2. METODE PENELITIAN
Metode penelitian berisi langkah-langkah kerja yang tersusun secara sistematis untuk menyelesaikan penelitian. Pada bagian ini disajikan waktu dan tempat penelitian, bahan dan alat, prosedur penelitian, dan analisis data.
2.1 Tempat dan Waktu Penelitian
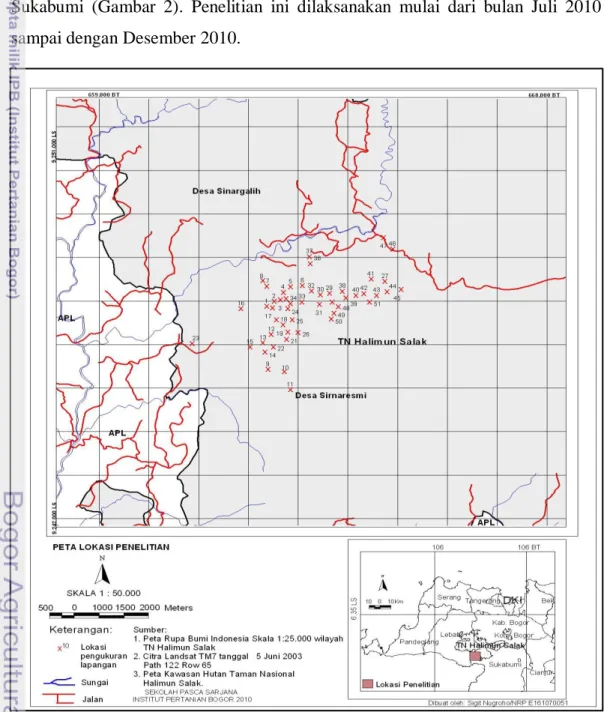
Lokasi penelitian ini adalah di kawasan hutan Gunung Surandil dan Gunung Pangkulahan TNGHS, yang terletak di Kecamatan Cisolok Kabupaten Sukabumi (Gambar 2). Penelitian ini dilaksanakan mulai dari bulan Juli 2010 sampai dengan Desember 2010.
2.2 Data, Software, Hardware dan Alat
Data yang digunakan dalam penelitian ini adalah :
a. Citra digital Landsat ETM7+ tanggal 6 Juni 2003, TM5 tanggal 26 September 2007, dan TM5 tanggal 5 Agustus 2008, dan citra Quickbird 2006.
b. Peta Rupabumi Indonesia Skala 1:25.000 daerah TNGHS.
Software , hardware dan alat yang digunakan dalam penelitian ini adalah : a. Satu perangkat komputer dan printer.
b. Perangkat lunak SIG ARCView 3.3 dan pemrosesan citra digital Envi v 4.1 dan Idrisi, FCD Mapper Versi 2.
c. Seperangkat alat untuk pengukuran di lapangan: GPS, Kompas, diameter tape, roll meter, clinometers, tally sheet, kamera fisheye.
2.3 Prosedur Penelitian
Prosedur penelitian adalah tahapan penelitian yang terdiri dari:
1. Tahap persiapan alat yang dilakukan adalah dengan mempersiapkan hardware dan software ARC View, Envi, Idrisi dan FCD Mapper yang akan digunakan untuk pengolahan data. Sedangkan tahap pengumpulan data awal meliputi penelusuran peta, citra satelit dan data sekunder yang akan digunakan melalui metode pencarian melalui situs internet dan instansi TNGHS, Kementerian Kehutanan dan Dinas Kehutanan.
2. Kerja Laboratorium Penginderaan Jauh dan SIG. Tahapan dalam proses ini adalah :
a. Pra pengolahan citra Landsat TM dan ETM
b. Melakukan ektsraksi citra Landsat dengan 4 metode klasifikasi untuk menghasilkan peta kerapatan hutan dan perubahan kerapatan hutan (degradasi).
3. Kerja lapangan
Tahap ini adalah melakukan uji akurasi terhadap klasifikasi kerapatan hutan dengan keadaan di lapangan
2.4 Pengolahan Citra 2.4.1 Pra Pengolahan Citra
Penelitian ini menggunakan citra satelit Landsat yang direkam pada tahun 2003, 2007 dan 2008. Saluran atau band yang digunakan adalah kanal 1, kanal 2, kanal 3, kanal 4, kanal 5, kanal 6 dan kanal 7. Informasi yang dihasilkan oleh citra Landsat TM memegang peranan penting dalam penelitian ini. Kesalahan citra Landsat karena faktor eksternal pada saat perekamannya memerlukan koreksi radiometrik dalam penelitian ini. Kesalahan radiometrik dihilangkan dan atau diminimalisir dengan melakukan koreksi radiometrik pada awal pemrosesan. Sementara itu kesalahan geometri diakibatkan adanya sistem orbital satelit yang polar, pengaruh kelengkungan bumi, grafitasi dan topografi dikoreksi menggunakan referensi peta topografi dengan menggunakan titik kontrol-titik kontrol yang akurat. Pengolahan data dilakukan dengan langkah-langkah sebagai berikut:
A. Koreksi Geometrik
Koreksi geometrik yang paling mendasar adalah penempatan kembali posisi piksel sedemikian rupa sehingga posisi piksel terkoreksi secara planimetris. Tahapan koreksi geometrik ini adalah sebagai berikut :
a. Penentuan sistem koordinat, proyeksi dan datum sistem koordinat yang dipilih untuk koreksi ini adalah Universal Tranverse Mercator (UTM) dengan proyeksi yang digunakan adalah UTM 48 zone selatan. Pemilihan proyeksi ini disesuaikan dengan pembagian area pada sistem UTM, dimana Jawa Barat termasuk wilayah TNGHS berada pada zona South UTM row 48, sedangkan datum yang digunakan adalah World Geografic System 84 (WGS 84). Tahapan ini bertujuan untuk mendefinisikan informasi yang akan digunakan dalam proses koreksi selanjutnya.
b. Pemilihan titik-titik kontrol lapangan (Ground Control Point/GCP)
Pemilihan titik-titik kontrol lapangan dilakukan dengan mengidentifikasi objek-objek yang tersebar merata pada seluruh citra, relatif permanen, dan tidak berubah dalam kurun waktu yang lama. Objek-objek yang dijadikan
titik-titik kontrol lapangan tersebut adalah perpotongan jalan, sungai dan yang lainnya.
c. Perhitungan Root Mean Squared Error (RMSE) setelah GCP terpilih.
Selanjutnya dihitung akar dari kesalahan rata-rata kuadrat. Dianjurkan agar RMSE bernilai lebih kecil dari 0,5 piksel.
Pada penelitian ini citra Landsat ETM7+ tahun 2003 telah terkoreksi geometrik. Citra Landsat TM 5 tahun 2007 dan 2008 belum terkoreksi geometrik sehingga dilakukan proses koreksi image to image dengan referensi citra tahun 2003. Pada Tabel 1 dan 2 dapat dilihat titik control yang digunakan dan RMSE dalam proses koreksi geometrik.
Pada Tabel 1 ini didapatkan rata-rata RMSE seluruh titik kontrol pada citra tahun 2007 adalah 0.39. RMSE tersebut sudah dibawah 0.5 sehingga dapat dikatakan bahwa citra telah terkoreksi dengan baik. Pada Tabel 2 yang merupakan titik kontrol untuk citra tahun 2008 didapatkan RMSE 0.37 sehingga citra tahun 2008 dapat digunakan pada proses selanjutnya karena telah terkoreksi geometrik. Tabel 1 Titik kontrol pada citra Landsat tahun 2007 dalam koreksi geometrik
No Citra 2007 Citra 2003 Error RMSE
X Y X Y X Y 1 1164,25 512,75 830,25 624,00 0,05 0,54 0,54 2 457,25 233,50 119,50 347,50 0,07 -0,01 0,07 3 823,75 784,50 488,50 897,25 -0,03 -0,22 0,22 4 1647,00 1673,00 1309,50 1786,00 -0,13 -0,02 0,13 5 841,50 1838,00 506,75 1950,25 -0,20 -0,13 0,23 6 1572,25 1971,50 1233,75 2085,50 -0,21 -0,54 0,58 7 2296,75 882,00 1964,00 992,50 0,18 -0,07 0,20 8 1651,75 1055,50 1317,00 1168,00 0,16 -0,81 0,82 9 2262,25 479,75 1933,25 588,50 -0,06 0,15 0,16 10 2152,00 2012,25 1810,00 2126,75 -0,05 0,20 0,20 11 430,00 1900,50 96,75 2011,50 0,27 0,41 0,49 12 766,25 607,50 430,75 720,25 -0,05 -0,02 0,05 13 2163,00 1751,25 1822,75 1864,50 0,29 0,52 0,60 14 1708,50 771,75 1375,75 882,75 -0,30 0,00 0,30 Total RMSE 0,39
Tabel 2 Titik Kontrol pada citra landsat tahun 2008 dalam koreksi geometrik
No Citra 2008 Citra 2003 Error RMSE
X Y X Y X Y 1 1475,50 659,75 1295,00 610,00 -0,33 -0,54 0,63 2 1708,25 771,75 1541,50 685,75 -0,24 -0,24 0,34 3 1163,25 513,00 964,00 511,00 -0,08 0,11 0,13 4 392,50 884,00 254,75 994,25 0,07 0,12 0,14 5 317,50 1790,50 316,25 1901,75 -0,02 0,10 0,10 6 766,25 1910,75 775,75 1954,50 0,19 0,03 0,19 7 1660,50 1791,25 1639,50 1704,00 -0,36 0,04 0,36 8 2187,00 1891,75 2171,75 1726,00 0,00 0,03 0,03 9 2317,00 928,00 2166,00 749,50 -0,11 -0,03 0,29 10 1406,50 985,00 1272,25 942,25 0,80 0,50 0,80 11 819,50 769,50 660,50 817,00 0,16 -0,07 0,18 12 2215,50 767,50 2043,00 604,50 0,07 0,51 0,52 13 100,25 1325,75 32,50 1474,75 -0,34 -0,01 0,34 14 1321,00 863,00 1171,00 833,75 -0,13 0,44 0,46 15 1677,25 1106,75 1558,00 1022,50 0,23 0,01 0,23 16 928,25 1575,50 886,25 1599,00 0,08 -0,33 0,34 Total RMSE 0,37
Citra hasil koreksi yang akurat ini sangat bermanfaat dalam proses change
detection. Kesalahan dalam koreksi geometrik dapat mengakibatkan kesalahan
dalam identifikasi perubahan nilai piksel. Piksel yang seharusnya berposisi pada satu lokasi tertentu tetapi dapat berposisi di tempat lain akibat ketidakakuratan dalam koreksi geometri. Ketidakakuratan dalam posisi piksel akan berakibat pula pada kesalahan dalam hasil klasifikasi citra sehingga terjadi bias dalam proses
change detection.
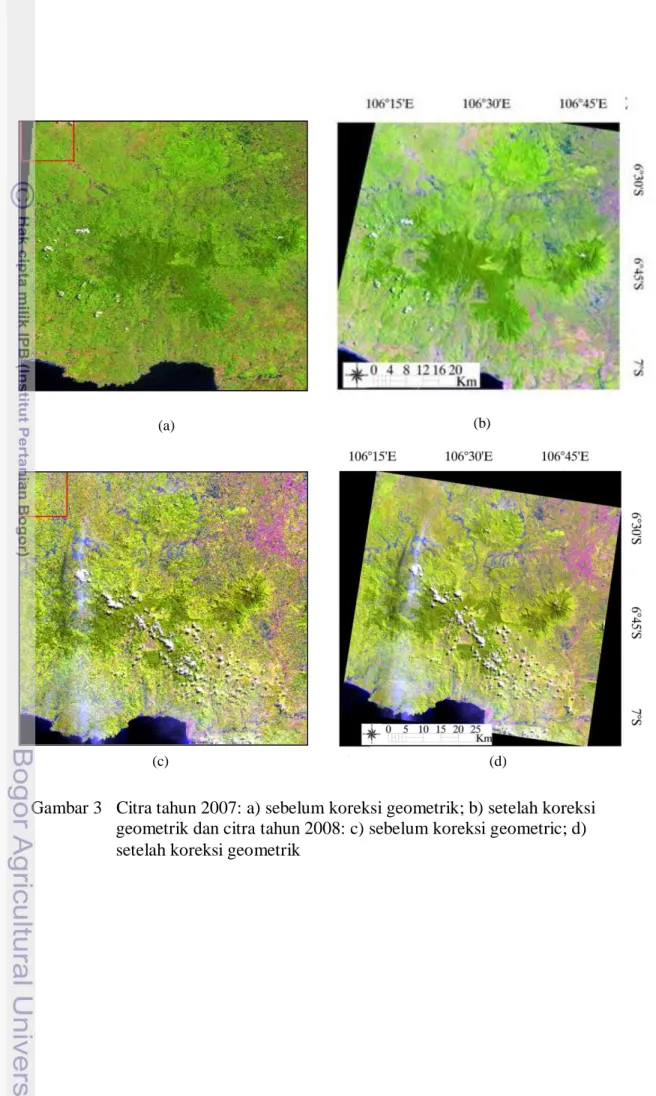
Gambar 3 menunjukkan citra Landsat tahun 2007 dan tahun 2008 sebelum koreksi geometrik dan setelah koreksi geomterik. Perbedaan citra sebelum dan setelah koreksi geometrik adalah posisi koordinat yang sudah sesuai dengan posisi sebenarnya di lapangan.
(a) (b)
(d) (c)
Gambar 3 Citra tahun 2007: a) sebelum koreksi geometrik; b) setelah koreksi geometrik dan citra tahun 2008: c) sebelum koreksi geometric; d) setelah koreksi geometrik
B. Koreksi Radiometrik
Koreksi radiometrik ditujukan untuk memperbaiki nilai piksel supaya sesuai dengan yang seharusnya yang biasanya mempertimbangkan faktor gangguan atmosfer sebagai sumber kesalahan utama. Efek atmosfer menyebabkan nilai pantulan obyek dipermukaan bumi yang terekam oleh sensor menjadi bukan merupakan nilai aslinya (khususnya pada gelombang yang lebih pendek), tetapi menjadi lebih besar oleh karena adanya hamburan atau lebih kecil karena proses serapan. Penelitian ini menggunakan citra satelit Landsat yang direkam pada tahun ETM7+ 2003, TM5 2007 dan 2008. Saluran atau band yang digunakan adalah kanal 1, kanal 2, kanal 3, kanal 4, kanal 5, kanal 6 dan kanal 7. Citra Landsat dalam setiap perekamannya mempunyai kualitas gangguan radiometrik yang berbeda-beda. Informasi yang dihasilkan oleh citra satelit Landsat TM memegang peranan penting dalam penelitian ini.
Metode yang digunakan dalam koreksi ini adalah dengan menggunakan
multiple-date image normalization dari obyek yang tidak mengalami perubahan
yaitu pseudo-invariant features/PIF. Obyek yang tidak mengalami perubahan tersebut adalah tubuh air yang dalam (deep water body), tanah terbuka yang kering (bare soil) dan atap bangunan yang luas (Jensen 2005). Proses koreksi radiometrik ini mutlak harus dilakukan dalam penelitian ini karena menggunakan data temporal. Metode ini menggunakan citra yang mempunyai kualitas yang baik sebagai acuan untuk mengkoreksi radiometrik citra yang lain.
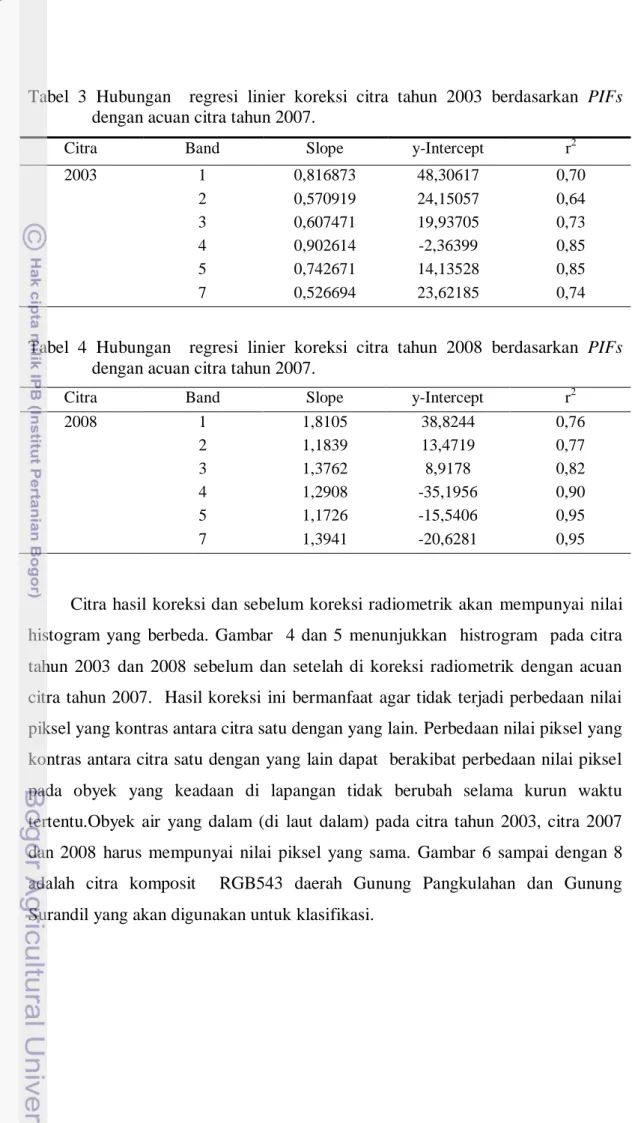
Berdasarkan citra tahun 2003, 2007 dan 2008 maka kualitas yang paling baik adalah citra tahun 2007 sehingga citra ini dipilih sebagai citra acuan. Citra tahun 2007 dipilih karena bersih dari liputan awan dan tidak terdapat efek haze. Selanjutnya dipilih obyek air dan bangunan pada citra tahun 2007 untuk dibuat hubungan regresi linier untuk mengoreksi citra tahun 2003 dan 2008. Pemilihan obyek air didasarkan bahwa obyek air merupakan obyek yang tidak mengalami perubahan dari waktu ke waktu. Pemilihan obyek bangunan dipastikan bahwa bangunan tersebut dari tahun 2003 sampai dengan 2008 tidak mengalami perubahan. Tabel 3 dan Tabel 4 menunjukkan hubungan matematis koreksi citranya.
Tabel 3 Hubungan regresi linier koreksi citra tahun 2003 berdasarkan PIFs dengan acuan citra tahun 2007.
Citra Band Slope y-Intercept r2
2003 1 0,816873 48,30617 0,70 2 0,570919 24,15057 0,64 3 0,607471 19,93705 0,73 4 0,902614 -2,36399 0,85 5 0,742671 14,13528 0,85 7 0,526694 23,62185 0,74
Tabel 4 Hubungan regresi linier koreksi citra tahun 2008 berdasarkan PIFs dengan acuan citra tahun 2007.
Citra Band Slope y-Intercept r2
2008 1 1,8105 38,8244 0,76 2 1,1839 13,4719 0,77 3 1,3762 8,9178 0,82 4 1,2908 -35,1956 0,90 5 1,1726 -15,5406 0,95 7 1,3941 -20,6281 0,95
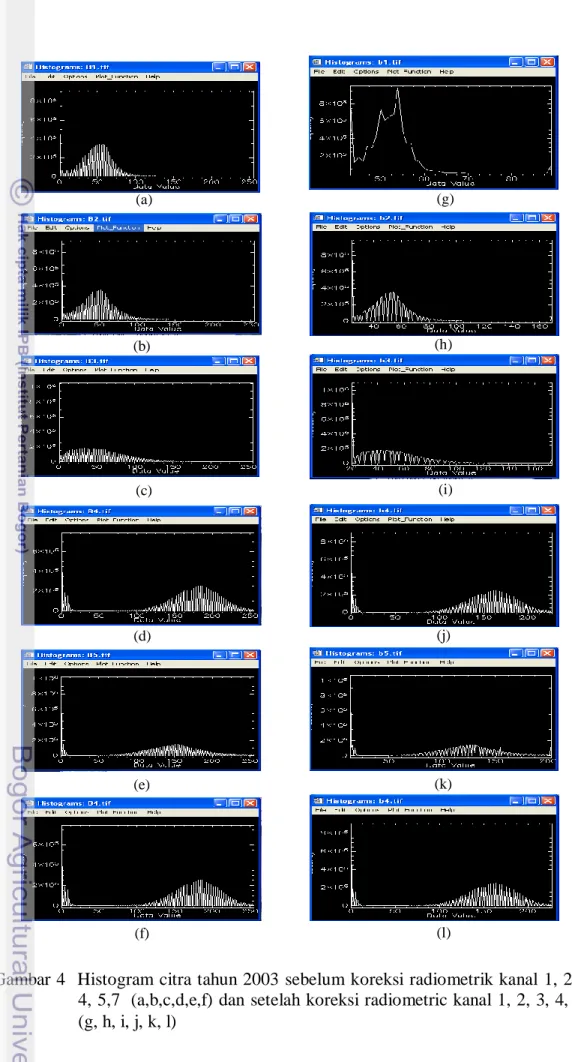
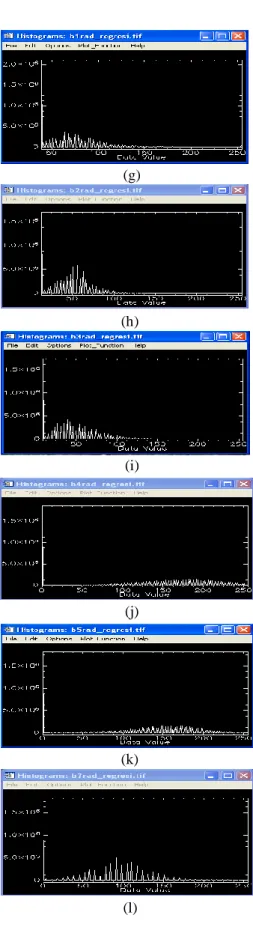
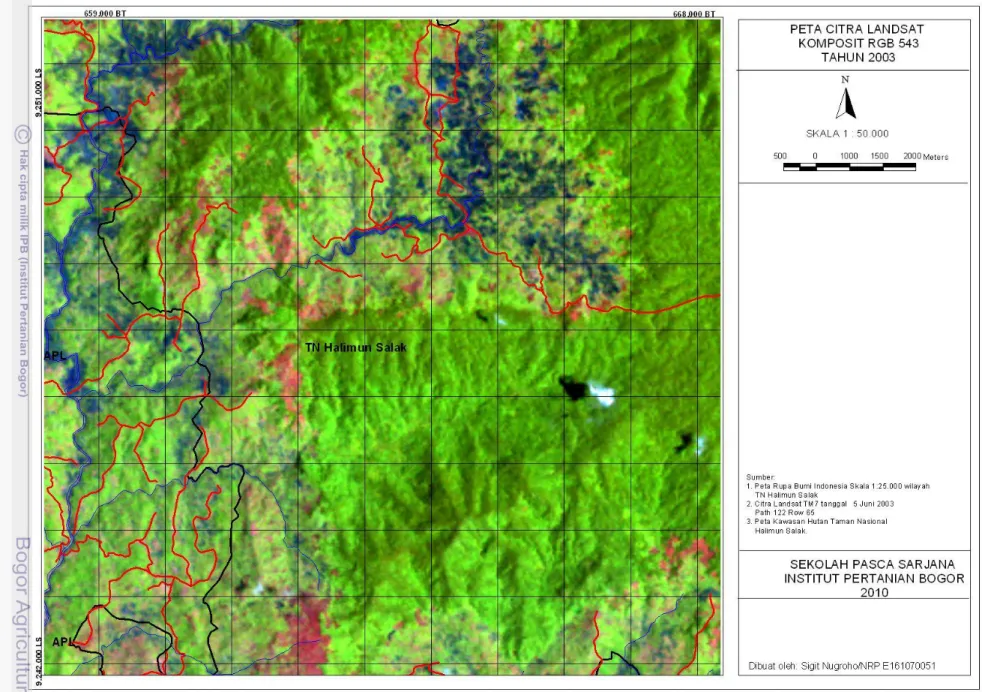
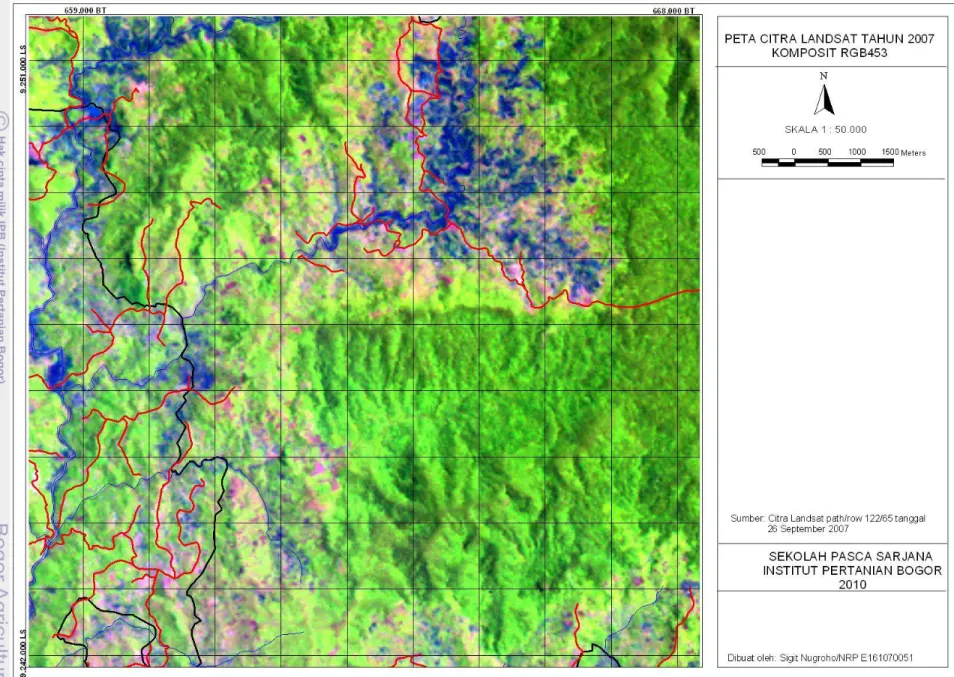
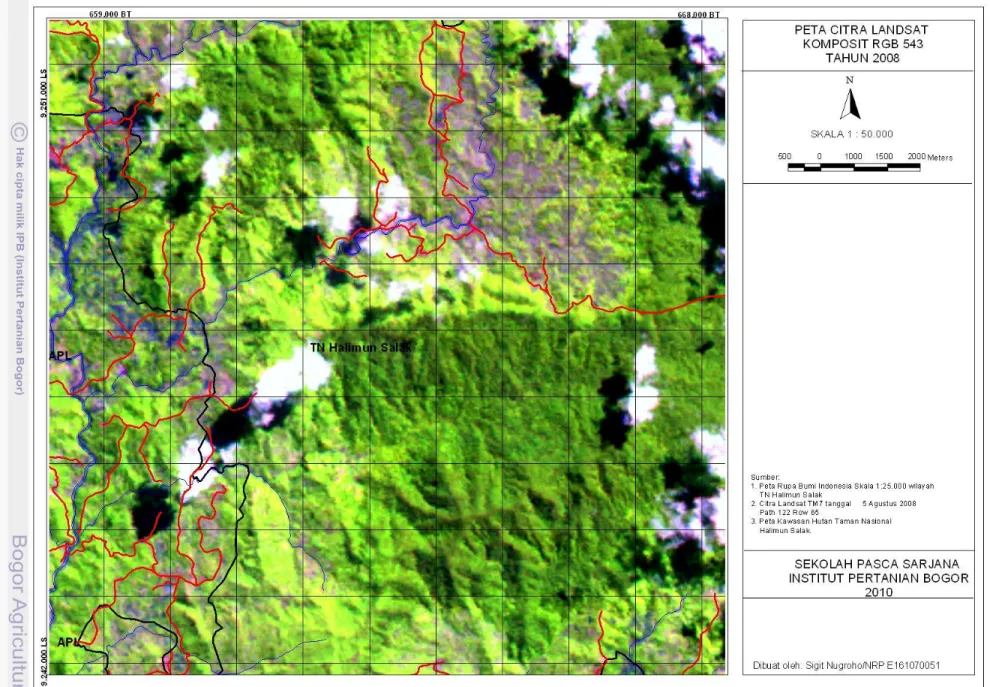
Citra hasil koreksi dan sebelum koreksi radiometrik akan mempunyai nilai histogram yang berbeda. Gambar 4 dan 5 menunjukkan histrogram pada citra tahun 2003 dan 2008 sebelum dan setelah di koreksi radiometrik dengan acuan citra tahun 2007. Hasil koreksi ini bermanfaat agar tidak terjadi perbedaan nilai piksel yang kontras antara citra satu dengan yang lain. Perbedaan nilai piksel yang kontras antara citra satu dengan yang lain dapat berakibat perbedaan nilai piksel pada obyek yang keadaan di lapangan tidak berubah selama kurun waktu tertentu.Obyek air yang dalam (di laut dalam) pada citra tahun 2003, citra 2007 dan 2008 harus mempunyai nilai piksel yang sama. Gambar 6 sampai dengan 8 adalah citra komposit RGB543 daerah Gunung Pangkulahan dan Gunung Surandil yang akan digunakan untuk klasifikasi.
(f) (l) (e) (k) (d) (j) (c) (i) (b) (h) (a) (g)
Gambar 4 Histogram citra tahun 2003 sebelum koreksi radiometrik kanal 1, 2, 3, 4, 5,7 (a,b,c,d,e,f) dan setelah koreksi radiometric kanal 1, 2, 3, 4, 5,7 (g, h, i, j, k, l)
(f) (l)
Gambar 5 Histogram citra tahun 2008 sebelum koreksi radiometrik kanal 1, 2, 3, 4, 5,7 (a,b,c,d,e,f) dan setelah koreksi radiometric kanal 1, 2, 3, 4, 5,7 (g, h, i, j, k, l) (e) (k) (d) (j) (c) (i) (b) (h) (a) (g)
Gambar 6 Peta citra komposit RGB 543 Gunung Surandil dan Gunung Pangkulahan sekitarnya tahun 2003
Gambar 7 Peta citra komposit RGB 543 Gunung Surandil dan Gunung Pangkulahan sekitarnya tahun 2007
Gambar 8 Peta citra komposit RGB 543 Gunung Surandil dan Gunung Pangkulahan sekitarnya tahun 2008
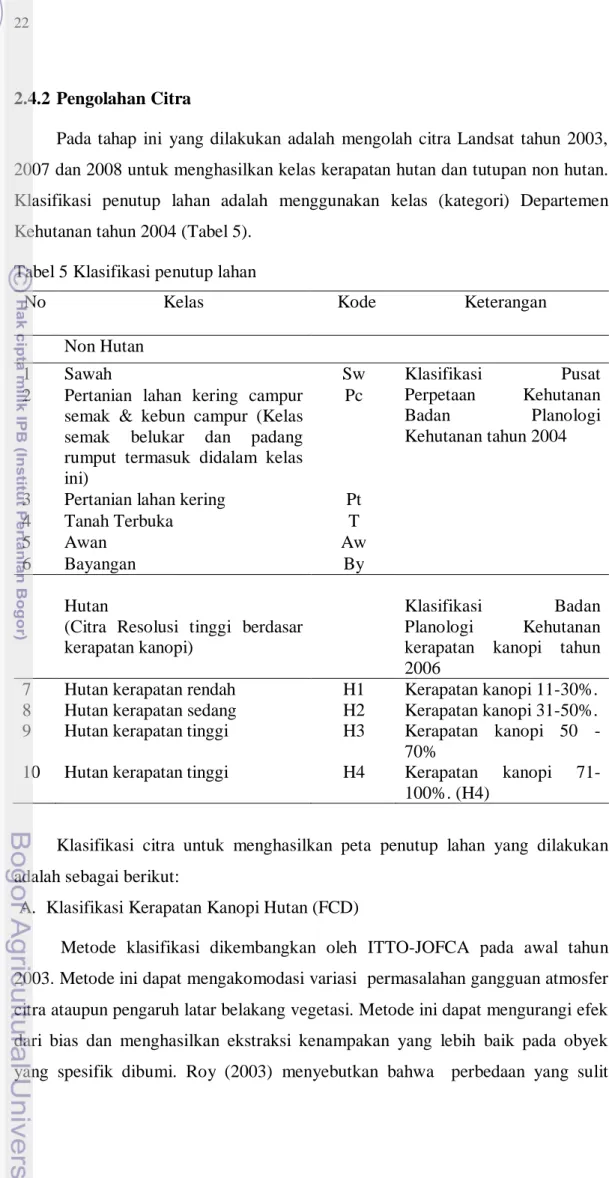
2.4.2 Pengolahan Citra
Pada tahap ini yang dilakukan adalah mengolah citra Landsat tahun 2003, 2007 dan 2008 untuk menghasilkan kelas kerapatan hutan dan tutupan non hutan. Klasifikasi penutup lahan adalah menggunakan kelas (kategori) Departemen Kehutanan tahun 2004 (Tabel 5).
Tabel 5 Klasifikasi penutup lahan
No Kelas Kode Keterangan
Non Hutan
1 Sawah Sw Klasifikasi Pusat
Perpetaan Kehutanan
Badan Planologi
Kehutanan tahun 2004 2 Pertanian lahan kering campur
semak & kebun campur (Kelas semak belukar dan padang rumput termasuk didalam kelas ini)
Pc
3 Pertanian lahan kering Pt
4 Tanah Terbuka T
5 Awan Aw
6 Bayangan By
Hutan
(Citra Resolusi tinggi berdasar kerapatan kanopi)
Klasifikasi Badan
Planologi Kehutanan
kerapatan kanopi tahun 2006
7 Hutan kerapatan rendah H1 Kerapatan kanopi 11-30%.
8 Hutan kerapatan sedang H2 Kerapatan kanopi 31-50%.
9 Hutan kerapatan tinggi H3 Kerapatan kanopi 50 -
70%
10 Hutan kerapatan tinggi H4 Kerapatan kanopi
71-100%. (H4)
Klasifikasi citra untuk menghasilkan peta penutup lahan yang dilakukan adalah sebagai berikut:
A. Klasifikasi Kerapatan Kanopi Hutan (FCD)
Metode klasifikasi dikembangkan oleh ITTO-JOFCA pada awal tahun
2003. Metode ini dapat mengakomodasi variasi permasalahan gangguan atmosfer citra ataupun pengaruh latar belakang vegetasi. Metode ini dapat mengurangi efek dari bias dan menghasilkan ekstraksi kenampakan yang lebih baik pada obyek yang spesifik dibumi. Roy (2003) menyebutkan bahwa perbedaan yang sulit
dipisahkan pada tutupan hutan dapat ditingkatkan dengan penggunaan kekuatan respon band inframerah. Panjang gelombang inframerah lebih sensitif pada kerapatan hutan dan kelas tumbuh-tumbuhan physiognomic. Biophysical
vegetation indices yang dalam perkembangannya disebut FCD indeks, melibatkan
indeks advanced vegetation index (AVI). Sedangkan untuk lebih detil dalam mengkategorikan status vegetasi digunakan bare soil index (BI). Dasar logika pendekatan ini berdasar pada hubungan timbal balik yang tinggi dari status vegetasi dan lahan terbuka. Oleh karena itu, kombinasi BI dan AVI digunakan dalam analisis ini. Untuk menyadap informasi pada shadow index (SI) digunakan melalui ekstraksi low radiance dari visible light. Pendekatan ini mengisolasikan kenampakan vegetasi menggunakan index AVI dan index BI. Kenampakan corak vegetasi distratifikasikan melalui (SI) atas dasar variasi tekstur pada bayangan kanopi pada tegakan hutan.
Proses pembuatan FCD menggunakan software FCD-Mapper Ver. 2. Proses ini diawali dengan:
a. Pra pemrosesan
Pemrosesan citra menggunakan software ini harus dilakukan dengan format software FCD-Mapper image format (FBI).
b. Pemrosesan data
Setelah pra pemrosesan selesai maka langkah selanjutnya adalah:
1. Prosedur untuk menghilangkan kesalahan radiometrik dan normalisasi citra dengan cara menghilangkan efek dari air, awan, bayangan awan dan haze. Awan, bayangan dan air dihilangkan dengan menggunakan tresholding. Efek
haze dihilangkan dengan menggunakan low pass filtering.
2. Membuat Indeks Vegetasi (VI) menggunakan beberapa algortima diantara adalah :
a. Normalized Differential Vegetation Index (NDVI) = (Near Infra
Red-Red) / (Near Infra Red +Red-Red);
b. Advanced Vegetation Index (AVI) = (Near Infra Red x (256-Red) x (Near
Infra Red -Red) + 1)1/3, 0 < (Near Infra Red -Red) (ITTO/JOFCA
c. Advanced Normalized Vegetation Index (ANVI ) adalah indeks sintetik dari NDVI dan AVI menggunakan Principal Component Analysis. 3. Membuat Bare Soil Index (BI) dengan algoritma:
BI = ((MIR+R) - (B+NIR)) / ((MIR+R) + (B+NIR)); dimana:
NIR = Near Infra-Red Band dan MIR = Middle Infra-Red Band
4. Membuat Thermal Index (TI) dengan cara mengkalibrasi nilai band thermal 5. Membuat Shadow Index (SI) dengan algoritma:
SI = ((256-B) x (256-G) x (256-R))1/3
dimana B= band biru, G = band hijau dan , R = band merah
6. Membuat Advanced Shadow Index (ASI) menggunakan langkah-langkah: Menentukan Forest Gap Detection yaitu jika VI lebih kecil dari threshold vegetasi, dengan melihat subyek piksel dari areal bukan hutan maka nilai ASI = 0. Membuat Black Soil Detection yaitu jika TI lebih besar dari threshold thermal dengan melihat subyek pada Black soil area dan ASI = 0. Proses ini untuk menghilangkan efek kesalahan dari tanah yang hitam menjadi areal bayangan hutan. Proses selanjutnya adalah Spatial Process, pada tutupan kanopi hutan yang rapat, areal yang ada bayangannya dari satelit dan pohon dari 3 pixel area yang dicari disekitar obyek pixel. Kemudian nilai SI maximum value sebagai SI subyek pixel.
7. Membuat Vegetation Density (VD) yaitu kerapatan tutupan vegetasi per pixel dihitung dengan Principal Component dari VI dan BI, dan dikalibrasi dengan minimum dan maximum tutupan vegetasi.
8. Membuat Scaled Shadow Index (SSI) yaitu kalibrasi dari Shadow Index pada areal berhutan.
9. Membuat Forest Cluster (FC) yang merupakan indikasi dari areal berhutan dengan algoritma:
FC=(VI x SI x (256-BI) +1)1/3 Dimana:
VI adalah indeks vegetasi terpilih diantara NDVI, AVI ANVI yang mempunyai koefisien korelasi tertinggi dengan BI.
10. Membuat Forest Canopy Density (FCD) yaitu kerapatan kanopi hutan (%) per piksel dengan algoritma:
FCD= √(VD x SSI +1)1/2 -1
Diagram alir klasifikasi FCD dapat dilihat pada Gambar 9 dan Gambar 10.
Gambar 9 Diagram alir umum klasifikasi Forest Canopy Density (Rikimaru, 2003) Selesai Scale Shadow Index Peta kerapatan vegetasi Citra Landsat Integrasi Model
Peta Kerapatan kanopi Pembuatan Vegetation Index (VI) Pembuatan Bare Soil Index (BI) Pembuatan Shadow Index (SI) Pembuatan Thermal Index (TI) Mulai
Gambar 10 Diagram alir lengkap proses klasifikasi Forest Canopy Density Selesai Mulai Formulasi FCD Peta Klas FCD Citra Landsat terkoreksi
Eliminasi awan, bayangan awan, air, dan haze
Pembuatan Indek Vegetasi (VI) : AVI, NDVI, ANVI
Pembuatan Indek Tanah Terbuka (BI)
Pembuatan Indek Thermal (TI)
Pembuatan Indek Bayangan (SI)
Peta AVI, NDVI, ANVI
Peta BI Peta TI Peta SI
Analisis PCA
VI Terbaik
Proses Pembuatan Advance Shadow Index (ASI): 1.Forest Gap Detection
2. Black soil detection
3. Spatial processing (filtering)
Peta ASI
Forest Clustering Kalibrasi Max & Min
Vegetasi
Peta Kerapatan Vegtasi (VD) Peta Scale Shadow Index (SSI) Citra Landsat bebas awan, air
Pada proses klasifikasi menggunakan FCD langkah pertama adalah reduksi terhadap area berawan, bayangan awan dan tubuh air. Reduksi areal berawan dan air dilakukan dengan menggunakan proses tresholding. Reduksi
haze dilakukan dengan low pass filtering. Hasil dari proses tersebut akan
menghasilkan cita yang bebas dari awan, bayangan dan air. Proses selanjutnya adalah pembuatan peta indek vegetasi yaitu peta Advancde Vegetation Index (AVI), Normalized Differential Vegetation Index (NDVI), dan Advanced
Normalized Vegetation Index (ANVI). Peta AVI, NDVI, dan ANVI dapat dilihat
pada Gambar 11 sampai dengan Gambar 13.
Setelah proses pembuatan peta indek vegetasi selesai maka dibuat peta
Bare Soil Index yang akan digunakan untuk mendeteksi areal tanah terbuka.
Gambar 14 menunjukan peta hasil Bare Soil Index Tahun 2003 sampai dengan Tahun 2008.
Proses selanjutnya dari klasifikasi FCD adalah melakukan Principal
Component Analisys dari indek vegetasi dengan indek tanah terbuka. Korelasi
yang tertinggi akan dipilih untuk digunakan pada proses pengolahan selanjutnya. Pada citra tahun 2003 dari ketiga indek vegatasi yaitu ANVI yang mempunyai korelasi yang tertinggi sebesar -0.761. Pada citra tahun 2007 dan 2008 yang tertinggi adalah NDVI yaitu 0.763 dan 0.593 (Gambar 15).
Proses selanjutnya adalah pemrosesan band 6 Citra Landsat untuk memperoleh peta Thermal Index (TI) yang akan digunakan dalam proses
clustering areal hutan pada proses selanjutnya. Peta TI dapat dilihat pada Gambar
16. Selain peta TI maka dihasilkan pula peta Shadow Index (Gambar 17) yaitu peta indeks bayangan pada citra sebagai akibat dari topografi maupun ketinggian tegakan di hutan.
Proses selanjutnya adalah pembuatan peta kerapatan vegetasi dengan cara membuat cara tresholding obyek tanah dengan obyek vegetasi seperti dapat dilihat pada Gambar 18. Proses ini akan menghasilkan peta kerapatan vegetasi tetapi belum dipisahkan antara vegetasi hutan dan vegetasi non hutan. Peta kerapatan vegetasi (VD) Tahun 2003 sampai dengan Tahun 2008 dapat dilihat pada Gambar 19.
Gambar 11 Peta AVI tahun a) 2003, b) 2007 dan c) 2008
Gambar 12 Peta NDVI tahun a) 2003, b) 2007 dan c) 2008
Gambar 13 Peta ANVI tahun a) 2003, b) 2007 dan c) 2008
6 o 30 ’ 6 o 45 ’ 7 o 00 ’ LS 6 o 30 ’ 6 o 45 ’ 7 o 00 ’ LS 6 o 30 ’ 6 o 45 ’ 7o 00 ’ LS 116o15’ 116o30’ 116o45’BT 116o15’ 116o30’ 116o45’BT 116o15’ 116o30’ 116o45’BT 6 o 30 ’ 6 o 45 ’ 7 o 00 ’ LS 6 o 30 ’ 6 o 45 ’ 7 o 00 ’ LS 6 o 30 ’ 6 o 45 ’ 7 o 00 ’ LS 116o15’ 116o30’ 116o45’BT 116o15’ 116o30’ 116o45’BT 116o15’ 116o30’ 116o45’BT 6 o 30 ’ 6 o 45 ’ 7 o 00 ’ LS 6 o 30 ’ 6 o 45 ’ 7 o 00 ’ LS 6 o 30 ’ 6 o 45 ’ 7 o 00 ’ LS 116o15’ 116o30’ 116o45’BT 116o15’ 116o30’ 116o45’BT 116o15’ 116o30’ 116o45’BT (a) (b) (c) (a) (b) (c) (a) (b) (c)
Gambar 14 Peta Bare Soil Index tahun a) 2003, b) 2007 dan c) 2008
Gambar 15 PCA Indek Vegetasi dengan indeks tanah terbuka tahun a) 2003, b) 2007, c) 2008
Gambar 16 Peta Thermal Index tahun a) 2003, b) 2007 dan c) 2008
(a) (b) (c) 6 o 30 ’ 6 o 45 ’ 7 o 00 ’ LS 6 o 30 ’ 6 o 45 ’ 7 o 00 ’ LS 6 o 30 ’ 6 o 45 ’ 7 o 00 ’ LS 116o15’ 116o30’ 116o45’BT 116o15’ 116o30’ 116o45’BT 116o15’ 116o30’ 116o45’BT 6 o 30 ’ 6 o 45 ’ 7 o 00 ’ LS 6 o 30 ’ 6 o 45 ’ 7 o 00 ’ LS 6 o 30 ’ 6 o 45 ’ 7 o 00 ’ LS 116o15’ 116o30’ 116o45’BT 116o15’ 116o30’ 116o45’BT 116o15’ 116o30’ 116o45’BT (a) (b) (c)
Gambar 17 Peta Shadow Index tahun a) 2003, b) 2007 dan c) 2008
Gambar 18 Proses tresholding tanah terbuka dengan vegetasi
Gambar 19 Peta Vegetation Density (VD) tahun a) 2003, b) 2007 dan c) 2008
6 o 30 ’ 6 o 45 ’ 7 o 00 ’ LS 6 o 30 ’ 6 o 45 ’ 7 o 00 ’ LS 6 o 30 ’ 6 o 45 ’ 7 o 00 ’ LS 116o15’ 116o30’ 116o45’BT 116o15’ 116o30’ 116o45’BT 116o15’ 116o30’ 116o45’BT (a) (b) (c) 6 o 30 ’ 6 o 45 ’ 7 o 00 ’ LS 6 o 30 ’ 6 o 45 ’ 7 o 00 ’ LS 6 o 30 ’ 6 o 45 ’ 7 o 00 ’ LS 116o15’ 116o30’ 116o45’BT 116o15’ 116o30’ 116o45’BT 116o15’ 116o30’ 116o45’BT (a) (b) (c)
Hasil proses selanjutnya adalah peta Scale Shadow Index . Setelah proses ini selesai maka proses selanjutnya adalah clustering untuk mengkategorikan cluster hutan dengan cara memilih kelas hutan dengan memperhatikan nilai indek vegetasi (VI), indek tanah terbuka (BI) , indeks bayangan (SI) dan Thermal Index (TI) seperti terlihat pada Gambar 20. Setelah proses ini selesai maka dilakukan proses pembuatan peta FCD.
Keterangan: Warna kuning adalah cluster hutan terpilih dengan kiteria FC > 147, VI > 124, BI < 127, SI > 196 dan TI < 195
Gambar 20 Proses Clustering klasifikasi hutan
Proses pengolahan data akhir FCD menghasilkan data kerapatan kanopi hutan dari 1-100%, kemudian dibagi kedalam 5 kelas yaitu non hutan (kerapatan kanopi 0-10%), kerapatan rendah (kerapatan kanopi 11-30%), kerapatan sedang (kerapatan kanopi 31-50%), kerapatan tinggi (kerapatan kanopi 51-100%). Proses
cropping dilakukan untuk menghasilkan peta tahun 2003, 2007 dan 2008 daerah
penelitian.
B. Klasifikasi Maximum Likelihood
Klasifikasi maximum likelihood merupakan salah satu klasifikasi terbimbing. Klasifikasi terbimbing dilakukan dengan arahan analis. Kriteria pengelompokan kelas ditetapkan berdasarkan penciri kelas yang diperoleh analis melalui pembuatan training area. Pemilihan training area harus dilakukan secara teliti. Kesalahan dalam menentukan training area akan menyebabkan kesalahan hasil klasifikasi. Karena data yang akan dicapai pada proses klasifikasi ini merupakan data yang lebih rinci dari sekedar penutup lahan hutan (kerapatan kanopi hutan) maka diperlukan training area yang detil pada kelas tutupan hutan.
Algortima yang digunakan dalam penentuan klasifikasi ini adalah dengan menggunakan metode maximum likelihood. Metode ini mempertimbangkan berbagai faktor diantaranya peluang dari suatu piksel untuk dikelaskan dalam kelas tertentu. Peluang ini sering disebut dengan
prior probability yang dapat dihitung dengan menghitung prosentase tutupan
pada citra yang akan diklasifikasi. Jika peluang ini tidak diketahui maka besarnya peluang dinyatakan sama untuk semua kelas.
Aturan pengambilan keputusan dalam klasifikasi ini adalah aturan Bayes (Jaya 2009). Secara matematis fungsi kepekatan dari peubah ganda adalah sebagai berikut:
P(X) = exp{-1/2(x-m)t
dimana:
P(xi) = peluang suatu set piksel x masuk ke dalam kelas-i x = vektor piksel pada posisi x,y
mi = vektor rata-rata dari suatu set band untuk kelas i [Cov]= diterminan matrik ragam peragam kelas-i t = matrik transposisi
Analisis separabilitas diperlukan dalam klasifikasi ini. Separabilitas adalah analisis kuantitatif yang memberikan informasi mengenai evaluasi keterpisahan area contoh dari setiap kelas, juga untuk mengetahui kombinasi band mana saja yang memberikan separabilitas yang terbaik untuk klasifikasi. Analisis ini dilakukan sebelum proses klasifikasi terhadap kelas-kelas tutupan lahan hasil area contoh.
Metode analisis separabilitas yang digunakan dalam penelitian ini adalah metode Tranformasi Divergensi (TD). Metode ini digunakan untuk mengukur tingkat keterpisahan antar kelas. Nilai TD antar kelas dapat dihitung menggunakan rumus di bawah ini.
dimana : TD = separabilitas antara kelas i dengan kelas j ij e = 2,718
Menurut Jaya (2009), kriteria tingkat keterpisahan antar kelas dari nilai transformasi divergensi adalah sebagai berikut.
a. Tidak terpisah (inseparable) : ≤ 1.600 b. Keterpisahan buruk (poor) : 1.601 – 1.699 c. Sedang (fair) : 1.700 – 1.899 d. Keterpisahan baik (good) : 1.900 – 1.999 e. Terpisah sempurna (excellent) : 2.000
Penentuan training area untuk citra Landsat tahun 2003, 2007 dan 2008 berdasarkan pada citra Quickbird tahun 2006 dan karakteristik dari spektralnya area contoh yang dibuat mewakili semua kelas tutupan hutan daerah yang telah ditentukan sebelumnya dan data ini digunakan untuk pengklasifikasian pada citra. Lampiran 3 menunjukkan visualisasi training area masing masing kelas tutupan hutan.
Proses klasifikasi ini dimulai dengan penentuan training area untuk citra Landsat tahun 2003, 2007 dan 2008 berdasarkan pada citra Quickbird tahun 2006 dan karakteristik dari spektralnya area contoh. Pada citra Quickbird didapatkan data bahwa terdapat beberapa kelas kerapatan hutan dan penutup lahan lainnya di lapangan. Penggunaan citra resolusi tinggi dapat digunakan untuk estimasi kerapatan hutan (Prasad 2009). Kerapatan hutan berdasarkan kerapatan kanopi sangat tinggi, tinggi, sedang, dan rendah tersebut dijadikan acuan dalam menentukan training area pada citra Landsat. Berdasarkan pola visualisasi dan nilai spektral tersebut maka dicari training area lain yang mempunyai karakteristik dan nilai spektral yang hampir sama. Pada penentuan area contoh ini setiap kelas tutupan hutan diwakili oleh piksel-piksel yang secara spektral berbeda, tetapi piksel-piksel tersebut relatif homogen untuk mewakili satu kelas
tutupan hutan tertentu. Hal ini dilakukan untuk menghindari kelas yang tumpang tindih spektral, sehingga dapat mengurangi keakuratan hasil klasifikasi. Diagram alir klasifikasi maximum likelihood dapat dilihat pada Gambar 21.
Gambar 21 Diagram alir klasifikasi maximum likelihood
Pola spektral untuk masing-masing kelas tutupan lahan pada citra tahun 2003 , tahun 2007 dan tahun 2008 adalah seperti Gambar 22. Berdasarkan analisis separabilitas menunjukkan bahwa rata-rata untuk nilai transformed divergence citra tahun 2003, 2007 dan 2008 adalah 1874, 1891 dan 1874 (Lampiran 1).
Ya
Pemilihan training area
Evaluasi separabilitas Data training area
Separabilitas diterima?
Citra Landsat terkoreksi
Data Lapangan
Mulai
Citra Quickbird
Evaluasi akurasi
Peta klasifikasi kerapatan hutan
Selesai Akurasi diterima? Ya Penggabungan kelas Tida k Penggabungan kelas Tidak
(a) B3 B4 B5 B2 B3 B4 B5 B2 H4 H3 H2 H1 Sw Pc T Aw By Pt H4 H3 H2 H1 Sw Pc T By Pt H4 H3 H2 H1 Sw Pc T Aw By Pt (b) (c)
Gambar 22 Grafik nilai rata-rata digital number area contoh untuk masing-masing kelas tutupan lahan (a) Citra Landsat 2003, (b) 2007 dan (c) 2008
B3 B4 B5 B2
Berdasarkan kriteria ini maka nilai tersebut adalah termasuk tingkat keterpisahan sedang. Pada kelas tutupan hutan yaitu hutan dengan berbagai tingkat kerapatan maka tingkat keterpisahan yang rendah adalah pada kelas hutan kerapatan sangat tinggi (H4) dengan hutan kerapatan tinggi (H3) dan hutan kerapatan sedang (H2) dengan hutan kerapatan rendah (H1). Pada H4 dan H3 karena mempunyai nilai keterpisahan rendah maka dilakukan proses reklas menjadi satu kelas hutan kerapatan tinggi (H3). Berdasarkan training area tersebut kemudian dilakukan proses klasifikasi untuk seluruh wilayah penelitian.
C. Klasifikasi Fuzzy
Metode klasifikasi fuzzy mempertimbangkan piksel-piksel yang bercampur (mixed make-up) dimana suatu piksel tidak dapat dikelaskan secara definitif ke satu kelas. Klasifikasi ini bekerja dengan menggunakan suatu fungsi keanggotaan, dimana kelas piksel tersebut ditentukan apakah lebih dekat dengan satu kelas tertentu atau kelas lainnya (Jaya, 2009).
Metode ini tidak mempunyai batas yang jelas dan masing-masing piksel dapat masuk ke beberapa kelas yang berbeda. Diperlukan suatu cara dengan membuat algoritma yang lebih sensitif terhadap sifat-sifat fuzzy. Klasifikasi ini didesain untuk membantu suatu pekerjaan yang kemungkinan tidak masuk secara tepat ke salah satu kategori kelas tertentu. Klasifikasi ini bekerja dengan suatu fungsi keanggotaan dimana piksel tersebut ditentukan apakah lebih dekat ke satu kelas atau kelas lainnya.
Salah satu algoritma yang paling banyak digunakan pengelompokan C-Means Fuzzy (FCM). Algoritma FCM mencoba untuk mengkelaskan data secara terbatas unsur X = {x1 ,..., xn} menjadi koleksi cluster yang samar dengan beberapa kriteria yang diberikan. Diketahui sebuah himpunan data berhingga, algoritma mengembalikan daftar dari pusat klaster C = {c1 ,...,} cc dan partisi matriks U = ui, j €[0, 1], i = 1,. . . , n, j = 1,. . . , C, di mana setiap elemen uij menyatakan sejauh mana elemen xi masuk ke cluster cj. Secara matematis adalah sebagai berikut:
Yang berbeda dari fungsi tujuan k- adalah dengan penambahan nilai-nilai keanggotaan uij dan m. Nilai m fuzzy menentukan tingkat kesamaran cluster. Sebuah hasil nilai m besar di uij keanggotaannya lebih kecil dan oleh karena itu disebut kluster fuzzy. Dalam batas m = 1, uij keanggotaan konvergen ke 0 atau 1. Dengan tidak adanya eksperimen atau pengetahuan domain, m adalah umumnya diatur ke 2. Algoritma dasar FCM, diberikan n titik data (x1,..., xn) menjadi berkelompok, sejumlah cluster c dengan (c1,..., Cc) pusat cluster, dan m tingkat ketidakjelasan klaster
Dalam clustering fuzzy, setiap titik memiliki tingkat kepemilikan cluster, seperti dalam logika fuzzy. Jadi, titik di tepi cluster dalam cluster adalah mempunyai tingkat yang lebih rendah daripada titik yang di pusat cluster. Setiap titik x memiliki nilai koefisien yang memberikan tingkat keberadaan di klaster k (x). Dengan klasifikasi fuzzy, titik pusat cluster adalah rata-rata dari semua titik, kemudian ditimbang dengan derajat keanggotaannya dengan alortima matematis sebaagai berikut:
Ck =
Tingkat keanggotaan, wx (x), berhubungan terbalik dengan jarak dari x ke pusat cluster. Hal ini juga tergantung pada parameter yang mengontrol m, berapa besar fungsi keanggotaan yang diberikan ke pusat terdekat.
Algoritma fuzzy ini memerlukan training area. Akan tetapi perbedaannya adalah metode ini dapat juga memperoleh informasi pada berbagai macam komponen kelas yang ditemukan dalam piksel yang bercampur. Training area ini tidak diharuskan mempunyai piksek-piksel yang sama atau homogen. Setelah menggunakan metode ini maka utility-nya akan membiarkan konfolusi dari fuzzy untuk membentuk konfolusi jendela bergerak pada saat klasifikasi menggunakan penetapan output berganda.
Langkah-langkah dalam klasifikasi fuzzy adalah sebagai berikut: 1. Pemilihan training area.
area pada klasifikasi terbimbing. Perbedaannya adalah training area yang
dipilih tidak selalu harus homogen. Penentuan training area untuk klasifikasi
fuzzy ini berbeda dengan klasifikasi maximum likelihood. Perbedaanya
terletak pada piksel-piksel untuk areal contoh tersebut tidak harus homogen untuk mewakili satu kelas tutupan hutan tertentu (Lampiran 4). Hal ini dilakukan karena klasifikasi fuzzy merupakan proses klasifikasi yang menetapkan suatu kelas tertentu bercampur dengan kelas yang lain. Suatu contoh adalah pada klas hutan kerapatan rendah pada kenyataannya adalah sulit dibedakan atau bercampur dengan kelas pertanian lahan kering bersemak, semak belukar maupun dengan kelas hutan kerapatan sedang. 2. Pembuatan matrik fuzzy
Matrik ini berfungsi sebagai fungsi tingkat keanggotaan pada setiap kelas. Fungsi keanggotaan ditunjukkan dengan nilai 0 – 1. Matrik ini akan digunakan dalam selanjutnya yaitu proses ektraksi. Penentuan matrik fungsi keanggotaan (membership function) didasarkan pada citra Quickbird. Cara penentuanya adalah menghitung fungsi keanggotaan 1 piksel pada lokasi
training area dengan kerapatan hutan di citra Quickbird.
Setiap piksel citra landsat resolusi 30 meter setara dengan 156 piksel citra Quickbird resolusi 2,44 m. Untuk mempermudah interpretasi secara visual maka citra Quickbird dibagi menjadi 5 kolom x 5 baris yang terdiri dari 12,5 m x 12,5 m. Pada setiap kolom dan baris diklasifikasikan secara visual ke dalam kelas H4, H3, H2 atau H1 kemudian dihitung proporsi setiap kelas terhadap total kolom dan baris. Contoh perhitungan penentuan fungsi keanggotaan hutan kerapatan tinggi (H3) citra Landsat dapat dilihat pada Gambar 23. Langkahnya adalah sebagai berikut:
Fungsi keanggotaan H3 = Jumlah H3 pada Citra Quicbird/Total Piksel = 21/25 = 0.84
Fungsi keanggotaan H2 = Jumlah H2 pada Citra Quicbird/Total Piksel = 2/25 = 0.08
Fungsi keanggotaan H1 = Jumlah H2 pada Citra Quicbird/Total Piksel = 2/25 = 0.08
Proses perhitungan semua kelas dapat dilihat pada Lampiran 6. Fungsi keanggotaan pada masing-masing kelas adalah seperti pada Tabel 6.
Tabel 6 Fungsi keanggotaan pada klasifikasi Fuzzy
No Kelas Penutup NH H Lahan Swh Pc Pt T Aw B H1 H2 H3 H4 1 NH Swh 1 0 0 0 0 0 0 0 0 0 Pc 0 0,9 0 0 0 0 0 0,1 0 0 Pt 0 0 0,8 0,1 0 0 0,1 0 0 0 T 0 0 0,1 0,8 0 0 0,1 0 0 0 Aw 0 0 0 0 1 0 0 0 0 0 B 0 0 0 0 0 1 0 0 0 0 2 H1 0 0 0,1 0 0 0 0,7 0,1 0,1 0 3 H2 0 0 0,1 0 0 0 0,2 0,7 0 0 4 H3 0 0 0 0 0 0 0,1 0,1 0,8 0 5 H4 0 0 0 0 0 0 0 0.1 0.1 0.8
Citra Quickbird Citra Landsat
Gambar 23 Penentuan fungsi keaggotaan pada kelas kerapatan hutan tinggi 3. Ekstraksi training area.
Proses ini adalah proses ekstraksi dari training area dan fungsi keanggotaan dari matrik fuzzy.
4. Klasifikasi fuzzy
Proses ini adalah proses klasifikasi fuzzy yang akan menghasilkan citra pada tiap kelas. Proses ini akan menghasilkan 10 peta sekaligus untuk masing masing kelas penutup lahan yaitu sawah, pertanian lahan kering bercampur semak, pertanian lahan kering, tanah terbuka, awan, bayangan awan, hutan kerapatan sangat tinggi, hutan kerapatan tinggi, hutan kerapatan sedang dan
H3 H3 H2 H1 H3 H3 H3 H3 H3 H3 H3 H3 H3 H3 H3 H3 H3 H4 H3 H3 H3 H1 H3 H3 H2
hutan kerapatan rendah. Nilai piksel yang dihasilkan menunjukkan antara 0 – 1. Berdasarkan 10 peta per kelas penutup lahan tersebut maka untuk mendapatkan satu buah peta hasil klasifikasi dilakukan proses hardener dengan menggunakan algoritma minimum possibilities. Proses hardener adalah suatu proses untuk menghasilkan peta tunggal dari masing-masing peta hasil klasifikasi pada kategori klasifikasi soft (fuzzy). Hasil klasifikasi fuzzy menghasilkan satu paket (raster group file) peta kelas penutup lahan yang mempunyai nilai fungsi keanggotaan masing-masing, oleh karena itu diperlukan penggabungan menjadi satu peta penutup lahan yang terdiri dari kelas-kelas penutup lahan dari masing-masing peta hasil klasifikasi fuzzy. Algoritma yang digunakan adalah minimum possibilities. Algoritma ini menggunakan nilai kemungkinan minimum terkecil dari nilai masing-masing fungsi keanggotaan. Diagram alir penelitian dapat dilihat pada Gambar 24.
Mulai Citra Quickbird Pemilihan training area Pembuatan matrik fungsi keanggotaan
Data training area
Ekstraksi training area
Klasifikasi
Hasil klasifikasi per kelas
Hardener
Peta klasifikasi kerapatan hutan Selesai
Nilai minimum posibilities
Citra Landsat terkoreksi
D. Klasifikasi Belief -Dempster-Shafer
Teori belief mendasarkan pada pengumpulan data dari suatu bukti dengan menerapkan peraturan tentang kombinasi berdasar pada pemrosesan
Dempster-Shafer Weight-Of-Evidence. Masing-masing file data masukan berisi tugas dasar
yang secara tidak langsung menghubungkan bukti ke arah suatu hipotesis di dalam suatu bingkai keputusan. Bingkai keputusan di dalam suatu konteks keputusan spesifik meliputi semua hipotesis yang mungkin. Teori belief membangun suatu pengetahuan mendasarkan dari data dan hipotesis yang
user-specified oleh masing-masing dukungan data. Operator sebagai pemakai dapat
menyaring tingkat kepercayaannya, derajat kemasuk-akalan dan gambaran interval kepercayaan untuk masing-masing hipotesis yang didukung bukti (Eastman 2003).
Teori Dempster-Shafer merupakan suatu varian dari teori kemungkinan Bayesian, yang dengan tegas mengenali keberadaan ketidak-tahuan dalam kaitan dengan informasi yang tidak sempurna. Perbedaan tingkat derajat kepercayaan pada akhirnya dikenal sebagai suatu interval kepercayaan, akan bertindak sebagai suatu ukuran ketidak-pastian tentang suatu hipotesis spesifik.
Klasifikasi belief (Belclas) adalah satu suatu kelompok metode soft. Metode ini adalah suatu proses pengambilan keputusan tentang keanggotaan kelas dengan segala piksel untuk masuk ke suatu kelompok tingkat keanggotaan pada setiap kelas yang mungkin. Seperti prosedur klasifikasi terbimbing, penggunaan training
area tetap dibutuhkan, untuk mengklasifikasikan setiap piksel. Tetapi tidak seperti
metoda maximum likelihood, output dari metode ini tidaklah peta tunggal penutup lahan, tetapi lebih dari satu set gambaran (per kelas) yang menyatakan aspek kepercayaan maupun tingkat masuk akal masing pixel pada masing-masing kelas.
Belclass menggolongkan suatu citra berdasar pada isi informasi dalam
signature file/training area yang dihasilkan sebelumnya. Harus ditetapkan untuk
masing-masing signature menggunakan suatu nilai kepercayaan. Algoritma yang digunakan dalam metode ini untuk decomposing data ke dalam statement yang masuk akal atau kepercayaan yang dianut. Pertama, kondisi kemungkinan dari
bukti, dari data training area, dievaluasi dan dimodifikasi oleh kemungkinan yang utama sama halnya dengan Bayclass. Tetapi sebagai ganti membuat normalisasi nilai piksel melalui penjumlahan dari setiap pertimbangan pada semua kelas.
Belclass menormalkan nilai-nilai relatif kedalam nilai maksimum yang terjadi di
manapun pada citra. Hasil ini adalah suatu nilai yang diinterpretasikan sebagai komponen dari suatu kelas. Secara matematis peluang suatu kelas adalah sebagai berikut:
P(hi e) = dimana:
P(hi e) = peluang dari hipotesis terbukti benar (posterior probability)
= peluang dari penemuan yang dipercaya dari hipotesisnya adalah benar (dihasilkan dari training area)
= peluang dari hipotesis tidak benar dari suatu bukti (prior probability)
Langkah-langkah dalam klasifikasi ini adalah sebagai berikut: 1. Pemilihan training area.
Pada langkah ini adalah sama dengan pembuatan training area pada klasifikasi maximum likelihood. Penentuan training area pada proses ini sama dengan yang dilakukan pada proses klasifikasi maximum likelihood, sehingga training area pada klasifikasi maximum likelihood digunakan pula pada klasifikasi ini. Proses klasifikasi ini menggunakan kriteria derajat kepercayaan (belief). Penentuan derajat kepercayaan ini ditentukan
thresholdnya berdasarkan tingkat kepercayaan dari citra Quickbird yang
mempunyai resolusi yang lebih tinggi dan hasil matrik konfusi antara klasifikasi citra dengan data lapangan hasil penelitian seperti terlihat pada Lampiran 7. Tabel 7 menunjukkan derajat kepercayaan per kelas penutupan lahan. Nilai threshold digunakan pada saat ekstraksi training area pada masing-masing kelas penutup lahan.
Tabel 7 Derajat kepercayaan klasifikasi Belief Dempster Shafer. Klasifikasi Penutup Lahan Derajat kepercayaan % Kepercayaan NH Sw 1 100 Pc 0,9 90 Pt 0,7 70 T 0,8 80 Aw 1 100 B 1 100 H1 0,7 70 H2 0,7 70 H3 0,8 80 H4 0,8 80
2. Ekstraksi training area.
Proses ini adalah ekstraksi training area yang telah dibuat pada tahap pertama.
3. Klasifikasi Belclass
Proses ini adalah proses klasifikasi yang akan menghasilkan citra pada tiap kelas. Proses ini akan menghasilkan 10 peta sekaligus untuk masing kelas penutup lahan yaitu sawah, pertanian lahan kering bercampur semak, pertanian lahan kering, tanah terbuka, awan, bayangan awan, hutan kerapatan sangat tinggi, hutan kerapatan tinggi, hutan kerapatan sedang dan hutan kerapatan rendah. Nilai piksel yang dihasilkan antara 0 – 1 yang menunjukkan tingkat kepercayaan. Nilai 1 merupakan tingkat kepercayaan tertinggi bahwa satu piksel tersebut masuk pada kelas tertentu. Berdasarkan hasil klasifikasi belief maka didapatkan sebanyak 10 peta. Berdasarkan 10 peta hasil tersebut maka untuk mendapatkan satu buah peta hasil klasifikasi dilakukan proses hardener dengan menggunakan algoritma minimum beliefs. Diagram alir penelitian dapat dilihat pada Gambar 25.
Gambar 25 Diagram alir klasifikasi belief 2.4.3 Change Detection
Pemantauan perubahan tutupan hutan menggunakan algoritma post
classification comparison (PCC). Change detection dilakukan dengan
menggunakan peta hasil klasifikasi yang mempunyai akurasi yang paling tinggi. Pengujian akurasi dilakukan antara klasifikasi FCD, maximum likelihood, fuzzy dan belief-dempster shafer dengan beberapa peubah di lapangan. Algoritma ini menggunakan matrik logic dengan cara melakukan overlay peta hasil klasifikasi tahun 2003, tahun 2007 dan tahun 2008 pada operasi SIG. Analisis deteksi degradasi secara temporal dilakukan pada areal yang tidak berawan. Klasifikasi degradasi hutan dilakukan dengan dasar perubahan kelas kerapatan hutan dari tahun 2003 sampai dengan tahun 2008 seperti terlihat pada Tabel 8.
Citra Landsat terkoreksi Mulai
Citra Quickbird
Pemilihan training area Data training area
Klasifikasi
Hasil klasifikasi per kelas
Hardener
Peta klasifikasi kerapatan hutan
Selesai Nilai minimum belief
Tabel 8. Klasifikasi degradasi secara temporal
No Kelas
Degradasi
Kriteria Penurunan Kelas
1 Ringan Turun 1
Tingkat
- Hutan Kerapatan Sangat Tinggi Ke Kerapatan Tinggi
- Hutan Kerapatan Tinggi Ke Kerapatan Sedang - Hutan Kerapatan Sedang Ke Kerapatan Rendah
2 Sedang Turun 2
Tingkat
- Hutan Kerapatan Sangat Tinggi Ke Kerapatan Sedang
- Hutan Kerapatan Tinggi Ke Hutan Kerapatan Rendah
3 Berat Turun 3
Tingkat
- Hutan Kerapatan Sangat Tinggi Ke Hutan Kerapatan Rendah 4 Sangat Berat/ Deforestasi Turun 4 Tingkat
- Hutan Kerapatan Sangat Tinggi Ke Non Hutan
2.5 Kerja Lapangan
Proses kerja lapangan mempunyai dua tujuan. Tujuan pertama adalah untuk mengidentifikasi tingkat degradasi di lapangan pada berbagai peubah di lapangan. Tujuan kedua adalah untuk menguji hasil klasifikasi dan peta degradasi tentative hasil analisis post classification comparison. Proses uji akurasi diawali dengan pembuatan desain sampel untuk kerja lapangan. Menurut Stehman (2001) diacu dalam Jensen (2005) metode uji akurasi menggunakan analisis statistik dibedakan menjadi dua yaitu model-based inference dan design-based inference.
Proses uji akurasi menggunakan model-based bukan ditujukan untuk menguji akurasi dari peta tematik (penutup lahan) yang dihasilkan tetapi lebih pada menguji akurasi proses klasifikasi yang menghasilkan peta penutup lahan.
Design-based didasarkan pada prinsip-prinsip statistik yang memperhatikan
karakteristik statistik dari populasi dari kerangka sampel. Pengukuran statistik yang biasanya dipakai adalah producer’s accuracy, user’s accuracy, overall
accuracy dan akurasi Kappa.
Ukuran sampel pada penelitian ini mengacu pada binomial probability
theory dengan tingkat akurasi yang diharapkan adalah 85% dan tingkat kesalahan
yang dapat diterima adalah 10%. Menurut Fitzpatrick (1981) diacu Jensen (2005), maka jumlah sampel yang harus diambil adalah
dimana:
N = jumlah sampel;
p = persen akurasi yang diharapkan; q = 100- p;
Z = 2 dihitung dari standar deviasi dari 1.96 pada tingkat kepercayaan 95%; E = minimum error yang diharapkan.
Sehinga jumlah sampel yang diambil adalah: = 51.
Desain sampel yang digunakan dalam penelitian ini menggunakan stratified
purposive sampling. Strata sampel plot yang diambil berdasarkan kelas kerapatan
hutan yang dihasilkan dan berdasarkan kelas perubahan tutupan hutan (degradasi
tentative) dari tahun 2003-2008. Jumlah tiap strata disesuaikan dengan nilai
sampel totalnya (N). Ukuran plot di lapangan dengan menggunakan citra resolusi antara 20-30 meter adalah dengan ukuran 50 x 50 meter (Huang et al, 2006). Pengambilan data tegakan pada diameter 5-10 cm dan >10 – 20 cm dikuadran I. Luas untuk pengambilan sampel 5-10 cm adalah 5 x 5 m, sedangkan luas untuk pengambilan sampel >10-20 cm adalah 10 x 10 m dari titik pusat plot. Data tegakan diameter > 20 cm diambil di semua kuadran dengan ukuran 25 x 25 m (Gambar 26).
Gambar 26 Desain sampel plot di lapangan
50 m 10 x10 m 50 m 5 x 5 m 25 x 25 m Diameter > 5 – 10 cm Diameter > 10 - 20 cm Diameter > 20 cm
Tititk Pusat plot
II
III IV
2.6 Identifikasi Peubah Degradasi Hutan di Lapangan
Kriteria untuk menentukan hutan terdegradasi di lapangan adalah dengan menggunakan peubah yaitu tegakan, indikator kanopi dan Leaf Area Index/LAI (Sprintsin et al. 2009; SEAMEO BIOTROP 2001; IPCC 2009). Kriteria degradasi adalah apabila terjadi penurunan volume, kerapatan tegakan (pohon/Ha), luas bidang dasar (m2/ha), crown indicator, kerapatan kanopi (%), dan Leaf Area Index (LAI) yang merupakan indikator yang digunakan dalam Global Circulations
Models for Predicting Global Warming (Kusakabe et al. 2000). Penggunaan
indikator kanopi dan LAI untuk pendugaan degradasi hutan didasarkan bahwa perubahan luas dan struktur kanopi akan mempengaruhi produksi tegakan (Breda 2003). Penggunaan peubah-peubah tersebut digunakan untuk dapat menghasilkan peubah yang terbaik untuk indikator degradasi hutan.
Persamaan luas bidang dasar (Lbds) yang digunakan adalah: Lbds = 0.25* *D2
dimana:
Lbds = Luas bidang dasar (m2/pohon); = 3.14; dan
D = Diameter Pohon (m).
Persamaan volume yang digunakan adalah: V= lbds *T*f
dimana:
V = volume (m3/pohon); Lbds = Luas bidang dasar ; T = Tinggi total pohon (m); F = faktor bentuk 0,7.
Data crown indicator adalah data CSI (crown size index), CDI (crown
damage index) dan VCR (Visual Crown Rating). Menurut SEAMEO BIOTROP
(2001), formula CSI adalah sebagai berikut: 1. CSI = 0.5*CD + 0.25* LCR + 0.25*Density
CD = Crown Diameter/ diameter tajuk (dalam meter diukur rata 2 kali pengukuran dengan diagonal);
LCR = Live Crown Ratio ( dalam % yaitu rasio panjang tajuk dibandingkan dengan tinggi pohon);
Density = Crown Density (dalam % yaitu persen tutupan tajuk). Sedangkan formula CDI adalah:
2. CDI = (Transparency + Dieback)/2 dimana :
Transparency = Folieage Transparency (dalam persen yaitu persentase
cahaya matahari yang masuk ke celah tajuk); dan
Dieback = Crown Dieback (dalam persen yaitu rasio kerusakan pada tajuk
cabang dengan total tajuk). 3. FCR = (CSI+CDI)/2
Leaf area index (LAI) adalah rasio total permukaan daun atas dibagi
dengan permukaan tanah dimana tumbuhan tersebut berada. Pengukuran LAI dapat dilakukan dengan 2 metode yaitu metode langsung (direct method) dan tidak langsung (indirect method). Penelitian ini menggunakan metode tidak langsung dengan menggunakan hemispherical photography (fisheye camera) untuk mengestimasi LAI.
Berdasarkan beberapa peubah-peubah tersebut maka dilakukan analisis regresi antara peubah Y yaitu kerapatan tegakan (Kt), lbds dan volume (V) dengan peubah X yaitu kerapatan kanopi (Kr), LAI, CSI, CDI dan VCR. Analisis ini akan menghasilkan peubah tajuk apa yang mempengaruhi tingkat degradasi hutan berdasarkan kerapatan tegakan, lbds dan volume. Secara matematis hubungan fungsi tersebut adalah sebagai berikut:
Kt = f (LAI), f (Kr), f (CSI), f (CDI), f (VCR) Lbds = f (LAI), f (Kr), f (CSI), f (CDI), f (VCR) V = f (LAI), f (Kr), f (CSI), f (CDI), f (VCR)
Klasifikasi kerapatan hutan berdasarkan semua peubah di lapangan dilakukan dengan menggunakan peubah kerapatan kanopi sebagai dasar (peubah X). Analisis regresi linier dan non linier dilakukan untuk pendugaan semua peubah dari peubah X yaitu kerapatan kanopi. Hal ini dilakukan karena pada klasifikasi citra yang digunakan sebagai training area adalah berdasarkan kerapatan kanopi pada citra Quickbird. Hubungan matematisnya adalah sebagai berikut:
Kt = f (Kr) secara linier dan non linier Lbds = f (Kr) secara linier dan non linier V = f (Kr) secara linier dan non linier LAI = f (Kr) secara linier dan non linier CSI = f (Kr) secara linier dan non linier CDI = f (Kr) secara linier dan non linier VCR= f (Kr) secara linier dan non linier
2.7 Uji Akurasi
Evaluasi akurasi terhadap besarnya kesalahan klasifikasi adalah untuk menentukan besarnya persentase ketelitian klasifikasi. Uji akurasi dilakukan dengan data lapangan dengan kriteria seperti pada Tabel 7. Evaluasi ketelitian pemetaan meliputi jumlah piksel sampel yang diklasifikasikan dengan benar atau salah, pemberian nama kelas secara benar, persentase banyaknya piksel dalam masing-masing kelas serta persentase kesalahan total.
Akurasi ketelitian pemetaan diuji dengan membuat matrik contingency yang lebih sering disebut dengan matriks kesalahan (confusion matrix). Akurasi yang dapat dihitung berdasarkan tabel di atas antara lain adalah user’s accuracy,
producer’s accuracy dan overall accuracy (Story dan Congalton diacu dalam
Jensen 2005). Secara matematis jenis-jenis akurasi di atas dapat dinyatakan dalam:
a. Users Accuracy = . Akurasi ini adalah untuk mengetahui seberapa besar kebenaran piksel hasil klasifikasi pada tiap kelas dengan
keadaan tiap kelas di lapangan;
b. Producers accuracy = . Akurasi ini adalah untuk mengetahui seberapa pasti analis dapat mengkelaskan areal pada tiap kategori kelas. c. Overall accuracy = . Akurasi ini adalah untuk mengetahui
total piksel yang benar dari seluruh piksel.
Producer’s accuracy atau akurasi pembuat adalah akurasi yang diperoleh
dari jumlah piksel yang benar dibagi dengan jumlah total piksel pada sampel per kelas. User’s accuracy atau akurasi pengguna adalah jumlah piksel yang benar dibagi dengan total piksel dalam kolom.
Nilai akurasi yang paling banyak digunakan adalah akurasi Kappa, karena nilai ini memperhitungkan semua elemen (kolom) dari matrik. Secara matematis akurasi Kappa dinyatakan dalam:
K = – ;
dimana :
N : Jumlah semua piksel yang digunakan untuk pengamatan; r : jumlah baris atau kolom pada matrik kesalahan;
: jumlah baris;
: jumlah piksel pada baris –i kolom j; : Jumlah kolom;
K : ∑ X (jumlah semua kolom pada baris ke-i) i+ ij; dan K : ∑ X (jumlah semua kolom pada lajur ke-j).
2.8 Batasan Operasional Hutan :
Lahan dengan luas lebih dari 0.25 Ha yang terdiri dari tegakan yang didominasi pohon dengan tutupan kanopi lebih dari 10 %.
Degradasi hutan:
Degradasi hutan adalah penurunan tutupan hutan selama masih tutupan kanopi lebih besar dari 10% dalam jangka waktu tertentu. Apabila tingkat tutupan kanopi
hutan sudah dibawah ambang 10 % maka sudah tidak disebut sebagai degradasi akan tetapi deforestasi.
Tutupan Kanopi/Kerapatan Kanopi :
Persentase permukaan tanah yang tertutupi oleh proyeksi vertikal dari garis keliling terluar alami dari daun.
Leaf Area Index (LAI) :
Rasio total permukaan daun atas dibagi dengan permukaan tanah dimana tumbuhan tersebut berada.
REDD :
Semua upaya pengelolaan hutan dalam rangka pencegahan dan atau pengurangan penurunan kuantitas tutupan hutan dan stok karbon yang dilakukan melalui berbagai kegiatan untuk mendukung pembangunan nasional yang berkelanjutan (Permenhut 30/2009).
Tabel 9 Tahapan proses penelitian (Input, Proses, Output)
Kegiatan Input Proses Output
1. Pengumpulan Data Citra
Citra Landsat Tahun 2003, 2007,2008
Pengumpulan data di TNGHS dan DEPHUT
Kompilasi data Citra TNGHS 2. Pengumpulan Data
Spasial Digital
Peta digital RBI, Kawasan Hutan,.
Pengumpulan data di TNGHS dan DEPHUT
Kompilasi data spasial digital 3. Pengumpulan Data
Sekunder Non Spasial
Data Pendukung Pengumpulan data di BPS, TNGHS, dan
Dinas Kehutanan
Kompilasi data sekunder non spasial 4. Pra Pengolahan Citra
Landsat
Citra Landsat Koreksi radiometrik
Koreksi geometrik
Cropping
Citra Wilayah TNGHS terkoreksi radiometrik dan geometrik
5. Pengolahan Citra Citra Landsat hasil pra
pengolahan
1.Klasifikasi FCD
2. Klasifikasi Maximum Likelihood 3. Klasifikasi Fuzzy
4. Klasifikasi Belief
Peta Tutupan Hutan Tahun 2003,2007 2008
6. Analisis Change
Detection
Peta Tutupan hutan tahun 2003,2007, 2008
Penggunaan algoritma
Post-clasification Comparison
Peta degradasi hutan
7. Kerja Lapangan dan Uji Akurasi
Peta Kerapatan Hutan, Degradasi hutan dan Lokasi Sampel
Pengujian Lapangan & Uji Akurasi
Hasil Uji Akurasi dan Metode Terbaik
Gambar 27 Diagram alir penelitian
53
Mulai
Selesai
1. Identifikasi degradasi hutan 2. Uji Akurasi Klasifikasi Citra
2008
3. Uji Akurasi Tingkat Degradasi (Perubahan tutupan hutan) Peta Kerapatan Hutan
2003,2007,2008
Peta Kerapatan Hutan 2003,2007,2008
Peta Kerapatan Hutan 2003,2007,2008
Peta Kerapatan Hutan 2003,2007,2008 Citra Terkoreksi Landsat TM
2003,2007,2008, Citra Landsat TM 2003,2007, 2008, Koreksi Radiometrik & Geometrik Klasifikasi Maximum Likelihood Klasifikasi FCD Klasifikasi Fuzzy Klasifikasi
Belief Dempster Shafer
Metode Paling Akurat Analisis
Post Clasification Comparison
Peta 2003,2007, 2008
Peta Degradasi Hutan Peta Degradasi Hutan
Tentatif
Analisis
Post Clasification Comparison
Gambar 27 merupakan proses penelitian yang dilakukan. Langkah awal adalah melakukan koreksi geometrik dan radiometrik. Setelah proses tersebut maka didapatkan citra yang telah terkoreksi. Langkah selanjutnya adalah melakukan klasifikasi citra tahun 2003, 2007 dan 2008 menggunakan 4 metode yaitu FCD, maximum likelihood, fuzzy dan belief dempster shafer. Hasil klasifikasi digunakan untuk uji akurasi di lapangan.
Lokasi pengujian lapangan diambil sebanyak 51 sampel pada berbagai kelas kerapatan hutan dan kelas degradasi hutan berdasarkan klasifikasi maximum
likelihood (Tabel 10 dan Tabel 11). Langkah selanjutnya dilakukan proses uji
akurasi. Hasil uji akurasi terbaik digunakan untuk proses perhitungan luas degradasi hutan dengan metode PCC.
Tabel 10 Jumlah sampel lapangan berdasarkan kelas degradasi hutan
No Degradasi Kriteria Penurunan Kelas (temporal) Jumlah
1 Sangat Berat (Deforestasi)
Turun 4 Tingkat Hutan Kerapatan Sangat Tinggi Ke Non Hutan 0
2 Berat Turun 3 Tingkat Hutan Kerapatan Sangat Tinggi Ke Hutan
Kerapatan Rendah
2
3 Sedang Turun 2 Tingkat Hutan Kerapatan Sangat Tinggi ke Kerapatan
Sedang
8
Hutan Kerapatan Tinggi Ke Kerapatan Rendah
4 Ringan Turun 1 Tingkat Hutan Kerapatan Sangat Tinggi Ke Kerapatan
Tinggi
21
Hutan Kerapatan Tinggi Ke Kerapatan Sedang
Hutan Kerapatan Sedang Ke Kerapatan
Rendah
5 Tetap Tetap 20
Tabel 11 Jumlah sampel lapangan berdasarkan kelas kerapatan hutan
No Klasifikasi kerapatan hutan Jumlah
1 Non Hutan 6 2 Rendah 7 3 Sedang 8 4 Tinggi 26 5 Sangat tinggi 4 Jumlah 51