CLUSTERING BERITA PADA MEDIA SOSIAL
MENGGUNAKAN K-MEANS
Rina Candra NS1, Sri Eniyati2
Program Studi Teknik Informatika Fakultas Teknologi Informasi, Universitas Stikubank Semarang Jl. Tri Lomba Juang No. 1 Semarang
Telp. (024)8311668
E-mail: [email protected]
ABSTRAK
MEDIA SOSIAL (Social Media) adalah saluran atau sarana pergaulan sosial secara online di dunia maya (internet). Para pengguna (user) media sosial berkomunikasi, berinteraksi, saling kirim pesan, dan saling berbagi (sharing), dan membangun jaringan (networking). Blog, jejaring sosial dan wiki merupakan bentuk media sosial yang paling umum digunakan oleh masyarakat di seluruh dunia.
Salah satunya adalah facebook. Facebook merupakan salah satu media sosial berisi berita -berita. Banyak berita yang diposting melalui facebook dan juga karena memiliki berbagai macam kategori, maka pada penelitian ini berita-berita yang telah diposting pada facebook akan diekstrasi menjadi data yang nantinya digunakan untuk pengelompokan jenis berita.
Kata Kunci: media sosial, facebook, ekstrasi dan pengelompokkan 1. PENDAHULUAN
1.1.Latar Belakang Masalah
Media sosial adalah sebuah media online, dengan para penggunanya bisa dengan mudah berpartisipasi, berbagi, dan menciptakan isi meliputi blog, jejaring sosial, wiki, forum dan dunia virtual. Blog, jejaring sosial dan wiki merupakan bentuk media sosial yang paling umum digunakan oleh masyarakat di seluruh dunia. Pendapat lain mengatakan bahwa media sosial adalah media online yang mendukung interaksi sosial dan media sosial menggunakan teknologi berbasis web yang mengubah komunikasi menjadi dialog interaktif.
Jejaring sosial merupakan situs dimana setiap orang bisa membuat web page pribadi, kemudian terhubung dengan teman-teman untuk berbagi informasi dan berkomunikasi. Jejaring sosial terbesar antara lain Facebook, Myspace, dan Twitter. Jika media tradisional menggunakan media cetak dan media broadcast, maka media sosial menggunakan internet. Media sosial mengajak siapa saja yang tertarik untuk berpertisipasi dengan memberi kontribusi dan feedback secara terbuka, memberi komentar, serta membagi informasi dalam waktu yang cepat dan tak terbatas. Setiap perguruan tinggi memiliki cara untuk berkomunikasi dengan mahasiswa dan masyarakat yang diharapkan menjadi calon mahasiswanya. Ada banyak cara yang digunakan untuk menginformasikan kepada masyarakat. Diantaranya melalui surat kabar, televisi dan media sosial. Media sosial menjadi tren saat ini, karena caranya dianggap murah dan mudah yang bisa berkomunikasi langsung dengan audiensnya. Permasalahannya perlu dicari cara berkomunikasi yang baik dan disukai oleh pengguna media sosial.
Pada penelitian ini akan di kelompokkan pesan atau berita-berita yang sudah diposting pada media sosial facebook milik fakultas Teknologi Informasi Unisbank. Pesan-pesan yang pernah ditulis akan diekstrasi yang akan menjadi suatu data yang akan digunakan untuk pengelompokkan jenis berita.
1.2.Perumusan Masalah
Dari rincian uraian di atas, rumusan masalah yang akan dibahas dalam penelitian ini meliputi :
a. Mengambil data yang akan dijadikan obyek analisa.Dalam hal ini adalah data media sosial facebook Fakultas Teknologi Informasi.
b. Menerapkan algoritma K-Means untuk mendapatkan pengelompokkannya 2. KAJIAN PUSTAKA
Data mining adalah proses yangmenggunakan teknik statistik, matematika,kecerdasan buatan, dan machine learninguntuk mengekstrasi dan mengidentifikasiinformasi yang bermanfaat dan pengetahuanyang terkait dari berbagai database besar.Menurut Larose (2006), data mining dibagimenjadi beberapa kelompok berdasarkan tugasyang dapat di lakukan, yaitu:
a. Deskripsi
Terkadang peneliti dan analisis secarasederhana ingin mencoba mencari cara untukmenggambarkan pola dan kecendrungan yangterdapat dalam data.
b. Estimasi
Estimasi hampir sama denganklasifikasi, kecuali variabel target estimasilebih ke arah numerik dari pada ke arahkategori.
c. Prediksi
Prediksi hampir sama dengan klasifikasidan estimasi, kecuali bahwa dalam prediksinilai dari hasil akan ada di masa mendatang.
d. Klasifikasi
Dalam klasifikasi, terdapat targetvariabel kategori. e. Pengklusteran
Clustering merupakan suatu metodeuntuk mencari dan mengelompokkan datayang memiliki kemiripan karakteriktik(similarity) antara satu data dengan data yanglain. Clustering merupakan salah satu metodedata mining yang bersifat tanpa arahan(unsupervised).
f. Asosiasi
Tugas asosiasi dalam data miningadalah menemukan atribut yang muncul dalam suatu waktu. Dalam dunia bisnis lebih umumdisebut analisis keranjang belanja.
Menurut Han & Kamber (2005) algoritma
K-Meansbekerjadenganmembagidatakedalamkbuahclusteryangtelahditentukan.Beberapa cara penghitungan jarak yangbiasa digunakan yaitu:
a. Euclidean distance : Formula jarak antar dua titik dalam satu, dua dan tiga dimensi secara berurutan.
b. Chebichev Distance : Di dalam Chebichev distance atauMaximum Metric jarak antar titikdidefinisikan dengan cara mengambil nilaiselisih terbesar dari tiap koordinat dimensinya.
Tedy dan Sri (2008) menggunakan algoritma K-Means untuk mengelompokkan mahasiswa berdasarkan nilai body mass index (bmi) & ukuran kerangka. Masalah kesehatan merupakan permasalahan yang sangat penting untuk diperhatikan, diantaranya adalah masalah BMI dan ukuran kerangka seseorang. Apabila seseorang telah mengetahui nilai BMInya, orangtersebut dapat mengontrol berat badan sehingga dapat mencapai berat badan normal yang sesuai dengan tinggibadan. Sedangkan apabila orang tersebut mengetahui ukuran kerangka tubuhnya maka orang tersebut dapatmengontrol berat badannya agar dapat selalu berada dalam keadaan ideal.membangun suatu sistem untuk mengelompokkan data yang adaberdasarkan status gizi dan ukuran rangkanya dengan memasukkan parameter kondisi fisik dari orang tersebut.Pengelompokkan data dilakukan dengan menggunakan metode clustering K-Means yaitu denganmengelompokkan n buah objek ke dalam k kelas berdasarkan jaraknya dengan pusat kelas. Dari hasil penelitian terhadap 20 data sampel diperoleh 3 kelompok mahasiswa berdasarkan nilai BMIdan ukuran rangka, yaitu BMI normal dan kerangka besar, BMI obesitas sedang dan kerangka sedang, BMIobesitas berat dan kerangka kecil.
Hartatik (2014) mengggunakan metode K-Means untuk mengelompokkan mahasiswa berdasarkan nilai ujian nasional dan IPK. Metodenya dengan membagi mahasiswa kedalam n klaster sehingga akan didapatkan pola pengelompokan yang diharapkan dapat menunjukkan hubungan antara keduanya. Untuk menerapkannya dibuat perangkat lunak untuk memmasukkan data yang akan dikelompokkan, memasukkan parameter, nilai IPK dan UN serta mengelompokkan data yang telah diinput sebelumnya.
3. METODOLOGI PENELITIAN 3.1.Metode Penelitian
1. Metode Pengumpulan Data a. Observasi
Observasi dilakukan di facebook media sosial FTI Universitas Stikubank Semarang untuk mendapatkan informasi dan data.
b. Studi Kepustakaan
Studi kepustakaan dilakukan untuk memperoleh literatur-literatur yang relevan dengan obyek penelitian.
2. Dalam penelitian ini, metode yang digunakan untuk pengolahan data mengacu pad gonunescu (2011) meliputi :
a. Persiapan Data
Persiapan data meliputi pengambilan data, pembersihan data, normalisasi data, transformasi data, pemilihan variabel dan sebagainya.
Data diambil diambil dari facebook FTI kemudian di analisis dengan menggunakan K-means. b. Proses Clustering
Membangun dan melakukan analisis cluster dengan menggunakan metode clustering yang tepat.
c. Implementasi
4. PEMBAHASAN 4.1. Persiapan Data
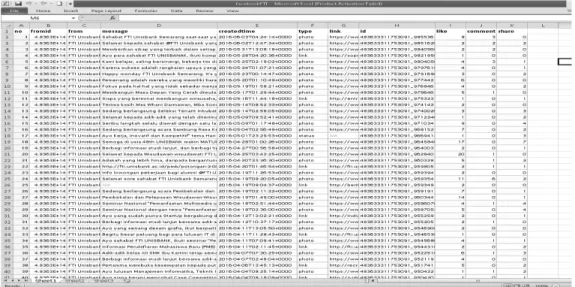
Pada penelitian ini digunakan bahasa R untuk mendapatkan dan mengolah data. Data yang akan diolah diperoleh dari facebook FTI Unisbank Semarang. Untuk mendapatkan data tersebut digunakan paket Rfacebook. Hasil dari Rfacebook disimpan kedalam file Excel. Sebagai gambaran proses pengolahan data dapat dilihat pada gambar 5.1.
Gambar 1. Alur Pengolahan Data
Data yang diperoleh dari facebook FTI Unisbank Semarang sebanyak 80 data yang berisi field-field sebagai berikut: 1. fromid 2. from 3. message 4. createdtime 5. type 6. link 7. id 8. like 9. comment 10. share
Gambar 2. Hasil Rfacebook ke Excel
Untuk keperluan clustering, hal pertama yang dilakukan adalah pembersihan data. Data yang diambil hanya message, like dan comment. Agar message bisa digunakan dalam perhitungan yang diperlukan untuk clustering, maka
dilakukan pengelompokan terhadap isi message. Kami membuat kelompok data yang terbagi menjadi 11 kategori yaitu: 1. Training 2. Ucapan 3. Mutiara 4. Lomba 5. Tip 6. Expo 7. Pmb 8. Lowongan 9. Alumni 10. Seminar 11. Info
Sehingga field yang ada sekarang menjadi message, like, comment dan kategori (catvalue). Dalam program yang
4.2. Clustering Data
Proses K-Means dimulai dengan menentukan variabel yang akan dihitung. Pada kasus pengelompokan berita yang ada pada facebook FTI, variabel yang digunakan adalah catvalue, like dan comment. Pada penelitian ini jumlah cluster ditentukan menjadi 3.
Proses k-means dengan bahasa R menggunakan algoritma defaultnya yaitu Hartigan-Wong. Untuk menerapkannya digunakan perintah sebagai berikut:
(kmeans.result) <- kmeans(fbfti, 3, nstart=1, trace=FALSE)
Program selengkapnya dapat dilihat pada kode program sebagai berikut: library(xlsx)
fbfti <- read.xlsx("fbFTI.xls", sheetIndex = 1) fbfti2 <- fbfti fbfti2$message <-NULL fbfti2$type <-NULL fbfti2$category <-NULL fbfti2$share <-NULL head(fbfti2) (kmeans.result <- kmeans(fbfti2,3))
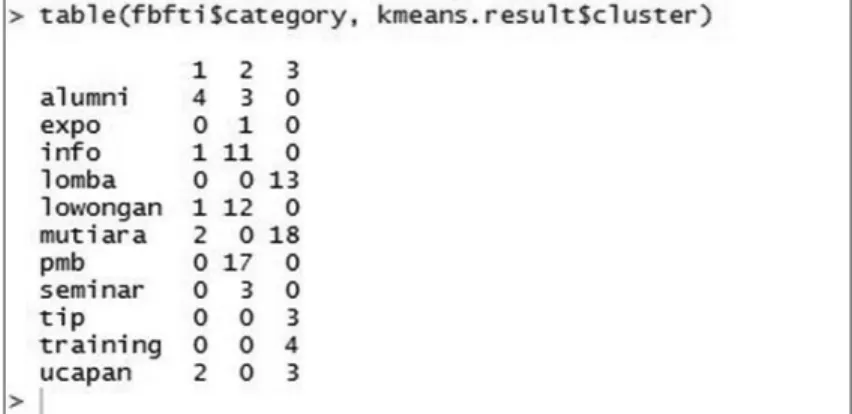
plot(fbfti2[c("like","catvalue")], col = kmeans.result$cluster) table(fbfti$category, kmeans.result$cluster)
hasilfbfti <- table(fbfti$message, kmeans.result$cluster)
write.xlsx(hasilfbfti, file = "fbfti-hasil.xlsx", sheetName="Hasil3", append=TRUE)
Hasil clustering dapat dilihat pada gambar 5.3. Dari gambar tersebut, kelompok berita telah terkategori menjadi 3 klaster.
Yang masuk kelompok 1 adalah berita alumni,info, lowongan, mutiara,ucapan dan pada kelompok 1 didoninasi pada berita almuni.
Untuk kelompok 2 adalah alumni, expo, info, lowongan, pmb, seminar dan didominasi pada berita pmb. Untuk kelompok 3 adalah lomba, mutiara,tip, training dan ucapan dan didominasi pada berita mutiara.
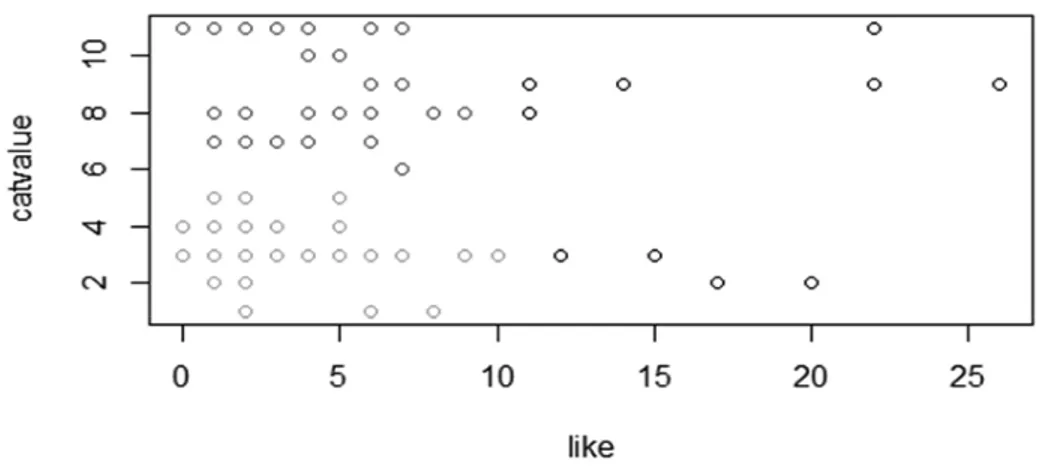
Dalam bentuk grafik peta klaster dapat dilihat pada gambar 5.4. Grafik tersebut menunjukkan posisi message yang disukai oleh pengguna facebook.
Gambar 4. Rplot Clustering
Dari hasil grafik dapat dijelaskan bahwa pada kategori yang ke- 9 (alumni), yang menyukai berita tersebut lebih dari 25 orang.
5.3. Hasil Clustering
Hasil clustering message facebook FTI terbagi menjadi 3 kelompok. Adapun contoh hasil pengelompokan data adalah sebagai berikut:
Tabel 1. Hasil Pengelompokkan Data
NO Message Klaster
1 15 hari lagi PMB jalur PMDK berakhir. Dan kesempatan mendapatkan beasiswa 2.5 juta juga ditutup. Mari segera daftarkan diri adik-adik, saudara, keponakan, atau teman Anda dan jadilah pemenang di era Digital yang sarat dengan IT dan DT. #MI #TI #SI #fti #ftiunisbank
1
2 3 Besar perguruan tinggi swasta di semarang
http://fti.unisbank.ac.id/pmb/unisbank-peringkat-3-pts-terbaik-se-kota-semarang
1 3 Adakah yang lebih hina, daripada bergantung kepada orang lain? Ikhtiar!
Berjuanglah membebaskan diri.. Jika engkau sudah bebas karena ikhtiarmu itu, barulah dapat engkau tolong orang lain. ( R. A. Kartini) Ayo para perempuan Indonesia, teruslah memantaskan diri menjadi pelita dalam kegelapan. Karena habis gelap terbitlah terang. Selamat Hari Kartini 21 April 2016. #kartini #kartini2016
1
4 Adik-adik atau saudara yang akan studi lanjut di bidang komputer, ini dia yang Wajib kalian pahami!
3 5 15 hari lagi PMB jalur PMDK berakhir. Dan kesempatan mendapatkan beasiswa
2.5 juta juga ditutup. Mari segera daftarkan diri adik-adik, saudara, keponakan, atau teman Anda dan jadilah pemenang di era Digital yang sarat dengan IT dan DT. #MI #TI #SI #fti #f
2
6 3 Besar perguruan tinggi swasta di semarang
http://fti.unisbank.ac.id/pmb/unisbank-peringkat-3-pts-terbaik-se-kota-semarang
3 7 Adakah yang lebih hina, daripada bergantung kepada orang lain? Ikhtiar!
Berjuanglah membebaskan diri.. Jika engkau sudah bebas karena ikhtiarmu itu,
barulah dapat engkau tolong orang lain. ( R. A. Kartini) Ayo para perempuan Indonesia, teruslah memantaskan diri menjadi pelita dalam kegelapan. Karena habis gelap terbitlah terang. Selamat Hari Kartini 21 April 2016. #kartini #kartini2016
8 Adik-adik atau saudara yang akan studi lanjut di bidang komputer, ini dia yang Wajib kalian pahami!
1 9 Adik-adik kelas XII SMK Ibu Kartini tetap semangat mengikuti trainig FAST
TRACK TECHNOPRENEUR dengan materi "Membangun Aplikasi Mobile untuk Startup Bisnis dengan IBuiltApp". Ayo kapan giliran sekolah kamu?
#fastracktechnopreneur #technopreneur #fti #ManajemenInformatika #SistemInformasi #TeknikInformatika
2
10 Ayo sahabat FTI UNISBANK, ikuti seminar "Pemanfaatan Multimedia untuk Pendidikan Dalam Era Mobile" bersama KEMDIKBUD. Senin, 18 April 2016 di ruang Seminar lt.9 kampus Mugas. #mobile #ftiunisbank #FTI #unisbank
1
Rekapitulasi kategori berita dapat dikelompokkan sebagai berikut: Tabel 2. Kategori Berita
Klaster 1 Klaster 2 Klaster 3
Alumni Info Lowongan Mutiara Ucapan Alumni Expo Info Lowongan Pmb Seminar Lomba Mutiara Tip Training Ucapan Terbanyak : Alumni Terbanyak : PMB Terbanyak : Mutiara
Hal ini dapat dijadikan bahan pertimbangan untuk pengelola facebook FTI, bahwa pesan-pesan yang disukai adalah pesan yang kategorinya berita tentang alumni, PMB dan kata-kata mutiara atau motivasi.
5. PENUTUP 5.1. Kesimpulan
Dari hasil kesimpulannya antara lain:
1. Data dari facebook FTI dapat dianalisa untuk memberikan gambaran pesan yang disukai oleh pengguna facebook FTI.
2. Sebagai bahan pertimbangan untuk pengelola facebook FTI, pesan-pesan yang disukai adalah pesan yang kategorinya berita tentang alumni, PMB dan kata-kata mutiara atau motivasi
5.2. Saran
1. Clustering bisa dibuat dengan jumlah kelompok lebih dari 3.
2. Untuk proses clustering dapat menggunakan dengan algoritma yang lain. Daftar Pustaka
Alsola., and Harrell. (2006). An Introduction to S and The Hmisc and Design Libraries J Han. and Kamber,M. (2005). Data mining: Concepts and Techniques. New York.
Hartatik, (2014). Pengelompokan Mahasiswa Berdasarkan Nilai Ujian Nasional dan IPK Menggunakan Metode K-Means. Seminar Nasional Informatika
Johan Oscar Ong. (2013). Implementasi Algoritma K-Means Clustering UntukMenentukan Strategi Marketing President University. Jurnal Ilmiah TeknikIndustri, vol. 12, no. 1.
Larose. Daniel T. (2006). Data Mining Methods and Models. Hoboken New Jersey: Jhon Wiley & Sons, Inc. Rismawan danKusumadewi, "Aplikasi K-Means Untuk PengelompokanMahasiswa Berdasarkan Nilai Body Mass Index (BMI) & Ukuran Kerangka"Seminar Nasional Aplikasi Teknologi Informasi, Yogyakarta, 2008, pp. ISSN: 1907-5022