Klasifikasi Naive Bayes Untuk Strategi Pemasaran
Mahasiswa Baru di Universitas Dian Nuswantoro
Naive Bayes Classification in marketing strategy of Dian
Nuswantoro University
Farahdiba Ramadhani1, Nova Rijati2
Fakultas Ilmu Komputer, Universitas Dian Nuswantoro Semarang e-mail: 1[email protected] , 2 [email protected]
Abstrak
Data Mining merupakan metode untuk menemukan suatu data dalam database
skala besar yang makin banyak terakumulasi sejalan dengan pertumbuhan teknologi
informasi. Data mining menggunakan pola yang mirip dengan teknik statistika dan
teknik matematika. Data mining diharapkan memberikan informasi yang berguna untuk
menghasilkan manfaat yang efektif dan efisien.
Pada data mining memiliki beberapa metode, salah satunya adalah Klasifikasi
Naive Bayes. Algoritma Naive Bayes ini dapat digunakan untuk memprediksi tingkat
probabilitas tertinggi pada suatu kota dengan program studi berdasarkan bukti yang
diberikan. Pengklasifikasi Naive Bayes adalah metode data mining yang dapat
digunakan untuk menunjang strategi pemasaran agar lebih efektif dan efisien.
Hasil dari penelitian ini adalah aplikasi dengan penerapan algoritma Naive
Bayes untuk membantu pemasaran marketing pada biro admisi Universitas Dian
Nuswantoro. Data yang digunakan adalah data mahasiswa aktif pada tahun
sebelumnya. Prediksi yang didapatkan, diharapkan dapat membantu untuk mendukung
strategi yang berdampak efektif dan efisien pemasaran.
Kata kunci—
data mining, klasifikasi, naive bayes
Abstract
Data mining is a method to find certain data in a big scale database widely
accumulated in line with information technology development. Data mining uses similar
pattern to statistical technique and mathematical one. Data mining is expected to
provide useful information to produce effective and efficient usefulness.
Data mining has some methods, one of which is Naive Bayes Classification.
Naive Bayes Algorithm can be employed to predict highest probability of a study
program of a certain city based on the evidences. Naive Bayes Classification is a data
mining method which can be used to support efficient and effective marketing strategy.
The result of the study is the application of Naive Bayes Algorithm in assisting
marketing division of Admission Bureau of Dian Nuswantoro University to market its
study program. Data used in this study is data of previous academic years active
students. The prediction resulted from the data is expected to help supporting efficient
and effective marketing strategy.
1. PENDAHULUAN
erguruan Tinggi merupakan salah satu penyelenggara pendidikan akademik, dalam perguruan tinggi ada lima jenis bentuk yakni universitas, institut, sekolah tinggi, akademi serta politeknik. Universitas merupakan salah satu lembaga perguruan tinggi yang terdiri dari sejumlah fakultas yang menyelenggarakan pendidikan ilmiah dan/atau profesional dalam sejumlah disiplin ilmu tertentu. Menurut data resmi Direktorat Jendral Republik Indonesia, saat ini sudah ada 100 Perguruan Tinggi Negeri di Indonesia, yang terdiri dari universitas, institut, sekolah tinggi, akademi, serta politeknik dan terdapat Perguruan Tinggi Swasta yang berjumlah 3.078 yang tersebar diseluruh Indonesia. Dengan jumlah Perguruan Tinggi Swasta yang begitu banyak, terjadi banyak persaingan untuk menarik para calon mahasiswa agar mendaftar pada Perguruan Tinggi Swasta. Persaingan tersebut sangat kuat dikarena apabila sebuah perguruan tinggi swasta tidak memiliki mahasiswa baru setiap tahunnya, maka universitas atau perguruan tinggi tersebut akan terancam tertutup dan tidak mendapatkan izin kembali sebagai perguruan tinggi swasta.
Universitas Dian Nuswantoro atau yang biasa disebut UDINUS merupakan salah satu perguruan tinggi swasta yang berlokasi di Semarang, Jawa Tengah. Menurut Buku Panduan Memilih Perguruan Tinggi 2010 Pusat Data dan Analisa Tempo, Universitas Dian Nuswantoro meraih peringkat tertinggi ke-3 untuk jurusan Teknik Komputer/ Teknologi Informasi Di Jawa Tengah, Udinus juga terpilih sebagai Perguruan Tinggi Swasta terbaik pertama pada tahun 2010. Pada tahun ajaran 2014/2015 Universitas Dian Nuswantoro memiliki data mahasiswa baru sebanyak 2.367 mahasiswa. Mahasiswa Universitas Dian Nuswantoro tidak hanya berasal dari Kota Semarang atau wilayah Jawa Tengah saja, mahasiswa Udinus juga berasal dari berbagai wilayah di Indonesia. Maka dengan adanya persaingan antara Perguruan Tinggi Swasta di Indonesia, maka Udinus membutuhkan strategi khusus pada pemasaran untuk mencari calon mahasiswa yang berkualitas dengan melakukan promosi yang dilakukan lebih efektif dan efisien. Promosi tersebut dilakukan dengan cara pemasaran untuk mencari calon mahasiswa yang memiliki kualitas baik dan agar pemasaran yang dilakukan lebih efektif dan effisien. Untuk dapat melakukan strategi pemasaran yang lebih efektif dan efisien, maka dalam perlu dilakukan pengolahan data-data yang telah didapatkan dari mahasiswa baru yang sudah menjalankan perkuliahan selama 2 semester atau lebih. Data tersebut Id, Asal Sekolah, Kota Asal, Progam Studi, Nilai Semester 1 dan Nilai Semester 2. Pada tahun-tahun berikutnya data tersebut bisa digunakan untuk bahan analisis dan evaluasi untuk mendukung strategi pemasaran pada Universitas Dian Nuswantoro.
Seiring dengan perkembangan teknologi hal tersebut dapat diatas dengan teknik pengelompokan data dengan data mining. Data mining adalah proses yang menggunakan statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar [1].
Klasifikasi memiliki pengertian secara umum yaitu kegiatan untuk mengelompokkan data yang mempunyai beberapa ciri yang sama dengan memisahkan data yang tidak sama.Klasifikasi ini dilakukan untuk mencari kota asal dan program studi yang mempunyai probabilitas tinggi sehingga dapat digunakan untuk strategi pemasaran. Konsep Klasifikasi Naive Bayes ditujukan untuk memprediksi probabilitas dimasa depan berdasarkan pengalaman dimasa sebelumnya.
Salah satu metode yang digunakan dalam data mining adalah Naive Bayes yang didasarkan dengan teori Keputusan Bayes. Naive Bayes mempunyai kemampuan klasifikasi seperti metode-metode klasifikasi yang lain (metode Decission Tree dan Neural Network). Metode Naive Bayes menetukan peluang kelas bersyarat dengan asumsi bahwa variabel bersifat bebas dengan mengasumsikan bahwa sebuah variabel tidak memiliki keterkaitan dengan variabel lainnya.Klasifikasi ini dilakukan dengan membandingkan nilai probabilitas
suatu objek yang berada pada satu kelas dengan nilai probabilitas suatu objek yang berada dikelas lainnya.
Hasil penelitian yang dilakukan oleh Burhan Alfironi Muktamar [2], Smart Marketing adalah aplikasi data mining menggunakan algoritma naive bayes classifier yang dapat memprediksi minat studi mahasiswa. Hasil dari uji coba 1000 data testingi yang diambil secara acak dari data induk mahasiswa tahun 2012 dengan data training yang diambil dari data induk mahasiswa tahun 2009 sampai 2011 menggunakan aplikasi Smart Marketing untuk prediksi minat studi didapatkan akurasi sebesar 92,7% dan error sebesar 7,3%.
Dengan latar belakang diatas, peneliti telah memaparkan secara singkat tentang kelebihan-kelebihan algoritma naive bayes classfier, maka penulis akan membuat sebuah aplikasi yang dapat menampilkan hasil dari data mining dengan algoritma naive bayes classfier untuk mendukung strategi pemasaran di bagian Admisi Universitas Dian Nuswantoro.
2. METODE PENELITIAN
Metode yang akan digunakan adalah klasifikasi menggunakan algoritma Naive Bayes. Dalam melakukan penelitian, penulis mengusulkan algoritma Naive Bayes untuk pencarian nilai probabilitas yang akan dilaksanakan sehingga proses yang berjalan dalam penelitian dapat sesuai dengan kehendak yang ingin dicapai yaitu :
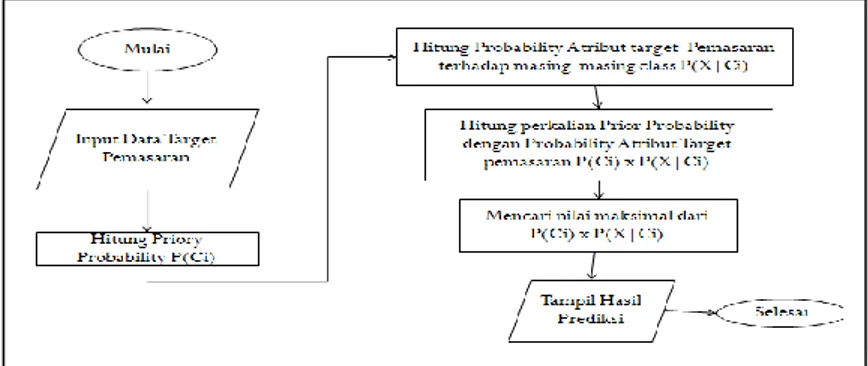
Gambar 1 Proses Klasifikasi Naove Bayes
Berikut adalah penjelasan mengenai proses klasifikasi Naive Bayes diatas :
1. Menginputkan data Target yang berupa data mahasiswa dengan variabel Id, Angkatan, Asal Sekolah, Provinisi, Kota, Fakultas, dan Program studi.
2. Menghitung nilai priorry probabilitas dari variabel provinsi dan kota.
3. Menghitung nilai probabilitas pada setiap atribut target pemasaran pada masing-masing kelas.
4. Menghitung perkalian prior probablity dengan probability artibut target pemasaran.
5. Mencari nilai maksimal pada nilai probabilitasnya. 𝑃(𝑌|𝑋1 … . 𝑋𝑛) = 𝑃(𝑌)𝑃(𝑋1,…,𝑋𝑛|𝑌)
𝑃(𝑋1,…,𝑋𝑛)
Keterangan :
P(Y|X1,...,Xn) Probabilitas data dengan vektor X pada kelas Y.
P(Y) Probabilitas awal kelas Y.
P(X1,...,Xn) Karakteristik dari klasifikasi.
Gambar 2 Metode Penyelesaian Masalah
Pada proses pembuatan aplikasi Admisi Marketing, penulis menggunakan metode-metode penyelesaian masalah sebagai berikut adalah pertama menganalisa masalah yang ada. Selanjutnya, pengambilan dan pengumpulan data yang dapat diambil dari studi pustaka, mengumpulkan data-data, wawancara dan pengunjungan situs yang sesuai dengan penelitian. Analisa Data adalah menganalisa data yang ada, data yang digunakan adalah data mahasiswa universitas dian nuswantoro angkatan 2013,2014,2015. Setalah menganalisa data, penulis melakukan perancangan sistem dan perancangan database. Setalah perancangan database selesai melakukan proses data mining klasifikasi menggunakan Algoritma Naive Bayes. Dari proses-proses tersebut akan menjadikan Aplikasi Admisi Marketing. Admisi Marketing adalah aplikasi data mining yang menggunakan algoritma naive bayes classifier yang dapat memprediksi setiap kota terhadap program-program studi yang ada pada Universitas Dian Nuswantoro Semarang. Admisi Marketing ini dapat mendukung strategi pemasaran khususnya di bagian Admisi Universitas Dian Nuswantoro.
3. HASIL DAN PEMBAHASAN
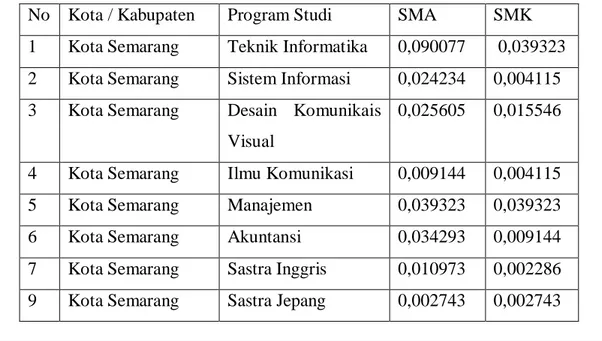
Hasil dari uji coba yang menggunakan data 2.200 dengan aplikasi Admisi Marketing untuk memprediksi probabilitas minat studi mahasiswa pada Kota Semarang sebagai sempel. Nilai-nilai probabilitas yang dilakukan dengan prediksi admisi marketing sebagai berikut :
Tabel 5.4 Nilai Probabilitasi Prediksi
No Kota / Kabupaten
Program Studi
SMA
SMK
1
Kota Semarang
Teknik Informatika
0,090077
0,039323
2
Kota Semarang
Sistem Informasi
0,024234
0,004115
3
Kota Semarang
Desain Komunikais
Visual
0,025605
0,015546
4
Kota Semarang
Ilmu Komunikasi
0,009144
0,004115
5
Kota Semarang
Manajemen
0,039323
0,039323
6
Kota Semarang
Akuntansi
0,034293
0,009144
7
Kota Semarang
Sastra Inggris
0,010973
0,002286
10
Kota Semarang
Kesehatan
Masyarakat
0,016918
0,005486
11
Kota Semarang
Rekam Medis
0,008687
0,005486
12
Kota Semarang
Teknik Elektro
0,001828
0,005486
13
Kota Semarang
Teknik Industri
0,004572
0,005486
Dari hasil uji coba tersebut dengan menggunakan data sampel kota Semarang dan Provinsi Jawa Tengah dapat dilihat nilai-nilai probabilitas yang berada pada Tabel 5.4. Hasil dari pengujian dengan variabel kota semarang dan asal sekolah SMA adalah yang memiliki probabilitas tertinggi pada program studi Teknik Informatika (0,09077) dan yang memiliki nilai probabilitas terendah pada program studi Teknik Elektro(0,001828). Sedangkan pada hasil dengan variabel kota semarang dan asal sekolah SMK adalah yang memiliki probabilitas tertinggi pada program studi Teknik Informatika (0,039323) dan yang memiliki nilai terendah pada program studi Sastra Inggris (0,002286).
Dari hasil uji coba yang sudah dilakukan dengan Admisi Marketing, dengan menggunakan rumus untuk mendapatkan nilai akurasi dan error dari Admisi marketing sebagai berikut :
Akurasi = 2187
2200= 0,9941 = 99,4%
Dari perhitungan akurasi untuk kinerja klasifikasi didapatkan akurasi sebesar 99,4% kemudian hasil uji coba dengan menggunakan rumus keselahan predikisi (error) sebagai berikut :
Error = 13
2200 = 0, 006 = 0,6%
Tampilan Menu Utama
Tampilan menu utama ini merupakan tampilan utama untuk melihat menu-menu yang ada pada aplikasi. Ada menu-menu bar pada baris aplikasi untuk masuk ke menu-menu lain. Pada halaman utama user juga dapat memilih data-data yang tersimpan seperti manajemen kota, manajemen mahasiswa, manajemen hasil dan manajemen data.
Tampilan Data Mahasiswa
Pada Tampilan Data Mahasiswa merupakan menu data mahasiswa yang terdapat form-form untuk user mengisi data mahasiswa dan menyimpan data mahasiswa. Form yang berada pada menu ini adalah id, angkatan, asal sekolah, nama sekolah, fakultas, program studi, alamat asal, Id kota, Ip Semester 1 dan Ip Semester 2. Pada menu ini user diharuskan memasukkan data mahasiswa dengan lengkap. Asal sekolah dimasukkan berdasarkan kategori SMA atau SMK saja, selain kategori tersebut di masukkan pada kategori SMA. Pemilihan kota user hanya perlu memasukkan id kota sehingga provinsi dan kota akan mencari dengan otomatis. Pada menu ini, user juga dapat melakukan pencarian data mahasiswa yang sudah tersimpan dengan cara memasukkan “id”. Dan pada menu ini juga user dapat melakukan penghapusan data mahasiswa.
Gambar 4 Tampilan Data Mahasiswa Tampilan Prediksi
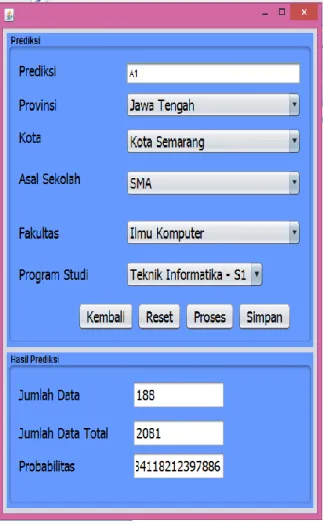
Tampilan prediksi ini dapat digunakan user untuk menyari prediksi yang sesuai dengan kategori yang diinputkan oleh user. Kategori tersebut akan di inputkan menggunakan form yang terdiri dari Prediksi, provinsi, kota, asal kota, fakultas, dan program studi. Hasil prediksi akan terlihat setelah dilakukan proses. Maka hasil akan keluar pada bagian hasil prediksi dengan form yang menerangkan jumlah data yang sesuai dengan kategori dan jumlah data total data mahasiswa keseluruhan. Setelah melakukan prediksi maka hasil prediksi akan tersimpan dan akan digunakan pada menu manajemen data.
Gambar 5 Tampilan Prediksi
4. KESIMPULAN
1. Admisi Marketing adalah aplikasi data mining yang menggunakan algoritma naive bayes classifier yang dapat memprediksi setiap kota terhadap program-program studi yang ada pada Universitas Dian Nuswantoro Semarang. Admisi Marketing ini dapat mendukung strategi pemasaran khususnya di bagian Admisi Universitas Dian Nuswantoro.
2. Hasil dari pengujian dengan variabel kota semarang dan asal sekolah SMA adalah yang memiliki probabilitas tertinggi pada program studi Teknik Informatika (0,09077) dan yang memiliki nilai probabilitas terendah pada program studi Teknik Elektro(0,001828). Sedangkan pada hasil dengan variabel kota semarang dan asal sekolah SMK adalah yang memiliki probabilitas tertinggi pada program studi Teknik Informatika (0,039323) dan yang memiliki nilai terendah pada program studi Sastra Inggris (0,002286).
3. Hasil dari uji coba yang menggunakan data mahasiswa angkatan tahun 2013, 2014, dan 2015 pada sempel data kota semarang,memiliki nilai akurasi 99,4 % dan error sebesar 0,6%.
5. SARAN
1. Admisi Marketing menggunakan data training dari data induk mahasiswa dari tahun 2013 sampai dengan 2015. Untuk menjaga akurasi, data training dapat diperbaharui dengan data induk mahasiswa tahun berikutnya.
2. Selain variabel, kota, provinsi, dan program studi untuk meningkatkan akurasi bisa ditambahkan variabel penghasilan orang tua.
3. Data mahasiswa sebaiknya dilakukakn secara otomatis. Untuk pengembangan berikutnya, inputan data mahasiswa bisa dicoba dengan melakukan secara otomatis untuk mempermudah memprediksi.
4. Untuk pengembangan berikutnya bisa dicoba dengan algoritma lain untuk mencari akurasi lebih tinggi seperti algoritma K-Nearest Neighbor, Decision Tree dan lain sebagainya.
5. Variabel asal sekolah yang berasal dari smk tidak memiliki keterangan jurusan seperti smk teknik industri dan lain sebagainya. Untuk pengembangan berikutnya, variabel asal sekolah bisa diinputkan lebih spesifik, misalnya : otomotif, elektro, tkj, dan lain sebagainya.
DAFTAR PUSTAKA
[1] Burhan Alfironi Muktamar,” Implementasi Data Mining dengan Naive Bayes Classifier untuk Mendukung Strategi Pemasaran di Bagian Humas STMIK AMIKOM YOGYAKARTA”,November 2013.
[2] Budanis Dwi Meilani and Nofi Susanti, “Aplikasi Data Mining Untuk Menghasilkan Pola Kelulusan Siswa Dengan Metode Naive Bayes”, Jurnal Link, Vol 21 , No.2, pp. 1-6, September 2014.
[3] Deny Wahyudi, A Haidar Mirxa, S.T,M.KOM, and Merrieayu P.H,M.KOM “Implementasi Data Mining Dengan Naive Bayes Classifier Untuk Mendukung Strategi Promosi (Studi Kasus Universitas Bina Darma Palembang)”, 2016.
[4] Ni Komang Sri Julyanti and I ketut Dedy Suryawan, “Data Mining Prestasi Akademik Dengan Naive Bayes Berdasarkan Atribut Improtance (AI)”
[5] Drs. M. Ngalim Purwanto, Psikologi Pendidikan, Bandung : PT Remaja Rosdakarya, 2007. hal. 25
[6] Fajar Astuti Hermawati, Data Mining, Yogyakarta : CV Andi Offset, 2013. hal. 5.
[7] Prasetyo, E. 2012. Data Mining Konsep dan Aplikasi Menggunakan Matlab. Yogyakarta : Andi. [8]Anonim.Landasan teori,https://library.binus.ac.id/eColls/eThesisdoc/Bab2/2013-1-00500-SI%20Bab2001.pdf. Diakses pada 28 Maret 2017 pukul 15.00 WIB
[8] Anonim. Naive Bayes,
http://repository.widyatama.ac.id/xmlui/bitstream/handle/123456789/3523/Bab%202.pdf?sequence= 4. Diakses pada 28 Maret 2017 Pukul 19.00 WIB