IDENTIFIKASI JENIS PENYAKIT DAUN TEMBAKAU
MENGGUNAKAN METODE GRAY LEVEL CO-OCCURRENCE
MATRIX (GLCM) DAN SUPPORT VECTOR MACHINE (SVM)
Nauval Zabidi Kurniawan1) Susijanto Tri Rasmana 2) Yosefine Triwidyastuti3)Program Studi/ Jurusan Sistem Komputer Institut Bisnis dan Informatika Stikom Surabaya
Jalan Raya Kedung Baruk 98 Surabaya, 60298
Email : 1)[email protected], 2)[email protected], 3)[email protected]
Abstrak:
Tembakau merupakan salah satu hasil produk pertanian yang diproses dari bagian daun tanaman tembakau. Masyarakat secara umum hanya mengetahui bahwa tembakau merupakan bahan baku utama rokok, akan tetapi pada kenyataannya ada banyak manfaat lain dari daun tembakau, mulai dari melepaskan gigitan lintah hingga sebagai obat HIV/AIDS dan sebagai biofuel. Pada perkembangannya ada dua faktor yang mempengaruhi kualitas tanaman tersebut, yaitu hama dan penyakit. Untuk meminimalisir penurunan kualitas tembakau, diperlukan sebuah metode analisis yang mampu mendeteksi penyakit pada daun tembakau sedini mungkin. Pada penelitian ini dibuat sebuah sistem yang mampu mendeteksi penyakit daun tembakau sebagai bentuk dari pengembangan teknologi digital (pengolahan citra). Dalam penelitian sistem analisis ini digunakan metode GrayLevel Co-occurrence Matrix (GLCM) dengan memanfaatkan ekstraksi fitur – fitur sebuah citra
dengan memperhatikan hubungan piksel ketetanggaan dan Support Vector Machine (SVM) sebagai pengklasifikasi jenis penyakit dengan bantuan kernel gaussian (rbf) dan polynomial. Pengujian sistem analisis ini menghasilkan tingkat keberhasilan yang beragam. Rata-rata tingkat keberhasilan pada sistem ini adalah 74% dengan persentase keberhasilan tertinggi 80% pada kernel polynomial dengan jarak piksel 1, 2, 3, 5 dan 6. Sedangkan persentase keberhasilan terkecil bernilai 63% pada kernel
gaussian (rbf) dengan jarak piksel 1.
Keyword: daun tembakau, GLCM, ekstraksi fitur, SVM, kernel.
Tembakau merupakan salah satu hasil produk pertanian yang diproses dari bagian daun tanaman tembakau. Masyarakat secara umum hanya mengetahui bahwa tembakau merupakan bahan baku utama rokok, akan tetapi pada kenyataannya ada manfaat lain dari daun tembakau, mulai dari melepaskan gigitan lintah hingga sebagai obat HIV/AIDS dan sebagai biofuel (Zulfikar, 2014).
Pada perkembangan tanaman tembakau ada dua faktor yang mempengaruhi kualitas tanaman tersebut, yaitu hama dan penyakit. Untuk meminimalisir penurunan kualitas tembakau, diperlukan sebuah metode
analisis yang mampu mendeteksi penyakit pada tembakau sedini mungkin. Beberapa metode yang telah dibuat sebelumnya untuk mendeteksi penyakit daun tembakau yaitu “Implementasi Jaringan Saraf Tiruan Untuk Mendeteksi Penyakit Tembakau (Nicotiana
Tabacum L) Dengan Metode
Backpropagation” (Nainggolan, 2011).
Namun metode tersebut hanya menghasilkan keluaran berupa tembakau berpenyakit atau tidak dengan mengolah variabel dari bentuk daun, warna daun, ada tidaknya bau daun, kondisi daun, ada tidaknya bercak pada daun, ada tidaknya bintik pada
JCONES Vol. 5, No. 1 (2016) 158-163
Journal of Control and Network Systems
Nauval Zabidi Kurniawan, Susijanto Tri Rasmana, Yosefine Triwidyastuti daun, bentuk batang, kondisi batang, warna
batang, warna akar dan kondisi akar. Sedangkan penyakit dari daun termbakau sendiri sangat kompleks. Daun tembakau rentan terkena penyakit baik yang disebabkan oleh hama, jamur bahkan virus.
Penelitian ini ditujukan untuk membuat sebuah sistem analisis yang mampu mendeteksi penyakit daun tembakau sebagai bentuk dari pengembangan teknologi digital (pengolahan citra) sehingga pendeteksian tidak lagi dilakukan secara manual. Dalam penelitian ini digunakan metode Gray Level
Co-occurrence Matrix (GLCM) untuk ekstraksi
fitur daun dan Support Vector Machine (SVM) untuk pengklasifikasian/identifikasi penyakit. GLCM yang memiliki fitur-fitur yang mampu mengekstraksi tekstur dengan lebih akurat dan SVM sebagai pengklasifikasi memiliki banyak kelebihan, salah satunya SVM mampu mengklasifikasikan suatu pattern yang tidak termasuk data yang dipakai dalam fase pembelajaran metode tersebut (Nugroho, A., Witarto, A., dan handoko, D., 2003).
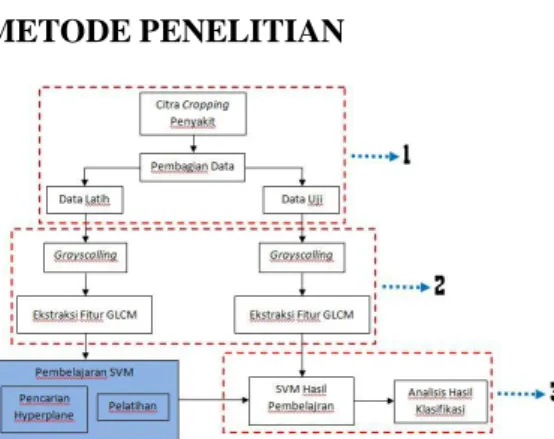
METODE PENELITIAN
Gambar 1. Blok diagram sistem keseluruhan Penelitian ini menggunakan masukan berupa citra cropping penyakit daun tembakau yang berukuran 96 x 96 piksel. Citra tersebut kemudian dibagi menjadi 2 bagian yakni citra data latih dan citra data uji (1). Kemudian citra data latih dan citra data uji diubah sifatnya dari RGB menjadi grayscale dengan menggunakan fungsi rgb2gray pada MATLAB. Setelah itu dicari ekstraksi fitur GLCM yang terdiri dari fitur contrast,
correlation, energy dan homogeneity dengan
menggunakan sudut 0˚, 45˚, 90˚ dan 135˚ dengan jarak piksel dari 1 sampai 10 piksel (2). Untuk data latih dilakukan pembelajaran SVM untuk didapat fungsi dari pemisah (hyperplane)
dari 2 kelas penyakit tersebut dengan tambahan bantuan fungsi kernel gaussian (rbf) dan kernel
polynomial. Tahap terakhir adalah melakukan
pengujian sistem terhadap citra data uji dan menganalisis hasil klasifikasi dari jarak piksel terhadap 2 fungsi kernel (3). Dan kemudian dicari jarak piksel dan fungsi kernel yang memberikan tingkat keberhasilan terbaik.
Citra Daun Tembakau
Sistem analisis ini menggunakan masukkan berupa citra dari daun tembakau. Citra daun tembakau disini berupa hasil
cropping dari gambar keseluruhan daun
tembakau dengan ukuran cropping 96 x 96 piksel. Cropping disini menggunakan bantuan
Photoshop CS 4. Bagian yang di-crop adalah
bagian dari daun tembakau yang terjangkit gejala penyakit lanas atau pun penyakit bercak karat. Ukuran 96 x 96 piksel dipilih karena setelah dilakukan pengambilan sampel sebelumnya menggunakan ukuran yang berbeda terdapat kendala ketika cropping terlalu besar atau terlalu kecil dari bagian daun yang terinfeksi penyakit tersebut
Gambar 2. Citra cropping dari gambar daun tembakau
Pembagian Citra Data Latih Dan Data
Uji
Setelah didapat sejumlah citra penyakit daun tembakau, maka dari kumpulan hasil cropping tersebut dibagi menjadi citra data latih dan citra data uji dalam folder berbeda. Total citra data latih sebanyak 58 citra dengan rincian citra 1 sampai citra 29 adalah citra data latih penyakit bercak karat dan citra 30 sampai 58 adalah citra penyakit lanas. Kemudian citra data latih diletakkan pada 1 folder. Untuk memudahkan pembagian kelas, jumlah citra untuk tiap-tiap jenis penyakit harus sama. Serta folder dari citra data latih direktorinya harus sama dengan folder dari sistem analisis yang akan dibuat.
Citra data uji sebanyak 30 citra dengan rincian citra 1 sampai citra 15 adalah citra data uji untuk penyakit bercak karat dan
citra 16 sampai citra 30 adalah citra penyakit lanas. Dan kumpulan citra data uji diletakkan pada folder terpisah dengan folder data latih tetapi tetap dalam 1 direktori dengan folder dari sistem analisis.
Grayscalling
Grayscalling adalah proses perubahan warna dari citra dari berwarna menjadi keabuan. Grayscalling citra diperlukan karena GLCM mengekstraksi fitur dengan memperhitungkan level aras keabuan ketetanggaan. Pengubahan dari citra berwarna menjadi bentuk grayscale biasanya mengikuti aturan seperti berikut :
I(i, j) = R(i, j) + G(i, j) + B(i, j) (1) 3
Dimana :
I(i, j) = Intensitas citra grayscale
R(i, j) = Intensitas warna merah dari citra asal G(i, j) = Intensitas warna hijau dari citra asal B(i, j) = Intensitas warna biru dari citra asal
Dalam sistem ini, grayscalling dilakukan pada citra data latih dan citra data uji. Untuk melakukan grayscalling di MATLAB, bisa menggunakan fungsi :
I = rgb2gray(„variabel_citra‟)
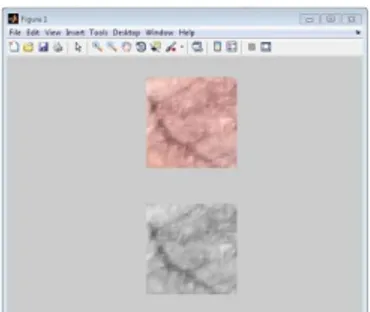
Gambar 3 adalah contoh hasil dari proses grayscalling dimana citra yang atas adalah citra yang bersifat RGB dan citra yang bawah adalah citra yang telah diubah menjadi
grayscale.
Gambar 3. Citra RGB (atas) dan citra grayscale (bawah)
Gray Level Co-occurrence Matrix
Setelah dilakukan grayscalling,
maka dicari matriks GLCM. Gray Level
Co-Occurrence Matrix (GLCM) merupakan metode yang paling sering digunakan untuk
analisis tekstur yang diperkenalkan oleh Haralick tahun 1973 (Mulkan S., 2012). Dalam membuat matriks GLCM digunakan 2 variabel utama, yaitu orientasi sudut (θ) dan jarak piksel (d). Pada penelitian ini digunakan orientasi sudut (θ) 0˚, 45˚, 90˚, 135˚ dan jarak piksel (d) yang digunakan mulai dari 1 sampai 10 piksel.
Gambar 4. Ilustrasi dari orientasi sudut dan jarak piksel
Co-occurrence matriks adalah matriks bujur sangkar dengan jumlah elemen sebanyak kuadrat jumlah level intensitas piksel pada citra. Setiap titik (i,j) pada matriks kookurensi berorientasi berisi peluang kejadian piksel bernilai (i) bertetangga dengan piksel bernilai (j) pada jarak (d) serta orientasi (180 − θ) (Pradnyana I., 2015). Tahapan dalam membuat matriks kookurensi adalah :
1. Membuat area kerja matriks.
2. Menentukan hubungan spasial antara piksel referensi dengan piksel tetangga dengan memperhatikan nilai sudut (θ) dan jarak piksel (d).
3. Menghitung jumlah kookurensi dan mengisikannya pada area kerja matriks. 4. Menjumlahkan matriks kookurensi dengan
transposenya untuk menjadikan simetris. 5. Normalisasi matriks untuk mengubahnya ke
bentuk probabilitas.
Ekstraksi Fitur – Fitur GLCM
Setelah didapat matriks kookurensi GLCM, dilanjutkan dengan mencari nilai fitur-fitur dari GLCM. Dalam penelitian ini, fitur-fitur GLCM yang digunakan antara lain fitur
energy, contrast, correlation dan homogeneity
dari 4 orientasi sudut dengan jarak piksel 1 sampai 10. Berikut penjelasan dari masing-masing fitur (Hartadi, 2011).
1. Contrast
Contrast menunjukkan ukuran penyebaran (momen inersia) elemen-elemen matriks citra. Jika letaknya jauh dari diagonal utama, maka nilai kekontrasannya besar.
Nauval Zabidi Kurniawan, Susijanto Tri Rasmana, Yosefine Triwidyastuti Secara visual, nilai kekontrasan adalah ukuran
variasi antar derajat keabuan suatu daerah citra.
𝑃(𝑖,𝑗 )(𝑖 − 𝑗)2 𝑁−1
𝑖,𝑗 =0
Dimana :
P(i,j) = nilai elemen matriks kookurensi
2. Correlation
Correlation menunjukkan ukuran
ketergantungan linear derajat keabuan citra sehingga dapat memberikan petunjuk adanya struktur linear dalam citra.
𝑃 𝑖,𝑗 [ 𝑖−𝜇𝑥 (𝑗 − 𝜇𝑦) (𝜎𝑥2)(𝜎𝑦2) ] 𝑁−1 𝑖,𝑗 =0 Dimana :
µx = nilai rata-rata elemen kolom pada matriks Pθ(i , j)
µy = nilai rata-rata elemen baris pada matriks Pθ(i , j)
σx = nilai standar deviasi elemen kolom pada matriks Pθ(i , j)
σy = nilai standar deviasi elemen baris pada matriks Pθ(i , j)
3. Energy
Energy menunjukkan ukuran konsentrasi pasangan intensitas pada matriks kookurensi. Nilai energy makin membesar bila pasangan piksel yang memenuhi syarat matriks intensitas kookurensi terkonsentrasi pada beberapa koordinat dan mengecil bila letaknya menyebar. 𝑃(𝑖,𝑗 )2 𝑁=1 𝑖,𝑗 =0
4. Homogeneity
Homogeneity menunjukkan kehomogenan variasi intensitas dalam citra. Citra homogen akan memiliki nilaihomogeneity yang besar. Nilai homogeneity
membesar bila variasi intensitas dalam citra mengecil dan sebaliknya.
𝑃(𝑖,𝑗 )
1 + (𝑖 − 𝑗)2 𝑁−1
𝑖,𝑗 =0
Kelinearan Nilai Fitur GLCM
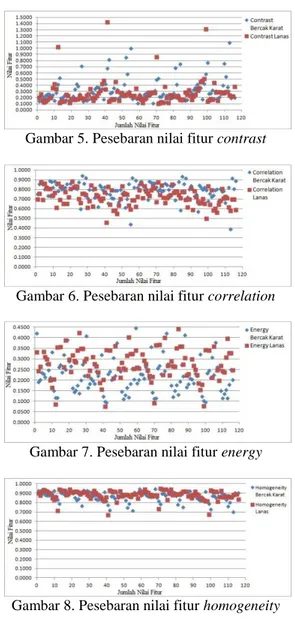
Setelah didapat nilai ekstraksi fitur GLCM, maka tahap selanjutnya adalah menentukan kelinearan citra tersebut dengan menggunakan Microsoft Office Excel secara manual dengan melihat pesebaran nilai fitur GLCM. Apabila dari hasil ekstraksi tersebut didapat bahwa citra tersebut bisa dipisahkan secara linear, maka penggunaan kernel untuk pelatihan SVM adalah kernel linear (default). Sedangkan jika hasil ekstraksi menunjukkan bahwa hasil tersebut tidak linear, maka diperlukan kernel untuk menyelesaikannya. Berikut pesebaran nilai fitur GLCM :
Gambar 5. Pesebaran nilai fitur contrast
Gambar 6. Pesebaran nilai fitur correlation
Gambar 7. Pesebaran nilai fitur energy
Gambar 8. Pesebaran nilai fitur homogeneity Gambar 5 sampai gambar 8 merupakan pesebaran dari nilai tiap fitur GLCM dari citra data latih. Dari gambar tersebut terlihat bahwa nilai fitur GLCM (2)
(3)
(4)
menunjukkan ketidaklinearan (tidak bisa dipisahkan secara linear), sehingga diperlukan modifikasi SVM dengan menambahkan fungsi kernel agar SVM mampu memisahkan nilai fitur dari penyakit bercak karat dan penyakit lanas dan didapat fungsi pemisah (classifier/hyperplane) dari data nilai fitur tersebut.
Pembagian Kelas
Pembagian kelas jenis penyakit adalah tahap dimana dari 58 data latih tersebut diklasifikasikan berdasarkan jenis penyakitnya. Citra 1 sampai 29 merupakan citra data latih untuk jenis penyakit bercak karat dan citra 30 sampai 58 merupakan citra data latih untuk jenis penyakit lanas. Pembagian kelas ini diperlukan untuk mengklasifikasikan nilai fitur GLCM dari data latih agar nanti sistem mampu mengklasifikasikan nilai fitur GLCM dari citra data uji dan didapatkan keluaran yang diinginkan.
Pelatihan SVM
Pelatihan SVM data latih ini bertujuan untuk pembelajaran dari SVM untuk mengklasifikasikan data latih sesuai dengan jenis penyakit. Pengklasifikasian data latih ini disesuaikan dari nilai ekstraksi fitur GLCM dari data latih dengan pembagian kelas jenis penyakit, sehingga didapat fungsi pemisah (classifier/hyperplane) yang optimal yang bisa memisahkan data latih dari 2 kelas jenis penyakit. Pada pelatihan ini digunakan function
‘svmtrain’ dengan tambahan fungsi kernel gaussian (rbf) dan fungsi kernel polynomial
untuk mengklasifikasikan antara fitur GLCM yang telah didapat dengan pembagian kelas. Dan hasil dari pelatihan klasifikasi SVM disimpat dalam file „SVMStruct.mat‟ agar nanti bisa digunakan sebagai pengklasifikasi untuk data uji.
HASIL DAN PEMBAHASAN
Ekstraksi Fitur GLCM
Ekstraksi fitur GLCM didapat ketika citra data telah diubah dari RGB menjadi
grayscale. Sehingga akan didapat nilai fitur
GLCM berupa nilai fitur energy, contrast,
correlation dan homogeneity.
Tabel 1. Hasil ekstraksi fitur contrast dan
correlation pada 5 citra pertama data uji
Tabel 2. Hasil ekstraksi fitur energy dan
homogeneity pada 5 citra pertama data uji
Dari tabel 1 dan 2 terlihat bahwa ekstraksi fitur GLCM telah didapat. Untuk tiap fitur didapat nilai ekstraksi dari sudut 0˚, 45˚, 90˚ dan 135˚.
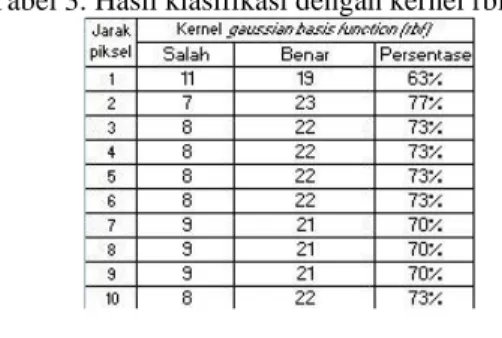
Hasil Klasifikasi SVM
1.
Menggunakan Kernel RBF
Pengujian menggunakan kernel rbf menghasilkan tingkat akurasi tertinggi sebesar 77% pada jarak piksel 2 piksel. Rata-rata data yang salah pada pengujian dengan kernel rbf sebanyak 8 data. Hasil pengujian menggunakan kernel RBF adalah sebagai berikut :
Tabel 3. Hasil klasifikasi dengan kernel rbf
2.
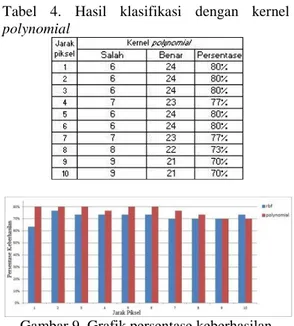
Menggunakan Kernel Polynomial
Pengujian menggunakan kernel
polynomial menghasilkan tingkat akurasi
tertinggi sebesar 80% pada jarak piksel 1, 2, 3, 5 dan 6 piksel. Rata-rata data yang salah pada pengujian dengan kernel polynomial sebanyak 7 data. Hasil pengujian menggunakan kernel
Nauval Zabidi Kurniawan, Susijanto Tri Rasmana, Yosefine Triwidyastuti Tabel 4. Hasil klasifikasi dengan kernel
polynomial
Gambar 9. Grafik persentase keberhasilan kernel RBF dan polynomial
KESIMPULAN
Berdasarkan dari hasil evaluasi dan pengujian yang sudah dilakukan dalam penelitian “Identifikasi Jenis Penyakit Daun Tembakau Menggunakan Metode Gray Level
Co-Occurrence Matrix (GLCM) Dan Support Vector Machine (SVM)” ini, sehingga dapat
disimpulkan sebagai berikut:
1. Ekstraksi fitur citra daun tembakau menggunakan Gray Level Co-occurrence
Matrix berhasil dilakukan. Hal ini terbukti
dengan didapat nilai-nilai dari fitur GLCM dengan orientasi sudut 0˚, 45˚, 90˚ dan 135˚ dan jarak piksel mulai dari 1 sampai 10 piksel. 2. Klasifikasi dengan menggunakan
Support Vector Machine dari nilai fitur GLCM
dapat dilakukan, terbukti dengan hasil keluaran yang didapat dari penelitian ini cukup tinggi, yakni sebesar 74%. Klasifikasi menggunakan
gaussian (rbf) menghasilkan tingkat keberhasilan tertinggi sebesar 77% pada jarak piksel 2 piksel. Sedangkan untuk kernel
polynomial didapat tingkat keberhasilan tertinggi sebesar 80% pada jarak piksel 1, 2, 3, 5 dan 6 piksel.
DAFTAR PUSTAKA
Budiarso, Z. 2010. Identifikasi Macan Tutul
Dengan Metode Gray Level Co-occurrence Matrix (GLCM). Skripsi Tidak Diterbitkan.
Semarang: Universitas Stikubank.
Direktorat Jenderal Perkebunan. 2011.
Pengenalan dan Pengendalian Penyakit Lanas (Phytophthora parasitica var. nicotianae) pada Tanaman Tembakau.
Jakarta: Kementerian Pertanian.
Fithri, D. 2013. Deteksi Penyakit Pada Daun
Tembakau Dengan Menerapkan Algoritma Artificial Neural Network. Kudus: Universitas Muria Kudus.
Ganis, Y. 2011. Klasifikasi Citra Dengan
Matriks Ko-okurensi Aras Keabuan (Gray Level Co-occurrence Matrix) Pada Lima Kelas Biji-bijian. Skripsi Tidak Diterbitkan.
Semarang: Universitas Diponegoro.
Gunawan, A. 2014. Identifikasi Jenis Kayu Menggunakan Support Vector Machine Berbasis Data Citra. Jurnal Ilmu Komputer
Agri-Informatika, 3(1): 1 – 8.
Hartadi, R. 2011. Deteksi Potensi Kanker
Payudara Pada Mammogram Menggunakan Metode Gray Level Co-Occurrence Matrices. Skripsi Tidak Diterbitkan. Semarang : Universitas Diponegoro.
Mabrur, A. 2011. Pengolahan Citra Digital
Menggunakan MATLAB. Tulungagung.
Nainggolan, D. 2011. Implementasi Jaringan
Saraf Tiruan Untuk Mendeteksi Penyakit Tembakau (Nicotiana Tabacum L) Dengan Metode Backpropagation. Skripsi Tidak
Diterbitkan. Medan: Universitas Sumatera Utara.
Nugroho, A., Witarto, A., dan Handoko, D. 2003. Support Vector Machine – Teori dan
Aplikasinya dalam Bioinformatika.
(Online). (http://ilmukomputer.com, diakses 16 Desember 2015).
Pradnyana, I. 2015. Perancangan Sistem
Pendeteksi Genangan Air Potensi Perkembangbiakan Nyamuk Melalui Foto Citra Udara Dengan Metode Gray Level Co-Occurrence Matrix (GLCM). Skripsi
Tidak Diterbitkan. Bandung: Universitas Telkom.
Santosa, B. 2005. Tutorial Support Vector
Machine. Surabaya: Institut Teknologi
Sepuluh Nopember.
Semangun, H. 2000. Penyakit – Penyakit
Tanaman Perkebunan di Indonesia.