1
SISTEM PENDUKUNG KEPUTUSAN PENGADAAN BUKU PERPUSTAKAAN
STIKOM SURABAYA MENGGUNAKAN METODE K-MEANS CLUSTERING
Arief Rahman Susanto 1)
1) S1 / Jurusan Sistem Informasi, Sekolah Tinggi Manajemen Informatika & Teknik Komputer Surabaya, email: [email protected]
Abstract: STIKOM Surabaya is one of colleges that uses computer technology to support operational activities. For example using computer technology for library. The current problem at STIKOM’s library is the officer still doesn’t know what book should be bought. This information can be performed more accurate using K-Means Clustering method. Using K-Means Clustering method, the officer at STIKOM’s Surabaya library can achieve more information about what new book should be bought.
Keywords : library, K-Means Clustering
Solusi pemanfaatan teknologi komputer sebagai alat bantu dalam mendukung kegiatan operasional suatu bidang usaha memudahkan manusia dalam mendapatkan data atau informasi secara cepat, tepat dan akurat sehingga efektivitas dan efisiensi kerja tercapai. STIKOM Surabaya merupakan salah satunya sekolah tinggi yang memanfaatkan teknologi komputer untuk mendukung kegiatan operasional sehari-harinya, contohnya adalah pemanfaatan teknologi komputer dalam proses pengadaan koleksi buku di perpustakaan.
Pada proses pengadaan koleksi buku baru, perpustakaan STIKOM Surabaya masih mengalami permasalahan. Permasalahan tersebut antara lain adalah petugas perpustakaan belum dapat mengetahui buku apa yang paling banyak dipinjam dalam periode tertentu dan untuk pembelian buku baru selama ini hanya berdasarkan usulan dari anggota perpustakaan
yang diajukan ke kaprodi. Hal ini dapat dipakai oleh petugas perpustakaan untuk memperoleh informasi buku yang lebih akurat dengan menerapkan metode K-means.
K-means adalah algoritma clustering
untuk data mining yang diciptakan tahun 70an dan berguna untuk melakukan clustering secara
unsupervised learning (pembelajaran yang tidak
terawasi) dalam suatu kumpulan data berdasarkan parameter tertentu. Menurut Kardi (2007), K-means adalah sebuah algoritma untuk mengklasifikasikan atau mengelompokkan objek-objek (dalam hal ini data) berdasarkan parameter tertentu ke dalam sejumlah group, sehingga dapat berjalan lebih cepat daripada hierarchical
clustering (jika k kecil) dengan jumlah variable
yang besar dan menghasilkan cluster yang lebih rapat.
Dengan adanya Sistem Pendukung Keputusan Pengadaan Buku Perpustakaan
2
STIKOM Surabaya Menggunakan MetodeK-means Clustering dapat bermanfaat bagi petugas
perpustakaan karena memperoleh informasi pembelian buku baru yang sesuai dengan minat mahasiswa dan jumlah buku yang dipinjam. Maka dari itu diperlukan sebuah sistem yang dapat menentukan buku apa yang akan dibeli agar bisa bermanfaat bagi anggota perpustakaan berdasarkan tiap angkatan dalam periode tertentu.
LANDASAN TEORI 1. Perpustakaan
Menurut Undang-undang Perpustakaan (UU nomor 43 tahun 2007) disebutkan bahwa perpustakaan adalah institusi pengelola koleksi karya tulis, karya cetak, dan/ atau karya rekam secara profesional dengan sistem yang baku guna memenuhi kebutuhan pendidikan, penelitian, pelestarian, informasi, dan rekreasi para pemustaka. Sedangkan menurut Sulistyo-Basuki (1991: 3) perpustakaan adalah: sebuah ruangan, bagian sebuah gedung, ataupun gedung itu sendiri yang digunakan untuk menyimpan buku dan terbitan lainnya yang biasanya disimpan menurut tata susunan tertentu untuk digunakan pembaca, bukan untuk dijual.
Institusi merupakan struktur dan mekanisma aturan dan kerjasama sosial yang mengawal perlakuan dua atau lebih individu. Institusi bisa juga berarti lembaga yaitu badan (organisasi) yang bermaksud melakukan suatu penyelidikan keilmuan atau melakukan suatu usaha. Pengelola berasal dari kata to manage yang berarti mengurus, mengatur, melaksanakan,
mengelola. Jadi pengelola adalah seseorang yang mengurus, mengatur, melaksanakan, mengelola. Koleksi berarti kumpulan benda yang digemari. Dengan demikian maka koleksi karya tulis, karya cetak dan/ atau karya rekam adalah kumpulan informasi yang berbentuk tulisan tangan, buku cetakan maupun yang direkam dalam berbagai media termasuk media elektronik dan digital. Profesional berarti memerlukan kepandaian khusus untuk menjalankan. Dengan demikian “mengelola koleksi karya tulis, karya cetak dan atau karya rekam secara profesional” berarti mengurus, mengatur, melaksanakan, mengelola kumpulan informasi dalam berbagai bentuk atau format dimana dalam melakukan pengelolaannya tersebut diperlukan keahlian khusus. Baku berarti sesuatu yang dipakai dasar ukuran (nilai, harga, dsb) standar. Jadi sistem baku merupakan sistem yang digunakan sebagai dasar dalam melakukan pengelolaan koleksi karya tulis, karya cetak dan atau karya rekam. Pemustaka menurut UU 43 tahun 2007 adalah pengguna perpustakaan, yaitu perseorangan, kelompok orang, masyarakat, atau lembaga yang memanfaatkan fasilitas layanan perpustakaan.
Dengan demikian maka makna dari kedua definisi yang dikutip pada awal tulisan ini adalah: perpustakaan merupakan institusi atau lembaga tempat menyimpan informasi dalam bentuk buku dan bentuk-bentuk lain yang disimpan menurut aturan tertentu yang baku untuk digunakan oleh orang lain (bukan hanya digunakan oleh pribadi) secara gratis untuk bermacam-macam tujuan atau kebutuhan seperti
3
untuk pendidikan, penelitian, pelestarian,informasi, dan rekreasi. Mari kita bandingkan dengan definisinya Wikipedia yang mendefinikan perpustakaan sebagai berikut:”A library is a collection of sources, resources, and services, and the structure in which it is housed; it is organized for use and maintained by a public body, an institution, or a private individual. In the more traditional sense, a library is a collection of books. It can mean the collection, the building or room that houses such a collection, or both.” Jadi makna beberapa definisi
tersebut memiliki pengertian yang sama yakni: (1) merupakan kumpulan bahan perpustakaan; (2) dikelola secara profesional dengan sistem tertentu (baku); (3) dikelola oleh lembaga atau institusi dan atau individu; (4) diselenggarakan untuk kebutuhan pemustaka.
2. Dewey Decimal Classification
Dewey Decimal Classification adalah
merupakan salah satu sistem pengklasifikasian koleksi buku yang ditemukan oleh Melvil Dewey. Nama lengkapnya Melville Louis Kassuth Dewey (1851-1931). Pada 1874 Dewey sebagai pustakawan di Amhers College, Massachuseetts, Tahun 1876 ia menerbitkan DDC edisi pertama dengan judul “A classification and subject index for a library”.
Terbit pertama kali hanya sebanyak 42 halaman yang berisi 12 halaman pendahuluan, 12 halaman bagan dan 18 halaman indeks. Sejak edisi pertama diterbitkan, DDC terus menerus mengikuti perkembangan ilmu pengetahuan.
Banyak subyek-subyek baru yang ditambahkan. Adakalanya notasi mengalami perluasan dan perubahan lokasi karena perkembangan subyek tersebut. Kelestarian DDC sampai dapat mencapai umur lebih seabad dan banyak pemakainya di dunia, disebabkan karena DDC secara berkala ditinjau kembali dan diterbitkan edisi barunya. Lembaga yang mengawasi dan mendukung penerbitan DDC ialah “The Lake
Placed Education Foundation” dan “The Library of Congress” di Amerika Serikat sarana
komunikasi diterbitkan “Decimal Classification,
adition, notes, decisions” (disingkat DC). DDC
dalam pengembangannya menggunakan sistem desimal angka arab sebagai simbol notasinya.
3. Sistem Pendukung Keputusan
Sistem Pendukung Keputusan atau yang biasa disebut Decision Support System (DSS) adalah sebuah sistem yang ditujukan untuk mendukung para pengambil keputusan manajerial untuk masalah semiterstruktur. Scott Morton mendefinisikan DSS sebagai “sistem berbasis computer interaktif, yang membantu para pengambil keputusan untuk menggunakan data dan berbagai model untuk memecahkan masalah-masalah tidak terstruktur” (Gory dan Scott Morton, 1971). Seperti yang disebutkan oleh Turban (2005: 136) yaitu DSS dimaksudkan untuk menjadi alat bantu bagi para pengambil keputusan untuk memperluas kapabilitas mereka, namun tidak untuk menggantikan penilaian mereka. DSS ditujukan untuk keputusan-keputusan yang memerlukan penilaian atau pada
4
keputusan-keputusan yang sama sekali tidakdapat didukung oleh algoritma. Sebagai istilah umum DSS digunakan untuk menggambarkan semua sistem terkomputerisasi yang mendukung pengambilan keputusan pada suatu organisasi. Tujuan utama dari DSS yaitu untuk mendukung dan meningkatkan pengambilan keputusan (Turban, 2005: 138).
Sesuai dengan konsep DSS diatas, maka menurut Turban (2005: 20) yang membedakan DSS dengan Sistem Informasi Manajemen adalah “Organisasi bisa saja memiliki suatu sistem manajemen pengetahuan untuk memandu seluruh personelnya dalam memecahkan masalah, ia dapat memiliki DSS tersendiri untuk pemasaran, keuangan, dan akuntansi, sistem SCM untuk produksi, dan beberapa sistem pakar untuk membuat diagnosis dan help desk perbaikan”. Jadi bisa dikatakan perbedaan antara Sistem Pendukung Keputusan (SPK) dengan Sistem Informasi Manajemen (SIM) dapat dilihat pada Tabel 1.
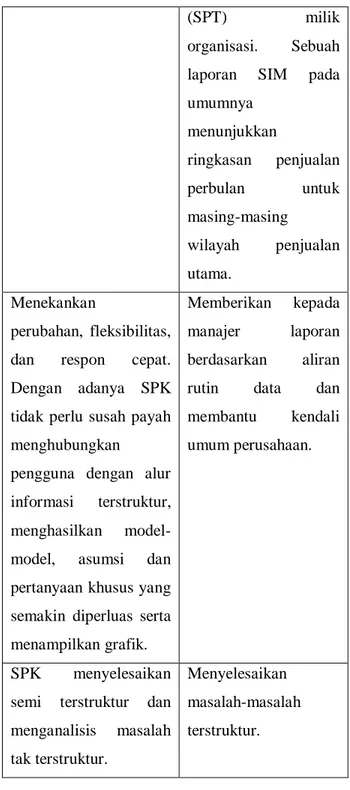
Tabel 1. Perbedaan Antara Sistem Pendukung Keputusan dengan Sistem Informasi Manajemen
(Laudon, 2005) Sistem Pendukung Keputusan (SPK) Sistem Informasi Manajemen (SIM) Memberikan serangkaian
kemampuan baru untuk keputusan-keputusan non rutin dan kendali pengguna.
Menghasilkan laporan regular terjadwal dan baku berdasarkan data yang diambil dan dirangkum dari sistem pemrosesan transaksi
(SPT) milik
organisasi. Sebuah laporan SIM pada umumnya menunjukkan ringkasan penjualan perbulan untuk masing-masing wilayah penjualan utama. Menekankan perubahan, fleksibilitas, dan respon cepat. Dengan adanya SPK tidak perlu susah payah menghubungkan
pengguna dengan alur informasi terstruktur, menghasilkan model-model, asumsi dan pertanyaan khusus yang semakin diperluas serta menampilkan grafik.
Memberikan kepada manajer laporan berdasarkan aliran rutin data dan membantu kendali umum perusahaan.
SPK menyelesaikan semi terstruktur dan menganalisis masalah tak terstruktur. Menyelesaikan masalah-masalah terstruktur. 4. Algoritma K-means
K-means adalah algoritma clustering
untuk data mining yang diciptakan tahun 70an dan berguna untuk melakukan clustering secara
5
terawasi) dalam suatu kumpulan databerdasarkan parameter tertentu. Menurut Kardi,
K-means adalah sebuah algoritma untuk
mengklasifikasikan atau mengelompokkan objek-objek (dalam hal ini data) berdasarkan parameter tertentu ke dalam sejumlah group.
K-means memiliki propeti : selalu ada
K cluster, paling tidak memiliki satu data dalam tiap cluster, cluster ini merupakan non-hierarki dan tidak akan terjadi overlap, dan setiap member dari sebuah cluster berdekatan di-cluster terhadap cluster lainnya karena kedekatan tidak selalu melibatkan pusat dari cluster itu. Kelebihan dari K-means cluster adalah : (Kardi, 2007)
a.
Dengan jumlah variable yang besar,K-means dapat berjalan lebih cepat
daripada hierarchical clustering (jika k kecil).
b.
K-means memungkinkanmenghasilkan cluster yang lebih rapat daripada hierarchical clustering, terutama jika cluster
berupa bola.
Selain memiliki kelebihan, K-means juga memiliki kekurangan. Kekurangan dari algoritma K-means ini adalah : (Kardi, 2007)
a. Kesulitan dalam membandingkan kualitas dari hasil cluster (seperti untuk perbedaan pembagian awal atau nilai dari K yang mempengaruhi hasil).
b. Jumlah cluster yang tepat dapat membuat kesulitan dalam
memprediksi berapakah K seharusnya.
c. Tidak akan bekerja dengan baik dengan cluster yang tidak berbentuk bulat.
d. Pembagian awal yang berbeda dapat menghasilkan akhir cluster yang berbeda. Hal ini membantu untuk menjalankan kembali program menggunakan nilai K yang berbeda, untuk perbandingan hasil akhir yang diperoleh.
Berikut adalah langkah-langkah dalam memproses algoritma K-means : (Larose, 2007)
1. Langkah pertama : tentukan terlebih dahulu jumlah k-cluster yang diinginkan.
2. Langkah kedua : lakukan inisialisasi untuk menentukan pusat cluster. 3. Langkah ketiga : untuk tiap baris
yang ada, temukan pusat cluster yang terdekat. Untuk menghitung distance atau jarak antara data dengan pusat cluster digunakan rumus Distance Euclidian :
(Sumber : Kantardzic, 2003) Dimana Xi adalah data, Mk adalah
centroid dari tiap-tiap cluster dan p
adalah jumlah kriteria yang ada. 4. Langkah keempat : menentukan grup
6
5. Langkah kelima : untuk tiap kcluster, temukan centroid (means)
dari cluster tersebut dan update lokasi dari pusat cluster ke dalam nilai centroid baru.
(Sumber : Jurnal Sistem dan Informatika Vol. 3, 2007) Dimana M k adalah mean yang baru, N k adalah jumlah dari pola pada
cluster k, dan X jk adalah pola nomor
urutan k yang menjadi anggota
cluster.
6. Langkah keenam : ulangi langkah ketiga 3 sampai ke 5 hingga batas nilai iterasi atau nilai toleransi (selisih M lama dan baru yang diperbolehkan untuk menghentikan algoritma) yang ditentukan atau masih ada data yang berpindah. Algoritma ini akan berhenti apabila
centroid tidak berubah lagi. Dengan kata lain,
algoritma berhenti ketika semua cluster C1, C2, C3…..Ck, dan semua baris dimiliki oleh setiap pusat cluster dalam cluster tersebut. Alternative lain, algoritma akan berhenti ketika beberapa criteria telah diketemukan, seperti tidak adanya pengurangan yang signifikan di dalam sum of
squared errors:
(Sumber : Larose, 2005)
Dimana p € Ci mewakili tiap data di dalam
cluster ke-I dan mi mewakili centroid dari cluster
ke-i.
Dari hasil cluster yang dihasilkan oleh algoritma K-means ini masih belum diketahui
cluster mana yang potensial. Untuk mencari cluster yang potensial terdapat berbagai cara.
Salah satunya adalah menggunakan Distance
Ecludian, akan tetapi ecludian untuk mencari cluster yang potensial dicari dengan menghitung
jarak centroid tiap-tiap cluster dengan titik nol sehingga rumus ecludiannya menjadi seperti rumus di bawah ini.
(Sumber : Kantardzic, 2003)
Dimana adalah centroid dari tiap-tiap cluster dan p adalah jumlah kriteria.
Dalam hal manfaat, algoritma ini tidak menjamin hasil yang optimal. Kualitas hasil akhir bergantung kepada besarnya jumlah cluster, dan dalam latihannya dapat lebih buruk dari hasil optimal. Semenjak algoritma ini menjadi lebih cepat, metode yang biasanya menjalankan algoritma ini dalam beberapa waktu dan menghasilkan cluster terbaik.
PERANCANGAN SISTEM
Tugas akhir ini berupa proyek pembuatan aplikasi penentuan buku baru pada perpustakaan dengan menggunakan desktop. Desktop ini dibuat sebagai media informasi seperti:
7
transaksi peminjaman, data buku, datamahasiswa, dan informasi-informasi yang di butuhkan lainnya sehingga dalam memenuhi kebutuhan informasi dapat terpecahkan.
Database
Gambar 1. Blok diagram sistem pengadaan buku perpustakaan
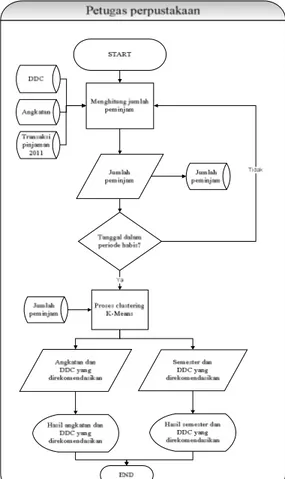
Sistem Flow Menentukan Buku yang Akan Dibeli
Pertama petugas perpustakaan melakukan proses menghitung jumlah peminjam. Proses ini mengambil database DDC, Angkatan dan Transaksi pinjaman 2011. Hasil dari proses yaitu jumlah peminjam yang akan dimasukkan ke dalam database. Jika seluruh tanggal yang dipilih dalam satu periode belum habis, maka akan kembali ke proses menghitung jumlah peminjam. Jika sudah habis, maka akan dilanjutkan ke proses clustering K-Means. Proses ini akan mengambil database jumlah peminjam. Output dari proses clustering ada dua, pertama adalah angkatan dan DDC yang direkomendasikan, kedua adalah semester dan DDC yang direkomendasikan.
Gambar 2. Sistem Flow Menentukan Buku yang Akan Dibeli
HASIL DAN PEMBAHASAN
Tujuan dibangunnya sistem ini adalah untuk membangun sebuah Sistem Pendukung Keputusan Pengadaan Buku Perpustakaan yang dapat membantu petugas untuk menentukan buku baru yang akan dipasok ke dalam Perpustakaan STIKOM Surabaya.
1. Form Utama
Pada saat pertama kali muncul form utama akan dalam keadaan pasif dimana menu yang hanya bisa diakses adalah menu Login.
8
Untuk mengaktifkan menu-menu lain, user haruslogin terlebih dahulu.
Gambar 4.1. Form Utama
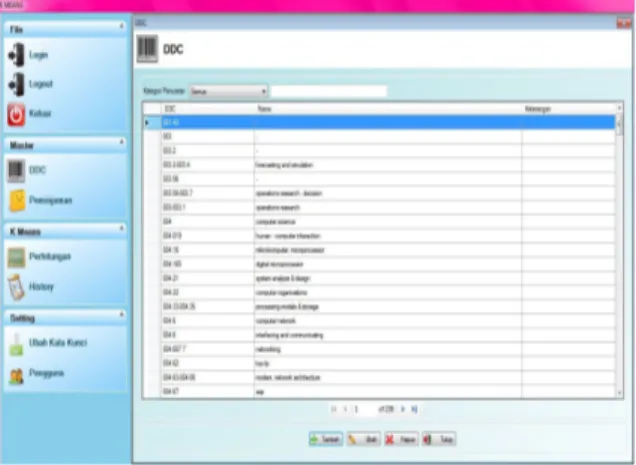
2. Form DDC
Pada form DDC, ditampilkan keseluruhan data DDC. Ada fasilitas cari data DDC berdasarkan semua, DDC, nama dan keterangan. Keseluruhan data DDC ditampilkan pada datagrid. Tombol tambah untuk menambah data DDC, ubah untuk mengubah data DDC, hapus untuk menghapus data DDC dan tutup untuk menutup tampilan.
Gambar 4.2 Form DDC
3. Form Pinjaman
Pada desain form pinjaman terdapat kategori pencarian yang terdiri dari semua, ID, induk, NIM, tanggal pinjam, jam pinjam, tanggal kembali 1, tanggal kembali 2, judul urut, DDC. Terdapat data grid untuk menampilkan data ID, induk, NIM, tanggal pinjam, jam pinjam, tanggal kembali 1, tanggal kembali 2, judul urut, DDC dan hapus. Tombol import berfungsi untuk mengambil data pinjaman, tombol hapus untuk menghapus data dan tombol tutup untuk menutup tampilan form pinjaman.
Gambar 4.3 Form Pinjaman
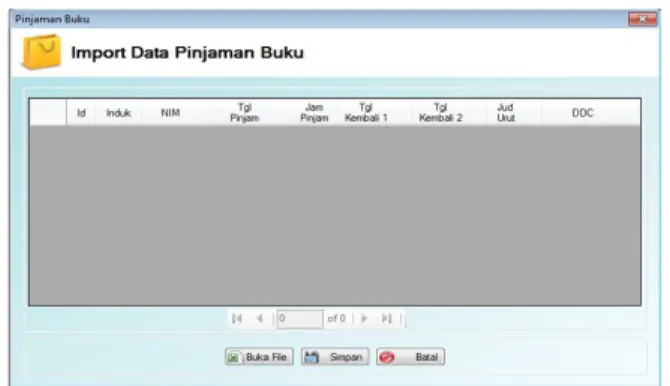
4. Form Import Data Pinjaman Buku Form ini berfungsi untuk mengambil data dari database excel yang sesuai dengan format tertentu. Apabila tidak sesuai maka file tidak dapat diambil. Data yang ditampilkan terdiri dari induk, NIM, tanggal pinjam, jam pinjam, tanggal kembali 1, tanggal kembali 2, judul urut, DDC dan hapus.
9
Gambar 4.4 Form Import Data Pinjaman Buku5.
Form K-Means
Gambar 4.5 Form K-Means
Form ini memproses data pinjaman sesuai dengan K-Means clustering. Data yang dipilih bisa sesuai dengan tanggal berapa sampai tanggal berapa. Lalu angkatan yang dipilih bisa dari 2008 saja ataupun dari 2008 sampai dengan 2011. Pada proses ini cluster awal bisa ditentukan sejumlah berapa cluster dan nilainya juga bisa ditentukan. Pada tombol hitung, maka akan dilakukan proses clustering sesuai dengan berapa iterasi. Hasil akhir akan langsung dapat dilihat.
6.
Form Laporan Hasil Perhitungan
Gambar 4.6 Form Laporan Hasil Perhitungan Form ini menghasilkan laporan data tiap
cluster untuk tiap angkatan. Misalkan dari data
uji coba yang dilakukan, cluster 1 menghasilkan
DDC
Management of Production
untukangkatan 2009, cluster 2 menghasilkan DDC
Java Programming untuk angkatan 2010, cluster 3 menghasilkan DDC Algoritma untuk angkatan
2011 dan cluster 4 menghasilkan DDC Java
Programming untuk angkatan 2008.
KESIMPULAN
Berdasarkan hasil uji coba dan analisa yang telah dilakukan dalam pembuatan aplikasi Pengadaan Buku Baru Perpustakaan STIKOM SURABAYA, dapat diambil kesimpulan sebagai berikut :
1. Aplikasi yang dibuat dapat mendukung manajemen perpustakaan dalam menentukan buku baru apa yang harus dibeli.
2. Aplikasi penilaian DDC menghasilkan nilai pada setiap DDC dan akan menghasilkan nilai akhir sebagai ukuran untuk menentukan kriteria DDC.
10
3. Berdasarkan dari uji coba yang telahdilakukan, dapat disimpulkan bahwa metode
K-Means dapat menghasilkan cluster yang
dianggap potensial berdasarkan jarak data dengan centroid/ mean terdekat.
4. Hasil penilaian DDC sudah dapat digunakan untuk mengetahui buku apa yang harus dibeli sesuai DDC.
5. Dengan adanya sistem ini, dapat mempermudah dan mempercepat proses pembelian buku baru.
DAFTAR PUSTAKA
Basuki, Sulistyo. 1991. Pengantar Ilmu Perpustakaan. Gramedia Pustaka Utama
ervhint_hunter. 2011. Arsitektur PostgresQL, (http://www.docstoc.com/docs/10939054 9/Arsitektur-PostgresQL---001, diakses 7 April 2012).
Gunadarma. 2005. Teknik-teknik Data Mining. (http://staffsite.gunadarma.ac.id/, diakses 10 April 2012).
Han, Jiawei and Micheline Kamber. 2007. Data
Mining: Concepts and Techniques. San
Fransisco : Mogan Kaufman Publhisers. Kardi. 2007. K-means Clustering Tutorial,
(http://people.revoledu.com/kardi/index. html, diakses 2 April 2012).
Kantardzic, Mehmed. 2003. Data Mining:
Concepts, Models, Methods, and
Algorithms. New Jerysey : A John Wiley
& Sons, Inc.
Larose, Daniel T. 2005. Discovering Knowledge
In Data An Introduction To Data Mining.
New Jersey : A John Wiley & Sons, Inc. Laudon, Kenneth C. And Jane P.Laudon. 2005.
Sistem Informasi Manajemen :
Mengelola Perusahaan Digital.
Yogyakarta : Penerbit Andi.
Saleh, Ir. Abdul Rahman, M.Sc. 2010. Definisi
Perpustakaan,
http://rahman.staff.ipb.ac.id/2010/12/07/ definisi-perpustakaan/, diakses 25 April 2010).