MESIN PENCARI LAGU
BERDASARKAN LIRIK LAGU MENGGUNAKAN METODE
MODEL RUANG VEKTOR
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh:
L. DIMAS ARYO BIMO YP.
06 5314 103
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS dan TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
SONG SEARCH ENGINE BASED ON SONG LYRIC USING
VECTOR SPACE MODEL METHOD
A THESIS
Present as Partial Fulfillment of the Requirements
To Obtain the Bachelor of Computer
In Informatics Engineering Department
By :
L. DIMAS ARYO BIMO YP.
06 5314 103
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCINECE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
iii
SKRIPSI
MESIN PENCARI LAGU
BERDASARKAN LIRIK LAGU MENGGUNAKAN METODE
MODEL RUANG VEKTOR
Oleh :
L. Dimas Aryo Bimo YP.
NIM : 06 5314 103
Telah Disetujui Oleh :
Dosen Pembimbing Tugas Akhir
iv
SKRIPSI
MESIN PENCARI LAGU
BERDASARKAN LIRIK LAGU MENGGUNAKAN METODE
MODEL RUANG VEKTOR
Dipersiapkan dan ditulis Oleh :
L. Dimas Aryo Bimo YP.
NIM : 06 5314 103
Telah dipertahankan di depan Panitia Penguji
Pada tanggal 14 Desember 2010
dan dinyatakan memenuhi syarat
Susunan Panitia Penguji
Nama Lengkap Tanda Tangan
Ketua Sri Hartati Wijono, S.Si., M.Kom. ………... Sekretaris Puspaningtyas Sanjoyo Adi, S.T., M.T. ………...
Anggota Alb. Agung Hadhiatma, S.T., M.T. ………...
Yogyakarta, ………...
Fakultas Sains dan Teknologi
Universitas Sanata Dharma
Dekan
v
PERNYATAAN KEASLIAN KARYA
Saya menyatakan sesungguhnya bahwa skripsi yang saya tulis ini tidak memuat karya orang lain kecuali telah disebutkan dalam kutipan atau daftar pustaka, sebagaimana layaknya karya ilmiah.
Yogyakarta, Januari 2012 Penulis ,
vi
PERNYATAAN PERSETUJUAN
PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertandatangan di bawah ini, saya mahasiswa Universitas Sanata Dharma : Nama : L. Dimas Aryo Bimo YP.
NIM : 06 5314 103
Demi pengembangan ilmu pengetahuan, saya memberikan kepada perpustakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul:
MESIN PENCARI LAGU
BERDASARKAN LIRIK LAGU MENGGUNAKAN METODE MODEL
RUANG VEKTOR
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada perpustakaan Universitas Sanata Dharma hak untuk menyimpan, mengalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data, mendistribusikannya secara terbatas dan mepublikasikannya di internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun memberikan royalty kepada saya selama tetap mencantumkan nama saya sebagai penulis. Demikian pernyataan ini, yang saya buat dengan sebenarnya.
Dibuat di Yogyakarta,
Pada tanggal : Januari 2012 Yang menyatakan
vii
HALAMAN PERSEMBAHAN
Skripsi ini saya persembahkan untuk :
Bapak dan Ibu E. Yudhiatmoko, H. Mas Dinda YP., dan B. Susilowati PP. atas semangat, kasih, sarana dan prasarana, sehingga skripsi ini dapat terselesaikan dengan
baik.
Untuk sahabat dan teman- temanku, terimakasih atas segala bentuk motivasi dan pembelajaran yang kalian berikan.
viii
HALAMAN MOTO
“ If you do not believe you would not succeed and
ix
KATA PENGANTAR
Penulis menghaturkan puji syukur kepada Tuhan YME atas berkat dan bimbingan-Nya sehingga penulis dapat menyelsaikan skripsi dengan baik. Skripsi adalah studi akhir yang merupakan salah satu tugas akhir yang diwajibkan pada mahasiswa Program Studi Teknik Informatika Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta setelah lulus mata kuliah teori, praktikum, dan kerja praktek. Tujuan dari pembuatan skripsi ini adalah sebagai salah satu syarat untuk mencapai derajat sarjana computer dari Program Studi Teknik Informatika Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta.
Penulis menyadari bahwa dalam pembuatan skripsi ini tidak terlepas dari bantuan berbagai pihak yang telah menyumangakn pikiran, tenaga, dan bimbingan kepada penulis baik secara langsug maupun tidak langsung. Oleh sebab itu. Penulis mengucapkan terimakasih kepada:
1. Bapak Yosef Agung Cahyanta, S.T., M.T. selaku Dekan Fakultas Sains dan
Teknologi Universitas Sanata Dharma Yogyakarta.
2. Ibu Ridowati Gunawan S. Kom., M.T. selaku Ketua Jurusan Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta.
3. Bapak Alb. Agung Hadhitama S.T., M.T. selaku Dosen pembimbing yang telah memberikan bimbingan dan masukan yang sangat berarti kepada penulis.
4. Ibu Sri Hartati Wijono, S.Si., M.Kom. dan Bapak Puspaningtyas Sanjoyo Adi, S.T., M.T. selaku Dosen penguji.
x Demikian laporan skripsi ini dibuat dengan usaha terbaik dari penulis. Tetapi jika masih ada kekurangan yang disebabkan keterbatasan waktu dan pengetahuan yang dimiliki penulis, maka kritik dan saran yang bersifat membangun sangat diharapkan demi kesempurnaan laporan ini. Akhir kata semoga laporan ini dapat berguna bagi semua pihak yang membutuhkan.
Yogyakarta, Januari 2012
xi
ABSTRAKSI
xii ABSTRACT
To searh a song in database collection, users need to remember the title of that song.
However, the problem emerges when the users do not remember the title of the songs
or the lyrics, but just remembering part of lyrics. This thesis conduct a research to
facilitate user to find song with part of lyrics which users remember based on
Information Retrieval System theory using vector space model with the higher
xiii
DAFTAR ISI
HALAMAN JUDUL... i
HALAMAN PERSETUJUAN PEMBIMBING ... iii
HALAMAN PENGESAHAN... iv
PERNYATAAN KEASLIAN KARYA ... v
PERNYATAAN PERSETUJUAN ... vi
HALAMAN PERSEMBAHAN ... vii
HALAMAN MOTO ... viii
KATA PENGANTAR ... ix
ABSTRAKSI ... xi
ABSTRACT ... xii
DAFTAR ISI ... xiii
DAFTAR TABEL ... xiiiv
DAFTAR GAMBAR ... xiiiv
BAB I Error! Bookmark not defined. PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 2
1.3 Tujuan ... 2
1.4 Batasan Masalah ... 2
1.5 Metodologi Penelitian ... 3
1.6 Sistematika Penulisan ... 4
BAB II ... 6
LANDASAN TEORI ... 6
2.1 Pengertian Sistem Temu Kembali Informasi ... 6
2.2 Pengindeksan (indexing ) dalam Sistem Temu Kembali ... 11
2.2.2 Parsing ... 11
2.2.3 Stemming ... 12
2.2.4 Porter Stemmer for Bahasa Indonesia ... 13
2.3 Pembobotan kata ... 15
2.3.1 Metode TF/IDF ... 17
2.3.2 Ilustrasi TF/IDF ... 20
2.4 Teknik- teknik temu kembali informasi ... 20
2.4.1 Model Ruang Vektor (Vector Space Model) ... 20
2.4.2 Ilustrasi perhitungan Model Ruang Vektor (Vector Space Model) ... 24
2.5 Contoh proses pencarian lirik lagu secara manual ... 26
2.6 Evaluasi Sistem Temu Kembali Informasi ... 26
BAB III ... 28
ANALISIS DAN PERANCANGAN... 28
3.1 Analisa Sistem ... 28
3.1.1 Analisis Kebutuhan ... 28
3.2 Metode Pengumpulan Data ... 28
3.3 Perancangan Sistem ... 29
xiv
3.3.1.1 Aktor ... 29
3.3.1.2Diagram Use Case ... 31
3.3.1.3 Tabel Use Case ... 32
3.3.1.4 Tabel Skenario Use Case ... 32
3.3.2 Bagan Alir Program ... 37
3.3.3 Perancangan Database ... 52
3.4 Perancangan Antarmuka (Interface) ... 56
3.5 Class Diagram ... 61
Gambar 3.20 Class Diagram Searching ... 63
BAB IV ... 64
IMPLEMENTASI ... 64
4.1 Spesifikasi Software dan Hardware yang digunakan ... 64
4.1.1 Spesifikasi Software ... 64
4.1.2 Spesifikasi Hardware ... 64
4.2 Koneksi Basis Data MySql dengan Sistem ... 64
4.3 Core Sistem Mesin Pencari ... 64
4.4 Pembuatan Antarmuka (Interface) ... 71
4.4.1 Halaman Menu Utama Pengguna ... 71
4.4.2 Halaman Pencarian ... 72
4.4.3 Halaman About ... 74
4.4.4 Halaman Login ... 74
4.4.5 Halaman Menu Utama Administrator ... 75
4.4.7 Halaman Searching ... 76
4.4.8 Halaman Edit Password ... 76
4.4.9 Halaman Edit Stopword ... 77
4.4.10 Halaman Edit Dictionary ... 78
4.5 Dokumentasi Program ... 79
BAB V... 80
ANALISA HASIL ... 80
5.1 Proses Indexing ... 80
5.2 Proses Pencarian ( Searching ) ... 82
5.3 Proses Edit Stopword dan Kamus (Dictionary) ... 83
5.4 Analisa Hasil Kuisioner Responden ... 84
5.5 Analisa Hasil Percobaan Penulis ... 87
BAB VI ... 95
KESIMPULAN ... 95
6.1 Kesimpulan ... 95
6.2 Saran ... 95
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Banyaknya lagu yang beredar di Indonesia pada saat ini, tidak memungkinkan masyarakat untuk dapat menghafal semua lirik lagu yang ada. Dalam hal ini, lirik lagu berbahasa Indonesia. Sebagai contoh, ketika seorang pelanggan berkunjung ke tempat karaoke, di dalam ruangan karaoke hanya disediakan aplikasi pencarian berdasarkan judul lagu dan jenis bahasa dari lagu sebagai fasilitas pemilihan lagu dari koleksi lagu yang ada. Masalah yang sering dialami pelanggan adalah lupa atau ketidaktahuan pelanggan terhadap judul lagu yang akan dimainkan, sedangkan pelanggan hanya dapat mengingat sepotong lirik dari lagu yang dimaksud. Hal ini tentu saja akan mengurangi kenyamanan pelanggan saat berkaraoke. Untuk mengatasi permasalahan tersebut, maka dibutuhkan suatu sistem atau aplikasi pencari lirik lagu yang dapat memberikan informasi berupa lirik sekaligus judul lagu berdasarkan potongan lirik lagu sebagai kata kunci pencarian, dengan tingkat kesesuaian yang paling maksimal. Salah satu cara yang digunakan untuk membangun sistem pencari lirik lagu adalah dengan menggunakan sistem temu kembali informasi.
2 dokumen yang relevan dengan query dari user.
Teknik untuk melakukan proses indexing adalah dengan memberikan bobot terhadap tiap kata berdasarkan frekuensi kemunculan kata pada suatu dokumen lirik dan menyimpannya ke dalam koleksi database. Dari proses indexing ini, teknik yang dapat digunakan untuk mencari dokumen yang relevan dengan query dari pengguna adalah berdasarkan jumlah frekuensi kemunculan kata paling banyak, dengan teknik ini akan ditemukan urutan dokumen yang berhasil ditemukan berdasarkan jumlah frekuensi kemunculan kata.
1.2 Rumusan Masalah
Bagaimana cara mengimplementasikan program mesin pencari untuk mempermudah pencarian data lirik dan berdasarkan potongan lirik tertentu dengan tingkat kesesuaian tertinggi?
1.3 Tujuan
Membuat program mesin pencari untuk mempermudah pencarian lagu dari koleksi lagu berdasarkan lirik tertentu dengan tingkat kesesuaian tinggi.
1.4 Batasan Masalah
Dalam aplikasi mesin pencari data lagu dilakukan beberapa batasan sebagai berikut :
1. Data yang dapat diproses adalah data teks (*.txt) untuk data lirik dan (*.mp3) untuk data lagu.
3 19 berbahasa Indonesia.
3. Pencarian data berdasarkan jumlah frekuensi kemunculan kata dalam lirik.
1.5 Metodologi Penelitian
Dalam penyusunan tugas akhir dan pembuatan program bantu pencarian data lirik lagu, digunakan beberapa metode untuk mencari informasi yang diperlukan, yaitu:
1. Metode studi literatur
Mencari dan mengumpulkan literatur- literatur yang berkaitan dengan permasalahan yang dikerjakan, yaitu mengenai sistem temu kembali informasi (Information retrieval system) menggunakan metode model ruang vektor (vector space model), data lirik lagu melalui internet dan media informasi lainnya.
2. Metode pengembangan sistem
Metode pengembangan sistem yang dipakai dalam pembuatan program bantu pencarian data lagu menggunakan metode Linear Sequential Model/ Waterfall Model. Model ini adalah model klasik yang bersifat sistematis, berurutan dalam membangun perangkat lunak. Berikut ini adalah gambaran dari waterfall model.
Fase-fase dalam Waterfall Model menurut referensi Pressman:
1. Analisa: Membuat bagan alir program, diagram arus data (DFD) dan ER-Diagram.
4 3. Implementasi: Menerapkan hasil analisa dan desain pada tahap
sebelumnya.
4. Testing: Menguji dan menganalisa hasil program.
Gambar 1.1 Fase-fase dalam Waterfall Model menurut referensi Pressman
1.6 Sistematika Penulisan
BAB I PENDAHULUAN
Memberikan gambaran secara umum tentang isi skripsi yang meliputi: Latar belakang, rumusan masalah, batasan masalah, tujuan dan manfaat, metode penelitian dan sistematika penulisan.
BAB II LANDASAN TEORI
Berisi konsep dasar sistem temu kembali informasi (information retrieval system), bagian- bagian dari sistem temu kembali informasi, teknik- teknik temu- kembali informasi, dan evaluasi sistem temu kembali informasi.
BAB III ANALISIS DAN PERANCANGAN SISTEM
5 kamus data, E-R diagram sistem, perancangan proses, perancangan basis data, perancangan modul, perancangan tampilan masukan dan keluaran untuk pengguna, dan perancangan teknologi.
BAB IV IMPLEMENTASI
Berisi penjelasan dan fungsi program bantu pencarian sebagai alat bantu pencarian data lirik dan lagu.
BAB V ANALISIS HASIL
Berisi evaluasi program sistem temu- kembali informasi, kelebihan dan kekurangan program.
BAB VI KESIMPULAN DAN SARAN
Berisi kesimpulan dan saran dari pembuatan program bantu pencarian data lirik dan lagu
6
BAB II
LANDASAN TEORI
2.1 Pengertian Sistem Temu Kembali Informasi
Sistem temu kembali informasi (information retrieval system), adalah suatu proses untuk mengidentifikasi, kemudian memanggil (retrieve) suatu data dari suatu simpanan file, sebagai jawaban atas permintaan informasi. Menurut Lancaster (1968) dalam Rijsbergen (1979):” Sebuah information retrieval system
(Sistem temu kembali informasi) tidak memberitahu (yakni tidak mengubah pengetahuan) pengguna mengenai masalah yang ditanyakannya. Sistem tersebut hanya memberi-tahukan keberadaan (atau ketidakberadaan) dan keterangan dokumen- dokumen yang berhubungan dengan permintaannya.”
7 2n = jumlah kemungkinan himpunan bagian dari dokumen yang
ditemukan.
Sistem temu-kembali akan mengambil salah satu dari kemungkinan tersebut. Sistem temu-kembali informasi pada dasarnya dibagi dalam dua komponen utama yaitu sistem pengindeksan (indexing) yang menghasilkan basis data sistem dan temu-kembali yang merupakan gabungan dari user interface dan look-up-table.
Sistem temu kembali informasi (information retrieval system) digunakan untuk menemukan kembali (retrieve) informasi-informasi yang relevan terhadap kebutuhan pengguna dari suatu kumpulan informasi secara otomatis.
Sistem
Temu Kembali
Informasi
Query
1. Dok1 2. Dok2
3. Dok3 Hasil
Pencarian
Koleksi Dokumen
Hasil Pencarian
8 Salah satu aplikasi umum dari sistem temu kembali informasi adalah search engine atau mesin pencarian yang terdapat pada jaringan internet. Pengguna dapat mencari halaman-halaman web yang dibutuhkannya melalui search engine.
Sistem temu kembali informasi terutama berhubungan dengan pencarian informasi yang isinya tidak memiliki struktur. Demikian pula ekspresi kebutuhan pengguna yang disebut query, juga tidak memiliki struktur. Hal ini yang membedakan sistem temu kembali informasi dengan sistem basis data. Dokumen adalah contoh informasi yang tidak terstruktur. Isi dari suatu dokumen sangat tergantung pada pembuat dokumen tersebut.
9
Gambar 2.2 Bagian-bagian Sistem Temu Kembali Informasimenurut referensi Rila Mandala dan Hendra Setiawan
Gambar 2.2 memperlihatkan bahwa terdapat dua buah alur operasi pada sistem temu kembali informasi. Alur pertama dimulai dari koleksi dokumen dan alur kedua dimulai dari query pengguna. Alur pertama yaitu pemrosesan terhadap koleksi dokumen menjadi basis data indeks tidak tergantung pada alur kedua. Sedangkan alur kedua tergantung dari keberadaan basis data indeks yang dihasilkan pada alur pertama.
10 1. Text Operations (operasi terhadap teks) yang meliputi pemilihan kata-kata
dalam query maupun dokumen (term selection) dalam transformasi dokumen atau query menjadi termsindex (indeks dari kata-kata).
2. Query formulation (formulasi terhadap query) yaitu memberi bobot pada indeks kata-kata query.
3. Ranking (pengurutan), mencari dokumen-dokumen yang relevan terhadap query dan mengurutkan dokumen tersebut berdasarkan kesesuaiannya dengan query.
4. Indexing (pengindeksan), membangun basis data indeks dari koleksi dokumen. Dilakukan terlebih dahulu sebelum pencarian dokumen dilakukan.
Sistem temu kembali informasi menerima query dari pengguna, kemudian melakukan perangkingan terhadap dokumen pada koleksi berdasarkan kesesuaiannya dengan query. Hasil pengurutan yang diberikan kepada pengguna merupakan dokumen yang menurut sistem relevan dengan query. Namun relevansi dokumen terhadap suatu query merupakan penilaian pengguna yang subjektif dan dipengaruhi banyak faktor seperti topik, pewaktuan, sumber informasi maupun tujuan pengguna.
11
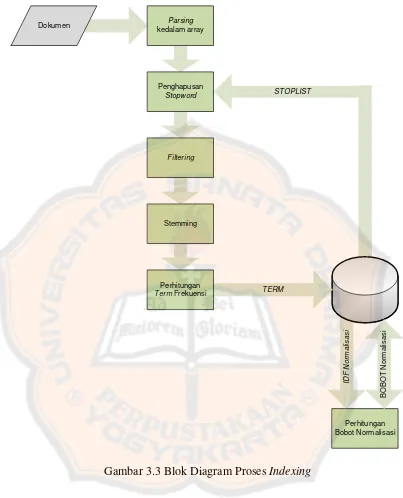
2.2 Pengindeksan (indexing ) dalam Sistem Temu Kembali
Indexing merupakan sebuah proses untuk melakukan pengindeksan terhadap kumpulan dokumen yang akan disediakan sebagai informasi kepada pemakai. Proses pengindeksan bisa secara manual ataupun secara otomatis. Dewasa ini, sistem pengindeksan secara manual mulai digantikan oleh sistem pengindeksan otomatis. Adapun tahapan dari pengindeksan adalah sebagai berikut :
Parsing dokumen yaitu proses pengambilan kata-kata dari kumpulan dokumen.
Stoplist yaitu proses pembuangan kata tidak penting seperti: tetapi, yaitu, sedangkan, dan sebagainya.
Stemming yaitu proses penghilangan/ pemotongan dari suatu kata menjadi bentuk dasar. Kata “diadaptasikan” atau “beradaptasi”
menjadi kata “adaptasi” sebagai istilah.
Term Weighting dan Inverted File yaitu proses pemberian bobot pada istilah.
2.2.2 Parsing
12 tidak signifikan dalam membedakan dokumen atau query misalnya kata-kata tugas seperti yang, hingga, dan dengan.
2.2.3 Stemming
Stemming adalah proses penghilangan prefiks dan sufiks dari query dan istilah - istilah dokumen (Grossman, 2002). Stemming dilakukan atas dasar asumsi bahwa kata-kata yang memiliki stem yang sama memiliki makna yang serupa sehingga pengguna tidak keberatan untuk memperoleh dokumen-dokumen yang di dalamnya terdapat kata-kata dengan stem yang sama dengan kuerinya. Teknik-teknik stemming dapat dikategorikan menjadi:
Berdasarkan aturan sesuai bahasa tertentu Berdasarkan kamus
13 menangani dokumen dalam Bahasa Indonesia. Bahasa Indonesia memiliki daftar kata buang (stoplist) serta sistem pembentukan kata yang sangat berbeda dengan bahasa Inggris, sehingga diperlukan IRS yang khusus untuk Bahasa Indonesia.
2.2.4 Porter Stemmer for Bahasa Indonesia
Porter Stemmer for Bahasa Indonesia dikembangkan oleh Fadillah Z. Tala pada tahun 2003. Implementasi Porter Stemmer for Bahasa Indonesia berdasarkan English Porter Stemmer yang dikembangkan oleh W.B. Frakes pada tahun 1992. Karena bahasa Inggris datang dari kelas yang berbeda, beberapa modifikasi telah dilakukan untuk membuat Algoritma Porter dapat digunakan sesuai dengan bahasa Indonesia. Desain dari Porter Stemmer for Bahasa Indonesia dapat dilihat pada gambar 2.3 di bawah ini:
14 Pada gambar 2.3 terlihat beberapa langkah 'removal' menurut aturan yang ada pada tabel 2.1 sampai dengan tabel 2.5.
Tabel 2.1: Kelompok rule pertama : inflectional particles Suffix Replacement Measure
Condition
Tabel 2.2: Kelompok rule kedua :inflectional possesive pronouns Suffix Replacement Measure
Condition
Tabel 2.3: Kelompok rule ketiga: first order of derivational prefixes Prefix Replacement Measure
Condition
Tabel 2.4: Kelompok rule keempat: second order of derivational prefixes Prefix Replacement Measure
15
pel NULL 2 ajar pelajar → ajar
pe NULL 2 NULL pekerja → kerja
Tabel 2.5: Kelompok rule kelima: derivational suffixes Suffix Replacement Measure
Condition (per)janjian → janji
i NUUL 2 V|K…c1c1,c1≠ s, c2≠ i
Didalam memberikan bobot pada sebuah istilah, terdapat berbagai macam teknik antara lain yaitu :
1. Teknik pembobotan berdasarkan frekuensi kemunculan istilah pada satu dokumen. Teknik pembobotan ini cukup sederhana dimana bobot suatu istilah pada sebuah dokumen berdasarkan jumlah kemunculannya pada dokumen tersebut.
16 w(t,d) = tf(t,d)*log(N/nt)
tfik merupakan frekuensi dari istilah k dalam dokumen i. n adalah jumlah dokumen dalam kumpulan dokumen. dfk adalah jumlah dokumen yang mengandung istilah k. Maxj tfij adalah frekuensi istilah terbesar pada satu dokumen.
Pada teknik pembobotan ini, bobot istilah telah dinormalisasi. Dalam menentukan bobot suatu istilah tidak hanya berdasarkan frekuensi kemunculan istilah di satu dokumen, tetapi juga memperhatikan frekuensi terbesar pada suatu istilah yang dimiliki oleh dokumen bersangkutan. Hal ini untuk menentukan posisi relatif bobot dari istilah dibanding dengan istilah-istilah lain di dokumen yang sama. Selain itu teknik ini juga memperhitungkan jumlah dokumen yang mengandung istilah yang bersangkutan dan jumlah keseluruhan dokumen. Hal ini berguna untuk mengetahui posisi relatif bobot istilah bersangkutan pada suatu dokumen dibandingkan dengan dokumen-dokumen lain yang memiliki istilah yang sama. Sehingga jika sebuah istilah mempunyai frekuensi kemunculan yang sama pada dua dokumen belum tentu mempunyai bobot yang sama.
17 Dimana :
w(t,d) adalah bobot dari term t dalam dokumen d. tf(t,d) adalah frekuensi term dalam dokumen(tf).
N merupakan ukuran data training yang digunakan untuk penghitungan IDF.
nt adalah jumlah dari dokumen yang ditraining yang mengandung nilai t.
Fungsi metode ini adalah untuk mencari representasi nilai dari tiap-tiap dokumen dari suatu kumpulan data training (training set).
2.3.1 Metode TF/IDF
Metode TF/IDF (Robertson, 2005) merupakan suatu cara untuk memberikan bobot hubungan suatu kata (term) terhadap dokumen. Metode ini menggabungkan dua konsep untuk perhitungan bobot yaitu, frekuensi kemunculan sebuah kata didalam sebuah dokumen tertentu dan inverse frekuensi dokumen yang mengandung kata tersebut. Frekuensi kemunculan kata didalam dokumen yang diberikan menunjukan seberapa penting kata tersebut didalam dokumen. Frekuensi dokumen yang mengandung kata tersebut menunjukkan seberapa umum kata tersebut muncul. Sehingga bobot hubungan antara sebuah kata dan sebuah dokumen akan tinggi apabila frekuensi kata tersebut tinggi, didalam dokumen dan frekuensi keseluruhan dokumen yang mengandung kata tersebut rendah pada kumpulan dokumen (database).
18 Wij = tfij * IDF
Wij = tfij * Log(N/n) Dimana:
Wij = bobot kata (term) tj terhadap dokumen di tfij = jumlah kemunculan kata/ term tj dalam di
N = jumlah semua dokumen yang ada dalam database n = banyaknya dokumen yang mengandung kata (term)
Berdasarkan rumus diatas, berapapun besarnya tfij, apabila N = n maka akan didapatkan hasil 0 (nol) untuk perhitungan IDF. Untuk itu dapat ditambahkan nilai 1 (satu) pada sisi IDF, sehingga perhitungan bobotnya menjadi seperti berikut:
Wij = tfij *( Log(N/n) +1)
Untuk menstandarisasi nilai bobot kedalam interval 0 sampai dengan 1, maka rumus Tf-Idf yang menggunakan normalisasi menjadi seperti berikut:
Dimana:
Wij = bobot kata (term) tj terhadap dokumen di tfij = jumlah kemunculan kata/ term tj dalam di
tfik = jumlah kemunculan kata/ term tj dalam semua dokumen N = jumlah semua dokumen yang ada dalam database n = banyaknya dokumen yang mengandung kata (term)
19
Gambar 2.4 Ilustrasi Algoritma TF/IDF
Perhitungan hubungan Term t1 dalam dokumen D2 :
w13 = 3*(Log(5/3)+1) w13 = 3* 1.221849 w13 = 3.665546
Keterangan:
D1,D2,D3,D4,D5 = dokumen
tf = banyaknya kata yang dicari pada sebuah dokumen D = total dokumen
df = banyaknya dokumen yang megandung kata yang dicari. W = bobot dokumen terhadap kata yang dicari
20
2.3.2 Ilustrasi TF/IDF
Query / Kata kunci(kk) = joni susi bungkus Dokumen 1 (D1) = joni adu bungkus
Dokumen 2 (D2) = susi adu lari bungkus roti Dokumen 3 (D3) = susi susi adu lari lari roti Jumlah dokumen (D) = 3
Tabel 2.6 Perhitungan TF/IDF
2.4 Teknik- teknik temu kembali informasi
Salah satu teknik temu- kembali informasi yang sudah dikembangkan yaitu teknik vector space model (model ruang vektor). Untuk lebih jelasnya mengenai teknik model ruang vektor ini dapat dilihat pada penjelasan berikut.
2.4.1 Model Ruang Vektor (Vector Space Model)
21 sebagai vektor berdimensi n. Sebagai contoh terdapat 3 buah kata (T1, T2 dan T3), 2 buah dokumen (D1 dan D2) serta sebuah query Q. Masing-masing bernilai :
D1 = 2T1+3T2+5T3 D2 = 3T1+7T2+0T3 Q = 0T1+0T2+2T3
Gambar 2.5 Representasi dokumen dan vektor pada ruang vektor
Koleksi dokumen direpresentasikan dalam ruang vektor sebagai matriks kata-dokumen (terms-documents matrix). Nilai dari elemen matriks wij adalah
bobot kata i dalam dokumen j. Misalkan terdapat sekumpulan kata T sejumlah n, yaitu T = (T1, T2, … , Tn) dan sekumpulan dokumen D sejumlah m, yaitu D =
(D1, D2, … , Dm) serta wij adalah bobot kata i pada dokumen j. Maka representasi
22
T1 T2 …. Tn
D1 w11 w21 … wn1
D2 w12 w22 … wn2
: : : :
: : : :
Dm w1m w2m … wnm
Penentuan relevansi dokumen dengan query dipandang sebagai pengukuran kesamaan (similarity measure) antara vektor dokumen dengan vektor query. Semakin “sama” suatu vektor dokumen dengan vektor query maka dokumen dapat dipandang semakin relevan dengan query. Salah satu pengukuran kesesuaian yang baik adalah dengan memperhatikan perbedaan arah (direction difference) dari kedua vektor tersebut. Perbedaan arah kedua vektor dalam geometri dapat dianggap sebagai sudut yang terbentuk oleh kedua vektor. Gambar 2.5 mengilustrasikan kesamaan antara dokumen D1, dan D2 dengan query Q.
Sudut Ө1 menggambarkan kesamaan dokumen D1 dengan query sedangkan sudut
23 Gambar 2.6 Representasi grafis sudut vector dokumen dan query
Jika Q adalah vektor query dan D adalah vektor dokumen, yang
merupakan dua buah vektor dalam ruang berdimensi-n, dan Ө adalah sudut yang dibentuk oleh kedua vektor tersebut. Maka :
θ
Q • D adalah hasil perkalian dalam (inner product) kedua vektor, sehingga jika Q = (0t1, 0t2, 2t3)
24
Kedekatan query dan dokumen diindikasikan dengan sudut yang dibentuk. Nilai cosinus yang cenderung besar mengindikasikan bahwa dokumen cenderung sesuai query. Nilai cosinus sama dengan 1 mengindikasikan bahwa dokumen sesuai dengan dengan query.
2.4.2 Ilustrasi perhitungan Model Ruang Vektor (Vector Space Model)
Tabel 2.7 Perhitungan Vector Space Model
25
Sqrt Sum(Di) = 𝑺𝑸𝑹𝑻( 𝒏𝒋=𝟏𝑫𝒊𝟐,𝒋)
dimana j = kata didalam database
maka untuk perhitungan Sqrt Sum(Di) = 𝑺𝑸𝑹𝑻( 𝒏𝒋=𝟏𝑫𝟐𝟐,𝒋)
= 0 + 0.2 + 0.3333 + 0.2 + 0.5 + 0.5
= 1.7333
= 1.3166
Sum(Q • Di) = ( 𝒏𝒋=𝟏𝑸𝒋𝑫𝒊,𝒋)
dimana j = kata didalam database
maka untuk perhitungan Sum(Q • Di) = ( 𝒏𝒋=𝟏𝑸𝒋𝑫𝟑,𝒋)
=0 + 0.16 + 0 + 0 + 0 + 0 = 0.16
Menghitung Cosinus sudut antara vektor query dengan vektor data :
Cosine (Di) = SUM (q • Di ) / [sqrt(q)*sqrt(Di)] D1 = 1.25 / (1.3038405*1.35401) = 0.70805
D2 = 0.29 / (1.3038405*1.3166) = 0.16894
26 Tabel 2.8 Hasil perhitungan vector space model
D1 0.70805 rangking 1
D2 0.16894 rangking 2
D3 0.07867 rangking 3
2.5 Contoh proses pencarian lirik lagu secara manual
Contoh proses pencarian lirik lagu menggunakan metode ruang verktor secara manual disertakan dalam lampiran 1.
2.6 Evaluasi Sistem Temu Kembali Informasi
Dalam bidang temu kembali informasi (information retrieval) terdapat berbagai metode yang digunakan dalam pembobotan kata, pengukuran kesesuaian, perangkingan, umpan balik relevansi, model sistem temu kembali informasi dan lain-lain. Sehingga diperlukan suatu ukuran sebagai perbandingan keefektifan metode-metode tersebut.
Tujuan dari sistem temu kembali informasi yang ideal adalah : 1. Menemukan seluruh dokumen yang relevan terhadap suatu query.
2. Hanya menemukan dokumen relevan saja, artinya tidak terdapat dokumen yang tidak relevan pada dokumen hasil pencarian.
Dua keadaan tersebut digunakan untuk menghitung performansi sistem temu kembali, yaitu recall dan precision.
27 Sedangkan precision dinyatakan sebagai bagian dokumen relevan yang
ditemukan:
Keduanya menggambarkan performansi dari sistem temu kembali informasi dengan melakukan perhitungan terhadap jumlah dokumen relevan hasil pencarian.
Tabel 2.9 Tabel Perhitungan Recall and Precision
Relevan Tidak Relevan Total
Ditemukan (a) 1 (b)0 (a+b) 1
Tidak Ditemukan (c) 0 (d) 0 (c+d) 0
28
BAB III
ANALISIS DAN PERANCANGAN
3.1 Analisa Sistem
Pada bagian ini akan dijelaskan mengenai analisis sistem, metode pengumpulan data dan perancangan sistem mesin pencari data lirik dan lagu dalam koleksi lagu.
3.1.1 Analisis Kebutuhan
Kebutuhan yang dibutuhkan oleh pengguna dari mesin pencari data lirik dan lagu dalam koleksi lagu adalah:
1. Pengguna membutuhkan program untuk membantu dalam mencari dokumen dari koleksi lirik lagu yang sesuai dengan penggalan lirik yang diinginkan.
2. Administrator membutuhkan program yang dapat secara otomatis melakukan proses indexing ketika user menambahkan dokumen baru ke dalam koleksi lirik.
3. Administrator membutuhkan program yang dapat mengelola atau memanage daftar stoplist dan kamus baik untuk menambah, merubah, atau menghapus daftar stoplist.
3.2 Metode Pengumpulan Data
29 didapatkan dari media CD lagu dan internet. Data lirik yang didapat, akan melalui proses pemindahan ke dalam bentuk data teks (.txt) secara manual. Penamaan dokumen lirik berdasarkan judul lagu yang didapatkan dari media CD lagu dan internet, pada proses pengumpulan data tidak dilakukan pemeriksaan mengenai kebenaran data, baik data lirik maupun lagu karena penulis hanya mengacu pada data yang disediakan oleh sumber.
3.3Perancangan Sistem
3.3.1 Model Use Case
3.3.1.1Aktor
Dalam mesin pencari data lirik dan lagu dalam koleksi lagu hanya terdapat dua aktor yang terlibat yaitu Administrator dan User.
Tabel 3.1 Tabel Aktor yang terlibat
Aktor Hak Akses
Administrator Login
Menambah, mengedit, dan menghapus data stopword
Menambah, mengedit, dan menghapus data kamus
Menambah data lirik dengan melakukan indexing
Menambah data lagu bersamaan dengan proses indexing data lirik
Mengedit password
30
Memutar lagu, sesuai dengan data yang didapat dari hasil pencarian data lirik
Logout
Pengguna/ User Melakukan pencarian data lirik
31
3.3.1.2Diagram Use Case
Terdapat delapan use case dalam mesin pencari data lirik dan lagu dalam koleksi lagu yaitu: tambah dokumen lagu, tambah daftar stoplist, rubah daftar stoplist, hapus daftar stoplist, tambah daftar kamus, rubah daftar kamus, hapus daftar kamus, dan cari dokumen lirik. Untuk use case tambah daftar stoplist, rubah daftar stoplist, dan hapus daftar stoplist dijadikan dalam satu package yakni manage stoplist. Begitu juga untuk use case tambah kamus, ubah kamus, dan hapus kamus dijadikan dalam satu package manage kamus. Untuk lebih jelasnya dapat dilihat dalam gambar 3.1 di bawah ini:
32
3.3.1.3Tabel Use Case
Tabel 3.2 Tabel Use Case
Nama Use Case Keterangan Aktor
Login Verifikasi untuk mengakses menu utama dengan cara memasukkan username dan password
Administrator
Logout Keluar dari Program Administrator
Indexing Menambah koleksi dokumen lirik dan lagu yang ada
Administrator
Mengelola daftar stoplist Menambah, merubah, dan menghapus data dalam daftar stoplist
Administrator
Mengelola kamus Menambah, merubah dan menghaopus data dalam kamus
Administrator
Cari dokumen Mencari dokumen dalam koleksi dokumen yang sesuai dengan kriteria yang diinginkan
Administrator, User
3.3.1.4Tabel Skenario Use Case
Tabel 3.3 Tabel Skenario Use Case Login
Use Case : Login
Aktor : Administrator
Trigger :Usecase ini berjalan ketika Administrator mengeksekusi menu login
Aksi Aktor Reaksi Sistem
Skenario Normal
1. Aktor memanggil halaman Login admin
2.Sistem menampilkan halaman login admin
3. Aktor mengisi password 4.Aktor menekantombol login
33 6. Sistem menampilkan form halaman Aktor
Skenario Alternatif
5.Jika password salah maka sistem akan menampilkan pesan dialog bahwa password yang dimasukkan salah Tabel 3.4 Tabel Skenario Use Case Logout
Use Case : Logout Aktor : Administrator
Trigger :Usecase ini berjalan ketika Administrator mengeksekusi menu logout
Aksi Aktor Reaksi Sistem
Skenario Normal
1. Aktor mengeksekusi menu logout
2.Sistem keluar dari halaman administrator, kembali ke halaman pengguna
Tabel 3.5 Tabel Skenario Use Case Indexing Use Case : Indexing
Aktor : Administrator
Trigger :Usecase ini berjalan ketika Administrator mengeksekusi menu indexing
Aksi Aktor Reaksi Sistem
Skenario Normal
1. Aktor mengeksekusi menu indexing
2.Sistem menampilkan halaman indexing
3. Aktor memilih file lirik dengan mengeksekusi tombol browse 4. Aktor memilih file lagu dengan mengeksekusi tombol browse 5.Aktor mengeksekusitombol indexing
6. Sistem melakukan proses indexing 7. Apabila proses berhasil, Sistem menampilkan pesan dialog bahwa proses indexing berhasil
Skenario Alternatif
34 Tabel 3.6 Tabel Skenario Use Case Tambah Stoplist
Use Case : Tambah Stoplist Aktor : Administrator
Trigger :Usecase ini berjalan ketika Administrator mengeksekusi menu Stoplist
Aksi Aktor Reaksi Sistem
Skenario Normal
1. Aktor mengeksekusi menu stoplist
2.Sistem menampilkan halaman stoplist
3. Aktor memasukkan stoplist baru 4.Aktor mengeksekusitombol Add
5. Sistem melakukan proses input ke dalam daftar stoplist
Tabel 3.7 Tabel Skenario Use Case Edit Stoplist Use Case : EditStoplist
Aktor : Administrator
Trigger :Usecase ini berjalan ketika Administrator mengeksekusi menu Stoplist
Aksi Aktor Reaksi Sistem
Skenario Normal
1. Aktor mengeksekusi menu stoplist
2.Sistem menampilkan halaman stoplist
3. Aktor memilih stoplist yang akan di edit dari daftar
4. Aktor melakukan edit kata
5.Aktor mengeksekusitombol Edit
6. Sistem melakukan proses update ke dalam daftar stoplist
Tabel 3.8 Tabel Skenario Use Case hapus Stoplist Use Case : Hapus Stoplist
Aktor : Administrator
Trigger :Usecase ini berjalan ketika Administrator mengeksekusi menu Stoplist
Aksi Aktor Reaksi Sistem
Skenario Normal
1. Aktor mengeksekusi menu stoplist
35 3. Aktor memilih stoplist yang akan di
hapus dari daftar
4.Aktor mengeksekusitombol delete
6. Sistem melakukan proses delete kata dari daftar stoplist
Tabel 3.9 Tabel Skenario Use Case Tambah Kamus Use Case : Tambah Kamus
Aktor : Administrator
Trigger :Usecase ini berjalan ketika Administrator mengeksekusi menu Dictionary
Aksi Aktor Reaksi Sistem
Skenario Normal
1. Aktor mengeksekusi menu dictionary
2.Sistem menampilkan halaman dictionary
3. Aktor memasukkan dictionary baru 4.Aktor mengeksekusitombol Add
5. Sistem melakukan proses input ke dalam daftar dictionary
Tabel 3.10 Tabel Skenario Use Case Edit Kamus Use Case : Edit Kamus
Aktor : Administrator
Trigger :Usecase ini berjalan ketika Administrator mengeksekusi menu Dictionary
Aksi Aktor Reaksi Sistem
Skenario Normal
1. Aktor mengeksekusi menu dictionary
2.Sistem menampilkan halaman dictionary
3. Aktor memilih dictionary yang akan di edit dari daftar
4. Aktor melakukan edit kata
5.Aktor mengeksekusitombol Edit
36 Tabel 3.11 Tabel Skenario Use Case Hapus Kamus
Use Case : Hapus Kamus Aktor : Administrator
Trigger :Usecase ini berjalan ketika Administrator mengeksekusi menu Dictionary
Aksi Aktor Reaksi Sistem
Skenario Normal
1. Aktor mengeksekusi menu dictionary
2.Sistem menampilkan halaman dictionary
3. Aktor memilih dictionary yang akan di hapus dari daftar
4.Aktor mengeksekusitombol delete
6. Sistem melakukan proses delete kata dari daftar dictionary
Tabel 3.12 Tabel Skenario Use CaseSearching Use Case : Searching
Aktor : Administrator dan User
Trigger :Usecase ini berjalan ketika Administrator mengeksekusi menu Searching
Aksi Aktor Reaksi Sistem
Skenario Normal
1. Aktor mengeksekusi menu searching
2.Sistem menampilkan halaman searching
3. Aktor memasukkan kata kunci 4. Aktor mengeksekusi tombol search
5. Sistem melakukan proses searching 6. Apabila proses berhasil, Sistem menampilkan daftar judul lagu yang sesuai dengan kata kunci dengan rangking tertinggi berada paling atas. 5. Aktor memilih judul lagu
7. Sistem menampilkan lirik lagu dan tombol media player (play dan stop)
Skenario Alternatif
6.Apabila proses gagal, Sistem
menampilkan pesan dialog bahwa data tidak ditemukan
37 pada mediaplayer
9. Sistem memutar lagu 10. Aktor mengeksekusi tombol stop
pada mediaplayer
11. Sistem berhenti memutar lagu
3.3.2 Bagan Alir Program
Bagan alir program (program Flowchart ) merupakan bagan yang menjelaskan secara rinci langkah-langkah dari proses program. Bagan ini terdiri dari dua macam, yaitu bagan blok digaram dan alir logika program (program logic Flowchart . Bagan blok digaram digunakan untuk menjelaskan urutan langkah proses dalam program. Bagan alir program digunakan untuk menggambarkan tiap-tiap langkah di dalam program komputer secara logika.
3.3.2.1. Algoritma proses indexing
38
X bentuk kata dasar Merubah kata ke
(stemming)
Copy Dokumen ke lokasi yang ditentukan
Dok1 Dok2 Dokumen Simpan nama dokumen ke
database Ambil nama dokumen
Kata cari Term Simpan daftar kata ke
database Hapus
Stopword
Gambar 3.2 Ilustrasi Proses Indexing
39
40 Berikut ini adalah penjelasan untuk setiap proses dalam proses indexing dokumen:
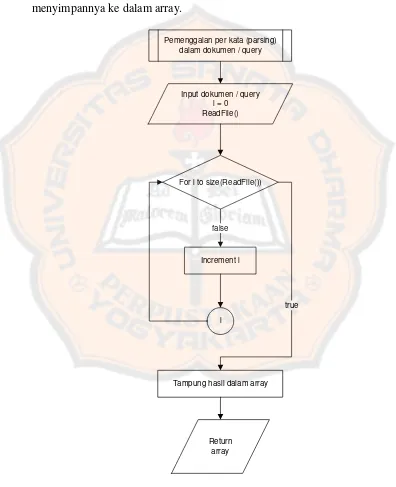
1. Parsing ke dalam array
Proses ini berfungsi untuk memotong-motong dokumen kata per kata dan menyimpannya ke dalam array.
Pemenggalan per kata (parsing) dalam dokumen / query
Input dokumen / query i = 0 ReadFile()
For i to size(ReadFile())
Tampung hasil dalam array Increment i
i
Return array false
true
41 2. Proses penghapusan stopword dari array
42
Remove Stopword dari array
Kata - array[i] i to jumlah array
j to jumlah stopword
If kata = stopword[ j]
j
Jadikan kata array [i] sebagai kata
penting
i
Return seluruh kata penting dari dokumen / query
yang dipilih
Remove array [i] true
true
false false
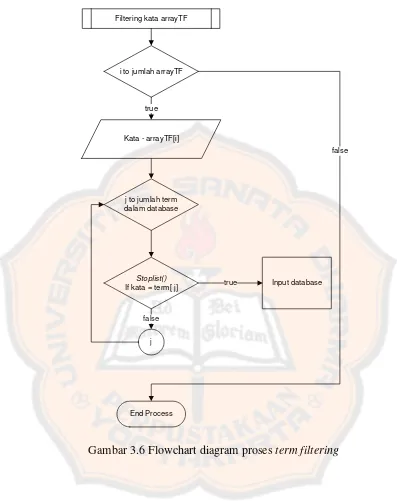
43 3. Proses TermFiltering
44
Filtering kata arrayTF
Kata - arrayTF[i] i to jumlah arrayTF
j to jumlah term dalam database
Stoplist()
If kata = term[ j]
j
Input database true
true
false
false
End Process
Gambar 3.6 Flowchart diagram proses term filtering
4. Proses Stemming
Proses ini digunakan untuk mencari kata dasar dari kata yang ada dalam array, proses stemming menggunakan algoritma Porter Stemmer for Bahasa Indonesia yang di terapkan di dalam kelas Tokenizer() milik Bapak Puspaningtyas Sanjaya Adi, S.T, M.T.
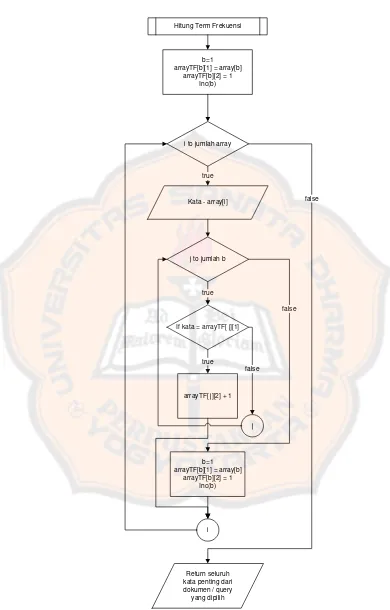
46 Hitung Term Frekuensi
Kata - array[i] i to jumlah array
j to jumlah b
If kata = arrayTF[ j][1]
j
47 6. Proses Perhitungan Bobot
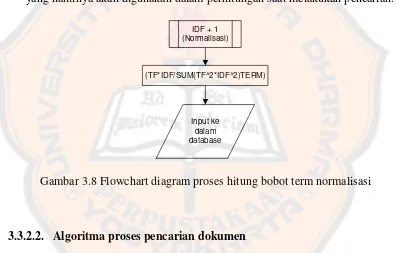
Proses perhitungan bobot ini dilakukan berdasarkan hasil perhitungan TF-IDF. Hasil IDF dari perhitungan TF-IDF kemudian dinormalisasi dengan menambahkan angka 1 (satu) pada IDF yang kemudian disimpan kedalam field IDF-Normalisasi pada tabel ta_term. Untuk mendapatkan bobot normalisasi, maka dilakukan perhitungan pada sistem sehingga menghasilkan bobot normalisasi yang kemudian disimpan kedalam database sebagai bobot yang nantinya akan digunakan dalam perhitungan saat melakukan pencarian.
IDF + 1 (Normalisasi)
(TF*IDF/SUM(TF^2*IDF^2)TERM)
Input ke dalam database
Gambar 3.8 Flowchart diagram proses hitung bobot term normalisasi
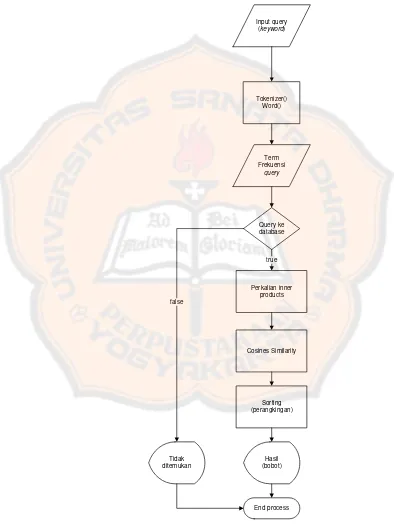
3.3.2.2. Algoritma proses pencarian dokumen
48
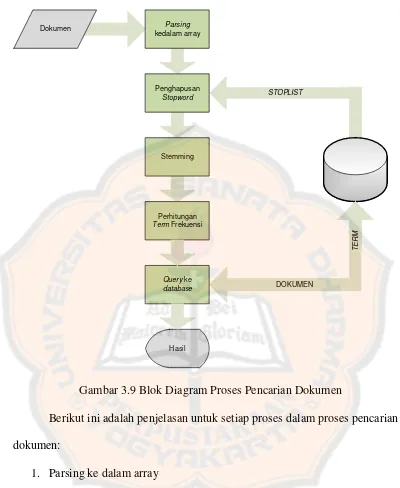
Gambar 3.9 Blok Diagram Proses Pencarian Dokumen
Berikut ini adalah penjelasan untuk setiap proses dalam proses pencarian dokumen:
1. Parsing ke dalam array
Proses parsing dari query ke dalam array sama dengan proses parsing dokumen ke dalam array.
2. Proses penghapusan stopword dari array
49 3. Proses Stemming
Proses ini digunakan untuk mencari kata dasar dari kata yang ada dalam array, proses stemming menggunakan algoritma Porter Stemmer for Bahasa Indonesia yang di terapkan di dalam kelas Tokenizer() milik Bapak Puspaningtyas Sanjaya Adi, S.T, M.T.
4. Proses Perhitungan Term Frekuensi
50 5. Proses query ke database
Proses query ke database dilakukan untuk mencari daftar term beserta bobotnya, dan daftar dokumen. Bobot kata berdasarkan bobot TF-IDF, proses perhitungan bobot kata dilakukan pada sisi database yakni dengan menambahkan formula pada query (queryTF[][]) dan dokumen (arrayTF[][]). Dari query dan dokumen akan menghasilkan ResultSet berupa daftar bobot tiap term serta dokumen yang berhubungan dan nilai IDF untuk setiap term. Untuk mendukung perhitungan cosines similarity antara term dokumen dan query, setiap bobot term hasil pada TF-IDF dilakukan perhitungan terlebih dahulu.
6. Proses perhitungan Vector Space Model
51 menentukan urutan rangking dari dokumen yang berhasil di dapatkan dari proses query, selanjutnya setelah array hasil[][] selesai diurutkan akan ditampilkan kepada user.
Input query
52
3.3.3 Perancangan Database
Berikut ini langkah-langkah yang akan dilakukan dalam perancangan database, yaitu :
a) Conceptual Database Design b) Logical Database Design c) Physical Database Design
Conceptual Database Design
53
Gambar 3.12 Relasi Antar Tabel Physical Database Design
Desain dari basis data yang akan digunakan dalam program mesin pencari data lirik dan lagu dalam koleksi lagu dapat dijabarkan sebagai berikut
1. Tabel ta_term
Tabel term berisikan data daftar term atau kata ,Df (Document Frequency) dan Idf (Inverse Document Frequency) dalam database.
Nama Tabel : ta_term Nama Field Kunci : id_term
Tabel ini berisi sejumlah field yang dijabarkan sebagai berikut Tabel 3.13 Tabel Term
Nama Field Tipe Data Ukuran Keterangan
54 Term Varchar 100 Isi term atau kata
Df Integer 255 Jumlah Dokumen
Idf Double 6.5 Bobot kata
2. Tabel ta_indek
Tabel ta_indek berisikan data daftar id_index, id_term, id_lirik, tf (term frekuensi) dan bobot dalam database.
Nama Tabel : ta_indek Nama Field Kunci : id_term_list
Tabel ini berisi sejumlah field yang dijabarkan dalam tabel 3.3 Tabel 3.14 Tabel Term_List
Nama Field Tipe Data Ukuran Keterangan
Id_index Integer 255 Sebagai field kunci tabel term_list
Id_term Integer 255 Sebagai Foreign key dari tabel term
Id_lirik Integer 255 Sebagai Foreign key dari tabel dokumen
Tf Integer 255 Jumlah term frekuensi atau jumlah kemunculan kata
bobot Double 6.5 Bobot kata
3. Tabel ta_doclyric
Tabel ta_doclyric berisikan data daftar id_lyric, title, dan song dalam database.
55 Nama Field Kunci : id_lyric
Tabel ini berisi sejumlah field yang dijabarkan dalam tabel 3.4 Tabel 3.15 Tabel ta_doclyric
Nama Field Tipe Data Ukuran Keterangan
Id_Lirik Integer 255 Sebagai field kunci tabel dokumen
title Varchar 100 Link dokumen lirik song Varchar 100 Link dokumen lagu
4. Tabel ta_kamus
Tabel ta_kamus berisikan data daftar kata dasar dalam database. Nama Tabel : ta_kamus
Nama Field Kunci : kata_dasar
Tabel ini berisi sejumlah field yang dijabarkan dalam tabel 3.4 Tabel 3.16 Tabel ta_kamus
Nama Field Tipe Data Ukuran Keterangan
Kata_dasar Varchar 50 Sebagai field kunci sekaligus berisi kata dasar dalam tabel ta_kamus
5. Tabel ta_stoplist
Tabel term berisikan data daftar stopword dalam database. Nama Tabel : ta_stoplist
Nama Field Kunci : id_stopword
56 Tabel 3.17 Tabel Stoplist
Nama Field Tipe Data Ukuran Keterangan
Id_stopword Integer 255 Sebagai field kunci tabel stoplist stopword Varchar 100 Isi stopword daftar kata buang
6. Tabel Admin
Tabel admin berisikan data daftar admin dalam database.
Nama Tabel : Admin
Nama Field Kunci : id_admin
Tabel ini berisi sejumlah field yang dijabarkan dalam tabel 3.6 Tabel 3.18 Tabel ta_admin
Nama Field Tipe Data Ukuran Keterangan
Id_user Integer 100 Sebagai field kunci tabel admin Password Varchar 100 Isi password daftar admin
3.4 Perancangan Antarmuka (Interface)
57 1. Desain Menu Utama
Gambar 3.13 Desain Menu Utama
Form ini adalah form utama untuk user, dari form ini user dapat memilih menu yang diinginkan dengan menekan tombol yakni tombol Cari Dokumen, Help , About, dan Login.
2. Desain Form Pencarian
Gambar 3.14 Desain Form Pencarian
58 user atau admin, user atau admin dapat memasukkan kata kunci yang diiginkan pada jTextField1, kemudian menekan tombol cari dokumen. Daftar dokumen yang berhasil didapatkan akan ditampilkan pada ItemList. Untuk membaca isi dokumen user cukup memilih nama dokumen yang ada dalam daftar ItemList, dan program akan menampilkan isinya dalam jTextArea. Untuk memutar lagu dari dokumen user dapat menekan tombol Play dan tombol Stop untuk menghentikan lagu. Untuk mereset ulang pencarian cukup dengan menekan tombol Reset.
3. Desain Form Login
Gambar 3.15 Desain Form Login
59 4. Desain Form Menu Utama Admin
Gambar 3.16 Desain Form Menu Utama Admin
Form ini adalah form utama untuk administrator, pada form ini administrator dapat memilih menu yang diinginkan dengan menekan tombol yang disediakan yakni tombol Tambah Dokumen, Manage Stoplist, Logout, About dan Help.
5. Desain Form Admin Tambah Dokumen
Gambar 3.17 Desain Form Tambah Dokumen
60 akan ditambahkan, pada data lirik, dokumen yang dapat diproses hanya data yang mempunyai ekstensi *.txt. sedangkan pada data lagu data yang dapat diproses hanya data yang mempunyai ekstensi *.mp3. Tombol Reset digunakan untuk mereset isi dari jTextField ke kondisi kosong, sementara tombol Simpan Dokumen digunakan untuk menyimpan dokumen ke koleksi, dan secara otomatis akan melakukan proses indexing untuk data lirik ke dalam database. Konfirmasi dari proses ini akan ditampilkan pada bagian Konfirmasi penyimpanan dokumen. 6. Desain Form Admin Manage Stoplist
Gambar 3.18 Desain Form Manage Stoplist
61 dapat secara langsung memilih data yang ingin dirubah atau dihapus, yang kemudian ditampilkan dalam jTextFiled2.
3.5. Class Diagram
Class Diagram merupakan alat yang digunakan pada metodologi pengembangan sistem berorientasi objek. Class Diagram menggambarkan struktur sistem dari kelas- kelas beserta interaksinya.
Adapun rancangan Class Diagram dari mesin pencari data lirik dan lagu dalam koleksi lagu adalah sebagai berikut :
63 2. Class Diagram Searching
64
BAB IV
IMPLEMENTASI
4.1 Spesifikasi Software dan Hardware yang digunakan
4.1.1Spesifikasi Software
Sistem Operasi Microsoft Windows 7 Ultimate
Basis Data MySql Server 5.1
Bahasa Pemrograman Java J2SE
4.1.2Spesifikasi Hardware
Processor Intel Dual Core 1.8 GHz
Memory RAM 2GB DDR2
HardDisk 80 GB
4.2 Koneksi Basis Data MySql dengan Sistem
Untuk menghubungkan sistem dengan basis data MySql yang berfungsi untuk menyimpan data dari proses yang terdapat pada system.
Driver koneksi basis data menggunakan MySql JDBC Driver dengan lokasi basis data pada localhost, port 3306 dengan nama basis data db_ta. untuk koneksi ke dalam server basis data menggunakan user dengan nama “root” dan password dikosongkan ( “ “ ).
4.3. Core Sistem Mesin Pencari
4.3.1. Core Sistem untuk Indexing
66
4.3.2. Core Sistem untuk Searching
Input “keyword” String
hasilPencarian tipe data Vector
token obyek Class Tokenizer
token.setData(keyword)
token.makeTokens()
termTmp tipe data List
termTmp = token.getParsing()
termCari List obyek ArrayList
67
A.Proses pengambilan data ke data base
sim obyek TaIndek
hasilSimilarity obyek ArrayList
trm3 = null tipe data Term
allSImTmp obyek ArrayList
68
B. Hitung Total bobot Query kuadrat
for a = 0 to allSimTmp.size()
simTmp tipe data TaIndek
simTmp allSImTmp.get(a)
bobotQueryNorm = (simTmp.getBobot()*simTmp.getBobot())
SUMBobotQuery = SUMBobotQuery + bobotQueryNorm
End for
hslSimilarity obyek ArrayList
for i =0 to TaLyric.getLyricList().size()
tmp tipe data TaLyric
tmp = lirikList.get(i)
simKat tipe data List
simKat = sim.getSimilarityDokumen(cariKata,tmp.getId_lyric())
simAllKat tipe data List
simAllKat = sim.getSimilarityAllDokumen(tmp.getId_lyric())
hasilPencarian.add(tmp.getId_lyric())
B-1. Cek kesamaan Term INNER PRODUCT (VSM)
69
B-2. Hitung total bobot query index j
for g =0 to simAllKat.size()
C. Menampung hasil pencarian
70
D. Mengurutkan hasil Pencarian (Sorting)
71 return hslAkhir;
End for
4.4Pembuatan Antarmuka (Interface)
Antarmuka merupakan tampilan yang nantinya akan berinteraksi langsung dengan pengguna. Antarmuka untuk aplikasi program ini adalah sebagai berikut:
4.4.1 Halaman Menu Utama Pengguna
72 Gambar 4.1 Halaman Utama User
4.4.2 Halaman Pencarian
74
4.4.3 Halaman About
Halaman About berisi tentang informasi data diri pembuat program.
Gambar 4.3 Form About
4.4.4 Halaman Login
Halaman ini digunakan untuk proses login administrator. Untuk masuk ke dalam halaman menu utama administrator, maka administrator harus memasukkan password ke dalam password field yang terdapat di dalam halaman login. Akan tetapi apabila password salah, maka akan muncul pesan bahwa password yang dimasukkan salah.
75
4.4.5 Halaman Menu Utama Administrator
Halaman menu utama administrator akan ditampilkan jika proses login sukses. Pada halaman ini di dalamnya terdapat dua menubar, yaitu menubar File dan menubar Edit. Pada menubar File terdapat menu Indexing yang digunakan untuk menampilkan halaman indexing, menu Searching untuk menampilkan halaman pencarian, dan menu Logout untuk keluar dari halaman menu utama administrator, kembali ke halaman menu utama pengguna. Sedangkan pada menubar Edit terdapat menu Password untuk menampilkan halaman edit password, menu Stopword untuk menampilkan halaman pengelolaan stopword, dan menu Dictionary untuk menampilkan halaman pengelolaan kamus (kata dasar).
Gambar 4.5 Halaman Utama Administrator
4.4.6 Halaman Indexing
76 dokumen lirik (teks). Dalam proses indexing, dokumen teks melewati lima proses, yaitu proses pemotongan kata (parsing), penghapusan stopword, stemming, perhitungan term frequency (Tf), dan filtering.
Gambar 4.6 Halaman Indexing
4.4.7 Halaman Searching
Halaman searching pada menu administrator, merupakan halaman yang sama dengan halaman searching pada menu user dengan proses yang sama. ( Gambar 4.2 Hasil Pencarian Pada Form Search )
4.4.8Halaman Edit Password
77 yang lama. Jika autentikasi bernilai benar, maka password lama akan diganti dengan password yang baru dan akan muncul pesan konfirmasi bahwa password telah sukses diubah, jika bernilai salah, maka akan muncul pesan konfirmasi bahwa password lama salah.
Gambar 4.7 FormManage Password Administrator
4.4.9 Halaman Edit Stopword
78 Gambar 4.8 FormManage Stopword Administrator
4.4.10 Halaman Edit Dictionary
79 Gambar 4.9 FormManage Dictionary ( kamus )
4.5. Dokumentasi Program
80
BAB V
ANALISA HASIL
5.1.Proses Indexing
Gambar 5.1 Halaman Indexing
Pada proses indexing, administrator akan memasukkan dokumen teks yang berekstensi .txt ke dalam file input pada form indexing dengan mencari letak dokumen tersebut menggunakan tombol browse. Begitu juga dengan data lagu yang akan dimasukkan. Setelah kedua data dimasukkan ke dalam file input, kemudian administrator harus menekan tombol indexing untuk memulai proses indexing dokumen.
81 setiap term.
Pada percobaan, penulis menggunakan dokumen sebanyak 78 dokumen. Pada dokumen ke 78, interval waktu yang diperlukan untuk proses indexing kurang lebih 10 menit, dan untuk proses indexing terhadap semua data yang ada membutuhkan waktu lebih kurang 20 jam (efisien).
Gambar 5.2 pesan dialog Indexing berhasil.
82
5.2.Proses Pencarian ( Searching )
Gambar 5.3 Halaman Searching
83
5.3.Proses Edit Stopword dan Kamus (Dictionary)
Gambar 5.4 Halaman Edit Stopword
84 Pada halaman edit stopword dan dictionary (kamus), administrator dapat melakukan update terhadap data stopword dan kamus.
5.4.Analisa Hasil Kuisioner Responden
Pada sub bab ini akan dibahas mengenai evaluasi hasil dari implementasi mesin pencari data lirik dan lagu dalam koleksi data lirik dan lagu dengan media kuisioner yang dibagikan kepada 30 orang responden dari berbagai tingkat umur dan pekerjaan.
Pada media kuisioner responden diminta untuk menuliskan penggalan lirik lagu yang kemudian akan digunakan sebagai kata kunci untuk membantu pencarian data dengan menggunakan aplikasi mesin pencari data lirik dan lagu dalam koleksi lirik dan lagu. Dari hasil yang ditampilkan oleh aplikasi, responden dapat menentukan sesuai atau tidaknya data yang ditampilkan oleh sistem dengan hasil yang diinginkan oleh responden. Hasil yang diperoleh dari responden kemudian akan digunakan untuk menentukan nilai recall – precision. Untuk data pertanyaan kuisioner dan tabel hasil dari kuisioner terhadap responden dapat dilihat pada lampiran 3 dan 4.
Hasil yang diperoleh dari media kuisioner yang dibagikan kepada 30 orang responden berdasarkan kata kunci yang paling banyak digunakan oleh responden. Berikut adalah daftar kata kunci yang sering digunakan oleh responden untuk mencari dokumen:
Tabel 5.1 Tabel kata kunci responden
Responden Kata Kunci Dokumen
BERNADETA SUSILOWATI PP.
Kirana jamah aku, jamahlah rinduku
Kirana.txt
CHANDRA HUTAGAOL Kirana jamah aku, jamahlah rinduku
Kirana.txt
OPIK TRI HANDONO Kirana jamah aku, jamahlah rinduku
Kirana.txt
85 rinduku
Gambar 5.6 Hasil Pencarian (“Kirana jamah aku, jamahlah rinduku”)
Pada gambar di atas, bobot dokumen diperoleh dari nilai cosines similarity menggunakan metode model ruang vektor untuk kata kunci “Kirana jamah aku, jamahlah rinduku”. Urutan dokumen berdasarkan nilai cosines similarity dari yang paling besar ke yang paling kecil, apabila nilai cosines similarity dari dokumen bernilai 0 (nol), maka dokumen tidak dimunculkan didalam daftar dokumen. Berikut ini adalah tabel perangkingan bobot dari pencarian :
Tabel 5.2 Tabel perangkingan bobot pencarian responden
RANGKING DOKUMEN BOBOT
1 Kirana.txt 0.2431645
2 Restoe Boemi.txt 0.0571895
3 Larut.txt 0.0171347
86
5 Satu.txt 0.0086951
6 Cinta Kan Membawamu Kembali.txt 0.0076410 7 Perasaanku Tentang Perasaanku Kepadamu.txt 0.0075429
8 Pupus.txt 0.0072687
9 Ketika Tidak Sedang Bercinta Lagi.txt 0.0068708
10 Kangen.txt 0.0068533
11 Roman Picisan.txt 0.0057269
Dari hasil kuisioner yang didapatkan untuk kata kunci “Kirana jamah aku, jamahlah rinduku”, hubungan nilai recall-precision dapat ditampilkan dalam tabel di bawah ini :
Relevan Tidak Relevan Total
Ditemukan (a) 1 (b) 10 (a+b) 11
Dari recall – precision, dapat diketahui hasil uji performansi sistem dalam proses pencarian. Hasil uji performansi dihitung menggunakan rumus
𝐏=(𝐑𝐄𝐓𝐑𝐈𝐄𝐕𝐄𝐃𝐃𝐎𝐂.−𝐃𝐎𝐂.𝐑𝐀𝐍𝐊 + 𝟏)
𝐑𝐄𝐓𝐑𝐈𝐄𝐕𝐄𝐃𝐃𝐎𝐂.
Dimana
P = performansi