1
BAB II
LANDASAN TEORI
2.1
Knowledge base
Sebuah knowledge base adalah repositori informasi yang tersentralisasi. Sebuah perpustakaan publik, sebuah basis data yang terkait dengan informasi tentang subjek tertentu, dan berbagai macam web “what is” dapat dianggap sebagai contoh knowledge base [JOH07].
Dalam kaitannya dengan teknologi informasi, sebuah knowledge base adalah sebuah sumber yang machine-readable untuk memperoleh informasi, lebih umum dalam bentuk online, atau memiliki kapabilitas untuk diletakkan secara online. Sebuah knowledge base digunakan untuk mengoptimasi koleksi, organisasi, dan pengambilan informasi untuk sebuah organisasi atau untuk publik [JOH07].
Istilah knowledge seringkali disalahartikan dengan istilah informasi dan data, padahal tiga istilah tersebut memiliki arti yang berbeda. Data adalah sesuatu informasi yang bersifat mentah [DIK08] dan dapat berbentuk apapun. Contoh data adalah sebuah spreadsheet.
Informasi adalah data yang diberikan arti dengan koneksi relasi [DIK08]. Arti di sini dapat menjadi berguna, namun tidak selalu demikian. Informasi yang dihasilkan dengan melakukan query pada sebuah basis data relasional adalah salah satu contohnya.
Knowledge adalah sekumpulan informasi dalam bidang tertentu yang berguna. Ingatan manusia adalah salah satu contoh dari knowledge yang kita ketahui sehari-hari. Knowledge memiliki arti untuk mereka sendiri, namun tidak memiliki kemampuan untuk menghasilkan knowledge lanjutan sebagai turunan dari knowledge tersebut [DIK08].
2.1.1 Struktur Knowledge base
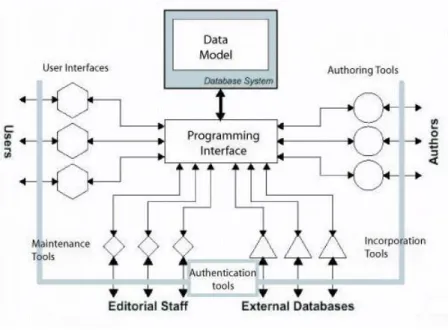
Struktur dari TUSK knowledge base [TUS08] dijadikan sebagai contoh dari sebuah struktur knowledge base. TUSK knowledge base adalah knowledge base dari TUFTS university di Amerika Serikat. Struktur TUSK divisualisasikan dengan Gambar II-1.
Gambar II-1 Struktur knowledge base pada TUSK
Dari Gambar II-1, dapat dilihat bahwa sebuah TUSK knowledge base terdiri dari bagian-bagian user interfaces, maintenance tools, authoring tools, incorporation tools, authentication tools, programming interface, dan model data sebagaimana dijabarkan berikut:
1. Data model
Struktur data yang digunakan adalah struktur data yang memberikan kemudahan untuk melakukan integrasi konten dengan menggunakan DBMS. Untuk TUSK, detail struktur data yang dimilikinya tidak dikemukakan kepada publik.
2. Programming interface
Antarmuka pemrograman berbasis objek didesain untuk menyembunyikan detail dari sistem basis data dan menyederhanakan operasi-operasi yang sering dilakukan oleh pengguna knowledge base, seperti penambahan, penghapusan, dan pengeditan informasi.
3. Authoring tools
Kakas penulisan diimplementasikan ke dalam knowledge base, agar sang pemilik informasi sewaktu-waktu dapat melakukan pengelolaan data mereka di dalam sistem, seperti pengeditan, atau penambahan informasi.
4. Incorporation tools
Program tertentu dibuat untuk memudahkan knowledge base untuk mengasosiasikan data dari sumber lainnya. Beberapa implementasinya adalah penambahan referensi URL ke dalam sebuah informasi di dalam knowledge base dan pertukaran informasi yang dimiliki dengan knowledge base lain.
5. Maintenance tools
Kakas administratif yang relatif simpel dibuat untuk memudahkan tugas dari manajemen informasi.
6. User Interface
Antarmuka pengguna yang ada disini merupakan sebuah tampilan yang memungkinkan pengguna untuk dapat melakukan pencarian informasi di dalam internal sebuah knowledge base dan di dalam jaringan knowledge base.
7. Authentication Tools
Kakas autentitikasi di sini diperuntukkan kepada administrator dan penulis untuk dapat melakukan autentikasi dirinya ketika berinteraksi dengan knowledge base.
2.1.2 Contoh Penerapan Knowledge base
Pada saat ini, sudah tersebar banyak sekali knowledge base yang dapat diakses dengan mudah dengan menggunakan internet browser saja. Setiap perusahaan besar yang memiliki bisnis berkaitan dengan teknologi informasi, atau bahkan yang tidak memiliki kaitan sekalipun, sudah
mulai menggunakan knowledge base sebagai alat untuk berkomunikasi dengan dunia luar, baik dengan pembeli maupun investor.
Selain perusahaan, universitas sebagai sebuah institusi juga sudah mulai menyediakan knowledge base sebagai gudang informasi yang akurat. Di sini hanya akan dibahas mengenai tiga buah contoh knowledge base yang dapat diakses dengan bebas oleh pengguna awam.
2.1.2.1 Apple Support
Apple Support (http://kbase.info.apple.com/) adalah sebuah knowledge base dari Apple Inc. yang berfungsi sebagai layanan bantuan bagi para pengguna jika ada masalah atau hal-hal yang ingin diketahui tentang produknya. Di dalam interface yang diberikan, Apple Support memberikan banyak pilihan tentang pencarian yang dilakukan.
Pencarian dapat dilakukan dengan pencarian terhadap artikel yang mengandung kata tertentu, mengandung lebih dari satu kata tertentu, atau bahkan dapat dilakukan pencarian tanpa kata tertentu yang telah ditentukan. Pilihan kategori yang diberikan dibuat dalam menu yang sederhana, namun menarik. Pengguna dapat memilih bahasa, produk, dan kategori tertentu dari informasi yang diinginkan.
Jika pengguna merupakan pengguna awam yang tidak ingin disulitkan dengan segala kerumitan pencarian tingkat lanjut, dapat juga memilih untuk menggunakan basic search yang cara kerjanya hampir sama dengan mesin pencari google.
2.1.2.2 MozillaZine
MozillaZine (http://kb.mozillazine.org/Knowledge_Base) adalah sebuah knowledge base yang mengkhususkan diri pada produk dan aplikasi keluaran mozilla.
Halaman utama MozillaZine berisi pilihan produk yang didukung oleh mozilla. Setiap produk dilengkapi dengan FAQ dan artikel lengkap dari produk tersebut. Selain itu juga tersedia fitur pencarian, baik untuk pencarian umum untuk seluruh produk dan aplikasi mozilla, atau hanya terbatas pada produk atau aplikasi tertentu saja.
2.1.2.3 UITS
UITS (http://kb.iu.edu/) adalah knowledge base yang bertujuan untuk pelayanan informasi kepada masyarakat terkait teknologi informasi. Knowledge base ini dimiliki oleh Universitas Indiana di Amerika Serikat. UITS sendiri adalah singkatan dari University Information Technology Services.
Layanan ini pada awalnya merupakan tanya jawab manual antara pihak universitas dan masyarakat pada awal tahun 1980an. Seiring berjalannya waktu, data pertanyaan yang semakin banyak terkumpul menyebabkan pihak universitas merasa perlu untuk membuah sebuah knowledge base terkait dengan teknologi informasi. Dan akhirnya, pada tahun 1988 terbentuklah online knowledge base mereka yang pertama, dan terus berkembang sampai saat ini.
Pada tahun 2007, pengunjung knowledge base ini mencapai 10,5 juta oran dan pada saat ini mengandung lebih dari 13.500 dokumen.
2.2 Struktur Repositori
Knowledge base
Ketika berbicara tentang struktur repositori knowledge base, aspek utama yang terkait dengan hal tersebut adalah klasifikasi yang digunakan untuk melakukan penstrukturan informasi. Pada Sub bab ini akan dibahas mengenai beberapa standar klasifikasi untuk repositori data [GAR04], yaitu controlled vocabularies, taxonomy, thesauri, faceted classification, serta ontology.
2.2.1 Controlled Vocabularies
Controlled vocabularies adalah sebuah indeks istilah yang nantinya akan digunakan untuk standardisasi kata kunci yang digunakan pada sebuah dokumen. Controlled vocabularies ini diharapkan mampu untuk menghilangkan terjadinya kerancuan mengenai adanya beberapa istilah yang memiliki arti sama, dan digunakan sebagai kata kunci dalam dokumen yang berbeda. Sebagai contoh, “wanita” dan “perempuan” kurang lebih memiliki arti yang sama. Dalam pemberian kata kunci untuk setiap dokumen yang berkaitan dengan wanita/perempuan, harus ditentukan satu kata yang menjadi kunci.
2.2.2 Taxonomy
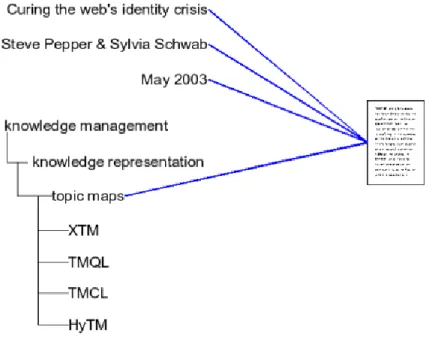
Taxonomy adalah klasifikasi berdasarkan subjek yang mengatur controlled vocabulary yang dimiliki ke dalam sebuah hierarki. Taxonomy membantu pengguna untuk mendeskripsikan subjek. Namun, dari sisi metadata, nyaris tidak ada perbedaan signifikan dengan controlled vocabulary. Sehingga dapat disimpulkan bahwa taxonomy sendiri bukanlah metadata, namun dapat digunakan untuk mengelompokan subjek berdasarkan hierarki tertentu. Contoh dari taxonomy dapat dilihat pada Gambar II-2.
Gambar II-2 Contoh taxonomy
Pada Gambar II-2, digambarkan bagaimana sebuah taxonomy (bentuk hiearki) mengacu kepada sebuah informasi. Setiap node pada taxonomy ini pada implementasinya akan mengacu pada beberapa informasi, dimana setiap informasi tersebut akan memiliki metadata yang tidak berkaitan dengan keberadaan taxonomy.
2.2.3 Thesaurus
Istilah thesaurus telah digunakan sejak lama untuk mendeskripsikan hal yang berkaitan dengan struktur klasifikasi objek. Thesaurus memiliki dua buah standar ISO, yaitu ISO2788 untuk mendeskripsikan thesaurus monolingual, dan ISO5964 untuk thesaurus multilingual.
Pada dasarnya, thesaurus merupakan pengembangan dari taxonomy dengan menambahkan properti-properti berikut untuk mendeskripsikan subjek:
1. BT (broader term)
Merujuk kepada istilah yang artinya lebih luas, yang memiliki makna yang kurang spesifik untuk istilah tertentu. Istilah NT (Narrowed Term) adalah lawan kata dari BT. Jika ditilik lebih jauh, sebuah taxonomy adalah thesauri yang
hanya menggunakan properti BT/NT, sehingga dapat disebut bahwa setiap thesaurus mengandung sebuah taxonomy.
2. SN (scope note)
SN adalah sebuah kalimat yang disertakan ke dalam istilah untuk menjelaskan arti dan cakupan dari istilah tersebut. Hal ini sangat berguna ketika arti dari sebuah istilah tidak dapat dipastikan dari konteks yang digunakan.
3. USE
Merupakan referensi menuju istilah lainnya yang lebih disarankan penggunaannya dibandingkan dengan penggunaan istilah ini. Mengimplikasikan bahwa istilah yang digunakan memiliki sinonim (kebalikan dari istilah ini disebut UF). Jika sebuah istilah A merujuk kepada istilah B dengan USE, maka istilah B akan merujuk kepada istilah A dengan UF. Di sini dapat disimpulkan bahwa penggunaan istilah B lebih disarankan dari penggunaan istilah A dalam suatu thesaurus.
4. TT (top term)
Merujuk kepada istilah yang memiliki arti paling luas dari seluruh istilah yang ada pada suatu thesaurus. Informasi ini bersifat redundan pada setiap subjek yang ada.
5. RT (related term)
Merupakan referensi kepada istilah yang terkait, dimana istilah terkait ini tidak tercakup di dalam klasifikasi properti-properti lainnya (BT/NT, USE/UF)
Gambar II-3 Contoh thesaurus
Gambar II-3 merupakan contoh dari thesaurus dari istilah “berries” [ADEC00]. Dapat dilihat pada Gambar tersebut, bahwa top-term, NT/BT, dan RT untuk istilah “berries” telah terdefinisi. 2.2.4 Faceted Classification
Ide untuk klasifikasi faset adalah untuk mengklasifikasikan dokumen dengan memilih sebuah istilah untuk setiap kategori / faset untuk mendeskripsikan dokumen di dalam dimensi yang berbeda. Hal ini akan menjelaskan dokumen dari banyak sudut pandang yang berbeda. Ranganathan, penemu dari klasifikasi faset (yang disebut juga Colon Classification) [GAR04], menjelaskan bahwa klasifikasi ini terdiri atas lima kategori / faset, yaitu:
1. Personality: Faset ini ditujukan untuk subjek utama dari dokumen, dan dianggap sebagai faset utama
2. Matter: Material atau substansi yang berkaitan dengan dokumen tersebut 3. Energy: Proses atau aktifitas yang dideskripsikan oleh dokumen
4. Space: Lokasi yang dideskripsikan oleh dokumen 5. Time: Waktu yang dideskripsikan oleh dokumen
Harus diperhatikan bahwa pada prakteknya, kategori / faset yang digunakan tidak harus sama seperti yang dikemukakan oleh Ranganathan. Gambar II-4 berikut akan diberikan sebuah contoh implementasi dari klasifikasi faset pada sebuah website.
Gambar II-4 Contoh klasifikasi faset [ADK05]
Pada Gambar II-4 ini, kategori / faset yang digunakan adalah tipe, material dan kejadian khusus berkaitan dengan topik yang dikategorikan, yaitu perhiasan. Pada tahun 2005, 69% dari website yang ada di dunia menggunakan klasifikasi faset ini [ADK05].
2.2.5 Ontology
Istilah ontology / ontologi di dalam lingkup computer science memiliki arti sebagai sebuah model untuk mendeskripsikan dunia yang terdiri atas sebuah set dari tipe, properti, dan tipe relasi. Penggunaan istilah ontologi juga mengandung pengharapan bahwa akan terjadi kemiripan yang sangat dekat antara dunia nyata dengan fitur dari model ontologi tersebut.
Dalam kaitan dengan klasifikasi repositori knowledge base, ontologi adalah puncak dari semua jenis klasifikasi yang telah kita pelajari. Penjelasannya adalah bahwa ontologi memiliki kosakata yang terbuka, dimana semua jenis klasifikasi lainnya tertutup untuk kosakata baru.
Thesaurus / thesauri dapat dianggap sebagai sebuah ontologi yang hanya terdiri dari satu tipe yaitu “term”, sebuah properti yang disebut “scope note”, dan tiga relasi (BT/NT, USE/UF, dan
RT). Namun karena tipe yang tercakup terbatas, kekuatan untuk melakukan deskripsi yang dimiliki thesauri menjadi sangat lemah.
Di dalam dunia computer science, ontologi telah banyak digunakan untuk pendefinisian bahasa untuk kepentingan berbagai hal. Dan di dalam information retrieval, topic map adalah salah satu ontologi yang telah dibuat untuk menjadi framework dalam pelaksanaannya.
Gambar II-5 adalah contoh dari sebuah ontologi [NCSU03]. Ontologi pada Gambar tersebut dapat dideskripsikan sebagai berikut: ”Ships are a kind of Watercraft, or Sea Vessel. Ships have a Crew and Cargo. Through the transitivity of the hypernym relation, Ships also have a Location. The Location of a Ship has a Longitude and Latitude”.
Dalam bahasa Indonesia dapat diartikan seperti berikut ”Kapal laut adalah sejenis kendaraan laut, atau Sea Vessel. Kapal laut memiliki seorang kru dan kargo. Melalui relasi hipernim, kapal laut juga memiliki sebuah lokasi. Lokasi dari sebuah kapal laut memiliki longitude dan latitude”.
2.2.5.1 Topic Map Ontology
Topic map merupakan salah satu ontologi yang digunakan dalam membentuk repositori dari knowledge base. Dalam pembuatannya, topic map bukan hanya melakukan replikasi dari indeks pada hardcopy biasa, namun topic map melakukan generalisasi dari indeks tersebut, dan memperluas cakupannya.
Hal ini dimungkinkan dengan “memisahkan” indeks dengan informasi yang terkandung, sehingga nantinya indeks ini dapat digunakan pada kumpulan informasi yang berbeda. Selain itu, karena indeks yang terdapat di dalam topic map pada dasarnya adalah kumpulan informasi, indeks tersebut dapat menjadi layer informasi pada topic map lainnya.
Topic map terdiri atas tiga bagian penting, yaitu Topic, Association, dan Occurrence (TAO). Topic / topik adalah “sesuatu”, dimana sebuah kota, seseorang, konsep, dan apa saja dapat menjadi sebuah topik. Istilah topik merujuk kepada sebuah objek atau node di dalam topic map yang merepresentasikan subjek. Disana harus ada sebuah relasi satu-satu antara topik dan subjek, dengan setiap topik direpresentasikan oleh sebuah subjek, dan setiap subjek hanya direpresentasikan oleh sebuah topik.
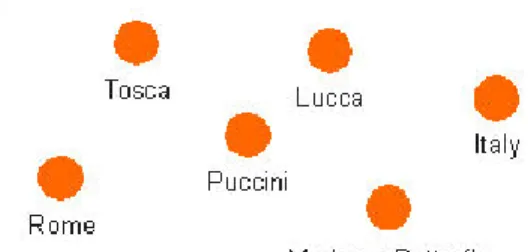
Gambar II-6 Contoh kumpulan topik
Gambar II-6 memperlihatkan sekumpulan topik yang memiliki keterkaitan, dimana semua topik yang tergambarkan di atas bertemakan negara Italia.
Masing-masing topik akan relevan dengan beberapa informasi di dalam repositori knowledge base. Hubungan antara topik dengan informasi ini disebut dengan occurrence. Karena keberadaannya yang mengurangi independensi dari topic map, informasi mengenai occurrence
ini pada umumnya tidak disimpan sebagai bagian dari topic map. Penulisan occurrence ini biasanya menggunakan URI (Uniform Resource Identifier).
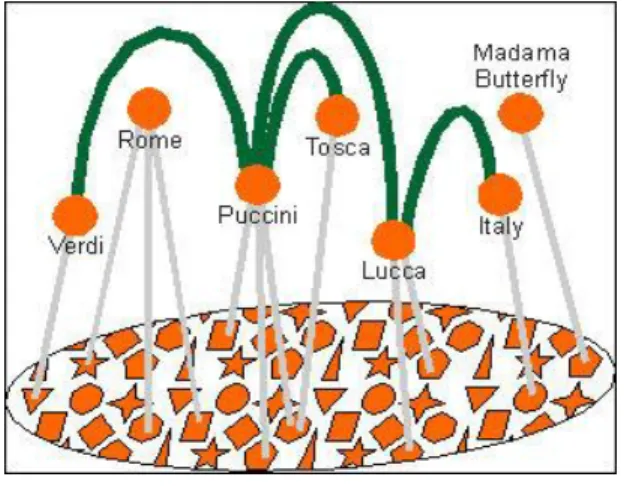
Garis tebal pada Gambar II-7 menggambarkan occurrence pada sebuah topic map. Dapat dilihat pada Gambar tersebut bahwa sebuah topik dapat memiliki beberapa occurrences sekaligus.
Gambar II-7 Contoh occurrences
Selain occurrence yang menghubungkan antara topik dan informasi, di dalam topic map juga didefinisikan hubungan antar topic map yang disebut dengan association. Association / asosiasi memiliki pengelompokan berdasarkan jenis hubungan antar topic tersebut, yang akan mempermudah implementasi antarmuka yang user-friendly.
Gambar II-8 Contoh asosiasi
Gambar II-8 menggambarkan sebuah struktur dari topic map. Kumpulan lingkaran tebal di bagian atas Gambar merupakan topik, dihubungkan dengan garis tebal yang merupakan asosiasi. Tidak semua topik akan memiliki asosiasi, dan juga ada beberapa topik yang memiliki lebih dari
satu asosiasi. Setiap topik akan mengacu pada satu atau lebih informasi yang digambarkan sebagai bermacam-macam bentuk geometri pada bagian dasar dari Gambar tersebut.
Saat ini, umumnya sistem yang memiliki indeks menyisipkan kode tertentu di dalam dokumen untuk melakukan pengindeksan. Salah satu keuntungan penggunaan topic map adalah bahwa dokumen itu sendiri tidak perlu dimodifikasi.
2.2.6 Penilaian Tingkat Kepercayaan Informasi Pada Struktur Knowledge base Penilaian kebenaran dan relevansi informasi di dalam knowledge base dapat menggunakan beberapa cara. Di antaranya adalah penggunaan model statistical information retrieval dan vector space [CHR04] untuk knowledge base umum, serta occurrences embedded definition [KAL04] yang khusus digunakan pada topic map. Pada Sub bab berikut ini akan dijelaskan sekilas mengenai masing-masing model penilaian tersebut.
2.2.6.1 Statistical Information Retrieval
Model ini dibuat dengan merepresentasikan dokumen menggunakan sebuah set dari indeks istilah. Setiap istilah dilihat sebagai variabel boolean, dimana nilai true berarti istilah tersebut terdapat pada dokumen tertentu dan dapat dikombinasikan dengan istilah lainnya dengan menggunakan operator ’AND’, ’OR’, dan ’NOT’. User query merepresentasikan sebuah ekspresi boolean, dan dokumen yang dihasilkan harus memenuhi ekspresi boolean tersebut.
Kelemahan dari model ini adalah hasil yang dimiliki hanya memiliki dua nilai saja, yaitu benar atau salah. Hal ini menjadikan pengurutan atas informasi menjadi hal yang tidak mungkin dilakukan.
2.2.6.2 Vector Space
Cara ini memodelkan dokumen ke dalam sebuah set vektor di dalam ruang vektor, dimana setiap istilah yang unik merepresentasikan keberadaan sebuah dimensi dari ruang tersebut. Penilaian dilakukan dengan membandingkan kata kunci di dalam ruang vektor tersebut dan menghitung signifikansinya. Hal ini menjadi mahal dikarenakan pembuatan model vector space ini membutuhkan ruang dan usaha yang besar dalam pelaksanaannya.
Di luar kekurangannya karena proses pembentukan yang menghabiskan banyak sumber daya, pengurutan dokumen dengan model vector space ini dapat dilaksanakan dengan baik dan menghasilkan dokumen terurut sesuai dengan kata kunci yang diberikan.
2.2.6.3 Occurrences Embedded Definition
Di dalam sebuah topic map, penilaian kebenaran dan relevansi informasi dipermudah dengan adanya occurrence. Setiap informasi yang terkait dengan topik tertentu dapat ditambahkan sebuah metadata yang mendefinisikan penilaian tersebut.
Metadata ini dapat didefinisikan oleh perancang topic map sesuai dengan kebutuhan knowledge base, dan tidak ada standar yang pasti mengenai hal tersebut, sehingga memiliki fleksibilitas yang tinggi.
2.3
Web services
Web services adalah sistem pertukaran informasi berbasis XML yang menggunakan internet untuk interaksi antara aplikasi [ION07]. Teknologi ini merupakan standar yang diadopsi oleh banyak vendor perangkat lunak, karena memiliki standar terbuka. Standar terbuka ini yang memungkinkan aplikasi web service yang diimplementasi oleh vendor berbeda dapat berkomunikasi satu sama lain.
Perkembangan web services yang begitu cepat menyebabkan lahirnya ekstensi-ekstensi web services yang memperluas fungsi web services itu sendiri. Untuk membedakan web services dasar dengan ekstensi-ekstensinya, maka keduanya dibedakan menjadi web services generasi pertama dan web services generasi kedua.
2.3.1 Web Services Generasi Pertama [ERL04]
Web services generasi pertama adalah pondasi dari teknologi web services ini sendiri. Implementasi dari teknologi ini, yang berupa aplikasi web services, saling berinteraksi satu sama lain dengan menggunakan dokumen berformat XML dan protokol pengiriman pesan SOAP (Simple Object Access Protocol) melalui HTTP. Format XML, SOAP, dan HTTP ini juga merupakan standar terbuka yang dapat diadopsi.
Sebuah aplikasi web service tentunya tidak dapat langsung diketahui bagaimana penggunaannya. Oleh karena itu, aplikasi ini harus menyediakan deskripsi service. Untuk deskripsi ini, web service juga memiliki standar terbuka yaitu WSDL (Web Service Description Language).
Standard web service juga menyediakan mekanisme pencarian aplikasi web service, yaitu UDDI (Universal Description Discovery and Integration). UDDI ini dapat dianalogikan sebagai catalog web service di dunia maya, sehingga memungkinkan sebuah aplikasi web service dapat menemukan aplikasi lain yang dibutuhkan. Namun penggunaan UDDI sendiri saat ini belum banyak diadopsi. Spesifikasi web service seperti yang dijelaskan sebelumnya merupakan dasar dari aplikasi web services, yang dapat disebut sebagai web services generasi pertama.
Gambaran umum keterhubungan dari standar-standar tersebut dapat dilihat pada Gambar II-9.
Gambar II-9 Keterhubungan antar komponen dari web services [ERL04] 2.3.1.1 Web Service Description Language (WSDL)
Web Services Description Language (WSDL) adalah bahasa berbasis XML yang digunakan untuk mendeskripsikan web services [ERL04]. Adanya WSDL memungkinkan kita mengatahui jenis deskripsi layanan yang disediakan dan fungsi-fungsi apa saja yang dimiliki sebuah aplikasi web service.
Struktur umum dari WSDL adalah sebagai berikut [ERL04]: <definitions> <interface> <operation> … </operation> </interface> <message> <part> … </part> … </message> <service> <endpoint> … </endpoint> … </service> <binding> … </binding> </definitions>
Penjelasan dari elemen-elemen yang ada di dalam bahasa ini dijelaskan sebagai berikut:
1. Elemen interface merepresentasikan interface dari web service, dan terdiri atas operasi-operasi yang dimiliki oleh web service dengan tag operation.
2. Elemen message merepresentasikan semua input dan output message dari operation. Sebuah message dapat terdiri atas satu parameter atau lebih. Untuk itu digunakan komponen part.
3. Elemen service menyimpan koleksi dari endpoint, yang menyimpan alamat fisik dan informasi protokol. Setiap komponen endpoint dapat mereferensi elemen binding, dan lalu dihubungkan dengan informasi endpoint pada operasi tertentu.
4. Elemen binding mengasosiasikan dirinya dengan konstruksi operation. 2.3.1.2 Simple Object Access Protocol (SOAP)
Simple Object Access Protocol merupakan protokol untuk menukarkan pesan berbasis XML dalam jaringan komputer [ERL04]. Umumnya SOAP melalui protokol HTTP. Struktur pesan SOAP adalah sebagai berikut [ERL04].
<env:Envelope xmlns:env=”http://www.w3.org/2003/05/soap-envelope”> <env:Header> … </env:Header> <env:Body> … </env:Body> </env:Envelope>
Elemen envelope membentuk dokumen pesan terdiri atas bagian body dan header. Elemen header sifatnya opsional. Penggunaan header umumnya adalah untuk implementasi ekstensi SOAP dan data-data tambahan, sementara body bertujuan untuk menyimpan pesan.
2.3.1.3 Universal Description Discovery and Integration (UDDI)
Universal Description Discovery and Integration (UDDI) adalah registry berbasis XML yang bersifat platform-independent [ERL04]. UDDI memungkinkan sebuah bisnis untuk mempublikasikan service mereka sehingga aplikasi mereka dapat digunakan oleh aplikasi lainnya.
UDDI mengorganisasikan registry dalam enam tipe data [ERL04]:
1. Business Entity, menyimpan informasi profil mengenai bisnis yang disimpan, termasuk nama, deskripsi, dan unique identifier.
2. Business Service, merepresentasikan layanan aktual yang ditawarkan oleh bisnis terdaftar, disimpan dalam elemen businessEntity
3. Specification Pointers, menyimpan halaman dari business service ke informasi implementasi, disebut juga binding components
4. Service types, menyediakan informasi dari definisi pointer
5. Business relationships, direpresentasi dengan publisherAssertion, menyimpan hubungan antara entitas bisnis dengan yang lainnya
6. Subscriptions, direpresentasi dengan elemen subscription, memungkinkan subscriber mendapatkan notifikasi saat profil business entity diperbaharui.
2.3.2 Web Service Generasi Kedua [ERL04]
Perkembangan teknologi web services berlanjut pada munculnya ekstensi-ekstensi dari web service, yang biasa disebut second generation web services atau WS-* [ERL04]. Ekstensi ini merupakan pengembangan dari teknologi web services dasar yang muncul disebabkan kebutuhan-kebutuhan yang ada di dalam enterprise.
Adapun beberapa ekstensi yang jamak digunakan adalah WS–Coordination, WS–Transaction, Business Process Execution Language for Web Services (BPEL4WS atau BPEL), WS-ReliableMessaging, WS–Addressing, WS–Policy, WS–PolicyAssertions, WS– PolicyAttachments, WS –Attachments, dan SOAP with Attachments (SwA).
Perkembangan dari teknologi ekstensi ini tidak berhenti pada ekstensi-ekstensi yang ada di atas. Seiring dengan berjalannya waktu, standar ini akan terus berkembang.
2.3.3 Jenis-Jenis Penggunaan Web Service
Di dalam penggunaannya, ada banyak cara yang dapat dilakukan untuk mengimplementasikan sebuah web services pada suatu network. Dimana beberapa cara paling populer di antaranya adalah SOAP dan representational state transfer. Berikutnya akan dibahas secara umum mengenai masing-masing cara tersebut.
2.3.3.1 SOAP Web service
Sebuah SOAP web service memiliki dua buah batasan implementasi, yaitu:
1. Kecuali untuk binary data attachment, pesan-pesan harus menggunakan SOAP (Simple Object Access Protocol)
2. Deskripsi untuk sebuah service harus diimplementasikan menggunakan WSDL (Web services Description Language).
SOAP web service adalah bentuk web service yang paling umum di dalam dunia industri. Sebagian orang akan dengan mudah mengartikan sebuah “web service” menjadi service SOAP dan WSDL. [SOAP07] menyatakan bahwa SOAP menyediakan “sebuah konstruksi pesan yang
dapat dipertukarkan melalui berbagai macam protokol yang ada”. Hal tersebut dapat diartikan bahwa SOAP berperan seperti sebuah amplop yang membawa pesannya. Satu keuntungan dari SOAP adalah bahwa SOAP memperbolehkan range pertukaran pesan yang cukup banyak, dari mulai request and response secara tradisional, sampai dengan broadcasting dan korelasi antar pesan yang rumit. SOAP web service terdiri atas dua jenis, yaitu SOAP RPC dan document-centric SOAP.
SOAP RPC (remote procedure call) web service adalah sebuah web service yang menyamarkan sebuah antarmuka RPC yang bersifat application-specific melalui sebuah antarmuka generic. Secara efektif, hal ini mendeskripsikan tingkah laku dari sistem dan semantik aplikasinya. Karena tingkah laku sistem sangat sulit ditentukan di dalam lingkungan terdistribusi, aplikasi yang dibuat dengan menggunakan web service jenis ini pada umumnya tidak dapat dijalankan dengan baik.
Document-centric SOAP web service adalah sebuah implementasi dari web service yang mengikuti kaidah yang dimiliki oleh konsep SOA (service-oriented architecture) secara keseluruhan, dimana sebuah unit terkecil dari komunikasi adalah sebuah pesan, dan bukan sebuah operasi. Hal ini sering disebut sebagai sebuah “message-oriented” service.
2.3.3.2 REST Web service
Representational State Transfer (REST) web service adalah sebuah Service Oriented Architecture yang berbasiskan pada konsep “resource”. Sebuah resource adalah apa saja yang memiliki sebuah Uniform Resource Identifier. Sebuah resource mungkin memiliki nol atau lebih representasi. Biasanya, orang akan mengatakan bahwa sebuah resource tidak eksis jika tidak ada representasi yang tersedia untuk resource tersebut. Sebuah REST web service memiliki batasan sebagai berikut:
1. Antarmuka dibatasi hanya untuk HTTP. Semantik berikut didefinisikan untuk antarmuka: a. HTTP GET digunakan untuk memperoleh sebuah representasi dari resource.
Seorang pengguna menggunakan hal tersebut untuk mendapatkan representasi dari sebuah URI. Service yang disediakan melalui antarmuka ini harus tidak menimbulkan keberatan dari pengguna.
b. HTTP DELETE digunakan untuk menghapus representasi dari sebuah resource c. HTTP POST digunakan untuk melakukan update atau membuat representasi dari
resource
d. HTTP PUT digunakan untuk membuat representasi dari sebuah resource
2. Hampir semua pesan dikirimkan menggunakan XML, dibatasi oleh sebuah skema yang tertulis dalam bahasa skema tertentu seperti XML Schema dari W3C atau RELAX NG. 3. Pesan yang simpel dapat dikodekan dengan mengunakan URL encoding.
4. Service dan penyedia service haruslah merupakan sebuah resource, sedangkan seorang pengguna dapat saja berupa sebuah resource.
REST web services membutuhkan dukungan infrastruktur yang sederhana selain HTTP standar dan teknologi XML processing, yang pada saat ini sudah didukung dengan baik oleh semua bahasa pemrograman dan platform. REST web services menjadi sederhana dan efektif karena HTTP adalah antarmuka yang paling luas tersedia, dan sudah cukup baik untuk kebanyakan aplikasi. Di dalam banyak kasus, kesederhanaan dari HTTP memberikan lebih banyak kelebihan dibandingkan dengan kesulitan dari pengenalan tambahan sebuah transport layer.
![Gambar II-4 Contoh klasifikasi faset [ADK05]](https://thumb-ap.123doks.com/thumbv2/123dok/2625599.2245855/9.918.354.558.223.502/gambar-ii-contoh-klasifikasi-faset-adk.webp)
![Gambar II-5 adalah contoh dari sebuah ontologi [NCSU03]. Ontologi pada Gambar tersebut dapat dideskripsikan sebagai berikut: ”Ships are a kind of Watercraft, or Sea Vessel](https://thumb-ap.123doks.com/thumbv2/123dok/2625599.2245855/10.918.218.700.592.913/gambar-ontologi-ontologi-gambar-tersebut-dideskripsikan-berikut-watercraft.webp)
![Gambar II-9 Keterhubungan antar komponen dari web services [ERL04] 2.3.1.1 Web Service Description Language (WSDL)](https://thumb-ap.123doks.com/thumbv2/123dok/2625599.2245855/15.918.291.631.511.807/gambar-keterhubungan-antar-komponen-services-service-description-language.webp)
