1
PREDIKSI HASIL PEMILU LEGISLATIF KABUPATEN LOMBOK TIMUR MENGGUNAKAN ALGORITMA NAIVE BAYES BERBASIS PSO
‘Alimuddin1
, Muhammad Sadali2, Muhammad Wasil3 1,2,3
Universitas Hamzanwadi [email protected]
Abstrak
Pemilihan Umum merupakan sarana pelaksanaan kedaulatan rakyat yang diselenggarakan secara langsung, umum, bebas, rahasia, jujur dan adil berdasarkan Pancasila dan Undang-Undang Dasar Negara Republik Indonesia Tahun 1945. Pemilu diselenggarakan adalah untuk memilih pimpinan baik presiden dan wakil presiden, anggota DPR, DPD, dan DPRD. Banyak penelitian yang menggunakan metode naïve bayes maupun classification tree dalam memprediksi hasil pemilu tetapi nilai akurasi yang dihasilkan masih kurang akurat.
Dalam penelitian ini digunakan model algoritma naïve bayes berbasis Particle Swarm Optimization untuk mendapatkan rule dalam memprediksi hasil pemilihan legislatif dan memberikan nilai akurasi yang lebih baik. Pengujian naïve bayes dalam prediksi hasil pemilu legislatif Kabupaten Lombok Timur diperoleh akurasi 85,14% dan nilai AUC 0,978. Setelah pengujian naïve bayes berbasis PSO sebagai fitur seleksi diperoleh nilai akurasi 96,62% dan nilai AUC 0,971. Setelah penggunaan PSO sebagai fitur seleksi dapat meningkatkan akurasi prediksi hasil pemilu legislatif Kabupaten Lombok Timur dengan tingkat diagnosa Excellent Classification, dan pengujian ROC Curve mendapatkan hasil lebih baik untuk algoritma tersebut.
Kata Kunci: Algorithma Naïve Bayes, PSO, Prediksi hasil pemilu legislative Kabupaten Lombok Timur
PENDAHULUAN
Pemilihan Umum merupakan sarana dan wadah pelaksanaan kedaulatan rakyat yang diselenggarakan secara langsung, umum, bebas, rahasia, jujur dan adil dalam Negara Kesatuan Republik Indonesia berdasarkan Pancasila dan Undang-Undang Dasar Negara Republik Indonesia (UUD RI) Tahun 1945[1]. Pemilu merupakan sarana untuk menentukan pemimpin dari sebuah negara demokrasi. Pasal 1 angka (1) Undang-Undang Nomor 10 Tahun 2008 Tentang Pemilihan Umum Anggota Dewan Perwakilan Rakyat, Dewan Perwakilan Daerah, dan Dewan Perwakilan Rakyat Daerah yang menyatakan “pemilihan umum untuk selanjutnya disebut pemilu. Undang-Undangan Nomor 25 Tahun 2011[2].
Peristiwa-peristiwa politik, seperti adanya pemilihan presiden (pilpres), pemilihan legislative (pileg), pergantian pemerintahan, pengumuman kabinet menteri, kerusuhan politik, peperangan dan peristiwa lainnya sangat mempengaruhi harga dan volume perdagangan dibursa efek karena peristiwa- peristiwa politik berkaitan erat dengan kestabilan perekonomian negara. Pada pemilu legislative tanggal 9 April 2014 sebanyak 588 calon anggota legislative dari 12 partai politik peserta pemilu bertarung untuk
2
memperebutkan 50 kursi anggota dewan perwakilan rakyat daerah kabupaten Lombok Timur. Dari jumlah data calon tetap (DCT) KPU tersebut dua (2) orang meninggal dunia
sebelum proses pemilihana sehingga penelitian ini menggunakan 588 data calon anggota Dewan Perwakilan Rakyat Daerah Kabupaten Lombok Timur. Naïve Bayes adalah metode Bayesian Learning yang paling cepat dan sederhana. Hal ini berasal dari teorema Bayes dan hipotesis kebebasan, menghasilkan klasifier statistik berdasarkan peluang. Ini adalah teknik sederhana. Naïve bayes merupakan algoritma klasifikasi yang efektif dalam mendapatkan hasil yang akurat dan efisien dalam proses penalaran memanfaatkan input yang ada dengan cara yang relatif cepat. Algoritma ini bertujuan untuk melakukan klasifikasi data pada klas tertentu. Kelebihan Naïve.
Domingos dan Pazzani (1997) pada papernya menjelaskan performa Naïve Bayes dalam fungsi zero-one loss. Fungsi zero-one loss ini mendefinisikan error hanya sebagai pengklasifikasian yang salah. Tidak seperti fungsi error yang lain seperti squared error, fungsi zero-one loss tidak memberi nilai suatu kesalahan perhitungan peluang selama peluang maksimum ditugaskan kedalam kelas yang benar. Ini berarti bahwa Naïve Bayes dapat mengubah peluang posterior dari tiap kelas, tetapi kelas dengan nilai peluang posterior maksimum jarang diubah [3]
Peneliti sebelumnya memprediksi pemilihan umum anggota legislative DKI Jakarta 2014 dengan menggunakan metode naïve bayes dengan Algoritma Genetika sebagai Fitur Seleksi dengan akurasi 97,84% dan nilai AUC 0,994 [4]. Prediksi pemilu legislative DKI Jakarta tahun 2012 menggunakan metode neural network berbasis particle swarm optimization dengan akurasi Algoritma neural network menghasilkan nilai akurasi sebesar 98,50 % dan nilai AUC sebesar 0,982, namun setelah dilakukan penambahan yaitu algoritma neural network berbasis particle swarm optimization nilai akurasi sebesar 98,85 % dan nilai AUC sebesar 0,996. Sehingga kedua metode tersebut memiliki perbedaan tingkar akurasi yaitu sebesar 0,35 % dan perbedaan nilai AUC sebesar 0,14.[5]
PSO sangat menarik untuk pemilihan fitur dimana kawanan partikel akan menemukan kombinasi fitur terbaik pada saat pencarian ruang masalah dan PSO dapat menemukan solusi yang optimal dengan cepat [6]. PSO banyak digunakan untuk memecahkan masalah optimasi, serta sebagai masalah seleksi fitur [7]. Dalam teknik PSO terdapat beberapa cara untuk melakukan pengoptimasian diantaranya, meningkatkan bobot atribut (attribute weight) terhadap semua atribut atau variabel yang dipakai, menseleksi atribut (attribute selection), dan feature selection.
3
Untuk dapat memberikan perbandingan akurasi salah satu algoritma optimasi yang cukup populer adalah PSO (Particle Swarm Optimization). Algoritma PSO terinspirasi dari kelompok yang dinamis, bersinergi dan dapat terorganisir dari simulasi komputer dari pergerakan koordinat. Particle swarm optimization (PSO) merupakan teknik komputasi evolusioner yang mampu menghasilkan solusi optimal secara global dalam ruang pencarian melalui interaksi individu dalam segerombolan partikel. Setiap partikel menyampaikan informasi berupa posisi terbaiknya kepada partikel yang lain dan menyesuaikan posisi dan kecepatan masing-masing berdasarkan informasi yang diterima mengenai posisi yang terbaik tersebut [8]. Particle swarm optimization dapat digunakan sebagai teknik optimasi untuk mengoptimalkan subset fitur dan parameter secara bersamaan [9]. Ketika algoritma naïve bayes digunakan dalam algoritma klasifikasi, Particle Swarm Optimization mampu meningkatkan akurasi lebih baik daripada sebelum digunakan Particle Swarm Optimization.
Penelitian ini akan melakukan prediksi untuk nilai akurasi pemilu legislative Lombok Timur dengan variable yang di tambahkan dapat berpengaruh meningkatkan akurasi pada model naïve bayes dan particle swarm optimization.
Pemilu
Pemilihan umum (pemilu) merupakan instrumen penting dalam negara demokrasi yang menganut sistem perwakilan [13]. Pemilu berfungsi sebagai alat penyaring bagi “politikus-politikus” yang akan mewakili dan membawa suara rakyat didalam lembaga perwakilan. Pemilu adalah sarana pelaksanaan kedaulatan rakyat yang dilaksanakan secara langsung, umum, bebas, rahasia, jujur, dan adil dalam Negara Kesatuan Republik Indonesia berdasarkan Pancasila dan Undang-Undang Dasar Negara Republik Indonesia Tahun 1945. (UU No. 10 Tahun 2008). Penyelenggaraan Pemilu yang baik dan berkualitas akan meningkatkan derajat kompetisi yang sehat, partisipatif, dan keterwakilan yang makin kuat dan dapat dipertanggungjawabkan.
Pemilu di Indonesia dapat dibedakan menjadi dua yakni: 1. Pemilu Orde Baru
Pemilu orde baru dimulai pada tahun 1955 sebagai pemilu pertama yang diselenggarakan di negara Republik Indonesia. Jumlah kursi tidak ditentukan oleh jumlah penduduk saja tetapi juga didasarkan pada wilayah administrasi atau dikenal dengan pemilihan proporsional atau tidak murni.
4 2. Pemilu Era Reformasi
Proses pemilu ditahun 1999 dilakukan sebelum habis masa kepemimpinan karena telah gagal dalam membangun system demokrasi sehingga pada tahun 1997 dianggap pemerintah dan lembaga lainnya tidak dapat dipercaya. Pemilu pada tahun 1997 menjadi tonggak era reformasi.
Data Mining
Data Mining merupakan teknologi baru yang sangat berguna untuk membantu perusahaan-perusahaan menemukan informasi yang sangat penting dari gudang data mereka. Data mining adalah aplikasi algoritma spesifik untuk mengekstrak pola dari data [14]. Beberapa aplikasi data mining fokus pada prediksi, mereka meramalkan apa yang akan terjadi dalam situasi baru dari data yang menggambarkan apa yang terjadi di masa lalu [15]. Data mining adalah proses menemukan korelasi baru yang bermakna, pola dan tren dengan memilah-milah sejumlah besar data yang tersimpan dalam repositoru, menggunakan teknologi penalaran pola serta teknik-teknik statistik dan matematika [16]. Secara sederhana data mining adalah penambangan atau penemuan informasi baru dengan mencari pola atau aturan tertentu dari sejumlah data yang sangat besar [17].
Data Mining dapat berperan dalam: 1. Estimasi
Model dibangun dari data dengan record yang lengkap, yang menyediakan nilai dari variabel sebagai prediktor, kemudian estimasi nilai dari variable target ditentukan berdasarkan nilai dari variabel prediktor. Penentuan kebijakan atau suatu nilai pada proses yang akan dilakukan. Estimasi dapat dilakukan dari data-data lama yang akan diolah.
2. Prediksi
Algoritma prediksi sama dengan algoritma estimasi di mana label/ target/ class bertipe numerik, bedanya adalah data yang digunakan merupakan data rentetan waktu (data time series). Sifat prediksi bisa menghasilkan class berdasarkan berbagai atribut yang kita sediakan. Penentuan hasil dari proses yang sedang berlangsung. Data-data yang digunakan untuk prediksi berasal dari data yang ada saat proses sedang berlangsung.
3. Klasifikasi
Algoritma yang menggunakan data dengan target/class/label berupa nilai kategorikal (nominal). Pengelompokan data-data yang ada menjadi dalam kelompok yang sudah ditentukan nama kelompoknya.
5 4. Klastering
Klastering merupakan mengelompokkan data, hasil observasi dan kasus ke dalam class yang mirip, koleksi data yang mirip antara satu dengan yang lain, dan memiliki perbedaan bila dibandingkan dengan data dari klaster lain. Pengelompokan data-data yang ada dan memiliki beberapa kesamaan menjadi dalam kelompok yang tidak perlu ditentukan nama kelompoknya.
5. Asosiasi
Algoritma association rule (aturan asosiasi) adalah algoritma yang menemukan atribut yang “muncul bersamaan”. Pengelompokan data-data yang saling terkait dan berhubungan. Algoritma asosiasi akan mencari aturan yang menghitung hubungan diantara dua atau lebih atribut [18].
2.2.3 Pengertian Naïve Bayes
Naïve Bayes adalah metode Bayesian Learning yang paling cepat dan sederhana [19].
Algoritma Naive Bayes merupakan salah satu algoritma yang terdapat pada teknik klasifikasi.
Naïve bayes classifier adalah salah satu algoritma dalam teknik data mining yang
menerapkan teori Bayes dalam klasifikasi [20]. Naive Bayes merupakan pengklasifikasian dengan metode probabilitas dan statistik yang dikemukan oleh ilmuwan Inggris Thomas
Bayes, yaitu memprediksi peluang dimasa depan berdasarkan pengalaman dimasa
sebelumnya sehingga dikenal sebagai Teorema Bayes. Teorema tersebut dikombinasikan dengan Naive Bayes dimana diasumsikan kondisi antar atribut saling bebas. Klasifikasi Naive
Bayes diasumsikan bahwa ada atau tidak ciri tertentu dari sebuah kelas tidak ada
hubungannya dengan ciri dari kelas lainnya [21].
Teorema Bayes memiliki bentuk umum sebagai berikut. Keterangan:
X : data dengan class yang belum diketahui
H : hipotesis data X merupakan suatu class spesifik
P(H|X) : probabilitas hipotesis H berdasar kondisi X (posteriori probability) P(H) : probabilitas hipotesis H (prior probability)
P(X|H) : probabilitas X berdasar kondisi pada hipotesis H P(X) : probabilitas dari X
Tahapan dalam metode Naïve Bayes adalah [22]: 1. Penentuan kategori data
6
Naive Bayes melakukan klasifikasi pada nilai probabilitas p(C= ci | D=dj) yaitu probabilitas ci dan data dj. Klasifikasi dilakukan agar dapat menentukan c ɛ C dari data d ɛ D dimana C={c1, c2, c3, ..., ci} dan D={d1, d2, d3, d... dj} (Trisedya & Jais, 2009). Penentuan dari kategori sebuah data dilakukan dengan mencari nilai maksimal dari p(C=ci | D=dj) pada P={ p(C=ci | D=dj) | c ɛ C dan d ɛ D}. Nilai probabilitas p(C=ci | D=dj) dapat dihitung dengan persamaan Mitchell tahun 2005.
Dengan p(D=dj | C=ci) merupakan nilai probabilitas dari kemunculan dokumen dj jika diketahui data tersebut berkategori ci, p(C=ci) adalah nilai probabilitas kemunculan kategori ci dan p(D = dj) adalah nilai probabilitas kemunculan dokumen dj.
2. Menghitung probabilitas
Naive Bayes menganggap sebuah data sebagai sekumpulan dari kata-kata yang menyusun data tersebut, dan tidak memperhatikan urutan kemunculan kata pada data. Perhitungan probabilitas p(C = ci | D = dj) dapat dituliskan sebagai berikut:
Dengan adalah hasil perkalian dari probabilitas kemunculan semua kata pada data dj.
1. Proses klasifikasi
Proses klasifikasi dilakukan dengan membuat model probabilistik dari data training, yaitu dengan menghitung nilai p(wk | c). Un
2. Melakukan pengkategorian nilai
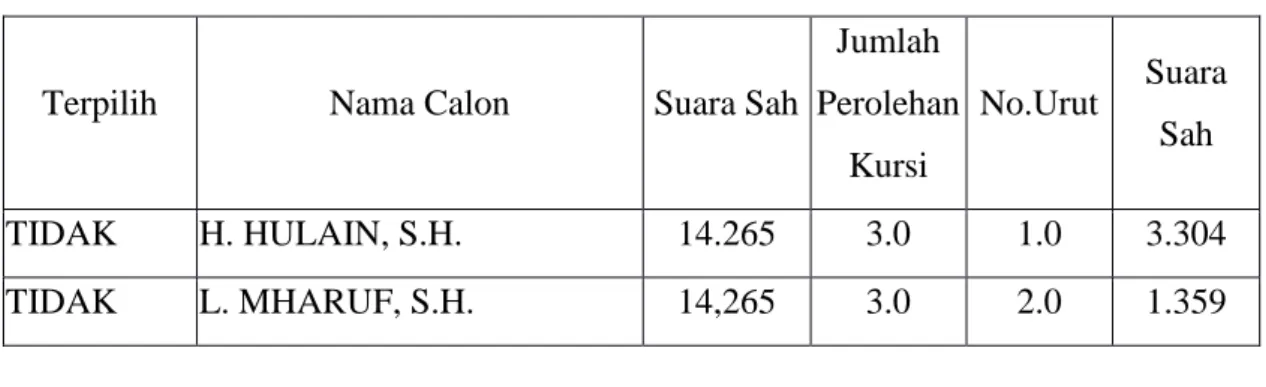
Contoh penerapan metode Naïve Bayes dalam pengolahan data KPU adalah sebagai berikut :
Tabel 1. Atribut dan Dataset DPRD KPU Lotim 2014
Terpilih Nama Calon Suara Sah
Jumlah Perolehan Kursi No.Urut Suara Sah TIDAK H. HULAIN, S.H. 14.265 3.0 1.0 3.304 TIDAK L. MHARUF, S.H. 14,265 3.0 2.0 1.359
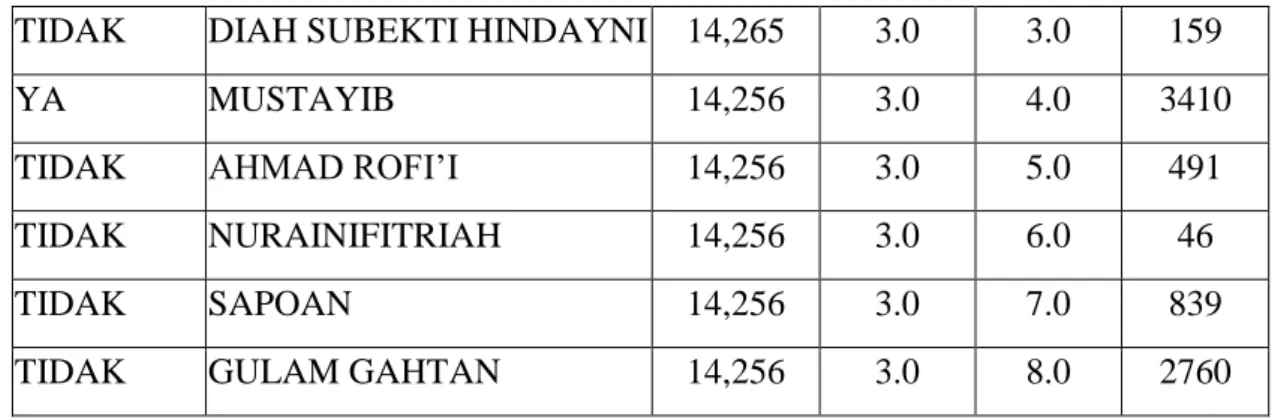
7
TIDAK DIAH SUBEKTI HINDAYNI 14,265 3.0 3.0 159
YA MUSTAYIB 14,256 3.0 4.0 3410
TIDAK AHMAD ROFI’I 14,256 3.0 5.0 491
TIDAK NURAINIFITRIAH 14,256 3.0 6.0 46
TIDAK SAPOAN 14,256 3.0 7.0 839
TIDAK GULAM GAHTAN 14,256 3.0 8.0 2760
Dari data tabel 1 kemudian dilakukan pengolahan data yaitu mencari nilai accuracy dari data tersebut untuk dapat disimpulkan akurasi yang diperolah dari data tersebut, adapun hasil pengolahan selanjutnya antara lain :
Tabel 2. Model comfucition matrik untuk metode Naïve Bayes
2.2.4 Particle Swarm Optimization
Untuk menemukan solusi yang optimal, masing-masing partikel bergerak ke arah posisi yang terbaik sebelumnya dan posisi terbaik secara global. Sebagai contoh, partikel ke-i dinyatakan sebagai: xi = (xi1, xi2,....xid) dalam ruang dimensi. Posisi terbaik sebelumnya dari partikel ke-i dke-iske-impan dan dke-inyatakan sebagake-i pbestke-i = (pbestke-i,1, pbestke-i,2,...pbestke-i,d). Indeks partke-ikel terbaik diantara semua partikel dalam kawanan group dinyatakan sebagai gbestd. Kecepatan partikel dinyatakan sebagai: vi = (vi,1,vi,2,....vi,d). Modifikasi kecepatan dan posisi partikel dapat dihitung menggunakan kecepatan saat ini dan jarak pbesti, gbestd seperti ditunjukan persamaan berikut:
vi,d = w * vi,d + c1 * R * (pbesti,d - xi,d) + c2 * R * (gbestd - xi,d) (2.1) xid = xi,d + vi,d (2.2)
Dimana:
Vi, d : Kecepatan partikel ke-i pada iterasi ke-i
W : Faktor bobot inersia
c1, c2 : Konstanta akselerasi (learning rate)
8
Xi, d : Posisi saat ini dari partikel ke-i pada iterasi ke-i Pbesti : Posisi terbaik sebelumnya dari partikel ke-i
Gbesti :Partikel terbaik diantara semua partikel dalam satu kelompok atau populasi
N : Jumlah partikel dalam kelompok
D : Dimensi
METODE Desain Penelitian
Penelitian yang umum ada empat metode digunakan yaitu Action Reserch, Experiment, Case
Study, dan Survey . Adapun metode penelitian yang digunakan adalah bentuk penelitian Experiment. Penelitian eksperimen merupakan sebuah penyelidikan hubungan kausal
menggunakan test dikendalikan oleh peneliti [23].
Dalam penelitian ini akan dilakukan beberapa langkah-langkah atau tahapan-tahapan Penelitian seperti pada alur gambar dibawah ini;
1. Pengumpulan data 2. Pengolahan data awal
3. Model/metode yang diusulkan 4. Pengujian model
5. Evaluasi dan validasi hasil
Pengumpulan Data
Data penelitian ini bersumber dari Daftar Calon Tetap (DPT) anggota legislative kabupaten Lombok Timur, seperti pada table 3.
9
Dataset berjumlah 588 Orang calon anggota yang akan memperebutkan50 kursi DPRD tahun 2014
Pengolahan Data Awal
Data awal yang didapatkan dari KPU Kabupaten Lombok Timur tahun 2014 dan setelah diumumkan daftar calon tetap telah menjadi data public untuk diketahui dan diumumkan ke khalayak umum. Data awal berjumlah 590 dan meninggal sebelum pemilihan 2 orang sehingga dihilangkan sehingga menjadi 588 orang.
1. Data validation
2. Data integration dan transformation 3. Data size reduction and discritizaton
10 Metode Yang diusulkan
HASIL PENELITIAN DAN PEMBAHASAN Evaluasi dan Validasi
Hasil Pengujian Metode Naïve Bayes
1. Confusion Matrix
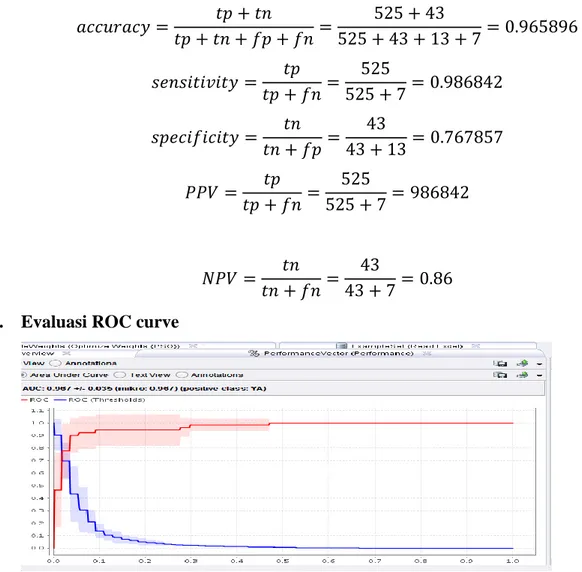
Berdasarkan data training sebanyak 588 record dengan 13 atribut diantaranya adalah nama parpol, nama caleg, jenis kelamin, usia caleg, pendidikan terakhir, pekerjaan, daerah pemilihan, no urut caleg, nomor urut parpol, suara sah caleg, suara sah partai, jumlah perolehan kursi, terpilih dan tidak terpilih, yang dimodelkan dengan algoritma naïve bayes diperoleh hasil sebagai berikut:
Table. 5. Eksperimen comfusion Matrix Naïve Bayes dan Particle Swarm Optimization
Jumlah true positive (tp) adalah 525 record diklasifikasikan sebagai TIDAK terpilih dan
False Negative (fn) sebanyak 7 record diklasifikasikan sebagai TIDAK terpilih tetapi YA
terpilih. Jumlah true negative (tn) adalah 43 record diklasifikasikan YA terpilih dan false
11
Dari confusion matrix diatas, terlihat bahwa akurasi dengan menggunakan algoritma naïve bayes adalah sebesar 85,14%. Perhitungan sensitivity, specifity, ppv, dan npv adalah sebagai berikut:
b. Evaluasi ROC curve
Gambar 5.1 Nilai AUC model naïve bayes
Berdasarkan grafik ROC diatas, terlihat bahwa nilai AUC (Area Under Curve) sebesar 0,967 dengan tingkat akurasi Excellent Classification.
12
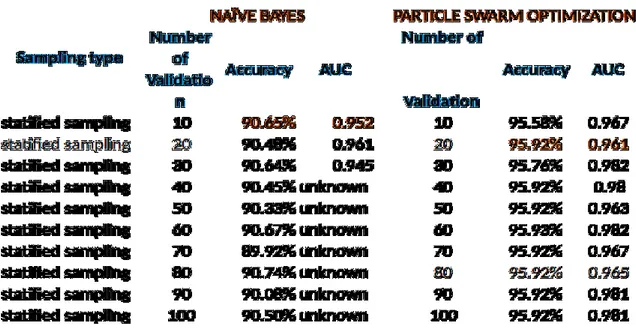
Pada penambahan variable jenis kelamin sebagai predictor (nama parpol, nama caleg, suara sah caleg, dan Jenis Kelamin) dalam penelitian ini diperoleh nilai accuracy pada Naïve bayes dengan nilai tertinggi pada number of validation ke-80 yakni accuracy 90.74% dan AUC :unknown, dan setelah diterapkan Particle Swarm Optimization diperoleh accuracy lebih tinggi pada number of validation ke 90 dengan accuracy 95.59% dan AUC: 0.964.
Tabel 7. Pengaruh penambahan variable Usia dalam peningkatan accuracy Naïve Bayes dan Particle swarm Optimization
Pada penambahan variable usia sebagai predictor (nama parpol, nama caleg, suara sah caleg, dan usia) dalam penelitian ini diperoleh nilai accuracy pada Naïve bayes dengan nilai tertinggi pada number of validation ke-10 yakni accuracy 90.65% dan AUC :0.952, dan setelah diterapkan Particle Swarm Optimization diperoleh accuracy lebih tinggi pada number of validation ke 30 dengan accuracy 95.92% dan AUC: 0.961.
Tabel 8. Pengaruh penambahan variable Pendidikan dalam peningkatan accuracy Naïve Bayes dan Particle swarm Optimization
13
Pada penambahan variable tingkat pendidikan sebagai predictor (nama parpol, nama caleg, suara sah caleg, dan tingkat pendidikan) dalam penelitian ini diperoleh nilai accuracy pada Naïve bayes dengan nilai tertinggi pada number of validation ke-20 yakni accuracy 86.56% dan AUC : 0.884, dan setelah diterapkan Particle Swarm Optimization diperoleh accuracy lebih tinggi pada number of validation ke 80 dengan accuracy 95.58% dan AUC: 0.976. Tabel. 9. Pengaruh penambahan variable Pekerjaan dalam peningkatan accuracy Naïve Bayes
dan Particle swarm Optimization
Pada penambahan variable pekerjaan sebagai predictor (nama parpol, nama caleg, suara sah caleg, dan pekerjaan) dalam penelitian ini diperoleh nilai accuracy pada Naïve bayes dengan nilai tertinggi pada number of validation ke-30 yakni accuracy 86.75% dan AUC : 0.915, dan setelah diterapkan Particle Swarm Optimization diperoleh accuracy lebih tinggi pada number of validation ke 90 dengan accuracy 95.59% dan AUC: 0.977.
PEMBAHASAN HASIL PENGUJIAN
Berdasarkan penelitian yang telah dilakukan, bahwa prediksi Pemilu Legislative Kabupaten Lombok Timur menggunakan Data Calon Tetap (DCT) KPU Kabupaten Lombok Timur tahun 2014 sebanyak 588 record. Adapun atribut digunakan sebanyak 13 atribut yakni 1) nama parpol, 2) nama caleg, 3) jenis kelamin, 4) pendidikan terakhir, 5) usia, 6) pekerjaan, 7) nomor urut parpol,8) suara sah partai, 9) jumlah perolehan kursi, 10) daerah pemilihan, 11) no urut caleg, 12) suara sah caleg, dan 13) Terpilih atau tidak terpilih (Ya dan Tidak) sebagai
14
atribut predictor. Dataset di uji untuk mendapatkan nilai accuracy yang menyebabkan masing-masing atribut memiliki daya bobot sehingga terlihat atribut yang lebih berpengaruh dalam meningkatkan accuracy. Masing-masing memiliki kesempatan yang sama dengan dibantu model algoritma naïve bayes dengan fitur seleksi menggunakan algoritma particle
swarm optimization, diperoleh hasil sebagai berikut:
Tabel 10. Perbandingan nilai accuracy dari variable yang ditambahkan
Pada tabel 10 terdapat perbedaan akurasi dari hasil penambahan variable yang tentunya dapat berpengaruh pada nilai akurasi pada prediksi pemilu legislative kabupaten Lombok Timur. Peningkatan akan lebih baik tergambar dalam grafik bar dibawah ini:
15
Table. 11 Pengaruh penambahan Variabel Pada Naïve Bayes sebelum diberikan Particle Swarm Optimization fitur seleksi
Pada grafik bar diatas dari penambahan 4 variabel dalam penelitian ini dapat berpengaruh dengan diperoleh peningkatan accuracy pada model Naïve Bayes dengan berbasiskan particle
swarm optimization. Dari variable usia dengan accuracy naïve bayes 90.65% menjadi 95.93
terdapat peningkatan 5.27%. Pada variable jenis kelamin accuracy naïve bayes 90.74% menjadi 95. 59% terdapat peningkatan accuracy 4.85%. pada variable pekerjaan accuracy naïve bayes 86.75% menjadi 95.59% terdapat peningkatan accuracy 8.84%. pada variable pendidikan accuracy naïve bayes 86.56% menjadi 95.58%. sedangkan pada variable nomor urut caleg accuracy 89.79 menjadi 95.59% sehingga terdapat peningkatan accuracy 5.80%.
Jumlah true positive (tp) adalah 524 record diklasifikasikan sebagai TIDAK terpilih dan
False Negative (fn) sebanyak 10 record diklasifikasikan sebagai TIDAK terpilih tetapi YA
terpilih. Jumlah true negative (tn) adalah 40 record diklasifikasikan YA terpilih dan false
16
Dari confusion matrix di atas, terlihat bahwa akurasi dengan menggunakan algoritma naïve bayes adalah sebesar 95,59%.
Pada proses pengolahan accuracy true positif dijumlahkan dengan true negative kemudian dibagi dari hasil penjumlahan true positif, true negative, false positif, dan false negative sehingga menghasilkan nilai accuracy = , nilai sensitivity diperoleh , nilai specificitynya 0.419048. Sedangan PPV (positive predictive value) atau precision adalah proporsi kasus dengan hasil diagnosa positif menghasilkan dan Negative Predictive
Value adalah proporsi kasus dengan diagnose negative menghasilkan nilai 0.8.
c. Evaluasi ROC curve
17
Berdasarkan grafik ROC diatas, terlihat bahwa nilai AUC (Area Under Curve) sebesar 0,961 dari pengaruh penambahan variable usia pada dataset yang diolah baik pada naïve bayes dan particle swarm optimization dengan tingkat akurasi Excellent Classification.
KESIMPULAN DAN SARAN Kesimpulan
Penelitian ini dengan Naïve Bayes berbasis Algoritma Particle Swarm Optimization sebagai fitur seleksi dan algoritma naïve bayes tanpa fitur seleksi, dapat diterapkan pada prediksi pemilu legislatif Kabupaten Lombok Timur. Keduanya menghasilkan akurasi yang excellent. Prediksi hasil pemilu legislatif Kabupaten Lombok Timur dengan algoritma naïve bayes tanpa fitur seleksi memiliki akurasi 85,14% dengan nilai AUC 0.978, sedangkan prediksi hasil pemilu legislatif Kabupaten Lombok Timur menggunakan algoritma naïve bayes dengan algoritma particle swarm optimization sebagai fitur seleksi memiliki akurasi 96.61% dengan nilai AUC 0,972. Jadi prediksi pemilu legislatif Kabupaten Lombok Timur menggunakan algoritma naïve bayes berbasis Particle Swarm Optimization sebagai fitur seleksi lebih baik atau unggul dibandingkan menggunakan algoritma naïve bayes tanpa fitur seleksi.
Penambahan variable masing-masing memiliki pengaruh dalam meningkatkan akurasi naïve bayes, dan naïve bayes berbasis particle swarm optimization yang bermanfaat pada untuk menemukan output minimum atau maksimum atau hasil. Input terdiri dari variable. Dalam penelitian ini penambahan variable usia memberikan pengaruh lebih tinggi sebagaimana dapat diperhatikan dipembahasan eksperimen atau percobaan tersebut diatas. Variable usia memberikan akurasi 90.65% dan setelah diterapkan Particle swarm optimization meningkat accurasi 95.92% dengan rata-rata perbandingannya 0.6765%
Saran
Saran-saran dalam penelitian ini yang diusulkan sebagai berikut:
1. Penelitian ini dapat dikembangkan dengan menggunakan metode-metode klasifikasi data mining lainnya untuk melakukan perbaikan dan sebagai bahan perbandingan untuk dapat meningkatkan akurasi prediksi.
2. Penelitian ini dapat dikembangkan dengan menggunakan algoritma fitur seleksi atau dengan algoritma optimasi lainnya.
3. Penelitian ini diharapkan dapat sebagai parameter oleh para calon dewan untuk mempersiapkan amunisi informasi prediksi pemilu legislatif kabupaten Lombok Timur.
18
4. Beberapa variable sebagai indicator-indikator yang cukup besar menentukan keberhasilan adalah usia, nomor urut caleg, pendidikan sang calon anggota legislative.
DAFTAR PUSTAKA
[1] Santoso, T. (2004). Pelanggaran pemilu 2004 dan penanganannya. Jurnal demokrasi dan
Ham , 9-29.
[2] Kaelani, Prof.Dr.M.S., (2010), Pendidikan Pancasila, Edisi Reformasi. PT. Paradigma. Yogyakarta.
[3] Domingos, P., and Pazzani, M. (1997). On the optimality of the Simple Bayesian
Classifier under Zero-One Loss.
[4] Diana Tri Wahyuni, 2014. Prediksi Hasil Pemilu Legislatif DKI Jakarta menggunakan
Algoritma Naive Bayes dengan Algoritma Genetika sebagai Fitur Seleksi. Program Studi
Teknik Informatika - S1, Fakultas Ilmu Komputer, Universitas Dian Nuswantoro Semarang
[5] Muhammad Badrul (2012). Prediksi Hasil Pemilu Legislatif DPRD DKI Jakarta dengan
Neural Network berbasis Particle Swarm Optimization.
[6] Parimala, R., & Nallaswamy, R. (2012). Feature Selection using a Novel Particle Swarm Optimization and It’s Variants. I.J. Information Technology and Computer Science, , 16-24.
[7] Zhao, M., Fu, C., Ji, L., Tang, K., & Zhou, M. (2011). Feature Selection And Parameter Optimization For Support Vector Machines: A New Approach Based On Genetic Algorithm With Feature Chromosomes. School Of Computer Science And Technology , 5197–5204.
[8] Shuzhou, W., & Bo, M. (2011). Parameter Selection Algorithm for Support Vector Machine. Procedia Environmental Sciences, 11, 538-544.
[9] Yun, L., Qiu-yan, C. & Hua, Z. (2011). Application of the PSO-SVM model for Credit Scoring. Seventh International Conference on Computational Intelligence and Security, 47-51.
[10] Nagadevara, & Vishnuprasad. (2005). Building Predictive models for election result in india an application of classification trees and neural network. Journal of Academy of
Business and Economics Volume 5
[11] Borisyuk, R., Borisyuk, G., Rallings, C., & Thrasher, M. (2005). Forecasting the 2005
General Election:A Neural Network Approach. The British Journal of Politics & International Relations Volume 7, Issue 2 , 145-299.
19
[12] Rigdon, S. E., Jacobson, S. H., Sewell, E. C., & Rigdon, C. J. (2009). A Bayesian
Prediction Model For the United State Presidential Election. American Politics Research volume.37 , 700-724
[13] Mahfud MD, 2011, Politik Hukum di Indonesia, edisi revisi. Rajawali pers.PT.Rajagrapindo persada
[14] Abraham, A., Grosan, C., Ramos, V., (2006). Swarm Intelligence in Data Mining. Springer-Verlag Berlin Heidelberg
[15] Maimon, O., & Rokach, L. (2010). Data Mining and Knowledge Discovery Handbook. London: Springer.
[16] Larose, D. T. (2007). Data Mining Methods And Models. New Jersey: A John Wiley & Sons
[17] Davies, and Paul Beynon, 2004, “Database Systems Third Edition”, Palgrave
Macmillan, New York
[18] Chapman, P., Clinton, J., Kerber, R., Khabaza, T., Reinartz, T., Shearer, C., Wirth, R. 2000. CRISP-DM 1.0 : Step-by-Step Data Mining Guide
[19] Ebranda A.W, Novi Triana, Mardiani, Tinaliah, Penerapan metode naïve bayes untuk
sistem Klasifikasi sms pada smartphone android. Jurusan Teknik Informatika STMIK
MDP.
[20] Chapman, P., Clinton, J., Kerber, R., Khabaza, T., Reinartz, T., Shearer, C., Wirth, R. 2000. CRISP-DM 1.0 : Step-by-Step Data Mining Guide.
[21] Bustami, Penerapan algoritma naive bayes Untukmengklasifikasi data nasabah
Asuransi. Dosen Teknik Informatika Universitas Malikussaleh.
[22] Larose, D. T. (2007). Data Mining Methods And Models. New Jersey: A John Wiley & Sons.
[23] Sardini, N. H. (2011). Restorasi penyelenggaraan pemilu di Indonesia.Yogyakarta: Fajar Media Press.