Analisis Klasifikasi Sentimen dan
Peringkasan pada Review Produk
Menggunakan Metode Unsupervised
Muhammad Husein Adnan
#1, Warih Maharani
#2, Anisa Herdiani
#3 1,2,3Prodi S1 Teknik Informatika, Fakultas Informatika, Universitas Telkom Jl. Telekomunikasi No. 01, Terusan Buah Batu, Bandung, Jawa Barat, IndonesiaAbstract
Improved e-commerce transaction has made market players switched buying and selling process to modern level via internet. Many online buying and selling website providers that arise until make consumer easy to argue about the product witch he bought. Unfortunately, an existing argument about a product have big number and make it difficult to conclude. So, in this experiment has been analyzed to make a system that can do sentiment classification and make product reviews summarization from that product. Product Reviews, generally not only about that product but also reviews about its fitur. So, analysis also do to get what feature that reviews in the argument and what opinion word that follow the feature using Noun Phrase Chunking and Double Propagation method. Aspect Classification and entity has been doing to decide the argument in the reviews to positif argument and negative argument. There are many methods to do this classification, but in this experiment has been used Unsupervised method based on polarity similarity assumption in every two adjective that appear together connected with “and” conjunction that capable give sentiment orientation exactly.
Keywords: Sentiment, Classification, Noun Phrase Chunking, Double Propagation, Unsupervised,
Review Product.
Abstrak
Peningkatan transaksi e-commerse telah membuat para pelaku pasar mengalihkan proses jual-beli ke arah modernisasi melalui internet. Banyak Website penyedia layanan jual-beli online yang bermunculan hingga memudahkan juga bagi konsumen untuk mengutarakan opininya mengenai produk yang dia beli serta produsen dalam mengetahui opini konsumen tersebut. Sayangnya opini mengenai review suatu produk yang dijumpai, jumlah nya sangat banyak dan menyulitkan untuk ditarik kesimpulan. Pada penelitian ini dilakukan analisis untuk membuat sebuah sistem yang dapat memberikan klasifikasi dan ringkasan atas review produk tersebut. Review tehadap suatu produk, umumnya tidak hanya kepada produk itu sendiri namun lebih banyak kepada fitur-fiturnya. Untuk itu dilakukan juga analisis untuk dapat mengambil fitur-fitur dari produk dan kata opininya menggunakan metode Noun Phrase Chunking dan Double Propagation. Klasifikasi ditingkat aspek dilakukan untuk menentukan opini–opini pada review produk kedalam opini positif dan negatif. Ada banyak metode untuk melakukan klasifikasi tersebut, pada penelitian ini digunakan metode Unsupervised berbasis kesamaan polarity pada setiap kata opini yang muncul bersamaan yang dihubungkan dengan sebuah konjungsi “and” yang mampu memberikan orientasi opini dengan tepat.
ISSN 2460-3295
socj.telkomuniversity.ac.id/indosc doi:10.21108/indosc.2016.116Sept 2016. pp. 35-44
Kata kunci: Sentimen, Klasifikasi, Noun Phrase Chunking, Double Propagation, Unsupervised, Review Product
I. PENDAHULUAN
ERTUMBUHAN transaksi e-commerse telah mendorong masyarakat memilih melakukan jual beli melalui media online. Hal ini mengakibatkan munculnya banyak website jual beli online yang juga memberikan ruang bagi pembeli dalam mengutarakan ulasan akan suatu produk yang telah dibelinya. Perusahaan survey asal Chicago yang bernama PowerReviews mengatakan dari 800 customer di Amerika Serikat, 95% diantaranya melaporkan ulasannya atas produk yang telah dibelinya [1]. Tren ini mengakibatkan jumlah review sangat besar dan menyulitkan pengguna dalam menarik suatu kesimpulan. Untuk itu dibutuhkan sebuah sistem yang mampu memberikan ringkasan opini tersebut. Dalam sebuah review, komentar yang diberikan berada pada level aspek sehingga dilakukan identifikasi fitur produk dan kata opini. Pada banyak kasus sentimen analisis, proses tersebut dilakukan menggunakan metode berbasis lexicon. Metode ini akan mengalami kendala ketika lexicon yang tersedia tidak mampu memberikan lexicon yang lengkap (universal) untuk setiap domain aspek fitur yang akan diambil [2]. Untuk itu digunakan metode ekstraksi fitur menggunakan metode Noun Phrease Chunking dan Double Propagation yang berbasis kepada struktur suatu kalimat itu sendiri. Dengan adanya kata opini yang orientasi sentimennya bergantung pada objek yang di komentari dan tidak selalu sama orientasinya pada semua objek maka, proses klasifikasi dilakukan dengan menggunakan metode Unsupervised yang berbasis kesamaan polarity pada setiap dua
adjective yang muncul bersamaan yang dihubungkan dengan konjungsi “and” untuk melakukan pemberian
orientasi kata opini terhadap fitur produknya [3].
Proses analisis dilakukan pada tahap ekstraksi fitur, penanganan lanjutan terhadap metode ekstraksi fitur dan proses pemberian orientasi sentimen pada setiap kata opini yang melekat pada fitur produk. Penelitian menggunakan lima dataset dari lima produk yang berisi review produk berbahasa inggris yang berasal dari amazon.com dan digunakan sebelumnya pada penelitian Bing Liu tahun 2004. Beberapa skema pengujian telah disiapkan untuk mengetahui pengaruh setiap skema pada proses yang dilakukan pada penelitian ini.
II.TINJAUAN PUSTAKA A. Analisis Sentimen
Analisis Sentimen Mining merupakan sebuah bidang studi yang menganalisis pendapat, sentimen, evaluasi, sikap dan emosi terhadap suatu entitas seperti produk, jasa, organisasi, individu, masalah, topik dan atribut dari entitas tersebut [4]. Ada banyak sebutan dari analis sentimen ini, seperti opinion mining, opinion extraction, sentimen mining, subjectivity analysis, affect analysis, emotion analysis, review mining dan lain sebagainya. Analisis sentimen dapat dilakukan pada beberapa level seperti: dokumen, kalimat, entitas/aspek. Masing-masing level tersebut akan menghasilkan sentimen positif dan sentimen negatif. Pada penelitian ini, analisis sentimen dilakukan pada level aspek karena dalam satu dokumen berisi banyak kalimat komentar dan dalam satu kalimat komentar terdapat beberapa aspek yang masing-masing memiliki sentimen yang berbeda-beda.
B. Lemmatization
Lemmatization merupakan proses pembentukan sebuah kata kedalam bentuk lemma-nya [5]. Lemma
sendiri merupakan bentuk kata paling dasar dari sebuah kata yang memiliki arti pada kamus. Proses yang dilakukan lemma dalam merubah suatu kata yaitu bukan dengan memotong awalan ataupun akhiran secara langsung melainkan dengan cara membandikan setiap kata dengan daftar kata yang berada di kamus sehingga hasilnya tetap memiliki makna bukan sekedar potongan bagian kata. Contoh proses lemmatization:
Sebelum: this camera is perfect for an enthusiastic amateur photographer. Sesudah: this camera be perfect for a enthusiastic amateur photographer.
C. Dependency Parsing
Dependency Parsing pada sebuah kalimat merupakan sebuah proses penjabaran relasi dari bagian-bagian
kalimat (kata-kata) tersebut berdasarkan Dependency Grammar. Dependency Grammar merupakan sebuah teori sintaksis yang mendasarkan pada Dependency Relation atau hubungan kata dalam kalimat. Proses
Dependency Parsing dapat dilakukan dengan menggunakan Stanford Dependency Parser. Contoh:
Input: Bell, based in Los Angeles, makes and distributes electronic, computer and building products Output:
nsubj(makes-8, Bell-1) nsubj(distributes-10, Bell-1) vmod(Bell-1, based-3) nn(Angeles-6, Los-5) prep in(based-3, Angeles-6) root(ROOT-0, makes-8)
conj and(makes-8, distributes-10) amod(products-16, electronic-11) conj and(electronic-11, computer-13) amod(products-16, computer-13) conj and(electronic-11, building-15) amod(products-16, building-15) dobj(makes-8, products-16) dobj(distributes-10, products-16)
Pada penelitian ini tag yang digunakan ada empat yaitu amod, dobj, subj dan conj. Berikut penjelasannya: 1. amod: adjectival modifier
Sebuah adjectival modifier dari sebuah Noun Phrase merupakan setiap frase kata sifat yang berfungsi untuk mengubah arti Noun Phrase. Contoh: “Sam eats red meat" menghasilkan amod(meat, red) [6]. 2. dobj: direct object
Sebuah direct object dari sebuah Verb Phrase adalah frase kata benda yang merupakan akusatif objek dari kata kerja. Akusatif sendiri merupakan kata benda yang memiliki sesuatu dilakukan untuk itu. Contoh: “She gave me a raise" menghasilkan dobj (gave, raise) [6]
3. nsubj: nominal subject
Sebuah subjek nominal merupakan frase kata benda yang merupakan subjek sintaksis klausa. Hubungan ini belum tentu selalu menghasilkan kata kerja, ketika kata kerja merupakan kata kerja copular (kata kerja yang menghubungkan kata kerja kalimat dengan kata kerja komplemen atau pelengkap) akar klausa adalah komplemen dari kata kerja copular, maka dapat menghasilkan kata sifat atau kata benda. Contoh: “Clinton defeated Dole" menghasilkan nsubj (defeated, Clinton) [6].
4. conj: conjunct
Sebuah konjungsi merupakan sebuah hubunganantara dua elemen yang dihubungkan oleh konjungsi koordinasi seperti and, or, dll. Bagian pertama merupakan element utama dalam relasi, sedangkan bagian kedua bergantung pada bagian pertama yang dihubungkan dengan penghubung konjungsi. Contoh: “Bill
is big and honest" menghasilkan conj (big, honest) [6].
D. Text Chunking
Text Chunking adalah proses untuk membagi text kedalam bagian-bagian text yang berbentuk kata-kata
yang berkorelasi secara siktaksis seperti Noun Group (kelompok kata benda), Verb Group (kelompok kata kerja) tetapi tidak menentukan stuktur atau role (peran) kelompok kata tersebut dalam kalimat utamanya [7]. Proses Chunking ini membutuhkan proses POS Tagging untuk dapat diketahui tag-tag setiap kata terlebih
dahulu pada sebuah teks. Hasilkan akan terlihat mana yang merupakan text chunk yang dapat berupa frase kata benda maupun frase kata kerja. Contoh dari hasil proses chunking ini adalah sebagai berikut:
Input: this_DT camera_NN is_VBZ perfect_JJ for_IN an_DT enthusiastic_JJ amateur_JJ photographer_NNP ._. Output: this_DT B-NP camera_ NN I-NP is_VBZ B-VP perfect_JJ B-ADJP for_IN B-PP an_DT B-NP enthusiastic_JJ I-NP amateur_JJ I-NP photographer_NNP I-NP ._. O
Noun Phrase : this camera, an enthusiastic amateur photographer
Verb Phrase : is
Contoh diatas menunjukkan hasil dari proses chunking dimana terdapat tiga tag tambahan untuk setiap kata. Tag tersebut disebut merupakan tag IOB, yang terdiri dari I-inside, O-outside, B-begin. B-begin merupakan kata awal dari chunk. I-inside merupakan kata bagian dari chunk setelah kata berlabel B.
O-outside merupakan kata diluar chunk atau yang tidak merupakan bagian dari chunk.
E. Nearest Opinion Word
Nearest Opinion Word Merupakan salah satu cara yang simpel dalam proses Feature-Opinion Association Problem (FOA) yaitu dengan memasangkan kata opini dengan kandidat fitur terdekat [8]. Metode tersebut
mencari nilai jarak kedekatan suatu kata opini dengan kata fitur, dimana kata opini yang paling dekat dengan salah satu kata fitur produk, maka akan menjadi kata opini dari kata fitur produk tersebut. Kedekatan dinyatakan dengan nilai rel(f,w) terbesar. rel(f,w) memiliki rumus perhitungan sebagai berikut:
𝑟𝑒𝑙(𝑓, 𝑤) =
1
𝑑𝑖𝑠𝑡(𝑓, 𝑤)
rel(f,w) merupakan nilai invers dari jarak antara kata opini(w) dengan kata fitur produk(f) tertentu yang
dinyatakan dengan dist(f,w). Dengan metode ini kata opini akan menjadi milik kata fitur yang jaraknya paling dekat dengan dirinya. Metode ini juga dilengkapi dengan sebuah threshold yang akan menjadi batas maksimum terjauh kedekatan antara suatu kata opini dengan kata fitur. Dengan kata lain, kata opini akan menjadi pasangan suatu kata fitur yang jaraknya paling dekat dan memenuhi batas maksimum terjauh jarak antar keduanya.
F. Propagation Polarity
Proses ini digunakan untuk melakukan pemberian label pada setiap node kata opini berdasarkan node yang telah memiliki label polarity. Metode ini memberikan nilai 1 untuk node kata opini berlabel positif dan nilai 0 untuk node kata opini berlabel negatif. Dan untuk node yang belum memiliki label diberikan nilai 0.5. Selanjutnya digunakan rumus 2 untuk melalukan proses Propagation Polarity.
𝒑
𝒕(𝒙) =
∑𝒚∈𝑵(𝒙)𝒘(𝒚,𝒙)∙𝒑𝒕−𝟏(𝒚)∑𝒚∈𝑵(𝒙)𝒘(𝒚,𝒙)
Dimana 𝑝𝑡(𝑥) merupakan nilai polarity adjective pada iterasi t. N(x) merupakan himpunan dari tetangga x.
w(y,x) adalah nilai bobot antara x dengan tetangganya y dimana 𝑤(𝑥. 𝑦) = 1 + log(#𝑚𝑜𝑑(𝑦. 𝑥)). Nilai
#𝑚𝑜𝑑(𝑦. 𝑥) adalah nilai frekuensi kemunculan y dan x dalam modifier (muncul
bersamaan/merepresentasikan polarity) dari satu Fitur Produk (sama) yaitu nilai yang terdapat edge yang menghubungkan kedua node. Iterasi akan terus dilakukan hingga nilai bobot pada node tidak berubah lagi.
(1)
G. Evaluasi
Pada penelitian ini evaluasi dilakukan berbasis kalimat, untuk setiap kalimat akan dihitung performansinya dan selanjutnya akan dihitung rata-ratanya dalam satu dokumen. Untuk ekstraksi fitur performansi dihitung melalui nilai precision, recall dan f-score. Untuk proses klasifikasi atau perberian orientasi opini performansi ditunjukkan dengan melalui nilai akurasi.
Table 1. Evaluasi Ekstraksi Fitur
No. Fitur Label Fitur Prediksi Prec Rec
1 - - 1.0 1.0 2 - camera 0.0 0.0 3 autofocus scene mode - 0.0 0.0 4 camera camera photographer 0.5 1.0 5 weight day 0.0 0.0 Rata-Rata 0.3 0.4
Table 2. Evaluasi Klasifikasi
No. Polarity Fitur Label Polarity Fitur Prediksi Akurasi
1 - - 0.0 2 camera[+] camera[+] 1.0 3 camera[-] camera[-] 1.0 4 camera[+] camera[-] 0.0 5 camera[+] camera[+] camera[+] 1.0 6 camera[+] camera[+] camera[-] 0.5 7 camera[+] size[+] camera[+] camera[-] camera[0] size[+] 0.5 8 camera[+] camera[-] camera[+] 0.5 Rata-Rata 4.5 / 7 = 64.3 %
III. METODE PENELITIAN DAN ANALISA HASIL
A. Gambaran Umum Sistem
Sistem yang dibangun pada penelitian ini adalah sebuah sistem yang dapat memberikan orientasi sentimen positif atau sentimen negatif pada aspek produk yang terdapat dalam kalimat opini. Selain memberikan orientasi sentimen, sistem ini juga dapat memberikan ringkasan terhadap opini-opini tersebut berdasarkan fitur-fitur produk. Task yang dilakukan pada sistem ini terbagi menjadi 3 proses utama, (1) ekstraksi pasangan aspek fitur produk dan opininya, (2) memberikan orientasi sentimen kepada setiap aspek fitur produk berdasarkan orientasi kata opininya, (3) pembangkitan ringkasan. Proses-proses tersebut digambarkan dalam bentuk flowchart sebagai berikut:
0 10 20 30 40 50 Apex AD2600 Progressive-scan DVD player
Canon G3 Creative Labs Nomad Jukebox
Zen Xtra 40GB
Nikon coolpix 4300
Nokia 6610
F-Score Perbandingan Metode NP Chunking dan Modif NP Chunking
Tanpa Modifikasi Dengan Modifikasi Start End Dataset Pasangan Aspek dan Opini Dataset Hasil Preprocessing Pasangan Aspek dan Polaritasnya Peringkasan Ringkasan Aspek dan Polaritasnya Ekstraksi Fitur Ekstraksi Fitur Noun Phrase Chunking Double Propagation Rules Postprocessing NP Chunking Penghilangan Aspek tanpa Pasangan Opini Stop Word Removal
Postprocessing Double Propagation Rules
Penghilangan Aspek tanpa Pasangan Opini Multiword Generation Pemilihan Pasangan Aspek dan Opini Penentuan Polaritas Opini pada Aspek
Conjunction Set Wordnet Propagation Polarity Pembangkitan Graph Pembangkitan Seeds Pemberian Orientasi Opini Pembangkitan Konjungsi Opini Preprocessing Lemmatization Stop Word Removal Stemming
POS Tagging Dependecy Parser
Gambar 2. Gambaran Umum Sistem
B. Ekstraksi Aspek Fitur Produk dan Opini Noun Frase Chunking
Ekstraksi Fitur dilakukan dengan menjadikan Noun Frase sebagai kandidat fitur produk karena secara umum fitur produk berbentuk kata benda atau frase kata benda [9]. Digunakan juga proses Modifikasi Noun
Frase Chunking yaitu dengan mengambil bagian dari Noun Frase yang berupa kata benda saja sebagai sebagai
kandidat fitur produk. Setelah kandidat fitur produk terekstrak dilakukan postprocessing dengan melakukan
Stop Word Removal untuk menghapus kandidat fitur produk yang masuk dalam daftar kata Stop Word.
Pengambilan kata opini yang akan menjadi pasangan dari fitur produk dilakukan dengan metode Nearest
Opinion Word dan berdasarkan pengujian min threshold yang digunakan adalah 0.5. Fitur yang tidak memiliki
pasangan oipini akan dihapus karena tidak dapat diketahui orientasi opinininya.
Gambar 4. F-Score Perbandingan Penggunaan Postprocessing
Berdasarkan hasil pengujian, ekstraksi dengan metode penggunaan Noun Phrase sebagai kandidat fitur produk mengalami banyak kesalahan identifikasi, untuk itu digunakan modifikasi yang dapat memperbaiki kesalah ekstraksi fitur produk tersebut. Kandidat fitur yang dihasilkan berjumlah sangat banyak untuk itu digunakan Stop Word Removal untuk menyaring kandidat fitur yang salah identifikasi. Hasil ekstraksi dengan metode ini menghasilkan nilai f-score tertinggi sebesar 39.07% pada dokumen Nokia.
0 10 20 30 40 50 Apex AD2600 Progressive-scan DVD player
Canon G3 Creative Labs Nomad Jukebox
Zen Xtra 40GB
Nikon coolpix 4300
Nokia 6610
F-Score Perbandingan Penggunaan Postprocessing
Tanpa Posprocessing Posprocessing (Stop Word Removal)
Gambar 3. Hasil Pengujian Perbandingan NP Chunking dan Modif NP Chunking
0 10 20 30 40 50 Apex AD2600 Progressive-scan DVD player
Canon G3 Creative Labs Nomad Jukebox
Zen Xtra 40GB
Nikon coolpix 4300
Nokia 6610 F-Score Perbandingan dengan Penambahan
Rules dan Tidak
Tanpa Tambahan Rules Dengan Tambahan Rules
C. Ekstraksi Aspek Fitur Produk dan Opini Double Propagation
Ekstraksi Fitur dilakukan berbasis rules Double Propagation yang dapat mengambil fitur produk dan opini secara langsung. Ekstraksi ini menggunakan seeds dua kata opini yaitu good dan bad yang selanjutnya proses pengambilan fitur berlangsung secara terus menurus hingga tidak ada lagi fitur yang terambil [2]. Rules yang digunakan berjumlah delapan seperti tertera pada table 3.
Table 3. Double Propagation Rules [2]
Rule Observation Constraints Action
R11 O → amod → W W is a noun W→T
R12 O → dobj → W1 ← subj ← W2 W2 is a noun W2→T
R21 T ← amod ← W W is an adjective W→O
R22 T → subj → W1 ← dobj ← W2 W2 is an adjective W2→O
R31 T → conj → W W is a noun W→T
R32 T → subj → W1 ← dobj ← W2 W2 is a noun W→T
R41 O → conj → W W is an adjective W→O
R42 O → Dep1 → W1 ← Dep2 ← W2 Dep1==Dep2, W2 is an adjective W2→O
Table 4. Tambahan Rules
Rules Constraints Action
O → subj → W W is a noun W→T
T ← subj ← W W is an adjective W→O
W1 ← subj ← W2 W1 is a noun, W2 is verb W1→T
Untuk dapat mengidentifikasi fitur yang lebih banyak, digunakan tambahan tiga rules yang ditunjukkan pada tabel 4. Kandidat fitur yang didapatkan pada proses ini berupa satu kata saja sehingga digunakan pembangkitan multiword yang mewadai fitur yang terdiri dari dua kata yaitu dengan mengambil gabugan dua kata yang muncul dan keduanya merupakan kata benda. Multiword akan dibangkitkan jika dari dua kata tersebut, kata yang dibelakang merupakan kandidat fitur.
Gambar 6. Hasil Pengujian Perbandingan Penggunaan Postprocessing dan tanpa Posprocessing
Berdasarkan pengujian dengan metode Double Propagation, kandidat fitur yang dihasilkan masih dirasa kurang sehingga diberikan penambahan rules dan meningkatkan performansi ekstraksi fitur. Dengan adanya pembangkitan multiword fitur produk yang terdiri dari dua kata dapat diidentifikasi sehingga meningkatkan performansi ekstraksi fitur juga. Nilai f-score yang tertinggi yang dapat dicapai pada proses ekstraksi fitur dengan menggunakan metode ini adalah 46.2% pada dokumen Nokia.
0 10 20 30 40 50 Apex AD2600 Progressive-scan DVD player
Canon G3 Creative Labs Nomad Jukebox
Zen Xtra 40GB
Nikon coolpix 4300
Nokia 6610
F-Score Perbandingan Penggunaan Postprocessing
Tanpa Posprocessing Multiword Geration
Gambar 5. Hasil Pengujian Perbandingan Double Propagation dengan Penambahan Rules
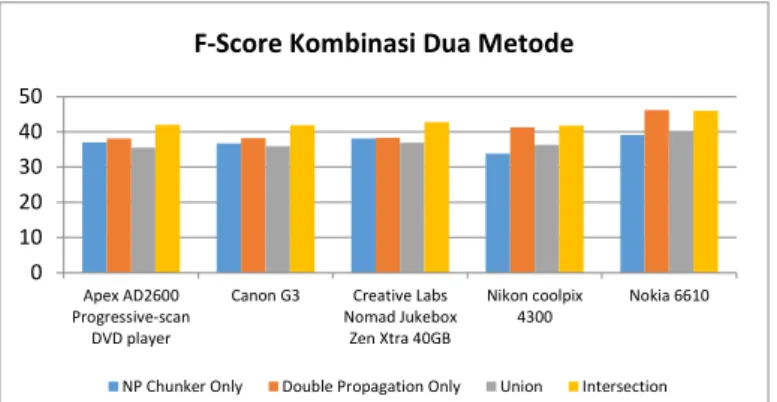
D. Kombinasi Ekstraksi Fitur
Hasil Ekstraksi Fitur dari kedua metode dikombinasikan melalui sebuah Union dan Intersection.
Gambar 7. Hasil Ekstraksi Fitur Kombinasi
Kombinasi Union menghasilkan nilai f-score yang lebih rendah karena kandidat fitur yang diidentifikasi tertalu banyak, sedangkan Intersection mengurangi kandidat fitur yang teridentifikasi sehingga menaikkan performansi terutama karena banyak kalimat review yang tidak berlabel fitur.
E. Pemberian Orientasi Opini
Pemberian Opini dilakukan dengan metode Unsupervised berdasarkan anggapan bahwa dua adjective yang muncul bersamaan dan dihubungkan dengan konjungsi “and” mempunyai satu polaritas yang sama [3]. Ada empat tahapan dalam melakukan klasifikasi ini, berikut penjelasnnya:
1. Extracting Adjactive Conjunction
Pada tahapan ini dilakukan ekstraksi pasangan (dua) adjective dari data yang digunakan untuk penelitian. Karena datanya sedikit dan tidak mencakup semua kata opini yang terekstrak pada proses ekstraksi fitur, digunakan 300.000 Electronics Reviews (objek sama) untuk dilakukan ekstraksi konjungsi adjective. 2. Pembangkitan Seeds
Seeds yang digunakan untuk proses ini adalah pasangan adjective yang memiliki polaritas yang sangat
jelas berlawanan. Pasangan ini merupakan pasangan yang satu dengan yang lainnya memiliki kata yang sama namun yang satu memiliki imbuhan ‘un’,‘in’, ‘dis’, ‘non’, dan ‘im’ yang berarti tidak. Contoh:
clean dan unclean. Seeds yang didapatkan dari Wordnet berjumlah 620 dan sekaligus diberikan nilai
polaritas menggunakan SentiWordnet. 3. Pembangkitan Graph
Graph yang dibangkitkan berisi node yang merupakan adjective dari daftar konjungsi serta kata opini
hasil ekstraksi fitur jika belum ada dalam daftar konjungsi adjective. Sebelum dibangkitkan, node akan diberikan bobot, jika masuk dalam seeds positif akan diberi nilai 1 (hijau), jika negatif akan diberikan nilai 0 (merah) dan jika tidak terdaftar dalam seeds diberi nilai 0.5 (biru) yang berarti belum memiliki polaritas/orientasi sentimen. Antar node akan dihubungkan dengan edge yang menunjukkan dua node pernah muncul sebagi pasangan konjugsi adjective. Edge juga akan diberikan bobot berapa kali pasangan konjungsi tersebut muncul. Karena data yang digunakan belum cukup memberikan semua adjective yang menaungi setiap kata opini yang terektrak, digunakan pembangkitan nilai Hits dari Bing Search Engine pada setiap node yang dibandingkan kedekatannya dengan node Excellent dan node Poor. Sebagi contoh kata good, good near excellent: 110 dan good near poor: 98, maka good lebih dekat dengan Excellent, untuk itu akan ditarik edge antara good dan excellent (jika belum terhubung) dan akan diberikan penambahan bobot 1 untuk edge yang sudah ada.
0 10 20 30 40 50 Apex AD2600 Progressive-scan DVD player
Canon G3 Creative Labs Nomad Jukebox
Zen Xtra 40GB
Nikon coolpix 4300
Nokia 6610
F-Score Kombinasi Dua Metode
4. Propagation Polarity
Proses ini melakukan proses pemberian polaritas pada node-node yang belum memiliki polaritas menggunakan rumus propagation polarity. Hasil dari proses ini setiap node memiliki polaritas kecuali node biru yang mempunyai tetangga positif dan negatif yang sama sehingga tidak memiliki polaritas. Graph dapat digunakan untuk merubah kata opini menjadi sebuah orientasi sentimen positif atu negatif.
Gambar 9. Hasil Akurasi Pemberian Orientasi Opini
Metode ini mampu memberikan nilai akurasi tertinggi 91.21 % dalam melakukan pemberian oerientasi opini. Metode ini mempunyai keunggulan dapat memberikan orientasi tepat pada opini yang bergantung pada objeknya namun akan memberikan hasil yang lebih baik ketika data yang digunakan merupakan data yang besar.
IV. KESIMPULAN
Berdasarkan hasil pengujian dan analisis yang telah dilakukan sebelumnya, maka dapat diambil kesimpulan sebagai berikut:
1. Penggunaan metode Noun Phrase Chunking dimana Noun Phrase digunakan sebagai kandidat fitur produk mengalami banyak kesalahan identifikasi fitur produk. Penggunaan modifikasi dan Stop
Word Removal sebagai proses lanjutan mampu memberikan perbaikan pada metode ini.
2. Penggunaaan metode Nearest Opinion Word pada proses pengekstrakan opini hasil ekstraksi fitur produk dengan Noun Phrase Chunking menghasilkan nilai akurasi tertinggi pada threshold 0.5 atau kata opini terjauh berjarak dua kata.
3. Penggunaan metode Double Propagation untuk melakukan prose Ekstraksi Fitur mampu menghasilkan nilai f-score yang lebih tinggi dibandingkan metode Noun Phrase Chunking. Penambahan rules pada metode ini mampu memberikan hasil ekstraksi fitur yang lebih baik dimana fitur yang lain dapat teridentifikasi. Penggunaan pembangkitan multiword mampu menangani pengekstrakan fitur produk yang terdiri dari dua kata.
4. Kombinasi Union menghasilkan performansi yang lebih buruk untuk dataset ini karena terlalu banyak fitur terkestrak. Kombinasi Itenrsection menghasilkan performansi lebih baik karena mengurangi fitur yang salah terekstrak
5. Penggunaan metode Unsupervised menghasilkan nilai akurasi tertinggi sebesar 76.97%. Dengan adanya bantuan dari nilai Hits dari Bing, maka didapatkan nilai akurasi tertinggi 91.21%. Metode ini memiliki keunggulan mampu memberikan orientasi dengan tepat pada kata opini yang orientasinya ditentukan oleh objeknya. Namun, penggunaanya akan lebih tepat untuk data yang besar karena membutuhkan kumpulan konjungsi kata sifat yang mampu mencakup semua kata opini yang terekstrak. Untuk data yang relatif lebih kecil, penggunaan nilai Hits dari Bing mampu membantu metode ini dalam melakukan pemberian orientasi yang lebih tepat.
Gambar 8. Graph Sebelum dan Sudah Proses Propagation Polarity 0 20 40 60 80 100 Apex AD2600 Progressive-scan DVD player
Creative Labs Nomad Jukebox Zen Xtra 40GB
Nokia 6610
Akurasi Pemberian Orientasi Opini
ACKNOWLEDGMENT
Penulis mengucapkan banyak terima kasih terhadap setiap pihak yang telah membantu hingga penelitian ini dapat diselesaikan.
REFERENSI
[1] PowerReviews. (2015, Feb.) [Online]. http://www.powerreviews.com/powerreviews-releases-study-on-the-impact-of-product-ratings-and-reviews-on-consumer-purchase-behavior/
[2] M. Cuadros, A. G. Pablos, S. Gaines, and G. Rigau, "V3: Unsupervised Generation of Domain Aspect Terms for," Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), p. 833–837, Aug. 2014. [3] S. Brody and N. Elhadad, "An Unsupervised Aspect-Sentiment Model for Online Reviews," Human Language
Technologies: The 2010 Annual Conference of the North American Chapter of the ACL, pp. 804-812, Jun. 2010. [4] B. Liu, Sentiment Analysis Opinion Mining. Morgan & Claypool Publishers, 2012.
[5] S. Nirenburg, Ed., Language Engineering for Lesser-studied Languages. IOS Press, 2009, p. 31. [6] M. C. de Marneffe and C. D. Manning, "Stanford Typed Dependencies Manual," Dec. 2013. [7] A. O. D. Community. (2016, Mar.) the Apache Software Foundation. [Online].
https://opennlp.apache.org/documentation/1.5.2-incubating/manual/opennlp.html
[8] K. T. Chan, "Improving Opinion Mining with Feature-Opinion Association and Human Computation," p. 31, 2009. [9] S. H. Ghorashi, R. Ibrahim, S. Noekhah, and S. N. Dastjerdi, "A Frequent Pattern Mining Algorithm for Feature
![Table 3. Double Propagation Rules [2]](https://thumb-ap.123doks.com/thumbv2/123dok/4270142.3137873/7.892.146.754.238.935/table-double-propagation-rules.webp)