i
SKRIPSI
Ditujukan Untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Teknik
Jurusan Teknik Informatika
Oleh :
Andreas Agus Winarno
035314032
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
DATA MINING UTILIZING WITH
NAÃVE BAYESSIAN CLASSIFICATION
METHOD
FOR 2006/2007 SEASON ENGLISH PREMIER LEAGUE
A Thesis
Presented as Partial Fulfillment of the Requirements
To Obtain the Engineering Bachelor Degree
In Informatics Engineering
By :
Andreas Agus Winarno
035314032
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
v
memuat karya atau bagian karya orang lain, kecuali yang telah disebutkan dalam
kutipan dan daftar pustaka, sebagaimana layaknya karya ilmiah.
Yogyakarta, 16 Desember 2007
Penulis
vi
HALAMAN MOTTO
Untuk segala sesuatu ada masanya, untuk
apapun di bawah langit ada waktunya.
(Pengkhotbah 3:1)
â¦
Jangan hanya menilai dari satu sudut pandang
â¦
Selalu ada pilihan dalam segala kondisi
â¦
vii
â¦.
Yahwe Eloim, Yesus Kristus Tuhan pemilik jiwaku, Bunda Maria Ibuku, St.
Andreas Pelindungku,
â¦.
Kedua orang tuaku yang telah membesarkan, membimbing dan
mendidikku dengan cinta, pengertian, dan kesabaran,
â¦
Kakak â kakakku, keluarga kecilku, yang akan selalu menyayangi dan
menerimaku apa adanya,
â¦
Astrisia Ratih Kusuma, my lily white,
â¦
All my friends in jogja city, we are no different each other, so we are
family,
â¦
viii
ABSTRAK
Pada setiap hasil pertandingan di liga sepakbola diduga dipengaruhi oleh
banyak faktor seperti pelatih dan pemain klub, tempat pertandingan, jadwal
pertandingan, sejarah pertemuan kedua klub yang bertanding, dan lain - lain.
Pada tugas akhir ini dibuat aplikasi untuk memprediksi juara liga Inggris
musim 2006/2007. Aplikasi ini akan melakukan proses prediksi terhadap setiap
pertandingan dari jadwal pada musim 2006/2007 berdasarkan dataâdata
pertandingan selama 5, 6, 7, 8, 9, dan 10 tahun sebelumnya. Algoritma yang akan
digunakan dalam proses prediksi yaitu algoritma
Naïve Bayessian, algoritma ini
menggunakan variabel-variabel yang ada pada data training untuk memprediksi
hasil pertandingan ke dalam sebuah kelas. Variabel-variabel yang digunakan pada
aplikasi ini yaitu, tempat pertandingan, waktu pertandingan, dan hasil
pertandingan sebelumnya antar kedua klub yang bertanding. Sedangkan kelas
yang digunakan pada aplikasi ini yaitu menang, seri, atau kalah.
ix
match from both clubs, etc.
On this thesis, I make application for predict champion of English premier
league season 2006/2007. This application will predict every match from schedule
on season 2006/2007 based on historical fact of match since five, six, seven, eight,
nine and ten years before season 2006/2007. Algorithm Naïve Bayessian has
choosed to perform that prediction. This algorithm use variables from data
training to predict result match in to a class. The variables are place of match, time
of match, and last result match from both clubs, and the class are win, draw, and
lose.
x
KATA PENGANTAR
Puji dan syukur saya haturkan kepada Tuhan Yesus Kristus, karena atas ijin
dan kehendak-Nya saya dapat menyelesaikan tugas akhir ini.
Dalam proses penulisan tugas akhir ini saya menyadari bahwa ada begitu
banyak pihak yang telah memberikan perhatian dan bantuan dengan caranya
masing-masing sehingga tugas akhir ini dapat selesai. Oleh karena itu saya ingin
mengucapkan terima kasih antara lain kepada :
1.
Bapak Ir. Gregorius Heliarko, S.J., S.S., B.S.T., M.A., M.Sc. selaku Dekan
Fakultas Sains dan Teknologi, Universitas Sanata Dharma.
2.
Ibu Ridowati Gunawan, S.Kom., M.T., selaku Dosen Pembimbing Tugas
Akhir dan Dosen Pembimbing Akademik, yang telah banyak memberikan
bimbingan,
dukungan,
motivasi
dan
fasilitas
yang
mendukung
terselesaikannya tugas akhir ini. Terima kasih juga atas kesempatan yang
diberikan kepada saya untuk kerja
part time
di Lab. Komputer Lanjut.
3.
Ibu Agnes Maria Polina, S.Kom., M.Sc., selaku Ketua Jurusan Teknik
Informatika.
4.
Bapak St. Wisnu Wijaya, S.T., M.T dan Bapak DS. Bambang Soelistijanto,
S.T., M.Sc. selaku panitia penguji yang telah memberikan banyak kritik dan
saran untuk tugas akhir saya.
xi
bantuan-bantuan dan informasinya, Mas Danang atas pinjaman obengnya,
Pak Dar atas doa, senyum, wejangan-wejangan tentang pengalaman hidup,
serta kesabarannya. Sekali lagi terima kasih atas kerja sama dan semua
bantuannya terutama selama kita menjadi
partner
sebagai laboran.
8.
Bapak dan Ibu tercinta. Terima kasih atas semua yang telah dilakukan
untukku, doa, semangat, dukungan dan cintanya sehingga saya bisa
menyelesaikan studi dengan lancar. Semoga saya bisa membalas cinta tulus
kalian.
9.
Kakak-kakakku. Walau kita sering berjauhan tapi aku selalu sayang pada
kalian, semoga kita sama-sama menjadi anak yang berbakti.
xii
12.
Teman-teman kost Ibu Siti : Gasong, S.T., Peteka, S.T., Gento, Mambu,
S.Pd., Natan, Gemblung, Kentung, Agus. Terima kasih atas hariâhari yang
selalu diisi dengan
WE9
. Keberadaan kalian telah memberikan warna-warni
dalam hidupku.
13.
Teman-temanku dari Bekasi yang kuliah di Jogja, Udhay, Benny, Bibir,
Oscar, Sudung, Kumis, Arbi, Sugeng, Otonx, Bayu, Lucy, Efran, Davied,
Babang dan semua yang tersebutkan namanya.
coz weâre all family,
remember us until the sun canât shine anymore....
.
14.
Seluruh pihak yang telah ambil bagian dalam proses penulisan tugas akhir
ini yang tidak bisa saya sebutkan satu per satu.
Dengan rendah hati saya menyadari bahwa tugas akhir ini masih jauh dari
sempurna, oleh karena itu berbagai kritik dan saran untuk perbaikan tugas akhir
ini sangat saya harapkan. Akhir kata, semoga tugas akhir ini bermanfaat bagi
semua pihak. Terima kasih.
Yogyakarta, 16 Desember 2007
xiii
HALAMAN PERSETUJUAN ...
HALAMAN PENGESAHAN ...
PERNYATAAN KEASLIAN KARYA ...
HALAMAN MOTTO ...
HALAMAN PERSEMBAHAN ...
ABSTRAK...
ABSTRACT ...
KATA PENGANTAR ...
DAFTAR ISI ...
DAFTAR GAMBAR ...
DAFTAR TABEL ...
iii
iv
v
vi
vii
viii
ix
x
xiii
xvi
xviii
BAB I.
PENDAHULUAN
1.1
Latar Belakang Masalah ...
1.2
Rumusan Masalah ...
1.3
Batasan Masalah ...
1.4
Tujuan Penelitian ...
1.5
Manfaat Penelitian ...
1.6
Metodelogi Penelitian ...
1.7
Sistematika Penulisan ...
1
2
2
3
3
4
xiv
BAB II.
LANDASAN TEORI
2.1
Data Mining ...
2.2
Classification
dalam data mining...
2.3
Metode
Naive
Bayesian Classification
...
2.3.1
Sejarah Thomas Bayes
...
2.3.2
Teorema Bayes ...
2.3.3
Naive Bayesian ...
BAB III. ANALISIS DAN DESAIN SISTEM
3.1
Analisis Sistem ...
3.2
Use Case Diagram ...
3.3
Class Diagram ...
3.4
E-R Diagram ...
3.5
Desain Database ...
3.6
Perhitungan menggunakan algoritma
Naive Bayesian
...
3.7
Desain User Interface ...
3.8
Flowchart
yang diimplementasikan dalam sistem ...
BAB IV. IMPLEMENTASI SISTEM
4.1
Spesifikasi
Software
dan Hardware yang digunakan ...
4.2
Koneksi Basisdata dengan sistem ...
4.3
Pembuatan Antar Muka ...
6
10
12
12
13
14
16
17
18
19
20
25
35
45
49
50
xv
5.2
Kelebihan dan Kekurangan Sistem ...
5.2.1
Kelebihan Sistem ...
5.2.2
Kekurangan Sistem ...
BAB VI. PENUTUP
6.1
Kesimpulan ...
6.2
Saran ...
DAFTAR PUSTAKA
LAMPIRAN
77
77
77
78
79
xvi
DAFTAR GAMBAR
Gambar
Keterangan
Halaman
2.1
Tahap-Tahap Pada KDD
9
3.1
Use Case Diagram
17
3.2
Class Diagram
18
3.3
E-R Diagram
19
3.4
Form Menu Utama
35
3.5
Form Browse Data Musim
36
3.6
Form Browse Data Jadwal
37
3.7
Form Browse Data Hasil Pertandingan
38
3.8
Form Browse Data Klub
39
3.9
Form Load Data
40
3.10
Form Clean Data
41
3.11
Form Prediksi
42
3.12
Form Hasil Prediksi
43
3.13
Form Analisa Prediksi
44
3.14
Flowchart Sistem Proses Prediksi
45
3.15
Flowchart Proses Penghitungan Prior Probability
dan Likelihood
46
3.16
Flowchart Proses Prediksi Hasil
47
4.1
Form Menu Utama
58
xvii
4.5
Form Prediksi (Proses Prediksi)
63
4.6
Form Hasil Prediksi
64
4.7
Form Detil Prediksi
65
4.8
Form Analisa Prediksi
66
4.9
Form Detil Analisa Prediksi
67
4.10
Form Browse Data Klub
68
4.11
Form Browse Data Jadwal
69
4.12
Form Browse Data Musim
70
xviii
DAFTAR TABEL
Tabel
Keterangan
Halaman
3.1
Propertis dari tabel Musim
20
3.2
Propertis dari tabel Klub
20
3.3
Propertis dari tabel Stadion
21
3.4
Propertis dari tabel Hasil_Pertandingan
21
3.5
Propertis dari tabel Jadwal
21
3.6
Propertis dari tabel Training
22
3.7
Propertis dari tabel Cleaning
22
3.8
Propertis dari tabel naive_bayes
23
3.9
Propertis dari tabel Prediksi
24
3.10
Jadwal Arsenal vs Aston Villa Musim 2006/2007
25
3.11
Data Training Arsenal vs Aston Villa
dalam 5 tahun sebelum 2006/2007
26
3.12
Tabel Cleaning Arsenal vs Aston Villa
28
3.13
Tabel jadwal setelah di-cleaning
31
1
1.1
Latar Belakang Masalah
Saat musim 2006/2007 Liga Inggris (FA Premier League) akan bergulir,
pasar taruhan sepakbola di Eropa khususnya di Inggris memprediksi klub mana
yang akan menjadi juara di liga tersebut. Dengan adanya prediksi kita dapat
menjagokan suatu klub di bursa taruhan pada musim liga ini.
Variabel-variabel yang diduga dapat digunakan untuk memprediksi juara
Liga Inggris musim 2006/2007 yaitu, pemain dan pelatih klub, keletihan pemain,
pemain yang cidera, tempat pertandingan berlangsung (home/away), musim saat
pertandingan (summer,
autumn,
winter,
spring), hasil pertandingan sebelumnya
dan lainnya. Dalam tugas akhir ini, karena adanya keterbatasan dalam data, maka
tidak semua variabel digunakan, sehingga hanya beberapa variabel yang akan
digunakan yaitu, tempat pertandingan berlangsung (home/away), musim saat
pertandingan (summer,
autumn,
winter,
spring), dan hasil pertandingan
sebelumnya (win, draw, lose).
Setelah variabel-variabel penyusun prediksi ditentukan maka peran data
mining dengan metode
Naive Bayesian Classification
untuk menggali informasi
2
1.2
Rumusan Masalah
Dalam Tugas Akhir ini dapat dirumuskan beberapa rumusan masalah
sebagai berikut, yaitu
a.
Bagaimana mengimplementasikan
Naive Bayesian Classification untuk
memprediksi hasil dari setiap pertandingan sehingga juara liga utama
Inggris dapat diprediksi?
b.
Menganalisa keakuratan metode
Naive Bayesian Classification
dalam
memprediksi juara Liga Inggris musim 2006/2007.
1.3
Batasan Masalah
Permasalahan dalam tugas akhir ini dibatasi pada pembuatan program yang
dapat menyelesaikan masalah di atas, dengan batasan-batasan yaitu
a.
Variabel-variabel untuk memprediksi pertandingan yaitu, tempat
pertandingan berlangsung (home/away), musim saat pertandingan
(summer, autumn, winter, spring), dan hasil pertandingan sebelumnya
(win, draw, lose).
b.
Metode yang digunakan untuk melakukan prediksi nilai
class yaitu
Naive Bayesian Classification, dan dalam kasus ini yang menjadi
class
ialah hasil pertandingan yaitu menang, seri, atau kalah.
c.
Sedangkan sumber data yang digunakan ialah semua pertandingan pada
divisi utama Liga Inggris sejak musim 1904/1905 sampai dengan musim
2005/2006, ditambah dengan semua pertandingan pada divisi-divisi yang
dengan 2005/2006 yang mengandung 2 klub divisi utama musim
2006/2007 saling berlawanan.
d.
Untuk membandingkan hasil prediksi, maka prediksi dilakukan sebanyak
6 kali dengan kondisi 5, 6, 7, 8, 9, 10 tahun sebelum kompetisi musim
2006/2007, semua hasil prediksinya disimpan di dalam basis data.
1.4
Tujuan Penelitian
Tugas Akhir ini mempunyai tujuan penelitian, yaitu menerapkan algoritma
Naive Bayesian
sebagai salah satu metode
Classification Data Mining
untuk
menganalisis statistik pertandingan liga sepakbola Inggris agar dapat memprediksi
setiap pertandingan musim 2006/2007, sehingga juara Liga Inggris musim
2006/2007 dapat diprediksi.
1.5
Manfaat Penelitian
Adapun manfaat dari penelitian yang dilakukan adalah
a.
Membantu memprediksi hasil dari sebuah pertandingan di liga Inggris
pada musim 2006/2007.
b.
Membantu memprediksi hasil akhir dari liga Inggris pada musim
4
1.6
Metode Penelitian
Metode penelitian yang digunakan untuk membuat tugas akhir ini adalah:
a.
Penelitian pustaka, yaitu dengan mempelajari hal-hal yang berkaitan
dengan Data Mining
metode Naive Bayesian, dengan mengumpulkan dan
mempelajari informasi dari buku-buku, artikel dan website internet.
b.
Interview, yaitu dengan melakukan konsultasi atau tanya jawab dengan
orang-orang yang memiliki pengetahuan dan wawasan yang berhubungan
dengan topik tugas akhir ini.
c.
Penelitian dan pengumpulan data statistik liga sepakbola Inggris dari
internet.
d.
Melakukan proses
Selection, yaitu mencari sekumpulan target data dari
database untuk dikenai proses Knowledge Discovery.
e.
Melakukan proses
Preprocessing, yaitu membersihkan dan menyiapkan
data dengan cara menghilangkan noise jika ada, menentukan strategi untuk
menangani kolom data yang hilang.
f.
Melakukan proses
Transformation, yaitu mengurangi dimensi, jumlah
variabel pada training data sehingga dapat dilakukan metode
Naive
Bayesian.
g.
Melakukan proses
Data Mining, yaitu pencarian pola pada training data
menggunakan metode Naive Bayesian.
h.
Melakukan proses Interpretation/Evaluation, yaitu menafsirkan pola yang
1.7
Sistematika Penulisan
BAB I PENDAHULUAN
Bab ini berisi penjelasan latar belakang penulis mengambil topik,
rumusan masalah, batasan masalah, tujuan penelitian, metode
penelitian, serta sistematika penulisan laporan.
BAB II LANDASAN TEORI
Bab ini berisi penjelasan tentang prinsip dan konsep dasar yang
diperlukan untuk memecahkan masalah yang dibahas pada Bab I.
BAB III ANALISIS DAN PERANCANGAN SISTEM
Bab ini membahas mengenai sumber data, use case, perancangan
dimensional database, kamus data, contoh perhitungan metode
Naive Bayessian, perancangan antar muka, dan
flowchart
aplikasi
ini.
BAB IV IMPLEMENTASI SISTEM
Bab ini berisi tentang penjelasan mengenai proses implementasi
aplikasi sesuai dengan analisa dan rancangan yang telah dibuat.
BAB V
ANALISIS HASIL IMPLEMENTASI
Bab ini berisi analisa mengenai aplikasi perangkat lunak yang telah
dibuat, serta kelebihan dan kekurangan aplikasi.
BAB VI PENUTUP
Bab ini berisi kesimpulan yang diperoleh dari keseluruhan proses
pembuatan tugas akhir ini, serta beberapa saran untuk
6
BAB II
LANDASAN TEORI
2.1.
Data Mining
Data mining juga dikenal dengan sebutan
Knowledge Discovery in
Databases (KDD) didefinisikan sebagai proses pengekstraksian secara implisit
yang tidak mudah, yang sebelumnya tidak diketahui dan merupakan informasi
yang potensial dari data
1.
Data mining adalah sekumpulan aktifitas yang dilakukan untuk menggali
pengetahuan dari kumpulan data agar didapatkan model yang berarti. Dua tujuan
utama yang diperoleh dari data mining yaitu uraian (description) dan prediksi
(prediction). Oleh karena itu ada kemungkinan aktifitas data mining diarahkan ke
dalam salah satu dari dua kategori berikut :
a.
Data mining yang bersifat prediksi menghasilkan pemodelan dari sistem yang
diuraikan oleh keadaan data.
b.
Data mining yang bersifat deskripsi menghasilkan informasi yang baru dan
bersifat penting berdasarkan pada data yang tersedia.
Tujuan-tujuan tersebut dapat tercapai dengan penggunaan teknik data
mining. Berdasarkan tugas data mining, metode-metode yang biasa dipakai terdiri
atas:
a.
Classification adalah proses penemuan model yang bersifat prediksi dan
menggolongkan data item ke dalam beberapa kelas yang sudah dikenal.
1
b.
Regression adalah proses penemuan model yang bersifat prediksi dan mampu
memetakan data item dengan sebuah angka nyata (real value) dari nilai
variabel ramalan.
c.
Clustering adalah suatu tugas deskriptif umum yang dipakai orang untuk
mencari serta mengidentifikasi suatu himpunan yang terbatas untuk
cluster
kategorial sehingga dapat menguraikan data.
d.
Summarization adalah suatu tugas deskriptif tambahan yang melibatkan
metode untuk penemuan sebuah uraian ringkas dari keseluruhan atau sebagian
data.
e.
Dependecy Modeling adalah menemukan perubahan dan penyimpangan yang
paling penting dalam data.
Proses KDD dapat dilihat pada gambar 2.1 dengan langkah-langkah
sebagai berikut :
1.
Pertama-tama ialah mengembangkan sebuah pemahaman dari daerah aplikasi
yang
bersangkut
paut
dengan
pengetahuan
terlebih
dahulu
dan
mengidentifikasi tujuan dari proses KDD dari sudut pandang konsumen.
2.
Langkah yang kedua ialah membuat himpunan target data, yaitu dengan cara
memilih sebuah himpunan data, atau memfokuskan pada sebuah himpunan
bagian dari variabel atau sample data, yang padanya proses
discovery
dilakukan.
3.
Langkah ketiga ialah
Data Cleaning and Preprocessing. Langkah dasarnya
meliputi menghilangkan derau bila tepat, mengumpulkan informasi yang
8
untuk menangani field data yang hilang, dan menghitung informasi
berdasarkan waktu dan perubahan.
4.
Langkah keempat yaitu Data Reduction and Projection. Mencari ciri-ciri yang
berguna untuk merepresentasikan ketergantungan data dengan tujuan dari
tugas. Dengan pengurangan dimensi atau perubahan metode, jumlah variabel
yang efektif dibawah pertimbangan apakah dapat di dikurangi atau
representasi yang tidak berbeda untuk data dapat ditemukan.
5.
Langkah kelima ialah mencocokan tujuan dari proses KDD (pada langkah 1)
untuk sebuah metode data mining yang khusus. Contohnya,
summarization,
classification, regression, clustering, dan yang lainnya, seperti yang dijelaskan
oleh Fayyad, Piatetsky-Shapiro, and Smyth (1996).
6.
Langkah yang keenam ialah
Exploratory Analysis, Modelling and Hypotesis
Selection:
memilih algoritma data-mining dan menentukan metode untuk
digunakan pada pencarian pola data. Proses ini meliputi menentukan model
mana dan parameter mungkin perlu (contohnya; pemodelan dari data
kategorial berbeda dengan pemodelan dari vektor dari yang nyata) dan
mencocokan metode data-mining yang khusus dengan seluruh kriteria dari
proses KDD (contohnya, end user mungkin akan lebih tertarik dalam
memahami model daripada kemampuan memprediksinya).
7.
Langkah ketujuh ialah data mining: proses pencarian pola dari kepentingan
dalam sebuah bentuk representasi yang khusus atau sebuah himpunan dari
clustering. Pengguna dapat sangat membantu metode data-mining dengan cara
melakukan langkah sebelumnya dengan tepat.
8.
Langkah kedelapan ialah menafsirkan pola yang telah digali, mungkin
kembali ke salah satu dari langkah 1 sampai 7 iterasi lebih jauh. Langkah ini
dapat juga melibatkan visualisasi dari pola yang sudah digali dan pemodelan
atau visualisasi dari data yang berasal dari model-model yang sudah digali.
9.
Langkah kesembilan ialah melakukan tindakan pada
discovered
knowledge:
menggunakan
knowledge secara langsung, menggabungkan
knowledge ke
dalam sistem yang lain untuk tindakan lebih lanjut, atau melakukan
dokumentasi sederhana dan membuat laporan untuk pihak yang tertarik.
Proses ini juga meliputi pengecekan untuk memecahkan konflik potensial
dengan sebelumnya mempercayai knowledge.
Gambar 2.1 Tahap-tahap pada
KDD
22
10
2.2.
Classification
dalam data mining
Classification adalah proses penemuan model yang bersifat prediksi yang
menggolongkan data item ke dalam beberapa kelas yang sudah dikenal.
Classification
didasarkan pada algoritma induktif yang memberikan inputan
berupa kumpulan sampel yang terdiri dari atributâatribut dan kelasâkelas yang
sama. Classification mempunyai beberapa macam metode yang dapat disesuaikan
dengan kebutuhan aplikasi yang akan dibangun.
Beberapa metode
classification
yang sering digunakan adalah sebagai
berikut:
a.
Classification by decision tree induction
Decision tree ialah sebuah flow chart yang seperti struktur pohon dimana
setiap titik merupakan atribut yang telah diuji. Setiap cabang merupakan
pembagian berdasarkan hasil uji dan titik akhir merupakan pembagian kelas
yang dihasilkan. Bagian awal dari pohon keputusan ini adalah titik akar. Pada
umumnya proses dari setiap pohon keputusan adalah mengadopsi strategi
pencarian
top down
untuk solusi ruang pencariannya. Pada proses
mengklasifikasikan sampel yang tidak diketahui, nilai atribut akar akan diuji
pada pohon keputusan dengan cara melacak jalur dari akar sampai titik akhir
dan kemudian akan diprediksikan kelas yang ditempati sampel baru itu.
b.
Naive Bayesian Classification
Naive Bayesian adalah klasifikasi model secara statistik.
Naive Bayesian
memprediksi dengan cara menghitung probabilitas tiap nilai pada atribut untuk
kelas tertentu, prediksi dilakukan dengan penghitungan secara statistik dengan
sumber nilai pada atribut dari data-data yang ingin diprediksi.
c.
Associative Classification Model
Dalam penelitian data mining aturan
associative
adalah sebuah aturan yang
sangat penting untuk memecahkan berbagai masalah dalam klasfikasi dan
memiliki aktivitas tinggi dan pengembangannya.
Associative Classification
Model
memiliki algoritma yang banyak dan masingâmasing algoritma
memiliki kelebihan dan kekurangan maupun kecocokan untuk diterapkan pada
suatu kasus.
d.
Classification by neural network
Dasar dari neural network aslinya dikembangkan oleh ahli psikologis dan ahli
neurobiologist. Mereka menguji dan mengkomputasikan analogi dari sarafâ
saraf. Secara garis besar
neural network
dikondisikan sekumpulan input
output yang berhubungan dan setiap hubungan telah memiliki nilainya
masingâmasing. Ketika dalam prosesnya
neural network
menguji kesamaan
bobotâbobot nilai dengan tujuan memprediksikan label kelas yang benar untuk
sampel yang baru.
e.
KâNearest Neighbour Classifiers
KâNearest Neighbour Classifiers
didasarkan pada analogi. Sampel uji
digambarkan dengan atribut numerik n-dimensional. Tiap sampel mewakili
12
diberikan maka sebuah klasifier kânearest neighbour
mencari bentuk untuk k
sampel uji yang paling dekat dengan sampel baru.
KâNearest Neighbour
Classifiers
dapat
digunakan
untuk
memprediksi
sampel
uji dan
mengklasifikasikan ke dalam kelas dari titik didekatnya.
2.3.
Metode
Naive
Bayesian Classification
2.3.1.
Sejarah Thomas Bayes
Pendeta Thomas Bayes (1702-1761) adalah seorang ahli theologi dan
matematika. Dimotivasi oleh kepercayaan religiusnya, dia menggagas argumen
mengenai keberadaan Tuhan yang dikenal dengan
argument by design. Pada
dasarnya, isi argumen tersebut ialah : âtanpa mengasumsikan keberadaan akan
Tuhan, operasi dalam jagat raya adalah tidak sangat tidak mungkin, oleh karena
itu, selama operasi dalam jagat raya merupakan sebuah fakta, sangatlah mungkin
bahwa Tuhan memang adaâ. Untuk mendukung argumen ini, Bayes menghasilkan
sebuah teori matematika umum yang memperkenalkan kemungkinan probabilistic
inferences (frekuensi yang muncul pada percobaan awal). Pusat dari teori ini ialah
teorema yang sekarang lebih dikenal sebagai Teorema Bayes (1764) yang
mengatakan bahwa fakta dari seorang mengkonfirmasi kemungkinan dari
hipotesis hanyalah tingkat kemunculan dari fakta tersebut dapat lebih mungkin
terjadi dengan asumsi dari hipotesis dibandingkan tanpa asumsi.
Statement umum dari Teorema Bayes adalah fakta dari seorang
mengkonfirmasi kemungkinan dari hipotesis hanyalah tingkat kemunculan dari
fakta tersebut dapat lebih mungkin terjadi dengan asumsi dari hipotesis
dibandingkan tanpa asumsi. Secara khusus didapatkan sebagai berikut :
)
(
)
(
)
|
(
)
|
(
D
P
h
P
h
D
P
D
h
P
=
...
Rumus 2.1
dimana :
D adalah himpunan training data.
h adalah hipotesis.
P(h | D) adalah posterior probability, Contoh : kondisi kemungkinan dari
hipotesis h setelah training data (evidence) muncul.
P(h) adalah
prior probability dari hipotesis
h. Kuantitas non-klassikal ini
sering ditemukan dengan melihat data dari masa lampau (atau dalam training
data).
P(D) adalah prior probability dari training data D. Kuantitas ini sering berupa
nilai yang konstan,
P
(
D
)
=
P
(
D
|
h
)
P
(
h
)
+
P
(
D
|
¬
h
)
P
(
¬
h
)
, dimana dapat
dikomputasi dengan mudah ketika kita menemukan bahwa
P
(
h
|
D
)
dan
)
|
(
h
D
P
¬
adalah 1.
P(D|h) adalah probabilitas dari D yang berasal dari hipotesis h, dan biasa
disebut dengan likelihood. Kuantitas ini mudah untuk dihitung selama
memberikan nilai 1 ketika D dan h konsisten, dan memberikan nilai 0 ketika
14
2.3.3.
Naive Bayesian
Dengan asumsi Naive Bayesian dimana atribut â atribut dari training data
dianggap terpisah dan independen maka rumus 2.1 berubah menjadi seperti
dibawah ini.
)
(
)
(
)
|
(
)...
|
(
)
|
(
)
|
(
1 2D
P
h
P
h
D
P
h
D
P
h
D
P
D
h
P
=
n...
Rumus 2.2
D adalah himpunan training data
h adalah hipotesis
P(h | D) adalah probabilitas dari hipotesis h setelah
evidence
D muncul atau
sering disebut posterior probability.
P(h) adalah probabilitas dari hipotesis
h sebelum
evidence
D muncul atau
sering disebut prior probability.
P(D) adalah probabilitas dari evidence D, dimana P(D) bernilai irrelevant atau
sama dengan kelas yang lain.
P(D1|h), P(D2|h),P(Dn|h) adalah probabilitas dari setiap D1,D2,Dn
untuk
hipotesis h biasa disebut dengan likelihood.
Oleh karena
P(D)
bernilai
irrelevant
maka hanya persamaan
)
(
)
|
(
)...
|
(
)
|
(
)
|
(
h
D
P
D
1h
P
D
2H
P
D
h
P
D
P
=
nyang perlu digunakan untuk mencari
suatu peluang.
Jika ada
P(D
n|h) yang memiliki nilai = 0, maka
P(h | D) = 0. Untuk
mencegah hal itu maka dilakukan penambahan nilai 1 ke setiap
evidence
dalam
perhitungan sehingga probabilitas tidak akan bernilai 0. Langkah ini sering
Jika dalam memprediksi ada evidence pada test data yang tidak diketahui,
16
BAB III
ANALISIS DAN PERANCANGAN SISTEM
3.1. Analisis Sistem
Sistem yang dibuat akan memiliki kemampuan untuk memprediksi
menggunakan metode Naive Bayesian Classification. Sistem ini tidak
memerlukan inputan sumber data dari user, karena diasumsikan sumber data
untuk memprediksi sudah tersimpan pada database. Sehingga user hanya perlu
memasukkan inputan berupa lamanya sumber data yang akan digunakan untuk
memprediksi dalam tahun. Pilihan inputan tersebut hanya ada lima, yaitu 5, 6, 7,
8, 9, 10 tahun sebelum musim 2006/2007. Selanjutnya program yang akan
meneruskan proses prediksi dengan bantuan dari user yang berupa inputan
penekanan tombol.
Sumber data yang digunakan dalam pembuatan sistem ini bersumber dari
internet, yaitu :
a.
Data hasil pertandingan liga utama Inggris dari musim 1904/1905
sampai dengan 2005/2006, ditambah dengan semua pertandingan pada
divisi-divisi yang lain dan kompetisi piala Liga dan FA sejak musim
1989/1990 sampai dengan 2005/2006 yang mengandung 2 klub divisi
utama musim 2006/2007 saling berlawanan. Data ini diambil dari
http://www.esportsdata.com
, format data aslinya berupa
image gif yang
maka data harus direkap secara manual ke dalam file dengan format
CSV, agar dapat dimigrasikan ke database.
b.
Data
keadaan
iklim/musim
di
Inggris
diambil
dari
http://www.woodlands-junior.kent.sch.uk/customs/questions/weather/seasons.htm.
c.
Data
jadwal
musim
2006/2007
yang
diambil
dari
http://www.premierleague.com
d.
Data
klub
diambil
dari
http://www.premierleague.com
dan
http://www.4thegame.com/football-statistics/
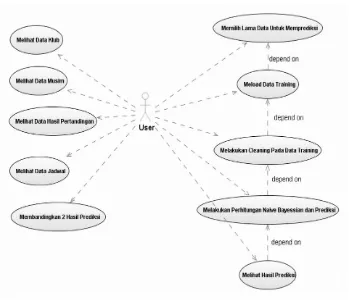
3.2. Use Case Diagram
18
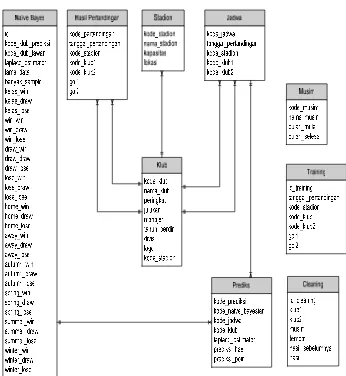
3.3. Class Diagram
3.4. E-R Diagram
20
3.5. Desain Database
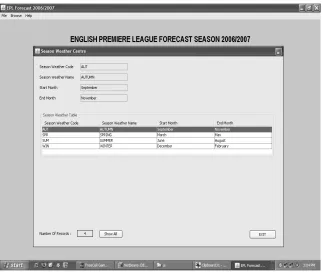
Sistem ini dirancang dengan 9 tabel, yaitu tabel Musim, Klub, Stadion,
Hasil_Pertandingan, Jadwal, Training, Cleaning, Naive_Bayes, Prediksi.
Tabel 3.1 Propertis dari tabel Musim
!
Tabel 3.2 Propertis dari tabel Klub
"
#
"
$
#
%
#
&
!
'
Tabel 3.3 Propertis dari tabel Stadion
'
Tabel 3.4 Propertis dari tabel Hasil_Pertandingan
(
$
(
$
Tabel 3.5 Propertis dari tabel Jadwal
22
Tabel 3.6 Propertis dari tabel Training
Tabel 3.7 Propertis dari tabel Cleaning
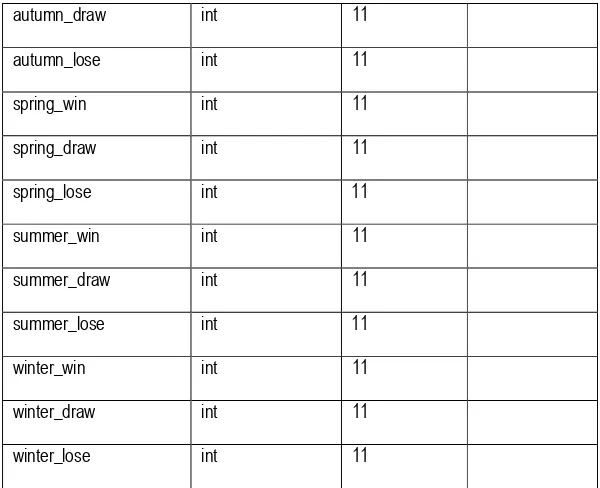
Tabel 3.8 Propertis dari tabel naive_bayes
+
)
!
,
-!
)
)
)
)
)
)
)
) )
)
)
)
)
)
)
)
) ! )
) !
)
) !
24
)
)
)
)
)
)
)
)
)
)
Tabel 3.9 Propertis dari tabel Prediksi
!
# )
-3.6.
Perhitungan menggunakan algoritma
Naive Bayesian
Contoh penerapan algoritma Naïve Bayesian untuk memprediksi hasil
pertandingan antara dua klub Arsenal dan Aston Villa dari salah satu sisi klub
yaitu Arsenal, ialah sebagai berikut.
Pada musim 2006/2007 kedua klub tersebut dijadwalkan dua kali bertemu
yaitu seperti pada tabel 3.10.
Tabel 3.10 Jadwal Arsenal vs Aston Villa Musim 2006/2007
$ )
.
/ 0
1
2
!
0
0
3
4 %
4
3
*
0
3
0
Langkah selanjutnya ialah :
1.
Proses Seleksi
Untuk dapat memprediksi, kita harus melakukan proses seleksi
terhadap data dari seluruh data hasil pertandingan yang ada di basis
data. Misalnya kita seleksi data berdasarkan 5 tahun sebelum musim
2006/2007, berarti awal seleksi kita mulai dari tanggal 1 Agustus 2001
karena kompetisi selalu dimulai setelah tanggal tersebut. Sampai
dengan tanggal 31 Mei 2006, sebab kompetisi selalu berakhir sebelum
tanggal tersebut.
Data training yang didapatkan dari proses seleksi diatas ialah
26
Tabel 3.11 Data Training Arsenal vs Aston Villa
dalam 5 tahun sebelum 2006/2007
*
.
5
5
/
2
!
0
0
3
"
4 %
3
*
0
3
0
/
2
!
0
0
3
"
& 0
"
3
*
0
3
0
4 0
"
2
!
0
0
3
6 $
&
3
*
0
3
0
1 7
&
2
!
0
0
3
"
8
8
3
*
0
3
0
"
"
8
3
*
0
3
0
0
1
2
!
0
0
3
8
2.
Proses Cleaning
Data training perlu di-cleaning agar dapat diproses pada tahap
selanjutnya. Untuk itu diperlukan sumber data yang lain untuk
membantu proses ini, sumber data itu ialah :
a.
Tabel Musim
Tabel ini berisi data-data musim yang terjadi di Inggris, hal yang
terpenting dari tabel ini ialah untuk mengetahui musim saat
pertandingan tersebut terjadi. Tabel ini sudah dijelaskan pada
b.
Tabel Klub
Tabel ini berisi data-data klub yang bersangkutan, hal yang
terpenting dari tabel ini ialah untuk mengetahui stadion tempat
bermarkasnya klub tersebut. Tabel ini sudah dijelaskan pada bagian
3.5.
Dengan bantuan kedua tabel itu, maka proses cleaning dapat
dilaksanakan. Langkahnya selanjutnya ialah sebagai berikut, untuk
setiap barisnya ulangi keempat langkah dibawah ini.
a.
Lakukan pencocokan isi field stadion dengan stadion milik klub
yang akan diprediksi, bila cocok maka field tempat pada tabel
clean diisi dengan Home, bila tidak cocok isi dengan Away.
b.
Lakukan pencocokan isi field tanggal_pertemuan dengan isi field
bulan_mulai dan bulan_selesai pada tabel musim, bila isi field
tanggal_ pertemuan berada diantara isi field bulan_mulai dan
bulan_selesai maka field musim pada tabel clean diisi dengan
nama_musim pada tabel musim sesuai dengan hasil pencocokan
tersebut.
c.
Lakukan perhitungan mencari selisih antara gol milik klub yang
akan diprediksi dengan gol milik klub lawannya berdasarkan pada
hasil pertandingan sebelumnya. Bila selisih lebih dari 0 maka isi
field hasil_sebelumnya dengan WIN, bila selisih sama dengan 0
maka isi field hasil_sebelumnya dengan DRAW, bila kurang dari 0
28
d.
Lakukan perhitungan mencari selisih antara gol milik klub yang
akan diprediksi dengan gol milik klub lawannya pada baris
tersebut. Bila selisih lebih dari 0 maka isi field hasil dengan WIN,
bila selisih sama dengan 0 maka isi field hasil dengan DRAW, bila
kurang dari 0 maka isi field hasil dengan LOSE.
Setelah proses cleaning selesai dilakukan maka terbentuklah
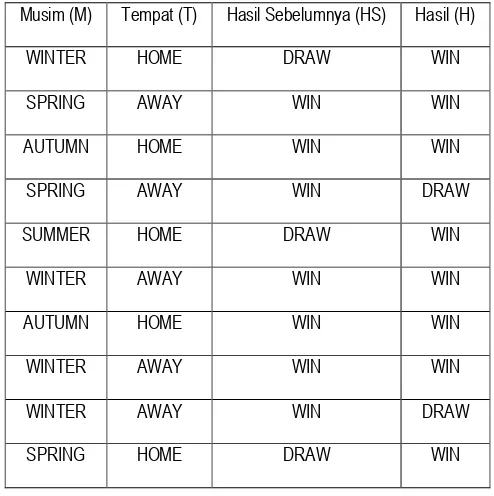
tabel cleaning antara Arsenal vs Aston Villa seperti pada tabel 3.12.
Tabel 3.12 Tabel Cleaning Arsenal vs Aston Villa
%
,%-
, -
2
.
! ,2.-
2
,2-9+
:(
27%:
(09
9+
.*(+ 5
090;
9+
9+
0
%
27%:
9+
9+
.*(+ 5
090;
9+
(09
. %%:(
27%:
(09
9+
9+
:(
090;
9+
9+
0
%
27%:
9+
9+
9+
:(
090;
9+
9+
9+
:(
090;
9+
(09
.*(+ 5
27%:
(09
9+
3.
Proses Penghitungan Prior Probability dan Likelihood
Berdasarkan pada tabel 3.12, kita dapat menghitung nilai prior
probability dan
likelihood. Dan hasil akhir penghitungannya ialah
a.
Prior Probability :
i.
Class (Hasil)
*,2<9+ - < 6=
*,2< (09- < =
*,2<'7.:- < =
b.
Likelihood :
i.
Tempat
*, <27%:>2 < 9+ - < 8=6
*, <090;>2 < 9+ - < "=6
*, <27%:>2 < (09- < =
*, <090;>2< (09- < =
*, <27%:>2 < '7.:- < =
*, <090;>2<'7.:- < =
ii.
Musim
*,%<.*(+ 5>2<9+ - < =6
*,%<9+
:(>2<9+ - < "=6
*,%<.*(+ 5 >2< (09- < =
*,%<9+
:(>2< (09- < =
*,%<.*(+ 5 >2<'7.:- < =
*,%<9+
:(>2<'7.:- < =
*,%<0
% >2<9+ - < =6
*,%<. %%:(>2<9+ - < =6
*,%<0
% >2< (09- < =
*,%<. %%:(>2< (09- < =
*,%<0
% >2<'7.:- < =
*,%<. %%:(>2<'7.:- < =
iii.
Hasil Sebelumnya
*,2.<9+ >2<9+ - < 8=6
*,2.<9+ >2< (09- < =
*,2.<9+ >2<'7.:- < =
*,2.< (09>2<9+ - < "=6
*,2.< (09>2< (09- < =
*,2.< (09>2<'7.:- < =
*,2.<'7.:>2<9+ - < =6
*,2.<'7.:>2< (09- < =
30
LAPLACE ESTIMATOR
Bila ada nilai yang bernilai 0, maka dilakukan penambahan
nilai satu pada setiap evidence sehingga tidak ada yang akan bernilai 0.
Berikut ialah nilai
prior probability
dan
likelihood
setelah laplace
estimator.
a.
Prior Probability :
i.
Class (Hasil)
*,2<9+ - < /= "
*,2< (09- < "= "
*,2<'7.:- < = "
b.
Likelihood :
i.
Tempat
*, <27%:>2 < 9+ - < 1=
*, <090;>2 < 9+ - < &=
*, <27%:>2 < (09- < =&
*, <090;>2< (09- < "=&
*, <27%:>2 < '7.:- < =
*, <090;>2<'7.:- < =
ii.
Musim
*,%<.*(+ 5>2<9+ - < "=
*,%<9+
:(>2<9+ - < &=
*,%<.*(+ 5 >2< (09- < =1
*,%<9+
:(>2< (09- < =1
*,%<.*(+ 5 >2<'7.:- < =&
*,%<9+
:(>2<'7.:- < =&
*,%<0
% >2<9+ - < "=
*,%<. %%:(>2<9+ - < =
*,%<0
% >2< (09- < =1
*,%<. %%:(>2< (09- < =1
*,%<0
% >2<'7.:- < =&
*,%<. %%:(>2<'7.:- < =&
iii.
Hasil Sebelumnya
*,2.<9+ >2<9+ - < 1=
*,2.<9+ >2< (09- < "=8
*,2.<9+ >2<'7.:- < ="
*,2.< (09>2< (09- < =8
*,2.< (09>2<'7.:- < ="
*,2.<'7.:>2<9+ - < =
*,2.<'7.:>2< (09- < =8
*,2.<'7.:>2<'7.:- < ="
4.
Proses Prediksi
Setelah mendapatkan nilai-nilai
prior probability
dan
likelihood, kita dapat memprediksi hasil pertandingan dari jadwal pada
tabel 3.10.
a.
Lakukan langkah-langkah seperti pada proses cleaning pada tabel
3.10 sehingga didapatkan bentuk jadwal seperti berikut :
Tabel 3.13 Tabel jadwal setelah di-
cleaning
$ )
%
,%-
, -
2
.
! ,2.-
2
,2-?
. %%:(
27%:
9+
@
;
.*(+ 5
090;
(09
@
b.
Kemudian hitunglah setiap kemungkinan sesuai dengan kondisi
terhadap class-nya untuk jadwal X.
i.
P(WIN|X)
= P(X|WIN) * P(H=WIN)
= P(M=SUMMER|H=WIN) * P(T=HOME|H=WIN) *
P(HS=WIN|H=WIN) * P(H=WIN)
32
= 27/715
â
0.03776
ii.
P(DRAW|X)
= P(X|DRAW) * P(H=DRAW)
= P(M=SUMMER|H=DRAW) * P(T=HOME|H=DRAW) *
P(HS=WIN|H=DRAW) * P(H=DRAW)
= 1/6 * 1/4 * 3/5 * 3/13
= 3/520
â
0.00577
iii.
P(LOSE|X)
= P(X|LOSE) * P(H=LOSE)
= P(M=SUMMER|H=LOSE) * P(T=HOME|H=LOSE) *
P(HS=WIN|H=LOSE) * P(H=LOSE)
= 1/4 * 1/2 * 1/3 * 1/13
= 1/312
â
0.00321
Jadi prediksi untuk jadwal X ialah :
Prosentase prediksi WIN =
0.03776/(0.03776+0.00577+0.00321) *
100%
=
80.79 %.
Prosentase prediksi DRAW =
0.00577/(0.03776+0.00577+0.00321) *
100%
=
12.34 %.
c.
Ulangi langkah b untuk jadwal Y.
i.
P(WIN|Y)
= P(Y|WIN) * P(H=WIN)
= P(M=SPRING|H=WIN) * P(T=AWAY|H=WIN) *
P(HS=DRAW|H=WIN) * P(H=WIN)
= 3/12 * 4/10 * 4/11 * 9/13
= 18/715
â
0.02517
ii.
P(DRAW|Y)
= P(Y|DRAW) * P(H=DRAW)
= P(M=SPRING|H=DRAW) * P(T=AWAY|H=DRAW) *
P(HS=DRAW|H=DRAW) * P(H=DRAW)
= 2/6 * 3/4 * 1/5 * 3/13
= 3/260
â
0.01154
iii.
P(LOSE|Y)
= P(Y|LOSE) * P(H=LOSE)
= P(M=SPRING|H=LOSE) * P(T=AWAY|H=LOSE) *
P(HS=DRAW|H=LOSE) * P(H=LOSE)
= 1/4 * 1/2 * 1/3 * 1/13
34
Jadi prediksi untuk jadwal Y ialah :
Prosentase prediksi WIN =
0.02517/(0.02517+0.01154+0.00321) *
100%
=
63.07 %,
Prosentase prediksi DRAW =
0.01154/(0.02517+0.01154+0.00321)
* 100%
=
28.90 %,
Prosentase prediksi LOSE =
0.00321/(0.02517+0.01154+0.00321) *
100%
=
8.03 %,
Maka, Arsenal diprediksikan akan menang saat melawan Aston Villa
3.7. Desain User Interface
Dalam analisis sistem ini, user dapat melihat isi data-data pada tabel klub,
musim, jadwal dan hasil pertandingan. Pada program utama, user dapat
melakukan prediksi berdasarkan lama data yang dipilih untuk melakukan
prediksi.
a.
Form Menu Utama
36
b.
Form Browse Data Musim
c.
Form Browse Data Jadwal
38
d.
Form Browse Data Hasil Pertandingan
e.
Form Browse Data Klub
40
f.
Form Load Data
g.
Form Clean Data
42
h.
Form Prediksi
i.
Form Hasil Prediksi
44
j.
Form Analisa Prediksi
3.8.
Flowchart
yang diimplementasikan dalam sistem
46
Gambar 3.15
Flowchart
Proses Penghitungan
Prior Probability
48
Cara kerja sistem ini dapat digambarkan seperti pada gambar 3.14, yaitu
diawali dengan
user memilih lama data untuk menyaring sumber data untuk
memprediksi. Kemudian proses load data mentah dari basisdata akan dilakukan,
setelah itu dilakukan proses pembentukan data training, dan dilanjutkan dengan
proses cleaning untuk memudahkan pada proses selanjutnya.
Setelah data training sudah di-cleaning, maka proses penghitungan
prior
probability dan likelihood untuk setiap atribut dan kelas dapat dilakukan. Apabila
dalam proses ini ditemukan kemungkinan pada attribut atau class yang bernilai 0
maka dilakukan proses Laplace Estimator, seperti terlihat pada gambar 3.15.
Untuk memulai proses prediksi, diperlukan jadwal yang telah disesuaikan
bentuknya seperti data training yang disebut
data test. Selanjutnya tinggal
menghitung setiap kemungkinan menang, seri, atau kalah. Dari proses ini dapat
diperkirakan kemungkinan hasil akhir sebuah pertandingan. Hal tersebut terlihat
pada gambar 3.16.
Untuk memperkirakan klub mana yang peluangnya paling besar untuk juara,
harus dilakukan prediksi pada setiap jadwal pertandingan dari semua sisi klub.
Setelah setiap jadwal pada musim 2006/2007 selesai diprediksi maka dapat
disimpulkan klasemen akhir dari liga utama Inggris, dengan acuan jumlah poin
berdasarkan pada; jika menang maka poin = 3, jika seri maka point = 1, atau jika
kalah maka point = 0. Besar peluang sebuah klub juara dihitung dari jumlah poin
49
Pada bab ini akan dibahas bagaimana pengimplementasian sistem dari
tahap analisis dan desain ke dalam bahasa pemrograman, serta proses ilustrasi
pengujian sistem.
4.1.
Spesifikasi
Software
dan Hardware yang digunakan
Sistem ini dibuat dengan spesifikasi
Software
dan
Hardware
sebagai
berikut.
1.
Spesifikasi
Software
a.
Sistem Operasi Microsoft Windows XP Professional SP 2.
b.
IDE NetBeans 5.5.
c.
Basisdata MySQL 5.0.
d.
Bahasa Pemrograman J2SE, Persistence API.
2.
Spesifikasi
Hardware
a.
Processor AMD Athlon 64.
b.
Memori 768 MB.
50
4.2.
Koneksi Basisdata dengan sistem
Koneksi pada sistem ini menggunakan teknologi persistence dengan
library TopLink dari Oracle, namun sistem ini menggunakan MySQL 5.0 sebagai
basisdata. Tabel-tabel yang dibutuhkan untuk membangun sistem ini ialah sebagai
berikut.
1.
Tabel Klub
Tabel klub digunakan untuk menyimpan data-data setiap klub. Tabel
klub dibuat dengan sintaks SQL sebagai berikut:
CREATE TABLE `klub` ( `kode_klub` varchar(10) NOT NULL, `nama_klub` varchar(30) NOT NULL, `peringkat` int(2) NOT NULL default '0', `julukan` varchar(30) NOT NULL, `manajer` varchar(100) NOT NULL, `tahun_berdiri` varchar(4) NOT NULL default '0000', `divisi` varchar(100) NOT NULL, `logo` longblob NOT NULL, `kode_stadion` varchar(10) NOT NULL, PRIMARY KEY (`kode_klub`), KEY `FK_klub_1` (`kode_stadion`),
CONSTRAINT `FK_klub_1` FOREIGN KEY (`kode_stadion`) REFERENCES `stadion` (`kode_stadion`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
2.
Tabel Stadion
Tabel stadion digunakan untuk menyimpan data-data setiap stadion.
Tabel stadion dibuat dengan sintaks SQL sebagai berikut:
3.
Tabel Musim
Tabel musim digunakan untuk menyimpan data-data musim yang
terjadi di Inggris. Tabel musim dibuat dengan sintaks SQL sebagai
berikut:
CREATE TABLE `musim` ( `kode_musim` varchar(10) NOT NULL, `nama_musim` varchar(10) NOT NULL, `bulan_mulai` varchar(20) NOT NULL, `bulan_selesai` varchar(20) NOT NULL, PRIMARY KEY (`kode_musim`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1
4.
Tabel Jadwal
Tabel jadwal digunakan untuk menyimpan data-data jadwal
pertandingan pada musim 2006/2007. Tabel jadwal dibuat dengan
sintaks SQL sebagai berikut:
CREATE TABLE `jadwal` ( `kode_jadwal` varchar(10) NOT NULL, `tanggal_pertandingan` date NOT NULL, `kode_stadion` varchar(10) NOT NULL, `kode_klub1` varchar(10) NOT NULL, `kode_klub2` varchar(10) NOT NULL, PRIMARY KEY (`kode_jadwal`), KEY `FK_jadwal_1` (`kode_klub1`), KEY `FK_jadwal_3` (`kode_stadion`), KEY `FK_jadwal_2` (`kode_klub2`),
CONSTRAINT `FK_jadwal_1` FOREIGN KEY (`kode_klub1`) REFERENCES `klub` (`kode_klub`),
CONSTRAINT `FK_jadwal_2` FOREIGN KEY (`kode_klub2`) REFERENCES `klub` (`kode_klub`),
CONSTRAINT `FK_jadwal_3` FOREIGN KEY (`kode_stadion`) REFERENCES `stadion` (`kode_stadion`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
5.
Tabel Hasil Pertandingan
Tabel hasil pertandingan digunakan untuk menyimpan data-data hasil
pertandingan sebagai sumber data untuk memprediksi. Tabel hasil
pertandingan dibuat dengan sintaks SQL sebagai berikut:
CREATE TABLE `hasil_pertandingan` (
52
`kode_stadion` varchar(10) NOT NULL, `kode_klub1` varchar(10) NOT NULL, `kode_klub2` varchar(10) NOT NULL, `gol1` int(2) unsigned NOT NULL, `gol2` int(2) unsigned NOT NULL, PRIMARY KEY (`kode_pertandingan`), KEY `FK_hasil_pertandingan_1` (`kode_klub1`), KEY `FK_hasil_pertandingan_3` (`kode_stadion`), KEY `FK_hasil_pertandingan_2` (`kode_klub2`), CONSTRAINT `FK_hasil_pertandingan_1` FOREIGN KEY (`kode_klub1`) REFERENCES `klub` (`kode_klub`),
CONSTRAINT `FK_hasil_pertandingan_2` FOREIGN KEY (`kode_klub2`) REFERENCES `klub` (`kode_klub`),
CONSTRAINT `FK_hasil_pertandingan_3` FOREIGN KEY (`kode_stadion`) REFERENCES `stadion` (`kode_stadion`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
6.
Tabel Training
Tabel training digunakan untuk menyimpan data traning yang
digunakan satu kali untuk satu proses prediksi. Tabel training dibuat
dengan sintaks SQL sebagai berikut:
CREATE TABLE `training` (
`id_training` int(10) unsigned NOT NULL, `tanggal_pertandingan` date NOT NULL, `kode_stadion` varchar(10) NOT NULL, `kode_klub1` varchar(10) NOT NULL, `kode_klub2` varchar(10) NOT NULL, `gol1` int(2) unsigned NOT NULL, `gol2` int(2) unsigned NOT NULL, PRIMARY KEY (`id_training`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1
7.
Tabel Cleaning
Tabel cleaning digunakan untuk menyimpan data dari proses cleaning
dari data training. Tabel ini digunakan satu kali untuk satu proses
prediksi. Tabel cleaning dibuat dengan sintaks SQL sebagai berikut:
CREATE TABLE `cleaning` (
`id_cleaning` int(11) unsigned NOT NULL auto_increment, `klub1` varchar(10) NOT NULL,
8.
Tabel Naïve Bayes
Tabel naïve bayes digunakan untuk menyimpan semua data dari proses
perhitungan
prior probability
dan
likelihood
dari data cleaning. Tabel
naïve bayes dibuat dengan sintaks SQL sebagai berikut:
CREATE TABLE `naive_bayes` (
`id` int(11) unsigned NOT NULL auto_increment, `kode_klub_prediksi` varchar(10) NOT NULL, `kode_klub_lawan` varchar(10) NOT NULL, `laplace_estimator` tinyint(1) NOT NULL,
`lama_data` int(11) NOT NULL, `banyak_sample` int(11) NOT NULL, `kelas_win` int(11) NOT NULL, `kelas_draw` int(11) NOT NULL, `kelas_lose` int(11) NOT NULL, `win_win` int(11) NOT NULL, `win_draw` int(11) NOT NULL, `win_lose` int(11) NOT NULL, `draw_win` int(11) NOT NULL, `draw_draw` int(11) NOT NULL, `draw_lose` int(11) NOT NULL, `lose_win` int(11) NOT NULL, `lose_draw` int(11) NOT NULL, `lose_lose` int(11) NOT NULL, `home_win` int(11) NOT NULL, `home_draw` int(11) NOT NULL, `home_lose` int(11) NOT NULL, `away_win` int(11) NOT NULL, `away_draw` int(11) NOT NULL, `away_lose` int(11) NOT NULL, `autumn_win` int(11) NOT NULL, `autumn_draw` int(11) NOT NULL, `autumn_lose` int(11) NOT NULL, `spring_win` int(11) NOT NULL, `spring_draw` int(11) NOT NULL, `spring_lose` int(11) NOT NULL, `summer_win` int(11) NOT NULL, `summer_draw` int(11) NOT NULL, `summer_lose` int(11) NOT NULL, `winter_win` int(11) NOT NULL, `winter_draw` int(11) NOT NULL, `winter_lose` int(11) NOT NULL, PRIMARY KEY (`id`),
KEY `FK_naive_bayes_1` (`kode_klub_prediksi`), KEY `FK_naive_bayes_2` (`kode_klub_lawan`), CONSTRAINT `FK_naive_bayes_1` FOREIGN KEY (`kode_klub_prediksi`) REFERENCES `klub` (`kode_klub`) ON UPDATE CASCADE,
CONSTRAINT `FK_naive_bayes_2` FOREIGN KEY (`kode_klub_lawan`) REFERENCES `klub` (`kode_klub`) ON UPDATE CASCADE
54
9.
Tabel Prediksi
Tabel prediksi digunakan untuk menyimpan semua hasil prediksi dari
semua jadwal. Tabel prediksi dibuat dengan sintaks SQL sebagai
berikut:
CREATE TABLE `prediksi` (
`kode_prediksi` varchar(10) NOT NULL, `kode_naive_bayesian` int(11) unsigned NOT NULL, `kode_jadwal` varchar(10) NOT NULL, `kode_klub` varchar(10) NOT NULL, `laplace_estimator` tinyint(1) NOT NULL, `prediksi_hasil` varchar(10) NOT NULL, `prediksi_poin` int(1) unsigned NOT NULL, PRIMARY KEY (`kode_prediksi`), KEY `FK_prediksi_1` (`kode_jadwal`), KEY `FK_prediksi_2` (`kode_klub`), KEY `FK_prediksi_naive` (`kode_naive_bayesian`), CONSTRAINT `FK_prediksi_1` FOREIGN KEY (`kode_jadwal`) REFERENCES `jadwal` (`kode_jadwal`),
CONSTRAINT `FK_prediksi_2` FOREIGN KEY (`kode_klub`) REFERENCES `klub` (`kode_klub`),
CONSTRAINT `FK_prediksi_naive` FOREIGN KEY (`kode_naive_bayesian`) REFERENCES `naive_bayes` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
Untuk menerapkan teknologi persistence, maka hal-hal yang dibutuhkan
ialah sebagai berikut.
1.
Persistence API
Bagian yang terpenting dalam pengimplementasian teknologi
persistence ini ialah adanya file persistence.xml di dalam package
(folder) META-INF dan file berekstensi dbschema.
Adapun file persistence.xml berisi sebagai berikut :
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd">
<persistence-unit name="Persistence_SAPU" transaction-type="RESOURCE_LOCAL"> <provider>oracle.toplink.essentials.ejb.cmp3.EntityManagerFactoryProvider</provider> <class>my.entity.Stadion</class>
<class>my.entity.Musim</class> <class>my.entity.NaiveBayes</class> <properties>
<property name="toplink.jdbc.user" value="agus"/> <property name="toplink.jdbc.password" value="agus"/>
<property name="toplink.jdbc.url" value="jdbc:mysql://localhost:3306/ta"/> <property name="toplink.jdbc.driver" value="com.mysql.jdbc.Driver"/> </properties>
</persistence-unit> </persistence>
File ini berfungsi sebagai deskriptor dari persistence itu sendiri,
file ini mencatat class yang berfungsi sebagai
mapping table
dari
tabel-tabel pada basis data. Selain itu juga mencatat nama user, password,
dan host dari basisdatanya, dan juga mencatat class yang digunakan
sebagai konektor dari Java ke MySQL.
Sedangkan file yang berekstensi dbschema dicatat dengan nama
Persistence_SAPU, tetapi dalam package META-INF file tersebut bernama
Persistence_SA.dbschema.
2.
Entity Class
Entity Class berfungsi sebagai
mapping table
dari tabel-tabel
pada basisdata. Contoh entity class ialah sebagai berikut :
package my.entity;
import java.io.Serializable; import java.util.Collection;
import javax.persistence.CascadeType; import javax.persistence.Column; import javax.persistence.Entity; import javax.persistence.Id;
import javax.persistence.NamedQueries; import javax.persistence.NamedQuery; import javax.persistence.OneToMany; import javax.persistence.Table;
@Entity
@Table(name = "stadion")
public class Stadion implements Serializable {
@Id
@Column(name = "kode_stadion", nullable = false) private String kodeStadion;
@Column(name = "nama_stadion", nullable = false) private String namaStadion;
56
@Column(name = "lokasi") private String lokasi;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "kodeStadion") private Collection<Klub> klubCollection;
public Stadion() { }
public Stadion(String kodeStadion) { this.kodeStadion = kodeStadion; }
public Stadion(String kodeStadion, String namaStadion) { this.kodeStadion = kodeStadion;
this.namaStadion = namaStadion; }
public String getKodeStadion() { return this.kodeStadion; }
public void setKodeStadion(String kodeStadion) { this.kodeStadion = kodeStadion;
}
public String getNamaStadion() { return this.namaStadion; }
public void setNamaStadion(String namaStadion) { this.namaStadion = namaStadion;
}
public Integer getKapasitas() { return this.kapasitas; }
public void setKapasitas(Integer kapasitas) { this.kapasitas = kapasitas;
}
public String getLokasi() { return this.lokasi; }
public void setLokasi(String lokasi) { this.lokasi = lokasi;
}
public Collection<Klub> getKlubCollection() { return this.klubCollection;
}
public void setKlubCollection(Collection<Klub> klubCollection) { this.klubCollection = klubCollection;
}
}
Class ini terbentuk dengan bantuan IDE NetBeans 5.5. Class ini
memiliki sifat yang mirip dengan tabel pada basisdata, karena pada
di tabel stadion. Bandingkan dengan perintah DDL untuk tabel stadion
dibawah ini.
CREATE TABLE `stadion` ( `kode_stadion` varchar(10) NOT NULL, `nama_stadion` varchar(100) NOT NULL, `kapasitas` int(10) unsigned default NULL, `lokasi` varchar(100) default NULL, PRIMARY KEY (`kode_stadion`) )
4.3.
Pembuatan Antar Muka
Antar muka atau lebih dikenal dengan sebutan GUI merupakan tampilan
yang langsung