Gunawan dan Denny Cahyadi
Sekolah Tinggi Teknik Surabaya
[email protected], [email protected]
Abstract
Japanese websites usually written in Kanji characters. For the beginner, reading Kanji can be tough since it has many sound variations. One way to read Kanji easier is by using specialized Hiragana character called Furigana to show the proper way of reading.
In this paper a web application which capable to generate Furigana text on Japanese websites which contains Kanji is proposed. Furigana generation is done based on a Japanese dictionary. However it is impossible to lookup a sentence in a dictionary. Hence a task to divide sentence into words is
needed. Since Japanese doesn’t have special
delimiter to separate words, a special segmentation algorithm is needed.
Segmentation is done through Natural Language Processing approach by using d-bigram and linking string model. The model gain knowledge from a corpus and use it to segment the sentence. After segmentation, each word can be looked up on dictionary to produce proper Furigana. Lastly Ruby tag is used to display Furigana on browser.
In the end of this work, a test to reveal the system's performance in accuracy is done. Using the method proposed above, the system can achieve 94% accuracy at character level and 89% accuracy at word level. Based on the research in Kanji to Hiragana conversion so far, the performance achieved by the system is considered good.
1. PENDAHULUAN
Bahasa Jepang merupakan bahasa yang cukup kompleks dalam hal penulisan. Pada bahasa Jepang dikenal empat macam huruf, yaitu Hiragana,
Katakana, Kanji, dan Romaji. Hiragana dan Kata-kana adalah huruf phonemic dimana setiap karakter menyimbolkan satu bunyi tanpa memiliki arti. Huruf kanji yang lebih kompleks, merupakan huruf
pictographic dimana setiap karakter dapat memberi arti pada suatu makna. Romaji adalah huruf latin yang digunakan dalam bahasa Jepang..
Dari keempat huruf tersebut, Kanji merupakan huruf yang paling kompleks karena jumlahnya yang banyak [7] dan adanya variasi bunyi (cara baca). [14] Cara baca huruf Kanji ditentukan oleh konteks katanya. Inilah yang menyebabkan upaya untuk
memperlajari huruf Kanji tidak dapat dilakukan dalam waktu singkat.
Kompleksitas penggunaan huruf Kanji dapat dikurangi dengan penggunaan huruf Furigana. [10]
Furigana merupakan huruf Hiragana yang ditulis di sebelah atau di atas huruf Kanji dan berfungsi untuk menunjukkan cara baca huruf Kanji tersebut.
Gambar 1. Furigana dan Kanji
Penggunaan huruf Furigana sudah umum dilakukan pada buku-buku berbahasa Jepang. Sayangnya huruf ini masih sedikit digunakan pada halaman web. Dengan demikian diperlukan suatu aplikasi yang mampu menghasilkan teks Furigana
pada halaman web berbahasa Jepang yang mengandung huruf Kanji.
Pada sisi lainnya, perkembangan disiplin ilmu
Natural Language Processing (NLP) boleh dikatakan masuk pada masa renaissance saat web
menyediakan miliaran dokumen berbahasa alami dari pelbagai bangsa, termasuk Jepang. Perkembang-an yPerkembang-ang signifikPerkembang-an tampak pada pendekatPerkembang-an kaum
experimentalist, yang ditunjukkan melalui peman-faatan corpus dan terlibatnya disiplin statistika dan
machine learning seperti yang dilakukan pada penelitian ini, yaitu pengembangan aplikasi web generator teks Furigana.
2. LANDASAN TEORI
Terdapat tiga teori yang mendukung penelitian ini. Berikut akan dijelaskan secara singkat mengenai model d-bigram, mutual information, dan model
linking string.
2.1. MODEL
D-BIGRAM
Model d-bigram merupakan varian dari model n-gram yang memperhitungkan jarak pemisah. Model
Model d-bigram didefinisikan sebagai bigram
dengan pasangan elemen bahasa yang terpisah sejauh satuan jarak d. Pada n-gram perhitungan dilakukan terhadap beberapa elemen bahasa yang berurutan dan saling menempel. Sementara pada d-bigram elemen yang diperhitungkan terpisah sejauh
d satuan elemen. Model d-bigram hanya memperhitungkan kemunculan pasangan dua elemen bahasa, tidak seperti n-gram yang bisa memperhitungkan sejumlah anggota berpasangan sesuai nilai n yang diberikan. Pada penelitian ini elemen bahasa yang diperhitungkan adalah karakter.
Model d-bigram memperoleh pengetahuan dari
corpus untuk menghasilkan tabel d-bigram. Tabel d-bigram adalah tabel yang mencatat peluang kemunculan pasangan karakter yang ditemukan pada
corpus. Tabel ini selanjutnya digunakan untuk melakukan perhitungan linking score pada model
linking string.
2.2.
MUTUAL
INFORMATION
Pada ilmu statistika mutual information dari dua variabel acak merupakan nilai yang menunjukkan hubungan ketergantungan (mutualdependence) antar kedua variabel itu. Dalam hal ini nilai mutual information menunjukkan seberapa besar pengaruh munculnya suatu variabel terhadap variabel lainnya. Dalam konteks analisa bahasa, variabel-variabel yang diperhitungkan adalah karakter-karakter yang muncul pada suatu string. Selain itu tedapat sebuah variabel lagi yang mempengaruhi nilai mutual information, yaitu jarak pemisah antar karakter. Karakter yang muncul berdekatan cenderung memiliki hubungan yang lebih erat daripada karakter yang muncul berjauhan. Dengan demikian jarak pemisah juga ikut diperhitungkan dalam perhitungan
mutual information dengan rumus sebagai berikut:
)
yang terpisah sejauh d karakter
P(x) : peluang kemunculan karakter x P(x, y) : peluang kemunculan karakter x dan y
bersama sama
2.3. MODEL
LINKING STRING
Linking string adalah suatu string (kata) yang terbentuk karena kuatnya hubungan antar karakter yang menyusunnya. Hubungan karater ini dilihat dari seberapa sering suatu pasangan karakter muncul bersama-sama pada sekumpulan teks. Pasangan karakter yang sering muncul bersamaan dianggap sebagai hubungan yang kuat dan sebaliknya.
Hubungan antar karakter ini selanjutnya disebut sebagai linking score, yang didefinisikan sebagai nilai yang menunjukkan peluang kemunculan sebuah karakter terhadap karakter sebelumnya yang dipengaruhi oleh kemunculan beberapa karakter yang mendahuluinya. [12] Dari perspektif statistika
linkingscore sebenarnya pengembangan dari mutual information. Berikut ini adalah rumus yang digunakan untuk perhitungan linking score:
dmax : Jarak maksimum yang diperhitungkan
wj : Karakter ke-j
g(d) : Fungsi bobot untuk menentukan pengaruh jarak terhadap perhitungan
3. ARSITEKTUR
Sistem yang dikembangkan berfungsi untuk menambahkan teks Furigana pada suatu halaman
web yang mengandung teks Kanji. Input sistem adalah URL sebuah halaman web yang akan ditambahi teks Furigana. Output sistem adalah teks berformat HTML (halaman web) yang telah ditambahi Furigana. Antara input dan output terdapat beberapa proses yang perlu dilakukan.
Gambar 2. Arsitektur Sistem
Preproses
Halaman web yang telah dilengkapi dengan Furigana Teks yang mengandung kanji
Pertama kali sistem menerima input berupa URL
sebuah website yang menjadi target. Selanjutnya dilakukan fetching terhadap website target ini. Pada proses fetching dilakukan juga beberapa proses tambahan seperti proses decoding serta pemisahan antara tag dan teks. Proses ini disebut juga sebagai tahap preproses saat program dijalankan (runtime). Tahap ini akan menghasilkan teks yang siap diolah pada proses pembuatan Furigana.
Selanjutnya teks diolah pada tahap pembuatan
Furigana atau disebut juga sebagai proses translasi. Proses translasi memerlukan bantuan berupa tabel d-bigram dan kamus. Keduanyadiperoleh dari corpus
dan kamus yang telah mengalami preproses
sebelumnya. Proses pengambilan data pada corpus
untuk membuat tabel d-bigram dan proses penyesuaian format kamus dilakukan pada tahap
preproses sebelum program dijalankan (offline). Dengan menggunakan tabel d-bigram dan kamus maka proses translasi dapat menghasilkan output berupa teks Furigana. Aliran data berakhir sampai tahap ini, tentu saja setelah data dikirimkan kembali kepada user dalam bentuk halaman web.
4. IMPLEMENTASI
Implementasi sistem ini terbagi ke dalam dua tahap. Tahap pertama adalah tahap preproses yang bertujuan menyiapkan segala data yang diperlukan untuk tahap selanjutnya dan tahap kedua adalah generator Furigana. Berikut ini dijelaskan detail dari masing-masing tahap.
4.1. PREPROSES
Preproses pertama yang dilakukan adalah
cleansing corpus dan pembuatan tabel d-bigram. Tabel d-bigram diperoleh dengan melakukan analisa statistik karakter pada corpus. Corpus yang digunakan adalah Wikipedia XML Corpus yang terdiri dari 187.000 dokumen berbahasa Jepang. Tahap cleansing diperlukan karena isi corpus tidak murni teks berbahasa Jepang, melainkan tercampur dengan tag-tag XML.
Pembuatan tabel d-bigram dilakukan dengan menghitung jumlah kemunculan masing-masing karakter pada corpus. Pada saat scanning, setiap ditemukan karakter baru maka ditambahkan entry
baru pada tabel. Setiap ditemukan karakter yang telah ada, maka jumlah kemuncuka karakter itu di-tambah. Karena informasi yang diinginkan berupa peluang kemunculan maka perlu dihitung juga ratio masing-masing karakter terhadap jumlah total karakter yang terdapat pada corpus. Tabel d-bigram
diimplementasikan dalam bentuk hash table.[13]
Preproses kedua adalah mempersiapkan kamus. Kamus yang digunakan adalah EDICT merupakan kamus Jepang-Inggris berupa plain textfile yang ditulis dengan format EUC-JP. Setiap baris pada
kamus memuat suatu kata lengkap dengan atribut-atributnya seperti cara baca, terjemahan ke bahasa Inggris, jenis kata, dan prioritas. Beberapa atribut lain yang tersedia tidak diperlukan oleh sistem ini, sehingga perlu dilakukan pembuangan atribut yang tidak digunakan. Kamus akan dibuat ke dalam dua jenis. Jenis pertama menyimpan seluruh kata dalam bentuk kata dasar. Sementara itu jenis kedua hanya menyimpan kata-kata yang dapat mengalami per-ubahan bentuk saja yaitu kata kerja dan kata sifat, namun dilengkapi dengan ciri perubahan katanya.
Tahap preproses terakhir merupakan preproses
yang dilakukan setiap kali program dijalankan. Terdapat tiga hal yang dilakukan pada tahap ini yaitu:
Mengidentifikasi jenis encoding yang digunakan oleh halaman web. Jenis encoding yang dapat ditangani adalah UTF-8, Shift_JIS, dan EUC-JP. Melakukan decoding berdasarkan jenis encoding. Melakukan ekstraksi teks, yaitu memisahkan
antara tag dan teks, serta memilih teks mana saja yang mengandung Kanji. Hanya teks yang mengandung Kanji yang akan diproses lebih lanjut.
Tahap preproses menghasilkan output berupa teks yang mengandung huruf Kanji saja. Teks inilah yang selanjutnya diproses pada generator Furigana.
4.2. GENERATOR
FURIGANA
Generator Furigana terbagi menjadi beberapa subproses yaitu perhitungan linking score,
segmentasi, penanganan perubahan kata, lookup
pada kamus, dan penyusunan karakter Furigana. Pada tahap ini terjadi proses segmentasi kalimat secara berulang-ulang hingga didapatkan kata yang cocok.
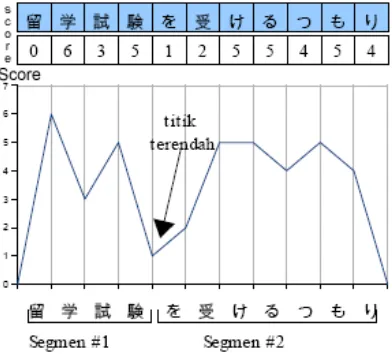
Gambar 3. Linking Score dan Segmentasi
Pembuatan Furigana diawali dengan perhitungan
rumus linking score yang telah dijelakskan sebelumnya. Selanjutnya linking score pada tiap-tiap karakter digunakan sebagai pertimbangan untuk melakukan segmentasi.
Proses segmentasi dan proses lookup pada kamus diimplementasikan sebagai fungsi recursive. Dengan menggunakan teknik divide and conquer suatu string bahasa Jepang akan dipotong menjadi segmen-segmen kecil lalu dicari solusi untuk setiap segmen-segmen. Segmen yang belum cukup pendek atau tidak dapat ditemukan pada kamus akan terus dipotong sampai ditemukan pada kamus atau hanya tersisa satu karakter saja.
Segmentasi dilakukan dengan membagi string menjadi dua bagian berdasarkan titik linking score
terendahnya. Segmenatasi yang dilakukan secara
recursive mengasilkan segmen-segmen yang hubungannya dapat digambarkan sebagai sebuah
tree. Pada gambar 4, segmen kiri masih dapat dibagi menjadi dua segmen lagi dan segmen kanan terbagi menjadi tiga segmen.
Gambar 4. Tree Hasil Segmentasi
Pada tree dapat terlihat bahwa tiap-tiap leaf
merupakan segmen yang berhasil ditemukan pada kamus. Pencarian pada kamus akan menghasilkan bunyi Kanji yang bersangkutan berupa karakter
Furigana. Pada beberapa kasus, kata yang diperoleh dari hasil segmentasi tidak dapat langsung ditemukan pada kamus. Hal ini disebabkan oleh adanya perubahan bentuk kata terkait dengan penggunaannya pada kalimat dan tenses (bentuk waktu). Dengan demikian diperlukan sebuah proses lagi untuk mengembalikan kata-kata berimbuhan menjadi bentuk dasarnya. Hal ini dapat dilakukan dengan menganalisa teknik perubahan kata itu. Pencarian pada kamus yang sukses pada akhirnya menghasilkan teks furigana yang cocok untuk setiap kata. Pada tahap terakhir, karakter Furigana disusun menggunakan tag ruby agar dapat ditampilkan pada
browser.
Keseluruhan proses ini dilakukan untuk semua segmen sampai seluruh teks input yang diberikan telah ditambahkan dengan Furigana. Akhirnya teks yang telah dilengkapi dengan tag ruby dikembalikan pada browser dan ditampilkan sebagai Furigana.
5. UJICOBA
Ujicoba dilakukan untuk menguji performa program. Terdapat tiga aspek yang diujicoba yaitu akurasi sistem, kecepatan proses, dan fungsionalitas. Ujicoba akurasi sistem dan kecepatan proses dilakukan terhadap testing corpus. Sedangkan ujicoba fungsionalitas dilakukan terhadap 20 website
berbahasa Jepang.
Ujicoba akurasi sistem dilakukan dengan cara membandingkan output sistem dengan output ideal. Untuk pengujian ini digunakan Microsoft IME Corpus yang terdiri dari 6000 kalimat berbahasa Jepang (160.000 kata) yang diperoleh secara acak dari surat kabar Kyodo dalam periode setahun.
Corpus ini merupakan corpus paralel yang terdiri dari dua bagian. Bagian pertama adalah teks asli (mengandung keempat jenis karakter Jepang) dan bagian kedua adalah cara baca dari bagian pertama yang ditulis dengan Hiragana (Furigana). Bagian kedua corpus ini merupakan cara baca ideal yang telah dibuat oleh para pakar bahasa Jepang.
Pada saat ujicoba, bagian pertama pada corpus diumpan pada sistem sehingga sistem menghasilkan output berupa Furigana. Selanjutnya output dari sistem dibandingkan dengan Furigana pada bagian kedua dari corpus. Persentasi kemiripan output sistem dengan bagian kedua corpus dianggap se-bagai akurasi.
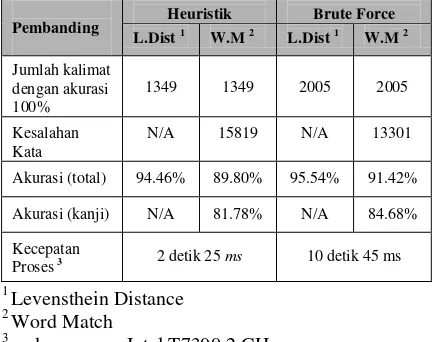
Terdapat dua metode pembandingan yang di-gunakan, yaitu Levensthein Distance dan Word Match. Levensthein Distance menganalisa kemiripan pada level karakter dengan menghitung edit-distance
antara dua string. Hasil ujicoba menunjukkan bahwa output sistem memiliki tingkat kemiripan rata-rata sebesar 94.12%.
Tabel 1. Hasil Ujicoba terhadap 6000 Kalimat Berbahasa Jepang
Pembanding Heuristik Brute Force
L.Dist 1 W.M 2 L.Dist 1 W.M 2
Jumlah kalimat dengan akurasi 100%
1349 1349 2005 2005
Kesalahan Kata
N/A 15819 N/A 13301
Akurasi (total) 94.46% 89.80% 95.54% 91.42%
Akurasi (kanji) N/A 81.78% N/A 84.68%
Kecepatan
Proses3 2 detik 25 ms 10 detik 45 ms
1
Levensthein Distance 2
Word Match 3
pada prosesor Intel T7300 2 GHz
Metode kedua yang digunakan adalah Word Match.
Word Match menganalisa tingkat kemiripan dua
perhitungan hanya dilakukan untuk kata-kata yang mengandung Kanji saja maka akurasi yang dicapai adalah 81.78%.
Ujicoba kedua yang dilakukan adalah ujicoba kecepatan proses. Ujicoba dilakukan dengan membandingkan kecepatan proses sistem yang menggunakan heuristik berupa perhitungan linking score dengan sistem yang menggunakan metode
brute force. Yang dimaksud dengan brute force
adalah mencoba segala kemungkinan segmen saat melakukan segmentasi. Ujicoba bertujuan untuk mengetahui efisiensi penggunaan perhitungan
linking score beserta tabel d-bigram.
Ujicoba dilakukan dengan mengambil waktu rata-rata dari 10 kali proses terhadap testing corpus. Ujicoba dilakukan pada komputer dengan prosesor
Intel Core2 Duo T7300. Hasil ujicoba menunjukkan bahwa sistem dengan heuristik linking score
memiliki waktu rata-rata 2 detik 25 ms, sedangkan sistem dengan brute force memiliki waktu rata-rata 10 detik 54 ms. Hal ini menunjukkan bahwa
linking score mengurangi sedikit akurasi jika dibandingkan dengan brute force. Brute force
mampu mencapai akurasi 95.54% dengan
Levenstehin Distance dan 91.42% dengan Word Match. Brute force sedikit lebih unggul dalam hal akurasi.
Ujicoba terakhir yang dilakukan adalah menguji kerja sistem pada 20 website berbahasa Jepang. Ujicoba ini berupaya menemukan kelemahan sistem. Hasil ujicoba menunjukkan bahwa sistem berjalan dengan baik pada sebagian besar website
berita bahasa Jepang. Namun demikian terdapat beberapa website yang tidak mampu ditangani akibat teknis pemrograman web tersebut. Halaman tidak dapat ditangani diantaranya halaman yang me-redirect ke halaman lain, halaman yang berada di dalam frame, halaman yang mutlak memerlukan
cookies, atau halaman yang mengunakan encoding
yang tidak umum, di luar UTF-8, EUC-JP dan
Shift_JIS.
5a. Sebelum Proses
5b. Setelah Proses
6. KESIMPULAN
Aplikasi yang dibuat memiliki kemampuan untuk menghasilkan teks Furigana untuk huruf-huruf kanji yang terdapat halaman web berbahasa Jepang. Berdasarkan hasil ujicoba. huruf Furigana
yang dihasilkan memiliki tingkat akurasi cukup tinggi.
Penggunaan linking score pada proses segmentasi sebagai acuan posisi segmentasi mampu meningkatkan performa sistem dari segi kecepatan secara signifikan. Walaupun demikian, linking score masih memberikan akurasi sedikit lebih rendah daripada metode brute force.
Penggunaan informasi statistik karakter hanya mampu menangani konteks kata. Cara baca yang tergantung pada konteks kalimat tidak mampu ditangani oleh aplikasi yang hanya mengandalkan informasi statistik karakter dan kamus.
Sistem ini merupakan corpus-based learning
sehingga performa sistem sangat tergantung pada isi training corpus. Corpus merupakan sumber informasi bigram yang digunakan pada saat segmentasi. Corpus yang spesifik pada bidang tertentu (misal politik, kesehatan) hanya akan menghasilkan informasi yang spesifik pada bidang tersebut. Dengan demikian kata-kata yang mampu ditangani dengan baik hanyalah kata-kata pada bidang itu juga. Untuk menangani kata dengan konteks umum maka diperlukan training corpus
dengan konteks umum pula.
7. DAFTAR PUSTAKA
[1] Breen, Jim, Edict – Japanese / English Dictio-naryProject, http://www.csse.monash.edu .au/~ jwb/edict.html, 2007.
[2] Brin, Sergey, Lawrence Page, The Anatomy of a Large-Scale Hypertextual Web Search Engine, Computer Networks and ISDN Systems Vol. 30, pp 107-117, Stanford, 1998. [3] Cahyadi, Denny, Studi Analisa Segmentasi
Teks Bahasa Jepang Menggunakan Model D-Bigram, Sekolah Tinggi Teknik Surabaya, Surabaya, 2007.
[4] Cerone, Nick, Max Krause, John Boates,
Lexicon Design Using Perfect Hash Function, Human Interface and the User Interface Vol. 1981, pp.69-78, ACM, New York, 1981. [5] Constantine, P. Papageorgiou, Japanese Word
Segmentation by Hidden Markov Model, Human Language Technology Conrference, pp.283-288, New Jersey, 1994.
[6] Gunawan, Knowledge Discovery in Databases and Data Mining, http://www.hansmichael. com/download/dmkdd03-6up.pdf, 2007. [7] Joyo Kanji List – Japanese Reference,
http://www.jref.com/language/joyo_kanji.shtm l, 2007.
[8] Kubota, Rie Ando, Lillian Lee, Mostly-Unsupervised Statistical Segmentation of Japanese Kanji Sequences, Natural Language Engineering Vol. 9, pp.127-149, Cambridge University Press, Cambridge, 2003.
[9] Manning, Christoper D., Hinrich Schutze,
Foundation of Statistical Natural Language Processing, The MIT Press, London, 2003. [10] Minna no Nihongo Shokyuu I Edisi
Terjemahan dan Keterangan Tatabahasa, IMAF Press, Surabaya, 2006.
[11] Minna no Nihongo Shokyuu II, IMAF Press, Surabaya, 2006.
[12] Nobesawa, Shiho, et al, Segmenting Sentences into Linky Strings Using D-bigram Statistics, In Colling, Copenhagen, 1996.
[13] N-Gram Class - Open NLP, http://opennlp. sourceforge.net/api/opennlp/tools/ngram/Ngra m .html, 2008.
[14] Picone, Joseph, et al., Kanji to Hiragana Conversion Based on a Length-constrained N-gram Analysis, IEEE Transactions on Speech and Audio Processing VOL. 7, pp.685-696, No. 6, 1999.
[15] Ruby - World Wide Web Consortium Working Draft, http://www.w3.org/TR/1998/WD-ruby-19981221, 1998.