (KH) 1652 Cyan Dominan karang hidup Karang mati 2(KM) 68 Magenta Dominan karang mati
Lamun 3(L) 599 Green Dominan lamun Pasir 4(P) 1383 Yellow Dominan pasir Pasir campur
karang
5(PK) 375 Maroon
Campuran pasir dan karang Pasir campur
lamun
6(PL) 279 Purple Hamparan pasir ditumbuhi lamun
Daratan 7(D) 612 Red Pemukiman penduduk dan karang mati yang timbul di permukaan air
Laut 8(L) 2764 Blue Perairan terendam lebih dalam Total jumlah
pixel
7,737
3) Model Pembelajaran/Training ANN
Pelatihan (training) ANN dalam penelitian ini ditempuh dengan dua cara pembelajaran (learning), yaitu unsupervised learning (algoritma SOM) dan supervised learning (algoritma Backpropagation).
Algoritma SOM (self organizing map)
Desain unsupervised learning menggunakan algoritma SOM (Kohonen 1984) memiliki kemampuan atau pengorganisasian mandiri tanpa adanya pendefinisian kelas sebelumnya, sehingga membentuk suatu klaster. Pendekatan ini memerlukan Parameter training (Tabel 3-3) dengan input minimal dari user (unit input layer) untuk membagi jumlah kelas/klaster yang dihasilkan (unit output layer):
a. Unit input layer xi diaktifkan oleh input data citra. Input nilai pixel citra secara
linear dibuat dari skala 0.0 dan 1.0 untuk input dengan Band minimum dan maksimum.
b. Unit output layer yj merupakan output klaster. Output layer adalah kelompok
yang paling dekat/mirip radius ketetanggan pixel dari masukan yang diberikan.
Dimana:
xi : input variabel dari node i dalam input layer
yj : output node k dalam output layer (nilai prediksi untuk node j) wji : bobot koneksi node i
input layer dengan node j dalam output layer
Gambar 3-4 Jaringan Algoritma ANN-SOM
Pelatihan jaringan Algoritma ANN-SOM (Gambar 3-3) melalui langkah berikut:
(1) Inisialisasi:
• bobot-bobot wij (biasanya random antara 0 - 1)
• laju pemahaman awal dan faktor penurunannya
• bentuk dan jari-jari (=R) topologi sekitarnya (2) Jika kondisi henti gagal, lakukan langkah 3-8. (3) Untuk setiap vektor masukan x, lakukan langkah 3-6 (4) Untuk setiap j, hitung:
... (3-3)
dimana adalah input neuron ke i pada iterasi n, dan adalah bobot dari input neuron i ke output neuron j pada iterasi n.
(5) Tentukan indeks j sehingga djminimum
(6) Untuk setiap neuron j disekitar J modifikasi bobot:
w
jibaru= w
ji lama+
α
(x
ji– w
jilama) ... (3-4)
(7) Perbaiki kecepatan pembelajaran (mulai dengan 0.5 dan turunkan 0.001) (8) Uji kondisi penghentianKondisi penghentian iterasi adalah selisih antara wji saat itu dengan wji pada
iterasi sebelumnya. Apabila semua wji hanya berubah sedikit saja, berarti
iterasi sudah mencapai konvergensi sehingga dapat dihentikan. Output layer Wji • • • • Y3 X0=1 Y1 Y2 Yj X1 X2 Xi Input layer
Algoritma Backpropagation
Algoritma ANN BP dengan parameter pelatihan (Tabel 3-4) didesain berikut:
(1) Kontribusi Ambang (threshold) dengan nilai 0-1. Kontribusi training threshold menentukan besarnya kontribusi bobot internal dengan baik ke tingkat aktivasi node. Hal ini digunakan untuk mengatur bobot perubahan untuk bobot internal node. Pelatihan algoritma interaktif menyesuaikan bobot antara node dan secara opsional ambang node untuk meminimalkan kesalahan antara lapisan output dan respon yang diinginkan. Pengaturan kontribusi thereshold training ke nol tidak mengatur node bobot internal. Penyesuaian bobot internal juga dapat menyebabkan klasifikasi yang lebih baik, tetapi terlalu berat banyak juga bisa menyebabkan generalisasi miskin.
(2) Tingkat Pelatihan (training rate) dengan nilai 0-1. Tingkat pelatihan menentukan besarnya penyesuaian bobot. Tingkat yang tinggi akan mempercepat pelatihan, tetapi juga meningkatkan resiko goyangan (oscillation) atau tidak bertemu di satu tempat (non-convergence) dari hasil pelatihan.
(3) Momentum Pelatihan (training momentum) dengan nilai 0-1. Memasukan tingkat momentum lebih besar dari nol memungkinkan untuk mengatur tingkat pelatihan yang lebih tinggi tanpa osilasi. Tingkat momentum yang lebih tinggi melatih dengan langkah lebih besar dari momentum yang lebih rendah. Pengaruhnya adalah untuk mendorong perubahan bobot selama proses berlangsung.
(4) Kriteria RMS, masukan nilai kesalahan RMS dimana pelatihan harus berhenti. Jika kesalahan RMS seperti yang disajikan dalam plot selama pelatihan turun dibawah nilai masuk, pelatihan akan berhenti, bahkan jika jumlah iterasi belum terpenuhi. Klasifikasi ini kemudian akan dieksekusi. (5) Pelatihan Iterasi, jumlah iterasi pelatihan diatur hingga maksimum 10.000
dengan waktu terlatih sekitar 30 menit untuk area penelitian kecil.
a. Unit input layer yang diaktifkan oleh input data citra. Input nilai pixel citra secara linear dibuat dari skala 0.0 dan 1.0 dengan Band minimum dan maksimum.
b. Hidden layer diantara input layer dan output layer. Hitung unit input layer ke unit hidden layer (pers. 3-5) dan hidden layer ke unit output layer (pers. 3-6).
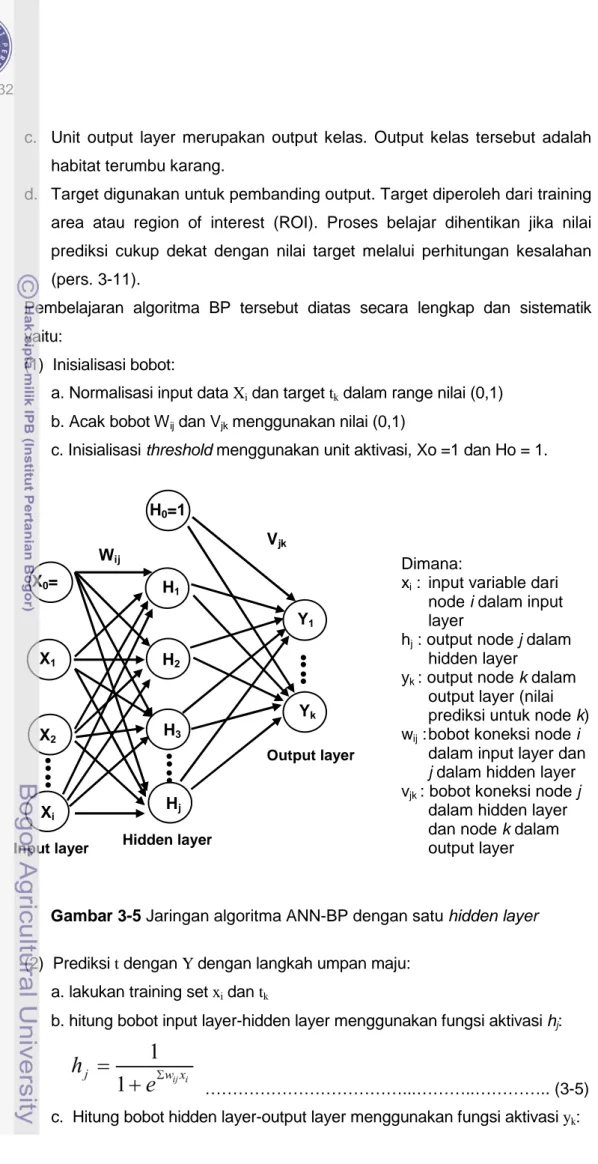
c. Unit output layer merupakan output kelas. Output kelas tersebut adalah habitat terumbu karang.
d. Target digunakan untuk pembanding output. Target diperoleh dari training area atau region of interest (ROI). Proses belajar dihentikan jika nilai prediksi cukup dekat dengan nilai target melalui perhitungan kesalahan (pers. 3-11).
Pembelajaran algoritma BP tersebut diatas secara lengkap dan sistematik yaitu:
(1) Inisialisasi bobot:
a. Normalisasi input data Xi dan target tk dalam range nilai (0,1)
b. Acak bobot Wij dan Vjk menggunakan nilai (0,1)
c. Inisialisasi threshold menggunakan unit aktivasi, Xo =1 dan Ho = 1.
Dimana:
xi : input variable dari node i dalam input layer
hj : output node j dalam hidden layer
yk : output node k dalam output layer (nilai prediksi untuk node k) wij : bobot koneksi node i
dalam input layer dan j dalam hidden layer vjk : bobot koneksi node j
dalam hidden layer dan node k dalam output layer
Gambar 3-5 Jaringan algoritma ANN-BP dengan satu hidden layer (2) Prediksi t dengan Y dengan langkah umpan maju:
a. lakukan training set xi dan tk
b. hitung bobot input layer-hidden layer menggunakan fungsi aktivasi hj:
………...………..………….. (3-5) c. Hitung bobot hidden layer-output layer menggunakan fungsi aktivasi yk:
Vjk Wij • • • • Output layer Hidden layer Y1 H2 Xi Hj Input layer X2 H3 X0= 1 Yk X1 H1 H0=1 • • • • • • • •
………...………..………. (3-6) (3) Minimalkan kesalahan bobot dengan penyesuaian Vjk dan Wij
menggunakan langkah umpan balik.
a. Hitung kesalahan dari node dalam output layer (δk) untuk disesuaikan dengan bobot vjk.
………...….…..…...(3-7) ………...…...….(3-8) b. Hitung kesalahan dalam node input layer yang disesuaikan dengan bobot Wij
………..…...(3-9)
……...……...………...……... (3-10)
(4) Pindahkan pada pelatihan data selanjutnya, dan ulangi langkah 2. Proses pembelajaran berhenti jika Yk cukup mendekati target Tk Penentuannya
dapat berdasarkan error E, proses pembelajaran berhenti ketika E<0.0001.
dimana ……...………….(3-11)
Dimana:
Tkp = nilai target data p dari training set node k
Yp = nilai prediksi data p dari training set node k
Jaringan dapat digunakan untuk memprediksi t melalui x setelah training selesai.
Algoritma Adaptive Boosting
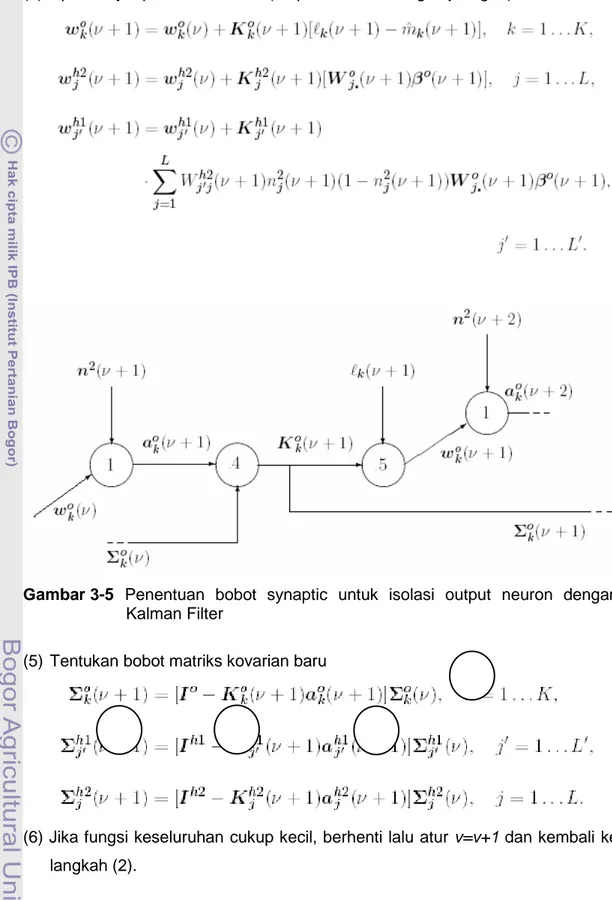
Algoritma Adaptive Boosting (AdaBoost) merupakan standar klasifikasi ANN yang difokuskan pada struktur MLP (Richards and Jia 1999 dan Duda et al. 2001). Algoritma AdaBoost (Gambar 3-5) dibedakan dengan algoritma BP pada jumlah layernya, yaitu memiliki tiga layer dan dua hidden layer. Mekanisme pelatihan data menggunakan kalman filtering (Bishop 1995). Prosedur pelatihan
Kalman filter adalah fungsi kuadrat linear square error output jaringan yang menyimpulkan semua bobot pengamatan:
dan dengan jumlah acak.
(2) Pilih pasangan acak (g(v+1), l(v+1) dengan distribusi probabilitas p(v) yang tepat dan menentukan vektor output layer tersembunyi menurut persamaan:
.
dan network output berdasarkan:
set
dan
(4) Update synaptik bobot matrik (umpan mundur dengan jaringan):
Gambar 3-5 Penentuan bobot synaptic untuk isolasi output neuron dengan Kalman Filter
(5) Tentukan bobot matriks kovarian baru
(6) Jika fungsi keseluruhan cukup kecil, berhenti lalu atur v=v+1 dan kembali ke langkah (2).
Sedangkan pembelajaran algoritma ANN-AdaBoost secara sistematik dijalankan sebagai berikut:
(1) Set p1(v) = 1/n, v = 1 ... n, dimana n adalah jumlah observasi dalam susunan data training area. Set i = 1.
(2) Set r = 0.
(3) Buat sebuah jaringan neural network N (i) yang baru dengan bobot synaptic acak. Latih N dengan algoritma (1) dan distribusi sampling pi(v). Setelah pelatihan selesai, biarkan Ui menjadi himpunan pengamatan yang salah diklasifikasikan.
(4) Kalkulasi Єi =
∑
vЄUipi(v). Jika Єi<1/2 maka lanjut, jika r<5 maka set r = r+1, putuskan misalnya N(i) dan kembali ke langkah (3), lalu berhenti.(5) Hitung Єi / (1- Єi ) dan update distribusi sampling:
dimana
Dimana:
Ni : input variable dari node input layer i
L’ : output node j (hidden layer 1) L : output node j (hidden layer 2)
K : kelas output node k dalam output layer
v : Identitas dari contoh training 0 : bias input
Gambar 3-6 Jaringan algoritma AdaBoost dengan dua lapisan hidden layer
• • • • • • • Hidden layer 1 • • • • • • • Hidden layer 2 k L 1 0 N1 Ni N J’1 J’i L’ 1 J1 Ji 1 0 0 Output layer Input layer 1 g1(V) g2(V) gN(V) m1(V) MK(V) 1 1 K MK(V) • • • •
(6) Set i = i + 1. Jika i>75 maka berhenti, lalu kembali ke langkah (2). Proses pembelajaran berhenti ditunjukkan dengan jumlah iterasi dan nilai quadratic error yang diinginkan. Proses berhenti ini merupakan ukuran validasi sistem. Data validasi merupakan set data pasangan input-output pembelajaran yang dibagi kedalam dua set data, yaitu data training dan data validasi. Data training tersebut setelah dilakukan proses pembelajaran, selanjutnya divalidasi menggunakan satu set data input-output baru yang bertujuan untuk menghubungkan dengan baik pasangan data input-output.
3.5 Analisis Penilaian Akurasi
Pengamatan objek di lapangan dilakukan secara ‘rapid mobile’ dan menganut prinsip ‘penutupan lahan dominan’ untuk membuat klasifikasi daerah pengamatan dan kodefikasi untuk keperluan simplikasi (Tabel 3-5). Pengambilan data lapangan tersebut dengan cara kombinasi pandangan mata dan penggunaan kamera digital dari permukaan air (dari atas perahu yang bergerak). Di setiap lokasi tertentu, jenis penutupan lahan ditentukan dan dicatat posisinya dengan GPS. Data GPS tersebut kemudian dianalisis akurasi posisinya untuk dipergunakan dalam uji akurasi tematik selanjutnya.
3.5.1 Akurasi Posisi GPS
Akurasi posisi hasil survei GPS dengan pendekatan DGPS untuk keperluan uji akurasi dihitung menggunakan formulasi:
dimana
,
...(3-13) Dimana;E1 = nilai terkoreksi posisi lintang dan bujur ke ij Ê = rata-rata nilai posisi lintang dan bujur E = nilai posisi lintang dan bujur
∆E = selisih nilai E terhadap nilai rata-rata perhitungan dalam satu hari 3.5.2 Akurasi peta tematik
Akurasi peta tematik dianalisa dengan uji ketelitian matrik konfusi (Congalton dan Green 1997; 2009). Matrik konfusi ditentukan berdasarkan persentase akurasi klasifikasi dari perbandingan antar kelas habitat ekosistem terumbu karang yang terbentuk dengan jumlah pixel yang benar masuk pada training area hasil survey lapangan (Tabel 3-6).
Tabel 3-6 Matrik konfusi (confussion matrix)
Training Area Total Baris
n+k User accuracy Hasil Klasifikasi A B... ... D n+k nkk /n+k A nii ... ... ... ... ... B ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... D ... ... ... n+k ... ... Total Kolom nk+ ... ... ... n ... Producer accuracy nkk/n+k ... ... ... ... ... Overall accuracy
Berdasarkan matrik tersebut dihitung secara matematis uji overall accuracy, producer accuracy, dan user accuracy:
% 100 × =
∑
n n accuracy overall kk ; ………...…….(3-14)%
100
×
=
+ k kkn
n
accuracy
producer
; ………...…...(3-15)%
100
×
=
+k kkn
n
accuracy
user
; ………....………..(3-16) Dimana;- Overall accuracy adalah persentase pixel-pixel yang tepat dikelaskan, - Producer accuracy adalah peluang rata-rata (%) suatu pixel menunjukkan
sebaran masing-masing kelas hasil klasifikasi lapangan.
- User accuracy adalah peluang rata-rata (%) suatu pixel secara aktual mewakili kelas-kelas hasil klasifikasi citra.