BAB V IMPLEMENTASI
5.1. Pembangunan Data Warehouse
Dalam penelitian ini tahap an yang dilakukan dalam proses pembangunan data warehouse adalah :
1. Memilih bisnis proses yang akan dimodelkan.
Dalam hal ini akan dibuat data warehouse diabetes yang akan dijadikan sebagai sumber data bagi implemetasi algoritme CPAR . Sumber data bagi data warehouse diabetes berasal dari basis data sistem informasi pasien rawat jalan, pasien rawat inap RSPP . Data flow diagram serta kamus data dari sistem informasi pasien rawat jalan, sistem informasi pasien rawat inap RSPP terdapat pada Lampiran 1 sampai dengan Lampiran 3.
2. Memilih bagian kecil dari bisnis proses SIM RSPP.
Data pasien rawat jalan dan pasien rawat inap dikumpulkan dari registrasi pasien rawat jalan, registrasi pasien rawat inap serta dari masukkan yang ada dimasing -masing unit layanan.
Modul Registrasi
Unit ini berfungsi sebagai pintu masuk pasien ke RSPP, oleh karena itu hal pertama yang harus dilakukan pasien ketika hendak berobat adalah mendaftar. Modul registrasi bertugas memberikan sebuah nomor medical record (MR) kepada pasien baru, melakukan pendaftaran dan penjadwalan pasien ke unit layanan. Data registrasi yang dimasukkan akan menjadi acuan unit lain ketika memberikan pelayanan.
Pada modul registrasi semua data pasien (pasien baru atau pasien lama) dipelihara dan disimpan. Data pasien ini akan digunakan oleh setiap unit layanan dalam memberikan pelayanan. Setiap pasien yang akan berobat atau mengunakan unit layanan, diberikan sebuah nomor regis trasi. Nomor registrasi ini berfungsi sebagai pengenal pasien ketika melakukan transaksi di setiap poliklinik atau unit layanan.
Modul Unit Layanan
Secara umum, hal-hal yang dialkukan di setiap unit layanan adalah memberikan diagnosa, memberikan tindakan, jika diperlukan memberikan obat-obatan atau peralatan yang dibutuhkan untuk melakukan tindakan, mengeluarkan resep jika ada, dan terakhir mengeluarkan tagihan berdasarkan tindakan dan obat-obatan yang diberikan.
3. Memilih dimensi yang akan diimplementasikan ke setiap fact table. Hasil dari proses perancangan data warehouse diabetes terdapat pada Gambar 13. Kamus data data warehouse diabetes terdapat pada Lampiran 4.
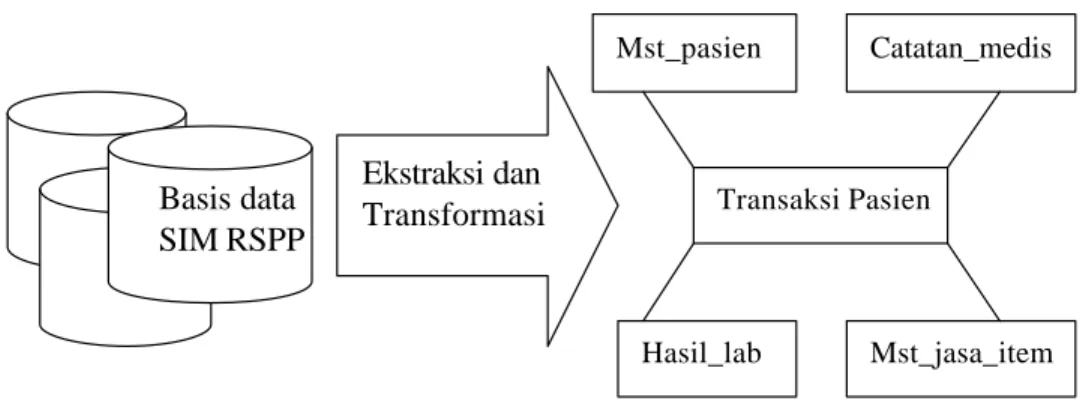
4. Melakukan proses ekstraksi dan transformasi dari basis data SIM RSPP ke data warehouse menggunakan perintah-perintah SQL diperlihatkan pada Gambar 14.
Gambar 14. Relasi antartabel skema bintang data warehouse diabetes.
Gambar 15. Ekstraksi dan transformasi basis data SIM RSPP
5.2. Pembangunan Model Klasifikasi
Pembuatan model klasifikasi menggunakan algoritme CPAR dengan tahapan seperti pada Gambar 8 dan Gambar 9. Pada tahap awal algoritme CPAR membaca data dalam bentuk array dua dimensi dimana kolom terakhir menunjukkan kelas. Berdasarkan kelas tersebut data dikelompokkan menjadi contoh positif (P) dan contoh negatif (N). Setiap atribut pada contoh positif dan contoh negatif dihitung bobot totalnya, dimasukkan kedalam tabel PN array. Tabel PN array berisi informasi tentang atribut serta bobot total contoh positif (WP) dan bobot total contoh negatif (WN). Menghitung total weight threshold (TWT) dengan mengalikan jumlah bobot po sitif dan konstanta yang telah ditetapkan yaitu 0.05. Proses pembentukan aturan secara berulang dilakukan selama nilai total bobot contoh positif lebih besar dari nilai TWT. Selama proses pembentukan aturan, algoritme CPAR menyalin contoh positif P ke contoh positif sementara P’, contoh negatif N ke contoh negatif sementara N’, atribut A ke atribut sementara A’, PN array ke PN’ array sementara. Nilai- ilai yang ada pada PN’ array akan menjadi acuan untuk menghitung gain. Atribut-atribut yang dipilih sebagai kandidat pembentuk aturan diambil berdasarkan atribut yang memiliki nilai gain terbesar atau yang memiliki nilai gain yang serupa (gain similarity ratio). Flowchart algoritme CPAR diperlihatkan pada Gambar 15.
Basis data SIM RSPP
Ekstraksi dan
Transformasi Transaksi Pasien
Mst_pasien Catatan_medis
+ − + = | | | | | | log | * | | * | | * | log | * | ) ( N P P N P P P p Gain Baca Data
Tentukan contoh positif (P) Tentukan contoh negatif (N)
Tentukan bobot contoh positif (WP) Tentukan bobot contoh negatif (WN) Tentukan daftar atribut A
Tentukan daftar contoh positif dan contoh negatif PN array
TWT =
total bobot contoh positif × 0.05
Total bobot Contoh negatif=0
Rule_list=Rule_list_temp; Revisi bobot contoh positif dengan decay factor; Sesuaikan PN array berdasarkan bobot contoh positif yang baru Total bobot
contoh positif 〉 TWT
P’ = P; N’ = N;A’ = A; PN’ array = PN array
Tentukan Gain Terbesar
Gain te rbesar 〉 TWT
Local Gain Threshold (LGT) = Gain terbesar × 0.6
Rule_list = Rule_list_temp
Baca atribut A[i] Satu persatu
EOF
Gain(A[i]) 〉 LGT
Sisipkan A[i] ke rule_list_temp
Hapus record pada P’ dan N’yang tidak mengandung A[i];
P’_temp = P’; N’_temp = N’;
Tentukan PN_temp berdasarkan P’_temp dan N’_temp
Selesai Tidak Ya Tidak Ya Tidak 1 Ya Tidak 1
Hitung Gain A[i]
2 2 2 Ya 2 Ya Tidak Mulai Perhitungan Gain 1 Rule_list = Rule_list_temp
Gambar 16 Flowchart algoritme CPAR 5.2.1. Preproses Data
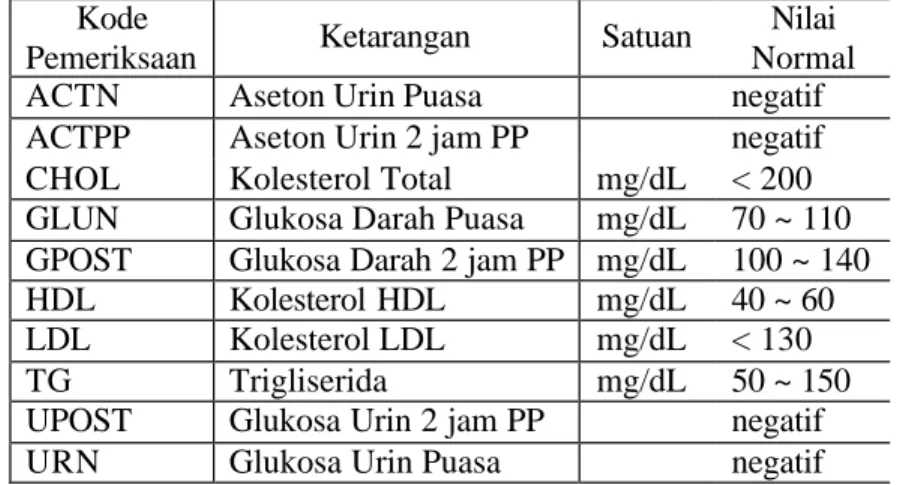
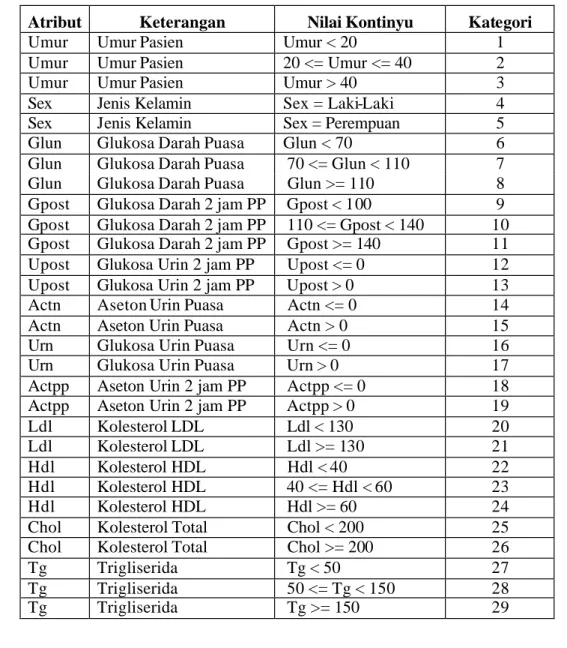
Pembangunan model klasifikasi dengan algoritme CPAR menggunakan PL/SQL. Pada penelitian ini digunakan DBMS Oracle 9i. Pada tahap awal data yang berasal dari relasi antara tabel mst_pasien, hasil_lab dan catatan_medis yang terdapat pada data warehouse diabetes ditransformasi ke dalam working database sampel_data, selanjutnya diubah ke dalam bentuk kategori. Penentuan pembentukan nilai kategori terhadap data-data hasil laboratorium didasarkan atas referensi yang ada di SIM RSPP seperti diperlihatkan pada Tabel 5. Penentuan kelas positif diabetes atau negatif diabetes ditentukan oleh diagnosa yang terdapat pada tabel catatan_medis. Kelas ditetapkan sebagai positif diabetes jika kode ICD pada diagnosa adalah E.10 Insulin -dependent diabetes mellitus atau E.11 Non-insulin-dependent diabetes mellitus atau E.12 Malnutrition -related diabetes mellitus atau E.13 Other specified diabetes mellitus atau E.14 Unspecified diabetes mellitus. Pembentukan nilai kategori selengkapnya diperlihatkan pada Tabel 6.
Tabel 5. Nilai referensi hasil laboratorium Kode
Pemeriksaan Ketarangan Satuan
Nilai Normal
ACTN Aseton Urin Puasa negatif
ACTPP Aseton Urin 2 jam PP negatif CHOL Kolesterol Total mg/dL < 200 GLUN Glukosa Darah Puasa mg/dL 70 ~ 110 GPOST Glukosa Darah 2 jam PP mg/dL 100 ~ 140
HDL Kolesterol HDL mg/dL 40 ~ 60
LDL Kolesterol LDL mg/dL < 130
TG Trigliserida mg/dL 50 ~ 150
UPOST Glukosa Urin 2 jam PP negatif
Tabel 6. Kategori untuk tabel sampel_ data
Atribut Keterangan Nilai Kontinyu Kategori
Umur Umur Pasien Umur < 20 1
Umur Umur Pasien 20 <= Umur <= 40 2
Umur Umur Pasien Umur > 40 3
Sex Jenis Kelamin Sex = Laki-Laki 4
Sex Jenis Kelamin Sex = Perempuan 5
Glun Glukosa Darah Puasa Glun < 70 6
Glun Glukosa Darah Puasa 70 <= Glun < 110 7 Glun Glukosa Darah Puasa Glun >= 110 8 Gpost Glukosa Darah 2 jam PP Gpost < 100 9 Gpost Glukosa Darah 2 jam PP 110 <= Gpost < 140 10 Gpost Glukosa Darah 2 jam PP Gpost >= 140 11 Upost Glukosa Urin 2 jam PP Upost <= 0 12 Upost Glukosa Urin 2 jam PP Upost > 0 13
Actn Aseton Urin Puasa Actn <= 0 14
Actn Aseton Urin Puasa Actn > 0 15
Urn Glukosa Urin Puasa Urn <= 0 16
Urn Glukosa Urin Puasa Urn > 0 17
Actpp Aseton Urin 2 jam PP Actpp <= 0 18 Actpp Aseton Urin 2 jam PP Actpp > 0 19
Ldl Kolesterol LDL Ldl < 130 20
Ldl Kolesterol LDL Ldl >= 130 21
Hdl Kolesterol HDL Hdl < 40 22
Hdl Kolesterol HDL 40 <= Hdl < 60 23
Hdl Kolesterol HDL Hdl >= 60 24
Chol Kolesterol Total Chol < 200 25
Chol Kolesterol Total Chol >= 200 26
Tg Trigliserida Tg < 50 27
Tg Trigliserida 50 <= Tg < 150 28
Tg Trigliserida Tg >= 150 29
Data yang sudah dalam bentuk kategori selanjutnya ditransformasi ke dalam bentuk array dua dimensi dan dilakukan proses cleaning dengan menghapus baris -baris yang tidak lengkap. Sampel hasil transformasi, integrasi dan cleaning data yang berasal dari tabel mst_pasien, hasil_lab serta catatan_medis pada data warehouse diabetes seperti pada Lampiran 5. Untuk
menjelaskan tahapan pembuatan model klasifikasi, digunakan contoh sampel data yang terdiri dari 20 record sebagai data training (Tabel 7).
Tabel 7. Contoh sampel data.
Umur Sex Glun Gpost Upost Actn Urn Actpp Ldl Hdl Chol Tg Kelas
3 5 7 9 12 14 16 18 21 22 26 29 31 3 5 7 11 12 14 16 18 21 23 26 29 31 3 4 8 11 13 14 16 18 21 23 26 29 30 3 5 8 10 12 14 16 18 21 23 26 29 31 3 5 8 11 13 14 17 18 21 24 26 29 30 3 5 7 11 12 14 16 18 20 24 25 29 31 3 5 8 11 13 14 16 18 21 23 26 29 30 3 5 7 10 12 14 16 18 21 23 26 29 31 3 4 8 11 13 14 16 18 20 23 26 29 30 3 5 7 9 12 14 16 18 20 23 25 29 31 3 5 7 9 12 14 16 18 20 23 25 29 31 3 5 7 11 12 14 16 18 20 24 25 29 31 3 4 8 11 12 14 17 18 20 24 25 29 31 3 5 7 9 12 14 16 18 21 23 26 29 31 3 5 7 11 12 14 16 18 21 23 26 29 30 3 5 8 11 13 14 16 18 21 23 26 29 30 3 5 7 9 12 14 16 18 21 23 26 29 31 1 4 7 9 12 14 16 18 20 23 25 29 31 3 5 7 9 12 14 16 18 21 23 26 29 31 2 5 8 11 12 14 16 18 20 24 25 29 31
5.2.2. Pembentukan sampel positif dan sampel negatif
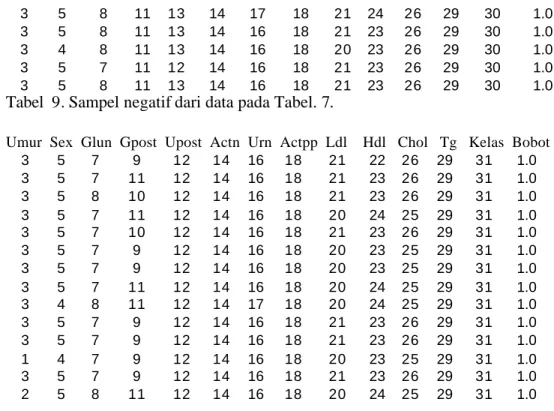
Kolom terakhir pada sampel data pada Tabel 7 menunjukkan kelas. Angka 30 menunjukkan kelas positif diabetes dan 31 menunjukkan kelas negatif diabetes. Data training kemudian dipisahkan menjadi sampel positif (data pasien dengan diagnosa positif diabetes) dan sampel negatif (data pasien dengan diagnosa negatif diabetes). Sampel data positif dari Tabel 7 diberikan dalam Tabel 8, sedangkan sampel negatif diberikan dalam Tabel 9.
Kolom 1 sampai dengan kolom ke 12 pada Tabel 9 dan Tabel 10 berisi kategori 1 sampai dengan 29. Kolom ke 14 berisi bobot total setiap record dari contoh positif P dan contoh negatif N.
Tabel 8. Sampel positif dari data pada Tabel 7
Umur Sex Glun Gpost Upost Actn Urn Actpp Ldl Hdl Chol Tg Kelas Bobot
3 5 8 11 13 14 17 18 21 24 26 29 30 1.0
3 5 8 11 13 14 16 18 21 23 26 29 30 1.0
3 4 8 11 13 14 16 18 20 23 26 29 30 1.0
3 5 7 11 12 14 16 18 21 23 26 29 30 1.0
3 5 8 11 13 14 16 18 21 23 26 29 30 1.0
Tabel 9. Sampel negatif dari data pada Tabel. 7.
Umur Sex Glun Gpost Upost Actn Urn Actpp Ldl Hdl Chol Tg Kelas Bobot
3 5 7 9 12 14 16 18 21 22 26 29 31 1.0 3 5 7 11 12 14 16 18 21 23 26 29 31 1.0 3 5 8 10 12 14 16 18 21 23 26 29 31 1.0 3 5 7 11 12 14 16 18 20 24 25 29 31 1.0 3 5 7 10 12 14 16 18 21 23 26 29 31 1.0 3 5 7 9 12 14 16 18 20 23 25 29 31 1.0 3 5 7 9 12 14 16 18 20 23 25 29 31 1.0 3 5 7 11 12 14 16 18 20 24 25 29 31 1.0 3 4 8 11 12 14 17 18 20 24 25 29 31 1.0 3 5 7 9 12 14 16 18 21 23 26 29 31 1.0 3 5 7 9 12 14 16 18 21 23 26 29 31 1.0 1 4 7 9 12 14 16 18 20 23 25 29 31 1.0 3 5 7 9 12 14 16 18 21 23 26 29 31 1.0 2 5 8 11 12 14 16 18 20 24 25 29 31 1.0 5.2.3. Pembentukan PN array
Pada awal proses setiap record mempunyai bobot 1.0. Kategori 1 dan 2 tidak muncul pada sampel positif dan muncul satu kali pada sampel negatif, sehingga bobot sampel positif (Wp) dan bobot sampel negatif (Wn) pada kategori 1 dan 2 adalah 0 dan 1. Bobot sampel positif dan bobot sampel negatif untuk setiap kategori selengkapnya diperlihatkan pada Tabel 10.
Tabel 10. PN array
Kategori sampel Bobot Kategori positif Bobot sampel negatif Bobot sampel positif Bobot sampel negatif 1 0 1 16 5 13 2 0 1 17 1 1 3 6 12 18 6 14 4 2 2 19 0 0 5 4 12 20 1 7 6 0 0 21 5 7 7 1 11 22 0 1 8 5 3 23 5 9 9 0 7 24 1 4 10 0 2 25 0 7 11 6 5 26 6 7
12 1 14 27 0 0
13 5 0 28 0 0
14 6 14 29 6 14
15 0 0
Jumlah record pada sampel positif pada Tabel 8 adalah 6 dan setiap record pada awal proses berbobot 1, sehingga bobot total dari sampel positif pada awal proses adalah 6. Total Weight Threshold (TWT) dihitung berdas arkan rumus :
TWT = total bobot sampel positif × 0.05 = 6 × 0.05 = 0.3
Seluruh kategori pada sampel positif selanjutnya diproses satu persatu sampai bobot totalnya lebih kecil dari nilai TWT yaitu 0.3.
5.2.4. Pembentukan Gain
Sebagai contoh untuk menghitung Gain dipilih kategori 4 yang muncul 2 kali pada sampel positif (Wp) dan 2 kali pada sampel negatif (Wn), sehingga sesuai dengan formula Gain(p) didapat :
+ − + = 14 6 6 log 2 2 2 log 2 ) 4 ( Gain = 1.02
nilai Gain pada atribut 4 adalah 1.02. Bobot sampel positif, bobot sampel negatif serta nilai Gain untuk setiap kategori selengkapnya diperlihatkan pada Tabel 11. Dalam penelitian ini decay factor ditentukan 0.3 dan global minimum threshold 0.7.
Tabel 11. Kategori dan nilai Gain
Kategori Bobot sampel positif Bobot sampel negatif Gain Kategori Bobot sampel positif Bobot sampel negatif Gain 1 0 1 0.00 16 5 13 -0.38 2 0 1 0.00 17 1 1 0.51 3 6 12 0.63 18 6 14 0.00 4 2 2 1.02 19 0 0 0.00 5 4 12 -0.73 20 1 7 -0.87 6 0 0 0.00 21 5 7 1.64 7 1 11 -1.28 22 0 1 0.00 8 5 3 3.67 23 5 9 0.87 9 0 7 0.00 24 1 4 -0.41 10 0 2 0.00 25 0 7 0.00 11 6 5 3.58 26 6 7 2.58
12 1 14 -1.50 27 0 0 0.00
13 5 0 6.02 28 0 0 0.00
14 6 14 0.00 29 6 14 0.00
15 0 0 0.00
Pada Tabel 11 terlihat Gain terbesar adalah pada kategori 13 (Gain = 6.02). Local Gain Threshold (LGT) dihitung berdasarkan rumus :
LGT = Gain terbesar × Gain_similarity_ratio = 6.02 × Gain_similarity_ratio
= 6.02 × 0.6 = 3.61
Ada dua kategori yang nilai Gain-nya di atas LGT yaitu 13 dan 8. Selanjutnya kedua kategori tersebut diproses satu persatu, yaitu dengan menyisipkan rule 13 → 30 ke rule list sementara, menyalin sampel positif dan sampel negatif dengan menghapus baris yang tidak berisi atribut 13, sehingga record kelima pada Tabel 8 dihapus. Sehingga sampel positif menjadi:
Umur Sex Glun Gpost Upost Actn Urn Actpp Ldl Hdl Chol Tg Kelas Bobot
3 4 8 11 13 14 16 18 21 23 26 29 30 1.0
3 5 8 11 13 14 17 18 21 24 26 29 30 1.0
3 5 8 11 13 14 16 18 21 23 26 29 30 1.0
3 4 8 11 13 14 16 18 20 23 26 29 30 1.0
3 5 8 11 13 14 16 18 21 23 26 29 30 1.0
Sedangkan untuk sampel negatif tidak memiliki anggota.
Karena sampel negatif kosong, maka rule 13 → 30 disisipkan ke dalam rule list. Laplace accuracy (LA) yang berguna untuk mengetahui kekuatan prediksi dihitung berdasarkan formula :
L.A = (nc+1) / (ntot+f)
Dimana nc adalah jumlah sampel yang memenuhi kelas 30 yaitu 5 (jumlah kategori 13 pada kelas 30), ntot adalah jumlah total sampel yang memenuhi body dariaturan yaitu 5 (jumlah kategori 13 pada keseluruhan sampel) , f adalah jumlah kelas yaitu 2 (kelas 30 dan 31). Sehingga didapat LA= (5+1)/(5+2)=0.86.
Bobot sampel positif selanjutnya direvisi dengan menggunakan decay factor. Bobot sampel positif yang baru adalah:
Umur Sex Glun Gpost Upost Actn Urn Actpp Ldl Hdl Chol Tg Kelas Bobot 3 4 8 11 13 14 16 18 21 23 26 29 30 0.33 3 5 8 11 13 14 17 18 21 24 26 29 30 0.33 3 5 8 11 13 14 16 18 21 23 26 29 30 0.33 3 4 8 11 13 14 16 18 20 23 26 29 30 0.33 3 5 7 11 12 14 16 18 21 23 26 29 30 1.0 3 5 8 11 13 14 16 18 21 23 26 29 30 0.33
Nilai bobot sampel positif sekarang adalah 2.65, masih lebih besar dari 0.3, sehingga kategori berikutnya yaitu 8 yang memiliki nilai Gain diatas LGT diproses den gan menyisipkan atribut 8 → 30 ke rule list sementara dan menyalin sampel positif dan sampel negatif sebelumnya dengan menghapus baris yang tidak berisi kategori 8. Sampel positif setelah dilakukan penghapusan baris yang tidak berisi kategori 8 adalah:
Umur Sex Glun Gpost Upost Actn Urn Actpp Ldl Hdl Chol Tg Kelas Bobot
3 4 8 11 13 14 16 18 21 23 26 29 30 1.0
3 5 8 11 13 14 17 18 21 24 26 29 30 1.0
3 5 8 11 13 14 16 18 21 23 26 29 30 1.0
3 4 8 11 13 14 16 18 20 23 26 29 30 1.0
3 5 8 11 13 14 16 18 21 23 26 29 30 1.0
Sedangkan untuk sampel negatif tidak memiliki anggota.
Karena sampel negatif kosong, maka kategori 8 → 30 disisipkan ke dalam rule list. Laplace accuracy untuk aturan tersebut adalah:
LA= (5+1)/(8+2)=0.60.
Bobot sampel positif selanjutnya direvisi dengan menggunakan decay factor. Bobot sampel positif yang baru adalah:
Umur Sex Glun Gpost Upost Actn Urn Actpp Ldl Hdl Chol Tg Kelas Bobot
3 4 8 11 13 14 16 18 21 23 26 29 30 0.11 3 5 8 11 13 14 17 18 21 24 26 29 30 0.11 3 5 8 11 13 14 16 18 21 23 26 29 30 0.11 3 4 8 11 13 14 16 18 20 23 26 29 30 0.11 3 5 7 11 12 14 16 18 21 23 26 29 30 1.0 3 5 8 11 13 14 16 18 21 23 26 29 30 0.11
Setelah kedua kategori 13 dan 8 d iproses, langkah selanjutnya menghitung Gain dengan bobot sampel yang sudah disesuaikan . Hasil perhitungan Gain tersebut diberikan pada Tabel 12.
Tabel 12. Hasil perhitungan Gain setelah kategori 13 dan 8 diproses .
Kategori Bobot sampel positif Bobot sampel negatif Gain Kategori Bobot sampel positif Bobot sampel negatif Gain 1 0 1 0.00 16 2.32 13 -1.58 2 0 1 0.00 17 0.33 1 -0.06 3 2.65 12 -1.34 18 2.65 14 -1.68 4 0.66 2 -0.13 19 0 0 0.00 5 1.99 12 -1.48 20 0.33 7 -0.63 6 0 0 0.00 21 2.32 7 -0.43 7 1 11 -1.28 22 0 1 0.00 8 1.65 3 0.28 23 2.32 9 -0.88 9 0 7 0.00 24 0.33 4 -0.45 10 0 2 0.00 25 0 7 0.00 11 2.65 5 0.38 26 2.65 7 -0.23 12 1 14 -1.50 27 0 0 0.00 13 1.65 0 1.99 28 0 0 0.00 14 2.65 14 -1.68 29 2.65 14 -1.68 15 0 0 0.00
Kategori 13 dan 8 tidak disertakan pada proses selanjutnya sehingga nilai Gain pada kategori 13 dan 8 diabaikan, Gain maksimum sekarang adalah 0.38 yang berarti lebih kecil dari global minimu m 0.7, sehingga proses dihentikan. Cara yang sama digunakan untuk kelas 31. Pada akhir proses semua rule d isisipkan ke dalam rule list, dan dihitung akurasinya menggunakan Laplace accuracy (LA) sehingga didapat : No. Rule LA 1 13 → 30 0.86 2 8 → 30 0.60 3 7 ∧ 12 → 31 0.88 4 9 → 31 0.89 5 25 → 31 0.89 5.3. Program Aplikasi
Untuk memudahkan penggunaan aplikasi oleh pemakai maka dibuat program antar muka yang dibangun dengan menggunakan modus grafik. Dua