Analisis Perilaku Pembayaran
Anggota Pusat Kebugaran Silver Sport Club Salatiga
dengan
Clustering Data Mining
Artikel Ilmiah
Peneliti:
Rifky Hangga Permana (672010606) Magdalena A. Ineke Pakereng, M.Kom.
Program Studi Teknik Informatika
Fakultas Teknologi Informasi
Universitas Kristen Satya Wacana
ii
Analisis Perilaku Pembayaran
Anggota Pusat Kebugaran Silver Sport Club Salatiga
dengan
Clustering Data Mining
Artikel Ilmiah
Diajukan kepada
Fakultas Teknologi Informasi
untuk memperoleh gelar Sarjana Komputer
Peneliti:
Rifky Hangga Permana (672010606) Magdalena A. Ineke Pakereng, M.Kom.
Program Studi Teknik Informatika
Fakultas Teknologi Informasi
Universitas Kristen Satya Wacana
Analisis Perilaku Pembayaran
Anggota Pusat Kebugaran Silver Sport Club Salatiga
dengan
Clustering
Data mining
1)
Rifky Hangga Permana 2)Magdalena A. Ineke Pakereng,
Fakultas Teknologi Informasi Universitas Kristen Satya Wacana Jl. Diponegoro 52-60, Salatiga 50711, Indonesia
Email: 1)[email protected], 2) [email protected]
Abstract
Silver Sport Club Salatiga seeks to sustain business and at the same time also increases the number of members who come to exercise. A customer retention strategy requires knowledge of customer characteristics, which can be obtained from the information systems used by the company. This study aims to develop software that can be used to shape customer segmentation in the Silver Sport Club. The method used in this research is clustering with K-Means algorithm. The result of this research is the application of Silver Sprot Club customer data clustering. Benefits that can be given by the cluster forming results are, the discovery of new knowledge, namely the pattern of attendance and payment patterns of customers. For Silver Sport Club, this knowledge can be used as a basis to provide promotions, discounts, or other business strategies.
Keywords: Clustering, Data Mining, K-Means
Abstrak
Silver Sport Club Salatiga berusaha untuk mempertahankan usaha dan pada saat yang bersamaan juga meningkatkan jumlah member yang datang untuk berolah raga. Strategi mempertahankan pelanggan memerlukan pengetahuan tentang karakteristik pelanggan, yang dapat diperoleh dari sistem informasi yang digunakan oleh perusahaan tersebut. Penelitian ini bertujuan untuk mengembangkan perangkat lunak yang dapat digunakan untuk membentuk segmentasi pelanggan yang ada di Silver Sport Club. Metode yang digunakan pada penelitian ini adalah
clustering dengan algoritma K-Means. Hasil dari penelitian ini adalah aplikasi clustering data pelanggan Silver Sport Club. Manfaat yang dapat diberikan oleh hasil pembentukan cluster tersebut adalah ditemukannya pengetahuan baru, yaitu pola kehadiran dan pola pembayaran pelanggan. Bagi Silver Sport Club, pengetahuan ini dapat digunakan sebagai dasar untuk memberikan promosi, diskon, atau strategi bisnis yang lain.
Kata Kunci: Clustering, Data Mining, K-Means
1)
Mahasiswa Program Studi Pendidikan Teknologi Informasi dan Komputer, Fakultas Teknologi Informasi, Universitas Kristen Satya Wacana
2)
1
1. Pendahuluan
Sektor usaha yang bergerak dalam bidang rekreasi dan pariwisata memberikan sumbangan 10 persen dari total PDB [1]. Salah satu usaha yang masuk kategori rekreasi ini adalah UMKM dalam bidang olah raga. UMKM jenis ini pada umumnya menyediakan jasa sewa sarana dan lokasi olah raga dan kebugaran. Salah satu daerah di Indonesia yang mengalami kemajuan di bidang UMKM yaitu Salatiga. Berdasarkan data UMKM binaan tri wulan IV tahun 2013 yang diperoleh dari Dinas Perindustrian, Perdagangan, Koperasi dan UMKM kota Salatiga, jumlah UMKM yang terdaftar mencapai 1.008 unit dengan jenis usaha perternakan, pertanian, industri, pengolahan, perdagangan, hotel, restoran, bangunan, pertambangan dan galian, komunikasi, gas, air bersih, dan jasa-jasa lain. Penyerapan jumlah tenaga kerja pada UMKM Salatiga pada tahun 2013 mencapai 4.0063 orang yang merupakan jumlah dari penyerapan tenaga kerja usaha mikro sebanyak 3.129 orang, usaha kecil 928 orang, usaha menengah sebanyak 6 orang [2].
Silver Club Sport merupakan salah satu UKM di Salatiga, yang memiliki bidang usaha persewaan sarana dan lokasi kebugaran dengan memiliki visi untuk menjadi pusat kegiatan olahraga dan kebugaran di Salatiga. Pendapatan perusahaan diperoleh dari biaya membership yang dibayarkan oleh pelanggannya tiap bulan. Berdasarkan hasil wawancara dengan pemilik usaha, Silver Club Sport berusaha untuk mempertahankan jumlah pelanggan 100 pelanggan tiap bulan. Strategi mempertahankan pelanggan ini memerlukan pengetahuan tentang karakteristik pelanggan. Tiap pelanggan memiliki atribut yang berbeda-beda, seperti umur, status pekerjaan, lama menjadi anggota, dan ketertiban dalam hal membayar biaya membership. Pengetahuan tentang pelanggan merupakan aset yang kritikal [3]. Usaha untuk mengumpulkan, mengelola dan membagi pengetahuan tentang pelanggan dapat menjadi kegiatan yang penting bagi suatu usaha kecil menengah (UKM) [4]. Berdasarkan informasi tersebut, dapat dikatakan bahwa Silver Club Sport menghadapi masalah yaitu bagaimana mempertahankan pelanggan, meningkatkan pelanggan.
Silver Club Sport memiliki dasar pengetahuan pelanggan diperoleh dari sistem informasi yang selama ini digunakan untuk mencatat pendaftaran, pembayaran, dan kehadiran pelanggan. Pengetahuan tentang pelanggan dapat diperoleh dari sistem informasi yang digunakan oleh perusahaan [5]. Selama ini, solusi yang digunakan untuk memahami data pelanggan adalah dengan menggunakan aplikasi spreadsheet. Informasi yang diperoleh dari proses tersebut adalah jumlah kehadiran pelanggan per bulan, jumlah hadir per pelanggan dalam bulan tertentu, dan jumlah pelanggan baru per bulan.
lebih dalam untuk mengenali pola perilaku pelanggan, yaitu dalam hal pola kedatangan dan pola pembayaran.
Proses segmentasi ini dapat ditempuh dengan menggunakan teknik Knowledge Discovery Data mining [8]. Salah satu metode pengenalan pola dalam KDD adalah teknik clustering. Algoritma yang sering digunakan adalah K-Means [9]. K-Means merupakan salah satu metode data non-hierarchical clustering yang dapat mengelompokkan data ke dalam beberapa cluster berdasarkan kemiripan dari data tersebut, sehingga data yang memiliki karakteristik yang sama dikelompokkan dalam satu cluster dan yang memiliki karakteristik yang berbeda dikelompokkan dalam cluster yang lain yang memiliki karakteristik yang sama [7]. Pada penerapannya di Silver Sport Club, maka satu cluster akan mewakili satu segmen pelanggan.
Penelitian ini bertujuan untuk menggali perilaku pembayaran ini, kemudian menghubungkan perilaku pembayaran dengan perilaku kedatangan anggota yaitu seberapa rajin anggota club untuk datang berolahraga dalam satu minggu atau bulan. Analisis akan dilakukan dengan teknik clustering dengan atribut yang digunakan adalah rata-rata jeda waktu pembayaran, dan rata-rata kedatangan anggota club per bulan.
2. Tinjauan Pustaka
Terdapat beberapa penelitian terdahulu yang digunakan sebagai acuan pada penelitian ini. Penelitian-penelitian ini menggunakan data mining untuk tujuan mengenali melakukan klasifikasi data, sehingga hasilnya dapat digunakan sebagai pendukung pengambilan keputusan. Wei pada penelitiannya [10] menggunakan teknik data mining untuk mengidentifikasi tipe pelanggan pada penyedia layanan tata rambut. Teknik yang digunakan merupakan kombinasi antara self-orginizing map (SOM) dan K-means untuk diterapkan pada model RFM (recency, frequency, dan monetary). Teknik tersebut membantu mengidentifikasi empat tipe pelanggan, yaitu pelanggan setia, pelanggan potensial, pelanggan baru dan pelanggan hilang, dan kemudian membangun strategi pemasaran yang spesifik bagi empat tipe pelanggan tersebut. Wei tidak menyebutkan angka tingkat akurasi dari identifikasi yang dihasilkan. Namun berhasil mengidentifikasi pelanggan ke dalam empat kategori, sekaligus memberikan kebiasaan dan saran strategi bisnis untuk tiap jenis pelanggan. Untuk pelanggan setia, penting untuk diberikan layanan yang dapat dikostumisasi sewaktu-waktu, memberikaan promosi layanan yang dapat dicoba secara gratis, dan mengirimkan informasi tentang produk dan layanan yang baru. Bagi pelanggan yang potensial, strateginya adalah dengan memberikan informasi tentang kegiatan promosi yang akhir-akhir ini dilakukan, dan layanan spesial untuk perawatan rambut. Salon juga dapat memberikan gift atau diskon untuk tiap transaksi dengan batas jumlah tertentu. Bagi pelanggan baru, salon dapat memberikan layanan yang nyaman dengan tujuan untuk membuat pelanggan tinggal lebih lama. Parkir gratis dan konsultasi gratis juga dapat mendukung strategi ini sehingga pelanggan baru tertarik untuk data lagi. Bagi kategori pelanggan yang hilang, pihak salon dapat menggunakan media promosi yang murah sebagai contoh email dan sms, untuk menginformasikan promosi produk dan layanan yang baru.
3
mining yang digunakan dengan mengelompokkan data berdasarkan kemiripan data tersebut. Pada penelitian tersebut, clustering digunakan untuk membantu menemukan sejumlah aturan dari data transaksi penjualan produk buku pada Toko Buku Gramedia Palembang, sehingga untuk selanjutnya dapat digunakan sebagai pertimbangan dalam menentukan strategi penjualan yang efektif.
Ramadhani menggunakan K-Means untuk menentukan strategi promosi Universitas Dian Nuswantoro [12]. Proses penerimaan mahasiswa baru Universitas Dian Nuswantoro menghasilkan data mahasiswa yang sangat besar berupa data profil mahasiswa dan data kegiatan belajar mengajar. Hal tersebut terjadi secara berulang dan menimbulkan penumpukan terhadap data mahasiswa, sehingga mempengaruhi pencarian informasi terhadap data tersebut. Penelitian ini bertujuan untuk melakukan pengelompokan terhadap data mahasiswa Universitas Dian Nuswantoro dengan memanfaatkan proses data mining dengan menggunakan teknik Clustering. Metode yang digunakan adalah CRISP-DM dengan melalui proses business understanding, data understanding, data preparation, modeling, evaluation dan deployment. Algoritma yang digunakan untuk pembentukan cluster adalah algoritma K-Means. K-Means merupakan salah satu metode data non-hierarchical clustering yang dapat mengelompokkan data mahasiswa ke dalam beberapa cluster berdasarkan kemiripan dari data tersebut, sehingga data mahasiswa yang memiliki karakteristik yang sama dikelompokkan dalam satu cluster dan yang memiliki karakteristik yang berbeda dikelompokkan dalam cluster yang lain. Implementasi menggunakan Rapid Miner 5.3 digunakan untuk membantu menemukan nilai yang akurat. Atribut yang digunakan adalah kota asal, program studi dan IPK mahasiswa. Cluster mahasiswa yang terbentuk adalah tiga cluster, dengan cluster pertama 804 mahasiswa, cluster kedua 2792 mahasiswa dan cluster ketiga sejumlah 223 mahasiswa. Hasil dari penelitian ini digunakan sebagai salah satu dasar pengambilan keputusan untuk menentukan strategi promosi berdasarkan cluster yang terbentuk oleh pihak admisi UDINUS.
Pada penelitian Via, Nugroho dan Syafrizal [13], digunakan algoritma Naïve Bayes untuk membangun sistem pendukung keputusan klasifikasi tingkat keganasan kanker payudara. Kanker payudara merupakan salah satu jenis kanker yang sering ditemukan pada kebanyakan wanita. Kanker ini ditandai dengan sel-sel abnormal yang tumbuh di luar kendali pada payudara. Hal ini menunjukkan bahwa kanker payudara adalah penyakit yang sangat ganas dan karenanya memerlukan pemeriksaan intensif dengan mendeteksi dini tingkat keganasan kanker payudara. Penelitian tersebut menganalisis tentang pengelompokan data kanker payudara untuk mengetahui kanker tersebut termasuk kanker jinak atau kanker ganas. Penelitian tersebut menggunakan 9 atribut sebagai masukan sistem dan data set yang digunakan adalah data set publik Breast Cancer Wisconsin Original (WBCO) yang diambil dari UCI Machine Learning. Untuk mengklasifikasi tingkat keganasan dapat dilakukan dengan pemanfaatan bio informatic dengan menggunakan teknik data mining salah satunya adalah algoritma Naïve Bayes Classifier (NBC). Berdasarkan hasil pengujian dengan confusion matrix diketahui bahwa NBC yang diterapkan untuk melakukan klasifikasi tingkat keganasan kanker payudara memiliki akurasi pola yang cukup besar yaitu 97,82%, sedangkan error rate yang dihasilkan sebesar 2,18%. Hasil penelitian tersebut menunjukkan bahwa dengan error rate yang cukup kecil maka algoritma Naïve Bayes Classifier terbukti cukup bagus untuk melakukan klasifikasi pada data WBCO.
Pada penelitian Amborowati, dianalisis dukungan business intelligence khususnya pada bidang marketing intelligence pada strategi pemasaran dengan metode yang digunakan adalah studi literatur. Dan hasilnya adalah bahwa dukungan marketing intelligence pada strategi pemasaran dari sisi teknologi adalah untuk melakukan segmentasi pasar/ konsumen yang salah satunya dengan teknologi data mining.
Berdasarkan penelitian-penelitian terkait data mining dan clustering, maka dilakukan penelitian yang membahas tentang data mining untuk mengenali perilaku pembayaran anggota club pusat kebugaran Silver Sport Club Salatiga. Rumusan masalah dalam penelitian adalah bagaimana menggali perilaku pembayaran anggota club, dan menghubungkan perilaku pembayaran dengan perilaku kedatangan anggota yaitu seberapa rajin anggota club untuk datang berolahraga dalam satu minggu atau bulan.
Penelitian ini menggunakan data mining untuk menemukan pengetahuan dari tumpukan data. Pada bagian ini dibahas beberapa teori yang digunakan yaitu data mining dan knowledge discovery in database, clustering sebagai salah satu teknik dalam data mining, dan algoritma K-Means yang merupakan salah satu algoritma untuk pembentukan cluster.
Data mining merupakan solusi yang mampu menemukan kandungan informasi yang tersembunyi berupa pola dan aturan sekumpulan data yang besar agar mudah dipahami [15]. Data mining didefinisikan sebuah proses untuk menemukan hubungan, pola, dan tren baru yang bermakna dengan menyaring data yang sangat besar, yang tersimpan dalam penyimpanan menggunakan teknik pengenalan pola seperti teknik statistik dan matematika.
Data mining dan knowledge discovery in database (KDD) merupakan istilah yang memiliki konsep yang berbeda akan tetapi saling berkaitan karena data mining adalah bagian dalam proses knowledge discovery in database [16]. KDD adalah kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. Keluaran dari data mining ini dapat digunakan untuk memperbaiki pengambilan keputusan di masa depan.
Clustering merupakan metode pengelompokan data, record, pengamatan, atau memperhatikan untuk membentuk kelas-kelas objek baru yang memiliki kemiripan satu dengan yang lainnya. Contoh penerapan clustering dalam bisnis dan penelitian adalah: 1) Mendapatkan kelompok-kelompok konsumen untuk target pemasaran dari suatu produk
bagi perusahaan yang tidak memiliki dana pemasaran yang besar.
2) Untuk tujuan audit akuntansi, yaitu melakukan pemisahan terhadap perilaku finansial dalam baik dan mencurigakan.
5
Clustering adalah proses membagi dataset ke dalam kelompok-kelompok dengan anggota tiap kelompok memiliki kedekatan sifat atau perilaku. Clustering merupakan pembelajaran tanpa pengawasan (unsupervised learning). Clustering dapat mengungkap hubungan yang sebelumnya tidak terdeteksi dalam dataset. Ada banyak aplikasi untuk clustering. Misalnya, dalam bisnis, clustering dapat digunakan untuk menemukan dan mengenali segmen pelanggan, untuk tujuan pemasaran. Pada bidang biologi, dapat digunakan untuk klasifikasi tumbuhan dan hewan berdasarkan fitur/ciri khas yang dimiliki, seperti cara berkembang biak, alat pernafasan yang dimiliki, sistem pencernaan, dan lain-lain [17].
Tan membagi clustering dalam dua kelompok, yaitu hierarchical and partitional clustering [18]. Partitional Clustering disebutkan sebagai pembagian obyek-obyek data ke dalam kelompok yang tidak saling overlap sehingga setiap data berada tepat di satu cluster [19]. Hierarchical clustering adalah sekelompok cluster yang bersarang seperti sebuah pohon berjenjang (hirarki) [20]. Algoritma clustering terbagi ke dalam kelompok besar seperti berikut:
1. Partitioning algorithms: algoritma dalam kelompok ini membentuk bermacam partisi dan kemudian mengevaluasinya dengan berdasarkan beberapa kriteria.
2. Hierarchy algorithms: pembentukan dekomposisi hirarki dari sekumpulan data menggunakan beberapa kriteria.
3. Density-based: pembentukan cluster berdasarkan pada koneksi dan fungsi densitas [21].
4. Grid-based: pembentukan cluster berdasarkan pada struktur multiple-level granularity.
5. Model-based: sebuah model dianggap sebagai hipotesa untuk masing-masing cluster dan model yang baik dipilih di antara model hipotesa tersebut.
Algoritma K-Means adalah algoritma clustering yang paling popular dan banyak digunakan dalam dunia industri [22]. Algoritma ini disusun atas dasar ide yang sederhana. Algoritma K-Means merupakan model centroid. Model centroid adalah model yang menggunakan centroid untuk membuat cluster. Centroid adalah “titik tengah” suatu cluster yang berupa nilai. Centroid digunakan untuk menghitung jarak suatu obyek data terhadap centroid.
(1) Rumus untuk K-Means ditunjukkan pada Persamaan 1. J adalah fungsi objective, k adalah jumlah kluster, n adalah jumlah data, xi adalah data ke-I, cj adalah titik tengah cluster ke-j. ||xi-cj||2 adalah fungsi jarak. Fungsi jarak digunakan untuk mengukur jarak antara satu data terhadap suatu cluster.
Pada awalnya ditentukan berapa cluster yang akan dibentuk. Sembarang obyek atau elemen pertama dalam cluster dapat dipilih untuk dijadikan sebagai titik tengah (centroid point) cluster. Algoritma K-Means selanjutnya akan melakukan pengulangan sampai terjadi kestabilan (tidak ada obyek yang dapat dipindahkan). Berikut langkah-langkahnya :
1. Menentukan koordinat titik tengah setiap cluster.
2. Menentukan jarak setiap obyek terhadap koordinat titik tengah.
1. Tentukan k sebagai jumlah cluster yang dibentuk. Untuk menentukan banyaknya cluster k dilakukan dengan beberapa pertimbangan seperti pertimbangan teoritis dan konseptual yang mungkin diusulkan untuk menentukan berapa banyak cluster. 2. Bangkitkan k Centroid (titik pusat cluster) awal secara random. Penentuan centroid
awal dilakukan secara random/acak dari objek-objek yang tersedia sebanyak k cluster, kemudian untuk menghitung centroid cluster ke-i berikutnya,
3. Hitung jarak setiap objek ke masing-masing centroid dari masing-masing cluster. Ada beberapa cara penghitungan jarak yang biasa digunakan yaitu: Euclidean distance, Manhattan distance disebut juga taxicab, Chebichev distance. Persamaan untuk Euclidean distance yang digunakan pada penelitian ini adalah sebagai berikut:
(2) dengan 𝑑 (𝑥𝑖 , 𝜇𝑖) adalah jarak antara cluster𝑥 dengan pusat cluster𝜇 pada kata ke i ,
𝑥𝑖 adalah bobot kata ke i pada cluster yang ingin dicari jaraknya, 𝜇𝑖 bobot kata ke i
pada pusat cluster.
4. Alokasikan masing-masing objek ke dalam centroid yang paling terdekat.
5. Lakukan iterasi, kemudian tentukan posisi centroid baru dengan menghitung rata-rata tiap atribut yang dimiliki oleh objek-objek di dalam cluster. Persamaan yang digunakan untuk menentukan titik baru (centroid) cluster adalah berikut:
(3) Dimana 𝑛𝑘 = jumlah data dalam cluster, dan 𝑑𝑖 = jumlah dari nilai jarak yang masuk dalam masing-masing cluster
6. Ulangi langkah 3 jika posisi centroid mengalami perubahan nilai, atau jika batas maksimal iterasi sudah tercapai.
Pada clustering, diperlukan nilai jarak yang digunakan untuk menentukan kedekatan suatu data terhadap titik pusat cluster. Pendekatan pengukuran jarak di antaranya adalah Euclidean distance dan Manhattan distance.
Euclidean distance adalah perhitungan jarak dari 2 buah titik dalam Euclidean space. Euclidean space diperkenalkan oleh Euclid, seorang matematikawan dari Yunani sekitar tahun 300 SM. untuk mempelajari hubungan antara sudut dan jarak. Euclidean ini berkaitan dengan Teorema Phytagoras dan biasanya diterapkan pada 1, 2 dan n dimensi [24].
Pada bidang 1 dimensi, rumus Euclidean diberikan:
(4)
Pada bidang 2 dimensi, jika p= (p1,p2) dan q = (q1, q2), maka jarak dapat diperoleh dengan rumus:
(5)
7
(6)
Manhattan distance/City Block distance, merupakan salah satu teknik yang sering digunakan untuk menentukan kesamaan antara dua buah obyek. Pengukuran ini dihasilkan berdasarkan penjumlahan jarak selisih antara dua buah obyek dan hasil yang didapatkan dari Manhattan distance bernilai mutlak Dimana, Manhattan distance melakukan perhitungan jarak dengan cara tegak lurus [25].
(7)
Sebagai contoh, jarak antara (p1, p2) dan (q1, q2) adalah:
(8)
3. Metode Penelitian
Pada penelitian ini dilakukan analisis perilaku pembayaran yang dilakukan oleh anggota Silver Sport Club. Anggota club melakukan pembayaran sesuai dengan jenis keanggotaan. Sebagai contoh, dengan membayar 80 ribu rupiah, maka anggota club dapat menggunakan fasilitas club selama 30 hari. Setelah masa 30 hari ini, anggota club perlu melakukan pembayaran lagi, yang disebut dengan “reload”. Tidak ada denda yang diberikan jika pembayaran terlambat, namun konsekuensinya adalah anggota club dengan masa keanggotaan yang belum “reload”, tidak diijinkan masuk dan menggunakan fasilitas club. Bagi sisi pengusaha club, anggota yang paling menguntungkan adalah anggota yang sesegera mungkin melakukan “reload”.
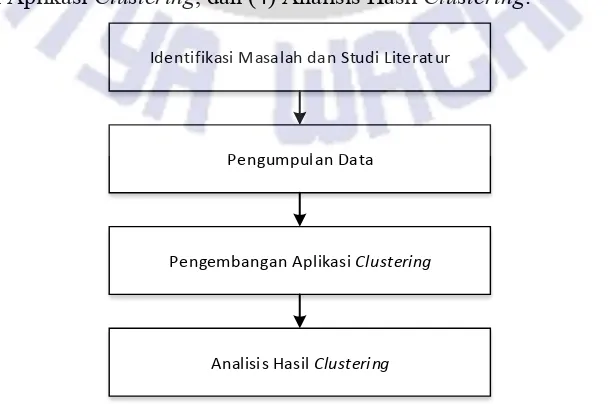
Penelitian yang dilakukan, diselesaikan melalui tahapan penelitian yang terbagi dalam empat tahapan, yaitu: (1) Identifikasi masalah dan studi literatur, (2) Pengumpulan Data, (3) Pengembangan Aplikasi Clustering, dan (4) Analisis Hasil Clustering.
Identifikasi Masalah dan Studi Literatur
Pengumpulan Data
Pengembangan Aplikasi Clustering
Analisis Hasil Clustering
Tahapan penelitian pada Gambar 2, dapat dijelaskan sebagai berikut. Tahap pertama: identifikasi masalah dan studi literatur, yaitu bagaimana menganalisis perilaku pelanggan berdasarkan data pelanggan yang ada di Silver Sport Club, dan bagaimana menerapkan hasil analisis tersebut untuk kemajuan usaha Silver Sport Club. Studi literatur dilakukan dengan tujuan menemukan dan mempelajari penelitian terdahulu dan teori mengenai pengolahan data, terutama data pelanggan untuk mengenali karakteristik pelanggan, sehingga dapat bermanfaat untuk kemajuan bisnis; Tahap kedua: pengumpulan data, yaitu data yang berasal dari sistem informasi absensi yang saat ini digunakan oleh Silver Sport Club. Data yang diambil adalah sebagian data, bukan keseluruhan data. Data ini meliputi tabel Member, tabel Pembayaran, dan tabel Absensi; Tahap ketiga: pengembangan aplikasi clustering. Pada tahap ini dikembangkan sebuah aplikasi clustering, yang berfungsi untuk membaca data yang telah diambil dari tahap kedua, dan melakukan proses clustering; dan Tahap keempat: analisis hasil clustering. Analisis dilakukan pada cluster yang terbentuk dari tahap ketiga. Pada tahap ini diharapkan untuk diperoleh pengetahuan baru mengenai perilaku kedatangan dan pembayaran yang dilakukan oleh anggota club.
9
4. Hasil dan Pembahasan
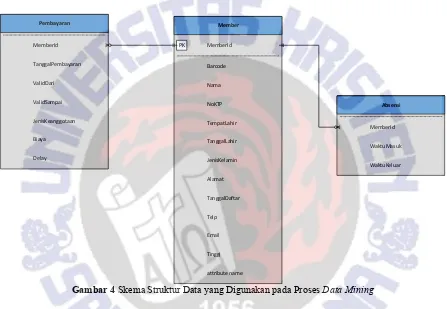
Aplikasi cluster dikembangkan dengan menggunakan pustaka .Net Framework 4.5, dengan database yang digunakan adalah Sql Server 2012 Express Edition. Penulisan program dilakukan dengan menggunakan Visual Studio 2015. Data yang digunakan pada penelitian ini, terdiri dari 2859 record data member, dan 45,509 record catatan kehadiran member. Data diperoleh dari pengelola Silver Sport Club, yang merupakan catatan kehadiran member sejak bulan Februari 2012 sampai dengan November 2017. Database ini terdiri dari beberapa tabel, beberapa tabel yang digunakan untuk proses analisis adalah tabel Member, tabel Pembayaran dan tabel Absensi. Struktur tabel dan hubungan antar tabel
Gambar 4 Skema Struktur Data yang Digunakan pada Proses Data Mining
Tiga tabel tersebut kemudian disederhanakan, sehingga mudah untuk proses analisis K-Means. Berdasarkan tabel-tabel tersebut, diambil field MemberId, TanggalDaftar dari tabel Member. Pada tabel pembayaran, dilakukan proses penyatuan (aggregate) dengan fungsi rata-rata, sehingga diperoleh rata-rata keterlambatan pembayaran tiap member. Demikian juga pada tabel absensi, dilakukan perhitungan rata-rata kehadiran member tiap bulan. Hasil akhir diringkas ke dalam satu tabel, dengan struktur dan contoh data ditunjukkan pada Tabel 1.
Tabel 1 Struktur Tabel dan Contoh Data Untuk Proses Analisis
Member Umur
1004 69 1 0.014 0.00
1005 69 35 0.507 379.00
1006 69 3 0.043 0.00
1007 69 94 1.362 60.45
1008 69 1 0.014 0.00
1009 69 1 0.014 0.00
1012 69 2 0.029 0.00
1013 69 2 0.029 -4.09
1014 69 278 4.029 14.57
1015 69 28 0.406 -2.14
3740 30 5 0.167 0.00
3741 30 34 1.133 17.64
3742 30 21 0.700 26.34
3743 30 15 0.500 26.34
3744 30 4 0.133 0.00
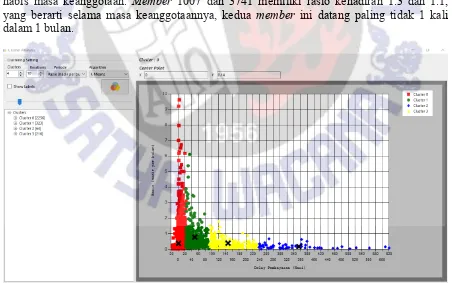
Pada Tabel 1 ditunjukkan, bahwa member 1001 terdaftar sebagai anggota sejak 69 bulan yang lalu, terhitung sampai dengan bulan November 2017. Member 1001 memiliki catatan datang 1 kali selama 69 bulan, rasio kedatangannya berarti 0.014 per bulan. Rata-rata keterlambatan pembayaran member tersebut adalah 117.69 hari. Member 1013, memiliki rata-rata kehadiran per bulan yaitu 0.029 kali per bulan. Member 1013 memiliki catatan pembayaran -4.09 hari, yang berarti member tersebut membayar 4 hari sebelum habis masa keanggotaan. Member 1007 dan 3741 memiliki rasio kehadiran 1.3 dan 1.1, yang berarti selama masa keanggotaannya, kedua member ini datang paling tidak 1 kali dalam 1 bulan.
Gambar 5 Tampilan Hasil Implementasi Aplikasi Clustering
11
akan berhenti pada iterasi tertentu, yaitu ketika iterasi N menghasilkan cluster sama seperti pada iterasi N-1 (iterasi sebelumnya).
Gambar 6 Hasil Pembentukan 2 Cluster
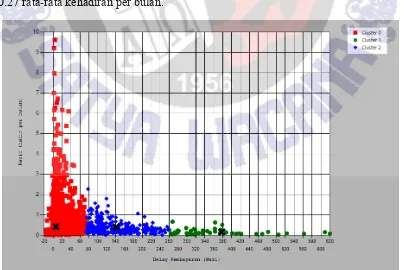
Proses pembentukan cluster 2 cluster, ditunjukkan pada Gambar 6. Cluster-0 memiliki jumlah anggota 2664, dan sisanya yaitu 195 berada di cluster-1. Cluster-0 memiliki nilai rata-rata (titik tengah) yaitu 10.69 hari keterlambatan pembayaran, dan 0.42 rata-rata kehadiran dalam 1 bulan. Cluster-1 memiliki rata-rata 233.32 hari keterlambatan, dan 0.27 rata-rata kehadiran per bulan.
Pada Gambar 7 ditunjukkan hasil pembentukan 3 cluster. Pengelompokan ke dalam 3 cluster ini dapat memperjelas makna tiap cluster. Sebagai contoh pada cluster-0, adalah cluster paling menguntungkan bagi pemilik tempat fitnes. Cluster ini terdiri dari member yang memiki rata-rata pembayaran terlambat 6 hari, dengan maksimal keterlambatan adalah 73 hari, dan paling cepat adalah 16 hari sebelum batas pembayaran.
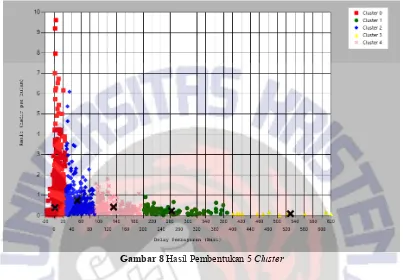
Gambar 8 Hasil Pembentukan 5 Cluster
Pada Gambar 8 dibentuk 5 cluster, sehingga pada tiap cluster berisi member-member yang memiliki kriteria lebih mirip. Informasi tiap cluster ditunjukkan pada Tabel 2. Pada Tabel 2 ditunjukkan bahwa semakin kecil nilai rata-rata kehadiran per bulan, maka angka keterlambatan cenderung membesar. Promosi dapat diberikan kepada member sehingga dapat memotivasi untuk lebih rajin berolahraga, sehingga akan memberikan pengaruh pada ketepatan waktu membayar.
Tabel 2 Statistik Cluster yang Dibentuk
Nomor
Proses pembentukan cluster memiliki batas iterasi maksimal yang berbeda, demikian juga waktu proses yang dibutuhkan. Pada Tabel 3 dilakukan pengujian pembentukan cluster dari sejumlah 2, kemudian ditingkatkan satu demi satu sampai mencapai jumlah 7 cluster.
Tabel 3 Pengujian Pembentukan Cluster Jumlah Cluster Iterasi Lama Proses (detik)
2 12 0.49
3 32 0.63
13
5 32 0.89
6 33 1.01
7 32 1.02
Semakin banyak cluster yang harus dibentuk, semakin lama waktu proses yang diperlukan. Jumlah iterasi yang diperlukan tidak dipengaruhi oleh jumlah cluster yang harus dibentuk. Pada Tabel 3 ditunjukkan bahwa untuk membentuk 3 cluster sama dengan untuk 5 dan 7 cluster, yaitu 32 iterasi. Sedangkan untuk membentuk 6 cluster, diperlukan putaran yang lebih banyak yaitu 33 iterasi.
5. Simpulan
Berdasarkan penelitian yang telah dilakukan, maka dapat disimpulkan bahwa dengan menggunakan K-Means, maka dapat dibentuk cluster-cluster member yang merupakan segmentasi konsumen Silver Sport Club. Tiap cluster memberikan informasi perilaku member dalam hal pembayaran dan rata-rata kehadiran seorang member per bulan. Berdasarkan proses data mining dengan K-Means untuk membentuk 5 cluster, diketahui bahwa semakin kecil nilai rata-rata kehadiran per bulan, maka angka keterlambatan cenderung membesar. Dengan menggunakan informasi ini maka pihak pengelola usaha dapat memberikan promosi yang dapat memotivasi member untuk lebih rajin datang berolahraga, sehingga dapat mengurangi rentang waktu keterlambatan pembayaran.
6. Daftar Pustaka
[1]. Mutmainah, D. A. 2016. Kontribusi UMKM Terhadap PDB Tembus Lebih Dari 60 Persen. CNN Indonesia.
[2]. Hapsari, P. P., Hakim, A. & Noor, I. 2014. Pengaruh Pertumbuhan Usaha Kecil Menengah (UKM) terhadap Pertumbuhan Ekonomi Daerah (Studi di Pemerintah Kota Batu). WACANA, Jurnal Sosial dan Humaniora 17, 88–96.
[3]. Winer, R. S. 2001. A Framework for Customer Relationship Management. California Management Review 43, 89–105. (doi:10.2307/41166102)
[4]. Garcia-Murillo, M. & Annabi, H. 2002. Customer knowledge management. Journal
of the Operational Research Society 53, 875–884.
(doi:10.1057/palgrave.jors.2601365)
[5]. Jamhur, A. I. 2017. Penerapan Data Mining untuk Menganalisa Jumlah Pelanggan Aktif dengan Menggunakan Algoritma C 4.5. Majalah Ilmiah UPI-YPTK 23.
[6]. Garcia, I., Pacheco, C. & Martinez, A. 2012. Identifying critical success factors for adopting CRM in small: A framework for small and medium enterprises. Software Engineering Research, Management and Applications 2012 , 1–15.
[7]. Nugraheni, Y. 2011. Data Mining dengan Metode Fuzzy untuk Customer Relationship Management (CRM) pada Perusahaan Retail. Universitas Udayana. Denpasar
[8]. Maghfirah, M., Adji, T. B. & Setiawan, N. A. 2015. Menggunakan Data Mining untuk Segmentasi Customer pada Bank untuk Meningkatkan Customer Relationship Management (CRM) dengan Metode Klasifikasi (Algoritma J-48, ZERO-R dan Naive Bayes). Prosiding SNST Fakultas Teknik 1.
[9]. Widayani, W., Kusrini, K. & Al Fatta, H. 2015. Perancangan Sistem Pendukung Keputusan Penentuan Impor Bawang Merah. Creative Information Technology Journal 2, 181–191.
Expert Systems with Applications 40, 7513–7518.
[11]. Putri, T. U., Herdiansyah, M. I. & Purnamasari, S. D. 2014. Penerapan Data Mining untuk Menentukan Strategi Penjualan pada Toko Buku Gramedia Palembang dengan Menggunakan Metode Clustering. Jurnal Mahasiswa Teknik Informatika
[12]. Ramadhani, R. D. 2014. Data Mining Menggunakan Algoritma K-Means Clustering Untuk Menentukan Strategi Promosi Universitas Dian Nuswantoro. Jurnal Sistem Informasi 12.
[13]. Via, Y. V., Nugroho, B. & Syafrizal, A. 2015. Sistem Pendukung Keputusan Klasifikasi Tingkat Keganasan Kanker Payudara Dengan Metode Naive Bayes Classifier. SCAN-Jurnal Teknologi Informasi dan Komunikasi 10, 63–68.
[14]. Amborowati, A. & Suyanto, M. 2015. Penerapan Metode Asosiasi Data Mining Menggunakan Algoritma Apriori untuk Mengetahui Kombinasi Antar Itemset pada Pondok Kopi. In Seminar Nasional Informatika (SEMNASIF),
[15]. Soumen Chakrabarti, Martin Ester, Usama Fayyad, Johannes Gehrke, Jiawei Han, Shinichi Morishita, Gregory Piatetsky-Shapiro, W. W. 2015. Data Mining Curriculum. http://www.kdd.org/curriculum/index.html. Diakses 5 Januari 2016. [16]. Fayyad, U., Piatetsky-Shapiro, G. & Smyth, P. 1996. From data mining to knowledge
discovery in databases. AI magazine 17, 37.
[17]. Ahmed, S. R. 2004. Applications of data mining in retail business. In International Conference on Information Technology: Coding Computing, ITCC, pp. 455– 459.(doi:10.1109/ITCC.2004.1286695)
[18]. Tan, P.-N., Steinbach, M. & Kumar, V. 2013. Data Mining Cluster Analysis: Basic Concepts and Algorithms.
[19]. Popat, S. K. & Emmanuel, M. 2014. Review and Comparative Study of Clustering Techniques. International Journal of Computer Science and Information Technologies 5, 805–812.
[20]. Zhao, Y. & Karypis, G. 2002. Evaluation of hierarchical clustering algorithms for document datasets. In Proceedings of the eleventh international conference on Information and knowledge management, pp. 515–524.
[21]. Chen, Y. & Tu, L. 2007. Density-based clustering for real-time stream data. In Proceedings of the 13th ACM SIGKDD international conference on Knowledge discovery and data mining, pp. 133–142.
[22]. Berkhin, P. 2004. Survey Of Clustering Data Mining Techniques. Accrue Software, San Jose, CA, 2002.
[23]. Agusta, Y. 2007. K-means--penerapan, permasalahan dan metode terkait. Jurnal Sistem dan Informatika 3, 47–60.
[24]. Nurchalifatun, F. 2015. Penerapan Metode Asosiasi Data Mining Menggunakan Algoritma Apriori untuk Mengetahui Kombinasi Antar Itemset pada Pondok Kopi. Fakultas Ilmu Komputer, Universitas Dian Nuswantoro
[25]. Sinwar, D. & Kaushik, R. 2014. Study of Euclidean and Manhattan Distance Metrics using Simple K-Means Clustering. International Journal for Research in Applied Science and Engineering Technology (IJRASET) 2, 270–274.
![Gambar 1 Clustering [17]](https://thumb-ap.123doks.com/thumbv2/123dok/3725151.1814261/13.595.106.515.512.725/gambar-clustering.webp)