i
TUGAS AKHIR
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Teknik Program Studi Teknik Informatika
Disusun Oleh : WENING TYAS ASIH
045314022
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
IN POOR AREA
FINAL ASSIGNMENT Presented as a Meaning for Gaining Engineering Holder in Informatics Engineering Study Program
By :
WENING TYAS ASIH 045314022
INFORMATICS ENGINEERING DEPARTEMENT
SCIENCE AND TECHNOLOGY FACULTY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
v
yang pernah diajukan untuk memperoleh gelar kesarjanaan di suatu Perguruan Tinggi, dan sepanjang pengetahuan saya juga tidak terdapat karya atau pendapat yang pernah ditulis atau diterbitkan oleh orang lain, kecuali yang secara tertulis diacu dalam naskah ini dan disebutkan dalam daftar pustaka.
Yogyakarta, 21 Agustus 2008 Penulis
vi Nama : Wening Tyas Asih Nomor Mahasiswa : 045314022
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul :
APLIKASI PROGRAM PENGELOMPOKKAN PENDUDUK BERDASARKAN KEMAMPUAN EKONOMI UNTUK DAERAH MISKIN DENGAN FUZZY C-MEANS
beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada Perpustakaan Universitas Sanata Dharma hak untuk menyimpan, mengalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data, mendistribusikan secara terbatas, dan mempublikasikannya di Internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun memberikan royalti kepada saya selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini yang saya buat dengan sebenarnya. Dibuat di Yogyakarta
Pada tanggal : 21 Agustus 2008
Yang menyatakan
vii
MY JESUS CHRIST
KELUARGAKU
BAPAK & IBU
RILO
SAHABATKU
ANDIS, VITA, DENI
YANG SELALU SETIA
viii
koordinasi, pengendalian dan sebagai pendukung pengambilan berbagai kebijakan bagi pemerintah dan masyarakat luas. Kemudahan serta ketepatan untuk memperoleh informasi dalam pengelompokkan penduduk miskin akan mempermudah pemerintah serta badan instansi terkait dalam memberikan program bantuan atau subsidi kepada penduduk. Terutama untuk daerah miskin dan tertinggal dengan angka kemiskinan yang cukup tinggi yang sangat memerlukan bantuan, baik dari pemerintah ataupun pihak-pihak lain.
ix
controlling and supporting various policies making by government and for society. The easiness to access the information and its accuracy to clustering the poor resident, facilitating the government and its agents in providing their aid and subsidy program to society, especially in poor regions and underdeveloped territory with high poverty rate, which were very need relief from government and other institutions.
Regarding with the problem mentions above, the Application Program with Fuzzy C-Means Method for Clustering Resident Based on Financial Affordability in Poor Area. Fuzzy C-Means as a clustering method based on the fuzzy logic was clustering technique where the existence of each data point in the cluster was determined by membership degree.
x
Program Pengelompokkan Penduduk Berdasar Kemampuan Ekonomi untuk Daerah Miskin dengan Fuzzy C-Means” ini.
Penulis menyadari bahwa keberhasilan tugas akhir ini tidak lepas dari bantuan, dukungan serta bimbingan dari berbagai pihak terkait. Pada kesempatan ini penulis bermaksud mengucapkan terima kasih kepada:
1. Bapak, ibu dan Adityas Rilo Pambudi sebagai keluarga penulis.
2. Bapak Albertus Agung Hadhiatma, S.T., M.T., selaku pembimbing TA.
3. Ibu Agnes Maria Polina, S.Kom., M.Sc., beserta para dosen dan karyawan Jurusan Teknik Informatika Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta.
4. Romo Ir. Greg. Heliarko SJ, S.S., B.S.T., M.A., M.Sc., beserta seluruh keluarga besar Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta.
5. Segenap staff pemerintahan daerah kecamatan Karangmojo, Gunungkidul.
6. Segenap staff pemerintahan daerah desa Wiladeg, kecamatan Karangmojo, Gunungkidul.
7. Segenap staff KPPTSP BAPPEDA kabupaten Gunungkidul.
8. Segenap staff Badan Pusat Statistika (BPS), kabupaten Gunungkidul.
xi
11.Teman – teman mahasiswa Teknik Informatika USD angkatan 2004. 12.Semua pihak yang tidak dapat penulis sebutkan satu – persatu.
Penulis menyadari akan kekurangan dalam penulisan naskah tugas akhir ini. Untuk itu penulis mengharapkan kritik dan saran dari pembaca. Akhir kata, semoga Tugas Akhir ini bermanfaat. Terima kasih.
Yogyakarta, 21 Agustus 2008
xii
HALAMAN JUDUL ... i
HALAMAN JUDUL (INGGRIS)... ii
LEMBAR PERSETUJUAN PEMBIMBING ... iii
LEMBAR PENGESAHAN ... iv
LEMBAR PERNYATAAN KEASLIAN KARYA ... v
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI ... vi
PERSEMBAHAN ... vii
INTISARI ... viii
ABSTRACT ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR GAMBAR ...xvii
DAFTAR TABEL ... xix
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Rumusan Masalah ... 3
1.3 Batasan Masalah ... 4
1.4 Tujuan Penelitian ... 4
1.5 Metode Penelitian ... 4
xiii
2.2.1 Himpunan Tegas (Crisp Set)... 8
2.2.2 Himpunan Fuzzy (Fuzzy Set) ... 10
2.3 Fuzzy Clustering ... 12
2.3.1 Partisi Klasik (Hard Partition) ... 13
2.3.2 Partisi Fuzzy (Fuzzy Partition) ... 15
2.4 Ukuran Fuzzy ... 16
2.5 Fuzzy C-Means (FCM) ... 17
2.5.1 Algoritma FCM... 18
2.5.2 Contoh FCM ... 20
BAB III PERANCANGAN SISTEM ... 33
3.1 Gambaran Umum Sistem ... 33
3.2 Use Case Diagram... 34
3.3 Perancangan Fuzzy C-Means dan Penamaan Cluster... 36
3.3.1 Perancangan FCM 4 Cluster ... 36
3.3.1.1 Contoh FCM 4 Cluster... 41
3.3.2 Perancangan FCM 2 Cluster ... 49
3.3.2.1 Contoh FCM 2 Cluster... 54
3.4 Perancangan Proses... 61
3.4.1 Diagram Konteks Sistem ... 61
xiv
3. Overview DAD Level 2 ... 64
4. Overview DAD Level 3 ... 65
5. Overview DAD Level 4 ... 65
6. Overview DAD Level 5 ... 66
3.5 Perancangan Basisdata... 67
3.5.1 ER Diagram ... 67
3.5.2 Relational Model... 67
1. Entitas Login ... 67
2. Entitas Penduduk ... 68
3.5.3 Rancangan Tabel... 69
1. Tabel Login... 69
2. Tabel Penduduk ... 69
3.6 Perancangan Antarmuka ... 71
1. Tampilan Login... 71
2. Tampilan Tambah Data Penduduk... 72
3. Tampilan Menu Utama Admin ... 72
4. Tampilan Ubah Password ... 73
5. Tampilan Pengelompokkan Penduduk ... 74
6. Tampilan Hasil Pengelompokkan Penduduk ... 74
xv
4.1.1 Lingkungan Perangkat Keras... 77
4.1.2 Lingkungan Perangkat Lunak ... 77
4.2 Implementasi Algoritma Fuzzy C-Means 2 Cluster ... 78
4.2.1 Menentukan Input Data... 78
4.2.2 Menentukan c, w, MaxIter, ξ, P0 dan t ……….………... 79
4.2.3 Membangkitkan Bilangan Random……….…….. 80
4.2.4 Menghitung Pusat Cluster………..……… 81
4.2.5 Menghitung Fungsi Objektif………..………. 82
4.2.6 Menghitung Perubahan Matrik Partisi……… 84
4.2.7 Cek Kondisi Berhenti………. 86
4.2.8 Penamaan Cluster……….. 87
4.3 Implemantasi Algoritma Fuzzy C-Means 4 Cluster ... 88
4.3.1 Menentukan c, w, MaxIter, ξ, P0 dan t ……….………... 89
4.3.2 Membangkitkan Bilangan Random……….…….. 89
4.3.3 Menghitung Pusat Cluster………..……… 90
4.3.4 Menghitung Fungsi Objektif………..………. 92
4.3.5 Menghitung Perubahan Matrik Partisi……… 95
4.3.6 Cek Kondisi Berhenti………. 97
xvi
4.4.2 Menu Utama Administrator……… 100
4.4.3 Tambah Data Pokmas... 101
4.4.5 Ubah Password ... 102
4.4.6 Menu Utama User ... 103
4.4.7. Pengelompokkan Penduduk ... 104
4.4.8 Hasil Pengelompokkan Penduduk ... 105
4.5 Hasil Implementasi ... 106
4.5.1 Hasil Implementasi FCM 4 Cluster ... 107
4.5.2 Hasil Implementasi FCM 2 Cluster ... 112
BAB V PENUTUP ... 118
5.1 Kesimpulan ... 118
5.2 Saran ... 118
xvii
Gambar 2.2. Flowchart Algoritma Fuzzy C-Means... 18
Gambar 2.3. Grafik kecenderungan data dengan pusat cluster yangpertama ... 24
Gambar 2.4. Grafik kecenderungan data dengan pusat cluster yang kedua .. 28
Gambar 2.5. Grafik kecenderungan data dengan pusat cluster yang ketiga ... 32
Gambar 3.1. Flowchart Sistem ... 34
Gambar 3.2. Usecase Diagram Administrator ... 35
Gambar 3.3. Usecase Diagram User ... 36
Gambar 3.4. Diagram Konteks Sistem ... 61
Gambar 3.5. Bagan Berjenjang ... 62
Gambar 3.6. Overview DAD Level 0 ... 63
Gambar 3.7. Overview DAD Level 1 Proses 1 ... 64
Gambar 3.8. Overview DAD Level 1 Proses 2 ... 64
Gambar 3.9. Overview DAD Level 1 Proses 3 ... 65
Gambar 3.10. Overview DAD Level 1 Proses 4 ... 65
Gambar 3.11. Overview DAD Level 1 Proses 5 ... 66
Gambar 3.12. Entity Relationship Diagram ... 67
Gambar 3.13. Translasi Entitas Login menjadi Relational Model ... 67
Gambar 3.14. Translasi Entitas Penduduk menjadi Relational Model ... 68
Gambar 3.15. Relational Model ... 68
xviii
Gambar 3.20. Desain Tampilan Pengelompokkan Penduduk ... 74
Gambar 3.21. Desain Tampilan Hasil Pengelompokkan 2 Cluster ... 75
Gambar 3.22. Desain Tampilan Hasil Pengelompokkan 4 Cluster ... 75
Gambar 3.23. Desain Tampilan Menu Utama User... 76
Gambar 4.1. Tampilan Login ... 99
Gambar 4.2. Tampilan Menu Utama Admin ...100
Gambar 4.3. Tampilan Tambah Data Penduduk...101
Gambar 4.4. Tampilan Ubah Password ...102
Gambar 4.5. Tampilan Menu Utama User...103
Gambar 4.6. Tampilan Pengelompokkan Penduduk ...104
Gambar 4.7. Tampilan Hasil Pengelompokkan 2 Cluster ...105
xix
Tabel 2.2 Tabel perhitungan data Xij dengan pusat cluster 5,5 ... 22
Tabel 2.3 Tabel perhitungan data Xij dengan pusat cluster 15 , 15 ... 22
Tabel 2.4 Tabel perhitungan matrik partisi baru... 23
Tabel 2.5 Tabel Matrik Partisi Baru... 23
Tabel 2.6 Tabel perkalian data dengan (µik)2... 25
Tabel 2.7 Tabel perhitungan data Xij dengan pusat cluster V1j... 26
Tabel 2.8 Tabel perhitungan data Xij dengan pusat cluster V2j... 26
Tabel 2.9 Tabel perhitungan fungsi keanggotaan baru ... 27
Tabel 2.10 Tabel perkalian data Xijdengan (µik)2... 29
Tabel 2.11 Tabel perhitungan data Xij dengan pusat cluster V1j... 30
Tabel 2.12 Tabel perhitungan data Xij dengan pusat cluster V1j... 31
Tabel 2.13 Tabel fungsi keanggotaan baru ... 32
Tabel 3.1 Tabel data ... 41
Tabel 3.2 Tabel data... 42
Tabel 3.3 Tabel matrik random (µik)2... 43
Tabel 3.4 Tabel perkalian data Xijdengan (µi1) 2 ... 44
Tabel 3.5 Tabel perkalian data Xijdengan (µi2)2... 44
Tabel 3.6 Tabel fungsi keanggotaan baru ... 45
Tabel 3.7 Tabel perkalian data Xijdengan (µi2)... 45
xx
Tabel 3.11 Tabel perhitungan derajat fungsi keanggotaan baru ... 48
Tabel 3.12 Tabel fungsi keanggotaan baru ... 49
Tabel 3.13 Tabel data... 54
Tabel 3.14 Tabel data... 55
Tabel 3.15 Tabel matrik random (µik)2... 56
Tabel 3.16 Tabel perkalian data Xij dengan (µi1) 2 ... 57
Tabel 3.17 Tabel perkalian data Xijdengan (µi2) 2 ... 57
Tabel 3.18 Tabel pusat cluster ... 58
Tabel 3.19 Tabel perhitungan data Xij dengan pusat cluster V2j... 58
Tabel 3.20 Tabel perhitungan
( )
12 2 2 1 1 i j j ij V X − µ = ... 59Tabel 3.21 Tabel perhitungan matrik partisi baru... 60
Tabel 3.22 Tabel fungsi keanggotaan baru ... 60
Tabel 3.23 Tabel Login ... 69
Tabel 3.24 Tabel Penduduk ... 70
Tabel 4.1 Tabel Penduduk ...106
Tabel 4.2 Tabel Hasil Pengelompokkan 2 Cluster...112
BAB I
PENDAHULUAN
1.1LATAR BELAKANG
Kebutuhan informasi mengenai karakteristik kemiskinan sangat diperlukan
untuk koordinasi, pengendalian dan sebagai pendukung pengambilan berbagai
kebijakan bagi pemerintah dan masyarakat luas. Kemudahan serta ketepatan untuk
memperoleh informasi dalam pengelompokkan penduduk miskin akan
mempermudah pemerintah serta badan instansi terkait dalam memberikan program
bantuan atau subsidi kepada penduduk. Terutama untuk daerah miskin dan tertinggal
dengan angka kemiskinan yang cukup tinggi yang sangat memerlukan bantuan, baik
dari pemerintah ataupun pihak-pihak lain.
Guna memberikan informasi kemiskinan yang dibutuhkan, pengelompokkan
penduduk dilakukan oleh berbagai pihak, baik dari lembaga pemerintah maupun
lembaga non pemerintah, misalnya BPS, BKKBN, Departemen Perekonomian, LSM,
maupun pemerintah desa sebagai unit terkecil pemerintahan, menggunakan berbagai
cara dan kriteria pengelompokkan yang berbeda-beda. Beberapa jenis
pengelompokkan misalnya, yang pertama sesuai dengan BPS (Badan Pusat
Yang kedua sesuai dengan BKKBN, terdapat empat kelompok yaitu, PraKS (Pra
Keluarga Sejahtera), KS I (Keluarga Sejahtera I), KS II, dan KS III .
Sebagai unit paling kecil dalam pemerintahan, desa dianggap perlu untuk
melakukan pengelompokkan. Karena sebagai pihak yang berhadapan langsung
dengan penduduk dan menangani berbagai permasalah yang berkaitan dengan
penduduk sehingga perlu memiliki informasi yang akurat mengenai kemiskinan di
daerahnya.
Pada proses pengelompokkan penduduk di tingkat desa, data keluarga miskin
dan rawan pangan akan dikumpulkan dan dilakukan pengelompokkan oleh
musyawarah desa. Proses pengelompokkan dilakukan secara manual. Data penduduk
akan diperiksa satu per satu, dibandingkan dengan data penduduk yang lainnya dan
diseleksi, setelah itu dilakukan proses perankingan. Hal tersebut tentu saja kurang
efisien karena akan memakan banyak waktu dan tidak menutup kemungkinan
terjadinya human error.
Disisi lain, pihak-pihak yang berwenang melakukan pengelompokkan sering
kali dihadapkan pada permasalahan yang berbenturan dengan kepentingan pribadi,
kelompok maupun golongan. Yang dapat menyebabkan ketidak akuratan hasil
Berkaitan dengan berbagai masalah tersebut, maka dibuat aplikasi
Pengelompokkan Penduduk Berdasar Kemampuan Ekonomi untuk Daerah Miskin
dengan Fuzzy C-Means. Fuzzy C-Means sebagai suatu metode pengelompokkan yang
didasarkan pada logika kabur, merupakan salah satu cara praktis dalam melakukan
pengelompokkan, dimana keberadaan tiap titik data dalam kelompok/cluster
ditentukan oleh derajat keanggotaan (Sri Kusumadewi, 2004). Penggunaan aplikasi
ini untuk melakukan pengelompokkan masyarakat berdasar kriteria jumlah
penghasilan, luas bangunan tempat tinggal dan rekening listrik. Program ini akan
menangani pengelompokkan sesuai dengan BPS (Badan Pusat Statistika), penduduk
Mampu dan Tidak Mampu. Yang kedua sesuai dengan BKKBN yaitu, PraKS (Pra
Keluarga Sejahtera), KS I (Keluarga Sejahtera I), KS II, dan KS III .
Program ini ditujukan untuk daerah-daerah miskin, terpencil atau tertinggal
untuk menentukan range kemampuan ekonomi penduduk dengan standar yang
terdapat pada tempat tersebut. Sehingga hasil dari pengelompokan juga dapat dipakai
sebagai pembanding dengan daerah lain untuk menentukan standar kualitas
kemiskinan yang lebih baik.
1.2RUMUSAN MASALAH
Bagaimana membuat aplikasi yang dapat membantu pemerintah desa
I (Keluarga Sejahtera I), KS II, dan KS III serta pengelompokkan ke dalam kelompok
penduduk Mampu dan Tidak Mampu dengan menerapkan Fuzzy C-Means ?
1.3 BATASAN MASALAH
Sesuai dengan rumusan masalah diatas, maka batasan yang diberlakukan
dalam tugas akhir ini adalah :
1. Data diambil dari desa Wiladeg, kecamatan Karangmojo,Gunungkidul
2. Program menggunakan Java TM dengan IDE NetBeans 5 dan MySQL 5 sebagai
database.
1.4 TUJUAN PENELITIAN
Tujuan dari tugas akhir ini adalah membuat sistem aplikasi Pengelompokkan
Penduduk Berdasar Kemampuan Ekonomi untuk Daerah Miskin dengan Fuzzy
C-Means yang diharapkan dapat memberikan informasi penggelompokkan penduduk
yang akurat dapat membantu pemerintah untuk mengelompokkan penduduk, sesuai
dengan kemampuan ekonomi.
1.5 METODOLOGI PENELITIAN
Metode yang digunakan dalam penyusunan tugas akhir ini adalah
1. Tinjauan pustaka
Mempelajari bahan-bahan tertulis seperti buku cetak, makalah, tutorial yang ada
2. Wawancara
Melakukan studi dengan metode wawancara kepada dosen, perangkat desa
ataupun pihak-pihak yang berhubungan dengan permasalahan yang dibahas dalam
tugas akhir ini.
3. Pengumpulan data
Mengumpulkan data-data yang berkaitan dengan sistem yang sedang dikerjakan.
4. Perancangan Model Fuzzy C-Means dan Perancangan Program
Perancangan model Fuzzy C-Means dan perancangan sistem, meliputi
perancangan umum sistem, perancangan basisdata, dan perancangan antarmuka.
5. Implementasi
Menterjemahkan hasil rancangan model Fuzzy C-Means dan rancangan program
menggunakan bahasa pemrograman.
6. Penulisan tugas akhir
Pembuatan laporan sampai dengan pembuatan kesimpulan dari implementasi
sistem yang telah dilakukan.
1.6 SISTEMATIKA PEMBAHASAN
Penulisan tugas akhir ini tersusun dari 5 (lima) bab dengan sistematika
penulisan sebagai berikut :
BAB I PENDAHULUAN
Bab Pendahuluan berisi latar belakang masalah, rumusan masalah, tujuan
BAB II LANDASAN TEORI
Bab ini menjelaskan tentang landasan teori yang akan menjadi dasar
dibuatnya sistem aplikasi Pengelompokkan Penduduk Berdasar Kemampuan
Ekonomi untuk Daerah Miskin dengan Fuzzy C-Means.
BAB III ANALISIS DAN PERANCANGAN SISTEM
Bab ini berisi tentang perancangan sistem, meliputi perancangan umum
sistem, perancangan Fuzzy C-Means 2 cluster dan Fuzzy C-Means 4 cluster,
perancangan basisdata dan perancangan antarmuka.
BAB IV IMPLEMENTASI SISTEM DAN HASIL
Bab ini berisi implementasi program (coding) dari sistem yang akan dibuat,
pembahasan penerapan algoritma Fuzzy C-Means, implemantasi antarmuka dan hasil
implementasi.
BAB V PENUTUP
Bab ini berisi kesimpulan dari sistem yang telah dibuat, serta saran untuk
BAB II
LANDASAN TEORI
2.1 PENGANTAR LOGIKA FUZZY
Orang yang belum pernah mengenal logika fuzzy pasti akan mengira bahwa
logika fuzzy adalah sesuatu yang amat rumit dan tidak menyenangkan. Namun, sekali
seseorang mulai mengenalnya, ia pasti akan sangat tertarik dan akan menjadi
pendatang baru untuk ikut serta mempelajari logika fuzzy. Logika fuzzy dikatakan
sebagai logika baru yang lama, sebab ilmu tentang logika fuzzy modern dan metode
baru ditemukan beberapa tahun lalu, padahal sebenarnya konsep tentang logika fuzzy
itu sendiri sudah ada sejak lama.
Logika fuzzy adalah suatu cara yang tepat untuk memetakan suatu ruang input ke
dalam suatu ruang output. Sebagai contoh :
1. Manajer pergudangan mengatakan pada manajer produksi seberapa banyak
persediaan barang pada akhir minggu ini, kemudian manajer produksi akan
memetakan jumlah barang yang harus diproduksi esok hari.
2. Pelayan restoran memberikan pelayanan terhadap tamu, kemudian tamu akan
memberikan tip yang sesuai atas baik tidaknya pelayan yang diberikan;
3. Anda mengatakan pada saya seberapa sejuk ruangan yang anda inginkan, saya
Salah satu contoh pemetaan suatu input-output dalam bentuk grafis seperti pada
Gambar 2.1.
Gambar 2.1.Black box
Antara input-output terdapat satu kotak hitam yang harus memetakan input ke output
yang sesuai.
2.2 KONSEP DASAR HIMPUNAN FUZZY
2.2.1 Himpunan Tegas (Crisp Set)
Secara intuitif kita memahami himpunan sebagai suatu kumpulan atau
koleksi obyek-obyek (konkret maupun abstrak) yang mempunyai kesamaan
sifat tertentu. Suatu himpunan haruslah terdefinisi secara tegas, dalam arti
bahwa untuk setiap obyek selalu dapat ditentukan secara tegas apakah obyek
tersebut merupakan anggota himpunan itu atau tidak. Dengan perkataan lain,
untuk setiap himpunan terdapat batas yang tegas antara obyek-obyek yang
himpunan itu. Oleh karenanya, himpunan semacam itu seringkali juga disebut
himpunan tegas (crisp set).
Ada beberapa cara untuk menyatakan suatu himpunan, yaitu:
1. Cara daftar, yaitu menyatakan suatu himpunan dengan menuliskan satu
per satu lambang anggota-anggotanya diantara tanda kurung kurawal.
Cara ini biasanya dipakai untuk himpunan-himpunan yang diskret.
Sebagai contoh, himpunan A yang beranggotakan a1, a2, a3, …, an dapat
dituliskan sebagai:
A = {a1, a2, a3, …, an}
2. Notasi pembentuk himpunan
Himpunan terdiri atas semua nilai x yang memenuhi P (x). Adapun
penulisannya adalah sebagai berikut:
A = { x | P(x) }
3. Fungsi keanggotaan (membership function)
Fungsi keanggotaan dari suatu himpunan A dalam U = Universal of
Discourse yang dinotasikan sebagai:
=
] [x A
µ
1, jika x ε A
Maksudnya, yaitu:
• satu (1), berarti bahwa suatu item menjadi anggota dalam suatu
himpunan.
• nol (0), berarti bahwa suatu item tidak menjadi anggota dalam suatu
himpunan.
Contoh :
Jika diketahui : S={1,3,5,7,9} adalah semesta pembicaraan; A={1,2,3}
dan B={3,4,5}, maka dapat dikatakan bahwa:
• Nilai keanggotaan 1 pada himpunan A, µA(1)=1, karena 1∈ A.
• Nilai keanggotaan 3 pada himpunan A, µA(3)=1, karena 3 ∈A.
• Nilai keanggotaan 2 pada himpunan A, µA(2)=0, karena 2∈A.
• Nilai keanggotaan 4 pada himpunan B, µB(2)=0, karena 4∈B.
2.2.2 Himpunan Fuzzy (Fuzzy Set)
Kalau pada himpunan crisp nilai keanggotaan hanya ada 2
kemungkinan, yaitu 0 dan 1; pada himpunan fuzzy nilai keanggotaan terletak
pada rentang 0 sampai 1. Apabila x memiliki nilai keanggotaan fuzzy
0 ] [x =
A
µ berarti x tidak menjadi anggota himpunan A, demikian pula
apabila x memiliki nilai keanggotaan fuzzy µA [x]=1 berarti x menjadi
anggota penuh pada himpunan A.
a. Linguistik, yaitu penamaan suatu grup yang mewakili suatu keadan atau
kondisi tertentu dengan menggunakan bahasa alami, seperti: MUDA,
PAROBAYA, dan TUA.
b. Numeris, yaitu suatu nilai (angka) yang menunjukkan ukuran dari suatu
variabel, seperti: 40, 25, dan 50.
Ada beberapa hal yang perlu diketahui dalam memahami sistem fuzzy,
yaitu:
a. Variabel fuzzy
Variabel fuzzy merupakan variabel yang hendak dibahas dalam suatu
sistem fuzzy. Contoh: umur, temperatur, dan permintaan.
b. Himpunan fuzzy
Himpunan fuzzy merupakan suatu grup yang mewakili suatu kondisi atau
keadaan tertentu dalam suatu variabel fuzzy.
Contoh:
• Variabel umur, terbagi menjadi 3 himpunan fuzzy, yaitu MUDA,
PAROBAYA, dan TUA.
• Variabel temperatur, terbagi menjadi 5 himpunan fuzzy, yaitu:
DINGIN, SEJUK, NORMAL, HANGAT, dan PANAS.
c. Semesta pembicaraan
Semesta pembicaraan adalah keseluruhan nilai yang diperbolehkan untuk
merupakan himpunan bilangan real yang senantiasa naik (bertambah)
secara monoton dari kiri ke kanan. Nilai semesta pembicaraan dapat
berupa bilangan positif maupun negatif. Adakalanya nilai semesta
pembicaraan ini tidak dibatasi nilai atasnya.
Contoh:
• Semesta pembicaraan untuk variabel umur: [0 +∞]
• Semesta pembicaraan untuk variabel temperatur: [0, 40]
d. Domain
Domain himpunan fuzzy adalah keseluruhan nilai yang diijinkan dalam
semesta pembicaraan dan boleh dioperasikan dalam suatu himpunan
fuzzy. Seperti halnya semesta pembicaraan, domain merupakan himpunan
bilangan real yang senantiasa naik (bertambah) secara monoton dari kiri
ke kanan. Nilai domain dapat berupa bilangan positif maupun negatif.
Contoh domain himpunan fuzzy:
• MUDA = [0, 45]
• PAROBAYA = [35, 55]
• TUA = [45, +∞]
2.3 FUZZY CLUSTERING
Untuk mengelompokkan para pengambil keputusan menjadi
kelompok-kelompok kecil, berdasarkan persamaan karakteristik, dibutuhkan suatu mekanisme
dilakukan sedemikian rupa sehingga setiap objek berada tepat pada satu partisi.
Namun, adakalanya kita tidak dapat menempatkan suatu objek tepat pada suatu
partisi, karena sebenarnya obyek tersebut terletak diantara 2 atau lebih partisi yang
lain. Pada logika fuzzy, ada beberapa metode yang dapat digunakan untuk melakukan
pengelompokkan sejumlah data yang sering dikenal dengan nama fuzzy custering.
Pada kebanyakan situasi, fuzzy clustering, lebih alami jika dibandingkan dengan
pengclusteran secara klasik. Suatu algoritma clustering dikatakan sebagai algoritma
fuzzy clustering jika dan hanya jika algoritma tersebut menggunakan parameter
strategi adaptasi secara soft competitive (non-crisp) (Baraldi, 1998). Sebagian besar
algoritma fuzzy clustering didasarkan atas optimasi fungsi obyektif atas modifikasi
dari fungsi obyektif tersebut.
Pemulihan algoritma clustering yang tepat, sangatlah penting demi suksesnya
proses clustering. Secara umum, algoritma pengclusteran dicirikan berdasarkan
ukuran kedekatan dan kriteria pengclusteran (Vazirgiannis, 2003). Ukuran kedekatan
menunjukkan seberapa dekat kedekatan fitur antara 2 data; sedangkan criteria
pengclusteran biasanya diekspresikan dengan menggunakan fungsi atau biaya tipe
aturan yang lainnya.
2.3.1 Partisi Klasik (hard partition)
Konsep partisi menjadi bagian yang sangat penting bagi proses
pengclusteran. Tujuan proses pengclusteran pada partisi klasik adalah
asumsi bahwa c diketahui (Babuska, 2005). Dengan menggunakan teori
himpunan klasik, partisi klasik X dapat didefinisikan sebaga suatu keluarga
dari himpunan bagian-himpunan bagian (Ai | 1 ≤ i ≤ c}⊂ P(X), P(X) adalah
power set dari X, dengan property sebagai berikut (Bezdek, 1981):
c
i
i X A 1
=
= (2.1)
; φ
=
∩A
Ai 1 ≤ i≠j ≤ c (2.2)
;
X Ai ⊂ ⊂
φ 1 ≤ i ≤ c (2.3)
Persamaan 2.1 menunjukkan bahwa union dari himpunan bagian Ai
berisi semua data. Himpunan bagian-himpunan bagian harus bersifat disjoin
(Persamaan 2.2), dan tidak boleh ada yang berupa himpuna kosong
(Persamaan 2.3). Dalam bentuk fungsi keanggotaan, suatu partisi dapat
direpresentasikan sebagai matriks partisi U = [µik]cxn. Baris ke-i pada matriks
tersebut berisi nilai keangotaan µI pada himpunan bagian Ai. Bersadarkan
persamaan 2.1, maka elemen-elemen pada matriks U harus memenuhi kondisi
sebagai berikut :
{ }
0,1;∈
ik
µ 1 ≤ i ≤ c; 1 ≤ k ≤ n (2.4)
=
=
c
i ik 1
1
µ ; 1 ≤ k ≤ n (2.5)
0 < =
c
i ik 1
Semua kemungkinan partisi dari matriks X disebut dengan hard
partitioning space (Bezdek, 1981), yang didefinisikan sebagai:
∀ < < ∀ = ∀ ∈ ℜ ∈ = = = , 0 ; , 1 , }, 1 , 0 { | 1 1 n k k i U M c i ik c i ik ik cxn
hc µ µ µ (2.7)
2.3.2 Partisi fuzzy (fuzzy partition)
Jika pada matriks, suatu data secara eksekusif menjadi anggota hanya
pada satu cluster saja, tidak demikia halnya dengan partisi fuzzy. Pada partisi
fuzzy, nilai keanggotaan suatu data pada suatu cluster, µik, terletak pada
interval [0,1]. Matriks partisi pada partisi fuzzy memenuhi kondisi sebagai
berikut (Ruspini, 1970):
]; 1 , 0 [ ∈ ik
µ 1 i c; 1 k n (2.8)
= = c i ik 1 1
µ ; 1 k n (2.9)
0 < = c k ik 1
µ < n; 1 i c (2.10)
Baris ke-I pada matriks partisi U berisi nilai keanggotaan data pada himpunan
bagian fuzzy Ai. Jumlah derajat keanggotaan setiap data pada semua cluster
(jumlah setiap kolom) bernilai 1 (persamaan 2.9).
Semua kemungkinan partisi dari matriks X disebut dengan fuzzy partitioning
space, yang didefinisikan sebagai :
∀ < < ∀ = ∀ ∈ ℜ ∈ = = = c i ik c i ik ik cxn
fc U i k k n i
M 1 1 , 0 ; , 1 ; , ), 1 , 0 (
2.3.3 Partisi probabilistic (probabilistic partition)
Tidak seperti halnya kedua partisi di atas, pada partisi probabilistic
jumlah nilai keanggotaan suatu data pada semua cluster tidak harus 1, namun
untuk menjamin suatu data menjadi anggota dari (paling tidak) satu cluster,
maka diharuskan ada nilai keanggotaan yang bernilai lebih dari 0.
Matriks partisi pada partisi fuzzy memenuhi kondisi sebagai berikut
(Krishnapuram, 1993): ]; 1 , 0 [ ∈ ik
µ 1 i c; 1 k n (2.12)
0 , >
∃i µik ; ∀k (2.13)
0 < = c k ik 1
µ < n; 1 i c (2.14)
Semua kemungkinan partisi dari matriks X disebut dengan possibilistic
partitioning space, yang didefinisikan sebagai :
∀ < < ∀ = ∀ ∈ ℜ ∈ = = = c i ik c i ik ik cxn
pc U i k k n i
M 1 1 , 0 ; , 1 ; , ), 1 , 0 (
|µ µ µ (2.15)
2.4 UKURAN FUZZY
Ukuran fuzzy menunjukkan derajat kekaburan dari himpunan fuzzy. Secara
umum ukuran kekaburan dapat ditulis sebagai suatu fungsi (Yan, 1994):
F:P(X) R (2.16)
dengan P(X) adalah himpunan semua subset dari X; f(A) adalah suatu fungsi yang
Dalam mengukur nilai kekaburan, fungsi f harus mengikuti hal-hal sebagai berikut
(Yan, 1994):
1. f(A) = 0 jika dan hanya jika A adalah himpunan crisp.
2. jika A < B, maka f(A) f(B). disini, A < B berarti B lebih kabur dibanding A
(atau A lebih tajam dibanding B). relasi ketajaman A<B didefinisikan dengan:
µA(x) µB(x), jika µB(x) 0,5 dan (2.17)
µA(x) µB(x), jika µB(x) 0,5 (2.18)
3. f(A) akan mencapai maksimum jika dan hanya jika A benar-benar kabur
secara maksimum. Tergantung pada interpretasi derajat kekaburan, nilai fuzzy
maksimal biasanya terjadi pada saat µA[x] = 0,5 untuk setiap x.
2.5 FUZZY C-MEANS (FCM)
Fuzzy C-Means (FCM) adalah suatu teknik pengclusteran data yang mana
keberadaan tiap-tiap data dalam suatu cluster ditentukan oleh nilai keanggotaan.
Teknik ini pertama kali dikenalkan oleh Jim Bezdek pada tahun 1981. konsep dasar
FCM, pertama kali adalah menentukan pusat cluster yang akan menandai lokasi
rata-rata untuk tiap-tiap cluster. Pada kondisi awal, pusat cluster ini masih belum akurat.
Tiap-tiap data memiliki derajat keanggotaan untuk tiap-tiap cluster. Dengan cara
memperbaiki pusat cluster dan nilai keanggotaan dan nilai keanggotaan tiap-tiap data
lokasi yang tepat. Perulangan ini berdasarkan pada minimisasi fungsi obyektif
(Gelley, 2000).
2.5.1 Algortima FCM
Algoritma Fuzzy C-Means (FCM) adalah sebagai berikut :
START
Baca: Data C MaxIter e Po t
Hitung: i = ukuran banyaknya data j = ukuran banyaknya variabel k = c
µik
Hitung Vkj
Hitung µik
Hitung Pt
| Pt – Pt-1 |
Atau t> MaxIter
Output Pt
µik
Vkj
Hitung t = t + 1
1. Input data yang akan dicluster X, berupa matriks berukuran n x m (n=
jumlah sampel data, m= atribut setiap data). Xij = data sampel ke-i (i=1,2,.
. . .,n), atribut ke-j (j=1,2,. . . .,m).
2. Tentukan :
• Jumlah cluster = c;
• Pangkat = w;
• Maksimum iterasi = MaxIter;
• Error terkecil yang diharapkan = ξ
• Fungsi obyektif awal = P0 = 0;
• Iterasi awal = t=1;
3. Bangkitkan bilangan random µik , i=1,2,. . . . ,n; k=1,2,. . . . ,c; sebagai
elemen-elemen matriks partisi awal U.
Hitung:
=
= c
k ik ik ik
d d
1
µ
ik
d = bilangan random.
dengan j=1,2,. . . .,m dan c=jumlah cluster yang akan dibentuk.
4. Hitung pusat cluster ke-k: Vkj, dengan k=1,2,. . . .,c; dan j=1,2,. . . . ,m.
( )
(
)
( )
= =
= n
i
w ik n
i
ij w ik kj
X V
1 1
*
5. Hitung fungsi obyektif pada iterasi ke-t, Pt;
(
)
( )
= = =−
=
n i c k w ik m j kj ijt
X
V
P
1 1 1
2
µ
6. Hitung perubahan matriks partisi :
(
)
(
)
= − − = − − − − = c k w m j kj ij w kj ij ik V X V X 1 1 1 1 2 1 1 2 µ7. Cek kondisi berhenti :
• Jika : ( |Pt – Pt-1| < ξ) atau (t>MaxIter) maka berhenti;
• Jika tidak: t=t+1 , ulangi langkah ke-4
2.5.2 Contoh Penggunaan Fuzzy Clustering
Misalnya terdapat contoh data X1, X2,..., X6 yang memiliki dua
variabel f1 dan f2 sebagai berikut :
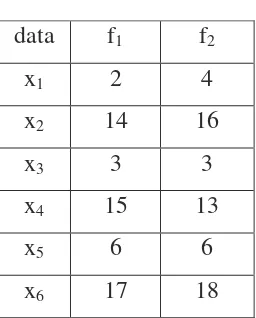
Tabel 2.1. (Tabel data Xij)
data f1 f2
x1 2 4
x2 14 16
x3 3 3
x4 15 13
x5 6 6
Data tersebut akan dibagi ke dalam dua kelompok, maka ditentukan:
• Jumlah cluster = 2;
• Pangkat = 2;
• Maksimum iterasi = MaxIter =100
• Error terkecil yang diharapkan = ξ= 0,001
• Fungsi obyektif awal = P0 = 0;
• Iterasi awal = t = 1;
Pada contoh kasus ini, pusat cluster (Vkj) awal telah ditentukan yaitu
5,5 dan 15,15; sehingga dicari matrik partisi yang baru dengan langkah
sebagai berikut:
(
)
(
)
= − − = − − = − − = c k w m j kj ij w m j kj ij ik V X V X 1 1 1 1 2 1 1 1 2µ dengan i = 1,2 dan k=1,2
Tabel 2.2 dan tabel 2.3 di bawah ini memperlihatkan proses pengurangan data
(Xij) dengan pusat cluster (Vkj). Kemudian pada tabel 2.4, hasil pengurangan
data pada tabel 2.2 dan tabel 2.3 akan dipangkatkan (-1) dan dijumlahkan.
Tabel 2.2 (Tabel perhitungan data Xij dengan pusat cluster 5,5)
(Xj1-V11) (Xj2-V12) (Xj1-V11 )2 (Xj2-V12)2
−
=
2 2
1
1) (
j
j ij V
X
-3 -1 9 1 10
9 11 81 121 202
-2 -2 4 4 8
10 8 100 64 164
1 1 1 1 2
12 13 144 169 313
Tabel 2.3(Tabel perhitungan data Xij dengan pusat cluster 15 , 15)
(Xj1-V21) (Xj2-V22) (Xj1-V21 )2 (Xj2-V22)2
(
−)
=
2 2
1 2 j
j ij V
X
-13 -11 169 121 290
-1 1 1 1 2
-12 -12 144 144 288
0 -2 0 4 4
-9 -9 81 81 162
Tabel 2.4.(Tabel perhitungan matrik partisi baru)
L1=
1 2 2
1
1) (
−
=
−
j
j ij V
X L2=
(
)
1 2 2
1 2
−
=
−
j
j ij V
X
Ltotal=L1+L2
0,1 0,003448 0,103448
0,0049505 0,5 0,50495
0,125 0,003472 0,128472
0,00609756 0,25 0,256098
0,5 0,006173 0,506173
0,00319489 0,076923 0,080118
Tabel 2.5. (Tabel Matrik Partisi Baru)
µ baru = L / Ltotal
1
µ µ2
0,966666667 0,033333
0,009803922 0,990196
0,972972973 0,027027
0,023809524 0,97619
0,987804878 0,012195
0,039877301 0,960123
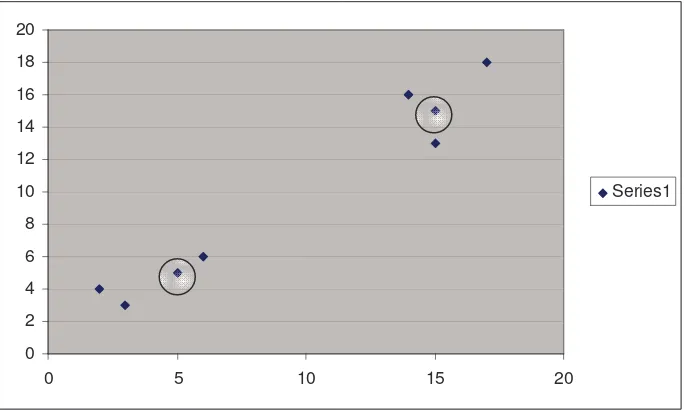
Setiap data akan memiliki kecenderungan terhadap suatu pusat cluster
tertentu. Derajat keanggotaan terbesar menunjukkan kecenderungan tertinggi
suatu data untuk masuk menjadi anggota suatu kelompok/cluster. Pada
terlihat pada tabel 2.5 diatas dapat direpresentasikan pada Gambar
kecenderungan data dengan pusat cluster di bawah ini:
Gambar 2.3 (Grafik kecenderungan data dengan pusat cluster yang pertama )
0 2 4 6 8 10 12 14 16 18 20
0 5 10 15 20
Series1
Pada iterasi yang kedua dapat dihitung kembali pusat cluster Vkj , dengan
persamaan di bawah ini:
(
)
( )
= =
= 6
1 2 6
1
2
* ) (
i ik i
ij ik
kj
X V
µ µ
Tabel 2.6 berikut menunjukkan perhitungan perkalian data ( Xij ) dengan
(µij)2 yang akan digunakan dalam perhitungan pusat cluster (Vkj ) dibawah
Tabel 2.6 (Tabel perkalian data dengan (µik) 2
)
Pusat cluster :
(
)
( )
= = = 6 1 2 1 6 1 1 2 1 11 * ) ( i i i i i X V µ µ=10,60035/2,859133 = 3,707541
V12 = 12,46989 / 2,859133 = 4,361424
V21 = 43,69756461 / 2,85726201 = 15,29350982
V22 = 44,67670329 / 2,85726201 = 15,63619407
Berikut bentuk matrik pusat cluster:
7 15,6361940 2 15,2935098 4,361424 3,707541
Setelah di dapat pusat cluster (Vkj ), akan dicari Fungsi Objektif yang dapat
dihitung dengan persamaan:
Data (Xij) * (µi1)2 Data (Xij) * (µi2)2
(µi1)2 (µi2)2 X j1 X j2 X j1 X j2
0,934444 0,00111111 1,868889 3,737778 0,002222222 0,004444444
9,61E-05 0,98048827 0,001346 0,001538 13,72683583 15,68781238
0,946676 0,00073046 2,840029 2,840029 0,002191381 0,002191381
0,000567 0,95294785 0,008503 0,00737 14,29421769 12,388322
0,975758 0,00014872 5,854551 5,854551 0,000892326 0,000892326
0,00159 0,9218356 0,027033 0,028624 15,67120516 16,59304076
Fungsi objektif
(
)
( )
= = =−
=
6 1 2 1 2 2 1 2 i k ik j kj ijt
X
V
P
µ
Detil perhitungan fungsi objektif dapat dilihat pada tabel 2.7 berikut:
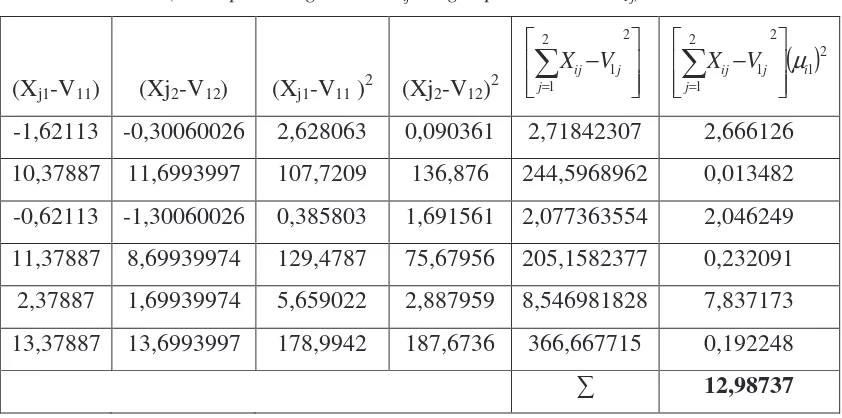
Tabel 2.7. (Tabel perhitungan data Xij dengan pusat cluster V1j)
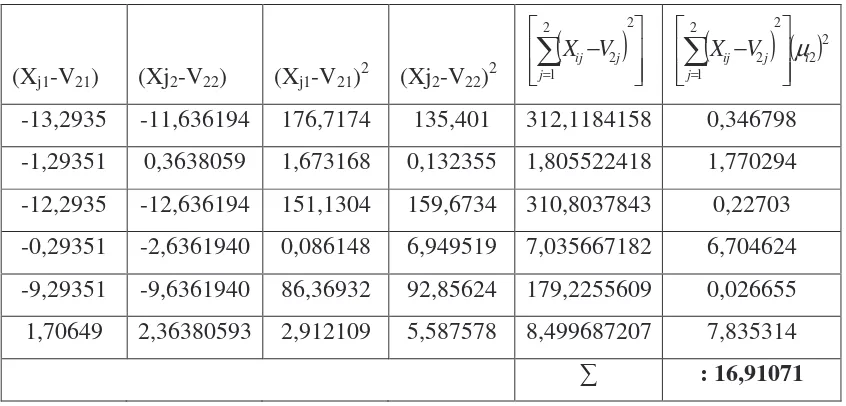
Tabel 2.8. (Tabel perhitungan data Xij dengan pusat cluster V2j)
(Xj1-V11) (Xj2-V12) (Xj1-V11 )2 (Xj2-V12)2
− = 2 2 1 1 j j ij V
X
( )
122 2 1 1 i j j ij V
X − µ
=
-1,70754 -0,36142388 2,915697 0,130627 3,046323831 2,84662
10,29246 11,6385761 105,9347 135,4565 241,3911643 0,023202
-0,70754 -1,36142388 0,500614 1,853475 2,354089393 2,228561
11,29246 8,63857612 127,5196 74,625 202,1446254 0,114594
2,292459 1,63857612 5,255368 2,684932 7,940299504 7,747815
13,29246 13,6385761 176,6895 186,0108 362,7002221 0,576766
13,53756
(Xj1-V21) (Xj2-V22) (Xj1-V21)2 (Xj2-V22)2
(
−)
= 2 2 1 2 j j ij VX
(
)
( )
222 2 1 2 i j j ij V
X − µ
=
-13,2935 -11,636194 176,7174 135,401 312,1184158 0,346798
-1,29351 0,3638059 1,673168 0,132355 1,805522418 1,770294
-12,2935 -12,636194 151,1304 159,6734 310,8037843 0,22703
-0,29351 -2,6361940 0,086148 6,949519 7,035667182 6,704624
-9,29351 -9,6361940 86,36932 92,85624 179,2255609 0,026655
1,70649 2,36380593 2,912109 5,587578 8,499687207 7,835314
Maka akan di hasilkan fungsi objektif sebagai berikut:
Fungsi objektif:
(
)
( )
= = =
−
=
6 1 2 1 2 2 1 2 i k ik j kj ijt
X
V
P
µ
= 30,44827Langkah selanjutnya dengan memperbaiki matrik partisi (derajat
keanggotaan). Tabel 2.9 berikut menunjukkan detil perhitungan fungsi
keanggotaan baru.
Tabel 2.9 (Tabel perhitungan fungsi keanggotaan baru)
µ baru = L / Ltotal
L1 = 1 2 2 1 1) ( − = − j j ij V X L2 =
(
)
1 2 2 1 2 − = − j j ij V XL total µ1 µ2
0,328265 0,003204 0,331468 0,990334186 0,003235183
0,004143 0,553856 0,557999 0,007424124 0,992575876
0,424793 0,003217 0,42801 0,992482739 0,003241834
0,004947 0,142133 0,14708 0,033634465 0,966365535
0,12594 0,00558 0,131519 0,957576133 0,042423867
0,002757 0,117651 0,120408 0,02289787 0,97710213
Matrik fungsi keanggotaan baru
Pada iterasi yang kedua ini dapat dilihat perubahan pusat cluster dari titik 5;5
dan 15;15 menjadi 3,707541; 4,361424 dan 15,29350982;15,63619407 akan
terlihat pada Grafik kecenderungan data dengan pusat cluster yang kedua di
bawah ini:
Gambar 2.4. (Grafik kecenderungan data dengan pusat cluster yang kedua)
0 2 4 6 8 10 12 14 16 18 20
0 5 10 15 20
Series1
Pada iterasi yang ketiga dapat dihitung kembali pusat cluster Vkj, sama seperti
pada iterasi sebelumnya. Detil perhitungan pusat cluster dapat dilihat dari
tabel 2.10 berikut menunjukkan perkalian data ( Xij ) dengan (µij)2 untuk
Tabel 2.10 (Tabel perkalian data Xijdengan (µik) 2
)
Pusat cluster baru :
(
)
( )
= = = n i i i i i X V 1 2 1 6 1 1 2 1 11 * ) ( µ µ=10,44496/2,884447 = 3,621130023
V12 = 12,40485/ 2,884447 = 4,300600265
V21 = 44,04206829/ 2,87561855 = 15,31568514
V22 = 45,09950684/ 2,87561855= 15,68341074
Berikut bentuk matrik pusat cluster
4 15,6834107 4 15,3156851 5 4,30060026 3 3,62113002
Di bawah grafik kecenderungan data terhadap pusat cluster. Pada grafik
dibawah ini, dapat dilihat pusat cluster yang bergeser posisinya dari titik Data (Xij) * (µi1)2 Data (Xij) * (µi2)2
(µ i1)2 (µi2)2 X j1 (µi1)2 (µi2)2 X j1
0,980762 1,0466E-05 1,961524 3,923047 2,09328E-05 4,18656E-05
5,51E-05 0,98520687 0,000772 0,000882 13,79289617 15,76330991
0,985022 1,0509E-05 2,955066 2,955066 3,15285E-05 3,15285E-05
0,001131 0,93386235 0,016969 0,014707 14,00793521 12,14021052
0,916952 0,00179978 5,501712 5,501712 0,010798707 0,010798707
0,000524 0,95472857 0,008913 0,009438 16,23038574 17,18511431
3,707541; 4,361424 dan 15,29350982;15,63619407 menjadi 3,621130023;
4,300600265 dan 15,31568514; 15,68341074
Gambar 2.5.(Grafik kecenderungan data dengan pusat cluster yang ketiga)
0 2 4 6 8 10 12 14 16 18 20
0 5 10 15 20
Series1
Pada iterasi ke tiga ini dihitung fungsi objektif. Tabel 2.11 dan tabel 2.12
berikut ini merupakan detil perhitungan data Xij dengan pusat cluster Vkj
Tabel 2.11 (Tabel perhitungan data Xij dengan pusat cluster V1j)
(Xj1-V11) (Xj2-V12) (Xj1-V11 )2 (Xj2-V12)2
−
=
2 2
1 1 j
j ij V
X
( )
122 2
1
1 i
j
j ij V
X − µ
=
-1,62113 -0,30060026 2,628063 0,090361 2,71842307 2,666126
10,37887 11,6993997 107,7209 136,876 244,5968962 0,013482
-0,62113 -1,30060026 0,385803 1,691561 2,077363554 2,046249
11,37887 8,69939974 129,4787 75,67956 205,1582377 0,232091
2,37887 1,69939974 5,659022 2,887959 8,546981828 7,837173
13,37887 13,6993997 178,9942 187,6736 366,667715 0,192248
Tabel 2.12 (Tabel perhitungan data Xij dengan pusat cluster V1j )
Maka dihasilkan fungsi objektif sebagai berikut:
Fungsi objektif:
(
)
( )
= = =
−
=
6
1 2
1
2 2
1
2
i k
ik j
kj ij
t
X
V
P
µ
= 29,7727Langkah berikutnya dengan memperbaiki matrik partisi, berikut tabel detil
perhitungannya:
(Xj1-V21) (Xj2-V22) (Xj1-V21)2 (Xj2-V22)2
(
−)
=
2 2
1 2 j
j ij V
X
(
)
( )
222 2
1
2 i
j
j ij V
X − µ
=
-13,3157 -11,6834107 177,3075 136,5021 313,8095571 0,003284
-1,31569 0,31658926 1,731027 0,100229 1,831256145 1,804166
-12,3157 -12,6834107 151,6761 160,8689 312,5450083 0,003285
-0,31569 -2,68341074 0,099657 7,200693 7,300350281 6,817522
-9,31569 -9,68341074 86,78199 93,76844 180,5504331 0,324952
1,684315 2,31658926 2,836917 5,366586 8,203502375 7,832118
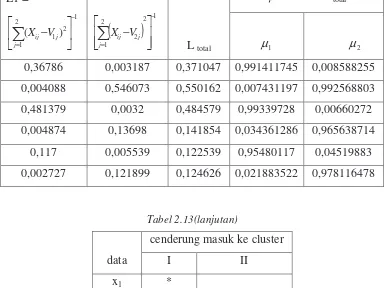
Tabel 2.13 (Tabel fungsi keanggotaan baru)
µ baru = L / Ltotal
L1 =
1 2 2
1
1 ) (
−
=
−
j
j ij V
X
L2 =
(
)
1 2 2
1 2
−
=
−
j
j ij V
X
L total µ1 µ2
0,36786 0,003187 0,371047 0,991411745 0,008588255
0,004088 0,546073 0,550162 0,007431197 0,992568803
0,481379 0,0032 0,484579 0,99339728 0,00660272
0,004874 0,13698 0,141854 0,034361286 0,965638714
0,117 0,005539 0,122539 0,95480117 0,04519883
0,002727 0,121899 0,124626 0,021883522 0,978116478
Tabel 2.13(lanjutan)
Langkah terakhir adalah cek kondisi sebagai berikut.
Cek kondisi berhenti: P2 – P1= 30,44827-29,7727= 0,675577
Iterasi akan dihentikan jika telah memenuhi syarat berhenti yaitu:
Jika : ( |Pt – Pt-1| < ξ) atau (t>MaxIter).
cenderung masuk ke cluster
data I II
x1 *
x2 *
x3 *
x4 *
x5 *
BAB III
PERANCANGAN SISTEM
3.1Gambaran Umum Sistem
Sistem ini digunakan untuk melakukan pengelompokkan penduduk
berdasarkan kemampuan ekonomi. Pengelompokkan dilakukan untuk memberikan
informasi mengenai anggota masing-masing cluster/kelompok. yang digunakan untuk
membantu melakukan koordinasi, pengendalian dan sebagai pendukung pengambilan
berbagai kebijakan bagi pemerintah dan masyarakat luas, terkait dalam pemberian
program bantuan atau subsidi kepada penduduk, serta pendataan maupun sensus
penduduk
Pada sistem ini akan terdapat 2 macam pengelompokkan, pertama
pengelompokkan penduduk menurut BKKBN. Penduduk dibagi menjadi empat
golongan, yaitu, PraKS (Pra Keluarga Sejahtera), KS I (Keluarga Sejahtera I), KS II,
dan KS III. Yang kedua adalah pengelompokkan menurut BPS (Badan Pusat
Statistika), disini penduduk dibagi ke dalam dua kelompok, yaitu, keluarga miskin
dan keluarga mampu.
Flowchart system pengelompokkan penduduk sebagai berikut:
1. Admin menginputkan data penduduk yang berupa: No KK, Nama Kepala
Keluarga, Tanggal Lahir, Jenis Kelamin, Alamat, Luas Lantai Bangunan
2. Admin menginputkan data penduduk yang berupa: No KK, Nama Kepala
Keluarga, Tanggal Lahir, Jenis Kelamin, Alamat, Luas Lantai Bangunan
Tempat Tinggal, Jumlah Penghasilan, Pendidikan Tertinggi, Rekening Listrik
3. Proses pengelompokkan/clustering.
4. Output berupa hasil clustering, yaitu kelompok-kelompok/cluster yang
terbentuk beserta dengan penduduk yang menjadi anggotanya.
Clustering, Penentuan nama
kelompok Input: data penduduk
start
Output: Hasil custering.
end
Gambar 3.1 Flowchart Sistem
3.2 Use Case Diagram
Skenario use case menjelaskan uraian kegiatan dalam setiap use case :
1. Pada sistem ini yang menjadi actor adalah administrator dan user. Admin akan
2. Admin memiliki kewenangan untuk melakukan proses update data penduduk,
yang meliputi proses input, edit dan delete data penduduk.
3. Admin dapat melakukan proses pencarian data penduduk.
4. Admin dapat melakukan proses clustering/pengelompokkan.
5. Admin juga dapat melakukan proses ganti password.
6. Semua yang dilakukan oleh admin bersifat depend on atau tergantung pada
proses login. Artinya, jika proses login tidak berhasil, maka admin tidak bisa
melakukan proses-proses di atas.
7. User dapat melakukan proses cari data penduduk.
8. User juga bisa melakukan proses clustering/pengelompokkan.
Ubah password
Update data penduduk
Proses pengelompokkan/ clustering
Cari data penduduk Login
admin
Depend on
Cari data penduduk
Proses pengelompokkan user
Gambar 3.3 Usecase Diagram User
3.3Perancangan Fuzzy C-Means dan Penamaan Cluster
3.3.1 Perancangan Fuzzy C-Mens 4 Cluster
Perancangan untuk pengelompokkan penduduk ke dalam empat
cluster, atau pengelompokkan menurut BKKBN adalah sebagai berikut:
1. Input data:
Input data yang akan dicluster Xij, adalah data penduduk yang berupa
matrik berukuran n x 3 (n= jumlah data yang akan diclusterkan dan 3
adalah jumlah kriteria data yang digunakan). Pada program ini,
variabel/kriteria data pengelompokkan sebagai berikut:
X i1 = jumlah penghasilan.
X i2 = luas bangunan tempat tinggal (dalam m2).
X i3 = rekening listrik
Untuk mempermudah dalam perhitungan, data jumlah penghasilan dibagi
dengan 150000, data luas bangunan dibagi dengan 90 dan untuk data
rekening listrik dibagi dengan 20000. Hal ini untuk menyamakan nilai
2. Ditentukan:
o Jumlah cluster = c = 4
Pengelompokkan sebagai berikut:
• Pra KS (Keluarga Sejahtera)
• KS I
• KS II
• KS III
o Pangkat = w = 2
o Maksimum iterasi = MaxIter = 100
o Error terkecil yang diharapkan = ξ= 0,00001
o Fungsi obyektif awal = P0 = 0;
o Iterasi awal = t =1
3. Membangkitkan bilangan random
Membangkitkan bilangan random berupa matrik µik, i = 1, 2, …n; k = 1,
2, 3, 4; sebagai elemen-elemen matrik partisi U, dimana n = jumlah data
penduduk dan k adalah jumlah kolom yang disesuaikan dengan jumlah
cluster yang akan dibentuk yaitu 4.
Hitung:
=
= c
k ik ik ik
d d
1
µ
ik
d = bilangan random
Matrik partisi yang dihasilkan akan berukuran n x 4, n = jumlah data dan 4
adalah jumlah cluster yang akan dibentuk. Matrik partisi jika dijumlahkan
tiap barisnya akan bernilai 1.
4. Menghitung pusat cluster
Menghitung pusat cluster ke-k: Vkj, dengan k=1,2,. . . .,4; dan j=1,2,3.
( )
(
)
( )
= = = n i ik n i ij ik kj X V 1 2 1 2 * µ µAkan terdapat 4 pusat cluster yang dihasilkan. Tiap pusat cluster memiliki
3 variabel data sesuai dengan variabel/kriteria pengelompokkan. Sehingga
matrik pusat cluster yang terbentuk akan berukuran 4 x 3.
Pusat cluster yang pertama adalah: V11, V12 dan V13, kemudian pusat
cluster yang kedua adalah V21, V22 dan V23, pusat cluster yang ketiga
adalah V31, V32 dan V33, sedangkan pusat cluster yang keempat yaitu V41,
V42, dan V43. Berikut adalah bentuk matrik pusat cluster-nya:
43 33 23 13 42 32 22 12 41 31 21 11 V V V V V V V V V V V V
Misalnya untuk menghitung pusat cluster V11 dan V23 detil
(
)
= = = n i i n i i i X V 1 2 1 1 1 2 1 11 ) ( * ) ( µ µ(
)
= = = n i i n i i i X V 1 2 2 1 3 2 2 23 ) ( * ) ( µ µ5. Menghitung fungsi objektif
Untuk menghitung fungsi objektif digunakan rumus sebagai berikut:
(
)
( )
= = =−
=
n i k ik j kj ijV
X
P
1 4 1 2 3 1 2 1µ
Misalnya untuk perhitungan data Xij dengan pusat cluster Vkj.
penjabaranya sebagai berikut:
=
n
i1
((Xj1-V11)2+(Xj2-V12)2+(Xj3-V13)2) * (µi1)2
=
n
i1
((Xj1-V21)2+(Xj2-V22)2+(Xj3-V23)2) * (µi2)2
=
n
i 1
((Xj1-V31)2+(Xj2-V32)2+(Xj3-V33)2) * (µi3)2
=
n
i 1
((Xj1-V41)2+(Xj2-V42)2+(Xj3-V43)2) * (µi4)2
+
(
)
( )
= = =−
=
n i k ik j kj ijV
X
P
1 4 1 2 3 1 2 1µ
6. Menghitung perubahan matrik partisi
Misalnya untuk menghitung perubahan matrik partisi µi1, perumusannya sebagai berikut:
(
)
(
)
(
)
[
]
(
)
(
)
(
)
[
]
= − − − + − + − − + − + − = 4 1 1 2 3 13 2 2 12 2 1 11 1 2 13 13 2 12 12 2 11 11 11 k k kk X V X V
V X V X V X V X µ
7. Cek kondisi berhenti
Untuk menghentikan iterasi dilakukan pengecekkan kondisi berhenti. Pada
program ini ditentukan:
• Jika : ( |Pt – Pt-1| < ξ) atau (t>MaxIter) maka berhenti;
• Jika tidak: t = t +1 , ulangi langkah ke-4
Sehingga iterasi akan dihentikan jika |Pt – Pt-1| < 0,00001 atau jumlah
iterasi telah lebih dari 100 kali.
8. Penamaan kelompok
Pada aplikasi untuk menentukan suatu kelompok/cluster itu apakah Pra
KS, KS I , KS II atau KS III menggunakan rumus besar vektor, yaitu
sebagai berikut: 2 3 2 2 2
1 a a
a
a= + + Dengan a1 = Vk1; a2 = Vk2; dan a3 = Vk3.
Akan terdapat 4 hasil perhitungan besar vektor, sesuai dengan jumlah
pusat cluster yang dihasilkan, yaitu 4. Nilai a yang terkecil berarti pusat
cluster tersebut memiliki besar vektor yang terkecil karena nilai pusat
cluster tersebut paling kecil dibanding pusat cluster yang lain, sehingga
karena itu cluster yang dihasilkan dinamakan Pra KS. Kemudian untuk
nilai a yang memiliki nilai terkecil yang kedua cluster tersebut bernama
KS I, sedangkan nilai a yang terkecil yang ketiga bernama KS II, dan nilai
a yang terbesar, cluter-nya bernama KS III.
3.3.1.1 Contoh Fuzzy C-Mens 4 Cluster
1. Input data penduduk yang diberikan untuk pegelompokkan sebagai
berikut:
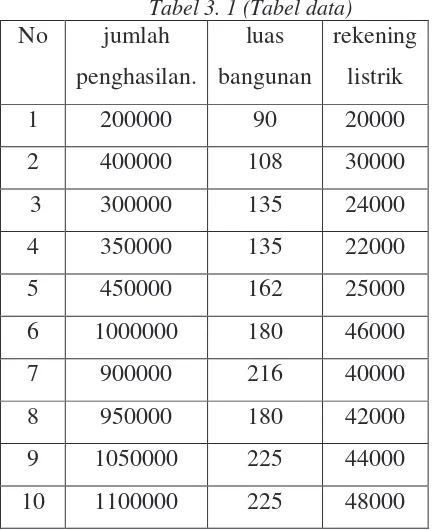
Tabel 3. 1 (Tabel data)
No jumlah
penghasilan.
luas
bangunan
rekening
listrik
1 200000 90 20000
2 400000 108 30000
3 300000 135 24000
4 350000 135 22000
5 450000 162 25000
6 1000000 180 46000
7 900000 216 40000
8 950000 180 42000
9 1050000 225 44000
Setelah dilakukan penyamaan nilai satuan skala, maka didapat tabel
data sebagai berikut:
Tabel 3.2 (Tabel data)
No Xj1 Xj2 Xj3
1 1 1 1
2 2 1.2 1.5
3 1.5 1.5 1.2
4 1.75 1.5 1.1
5 2.25 1.8 1.25
6 5 2 2.3
7 4.5 2.4 2
8 4.75 2 2.1
9 5.25 2.5 2.2
10 5.5 2.5 2.4
2. Menentukan matrik partisi awal, dengan membangkitkan bilangan
random. Berikut ini adalah bilangan random yang dihasilkan:
3. Perhitungan pusat cluster, mengunakan persamaan:
(
)
( )
= =
= 10
1 2 10
1
2
* ) (
i ik i
ij ik
kj
X V
µ µ
Untuk menghitung pusat cluster, pertama dihitung matrik random kuadrat
terlebih dahulu. Berikut tabel hasil perhitungan matrik random (µik)2
Tabel 3.3 (Tabel perhitungan matrik random (µik)2)
Matrik random kuadrat (µik)2 kemudian dikalikan dengan data (Xij),
tabel 3.4, tabel 3.5, tabel 3.6 dan tabel 3.7 menunjukkan detil perhitungan
tersebut.
(µi1)2 (µi2)2 (µi3)2 (µi3)2
0,36 0,01 0,04 0,01
0,09 0,01 0,0625 0,1225
0,49 0,04 0,0016 0,0036
0,04 0,0324 0,25 0,0144
0,25 0,16 0,0081 0,0001
0,0225 0,0625 0,04 0,16
0,01 0,0225 0,2025 0,09
0,4225 0,0025 0,01 0,04
0,01 0,0225 0,16 0,1225
0,0196 0,0676 0,0625 0,1225
Tabel 3.4 (Tabel perkalian data Xijdengan (µi1)
2
)
1 2 1) *
(µi Xi 2 2
1) *
(µi Xi 2 3
1) *
(µi Xi
0,36 0,36 0,36
0,18 0,108 0,135
0,735 0,735 0,588
0,07 0,06 0,044
0,5625 0,45 0,3125
0,1125 0,045 0,05175
0,045 0,024 0,02
2,006875 0,845 0,88725
0,0525 0,025 0,022
0,1078 0,049 0,04704
4,232175 2,701 2,46754
Tabel 3.5 (Tabel perkalian data Xijdengan (µi2)2)
1 2 2) *
(µi Xi 2
2 2) *
(µi Xi 3
2 2) *
(µi Xi
0,01 0,01 0,01
0,02 0,012 0,015
0,06 0,06 0,048
0,0567 0,0486 0,03564
0,36 0,288 0,2
0,3125 0,125 0,14375
0,10125 0,054 0,045
0,011875 0,005 0,00525
0,118125 0,05625 0,0495
0,3718 0,169 0,16224
Tabel 3.6 (Tabel perkalian data Xij dengan (µi3) 2
)
1 2 3) *
(µi Xi 2 2
3) *
(µi Xi 2 3
3) *
(µi Xi
0,04 0,04 0,04
0,125 0,075 0,09375
0,0024 0,0024 0,00192
0,4375 0,375 0,275
0,018225 0,01458 0,010125
0,2 0,08 0,092
0,91125 0,486 0,405
0,0475 0,02 0,021
0,84 0,4 0,352
0,34375 0,15625 0,15
2,965625 1,64923 1,440795
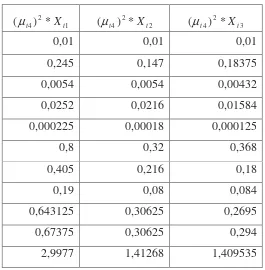
Tabel 3.7 (Tabel perkalian data Xijdengan (µi2))
1 2 4) *
(µi Xi 2 2
4) *
(µi Xi 2 3
4) *
(µi Xi
0,01 0,01 0,01
0,245 0,147 0,18375
0,0054 0,0054 0,00432
0,0252 0,0216 0,01584
0,000225 0,00018 0,000125
0,8 0,32 0,368
0,405 0,216 0,18
0,19 0,08 0,084
0,643125 0,30625 0,2695
0,67375 0,30625 0,294
Tabel 3.8 (Tabel pusat cluster)
4. Menghitung fungsi objektif, menggunakan persamaan:
(
)
( )
= = =
−
=
10
1 4
1
2 5
1
2 1
i k
ik j
kj
ij
V
X
P
µ
Berikut adalah detil pehitungan fungsi objektif untuk data Xij dan pusat
cluster V1j:
Tabel 3.9 (Tabel perhitungan data Xij dengan pusat cluster V1j)
(Xj1-V11) (Xj2-V12) (Xj3-V13)
-1,46832 -0,57529 -0,43913
-0,46832 -0,37529 0,060866
-0,96832 -0,07529 -0,23913
-0,71832 -0,07529 -0,33913
-0,21832 0,224705 -0,18913
2,531684 0,424705 0,860866
2,031684 0,824705 0,560866
2,281684 0,424705 0,660866
2,781684 0,924705 0,760866
3,031684 0,924705 0,960866
1 i
V Vi2 Vi3
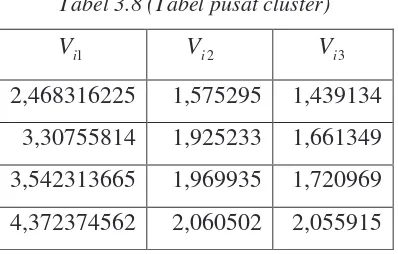
2,468316225 1,575295 1,439134
3,30755814 1,925233 1,661349
3,542313665 1,969935 1,720969
Tabel 3.10 (Tabel perhitungan
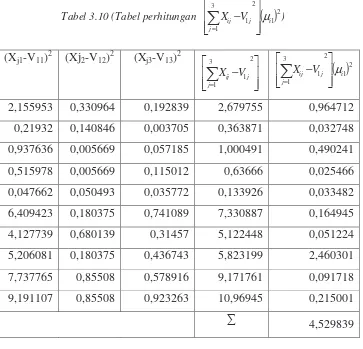
( )
12 2 3 1 1 i j j ij VX − µ
=
)
(Xj1-V11)2 (Xj2-V12)2 (Xj3-V13)2
− = 2 3 1 1 j j ij V
X
( )
122 3 1 1 i j j ij V
X − µ
=
2,155953 0,330964 0,192839 2,679755 0,964712
0,21932 0,140846 0,003705 0,363871 0,032748
0,937636 0,005669 0,057185 1,000491 0,490241
0,515978 0,005669 0,115012 0,63666 0,025466
0,047662 0,050493 0,035772 0,133926 0,033482
6,409423 0,180375 0,741089 7,330887 0,164945
4,127739 0,680139 0,31457 5,122448 0,051224
5,206081 0,180375 0,436743 5,823199 2,460301
7,737765 0,85508 0,578916 9,171761 0,091718
9,191107 0,85508 0,923263 10,96945 0,215001
4,529839
Perhitungan yang sama juga dilakukan untuk data Xij dengan pusat cluster
V2j , V3j dan V4j , sehingga akan dihasilkan fungsi objektif sebagai berikut:
(
)
( )
= = =−
=
10 1 4 1 2 3 1 2 1 i k ik j kj ijV
X
P
µ
= 9,9830604995. Memperbaiki matrik partisi atau derajat keanggotaan dengan persamaan:
Berikut detil perhitunganya:
Tabel 3.11 (Tabel perhitungan derajat fungsi keanggotaan yang baru)
L1=
1 2 2 1 1 − = − j j ij V X
L2=
1 2 2 1 2 − = − j j ij V X
L3=
1 2 2 1 3 − = − j j ij V X
L4=
1 2 2 1 4 − = − j j ij V
X LTOTAL=
L1+L2+L3+L4
0,373168382 0,151097 0,1262 0,073462 0,723927
2,748229118 0,442145 0,331086 0,149753 3,671213
0,999509357 0,273154 0,214441 0,107558 1,594663
1,570697891 0,34224 0,26186 0,123384 2,298183
7,466788906 0,767271 0,520626 0,191504 8,94619
0,136409143 0,30508 0,406334 2,187457 3,03528
0,195219154 0,567535 0,847474 7,425352 9,03558
0,171726921 0,438858 0,623801 6,747412 7,981798
0,109030314 0,227605 0,291832 1,01611 1,644576
Tabel 3.12 (Tabel matrik partisi baru y)
L1/LTOTAL
(µi1)
L2/LTOTAL
(µi2)
L3/LTOTAL
(µi3)
L4/LTOTAL
(µi4)
0,515478 0,208719 0,174327 0,101477
0,748589 0,120436 0,090184 0,040791
0,626784 0,171293 0,134474 0,067449
0,683452 0,148918 0,113942 0,053688
0,834633 0,085765 0,058195 0,021406
0,044941 0,100511 0,13387 0,720677
0,021606 0,062811 0,093793 0,82179
0,021515 0,054982 0,078153 0,84535
0,066297 0,138397 0,177451 0,617855
0,081584 0,157481 0,195631 0,565304
3.3.2 Perancangan Fuzzy C-Means 2 Cluster
Perumusan model matematis untuk pengelompokkan penduduk ke
dalam dua cluster, atau pengelompokkan menurut BPS adalah sebagai berikut:
1. Input data:
Input data yang diunakan sama dengan penelompokkan untuk 4 cluster.
Input data yang akan dicluster Xij, adalah data penduduk yang berupa
matrik berukuran n x 3 (n= jumlah data yang akan diclusterkan dan