IMPLEMENTASI ALGORITMA K-MEANS UNTUK
KLASTERISASI MAHASISWA BERDASARKAN PREDIKSI
WAKTU KELULUSAN
SKRIPSI
Disusun Oleh :
ALVI SYAHRIN
NPM. 0934010254
J URUSAN TEKNIK INFORMATIKA
FAKULTAS TEKNOLOGI INDUSTRI
UNIVERSITAS PEMBANGUNAN NASIONAL “VETERAN”
J AWA TIMUR
SKRIPSI
Diajukan Untuk Memenuhi Sebagai Per syaratan
Dalam Memperoleh Gelar Sarjana Komputer
J ur usan Teknik Infor matika
Disusun Oleh :
ALVI SYAHRIN
NPM. 0934010254
J URUSAN TEKNIK INFORMATIKA
FAKULTAS TEKNOLOGI INDUSTRI
UNIVERSITAS PEMBANGUNAN NASIONAL “VETERAN”
J AWA TIMUR
PENYUSUN : ALVI SYAHRIN
ABSTRAKSI
Waktu kelulusan merupakan permasalahan umum bagi pihak universitas dan mahasiswa, karena kedua pihak tersebut sama-sama tidak dapat memprediksi waktu kelulusan mahasiswa. Dengan adanya masalah ini, perlu untuk menciptakan sistem yang dapat memprediksi tingkat kelulusan mahasiswa.
Teknik clustering dapat memecahkan masalah ini, yakni dengan menggunakan
algoritma K-Means.
Aplikasi ini mengimplementasi algoritma K-Means ke dalam studi kasus tersebut. Aplikasi ini terdiri dari empat fungsi, yakni ‘Cluster’, ‘Show Centroid’, ‘Show the Graphic’, dan ‘Evaluate the Cluster’. ‘Cluster’ digunakan untuk membagi data mahasiswa ke dalam kelas-kelas berdasarkan prediksi waktu
kelulusannya. ‘Show Centroid’ digunakan untuk melihat centroid akhir dari
proses iterasi. ‘Show the Graphic’ digunakan untuk menampilkan posisi tingkat
kelulusan mahasiswa. ‘Evaluate the Cluster’ digunakan untuk menghitung nilai
optimal dari hasil cluster tersebut.
Dengan adanya aplikasi ini, pihak universitas dapat melihat hasil prediksi tingkat kelulusan mahasiswa. Maka, bila terdapat mahasiswa yang menduduki peringkat terendah dalam prediksi kelulusan, pihak universitas dapat memberikan bimbingan intensif atau semester pendek khusus, untuk membantu mahasiswa tersebut dalam mengejar ketertinggalannya.
KATA PENGANTAR
Assalamu’alaikum Warrahmatullahi Wabarakatuh
Segala puji bagi Allah S.W.T atas segala limpahan karunia dan kasih
sayang-Nya, sehingga dengan segala keterbatasan waktu, tenaga, dan pikiran yang
dimiliki oleh penulis, akhirnya laporan tugas akhir yang berjudul
“
I
MPLEMENTASI ALGORITMA K-MEANS UNTUK KLASTERISASIMAHASISWA BERDASARKAN PREDIKSI WAKTU KELULUSAN” dapat
diselesaikan sesuai dengan waktu yang telah ditetapkan.
Melalui skripsi ini, penulis merasa mendapat kesempatan besar untuk
memperdalam ilmu pengetahuan yang diperoleh selama di perkuliahan, terutama
dengan implementasi Teknologi Informasi dalam kehidupan sehari-hari. Meski
demikian, penulis menyadari bahwa skripsi ini masih memiliki beberapa
kekurangan. Oleh karena itu, kritik dan saran yang bersifat membangun sangatlah
diharapkan dari berbagai pihak agar tugas akhir ini bisa berkembang lebih baik lagi,
sehingga dapat memberikan manfaat bagi semua pihak yang membutuhkannya.
Dalam penyusunan tugas akhir ini, banyak pihak yang telah memberikan
bantuan baik materiil maupun spiritual ini, sehingga pada kesempatan ini penulis
mengucapkan rasa terima kasih yang sebesar-besarnya kepada:
1. ALLAH S.W.T. Alhamdulillah atas segala kelancaran dan kemudahan yang
selalu Engkau limpahkan kepada penulis. Dan, sungguh, semua ini dapat
Terimakasih banyak telah bersabar membimbing dan memberi saran yang
sangat bermanfaat kepada penulis.
3. Ibu Dr.Ir Ni Ketut Sari,MT selaku ketua jurusan Teknik Informatika, UPN
“Veteran” Jawa Timur, sekaligus dosen pembimbing II yang senantiasa
menyediakan waktu luang bagi penulis untuk berkonsultasi.
4. Hillman Himawan, Shelly Yudha F., Agus Setyawan, dan Rachmah Eka
Sari untuk bantuannya selama empat tahun terakhir penuh perjuangan ini.
5. Kawan-kawan TF ’09 yang senantiasa memberi dukungan.
6. Keluarga yang tak pernah henti-hentinya berdoa demi kebaikan penulis
dalam menyelesaikan tugas akhir ini.
Serta pihak-pihak lain yang ikut memberikan informasi dan data-data di
dalam menyelesaikan laporan skripsi ini, penulis mengucapkan terima kasih.
Akhir kata penulis harap agar tugas akhir yang disusun sesuai dengan
kemampuan dan pengetahuan yang sangat terbatas ini dapat bermanfaat bagi semua
pihak yang membutuhkan.
Wassalamu’alaikum Warrahmatullahi Wabarakatuh
Surabaya, Mei 2013
DAFTAR ISI
Abstraksi ... i
KATA PENGANTAR ... ii
DAFTAR ISI ... iv
DAFTAR TABEL ... vi
DAFTAR GAMBAR ... ix
DAFTAR LAMPIRAN ... xiv
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah... 4
1.3 Batasan Masalah ... 4
1.4 Tujuan ... 5
1.5 Manfaat ... 5
BAB II TINJAUAN PUSTAKA ... 6
2.1 Penelitian Terdahulu ... 6
2.1.1 Sepuluh Algoritma Data Mining Terbaik ... 6
2.1.2 Pengelompokkan Mahasiswa Berdasarkan Body Mass Index ... 8
2.2.1 Data Mining... 12
2.2.2 Clustering ... 15
2.2.3 Algoritma K-Means ... 17
2.2.4 Silhouette... 21
2.2.5 MATLAB ... 22
BAB III PERANCANGAN SISTEM ... 25
3.1 Data Set ... 25
3.2 Rancangan Penelitian ... 28
3.2.1 Diagram UML ... 30
3.2.1.1 Use Case ... 32
3.2.1.2 Activity Diagram ... 33
3.2.2 Flowchart ... 41
3.3 Rancangan Uji Coba dan Evaluasi ... 46
BAB IV HASIL DAN PEMBAHASAN ... 49
4.1 Lingkungan Implementasi ... 49
4.2 Implementasi ... 49
4.3 Hasil Uji Coba dan Evaluasi ... 51
BAB V KESIMPULAN DAN SARAN... 100
5.2 Saran ... 101
DAFTAR PUSTAKA ... 102
Tabel 2.1 Parameter Fungsi K-Means ... 21
Tabel 2.2 Parameter Fungsi-fungsi MATLAB ... 24
Tabel 3.1 Data Set ... 25
Tabel 3.2 Skenario Fungsi Mengklaster Data ... 34
Tabel 3.3 Skenario Fungsi Melihat Pusat Klaster ... 36
Tabel 3.4 Skenario Melihat Grafik ... 38
Tabel 3.5 Skenario Mengevaluasi Hasil Klaster ... 40
Tabel 3.6 Rancangan Tampilan GUI ... 47
Tabel 3.7 Rancangan Warna Plotting ... 48
Tabel 4.1 Jumlah Anggota Cluster Random 2 ... 53
Tabel 4.2 Centroid Random 2 Uji Coba 1... 54
Tabel 4.3 Centroid Random 2 Uji Coba 2... 54
Tabel 4.4 Centroid Random 2 Uji Coba 3... 54
Tabel 4.5 Jumlah Anggota Cluster Random 3 ... 58
Tabel 4.6 Centroid Random 3 Uji Coba 1... 58
Tabel 4.7 Centroid Random 3 Uji Coba 2... 59
Tabel 4.8 Centroid Random 3 Uji Coba 3... 59
Tabel 4.10 Centroid Random 4 Uji Coba 1 ... 64
Tabel 4.11 Centroid Random 4 Uji Coba 2 ... 64
Tabel 4.12 Centroid Random 4 Uji Coba 3 ... 64
Tabel 4.13 Jumlah Anggota Cluster Random 5... 68
Tabel 4.14 Centroid Random 5 Uji Coba 1 ... 69
Tabel 4.15 Centroid Random 5 Uji Coba 2 ... 69
Tabel 4.16 Centroid Random 5 Uji Coba 3 ... 70
Tabel 4.17 Jumlah Anggota Cluster Random 6... 74
Tabel 4.18 Centroid Random 6 Uji Coba 1 ... 75
Tabel 4.19 Centroid Random 6 Uji Coba 2 ... 75
Tabel 4.20 Centroid Random 6 Uji Coba 3 ... 75
Tabel 4.21 Jumlah Anggota Cluster Random 7... 80
Tabel 4.22 Centroid Random 7 Uji Coba 1 ... 80
Tabel 4.23 Centroid Random 7 Uji Coba 2 ... 81
Tabel 4.24 Centroid Random 7 Uji Coba 3 ... 81
Tabel 4.25 Nilai Optimal Random ... 85
Tabel 4.26 Centr1oid Default 2 ... 86
Tabel 4.27 Centroid Default 3 ... 88
Tabel 4.28 Centroid Default 4 ... 90
Tabel 4.31 Centroid Default 7 ... 97
DAFTAR GAMBAR
Gambar 2.1 Flowchart Algoritma K-Means ... 18
Gambar 3.1 Rancangan Pemrosesan ... 29
Gambar 3.2 Aktor ... 30
Gambar 3.3 Use Case ... 31
Gambar 3.4 Use Case Diagram ... 32
Gambar 3.5 Activity Diagram Mengklaster Data ... 35
Gambar 3.6 Activity Diagram Melihat Pusat Klaster ... 37
Gambar 3.7 Activity Diagram Melihat Grafik Klaster ... 39
Gambar 3.8 Activity Diagram Mengevaluasi Hasil Klaster ... 41
Gambar 3.9 Flowchart Utama ... 42
Gambar 3.10 Flowchart CalcInit ... 43
Gambar 3.11 Flowchart Next ... 44
Gambar 3.12 Rancangan GUI ... 48
Gambar 4.1 Implementasi Algoritma K-Means I ... 50
Gambar 4.2 Implementasi Algoritma K-Means II ... 51
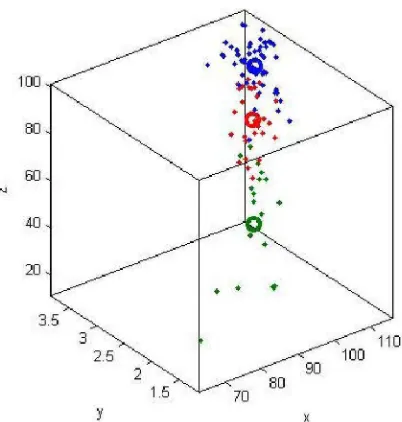
Gambar 4.3 Plotting Random 2 Uji Coba 1 ... 54
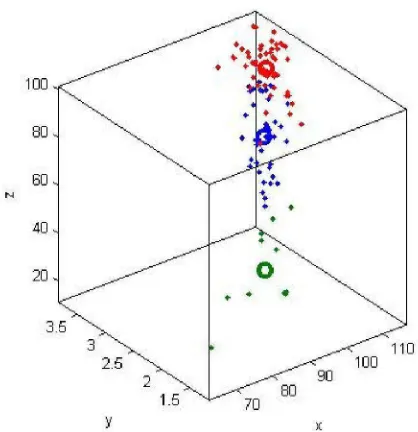
Gambar 4.4 Plotting Random 2 Uji Coba 2 ... 55
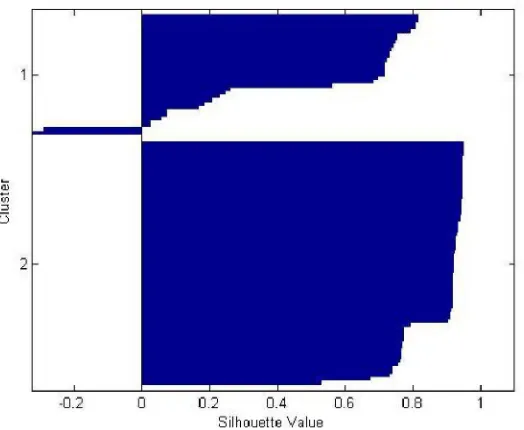
Gambar 4.7 Silhouette Random 2 Uji Coba 2 ... 56
Gambar 4.8 Silhouette Random 2 Uji Coba 3 ... 57
Gambar 4.9 Tingkat Optimal Random 2 Uji Coba 1 ... 57
Gambar 4.10 Plotting Random 3 Uji Coba 1 ... 59
Gambar 4.11 Plotting Random 3 Uji Coba 2 ... 60
Gambar 4.12 Plotting Random 3 Uji Coba 3 ... 60
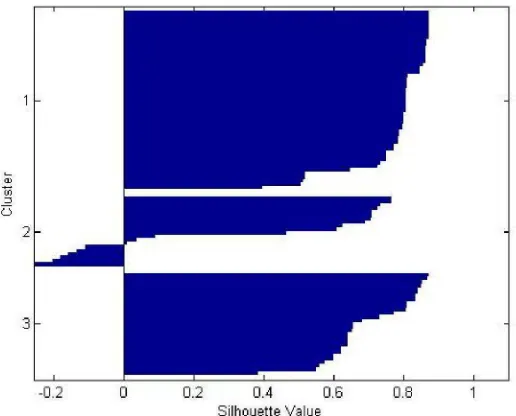
Gambar 4.13 Silhouette Random 3 Uji Coba 1 ... 61
Gambar 4.14 Silhouette Random 3 Uji Coba 2 ... 61
Gambar 4.15 Silhouette Random 3 Uji Coba 3 ... 62
Gambar 4.16 Tingkat Optimal Random 3 Uji Coba 1 ... 62
Gambar 4.17 Tingkat Optimal Random 3 Uji Coba 2 ... 62
Gambar 4.18 Tingkat Optimal Random 3 Uji Coba 3 ... 62
Gambar 4.19 Plotting Random 4 Uji Coba 1 ... 65
Gambar 4.20 Plotting Random 4 Uji Coba 2 ... 65
Gambar 4.21 Plotting Random 4 Uji Coba 3 ... 66
Gambar 4.22 Silhouette Random 4 Uji Coba 1 ... 66
Gambar 4.23 Silhouette Random 4 Uji Coba 2 ... 67
Gambar 4.24 Silhouette Random 4 Uji Coba 3 ... 67
Gambar 4.26 Tingkat Optimal Random 4 Uji Coba 2 ... 68
Gambar 4.27 Tingkat Optimal Random 4 Uji Coba 3 ... 68
Gambar 4.28 Plotting Random 5 Uji Coba 1 ... 70
Gambar 4.29 Plotting Random 5 Uji Coba 2 ... 71
Gambar 4.30 Plotting Random 5 Uji Coba 3 ... 71
Gambar 4.31 Silhouette Random 5 Uji Coba 1 ... 72
Gambar 4.32 Silhouette Random 5 Uji Coba 2 ... 72
Gambar 4.33 Silhouette Random 5 Uji Coba 3 ... 73
Gambar 4.34 Tingkat Optimal Random 5 Uji Coba 1 ... 73
Gambar 4.35 Tingkat Optimal Random 5 Uji Coba 2 ... 73
Gambar 4.36 Tingkat Optimal Random 5 Uji Coba 3 ... 73
Gambar 4.37 Plotting Random 6 Uji Coba 1 ... 76
Gambar 4.38 Plotting Random 6 Uji Coba 2 ... 76
Gambar 4.39 Plotting Random 6 Uji Coba 3 ... 77
Gambar 4.40 Silhouette Random 6 Uji Coba 1 ... 77
Gambar 4.41 Silhouette Random 6 Uji Coba 2 ... 78
Gambar 4.42 Silhouette Random 6 Uji Coba 3 ... 78
Gambar 4.43 Tingkat Optimal Random 6 Uji Coba 1 ... 79
Gambar 4.44 Tingkat Optimal Random 6 Uji Coba 2 ... 79
Gambar 4.47 Plotting Random 7 Uji Coba 2 ... 82
Gambar 4.48 Plotting Random 7 Uji Coba 3 ... 82
Gambar 4.49 Silhouette Random 7 Uji Coba 1 ... 83
Gambar 4.50 Silhouette Random 7 Uji Coba 2 ... 83
Gambar 4.51 Silhouette Random 7 Uji Coba 3 ... 84
Gambar 4.52 Tingkat Optimal Random 7 Uji Coba 1 ... 84
Gambar 4.53 Tingkat Optimal Random 7 Uji Coba 2 ... 84
Gambar 4.54 Tingkat Optimal Random 7 Uji Coba 3 ... 84
Gambar 4.55 Plotting Default 2 ... 86
Gambar 4.56 Silhouette Default 2 ... 87
Gambar 4.57 Tingkat Optimal Default 2 ... 87
Gambar 4.58 Plotting Default 3 ... 88
Gambar 4.59 Silhouette Default 3 ... 89
Gambar 4.60 Tingkat Optimal Default 3 ... 89
Gambar 4.61 Plotting Default 4 ... 91
Gambar 4.62 Silhouette Default 4 ... 91
Gambar 4.63 Tingkat Optimal Default 4 ... 92
Gambar 4.64 Plotting Default 5 ... 93
Gambar 4.66 Tingkat Optimal Default 5 ... 94
Gambar 4.67 Plotting Default 6 ... 95
Gambar 4.68 Silhouette Default 6 ... 96
Gambar 4.69 Tingkat Optimal Default 6 ... 96
Gambar 4.70 Plotting Default 7 ... 98
Gambar 4.71 Silhouette Default 7 ... 98
Lampiran 1: Tabel Clustering Random 2 ... 104
Lampiran 2: Tabel Clustering Random 3 ... 107
Lampiran 3: Tabel Clustering Random 4 ... 109
Lampiran 4: Tabel Clustering Random 5 ... 112
Lampiran 5: Tabel Clustering Random 6 ... 115
Lampiran 6: Tabel Clustering Random 7 ... 118
Lampiran 7: Tabel Clustering Default 2 ... 121
Lampiran 8: Tabel Clustering Default 3 ... 124
Lampiran 9: Tabel Clustering Default 4 ... 126
Lampiran 10: Tabel Clustering Default 5 ... 129
Lampiran 11: Tabel Clustering Default 6 ... 132
BAB I
PENDAHULUAN
1.1Latar Belakang
Lulus tepat waktu adalah keinginan seluruh mahasiswa. Tidak hanya itu,
lulus tepat waktu adalah keuntungan bagi dua pihak. Pertama, pihak mahasiswa,
karena dengan begitu mahasiswa akan mendapatkan pekerjaan dengan lebih
mudah karena perusahaan cenderung mencari fresh graduate. Kedua, pihak
universitas, karena seiring tepatnya waktu kelulusan mahasiswa, hal itu akan
membantu memajukan kualitas universtas tersebut, seperti peningkatan akreditasi.
Sayangnya, waktu kelulusan mahasiswa tidak selalu dapat dideteksi secara
dini, sehingga bisa mengakibatkan keterlambatan kelulusan. Hal ini tentunya
merugikan kedua pihak. Untuk memecahkan masalah tersebut, perlu adanya suatu
sistem atau program yang dapat mengelompokkan golongan mahasiswa
berdasarkan prediksi waktu kelulusan. Dalam tugas akhir ini, pengelempokkan
mahasiswa dilakukan dengan cara clustering, menggunakan algoritma k-Means.
Clustering merupakan teknik yang sudah cukup dikenal dan banyak
dipakai dalam data mining. Sampai sekarang para ilmuwan dalam bidang data
mining masih melakukan berbagai usaha untuk melakukan perbaikan model klaster karena metode yang dikembangkan masih bersifat heuristik. Dari beberapa
teknik klastering yang paling sederhana dan umum adalah algoritma k-Means,
Peneliti-peneliti terdahulu telah melakukan proses clustering dengan menggunakan algoritma k-Means untuk memecahkan masalah serupa. Salah satu
contoh pada paper nasional berjudul, “Aplikasi K-Means Untuk
Pengelompokan Mahasiswa Berdasar kan Nilai Body Mass Index (BMI) &
Ukuran Kerangka”. Peneliti tersebut menjelaskan bahwa, “Masalah kesehatan
merupakan permasalahan yang sangat penting untuk diperhatikan, diantaranya adalah masalah BMI dan ukuran kerangka seseorang. Apabila seseorang telah mengetahui nilai BMI-nya, orang tersebut dapat mengontrol berat badan sehingga dapat mencapai berat badan normal yang sesuai dengan tinggi badan. Pada penelitian ini, penulis mencoba membangun suatu sistem untuk mengelompokkan data yang ada berdasarkan status gizi dan ukuran rangkanya dengan memasukkan parameter kondisi fisik dari orang tersebut. Pengelompokkan data dilakukan dengan menggunakan metode clustering K-Means, yaitu dengan mengelompokkan n buah objek ke dalam k kelas berdasarkan jaraknya dengan pusat kelas...” (Tedy Rismawan dan Sri Kusumadewi, 2008)
Selain itu, paper bertaraf internasional pun pernah mengimplementasikan
algoritma k-Means. Paper tersebut berjudul “Application of K-Means Clustering
Algorithm for Prediction of Students’ Academic Performance”. Peneliti tersebut
menjelaskan bahwa, “Kemampuan untuk memantau progress akademik siswa
3
untuk mengatur nilai mereka sesuai dengan tingkat kinerja. Dalam paper ini, kami juga mengimplementasi algoritma k-Means untuk menganalisa hasil data. Data yang diuji adalah data-data siswa pada lembaga swasta di Nigeria yang mana bagus bila dipantau progres akademiknya.” (O.J, Oyelade dkk, 2010)
Dengan menggunakan algoritma k-Means, paper bertaraf internasional
tersebut menghasilkan data-data siswa yang telah dikelompokkan berdasarkan
GPA (Grade Point Average), mulai dari tiga sampai lima klaster.
Berdasarkan penelitian-penelitian yang telah dirangkum pada kedua paper
di atas, telah dibuktikan bahwa algoritma k-Means dapat menunjukkan
keberhasilannya dalam mengelompokkan data. Paper-paper tersebut akan
dijelaskan secara mendetail pada sub-bab “Peneliti Terdahulu” untuk semakin
menguatkan alasan penggunaan algoritma k-Means dalam tugas akhir ini.
Dalam tugas akhir ini, set obyeknya adalah data mahasiswa. Terdapat tiga
parameter yang digunakan sebagai parameter prediksi kelulusan, antara lain
jumlah SKS yang telah diambil, IPK, dan presentase kehadiran. Sehingga akan
menghasilkan data tiga dimensi. Data mahasiswa akan diproses dalam algoritma
k-Means. Algoritma tersebut akan memrosesnya, sehingga nantinya akan
terbentuk kelas-kelas yang berisi mahasiswa dengan karateristik serupa.
Karateristik serupa tersebut dapat membantu pihak universitas untuk memprediksi
waktu kelulusan golongan mahasiswa. Program akan disusun menggunakan
MATLAB R2010b.
Sejauh ini, pembahasan tentang pengelompokkan mahasiswa berdasarkan
dalam sudut pandang informatika. Jadi, menggabungkan teknik clustering dan studi kasus ini akan sangat bermanfaat nantinya jika diterapkan pada
kampus-kampus.
1.2Rumusan Masalah
Berikut adalah rumusan-rumusan masalah untuk menemukan solusi dari
permasalahan di atas:
a. Mengumpulkan data mahasiswa berdasarkan parameter SKS, IPK, dan
akumulasi presentase kehadiran.
b. Mengklasterisasi mahasiswa dengan menggunakan algoritma k-Means.
c. Mengimplementasi algoritma K-Means dengan program MATLAB.
1.3Batasan Masalah
Dari permasalahan-permasalahan di atas, maka batasan-batasan dalam
tugas akhir ini adalah:
a. Program dibangun dengan menggunakan MATLAB versi R2010b dan
tidak diintegerasikan dengan program lain, seperti database maupun
hal-hal yang berhubungan dengan penyimpanan data.
b. Parameter dibatasi sebanyak tiga aspek. Jumlah klaster dibatasi dari dua
sampai tujuh.
c. Data mahasiswa yang diuji adalah 100 data mahasiswa Universitas
5
1.4Tujuan
Mengacu pada perumusan masalah di atas, tujuan yang hendak dicapai
dalam penyusunan tugas akhir ini antara lain:
a. Mengklaster data-data mahasiswa berdasarkan parameter yang ada.
b. Menghasilkan program yang dapat menunjukkan hasil data setelah melalui
proses clustering, beserta grafiknya.
c. Menampilkan plotting data untuk melihat kecendurungan pengelompokkan
data.
1.5Manfaat
Bila program ini berhasil diimplementasikan, maka manfaat yang dapat
diberikan antara lain:
a. Pihak universitas dapat melihat hasil pengelompokkan mahasiswa,
sehingga dapat mengetahui mahasiswa mana saja yang membutuhkan
bimbingan atau semester pendek khusus.
b. Mahasiswa dapat mengetahui ia berada di kelas mana, sehingga
2.1 Penelitian Terdahulu
2.1.1 Sepuluh Algoritma Data Mining Terbaik
Berikut adalah identitas paper:
Judul : Top 10 Algorithms in Data mining
Penulis : Xindong Wu, Vipin Kumar, J. Ross Quinlan, Joydeep Ghosh,
Qiang Yang, Hiroshi Motoda, Geoffrey J. McLachlan, Angus Ng, Bing Liu,
Philip S. Yu, Zhi-Hua Zhou, Micheal Steinbach, David J. Hand, Dan
Steinberg
Tahun : 2007 (InternationalPaper)
Paper ini menyajikan sepuluh algoritma data mining yang telah
diidentifikasi oleh IEEE (International Conference on Data mining) pada
Desember 2006, antara lain: C4.5, k-Means, SVM, Apriori, EM, PageRank,
AdaBoost, kNN, Naif Bayes, dan CART. Sepuluh algoritma ini merupakan
algoritma yang paling berpengaruh pada penelitian data mining. Setiap penelitian
algoritma, dideskripsikan mengenai algoritma tersebut, membahas manfaatnya,
meninjau penelitian saat ini dan masa depan algoritma tersebut. Sepuluh algoritma
ini mencakup klasifikasi, clustering, pembelajaran statistik, analisis asosiasi, dan mining link, yang semuanya merupakan topik penting dalam penelitian dan
7
Dalam upaya untuk mengidentifikasi beberapa algoritma paling
berpengaruh yang telah banyak digunakan dalam data mining, IEEE
mengidentefikasi sepuluh algoritma terbaik dalam presentasi data mining di
ICDM 2006, Hongkong.
Sebagai langkah pertama, dikumpulkan lebih dari 10 algoritma dalam data
mining dari para peneliti. Setiap nominasi algoritma, harus memberikan informasi berikut: (a) Nama algoritma; (b) Penjelasan singkat; (c) Perwakilan referensi
publikasi. Setiap algoritma yang dinominasi juga harus sudah dikutip dan
digunakan oleh peneliti lain di lapangan.
Setelah pengumpulan algoritma pada langkah pertama, para penulis paper
mengonfirmasi setiap algoritma dengan mengumpulkan kutipan/predikatnya di
Google Scholar pada akhir Oktober 2006. Algoritma yang tidak mencapai 50
kutipan/predikat. Algoritma yang tersisa kemudian diorganisir dalam 10 topik:
analisis asosiasi, klasifikasi, clustering, pembelajaran statistik, bagging, boosting,
pola sekuensial, mining terpadu, set kasar, linkmining, dan mining grafik. Delapan
belas algoritma ini dapat dilihat dalam:
htt p:/ / w w w .cs.uvm.edu/ ~icdm/ algorit hms/ CandidateList .sht ml.
Langkah ketiga adalah proses identifikasi. Penulis paper melakukan
keterlibatan yang lebih luas dari komunitas penelitian. Penulis mengundang
anggota Komite Program KDD-06 (International Conference on Knowledge
Discovery and Data mining), ICDM '06 (International Conference on Data
voting terhadap 18 kandidat algoritma. Hasil pemungutan suara dipresentasikan
pada ICDM '06 pada Top 10 Algorithms in Data mining.
Saat melakukan pencarian kutipan pada akhir Oktober 2006, ditemukan
bahwa algoritma k-Means telah dikutip sebanyak 1579 kali. Itu artinya algoritma
Means sudah banyak digunakan oleh banyak peneliti. Selain itu, algoritma
k-Means adalah satu-satunya algoritma clustering yang masuk ke dalam sepuluh
algoritma terbaik.
2.1.2 Pengelompokkan Mahasiswa Berdasar kan Body Mass Index
Berikut adalah identitas paper:
Judul : Aplikasi K-Means untuk Pengelompokkan Mahasiswa
Berdasarkan Nilai Body Mass Index (BMI) dan Ukuran Kerangka
Penulis : Tedy Rismawan dan Sri Kusumadewi
Tahun : 2008
Penulisan paper ini dilatarbelakangi oleh ketidaktahuan para mahasiswa
mengenai BMI dan ukuran rangka mereka. Mereka tidak tahu apakah mereka
berada pada posisi BMI normal atau tidak. Meskipun sepele, BMI yang tidak
normal sangat mempengaruhi kesehatan seseorang. Itulah mengapa hal ini perlu
dilakukan.
Setelah penulis paper mengumpulkan data mahasiswa yang meliputi tinggi
badan, berat badan, dan lingkar lengan bawah, penulis paper memroses data-data
tersebut menggunakan algoritma k-Means. Dari 20 data yang terkumpul, penulis
9
dalam algoritma k-Means. Hal tersebut membuat peneliti menyimpulkan bahwa
algoritma k-Means adalah salah satu algoritma yang efektif. Meskipun melakukan
pengulangan proses, tetapi algoritma k-Means selalu mengusahakan hasil cluster
yang berkualitas.
Hasil penelitian pada paper ini menyimpulkan bahwa algoritma clustering
k-Means dapat digunakan untuk mengelompokkan mahasiswa berdasarkan status
gizi dan ukuran rangka.
Langkah pertama yang dilakukan penulis paper adalah mengumpulkan data
mahasiswa yang meliputi tinggi badan, berat badan, dan lingkar lengan bawah.
Ketiga aspek tersebut kemudian disederhanakan menjadi dua parameter.
Parameter pertama adalah BMI (Body Mass Index) yang didapat dari pembagian
berat badan dan hasil kuadrat tinggi badan. Parameter kedua adalah ukuran rangka
yang didapat dari pembagian tinggi badan dan lingkar lengan bawah. Kedua
parameter tersebut kemudian digabungkan ke dalam satu tabel.
Kumpulan data tersebut kemudian diproses menggunakan algoritma
k-Means. Penulis paper menjelaskan perhitungan tersebut satu per satu. Mulai dari
penentuan jumlah cluster yakni tiga, lalu pemilihan centroid secara random,
perhitungan jarak Euclidean, sampai menunjukkan iterasi dari posisi cluster.
Perhitungan menghasilkan sembilan iterasi. Cluster pertama memiliki 12 anggota.
Cluster kedua memiliki 7 anggota. Cluster ketiga memiliki satu anggota.
Penelitian pada paper ini menyimpulkan bahwa algoritma k-Means dapat
digunakan untuk mengelompokkan mahasiswa berdasarkan status gizi dan ukuran
mahasiswa berdasarkan total SKS yang telah diambil, IPK, dan akumulasi
presentase kehadiran.
2.1.3 Pengelompokkan Siswa Berdasar kan Pr estasi Akademik
Berikut adalah identitas jurnal:
Judul : Application of K-Means Clustering Algorithm for Prediction of
Students’ Academic Performance
Penulis : Oyelade, Oladipupo, dan Obagbuwa
Tahun : 2010 (International Journal)
Kemampuan untuk memantau progress akademik siswa merupakan isu
penting untuk komunitas pembelajaran. Didirikan sebuah sistem yang digunakan
untuk menganalisis hasil akademik siswa. Hasil tersebut diambil berdasarkan pada
analisa cluster dan menggunakan standart statistik algoritma untuk mengatur nilai
mereka sesuai dengan tingkat kinerja. Dalam paper ini, penulis juga
mengimplementasi algoritma k-Means untuk menganalisa hasil data. Data yang
diuji adalah data-data siswa pada lembaga swasta di Nigeria yang mana bagus bila
dipantau progres akademiknya untuk tujuan membuat keputusan yang efektif oleh
akademik perencana.
Paper ini mengelompokkan para siswa berdasarkan prediksi prestasi
akademik. Aspek yang digunakan oleh penulis paper adalah GPA (Grade Point
Average). GPA (atau di Indonesia disebut IPK) adalah salah satu indikator umum
yang digunakan oleh kinerja akademik. Banyak universitas di Nigeria yang
11
program sarjana. Dalam beberapa universitas, persyaratan minimal IPK yang
ditetapkan bai siswa adalah 1,5. Meskipun demikian, untuk setiap program
pascasarjana, IPK 3,0 ke atas dianggap indikator kinerja akademik yang baik.
Oleh karena itu, IPK masih tetap merupakan faktor yang paling umum digunakan
oleh akademik perencana untuk mengevaluasi kemajuan dalam lingkungan
akademik.
Dengan bantuan data mining, seperti clustering, memungkinkan untuk
menemukan karateristik dari akademik kinerja siswa dan menggunakan
karateristik tersebut sebagai prediksi masa depan. Ada beberapa hasil menjanjikan
dari menggunakan algoritma k-Means dengan pengukuran jarak Euclidean, di
mana jarak ditentukan dengan menentukan kuadrat dari kedua jarak, lalu
menjumlahkan hasil kuadrat tersebut dan menemukan hasil akar dari penjumlahan
kuadrat.
Paper ini menguji data-data siswa dengan menggunakan jumlah cluster
sebanyak tiga, empat, dan lima. Sehingga menghasilkan cluster yang lebih
beragam. Sayangnya, penulis paper tidak menampilkan data siswa beserta cluster
index-nya, sehingga tidak terlihat hasil data sebenarnya.
Penulis paper menyimpulkan bahwa, algoritma clustering ini berfungsi baik
sebagai patokan untuk memantau perkembangan siswa kinerja perguruan tinggi.
Hal ini juga meningkatkan keputusan keputusan oleh perencana akademik untuk
memantau calon kinerja semester dengan semester dengan meningkatkan masa
Paper ini memiliki topik yang serupa dengan tugas akhir. Hanya berbeda
pada penggunaan parameter. Parameter yang digunakan dalam paper ini hanyalah
IPK, sedangkan tugas akhir ini menggunakan tiga parameter, antara lain SKS,
IPK, dan presentase kehadiran. Dengan penambahan parameter, hasil cluster akan
semakin optimal.
2.2 Landasan Teori
2.2.1 Data Mining
Data mining adalah serangkaian proses untuk menggali nilai tambah berupa informasi yang selama ini tidak diketahui secara manual dari suatu basis
data. Informasi yang dihasilkan diperoleh dengan cara mengekstraksi dan
mengenali pola yang penting atau menarik dari data yang terdapat dalam basis
data. Data mining terutama digunakan untuk mencari pengetahuan yang terdapat
dalam basis data yang besar sehingga sering disebut Knowledge Discovery in
Database (KDD). Proses pencarian pengetahuan ini menggunakan berbagai teknik
pembelajaran komputer (machine learning) untuk menganalisis dan
mengekstraksikannya. Proses pencarian bersifat iteratif dan interaktif untuk
menemukan pola atau model yang benar, baru, bermanfaat, dan dimengerti.
(Syamsuddin, Aries)
Kehadiran data mining dilatarbelakangi oleh beberapa hal antara lain:
a. Terjadinya overload data yang dialami oleh berbagai perusahaan.
13
menggunakan aplikasi komputer yang biasa disebut dengan On Line
Transaction Processing (OLTP).
b. Adanya ledakan informasi (explosion information) dari berbagai media,
terutama internet. Sebagian besar informasi yang disajikan oleh media
internet memiliki bentuk yang tak berstruktur. Media internet menyajikan
informasi dalam berbagai format file, bahasa, dan bentuk penyajian seperti
teks, gambar, suara atau pun video. Pertumbuhan yang pesat dari
akumulasi data atau informasi itu telah menciptakan kondisi dimana suatu
intuisi memiliki bergunung-gunung data, tetapi miskin informasi yang
bermanfaat (rich of data but poor of information).
Pemanfaatan data mining diperlukan untuk menangani tumpukan data
yang besar, namun sering kali tumpukan data yang besar ini dibiarkan saja, tanpa
dilakukan upaya untuk menggali informasi lebih jauh. Seakan-akan tumpukan
data dalam jumlah yang besar tersebut tidak memiliki manfaat sama sekali.
Pemanfaatan data itu dapat dilihat dalam dua sudut pandang, yaitu sudut pandang
komersial dan sudut pandang keilmuan. Dari sudut pandang komersial,
pemanfaatan data mining dapat digunakan untuk menangani meledaknya volume
data. Terkait dengan cara menyimpannya, mengestraknya serta
memanfaaatkannya. Berbagai teknik komputasi dapat digunakan untuk
menghasilkan informasi yang dibutuhkan. Informasi yang dihasilkan menjadi
asset untuk meningkatkan daya saing suatu intuisi. Data mining tidak hanya
digunakan untuk menangani persoalan menumpuknya data atau informasi dan
mining juga diperlukan untuk menyelesaikan permasalahan atau menjawab kebutuhan bisnis itu sendiri, antara lain:
a. Bagaimana mengetahui hilangnya pelanggan karena pesaing
b. Bagaimana mengetahui item produk atau konsumen yang memiliki
kesamaan karakteristik
c. Bagaimana mengidentifikasi produk-produk yang terjual bersamaan
dengan produk lain
d. Bagaimana memprediksi tingkat penjualan
e. Bagaimana menilai tingkat resiko dalam menentukan jumlah produksi
suatu item
f. Bagaimana memprediksi perilaku bisnis di masa yang akan datang.
Dari keenam permasalah di atas, dapat disimpulkan pula bahwa data
mining dapat menyelesaikan permasalahan dalam tugas akhir ini, yakni: bagaimana memprediksi waktu kelulusan mahasiswa? Namun, fungsi apa yang
umum diterapkan oleh data mining dalam menyelesaikan permasalahan ini?
Berikut adalah fungsi-fungsi yang umum diterapkan dalam data mining:
a. Association, adalah proses untuk menemukan aturan assosiatif antara suatu kombinasi item dalam suatu waktu.
b. Sequence, hampir sama dengan association bedanya sequence
diterapkan lebih dari satu periode.
15
untuk dapat memperkirakan kelas dari suatu objek yang labelnya tidak
diketahui.
d. Regretion, adalah proses pemetaan data dalam suatu nilai prediksi. e. Forecasting, adalah proses pengestimasian nilai prediksi berdasarkan pola-pola di dalam sekumpulan data.
f. Solution, adalah proses penemuan akar masalah dan problem solving
dari persoalan bisnis yang dihadapi atau paling tidak sebagai informasi
pendukung dalam pengambilan keputusan.
g. Clustering, adalah proses pengelompokan sejumlah data atau obyek ke
dalam kelompok-kelompok data (cluster) sehingga setiap cluster akan
berisi data yang saling mirip. Ini adalah fungsi yang akan digunakan dalam
tugas akhir ini. Clustering akan dibahas lebih lanjut dalam sub-bab
selanjutnya.
2.2.2 Clustering
Teknik cluster termasuk teknik yang sudah cukup dikenal dan banyak
dipakai dalam data mining. Sampai sekarang para ilmuwan dalam bidang data
mining masih melakukan berbagai usaha untuk melakukan perbaikan model
cluster karena metode yang dikembangkan sekarang masih bersifat heuristik.
Usaha-usaha untuk menghitung jumlah cluster yang optimal dan pengclusteran
yang paling baik masih terus dilakukan. Dengan demikian menggunakan metode
merupakan hasil yang optimal. Namun, hasil yang dicapai biasanya sudah cukup
bagus dari segi praktis.
Tujuan utama dari metode cluster adalah pengelompokkan sejumlah
data/obyek ke dalam cluster (group) sehingga dalam setiap cluster akan berisi data
yang semirip mungkin. Dalam clustering kita berusaha untuk menempatkan obyek
yang mirip (jaraknya dekat) dalam satu cluster dan membuat jarak antar cluster
sejauh mungkin. Ini berarti obyek dalam satu cluster sangat mirip satu sama lain
dan berbeda dengan obyek dalam cluster-cluster yang lain. Dalam teknik ini kita
tidak tahu sebelumnya berapa jumlah cluster dan bagaimana pengelompokannya.
Clustering adalah salah satu teknik unsupervised learning dimana kita tidak perlu melatih metode tersebut atau dengan kata lain, tidak ada fase learning. Masuk
dalam pendekatan unsupervised learning adalah metode-metode yang tidak
membutuhkan label atau pun keluaran dari setiap data yang diinvestigasi.
Sebaliknya, supervised learning adalah metode yang memerlukan training
(melatih) dan testing (menguji). Masuk ke dalam kategori ini adalah regresi,
neural network (ANN), analisis diskriminan (LDA), dan support vector machine
(SVM)
Ada dua pendekatan dalam clustering: partisioning dan hirarki. Dalam
partisioning kita mengelompokkan obyek x1, x2, x3, …, xn ke dalam k cluster. Ini
bisa dilakukan dengan menentukan pusat cluster awal, lalu dilakukan realokasi
obyek berdasarkan kriteria tertentu sampai dicapai pengelompokkan yang
optimum. Dalam cluster hirarki, kita mulai dengan membuat m cluster dimana
17
anggotanya adalah m obyek. Pada setiap tahap dalam prosedurnya, satu cluster
digabung dengan satu cluster yang lain. Kita bisa memilih berapa jumlah cluster
yang diinginkan dengan menentukan cut-off pada tingkat tertentu.
Dalam cluster, untuk menggabungkan dua atau lebih obyek menjadi satu
cluster, biasanya digunakan ukuran kemiripan atau ketidakmiripan. Semakin mirip dua obyek, semakin tinggi peluang untuk dikelompokkan dalam satu
cluster. Sebaliknya semakin tidak mirip semakin rendah peluang untuk
dikelompokkan dalam satu cluster.
Salah satu algoritma yang sering digunakan dan terbukti berhasil dalam
proses clustering adalah algoritma Means. Pembahasan mengenai Algoritma
k-Means dijelaskan pada sub-bab berikut.
2.2.3 Algoritma k-Means
Dari beberapa teknik clustering yang paling sederhana dan umum dikenal
adalah clustering k-Means. Algoritma k-Means merupakan metode clustering
berbasis jarak yang membagi data ke dalam sejumlah cluster. Algoritma k-Means
sering disebut sebagai clustering yang berulang-ulang, karena pada prosesnya
selalu terdapat pergantian pusat cluster baru di setiap iterasinya.
Algoritma k-Means dimulai dengan menentukan k—k merupakan
banyaknya cluster yang ingin dibentuk. Kemudian, tetapkan nilai pusat cluster
memilih jarak terkecil dari pusat cluster-nya. Selanjutnya, hitung cluster baru. Lakukan langkah tersebut hingga nilai centroid tidak berubah lagi.
Algoritma k-Means diperkenalkan oleh J.B. MacQueen pada tahun 1976,
salah satu algoritma clustering sangat umum yang mengelompokkan data sesuai
dengan karakteristik atau ciri-ciri bersama yang serupa. Grup data ini dinamakan
sebagai cluster. Data di dalam suatu cluster mempunyai ciri-ciri (atau fitur,
karakteristik, atribut, properti) serupa dan tidak serupa dengan data pada cluster
lain.
Dikutip dari susunan algoritma pada paper berjudul “An Efficient
Enhanced K-Means Clustering Algorithm” (2006) yang ditulis oleh Fahmi A.M,
dkk, berikut adalah flowchart algoritma K-Means:
19
Melalui bentuk algoritma di atas, maka berikut dapat disimpulkan
langkah-langkah algoritma K-Means dalam bahasa yang lebih mudah dipahami:
a. Menentukan k sebagai cluster yang ingin dibentuk. Variabel k
melambangkan banyaknya cluster yang ingin dibentuk.
b. Menentukan centroid. Centroid merupakan pusat cluster dan setiap
cluster pasti memiliki centroid. Inisialisasi centroid ini bisa dilakukan dengan berbagai cara. Yang paling sering dilakukan adalah dengan cara
random. Pusat-pusat cluster diberi nilai awal dengan angka-angka
random.
c. Menghitung jar ak antar centroid dan setiap data yang ada pada
setiap cluster. Seiring berkembangnya teknologi, algoritma K-Means
pun mengalami perkembangan, salah satunya perhitungan jarak. Ada
beberapa formula distance space yang telah diimplementasikan ke
dalam algoritma ini, dan terbukti berhasil. Salah satunya adalah jarak
Euclidean. Euclidean sering digunakan karena penghitungan jarak
dalam distance space ini merupakan jarak terpendek yang bisa
didapatkan antara dua titik yang diperhitungkan. Rumus jarak
Euclidean dapat dilihat pada persamaan (1).
( , ) = ( , ) = ( − ) + . . . + ( − ) = ( − ) … (2.1)
Keterangan:
d = Jarak Euclidean
q = Data obyek
n = Banyaknya data
d. Setelah menghitung seluruh jarak antar centroid dan nilai data, langkah
berikutnya adalah memilih jar ak terpendek/ter kecil dari centroid
-nya.
e. Menghitung centroid bar u dengan cara menghitung rata-rata dari
setiap jarak terkecil yang dimiliki setiap cluster.
f. Mengulangi langkah ke 3 hingga posisi data tidak mengalami
perubahan kembali. (Agusta, Yudi)
Dalam MATLAB, fungsi k-Means dapat diakses dengan menuliskan
script:
>> [cidx, ctrs] = kmeans(X, k, ‘dist’, ‘SqEuclidean’);
Output cidx menunjukkan kelompok atau kelas untuk data pada baris
tertentu. Sedangkan ctrs adalah centroid (pusat cluster) dimana ditentukan secara
random di awal. Sedangkan X adalah input data dan k adalah jumlah banyakny acluster yang hendak dibentuk. Fungsi ‘dist’ adalah perintah untuk menghitung
jarak. Fungsi ‘SqEuclidean’ adalah metode jarak yang hendak digunakan.
Berikut adalah beberapa parameter dan deskripsinya dari k-Means pada
21
Tabel 2.1 Parameter Fungsi K-Means
Parameter Value
‘Distance’ Perhitungan jarak dalam p-dimensi. K-Means menghitung pusat
cluster secara berbeda untuk pengukuran jarak yang berbeda. ‘SqEuclidean’ Perhitungan jarak dengan mengurangi obyek data
dengan centroid awal yang dipilih secara random.
Setiap centroid baru adalah rata-rata dari index
pada cluster tersebut.
‘cityblock’ Penjumlahan antara dua vektor dalam hukum
mutlak, sebanyak p-dimensi.
‘emptyaction’ Tindakan yang diambil bila cluster kehilangan seluruh
anggotanya.
‘error’ Menampilkan cluster yang kosong sebagai error
Sumber: Mathworks.com
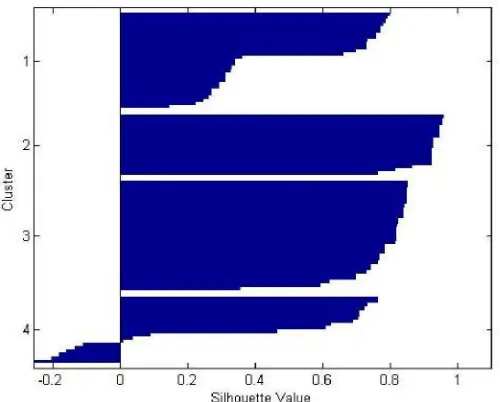
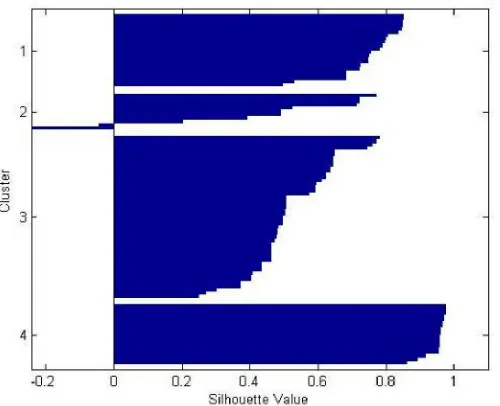
2.2.4 Silhouette
Silhouette merupakan salah satu cara untuk mengukur performansi hasil
cluster. Silhouette dalam diakses melalui MATLAB dengan menuliskan script:
>> [s,h] = silhouette(X, cidx, ‘SqEuclidean’)
Perintah silhouette akan memberikan output berupa jarak tiap titik
terhadap titik cluster yang sama disbanding terhadap titik di cluster yang lain. Nilai ini berkisar dari -1 sampai +1. Nilai +1 berarti titik yang bersangkutan
berjarak sangat jauh dari cluster yang lain, nilai 0 mengindikasikan bahwa titik
yang lain. Sedangkan nilai -1 mengindikasikan bahwa titik yang bersangkutan
berada pada cluster yang salah.
2.2.5 MATLAB
MATLAB adalah bahasa tingkat tinggi untuk perhitungan numerik,
visualisasi, dan pemrograman. MATLAB dapat digunakan untuk menganalisa
data, mengembangkan algoritma, membuat model dan aplikasi. Bahasa, alat, dan
built-in fungsi matematika sangat membantu pengguna untuk mencoba beberapa
pendekatan dan mencapai solusi lebih cepat dibandingkan dengan spreadsheet
atau bahasa pemrograman tradisional, seperti C / C + + atau Java ™. (Firmansyah,
A.)
MATLAB (yang berarti "matrix laboratory") diciptakan pada akhir tahun
1970-an oleh Cleve Moler, yang kemudian menjadi Ketua Departemen Ilmu
Komputer di Universitas New Mexico.Ia merancangnya untuk memberikan akses
bagi mahasiswa dalam memakai LINPACK dan EISPACK tanpa harus
mempelajari Fortran. Karyanya itu segera menyebar ke universitas-universitas lain
dan memperoleh sambutan hangat di kalangan komunitas matematika terapan.
Jack Little, seorang insinyur, dipertemukan dengan karyanya tersebut selama
kunjungan Moler ke Universitas Stanford pada tahun 1983. Menyadari potensi
komersialnya, ia bergabung dengan Moler dan Steve Bangert. Mereka menulis
ulang MATLAB dalam bahasa pemrograman C, kemudian mendirikan The
23
ditulis ulang tadi kini dikenal dengan nama JACKPAC. Pada tahun 2000,
MATLAB ditulis ulang dengan pemakaian sekumpulan pustaka baru untuk
manipulasi matriks, LAPACK.
MATLAB pertama kali diadopsi oleh insinyur rancangan kontrol (yang
juga spesialisasi Little), tapi lalu menyebar secara cepat ke berbagai bidang lain.
Kini juga digunakan di bidang pendidikan, khususnya dalam pengajaran aljabar
linear dan analisis numerik, serta populer di kalangan ilmuwan yang menekuni
bidang pengolahan citra.
MATLAB sangat handal untuk komputasi yang terkait dengan array atau
matriks. Kehandalan ini bisa terlihat mulai dari proses assignment variabel
terhadap nilai bertipe array atau matriks yang sederhana, sampai dengan operasi
perhitungannya yang cepat.
Kesederhanaan dalam proses assignment variabel terhadap nilai bertipe
array atau matriks ini disebabkan tidak diperlukannya pendefinisian ukuran (size)
array atau matriks pada variabel tersebut. Secara otomatis, size atau dimensi dari
variabel bertipe array ini akan menyesuaikan dengan array yang di-assign atau
dengan kata lain size untuk variabel bertipe array ini bersifat dinamis.
MATLAB juga menyediakan beberapa fungsi matematika dan statistic
secara praktis. Sehingga pengguna hanya perlu memanggil fungsi. Berikut adalah
Tabel 2.2 Fungsi-fungsi MATLAB
Kategori Fungsi Kegunaan
General
size(matrix) Menghitung jumlah baris dan kolom sebuah matrix.
randperm
Mengambil matrix secara acak berdasarkan
parameter.
sqrt Perhitungan kuadrat.
mean Menghitung rata-rata
zeros Membuat seluruh isi array menjadi nol.
ones Membuat seluruh isi array menjadi satu.
min Menentukan elemen terkecil dalam array.
max Menentukan elemen terbesar dalam array.
global Mendeklarasikan variabel secara global.
flipud Membalik posisi matrik dari atas ke bawah.
strcat Menyatukan 'string' secara horisontal.
dlmread Membaca file ASCII-delimited ke dalam matrix.
handles
Dapat mengakses fungsi yang tadinya tak dapat dipanggil.
str2num Mengkonversi variabel string menjadi numeric.
uitable Membuat tabel dua dimensi pada GUI.
uigetfile
kmeans Menjalankan fungsi k-Means.
dist Perhitungan jarak.
SqEuclidean
Perhitungan jarak dengan mengurangi obyek data dengan centroid awal yang dipilih secara random.
Silhouette silhouette
Mengukur kualitas cluster, beserta menampilkan
grafiknya.
Mempertahankan grafik saat ini dan menambahkan grafik lain tanpa kehilangan grafik sebelumnya.
scatter3
Menampilkan lingkaran pada lokasi yang
ditentukan.
LineWidth
Menentukan lebar obyek garis seperti pada grafik 2 atau 3 dimensi
box on Menampilkan batas sumbu saat ini
rotate3d on
Memungkinkan pengguna untuk merotasi grafik melalui mouse
BAB III
PERANCANGAN SISTEM
3.1 Data Set
Data set merupakan data yang akan diproses ke dalam program
implementasi algoritma K-Means. Dalam tugas akhir ini, data set terdiri dari 100
sample data, yang terdiri dari tiga aspek: SKS, IPK, dan Presentase Kehadiran.
Berikut adalah data setnya:
NPM SKS IPK
3.2 Rancangan Penelitian
Program ini dibuat untuk melakukan clustering sehingga data tersebut
terpecah sesuai golongannya, kemudian menampilkan hasil centroid akhir,
memplotting hasil clustering dalam bentuk grafik tiga dimensi, dan mengevaluasi
performansi cluster dengan menggunakan fungsi sillhouete. Dalam studi kasus
ini, berikut adalah kolom (parameter) yang digunakan sebagai aspek pembentukan
cluster:
a. IPK selama lima semester awal. IPK dipilih sebagai aspek pertama
karena mewakili kualitas seorang mahasiswa. Semakin tinggi IPK
seorang mahasiswa, memungkinkannya semakin mudah dalam
memecahkan masalah dalam tugas akhirnya.
b. SKS selama lima semester awal. SKS dipilih sebagai aspek kedua
karena untuk mengikuti skripsi seorang mahasiswa harus menempuh
135 SKS. Rendahnya SKS pada lima semester awal akan membuat
seorang mahasiswa terlambat dalam mengerjakan skripsi dikarenakan
harus menempuh ketertinggalan SKS-nya.
c. Akumulasi presentase kehadiran. Salah satu alasan utama
29
mengerjakan tugas akhir. Presentase kehadiran dipilih sebagai aspek
ketiga untuk mewakili tingkat kemalasan seorang mahasiswa.
Ada pun pemilihan lima semester awal, dikarenakan pada semester lima
(di Universitas Pembangunan Nasional ‘Veteran’ Jawa Timur, jurusan Teknik
Informatika), seorang mahasiswa sudah dapat memilih bidang minatnya. Ketika
sudah diketahui bidang minatnya, maka akan mudah bagi pihak universitas untuk
membantu merekomendasikan topik skripsi yang hendak diangkat. Sehingga pada
semester enam nanti, mahasiswa tersebut sudah dapat menelaah literatur secara
lebih dalam. Dilanjutkan pada semester tujuh untuk segera memulai skripsi.
Berikut adalah rancangan pemrosesan program:
3.2.1 Diagram UML
Unified Modeling Language (UML) adalah bahasa spesifikasi standar
untuk mendokumentasikan, menspesifikasikan, dan membangun sistem perangkat
lunak. Dalam tugas akhir ini, digunakan dua macam diagram untuk memodelkan
aplikasi berorientasi objek, yakni use case dan activity diagram.
3.2.1.1 Use Case
Use case Diagram berfungsi sebagai diagram yang menunjukkan
fungsi-fungsi dari sistem. Use case Diagram terdiri dari tiga konsep penting, antara lain:
a. Aktor
Pada dasarnya aktor bukanlah bagian dari use case diagram, namun
untuk dapat terciptanya suatu use case diagram diperlukan sebuah aktor.
Aktor tersebut mempresentasikan seseorang atau sesuatu (seperti
perangkat, sistem lain) yang berinteraksi dengan sistem. Sebuah aktor
mungkin hanya memberikan informasi inputan pada sistem, hanya
menerima informasi dari sistem atau keduanya menerima, dan memberi
informasi pada sistem. Aktor hanya berinteraksi dengan use case, tetapi
tidak memiliki kontrol atas use case. Aktor digambarkan dengan stick
man.
31
Aktor dapat digambarkan secara secara umum atau spesifik, dimana
untuk membedakannya kita dapat menggunakan relationship. Ada
beberapa kemungkinan yang menyebabkan actor tersebut terkait dengan
sistem antara lain:
1. Yang berkepentingan terhadap sistem dimana adanya arus
informasi baik yang diterimanya maupun yang dia inputkan ke
sistem.
2. Orang ataupun pihak yang akan mengelola sistem tersebut.
3. External resource yang digunakan oleh sistem.
Dalam tugas akhir ini, aktor hanya terdiri dari satu orang, yakni
pengguna sistem. Pengguna sistem akan dapat menjalankan seluruh fungsi
di dalam program tersebut.
b. Use Case
Use case adalah gambaran fungsionalitas dari suatu sistem, sehingga pengguna sistem paham dan mengerti mengenai kegunaan sistem yang
akan dibangun. Use case diagram adalah penggambaran sistem dari sudut
pandang pengguna sistem tersebut (user), sehingga pembuatan use case
lebih dititikberatkan pada fungsionalitas yang ada pada sistem, bukan
berdasarkan alur atau urutan kejadian.
c. Relasi
Relasi dari aktor ke use case bukan sekadar menunjukkan sebuah
interaksi, melainkan menggambarkan sisi fungsionalitas dari website
terhadap aktor. Berfungsi menggambarkan fungsionalitas yang diharapkan
sebuah sistem.
Dari ketiga konsep materi di atas, maka berikut adalah diagram use case
yang telah dirancang:
Gambar 3.4 Use case diagram
Pada gambar 3.3, use case diagram tersebut merepresentasikan fungsi
33
fungsi terhadap sistem, antara lain: mengklaster data, melihat pusat klaster,
melihat grafik klastering, mengevaluasi hasil klaster.
3.2.1.2 Activity Diagram
Activity Diagram adalah diagram yang menggambarkan interaksi antara
pengguna dan sistem, interaksi tersebut akan membentuk sebuah alur. Activity
diagram tidak menggambarkan use case secara keseluruhan, namun satu activity diagram mewakili satu fungsi pada use case.
Activity Diagram biasanya dibagi oleh satu swimlane, membentuk dua kolom yang berisikan pengguna dan sistem. Diagram ini dimulai dengan simbol
lingkaran berwarna hitam penuh. Dilanjutkan oleh diagram-diagram aktivitas
yang menggambarkan interaksi antar pengguna dan sistem. Diagram ini diakhiri
oleh end state yang bergambarkan lingkaran berwarna hitam, dengan warna putih
yang berada di sisinya. Berikut adalah penjelasan activity diagram sistem
berdasarkan fungsinya masing-masing.
a. Fungsi 1: Pengklasteran Data
Fungsi pengklasteran data akan menampilkan hasil clustering ke dalam
bentuk tabel pada halaman tersendiri (figure). Tabel tersebut akan terbagi
menjadi empat kolom. Tiga kolom pertama berasal dari data set (IPK,
SKS, presentase kehadiran). Kolom keempat merupakan cluster index
yang menyatakan berada di cluster manakah obyek data tersebut. Berikut
Tabel 3.2 Skenario Fungsi Mengklaster Data
NaUse case Mengklaster data
Nomor UC-001
Deskripsi Pengguna dapat menampilkan hasil clustering data dalam
bentuk tabel.
Kondisi
Awal
Pengguna membuka halaman awal program.
Kondisi
Akhir
Pengguna telah berhasil melihat hasil clustering data.
Alur Normal 1. Pengguna mengunggah data yang hendak di-cluster.
2. Sistem menampilkan data tersebut ke dalam tabel yang
telah disediakan.
3. Pengguna memilih option centroid method.
4. Pengguna menginput jumlah cluster yang diinginkan.
5. Pengguna menjalankan menu ‘cluster’.
A1. Pengguna menginput cluster di luar batasan.
6. Sistem menampilkan hasil clustering data ke dalam
tabel pada halaman baru.
Alur
Alternatif
A1. Pengguna menginput jumlah cluster di luar batasan.
1. Sistem menampilkan message-box “Must be less than
eight”.
2. Kembali ke nomor 4.
35
Setelah skenario disusun, maka tinggal mengimplementasikan
alur-alur tersebut ke dalam aktivitas diagram. Berikut adalah gambar aktivitas
diagramnya:
Gambar 3.5 Activity Diagram Mengklaster Data
b. Fungsi 2: Melihat Pusat Klaster
Fungsi melihat pusat klaster akan menampilkan centroid di dalam
bentuk tabel pada halaman tersendiri (figure). Tabel tersebut akan terbagi
menjadi k baris dan tiga kolom (k adalah variablel dari jumlah klaster).
dan posisi cluster tidak berubah-ubah lagi. Berikut adalah skenario fungsi ini:
Tabel 3.3 Skenario Fungsi Melihat Pusat Klaster
Nama Use
Pengguna membuka halaman awal program.
Kondisi Akhir
Pengguna telah berhasil melihat letak pusat cluster.
Alur Normal 1. Pengguna mengunggah data yang hendak di-cluster.
2. Sistem menampilkan data tersebut ke dalam table yang telah disediakan.
3. Pengguna memilih centroid method.
4. Pengguna menginput jumlah cluster yang diinginkan.
5. Pengguna menjalankan menu ‘show the centroid’.
A1. Pengguna menginput cluster di luar batasan
6. Sistem menampilkan pusat cluster dalam bentuk tabel
pada halaman baru.
Alur Alternatif
A1. Pengguna menginput jumlah cluster di luar batasan.
1. Sistem menampilkan message-box “Must be less than
eight”.
2. Kembali ke nomor 4.
37
Setelah skenario disusun, maka tinggal mengimplementasikan
alur-alur tersebut ke dalam aktivitas diagram. Berikut adalah gambar aktivitas
diagramnya:
Gambar 3.6 Activity Diagram Melihat Pusat Klaster
c. Fungsi 3: Melihat Grafik Klaster
Fungsi melihat grafik klaster akan menampilkan grafik dari hasil
klastering pada halaman tersendiri (figure). Grafik tersebut akan berbentuk
tiga dimensi, tiga garis koordinat, yakni X, Y, dan Z. Di dalam grafik
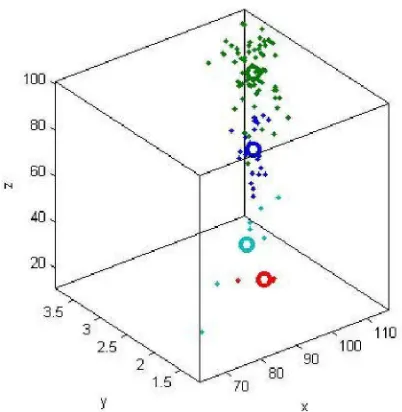
menggambarkan posisi data. Sementara warna-warna tersebut merupakan
cluster index-nya. Grafik tersebut dapat dirotasi dengan menggunakan
mouse sehingga pengguna dapat melihat kecenderungan datanya secara nyata. Berikut adalah skenario dari fungsi ini:
Tabel 3.4 Skenario Melihat Grafik Klastering
Nama Use
case
Melihat grafik klastering
Nomor UC-003
Deskripsi Pengguna dapat melihat grafik clustering di setiap kelas.
Kondisi Awal
Pengguna membuka halaman awal program.
Kondisi Akhir
Pengguna telah berhasil melihat melihat grafik clustering.
Alur Normal 1. Pengguna mengunggah data yang hendak di-cluster.
2. Sistem menampilkan data tersebut ke dalam table yang telah disediakan.
3. Pengguna memilih centroid method.
4. Pengguna menginput jumlah cluster yang diinginkan.
5. Pengguna menjalankan menu ‘show the graphic’.
A1. Pengguna menginput cluster di luar batasan
6. Sistem menampilkan hasil grafik clustering dalam
bentuk tiga dimensi, menyesuaikan parameter yang ada.
Alur Alternatif
A1. Pengguna menginput jumlah cluster di luar batasan.
1. Sistem menampilkan message-box “Must be less than
eight”.
2. Kembali ke nomor 4.
39
Setelah skenario disusun, maka tinggal mengimplementasikan alur-alur
tersebut ke dalam aktivitas diagram. Berikut adalah gambar aktivitas
diagramnya:
Gambar 3.7 Activity Diagram Melihat Grafik Klaster
d. Fungsi 4: Mengevaluasi Hasil Klastering
Fungsi mengevaluasi hasil klastering akan menampilkan grafik dari
pengukuran optimalisasi anggota cluster. Fungsi ini nantinya akan tampil
koordinat, yakni X dan Y. Garis X merupakan nilai perhitungan,
batasannya -1 sampai +1. Sementara garis Y merupakan cluster index.
Hasil perhitungan tersebut akan berbentuk bar kolom berwarna biru.
Berikut adalah skenario dari fungsi ini:
Tabel 3.5 Skenario Mengevaluasi Hasil Klastering
Nama Use
case
Mengevaluasi hasil klastering
Nomor UC-004
Deskripsi Pengguna dapat melihat hasil pengukuran optimalisasi
anggota clustering. Kondisi
Awal
Pengguna membuka halaman awal program.
Kondisi Akhir
Pengguna telah berhasil melihat hasil evaluasi cluster.
Alur Normal 1. Pengguna mengunggah data yang hendak di-cluster.
2. Sistem menampilkan data tersebut ke dalam table yang telah disediakan.
3. Pengguna memilih centroid method.
4. Pengguna menginput jumlah cluster yang diinginkan.
5. Pengguna menjalankan menu ‘evaluate the cluster’.
A1. Pengguna menginput cluster di luar batasan
6. Sistem menampilkan grafik pengukuran optimalisasi
clustering dalam bentuk tabel pada halaman baru. Alur
Alternatif
A1. Pengguna menginput jumlah cluster di luar batasan.
1. Sistem menampilkan message-box “Must be less than
eight”.
2. Kembali ke nomor 4.
41
Setelah skenario disusun, maka tinggal mengimplementasikan alur-alur
tersebut ke dalam aktivitas diagram. Berikut adalah gambar aktivitas
diagramnya:
Gambar 3.8 Activity Diagram Mengevaluasi Hasil Klastering
3.2.2 Flowchart
Flowchart merupakan sebuah diagram dengan simbol-simbol grafis yang menyatakan aliran algoritma atau proses yang menampilkan langkah-langkah
yang disimbolkan dalam bentuk kotak, beserta urutannya dengan menghubungkan
memberi solusi selangkah demi selangkah untuk penyelesaian masalah yang ada
di dalam proses atau algoritma tersebut. Untuk semakin memudahkan penulisan
program pengimplementasian algoritma k-Means, berikut adalah flowchart-nya:
43
Gambar 3.11 Flowchart Next
Ketiga flowchart di atas menggambarkan alur cara kerja program. Program
diawali ketika pengguna mengunggah file yang akan di-cluster. File tersebut akan
disimpan ke dalam variabel ‘data’. Selanjutnya, pengguna menginput jumlah
cluster yang diinginkan. Nominal yang dimasukkan akan disimpan ke dalam variabel ‘k’. Program kemudian akan mengecek, apakah k>7. Jika k>7, maka
program akan menampilkan pesan bahwa jumlah cluster harus berada di bawah
delapan dan diulang kembali ke bagian penginputan jumlah cluster. Jika k diisi
sesuai batasan, program akan melanjutkan proses decision sekali lagi. Apakah
centroid method yang dipilih Random atau Default? Jika “random”, maka
45
Fungsi MATLAB ini akan memilih centroid secara acak di setiap eksekusi. Jadi,
centroid dan hasil cluster tidak akan selalu sama setiap dieksekusi. Jika “default”, maka program akan memroses algoritma k-Means dengan satu per satu tanpa
menggunakan bantuan fungsi MATLAB. Dalam pilihan ‘default’, program akan
menginisialisasi centroid awal dari baris awal data. Program kemudian akan
menginisialisasi variabel temp untuk menyimpan cluster index yang
berubah-ubah. Selanjutnya, program menghitung jarak antar centroid tersebut dengan
obyek data. Setelah jaraknya ditemukan, dipilih jarak yang paling pendek. Ketika
jarak yang paling pendek telah ditemukan, program dapat menerjemahkannya
menjadi cluster index. Cluster index tersebut akan disimpan ke dalam variabel
‘temp’. Setelah itu, program akan menghitung centroid baru dengan cara
menjumlahkan data tersebut berdasarkan cluster index-nya, kemudian dihitung
rata-ratanya. Usai itu, program akan mengecek apakah posisi jarak terpendeknya
masih berubah? Jika ya, proses ini akan diulang kembali dari perhitungan jarak.
Jika tidak, program akan melanjutkan proses dalam menghasilkan hasil cluster
dalam bentuk tabel. Baik ‘random’ maupun ‘default’ akan menampilkan hasil
cluster dengan cara yang sama, hanya saja isinya berbeda. Begitu pula centroid
akhirnya—akan ditampilkan dengan cara yang sama.
Selanjutnya, berdasarkan hasil cluster yang ada, program akan
memplotting data. Cluster index ditandai dengan tanda ‘.’, sementara centroid
akan ditandai dengan ‘o’. Mode box dan rotasi diaktifkan supaya grafik terlihat
memiliki batas dan dapat dirotasi melalui mouse. Kemudian program akan
Proses terakhir adalah pengukuran optimalisasi anggota cluster yang
disebut dengan silhouette. Program akan memanggil fungsi silhouette pada
MATLAB berdasarkan data yang diunggah dan hasil cluster yang ada. Setelah itu,
program akan menampilkan grafik silhouette. Ketika seluruh fungsi berakhir,
maka program sudah bisa diselesaikan.
3.3 Rancangan Uji Coba dan Evaluasi
Pertama-tama, pengguna akan meng-uploadfile berisi data tiga kolom. File
tersebut harus terdiri dari tiga kolom. File yang di-upload ke dalam program harus
berformat .txt (ASCII—tab delimited). Untuk menghasilkan file tersebut,
pengguna dapat langsung mengkonversinya dari Microsoft Excel. Setelah
meng-upload data, tabel akan ditampilkan di sisi program.
Pengguna kemudian dapat menginput jumlah cluster yang diinginkan (k).
Jumlah cluster tidak boleh lebih dari tujuh. Setelah itu, pengguna memilih option
centroid method-nya, ingin secara random atau default. Random berarti centroid
awal dipilih secara acak, sehingga setiap kali program dijalankan, pilihan ini
selalu akan menghasilkan hasil cluster yang berbeda-beda. Default berarti
centroid yang dipilih berdasarkan value awalan data, sehingga meskipun program dijalankan berkali-kali, pilihan ini akan selalu menampilkan hasil yang tetap.
Selanjutnya, pengguna dapat memilih menu ‘Cluster’, ‘Show Centroid’, ‘Show the
47
pada halaman tersendiri, sehingga memudahkan pengguna untuk mencoba
menu-menu lain untuk mengolah data.
Tabel 3.6 Rancangan Tampilan GUI
J enis Tag Nama Keterangan
Static Text text8 Implementation of
k-Means Algorithm
-
text6 File Path -
text5 - Untuk menampilkan alamat
direktori file yang
diunggah.
popupmenu1 Random/Default Untuk memilih cara
meng-cluster data, apakah dengan
centroid yang random atau terinisialisasi.
Push Button
pushbutton1 Browse Untuk mengunggah file
yang hendak di-cluster.
Cluster Cluster Untuk meng-cluster data
sesuai centroid method
yang dipilih.
Centroid Show Centroid Untuk menampilkan
centroid akhir.
ShowGraphic Show the Graphic Untuk menampilkan grafik
hasil clustering.
ShowCluster Evaluate the Cluster Untuk mengevaluasi hasil
cluster dengan
menampilkan grafiknya.
Reset Reset Untuk menghapus field file
path dan number of clusters.
Table uitable2 - Untuk menampilkan data
Berdasarkan Tabel 3.6, berikut adalah rancangan tampilan pada GUI:
Gambar 3.12 Rancangan GUI
Merujuk pada gambar 3.12, terdapat fungsi ‘Show the Graphic’. Seperti
yang telah dijelaskan, fungsi ini akan menampilkan plotting hasil clustering. Tiap
anggota cluster memiliki warna berbeda, sehingga memudahkan pengguna untuk
membaca grafiknya:
Tabel 3.7 Rancangan Warna Plotting