commit to user
i
ESTIMASI PARAMETER MODEL KELAS LATEN MENGGUNAKAN ALGORITMA EXPECTATION- MAXIMIZATION (EM)
oleh
NURNAINI HIDAYATI M0105014
SKRIPSI
ditulis dan diajukan untuk memenuhi sebagian persyaratan memperoleh gelar Sarjana Sains Matematika
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SEBELAS MARET
SURAKARTA 2011
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
commit to user
iii ABSTRAK
Nurnaini Hidayati, 2011. ESTIMASI PARAMETER MODEL KELAS
LATEN MENGGUNAKAN ALGORITMA
EXPECTATION-MAXIMIZATION (EM). Fakultas Matematika dan Ilmu Pengetahuan Alam.
Universitas Sebelas Maret.
Klasifikasi adalah pengelompokan objek ke dalam beberapa kelompok berdasarkan ukuran kemiripan atau ciri-ciri umum antar objek. Dalam klasifikasi kadang ditemukan objek yang tidak bisa diukur secara langsung karena tidak mempunyai nilai kuantitatif. Objek tersebut disebut dengan variabel tidak terukur atau tidak terobservasi (variabel laten). Klasifikasi terhadap variabel laten memerlukan data-data ataupun variabel terobservasi yang digunakan sebagai indikator, yang biasa disebut sebagai variabel manifes. Alat statistik yang dapat digunakan untuk klasifikasi terhadap variabel laten berdasarkan variabel manifes yang keduanya bertipe kategorik adalah analisis kelas laten. Adanya variabel laten mengakibatkan metode estimasi maksimum likelihood tidak bisa digunakan secara langsung. Tujuan dari penelitian ini adalah mengkaji ulang estimasi parameter model kelas laten menggunakan algoritma expectation-maximization (EM).
Algoritma EM digunakan untuk menentukan nilai estimasi maksimum
likelihood dari parameter-parameter dalam model dengan menganggap data
terobservasi sebagai data yang tidak lengkap (incomplete data) yang dilakukan secara iteratif. Setiap iterasi dari algoritma EM terdiri dari dua tahap yaitu tahap penentuan harga harapan (tahap ekspektasi) untuk menggantikan informasi yang hilang pada permasalahan data yang tidak lengkap dan tahap pemaksimuman (tahap maksimisasi) sebagai upaya optimasi nilai parameter berdasarkan hasil pada tahap ekspektasi.
Hasil dari penelitian ini adalah pada tahap ekspektasi diperoleh fungsi yaitu ( ) ∑ ∑ ( | ) ∏ ∏ ( )
dan pada
tahap maksimisasi diperoleh estimator dengan persamaan ∑ ( | ) dan ∑ ( | )
∑ ( | ) . Kedua tahap
tersebut dilakukan secara iteratif hingga diperoleh estimator yang dapat memaksimumkan fungsi likelihood secara konvergen.
Kata kunci : estimasi maksimum likelihood, variabel laten, variabel manifes, data tidak lengkap, algoritma EM.
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
iv ABSTRACT
Nurnaini Hidayati, 2011. PARAMETER ESTIMATION OF LATENT CLASS MODEL USING THE EXPECTATION-MAXIMIZATION (EM) ALGORITHM. Faculty of Mathematics and Natural Sciences. Sebelas Maret University.
Classification is a grouping of the objects into several groups based on similarity measure or the common characteristic among the objects. In the classification sometimes finding the object that can not be measured directly because it does not have a quantitative value. That object is called unmeasured or unobserved variable (latent variable). Classifying latent variable requires data or observed variables used as indicators, commonly referred as manifest variable. Statistic tool used to classify the latent variable based on the manifest variable which both are categorical type is latent class analysis. Maximum likelihood estimation method can not be used directly because of the existence of latent variable. The aim of this research is to review the parameter estimation of latent class model using the Expectation-Maximization (EM) algorithm.
EM algorithm is used to determine the value of maximum likelihood estimation from parameters in the model with regarded the observed data as incomplete data proceeded iteratively. Each iteration of the EM algorithm consists of two steps, they are determination of the expectation value (expectation step) to replace the missing information on the incomplete data problem and maximization step as an effort to optimize the parameter value based on result in the expectations step.
The results of this research are the function, ( ) ∑ ∑ ( | ) ∏ ∏ ( )
is obtained in
the expectation step and the estimator ∑ ( | ) and
∑ ( | )
∑ ( | ) is obtained in the maximization step. Both steps are
proceeded iteratively until the estimator that can maximize the likelihood function in a convergent is obtained.
Key word : maximum likelihood estimation, latent variable, manifest variable, incomplete data, EM algorithm.
commit to user
v MOTO
“Maka sesungguhnya disamping ada kesukaran terdapat pula kemudahan. Sesungguhnya disamping ada kepayahan (jasmani) itu,
ada pula kelapangan” ( Al-insyirah 22 : 5-6)
Orang yang sukses adalah orang yang dapat mengalahkan rasa takut dan rasa malu
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
vi PERSEMBAHAN
Kupersembahkan karyaku ini kepada…
Bapak dan ibuku tersayang…
Kebahagiaan kalian adalah alasan sekaligus tujuan hidupku…
Seandainya aku bisa mencintai kalian lebih dari kalian mencintaiku…
Kakak dan adikku tersayang…
Terimakasih atas kasih sayang tak berbatas… Sahabat-sahabatku…
commit to user
vii KATA PENGANTAR
Bismillahirohmanirrohim. Alhamdulillahirobbil’alamin, puji syukur penulis panjatkan kehadirat Allah SWT, atas rahmat dan hidayah-Nya penulis dapat menyelesaikan skripsi ini.
Penulis menyadari bahwa dalam menyelesaikan skripsi ini banyak pihak yang telah membantu. Untuk itu, pada kesempatan ini penulis ingin mengucapkan terima kasih kepada:
1. Dra. Etik Zukhronah, M.Si sebagai Pembimbing I dan Drs. Pangadi, M.Si sebagai Pembimbing II yang telah memberikan bimbingan selama menyelesaikan skripsi.
2. Semua teman-teman Jurusan Matematika angkatan 2005. 3. Semua pihak yang telah membantu penyelesaian skripsi ini.
Penulis berharap semoga skripsi ini dapat bermanfaat bagi seluruh pembaca.
Surakarta, Maret 2011
perpustakaan.uns.ac.id digilib.uns.ac.id commit to user viii DAFTAR ISI Halaman HALAMAN JUDUL ………...………... i HALAMAN PENGESAHAN ………...………..….. ii ABSTRAK………...………... iii ABSTRACT………...………...…………... iv MOTO…....………...……….……… v PERSEMBAHAN……….………. vi
KATA PENGANTAR ………...………... vii
DAFTAR ISI ………...……….………. viii
DAFTAR TABEL………...……….……….. x
DAFTAR NOTASI ………...………..………... xi
BAB I PENDAHULUAN……….. 1
1.1 Latar Belakang Masalah………..……… 1
1.2 Perumusan Masalah………..………... 2
1.3 Tujuan Penelitian………..…..………. 2
1.4 Manfaat Penelitian………..………. 3
BAB II LANDASAN TEORI………...……….. 4
2.1 Tinjauan Pustaka………...………... 4
2.1.1 Probabilitas………... 4
2.1.2 Teorema Bayes………. 5
2.1.3 Metode Estimasi Maksimum Likelihood……….… 6
2.1.4 Model Campuran……….. 7
2.1.5 Ketidaksamaan Jensen.………...………. 8
2.1.6 Algoritma EM……….. 10
2.1.7 Metode Pengali Lagrange……… 15
2.1.8 Kriteria Pemilihan Model………. 16
2.2 Kerangka Pemikiran………...………... 18
BAB III METODE PENELITIAN………...……….. 19
commit to user
ix
4.1 Model Kelas Laten……….……..………..……….. 20
4.2 Estimasi Parameter Model Kelas Laten………...……… 23
4.2.1 Tahap Ekspektasi………..………..………... 24
4.2.2 Tahap Maksimisasi………..……… 25
4.3 Contoh Kasus………... 28
4.4.1 Hasil Estimasi Parameter………..……... 29
4.4.2 Pemilihan Model Terbaik………...…….. 34
BAB V PENUTUP………. 36
5.1 Kesimpulan………... 36
5.2 Saran……….... 37
DAFTAR PUSTAKA………. 38
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
x DAFTAR TABEL
Halaman Tabel 4.1 Analisis struktur laten berdasarkan variabel laten dan variabel
manifes…………...……….……….. 20
Tabel 4.2 Probabilitas individu berada pada kelas 1 dan 2 ( ) …..……..… 30 Tabel 4.3 Probabilitas bersyarat ( ) dengan 2 kelas laten ………...……. 30
Tabel 4.4 Probabilitas individu berada pada kelas 1, 2, dan 3 ( ) …...…… 31 Tabel 4.5 Probabilitas bersyarat ( ) dengan 3 kelas laten …….……..…. 31 Tabel 4.6 Probabilitas individu berada pada kelas 1, 2, 3, dan 4 ( ) …...… 33 Tabel 4.7 Probabilitas bersyarat ( ) dengan 4 kelas laten …..……….…. 33
commit to user
xi DAFTAR NOTASI
: variabel laten : variabel manifes
: banyaknya kelas pada variabel laten : banyaknya variabel manifes
: kemungkinan outcome variabel manifes : probabilitas individu berada pada kelas laten
: probabilitas variabel manifes dengan outcome dengan syarat
varibel laten pada kelas : banyaknya individu
: fungsi likelihood data lengkap : nilai awal untuk
: nilai awal untuk : estimator untuk : estimator untuk
: vektor indikator yang merepresentasikan keanggotaan individu
pada kelas laten : banyaknya iterasi ( ) : fungsi Lagrange
: pengali Lagrange
: banyaknya sel pada tabel kontingensi : frekuensi sel
̂ : frekuensi harapan sel : rasio likelihood
: uji kecocokan Chi-kuadrat
: distribusi Chi-kuadrat dengan dan derajat bebas yang sesuai
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
xii : maksimum log likelihood
commit to user
1 BAB I PENDAHULUAN 1.1 Latar Belakang Masalah
Secara umum klasifikasi adalah pengelompokan objek ke dalam beberapa kelompok berdasarkan ukuran kemiripan atau ciri-ciri umum antar objek. Dengan klasifikasi diharapkan objek-objek yang ada pada kelompok yang sama memiliki kemiripan yang lebih besar dibandingkan dengan antar objek pada kelompok yang berbeda. Objek dalam hal ini dapat berupa responden, brand atau produk, atau objek pengamatan lainnya.
Dalam usaha pengklasifikasian kadang ditemukan objek yang tidak bisa diukur secara langsung. Objek tersebut disebut dengan variabel tidak terukur (variabel laten) karena variabel tersebut tidak mempunyai nilai kuantitatif. Klasifikasi terhadap variabel laten memerlukan data-data ataupun variabel-variabel yang digunakan sebagai indikator, yang biasa disebut sebagai variabel-variabel manifes. Alat statistik yang sering digunakan untuk klasifikasi terhadap variabel laten adalah analisis faktor.
Dalam analisis faktor variabel yang diukur disyaratkan bertipe kontinu, padahal dalam kehidupan sehari-hari sering dijumpai data berupa data kategorik, yaitu data yang memiliki ukuran skala yang berupa kategori dan tidak memiliki ukuran kuantitatif. Sebagai contoh, filosofi politik diukur dalam 3 kategori yaitu liberal, moderat dan konservatif. Untuk melakukan klasifikasi pada data kategorik diperlukan suatu alat statistik yaitu analisis kelas laten atau latent class analysis (LCA).
Dalam analisis kelas laten, estimasi parameter diperlukan untuk mencari estimator dari parameter populasi yang besarnya tidak diketahui. Metode estimasi parameter yang sering digunakan adalah metode estimasi maksimum likelihood karena praktis digunakan untuk mendapatkan estimator yang tidak bias dan bervariansi minimum. Adanya variabel laten mengakibatkan metode estimasi maksimum likelihood tidak bisa digunakan secara langsung, sehingga diperlukan modifikasi atau augmented data agar metode estimasi maksimum likelihood dapat digunakan secara lebih sederhana.
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
2
Menurut Andersen [1], terdapat dua metode yang dapat digunakan untuk menyelasaikan estimasi maksimum likelihood pada model kelas laten, yaitu algoritma EM dan algoritma Newton Raphson. Haberman dalam Demster dkk. [4] berpendapat bahwa algoritma EM lebih lambat mencapai konvergen dibandingkan algoritma Newton Raphson, akan tetapi algoritma EM lebih sederhana karena tidak memerlukan matriks turunan kedua dari fungsi likelihood.
Dalam analisis kelas laten augmented data dilakukan dengan memasangkan data dari variabel manifes dengan data dari variabel laten. Oleh karena itu, augmented data disebut sebagai data lengkap dan data terobservasi disebut data tidak lengkap karena data dari variabel laten sebagai pasangannya tidak terobservasi. Menurut Demster dkk. [4], algoritma EM digunakan untuk menentukan nilai estimasi maksimum likelihood dari parameter-parameter jika dalam model terdapat data yang tidak lengkap (incomplete data).
Menurut Linzer dan Lewis [10], model kelas laten adalah model campuran dengan distribusi komponennya berupa tabel kontingensi multinomial dengan semua variabelnya independen. Oleh karena itu, algoritma EM dapat dijalankan memalui pendekatan model campuran.
Berdasarkan uraian tersebut, penelitian ini mengkaji ulang estimasi parameter model kelas laten menggunakan algoritma EM melalui pendekatan model campuran (mixture model).
1.2 Perumusan Masalah
Berdasarkan latar belakang masalah yang telah diuraikan, disusun perumusan masalah yaitu bagaimana estimasi parameter model kelas laten menggunakan algoritma EM melalui pendekatan model campuran.
1.3 Tujuan
Tujuan yang ingin dicapai dari penelitian ini adalah mengkaji ulang estimasi parameter model kelas laten menggunakan algoritma EM melalui pendekatan model campuran.
commit to user
1.4 Manfaat
Manfaat dari penelitian ini diharapkan dapat menambah wawasan mengenai analisis kelas laten sebagai metode klasifikasi jika dalam sebuah penelitian terdapat variabel yang tidak terobservasi atau tidak terukur (variabel laten). Selain itu diharapkan dapat menambah wawasan mengenai metode estimasi parameter model kelas laten dengan algoritma EM melalui pendekatan model campuran.
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
4 BAB II
LANDASAN TEORI
Bab ini terdiri dari dua subbab, yaitu tinjauan pustaka dan kerangka pemikiran.
2.1 Tinjauan Pustaka
Pada tinjauan pustaka diberikan pengertian dasar yang diperlukan pada pembahasan, yaitu konsep probabilitas, teorema Bayes, metode maksimum
likelihood, model campuran , ketidaksamaan Jensen, algoritma EM, dan metode
pengali Lagrange.
2.1.1 Probabilitas
Dalam suatu eksperimen, S menotasikan ruang sampel dan menggambarkan kejadian-kejadian yang mungkin terjadi. Suatu fungsi himpunan yang menghubungkan nilai nyata ( ) dengan setiap kejadian disebut probabilitas fungsi himpunan dan ( ) disebut probabilitas dari jika memenuhi persyaratan
1) ( ) untuk setiap 2) ( )
3) (⋃ ) ∑ ( )
(Jika adalah kejadian-kejadian yang mutually exlusive). Berikut diuraikan definisi mengenai konsep probabilitas. Definisi 2.1 (Krewski dan Biks, [9])
Misalkan suatu ruang sampel S terdiri dari himpunan-himpunan kejadian yang
tidak kosong (nonempty set) ( ) Himpunan-himpunan tersebut dikatakan
independen jika untuk sembarang dari kejadian berlaku
(⋂
) ∏ . /
commit to user
Sebuah himpunan dikatakan mutually independent (simply independent) jika himpunan tersebut k x k independen untuk semua nilai k.
Definisi 2.2 (Krewski dan Biks, [9])
Misalkan himpunan bagian dari S dan
maka kejadian disebut exhaustive.
Definisi 2.3 (Bain dan Engelhardt, [2])
Probabilitas kejadian A dengan syarat B didefinisikan sebagai
( | ) ( ) ( )
dengan ( )
2.1.2 Teorema Bayes Teorema 2.1 (Bain dan Engelhardt, [2])
Jika sembarang himpunan bagian dari dan adalah partisi dari
. Untuk dan berlaku ( | ) ( ) ( | )
∑ ( ) ( | ) Bukti:
Misalkan merupakan partisi dari ruang sampel , dengan yang bersifat
1) 2)
Misalkan adalah sembarang kejadian yang merupakan himpunan bagian dari , yang bersifat ( ) . Kejadian dapat dipandang sebagai gabungan kejadian-kejadian yang saling terpisah satu sama lain sebagai
( ) ( ) ( ) Probabilitas kejadian dapat ditulis sebagai
( ) ,( ) ( ) ( )- ( ) ( ) ( )
perpustakaan.uns.ac.id digilib.uns.ac.id commit to user 6 ∑ ( ) ( | ) ( )
Berdasarkan Definisi 2.3 diketahui bahwa
( | ) ( ( ) ) ( ) ( | )
( ) ( ) Persamaan (2.1) disubstitusikan ke persamaan (2.2) diperoleh
( | ) ( ) ( | ) ∑ ( ) ( | ) Terbukti
2.1.3 Metode Estimasi Maksimum Likelihood
Estimasi titik adalah suatu nilai tunggal yang dihitung berdasarkan pengukuran dari sampel dan digunakan sebagai estimator dari nilai parameter populasi yang besarnya tidak diketahui.
Definisi 2.4 (Bain dan Engelhardt, [2]). Fungsi kepadatan bersama dari
variabel random berukuran , yang diestimasi melalui
adalah ( ) dan fungsi inilah yang didefinisikan sebagai fungsi
likelihood. Untuk independen, fungsi likelihood adalah fungsi dari
yang dinotasikan dengan ( ) yaitu
( ) ( ) ( ) ( )
∏ ( ) ( )
Nilai yang memaksimumkan ( ) disebut sebagai estimator maksimum
likelihood yang dinotasikan dengan ̂ . Nilai ̂ diperoleh dengan cara
mendiferensialkan ( ) terhadap dan menyamakannya dengan 0. Untuk mempermudah perhitungan dalam mencari nilai ̂, ( ) dapat dimodifikasi ke dalam bentuk log karena fungsi log adalah monoton, oleh karena itu persamaan (2.3) dapat dimodifikasi menjadi
commit to user ( ) (∏ ( ) ) ∑ ( ) 2.1.4 Model Campuran
Fungsi distribusi model campuran merupakan kombinasi linear dari dua atau lebih fungsi kepadatan probabilitas (fkp). Kegunaan mendasar dari model campuran adalah dapat menggambarkan fkp yang rumit atau kompleks.
Berikut diberikan dua definisi mengenai fkp model campuran dan fungsi log likelihood data lengkap yang diambil dari McLachlan dan Peel [12].
Definisi 2.5.
Dimisalkan adalah sampel random berukuran , adalah vektor
random berdimensi p dalam dengan fungsi kepadatan probabilitas ( )
dengan . Dimisalkan ( ) adalah sampel random
terobservasi dengan adalah nilai terobservasi dari vektor random .
Diasumsikan diskrit, fungsi kepadatan probabilitas dari dapat ditulis
sebagai
( ) ∑ ( )
dengan dan ∑ . Parameter proporsi
campuran dan ( ) adalah fungsi kepadatan campuran untuk komponen
.
Banyaknya komponen campuran biasanya telah diketahui, tetapi pada banyak kasus banyaknya komponen campuran tidak diketahui dan harus ditentukan menggunakan data terobservasi.
Definisi 2.6.
Data lengkap didefinisikan sebagai ( ) dengan adalah data dari
variabel tidak terobservasi yang berpasangan satu-satu dengan sebagai data
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
8
( dan ) untuk menentukan keanggotaan setiap
individu dalam komponen model campuran dengan bernilai 1 jika
berasal dari kelas dan bernilai 0 untuk yang lain, fungsi log likelihoodnya
adalah ∑ ∑ ( ) 2.1.5 Ketidaksamaan Jensen
Ketidaksamaan Jensen merupakan alat statistik yang sangat bermanfaat dalam perhitungan matematika yang sulit, seperti logaritma penjumlahan dalam analisis kelas laten. Aplikasi dari ketidaksamaan Jensen meliputi algoritma EM, metode estimasi Bayesian dan inferensi Bayesian.
Berikut diberikan teorema dan definisi mengenai ketidaksamaan Jensen untuk fungsi cembung dan cekung yang diambil dari Harpaz dan Haralick [8]. Teorema 2.2.
Ketidaksamaan Jensen menyatakan jika adalah suatu fungsi cembung dan
suatu variabel random, berlaku
, ( )- ( , -) Definisi 2.7.
Suatu fungsi ( ) dikatakan sebagai fungsi cembung pada interval ( ) jika
( ) dan berlaku
( ( ) ) ( ) ( ) ( ) Teorema 2.3.
Jika ( ) adalah fungsi cembung pada interval ( ) dan jika
( ) dan dengan ∑ maka ∑
( ) (∑
commit to user
Bukti Teorema 2.3:
Teorema 2.3 dibuktikan secara induksi matematika. Persamaan (2.4) benar untuk dan , diasumsikan benar untuk dan akan dibuktikan benar untuk , ∑ ( ) ( ) ( ) ∑ ( ) ( ) ( ) (∑ ) ( ( ) ( ) ∑ ) (∑ ) Terbukti Bukti Teorema 2.2:
Jika adalah variabel random diskrit dengan sebagai probabilitasnya, maka persamaan (2.4) dapat ditulis kembali sebagai berikut
, ( )- ( , -)
dan jika ( ) benar-benar cembung (strictly convex) maka , - Terbukti
Teorema 2.4.
Jika ( ) diturunkan dua kali dalam ( ) dan ( ) maka ( ) disebut
fungsi cembung dalam ( )
Bukti :
Untuk membuktikan Teorema 2.4, digunakan deret Taylor orde dua yaitu ( ) ( ) ( )( ) ⁄ ( )( )
Jika ( ) maka
( ) ( ) ( )( )
Untuk ( ) dan diperoleh ( )( ) maka
perpustakaan.uns.ac.id digilib.uns.ac.id commit to user 10 + ( ) ( ) ( )( ) ( ( ) ) ( ( ) )( )( ) ( ) Dengan cara yang sama untuk diperoleh ( ) maka
( ) ( ) ( )( )
( ( ) ) ( ( ) )( ( )) ( ) Dengan mengalikan terhadap persamaan (2.5) dan ( ) terhadap persamaan (2.6) kemudian dijumlahkan akan menunjukkan ketidaksamaan kecembungan sebagai berikut ( ) ( ( ( ) ) ( ( ) )( )( )) ( ) ( ) ( ) . ( ( ) ) ( ( ) )( ( ))/ ( ) ( ) ( ) ( ( ) ) Terbukti Definisi 2.8.
Fungsi benar-benar cekung (strictly concave) jika – adalah benar-benar
cembung.
Teorema 2.5.
( ) adalah benar-benar cembung dalam ( ). Bukti:
( ) ( ) maka ( )
⁄ untuk ( ). Terbukti
Berdasarkan Teorema 2.5 dan Definisi 2.8, diketahui bahwa ( ) adalah fungsi yang benar-benar cekung, sehingga untuk ( ) berlaku
, ( )- ( , -) 2.1.6 Algoritma EM
Metode estimasi maksimum likelihood adalah metode klasik yang dapat digunakan secara praktis untuk mendapatkan estimator yang tidak bias dan bervariansi minimum atau uniformly minimum variance unbiased estimator (UMVUE). Tetapi, dalam kasus statistik dengan permasalahan data yang akan dicari nilai estimasinya tidak memuat informasi yang dibutuhkan secara lengkap,
commit to user
metode estimasi maksimum likelihood tidak bisa digunakan secara langsung. Solusi untuk permasalahan tersebut salah satunya adalah dengan algoritma EM.
Dalam algoritma EM digunakan istilah data lengkap dan data tidak lengkap. Agar metode estimasi maksimum likelihood dapat digunakan secara lebih sederhana, perlu dilakukan modifikasi atau augmented data. Augmented data tersebut disebut sebagai data lengkap dan data yang tersedia sebagai data tidak lengkap.
Suatu karakteristik utama dari algoritma EM adalah melakukan perhitungan secara iteratif (berulang-ulang) untuk mendapatkan estimator dengan adanya permasalahan data tidak lengkap. Menurut Demster dkk. [3], setiap iterasi dari algoritma EM terdiri dari dua tahap.
1) Tahap Ekspektasi atau Expectation Step (E Step)
Pada tahap ekspektasi dicari fungsi yaitu ekspektasi dari fungsi likelihood data lengkap berdasarkan data terobservasi yang digunakan untuk mengganti keberadaan atau keanggotaan setiap individu pada setiap kelas laten yang tidak diketahui. Fungsi dinotasikan sebagai
( ) | , ( | )-
2) Tahap Maksimisasi atau Maximization Step (M Step)
Pada tahap maksimisasi dicari nilai estimator yang dapat memaksimumkan fungsi yang telah didefinisikan pada tahap ekspektasi. Nilai estimator dinotasikan sebagai
( )
dengan adalah estimator untuk parameter pada iterasi ke- .
Kedua tahap tersebut akan dilakukan berulang-ulang hingga didapatkan estimator yang dapat memaksimumkan fungsi likelihood yang konvergen.
Berikut ini dijelaskan mengenai prosedur algoritma EM menurut Harpaz dan Haralick [8] dan sifat kekonvergenannya.
1) Prosedur algoritma EM
Dimisalkan adalah variabel manifes dan ( ) adalah data terobservasi sebagai data yang tidak lengkap dengan adalah vektor berdimensi
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
12
, . Dimisalkan ( ) adalah data lengkap dengan adalah variabel laten yang berkorespondensi satu-satu dengan dan ( ) adalah vektor data tidak terobservasi. Fungsi kepadatan bersama antara dan dinotasikan dengan ( | ) . Fungsi log likelihood data terobservasi didefinisikan sebagai
( ) ( ) ( | )
∑ ( | ) ( ) Permasalahan dalam memaksimumkan persamaan (2.7) adalah adanya bentuk logaritma penjumlahan dan data variabel yang tidak terobservasi. Ide dari algoritma EM adalah membangun batas bawah (lower bound) untuk fungsi
likelihood sehingga bentuk penjumlahan logaritma bisa diatasi.
Dimisalkan ( ) adalah sembarang fungsi kepadatan probabilitas dari dengan ∑ ( ) , persamaan (2.7) dapat ditulis kembali sebagai
( ) ∑ ( | ) ( ) ( ) ∑ ( ) ( | )
( ) Berdasarkan ketidaksamaan Jensen untuk fungsi cekung diperoleh
( ) ∑ ( ) ( | ) ( )
∑ ( ) ( | ) ∑ ( ) ( )
( ( )) ( ) ( ( )) adalah batas bawah dari fungsi likelihood.
Berikut dicari ( ) untuk persamaan (2.8) sehingga ( ( )) menjadi batas yang optimum (tight bound),
( ( )) ∑ ( ) ( | ) ( )
commit to user ( )* ( | ) ( ) + ( )[ ( | ) ( | ) ( ) ] ( )* ( | ) ( ) + ( ), ( | )- ( )* ( ) ( | )+ ( | ) ( ( )|| ( | )) ( ) ( ) ( ( )|| ( | )) disebut Kullback-Leiber Distance yang memiliki sifat
1. ( ( )|| ( | )) ( ) 2. ( ) ( ( )|| ( | ))
( ( )) menjadi batas yang optimum atau sama dengan ( ) jika ( ( )|| ( | )) minimum yaitu ketika ( ( )|| ( | )) .
Berikut ini dicari kondisi ( ( )|| ( | )) minimum, ( ( )|| ( | ))
( )*
( )
( | )+ ( ) kondisi persamaan (2.10) terjadi jika
( ) ( | ) ( ) Persamaan (2.11) disubstitusikan ke persamaan (2.8) diperoleh
( ( | )) ∑ ( | ) ( | ) ∑ ( | ) ( | ) ( ) ( ) dengan ( ) ∑ ( | ) ( | ) dan ( ) ∑ ( | ) ( | )
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
14
( ) disebut entropi dari ( | ) yang bernilai konstan. Dapat dibuktikan bahwa ( ) ( ) Bukti: ( ) ( ) ∑ ( | ) ( | ) ∑ ( | ) ( | ) ∑ ( | ) ( ( | ) ( | )) ∑ ( | ) ( ( ( | ) ( | ) )) [∑ ( | ) ( ( | ( | )))] [∑ ( | )] , - ( ) Terbukti bahwa ( ) ( ) maka ( ) ( ).
Memaksimumkan ( ( | )) sama dengan memaksimumkan ( ) Tahap penentuan fungsi inilah yang disebut dengan tahap ekspektasi yang kemudian akan dicari nilai estimator yang memaksimumkan fungsi Q tersebut pada tahap maksimisasi.
2) Kekonvergenan algoritma EM Teorema 2.6 (Dempster dkk. , [4])
Fungsi likelihood berdasarkan data terobservasi tidak mengalami penurunan setelah iterasi EM
( ) ( )
Bukti:
commit to user ( ) ( ( | )) ( ) ( ) dan ( ) ( ) * ( ) ( )+ * ( ) ( )+
Dari persamaan (2.12) diketahui bahwa ( ) ( ) . Pada tahap
maksimisasi dicari nilai yang dapat memaksimumkan fungsi sehingga dari definisi tersebut diperoleh informasi bahwa ( ) ( ) . Kekonvergenan algoritma EM dapat dibuktikan sebagai
( ) ( ) * ( ) ( )+
* ( ) ( )+
( ) Persamaan (2.13) menunjukkan bahwa fungsi log likelihood berdasarkan data terobservasi tidak mengalami penurunan setelah iterasi EM, maka demikian pula dengan fungsi likelihoodnya.
Terbukti
2.1.7 Metode Pengali Lagrange
Metode pengali Lagrange adalah sebuah teknik dalam menyelesaikan optimasi dengan kendala persamaan. Inti dari metode pengali Lagrange adalah mengubah persoalan titik ekstrim terkendala menjadi persoalan ekstrim bebas kendala. Fungsi yang terbentuk dari transformasi tersebut dinamakan fungsi Lagrange.
Definisi 2.9 (Gluss dan Wisstein, [5])
Misalkan permasalahan yang dihadapi adalah memaksimumkan ( ) dengan
kendala ( ) , maka fungsi Lagrangenya adalah
( ) ( ( ))
dengan adalah pengali Lagrange.
perpustakaan.uns.ac.id digilib.uns.ac.id commit to user 16 atau
Pada kasus variabel, jika fungsi objektifnya mempunyai bentuk ( ) dengan kendala ( ) , maka fungsi Lagrangenya adalah
( ) ( ( ))
2.1.8 Kriteria Pemilihan Model
Ada beberapa kriteria yang digunakan untuk memilih model terbaik dalam analisis kelas laten. Diantaranya adalah kriteria parsimony dan kriteria kecocokan model absolut.
1) Kriteria Parsimony
Sifat parsimony adalah sifat yang menghubungkan antara kecocokan model (dengan data) dengan banyaknya perameter dalam model yang bersangkutan. Prinsip dari sifat parsimony adalah kesederhanaan yaitu model sederhana lebih baik daripada model kompleks. Kesederhanaan dalam sifat
parsimony berarti banyaknya estimasi parameter lebih sedikit.
Dua ukuran parsimony yang digunakan dalam analisis kelas laten adalah
Akaike Information Criteria (AIC) dan Bayesian Information Criteria (BIC) yang
didefinisikan sebagai
dengan adalah maksimum log likelihood dan adalah jumlah parameter yang diestimasi.
Nilai dan yang lebih kecil merepresentasikan keseimbangan optimum antara kecocokan model dengan banyaknya parameter, sehingga model yang lebih baik adalah model dengan nilai dan minimun. Namun menurut Lin dan Dayton dalam Linzer dan Lewis [10], lebih tepat digunakan
commit to user
untuk model kelas laten karena kesederhanaannya. Dan menurut Posada dan Buckley [13], akan memilih model lebih sederhana daripada untuk .
2) Kriteria Kecocokan Model Absolut
Kriteria kecocokan model absolut mengacu pada apakah model kelas laten merepresentasikan data dengan cukup baik atau model dapat dikatakan cocok dengan data tanpa membandingkan dengan model yang lain. Menurut Collins dan Lanza [2], terdapat dua statistik uji yang dapat digunakan untuk menguji hipotesis yang menyatakan kecocokan model dengan data yaitu statistik rasio likelihood ( ) dan uji kecocokan Chi-kuadrat ( ).
Dimisalkan terdapat variabel terobservasi (variabel manifes) dan setiap variabel terobservasi mempunyai kemungkinan outcome (kategori) dan tabel kontingensi yang dibentuk dari tabulasi silang variabel terobservasi memiliki sel sebanyak dengan ∏ . Frekuensi sel dilambangkan dengan dan ̂ adalah frekuensi harapan sel yang didefinisikan sebagai
̂ ∑ ∏ ∏( )
rasio likelihood dan uji kecocokan Chi-kuadratnya adalah ∑ ̂ ∑( ̂ ) ̂
Nilai dan dibandingkan dengan distribusi Chi-kuadrat ( ) yang sesuai dengan derajat bebas dalam model. Model dapat dikatakan cocok dengan data jika nilai dan lebih kecil dari . Derajat bebas yang bersesuaian dengan dan adalah
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
18
dengan adalah jumlah parameter yang diestimasi yaitu jumlah dari kelas laten dan probabilitas bersyarat ( ) yang diestimasi.
2.2 Kerangka Pemikiran
Mengacu pada tinjauan pustaka, dapat disusun suatu kerangka pemikiran yang mendasari penulisan skripsi ini. Dalam penelitian kadang terdapat variabel yang tidak dapat diukur secara langsung (unosreved variable) atau variabel tersebut tidak mempunyai ukuran kuantitatif, variabel tersebut disebut dengan variabel laten, sehingga diperlukan beberapa variabel terobservasi (observed
variable) yang dapat dijadikan sebagai alat ukur tidak langsung dari variabel
laten. Variabel-variabel tersebut sering dikenal sebagai variabel manifes atau variabel indikator (indicator variable). Dan alat statistik yang digunakan untuk klasifikasi terhadap variabel lalen dengan variabel manifes sebagai indikatornya yang keduanya bertipe kategorik adalah analisis kelas laten atau latent class
analysis (LCA).
Adanya variabel laten menyebabkan metode estimasi maksimum likelihood tidak bisa digunakan secara langsung untuk estimasi model kelas laten sehingga diperlukan modifikasi atau augmented data agar metode estimasi maksimum
likelihood dapat digunakan secara lebih sederhana. Metode estimasi yang dapat
digunakan untuk menyelasaikan estimasi maksimum likelihood dalam model kelas laten adalah algoritma EM dan algoritma Newton Raphson. Algoritma EM memiliki keunggulan lebih sederhana dan praktis digunakan dibandingkan dengan algoritma Newton Raphson. Dalam algoritma EM, augmented data disebut sebagai data lengkap dan data yang tersedia disebut sebagai data tidak lengkap.
Skripsi ini mengkaji ulang estimasi parameter model kelas laten menggunakan algoritma EM dengan memandang kelas pada variabel laten sebagai komponen dari model campuran.
commit to user
19 BAB III
METODE PENELITIAN
Metode yang digunakan dalam penulisan skripsi ini adalah studi literatur yaitu dengan mengumpulkan dan mempelajari referensi yang berupa buku dan jurnal yang berkaitan dengan materi algoritma EM dan model kelas laten. Berikut ini adalah langkah-langkah yang dilakukan dalam mengestimasi parameter model kelas laten.
1. Menentukan fungsi log likelihood data lengkap.
2. Mengestimasi parameter menggunakan algoritma EM dengan langkah-langkah sebagai berikut.
a. Input : data dari variabel manifes.
b. Menetapkan dan inisialisasi awal yaitu dan . c. Tahap ekspektasi
Menghitung ( | ) dan menentukan ( ). d. Tahap maksimisasi
Menghitung ( ).
e. Menetapkan .
Ulangi tahap ekspektasi dan maksimisasi hingga konvergen. f. Output : dan .
3. Memilih model terbaik berdasarkan 2.1.8. 4. Mengaplikasikan pada contoh kasus.
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
20 BAB IV PEMBAHASAN
Pada bab ini dibicarakan tiga pokok bahasan yaitu model kelas laten, estimasi perameter model kelas laten, dan contoh kasus.
4.1 Model Kelas Laten
Analisis struktur laten dapat diklasifikasikan berdasarkan tipe variabel manifes dan latennya seperti terdapat pada Tabel 4.1.
Tabel 4.1. Analisis struktur laten berdasarkan variabel laten dan variabel manifes
Variabel manifes
Variabel laten
Kontinu Kategorik
Kontinu Analisis faktor Analisis profil laten Kategorik Analisis ciri laten Analisis kelas laten Pada umumnya variabel laten pada analisis faktor dan analisis ciri laten adalah bertipe kontinu dan diasumsikan berdistribusi normal, sedangkan pada analisis profil laten dan analisis kelas laten variabel latennya bertipe kategorik dan diasumsikan berdistribusi multinomial. Variabel manifes pada analisis faktor dan analisis profil laten bertipe kontinu dan diasumsikan berdistribusi normal. Pada analisis ciri laten dan analisis kelas laten, variabel manifesnya bertipe kategorik dan diasumsikan berdistribusi binomial atau multinomial (Vermunt dan Magidson, [14]).
Menurut Linzer dan Lewis [10], analisis kelas laten pertama kali diperkenalkan oleh Lazarsfeld pada tahun 1950, dengan nama latents structure
analysis dengan variabel manifes dan variabel laten yang hanya terdiri dari dua
kategori. Goodman memperluas variabel manifes dan variabel laten menjadi politomi dan suatu model dapat terdapat lebih dari satu variabel laten.
Model dengan satu variabel laten ( ) dan 4 variabel manifes ( ) diilustrasikan oleh Goodman [7] pada Gambar 4.1.
commit to user
Gambar 4.1 Diagram path LCA
Dimisalkan terdapat variabel manifes dengan adalah variabel manifes ke- ( ) dan satu variabel laten sebanyak kelas. Probabilitas individu pada variabel adalah
( ) (( ) ( ) ( )) ∑ ( ) ( ) dan ( ) ( ) ( | ) ( ) ( | ) ( ) (⋂ | ) ( ) dengan ( ) adalah probabilitas kelas laten ( ).
Ide dasar dari kelas laten adalah independensi lokal yaitu variabel manifes independen dengan syarat variabel laten, sehingga probabilitas variabel manifes dengan syarat variabel laten adalah
( | ) ∏ ( | )
( ) Persamaan (4.3) disubstitusikan ke parsamaan (4.2) diperoleh
( ) ( ) ∏ ( | )
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
22
Persamaan (4.4) disubstitusikan ke parsamaan (4.1) diperoleh ( ) ∑ ( ) ∏ ( | ) dengan ∑ ( ) ( ) Persamaan (4.1) menyatakan bahwa individu-individu diklasifikasikan dalam kelas laten yang mutually exclusive dan exhaustive dan persamaan (4.4) menyatakan variabel manifes mutually independent (Goodman, [5]).
Dimisalkan setiap terdapat kemungkinan outcome. adalah nilai terobservasi dari variabel manives dengan bernilai 1 jika individu berasal dari respon variabel manifes dan 0 untuk yang lain. Terdapat variabel laten sebanyak kelas Menurut Linzer dan Lewis [10] probabilitas individu dengan
variabel manifes berpola ( ) berada pada kelas laten ( ) adalah ( ) ( | ) ∏ ∏( ) ( ) dengan ( | ) ( ) dan ∑ Fungsi kepadatan probabilitas untuk semua kelas adalah
( ) ∑ ( ) ( ) ∑ ∏ ∏( ) dengan ( ) ( )
commit to user
4.2 Estimasi Parameter Model Kelas Laten
Beberapa parameter statistik seperti rata-rata dan standar deviasi dapat dengan mudah diestimasi dengan menyelesaikan suatu persamaan yang dikenal dengan solusi close-form. Tetapi untuk model statistik yang kompleks seperti model kelas laten, penurunan secara close-form tidak bisa dicapai sehingga diperlukan augmented data untuk mendapatkan nilai parameter yang diinginkan.
Didefinisikan adalah variabel manifes dengan ( ) adalah data terobservasi dari variabel manifes dan adalah variabel laten dengan ( ) adalah vektor data tidak terobservasi. Data lengkap didefinisikan sebagai ( ) dan berpasangan satu-satu dengan dengan . Data menjadi tidak lengkap karena sebagai pasangan dari tidak tersedia. Adanya permasalahan data tidak lengkap tersebut dapat diatasi dengan algoritma EM untuk menyelesaikan estimasi maksimum likelihood.
Menurut Collins dan Lanza [3], seluruh data terobservasi adalah campuran dari beberapa kelas laten. Oleh karena itu, persamaan (4.8) dapat dipandang sebagai model campuran dengan sebagai proporsi campuran dan ( ) sebagai fungsi kepadatan multinomial dengan satu kali percobaan dengan bentuk fkp pada persamaan (4.6). Sehingga algoritma EM dapat digunakan melalui pendekatan model campuran.
Langkah awal yang dilakukan adalah menentukan fungsi likelihood dari data terobservasi, yaitu
( ) ∏ ( )
Untuk mempermudah perhitungan digunakan fungsi log likelihood sebagai ( ) ∏ ( ) ∑ ( ) ∑ ∑ ∏ ∏( ) ( )
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
24
Terdapat dua masalah dalam penentuan nilai maksimum fungsi log
likelihood pada persamaan (4.10) yaitu adanya bentuk logaritma penjumlahan
sebanyak mengakibatkan penurunan secara close form tidak dapat dicapai dan jumlah kelas tidak diketahui, sehingga digunakan fungsi log likelihood data lengkap. Berdasarkan Definisi 2.6 fungsi log likelihood data lengkap adalah
∑ ∑ ∏ ∏( ) ( )
dengan adalah vektor indikator yang merepresentasikan keanggotaan
(membership) individu pada kelas laten, bernilai 1 jika individu berasal dari kelas dan 0 untuk yang lain.
Algoritma EM dimulai dengan pemilihan nilai awal untuk dan yang diberi nama dan kemudian melalui tahap ekspektasi dan maksimisasi
secara berulang-ulang hingga dicapai dan yang konvergen.
4.2.1 Tahap Ekspektasi
Fungsi diperoleh dengan menentukan ekspektasi dari persamaan (4.11) berdasarkan variabel dengan syarat variabel . Fungsi ditentukan sebagai
( ) | [ ] | *∑ ∑ ∏ ∏( ) + ∑ ∑ | , ∏ ∏( ) ( ) Karena nilai dari biner yaitu 0 dan 1, maka ekspektasinya adalah hanya pada saat bernilai 1 yaitu ketika barasal dari kelas sebagai
| , - ( | ) ( | ) ( )
Dengan teorema Bayes diperoleh
| , -
( ) ( | ) ∑ ( ) ( | )
commit to user
( ) ∏ ∏ . ( | )/ ∑ ( ) ∏ ∏ . ( | )/
( ) Persamaan (4.7) dan persamaan (4.9) disubstitusikan ke persamaan (4.14) diperoleh | , - ∏ ∏ ( ) ∑ ∏ ∏ ( ) ( ) ( ) ∑ ( )
Substitusi nilai dan pada persamaan (4.15) diperoleh nilai probabilitas variabel pada kelas laten dengan syarat variabel dengan pola . Dimisalkan terdapat dua kelas laten, nilai parameter dan disubstitusikan ke persamaan (4.15), jika ( | ) mendekati nilai 1 dan ( | ) mendekati nilai 0 maka dapat disimpulkan data dengan pola berasal dari kelas laten pertama. Jadi pada tahap ekspektasi ditentukan dari mana asal masing-masing data yang terobservasi, apakah dari kelas pertama, kedua, dan seterusnya (banyaknya kelas ditentukan oleh peneliti).
Persamaan (4.13) disubstitusikan ke persamaan (4.12) diperoleh fungsi sebagai ( ) ∑ ∑ ( | ) ∏ ∏( ) 4.2.2 Tahap Maksimisasi
Dari persamaaan (4.5) diketahui ∑ ( ) , sehingga pemaksimumkan fungsi dapat dilakukan menggunakan metode pengali Lagrange dengan kendala ∑ ( ) . Fungsi Lagrangenya adalah
( ) ( ) (∑ ( )
perpustakaan.uns.ac.id digilib.uns.ac.id commit to user 26 ∑ ∑ ( | ) ∏ ∏( ) (∑ ) ( ) dengan adalah pengali Lagrange.
Berikut ini dicari nilai maksimum untuk dengan cara menurunkan persamaan (4.16) terhadap dan dan menyamakannya dengan 0,
( ) ∑ ( | ) ( ) ( ) ∑ ( ) Dari persamaan (4.17) diperoleh
∑ ( | )
( ) Persamaan (4.19) disubstitusikan ke persamaan (4.18) diperoleh
∑ ∑ ( | )
( ) Karena ∑ ( | ) maka dari persamaan (4.20) diperoleh – . Dengan mensubstitusikan – ke persamaan (4.19) diperoleh sebagai estimator dari sebagai
∑ ( | )
( )
sebagai estimator dari diperoleh dengan cara menyelesaikan
fungsi Lagrange dengan kendala ∑ sebagai
( ) ( ) (∑
commit to user ∑ ∑ ( | ) ∏ ∏( ) (∑ ) ( ) Nilai maksimum untuk diperoleh dengan cara menurunkan persamaan (4.22) terhadap dan dan menyamakannya dengan 0,
( ) ∑ ( | ) ( ) ( ) ∑ ( ) Dari persamaan (4.23) diperoleh
∑ ( | )
( )
Persamaan (4.25) disubstitusikan ke persamaan (4.24) diperoleh ∑ ∑ ( | )
( ) Karena bernilai 1 jika individu berasal dari respon variabel manifes dan
0 untuk yang lain, maka ∑ . Persamaan (4.26) menjadi
∑ ( | )
( ) Persamaan (4.27) disubstitusikan ke persamaan (4.25) diperoleh estimator untuk yang diberi label sebagai
∑ ( | )
∑ ( | ) ( ) Pemilihan nilai awal dan kompleksitas model kelas laten kadang menyebabkan fungsi log likelihood hanya mencapai maksimum lokal. Oleh karena itu lebih baik menjalankan algoritma lebih dari satu kali dengan nilai awal
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
28
yang berbeda untuk memastikan fungsi log likelihood telah mencapai maksimum global.
4.3 Contoh Kasus
Pada subbab ini dibahas mengenai penentuan tipe responden pada General
Social Survey tahun 1982 dengan sampel sebanyak 1202 responden, data diambil
dari McCutcheon [10] dilampirkan di Lampiran 1. General Social Survey merupakan survei sosiologis yang digunakan untuk mengumpulkan data tentang karakteristik demografi dan sikap warga Amerika Serikat. Survei tersebut dilakukan oleh National Opinion Research melalui tatap muka langsung dengan responden yang dipilih secara random.
Terdapat empat variabel manifes yang digunakan sebagai indikator untuk menentukan tipe responden. Berikut adalah penjelasan mengenai empat variabel manifes dengan masing-masing kategorinya.
1) Tujuan
Variabel tujuan merupakan variabel manifes mengenai opini responden terhadap tujuan dari survei. Responden diberi pertanyaan “Menurut anda, apakah tujuan dari survei ini baik atau hanya membuang waktu dan uang?”. Variabel ini terdiri dari tiga kategori yaitu
a) 1 untuk kategori baik b) 2 untuk kategori percaya c) 3 untuk kategori pemborosan. 2) Ketepatan
Variabel ketepatan merupakan variabel manifes mengenai opini responden tentang ketepatan pemilihan responden. Pertanyaan yang diberikan adalah “Apakah hasil survei dapat dipercaya?”. Variabel ini terdiri dari dua kategori yaitu
a) 1 untuk kategori tepat b) 2 untuk kategori tidak tepat.
commit to user
3) Pemahaman
Variabel ini mengenai penilaian petugas survei tehadap tingkat pemahaman responden terhadap pertanyaan-pertanyaan dalam survei dengan pertanyaan “Apakah pemahaman responden terhadap pertanyaan baik atau lemah?”. Variabel ini terdiri dari dua kategori yaitu
a) 1 untuk kategori baik b) 2 untuk kategori lemah. 4) Kerjasama
Variabel ini mengenai penilaian petugas survei terhadap sikap responden dalam menjawab pertanyaan. Pertanyaannya untuk petugas survei adalah “Bagaimana sikap responden saat menjawab pertanyaan?”. Variabel ini terdiri dari tiga kategori yaitu
a) 1 untuk ketegori tertarik b) 2 untuk kategori kooperatif c) 3 untuk ketegori tidak sabar.
Pada kasus ini tipe responden berperan sebagai variabel laten karena penentuan tipe responden dilakukan berdasarkan informasi yang diperoleh dari variabel manifes. Analisis diawali dengan estimasi parameter model dengan dua kelas laten kemudian tiga kelas laten dan empat kelas laten. Kemudian dilanjutkan dengan pemilihan model terbaik.
4.3.1 Hasil Estimasi Parameter
Estimasi parameter dengan algoritma EM dihitung menggunakan bantuan
software R 2.7.2 paket poLCA 1.1. Algoritma diawali tahap ekspektasi yaitu
inisialisasi nilai awal dilanjutkan dengan substitusi dan ke persamaan
(4.15) hingga diperoleh nilai ( | ). Tahap selanjutnya adalah tahap maksimisasi yaitu substitusi nilai ( | ) yang diperoleh pada tahap ekspektasi ke persamaan (4.21) dan (4.28). Paket poLCA 1.1 secara otomatis menentukan inisialisasi nilai awal secara random dengan ketentuan bernilai antara 0 dan 1. Hasil keluaran dari R 2.7.2 paket poLCA 1.1dilampirkan di Lampiran 2.
Berikut adalah hasil estimasi parameter dengan dua kelas laten, tiga kelas laten, dan empat kelas laten.
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
30
1) Dengan dua kelas laten
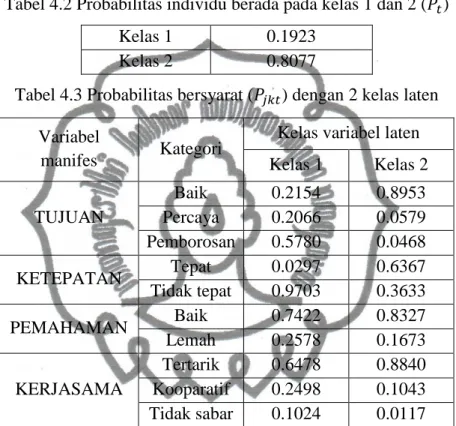
Algoritma EM dijalankan dengan 10 nilai awal yang berbeda untuk masing-masing parameter. Dengan maksimum iterasi sebanyak 500 iterasi algoritma telah mencapai konvergen. Nilai estimator untuk model dengan dua kelas laten disajikan pada Tabel 4.2 dan Tabel 4.3.
Tabel 4.2 Probabilitas individu berada pada kelas 1 dan 2 ( )
Kelas 1 0.1923
Kelas 2 0.8077
Tabel 4.3 Probabilitas bersyarat ( ) dengan 2 kelas laten
Variabel
manifes Kategori
Kelas variabel laten Kelas 1 Kelas 2 TUJUAN Baik 0.2154 0.8953 Percaya 0.2066 0.0579 Pemborosan 0.5780 0.0468 KETEPATAN Tepat 0.0297 0.6367 Tidak tepat 0.9703 0.3633 PEMAHAMAN Baik 0.7422 0.8327 Lemah 0.2578 0.1673 KERJASAMA Tertarik 0.6478 0.8840 Kooparatif 0.2498 0.1043 Tidak sabar 0.1024 0.0117
Dari Tabel 4.2 diketahui probabilitas seorang responden berada pada kelas satu adalah 0.1923 dan probabilitas responden berada pada kelas dua adalah 0.8077. Tipe responden pada kelas satu dan kelas dua dapat ditentukan berdasarkan Tabel 4.3. Pada kelas satu probabilitas tertinggi untuk variabel tujuan adalah pemborosan, probabilitas tertinggi untuk variabel ketepatan adalah tidak tepat, probabilitas tertinggi untuk variabel pemahaman adalah baik, dan probabilitas tertinggi untuk variabel kerjasama adalah tertarik. Disimpulkan bahwa responden pada kelas satu menilai survei adalah sesuatu yang sia-sia, menilai survei tidak tepat sasaran, namun memiliki pemahaman yang baik terhadap pertanyaan survei, dan menunjukkan kerjasama yang baik saat survei dilakukan. Dari ciri-ciri tersebut responden pada kelas satu dapat dinamakan sebagai responden skeptis.
commit to user
Dengan melihat probabilitas bersyarat tertinggi untuk masing-masing variabel manifes, disimpulkan bahwa responden pada kelas dua menilai survei memiliki tujuan yang baik, survei sudah tepat sasaran, memiliki pemahaman yang baik pada pertanyaan survei, dan menunjukkan kerjasama yang baik saat survei dilakukan. Dari ciri-ciri tersebut responden kelas dua dapat dinamakan sebagai responden ideal.
2) Dengan tiga kelas laten
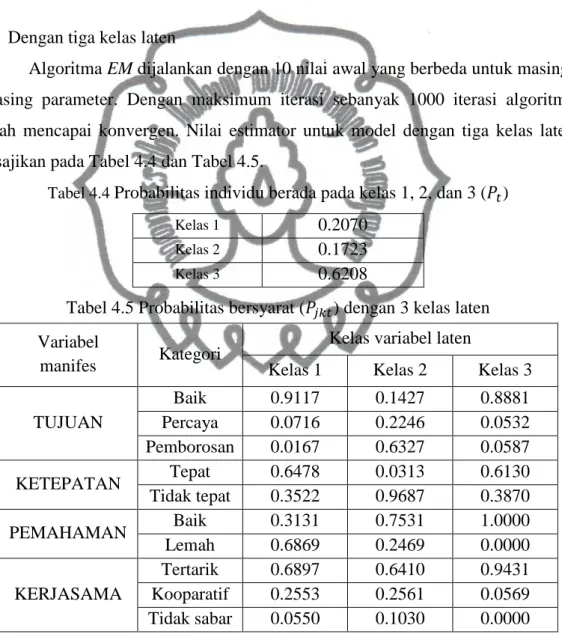
Algoritma EM dijalankan dengan 10 nilai awal yang berbeda untuk masing-masing parameter. Dengan maksimum iterasi sebanyak 1000 iterasi algoritma telah mencapai konvergen. Nilai estimator untuk model dengan tiga kelas laten disajikan pada Tabel 4.4 dan Tabel 4.5.
Tabel 4.4 Probabilitas individu berada pada kelas 1, 2, dan 3 ( )
Kelas 1 0.2070
Kelas 2 0.1723
Kelas 3 0.6208
Tabel 4.5 Probabilitas bersyarat ( ) dengan 3 kelas laten Variabel
manifes Kategori
Kelas variabel laten
Kelas 1 Kelas 2 Kelas 3 TUJUAN Baik 0.9117 0.1427 0.8881 Percaya 0.0716 0.2246 0.0532 Pemborosan 0.0167 0.6327 0.0587 KETEPATAN Tepat 0.6478 0.0313 0.6130 Tidak tepat 0.3522 0.9687 0.3870 PEMAHAMAN Baik 0.3131 0.7531 1.0000 Lemah 0.6869 0.2469 0.0000 KERJASAMA Tertarik 0.6897 0.6410 0.9431 Kooparatif 0.2553 0.2561 0.0569 Tidak sabar 0.0550 0.1030 0.0000 Dari Tabel 4.4 diperoleh informasi bahwa probabilitas responden masuk ke kelas satu sebesar 0.2070, kelas dua sebesar 0.1723, kelas tiga sebesar 0.6208. Tabel 4.5 memberikan informasi mengenai tipe responden setiap kelas. Pada kelas satu probabilitas bersyarat tertinggi untuk variabel manifes tujuan adalah baik,
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
32
probabilitas bersyarat tertinggi untuk variabel manifes ketepatan adalah tepat, probabilitas bersyarat tertinggi untuk variabel manifes pemahaman adalah lemah, dan probabilitas bersyarat tertinggi untuk variabel manifes kerjasama adalah tertarik. Dari informasi tersebut dapat dinyatakan responden pada kelas satu menilai survei mempunyai tujuan yang baik, survei yang dilakukan tepat sasaran, dan memikili pemahaman yang lemah terhadap pertanyaan survei tetapi bisa bekerjasama saat survei dilakukan. Berdasarkan ciri-ciri yang dimiliki, responden pada kelas satu dapat dinamakan responden optimis.
Berdasarkan probabilitas bersyarat variabel manifes tertinggi pada kelas dua, responden pada kelas dua cenderung melihat tujuan dari survei sebagai sesuatu yang sia-sia, menilai survei yang dilakukan tidak tepat sasaran, namun memiliki pemahaman yang baik terhadap survei dan dapat bekerjasama saat survei dilakukan. Berdasarkan ciri-ciri tersebut responden pada kelas dua memiliki pandangan yang negatif terhadap survei sehingga dapat dinamakan responden ragu-ragu atau skeptis.
Berdasarkan probabilitas bersyarat variabel manifes tertinggi kelas tiga, dapat disimpulkan responden pada kelas tiga memiliki penilaian yang bagus terhadap tujuan survei dan menganggap survei yang dilakukan tepat sasaran, memiliki pemahaman yang baik terhadap pertanyaan survei dan menunjukkan kerjasama yang baik saat survei dilakukan, sehingga responden pada kelas tiga dapat dinamakan sebagai responden ideal.
3) Dengan empat kelas laten
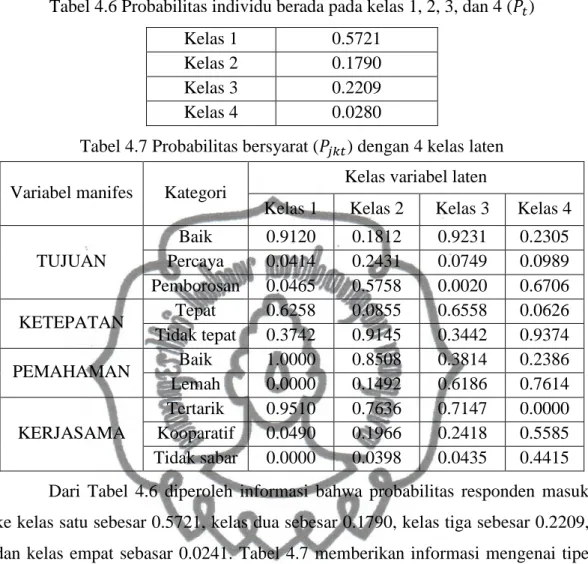
Algoritma EM dijalankan dengan 10 nilai awal yang berbeda untuk masing-masing parameter. Dengan maksimum iterasi sebanyak 5000 iterasi algoritma telah mencapai konvergen. Nilai estimator untuk model dengan empat kelas laten disajikan pada Tabel 4.6 dan Tabel 4.7.
commit to user
Tabel 4.6 Probabilitas individu berada pada kelas 1, 2, 3, dan 4 ( )
Kelas 1 0.5721
Kelas 2 0.1790
Kelas 3 0.2209
Kelas 4 0.0280
Tabel 4.7 Probabilitas bersyarat ( ) dengan 4 kelas laten Variabel manifes Kategori Kelas variabel laten
Kelas 1 Kelas 2 Kelas 3 Kelas 4
TUJUAN Baik 0.9120 0.1812 0.9231 0.2305 Percaya 0.0414 0.2431 0.0749 0.0989 Pemborosan 0.0465 0.5758 0.0020 0.6706 KETEPATAN Tepat 0.6258 0.0855 0.6558 0.0626 Tidak tepat 0.3742 0.9145 0.3442 0.9374 PEMAHAMAN Baik 1.0000 0.8508 0.3814 0.2386 Lemah 0.0000 0.1492 0.6186 0.7614 KERJASAMA Tertarik 0.9510 0.7636 0.7147 0.0000 Kooparatif 0.0490 0.1966 0.2418 0.5585 Tidak sabar 0.0000 0.0398 0.0435 0.4415 Dari Tabel 4.6 diperoleh informasi bahwa probabilitas responden masuk ke kelas satu sebesar 0.5721, kelas dua sebesar 0.1790, kelas tiga sebesar 0.2209, dan kelas empat sebasar 0.0241. Tabel 4.7 memberikan informasi mengenai tipe responden setiap kelas. Pada kelas satu probabilitas bersyarat tertinggi untuk variabel manifes tujuan adalah baik, probabilitas bersyarat tertinggi untuk variabel manifes ketepatan adalah tepat, probabilitas bersyarat tertinggi untuk variabel manifes pemahaman adalah baik, dan probabilitas bersyarat tertinggi untuk variabel manifes kerjasamaadalah tertarik. Dari informasi tersebut dapat dinyatakan responden pada kelas satu menilai survei mempunyai tujuan yang baik, survei yang dilakukan tepat sasaran, memikili pemahaman yang baik terhadap survei, dan bisa bekerjasama saat survei dilakukan. Berdasarkan ciri-ciri yang dimiliki, responden pada kelas satu dapat dinamakan responden ideal.
Berdasarkan probabilitas bersyarat variabel manifes tertingginya, responden pada kelas dua cenderung melihat tujuan dari survei sebagai sesuatu yang sia-sia, menilai survei yang dilakukan tidak tepat sasaran, namun memiliki
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
34
pemahaman yang baik terhadap survei dan dapat bekerjasama saat survei dilakukan. Berdasarkan ciri-ciri tersebut responden pada kelas dua dapat dinamakan responden ragu-ragu atau skeptis.
Responden pada kelas tiga menilai survei memiliki tujuan yang baik, survei yang dilakukan tepat sasaran,memiliki pemahaman yang lemah terhadap pertanyaan survei, dan menunjukan kerjasama yang baik saat survei dilakukan. Berdasarkan ciri-ciri tersebut responden pada kelas tiga dapat dinamakan responden optimis.
Responden pada kelas empat menilai survei sebagai sesuatu yang sia-sia, survei tidak tepat sasaran, mamiliki pemahaman yang lemah terhadap pertanyaan survei, dan dapat bekerjasama saat survei dilakukan walaupun tidak tertarik.Berdasarkan ciri-ciri tersebut responden pada kelas empat dapat dinamakan responden kurang ideal.
4.3.2 Pemilihan Model Terbaik
Pemodelan menggunakan software R 2.7.2 paket poLCA 1.1 diperoleh informasi kriteria pemilihan model pada Tabel 4.8.
Tabel 4.8 Informasi kriteria pemilihan model
model
2 kelas laten 5592.536 5658.729 79.337 93.253 22 33.924 3 kelas laten 5549.091 5650.926 21.392 23.532 15 24.996 4 kelas laten 5547.242 5681.719 6.043 5.113 8 15.507
Dari Tabel 4.8 diketahui nilai terkecil adalah model dengan empat kelas laten sedangkan nilai terkecil adalah model dengan tiga kelas laten. Karena maka lebih tepat digunakan daripada , oleh karena itu model terpilih adalah model dengan tiga kelas laten. Kemudian digunakan kriteria kecocokan model absolut untuk menentukan apakah model dengan tiga kelas laten cocok dengan data. Diketahui dari Tabel 4.8 bahwa model dengan tiga kelas laten yang memenuhi kriteria kecocokan model absolut karena nilai sebesar 21.392
commit to user
dan sebasar 23.532 lebih kecil dari nilai distribusi Chi-kuadrat dengan derajat bebas 15 dan sebesar 24.996.
Model dengan tiga kelas laten memenuhi kriteria parsimony dan kriteria kecocockan model absolut. Oleh karena itu disimpulkan bahwa responden
General Social Survey tahun 1982 diklasifikasikan menjadi tiga tipe responden
perpustakaan.uns.ac.id digilib.uns.ac.id commit to user 36 BAB V PENUTUP 5.1 Kesimpulan
Berdasarkan hasil dari pembahasan dapat diambil kesimpulan estimasi parameter model kelas laten menggunakan algoritma EM diawali dengan inisialisasi nilai awal yang dinotasikan dengan dan . Tahap selanjutnya tahap ekspektasi dan tahap maksimisasi sebagai berikut.
a) Tahap Ekspektasi
Pada tahap ekspektasi dilakukan substitusi dan untuk ( | ) sehingga diperoleh fungsi sebagai
( ) ∑ ∑ ( | ) ∏ ∏( ) b) Tahap Maksimisasi
Pada tahap maksimisasi dicari nilai parameter ( ) dengan
memaksimumkan fungsi yang diperoleh pada tahap ekspektasi menggunakan metode pengali Lagrange, hingga diperoleh
∑ ( | ) dan ∑ ( | ) ∑ ( | )
Kedua tahap tersebut dijalankan secara berulang-ulang sampai diperoleh estimator yang dapat memaksimumkan fungsi likelihood yang konvergen.
commit to user
5.2 Saran
Berdasarkan batasan masalah, skripsi ini hanya membahas tentang estimasi parameter model kelas laten menggunakan algoritma EM. Salah satu kesulitan yang dihadapai dalam penggunaan algoritma EM untuk estimasi parameter model kelas laten adalah adanya kemungkinan independensi lokal yang tidak terpenuhi akibatnya tidak ada model yang memenuhi kriteria kecocokan model absolut. Bagi pembaca yang tertarik pada pemodelan kelas laten, dapat melakukan penelitian mengenai estimasi parameter model kelas laten dengan permasalahan independensi lokal yang tidak terpenuhi.
Estimasi parameter model kelas laten dapat pula dilakukan dengan metode algoritma Newton Raphson melalui pendekatan loglinear. Selain itu masih terdapat analisis struktur laten yang dapat dikaji seperti analisis ciri laten dan analisis profil laten.
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
38
DAFTAR PUSTAKA
[1] Andersen, E. B., Latent Structure Analysis: A Survey, Scandinavian Journal of Statistics, vol. 9, no.1, pp. 1-22, 1982.
[2] Bain, L. J and M. Engelhardt, Introduction to Probability and Mathematical
Statistics, Duxbury Press, California, 1992.
[3] Collins, L. M. and S. T. Lanza, Latent Class and Latent Transition Analysis, John Wiley and Sons, New Jersey, USA, 2010.
[4] Dempster, A. D., N. M. Laird, and D. B. Rubin, Maximum Likelihood from
Incomplete Data via the EM Algorithm, Journal of the Royal Statistical
Society B, vol. 39, pp. 1-38, 1977.
[5] Gluss, D. and E. W. Weisstein, Lagrange Multiplier,
http://mathworld.world.wolfram.com/LagrangeMultiplier.html, 1999. [6] Goodman, L. A., Exploratory Latent Structure Analysis Using Both
Identifiable and Unidentifiable Models, American Journal of Biometrica,
vol. 61, no. 2, pp. 215-231, 1974.
[7] Goodman, L. A., The Analysis of Qualitative Variable When Some of the
Variables Are Unobservable, American Journal of Socioligy, vol. 79, no. 5,
pp. 1179-1259, 1974.
[8] Harpaz, R. and R. Haralick, The EM Algorithm as a Lower Bound
Optimization Technique, The Graduate Centre, New York, 2006.
[9] Krewski, D. and M. Bicks, A Note on Independent and Exhaustive Events, Journal of The American Statistican, vol. 38, no.4, pp. 290-291, 1984. [10] Linzer, D. A. and J. Lewis, poLCA: Polytomous Variable Latent Class
Analysis Version 1.1, http://userwww.service.emory.edu/~dlinzer/poLCA,
2006.
[11] McCutheon, A., Latent Class Analysis, SAGE Publication, Newbury Park, 1987.
commit to user
[12] McLachlan, G. and D. Peel, Finite Mixture Models, John Wiley and Sons, New York, USA, 2000.
[13] Posada, D. and T. R. Buckley, Model Selection and Model Averaging in
Phylogenetics: Advantages of Akaike Information Criterion and Bayesian Approaches Over Likelihood Ratio Test, Oxford Journal: Society of
Sistematic Biologists, vol. 53, no.5, pp. 793-808, 2004.
[14] Vermunt, J. K. and J. Magidson, Latent Variable,
http://www.statisticalinnovations.com/articles/articles.html#articles, 2000.
perpustakaan.uns.ac.id digilib.uns.ac.id
commit to user
40
LAMPIRAN
Lampiran 1 Data General Social Survey tahun 1982 dengan sampel sebanyak 1202 responden