33
KLASIFIKASI DOKUMEN TUGAS AKHIR MENGGUNAKAN ALGORITMA K-MEANS
Wulan Fatin Nasyuha¹, Husaini
2dan Mursyidah
31,2,3 Teknologi Informasi dan Komputer, Politeknik Negeri Lhokseumawe, Jalan banda Aceh-Medan KM.275,5, Buketrata- Lhokseumawe, 24301,P.O.Box 90 Telepon (0645) 4278, fax.42785, Indonesia.
E-mail: [email protected], [email protected], [email protected]
ABSTRAK
Klasifikasi dokumen merupakan pengelompokkan dokumen yang mempunyai beberapa katagori. jumlah dokumen semakin lama semakin bertambah dan beragam. ditawarkan satu alternatif dengan membuat sebuah aplikasi yang dapat membantu dalam proses pencarian dan penyajian dokumen menjadi lebih mudah sehingga dokumen tersebut dapat disesuai dengan katagori masing – masing. Tujuan penelitian pada pembuatan tugas akhir ini adalah untuk membahas proses klasifikasi dokumen tugas akhir menggunakan algoritma k-means dan menggunakan bahasa pemrograman C#. Dengan adanya teks yang dapat diolah menjadi sebuah data yang menunjukkan pengelompokan atau kategori dari isi teks tersebut. Dokumen tugas akhir yang berisi judul dan kata kunci abstrak yang menjadi penelitian, dan terdapat delapan katagori yaitu aplikasi android, jaringan komputer, keamanan jaringan, multimedia, pengolahan citra, sistem informasi, sistem informasi geografis, sistem pakar. Database yang digunakan adalah MySQL. Adapun tingkat keberhasilan yang telah diuji mendapatkan akurasi 90%.
Kata kunci : klasifikasi dokumen, algoritma k-means, MySQL
1.
PENDAHULUAN
Perkembangan jumlah dokumen setiap tahun semakin lama semakin bertambah dan beragam. Oleh karena itu, proses pencarian dan penyajian dokumen menjadi lebih sulit sehingga akan lebih mudah jika dokumen tersebut sudah tersedia sesuai dengan katagori masing – masing. Dokumen agar mudah di cari kembali bila sudah ditempatkan secara sistematis berdasarkan katagori tertentu. Perpustakaan Politeknik Negeri Lhokseumawe merupakan salah satu UPT yang menyediakan berbagai dokumen, baik dalam berbentuk buku, tugas akhir, jurnal dan sebagainya.
Perpustakan Politeknik Negeri Lhokseumawe memang sudah menyediakan dokumen dengan semaksimal mungkin, namun dokumen yang disediakan menurut bidang masing – masing. Oleh kerena itu, klasifikasi dokumen tugas akhir yang sesuai dengan katagori/tema memiliki teknik yang lebih spesifikasi untuk dokumen seperti ekstraksi teks secara otomatis. Hal ini untuk memberikan manfaat bagi pengguna yang ingin mencari tema dokumen tugas akhir secara otomatis, dan bertujuan untuk membahas proses klasifikasi dokumen tugas akhir menggunakan pengelomkolan atau kategori dari isi teks tersebut.
2.
METODE PENELITIAN
2.1 ALGORITMA K-MEANS
Algoritma k-means merupakan salah satu algoritma untuk mengklasifikasi dokumen teks. Adapun penerapan Algoritma K-Means sebagai berikut [1]:
1. Tentukan k (jumlah cluster) yang ingin dibentuk.
2. Bangkitkan k centroid (titik pusat cluster) awal secara random.
3. Untuk setiap record, temukan pusat cluster
terdekat dengan mengukur jarak record
dengan pusat cluster. Metode perhitungan jarak yang digunakan adalah Metode cosinus similarity.
4. Untuk setiap k cluster, temukan pusat cluster
dan ubah lokasi dari setiap pusat cluster
dengan nilai centroid yang baru. Pusat cluster
diperoleh dengan cara menghitung nilai rata-rata dari data-data yang berada pada cluster
yang sama.
5. Kembali ke langkah 3 – 5 sampai konvergen. 2.2 METODE COSINUS SIMILARITY
Cosine Similarity merupakan metode yang digunakan untuk menghitung similarity (tingkat kesamaan) antar dua buah objek. Perhitungan cosine
34
similarity yang memperhitungkan perhitungan pembobotan kata pada suatu dokumen dapat dinyatakan dengan persamaan 2.1 berikut [2]:
t k t j ij ij t k ik jk ijd
d
d
d
1 1 2 2 1.
cos
(2.1) Diketahui: ikd
= Nilai Pembobotan kata training jkd
= Nilai Pembobotan kata uji 2.3 Pembobotan TF-IDFPembobotan kata (term weighting) adalah proses pembobotan pada kata. Pembobotan dasar dilakukan dengan menghitung frekuensi kemunculan term dalam dokumen. Frekuensi kemunculan (term frequency) merupakan petunjuk sejauh mana term tersebut mewakili isidokumen. Semakin besar kemunculan suatu term dalam dokumen akan memberikan nilai kesesuian yang semakin besar. Nilai idf sebuah term dapat dihitung menggunakan persamaan 2.2 sebagai berikut [3]:
df
D
IDF
log
(2.2) Diketahui: D = jumlah dokumendf = jumlah kemunculan (frekuensi) term
terhadap D
Adapun persamaan yang digunakan untuk menghitung bobot (W) masing-masing dokumen terhadap kata kunci (query), menggunakan persamaan 2.3 berikut: t dt dt
tf
IDF
W
*
(2.3) Diketahui : d = dokumen uji t = term trainingtf = term frekuensi/frekuensi kata
Wd.t = bobot dokumen ke–d terhadap term ke–t.
Metode penelitian diperoleh dari beberapa dokumen dan kategori tema tugas akhir 2014 – 2015 di perpustakaan Politeknik Negeri Lhokseumawe. Adapun daftar pengumpulan data ditunjukkan pada tabel 2.1 berikut ini.
Table 2.1 Daftar Pengumpulan Data
No Katagori Jumlah 1 Aplikasi Android 19 2 Jaringan Komputer 24 3 Keamanan Jaringan 16 4 Multimedia 22 5 Pengolahan Citra 18 6 Sistem Informasi 24
7 Sistem Informasi Geografis 21
8 Sistem Pakar 26
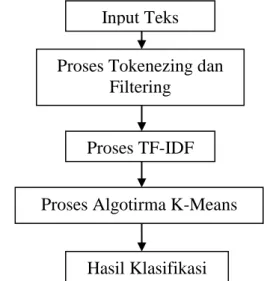
Pengumpulan dokumen yang telah diambil diimplementasikan menggunakan notepad dimana judul dan kata kunci abstrak dari setiap buku tugas akhir disimpan dalam format *.txt. adapun blok diagram proses klasifikasi ditunjukkan pada gambar 3.3 berikut ini.
Gambar 3.3 Blok Diagram Klasifikasi Dokumen Adapun proses kerja blok diagram ialah di tentukan k sebanyak 8, dari teks yang di uji maka akan bangkit k centroid yaitu kata android, karena kata tersebut masuk ke dalam 4 k. Selanjutnyan Proses pembobotan tf-idf, proses tf di tunjuukkan pada tabel 2.2 berikut ini:
Tabel 2.2 Proses tf id kata TF 1 2 3 4 5 6 7 8 9 1 fisher 2 2 mysql 1 1 7 3 database 1 4 4 mobile 1 7 2 3 5 android 2 28 2 13 12 6 pengacakan 1 7 shuffle 2 8 yates 2 9 eclipse 2 1 10 java 1 2 3 1
Input Teks
Proses Tokenezing dan
Filtering
Proses Algotirma K-Means
Proses TF-IDF
35
Selanjutnya mencari nilai df dengan jumlahkan nilai tf setiap kata dan dan mencari idf dengan menggunakan persamaan 2.2. Adapun proses df dan idf di tunjukkan pada tablel 2.3 berikut ini:Tabel 2.3 proses df dan idf
df idf log(D/df) 2 0.653213 9 0 5 0.255273 13 -0.1597 57 -0.80163 1 0.954243 2 0.653213 2 0.653213 3 0.477121 7 0.109144
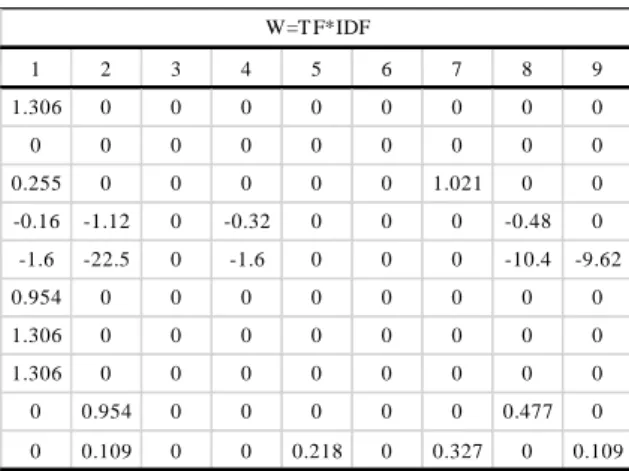
Untuk mencari bobot masing-masing kata menggunakan persamaan 2.3 di tunjukkan pada tabel 2.4 berikut ini:
Tabel 2.4 Pembobotan tf-idf
1 2 3 4 5 6 7 8 9 1.306 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0.255 0 0 0 0 0 1.021 0 0 -0.16 -1.12 0 -0.32 0 0 0 -0.48 0 -1.6 -22.5 0 -1.6 0 0 0 -10.4 -9.62 0.954 0 0 0 0 0 0 0 0 1.306 0 0 0 0 0 0 0 0 1.306 0 0 0 0 0 0 0 0 0 0.954 0 0 0 0 0 0.477 0 0 0.109 0 0 0.218 0 0.327 0 0.109 W=T F*IDF
Adapun pencari penbobotan kata dengan data uji di tunjukkan pada tabel 2.4 berikut ini:
Tabel 2.4 pembobotan kata dengan data uji
2 3 4 5 6 7 8 9 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0.261 0 0 0.179 0 0.051 0 0 0 0.077 0 35.99 0 2.57 0 0 0 16.71 15.42 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 W(UJI)*W(T FIDF)
Selanjutnya mencari rata-rata setiap k (cluster) menggunakan persamaan panjang vektor, ditunjukkan pada tabel 2.5 berikut ini:
Tabel 2.5 Panjang vektor
1 2 3 4 5 6 7 8 9 1.707 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0.065 0 0 0 0 0 1.043 0 0 0.026 1.25 0 0.102 0 0 0 0.23 0 2.57 503.8 0 2.57 0 0 0 108.6 92.54 0.911 0 0 0 0 0 0 0 0 1.707 0 0 0 0 0 0 0 0 1.707 0 0 0 0 0 0 0 0 0 0.911 0 0 0 0 0 0.228 0 0 0.012 0 0 0.048 0 0.107 0 0.012 2.948 22.54 8.953 7.958 10.11 9.046 9.618 14.33 15.99 PANJANG VEKT OR
Selanjutnya untuk mengklasifikasi menggunakan algoritma k-means, nilai rata-rata dari setiap k dihitung jarak terdekat dengan data uji. Adapun klasifikasi dokumen menggunakan algoritma k-means di tunjukkan pada tabel 2.6 berikut ini:
Tabel 2.6 Klasifikasi menggunakan algoritma k-means
NILAI JARAK ANTAR KATAGORI DENGAN KLASIFIKASI K-MEANS 2,1 3,1 4,1 5,1 6,1 7,1 8,1 9,1 0.54423 0 0.11173 0 0 0.00919 0.3973 0.32714 PRESENTASI 54.4232 0 11.173 0 0 0.91923 39.7302 32.7139 Diketahui: 1 = Uji 2 = Android 3 = Jaringan Komputer 4 = Keamanan Jaringan 5 = Multimedia 6 = Pengolahan Citra
36
7 = Sistem Informasi8 = Sistem Informasi Geografis 9 = Sistem Pakar
3.
HASIL DAN PEMBAHASAN
Dalam pengujian klasifikasi dokumen yang sesuai dengan teks yang dimasukkan menggunakan algoritma k-means, berikut pengujian dari Kategori Aplikasi Android:
Tabel 3.7 Hasil Pengujian Kategori Aplikasi Android
N o
Isi Teks Nilai Jarak Klasifikasi 1 fisher yates shuffle pengacakan android android mobile database mysql fisher yates shuffle
Aplikasi Android 54.4232 Aplikasi Android 54.4232% Jaringan Komputer 0 Keamanan Jaringan 11.1730 Multimedia 0 Pengolahan Citra 0 Sistem Informasi 0.91923 Sistem Informasi Geografis 39.7301 Sistem Pakar 32.6101 2 android hashing levenshtein distance android hashing levenshtein distance
Aplikasi Android 64.6326 Aplikasi Android 64.6326% Jaringan Komputer 0 Keamanan Jaringan 13.0732 Multimedia 0 Pengolahan Citra 1.11978 Sistem Informasi 0 Sistem Informasi Geografis 47.1889 Sistem Pakar 38.9011 3 warna android android warna
Aplikasi Android 95.1173 Aplikasi Android 95.1174% Jaringan Komputer 0 Keamanan Jaringan 19.2393 Multimedia 0.73552 Pengolahan Citra 10.4141 Sistem Informasi 0 Sistem Informasi Geografis 69.4461 Sistem Pakar 57.2493 4 linear congruent method lcm android uml android sdk eclipse lcm
Aplikasi Android 64.2479 Aplikasi Android 64.2479% Jaringan Komputer 0 Keamanan Jaringan 12.7582 Multimedia 3.14218 Pengolahan Citra 0 Sistem Informasi 1.74627 Sistem Informasi Geografis 46.4057 Sistem Pakar 37.9639 5 android fuzzy android mobile sdk mobile
Aplikasi Android 83.1638 Aplikasi Android 83.1639% Jaringan Komputer 0 Keamanan Jaringan 17.3474 Multimedia 0
device Pengolahan Citra 0 Sistem Informasi 0 Sistem Informasi Geografis
60.0191 Sistem Pakar 55.5139 Berdasarkan hasil pengujian kategori aplikasi android tingkat akurasinya ialah 100% berhasil, dikarenakan teks yang diinput sesuai dengan hasil klasifikasi katagorinya. Adapun terdapat pendekatan dengan katagori lain, tetapi nilai yang menunjukkan untuk kategori aplikasi android lebih besar. Adapun grafik dari teks no 1 yang digunakan pada tabel 3.2 yaitu “fisher yates shuffle pengacakan android android mobile database mysql fisher yates shuffle” sebagai berikut:
Gambar 1: Grafik Hasil Klasifikasi dari Teks "fisher yates shuffle pengacakan android android mobile
database mysql fisher yates shuffle".
4.
SIMPULAN
Setelah melakukan penelitian dan pembahasan mengenai klasifikasi dokumen tugas akhir menggunakan algoritma k-means pada bab terdahulu, maka dapat diambil simpulan sebagai berikut:
1. Klasifikasi dokumen memiliki tingkat persentase keakuratan yang cukup baik dalam melakukan proses pengelompokan berdasarkan data uji dengan data yang berasal dari database,
yaitu tingkat keakuratan mencapai 90%. 2. Jumlah kata yang disimpan dalam database
lebih banyak karena semakin banyak jumlah kata yang disimpan maka akan semakin banyak nilai frekuensi kata yang akan dibandingkan dengan teks uji. Namun akan semakin lama juga waktu yang dibutuhkan untuk proses klasifikasi dokumen.
3. Kesalahan pada saat tidak sesuai pengklasifikasi dokumen ialah karena terdapat kata yang sama dan nilai pembobotan kata dari kategori lain lebih besar. Hal ini mengakibatkan klasifikasi teks yang diinput lebih mendekati kategori lain.
DAFTAR ACUAN
[1] Wicaksono, G. W. 2012, (Desember). K-Means. hal. 1-1 (online),
37
http://galih.staff.umm.ac.id/2012/12/k-means/, diakses 03 Desember 2015
[2] Alexander, B. (2015). “The Distance Formula,” jurnal Interactive Mathematics Miscellany and Puzzles, (online),
http://www.cut-the-knot.org/pythagoras/DistanceFormula.shtml, diakses 03 December 2015
[3] I.G.A Oka, W. N. (2011). “Data Mining Metode Clasifikation K-Nearst Neighbor (Knn),” (online)
https://id.scribd.com/doc/57208138/Metode-Algoritma-KNN#download, diakses 08 Mei 2016