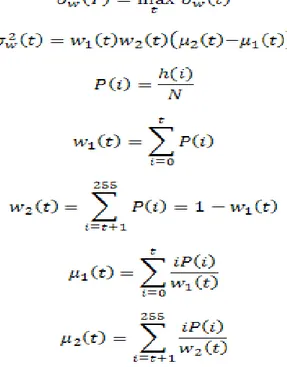BAB 2
LANDASAN TEORI
2. License plate recognition [4]
License plate recognition (LPR)adalah jenis teknologi, terutama perangkat lunak, yang
memungkinkan sistem komputer membaca secara otomatis nomor kendaraan dari gambar digital yang diambil dari kamera. Gambar digital yang diambil kemudian diterjemahkan kedalam teks dari plat nomor, sehingga sistem komputer dapat membacanya dengan mudah dan cepat menampilkan data jenis kendaraan, kepemilikan kendaraan serta data lain yang terkait. Selain itu ada beberapa tahap yang dilalui untuk license plate recognition. Tahap-tahap tersebut yaitu
sebagai berikut.
2.1 Image equisition & Grayscale [5]
Tahap awal dalam license plat recognition adalah memperoleh gambar palt nomor
kendaraan. Perangkat elektornik seperti optik, camera, webcam dan lain – lain yang dapaat digunakan untuk menangkap gambar yang diperoleh. Untuk sistem ini gambar akan diambil dengan kamera mobile device. Gambar akan disimpan sevagai format JPEG dan selanjutnya
gambar akan di ubah ke grayscale.
Pada proses grayscale ini gambar input yang berwarna dapat diubah menjadi gambar
yang tediri dari warna putih dan gradiasi warna hitam dengan menggunakan representasi warna
RGB. Pengubahan gambar ke dalam bentuk grayscale ini dilakukan dengan mengambil nilai
pixel dari suatu gambar input yang kemudian dihitung dengan persamaan yang ada yaitu :
2.2 Tresholding to BW [6]
Proses thresholding dilakukan dengan cara memeriksa apakah nilai intensitas dari sebuah pixel berada di bawah atau di atas sebuah nilai intensitythreshold yang telah ditentukan. Apabila
nilai pixel tersebut berada di atas batas nilai yang telah ditentukan, maka pixel tersebut akan
diubah menjadi putih yang berarti bahwa pixel tersebut merupakan karakter dan sebaliknya, bila
pixel tersebut berada di bawah batas nilai yang ditentukan maka pixel tersebut akan diubah
menjadi berwarna hitam yang berarti dianggap sebuah background.
Salah satu metode yang digunakan untuk tresholding adalah metode Otsu. Metode ini
merupakan operasi global, karena menggunakan informasi histogram citra secara global (meskipun teknik ini juga dikembangkan untuk operasi lokal). Citra yang diolah biasanya adalah citra keabuan yang bersifat bimodal atau memiliki dua bagian penting yaitu obyek (putih) dan latar (hitam). Teknik pengambangan Otsu berusaha mencari nilai keabuan ambang terbaik yang
dapat memisahkan antara obyek dan latar dengan memaksimalkan variansi antar kelas (obyek dan latar) atau meminimalkan variansi dalam kelas. Untuk lebih jelasnya tentang metode otsu
dapat di lihat di situs ini http://www.labbookpages.co.uk/software/imgProc/otsuThreshold.html. Nilai keabuan ambang optimal (T) dihitung dengan mencari nilai maksimum dari variansi
di mana h(i) adalah nilai histogram pada keabuan i, dengan asumsi citra yang diolah berupa citra
keabuan 8 bit dengan nilai keabuan dari 0 sampai dengan 255. Ilustrasi proses grayscaling dan thresholding :
Warna grayscale black & white
Gambar 2.1 Tresholding to B&W
0 0 1 0 0
0 1 0 1 0
0 1 1 1 0
1 1 0 1 1
2.3. Karakter Segmentasi
Karakter segmentasi adalah proses yang digunakan untuk memotong-motong gambar yang diproses menjadi beberapa bagian. Adapun beberapa tahap yang perlu dilakukan dalam proses character segmentation yaitu sebagai berikut.
2.3.1 Connexity [7]
Operator lokal piksel untuk proses scanning citra yang telah dijelaskan dapat
menggunakan operator lokal piksel 4-connexity atau 8-connexity. Bila menggunakan prinsip
4-connexity maka 2 piksel yang bersinggungan secara diagonal dianggap 2 objek, sedangkan pada
8-connexity dianggap 1 objek.
Gambar 2.2 Connexity
2.3.2 Labeling
Pada sistem koordinat pada gambar ada sedikit perbedaan dengan sistem koordinat pada kartesius, pada koordinat piksel gambar, dimulai dari pojok kiri atas, dengan kata lain pojok kiri atas adalah titik (0,0), sehingga di koordinat piksel gambar tidak mengenal nilai negatif. Pada arah vertikal dan arah horizontal juga memiliki perbedaan dengan koordinat kartesius, pada
koordinat piksel sumbu x adalah arah vertikal sedangkan pada sumbu y adalah arah horizontal. Untuk lebih jelasnya perhatikan gambar di bawah ini. titik (0,0) ada pada kiri atas suatu gambar
x
0,0
Y
Gambar 2.3 Preview koordinat piksel
Labeling adalah pemberian label pada tiap-tiap piksel yang bernilai 1 (putih). Untuk lebih
L2 L5 L5 L5 L5 L5 L5 L5 L6 L3 L3 L5 L5 L6 L3 L3 L5 L5 L3 L5 L5 L5 L5 L5 L5 L5 L5 L4
Gambar 2.4 proses labeling
Untuk metode labeling dalam hal ini menggunakan 8-connexity. Pada awalnya
melakukan scanning setiap piksel. Piksel yang bernilai satu (putih) akan diberi label. Pada
gambar 2.4, piksel (0,0) bernilai satu maka akan diberi label (L2). Piksel tersebut akan menjadi titik tengah atau sebagai P5 pada gambar 8-connexity. Kemudian piksel tersebut akan mencari
daerah sekitarnya apakah ada yang terhubung dengan piksel tersebut atau tidak, piksel akan mulai mengecek dari P2 → P3 → P6 → P9 → P8 → P7 → P4 → P1. Apabila ada yang terhubung dengan piksel tersebut atau bernilai satu, maka akan di beri label yang sama. Hal ini akan di lakukan terus menerus sampai tidak ada piksel yang terhubung dengan piksel tersebut. Apabila tidak ada yang terhubung lagi maka lanjutkan ke baris berikutnya dan label akan di
Dalam proses pemberian label pada tiap piksel juga menggunakan array. Array
berfungsi untuk menyimpan piksel (x,y) sebelumnya. Hal ini perlu dilakukan agar apabila piksel tidak menemukan lagi piksel yang bernilai satu, maka piksel tersebut akan kembali ke piksel sebelumnya. Proses array dapat dilihat pada label L3. Pada awalnya piksel (0,3) bernilai satu, kemudian piksel tersebut mengecek sekitarnya. Ternyata ada yang terhubung yaitu piksel (1,3), lalu piksel tersebut akan diberi label yang sama. Setelah diberi label, piksel (1,3) akan mengecek kembali sekitarnya. Ternyata ada lagi yang terhubung yaitu piksel (1,4), piksel tersebut kembali diberikan label yang sama. Setelah diberi label, piksel (1,4) kemudian mengecek kembali sekitarnya, ternyata ada yang masih terhubung yaitu piksel (0,5), piksel tersebut akan kembali diberi label yang sama. Setelah diberi label, piksel (0,5) kemudian mengecek kembali sekitarnya, ternyata ada yang masih terhubung yaitu piksel (0,4), piksel tersebut akan kembali diberi label yang sama. Setelah diberi label, piksel (0,4) akan mengecek kembali sekitarnya. Ternyata daerah sekitarnya sudah diberi label, maka piksel (0,4) akan kembali ke piksel (0,5). Kemudian piksel (0,5) akan mengecek kembali sekitanya apakah ada piksel yang bernilai satu (belum diberikan label) atau tidak. Ternyata tidak ada lagi yang terhubung maka piksel (0,5) akan kembali ke piksel (1,4). Kemudian piksel (1,4) akan mengecek lagi sekitanya apakah ada piksel yang bernilai satu (belum di berikan label) atau tidak. Ternyata tidak ada lagi yang terhubung maka piksel (1,4) akan kembali ke piksel (1,3). Kemudian piksel (1,3) akan mengecek lagi sekitanya apakah ada piksel yang bernilai satu (belum di berikan label) atau tidak. Ternyata tidak ada lagi yang terhubung,maka piksel (1,3) akan kembali ke piksel (0,3).
Character Recognition adalah pengenalan tiap-tiap karakter pada plat nomor. Dalam hal
ini proses pengenalan tiap-tiap karakter menggunakan perhitungan feedforward pada neural
network, sehingga akan menghasilkan 36 output yang nantinya akan menentukan suatu karakter.
Sebelum melakukan pengenalan, dilakukan proses pelatihan neural network untuk menentukan
nilai bobot terbaik pada tiap penghubung antar layar dengan menggunakan metode back propagation.
2.4.1 Neural Network [8]
Neural network adalah suatu sistem pemodelan data statistik non-linier yang dapat
memodelkan hubungan yang kompleks antara input dan output. Dengan kata lain neural network
ini memiliki kemampuan untuk dapat melakukan pembelajaran dan pendeteksian terhadap suatu pola data non-linier. Secara mendasar, sistem pembelajaran merupakan proses penambahan pengetahuan pada neural network yang bersifat kontinu sehingga pada saat digunakan
pengetahuan tersebut akan dieksploitasikan secara maksimal dalam mengenali suatu objek. Objek yang dapat dikenali dapat berupa data statistik linier maupun non-linier. Neural network
dapat memproses sejumlah besar informasi secara paralel dan terdistribusi, hal ini seperti yang telah diterapkan pada model kerja otak biologis.
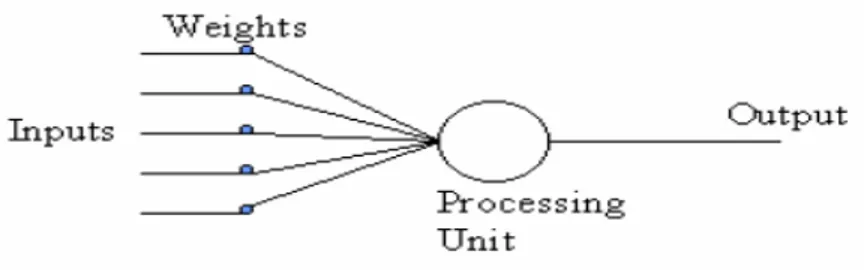
Gambar 2.5 NeuralNetwork
Neuron adalah bagian dasar dari pemrosesan suatu neural network. Gambar diatas ini merupakan
• Input merupakan bagian sistem yang digunakan untuk memberikan masukan pada sistem,
baik untuk proses pembelajaran maupun proses pengenalan objek.
• Weight merupakan bobot yang diberikan pada penghubung yang berfungsi untuk
meningkatkan dan menurunkan pengaruh suatu neuron terhadap input yang diberikan agar
sesuai dengan target pembelajaran.
• Processing unit merupakan tempat terjadinya proses komputasi pengenalan objek
berdasarkan pengetahuan yang diperoleh dari input dan bobot yang sudah ditentukan
sebelumnya.
• Output merupakan bagian yang memberikan hasil pembelajaran suatu objek atau target
pembelajaran. Setiap output dari neuron memiliki fungsi aktivasi yang menentukan apakah
informasi akan diteruskan ke neuron lain untuk diproses lagi atau tidak.
Sedangkan keuntungan dari penggunaan neural network adalah sebagai berikut:
• Mampu mengenali data non-linier.
• Memiliki toleransi terhadap suatu kesalahan dalam pengenalan suatu objek. • Mampu melakukan pengadaptasian terhadap pengenalan suatu objek. • Mampu diimplementasikan pada suatu hardware atau perangkat keras.
2.4.2. Model Neuron [9]
JST dibentuk sebagai generalisasi model matematika dari jaringan syaraf biologi, dengan asumsi :
b. Sinyal dikirimkan diantara neuron-neuron melalui penghubung-penghubung
c. Penghubung antar neuron memiliki bobot yang akan memperkuat atau memperlemah sinyal
d. Untuk menentukan output, setiap neuron menggunakan fungsi aktivasi (biasanya bukan
fungsi linier) yang dikenakan pada jumlahan input yang diterima. Besarnya output ini
selanjutnya dibandingkan dengan suatu batas.
JST ditentukan oleh tiga hal :
a. Pola hubungan antar neuron (disebut arsitektur jaringan)
b. Metode untuk menentukan bobot penghubung (disebut metode training/learning / algoritma)
c. Fungsi aktivasi
Sebagai contoh, perhatikan neuron pada Gambar 2.6.
Gambar 2.6. Model Sederhana Jaringan Syaraf Tiruan
Pada awalnya menerima input dari neuron Pi, P1 dan P2 dengan bobot hubungan
masing-masing adalah wi, w1 dan w2. Ketiga impuls neuron yang ada dijumlahkan N=P1w1 + P2w2 + Piwi
Hasil perhitungan di atas akan masuk ke dalam fungsi aktifasi. Apabila nilai fungsi aktivasi cukup kuat, maka sinyal akan diteruskan. Nilai fungsi aktivasi (keluaran model jaringan) juga dapat dipakai sebagai dasar untuk merubah bobot.
2.4.3. Arsitektur Neural Network [8]
Setiap neuron dapat memiliki beberapa masukan dan mempunyai satu keluaran. Jalur masukan pada suatu neuron bisa berisi data mentah atau data hasil olahan neuron sebelumnya
sedangkan hasil keluaran suatu neuron dapat berupa hasil akhir atau berupa bahan masukan bagi
neuron berikutnya. Jaringan neuron buatan terdiri atas kumpulan grup neuron yang tersusun
dalam lapisan.Gambar 2.7 di bawah ini menunjukkan struktur umum jaringan syaraf buatan yang bersifat feedforward (data diproses pada satu arah).
Gambar 2.7 Arsitektur Neural Network
1. Lapisan input (Input Layer)
Lapisan input berfungsi sebagai penghubung jaringan ke dunia luar (sumber data).
Neuron-neuron ini tidak melakukan perubahan apapun terhadap data,tapi hanya meneruskan data
ini ke lapisan berikutnya.
2. Lapisan tersembunyi (Hidden Layer)
Ox (j) = f(net)
Suatu jaringan dapat memiliki lebih dari satu lapisan tersembunyi (hidden layer) atau
bahkan bisa juga tidak memilikinya sama sekali. Jika jaringan memiliki beberapa lapisan tersembunyi, maka lapisan tersembunyi terbawah berfungsi untuk menerima masukan dari lapisan input. Besarnya nilai masukan (net) neuron ke-j pada lapisan tersembunyi ini tergantung
pada akumulasi jumlah perkalian antara nilai bobot (w, kekuatan hubungan antar neuron) dengan
nilai keluaran (O) neuron ke i pada lapisan sebelumnya (neuron input) ditambah dengan nilai
bias (w, neuron ke-j),atau
=
) (
net
j∑
W(ji).O(i)+W(j)Nilai bias ini merupakan nilai konstan yang dimiliki oleh setiap neuron (kecuali neuron
pada lapisan input) yang digunakan untuk memperbaiki keluaran jaringan agar dapat menyamai
atau mendekati nilai keluaran (output) yang diinginkan. Bobot wji bernilai 0 menunjukkan
bahwa antara neuron ke-j dan ke-i tidak terdapat hubungan.
Nilai keluaran neuron pada lapisan tersembunyi ini merupakan fungsi dari nilai
masukannya f (net (j)). Pada eksperimen ini digunakan fungsi Sigmoid,yaitu : Ox (j) = 1 / (1 + exp(-net(j)))
3. Lapisan Output (Output Layer)
Prinsip kerja neuron-neuron pada lapisan ini sama dengan prinsip kerja neuron-neuron
pada lapisan tersembunyi (hidden layer) dan di sini juga digunakan fungsi Sigmoid, tapi keluaran
dari neuron pada lapisan ini sudah dianggap sebagai hasil dari proses.
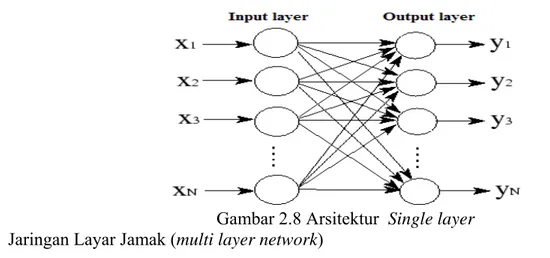
Beberapa arsitektur jaringan yang sering dipakai dalam jaringan syaraf tiruan antara lain : Jaringan Layar Tunggal (single layer network)
Dalam jaringan ini, sekumpulan input neuron dihubungkan langsung dengan sekumpulan
output nya. Dalam beberapa model (misal perceptron), hanya ada sebuah unit neuronoutput.
Gambar 2.8 Arsitektur Single layer
Jaringan Layar Jamak (multi layer network)
Jaringan layar jamak merupakan perluasan dari layar tunggal. Dalam jaringan ini, selain unit
input dan output, ada unit-unit lain (sering disebut layar tersembunyi/hidden layer).
Dimungkinkan pula ada beberapa layar tersembunyi. Sama seperti pada unit input dan output,
Gambar 2.9 Arsitektur Multi Layer
2.4.4 Proses Training Neural Network
Proses training / pembelajaran merupakan suatu metode untuk proses pengenalan suatu
objek yang bersifat kontinu yang selalu direspon secara berbeda dari setiap proses pembelajaran tersebut. Tujuan dari pembelajaran ini sebenarnya untuk memperkecil tingkat error dalam
pengenalan suatu objek. Secara mendasar, neural network memiliki sistem pembelajaran yang
terdiri atas beberapa jenis berikut:
¾ Supervised Learning
¾ Unsupervised Learning
2.4.4.1 Supervised Learning
Sistem pembelajaran pada metode supervised learning adalah sistem pembelajaran
dimana, setiap pengetahuan yang akan diberikan kepada sistem, pada awalnya diberikan suatu acuan untuk memetakan suatu masukan menjadi suatu keluaran yang diinginkan. Proses pembelajaran ini akan terus dilakukan selama kondisi error atau kondisi yang diinginkan belum
tercapai. Adapun setiap perolehan error akan dikalkulasikan untuk setiap pemrosesan hingga
data atau nilai yang diinginkan telah tercapai.
2.4.4.2 Unsupervised Learning
Pada metode ini tidak menggunakan nilai acuan untuk pemetaan input agar dapat
dihasilkan target output yang diharapkan. Hal ini dikarenakan sistem pada metode ini bergantung
sepenuhnya pada hasil komputasi disetiap tahapan pemrosesan untuk mendapatkan nilai target yang dikehendaki. Setiap proses pada metode ini akan mengkalkulasikan setiap langkah pada nilai bobot yang dikehendaki.
2.4.5 Metode Backpropagation
Algoritma pelatihan Backpropagasi (Back Propagation) atau ada yang
menterjemahkannya menjadi propagasi balik, pertama kali dirumuskan oleh Werbos dan dipopulerkan oleh Rumelt dan McClelland untuk dipakai pada jaringan saraf tiruan dan selanjutnya algoritma ini biasa disingkat dengan BP. Algoritma ini termasuk pelatihan
supervised dan didesain untuk operasi pada jaringan feedforward multi lapis.
Metode BP ini banyak diaplikasikan secara luas. Sekitar 90%, bahkan lebih BP telah berhasil diaplikasikan di berbagai bidang, diantaranya diterapkan di bidang finansial, pengenalan pola tulisan tangan, pengenalan pola suara, sistem kendali, pengolahan citra medika dan masih banyak lagi keberhasilkan BP sebagai salah satu metode komputasi yang handal.
Algoritma ini juga banyak dipakai pada aplikasi pengaturan karena proses pelatihannya didasarkan pada hubungan yang sederhana, yaitu Jika keluaran memberikan hasil yang salah, maka penimbang (weight) dikoreksi supaya error nya dapat diperkecil dan respon jaringan
selanjutnya diharapkan akan lebih mendekati harga yang besar. BP juga berkemampuan untuk memperbaiki penimbang pada lapisan tersembunyi (hidden layer).
Secara garis besar, mengapa algoritma ini disebut sebagai propagasi balik, dapat dideskripsikan sebagai berikut. Ketika jaringan diberikan pola masukan sebagai pola pelatihan maka pola tersebut menuju ke unit-unit pada lapisan tersembunyi untuk diteruskan ke unit-unit lapisan keluaran. Kemudian unit-unit lapisan keluaran memberikan tanggapan yang disebut sebagai keluaran jaringan. Saat keluaran jaringan tidak sama dengan keluaran yang diharapkan maka keluaran akan menyebar mundur (backward) pada lapisan tersembunyi diteruskan ke unit
pada lapisan masukan. Oleh karena itu maka mekanisme pelatihan tersebut dinamakan
backpropagation / propagasi balik.
Tahap pelatihan ini merupakan langkah bagaimana suatu jaringan saraf itu berlatih, yaitu dengan cara melakukan perubahan penimbang (weight). Sedangkan pemecahan masalah baru
akan dilakukan jika proses pelatihan tersebut selesai, fase tersebut adalah fase mapping atau
proses pengujian/testing.
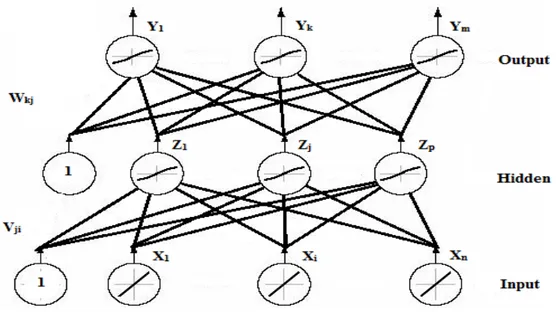
2.4.6 Arsitektur Backpropagation
Backpropagation memiliki beberapa unit yang ada dalam satu atau lebih layar
tersembunyi. Gambar berikut adalah arsitektur backpropagation dengan X buah masukan
(ditambah sebuah bias), sebuah layar tersembunyi yang terdiri dari Y unit (ditambah sebuah bias), serta Z buah unit keluaran.
Gambar 2.10 Arsitektur Backpropagation
2.4.7. Pelatihan Standar Backpropagation [11]
Pelatihan Backpropagation meliputi 3 fase. Fase pertama adalah fase maju. Pola masukan
dihitung maju mulai dari layar masukan hingga layar keluaran menggunakan fungsi aktivasi yang ditentukan. Fase kedua adalah fase mundur. Selisih antara keluaran jaringan dengan target yang diinginkan merupakan kesalahan yang terjadi. Kesalahan tersebut dipropagasikan mundur, dimulai dari garis yang berhubungan langsung dengan unit-unit di layar keluaran. Fase ketiga adalah modifikasi bobot untuk menurunkan kesalahan yang terjadi.
Fase I: Propagasi Maju
Selama propagasi maju, sinyal masukan (= Xi) dipropagasikan ke layar tersembunyi menggunakan fungsi aktivasi yang ditentukan. Keluaran dari setiap unit layar tersembunyi (= Yj) tersebut selanjutnya dipropagasikan maju lagi ke layar tersembunyi di atasnya menggunakan fungsi aktivasi yang ditentukan. Demikian seterusnya hingga menghasilkan keluaran jaringan (= Zk). Berikutnya, keluaran jaringan (= Zk) dibandingkan dengan target yang harus dicapai (= tk).
Selisih tk - zk adalah kesalahan yang terjadi. Jika kesalahan ini lebih kecil dari batas toleransi yang ditentukan, maka iterasi dihentikan. Akan tetapi apabila kesalahan masih lebih besar dari batas toleransinya, maka bobot setiap garis dalam jaringan akan dimodifikasi untuk mengurangi kesalahan yang terjadi
Fase II: Propagasi Mundur
Berdasarkan kesalahan tk- zk, dihitung faktor δk (k = 1,2,..., m) yang dipakai untuk mendistribusikan kesalahan di unit yk ke semua unit tersembunyi yang terhubung langsung dengan yk. δk juga dipakai untuk mengubah bobot garis yang berhubungan langsung dengan unit keluaran.
Dengan cara yang sama, dihitung faktor δj di setiap unit di layar tersembunyi sebagai dasar perubahan bobot semua garis yang berasal dari unit tersembunyi di layar di bawahnya. Demikian seterusnya hingga semua faktor δ di unit tersembunyi yang berhubungan langsung dengan unit masukan dihitung.
Fase III: Perubahan Bobot
Setelah semua faktor δ dihitung, bobot semua garis dimodifikasi bersamaan. Perubahan bobot suatu garis didasarkan atas faktor δ neuron di layar atasnya.Sebagai contoh, perubahan
bobot garis yang menuju ke layar keluaran didasarkan atas δk yang ada di unit keluaran. Ketiga fase terebut diulang-ulang terus hingga kondisi penghentian dipenuhi. Umumnya kondisi penghentian yang sering dipakai adalah jumlah iterasi atau kesalahan. Iterasi akan dihentikan
jika jumlah iterasi yang dilakukan sudah melebihi jumlah maksimum iterasi yang ditetapkan
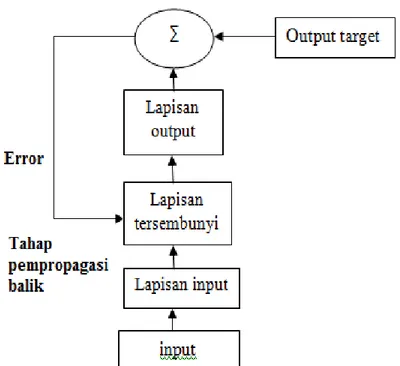
Gambar 2.11 Alur Kerja Propagasi Balik
Algoritma pelatihan untuk jaringan dengan satu layar tersembunyi (dengan fungsi aktivasi sigmoid biner) adalah sebagai berikut :
Langkah 0 : Inisialisasi semua bobot dengan bilangan acak kecil.
Langkah 1 : Jika kondisi penghentian belum terpenuhi, lakukan langkah 2 – 9. Langkah 2 : Untuk setiap pasang data pelatihan, lakukan langkah 3 – 8. Fase I : Propagasi maju
Langkah 3 : Tiap unit masukan menerima sinyal dan meneruskannya ke unit tersembunyi di atasnya
Langkah 4 : Hitung semua keluaran di unit tersembunyi Zj (j = 1, 2, .. , p) Z_netj = Vj0 +
Zj = f(z_netj) = _
y_netk = Wk0 +
yk = f(y_netk) = _ Fase II : Propogasi mundur
Langkah 6 : Hitung faktor δ unit keluaran berdasarkan kesalahan di setiap unit keluaran yk (k = 1, 2, .. , m)
δk = ( tk – yk ) f ’( y_netk ) = ( tk – yk ) yk ( 1 - yk )
δk merupakan unit kesalahan yang akan dipakai dalam perubahan bobot layar di bawahnya (langkah 7).
Hitung suku perubahan bobot Wkj (yang akan dipakai nanti untuk merubah bobot Wkj) dengan laju percepatan α
Δ Wkj = αδk Zj ; k = 1, 2, .. ,m ; j = 0, 1, .. , p
Langkah 7 : Hitung faktor δ unit tersembunyi berdasarkan kesalahan di setiap unit tersembunyi Zj (j = 1, 2, .. , p)
δ_netj =
Faktor δ unit tersembunyi :
δj = δ _net j f ‘( z_net j ) = δ _net j zj ( 1 - zj )
Hitung suku perubahan bobot Vji (yang akan dipakai nanti untuk merubah bobot Vji) Δ Vji = αδj xi ; j = 1, 2, .. , p ; i = 0, 1, .. , n
Langkah 8 : Hitung semua perubahan bobot Perubahan bobot garis yang menuju ke unit keluaran ;
Wkj (baru) = Wkj (lama) + Δ Wkj (k = 1, 2, .. , m ; j = 0, 1, .. , p)
Perubahan bobot garis yang menuju ke unit tersembunyi :
Vji (baru) = Vji (lama) + Δ Vji (j = 1, 2, .. , p ; i = 0, 1, .. , n)
Setelah pelatihan selesai dilakukan, jaringan dapat dipakai untuk pengenalan pola. Dalam hal ini, hanya propogasi maju (langkah 4 dan 5) saja yang dipakai untuk menentukan keluaran jaringan. Apabila fungsi aktivasi yang dipakai bukan sigmoid biner, maka langkah 4 dan 5 harus disesuaikan. Demikian juga turunannya pada langkah 6 dan 7.
2.4.8 Fungsi Aktivasi [11]
Dalam jaringan syaraf tiruan, fungsi aktivasi dipakai untuk menentukan keluaran suatu
neuron. Argumen fungsi aktivasi adalah net masukan (kombinasi linier masukan dan bobotnya).
Jika net = ∑ xi wi , maka fungsi aktivasinya adalah f (net) = f ( ∑ xi wi ). Beberapa fungsi aktivasi yang sering dipakai adalah sebagai berikut : a. Fungsi Sigmoid
f (x) =
dengan turunan f ’ (x) = f (x) ( 1 – f (x))
Fungsi sigmoid sering dipakai karena nilai fungsinya yang terletak antara 0 dan 1 dan dapat diturunkan dengan mudah.
b. Fungsi Identitas
Fungsi identitas sering dipakai apabila kita menginginkan keluaran jaringan berupa sembarang bilangin riil (bukan hanya pada range [0, 1] atau [-1, 1]).
Dalam backpropagation, fungsi aktivasi yang dipakai harus memenuhi beberapa syarat,
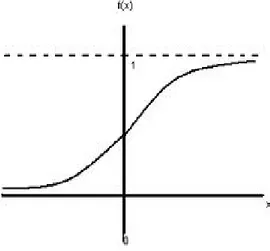
yaitu : kontinu, terdiferensial dengan mudah dan merupakan fungsi yang tidak turun. Salah satu fungsi yang memenuhi ketiga syarat tersebut sehingga sering dipakai adalah fungsi sigmoid biner yang memiliki range (0, 1).
f (x) =
dengan turunan f ’ (x) = f (x) ( 1 – f (x))
Grafik fungsinya tampak pada gambar 2.12
Gambar 2.12 fungsi sigmoid
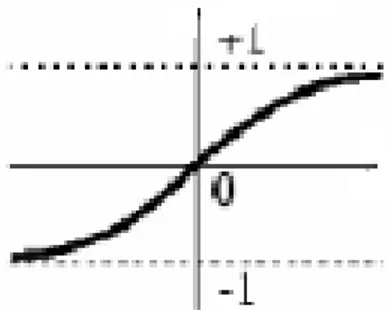
Fungsi lain yang sering dipakai adalah fungsi sigmoid bipolar yang bentuk fungsinya mirip dengan fungsi sigmoid biner, tapi dengan range (-1, 1).
f (x) = 1 dengan turunan f ’(x) =
Gambar 2.13 Sigmoid bipolar
Fungsi sigmoid memiliki nilai maksimum = 1. Maka untuk pola yang targetnya > 1, pola masukan dan keluaran harus terlebih dahulu ditransformasi sehingga semua polanya memiliki
range yang sama seperti fungsi sigmoid yang dipakai. Alternatif lain adalah menggunakan fungsi
aktivasi sigmoid hanya pada layar yang bukan layar keluaran. Pada layar keluaran, fungsi aktivasi yang dipakai adalah fungsi identitas : f (x) = x.
2.5 Database [12]
Android memlki fasilitas untuk membuat database yang dikenal dengan SQLite. SQLite
adalah salah satu software yang embedded yang sangat populer, kombinasi SQL interface dan
penggunaan memory yang sangat sedikit dengan kecepatan yang sangat cepat. SQLite di android
termasuk dalam Android Runtime, sehingga setiap versi dari android dapat membuat database
dengan SQLite.
Dalam sistem android memiliki beberapa teknik untuk melakukan penyimpanan data.Teknik yang umum digunakan adalah sebagai berikut
• Shared Preferences yaitu menyimpan data berupa nilai (value) dalam bentuk groups key
yang di kenal dengan preferences.
• Files yaitu menyimpan data dalam file, dapat berupa menulis ke file atau membaca dari
• SOLite Databases yaitu mennyimpan data dalam bentuk Databases.
• Contenct Providers yaitu menyimpan data dalam bentuk content provider services.
2.6 PrinterShare [13]
Aplikasi tambahan untuk android yang digunakan adalah PrinterShare, aplikasi populer
produksi developerMobile Dynamix. PrinterShare mempunyai dua mode yaitu Nearby
dan Remote. Mode Nearby memungkinkan untuk menghubungkan smartphone
dengan printer melalui jaringan WiFi. Untuk menggunakan mode Nearby dengan koneksi
langsung antara smartphone dan printer, caranya cukup sederhana :
1. Download dan InstallPrinterShare pada perangkat Android
2. Pastikan komputer dan printer telah terkoneksi, ter-setting dan siap untuk digunakan,
3. Download dan InstallPrinterSharedesktop client pada komputer,
4. Pada PrinterSharedesktop client komputer, cari printer yang digunakan pada list'Local Printers' dan klik Share.
5. Selanjutnya PrinterShare pada android akan langsung mendeteksi printer yang
di share tersebut.
Apabila tidak memiliki koneksi WiFi, maka bisa menggunakan mode Remote. Mode ini
hampir mirip dengan mode Nearby menggunakan desktop client, hanya saja pada mode ini akan
menggunakan jaringan internet sebagai perantara antara android dan komputer. Caranya adalah
sebagai berikut :
1. Download dan InstallPrinterShare pada perangkat Android
2. Pastikan komputer dan printer telah terkoneksi, ter-setting dan siap untuk digunakan,
4. Pada PrinterSharedesktop client komputer, cari printer yang digunakan pada list'Local Printers' dan klik Share.
5. Pada android, klik Menu -> Remote Printers -> create User ID. User ID bisa temukan
pada sudut kiri atas PrinterSharedesktop client.
6. Selanjutnya semua perangkat sudah siap untuk melakukan print. Saat memilih file untuk
di-print, desktop client mengeluarkan notifikasi, klik New job -> Print. Langkah
notifikasi diperlukan untuk mencegah pengguna lain mengakses printer.