(M.2)
ANALISIS KOMPONEN UTAMA
DATA TIDAK LENGKAP DENGAN METODE
VARIATIONAL BAYESIAN PRINCIPAL COMPONENT ANALYSIS (VBPCA)
Ricky Yordani1, Suwanda2, I G. N. Mindra Jaya3
Mahasiswa Program Magister Statistika Terapan Universitas Padjajaran Bandung1
Jurusan Statistika Universitas Islam Bandung2
Jurusan Statistika Universitas Padjajaran Bandung3
e-mail : [email protected], [email protected]2, [email protected]3
Abstrak
Analisis komponen utama (AKU) adalah teknik analisis data yang dapat memberikan transformasi linear dari data dengan mempertahankan keragaman data, dengan tujuan untuk mereduksi dimensi variabel asal sehingga dapat meminimumkan matriks korelasi. Metode AKU kemudian dihadapkan dengan adanya berbagai masalah yang muncul dalam analisis multivariat. Salah satu masalah dalam prosedur AKU yang standar adalah tidak jelas dalam mengatasi adanya gugusan data yang tidak lengkap, misalnya saat ada beberapa nilai yang hilang. Prosedur standar AKU pada data tidak lengkap dapat mengakibatkan overfitting pada saat terdapat relatif banyak nilai yang hilang. Dalam studi ini disampaikan analisis AKU pada data tidak lengkap dengan menggunakan Variational Bayesian Principal Component Analysis (VBPCA). VBPCA menggunakan pendekatan Expectation-Maximization (EM) dan inferensi Bayesian untuk menghitung kemungkinan dalam merekonstruksi nilai yang hilang. Teknik algoritma VBPCA diperkirakan dapat mentoleransi relatif tinggi terhadap data yang tidak lengkap (persentase nilai hilang > 35 % terhadap keseluruhan nilai saat lengkap) dan mampu mengatasi adanya overfitting.
Kata Kunci : Variational Bayesian PCA, Analisis Komponen Utama, missing value, Algoritma EM, overfitting
1. PENDAHULUAN
Analisis Komponen Utama (AKU)–Principal Component Analysis (PCA)- merupakan metode analisis multivariat yang bertujuan memperkecil dimensi variabel asal sehingga diperoleh variabel baru (komponen utama) yang tidak saling berkorelasi tetapi menyimpan sebagian besar informasi yang terkandung pada variabel asal. Dimisalkan gugus data Y dengan n buah observasi pengukuran dan d buah variabel asal, sehingga dimensi dari gugus data Y adalah n x d. Banyaknya d buah komponen yang diperlukan untuk menghasilkan keragaman total dapat dijelaskan oleh k buah komponen, dengan k < d. Sehingga banyaknya informasi yang terkandung dalam d buah variabel asal sedapat mungkin juga terdapat dalam k buah komponen utama.
AKU dihadapkan dengan masalah yang muncul saat terdapat gugusan data yang tidak lengkap, misalnya saat ada beberapa nilai yang hilang. Ketidaklengkapan data dapat
mengakibatkan kurang akurat dalam menganalisis dan mengevaluasi hasil penelitian. Walaupun begitu, banyak peneliti tidak menyadari pentingnya melaporkan dan mengelola nilai hilang, dan biasanya editor tidak mendesak peneliti menyediakan informasi penting ini (Schlomer dkk, 2010). Prosedur AKU klasik dalam mengatasi masalah ini biasanya dengan menghilangkan observasi yang mengandung data yang tidak lengkap. Langkah tersebut merupakan suatu tindakan yang dapat membuang informasi ketika observasi yang terdapat nilai hilang memiliki proporsi yang tinggi tetapi hanya satu atau dua variabel yang nilainya hilang.
Pembahasan analisis data tidak lengkap selalu berkaitan dengan mekanisme nilai yang hilang pada data tidak lengkap tersebut. Takane dan Takane (2003) memaparkan teknik AKU saat nilai yang hilang mengikuti mekanisme MNAR seperti yang telah diperkenalkan oleh Shibayana tahun 1988 sebagai metode TE (test equating) dan juga sebelum itu telah diperkenalkan oleh Meulman tahun 1982 metode MDP (missing data passive).
Beberapa teknik menganalisis AKU pada saat nilai hilang mempunyai mekanisme MAR diantaranya dipaparkan oleh Ilin dan Raiko (2010), yang dibedakan menjadi dua teknik, yaitu : (1) Teknik Least Squares, dan (2) Model Probabiliti untuk AKU. Teknik Least Square mencakup berbagai teknik, diantaranya The Cost Function, Algoritma W-X dan Gradient Descent Algorithm. Berdasarkan Ilin dan Raiko (2010), teknik-teknik tersebut cukup baik bila nilai yang hilangnya sedikit, tapi tidak dapat diaplikasikan saat nilai yang hilangnya banyak karena dapat mengakibatkan overfitting. Diantara akibat overfitting saat nilai hilangnya banyak adalah metode tersebut mampu menganalisis komponen utama tetapi model yang dibentuk tidak cukup bagus karena parameter yang dihasilkan tidak mampu memprediksi nilai yang hilang secara akurat.
Model Probabiliti untuk AKU dengan adanya nilai yang hilang antara lain Probabilistic PCA (PPCA) dan Variational Bayes PCA (VBPCA). VBPCA diperkenalkan oleh Bishop tahun 1999 untuk memilih banyaknya komponen dalam AKU, yang kemudian tahun 2003 oleh Oba dkk dilakukan penerapan metode VBPCA untuk data yang hilang pada gugusan gen.
Berdasarkan Ilin dan Raiko juga, selain teknik Least Square dan Probabiliti dapat pula digunakan teknik metode Singular Value Decomposition (SVD). Tetapi metode ini sulit menghasilkan matriks kovarian saat terdapat data tidak lengkap, sehingga dilakukan substitusi nilai yang hilang dengan menggunakan rata-rata variabelnya. Terjadinya perkembangan metodologi dalam mengestimasi nilai yang hilang selain mengimputasinya dengan rata-rata variabelnya, menjadikan metode ini menjadi kurang akurat.
Metode AKU data tidak lengkap yang memberikan estimasi akurasi rata-rata bagus adalah VBPCA dan PPCA (Stacklies dkk, 2007). Berdasarkan Ilin dan Raiko (2010), PPCA
merupakan metode yang cukup bagus digunakan pada data yang tidak lengkap, tetapi dapat terjadi overfitting saat data yang lengkapnya sedikit. Overfitting tersebut misalnya komponen utama yang terbentuk hanya dipengaruhi variabel observasi tertentu saja, sehingga diperlukan informasi yang dapat mengatasi kelemahan tersebut. Informasi tersebut dapat berupa informasi tambahan melalui fungsi kepadatan prior dalam Bayesian Framework yang mengasumsikan semua parameter akan dianggap sebagai variabel acak. Sehingga dengan mengkombinasikan informasi tambahan prior sebelum melakukan AKU diharapkan mampu mengatasi kelemahan overfitting yang terdapat pada PPCA.
Studi ini mengkaji konsep VBPCA dengan membandingkan hasilnya dengan PPCA. Untuk memberikan gambaran aplikasi metode tersebut, pembahasan dilakukan pada data hasil pengolahan Survei Sosial Ekonomi Nasional (SUSENAS) tahun 2007 tentang indikator– indikator Millenium Development Goals (MDGs) pada kabupaten/kota di Kawasan Indonesia Timur dengan melakukan simulasi kasus terdapat nilai hilang pada data lengkap tersebut. 2. TINJAUAN PUSTAKA
2.1 Analisis Faktor (AF)
Analisis Faktor (AF) merupakan suatu metode multivariat yang bertujuan menjelaskan hubungan antara banyaknya korelasi variabel yang sulit diamati menjadi sedikit variabel dari jumlah variabel awal. AF dapat menggambarkan peragam diantara banyak variabel sebenarnya yang dapat dibagi ke dalam beberapa sifat yang mendasar namun tidak dapat diobservasi kuantitasnya (variabel laten), disebut juga sebagai faktor. Faktor merupakan kumpulan variabel laten yang mampu mencerminkan variabel observasinya.
Misalkan terdapat S matriks kovarians dari vektor variabel acak Y⊤ = [Y1,Y2,..., Yd],
dengan rataan . Model faktor dibentuk agar y menjadi linear dan bergantung dengan variabel acak yang tidak terobservasi xl yang disebut sebagai skor faktor yang dilambangkan
dengan matriks X, dan terdapat menyatakan kesalahan sisa, serta terdapat wl yang
merupakan faktor loading yang dilambangkan dengan matriks W. Sehingga persamaan AF dalam bentuk matriks
× = × × + × + × (1) Hubungan antara AKU dengan AF, bahwa untuk mencari skor faktor AK dapat menggunakan AKU. Sehingga metode AKU dan AF menggunakan hubungan analisis antara variabel observasi dengan variabel latennya.
2.2 Asumsi Mekanisme Nilai Hilang (Missing Value)
Mekanisme nilai hilang oleh Little dan Rubin (1987) diklasifikasikan sebagai berikut : 1. Missing completely at random (MCAR): mekanisme kasus saat pola nilai hilang pada
variabel tidak berkaitan dengan variabel lain atau terhadap dirinya. Pola terjadi secara tidak sistematik dan dapat dianggap sebagai random subsample dari hipotesis data saat lengkap.
2. Missing at random (MAR): mekasnisme kasus saat terjadi kaitan antara variabel data yang memuat nilai hilang dengan variabel data yang tidak terdapat nilai hilang. Pola terjadi secara sistematik menjelaskan kecenderungan terdapat korelasi.
3. Nonignorable: mekanisme nilai hilang dengan nilaiyang hilang jelas tergantung dengan variabel yang tidak lengkap tersebut. Dikenal juga sebagai NMAR “Not Missing at Random” atau MNAR “Missing Not at Random”.
3. METODOLOGI
3.1 Probabilistic PCA (PPCA)
PPCA mengkombinasikan antara pendekatan algoritma Expectation-Maximization (EM) dengan model probabilistik. Pendekatan EM didasarkan dengan asumsi variabel laten (skor) dan kesalahan sisa berdistribusi normal.
3.2 Variational Bayesian PCA (VBPCA)
VBPCA juga menggunakan pendekatan EM yang dikombinasikan dengan metode penaksiran Bayesian untuk menghitung kemungkinan dari nilai yang ditaksir. VBPCA dikembangkan khususnya untuk mengestimasi nilai yang hilang dan didasarkan atas kerangka kerja Variational Bayes (VBF) dengan automatic relevance determination (ARD). Pada VBPCA, ARD menjadikan perbedaan skala terhadap komponen utama, skor dan nilai eigen ketika dibandingkan dengan AKU klasik ataupun PPCA. Metode ini yang mendasari antar komponen utama tidak perlu saling ortogonal. Menurut Oba dkk (2003), memaksakan keortogonalan antar komponen dapat membuat prediksi semakin tidak baik. Oba dkk tersebut juga menyatakan bahwa perbedaan antara nilai eigen yang sebenarnya dengan yang diprediksi semakin jauh berbeda saat obeservasinya sedikit, karena dapat mengakibatkan kurangnya informasi dalam menentukan loading. Sehingga VBPCA menghasilkan penimbang dari faktor untuk memperkirakan nilai yang hilang menjadi berbeda dengan teknik AKU biasa, tetapi estimasi terhadap nilai yang hilang semakin baik.
Estimasi data yang tidak lengkap dengan VBPCA terdiri atas tiga proses dasar, yaitu (1) Analisis Faktor dengan Komponen Utama; (2) Estimasi Bayesian; (3) Algoritma EM. AKU mewakili variasi dari d-dimensi dari vektor y sebagai kombinasi linear dari sumbu utama
vektor wl (1≤ ≤ ) dengan nilai yang relatif kecil ( < ), sehingga menghasilkan
persamaan seperti persamaan (1). Dengan menggunakan nilai spesifik yang ditentukan dari banyaknya k, AKU mengandung xl dan wl saat jumlah kesalahan kuadrat ‖ ‖ minimum dari
seluruh data Y.
Saat data lengkap, xl dan wl dihitung dengan langkah awal menetukan kovarian matriks
S dari vektor yi (1≤ ≤ ) dengan diasumsikan rata-rata dari Y adalah = . Dimisalkan
(λ,u) sebagai pasangan nilai dan vektor eigen dari matriks S, sehingga vektor loading komponen utama ke-l, = , dengan skor faktor ke-l untuk menyatakan vektor y adalah = ( / ) .
Untuk gugus data yang memiliki nilai yang hilang, dalam analisis faktor komponen utama bagian yang tidak lengkap (y*) diestimasi dari variabel observasi yang lengkap (yobs)
dengan menggunakan hasil dari AKU. Dimisalkan wlobs dan wl* sebagai bagian dari sumbu
utama wl, yang masing-masing menyatakan vektor loading data yang lengkap dan yang tidak
lengkap dalam y. Kemudian, misalkan = ( , ∗) dengan masing-masing Wobs atau W*
menyatakan matriks yang kolomnya berisi vektor wlobs, …,wkobs atau w1*, . . . , wk*.
Nilai skor faktor = ( ,⋯, ) dari vektor y didapatkan dengan meminimumkan kesalahan sisa , = − dengan solusi least square adalah:
= ( ) (2)
sehingga
∗= ∗ (3)
Tahapan selanjutnya membentuk model probabilistik berdasarkan asumsi residual error dan skor faktor (1≤ ≤ ) berdistribusi normal. Estimasi Bayesian mendapatkan distribusi posterior dan X menggunakan teorema Bayes.
(4)
( ) dinamakan distribusi prior, yang menyatakan pilihan awal dari parameter , dengan
≡ { , , } sebagai gugusan parameter. Distribusi prior merupakan bagian dari model dan harus didefinisikan sebelum melakukan estimasi.
Diasumsikan conjugate prior untuk dan dan hirarki prior untuk W yaitu prior untuk W adalah ( | , ) dinyatakan dengan hyperparameter ∈ ℝ .
( | )≡ ( , , | ) = ( | ) ( )∏ , (5) dengan : ( | ) = , (6) , = , (7) ( ) = ̅ , (8)
,X Y|
Y X, |
p
p
p
( | ̅, ) merupakan distribusi gamma dengan hyperparameter ̅ dan :
( | ̅, )≡
Γ( ) exp[− ̅ + ( −1) ln ] (9) dengan Γ(. ) merupakan fungsi Gamma.
Variabel yang digunakan dalam prior tersebut , , dan ̅ merupakan hyperparameter yang mendefinisikan prior. Nilai aktualnya harus sudah ditentukan sebelum melakukan estimasi. Ditetapkan = = 10 , = 0 dan ̅ = 1 yang bersesuaian pada prior non-informatif. Sehingga distribusi posterior dari parameter dinyatakan dengan :
( ) = ( | , ) (10)
Prior hirarki ( | , ) dikenal sebagai ARD yang berperan besar dalam VBPCA ini. Sumbu utama ke-j dari wj mempunyai prior Gaussian dengan varian 1/( ) dikontrol oleh
hyperparameter yang ditentukan oleh estimasi ML tipe-II dari data.
Saat kita mengetahui parameter sebenarnya yang dilambangkan dengan , maka posterior dari data yang tidak lengkap adalah :
( ∗) = ( ∗| , ) (11)
dengan persamaan ( ∗| , ) didapatkan dengan memarjinalkan fungsi likelihood persamaan (4) dengan variabel observasi Yobs. Saat parameter posterior ( ) diasumsikan
sebagai ganti dari parameter sebenarnya, sehingga posterior dari nilai yang hilang adalah :
( ∗) =∫ ( ) ( ∗| , ) (12) bersesuaian dengan bayesian analisis faktor dengan komponen utama. Walaupun parameter posterior ( ) dapat diperoleh dengan estimasi Bayesian saat gugus data lengkap Y tersedia, tetapi dengan diasumsikan hanya sebagian dari gugus data Y yang tersedia (Yobs)
dan sebagiannya tidak ada (Y*), sehingga mendapatkan ( ) dan ( ∗) dilakukan secara simultan.
Aplikasi algoritma VBPCA terdiri atas beberapa tahapan langkah sebagai berikut: (a) melakukan analisis faktor komponen utama, dengan mengestimasi data yang hilang Y*; (b) tentukan conjugate distribusi prior; (c) menginisiasi distribusi posterior data hilang ( ∗) dengan melakukan imputasi terhadap data yang tidak lengkap; (d) mendapatkan distribusi posterior parameter dan ( ) berdasarkan data observasi Yobs dan berdasarkan distribusi
posterior yang baru dari data hilang ( ∗); (e) distribusi posterior data hilang ( ∗) kemudian diestimasi berdasarkan distribusi posterior ( ) yang baru; (f) Hyperparameter kemudian diupdate berdasarkan ( ) dan ( ∗); (g) ulangi proses langkah d sampai f hingga konvergen.
3.3 Estimasi Parameter
Menentukan jumlah komponen utama optimal yang mencakup informasi relevan dengan mengurangi adanya noise salah satunya dapat dilakukan dengan melakukan Cross Validation. Q2 merupakan ukuran yang dapat digunakan untuk melakukan internal cross
validation. Ukuran tersebut dapat mengestimasi struktur level dari gugusan data dan dapat optimal dalam memilih banyaknya komponen. Nilai maksimum dari Q2 adalah 1, yang berarti
seluruh keragaman dapat diwakili dalam memprediksi = .
Ukuran lain yang digunakan untuk dapat menentukan banyaknya komponen yang optimal didasarkan dari kesalahan estimasi, yaitu NRMSEP (normalized root mean square error). NRMSEP menormalkan perbedaan kuadrat untuk variabel tertentu antara nilai estimasi dan nilai sebenarnya dengan varian variabel tersebut. Dasar pemikiran dari ukuran ini adalah dapat memperlihatkan bahwa kesalahan dari prediksi dapat otomatis membesar bila variannya membesar.
(13)
= ∑ ∑ (14)
=∑ − / ( −1) merupakan varian dari variabel tersebut. Sehingga NRMSEP akan menjadi kecil bila varian internalnya besar.
Parameter NRMSEP dapat dijadikan kriteria dalam pemilihan ukuran error, tetapi parameter NRMSEP yang memperhitungkan varian tidak cocok untuk data observasi yang sedikit, karena varian akan menjadi tidak stabil saat sampelnya sedikit, sehingga lebih cocok digunakan kriteria parameter Q2.
2 = 1−∑ ∑ − 2 =1 =1 ∑=1∑ =1 2 2
dengan :
cross validation
nilai prediksi dari
NRMSEP = normalized root mean square error
= gugusan variabel yang memiliki data tidak lengkap (dimisalkan sebanyak )
= jumlah variabel yang
ij
Q
y
y
G
P
g
jtidak lengkap
O
gugusan dari observasi yang hilang dalam variabel
= jumlah observasi yang hilang dalam variabel ke-
nilai prediksi dari ke- dari variabel ke- saat menggunakan loadin
j ijkj
o
j
y
y
i
j
g ke-
k
4. APLIKASI, HASIL DAN PEMBAHASAN
Pada penerapan aplikasi dilakukan pada data lengkap hasil pengolahan Survei Sosial Ekonomi Nasional (SUSENAS) tahun 2007 tentang indikator-indikator tujuan pembangunan millennium (MDGs) pada kabupaten/kota di Kawasan Indonesia Timur (10 provinsi). Dengan ukuran observasi kabupaten/kota sebanyak 112, serta variabel yang dianalisis sebanyak 30 variabel seperti diperlihatkan pada tabel 1.
Data lengkap dari variabel indikator-indikator MDGs tersebut kemudian dilakukan simulasi kasus terdapat variabel yang mempunyai nilai hilang dengan mekanisme MAR, dengan presentase nilai hilang 5%, 10%, 35% dari keseluruhan nilai saat lengkap. Analisis yang dilakukan akan membahas perbadingan hasil dari VBPCA saat data tidak lengkap dengan AKU saat data lengkap serta perbandingan dengan metode PPCA pada data tidak lengkap.
5. KESIMPULAN
Pada gambar (1) terlihat estimasi yang dihasilkan cukup bagus, karena dengan loading komponen-komponen awal mampu menjelaskan keragaman data. Pada gambar (2) nilai eigen pada berbagai tingkat presentase data tidak lengkap metode PPCA yang dihasilkan mirip dengan nilai eigen AKU saat data lengkap, tetapi dengan metode VBPCA nilai eigen yang dihasilkan berbeda, dengan sebab seperti yang telah dijelaskan sebelumnya dengan skala nilai eigen yang dihasilkan berbeda dengan metode AKU klasik dan PPCA.
Pada Gambar (3) terlihat grafik NRMSEP metode VBPCA berada di bawah PPCA dalam berbagai presentase data tidak lengkap, disimpulkan bahwa metode VBPCA lebih baik dibanding dalam PPCA dalam menaksir nilai hilang pada proses AKU dan diperkirakan mampu mengatasi adanya overfitting karena hasil estimasinya lebih baik. Dari grafik juga disimpulkan bahwa VBPCA dapat digunakan untuk AKU pada presentase data tidak lengkap hingga 35 %.
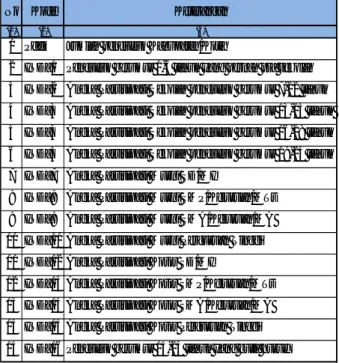
Tabel 1. Tabel Kode 30 Variabel dan Keterangan Indikator MDGs
Lanjutan Tabel 1.
No Kode Keterangan
(1) (2) (3)
1 Pddk Jumlah penduduk Kabupaten/Kota
2 IND_1 Penduduk berumur 0-6 tahun yang pernah pra sekolah 3 IND_2 Angka Partisipasi Sekolah penduduk berumur 7-12 tahun 4 IND_3 Angka Partisipasi Sekolah penduduk berumur 13-15 tahun 5 IND_4 Angka Partisipasi Sekolah penduduk berumur 16-18 tahun 6 IND_5 Angka Partisipasi Sekolah penduduk berumur 19-24 tahun 7 IND_7 Angka Partisipasi Murni SD/MI
8 IND_8 Angka Partisipasi Murni SMP/Kejuruan/MTs 9 IND_9 Angka Partisipasi Murni SMA/Kejuruan/MA 10 IND_10 Angka Partisipasi Murni Perguruan Tinggi 11 IND_12 Angka Partisipasi Kotor SD/MI
12 IND_13 Angka Partisipasi Kotor SMP/Kejuruan/MTs 13 IND_14 Angka Partisipasi Kotor SMA/Kejuruan/MA 14 IND_15 Angka Partisipasi Kotor Perguruan Tinggi 15 IND_16 Penduduk berumur 15-24 tahun yang buta huruf
No Kode Keterangan
(1) (2) (3)
16 IND_17 Penduduk berumur 15 tahun ke atas yang buta huruf 17 IND_18 Balita yang ditolong kelahirannya oleh tenaga medis 18 IND_27 Anak berumur 12-23 bulan yang diimunisasi Campak 19 IND_28 Anak berumur 1-4 tahun yang diimunisasi lengkap
20 IND_29 Anak berumur 6 bulan ke atas yang diberi ASI saja selama 6 bulan atau lebih 21 IND_30 Anak berumur 0-4 tahun yang memiliki akte kelahiran
22 IND_31 WUS yang sedang ber-KB 23 IND_41 WUS yang sedang ber-KB hormonal 24 IND_42 WUS yang sedang ber-KB mantap
25 IND_43 WUS yang sedang ber-KB dibanding laki-laki yang sedang ber-KB 26 IND_44 Remaja berumur 10-18 yang pernah kawin
27 IND_45 Angka ketergantungan penduduk 28 IND_46 Angka ketergantungan penduduk muda 29 IND_47 Angka ketergantungan penduduk tua 30 IND_48 Rasio jenis kelamin
(A) (B) (C)
Gambar 1. (A) Plot Komponen Utama 1 s.d 3 AKU klasik metode SVD; (B) Plot Komponen Utama 1 s.d 3 metode PPCA pada data MAR 5% ;(C) Plot Komponen Utama 1 s.d 3 dengan metode VBPCA pada data MAR 5%; (A) (B) (C)
Gambar 2.(A) Scree Plot Eigen Value pada data MAR 5%; (B) Scree Plot Eigen Value pada data MAR 10%; (C) Scree Plot Eigen Value pada data MAR 35%.
(A) (B) (C)
Gambar 3.(A) NRMSEP Komponen Utama Metode PPCA dan VBPCA pada data MAR 5%; (B) NRMSEP Komponen Utama Metode PPCA dan VBPCA pada data MAR 10%; (C) NRMSEP Komponen Utama Metode PPCA dan VBPCA pada data MAR 35%
-1 e + 0 6 -4 e + 0 5 2 e PC 1 R^2 = 1 -5 0 0 5 0 1 5 0 PC 2 R^2 = 0
-1e+06 -4e+05 2e+05
-5 0 0 5 0 1 0 0 -50 0 50 150 -50 0 50 100 -5 0 0 5 0 1 0 0 PC 3 R^2 = 0 -1 e + 0 6 -4 e + 0 5 2 e + 0 PC 1 R^2 = 1 -1 5 0 -5 0 0 5 0 PC 2 R^2 = 0
-1e+06 -4e+05 2e+05
-5 0 0 5 0 -150 -50 0 50 -50 0 50 -5 0 0 5 0 PC 3 R^2 = 0 1 1 1 1 1 1 1 1 1 1 2 4 6 8 10 0 5 0 0 0 0 1 0 0 0 0 0 1 5 0 0 0 0 Eigen Value S iz e 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3 PCA PPCA VBPCA 1 1 1 1 1 1 2 3 4 5 0 .8 0 0 .8 5 0 .9 0 0 .9 5 1 .0 0 Komponen Utama N R M S E P d a ta M A R 1 0 % 2 2 2 2 2 PPCA VBPCA -6 -4 -2 0 PC 1 R^2 = 1 -2 0 1 2 3 4 PC 2 R^2 = 0 -6 -4 -2 0 -3 -1 1 2 3 -2 0 1 2 3 4 -3 -1 1 2 3 -3 -1 1 2 3 PC 3 R^2 = 0 1 1 1 1 1 1 2 3 4 5 0 5 0 0 0 0 1 0 0 0 0 0 1 5 0 0 0 0 Eigen Value S iz e 2 2 2 2 2 3 3 3 3 3 PCA PPCA VBPCA 1 1 1 1 1 1 2 3 4 5 0 .7 5 0 .8 0 0 .8 5 0 .9 0 0 .9 5 1 .0 0 Komponen Utama N R M S E P D a ta M A R 5 % 2 2 2 2 2 PPCA VBPCA 1 1 1 1 1 1 1 1 1 1 2 4 6 8 10 0 5 0 0 0 0 1 0 0 0 0 0 1 5 0 0 0 0 Eigen Value S iz e 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3 PCA PPCA VBPCA 1 1 1 1 1 1 2 3 4 5 0 .7 5 0 .8 0 0 .8 5 0 .9 0 0 .9 5 1 .0 0 Komponen Utama N R M S E P d a ta M A R 3 5 % 2 2 2 2 2 PPCA VBPCA
6. DAFTAR PUSTAKA
Enders, C. K. (2010). Applied Missing Data Analysis. New York: Guilford Press.
Ilin, A. dan Raiko, T. (2010). Pratical Approach to Principal Component Analysis in the Presence of Missing Values. Journal of Machine Learning Research, 11, 1957-2000. Jolliffe, I. T. (2002). Principal Component Analysis. New York : Springer-Verlag, 2nd Edition.
Little, R. J. A., & Rubin, D. B. (1987). Statistical Analysis with Missing Data. Hoboken, NJ: Jhon Wiley & Sons.
Oba dkk. (2003). A Bayesian Missing Value Estimation Method for Gene Expression Profile Data. Bioinformatics, Vol.19, No.16, 2088-2096. Oxford University Press.
Schlomer dkk. (2010). Best Practices for Missing Data Management in Counseling Psychology. Journal of Counseling Psychology Vol. 57, No. 1, 1–10.
Stacklies, W. dan Redestig, H. (2011). The pcaMethods Package. Melalui < http://www.biocon-ductor.org/packages/2.8/bioc/vignettes/pcaMethods/inst/doc/ pcaMethods.pdf> [15/8/11]
Stacklies dkk. (2007). pcaMethods -a bioconductor package providing PCA methods for incomplete data. Bioinformatics, Vol. 23 No. 9, 1164-1167.
Takane, Y. dan Takane, Y. O. (2003). Relationships between Two Methos for Dealing with Missing Data in Principal Component Analysis. Behaviormetrik