Bayesian Mixture Model Averaging Untuk Mengidentifikasi Perbedaan Ekspresi Gen Percobaan Microarray - ITS Repository
Teks penuh
Gambar
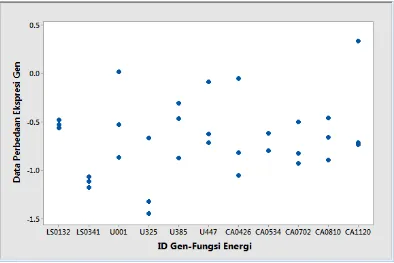
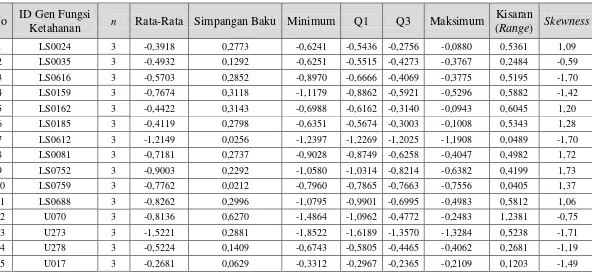
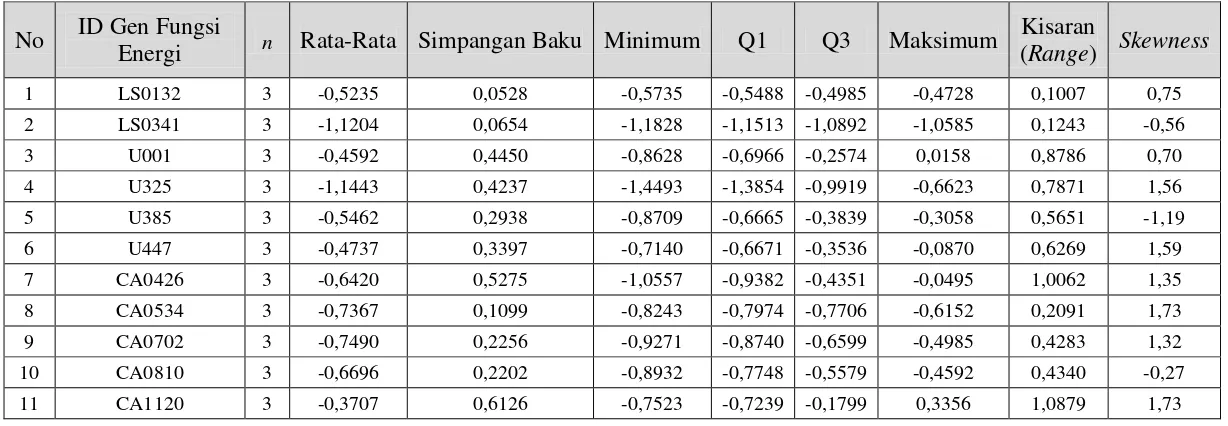
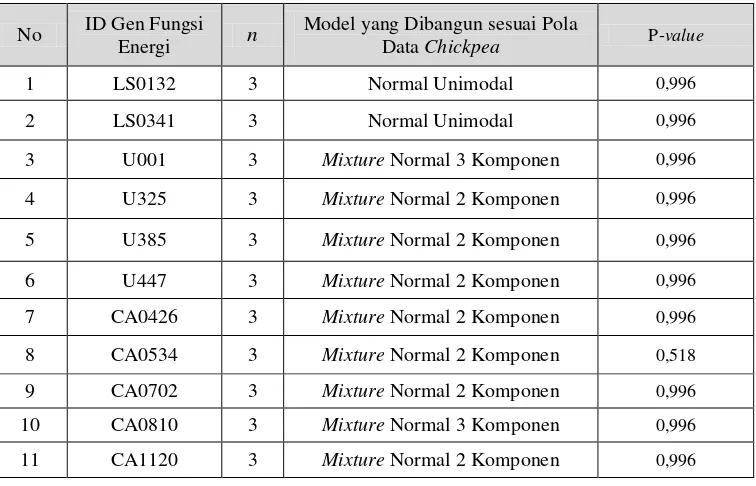
Dokumen terkait
Unit Kerja dalam Instansi yang memiliki kewenangan terhadap bidang tertentu yang berkaitan dengan aplikasi generik agar menyusun spesifikasi acuan atau spesifikasi dasar yang berisi
Dengan memanjatkan puji syukur kehadirat Allah SWT di atas rahmat dan hidayahnya penulis dapat menulis skripsi ini dengan judul "Pengaruh Leverage Terhadap
Bahwa, sebagai perwujudan dari pokok-pokok pikiran di atas, maka atas berkat rahmat Tuhan yang Maha Esa dibentuklah suatu organisasi ikatan alumni yang merupakan gabungan
Partisipasi peserta dapat dilihat dari pertanyaan yang diajukan dalam kegiatan diskusi dan keseriusan peserta di dalam mengikuti simulasi yang berkaitan dengan Sadar Wisata Desa.
Bahwa Undang-Undang yang dimohonkan untuk diuji terhadap UUD 1945 adalah Undang-Undang Nomor 13 Tahun 2003 tentang Ketenagakerjaan, Pasal 59 yang mengatur tentang Perjanjian
(1) Secara teoritis, penelitian ini diharapkan memberikan kontribusi bagi pengembangan ilmu penyuluhan pembangunan, khususnya yang berkaitan dengan pengembangan
Analisis data yang dilakukan dalam penelitian ini adalah sebagai berikut.Untuk data yang diperoleh melalui teknik observasi langsung dengan menggunakanlembar
1. RPI2-JM membutuhkan kajian aspek lingkungan dalam perencanaan pembangunan infrastruktur. KLHS dijadikan sebagai alat kajian lingkungan dalam RPI2-JM adalah karena RPI2-JM
