II-1 2.1 Data Mining
Secara sederhana data mining adalah penambangan atau penemuan informasi baru dengan mencari pola atau aturan tertentu dari sejumlah data yang sangat besar. Data mining juga disebut sebagai serangkaian proses untuk menggali nilai tambah berupa pengetahuan yang selama ini tidak diketahui secara manual dari suatu kumpulan data. Data mining, sering juga disebut sebagai knowledge discovery in database (KDD). KDD adalah kegiatan yang meliputi pengumpulan, pemakaian data, historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar [4].
Data mining adalah kegiatan menemukan pola yang menarik dari data dalam jumlah besar, data dapat disimpan dalam database, data warehouse, atau penyimpanan informasi lainnya. Data mining berkaitan dengan bidang ilmu – ilmu lain, seperti database system, data warehousing, statistik, machine learning, information retrieval, dan komputasi tingkat tinggi. Selain itu, data mining didukung oleh ilmu lain seperti neural network, pengenalan pola, spatial data analysis, image database, signal processing. Data mining didefinisikan sebagai proses menemukan pola-pola dalam data. Proses ini otomatis atau seringnya semiotomatis. Pola yang ditemukan harus penuh arti dan pola tersebut memberikan keuntungan, biasanya keuntungan secara ekonomi. Data yang dibutuhkan dalam jumlah besar [4].
Karakteristik Data Mining sebagai berikut :
Data mining berhubungan dengan penemuan sesuatu yang tersembunyi dan pola data tertentu yang tidak diketahui sebelumnya.
Data mining biasa menggunakan data yang sangat besar. Biasanya data yang besar digunakan untuk membuat hasil lebih dipercaya.
Data mining berguna untuk membuat keputusan yang kritis, terutama dalam strategi.
Berdasarkan beberapa pengertian tersebut dapat ditarik kesimpulan bahwa data mining adalah suatu teknik menggali informasi berharga yang terpendam atau tersembunyi pada suatu koleksi data (database) yang sangat besar sehingga ditemukan suatu pola yang menarik yang sebelumnya tidak diketahui. Kata mining sendiri berarti usaha untuk mendapatkan sedikit barang berharga dari sejumlah besar material dasar. Karena itu data mining sebenarnya memiliki akar yang panjang dari bidang ilmu seperti kecerdasan buatan (artificial intelligent), machine learning, statistik dan database. Beberapa metode yang sering disebutsebut dalam literatur data mining antara lain clustering, classification, association rules mining, neural network, genetic algorithm dan lain-lain [4].
Data mining adalah bagian integral dari penemuan pengetahuan dalam database (KDD), yang merupakan proses keseluruhan mengubah data mentah menjadi informasi yang bermanfaat [6].
2.1.1 Knowledge Discovery in Database (KDD)
Istilah data mining dan knowledge discovery in databases (KDD) sering kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. sebenarnya kedua istilah tersebut memiliki konsep yang berbeda, tetapi berkaitan satu sama lain. Salah satu tahapan dalam keseluruhan proses KDD adalah data mining.
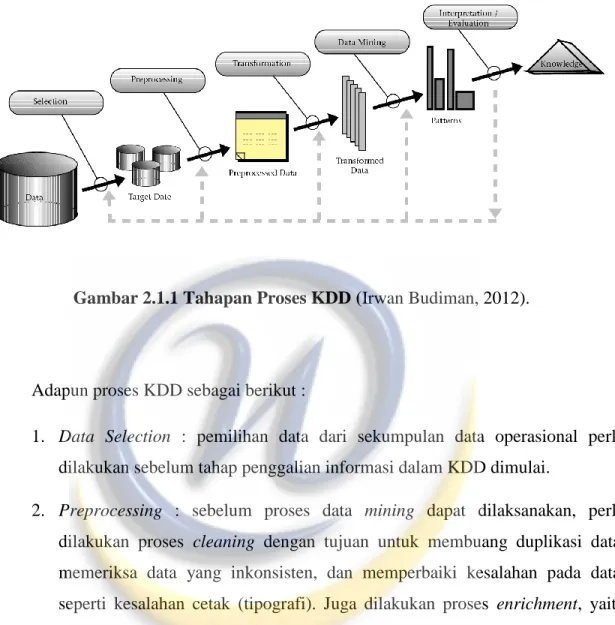
Knowledge Discovery in Database (KDD) adalah proses menentukan informasi yang berguna serta pola-pola yang ada dalam data. Informasi ini terkandung dalam basis data yang berukuran besar yang sebelumnya tidak diketahui dan potensial bermanfaat. Data Mining merupakan salah satu langkah dari serangkaian proses iterative KDD. Tahapan proses KDD dapat dilihat pada gambar 2.1.1.
Gambar 2.1.1 Tahapan Proses KDD (Irwan Budiman, 2012).
Adapun proses KDD sebagai berikut :
1. Data Selection : pemilihan data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai.
2. Preprocessing : sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning dengan tujuan untuk membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Juga dilakukan proses enrichment, yaitu proses “memperkaya” data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal. 3. Transformation : yaitu proses coding pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam database.
4. Data mining : proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu.
5. Interpretation / Evaluation : pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut dengan interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesa yang ada sebelumnya atau tidak [10].
2.2 Klasifikasi
Klasifikasi merupakan koleksi dari suatu record berupa training data set, dimana setiap record berisi seperangkat atribut dan salah satu atribut adalah suatu kelas. Yang harus dilakukan adalah mencari model untuk atribut kelas sebagai fungsi dari nilai atribut yang lain. Tujuannya adalah mendapatkan suatu kelas yang seakurat mungkin dari catatan record sebelumnya yang tidak terlihat. Satu set data tesdipersiapkan untuk menentukan keakuratan model dan sekaligus validasinya [6].
Klasifikasi adalah proses untuk menemukan model atau fungsi yang menggambarkan dan membedakan kelas data atau konsep dengan tujuan memprediksikan kelas untuk data yang tidak diketahui kelasnya [1].
2.2.1 Algoritma Naive Bayes
Bayesian classification adalah pengklasifikasian statistik yang dapat digunakan untuk memprediski probabilitas keanggotaan suatu class. Bayesian classification didasarkan pada Teorema Bayes yang memiliki kemampuan klasifikasi serupa dengan decesion tree dan neural network. Bayesian classification terbukti memiliki akurasai dan kecepatan yang tinggi saat diaplikasikan ke dalam database dengan data yang besar [2].
Teorema Bayes memiliki bentuk umum sebagai berikut :
H = Hipotesis data X merupakan suatu class spesifik.
P(H|X) = Probabilitas hipotesis H berdasarkan kondisi x (posteriori probabilitas). P(H) = Probabilitas hipotesis H (prior probabilitas).
P(X|H) = Probabilitas X berdasarkan kondisi tersebut. P(X) = Probabilitas dari X.
Ide dasar dari aturan Bayes adalah bahwa hasil hipotesis atau peristiwa (H) dapat diperkirakan berdasarkan pada beberapa bukti (X) yang diamati, ada beberapa hal penting dari aturan Bayes tersebut, yaitu :
1. Sebuah probabilitas awal/prior H atau P(H) adalah probabilitas dari suatu hipotesis sebelum bukti diamati.
2. Sebuah probabilitas akhir H atau P(H|X) adalah probabilitas dari suatu hipotesis setelah bukti diamati.
2.3 Pengertian Registrasi Ulang
Merupakan urutan prosedur administrasi yang wajib dijalani oleh setiap Calon Mahasiswa Baru yang telah lulus Ujian Saringan Masuk dan memutuskan untuk menjalani Pendidikan, dengan melengkapi persyaratan administrasi akademik dan melunasi kewajiban keuangan sesuai jadwal yang tertera pada Surat Panggilan / Peringkat.
Proses Registrasi ini bertujuan untuk memenuhi dan melengkapi seluruh Persyaratan Akademik sebagai Mahasiswa Baru, yang merupakan syarat mutlak guna diperolehnya NPM ( Nomor Pokok Mahasiswa) [7].
2.4 PHP
PHP adalah bahasa pemrograman web atau scripting language yang dijalankan diserver. PHP dibuat pertama kali oleh Rasmus Lerdorf, yang pada awalnya dibuat untuk menghitung jumlah pengunjung pada homepagenya. Pada waktu itu PHP bernama FI (Form Interpreter). Pada saat tersebut PHP adalah sekumpulan script yang digunakan untuk mengolah data form dari web.
Perkembangan selanjutnya adalah Rasmus melepaskan kode sumber tersebut dan menamakannya PHP/FI, pada saat tersebut kepanjangan dari PHP/FI adalah Personal Home Page/Form Interpreter. Pelepasan kode sumber ini menjadi open source, maka banyak programmer yang tertarik untuk ikut mengembangkan PHP.
Pada tahun 1997 sebuah perusahaan bernama Zend, menulis ulang interpreter PHP mejadi lebih bersih, lebih baik dan lebih cepat. Kemudian pada Juni 1998 perusahaan tersebut merilis interpreter baru untuk PHP dan meresmikan nama rilis tersebut menjadi PHP 3.0. Pada pertengahan tahun 1999, Zend merilis interpreter PHP baru dan rilis tersebut dikenal dengan PHP 4.0. PHP 4.0 adalah versi PHP yang paling banyak dipakai. Versi ini banyak dipakai sebab versi ini mampu dipakai untuk membangun aplikasi web kompleks tetapi tetap memiliki kecepatan proses dan stabilitas yang tinggi.
Pada Juni 2004 Zend merilis PHP 5.0. Versi ini adalah versi mutakhir dari PHP. Dalam versi ini, inti dari interpreter PHP mengalami perubahan besar. Dalam versi ini juga dikenalkan model pemrograman berorientasi objek baru untuk menjawab perkembangan bahasa pemrograman kearah pemrograman berorientasi objek. Hal yang menarik yang didukung oleh PHP adalah kenyataan bahwa PHP bisa digunakan untuk mengakses berbagai macam database seperti Access, Oracle, MySQL, dan lain-lain [9].