BAB 2 LANDASAN TEORI
Teks penuh
Gambar
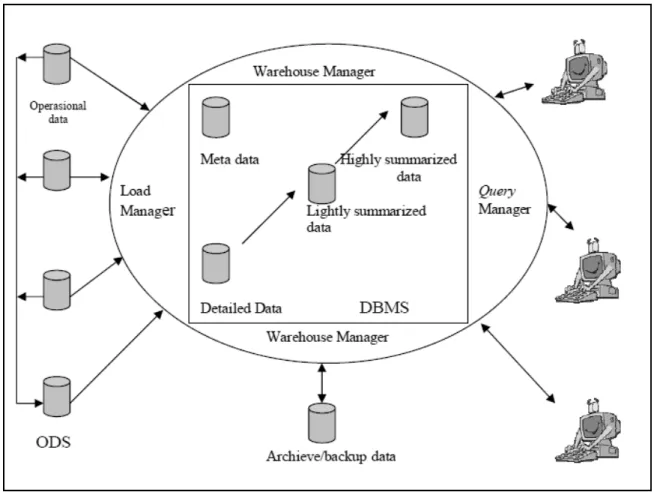

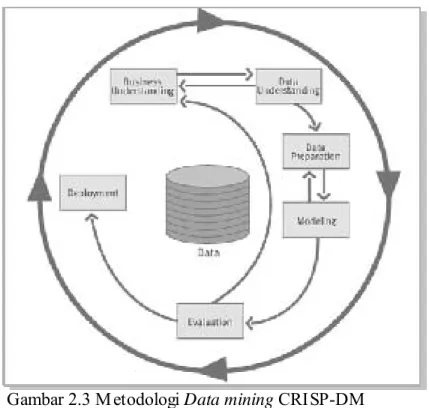
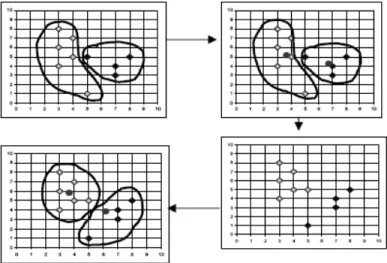
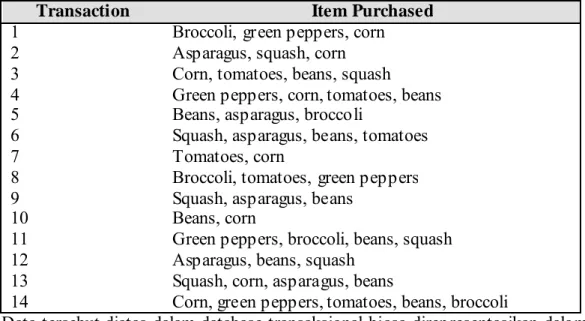


Garis besar
Dokumen terkait
Membentuk unit Pelaksana Kegiatan (Project Implementation unit ) Dalam Rangka Kegiatan Peningkatan Kapasitas Berkelanjutan untuk Desentralisasi (Sustainable Capacity
Yang dimaksud dengan “kawasan lindung provinsi” adalah kawasan lindung yang secara ekologis merupakan satu ekosistem yang terletak lebih dari satu wilayah kabupaten/kota
Apabila dilihat dari peubah bidang kerja yang diinginkan diperoleh bahwa untuk masa tunggu enam bulan ke atas, peluang alumni yang memiliki keinginan bekerja di bidang
Adapun faktor pendukung implementasi program pemberdayaan perempuan yaitu adanya regulasi yang mendukung kegiatan pemberdayaan perempuan dalam mewujudkan kesetaraan gender yaitu
Berdasarkan beberapa pengertian tersebut dapat ditarik kesimpulan bahwa data mining adalah suatu teknik menggali informasi berharga yang terpendam atau
Pre-Conditions Tata usaha dapat mencetak data diri pendaftar Post-Conditions Tata usaha telah mencetak data diri pendaftar Failed end Condition Tata usaha tidak dapat mencetak
membuat citra tegak satelit penginderaan jauh resolusi tinggi untuk keperluan survei dan pemetaan dalam rangka pembangunan informasi geospasial nasional dengan melakukan
“banyak siswi yang sering foto-foto hanya untuk mendapatkan pujian dari temen sekelasnya, soalnya mereka sering banget makai make up pada saat di kelas, dan
