Informasi Dokumen
- Penulis:
- Bondan Yudha Pratomo
- Pengajar:
- Romo Dr. Cyprianus Kuntoro Adi, S.J. M.A., M.Sc.
- Sekolah: Universitas Sanata Dharma
- Mata Pelajaran: Teknik Informatika
- Topik: Pengelompokan Peran Pemain Dota 2 Dalam Pertandingan Profesional Dengan Metode Agglomerative Hierarchical Clustering
- Tipe: skripsi
- Tahun: 2017
- Kota: Yogyakarta
Ringkasan Dokumen
I. PENDAHULUAN
Bab ini menjelaskan latar belakang penelitian, rumusan masalah, batasan masalah, tujuan penelitian, dan manfaat penelitian. Latar belakang penelitian menyoroti perkembangan teknologi dan dampaknya pada game online, khususnya DOTA 2, yang merupakan salah satu cabang eSports yang berkembang pesat. Penelitian ini bertujuan untuk mengelompokkan peran pemain dalam DOTA 2 menggunakan metode Agglomerative Hierarchical Clustering. Manfaat penelitian ini diharapkan dapat memperluas wawasan penulis dan memberikan referensi akademis bagi mahasiswa yang tertarik pada algoritma pengelompokan.
II. LANDASAN TEORI
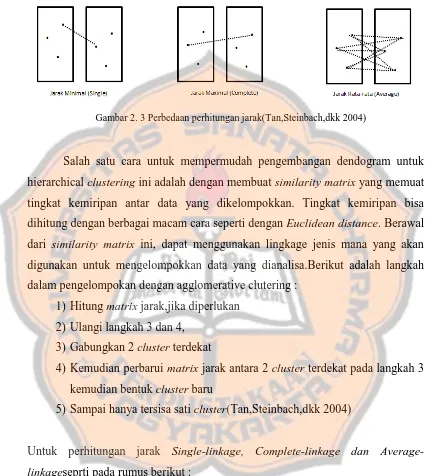
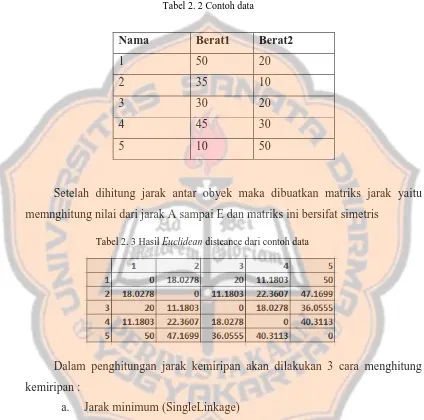
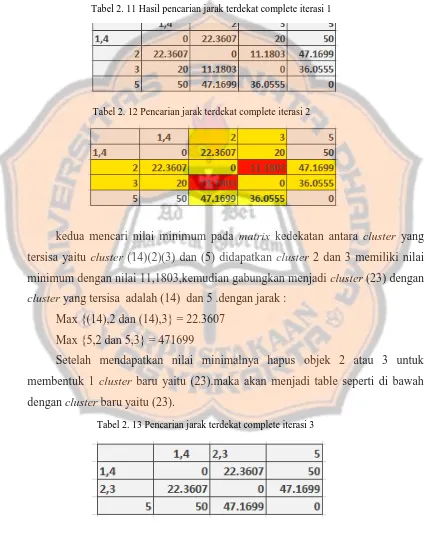
Bab ini membahas teori-teori yang mendasari penelitian, termasuk Knowledge Discovery in Database (KDD), pengertian clustering, dan jenis-jenis clustering. KDD adalah proses analisis data untuk menemukan pola dan informasi yang berguna. Clustering adalah teknik untuk mengelompokkan data berdasarkan kesamaan atribut. Metode Agglomerative Hierarchical Clustering, yang mencakup single-linkage, complete-linkage, dan average-linkage, dijelaskan secara mendetail. Teori ini penting untuk memahami cara sistem mengelompokkan data dalam penelitian ini.
2.1 Knowledge Discovery in Database
Menjelaskan proses KDD yang meliputi pemilihan data, pembersihan data, transformasi, data mining, dan interpretasi. Proses ini penting untuk memastikan data yang digunakan dalam penelitian adalah berkualitas dan relevan.
2.2 Pengertian Clustering
Definisi clustering dan tipe-tipe clustering seperti partitional, hierarchical, exclusive, dan fuzzy. Penjelasan ini memberikan dasar pemahaman tentang bagaimana data dapat dikelompokkan.
2.3 Dimensionality Reduction
Proses pengurangan dimensi data untuk mempermudah analisis. Metode PCA (Principal Component Analysis) digunakan untuk mengurangi kompleksitas data yang akan dikelompokkan.
2.4 Permainan DOTA 2
Deskripsi tentang DOTA 2 sebagai permainan strategi yang melibatkan kerjasama tim. Penjelasan tentang peran-peran dalam permainan ini, yaitu Carry, Support, dan Hard-support, yang menjadi fokus penelitian.
2.5 Pengujian Keakuratan Metode
Metode pengujian keakuratan clustering yang dilakukan dengan menggunakan confusion matrix dan teknik pengujian lainnya untuk memastikan validitas hasil penelitian.
III. METODOLOGI PENELITIAN
Bab ini menjelaskan tentang desain penelitian, analisa kebutuhan proses, dan implementasi perancangan sistem pengelompokan. Penelitian menggunakan data pertandingan DOTA 2 profesional untuk menerapkan metode Agglomerative Hierarchical Clustering. Proses pengumpulan data dilakukan dengan metode studi literatur dan pengumpulan data dari pertandingan yang telah berlangsung. Desain sistem juga dijelaskan dalam bentuk diagram blok untuk memudahkan pemahaman alur kerja penelitian.
3.1 Gambaran Umum
Menjelaskan sistem pengelompokan yang dibangun untuk menguji efektivitas metode Agglomerative Hierarchical Clustering dalam data pertandingan DOTA 2.
3.2 Desain Penelitian
Menjelaskan tahapan penelitian yang terdiri dari studi literatur, pengumpulan data, dan perancangan alat uji. Setiap tahapan dijelaskan untuk memberikan gambaran jelas tentang proses penelitian.
IV. IMPLEMENTASI HASIL DAN ANALISIS
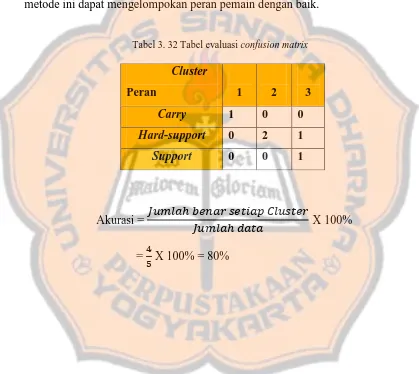
Bab ini memaparkan hasil penelitian dan analisis data yang diperoleh dari pengelompokan. Hasil dari pengelompokan peran pemain DOTA 2 ditampilkan, serta analisis akurasi yang dicapai melalui metode yang digunakan. Hasil ini memberikan wawasan tentang efektivitas metode Agglomerative Hierarchical Clustering dalam konteks permainan DOTA 2.
4.1 Hasil Penelitian dan Analisis
Menjelaskan hasil pengelompokan dan analisis data yang menunjukkan akurasi metode yang digunakan. Hasil ini penting untuk mengevaluasi keberhasilan penelitian.
V. KESIMPULAN DAN SARAN
Bab terakhir menyajikan kesimpulan dari penelitian serta saran untuk penelitian selanjutnya. Kesimpulan menegaskan bahwa metode Agglomerative Hierarchical Clustering efektif dalam mengelompokkan peran pemain DOTA 2, sementara saran berfokus pada pengembangan lebih lanjut dalam penelitian ini.
5.1 Kesimpulan
Menegaskan hasil penelitian yang menunjukkan akurasi tinggi dalam pengelompokan peran pemain DOTA 2.
5.2 Saran
Memberikan rekomendasi untuk penelitian mendatang agar dapat mengeksplorasi lebih dalam tentang pengelompokan dalam konteks permainan lainnya.