1. Nina Milana adalah mahasiswa jurusan Matematika, FMIPA, Universitas Negeri Malang 2. Abadyo adalah mahasiswa jurusan Matematika, FMIPA, Universitas Negeri Malang
CHAID UNTUK MENGKLASIFIKASI STATUS MAHASISWA SETELAH LULUS PERKULIAHAN
(Studi Kasus Pada Alumnus Prodi Matematika. Jurusan Matematika. FMIPA. Universitas Negeri Malang. Tahun 2007-2012)
Nina Milana1 dan Abadyo2 Universitas Negeri Malang E-mail : [email protected]
ABSTRAK : Tujuan penelitian ini adalah mengklasifikasi status mahasiswa
setelah lulus perkuliahan dengan menggunakan metode CHAID. Variabel terikat (dependent) adalah status mahasiswa setelah lulus perkuliaahan, sedangkan variabel bebasnya (independent) meliputi umur ketika yudisium, umur ketika bekerja pertama, jenis kelamin, status nikah ketika yudisium, IPK, kemampuan berbahasa Inggris dan keaktifan organisasi. Melalui metode CHAID (Chi-Square Automatic Interaction Detection) disimpulkan bahwa untuk alumnus yang bekerja kurang dari atau sama dengan 6 bulan memiliki karakteristik yaitu alumnus dengan status belum menikah ketika yudisium yang mempunyai IPK lebih dari 3.00 dan usia ketika bekerja pertama kali adalah kurang dari atau sama dengan 25 tahun. Kategori mendapatkan pekerjaan lebih dari 6 bulan memiliki karakteristik alumnus berstatus belum menikah ketika yudisium yang mempunyai IPK lebih dari 2.75 hingga kurang dari atau sama dengan 3.00, sedangkan untuk kategori yang tidak bekerja memiliki karakteristik alumnus yang sudah menikah ketika yudisium.
Kata kunci : CHAID, klasifikasi, status mahasiswa setelah lulus perkuliahan
Pengangguran sudah menjadi masalah pokok bangsa ini dan yang lebih menghawatirkan apabila pengangguran justru terjadi pada lulusan perguruan tinggi, dimana diketahui lulusan perguruan tinggi diharapkan bisa menjadi tonggak kebangkitan negara Indonesia ini untuk lebih baik kedepanya. Pada lulusan Prodi Matematika, FMIPA, Universitas Negeri Malang sendiri misalnya, tidak sedikit alumnus dari prodi matematika yang belum bekerja setelah lulus dari perkuliahan. Berbagai macam hal melatarbelakangi terjadinya pengangguran lulusan sarjana tersebut misalkan saja nilai IPK, keaktifan dalam organisasi, prestasi-prestasi yang pernah diperoleh selama perkuliahan dan lain sebagainya. Dengan mengklasifikasikan faktor-faktor yang mengakibatkan pangangguran untuk lulusan sarjana, maka diharapkan mampu memberikan informasi sehingga lulusan perguruan tinggi terutama untuk prodi matematika yang menganggur dapat diminimalisasikan.
Klasifikasi merupakan salah satu bahasan yang sering dikaji dalam statistika. Menurut Hamakonda dan Tairas (1991:1) klasifikasi adalah pengelompokkan yang sistematis pada sejumlah objek, gagasan, buku atau benda-benda lain ke dalam kelas atau golongan tertentu berdasarkan ciri-ciri yang sama.
Salah satu metode yang menggunakan tekhnik klasifikasi yaitu metode CHAID (Chi- Squared Automatic Interaction Detection). Metode CHAID umumnya dikenal sebagai metode pohon klasifikasi (Classification Tree Method). Inti dari metode ini adalah membagi data menjadi kelompok-kelompok yang lebih
kecil berdasarkan keterkaitan antara variabel terikat dengan variabel bebas. Analisis CHAID digunakan ketika data yang dipakai adalah data dengan variabel-variabel kategorik. Metode CHAID hanya efektif bila diterapkan pada data dengan pengamatan yang banyak (Steyn & Stumph, 1986). CHAID memiliki kelebihan yaitu pada hasil output yang mana output grafis berupa sebuah pohon klasifikasi sehingga membuat metode ini lebih mudah diintepretasikan karena bisa dilihat langsung bagaimana pola pemisahan dan penggabungan variabel bebas pada prosesnya.
Secara garis besar CHAID dapat dibagi dalam tiga tahap yaitu: 1. Tahap penggabungan (Merging)
Tahap penggabungan kategori dapat dilakukan pada variabel bebas yang memiliki kategori lebih dari dua. Penggabungan kategori ditetapkan dengan
cara mencari pasangan kategori yang memiliki lebih dari nilai paling besar
untuk setiap variabel bebas. Nilai dibandingkan dengan nilai
, jika nilai lebih besar dari maka kategori-kategori
tersebut digabungkan. Jika nilai terbesar masih labih kecil dari
maka tidak ada kategori dalam variabel bebas tersebut yang perlu digabungkan. Jika variabel bebas hanya memiliki dua kategori dan nilai
kurang dari maka variabel ini dikeluarkan dari model.
Periksa kembali kesignifikansian kategori baru setelah digabung dengan kategori lainnya dalam variabel independent, jika masih ada pasangan yang belum signifikan, ulangi langkah penggabungan kategori, namun jika semua sudah signifikan lanjutkan langkah berikutnya yakni menghitung p-value terkoreksi Bonferroni yang didasarkan pada hasil penggabungan.
2. Pemisahan (splitting)
tahap ini memilih variabel bebas yang mana yang akan digunakan sebagai
split node (pemisah node) yang terbaik. Pemilihan dikerjakan dengan
membandingkan p-value (dari tahap merging) pada setiap variabel bebas. Langkah splitting adalah dengan memilih variabel bebas yang memiliki
p-value terkecil (paling signifikan) yang akan digunakan sebagai split node, jika p-value kurang dari sama dengan tingkat spesifikasi alpha, split node
menggunakan variabel bebas ini, namun jika tidak ada variabel bebas dengan nilai p-value yang signifikan maka tidak dilakukan split dan node ditentukan sebagai terminal node (node akhir).
3. Penghentian (stopping)
Pembentukan pohon harus dihentikan sesuai dengan peraturan pemberhentian yakni jika tidak ada lagi variabel bebas yang signifikan atau jika pohon mencapai batas nilai maksimum pohon dari spesifikasi yang ditentukan.
CHAID akan membedakan variabel-variabel bebas kategorik menjadi tiga bentuk yang berbeda (Gallagher: 2000), yaitu:
a. Variabel Independent Monotonik
Yaitu variabel indenpenden yang kategori di dalamnya dapat dikombinasikan atau digabungkan oleh CHAID hanya jika keduanya berdekatan satu sama lain atau mengikuti urutan aslinya (data ordinal). Contohnya: usia atau pendapatan.
Yaitu variabel Independent yang kategori di dalamnya dapat dikombinasikan atau digabungkan ketika keduanya berdekatan ataupun tidak (data nominal). Contohnya: pekerjaan, kelompok etnik, dan area geografis.
Koreksi Bonferroni (Bonferroni Correction)
Koreksi Bonferroni adalah suatu proses koreksi yang digunakan ketika beberapa uji statistik untuk kebebasan atau ketidakbebasan dilakukan secara bersamaan (Sharp, 2002).
Ketika terdapat sebanyak uji perbandingan yang sudah dikatakan
bebas satu sama lain, peluang untuk melakukan kesalahan tipe 1 atau (dalam satu atau lebih uji-uji tersebut) akan sama dengan 1 dikurangi peluang untuk tidak melakukan kesalahan tipe satu dalam uji-uji tersebut, dimana nilainya akan lebih besar dari yang telah ditentukan. Secara umum hal tersebut dapat dirumuskan sebagai berikut:
1 − (1 − ) > , dimana :
= Pengali Bonferroni = salah tipe 1
Gallagher (2000) menyebutkan bahwa pengali Bonferroni untuk masing-masing jenis variabel bebas adalah sebagai berikut:
1. Variabel Independent Monotonik
= − 1
− 1
2. Variabel Independent Bebas
= (−1) ( − 1)
! ( − )!
dimana :
= Pengali Bonferroni
= Banyak kategori variabel bebas awal, dimana > = Banyak kategori variabel bebas setelah penggabungan.
Diagram Pohon (Tree Diagram)
Hasil pembentukan segmen dalam CHAID akan ditampilkan dalam sebuah diagram pohon. Diagram pohon CHAID mengikuti aturan “dari atas ke bawah” (Top-down stopping rule), dimana diagram pohon disusun mulai dari kelompok induk, berlanjut di bawahnya sub kelompok yang berturut-turut dari hasil pembagian kelompok induk berdasarkan kriteria tertentu (Myers, 1996).
Setiap node akan berisi keseluruhan sampel dan frekuensi absolut untuk tiap
kategori yang disusun di atasnya. Pada pohon klasifikasi CHAID terdapat istilah kedalaman (depth) yang berarti banyaknya tingkatan node-node sub kelompok sampai ke bawah pada node sub kelompok yang terakhir.
Secara ringkas, Bagozzi (1994) menyatakan bahwa, diagram pohon, yang merupakan inti dari analisis CHAID, akan berisi:
1. Simbol yang menerangkan tentang kategori tertentu (atau kategori-kategori yang telah digabungkan).
2. Sebuah ringkasan data dari variabel terikat dalam kelompok tersebut (misalnya persentase respon).
3. Ukuran sampel untuk kelompok biasa dilambangkan dengan “ ”.
METODOLOGI Sampel Penelitian
Sampel dalam penelitian ini adalah alumnus Prodi Matematika, Jurusan Matematika, FMIPA, Universitas Negeri Malang dari tahun 2007 hingga 2012 yang di ambil sebanyak 50 orang.
Variabel Penelitian
Penilitian ini menggunakan dua variabel yaitu variabel terikat dan
variabel bebas. Variabel terikat (dependent) yang dilambangkan dengan ( ),
maliputi: mahasiswa setelah lulus perkuliahan dengan status bekerja dengan
selang waktu menganggur kurang dari atau sama dengan 6 bulan ( ), mahasiswa
setelah lulus perkuliahan dengan status bekerja dengan selang waktu menganggur
lebih dari 6 bulan ( ), dan mahasiswa setelah lulus perkuliahan dengan status
tidak bekerja ( ). Variabel bebas (independent) yang dilambangkan dengan
( ) yang meliputi: umur saat yudisium ( ), umur saat mendapatkan pekerjaan
yang pertama ( ), jenis kelamin ( ), status pernikahan ketika responden
yudisium ( ), IPK ( ), kektifan dalam organisasi ( ), dan kemampuan bahasa
Inggris ( )
Dan pada penelitian ini data yang dipakai adalah data dengan variabel-variabel kategorik. Variabel kategorik adalah variabel-variabel yang memberikan label sesuai pengamatan dan dialokasikan untuk salah satu dari beberapa kemungkinan.
Sumber Data
Data yang dipakai dalam penelitian ini adalah data primer, yaitu data yang diperoleh melalui pembagian atau penyebaran daftar pertanyaan (kuesioner) yang diberikan kepada alumnus Prodi Matematika, Jurusan Matematika, FMIPA, Universitas Negeri Malang tahun lulus 2007-2012.
Analisa Data
Metode analisis data yang digunakan pada penelitian ini yaitu yang pertama membagi data berdasarkan kategori yang ditentukan kemudian menentukan semua skala variabel yang akan digunakan dengan tepat dan benar setelah itu dialakukan proses matematis analisis CHAID, dengan menerapkan 3 langkah analisis CHAID, yaitu langkah : penggabungan, pemisahan, dan pemberhentian. Dalam langkah penggabungan akan mulai diterapkan uji
chi-square dan pengali Bonferroni sebagai pengoreksinya, kemudian dilakukan iterasi
pada langkah kedua dan proses iterasi akan berhenti apabila sudah tidak ada lagi variabel independen yang tersisa untuk diuji hubungannya dengan variabel dependen, atau juga apabila terbentuknya node pada diagram pohon telah memenuhi batasan yang ditentukan. Proses ini disebut dengan proses pemberhentian. Yang terakhir adalah menentukan segmentasi status mahasiswa dengan menginter pretasikan diagram pohon CHAID dan menentukan target berdasarkan hasil segmentasi mahasiswa yang sudah terbentuk.
PEMBAHASAN
Pada iterasi pertama diperoleh variabel status pernikahan ketika
responden yudisium (X4) sebagai node awal atau kedalaman (depth) pertama, hal
tersebut dilakukan karena memiliki nilai chi-square terbesar yaitu 21.467. Iterasi kedua variabel IPK dimasukkan ke dalam diagram pohon untuk kedalaman ke-2
karena mempunyai nilai terbesar yaitu 17.653, kemudian dilakukan
proses penggabungan dan diperoleh kategori baru yaitu kategori 1 dengan kriteria
IPK 2.75 – 300 dan kategori 2 denga kriteria IPK > 3.00 dengan baru
yakni 14.330, p-value sebesar 0.002 dan nilai koreksi Bonferroni sebasar 0.41262. Iterasi ketiga variabel usia bekerja pertama masuk dalam pohon klasifikasi
sebagai kedalaman ketiga, karen memiliki terbesar yaitu 14.782,
kemudian dilakukan penggabunga kategori dan diperoleh kategori baru yakni kategori 1 dengan kriteria usia 21 – 25 tahun dan kategori 2 dengan kategori usia
> 25 tahun sehingga diperoleh nilai baru yakni 13.943, p-value 0.002
dan nilai koreksi Bonferroni sebesar 0.0975.
Analisis CHAID menghasilkan suatu diagram pohon yang
menggambarkan penggabungan berdasarkan hubungan antar variabel terikat
(dependent) dengan variabel bebas (independent). Berikut ini adalah diagram
pohon CHAID:
Gambar 4.9. Diagram pohon CHAID Sumber : data diolah SPSS 17.0 (2013)
Dari 7 variabel yang telah diolah dengan CHAID, ada 4 variabel yang berasosiasi atau memiliki keterkaitan dengan status pekerjaan alumnus, yaitu : 1. Status Pernikahan
2. IPK
Berikut adalah tabel klasifikasi beserta karakteristik dari pengklasifikasiannya berdasarkan pada diagram 4.9:
Tabel 4.21 Pengklasifikasian berdasarkan diagram pohon CHAID
Klasifikasi Node Karakteristik
Ke-1 1, 3 Alumnus berstatus belum menikah ketika yudisium yang mempunyai IPK kurang dari atau sama dengan 3.00.
Ke-2 1, 4,5
Alumnus berstatus belum menikah ketika yudisium yang mempunyai IPK lebih dari 3.00 dan usia ketika bekerja pertama kurang dari atau sama dengan 25 tahun.
Ke-3 1, 4, 6 Alumnus berstatus belum menikah ketika yudisium yang mempunyai IPK lebih dari 3.00 dan usia ketika bekerja pertama lebih dari 25 tahun.
Ke-4 2 Alumnus yang sudah menikah ketika yudisium
Sumber : data diolah (2013)
Berdasarkan pengklasifikasian pada tabel di atas, maka berikut ini diberikan tabel persentase setiap klasifikasinya:
Tabel 4.22 Persentase Pengklasifikasian
Klasifikasi
Bekerja ≤ bulan Bekerja > 6 bulan Tidak bekerja Jumlah alumni persentase Jumlah Alumni Persentase Jumlah Alumni Persentase Ke-1 3 21.4% 10 71.4% 1 7.1% Ke-2 21 91.3% 1 4.3% 1 4.3% Ke-3 1 25% 3 75% 0 0% Ke-4 1 11.1% 2 22.2% 6 66.7%
Sumber : data diolah (2013)
Pada kategori bekerja kurang dari atau sama dengan 6 bulan diperoleh
presentase tertinggi pada klsifikasi ke-2 yaitu sebesar 91.3% atau sebanyak 21
responden. Untuk kategori bekerja lebih dari 6 bulan diperoleh persentase
tertinggi pada klasifikasi ke-1 yakni sebesar 71.4% atau sebanyak 10 responden. Sedangkan untuk kategori tidak bekerja persentase tertinggi adalah pada
klasifikasi ke-4 yaitu dengan besar persentase 66.7% atau sebanyak 6 orang
responden.
Risk dan Classification
Tabel 4.26 Risk
Risk
Estimate Std. Error .200 .057 Growing Method: CHAID Dependent Variable: Status_Pekerjaan
Sumber : data diolah SPSS 17.0 (2013)
Tabel risk digunakan untuk menuguji kebaikan model. Estimasi
menunjukkan nilai 0.200 atau risiko sebesar 20%, hal ini memiliki arti bahwa
model akan salah memprediksi atau salah mengklasifikasi status pekerjaan responden sebesar 20%.
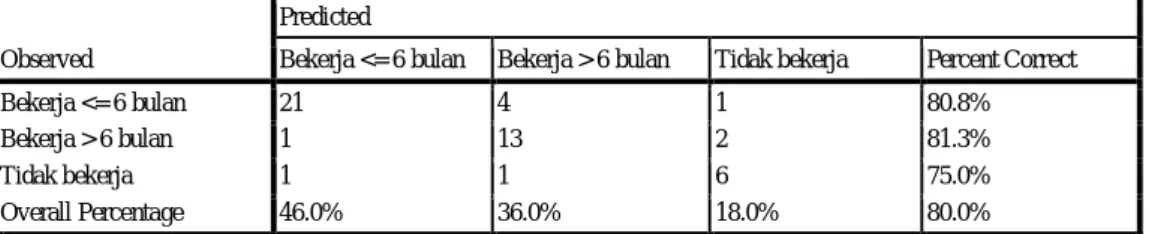
Tabel 4.27 Classification
Classification
Observed
Predicted
Bekerja <= 6 bulan Bekerja > 6 bulan Tidak bekerja Percent Correct
Bekerja <= 6 bulan 21 4 1 80.8%
Bekerja > 6 bulan 1 13 2 81.3%
Tidak bekerja 1 1 6 75.0%
Overall Percentage 46.0% 36.0% 18.0% 80.0%
Growing Method: CHAID
Dependent Variable: Status_Pekerjaan
Smber : data diolah SPSS 17.0 (2013)
Pada tabel Classification diketahui bahwa untuk kategori bekerja kurang dari atau sama denagn 6 bulan ada 26 reponden dengan prediksi modelnya adalah
bekerja bekerja kurang dari atau sama dengan 6 bulan sebanyak 21 responden
(good predicted), sedangkan untuk bekerja lebih dari 6 bulan sebanyak 4
responden dan tidak bekerja sebanyak 1 responden (misclasification).
Kategori bekerja lebih dari 6 bulan ada16 responden dengan prediksi
modelnya adalah 13 responden bekerja lebih dari 6 bulan, sedangkan 1 responden
bekerja kurang dari atau sama dengan 6 bulan dan 6 responden tidak bekerja
(misclasification).
Kategori tidak bekerja ada 8 responden dengan prediksi modelnya adalah tidak bekerja 6 responden (good predicted) dan 2 orang bekerja (misclasification).
Percent correct untuk overall percentage sebesar 80%, hal ini memiliki arti bahwa model pada kasus ini dapat dikatakan benar.
PENUTUP Kesimpulan
Dari proses analisis dengan metode CHAID (Chi-Square Automatic
Interaction Detection) diperoleh hasil bahwa untuk kategori mendapatkan
pekerjaan kurang dari atau sama dengan 6 bulan memiliki karakteristik yaitu
alumnus dengan status belum menikah ketika yudisium yang mempunyai IPK lebih dari 3.00 dan usia ketika bekerja pertama kali adalah kurang dari atau sama dengan 25 tahun. Kategori mendapatkan pekerjaan lebih dari 6 bulan memiliki karakteristik alumnus berstatus belum menikah ketika yudisium yang
mempunyai IPK lebih dari 2.75 hingga kurang dari atau sama dengan 3.00.
Sedangkan untuk kategori yang tidak bekerja memiliki karakteristik alumnus yang sudah menikah ketika yudisium.
Saran
Saran dalam penelitian berikutnya dalam penggunaan metode CHAID untuk mengklasifikasi status mahasiswa setelah lulus perkuliahaan (bekerja atau tidak bekerja) sebaiknya melibatkan lebih banyak varibel bebas misalnya mata kuliah konsentrasi yang diambil, banyak sedikitnya informasi lowongan kerja yang diperoleh alumnus, memiliki keahlian khusus dibidang lain dan lain
sebagainya, sehingga struktur CHAID yang terbentuk dapat memasukkan lebih banyak faktor-faktor yang berpengaruh terhadap status pekerjaan. Selain itu dengan lebih banyak variabel diharapkan hasil penelitian ini dapat lebih akurat. Metode CHAID ini dapat pula dilakukan untuk penelitian pada ruang lingkup yang lain, misalnya pada bidang kesehatan, pemasaran, perbankan dan lain sebagainya.
Daftar Pustaka
Bagozzi, R, P. 1994. Advenced Methode of Marketing Research. Oxford:
Blackwell publisher Ltd. (Online), www.gbv/de/dms/Advenced_
Methodes_of_Marketing_Research/128987839bagoz.pdf. Tanggal akses : 12 Desember 2012.
C, Gallagher. 1984. Risk Classification Aided by New Software Tool (CHAID-
Chi-Square Automatic Interaction Detector, National Underwrute Property and Casualty – Risk and Benefit Management , Vol.17, No. 19.
(Online), www.casact.org/library/ratemaking/90dp237.pdf. Tanggal akses: 28 Oktober 2012.
Du Toit, Steyn and Stump. 1986. Graphical Exploratory Data Analisys. New York: Springer-Verlag.
Ferdinand, Audusty, 2006, “ Metode Penelitian Management”, Badan Penerbit Universitas Diponegor, Semarang.
Hamandoko, Towa dan Tairas, J, 1999, Pengantar Klasifikasi Persepuluhan
Dewey. Jakarta:BPK Gunung Mulia.
Sekaran, Uma. 2003. Research Methods for Businiss: a skill Building Approach.
(4th ed). New York: John Wiley and Sons.
Sharp, A, J, Romanik. And S, Cierpicki. 2002. The Performance of Segmentation
Variables: A Compairative Study. (Online), http://130.195.95.71:8081/
www/ ANZMAC1998/Cd_rom/Sharp222.pdf. Tanggal akses: 15 Oktober 2012.
.
&tikel
oteto NimMiIffi
ini rclahdiperiksa dan disctr*ui. Matang Mei 2013 NrP. 19520424t974t2tffi