Table of Contents
Python: Real-World Data Science Meet Your Course Guide
What's so cool about Data Science? Course Structure
Course Journey
The Course Roadmap and Timeline
1. Course Module 1: Python Fundamentals
1. Introduction and First Steps – Take a Deep Breath A proper introduction Who is using Python today? Setting up the environment
Python 2 versus Python 3 – the great debate What you need for this course
Installing Python Installing IPython
Installing additional packages How you can run a Python program
Running Python scripts
Running the Python interactive shell Running Python as a service
How do we use modules and packages Python's execution model
Names and namespaces Scopes
Guidelines on how to write good code The Python culture
Hiding details and creating the public interface Composition Who can access my data? Third-party libraries Case study
Basic inheritance
Using an abstract base class Creating an abstract base class Demystifying the magic
Case study
5. Expecting the Unexpected Raising exceptions
Raising an exception
The effects of an exception Handling exceptions
The exception hierarchy Defining our own exceptions Case study
6. When to Use Object-oriented Programming Treat objects as objects
Adding behavior to class data with properties Properties in detail
Decorators – another way to create properties Deciding when to use properties
Using defaultdict
Converting bytes to text Converting text to bytes Mutable byte strings
Regular expressions Matching patterns
Matching a selection of characters Escaping characters
Matching multiple characters Grouping patterns together
Getting information from regular expressions Making repeated regular expressions efficient Serializing objects
Yield items from another iterable Coroutines
Back to log parsing
Closing coroutines and throwing exceptions
The relationship between coroutines, generators, and functions Case study
11. Python Design Patterns I The decorator pattern
A decorator example Decorators in Python The observer pattern
The strategy pattern 12. Python Design Patterns II
The adapter pattern
Reducing boilerplate and cleaning up Organizing and running tests
Ignoring broken tests Testing with py.test
One way to do setup and cleanup
A completely different way to set up variables Skipping tests with py.test
Imitating expensive objects How much testing is enough? Case study
Implementing it 14. Concurrency
The many problems with threads
Using executors to wrap blocking code Streams
Executors Case study
2. Course Module 2: Data Analysis
1. Introducing Data Analysis and Libraries Data analysis and processing
An overview of the libraries in data analysis Python libraries in data analysis
NumPy pandas Matplotlib PyMongo
The scikit-learn library
Loading and saving data Saving an array
Loading an array
Linear algebra with NumPy NumPy random numbers 3. Data Analysis with pandas
An overview of the pandas package The pandas data structure
Advanced uses of pandas for data analysis Hierarchical indexing
MayaVi 5. Time Series
Time series primer
Working with date and time objects Resampling time series
Interacting with data in text format Reading data from text format Writing data to text format
Interacting with data in binary format HDF5
Interacting with data in MongoDB Interacting with data in Redis
The simple value List
Set
Ordered set
7. Data Analysis Application Examples Data munging
3. Course Module 3: Data Mining 1. Getting Started with Data Mining
Introducing data mining
A simple affinity analysis example What is affinity analysis?
Product recommendations
Implementing a simple ranking of rules Ranking to find the best rules
A simple classification example What is classification?
Loading and preparing the dataset Implementing the OneR algorithm Testing the algorithm
2. Classifying with scikit-learn Estimators scikit-learn estimators
Nearest neighbors Distance metrics Loading the dataset
Moving towards a standard workflow Running the algorithm
3. Predicting Sports Winners with Decision Trees Loading the dataset
Collecting the data
4. Recommending Movies Using Affinity Analysis
5. Extracting Features with Transformers Feature extraction
Representing reality in models Common feature patterns Creating good features Feature selection
Selecting the best individual features Feature creation
6. Social Media Insight Using Naive Bayes Disambiguation
Downloading data from a social network Loading and classifying the dataset
Creating a replicable dataset from Twitter Text transformers
Bayes' theorem
Naive Bayes algorithm How it works
Application
Extracting word counts
Converting dictionaries to a matrix Training the Naive Bayes classifier Putting it all together
Evaluation using the F1-score
Getting useful features from models
7. Discovering Accounts to Follow Using Graph Mining Loading the dataset
Classifying with an existing model
Getting follower information from Twitter Building the network
8. Beating CAPTCHAs with Neural Networks Artificial neural networks
An introduction to neural networks Creating the dataset
Drawing basic CAPTCHAs
Splitting the image into individual letters Creating a training dataset
Adjusting our training dataset to our methodology Training and classifying
Back propagation Predicting words
Improving accuracy using a dictionary Ranking mechanisms for words Putting it all together
9. Authorship Attribution
Applications and use cases
Using a Web API to get data Reddit as a data source
Getting the data
Extracting text from arbitrary websites Finding the stories in arbitrary websites Putting it all together
Grouping news articles The k-means algorithm Evaluating the results
Extracting topic information from clusters Using clustering algorithms as transformers Clustering ensembles
Evidence accumulation How it works
Implementation Online learning
11. Classifying Objects in Images Using Deep Learning
Implementing neural networks with nolearn GPU optimization
When to use GPUs for computation Running our code on a GPU
Setting up the environment Application
Getting the data
Creating the neural network Putting it all together
12. Working with Big Data Big data
Training on Amazon's EMR infrastructure 13. Next Steps…
Extending the IPython Notebook
Chapter 2 – Classifying with scikit-learn Estimators More complex pipelines
Comparing classifiers
Chapter 3: Predicting Sports Winners with Decision Trees More on pandas
Chapter 4 – Recommending Movies Using Affinity Analysis The Eclat algorithm
Chapter 5 – Extracting Features with Transformers Vowpal Wabbit
Chapter 6 – Social Media Insight Using Naive Bayes
Natural language processing and part-of-speech tagging
Chapter 7 – Discovering Accounts to Follow Using Graph Mining More complex algorithms
Chapter 8 – Beating CAPTCHAs with Neural Networks Deeper networks
Reinforcement learning
Chapter 9 – Authorship Attribution Local n-grams
Chapter 10 – Clustering News Articles Real-time clusterings
Chapter 11 – Classifying Objects in Images Using Deep Learning Keras and Pylearn2
Mahotas
Chapter 12 – Working with Big Data Courses on Hadoop
Pydoop
Recommendation engine More resources
4. Course Module 4: Machine Learning
1. Giving Computers the Ability to Learn from Data How to transform data into knowledge
The three different types of machine learning
Making predictions about the future with supervised learning Classification for predicting class labels
Solving interactive problems with reinforcement learning Discovering hidden structures with unsupervised learning
Finding subgroups with clustering
Dimensionality reduction for data compression An introduction to the basic terminology and notations A roadmap for building machine learning systems
Preprocessing – getting data into shape Training and selecting a predictive model
Evaluating models and predicting unseen data instances Using Python for machine learning
2. Training Machine Learning Algorithms for Classification
Artificial neurons – a brief glimpse into the early history of machine learning
Implementing a perceptron learning algorithm in Python Training a perceptron model on the Iris dataset
Adaptive linear neurons and the convergence of learning Minimizing cost functions with gradient descent Implementing an Adaptive Linear Neuron in Python
Large scale machine learning and stochastic gradient descent 3. A Tour of Machine Learning Classifiers Using scikit-learn
Choosing a classification algorithm First steps with scikit-learn
Training a perceptron via scikit-learn
Modeling class probabilities via logistic regression
Logistic regression intuition and conditional probabilities Learning the weights of the logistic cost function
Training a logistic regression model with scikit-learn Tackling overfitting via regularization
Maximum margin classification with support vector machines Maximum margin intuition
Dealing with the nonlinearly separable case using slack variables Alternative implementations in scikit-learn
Solving nonlinear problems using a kernel SVM
Using the kernel trick to find separating hyperplanes in higher dimensional space
Maximizing information gain – getting the most bang for the buck Building a decision tree
Combining weak to strong learners via random forests K-nearest neighbors – a lazy learning algorithm
4. Building Good Training Sets – Data Preprocessing Dealing with missing data
Eliminating samples or features with missing values Imputing missing values
Understanding the scikit-learn estimator API Handling categorical data
Mapping ordinal features Encoding class labels
Performing one-hot encoding on nominal features Partitioning a dataset in training and test sets
Bringing features onto the same scale Selecting meaningful features
Sparse solutions with L1 regularization Sequential feature selection algorithms
Assessing feature importance with random forests 5. Compressing Data via Dimensionality Reduction
Unsupervised dimensionality reduction via principal component analysis
Total and explained variance Feature transformation
Principal component analysis in scikit-learn
Supervised data compression via linear discriminant analysis Computing the scatter matrices
Selecting linear discriminants for the new feature subspace Projecting samples onto the new feature space
LDA via scikit-learn
Using kernel principal component analysis for nonlinear mappings Kernel functions and the kernel trick
Implementing a kernel principal component analysis in Python Example 1 – separating half-moon shapes
Kernel principal component analysis in scikit-learn
6. Learning Best Practices for Model Evaluation and Hyperparameter Tuning
Streamlining workflows with pipelines
Loading the Breast Cancer Wisconsin dataset
Combining transformers and estimators in a pipeline Using k-fold cross-validation to assess model performance
The holdout method K-fold cross-validation
Debugging algorithms with learning and validation curves Diagnosing bias and variance problems with learning curves Addressing overfitting and underfitting with validation curves Fine-tuning machine learning models via grid search
Tuning hyperparameters via grid search
Algorithm selection with nested cross-validation Looking at different performance evaluation metrics
Reading a confusion matrix
Optimizing the precision and recall of a classification model Plotting a receiver operating characteristic
The scoring metrics for multiclass classification 7. Combining Different Models for Ensemble Learning
Learning with ensembles
Implementing a simple majority vote classifier
Combining different algorithms for classification with majority vote Evaluating and tuning the ensemble classifier
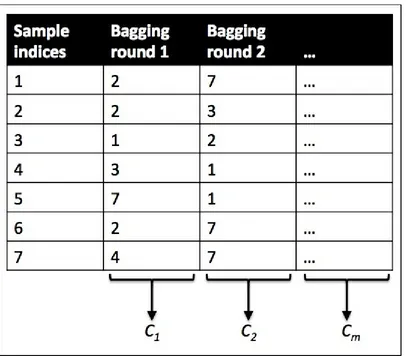
Bagging – building an ensemble of classifiers from bootstrap samples Leveraging weak learners via adaptive boosting
8. Predicting Continuous Target Variables with Regression Analysis Introducing a simple linear regression model
Exploring the Housing Dataset
Visualizing the important characteristics of a dataset
Implementing an ordinary least squares linear regression model
Solving regression for regression parameters with gradient descent Estimating the coefficient of a regression model via scikit-learn Fitting a robust regression model using RANSAC
Using regularized methods for regression
Turning a linear regression model into a curve – polynomial regression Modeling nonlinear relationships in the Housing Dataset
Dealing with nonlinear relationships using random forests Decision tree regression
Random forest regression A. Reflect and Test Yourself! Answers
Module 2: Data Analysis
Chapter 1: Introducing Data Analysis and Libraries Chapter 2: Object-oriented Design
Chapter 3: Data Analysis with pandas Chapter 4: Data Visualization
Chapter 5: Time Series
Chapter 6: Interacting with Databases
Chapter 7: Data Analysis Application Examples Module 3: Data Mining
Chapter 1: Getting Started with Data Mining
Chapter 2: Classifying with scikit-learn Estimators
Chapter 3: Predicting Sports Winners with Decision Trees Chapter 4: Recommending Movies Using Affinity Analysis Chapter 5: Extracting Features with Transformers
Chapter 6: Social Media Insight Using Naive Bayes
Chapter 7: Discovering Accounts to Follow Using Graph Mining Chapter 8: Beating CAPTCHAs with Neural Networks
Chapter 9: Authorship Attribution Chapter 10: Clustering News Articles
Chapter 11: Classifying Objects in Images Using Deep Learning Chapter 12: Working with Big Data
Module 4: Machine Learning
Chapter 1: Giving Computers the Ability to Learn from Data Chapter 2: Training Machine Learning
Chapter 3: A Tour of Machine Learning Classifiers Using scikit-learn
Hyperparameter Tuning
Chapter 7: Combining Different Models for Ensemble Learning Chapter 8: Predicting Continuous Target Variables with Regression Analysis
Python: Real-World Data Science
A course in four modules
Unleash the power of Python and its robust data science capabilities with your Course Guide Ankita Thakur
Learn to use powerful Python libraries for effective data processing and analysis
To contact your Course Guide
Meet Your Course Guide
Hello and welcome to this Data Science with Python course. You now have a clear pathway from learning Python core features right through to getting acquainted with the concepts and techniques of the data science field—all using Python!
This course has been planned and created for you by me Ankita Thakur – I am your Course Guide, and I am here to help you have a great journey along the pathways of learning that I have planned for you.
I've developed and created this course for you and you'll be seeing me through the whole journey, offering you my thoughts and ideas behind what you're going to learn next and why I recommend each step. I'll provide tests and quizzes to help you reflect on your learning, and code challenges that will be pitched just right for you through the course.
What's so cool about Data Science?
What is Data Science and why is there so much of buzz about this in the world? Is it of great importance? Well, the following sentence will answer all such questions:"This hot new field promises to revolutionize industries from business to government, health care to academia."
--The New York Times
The world is generating data at an increasing pace. Consumers, sensors, or scientific experiments emit data points every day. In finance, business, administration, and the natural or social sciences, working with data can make up a significant part of the job. Being able to efficiently work with small or large datasets has become a valuable skill. Also, we live in a world of connected things where tons of data is generated and it is humanly
impossible to analyze all the incoming data and make decisions. Human decisions are increasingly replaced by decisions made by computers. Thanks to the field of Data Science!
Data science has penetrated deeply in our connected world and there is a growing demand in the market for people who not only understand data science algorithms thoroughly, but are also capable of programming these algorithms. A field that is at the intersection of many fields, including data mining, machine learning, and statistics, to name a few. This puts an
immense burden on all levels of data scientists; from the one who is aspiring to become a data scientist and those who are currently practitioners in this field.
Treating these algorithms as a black box and using them in decision-making systems will lead to counterproductive results. With tons of algorithms and innumerable problems out there, it requires a good grasp of the underlying algorithms in order to choose the best one for any given problem.
the number one choice for a data scientist. Python has become the most
popular programming language for data science because it allows us to forget about the tedious parts of programming and offers us an environment where we can quickly jot down our ideas and put concepts directly into action. It has been used in industry for a long time, but it has been popular among
researchers as well.
In contrast to more specialized applications and environments, Python is not only about data analysis. The list of industrial-strength libraries for many general computing tasks is long, which makes working with data in Python even more compelling. Whether your data lives inside SQL or NoSQL
Course Structure
Frankly speaking, it's a wise decision to know the nitty-gritty of Python as it's a trending language. I'm sure you'll gain lot of knowledge through this course and be able to implement all those in practice. However, I want to highlight that the road ahead may be bumpy on occasions, and some topics may be more challenging than others, but I hope that you will embrace this
opportunity and focus on the reward. Remember that we are on this journey together, and throughout this course, we will add many powerful techniques to your arsenal that will help us solve even the toughest problems the data-driven way.
I've created this learning path for you that consist of four models. Each of these modules are a mini-course in their own way, and as you complete each one, you'll have gained key skills and be ready for the material in the next module.
Course Journey
We start the course with our very first module, Python Fundamentals, to help you get familiar with Python. Installing Python correctly is equal to half job done. This module starts with the installation of Python, IPython, and all the necessary packages. Then, we'll see the fundamentals of object-oriented programming because Python itself is an object-oriented programming language. Finally, we'll make friends with some of the core concepts of Python—how to get Python programming basics nailed down.
The third module, Data Mining, is designed in a way that you have a good understanding of the basics, some best practices to jump into solving
problems with data mining, and some pointers on the next steps you can take. Now, you can harness the power of Python to analyze data and create
insightful predictive models.
Finally, we'll move towards exploring more advanced topics. Sometimes an analysis task is too complex to program by hand. Machine learning is a modern technique that enables computers to discover patterns and draw conclusions for themselves. The aim of our fourth module, Machine
Learning, is to provide you with a module where we'll discuss the necessary details regarding machine learning concepts, offering intuitive yet
Chapter 1. Introduction and First
Steps – Take a Deep Breath
"Give a man a fish and you feed him for a day. Teach a man to fish and you feed him for a lifetime."
--Chinese proverb
According to Wikipedia, computer programming is:
"...a process that leads from an original formulation of a computing problem to executable computer programs. Programming involves activities such as analysis, developing understanding, generating algorithms, verification of requirements of algorithms including their correctness and resources consumption, and implementation (commonly referred to as coding) of algorithms in a target programming language".
In a nutshell, coding is telling a computer to do something using a language it understands.
Computers are very powerful tools, but unfortunately, they can't think for themselves. So they need to be told everything. They need to be told how to perform a task, how to evaluate a condition to decide which path to follow, how to handle data that comes from a device such as the network or a disk, and how to react when something unforeseen happens, say, something is broken or missing.
You can code in many different styles and languages. Is it hard? I would say "yes" and "no". It's a bit like writing. Everybody can learn how to write, and you can too. But what if you wanted to become a poet? Then writing alone is not enough. You have to acquire a whole other set of skills and this will take a longer and greater effort.
In the end, it all comes down to how far you want to go down the road.
Good code is short, fast, elegant, easy to read and understand, simple, easy to modify and extend, easy to scale and refactor, and easy to test. It takes time to be able to write code that has all these qualities at the same time, but the good news is that you're taking the first step towards it at this very moment by reading this module. And I have no doubt you can do it. Anyone can, in fact, we all program all the time, only we aren't aware of it.
Would you like an example?
Say you want to make instant coffee. You have to get a mug, the instant coffee jar, a teaspoon, water, and the kettle. Even if you're not aware of it, you're evaluating a lot of data. You're making sure that there is water in the kettle as well as the kettle is plugged-in, that the mug is clean, and that there is enough coffee in the jar. Then, you boil the water and maybe in the
meantime you put some coffee in the mug. When the water is ready, you pour it into the cup, and stir.
So, how is this programming?
Well, we gathered resources (the kettle, coffee, water, teaspoon, and mug) and we verified some conditions on them (kettle is plugged-in, mug is clean, there is enough coffee). Then we started two actions (boiling the water and putting coffee in the mug), and when both of them were completed, we finally ended the procedure by pouring water in the mug and stirring.
Can you see it? I have just described the high-level functionality of a coffee program. It wasn't that hard because this is what the brain does all day long: evaluate conditions, decide to take actions, carry out tasks, repeat some of them, and stop at some point. Clean objects, put them back, and so on.
All you need now is to learn how to deconstruct all those actions you do automatically in real life so that a computer can actually make some sense of them. And you need to learn a language as well, to instruct it.
A proper introduction
I love to make references to the real world when I teach coding; I believe they help people retain the concepts better. However, now is the time to be a bit more rigorous and see what coding is from a more technical perspective.
When we write code, we're instructing a computer on what are the things it has to do. Where does the action happen? In many places: the computer memory, hard drives, network cables, CPU, and so on. It's a whole "world", which most of the time is the representation of a subset of the real world.
If you write a piece of software that allows people to buy clothes online, you will have to represent real people, real clothes, real brands, sizes, and so on and so forth, within the boundaries of a program.
In order to do so, you will need to create and handle objects in the program you're writing. A person can be an object. A car is an object. A pair of socks is an object. Luckily, Python understands objects very well.
The two main features any object has are properties and methods. Let's take a person object as an example. Typically in a computer program, you'll
represent people as customers or employees. The properties that you store against them are things like the name, the SSN, the age, if they have a driving license, their e-mail, gender, and so on. In a computer program, you store all the data you need in order to use an object for the purpose you're serving. If you are coding a website to sell clothes, you probably want to store the height and weight as well as other measures of your customers so that you can
suggest the appropriate clothes for them. So, properties are characteristics of an object. We use them all the time: "Could you pass me that pen?" – "Which one?" – "The black one." Here, we used the "black" property of a pen to identify it (most likely amongst a blue and a red one).
Methods are things that an object can do. As a person, I have methods such as
So, now that you know what objects are and that they expose methods that you can run and properties that you can inspect, you're ready to start coding. Coding in fact is simply about managing those objects that live in the subset of the world that we're reproducing in our software. You can create, use, reuse, and delete objects as you please.
According to the Data Model chapter on the official Python documentation:
"Objects are Python's abstraction for data. All data in a Python program is represented by objects or by relations between objects."
We'll take a closer look at Python objects in the upcoming chapter. For now, all we need to know is that every object in Python has an ID (or identity), a type, and a value.
Once created, the identity of an object is never changed. It's a unique identifier for it, and it's used behind the scenes by Python to retrieve the object when we want to use it.
The type as well, never changes. The type tells what operations are supported by the object and the possible values that can be assigned to it.
The value can either change or not. If it can, the object is said to be mutable, while when it cannot, the object is said to be immutable.
How do we use an object? We give it a name of course! When you give an object a name, then you can use the name to retrieve the object and use it.
In a more generic sense, objects such as numbers, strings (text), collections, and so on are associated with a name. Usually, we say that this name is the name of a variable. You can see the variable as being like a box, which you can use to hold data.
button, or opening a web page and performing a search. We react by running our code, evaluating conditions to choose which parts to execute, how many times, and under which circumstances.
And to do all this, basically we need a language. That's what Python is for. Python is the language we'll use together throughout this module to instruct the computer to do something for us.
Enter the Python
Python is the marvelous creature of Guido Van Rossum, a Dutch computer scientist and mathematician who decided to gift the world with a project he was playing around with over Christmas 1989. The language appeared to the public somewhere around 1991, and since then has evolved to be one of the leading programming languages used worldwide today.
I started programming when I was 7 years old, on a Commodore VIC 20, which was later replaced by its bigger brother, the Commodore 64. The language was BASIC. Later on, I landed on Pascal, Assembly, C, C++, Java, JavaScript, Visual Basic, PHP, ASP, ASP .NET, C#, and other minor
languages I cannot even remember, but only when I landed on Python, I finally had that feeling that you have when you find the right couch in the shop. When all of your body parts are yelling, "Buy this one! This one is perfect for us!"
It took me about a day to get used to it. Its syntax is a bit different from what I was used to, and in general, I very rarely worked with a language that
About Python
Before we get into the gory details, let's get a sense of why someone would want to use Python (I would recommend you to read the Python page on Wikipedia to get a more detailed introduction).
Portability
Coherence
Python is extremely logical and coherent. You can see it was designed by a brilliant computer scientist. Most of the time you can just guess how a method is called, if you don't know it.
Developer productivity
According to Mark Lutz (Learning Python, 5th Edition, O'Reilly Media), a Python program is typically one-fifth to one-third the size of equivalent Java or C++ code. This means the job gets done faster. And faster is good. Faster means a faster response on the market. Less code not only means less code to write, but also less code to read (and professional coders read much more than they write), less code to maintain, to debug, and to refactor.
An extensive library
Python has an incredibly wide standard library (it's said to come with
Software quality
Python is heavily focused on readability, coherence, and quality. The
Software integration
Satisfaction and enjoyment
Last but not least, the fun of it! Working with Python is fun. I can code for 8 hours and leave the office happy and satisfied, alien to the struggle other coders have to endure because they use languages that don't provide them with the same amount of well-designed data structures and constructs. Python makes coding fun, no doubt about it. And fun promotes motivation and
productivity.
What are the drawbacks?
Probably, the only drawback that one could find in Python, which is not due to personal preferences, is the execution speed. Typically, Python is slower than its compiled brothers. The standard implementation of Python produces, when you run an application, a compiled version of the source code called byte code (with the extension .pyc), which is then run by the Python
interpreter. The advantage of this approach is portability, which we pay for with a slowdown due to the fact that Python is not compiled down to machine level as are other languages.
However, Python speed is rarely a problem today, hence its wide use regardless of this suboptimal feature. What happens is that in real life, hardware cost is no longer a problem, and usually it's easy enough to gain speed by parallelizing tasks. When it comes to number crunching though, one can switch to faster Python implementations, such as PyPy, which provides an average 7-fold speedup by implementing advanced compilation techniques (check http://pypy.org/ for reference).
When doing data science, you'll most likely find that the libraries that you use with Python, such as Pandas and Numpy, achieve native speed due to the way they are implemented.
Who is using Python today?
Not yet convinced? Let's take a very brief look at the companies that are using Python today: Google, YouTube, Dropbox, Yahoo, Zope Corporation, Industrial Light & Magic, Walt Disney Feature Animation, Pixar, NASA, NSA, Red Hat, Nokia, IBM, Netflix, Yelp, Intel, Cisco, HP, Qualcomm, and JPMorgan Chase, just to name a few.
Even games such as Battlefield 2, Civilization 4, and QuArK are implemented using Python.
Setting up the environment
Python 2 versus Python 3 – the great debate
Python comes in two main versions—Python 2, which is the past—and Python 3, which is the present. The two versions, though very similar, are incompatible on some aspects.
In the real world, Python 2 is actually quite far from being the past. In short, even though Python 3 has been out since 2008, the transition phase is still far from being over. This is mostly due to the fact that Python 2 is widely used in the industry, and of course, companies aren't so keen on updating their
systems just for the sake of updating, following the if it ain't broke, don't fix it
philosophy. You can read all about the transition between the two versions on the Web.
Another issue that was hindering the transition is the availability of third-party libraries. Usually, a Python project relies on tens of external libraries, and of course, when you start a new project, you need to be sure that there is already a version 3 compatible library for any business requirement that may come up. If that's not the case, starting a brand new project in Python 3 means introducing a potential risk, which many companies are not happy to take.
At the time of writing, the majority of the most widely used libraries have been ported to Python 3, and it's quite safe to start a project in Python 3 for most cases. Many of the libraries have been rewritten so that they are
compatible with both versions, mostly harnessing the power of the six (2 x 3) library, which helps introspecting and adapting the behavior according to the version used.
All the examples in this module will be run using this Python 3.4.0. Most of them will run also in Python 2 (I have version 2.7.6 installed as well), and those that won't will just require some minor adjustments to cater for the small incompatibilities between the two versions.
Note
What you need for this course
As you've seen there are too many requirements to get started, so I'veprepared a table that will give you an overview of what you'll need for each module of the course:
Module 1 Module 2 Module 3 Module 4
All the examples in this module rely on the Python 3 interpreter. Some of the examples in this module rely on third-party libraries that do not ship with Python. These are introduced within the module at the time they are used, so you do not need to install them in advance. However, for completeness, here is a list: probably run almost all of the code on a slower system too.
The exception here is with the final two chapters. In these chapters, I step through using Amazon Web Services (AWS) to run the code. This will probably cost you some money, but the advantage is less system setup than running the code locally. If you don't want to pay for those services, the tools used can all be set up on a local computer, but you will definitely need a modern system to run it. A processor built in at least 2012 and with more than 4 GB of RAM is necessary.
Installing Python
Python is a fantastic, versatile, and an easy-to-use language. It's available for all three major operating systems—Microsoft Windows, Mac OS X, and Linux—and the installer, as well as the documentation, can be downloaded from the official Python website: https://www.python.org.
Note
Windows users will need to set an environment variable in order to use Python from the command line. First, find where Python 3 is installed; the default location is C:\Python34. Next, enter this command into the command line (cmd program): set the environment to
PYTHONPATH=%PYTHONPATH%;C:\Python34. Remember to change the C:\Python34 if Python is installed into a different directory.
Once you have Python running on your system, you should be able to open a command prompt and run the following code:
$ python3
Python 3.4.0 (default, Apr 11 2014, 13:05:11) [GCC 4.8.2] on Linux
Type "help", "copyright", "credits" or "license" for more information.
>>> print("Hello, world!") Hello, world!
>>> exit()
Note that we will be using the dollar sign ($) to denote that a command is to be typed into the terminal (also called a shell or cmd on Windows). You do not need to type this character (or the space that follows it). Just type in the rest of the line and press Enter.
Installing IPython
IPython is a platform for Python development that contains a number of tools and environments for running Python and has more features than the standard interpreter. It contains the powerful IPython Notebook, which allows you to write programs in a web browser. It also formats your code, shows output, and allows you to annotate your scripts. It is a great tool for exploring datasets.
To install IPython on your computer, you can type the following into a command-line prompt (not into Python):
$ pip install ipython[all]
You will need administrator privileges to install this system-wide. If you do not want to (or can't) make system-wide changes, you can install it for just the current user by running this command:
$ pip install --user ipython[all]
This will install the IPython package into a user-specific location—you will be able to use it, but nobody else on your computer can. If you are having difficulty with the installation, check the official documentation for more detailed installation instructions: http://ipython.org/install.html.
With the IPython Notebook installed, you can launch it with the following: $ ipython3 notebook
To stop the IPython Notebook from running, open the command prompt that has the instance running (the one you used earlier to run the IPython
Installing additional packages
Python 3.4 will include a program called pip, which is a package manager that helps to install new libraries on your system. You can verify that pip is working on your system by running the $ pip3 freeze command, which tells you which packages you have installed on your system.
The additional packages can be installed via the pip installer program, which has been part of the Python standard library since Python 3.3. More
information about pip can be found at
https://docs.python.org/3/installing/index.html.
After we have successfully installed Python, we can execute pip from the command-line terminal to install additional Python packages:
pip install SomePackage
Already installed packages can be updated via the --upgrade flag: pip install SomePackage --upgrade
A highly recommended alternative Python distribution for scientific computing is Anaconda by Continuum Analytics. Anaconda is a free— including commercial use—enterprise-ready Python distribution that bundles all the essential Python packages for data science, math, and engineering in one user-friendly cross-platform distribution. The Anaconda installer can be downloaded at http://continuum.io/downloads#py34, and an Anaconda quick start-guide is available at https://store.continuum.io/static/img/Anaconda-Quickstart.pdf.
After successfully installing Anaconda, we can install new Python packages using the following command:
conda install SomePackage
The major Python packages that were used for writing this course are listed
As these packages are all hosted on PyPI, the Python package index, they can be easily installed with pip. To install NumPy, you would run:
$ pip install numpy
To install scikit-learn, you would run: $ pip3 install -U scikit-learn
Note
Important
Windows users may need to install the NumPy and SciPy libraries before installing scikit-learn. Installation instructions are available at
www.scipy.org/install.html for those users.
Users of major Linux distributions such as Ubuntu or Red Hat may wish to install the official package from their package manager. Not all distributions have the latest versions of scikit-learn, so check the version before installing it.
Those wishing to install the latest version by compiling the source, or view more detailed installation instructions, can go to
Most libraries will have an attribute for the version, so if you already have a library installed, you can quickly check its version:
>>> import redis
>>> redis.__version__ '2.10.3'
Running Python scripts
Python can be used as a scripting language. In fact, it always proves itself very useful. Scripts are files (usually of small dimensions) that you normally execute to do something like a task. Many developers end up having their own arsenal of tools that they fire when they need to perform a task. For example, you can have scripts to parse data in a format and render it into another different format. Or you can use a script to work with files and folders. You can create or modify configuration files, and much more. Technically, there is not much that cannot be done in a script.
It's quite common to have scripts running at a precise time on a server. For example, if your website database needs cleaning every 24 hours (for
example, the table that stores the user sessions, which expire pretty quickly but aren't cleaned automatically), you could set up a cron job that fires your script at 3:00 A.M. every day.
Note
According to Wikipedia, the software utility Cron is a time-based job scheduler in Unix-like computer operating systems. People who set up and maintain software environments use cron to schedule jobs (commands or shell scripts) to run periodically at fixed times, dates, or intervals.
Running the Python interactive shell
Another way of running Python is by calling the interactive shell. This is something we already saw when we typed python on the command line of our console.
So open a console, activate your virtual environment (which by now should be second nature to you, right?), and type python. You will be presented with a couple of lines that should look like this (if you are on Linux):
Python 3.4.0 (default, Apr 11 2014, 13:05:11) [GCC 4.8.2] on linux
Type "help", "copyright", "credits" or "license" for more information.
Those >>> are the prompt of the shell. They tell you that Python is waiting for you to type something. If you type a simple instruction, something that fits in one line, that's all you'll see. However, if you type something that requires more than one line of code, the shell will change the prompt to ..., giving you a visual clue that you're typing a multiline statement (or anything that would require more than one line of code).
Go on, try it out, let's do some basic maths:
>>> 2 + 4
I use the interactive shell every day. It's extremely useful to debug very quickly, for example, to check if a data structure supports an operation. Or maybe to inspect or run a piece of code.
When you use Django (a web framework), the interactive shell is coupled with it and allows you to work your way through the framework tools, to inspect the data in the database, and many more things. You will find that the interactive shell will soon become one of your dearest friends on the journey you are embarking on.
Another solution, which comes in a much nicer graphic layout, is to use
IDLE (Integrated DeveLopment Environment). It's quite a simple IDE, which is intended mostly for beginners. It has a slightly larger set of
capabilities than the naked interactive shell you get in the console, so you may want to explore it. It comes for free in the Windows Python installer and you can easily install it in any other system. You can find information about it on the Python website.
Running Python as a service
Apart from being run as a script, and within the boundaries of a shell, Python can be coded and run as proper software. We'll see many examples
Running Python as a GUI application
Python can also be run as a GUI (Graphical User Interface). There are several frameworks available, some of which are cross-platform and some others are platform-specific.
Tk is a graphical user interface toolkit that takes desktop application development to a higher level than the conventional approach. It is the
standard GUI for Tool Command Language (TCL), but also for many other dynamic languages and can produce rich native applications that run
seamlessly under Windows, Linux, Mac OS X, and more.
Tkinter comes bundled with Python, therefore it gives the programmer easy access to the GUI world, and for these reasons, I have chosen it to be the framework for the GUI examples that I'll present in this module.
Among the other GUI frameworks, we find that the following are the most widely used:
PyQt wxPython PyGtk
Describing them in detail is outside the scope of this module, but you can find all the information you need on the Python website in the GUI
Programming section. If GUIs are what you're looking for, remember to choose the one you want according to some principles. Make sure they:
Offer all the features you may need to develop your project Run on all the platforms you may need to support
How is Python code organized
Let's talk a little bit about how Python code is organized. In this paragraph, we'll start going down the rabbit hole a little bit more and introduce a bit more technical names and concepts.
Starting with the basics, how is Python code organized? Of course, you write your code into files. When you save a file with the extension .py, that file is said to be a Python module.
Note
If you're on Windows or Mac, which typically hide file extensions to the user, please make sure you change the configuration so that you can see the
complete name of the files. This is not strictly a requirement, but a hearty suggestion.
It would be impractical to save all the code that it is required for software to work within one single file. That solution works for scripts, which are usually not longer than a few hundred lines (and often they are quite shorter than that).
A complete Python application can be made of hundreds of thousands of lines of code, so you will have to scatter it through different modules. Better, but not nearly good enough. It turns out that even like this it would still be impractical to work with the code. So Python gives you another structure, called package, which allows you to group modules together. A package is nothing more than a folder, which must contain a special file, __init__.py that doesn't need to hold any code but whose presence is required to tell Python that the folder is not just some folder, but it's actually a package (note that as of Python 3.3 __init__.py is not strictly required any more).
$ tree -v example
I get a tree representation of the contents of the ch1/example folder, which holds the code for the examples of this chapter. Here's how a structure of a real simple application could look like:
example/
You can see that within the root of this example, we have two modules, core.py and run.py, and one package: util. Within core.py, there may be the core logic of our application. On the other hand, within the run.py module, we can probably find the logic to start the application. Within the util package, I expect to find various utility tools, and in fact, we can guess that the modules there are called by the type of tools they hold: db.py would hold tools to work with databases, math.py would of course hold
mathematical tools (maybe our application deals with financial data), and network.py would probably hold tools to send/receive data on networks.
As explained before, the __init__.py file is there just to tell Python that util is a package and not just a mere folder.
Had this software been organized within modules only, it would have been much harder to infer its structure. I put a module only example under the ch1/files_only folder, see it for yourself:
$ tree -v files_only
This shows us a completely different picture:
├── network.py └── run.py
How do we use modules and packages
When a developer is writing an application, it is very likely that they will need to apply the same piece of logic in different parts of it. For example, when writing a parser for the data that comes from a form that a user can fill in a web page, the application will have to validate whether a certain field is holding a number or not. Regardless of how the logic for this kind of
validation is written, it's very likely that it will be needed in more than one place. For example in a poll application, where the user is asked many question, it's likely that several of them will require a numeric answer. For example:
What is your age
How many pets do you own How many children do you have
How many times have you been married
It would be very bad practice to copy paste (or, more properly said: duplicate) the validation logic in every place where we expect a numeric answer. This would violate the DRY (Don't Repeat Yourself) principle, which states that you should never repeat the same piece of code more than once in your application. I feel the need to stress the importance of this principle: you should never repeat the same piece of code more than once in your application (got the irony?).
There are several reasons why repeating the same piece of logic can be very bad, the most important ones being:
There could be a bug in the logic, and therefore, you would have to correct it in every place that logic is applied.
You may want to amend the way you carry out the validation, and again you would have to change it in every place it is applied.
You may forget to fix/amend a piece of logic because you missed it when searching for all its occurrences. This would leave
wrong/inconsistent behavior in your application.
Python is a wonderful language and provides you with all the tools you need to apply all the coding best practices. For this particular example, we need to be able to reuse a piece of code. To be able to reuse a piece of code, we need to have a construct that will hold the code for us so that we can call that construct every time we need to repeat the logic inside it. That construct exists, and it's called function.
I'm not going too deep into the specifics here, so please just remember that a function is a block of organized, reusable code which is used to perform a task. Functions can assume many forms and names, according to what kind of environment they belong to, but for now this is not important. We'll see the details when we are able to appreciate them, later on, in the module.
Functions are the building blocks of modularity in your application, and they are almost indispensable (unless you're writing a super simple script, you'll use functions all the time).
Python comes with a very extensive library, as I already said a few pages ago. Now, maybe it's a good time to define what a library is: a library is a collection of functions and objects that provide functionalities that enrich the abilities of a language.
For example, within Python's math library we can find a plethora of
functions, one of which is the factorial function, which of course calculates the factorial of a number.
Note
In mathematics, the factorial of a non-negative integer number N, denoted as
N!, is defined as the product of all positive integers less than or equal to N. For example, the factorial of 5 is calculated as:
5! = 5 * 4 * 3 * 2 * 1 = 120
The factorial of 0 is 0! = 1, to respect the convention for an empty product.
input values and the concept of calling is not very clear for now, please just concentrate on the import part.
Note
We use a library by importing what we need from it, and then we use it.
In Python, to calculate the factorial of number 5, we just need the following code:
>>> from math import factorial >>> factorial(5)
120
Note
Whatever we type in the shell, if it has a printable representation, will be printed on the console for us (in this case, the result of the function call: 120).
So, let's go back to our example, the one with core.py, run.py, util, and so on.
In our example, the package util is our utility library. Our custom utility belt that holds all those reusable tools (that is, functions), which we need in our application. Some of them will deal with databases (db.py), some with the network (network.py), and some will perform mathematical calculations (math.py) that are outside the scope of Python's standard math library and therefore, we had to code them for ourselves.
Python's execution model
Names and namespaces
Say you are looking for a module, so you go to the library and ask someone for the module you want to fetch. They tell you something like "second floor, section X, row three". So you go up the stairs, look for section X, and so on.
It would be very different to enter a library where all the books are piled together in random order in one big room. No floors, no sections, no rows, no order. Fetching a module would be extremely hard.
When we write code we have the same issue: we have to try and organize it so that it will be easy for someone who has no prior knowledge about it to find what they're looking for. When software is structured correctly, it also promotes code reuse. On the other hand, disorganized software is more likely to expose scattered pieces of duplicated logic.
First of all, let's start with the module. We refer to a module by its title and in Python lingo, that would be a name. Python names are the closest abstraction to what other languages call variables. Names basically refer to objects and are introduced by name binding operations. Let's make a quick example (notice that anything that follows a # is a comment):
>>> n = 3 # integer number
>>> address = "221b Baker Street, NW1 6XE, London" # S. Holmes >>> employee = {
... 'age': 45, ... 'role': 'CTO',
... 'SSN': 'AB1234567', ... }
>>> # let's print them >>> n
3
>>> address
'221b Baker Street, NW1 6XE, London' >>> employee
{'role': 'CTO', 'SSN': 'AB1234567', 'age': 45}
>>> # what if I try to print a name I didn't define? >>> other_name
NameError: name 'other_name' is not defined
We defined three objects in the preceding code (do you remember what are the three features every Python object has?):
An integer number n (type: int, value: 3)
A string address (type: str, value: Sherlock Holmes' address)
A dictionary employee (type: dict, value: a dictionary which holds three key/value pairs)
Don't worry, I know you're not supposed to know what a dictionary is. We'll see in the upcoming chapter that it's the king of Python data structures.
Note
Have you noticed that the prompt changed from >>> to ... when I typed in the definition of employee? That's because the definition spans over multiple lines.
So, what are n, address and employee? They are names. Names that we can use to retrieve data within our code. They need to be kept somewhere so that whenever we need to retrieve those objects, we can use their names to fetch them. We need some space to hold them, hence: namespaces!
A namespace is therefore a mapping from names to objects. Examples are the set of built-in names (containing functions that are always accessible for free in any Python program), the global names in a module, and the local names in a function. Even the set of attributes of an object can be considered a namespace.
The beauty of namespaces is that they allow you to define and organize your names with clarity, without overlapping or interference. For example, the namespace associated with that module we were looking for in the library can be used to import the module itself, like this:
from library.second_floor.section_x.row_three import module
we walk into that namespace. Within this namespace, we look for
second_floor, and again we walk into it with the . operator. We then walk into section_x, and finally within the last namespace, row_tree, we find the name we were looking for: module.
Walking through a namespace will be clearer when we'll be dealing with real code examples. For now, just keep in mind that namespaces are places where names are associated to objects.
Scopes
According to Python's documentation, a scope is a textual region of a Python program, where a namespace is directly accessible. Directly accessible
means that when you're looking for an unqualified reference to a name, Python tries to find it in the namespace.
Scopes are determined statically, but actually during runtime they are used dynamically. This means that by inspecting the source code you can tell what the scope of an object is, but this doesn't prevent the software to alter that during runtime. There are four different scopes that Python makes accessible (not necessarily all of them present at the same time, of course):
The local scope, which is the innermost one and contains the local names.
The enclosing scope, that is, the scope of any enclosing function. It contains non-local names and also non-global names.
The global scope contains the global names.
The built-in scope contains the built-in names. Python comes with a set of functions that you can use in a off-the-shelf fashion, such as print, all, abs, and so on. They live in the built-in scope.
The rule is the following: when we refer to a name, Python starts looking for it in the current namespace. If the name is not found, Python continues the search to the enclosing scope and this continue until the built-in scope is searched. If a name hasn't been found after searching the built-in scope, then Python raises a NameError exception, which basically means that the name hasn't been defined (you saw this in the preceding example).
The order in which the namespaces are scanned when looking for a name is therefore: local, enclosing, global, built-in (LEGB).
scopes1.py
# Local versus Global
# we define a function, called local def local():
m = 7
print(m)
m = 5
print(m)
# we call, or `execute` the function local local()
In the preceding example, we define the same name m, both in the global scope and in the local one (the one defined by the function local). When we execute this program with the following command (have you activated your virtualenv?):
$ python scopes1.py
We see two numbers printed on the console: 5 and 7.
What happens is that the Python interpreter parses the file, top to bottom. First, it finds a couple of comment lines, which are skipped, then it parses the definition of the function local. When called, this function does two things: it sets up a name to an object representing number 7 and prints it. The Python interpreter keeps going and it finds another name binding. This time the
binding happens in the global scope and the value is 5. The next line is a call to the print function, which is executed (and so we get the first value printed on the console: 5).
After this, there is a call to the function local. At this point, Python executes the function, so at this time, the binding m = 7 happens and it's printed.
others three, but the suggested number of spaces to use is four. It's a good measure to maximize readability. We'll talk more about all the conventions you should embrace when writing Python code later.
What would happen if we removed that m = 7 line? Remember the LEGB rule. Python would start looking for m in the local scope (function local), and, not finding it, it would go to the next enclosing scope. The next one in this case is the global one because there is no enclosing function wrapped around local. Therefore, we would see two number 5 printed on the console. Let's actually see how the code would look like:
scopes2.py
# Local versus Global def local():
# m doesn't belong to the scope defined by the local function # so Python will keep looking into the next enclosing scope. # m is finally found in the global scope
print(m, 'printing from the local scope')
m = 5
print(m, 'printing from the global scope') local()
Running scopes2.py will print this:
(.lpvenv)fab@xps:ch1$ python scopes2.py 5 printing from the global scope
5 printing from the local scope
As expected, Python prints m the first time, then when the function local is called, m isn't found in its scope, so Python looks for it following the LEGB chain until m is found in the global scope.
Let's see an example with an extra layer, the enclosing scope: scopes3.py
def enclosing_func():
print(m, 'printing from the global scope') enclosing_func()
Running scopes3.py will print on the console:
(.lpvenv)fab@xps:ch1$ python scopes3.py 5 printing from the global scope
13 printing from the local scope
As you can see, the print instruction from the function local is referring to m as before. m is still not defined within the function itself, so Python starts walking scopes following the LEGB order. This time m is found in the enclosing scope.
Don't worry if this is still not perfectly clear for now. It will come to you as we go through the examples in the module. The Classes section of the Python tutorial (official documentation) has an interesting paragraph about scopes and namespaces. Make sure you read it at some point if you wish for a deeper understanding of the subject.
Guidelines on how to write good
code
Writing good code is not as easy as it seems. As I already said before, good code exposes a long list of qualities that is quite hard to put together. Writing good code is, to some extent, an art. Regardless of where on the path you will be happy to settle, there is something that you can embrace which will make your code instantly better: PEP8.
According to Wikipedia:
"Python's development is conducted largely through the Python
Enhancement Proposal (PEP) process. The PEP process is the primary mechanism for proposing major new features, for collecting community input on an issue, and for documenting the design decisions that have gone into Python."
Among all the PEPs, probably the most famous one is PEP8. It lays out a simple but effective set of guidelines to define Python aesthetic so that we write beautiful Python code. If you take one suggestion out of this chapter, please let it be this: use it. Embrace it. You will thank me later.
Coding today is no longer a check-in/check-out business. Rather, it's more of a social effort. Several developers collaborate to a piece of code through tools like git and mercurial, and the result is code that is fathered by many different hands.
Note
Git and Mercurial are probably the most used distributed revision control systems today. They are essential tools designed to help teams of developers collaborate on the same software.
abide with PEP8, it's not uncommon for any of them landing on a piece of code to think they wrote it themselves. It actually happens to me all the time (I always forget the code I write).
This has a tremendous advantage: when you read code that you could have written yourself, you read it easily. Without a convention, every coder would structure the code the way they like most, or simply the way they were taught or are used to, and this would mean having to interpret every line according to someone else's style. It would mean having to lose much more time just trying to understand it. Thanks to PEP8, we can avoid this. I'm such a fan of it that I won't sign off a code review if the code doesn't respect it. So please take the time to study it, it's very important.
In the examples of this module, I will try to respect it as much as I can. Unfortunately, I don't have the luxury of 79 characters (which is the
The Python culture
Python has been adopted widely in all coding industries. It's used by many different companies for many different purposes, and it's also used in education (it's an excellent language for that purpose, because of its many qualities and the fact that it's easy to learn).
One of the reasons Python is so popular today is that the community around it is vast, vibrant, and full of brilliant people. Many events are organized all over the world, mostly either around Python or its main web framework, Django.
Python is open, and very often so are the minds of those who embrace it. Check out the community page on the Python website for more information and get involved!
There is another aspect to Python which revolves around the notion of being
Pythonic. It has to do with the fact that Python allows you to use some idioms that aren't found elsewhere, at least not in the same form or easiness of use (I feel quite claustrophobic when I have to code in a language which is not Python now).
Anyway, over the years, this concept of being Pythonic has emerged and, the way I understand it, is something along the lines of doing things the way they are supposed to be done in Python.
To help you understand a little bit more about Python's culture and about being Pythonic, I will show you the Zen of Python. A lovely Easter egg that is very popular. Open up a Python console and type import this. What follows is the result of this line:
>>> import this
The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex.
Flat is better than nested. Sparse is better than dense. Readability counts.
Special cases aren't special enough to break the rules. Although practicality beats purity.
Errors should never pass silently. Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those!
Note
Downloading the example code
The code files for all the four parts of the course are available at
https://github.com/PacktPublishing/Data-Science-With-Python. There are two levels of reading here. One is to consider it as a set of
guidelines that have been put down in a fun way. The other one is to keep it in mind, and maybe read it once in a while, trying to understand how it refers to something deeper. Some Python characteristics that you will have to