BAB 2
LANDASAN TEORI
2.1 Konsep Kemiskinan
Kemiskinan dapat dilihat dari dua sisi yaitu kemiskinan absolut dan kemiskinan relatif. Kemiskinan absolut dan kemiskinan relatif adalah konsep kemiskinan yang mengacu pada kepemilikan materi dikaitkan dengan standar kelayakan hidup seseorang atau keluarga. Kedua istilah itu menunjuk pada perbedaan sosial (social distinction) yang ada dalam masyarakat berangkat dari distribusi pendapatan. Perbedaannya adalah bahwa pada kemiskinan absolut ukurannya sudah terlebih dahulu ditentukan dengan angka-angka nyata (garis kemiskinan) dan atau indikator atau kriteria yang digunakan, sementara pada kemiskinan relatif kategori kemiskinan ditentukan berdasarkan perbandingan relatif tingkat kesejahteraan antar penduduk.
2.1.1 Kemiskinan Absolut
Kemiskinan absolut atau mutlak berkaitan dengan standar hidup minimum suatu masyarakat yang diwujudkan dalam bentuk garis kemiskinan (poverty line) yang sifatnya tetap tanpa dipengaruhi oleh keadaan ekonomi suatu masyarakat. Garis Kemiskinan (poverty line) adalah kemampuan seseorang atau keluarga memenuhi kebutuhan hidup standar pada suatu waktu dan lokasi tertentu untuk melangsungkan hidupnya. Pembentukan garis kemiskinan tergantung pada definisi mengenai standar hidup minimum. Kemiskinan abosolut ini bisa diartikan dari melihat seberapa jauh perbedaan antara tingkat pendapatan seseorang dengan tingkat pendapatan yang dibutuhkan untuk memenuhi kebutuhan dasarnya. Tingkat pendapatan minimum merupakan pembatas antara keadaan miskin dengan tidak miskin.
2.1.2 Kemiskinan Relatif
Kemiskinan relatif pada dasarnya menunjuk pada perbedaan relatif tingkat kesejahteraan antar kelompok masyarakat yang berada dilapisan terbawah dalam persentil derajat kemiskinan suatu masyarakat digolongkan sebagai penduduk miskin. Dalam kategori seperti ini, yang digolongkan sebagai miskin sebenarnya sudah dapat mencukupi hak dasarnya, namun tingkat keterpenuhannya berada dilapisan terbawah.
Kemiskinan relatif memahami kemiskinan dari dimensi ketimpangan antar kelompok penduduk. Pendekatan ketimpangan tidak berfokus pada pengukuran garis kemiskinan, tetapi pada besarnya perbedaan antara 20 atau 10 persen masyarakat paling bawah dengan 80 atau 90 persen masyarakat lainnya. Kajian yang berorientasi pada pendekatan ketimpangan tertuju pada upaya memperkecil perbedaan antara yang berada dibawah (miskin) dan yang makmur dalam setiap dimensi statifikasi dan diferensiasi sosial. Ketimpangan merupakan suatu permasalahan yang berbeda dengan kemiskinan.
Dalam hal mengidentifikasi dan menentukan sasaran penduduk miskin, maka garis kemiskinan relatif cukup untuk digunakan dan perlu disesuaikan terhadap tingkat pembangunan negara secara keseluruhan. Garis kemiskinan relatif tidak dapat dipakai untuk membandingkan tingkat kemiskinan antar negara dan waktu karena tidak mencerminkan tingkat kesejahteraan yang sama.
2.2 Ukuran Kemiskinan
Untuk mengetahui jumlah penduduk miskin, sebaran dan kondisi kemiskinan diperlukan pengukuran kemiskinan yang tepat sehingga upaya untuk mengurangi kemiskinan melalui berbagai kebijakan dan program pengurangan kemiskinan akan efektif. Pengukuran kemiskinan yang dapat dipercaya menjadi instrument yang tangguh bagi pengambil kebijakan dalam memfokuskan perhatian pada kondisi hidup orang miskin. Pengukuran kemiskinan yang baik akan memungkinkan dalam melakukan evaluasi dampak dari pelaksanaan proyek, membandingkan kemiskinan
antar waktu dan menentukan target penduduk miskin dengan tujuan untuk menguranginya (World Bank, Introduction to Poverty Analysis, 2002 dalam Badan Pusat Statistik, 2008).
Metode penghitungan penduduk miskin yang dilakukan BPS sejak pertama kali hingga saat ini menggunakan pendekatan yang sama yaitu pendekatan kebutuhan dasar (basic needs approach). Dengan pendekatan ini, kemiskinan didefinisikan sebagai ketidakmampuan dalam memenuhi kebutuhan dasar. Dengan kata lain, kemiskinan dipandang sebagai ketidakmampuan dari sisi ekonomi untuk memenuhi kebutuhan makanan maupun non makanan yang bersifat mendasar. Berdasarkan pendekatan itu indikator yang digunakan adalah Head Count Index (HCI) yaitu jumlah dan persentase penduduk miskin yang berada di bawah garis kemiskinan (poverty line).
Selain head count index (𝑃0) terdapat juga indikator lain yang digunakan
untuk mengukur tingkat kemiskianan, yaitu indeks kedalaman kemiskinan (poverty gap index) atau (𝑃1) dan indeks keparahan kemiskinan (distributionally sensitive index) atau (𝑃2) yang dirumuskan oleh Foster-Greer-Thorbecke (Badan Pusat Statistik, 2008). Metode penghitungan ini merupakan dasar penghitungan persentase penduduk miskin untuk seluruh Kabupaten/Kota.
Rumus yang digunakan adalah:
𝑷∝ = 𝟏 𝑵 𝒁 − 𝒀𝒊 𝒁 ∝ (𝟐. 𝟏) 𝑸 𝒊=𝟏 Keterangan : 𝑍 = Garis kemiskinan
𝑖 = Rata-rata pengeluaran per kapita penduduk yang berada di bawah garis kemiskinan
𝑄 = Banyak penduduk yang berada di bawah garis kemiskinan
𝑁 = Jumlah penduduk
𝛼 = 0 ; Poverty head count index (𝑃0) 𝛼 = 1 ; Poverty gap index (𝑃1)
𝛼 = 2 ; Poverty distributionally sensitive index (𝑃2)
Head count index (𝑃0) merupakan jumlah persentase penduduk yang berada dibawah garis kemiskinan. Semakin kecil angka ini menunjukkan semakin berkurangnya jumlah penduduk yang berada dibawah garis kemiskinan. Demikian juga sebaliknya, bila angka (𝑃0) besar maka menunjukkan tingginya jumlah
persentase penduduk yang berada di bawah garis kemiskinan.
Poverty Gap Index (𝑃1) merupakan ukuran rata-rata kesenjangan pengeluaran
masing-masing penduduk miskin terhadap garis kemiskinan. Angka ini memperlihatkan jurang (gap) antara pendapatan rata-rata yang diterima penduduk miskin dengan garis kemiskinan. Semakin kecil angka ini menunjukkan secara rata-rata pendapatan penduduk miskin sudah semakin mendekati garis kemiskinan. Semakin tinggi angka ini maka semakin besar kesenjangan pengeluaran penduduk miskin terhadap garis kemiskinan atau dengan kata lain semakin tinggi nilai indeks menunjukkan kehidupan ekonomi penduduk miskin semakin terpuruk.
Distributionally Sensitive Index (𝑃2) memberikan gambaran mengenai
penyebaran pengeluaran di antara penduduk miskin. Angka ini memperlihatkan sensitivitas distribusi pendapatan antar kelompok miskin. Semakin kecil angka ini menunjukkan distribusi pendapatan di antara penduduk miskin semakin merata. Sebagai contohnya dapat dijelaskan dalam tabel 2.1.
Tabel 2.1
Contoh Perhitungan Persentase Penduduk Miskin
Penduduk ke Daerah – A Konsumsi *) P/NP #) 𝑍 − 𝑌𝑖 𝑍 𝑍 − 𝑌𝑖 𝑍 2 1 250.000 Npoor 2 210.000 Npoor 3 150.000 Npoor 4 125.000 Npoor 5 110.000 Npoor 6 105.000 Npoor 7 75.000 poor 0,25 0,0625 8 50.000 poor 0,5 0,25 9 50.000 poor 0,5 0,25 10 25.000 poor 0,75 0,5625 𝑃 =𝑄 𝑁 = 4 10= 0,4 𝑃 = 1 𝑁 𝑍 − 𝑌𝑖 𝑍 𝑄 𝑖=1 = 1 10 0,25 + 0,5 + 0,5 + 0,75 = 0,2 𝑃∝= 1 𝑁 𝑍 − 𝑌𝑖 𝑍 2 𝑄 𝑖=1 = 1 10(0,0625 + 0,25 + 0,25 + 0,5625) = 0,1125
Note: *) Rp/kapita/bulan; #) P=poor, NP=non-poor, dengan garis kemiskinan Z = Rp100.000/kapita/bulan.
Daerah A memiliki (𝑃0) yaitu sebesar 0,4, hal ini menunjukkan bahwa daerah
tersebut penduduk miskinnya mencapai 0,4 atau sebesar 40 persen. Bila dilihat dari Indeks kedalaman kemiskinan (poverty gap index) atau (𝑃1) daerah A dapat dilihat
(𝑃1) adalah sebesar 0,2 dan bila dilihat dari indeks keparahan kemiskinan (distributionally sensitive index) atau (𝑃2), daerah A memiliki (𝑃2) sebesar 0,1125.
2.3 Variabel Kesejahteraan Masyarakat yang Mempengaruhi Kemiskinan 2.3.1 Produk Domestik Regional Bruto (PDRB)
Menurut Badan Pusat Statistik (BPS) pengertian produk domestik regional bruto (PDRB) atas dasar harga konstan yaitu jumlah nilai produksi atau pengeluaran atau pendapatan yang dihitung menurut harga suatu tahun dasar tertentu. Indikator ini sangat bermanfaat untuk mengukur tingkat kehidupan masyarakat dan lebih tepat dipergunakan dibandingkan pendapatan per kapita. Dengan cara menilai kembali atau mendefinisikan berdasarkan harga-harga pada tingkat dasar dengan menggunakan indeks harga konsumen. Penghitungan atas dasar konstan berguna untuk melihat pertumbuhan ekonomi secara keseluruhan atau sektoral, juga untuk melihat perubahan struktur perekonomian suatu daerah dari tahun ke tahun.
Sesuai dengan uraian tersebut diatas, cara perhitungan PDRB dapat dinyatakan dengan rumus:
𝑃𝐷𝑅𝐵 = 𝐾𝑜𝑛𝑠𝑢𝑚𝑠𝑖 + 𝑇𝑎𝑏𝑢𝑛𝑔𝑎𝑛 (2.2)
Sedangkan untuk menghitung perubahan-perubahan yang terjadi (laju pertumbuhan) PDRB dapat dinyatakan dengan rumus:
𝐿𝑃𝐷𝑅𝐵 =𝑃𝐷𝑅𝐵𝑡 − 𝑃𝐷𝑅𝐵𝑡−1
𝑃𝐷𝑅𝐵𝑡−1
× 100% (2.3)
Keterangan :
𝐿𝑃𝐷𝑅𝐵𝑡 = Nominal Laju PDRB tahun tertentu
𝑃𝐷𝑅𝐵𝑡 = Nominal PDRB tahun tertentu
2.3.2 Pendidikan
Upaya pembangunan di bidang pendidikan bertujuan untuk peningkatan sumber daya manusia. Pendidikan mempunyai peranan penting bagi suatu bangsa dan merupakan salah satu sarana untuk meningkatkan kecerdasan dan keterampilan manusia. Kualitas sumber daya manusia antara lain sangat tergantung dari kualitas pendidikan. Pentingnya pendidikan tercermin dalam UUD’45 dan GBHN yang mengatakan bahwa pendidikan merupakan hak setiap warga negara yang bertujuan untuk mencerdaskan
kehidupan bangsa. Dengan demikian program pendidikan mempunyai andil besar terhadap kemajuan bangsa, ekonomi maupun sosial
Keadaan pendidikan penduduk secara umum dapat diketahui dari beberapa indikator seperti angka partisipasi sekolah, tingkat pendidikan yang ditamatkan dan angka melek huruf. Tingkat pendidikan sangat diperlukan untuk meningkatkan kesejahteraan penduduk. Keadaan seperti ini sesuai dengan hakikat pendidikan itu sendiri yakni merupakan usaha sadar untuk mengembangkan kepribadian dan kemampuan di dalam dan di luar sekolah yang berlangsung seumur hidup.
2.3.3 Ketenagakerjaan
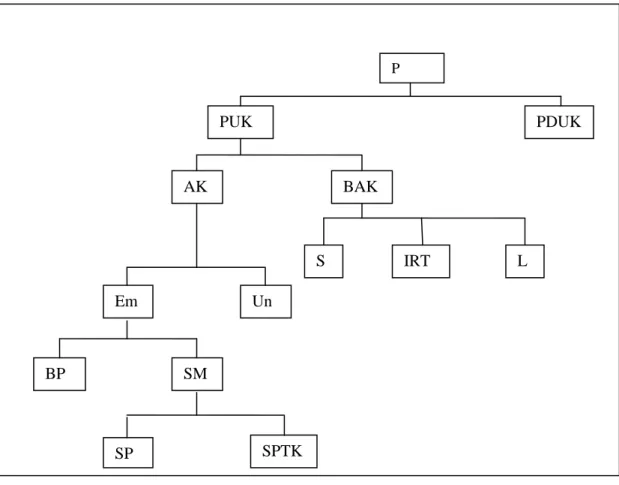
Gambar 2.1 dengan jelas dapat dilihat skema mengenai keadaan penduduk suatu Negara dengan segala potensinya untuk menghasilkan.
Gambar 2.1
Penduduk Dan Tenaga Kerja P PDUK PUK AK BAK IRT L S Em Un SM BP SPTK SP K
Berdasarkan Gambar 2.1, dapat pula dirumuskan beberapa persamaan. 𝑃 = 𝑃𝑈𝐾 + 𝑃𝐷𝑈𝐾 (2.4) 𝑃𝑈𝐾 = 𝐴𝐾 + 𝐵𝐴𝐾 (2.5) 𝐴𝐾 = 𝐸𝑚 + 𝑈𝑛 (2.6) 𝐵𝐴𝐾 = 𝑆 + 𝐼𝑅𝑇 + 𝐿 (2.7) 𝐸𝑚 = 𝐵𝑃 + 𝑆𝑀 (2.8) 𝑆𝑀 = 𝑆𝑃𝐾 + 𝑆𝑃𝑇𝐾 (2.9) Keterangan: P = Penduduk
PUK = Penduduk Usia Kerja, di Indonesia dengan batasan 10 tahun ke atas PDUK = Penduduk Di Luar Usia Kerja
Ak = Angkatan Kerja, yaitu penduduk dalam usia kerja yang sudah bekerja dan sedang mencari pekerjaan.
BAK = Bukan Angkatan Kerja, yaitu penduduk dalam usia kerja yang tidak bekerja dan belum ingin bekerja.
S = Sekolah
IRT = Ibu Rumah Tangga
L = Lainnya, yaitu penduduk yang cacat mental atau sebab lain sehingga tidak produktif.
Em = Bekerja
Un = Unemployment, yaitu penduduk yang menganggur karena belum mendapat pekerjaan disebut juga pengangguran terbuka.
BP = Bekerja Penuh, yaitu penduduk yang memiliki jam kerja lebih dari 35 jam per minggu
SM = Setengah Menganggur, yaitu penduduk yang bekerja di bawah 35 jam per minggu
SPK = Setengah Penganggur Kentara, yaitu penduduk yang memiliki jam kerja sedikit. Menurut SAKERNAS kurang dari 14 jam per minggu disebut setengah penganggur kritis, sedangkan antara 14 – 35 jam disebut setengah penganggur.
SPTK = Setengah Penganggur Tak Kentara, yaitu penduduk yang memilliki produktivitas rendah dan pendapatannya juga rendah.
Hanya membandingkan Em (bekerja) dan Un (menganggur) disebut pendekatan labor force approach atau pendekatan angkatan kerja, sedangkan melihat lebih teliti di antara penduduk yang bekerja penuh atau setengah menganggur disebut labor utilization approach. Pendekatan kedua lebih menggambarkan keadaan yang realistis tentang produktivitas penduduk.
Dalam konsep labor force approach telah disebutkan adanya angkatan kerja yang belum bekerja dan sedang/ingin mencari pekerjaan. Jumlah penduduk yang sedang mencari pekerjaan ini dalam pengertian ekonomi disebut pengangguran terbuka (open unemployment). Sebagai indikator biasanya dihitung persentasenya terhadap angkatan kerja dengan rumus:
𝑂𝑈 =𝑈𝑛 𝐴𝐾× 100% (2.10) Keterangan: OU = Open Unemployment Un = Unemployment AK = Angkatan Kerja 2.4 Analisis Regresi
Analisis regresi merupakan sebuah alat statistik yang memberikan penjelasan tentang pola hubungan (model) antara dua variabel atau lebih. Analisis regresi, dikenal dua jenis variabel yaitu variabel respons yaitu variabel yang keberadaannya dipengaruhi oleh variabel lainnya dan dinotasikan dengan 𝒴 dan variabel bebas yang keberadaannya tidak dipengaruhi oleh variabel lainnya dan dinotasikan dengan 𝒳.
2.5 Analisis Regresi Linier Berganda
Analisis regresi linier berganda (Multiple Linier Regression) ialah suatu alat analisis dalam ilmu statistik yang berguna untuk mengukur hubungan matematis antara lebih
dari dua peubah. Regresi linier berganda juga merupakan regresi di mana variabel terikatnya (𝒴) dihubungkan atau dijelaskan lebih dari satu variabel, mungkin dua, tiga dan seterusnya variabel bebas. Bentuk umum dari persamaan regresi linier berganda dapat ditulis sebagai berikut :
𝒴𝑖 = 𝛽0+ 𝛽1𝒳𝑖1+ 𝛽2𝒳𝑖2+ 𝛽3𝒳𝑖3+ … + 𝛽𝑘𝒳𝑖𝑘 + ℯ𝑖 (2.11)
Dengan 𝑖 = 1, 2, 3, … , 𝑛 dan errornya diasumsikan identik, independent dan berdistribusi normal dengan mean nol dan varians konstan. Asumsi-asumsinya dapat ditulis sebagai berikut :
1. 𝐸 𝑒𝑖 = 0, maka
a. 𝐸 𝒴𝑖 = 𝛽0+ 𝛽1𝒳𝑖1+ 𝛽2𝒳𝑖2+ 𝛽3𝒳𝑖3+ ⋯ + 𝛽𝑘𝒳𝑖𝑘
b. 𝛿𝐸 𝒴𝑖
𝛿𝒳𝑖𝑗 = 𝛽𝑗 menunjukkan seberapa jauh pengaruh 𝒳 terhadap Y apabila variabel-variabel lain tetap.
2. 𝐸 𝑒𝑖2 = 𝜎2, maka 𝑉𝑎𝑟 𝒴
𝑖 = 𝜎2
3. 𝐸 𝑒𝑖𝑒𝑗 = 0 untuk i tidak sama dengan j
4. 𝒳𝑖𝑗 adalah tetap untuk pengambilan sampel yang berulang-ulang; 𝑗 = 1, 2, 3, … 𝑘
5. Tidak ada hubungan linier di antara 𝒳𝑖𝑗 sehingga 𝜀𝑐𝑗𝒳𝑖𝑗 = 0, di mana 𝑐𝑗
adalah himpunan konstanta yang paling tidak memiliki satu anggota yang nilainya 0
6. lim𝑛→∞ 𝒳𝑖𝑗−𝒳𝑗 (𝒳𝑖𝑠−𝒳𝑠)
𝑛 = 𝑞𝑗𝑗
′ > 0 dan = 𝑞
𝑗𝑠′ untuk j tidak sama dengan s
lim 𝑛→∞
𝒳𝑖𝑗𝒳𝑖𝑠
𝑛 = 𝑞𝑗𝑠; 𝑞𝑗𝑗 > 0
Dengan asumsi-asumsi di atas, hasil estimasi dengan metode kuadrat terkecil dapat ditulis sebagai berikut :
𝑆 = 𝑒𝑖2 = 𝒴 𝑖− 𝒴𝑖 2 = (𝒴𝑖− 𝛽0− 𝛽1𝒳𝑖1−𝛽2𝒳𝑖2− 𝛽3𝒳𝑖3− ⋯ − 𝛽𝑘𝒳𝑖𝑘)2 𝑛 𝑖=1 𝑛 𝑖=1 𝑛 𝑖=1
Turunan pertama dari fungsi ini dapat ditentukan sebagai berikut.
𝛿𝑆
𝛿𝛽𝑗 = 0
dengan 𝑗 = 1, 2, 3, … , 𝑘. Proses ini akan menghasilkan persamaan dengan k faktor yang tidak diketahui seperti berikut ini.
𝛿𝑆 𝛿𝛽0 = 2 𝒴𝑖− 𝛽0− 𝛽1𝒳𝑖1−𝛽2𝒳𝑖2− 𝛽3𝒳𝑖3… − 𝛽𝑘𝒳𝑖𝑘 (−1) 𝑛 𝑖=1 = 0 𝛿𝑆 𝛿𝛽1 = 2 𝒴𝑖 − 𝛽0− 𝛽1𝒳𝑖1−𝛽2𝒳𝑖2− 𝛽3𝒳𝑖3… − 𝛽𝑘𝒳𝑖𝑘 𝑛 𝑖=1 −𝒳𝑖1 = 0 𝛿𝑆 𝛿𝛽2 = 2 𝒴𝑖− 𝛽0− 𝛽1𝒳𝑖1−𝛽2𝒳𝑖2− 𝛽3𝒳𝑖3… − 𝛽𝑘𝒳𝑖𝑘 𝑛 𝑖=1 −𝒳𝑖2 = 0 𝛿𝑆 𝛿𝛽3 = 2 𝒴𝑖− 𝛽0− 𝛽1𝒳𝑖1−𝛽2𝒳𝑖2− 𝛽3𝒳𝑖3… − 𝛽𝑘𝒳𝑖𝑘 𝑛 𝑖=1 −𝒳𝑖3 = 0 : : : 𝛿𝑆 𝛿𝛽𝑘 = 2 𝒴𝑖 − 𝛽0− 𝛽1𝒳𝑖1−𝛽2𝒳𝑖2− 𝛽3𝒳𝑖3… − 𝛽𝑘𝒳𝑖𝑘 𝑛 𝑖=1 −𝒳𝑖𝑘 = 0
atau dapat dituliskan menjadi 𝑘 persamaan normal seperti berikut ini :
𝛽0𝑛 + 𝛽1 𝒳1 + 𝛽2 𝒳2 + 𝛽3 𝒳3 + ⋯ + 𝛽𝑘 𝒳𝑘 = 𝒴 𝛽0 𝒳1 + 𝛽1 𝒳12 + 𝛽2 𝒳1𝒳2+ 𝒳1𝒳3+ ⋯ + 𝛽𝑘 𝒳1𝒳𝑘 = 𝒳1𝒴 𝛽0 𝒳2 + 𝛽1 𝒳2𝒳1+ 𝛽2 𝒳22 + 𝒳2𝒳3 + ⋯ + 𝛽𝑘 𝒳2𝒳𝑘 = 𝒳2𝒴 (2.12) 𝛽0 𝒳3 + 𝛽1 𝒳3𝒳1+ 𝛽2 𝒳3𝒳2+ 𝒳32 + ⋯ + 𝛽𝑘 𝒳3𝒳𝑘 = 𝒳3𝒴 : : : 𝛽0 𝒳𝑛 + 𝛽1 𝒳𝑘𝒳1+ 𝛽2 𝒳𝑘𝒳2+ 𝛽3 𝒳𝑘𝒳3+ 𝛽𝑘 𝒳𝑘𝒳1+ ⋯ + 𝛽𝑘 𝒳𝑘2= 𝒳𝑘𝒴
Penyelesaian dari persamaan 2.12 akan memberikan hasil estimasi berdasarkan metode OLS (ordinary least square), yang akan bersifat BLUE (Best Linier Unbiass Estimated).
Dengan menggunakan notasi matriks, model linier di atas dapat dituliskan secara lebih sederhana menjadi seperti berikut :
𝒴0 𝒴1 𝒴2 𝒴3 : : 𝒴𝑛 = 𝑛 𝒳1 𝒳2 𝒳3 : : 𝒳𝑛 𝒳1 𝒳11 𝒳21 𝒳31 : : 𝒳𝑛1 𝒳2 𝒳12 𝒳22 𝒳32 : : 𝒳𝑛2 … 𝒳𝑘 𝒳1𝑘 𝒳2𝑘 𝒳3𝑘 : : 𝒳𝑛𝑘 𝛽0 𝛽1 𝛽2 𝛽3 : : 𝛽𝑛 + 𝑒0 𝑒1 𝑒2 𝑒3 : : 𝑒𝑛 (2.13)
Model regresi pada persamaan (2.11) disebut model regresi global karena model regresi global mengasumsikan hubungan antara variabel respon dengan variabel prediktor adalah tetap, sehingga parameter yang diestimasi nilainya sama untuk semua tempat dimana data tersebut diamati.
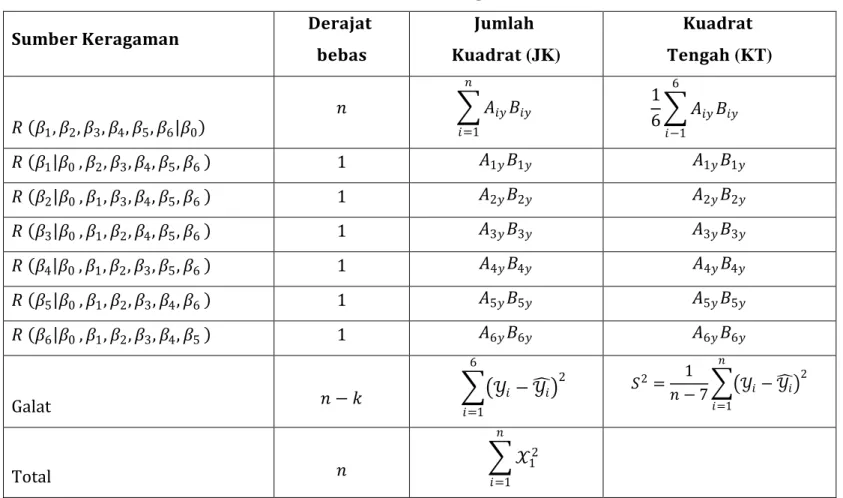
Pengujian kesesuaian model secara serentak dilakukan dengan analisis varians dengan hipotesis sebagai berikut.
𝐻0: 𝛽1, 𝛽2, 𝛽3, … , 𝛽𝑘 = 0
Tabel 2.2 Sidik Ragam 𝐒𝐮𝐦𝐛𝐞𝐫 𝐊𝐞𝐫𝐚𝐠𝐚𝐦𝐚𝐧 𝐃𝐞𝐫𝐚𝐣𝐚𝐭 𝐛𝐞𝐛𝐚𝐬 𝐉𝐮𝐦𝐥𝐚𝐡 𝐊𝐮𝐚𝐝𝐫𝐚𝐭 (JK) 𝐊𝐮𝐚𝐝𝐫𝐚𝐭 𝐓𝐞𝐧𝐠𝐚𝐡 (KT) 𝑅 𝛽1, 𝛽2, 𝛽3, 𝛽4, 𝛽5, 𝛽6 𝛽0 𝑛 𝐴𝑖𝑦𝐵𝑖𝑦 𝑛 𝑖=1 1 6 𝐴𝑖𝑦𝐵𝑖𝑦 6 𝑖−1 𝑅 𝛽1 𝛽0 , 𝛽2, 𝛽3, 𝛽4, 𝛽5, 𝛽6 1 𝐴1𝑦𝐵1𝑦 𝐴1𝑦𝐵1𝑦 𝑅 𝛽2 𝛽0 , 𝛽1, 𝛽3, 𝛽4, 𝛽5, 𝛽6 1 𝐴2𝑦𝐵2𝑦 𝐴2𝑦𝐵2𝑦 𝑅 𝛽3 𝛽0 , 𝛽1, 𝛽2, 𝛽4, 𝛽5, 𝛽6 1 𝐴3𝑦𝐵3𝑦 𝐴3𝑦𝐵3𝑦 𝑅 𝛽4 𝛽0 , 𝛽1, 𝛽2, 𝛽3, 𝛽5, 𝛽6 1 𝐴4𝑦𝐵4𝑦 𝐴4𝑦𝐵4𝑦 𝑅 𝛽5 𝛽0 , 𝛽1, 𝛽2, 𝛽3, 𝛽4, 𝛽6 1 𝐴5𝑦𝐵5𝑦 𝐴5𝑦𝐵5𝑦 𝑅 𝛽6 𝛽0 , 𝛽1, 𝛽2, 𝛽3, 𝛽4, 𝛽5 1 𝐴6𝑦𝐵6𝑦 𝐴6𝑦𝐵6𝑦 Galat 𝑛 − 𝑘 𝒴𝑖− 𝒴 𝑖 2 6 𝑖=1 𝑆2= 1 𝑛 − 7 𝒴𝑖− 𝒴 𝑖 2 𝑛 𝑖=1 Total 𝑛 𝒳12 𝑛 𝑖=1
Statistik uji dalam pengujian tersebut adalah :
𝐹𝑖𝑡𝑢𝑛𝑔 =𝐾𝑇 𝑅𝑒𝑔𝑟𝑒𝑠𝑖 𝐾𝑇 𝐺𝑎𝑙𝑎𝑡
dengan keputusan 𝐻0 di tolak jika 𝐹𝑖𝑡𝑢𝑛𝑔 > 𝐹𝑡𝑎𝑏𝑒𝑙 di mana 𝐹𝑡𝑎𝑏𝑒𝑙 (𝛼,𝑘,𝑛−𝑘). Adapun nilai koefisien determinasinya dapat dicari dengan perumusan :
𝑅2 = 𝐽𝐾 𝑅𝑒𝑔𝑟𝑒𝑠𝑖
𝐽𝐾 𝑇𝑜𝑡𝑎𝑙
Pengujian secara parsial dilakukan untuk mengetahui parameter apa saja yang signifikan terhadap model. Hipotesis dari pengujian ini adalah:
𝐻0: 𝛽𝑗 = 0
𝐻1: 𝛽𝑗 ≠ 0, dengan 𝑗 = 1, 2, 3, … , 𝑘
Statistik uji yang digunakan secara parsial adalah :
𝑡𝑖𝑡𝑢𝑛𝑔 = 𝛽𝑘 𝑆(𝛽𝑘) .
dengan keputusan 𝐻0 di tolak jika 𝑡𝑖𝑡𝑢𝑛𝑔 > 𝐹𝑡𝑎𝑏𝑒𝑙 di mana 𝑡𝑡𝑎𝑏𝑒𝑙 (𝛼,𝑘,𝑛−𝑘).
2.6 Metode Doolittle Dipersingkat (Abbreviated Doolittle Method)
Masalah pendugaan dalam regresi berganda adalah menyangkut penyelesaian persamaan normal yang merupakan gugus persamaan simultan dalam parameter model yang akan diduga.
Dalam pembahasan tentang model regresi berganda, terutama mengenai pendugaan parameter model, maka untuk memperoleh jawaban bagi gugus persamaan normal perlu mengetahui bagaimana cara membalik suatu matriks setangkup (𝒳′𝒳)
menjadi matriks kebalikan (𝒳′𝒳)−1 . Untuk gugus persamaan normal yang banyak sehingga membentuk matriks berukuran besar, maka proses pembalikan matriks menjadi tidak mudah, untuk itu diperlukan suatu metode pengerjaannya dapat dilakukan secara teratur. Salah satu metode yang memenuhi syarat adalah metode Doolittle dipersingkat (Abbreveited Doolittle Method).
Metode ini dilaporkan pertama kali oleh M. H. Doolittle, seoran ahli yang bekerja di kantor penelitian Geodesi, pada tanggal 9 November 1878. Sejak metode ini dilaporkan oleh Doolittle melalui papernya pada tanggal 9 November 1878, maka telah banyak digunakan untuk membantu memecahkan persamaan normal dalam regresi ganda. Metode ini bersifat umum, sehingga dapat dipakai untuk menyelesaikan k buah persamaan normal (k dapat menggambil nilai berapa saja, jadi bisa digunakan untuk memecahkan katakanlah 10, 25, 100, dan seterusnya). Dengan menggunakan fasilitas komputasi yang sederhana, seperti kalkulator, peneliti telah dapat menggunakan metode ini untuk menyelesaikan gugus persamaan normal dalam regresi ganda. Keuntungan dari penggunaan metode ini tidak hanya dalam pembalikan matriks setangkup, tetapi juga dapat menghitung berbagai jumlah kuadrat untuk pengujian hipotesis tentang parameter model yang diidentifikasi. Secara jelas dapat dikemukakan bahwa metode Doolittle dapat digunakan untuk memperoleh jawaban berikut:
1. Koefisien penduga parameter model (koefisien regresi b). 2. Jumlah kuadrat yang berkaitan dengan koefisien regresi. 3. Ragam dugaan regresi di antara pasangan koefisien regresi. 4. Peragam dugaan di antara pasangan koefisien regresi.
5. Elemen-elemen dari invers matriks (𝒳′𝒳) (untuk pembalikan matriks setangkup.
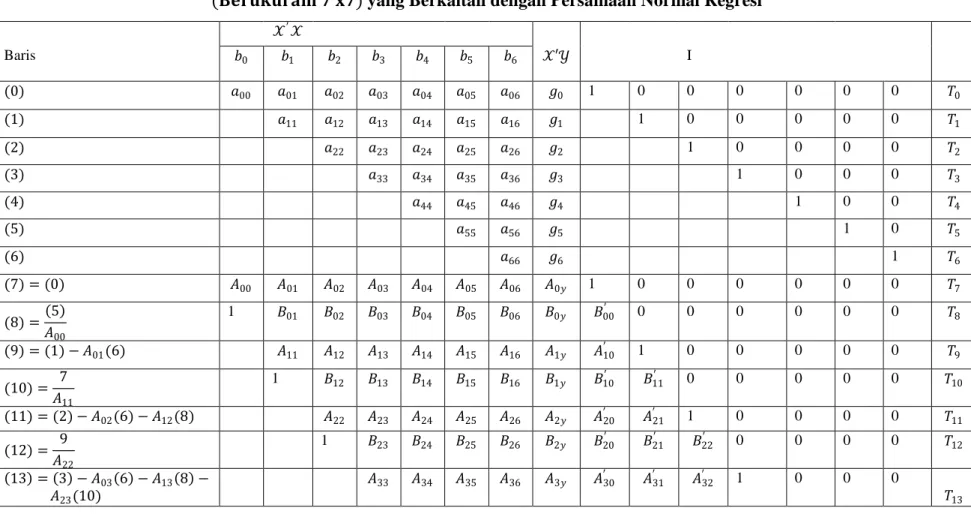
Adapun tahapan perhitungan untuk mendapatkan persamaan garis linier berganda dengan metode Doolittle Dipersingkat dalam penelitian ini adalah sebagai berikut:
1. Persiapan awal
Persiapan awal ini disebut juga forward solution yaitu untuk mendapatkan besaran-besaran yang diperlukan berdasarkan pengolahan baris-baris matriks
𝒳’𝒳 dan 𝒳′𝒴 serta matriks identitas I seperti teladan untuk model regresi linier
berganda yang melibatkan 6 peubah bebas 𝒳1, 𝒳2, 𝒳3, 𝒳4 , 𝒳5, 𝒳6 yang akan menjelaskan peubah tidak bebas 𝒴 dengan model pengamatan :
𝒴𝑖 = 𝛽0+ 𝛽1𝒳1+ 𝛽2𝒳2+ 𝛽3𝒳3+ 𝛽4𝒳4+ 𝛽5𝒳5+ 𝛽6𝒳6+ ℯ𝑖
Ilustrasi Penggunaan Metode Doolittle Dipersingkat Untuk Matriks Setangkup
(𝐁𝐞𝐫𝐮𝐤𝐮𝐫𝐚𝐦 𝟕 𝐱𝟕) yang Berkaitan dengan Persamaan Normal Regresi
𝒳′𝒳 Baris 𝑏0 𝑏1 𝑏2 𝑏3 𝑏4 𝑏5 𝑏6 𝒳′𝒴 I (0) 𝑎00 𝑎01 𝑎02 𝑎03 𝑎04 𝑎05 𝑎06 𝑔0 1 0 0 0 0 0 0 𝑇0 (1) 𝑎11 𝑎12 𝑎13 𝑎14 𝑎15 𝑎16 𝑔1 1 0 0 0 0 0 𝑇1 (2) 𝑎22 𝑎23 𝑎24 𝑎25 𝑎26 𝑔2 1 0 0 0 0 𝑇2 (3) 𝑎33 𝑎34 𝑎35 𝑎36 𝑔3 1 0 0 0 𝑇3 (4) 𝑎44 𝑎45 𝑎46 𝑔4 1 0 0 𝑇4 (5) 𝑎55 𝑎56 𝑔5 1 0 𝑇5 (6) 𝑎66 𝑔6 1 𝑇6 (7) = (0) 𝐴00 𝐴01 𝐴02 𝐴03 𝐴04 𝐴05 𝐴06 𝐴0𝑦 1 0 0 0 0 0 0 𝑇7 (8) = 5 𝐴00 1 𝐵01 𝐵02 𝐵03 𝐵04 𝐵05 𝐵06 𝐵0𝑦 𝐵00′ 0 0 0 0 0 0 𝑇8 (9) = (1) − 𝐴01(6) 𝐴11 𝐴12 𝐴13 𝐴14 𝐴15 𝐴16 𝐴1𝑦 𝐴10′ 1 0 0 0 0 0 𝑇9 (10) = 7 𝐴11 1 𝐵12 𝐵13 𝐵14 𝐵15 𝐵16 𝐵1𝑦 𝐵10′ 𝐵11′ 0 0 0 0 0 𝑇10 (11) = (2) − 𝐴02(6) − 𝐴12(8) 𝐴22 𝐴23 𝐴24 𝐴25 𝐴26 𝐴2𝑦 𝐴20′ 𝐴21′ 1 0 0 0 0 𝑇11 (12) = 9 𝐴22 1 𝐵23 𝐵24 𝐵25 𝐵26 𝐵2𝑦 𝐵20′ 𝐵21′ 𝐵22′ 0 0 0 0 𝑇12 13 = 3 − 𝐴03 6 − 𝐴13 8 − 𝐴23(10) 𝐴33 𝐴34 𝐴35 𝐴36 𝐴3𝑦 𝐴30′ 𝐴31′ 𝐴32′ 1 0 0 0 𝑇13
𝐴33 (15) = 4 − 𝐴04 6 𝐴14 8 − 𝐴24(10) − 𝐴34(12) 𝐴44 𝐴45 𝐴46 𝐴4𝑦 𝐴′40 𝐴41′ 𝐴42′ 𝐴43′ 1 0 0 𝑇15 (16) = 13 𝐴44 1 𝐵45 𝐵46 𝐵4𝑦 𝐵40′ 𝐵41′ 𝐵42′ 𝐵43′ 𝐵44′ 0 0 𝑇16 17 = 5 − 𝐴05 6 𝐴15 8 − 𝐴25 10 − 𝐴35 12 − 𝐴45 14 𝐴55 𝐴56 𝐴5𝑦 𝐴′50 𝐴51′ 𝐴52′ 𝐴53′ 𝐴54′ 1 0 𝑇17 (18) = 15 𝐴55 1 𝐵56 𝐵5𝑦 𝐵50′ 𝐵51′ 𝐵52′ 𝐵53′ 𝐵54′ 𝐵55′ 0 𝑇18 19 = 6 − 𝐴06 6 𝐴16 8 − 𝐴26 10 − 𝐴36 12 − 𝐴46 14 − 𝐴56 16 𝐴66 𝐴6𝑦 𝐴′60 𝐴61′ 𝐴62′ 𝐴63′ 𝐴64′ 𝐴′65 0 𝑇19 (20) = 1 𝐴66 1 𝐵6𝑦 𝐵60′ 𝐵61′ 𝐵62′ 𝐵63′ 𝐵64′ 𝐵65′ 𝐵66′ 𝑇20
2. Penentuan Koefisien Regresi
Penyelesaian langkah maju (forward solution) dari metode Doolittle dipersingkat (Tabel 2.3) menghasilkan persamaan :
1 𝛽0+ 𝐵01 𝛽1+ 𝐵02 𝛽2+ 𝐵03 𝛽3+ 𝐵04 𝛽4+ 𝐵05 𝛽5+ 𝐵06 𝛽6= 𝐵0𝑦 1 𝛽1+ 𝐵12 𝛽2+ 𝐵13 𝛽3+ 𝐵14 𝛽4+ 𝐵15 𝛽5+ 𝐵16 𝛽6 = 𝐵1𝑦 1 𝛽2+ 𝐵23 𝛽3+ 𝐵24 𝛽4+ 𝐵25 𝛽5+ 𝐵26 𝛽6 = 𝐵2𝑦 1 𝛽3+ 𝐵34 𝛽4+ 𝐵35 𝛽5+ 𝐵36 𝛽6 = 𝐵3𝑦 (2.14) 1 𝛽4+ 𝐵45 𝛽5+ 𝐵46 𝛽6 = 𝐵4𝑦 1 𝛽5+ 𝐵56 𝛽6 = 𝐵5𝑦 1 𝛽6 = 𝐵6𝑦
Sehingga solusi kebalikannya (backward solution) untuk mendapatkan koefisien regresi adalah:
𝛽6 = 𝐵6𝑦 𝛽5 = 𝐵5𝑦− 𝐵56 𝛽6 𝛽4 = 𝐵4𝑦 − 𝐵45 𝛽5− 𝐵46 𝛽6 𝛽3 = 𝐵3𝑦− 𝐵34 𝛽4− 𝐵35 𝛽5− 𝐵36 𝛽6 (2.15) 𝛽2 = 𝐵2𝑦− 𝐵23 𝛽3− 𝐵24 𝛽4− 𝐵25 𝛽5− 𝐵26 𝛽6 𝛽1= 𝐵1𝑦− 𝐵12 𝛽2− 𝐵13 𝛽3− 𝐵14 𝛽4− 𝐵15 𝛽5− 𝐵16 𝛽6 𝛽0 = 𝐵0𝑦− 𝐵01 𝛽1− 𝐵02 𝛽2− 𝐵03 𝛽3− 𝐵04 𝛽4− 𝐵05 𝛽5− 𝐵06 𝛽6
Dengan demikian, model dugaan yang diperoleh untuk model pengamatan diatas adalah model dugaan :
𝒴 𝑖 = 𝛽0+ 𝛽1𝒳1+ 𝛽2𝒳2+ 𝛽3𝒳3+ 𝛽4𝒳4 + 𝛽5𝒳5+ 𝛽6𝒳6 (2.16)
3. Penentuan matriks Kebalikan 𝒳′𝒳−1
Jika matriks 𝐶 = (𝑐𝑖𝑗)𝒳′𝒳−1 , maka perhitungan unsur matriks ini dapat
diperoleh melalui hubungan:
𝑐𝑖𝑗 = 𝐴′𝑘𝑖 𝐵𝑘𝑗′ 6
𝑘=0
(2.17)
Misalnya:
𝑐32 = 𝐴03′ 𝐵02′ + 𝐴′13 𝐵12′ + 𝐴23′ 𝐵22′ + 𝐴′33 𝐵32′ + 𝐴43′ 𝐵42′ + 𝐴′53 𝐵52′ + 𝐴63′ 𝐵62′ .
Kecuali unsur matriks baris terakhir yang dapat dibaca langsung dari tabel, yaitu 𝑐40 = 𝐵40′ , 𝑐41 = 𝐵41′ dan seterus
4. Tabel Sidik Ragam Perhatikan bahwa: 𝐴𝑖𝑦𝐵𝑖𝑦 = 1 𝑛 𝒴𝑖 𝑛 𝑖=1 2 (2.18) atau yang selama ini dikenal dengan istilah Faktor Koreksi (FK). Dengan
menggunakan Tabel Sidik Ragam yang biasa dikenal, maka Jumlah Kuadrat Regresi dapat dihitung berdasarkan Jumlah Kuadrat sumber keragaman ke 1, 2, 3, 4, 5 dan 6 pada Tabel 2.3, sedangkan Jumlah Kuadrat Total dapat dihitung berdasarkan jumlah kuadrat total pada Tabel 2.3 dikurangi FK.
5. Dugaan Ragam Koefisien Regresi
Untuk menentukan dugaan ragam setiap koefisien regresi digunakan
hubungan
𝑠𝑏2𝑖 = 𝑐𝑖𝑖𝑠2 (2.19)
dengan peragam
𝑠𝑏𝑖 ,𝑏𝑗 = 𝑐𝑖𝑗𝑠2 (2.20)