ABSTRAK
Penelitian ini bertujuan untuk menganalisis jenis persalinan dengan
menggunakan algoritma C4.5, yaitu salah satu metode pohon keputusan yang ada
dalam teori penambangan data (data mining). Data pasien persalinan diperoleh dari
sebuah rumah sakit umum di Yogyakarta, untuk tahun kelahiran 2010 - 2016. Data
yang digunakan berisi informasi tentang usia ibu, usia kandungan, berat badan, tinggi
badan, hasil tes laboratorium (hemoglobin, hematokrit, lekosit, trombosit, eritrosit,
glukosa, protein, dan HbsAG), pinggul sempit/tidak, hamil primi/tidak, hamil
tunggal/ganda, letak janin, presentasi janin, riwayat persalinan, ada riwayat
abortus/tidak, riwayat penyakit, taksiran bobot bayi, dan ketuban pecah dini/tidak dan
jenis persalinan (normal/caesar).
Sistem yang telah dibangun diuji dengan menggunakan teknik 7-fold cross
validation dengan jumlah sampel data sebanyak 288 data. Tingkat keakuratan sistem
yang dihasilkan sebesar 72,00 %.
ABSTRACT
The research aimed to analyze childbirth type using C4.5 algorithm which is
one of the decision tree methods available in the data mining theory. Childbirth
patients data was obtained from a public hospital in Yogyakarta, for the 2010-2016
period. Data that was used contains information about the age of the mother, the
gestational age, weight, height, laboratory test results (haemoglobin, hematocrit,
leukocytes, platelet, erythrocytes, glucose, protein, and HbsAg), narrow hip or not,
primigravida pregnancy or not, single or multiple pregnancy, fetus position, fetus
presentation, childbirth history, any abortion history or not, disease history, fetus
weight estimation, and early rupture of membrane or not, and childbirth type (normal
delivery / caesarian section).
The system that has been built was tested using 7-fold cross validation technic
on 288 data samples. The accuracy level of the system is 72.00%.
i
KLASIFIKASI PERSALINAN NORMAL ATAU CAESAR MENGGUNAKAN ALGORITMA C4.5
Skripsi
Diajukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh :
Laurensia Maria Nindia Bernita
125314090
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
CLASSIFICATION OF NORMAL OR CAESAREAN BIRTH USING C4.5 ALGORITHM
A Thesis
Presented as Partial Fullfillment of the Requirements
To Obtain the Sarjana Komputer Degree
In Informatics Engineering Study Program
By :
Laurensia Maria Nindia Bernita
125314090
INFORMATICS ENGINEERING STUDY PROGRAM DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
v
HALAMAN PERSEMBAHAN
"Pendidikan merupakan senjata paling ampuh yang bisa kamu gunakan untuk merubah dunia"
- Nelson Mandela -
Sebenarnya tantangannya bukan me-manage waktu tapi
me-manage diri kita sendiri.
- Mario Teguh -
Nothing is impossible.
Anything can happen as long as we believe.
Karya ini penulis persembahkan kepada :
Tuhan Yesus Kristus
Keluarga Tercinta
Sahabat dan Teman-teman
viii
ABSTRAK
Penelitian ini bertujuan untuk menganalisis jenis persalinan dengan
menggunakan algoritma C4.5, yaitu salah satu metode pohon keputusan yang
ada dalam teori penambangan data (data mining). Data pasien persalinan
diperoleh dari sebuah rumah sakit umum di Yogyakarta, untuk tahun kelahiran
2010 - 2016. Data yang digunakan berisi informasi tentang usia ibu, usia
kandungan, berat badan, tinggi badan, hasil tes laboratorium (hemoglobin,
hematokrit, lekosit, trombosit, eritrosit, glukosa, protein, dan HbsAG), pinggul
sempit/tidak, hamil primi/tidak, hamil tunggal/ganda, letak janin, presentasi
janin, riwayat persalinan, ada riwayat abortus/tidak, riwayat penyakit, taksiran
bobot bayi, dan ketuban pecah dini/tidak dan jenis persalinan (normal/caesar).
Sistem yang telah dibangun diuji dengan menggunakan teknik 7-fold
cross validation dengan jumlah sampel data sebanyak 288 data. Tingkat
keakuratan sistem yang dihasilkan sebesar 72,00 %.
ix
ABSTRACT
The research aimed to analyze childbirth type using C4.5 algorithm
which is one of the decision tree methods available in the data mining theory.
Childbirth patients data was obtained from a public hospital in Yogyakarta, for
the 2010-2016 period. Data that was used contains information about the age of
the mother, the gestational age, weight, height, laboratory test results
(haemoglobin, hematocrit, leukocytes, platelet, erythrocytes, glucose, protein,
and HbsAg), narrow hip or not, primigravida pregnancy or not, single or
multiple pregnancy, fetus position, fetus presentation, childbirth history, any
abortion history or not, disease history, fetus weight estimation, and early
rupture of membrane or not, and childbirth type (normal delivery / caesarian
section).
The system that has been built was tested using 7-fold cross validation
technic on 288 data samples. The accuracy level of the system is 72.00%.
x
KATA PENGANTAR
Puji syukur kepada Tuhan yang Maha Esa, atas berkat dan rahmatNya penulis
mampu menyelesaikan penelitian tugas akhir dengan judul “Klasifikasi Persalinan Normal atau Caesar Menggunakan Algoritma C4.5”.
Penelitian ini tidak akan selesai tanpa adanya dukungan, semangat, dan bantuan
dari banyak pihak. Untuk itu, pada kesempatan ini penulis ingin mengucapkan terima
kasih kepada :
1. Tuhan Yesus Kristus atas segala berkatNya yang melimpah.
2. Bapak Sudi Mungkasi, S.Si., M.Math. Sc., Ph.D selaku Dekan Fakultas
Sains dan Teknologi Universitas Sanata Dharma.
3. Ibu Dr. Anastasia Rita Widiarti selaku Ketua Program Studi Teknik
Informatika.
4. Romo Dr. Cyprianus Kuntoro Adi, S.J., M.A., M.Sc. selaku dosen
pembimbing tugas akhir dan dosen pembimbing akademik yang telah
memberikan motivasi, waktu dan kesabarannya dalam membimbing
penulis hingga dapat menyelesaikan tugas akhir ini.
5. Ibu P.H. Prima Rosa, S.Si., M.Sc. selaku dosen penguji tugas akhir.
6. Bapak Eko Hari Parmadi, S.Si., M.Kom selaku dosen penguji tugas
akhir.
7. Seluruh dosen yang telah mendidik dan memberikan ilmu pengetahuan
berharga selama penulis belajar di Universitas Sanata Dharma.
8. Seluruh staff sekretariat dan laboran yang turut membentu penulis dalam
menyelesaikan tugas akhir ini.
9. Pihak staff rumah sakit yang telah memberikan ijin dan bantuan sehingga
penulis memperoleh data penelitian.
10.Kedua orang tua, papa Drs. R. Stephanus Isnu Harya L. K. dan mama
Dra. Cosmasia Regina Swantati yang telah memberikan doa, perhatian,
semangat, dan dukungan yang tak henti-hentinya diberikan kepada
xi
11.Kakak Stevani Adhela G.P.C, S.Psi. dan adik Margaretha Kristiana T.
yang telah memberikan semangat, motivasi dan dukungan yang luar
biasa.
12.Mba Vita, Mas Tomi dan Anin atas dukungannya dan semangatnya.
Terima kasih sudah boleh tinggal di rumah kalian.
13.Keluarga besar yang telah memberikan doa, semangat dan dukungan.
14.Sahabat-sahabatku, Dhesty, Itha, Pryli, Imas, dan Astrid atas semangat
yang diberikan. Terima kasih atas kebersamaannya selama 4 tahun ini.
15.Sahabat-sahabat masa kecilku, Devita dan Tia atas dukungan dan
semangatnya, kalian luar biasa.
16.Teman-teman seperjuangan skripsi atas motivasi, semangat, bantuan dan
waktunya untuk belajar dan berdiskusi bersama.
17.Seluruh teman-teman TI angkatan 2012, terima kasih atas semangat,
dukungan serta kebersamaannya selama ini.
18.Pihak-pihak lain yang turut membantu dalam menyelesaikan tugas akhir
ini, yang tidak dapat disebutkan satu per satu.
Penelitian ini masih memiliki banyak kekurangan. Maka dari itu, penulis
menerima masukan saran dan kritik membangun yang berguna di masa yang akan
datang. Semoga penelitian tugas akhir ini dapat membawa manfaat bagi semua pihak.
Yogyakarta, 16 Februari 2017
xii
DAFTAR ISI
HALAMAN PERSETUJUAN ... ii
HALAMAN PENGESAHAN ... iii
HALAMAN PERSEMBAHAN ... iv
PERNYATAAN KEASLIAN KARYA ... vi
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI ... vii
ABSTRAK ... vii
ABSTRACT ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR GAMBAR ... xiv
DAFTAR TABEL ... xv
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 4
1.3 Tujuan Penelitian ... 4
1.4 Manfaat Penelitian ... 4
1.5 Batasan Masalah ... 4
1.6 Metodologi Penelitian ... 5
1.7 Sistematika Penulisan... 6
BAB II LANDASAN TEORI ... 7
2.1 Persalinan ... 7
2.1.1 Pengertian Persalinan ... 7
2.1.2 Jenis Persalinan ... 8
2.1.3 Faktor-Faktor yang Mempengaruhi Jenis Persalinan ... 8
2.2 Penambangan Data ... 11
2.2.1 Pengertian Penambangan Data ... 11
2.2.2 Proses Penambangan Data ... 12
2.2.3 Pengelompokan Penambangan Data ... 14
2.3 Klasifikasi ... 16
2.4 Pohon Keputusan ... 16
xiii
2.4.2 Kelebihan Pohon Keputusan ... 17
2.4.3 Kekurangan Pohon Keputusan ... 17
2.4.4 Algoritma Pohon Keputusan ... 18
2.4 Algoritma C4.5 ... 20
2.4.1 Definisi Algoritma C4.5 ... 20
2.5 K-Fold Cross Validation ... 23
2.6 Confusion Matriks dan Akurasi ... 24
BAB III METODOLOGI PENELITIAN ... 25
3.1 Data ... 25
3.2 Proses Sistem ... 25
3.2.1 Data Mentah ... 26
3.2.2 Transformasi Data ... 31
3.2.3 Data Testing dan Data Training ... 35
3.2.4 Pemodelan dengan Algoritma C4.5 ... 36
3.2.5 Pengujian Akurasi ... 44
3.2.6 Pengujian Data Tunggal ... 44
BAB IV IMPLEMENTASI SISTEM DAN ANALISA HASIL ... 45
4.1 Implementasi Sistem ... 45
4.1.1 Implementasi Source Code ... 45
4.1.2 Implementasi User Interface ... 56
4.2 Hasil dan Analisa ... 58
4.3 Pengujian Data ... 68
BAB V KESIMPULAN DAN SARAN ... 69
5.1 Kesimpulan ... 69
5.2 Saran ... 69
DAFTAR PUSTAKA ... 70
LAMPIRAN I ... 73
xiv
DAFTAR GAMBAR
Gambar 2. 1 Tahapan Penambangan Data ... 12
Gambar 2. 2 Contoh Pohon Keputusan ... 17
Gambar 3. 1 Diagram Blok ... 26
Gambar 3. 2 Pohon Keputusan Hasil Perhitungan Root / Node 1 ... 38
Gambar 3. 3 Pohon Keputusan Hasil Perhitungan Node 2 ... 40
Gambar 3. 4 Pohon Keputusan Hasil Perhitungan Node 3 ... 41
Gambar 3. 5 Pohon Keputusan Hasil Perhitungan Node 4 ... 43
Gambar 4. 1 Halaman Utama ... 56
Gambar 4. 2 Menu Tabel Data ... 57
Gambar 4. 3 Menu Klasifikasi ... 57
Gambar 4. 4 Menu Tree ... 57
Gambar 4. 5 Menu Uji Data Tunggal ... 58
Gambar 4. 6 Tree ... 65
xv
DAFTAR TABEL
Tabel 2. 1 Confusion Matriks untuk Kalasifikasi 2 Kelas...24
Tabel 3. 1 Data Atribut...26
Tabel 3. 2 Contoh Data Pasien Persalinan...30
Tabel 3. 3 Contoh Data Setelah Tahap Transformasi...34
Tabel 3. 4 Pembagian 7-fold...35
Tabel 3. 5 Contoh Data Pasien Persalinan...36
Tabel 3. 6 Perhitungan Root / Node 1...37
Tabel 3. 7 Perhitungan Node 2...38
Tabel 3. 8 Perhitungan Node 3...40
Tabel 3. 9 Perhitungan Node 4...42
1
BAB I PENDAHULUAN
Pada bab ini dijelaskan mengenai latar belakang masalah dari penelitian,
permasalahan penelitian, tujuan yang ingin dicapai, manfaat yang diharapkan,
batasan masalah, serta tahapan dalam penyelesaian tugas akhir.
1.1 Latar Belakang
Teknologi informasi akan terus berkembang seiring dengan
perkembangan jaman. Hal tersebut berdampak pada kebutuhan informasi
yang cepat dan akurat bagi kehidupan sehari-hari. Dimana teknologi
informasi memiliki peran penting terhadap kehidupan manusia di masa
sekarang dan masa akan datang. Hal ini dapat dilihat dari pemanfaatan
teknologi di berbagai bidang, seperti contohnya di bidang kedokteran atau
kesehatan.
Persalinan sebagai salah satu bagian dalam kedokteran kebidanan
merupakan proses fisiologis dimana uterus mengeluarkan atau berupaya
mengeluarkan janin dan plasenta setelah masa kehamilan 20 minggu atau
lebih untuk dapat hidup diluar kandungan melalui jalan lahir atau jalan
lain dengan bantuan atau tanpa bantuan (Manuaba, 1998). Persalinan
adalah suatu proses yang dialami oleh wanita yang akan berlangsung
dengan sendirinya, tetapi persalinan yang membahayakan ibu maupun
janinnya memerlukan pengawasan, pertolongan dan pelayanan dengan
fasilitas yang memadai.
Di dunia kedokteran kebidanan terdapat empat jenis proses
persalinan yang aman dilakukan (sumber:
http://tips-sehat-keluarga-bunda.blogspot.co.id), diantaranya : 1) persalinan normal adalah jenis
persalinan dimana bayi lahir melalui vagina, tanpa memakai alat bantu,
tidak melukai ibu maupun bayi (kecuali episiotomi), dan biasanya dalam
penting, diantaranya kekuatan ibu saat mengejan, keadaan jalan lahir, dan
keadaan janin. 2) Persalinan dengan alat bantu adalah persalinan yang
dilakukan apabila suatu kondisi menyebabkan janin tidak juga lahir meski
sudah terjadi bukaan penuh, sedangkan ibu telah kehabisan tenaga untuk
mengejan, maka dokter yang menangani akan melakukan persalinan
menggunakan alat bantu yang disebut vakum dan forsep. 3) Persalinan
dengan operasi caesar adalah jenis persalinan yang menjadi solusi akhir,
apabila proses persalinan normal dan penggunaan alat bantu sudah tidak
lagi bisa dilakukan untuk mengeluarkan janin dari dalam kandungan.
Persalinan caesar ini biasanya dilakukan karena kondisi tertentu (ketuban
bocor, bayi sungsang, persalinan bayi kembar atau terjadi komplikasi). 4)
Persalinan di dalam air (water birth) adalah jenis persalinan dengan
menggunakan bantuan air saat proses melahirkan. Ketika sudah
mengalami pembukaan sempurna, maka ibu hamil masuk ke dalam bak
yang berisi air dengan suhu 36-37 Celcius. Setelah bayi lahir, maka secara
pelan-pelan diangkat dengan tujuan agar tidak merasakan perubahan suhu
yang ekstrem. Dari keempat jenis persalinan diatas, yang biasa dilakukan
khususnya oleh masyarakat Indonesia adalah persalinan normal dan
persalinan dengan operasi caesar.
Pada masa lalu melahirkan dengan cara operasi merupakan hal
yang menakutkan karena dinilai berisiko kematian. Oleh karena itu,
pembedahan hanya dilakukan jika persalinan normal dapat membahayakan
ibu dan janinnya. Namun, seiring dengan berjalannya waktu serta
berkembangnya kecanggihan bidang ilmu kedokteran kebidanan
pandangan tersebut mulai bergeser. Kini bedah caesar (sectio caesarea)
kadang menjadi alternatif pilihan persalinan dengan beberapa
pertimbangan medis (Kasdu, 2003).
Ada 4 faktor yang perlu dipertimbangkan untuk menentukan
apakah seorang ibu hamil perlu melakukan operasi atau tidak (sumber:
http://www.kemangmedicalcare.com). Pertama, faktor bayi dalam
kandungan. Apakah berat janin (bobot tubuhnya) normal untuk usia
normal berkisar antara 2,5-4,0 kg. Keadaan plasenta dan tali pusar juga
menjadi perhatian khusus. Kedua, faktor ibu itu sendiri yang berkaitan
dengan ukuran punggul. Apakah ukuran pinggul ibu cukup luas untuk
dilewati bayinya kelak, sehingga perlu memperhatikan bobot bayi. Selain
itu, ibu pun harus dinyatakan sehat secara fisik, artinya tidak menderita
penyakit lain, seperti hipertensi, jantung dan diabetes. Ketiga, faktor
kontraksi saat menjelang persalinan. Apakah ada kontraksi simultan
ataukah hilang-timbul, bahkan tidak ada kontraksi sama sekali yang
mengharuskan si ibu diinduksi dengan pemberian hormon oksitosin
melalui infus atau prostaglandin melalui vagina. Keempat, faktor yang
sering dianggap remeh namun sebenarnya sangat berpengaruh, yaitu
kondisi psikis si ibu. Dukungan dari si ayah ataupun kerabat keluarga lain
sangat diperlukan demi kelancaran persalinan, selain tenaga medis yang
menanganinya.
Meskipun telah mempertimbangkan faktor-faktor penting diatas,
masih saja terjadi kesalahan penentuan jenis persalinan oleh dokter
kandungan sehingga dapat membahayakan ibu dan janin. Risiko terburuk
yang terjadi adalah kematian baik ibu, bayi, maupun keduanya. Apabila
hal tersebut terjadi tidak hanya keluarga calon bayi yang merasa dirugikan,
tapi instansi rumah sakit juga merasa dirugikan karena menganggap hal
tersebut adalah kesalahan dokter kandungan yang menangani persalinan
tersebut.
Berdasarkan latar belakang yang diuraikan diatas, untuk
mendukung kerja peranan dokter kebidanan dalam menentukan jenis
persalinan yang sebaiknya dilakukan oleh seorang ibu hamil diperlukan
suatu sistem deteksi persalinan berdasarkan aturan-aturan tertentu. Dengan
adanya sistem tersebut resiko terjadinya kesalahan dalam penentuan cara
persalinan dapat diminimalisir. Oleh karena itu penelitian ini menerapkan
teori penambangan data (data mining) dalam membangun sebuah sistem
untuk mengklasifikasi persalinan normal atau caesar dari seorang ibu
1.2 Rumusan Masalah
Berdasarkan latar belakang yang telah diuraikan di atas, maka
permasalahan yang dapat diambil dalam penelitian ini adalah :
1. Bagaimana pendekatan dengan algoritma C4.5 mampu
mengklasifikasi persalinan normal atau caesar?
2. Berapa tingkat keakuratan yang dihasilkan dari pemakaian
algoritma C4.5 dalam mengklasifikasi persalinan normal atau
caesar?
1.3 Tujuan Penelitian
Tujuan yang ingin dicapai dari penelitian ini adalah penambangan
data dengan algoritma C4.5 mampu mengklasifikasi jenis persalinan
normal atau caesar terhadap data pasien persalian.
1.4 Manfaat Penelitian
Manfaat yang diharapkan dengan adanya penelitian ini adalah
prediksi jenis persalinan dapat diketahui lebih dini sehingga baik pasien
dan dokter dapat mempersiapkan untuk melakukan tindakan yang tepat.
1.5 Batasan Masalah
Batasan masalah yang ditentukan dalam penelitian ini adalah :
1. Format file masukan adalah .xlsx.
2. Data yang diolah adalah data pasien persalinan.
4. Sumber data yang digunakan berasal dari sebuah rumah sakit
umum di Yogyakarta selama 7 tahun terakhir yaitu rentang tahun
2010 – 2016.
5. Penerapan penambangan data menggunakan algoritma C4.5.
1.6 Metodologi Penelitian
Metodologi yang dilakukan dalam menyelesaikan masalah pada
penelitian ini adalah sebagai berikut :
1. Studi Pustaka
a. Studi literatur, mempelajari materi dengan mengumpulkan
informasi melalui buku maupun website di internet yang
berkaitan dengan data mining algoritma C4.5.
b. Mengumpulkan data rekam medis pasien persalinan dengan
menyalinnya ke dalam sebuah file.
2. Penambangan Data
Pada penambangan data langkah penerapan metode
Knowledge Discovery in Database (KDD) adalah sebagai berikut :
a. Pembersihan data (data cleaning), menghilangkan noise
dan data yang tidak konsisten.
b. Integrasi data (data integration), menggabungkan data dari
berbagai sumber yang berbeda.
c. Seleksi data (data selection), menyeleksi atau mengambil
data yang relevan.
d. Transformasi data (data transformation), mengubah data
menjadi bentuk yang sesuai agar dapat ditambang.
e. Penambangan data (data mining), menerapkan teknik
penambangan data menggunakan algoritma C4.5.
f. Evaluasi pola (pattern evaluation), mengidentifikasi pola
1.7 Sistematika Penulisan
Secara garis besar, sistematika penulisan penelitian ini adalah
sebagai berikut:
BAB I PENDAHULUAN
Bab ini berisi tentang latar belakang permasalahan, rumusan
masalah, tujuan dan manfaat penelitian, batasan masalah, metodologi
penelitian, serta sistematika penulisan yang berisi tentang gambaran secara
singkat dari tiap-tiap bab yang ada dalam penelitian tugas akhir.
BAB II LANDASAN TEORI
Bab ini berisi teori-teori yang terkait dalam pembuatan penelitian
ini serta algoritma dan variabel pendukung yang diterapkan dalam
menyelesaikan masalah.
BAB III METODOLOGI PENELITIAN
Bab ini berisi tentang diskripsi data penelitian yang digunakan serta
proses umum sistem dan tahap-tahap penyelesaian masalah.
BAB IV ANALISA HASIL DAN IMPLEMENTASI SISTEM
Bab ini berisi tentang hasil yang diperoleh dari pengujian yang
dilakukan, serta implementasi dari perangkat lunak yang dibuat.
BAB V PENUTUP
Bab ini berisi kesimpulan yang dapat diambil dari hasil yang
diperoleh dalam melakukan penelitian tugas akhir dan saran untuk
7
BAB II
LANDASAN TEORI
Pada bab ini dijelaskan teori yang digunakan untuk mendukung penelitian
tugas akhir dalam mengklasifikasi persalinan normal atau caesar dengan
menggunakan algoritma C4.5.
2.1 Persalinan
2.1.1 Pengertian Persalinan
Definisi persalinan menurut beberapa tokoh adalah sebagai berikut:
1. Menurut Manuaba (2001), persalinan adalah proses pengeluaran
hasil konsepsi (janin dan urin) yang telah cukup bulan atau dapat
hidup diluar kandungan atau melalui jalan lain dengan bantuan atau
tanpa bantuan.
2. Menurut Sarwono (2002), persalinan adalah proses pengeluaran
janin yang terjadi pada kehamilan cukup bulan (37-42 minggu),
lahir spontan dengan presentasi belakang kepala yang berlangsung
dalam 18 jam tanpa komplikasi baik pada ibu maupun pada janin.
3. Menurut Yanti (2010), persalinan adalah serangkaian kejadian
yang berakhir dengan pengeluaran bayi cukup bulan atau hampir
cukup bulan, disusul dengan pengeluaran plasenta dan selaput janin
dari tubuh ibu.
Dari definisi diatas dapat disimpulkan bahwa persalinan merupakan
suatu kejadian yang dialami oleh wanita hamil dengan tujuan
mengeluarkan bayi yang ada dalam kandungan dengan usia cukup bulan,
2.1.2 Jenis Persalinan
Proses persalinan dibagi menjadi dua cara, yaitu (Sarwono, 2002) :
1. Persalinan normal, proses kelahiran janin pada kehamilan cukup
bulan (37 – 42 minggu), pada janin letak mamanjang, presentasi
belakang kepala yang disusul dengan pengeluaran plasenta dan
selukur proses kelahiran itu berakhir dalam waktu kurang dari 24
jam tanpa tindakan atau pertolongn buatan dan tanpa komplikasi.
2. Persalinan abnormal, biasa disebut persalinan caesar dimana
persalianan pervagianam dengan bantuan alat-alat maupun dinding
perut dengan operasi caesar.
2.1.3 Faktor-Faktor yang Mempengaruhi Jenis Persalinan
Ada beberapa faktor yang mempengaruhi jenis persalinan, antara
lain :
1. Usia
Usia reproduksi yang optimal bagi seorang ibu untuk
hamil dan melahirkan adalah 20-35 tahun karena pada usia ini
secara fisik dan psikologi ibu sudah cukup matang dalam
menghadapi kehamilan dan persalinan.
Pada usia <20 tahun organ reproduksi belum sempurna
secara keseluruhan dan perkembangan kejiwaan belum matang
sehingga belum siap menjadi ibu dan menerima kehamilannya.
Usia >35 tahun organ reproduksi mengalami perubahan karena
proses menuanya organ kandungan dan jalan lahir kaku atau
tidak lentur lagi. Selain itu peningkatan pada umur tersebut
akan mempengaruhi organ vital dan mudah terjadi penyakit
2. Anatomi Tubuh Ibu Melahirkan
Ibu yang memiliki tinggi badan <145 cm terjadi
ketidakseimbangan antara luas pinggul dan besar kepala bayi.
Sebagian besar kasus partus tak maju disebabkan oleh tulang
panggul ibu terlalu sempit sehinggga tidak mudah dilintasi
kepala bayi waktu bersalin. Proporsi wanita dengan rongga
panggul yang sempit menurun dengan meningkatnya tinggi
badan. Persalinan macet yang disebabkan pinggul sempit
jarang terjadi pada wanita bertubuh tinggi.
3. Riwayat Persalinan
Persalinan oleh ibu hamil dengan prematur, operasi
caesarea, bayi lahir mati, persalinan dengan induksi serta
semua persalinan tidak normal merupakan suatu resiko tinggi
pada persalinan berikutnya.
Sebuah penelitian di Medan yang dilakukan oleh
Sarumpaet tahun 1998-1999 menghasilkan bahwa ibu yang
mengalami komplikasi persalinan kemungkinan 7,3 kali lebih
besar mempunyai riwayat persalinan jelek dibandingkan yang
tidak mempunyai riwayat persalinan jelek.
4. Keadaan Pinggul
Ukuran pinggu ibu hamil merupakan faktor penting
dalam kelangsunagn persaliann, tetapi yang penting adalah
hubungan antara janin dengan pinggul ibu. Besarnya kepala
bayi dalam perbandingan luasnya pinggul ibu menentukan
apakah janin akan lahir normal atau membutuhkan bantuan
5. Presentasi
Hal yang biasa terjadi adalah ketika presentasi janin
pada daerah bagian kepala, seperti kepala belakang, dahi dan
muka akan mempermudah proses persalinan, namun
sebaliknya bila presentasi bokong maka dokter akan
mengambil tindakan selanjutnya.
6. Ketuban Pecah Dini
Apabila pada pinggul sempit, pintu atas pinggul tidak
tertutup dengan sempurna oleh janin, ketuban bisa pecah pada
pembukaan kecil. Bila kepala tertahan pada pintu atas pinggul,
seluruh tenaga dari uterus diarahkan ke bagian membran yang
menyentuh os internal, akibatnya ketuban pecah akan lebih
mudah terjadi.
7. Tes Darah
Melakukan tes darah pada masa kehamilan bertujuan
untuk mengetahui golongan darah dan mengetahui tingkatan
kadar gula darah di dalam tubuh. Gula darah yang tinggi bisa
menyebabkan komplikasi kehamilan. Kadar zat besi dan
hemoglobin didalam darah sangat penting untuk diperiksa
untuk mengetahui kondisa kesehatan pada ibu hamil. Terutama
ibu hamil yang memiliki riwayat anemia. Selain itu
pemeriksaan hemoglobin bertujuan untuk mengetahui kadar
hemoglobin dalam perkembangan kehamilan.
Tes darah umumnya dilakukan pada usia kehamilan 10
hingga 12 minggu dan akan dilakukan kembali pada usia
kehamilan memasuki usia 28 minggu bahkan saat mendekati
dilakukan untuk mengetahui antibodi yang dimiliki ibu hamil
untuk menjaga kesehatan ibu dan janin dalam menangkal
beberapa virus dan bakteri penyebab penyakit.
Selain faktor yang telah dijabarkan diatas masih ada
faktor-faktor lain yang dinilai dapat mendukung dalam penentuan jenis
persalinan.
2.2 Penambangan Data
2.2.1 Pengertian Penambangan Data
Penambangan data (data mining) merupakan serangkaian kegiatan
mengolah atau menambang data dalam jumlah besar yang tersimpan dalam
database, gudang data atau sumber data lainnya dengan tujuan
memperoleh informasi dan pengatahuan (Han & Kember, 2006).
Data mining merupakan proses semi otomatik yang menggunakan
teknik statistik, matematika, kecerdasan buatan, dan mechine learning
untuk mengekstraksi dan mengidentifikasi informasi pengetahun potensial
dan berguna yang bermanfaat yang tersimpan di dalam database besar
(Turban et al, 2005).
Menurut Gartner Group data mining adalah suatu proses
menemukan hubungan yang berarti, pola, dan kecenderungan dengan
memeriksa dalam sekumpulan besar data yang tersimpan dalam
penyimpanan dengan menggunakan teknik pengenalan pola seperti teknik
statistik dan matematika (Larose, 2006).
Berdasarkan definisi-definisi yang telah disampaikan, hal penting
yang terkait dengan data mining adalah (Larose, 2006) :
1. Data mining merupakan suatu proses otomatis terhadap data
2. Data yang akan diproses berupa data yang sangat besar.
3. Tujuan data mining adalah mendapatkan hubungan atau pola
yang mungkin memberikan indikasi yang bermanfaat.
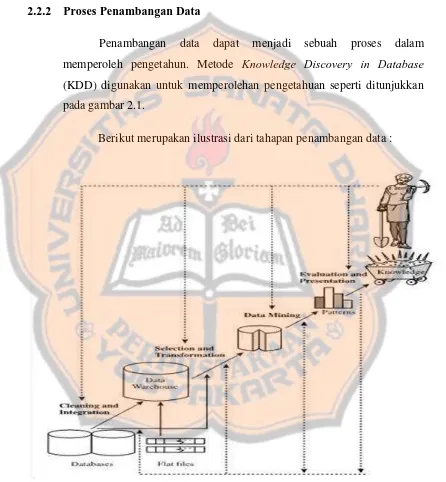
2.2.2 Proses Penambangan Data
Penambangan data dapat menjadi sebuah proses dalam
memperoleh pengetahun. Metode Knowledge Discovery in Database
(KDD) digunakan untuk memperolehan pengetahuan seperti ditunjukkan
pada gambar 2.1.
Berikut merupakan ilustrasi dari tahapan penambangan data :
Karena penambangan data adalah suatu rangkaian proses, maka
dibagi menjadi beberapa tahap dengan urutan sebagai berikut:
1. Pembersihan Data (Data Cleaning)
Tahap awal dalam penambangan data adalah
menghapus data yang tidak konsisten dan noise yang terdapat
dalam data, seperti data yang tidak relevan, data yang salah
ketik maupun data kosong yang tidak diperlukan.
2. Integrasi Data (Data Integration)
Tahap penggabungan data dari sumber penyimpanan
yang berbeda. Data-data ini akan digabungkan ke dalam suatu
tempat penyimpanan data dalam suatu tabel utuh.
3. Seleksi Data (Data Selection)
Proses pengambilan dan penyeleksian data yang
relevan dari sebuah database. Atribut-atribut data akan dicek
apakah relevan untuk dilakukan penambangan data. Atribut
yang tidak relevan tidak akan digunakan.
4. Transformasi Data (Data Transformation)
Tahap dimana data mengalami transformasi ke dalam
bentuk yang sesuai. Tujuan tranformasi dalam proses
penambangan data adalah agar bentuk yang dihasilkan lebih
mudah dipahami dan dapat ditambang.
5. Penambangan Data (Data Mining)
Merupakan proses penting dimana penambangan data
diterapkan dan diaplikasikan dengan menggunakan algoritma
6. Evaluasi Pola (Pattern Evaluation)
Pada tahap ini, dilakuakan proses identifikasi pola yang
menarik. Pola tersebut akan direpresentasikan dalam bentuk
pengetahuan berdasarkan beberapa pengukuran yang penting.
7. Presentasi Pengetahuan (Knowledge Presentation)
Pada tahap akhir, pengetahuan yang diperoleh
kemudian dipresentasikan kepada pengguna.
Tahap 1 sampai dengan tahap 4 merupakan langkah awal dalam
pemrosesan data dimana data dipersiapkan terlebih dahulu sebelum
dilakukan penambangan. Pada tahap penambangan data, pengetahuan
dasar akan digunakan. Pola-pola menarik akan dipresentasikan kepada
pengguna dan akan disimpan sebagai pengetahuan baru. Penambangan
data merupakan proses penting untuk dapat menemukan pola-pola
tersembunyi yang nantinya akan dievaluasi.
2.2.3 Pengelompokan Penambangan Data
Penambangan data dibagi menjadi beberapa kelompok berdasarkan
tugas yang dapat dilakukan, sebagai berikut (Larose, 2005) :
a. Deskripsi
Data dapat diasosiasikan dengan pembagian kelas atau
konsep. Cara ini digunakan untuk menggambarkan pola dan
b. Asosiasi
Tugas asosiasi adalah menemukan atribut yang muncul
dalam satu waktu. Dalam dunia bisnis lebih umum disebut
analisis market basket.
c. Klasifikasi
Pada klasifikasi terdapat target atribut kategori yaitu
kelasnya sudah diketahui dari awal. Sebagai contoh,
menentukan apakah suatu transaksi kartu kredit merupakan
transaksi yang curang atau bukan.
d. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali
atribut target lebih ke arah numerik daripada ke arah kategori.
Model dibangun menggunakan record lengkap yang
menyediakan nilai dari atribut target sebagai nilai prediksi.
e. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi,
namun dalam prediksi nilai dari hasil akan ada di masa
mendatang.
f. Pengklusteran
Pengklusteran merupakan pengelompokkan record,
pengamatan, atau memperhatikan dan membentuk kelas
objek-objek yang memiliki kemiripan. Cluster adalah kumpulan
record yang memiliki kemiripan antara satu dengan yang
lainnya dan memiliki ketidakmiripan dengan record-record
2.3 Klasifikasi
Klasifikasi adalah proses untuk menentukan model atau fungsi
yang menjelaskan atau membedakan konsep atau kelas data, dengan tujuan
untuk mendapatkan perkiraan kelas dari suatu objek yang labelnya tidak
diketahui. Model tersebut bisa berupa aturan “jika-maka”, pohon keputusan, formula matematis atau neural network. Secara umum proses
klasifikasi dibagi menjadi dua fase : learning dan test. Pada fase learning,
sebagaian data yang telah diketahui kelas datanya digunakan untuk
membentuk model perkiraan. Sedangkan pada fase test, model yang sudah
terbentuk diuji dengan sebagian data lainnya untuk mengetahui akurasi
dari model tersebut. Bila akurasinya menjukupi model ini dapat dipakai
untuk memprediksi kelas data yang belum diketahui.
2.4 Pohon Keputusan
2.4.1 Definisi Pohon Keputusan
Pohon keputusan (decision tree) merupakan salah satu metode
klasifikasi yang paling populer karena mudah untuk diinterpretasikan.
Pohon keputusan adalah model prediksi menggunakan struktur pohon atau
[image:33.595.83.521.94.669.2]struktur berhirarki. Contoh dari pohon keputusan dapat dilihat pada
Gambar 2.2. Pohon keputusanadalah struktur flowchart yang menyerupai
pohon (tree), dimana setiap percabangan menyatakan kondisi yang harus
dipenuhi dan tiap ujung pohon menyatakan kelas data. Pada pohon
keputusan setiap simpul daun menandai label kelas. Proses dalam pohon
keputusan yaitu mengubah bentuk data (tabel) menjadi model pohon (tree)
Gambar 2. 2 Contoh Pohon Keputusan (Pramudiono, 2008)
2.4.2 Kelebihan Pohon Keputusan
Kelebihan dari metode pohon keputusan adalah sebagai berikut
(Faruz El Said, 2009) :
1. Daerah pengambilan keputusan yang sebelumnya kompleks dan
sangat global, dapat diubah menjadi lebih simpel dan spesifik.
2. Eliminasi perhitungan-perhitungan yang tidak diperlukan, karena
ketika menggunakan metode pohon keputusan maka sample diuji
hanya berdasarkan kriteria atau kelas tertentu.
3. Fleksibel untuk memilih fitur dari internal node yang berbeda, fitur
yang terpilih akan membedakan suatu kriteria dibandingkan
kriteria yang lain dalam node yang sama. Secara fleksibel metode
pohon keputusan ini meningkatkan kualitas keputusan yang
dihasilkan jika dibandingkan ketika menggunakan metode
penghitungan satu tahap yang lebih konvensional.
2.4.3 Kekurangan Pohon Keputusan
Kekurangan dari metode pohon keputusan adalah sebagai berikut :
1. Terjadi overlap terutama ketika kelas-kelas dan kriteria yang
menyebabkan meningkatnya waktu pengambilan keputusan
dan jumlah memori yang diperlukan.
2. Terjadi akumulasi jumlah error dari setiap tingkat dalam
sebuah pohon keputusan yang besar.
3. Kesulitan dalam mendesain pohon keputusan yang optimal.
4. Hasil kualitas keputusan yang didapatkan dari metode pohon
keputusan sangat tergantung pada bagaimana pohon tersebut
didesain.
2.4.4 Algoritma Pohon Keputusan
Banyak algoritma yang dipakai dalam pembentukan pohon
keputusan, antara lain ID3, C4.5, CART.
a. ID3
Salah satu algoritma decision tree adalah algoritma ID3
(Iterative Dichotomiser 3). ID3 pertama kali dikembangkan
oleh J.Ross Quinlan di University of Sydney. ID3 pertama kali
disajikan pada tahun 1975 dalam sebuah buku, Machine
Learning. ID3 didasarkan pada konsep Learning System (CLS)
algoritma (Hamilton, 2001).
Kelebihan algoritma ID3 adalah sebagai berikut :
1. Dapat membuat aturan prediksi yang mudah
dimengerti.
2. Mampu membangun pohon keputusan dengan
cepat.
3. Mampu membangun pohon keputusan yang
pendek.
4. Hanya membutuhkan beberapa tes atribut hingga
Kekurangan algoritma ID3 adalah sebagai
berikut :
1. Jika contoh yang diteliti terlalu kecil / sederhana
mungkin membuat data over-classified.
2. Hanya satu atribut yang dapat dites dalam satu
waktu untuk membuat keputusan.
b. C4.5
Algoritma C4.5 adalah pengembangan dari ID3
(Iterative Dichotomiser 3) yang merupakan salah satu
algoritma pohon keputusan (Faruz El Said, 2009). Definisi
mengenai algoritma C4.5 selanjutnya akan dijelaskan pada
bagian 2.4.
c. CART
CART (Classification and Regression Tree) adalah
salah satu algoritma pohon keputusan. CART adalah sebuah
algoritma yang dapat menggambarkan hubungan antara varibel
respon (variabel dependen) dengan variabel prediktor (variabel
independen). Dalam CART setiap simpul dipecah menjadi 2
cabang. Menurut Breiman dkk (1993), bila variabel respon
berbentuk kontinu maka metode yang dipakai adalah metode
regression tree, sedangkan bila variabel respon memiliki skala
kategori maka metode yang dipakai adalah metode
classification tree.
Kelebihan algoritma ID3 adalah sebagai berikut :
1. Dapat melakukan komputasi dengan cepat.
2. Fleksibel dan memiliki dapat mengatur waktu
perhitungan.
1. Membagi hanya dengan satu variabel.
2. Memiliki pohon keputusan yang tidak stabil.
2.4 Algoritma C4.5
2.4.1 Definisi Algoritma C4.5
Algoritma C4.5 merupakan salah satu algoritma modern yang
digunakan untuk melakukan penambangan data. Dalam algoritma C4.5,
input berupa sampel training, label training dan atribut. Sampel training
berupa data contoh yang akan digunakan untuk membangun sebuah tree
yang telah diuji kebenarannya. Sedangkan atribut merupakan field-field
data yang nantinya akan digunakan sebagai parameter dalam melakukan
klasifikasi data.
Kelebihan algoritma C4.5 adalah sebagai berikut :
1. Mampu menangani atribut dengan tipe diskrit atau kontinu.
2. Mampu menangani atribut yang kosong (missing value)
3. Pembentukan model mudah dipahami.
4. Bisa memangkas cabang.
Kekurangan algoritma C4.5 adalah sebagai berikut :
1. Susah membaca data berjumlah besar.
Algoritma dasar C4.5 untuk membangun pohon keputusan adalah
sebagai berikut :
1. Memilih atribut sebagai akar (root).
2. Membuat cabang untuk masing-masing nilai.
3. Membagi kasus dalam cabang.
4. Mengulangi proses untuk masing-masing cabang sampai
Berikut adalah algoritma C4.5 (Mitchell, 1997) :
Algoritma C4.5
Input : sampel training, label training, atribut
Buat simpul akar untuk pohon yang dibuat.
Jika semua sampel positif, berhenti dengan suatu pohon
dengan satu simpul akar, beri label (+).
Jika semua sampel negatif, berhenti dengan suatu
pohon dengan satu simpul akar, beri label (-).
Jika atribut kosong, berhenti dengan suatu pohon
dengan satu simpul akar, dengan label sesuai dengan nilai yang terbanyak yang ada pada label training.
Untuk yang lain,
Mulai :
o A atribut yang mengklasifikasikan sampel
dengan hasil yang terbaik (berdasarkan gain ratio).
o Atribut keputusan untuk simpul akar A.
o Untuk setiap nilai, vi yang mungkin untuk A:
Tambahkan cabang di bawah akar yang
berhubungan dengan A = vi.
Tentukan sampel Svi sebagai subset dari
sampel yang mempunyai nilai vi untuk
atribut A.
Jika sampel Svi kosong :
Dibawah cabang tambahkan
simpul daun dengan label = nilai yang terbanyak yang ada pada label training.
Yang lain, tambah cabang baru
dibawah cabang yang sekarang C4.5 (sampel training, label training, atribut-[A]).
Sebelum memilih atribut sebagai akar, dilakukan perhitungan nilai
entropy yang dapat dilihat pada persamaan (2.1) (Craw, S).
...(2.1)
Keterangan:
S : Himpunan kasus
n : Jumlah partisi S
pi : Proporsi dari Si terhadap S
Untuk memilih atribut sebagai akar, didasarkan pada nilai gain
tertinggi dari atribut-atribut yang ada. Untuk menghitung gain digunakan
persamaan berikut seperti pada persamaan (2.2) (Craw, S).
...(2.2)
Keterangan:
S : Himpunan kasus
A : Atribut
n : Jumlah partisi atribut A
|Si| : Jumlah kasus pada partisi ke i
Untuk menghitung GainRatio perlu diketahui suatu term baru yang
disebut SplitInformation (pemisah informasi). SplitInformation dihitung
dengan persamaan sebagai berikut.
...(2.3)
Dimana sampai adalah c subset yang dihasilkan dari
pemecahan dengan menggunakan atribut A yang mempunyai sebanyak c
nilai. Selanjutnya GainRatio dihitung dengan persamaan berikut.
...(2.4)
2.5 K-Fold Cross Validation
Pada pendekatan ini, setiap data digunakan dalam jumlah yang
sama untuk pelatihan dan tepat satu kali untuk pengujian. Bentuk umum
pendekatan ini disebut dengan k-fold cross validation, yang memecah set
data menjadi k bagian set data dengan ukuran yang sama. Setiap kali
berjalan, satu pecahan berperan sebagai set data uji sedangkan pecahan
lainnya menjadi set data latih. Prosedur tersebut dilakukan sebanyak k kali
sehingga setiap data berkesempatan menjadi data uji tepat satu kali dan
menjadi data latih sebanyak k-1 kali. Total error didapatkan dengan
2.6 Confusion Matriks dan Akurasi
Confusion matriks merupakan tabel yang mencatat hasil kerja
klasifikasi. Contoh confusion matriks ditunjukkan dada tabel berikut :
Tabel 2. 1 Confusion Matriks untuk Kalasifikasi 2 Kelas
fij Kelas Hasil Prediksi (j)
Kelas = 1` Kelas = 0
Kelas Asli (i) Kelas = 1` f11 f10
Kelas = 0 f01 f00
Tabel 2.1 diatas merupakan contoh matrix confusion yang
melakukan klasifikasi masalah biner (dua kelas) untuk dua kelas, misalnya
kelas 0 dan 1. Setiap sel fij dalam matriks menyatakan jumlah record/data
dari kelas i yang hasil prediksinya masuk ke kelas j. Misalnya sel f11
adalah jumlah data dalam kelas 1 yang secara benar dipetakan ke kelas 1,
dan f10 adalah data dalam kelas 1 yang dipetakan secara salah ke kelas 0.
Berdasarkan isi confusion matriks, maka dapat diketahui jumlah
data dari masing-masing kelas yang diprediksi secara benar yaitu (f11+ f00)
dan data yang diklasifikasi secara salah yaitu (f10 + f01). Dengan
mengetahui jumlah data yang diklasifikasikan secara benar, maka dapat
diketahui akurasi hasil prediksi. Untuk menghitung akurasi digunakan
formula sebagai berikut (Prasetyo, 2014).
...(2.5)
[image:41.595.83.512.193.728.2]
BAB III
METODOLOGI PENELITIAN
Pada bab ini dijelaskan mengenai data yang digunakan pada penelitian
tugas akhir serta proses sistem yang akan dilakuakan dalam mengklasifikasi
persalinan normal atau caesar dengan menggunakan algoritma C4.5.
3.1 Data
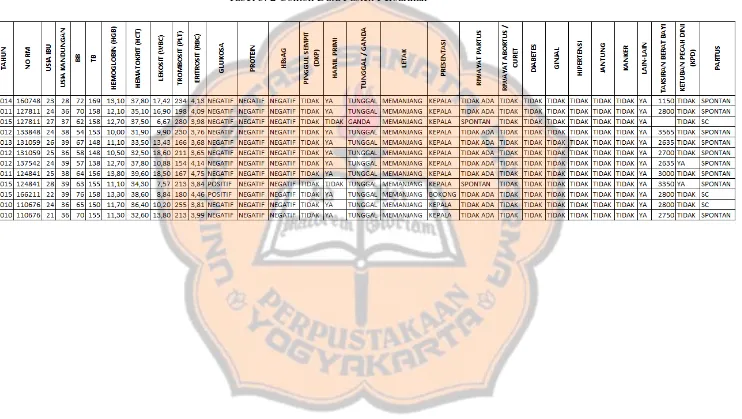
Data yang digunakan dalam penelitian ini adalah data pasien
persalinan yang diperoleh dari sebuah rumah sakit umum di Yogyakarta.
Data yang digunakan merupakan data pasien dari tahun 2010-2016. Data
tersebut berupa rekam medis pasien yang kemudian disalin ke dalam
sebuah file bertipe excel. Dari proses pengumpulan data, diperoleh jumlah
data sebanyak 315 data.
Data yang diperoleh terdiri dari : tahun masuk pasien, nomor rekam
medis, usia ibu, usia kandungan, berat badan, tinggi badan, hasil tes
laboratorium (hemoglobin, hematokrit, lekosit, trombosit, eritrosit,
glukosa, protein, dan HbsAG), pinggul sempit/tidak, hamil primi/tidak,
hamil tunggal/ganda, letak janin, presentasi janin, riwayat persalinan, ada
riwayat abortus/tidak, riwayat penyakit (diabetes, ginjal, hipertensi,
jantung, kanker, lain-lain), taksiran bobot bayi, ketuban pecah dini/tidak,
dan jenis persalinan (normal/caesar).
3.2 Proses Sistem
Masukkan sistem akan diproses menggunakan algoritma C4.5
dalam teori penambangan data. Alur sistem dan tahapan penelitian
Gambar 3. 1 Diagram Blok
3.2.1 Data Mentah
Dalam penelitian tugas akhir ini data yang digunakan adalah data
pasien persalinan dari sebuah rumah sakit umum di Yogyakarta. Untuk
mengidentifikasi jenis persalinan ibu hamil diukur dari ciri dan gejala
kehamilan, seperti usia, tinggi badan, ukuran pinggul, riwayat persalian,
dll. Selain ini juga perlu adanya hasil uji laboratorium, meliputi tes darah
saat mendekati persalinan serta tes glukosa dan protein. Atribut data
persalinan ditampilkan pada tabel 3.1 berikut :
Tabel 3. 1 Data Atribut
No
Nama Atribut Keterangan Nilai
1
Tahun Atribut ini menyimpan
data tahun diagnosa
pasien.
2010, 2011, 2012,
2013, 2014, 2015,
2016
2
Nomor rekam medis Atribut ini menyimpan
data nomor rekam medis
pasien.
5642, 8731, dst
3
Usia ibu Atribut ini menyimpan
data usia ibu.
17, 18, 19, 20, dst
4
Usia kandungan Atribut ini menyimpan
data usia kandungan
pasien saat persalinan.
5
Berat badan ibu Atribut ini menyimpan
data berat badan pasien
sebelum persalinan.
39, 40, 41, 42, dst
6
Tinggi badan ibu Atribut ini menyimpan
data tinggi badan pasien.
140, 142, 145, 148,
dst
7
Hemoglobin Atribut ini menyimpan
data hasil tes hemoglobin
pasien sebelum melakukan
persalinan.
Misal : 10.50, 11.40, 12, 70, dll
8
Hematokrit Atribut ini menyimpan
data hasil tes hemotokrit
pasien sebelum melakukan
persalinan.
Misal : 38.60, 31.50, 33.40, dll
9
Lekosit Atribut ini menyimpan
data hasil tes lekosit
pasien sebelum melakukan
persalinan.
Misal : 10.72, 14. 80, 8.84, dll
10
Trombosit Atribut ini menyimpan
data hasil tes trombosit
pasien sebelum melakukan
persalinan.
Misal : 206, 267, 230, dll
11
Eritrosit Atribut ini menyimpan
data hasil tes eritrosit
pasien sebelum melakukan
persalinan
Misal : 4.07, 3.65, 4.46, dll
12
Glukosa Atribut ini menyimpan
data hasil tes glukosa
pasien.
Positif, negatif,
trace
13
Protein Atribut ini menyimpan
data hasil tes protein
pasien.
Positif, negatif,
14
HBsAG Atribut ini menyimpan
data hasil tes HbsAG
pasien.
Positif, negatif,
trace
15
Pinggul sempit Atribut ini menyimpan
data apakah ukuran
pinggul pasien sempit.
Ya, tidak
16
Hamil primi Atribut ini menyimpan
data apakah kehamilan
pasien merupakan
kehamilan pertama.
Ya, tidak
17
Tunggal / ganda Atribut ini menyimpan
data apakah jumlah janin
tunggal atau ganda.
Tunggal, ganda
18
Letak Atribut ini menyimpan
data posisi janin.
Memanjang,
melintang
19
Presentasi Atribut ini menyimpan
data bagian tubuh mana
pada janin yang tampak
pertama kali saat proses
persalinan.
Kepala, bokong
20
Riwayat partus Atribut ini menyimpan
data riwayat persalinan
yang dimiliki pasien.
Spontan, SC, tidak
ada
21
Riwayat abortus /
curet
Atribut ini menyimpan
data apakah pasien ada
riwayat abortus / curet.
Ya, tidak
22
Diabetes Atribut ini menyimpan
data apakah pasien
memiliki riwayat penyakit
diabetes.
Ya, tidak
23
Ginjal Atribut ini menyimpan
data apakah pasien
memiliki riwayat penyakit
ginjal.
24
Hipertensi Atribut ini menyimpan
data apakah pasien
memiliki riwayat penyakit
hipertensi.
Ya, tidak
25
Jantung Atribut ini menyimpan
data apakah pasien
memiliki riwayat penyakit
jantung.
Ya, tidak
26
Kanker Atribut ini menyimpan
data apakah pasien
memiliki riwayat penyakit
kanker.
Ya, tidak
27
Lain-lain Atribut ini menyimpan
data apakah pasien
memiliki riwayat penyakit
lainnya.
Ya, tidak
28
Taksiran berat bayi Atribut ini menyimpan
data taksiran berat badan
bayi.
Misal : 1150, 2750,
3350, dll
29
Ketuban pecah dini Atribut ini menyimpan
data apakah ketuban pecah
dini.
Ya, tidak
30
Partus Atribut ini menyimpan
data jenis persalinan.
Spontan, SC
Dari total data yang diperoleh sebanyak 315 data, terdapat 27 data
yang masing-masing tidak diketahui nilainya pada 10 atau lebih atribut,
sehinggga 27 data tersebut dihapus. Maka data yang akan digunakan pada
tahap selanjutnya sebanyak 288 data. Contoh data pasien persalian
3.2.2 Transformasi Data
Pada tahap ini dilakukan pembuangan data yang tidak diperlukan
seperti data-data yang kurang relevan dalam penelitian. Dari data mentah
yang diperoleh, akan dilakukan penghapusan atribut tahun dan nomor
rekam medis karena dianggap tidak begitu berpengaruh sebagai variabel
penentu dalam melakukan klasifikasi. Maka atribut yang dihasilkan dari
proses seleksi adalah sebagai berikut :
a. Usia ibu
b. Usia kandunagn
c. Berat badan
d. Tinggi badan
e. Hemoglobin
f. Hematokrit
g. Lekosit
h. Trombosit
i. Eritrosit
j. Glukosa
k. Protein
l. HbsAG
m. Pinggul sempit
n. Hamil primi
o. Tunggal/ganda
p. Letak
q. Presentasi
r. Riwayat partus
s. Riwayat abortus/curret
t. Diabetes
u. Ginjal
v. Hipertensi
w. Jantung
y. Lain-lain
z. Kisaran berat bayi
aa. Ketuban pecah dini
bb.Partus
Pada tahap selanjutnya dilakukan peringkasan data atau proses
pengubahan data mentah menjadi data yang mudah dikelola. Dari data
yang diperoleh, sebagian besar berupa angka yang beragam, sehingga
perlu dilakukan pengelompokkan data berdasarkan jangkauan tertentu.
Atribut yang berisi data numerik akan dikelompokkan sesuai identifikasi
dalam ilmu kesehatan. Dilakukan pengelompokan nilai atribut berdasar
sumber yang diperoleh dari beberapa website atau blog kesehatan sebagai
berikut : www.alodokter.com, bidanku.com, www.babyfluffy.com,
healthy.detik.com, www.kompasiana.com, dan ririnprabandarisilalahi.
blogspot.co.id.
Nilai atribut dari semua data yang digunakan, baik nilai atribut
yang dikelompokkan dalam nilai tertentu atau tidak dikelompokkan akan
diubah menjadi nilai 1, 2, 3. Perubahan data numerik dan non numerik
adalah sebagai berikut :
a. Usia ibu
i. <20 atau >35 beresiko = 1
ii. 20-35 normal = 2
b. Usia kandungan
i. <37 atau >42 beresiko = 1
ii. 37-42 normal = 2
c. Berat badan
i. <55 atau >80 beresiko = 1
ii. 55-80 normal = 2
d. Tinggi badan
i. <145 beresiko = 1
e. Hemoglobin
i. <11.00 atau >15.00 beresiko = 1
ii. 11.00-15.00 normal = 2
f. Hematokrit
i. <30.00 atau >46.00 beresiko = 1
ii. 30.00-46.00 normal = 2
g. Lekosit
i. <10.00 atau >15.00 beresiko = 1
ii. 10.00-15.00 normal = 2
h. Trombosit
i. <200 atau >400 beresiko = 1
ii. 200-400 normal = 2
i. Eritrosit
i. <4.00 atau >5.50 beresiko = 1
ii. 4.00-5.50 normal = 2
j. Kisaran berat bayi
i. <2500 beresiko = 1
ii. 2500-4000 normal = 2
iii. >4000 obesitas = 3
k. Glukosa, protein, HbsAG
i. Negatif = 1
ii. Positif = 2
iii. Trace = 3
l. Pinggul sempit, hamil primi, riwayat abortus, diabetes, ginjal,
hipertensi, jantung, kanker, lain-lain, ketuban pecah dini
i. Tidak = 1
ii. Ya = 2
m. Tunggal/ganda
i. Ganda = 1
n. Letak
i. Melintang = 1
ii. Memanjang = 2
o. Presentasi
i. Bokong = 1
ii. Kepala = 2
p. Riwayat partus
i. SC = 1
ii. Spontan = 2
iii. Tidak ada = 3
q. Partus
i. SC = 1
ii. Spontan = 2
Pada tahap ini juga dilakukan pengisian data yang tidak diketahui
nilainya (missing value). Untuk setiap data yang tidak diketahui nilainya
akan diisi dengan nilai terbanyak dari setiap atribut. Contoh data yang
[image:51.595.87.535.89.694.2]sudah melewati tahap transformasi ditampilkan pada tabel 3.3 berikut :
3.2.3 Data Testing dan Data Training
Pada tahap ini hasil dari penambangan data berupa pola khusus
yang akan dievaluasi atau diteliti lagi apakah hasilnya sudah sesuai atau
belum. Untuk mengetahui apakah sistem yang akan dibangun ini sudah
baik atau belum, maka perlu dilakukan pengujian sistem menggunakan
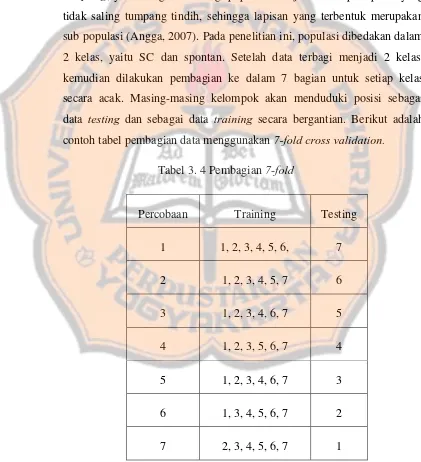
metode k-fold cross validation.
Pada penelitian ini pembagian data mengaju pada metode statifikasi
sampling, yaitu dengan membagi populasi menjadi beberapa lapisan yang
tidak saling tumpang tindih, sehingga lapisan yang terbentuk merupakan
sub populasi (Angga, 2007). Pada penelitian ini, populasi dibedakan dalam
2 kelas, yaitu SC dan spontan. Setelah data terbagi menjadi 2 kelas,
kemudian dilakukan pembagian ke dalam 7 bagian untuk setiap kelas
secara acak. Masing-masing kelompok akan menduduki posisi sebagai
data testing dan sebagai data training secara bergantian. Berikut adalah
[image:52.595.86.507.261.723.2]contoh tabel pembagian data menggunakan 7-fold cross validation.
Tabel 3. 4 Pembagian 7-fold
Percobaan Training Testing
1 1, 2, 3, 4, 5, 6, 7
2 1, 2, 3, 4, 5, 7 6
3 1, 2, 3, 4, 6, 7 5
4 1, 2, 3, 5, 6, 7 4
5 1, 2, 3, 4, 6, 7 3
6 1, 3, 4, 5, 6, 7 2
3.2.4 Pemodelan dengan Algoritma C4.5
Pada tahap ini dilakukan proses penambangan data dengan
algoritma C4.5. Data yang sudah melalui tahapan transformasi akan
dijadikan sebagai data training untuk proses pembentukan pohon
keputusan menggunakan algoritma C4.5. Proses pembentukan pohon
ditentukan dari perhitungan nilai Entopy, Gain, SplitInformation, dan
GainRatio untuk setiap atribut kemudian mencari nilai GainRatio tertinggi
yang akan menjadi simpul akar dari pohon. Proses pembentukan pohon
dilakukan secara rekursif hingga seluruh data memiliki kelas. Setelah
perhitungan selesai akan ditampilkan hasil pohon yang terbentuk.
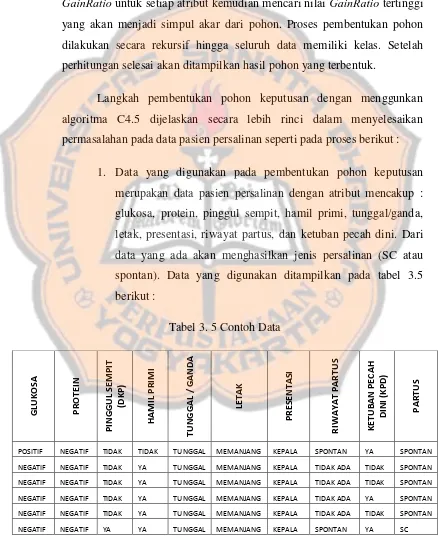
Langkah pembentukan pohon keputusan dengan menggunkan
algoritma C4.5 dijelaskan secara lebih rinci dalam menyelesaikan
permasalahan pada data pasien persalinan seperti pada proses berikut :
1. Data yang digunakan pada pembentukan pohon keputusan
merupakan data pasien persalinan dengan atribut mencakup :
glukosa, protein, pinggul sempit, hamil primi, tunggal/ganda,
letak, presentasi, riwayat partus, dan ketuban pecah dini. Dari
data yang ada akan menghasilkan jenis persalinan (SC atau
spontan). Data yang digunakan ditampilkan pada tabel 3.5
[image:53.595.87.525.220.758.2]berikut :
Tabel 3. 5 Contoh Data
GLUK OS A PROTE IN PI N GG UL S E M PI T (DK P) H A M IL PRIM I TU N GG A L / G A N D A LE TA K PRE S E N TA S I R IW A Y A T P A R T US K E TU B A N PE CA H D INI ( K PD ) PA R TU S
POSITIF NEGATIF TIDAK TIDAK TUNGGAL MEMANJANG KEPALA SPONTAN YA SPONTAN
NEGATIF NEGATIF TIDAK YA TUNGGAL MEMANJANG KEPALA TIDAK ADA TIDAK SPONTAN
NEGATIF NEGATIF TIDAK YA TUNGGAL MEMANJANG KEPALA TIDAK ADA TIDAK SPONTAN
NEGATIF NEGATIF TIDAK YA TUNGGAL MEMANJANG KEPALA TIDAK ADA YA SPONTAN
NEGATIF NEGATIF TIDAK YA TUNGGAL MEMANJANG KEPALA TIDAK ADA TIDAK SPONTAN
NEGATIF NEGATIF TIDAK TIDAK TUNGGAL MEMANJANG BOKONG SPONTAN TIDAK SC
NEGATIF TRACE TIDAK YA TUNGGAL MEMANJANG KEPALA TIDAK ADA TIDAK SC
NEGATIF NEGATIF YA YA TUNGGAL MEMANJANG KEPALA TIDAK ADA TIDAK SC
NEGATIF NEGATIF TIDAK TIDAK TUNGGAL MELINTANG KEPALA SC TIDAK SC
NEGATIF NEGATIF TIDAK TIDAK GANDA MEMANJANG KEPALA SPONTAN TIDAK SC
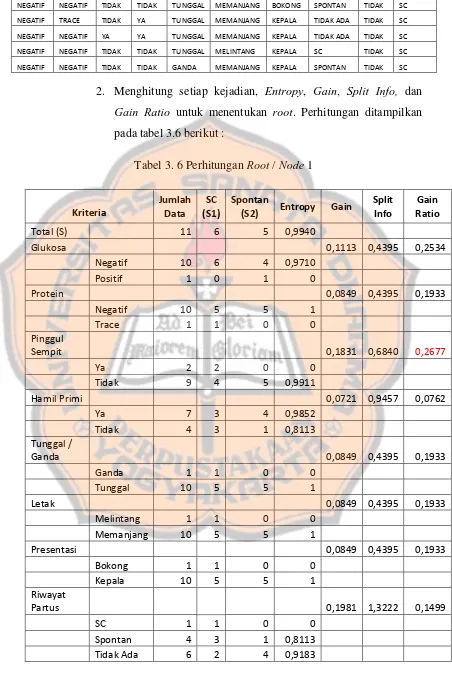
2. Menghitung setiap kejadian, Entropy, Gain, Split Info, dan
Gain Ratio untuk menentukan root. Perhitungan ditampilkan
[image:54.595.88.540.90.769.2]pada tabel 3.6 berikut :
Tabel 3. 6 Perhitungan Root / Node 1
Kriteria Jumlah Data SC (S1) Spontan
(S2) Entropy Gain
Split Info
Gain Ratio
Total (S) 11 6 5 0,9940
Glukosa 0,1113 0,4395 0,2534
Negatif 10 6 4 0,9710
Positif 1 0 1 0
Protein 0,0849 0,4395 0,1933
Negatif 10 5 5 1
Trace 1 1 0 0
Pinggul
Sempit 0,1831 0,6840 0,2677
Ya 2 2 0 0
Tidak 9 4 5 0,9911
Hamil Primi 0,0721 0,9457 0,0762
Ya 7 3 4 0,9852
Tidak 4 3 1 0,8113
Tunggal /
Ganda 0,0849 0,4395 0,1933
Ganda 1 1 0 0
Tunggal 10 5 5 1
Letak 0,0849 0,4395 0,1933
Melintang 1 1 0 0
Memanjang 10 5 5 1
Presentasi 0,0849 0,4395 0,1933
Bokong 1 1 0 0
Kepala 10 5 5 1
Riwayat
Partus 0,1981 1,3222 0,1499
SC 1 1 0 0
Spontan 4 3 1 0,8113
Ketuban
Pecah Dini 0,0495 0,8454 0,0585
Ya 3 1 2 0,9183
Tidak 8 5 3 0,9544
Dari hasil perhitungan pada tabel 3.6 diatas diperoleh nilai
GainRatio tertinggi adalah pinggul sempit yaitu sebesar 0.2677. dengan
Demilkian pinggul sempit terbentuk sebagai root dari pohon keputusan.
Pada atribut pinggul sempit ada dua nilai atribut, yaitu “ya” dan “tidak”. Nilai atribut “ya” sudah mengklasifikasikan jenis persalinan SC, sehingga
tidak perlu dilakukan perhitungan lebih lanjut, tetapi untuk nilai atrbut
“tidak” masih perlu dilakukan perhitungan lebih lanjut.
Pohon keputusan yang terbentuk pada perhitungan root
[image:55.595.113.543.81.146.2]ditampilkan pada gambar 3.2 berikut :
Gambar 3. 2 Pohon Keputusan Hasil Perhitungan Root / Node 1
3. Menghitung setiap kejadian, Entropy, Gain, Split Info, dan
Gain Ratio untuk menentukan node 2. Perhitungan untuk
[image:55.595.83.519.128.679.2]mencari node 2 ditampilkan pada tabel 3.7 berikut :
Tabel 3. 7 Perhitungan Node 2
Kriteria Jumlah
Data SC (S1)
Spontan
(S2) Entropy Gain
Split Info
Gain Ratio
Pinggul Sempit Tidak 9 4 5 0,9911 Glukosa 0,1022 0,5033 0,2031
Negatif 8 4 4 1
Protein 0,1427 0,5033 0,2835
Negatif 8 5 3 0,9544
Trace 1 1 0 0
Hamil Primi 0,2294 0,9911 0,2315
Ya 5 1 4 0,7219
Tidak 4 3 1 0,8113
Tunggal / Ganda 0,1427 0,5033 0,2835
Ganda 1 1 0 0
Tunggal 8 3 5 0,9544
Letak 0,1427 0,5033 0,2835
Melintang 1 1 0 0
Memanjang 8 3 5 0,9544
Presentasi 0,1427 0,5033 0,2835
Bokong 1 1 0 0
Kepala 8 3 5 0,9544
Riwayat Partus 0,2839 1,3516 0,2100
SC 1 1 0 0
Spontan 3 2 1 0,9183
Tidak Ada 5 1 4 0,7219
Ketuban Pecah
Dini 0,2248 0,7642 0,2941
Ya 2 0 2 0
Tidak 7 4 3 0,9852
Dari hasil perhitungan pada tabel 3.7 diatas diperoleh nilai
GainRatio tertinggi adalah ketuban pecah dini yaitu sebesar 0.2941.
Dengan demilkian ketuban pecah dini terbentuk sebagai node 2 dari pohon
keputusan. Pada atribut pinggul sempit ada dua nilai atribut, yaitu “ya” dan
“tidak”. Nilai atribut “ya” sudah mengklasifikasikan jenis persalinan
spontan, sehingga tidak perlu dilakukan perhitungan lebih lanjut, tetapi
untuk nilai atrbut “tidak” masih perlu dilakukan perhitungan lebih lanjut.
Pohon keputusan yang terbentuk dari perhitungan node 2
Gambar 3. 3 Pohon Keputusan Hasil Perhitungan Node 2
4. Menghitung setiap kejadian, Entropy, Gain, Split Info, dan
Gain Ratio untuk menentukan node 3. Perhitungan untuk
mencari node 3 ditampilkan pada tabel 3. 8 berikut :
Tabel 3. 8 Perhitungan Node 3
Kriteria Jumlah
Data SC (S1)
Spontan
(S2) Entropy Gain
Split Info
Gain Ratio
Ketuban Pecah Dini Tidak 7 4 3 0,9852
Glukosa 0 0 0
Negatif 7 4 3 0,9852
Positif 0 0 0 0
Protein 0,1281 0,5917 0,2165
Negatif 6 3 3 1
Trace 1 1 0 0
Hamil Primi 0,5216 0,9852 0,5295
Ya 4 1 3 0,8113
Tidak 3 3 0 0
Tunggal / Ganda 0,1281 0,5917 0,2165
Ganda 1 1 0 0
Tunggal 6 3 3 1
Letak 0,1281 0,5917 0,2165
Melintang 1 1 0 0
Memanjang 6 3 3 1
Bokong 1 1 0 0
Kepala 6 3 3 1
Riwayat Partus 0,5216 1,3788 0,3783
SC 1 1 0 0
Spontan 2 2 0 0
Tidak Ada 4 1 3 0,8113
Dari hasil perhitungan pada tabel 3.8 diatas diperoleh nilai
GainRatio tertinggi adalah hamil primi yaitu sebesar 0.5295. Dengan
demilkian hamil primi terbentuk sebagai node 3 dari pohon keputusan.
Pada atribut pinggul sempit ada dua nilai atribut, yaitu “ya” dan “tidak”. Nilai atribut “tidak” sudah mengklasifikasikan jenis persalinan SC,
sehingga tidak perlu dilakukan perhitungan lebih lanjut, tetapi untuk nilai
atrbut “ya” masih perlu dilakukan perhitungan lebih lanjut.
Pohon keputusan yang terbentuk dari perhitungan node 3
[image:58.595.82.512.264.711.2]ditampilkan pada gambar 3.4 berikut :
5. Menghitung setiap kejadian, Entropy, Gain, Split Info, dan
Gain Ratio untuk menentukan node 4. Perhitungan untuk
[image:59.595.87.543.186.639.2]mencari node 4 ditampilkan pada tabel 3.9 berikut :
Tabel 3. 9 Perhitungan Node 4
Kriteria Jumlah Data
SC (S1)
Spontan
(S2) Entropy Gain
Split Info
Gain Ratio
Hamil Primi Ya 4 1 3 0,811278
Glukosa 0 0 0
Negatif 4 1 3 0,811278
Positif 0 0 0 0
Protein 0,8113 0,8113 1
Negatif 3 0 3 0
Trace 1 1 0 0
Tunggal /
Ganda 0 0 0
Ganda 0 0 0 0
Tunggal 4 1 3 0,811278
Letak 0 0 0
Melintang 0 0 0 0
Memanjang 4 1 3 0,811278
Presentasi 0 0 0
Bokong 0 0 0 0
Kepala 4 1 3 0,811278
Riwayat
Partus 0 0 0
SC 0 0 0 0
Spontan 0 0 0 0
Tidak Ada 4 1 3 0,811278
Dari hasil perhitungan pada Tabel 3.9 diatas diperoleh nilai
GainRatio tertinggi adalah protein yaitu sebesar 1. Dengan demilkian
protein terbentuk sebagai node 4 dari pohon keputusan. Pada atribut
Pohon keputusan yang terbentuk dari perhitungan node 4
[image:60.595.87.510.135.628.2]ditampilkan pada gambar 3.5