i
PENGELOMPOKAN ANGGOTA BARU PADUAN SUARA MAHASISWA MENGGUNAKAN METODE AGGLOMERATIVE HIERARCHICAL
CLUSTERING
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Informatika
oleh : Joni Rourensius
145314016
PROGRAM STUDI INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA 2019
ii
CLUSTERING NEW MEMBER OF STUDENT CHOIR USING AGGLOMERATIVE HIERARCHICAL CLUSTERINGMETHOD
A THESIS
Presented as Partial Fullfilment of the Requirement to Obtain the Sarjana Komputer Degree
in Informatics Study Program
By : Joni Rourensius
145314016
INFORMATICS STUDY PROGRAM FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY YOGYAKARTA
v
HALAMAN PERSEMBAHAN
Skripsi ini saya persembahkan kepada keluarga saya tercinta, dosen-dosen yang berjasa, dan semua orang terdekat saya.
“You may say I’m a dreamer, but I’m not the only one”
-
John Lennon –
viii
INTISARI
Cantus Firmus adalah salah satu unit kegiatan mahasiswa terbesar di Universitas Sanata Dharma. Paduan suara ini setiap tahunnya melakukan penerimaan anggota baru, jumlah pendaftar setiap tahunnya berjumlah ratusan. Melalui proses seleksi tersebut, diperoleh data seleksi penerimaan anggota baru dan data tersebut kemudian akan dikelompokkan menggunakan Agglomerative Hierarchical Clustering dengan menggunakan 3 metode didalamnya yakni Single-linkage, Average-Single-linkage, dan Complete-linkage.
Dalam proses pengelompokkan yang dilakukan, data kemudian akan dikelompokkan kedalam 4 kelompok jenis suara yaitu Sopran, Alto, Tenor, dan Bass. Tujuannya adalah untuk mengetahui apakah metode Agglomerative Hierarchical Clustering dapat dengan baik mengelompokkan data sesuai dengan jenis suara mereka. Oleh karena itu, hasil dari pengelompokkan kemudian akan diuji akurasinya menggunakan metode Confusion Matrix.
Dari ketiga metode yang diujikan, diketahui metode Complete-linkage menghasilkan akurasi yang paling tinggi yaitu 84% karena metode ini menggunakan pengambilan nilai jarak yang paling besar ketika proses pengelompokan dilakukan, sehingga masing-masing cluster memiliki jarak yang paling maksimal. Metode Average-linkage dan Single-linkage diketahui menghasilkan akurasi yang lebih rendah.
Kata kunci : Pengelompokan anggota baru Cantus Firmus, Agglomerative Hierarchical Clustering, Single-linkage, Average-linkage, Complete-linkage
ix
ABSTRACT
Cantus Firmus is one of the largest student activity units at Sanata Dharma University. This choir conducts the process of accepting new members each year, the number of registrants every year is in the hundreds. Through the selection process, new member selection data is obtained and then the data will be grouped using Agglomerative Hierarchical Clustering with 3 methods, that is Single-linkage, Average-Single-linkage, and Complete-linkage.
In the clustering process, the data will then be grouped into 4 groups of voice classification namely Soprano, Alto, Tenor, and Bass. The purpose is to find out whether the Agglomerative Hierarchical Clustering method can properly group data according to their voice classification. Therefore, the results of the grouping will then be tested for accuracy using the Confusion Matrix method.
Three methods were tested, it is known that the Complete-linkage method produces the highest accuracy which is 84% because this method uses the largest distance retrieval value when the grouping process is carried out, so that each cluster has the maximum distance. The Average-linkage and Single-linkage methods are known to produce lower accuracy in this case.
Keywords : Clustering new member of Cantus Firmus, Agglomerative Hierarchical Clustering, Single-linkage, Average-linkage, Complete-linkage
x
KATA PENGANTAR
Puji dan syukur saya sebagai penulis panjatkan kepada Tuhan Yang Maha Esa atas segala berkat, bimbingan, dan rahmat yang telah dilimpahkan kepada penulis sehingga dapat menyelesaikan tugas akhir yang berjudul “Pengelompokan Anggota Baru Paduan Suara Mahasiswa menggunakan Metode Agglomerative Hierarchical Clustering” yang merupakan salah syarat yang diperlukan untuk menyelesaikan studi dan memperoleh gelar sarjana pada program studi Informatika Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta.
Penulis juga dengan segenap kerendahan hati ingin mengucapkan terima kasih yang sebanyak-banyaknya kepada pihak-pihak berikut karena tugas akhir ini dapat terselesaikan :
1. Seluruh keluarga saya, kedua orang tua dan kelima kakak saya yang telah memberikan dukungan, semangat, dan perhatian yang sangat membantu penulis dalam mengerjakan tugas akhir.
2. Romo Dr. Cyprianus Kuntoro Adi, S.J. M.A., M.Sc. yang merupakan dosen pembimbing penulis yang memberikan bimbingan untuk penulis dalam mengerjakan tugas akhir.
3. Samuel, mas Dedi, mbak Vani, dan Jessica yang selalu menemani, memotivasi, membantu, hingga menghibur penulis dalam menyelesaikan tugas akhir.
4. Semua orang yang memberikan semangat untuk tidak menyerah dan membantu sesuai dengan kebutuhan penulis, terima kasih.
Penulis menyadari penulisan tugas akhir ini masih jauh dari sempurna. Kritik dan saran yang membangun diharapkan akan membantu tugas akhir ini. Akhir kata, semoga tugas akhir ini memberikan informasi yang bermanfaat bagi yang membutuhkan.
xi
DAFTAR ISI
HALAMAN JUDUL ... i
HALAMAN JUDUL (INGGRIS) ... ii
HALAMAN PERSETUJUAN PEMBIMBING .... Error! Bookmark not defined. HALAMAN PENGESAHAN ... iii
HALAMAN PERSEMBAHAN ... v
PERNYATAAN KEASLIAN KARYA ... v
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS ... vi
INTISARI ... viii
ABSTRACT ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xi
DAFTAR TABEL ... xiv
DAFTAR GAMBAR ... xvi
BAB I PENDAHULUAN ... 1 1.1. Latar Belakang ... 1 1.2. Rumusan Masalah ... 4 1.3. Tujuan Penelitian ... 4 1.4. Batasan Masalah ... 4 1.5. Manfaat Penelitian ... 5 1.6. Metodologi Penelitian ... 5 1.7. Sistematika Penulisan ... 6
BAB II LANDASAN TEORI ... 7
2.1. Euclidean Distance ... 7
xii
2.3. Himpunan Data ... 8
2.4. Konsep Analisis Cluster ... 10
2.4.1 Pengertian Analisis Cluster ... 10
2.4.2 Prosedur Analisis Cluster ... 11
2.5. Tipe Clustering ... 12
2.6. Tipe Cluster ... 13
2.7. Hierarchical Clustering ... 14
2.7.1. Agglomerative Hierarchical Clustering ... 15
2.7.2. Algoritma Agglomerative Hierarchical Clustering ... 21
2.8. Confusion Matriks ... 22
BAB III METODE PENELITIAN... 24
3.1. Data ... 24
3.2. Tahapan Penelitian ... 26
3.2.1. Studi Literatur ... 26
3.2.2. Pengumpulan Data ... 27
3.2.3. Pembuatan Alat Uji ... 27
3.2.4. Pengujian ... 27
3.3. Analisa Kebutuhan Proses ... 28
3.4. Desain Interface ... 28
3.5. Gambaran Umum Sistem ... 29
3.5.1. Tahap Agglomerative Hierarchical Clustering ... 30
3.5.2. Tahap Output ... 34
3.6. Implementasi Rancangan ... 34
3.6.1. Diagram Konteks ... 34
3.6.2. Data Flow Diagram Level 1 ... 35
3.6.3. Data Flow Diagram Level 2 ... 36
3.7. Penjelasan Proses ... 37
xiii 3.7.2. Pre-processing ... 37 3.7.3. Pengukuran jarak ... 41 3.7.4. Clustering ... 42 3.7.5. Perhitungan akurasi ... 53 3.8. Spesifikasi Alat ... 54
BAB IV IMPLEMENTASI HASIL DAN ANALISA ... 55
4.1. Hasil Clustering dan Pengujian Confusion ... 55
4.2. Hasil Penelitian dan Analisa ... 62
BAB V KESIMPULAN DAN SARAN ... 67
5.1. Kesimpulan ... 67
5.2. Saran ... 68
DAFTAR PUSTAKA ... 69
xiv
DAFTAR TABEL
Tabel 2. 1 Contoh Data Single-linkage ... 16
Tabel 2. 2 Penyelesaian contoh data Single-linkage ... 17
Tabel 2. 3 Contoh data Complete-linkage ... 18
Tabel 2. 4 Penghitungan jarak cluster contoh data Complete linkage ... 18
Tabel 2. 5 Penyelesaian contoh data Complete-linkage ... 19
Tabel 2. 6 Contoh data Average-linkage ... 20
Tabel 2. 7 Penghitungan jarak contoh data Average-linkage ... 20
Tabel 2. 8 Penyelesaian contoh data Average-linkage ... 21
Tabel 3. 1 Deskripsi atribut data ... 25
Tabel 3. 2 Variabel Jenis Kelamin ... 38
Tabel 3. 3 Variabel Jenis Suara ... 38
Tabel 3. 4 Variabel Range Nada ... 38
Tabel 3. 5 Variabel Karakter Suara ... 38
Tabel 3. 6 Variabel Noise ... 39
Tabel 3. 7 Variabel Ketebalan Suara ... 39
Tabel 3. 8 Variabel Nada Tinggi ... 39
Tabel 3. 9 Pembobotan Variabel Jenis Kelamin ... 39
Tabel 3. 10 Pembobotan Variabel Jenis Suara ... 40
Tabel 3. 11 Pembobotan Variabel Range Nada ... 40
Tabel 3. 12 Pembobotan Variabel Karakter Suara ... 40
Tabel 3. 13 Pembobotan Variabel Noise ... 40
Tabel 3. 14 Pembobotan Variabel Ketebalan Suara... 41
Tabel 3. 15 Pembobotan Variabel Nada Tinggi ... 41
Tabel 3. 16 Contoh 5 data ... 41
Tabel 3. 17 Contoh matrik jarak ... 42
xv
Tabel 3. 19 Hasil pencarian objek terdekat single iterasi 1 ... 43
Tabel 3. 20 Pencarian objek terdekat single iterasi 2 ... 44
Tabel 3. 21 Hasil pencarian objek terdekat single iterasi 2 ... 44
Tabel 3. 22 Pencarian objek terdekat single iterasi 3 ... 44
Tabel 3. 23 Hasil cluster Single-linkage ... 45
Tabel 3. 24 Pencarian objek terdekat average iterasi 1 ... 46
Tabel 3. 25 Hasil pencarian objek terdekat average iterasi 1 ... 47
Tabel 3. 26 Pencarian objek terdekat average iterasi 2 ... 47
Tabel 3. 27 Hasil pencarian objek terdekat average iterasi 2 ... 48
Tabel 3. 28 Pencarian objek terdekat average iterasi 3 ... 48
Tabel 3. 29 Hasil cluster average-linkage ... 48
Tabel 3. 30 Pencarian objek terdekat complete iterasi 1 ... 49
Tabel 3. 31 Hasil pencarian objek terdekat complete iterasi 1 ... 50
Tabel 3. 32 Pencarian objek terdekat complete iterasi 2 ... 50
Tabel 3. 33 Hasil pencarian objek terdekat complete iterasi 2 ... 51
Tabel 3. 34 Pencarian objek terdekat complete iterasi 3 ... 51
Tabel 3. 35 Hasil cluster complete-linkage ... 52
Tabel 3. 36 Perhitungan Confusion Matrix ... 53
Tabel 4. 1 Confusion Matriks Pengujian Single-linkage ... 57
Tabel 4. 2 Confusion Matriks Pengujian Average-linkage ... 59
xvi
DAFTAR GAMBAR
Gambar 2. 1 Prosedur Analisis Cluster (Modul UII) ... 11
Gambar 3. 1 Data Mentah Lembar Penilaian Vokal ... 25
Gambar 3. 2 Desain Interface ... 28
Gambar 3. 3 Diagram blok sistem ... 29
Gambar 3. 4 Flowchart Single-linkage ... 31
Gambar 3. 5 Flowchart Complete-linkage ... 32
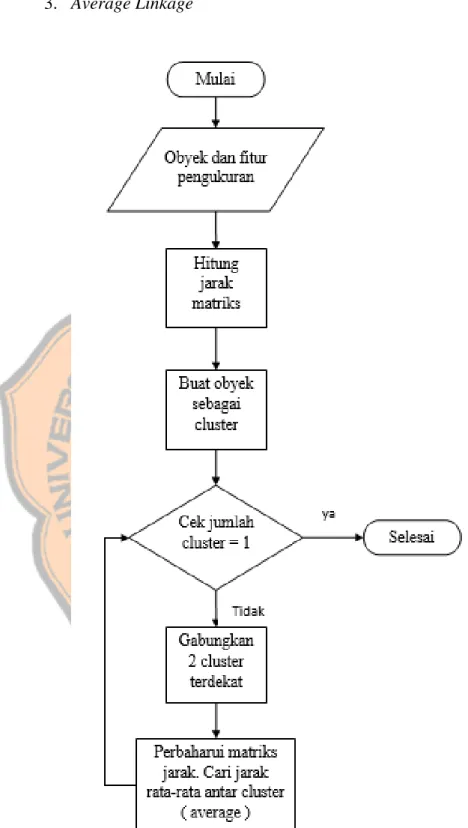
Gambar 3. 6 Flowchart Average-linkage ... 33
Gambar 3. 7 Diagram Konteks proses clustering ... 34
Gambar 3. 8 Data Flow Diagram level 1 ... 35
Gambar 3. 9 Diagram Data Flow level 2 clustering ... 36
Gambar 3. 10 Dendogram cluster single-linkage ... 45
Gambar 3. 11 Dendogram cluster average-linkage ... 49
Gambar 3. 12 Dendogram cluster complete-linkage... 52
Gambar 4. 1 Pengujian metode Single-linkage ... 56
Gambar 4. 2 Dendogram Single-linkage ... 57
Gambar 4. 3 Pengujian metode Average-linkage ... 58
Gambar 4. 4 Dendogram Average-linkage ... 59
Gambar 4. 5 Pengujian metode Complete-linkage ... 60
Gambar 4. 6 Dendogram Complete-linkage ... 61
1
BAB I
PENDAHULUAN
Bab ini akan menjelaskan bagaimana latar belakang, rumusan masalah, tujuan, manfaat, metodologi, batasan, dan sistematika dalam penelitian yang akan dilakukan.
1.1. Latar Belakang
Unit Kegiatan Mahasiswa Paduan Suara Mahasiswa Cantus Firmus adalah salah satu unit kegiatan mahasiswa terbesar di Universitas Sanata Dharma. Paduan Suara Mahasiswa Cantus Firmus mulai dibentuk pada tahun 1981 sebagai paduan suara gereja dengan nama Paduan Suara Dwiyarkara. Selanjutnya, paduan suara ini berkembang menjadi paduan suara umum pada tahun 1991, dan berada di bawah sub–UK (Unit Kegiatan) Kesenian. Setelah meraih berbagai prestasi 20 Oktober 1998, paduan suara ini disahkan menjadi UKM (Unit Kegiatan Mahasiswa) Universitas Sanata Dharma Yogyakarta. Sebagai sebuah civitas academica Universitas Sanata Dharma, Paduan Suara Mahasiswa Cantus Firmus secara berkala mengisi acara Wisuda dan Dies Natalis Universitas Sanata Dharma yang diadakan setiap tahunnya. Selain program rutin tersebut Paduan Suara Mahasiswa Cantus Firmus juga mengadakan konser tahunan, dan mengikuti perlombaan-perlombaan di tingkat regional hingga nasional.
Setiap tahun ajaran baru, Universitas Sanata Dharma menerima kurang lebih 3000 mahasiswa baru. Para Mahasiswa tersebut akan dikenalkan dengan seluruh UKM pada saat expo UKM inisiasi berlangsung. Dari jumlah mahasiswa baru tersebut, pendaftar Paduan Suara Mahasiswa Cantus Firmus setiap tahunnya kurang lebih 200-400
orang. Dan dari jumlah pendaftar tersebut, rata-rata anggota baru yang diterima kurang lebih 50-60 orang. Proses seleksi penerimaan anggota baru Paduan Suara Mahasiswa Cantus Firmus menghasilkan kumpulan data individual tiap pendaftar yang terdiri dari data vokal dan data lainnya. Dari data tersebutlah, akan diketahui keputusan untuk anggota baru yang akan diterima.
Jenis suara anggota-anggota baru Paduan Suara Mahasiswa Cantus Firmus ditentukan sejak pengumuman hasil penerimaan anggota baru Paduan Suara Mahasiswa Cantus Firmus. Panitia penerimaan anggota baru Paduan Suara Mahasiswa Cantus Firmus mengelompokkan jenis suara anggota baru berdasarkan informasi yang diberikan anggota baru sendiri dan hasil seleksi yang menghasilkan data vokal individu. Hal ini nyatanya sangat rawan akan kesalahan. Karena pada praktiknya, sering terjadi kesalahan dalam penempatan jenis suara yang dimiliki calon penyanyi tersebut. Biasanya kesalahan penempatan jenis suara untuk anggota-anggota Paduan Suara Mahasiswa Cantus Firmus akan terlihat setelah melalui proses pelatihan-pelatihan untuk berbagai kepentingan, salah satunya yang paling sering terjadi adalah pelatihan yang dilakukan untuk kepentingan perlombaan baik yang tingkat regional hingga ketingkat yang nasional. Penyanyi akan lebih sering menjalani berbagai latihan tambahan, dan setelah beberapa waktu akan dilakukan tes kemampuan selama pelatihan perlombaan, dan dari tes kemampuan inilah pelatih akan mulai merasa jika ada kesalahan dalam penempatan jenis suara seseorang atau beberapa penyanyi, yang artinya penyanyi yang ditempatkan pada jenis suara tertentu dirasa seharusnya berada di jenis suara yang satunya. Akibatnya penyanyi yang sudah menjalani persiapan serta pelatihan yang panjang hingga mulai terbiasa dengan jenis suara yang ditempatkan sebelumnya harus beradaptasi kembali dengan jenis suara baru yang ditempatkan ulang selama proses pelatihan. Hal tersebut tentulah tidak mudah dan menghambat jalannya proses latihan yang berlangsung saat itu,
dimana penyanyi harus mempelajari kembali lagu-lagu tersebut dengan jenis suara yang berbeda.
Dengan batas waktu yang singkat untuk mempersiapkan lomba dan penyanyi sendiri masih memiliki tanggung jawab lain sebagai seorang mahasiswa. Kesalahan seperti ini memakan waktu yang cukup banyak untuk penyesuaian dan sangat tidak efektif. Oleh karena itu muncul ide untuk studi kasus terhadap data penilaian penerimaan anggota baru Paduan Suara Mahasiswa Cantus Firmus dengan melakukan clustering terhadap data seleksi anggota-anggota baru Paduan Suara Mahasiswa Cantus Firmus sejak awal sehingga masalah yang dihadapi Paduan Suara Mahasiswa Cantus Firmus tersebut diharapkan dapat dicegah sejak dini.
Studi kasus terhadap data penilaian penerimaan anggota baru Paduan Suara Mahasiswa Cantus Firmus sebenarnya sudah pernah dilakukan oleh Yosef Yudha Prasetya (2012). Dalam penelitiannya, Yosef Yudha Prasetya membuat sistem seleksi penerimaan anggota baru Paduan Suara Mahasiswa Cantus Firmus menggunakan pendekatan logika kabur dan multi-attribute decision making. Yosef Yudha Prasetya membuat sistem untuk membantu proses pengambilan keputusan penerimaan anggota baru dengan menggabungkan hasil penilaian tahap vokal dan tahap wawancara hingga mendapatkan keputusan untuk menerima anggota baru atau tidak. Perbedaan penelitian ini dengan penelitian sebelumnya yaitu penelitian ini akan berfokus untuk membuat sistem yang mengelompokan jenis suara calon anggota baru Paduan Suara Mahasiswa Cantus Firmus dengan melakukan Clustering terhadap dataset seleksi tahap vokal anggota baru Paduan Suara Mahasiswa Cantus Firmus dan kemudian akan dihasilkan cluster untuk setiap jenis suara untuk anggota-anggota baru sebelum kemudian menjadi anggota-anggota tetap Paduan Suara Mahasiswa Cantus Firmus.
Pada studi kasus ini, proses Clustering akan membagi data individual tiap anggota baru Paduan Suara Mahasiswa Cantus Firmus yang di dapatkan ketika seleksi tahap vokal anggota baru Paduan Suara
Mahasiswa Cantus Firmus menjadi 4 cluster jenis suara dengan menggunakan metode Agglomerative Hierarchical Clustering. Jika cluster yang telah berhasil dikelompokkan menggunakan metode Hierarchical Clustering mendapatkan tingkat akurasi yang baik, diharapkan dapat mempermudah Paduan Suara Mahasiswa Cantus Firmus dalam mengelola dan mengelompokkan anggota-anggota baru kedalam jenis suara yang mirip satu sama lain.
1.2. Rumusan Masalah
Berdasarkan latar belakang yang ada, dapat dirumuskan masalah berupa : Apakah metode Agglomerative Hierarchical Clustering mampu dengan baik mengelompokan anggota baru UKM Paduan Suara Mahasiswa Cantus Firmus dalam jenis-jenis suara yang mirip satu sama lain berdasarkan dataset seleksi tahap vokal mereka?
1.3. Tujuan Penelitian
Tujuan penelitian ini adalah untuk mengetahui apakah metode Agglomerative Hierarchical Clustering mampu dengan baik mengelompokkan anggota baru UKM Paduan Suara Mahasiswa Cantus Firmus dalam jenis-jenis suara yang mirip satu sama lain dan menghasilkan akurasi yang baik .
1.4. Batasan Masalah
Masalah akan dibatasi sebagai berikut :
1. Metode yang digunakan adalah metode Agglomerative Hierarchical Clustering.
2. Data yang digunakan adalah dataset anggota baru Paduan Suara Mahasiswa Cantus Firmus angkatan 2016 dan 2017.
3. Preprocessing dilakukan secara manual dan tidak melalui sistem.
4. Jenis suara yang dikelompokkan terbagi menjadi 4 yakni Sopran, Alto, Tenor, Bass.
1.5. Manfaat Penelitian
Berdasarkan tujuan di atas, manfaat yang dapat diberikan adalah diharapkan dapat membantu pihak UKM Paduan Suara Mahasiswa Cantus Firmus dalam mengelompokkan anggota baru berdasarkan jenis suara.
1.6. Metodologi Penelitian
Metode penelitian pada penyusunan penulisan ini, adalah : 1. Studi literatur dengan tujuan :
a. Mempelajari dan memahami metode Hierarchical Clustering dalam data mining.
b. Mengetahui data individual untuk paduan suara.
2. Pengumpulan data melalui UKM Paduan Suara Mahasiswa Cantus Firmus Universitas Sanata Dharma
3. Merancang dan mengimplementasikan algoritma ke dalam sistem 4. Melakukan pengujian sistem menggunakan data yang diperoleh 5. Melakukan analisis hasil pengelompokan data
6. Menentukan kesimpulan dari hasil implementasi dan analisis 7. Penyusunan laporan Tugas Akhir.
1.7. Sistematika Penulisan
BAB I. Pendahuluan
Bab ini akan berisi latar belakang, rumusan masalah, tujuan, batasan masalah, manfaat, metodologi penelitian, dan sistematika penulisan.
BAB II. Landasan Teori
Bab ini mengemukakan teori yang berkaitan dengan masalah pada tugas akhir. Teori tersebut akan menjadi acuan selama proses perancangan hingga tahap implementasi tugas akhir ini.
BAB III. Metode Penelitian
Bab ini akan mengemukakan tentang data, tahap-tahap penelitian, desain interface, gambaran umum sistem, dan spesifikasi alat.
BAB IV. Implementasi dan Analisis Hasil
Bab ini akan mengemukakan hasil implementasi yakni gambar antar muka, gambar kode program, dan hasil dari analisis penelitian
BAB V. Kesimpulan dan Saran
Bab ini berisi kesimpulan dari hasil tugas akhir yang dibuat dan saran untuk pengembangan penelitian selanjutnya.
7
BAB II
LANDASAN TEORI
Bab ini berisi tentang teori-teori yang akan digunakan dalam penelitian ini. Teori-teori tersebut meliputi Euclidean Distance, Cosine Similarity, Konsep Analisis Cluster, Tipe Clustering, Hierarchical Clustering dan Confusion Matriks.
2.1. Euclidean Distance
Euclidean Distance digunakan untuk menghitung nilai kedekatan antara dua dokumen. Perhitungan Euclidean Distance dirumuskan sebagai berikut (Prasetyo, 2014) : d( A,B ) = (2.1) Atau d( A,B ) = (2.2) Keterangan : : Jumlah atribut : Data 2.2. Cosine Similarity
Dalam buku Data Mining : Pengelolahan Data menjadi informasi menggunakan matlab (Prasetyo, 2014), ukuran kemiripan yang sering digunakan untuk mengukur kemiripan dua dokumen x dan y adalah Cosine Similarity. Kemiripan yang diberikan adalah 1 jika dua vektor x dan y
sama, dan bernilai 0 jika kedua vektor berbeda. Nilai jaak 1 menyatakan sudut yang dibentuk oleh vektor x dan y adalah , yang artinya vektor x dan y adalah sama dalam hal jarak.
Perhitungan Cosine Similarity dirumuskan sebagai berikut :
S(x , y) = cos(x , y) = (2.3)
Tanda titik ( ) melambangkan inner-product,
x y = (2.4)
Tanda adalah panjang dari vektor x, dimana :
= = (2.5)
2.3. Himpunan Data
Himpunan data dibangun dari objek-objek data, dimana objek data menyatakan sebuah entitias. Misalnya pada himpunan data universitas, objek bisa berupa mahasiswa, dosen, mata kuliah. Objek biasanya digambarkan menggunakan atribut. Pada banyak referensi, objek data disebut juga sebagai sampel, contoh, atau titik data. Sementara itu, objek-objek data disimpan dalam suatu basis data yang disebut tuple, diamana baris menyatakan objek-objek data dan kolom menyatakan atribut.
Atribut adalah simbol yang mengambarkan identitas atau karakteristik suatu kelompok. Atribut adalah data field, yang mempresentasikan karakteristik atau fitur dari objek data. Pada bidang lain atribut disebut juga sebagai dimensi, fitur , atau variabel.
1. Atribut Nominal
Atribut nominal disebut juga kategorial karena nilainya menggambarkan kategori, kode, atau status, yang tidak memiliki urutan. Misalnya atribut Warna yang mempunyai dua kemungkinan nilai yakni Merah atau Putih. Atribut Kategori Pelanggan yang bisa bernilai Silver, Gold, atau Platinum. Atribut Kode Wilayah yang bisa bernilai A, B, C, D, atau E. Atribut nominal juga dapat berupa numerik. Misalnya Warna bisa bernilai 0 atau 1, dimana 0 menyatakan Merah dan 1 menyatakan Putih.
2. Atribut Biner
Atribut biner atau disebut juga dengan atribut boolean adalah atribut nominal yang hanya memiliki dua kategori nilai yaitu 0 atau 1, dimana 0 menyatakan Tidak (sesuatu yang negatif atau berdampak kecil) dan 1 menyatakan Ya ( sesuatu yang positif atau yang berdampak benar). Walaupun memiliki nilai kategorial seperti atribut nominal, dalam data mining atribut biner dipandang secara khusus karena memiliki karakter yang unik. Atribut biner dapat dibedakan menjadi dua, yaitu :
a. Atribut biner simetris, jika nilainya dianggap memberikan dampak yang setara, misalnya atribut Jenis Kelamin yang bernilai Pria atau Wanita (tidak penting mana yang harus bernilai 0 atau 1 karena keduanya dianggap setara).
b. Atribut biner asimetris, jika nilainya memberikan dampak berbeda, yang secara konvensi bernilai 1 untuk yang jarang terjadi, dan bernilai 0 untuk yang umum terjadi, misalnya Hasil Tes Buta Warna yang bernilai 1 (buta warna) dan 0 (tidak buta warna).
3. Atribut Numerik
Atribut numerik adalah kuantitatif, yang memiliki nilai berupa kuantitas yang terukur dan dinyatakan dalam nilai-nilai bulat (integer) atau riil (real). Atribut numerik bisa diskalakan secara inverval atau secara rasio. Sebagai contoh, temperatur udara dalam satuan Celcius adalah
atribut numerik yang bisa diskalakan secara interval namun tidak bisa diskalakan secara rasio.
4. Atribut Ordinal
Atribut ordinal memiliki nilai yang menggambarkan urutan atau peringkat (ranking).Namun, ukuran perbedaan antara dua nilai yang berurutan tidak diketahui. Misalnya, atribut Kategori Pelanggan yang bisa bernilai Silver, Gold, atau Platinum. Ketiga nilai tersebut memiliki urutan atau tingkatan, namun tidak menjelaskan seberapa besar perbedaan antara Silver dan Gold. Atribut ordinal sangat berguna dalam survei, yaitu untuk penilaian subjektif (kualitatif) yang tidak dapat diukur secara objektif.
5. Atribut Diskrit
Atribut diskrit memiliki nilai terbatas atau nilai terbatas tapi masih dapat dihitung, yang bisa bernilai bulat. Misalnya, atribut Temperatur Udara dalam satuan Celcius , yang bisa bernilai bulat antara 0 sampai 100. Atribut ini memiliki nilai riil atau pecahan yang dalam komputer yang biasanya direpresentasikan sebagai bilangan real atau floating-point.
2.4. Konsep Analisis Cluster
2.4.1 Pengertian Analisis Cluster
Analisis cluster merupakan salah satu teknik data mining yang bertujuan untuk mengidentifikasi sekelompok obyek yang mempunyai kemiripan karakteristik tertentu yang dapat dipisahkan dengan kelompok obyek lainnya, sehingga obyek yang berada dalam kelompok yang sama relatif lebih homogen daripada obyek yang berada pada kelompok yang berbeda (Hermawati, 2013). Jumlah kelompok yang dapat diidentifikasi tergantung pada banyak dan variasi data obyek. Tujuan dari pengelompokan sekumpulan data obyek ke dalam beberapa kelompok yang mempunyai karakteristik tertentu dan dapat dibedakan satu sama lainnya adalah untuk analisis dan interpretasi lebih lanjut sesuai dengan
tujuan penelitian yang dilakukan. Model yang diambil diasumsikan bahwa data yang dapat digunakan adalah data yang berupa data interval, frekuensi dan biner. Set data obyek harus mempunyai peubah dengan tipe yang sejenis tidak campur antara tipe yang satu dengan lainnya.
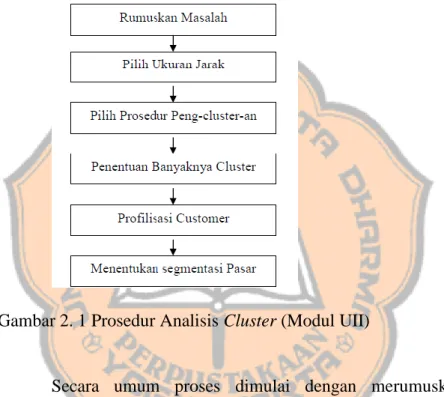
2.4.2 Prosedur Analisis Cluster
Gambar 2. 1 Prosedur Analisis Cluster (Modul UII)
Secara umum proses dimulai dengan merumuskan masalah pengklasteran dengan mendefinisikan variabel-variabel yang dipergunakan untuk dasar pengklasteran / pembentukan klaster. Kemudian pengambilan p pengukuran peubah pada n obyek pengamatan. Data tersebut dijadikan matriks data mentah berukuran m x p. Matrik tersebut ditransformasikan ke dalam bentuk matriks similaritas (kemiripan) berupa n x n yang dihitung berdasarkan pasangan-pasangan obyek p peubah. Konsep dasar pengukuran analisis cluster adalah konsep pengukuran jarak (distance) dan kesamaan (similarity). Distance adalah ukuran tentang jarak pisah antar obyek sedangkan similarity adalah ukuran kedekatan. Konsep ini penting karena pengelompokan pada analisis cluster didasarkan pada kedekatan. Pengukuran jarak (distance type measure) digunakan untuk data-data yang
bersifat matriks, sedangkan pengukuran kesesuaian (matching type measure) digunakan untuk data-data yang bersifat kualitatif.
2.5. Tipe Clustering
Clustering merupakan suatu kumpulan dari keseluruhan cluster Beberapa tipe penting dari clustering (Hermawati, 2013) adalah :
1. Partitional vs Hierarchical
Partitional clustering adalah pembagian objek data kedalam sub himpunan(cluster) yang tidak overlap sedemikian hingga tiap objek data berada dalam tepat satu sub-himpunan. Hierarchicalclustering merupakan sebuah himpunan cluster bersarang yang diatur sebagai suatu pohon hirarki. Tiap simpul(cluster) dalam pohon(kecuali simpul daun) merupakan gabungan dari anaknya(subcluster) dan simpul akar berisi semua objek
2. Exclusive vs non-exclusive
Semua bentuk clustering merupakan exclusive clustering, karena setiap objek berada tepat pada satu cluster. Sebaliknya dalam overlapping atau non-exclusiveclustering, sebuah objek dapat berada di lebih dari satu cluster secara bersamaan.
3. Fuzzy vs non-fuzzy
Dalam fuzzy clustering, sebuah titik termasuk dalam setiap cluster dengan suatu nilai bobot antara 0 dan 1. Jumlah dari bobot-bobot tersebut sama dengan 1. Clustering probabilitas mempunyai karakteristik yang sama.
4. Partital vs complete
Dalam completeclustering ,setiap objek ditempatkan dalam sebuah cluster. Tetapi dalam partial clustering, tidak semua objek ditempatkan dalam sebuah cluster. Kemungkinan ada objek yang tidak tepat untuk ditempatkan di salah satu cluster, misalkan berupa outlier atau noise.
2.6. Tipe Cluster
Clustering bertujuan menemukan kelompok (cluster) objek yang berguna, dimana gunanya tergantung dari tujuan analisa data. Secara visual ada beberapa tipe dari cluster, diantaranya :
1. Well-Separated Clusters : Sebuah cluster merupakan himpunan titik sedemikian rupa hingga tidak ada titik dalam sebuah cluster yang mendekati (atau lebih mirip ke setiap titik lain dalam cluster yang tidak ditempati titik tersebut.
2. Center-based : sebuah cluster adalah himpunan dari objek-objek sedemikian rupa hingga sebuah objek dalam sebuah cluster mendekati (lebih mirip) dengan ‘pusat’ dari sebuah cluster dibandingkan dengan pusat cluster lain. Pusat dari sebuah cluster dapat berupa centroid, yaitu rata-rata dari semua titik dalam cluster tersebut, atau medoid, merupakan representasi titik dari sebuah cluster.
3. Contigous cluster (Nearest neighbor atau Transitive) : dimana sebuah cluster merupakan himpunan titik sedemikian hingga sebuah titik dalam cluster mendekati (atau lebih serupa) dengan satu atau lebih titik lain dalam cluster tersebut dibandingkan denan titik yang tidak berada pada cluster tersebut.
4. Density-based : adalah dimana sebuah cluster merupakan suatu daerah titik yang padat, yang dipisahkan oleh daerah kepadatan rendah (low
-density), dari daerah kepadatan tinggi (high-density) yang lain. Digunakan ketika cluster-cluster tidak beraturan atau terjalin dan ketika terdapat noise dan outlier.
5. Shared property atau Conceptual Cluster , adalah cluster-cluster yang membagi beberapa sifat umumnya atau menyatakan konsep tertentu.
2.7. Hierarchical Clustering
Teknik hirarki (hierarchical methods) adalah teknik clustering membentuk kontruksi hirarki atau berdasarkan tingkatan tertentu seperti struktur pohon (struktur pertandingan) (Hermawati, 2013). Dengan demikian proses pengelompokkannya dilakukan secara bertingkat atau bertahap. Hasil dari pengelompokan ini dapat disajikan dalam bentuk dendogram.
Dua tipe utama hierarchicalclustering (Tan, dkk 2006) , yaitu :
Agglomerative:
1. Mulai dengan titik-titik sebagai individualclusters.
2. Pada tiap langkah, gabungkan pasangan cluster terdekat sampai hanya terdapat satu cluster (atau k cluster) yang tersisa
Divisive :
1. Mulai dengan satu,semua inclusivecluster.
2. Pada tiap langkah, pisahkan sebuah cluster sampai tiap cluster terdiri dari sebuah titik(atau ada k cluster).
Tradisional hierarchical algorithms menggunakan sebuah matriks similaritas atau matriks jarak dengan menggabungkan atau memisahkan satu cluster dalam tiap langkahnya.
2.7.1. Agglomerative Hierarchical Clustering
Agglomerative Hierarchical Clustering merupakan metode pengelompokan berbasis hierarki dengan pendekatan bottom up, yaitu proses pengelompokkan dimulai dari masing-masing data sebagai satu cluster, kemudian secara rekursif mencari cluster terdekat sebagai pasangan untuk bergabung sebagai satu cluster yang lebih besar (Prasetyo, 2014). Proses akan terus diulang sehingga akan tampak bergerak keatas membentuk sebuah hierarki.
Agglomerative Clustering merupakan teknik hierarchical clustering yang dimulai dengan kenyaatan bahwa setiap obyek membentuk clusternya masing-masing. Kemudian dua obyek dengan jarak terdekat bergabung (Fakultas Teknologi Industri UII). Selanjutnya obyek ketiga akan bergabung dengan cluster yang ada atau bersama obyek lain dan membentuk cluster baru. Hal ini tetap memperhitungkan jarak kedekatan antar obyek. Proses akan berlanjut hingga akhirnya terbentuk satu cluster yang terdiri dari keseluruhan obyek. Ada beberapa teknik dalam AgglomerativeClustering (Fakultas Teknologi Industri UII) yaitu:
1. Single linkage ( nearest neighbor methods )
Metode ini menggunakan prinsip jarak minimum yang diawali dengan mencari dua obyek terdekat dan keduanya membentuk cluster yang pertama.
Pada langkah selanjutnya terdapat dua kemungkinan, yaitu :
obyek ketiga akan bergabung dengan cluster yang telah terbentuk, atau
Proses ini akan berlanjut sampai akhirnya terbentuk cluster tunggal. Pada metode ini jarak antar cluster didefinisikan sebagai jarak terdekat antar anggotanya.
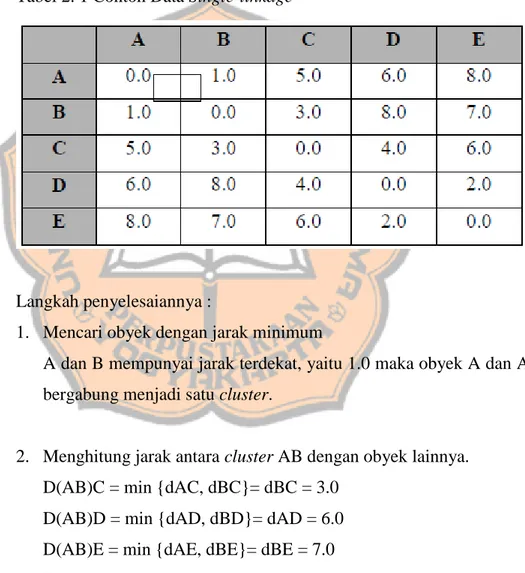
Contoh :
Terdapat matriks jarak antara 5 buah obyek, yaitu :
Tabel 2. 1 Contoh Data Single-linkage
Langkah penyelesaiannya :
1. Mencari obyek dengan jarak minimum
A dan B mempunyai jarak terdekat, yaitu 1.0 maka obyek A dan A bergabung menjadi satu cluster.
2. Menghitung jarak antara cluster AB dengan obyek lainnya. D(AB)C = min {dAC, dBC}= dBC = 3.0
D(AB)D = min {dAD, dBD}= dAD = 6.0 D(AB)E = min {dAE, dBE}= dBE = 7.0
Tabel 2. 2 Penyelesaian contoh data Single-linkage
3. Mencari obyek dengan jarak terdekat
D dan E mempunyai jarak yang terdekat yaitu 2.0 maka obyek D dan E bergabung menjadi satu cluster.
4. Menghitung jarak antara cluster dengan obyek lainnya. D(AB)C = 3.0
D(AB)(DE) = min {dAD, dAE, dBD, dBE} = dAD = 6.0 D(DE)C = min {dCD, dCE} = dCD = 4.0
5. Mencari jarak terdekat antara cluster dengan obyek dan diperoleh obyek C bergabung dengan cluster AB
6. Pada langkah yang terakhir, cluster ABC bergabung dengan DE sehingga terbentuk cluster tunggal.
2. Complete linkage ( furthest neighbor methods )
Metode ini merupakan kebalikan dari pendekatan yang digunakan pada single
Contoh :
Terdapat matriks jarak antara lima buah obyek yaitu :
Tabel 2. 3 Contoh data Complete-linkage
Langkah penyelesaiannya :
1. Mencari obyek dengan jarak minimum
A dan B mempunyai jarak terdekat yaitu 1.0 maka obyek A dan B bergabung menjadi satu cluster.
2. Menghitung jarak antara cluster AB dengan obyek lainnya. D(AB)C = max {dAC, dBC}= dAC = 5.0
D(AB)D = max {dAD, dBD}= dBD = 8.0 D(AB)E = max {dAE, dBE}= dAE = 8.0
Dengan demikian terbentuk matriks jarak yang baru
3. Mencari obyek dengan jarak terdekat.
D dan E mempunyai jarak terdekat yaitu 2.0 maka obyek D dan E bergabung menjadi satu cluster
4. Menghitung jarak antar cluster dengan obyek lainnya. D(AB)C = 5.0
D(AB)(DE) = max {dAD, dAE, dBD, dBE} = dAE = dBD = 8.0 D(DE)C = max {dCD, dCE} = dCE = 6.0
5. Maka terbentuklah matriks jarak yang baru, yaitu :
Tabel 2. 5 Penyelesaian contoh data Complete-linkage
6. Mencari jarak terdekat antara cluster dengan obyek dan diperoleh obyek C bergabung dengan cluster AB
7. Pada langkah yang terakhir cluster ABC bergabung dengan DE sehingga terbentuk cluster tunggal.
3. Average linkage methods ( between groups methods )
Metode ini mengikuti prosedur yang sama dengan kedua metode sebelumnya. Prinsip ukuran jarak yang digunakan adalah jarak rata-rata antar tiap pasangan obyek yang mungkin.
Tabel 2. 6 Contoh data Average-linkage
Langkah penyelesaiannya :
1. Mencari obyek dengan jarak minimum
A dan B mempunyai jarak terdekat, yaitu 1,0 maka obyek A dan B bergabung menjadi satu cluster.
2. Menghitung jarak antara cluster AB dengan obyek lainnya d(AB)C = max {dAC, dBC} = dAC = 5,0
d(AB)D = max {dAD, dBD} = dBD = 8,0 d(AB)E = max {dAE, dBE} = dAE = 8,0
Dengan demikian terbentuk matriks jarak yang baru :
3. Mencari obyek dengan jarak terdekat.
D dan E mempunyai jarak terdekat, yaitu 2,0 maka obyek D dan E bergabung menjadi satu cluster.
4. Menghitung jarak antara cluster dengan obyek lainnya. d(AB)C = 4,0
d(AB)(DE) = 1/2{dAD, dAE, dBD, dBE} = 7,25 d(DE)C = 1/2{dCD, dCE,} = dCE = 5,00
Maka terbentuklah matrik jarak yang baru, yaitu :
Tabel 2. 8 Penyelesaian contoh data Average-linkage
5. Mencari jarak terdekat antara cluster dengan obyek dan diperoleh obyek C bergabung dengan cluster AB.
6. Pada langkah yang terakhir, cluster ABC bergabung dengan DE sehingga terbentuk cluster tunggal
2.7.2. Algoritma Agglomerative Hierarchical Clustering
Algoritma Agglomerative Hierarchical Clustering untuk mengelompokkan n obyek adalah sebagai berikut (Tan, Steinbach dan Kumar, 2006) :
1. Hitung matriks kedekatan berdasarkan jenis jarak yang digunakan. 2. Ulangi langkah 3 sampai 4, hingga hanya satu kelompok yang tersisa. 3. Gabungkan dua cluster terdekat berdasarkan parameter kedekatan yang
ditentukan.
4. Perbarui matriks kedekatan untuk merepresentasikan kedekatan diantara kelompok baru dan kelompok yang tersisa.
5. Selesai.
2.8. Confusion Matriks
Pada penelitian ini, metode evaluasi clustering yang digunakan yaitu metode external evaluasi. External evaluasi bekerja dengan membandingkan hasil pengelompokan sistem dengan label class. Salah satu metode external evaluasi yaitu Confusion Matrix.
Confusion Matrix merupakan metode external evaluasi yang berisi informasi aktual dan dapat diprediksi (Kohavi dan Provost, 1998), dimana kinerja sistem dapat dievaluasi menggunakan data dalam matriks. Tabel berikut menunjukkan Confusion Matrix :
Prediksi Negatif Positif Aktual Negatif a b Positif c d Keterangan :
a : jumlah prediksi yang benar bahwa contoh bersifat negatif b : jumlah prediksi yang benar bahwa contoh bersifat negatif c : jumlah prediksi yang benar bahwa contoh bersifat positif d : jumlah prediksi yang salah bahwa contoh bersifat positif
perhitungan akurasi dirumuskan sebagai berikut :
24
BAB III
METODE PENELITIAN
Bab ini akan berisi rancangan penelitian yang menjelaskan mengenai data, tahapan-tahapan dalam penelitian, desain interface, gambaran umum sistem, implementasi rancangan, penjelasan proses dan spesifikasi alat.
3.1. Data
Data yang digunakan dalam penelitian ini adalah data yang telah dikumpulkan dalam proses seleksi penerimaan anggota baru di UKM Paduan Suara Mahasiswa Cantus Firmus yang kemudian menghasilkan data penilaian seleksi anggota baru Paduan Suara Mahasiswa Cantus Firmus. Penerimaan anggota baru tersebut dilaksanakan pada setiap tahunnya. Untuk penelitian ini, data penilaian seleksi anggota baru Paduan Suara Mahasiswa Cantus Firmus yang digunakan adalah data penilaian untuk periode 2016 dan 2017 (angkatan 2016 dan 2017). Data awal yang diperoleh peneliti selama pengambilan data berupa form data diri , form penilaian tahap vokal, dan form penilaian tahap wawancara motivasi. Peneliti hanya akan menggunakan form penilaian pada tahap vokal karena data pada form data diri dan motivasi tidak ada attribut yang diperlukan peneliti. Form penilaian tahap vokal yang terdiri dari 12 atribut seperti nama, prodi, angkatan, nilai notasi, nilai ketukan, nilai solfegio, nilai final, jenis suara, range nada, karakter suara, penguji, dan catatan tambahan.
Dari data penilaian seleksi anggota baru Paduan Suara Mahasiswa Cantus Firmus ini kemudian akan diolah melalui tahap preprocesing dan menghasilkan atribut final seperti nama, jenis kelamin, jenis suara, range nada, karakter suara, noise, ketebalan suara, dan nada tinggi. Proses pengolahan di tahap preprocesing akan
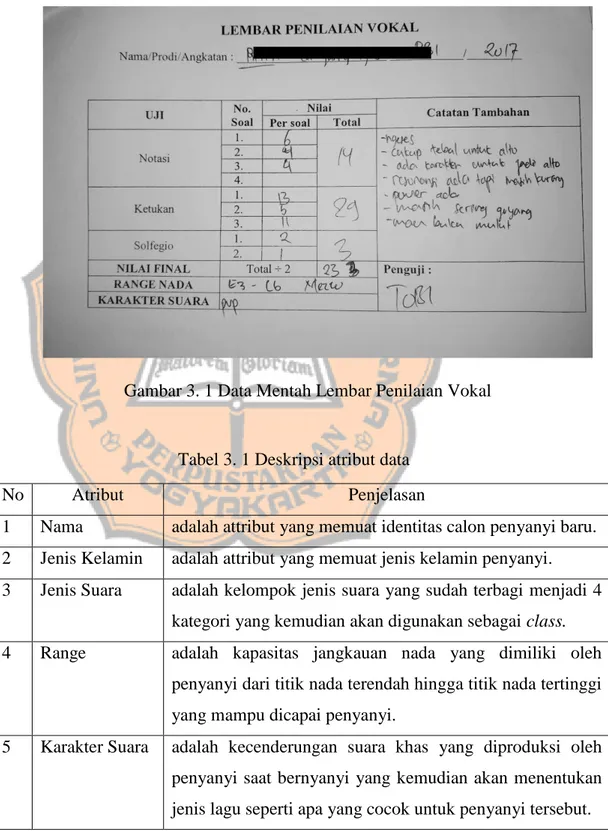
dilakukan secara manual. Beberapa attribut seperti noise, ketebalan suara, dan nada tinggi dihasilkan dari atribut catatan tambahan. Berikut contoh data dokumen penilaiannya :
Gambar 3. 1 Data Mentah Lembar Penilaian Vokal
Tabel 3. 1 Deskripsi atribut data
No Atribut Penjelasan
1 Nama adalah attribut yang memuat identitas calon penyanyi baru. 2 Jenis Kelamin adalah attribut yang memuat jenis kelamin penyanyi. 3 Jenis Suara adalah kelompok jenis suara yang sudah terbagi menjadi 4
kategori yang kemudian akan digunakan sebagai class. 4 Range adalah kapasitas jangkauan nada yang dimiliki oleh
penyanyi dari titik nada terendah hingga titik nada tertinggi yang mampu dicapai penyanyi.
5 Karakter Suara adalah kecenderungan suara khas yang diproduksi oleh penyanyi saat bernyanyi yang kemudian akan menentukan jenis lagu seperti apa yang cocok untuk penyanyi tersebut.
6 Noise adalah tingkat kejernihan produksi suara yang dihasilkan penyanyi.
7 Ketebalan Suara
adalah tingkat keras lembut produksi suara yang dihasilkan penyanyi.
8 Nada Tinggi adalah tingkat kestabilan yang dimiliki seorang penyanyi ketika memproduksi nada tinggi.
Setelah menetapkan jenis atribut yang akan digunakan kemudian memasukkan data kedalam Excel secara manual perindividunya, serta memasukkan juga atribut-atribut yang diperoleh dari pengolahan atribut catatan tambahan.
Dalam menemukan tingkat akurasi yang diperoleh dari hasil cluster, peneliti menentukan atribut jenis suara sebagai label class yang dimana label tersebut akan digunakan untuk membandingkan dengan hasil cluster yang dihasilkan oleh sistem kemudian untuk menemukan tingkat akurasinya.
3.2. Tahapan Penelitian
Penelitian ini akan dibagi menjadi 4 tahapan yaitu studi literatur, pengumpulan data, pembuatan alat uji, dan pengujian sistem. Untuk selengkapnya sebagai berikut.
3.2.1. Studi Literatur
Tahap ini adalah tahap proses pengumpulan informasi mengenai teori-teori penambangan data dan khususnya algoritma Agglomerative Hierarchical Clustering yang mendukung penelitian ini dalam mengelompokkan jenis suara anggota Paduan Suara Mahasiswa Cantus Firmus angkatan 2017 dari berbagai macam referensi ( buku, jurnal, karya ilmiah, ataupun artikel
lainnya). Peneliti juga menggali informasi dari literatur vokal untuk mempelajari mengenai jenis suara manusia dalam bernyanyi.
3.2.2. Pengumpulan Data
Pengumpulan data dilakukan menggunakan teknik dokumen. Dokumen yang diperoleh peneliti bersumber dari dokumen penilaian seleksi penerimaan anggota baru Paduan Suara Mahasiswa Cantus Firmus yang telah diarsipkan oleh Sekretaris Paduan Suara Mahasiswa Cantus Firmus.
3.2.3. Pembuatan Alat Uji
Pada tahap ini, akan dirancang suatu alat uji dengan perancangan interface dan pembuatan alat uji menggunakan Matlab R2016b untuk menguji metode Agglomerative Hierarchical Clustering untuk mengelompokkan jenis suara serta mendapatkan akurasi dari sistem yang telah dibangun dengan menggunakan Confusion Matriks. Alat uji kemudian memperlihatkan hasil pengelompokan (AHC) dan hasil perhitungan akurasi (Confusion matrix) kepada pengguna.
3.2.4. Pengujian
Tahap pengujian akan dilakukan menggunakan alat uji yang telah dibuat. Sebelumnya, data terlebih dahulu diproses secara manual oleh peneliti menggunakan aplikasi microsoft excel, kemudian akan diinputkan file tersebut kedalam sistem sehingga data yang telah dimasukkan dapat dilakukan proses clustering dengan metode-metode yang telah tersedia di dalam sistem. Hasil clustering yang dihasilkan kemudian akan dilakukan pengujian untuk mengukur tingkat akurasi menggunakan Confusion Matriks.
3.3. Analisa Kebutuhan Proses
Penelitian ini akan terbagi menjadi 2 tahapan penting yaitu tahap pengelompokan (clustering) dan tahap pengujian (testing). Pengelompokan akan menghasilkan 4 jenis cluster suara untuk penyanyi dan pengujiannya digunakan untuk menguji seberapa akurat metode yang digunakan dalam penelitian ini mampu mengelompokkan data dengan baik.
3.4. Desain Interface
User interface untuk pengelompokan jenis suara anggota baru Paduan Suara Mahasiswa Cantus Firmus hanya akan memiliki satu halaman tampilan. Dalam interface tersebut terdapat button “Input File” untuk memasukkan data yang akan diolah. Setelah data dimasukkan, data tersebut kemudian akan tampil dalam format tabel “Data Awal”. Selanjutnya user harus mengisi metode Agglomerative Hierarchical Clustering mana yang ingin di uji. Setelah melakukan pengisian radiobutton untuk metode Agglomerative Hierarchical Clustering yang akan di uji, tekan button “Clustering”, sehingga data akan di proses dan mendapatkan hasil pada tabel “Hasil Cluster” dari masing-masing metode yang dipilih diantara Single Linkage, Complete Linkage, dan Average Linkage. Kemudian juga akan tampil dendogram dari hasil pengelompokan menggunakan metode yang telah dipilih dan persentasi akurasi dari hasil pengujiannya.
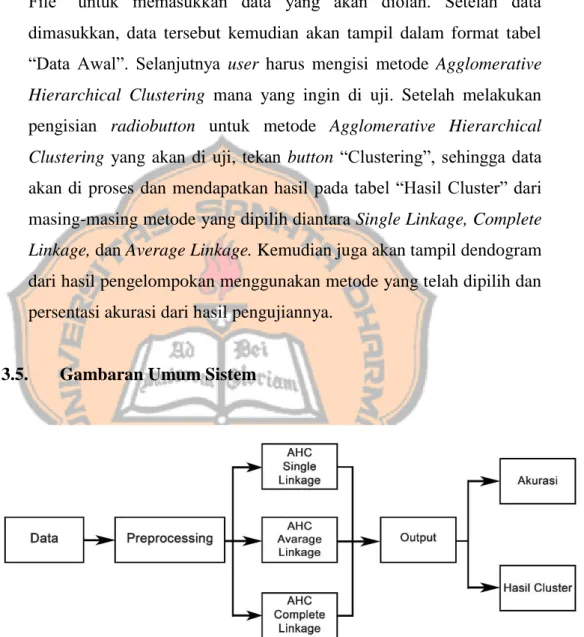
3.5. Gambaran Umum Sistem
Gambar 3. 3 Diagram blok sistem
Sistem ini digunakan untuk mengetahui tingkat akurasi yang dihasilkan oleh sistem dalam mengelompokan data penilaian seleksi anggota baru Paduan Suara Mahasiswa Cantus Firmus sehingga menghasilkan kelompok jenis suara penyanyi menggunakan metode
Agglomerative Hierarchical Clustering. Langkah awalnya adalah data penilaian anggota baru Paduan Suara Mahasiswa Cantus Firmus akan mengalami tahap preprocessing dimana data dibersihkan, diintegrasi, dan ditransformasi secara manual oleh peneliti. Proprocessing kemudian menghasilkan data yang siap diolah pada tahap clustering. Matrik jarak dihitung dengan menggunakan Euclidean Distance. Setelah itu, masing-masing data akan dikelompokkan berdasarkan karakteristik kedekatannya. Proses untuk pengelompokan ini akan terbagi dalam tiga metode yaitu Single Linkage, Average Linkage, dan Complete Linkage.
Hasil dari pengolahan pada tahap clustering kemudian akan diuji untuk menghitung tingkat akurasinya sehingga pada tahap terakhir terdapat output berupa dendogram yang menjadi visualisasi dari hasil pengelompokan yang sudah dilakukan dan tingkat akurasi yang dihitung menggunakan Confusion Matriks untuk metode yang diuji.
3.5.1. Tahap Agglomerative Hierarchical Clustering
Setelah data di preprocessing, data kemudian masuk ke dalam tahap clustering. Matriks jarak kemudian akan dihitung melalui metode Euclidean Distance. Dalam tahap clustering, terdapat proses pengelompokan dengan menggunakan 3 jenis metode yaitu Single Linkage, Complete Linkage, dan Avarage Linkage.
1. Single Linkage
2. Complete Linkage
3. Average Linkage
3.5.2. Tahap Output
Setelah hasil cluster ditampilkan, maka pengujian tingkat akurasi akan dilakukan untuk mengetahui keakuratan dari hasil pengelompokan menggunakan metode yang diujikan. Untuk melakukan pengujian akurasi tersebut, akan digunakan metode pengujian akurasi confusion matriks. Confusion matriks digunakan sebagai alat ukur untuk evaluasi karena data yang digunakan dalam penelitian ini sudah memiliki label. Confusion matriks juga merupakan metode yang mempermudah proses dalam menganalisa hasil dan juga mempermudah proses dalam melihat suatu permodelan antara 2 kelas yaitu class prediksi dan class aktual.
3.6. Implementasi Rancangan 3.6.1. Diagram Konteks
Gambar 3. 7 Diagram Konteks proses clustering
Gambar 3.7 adalah gambar diagram konteks yang biasa disebut juga sebagai data flow diagram level 0 dimana merupakan level tertinggi dalam suatu data flow diagram. Diagram ini menjelaskan ruang lingkup dari alat uji yang akan dibangun. Di lihat dari diagram tersebut, diketahui bahwa proses utama yang akan dilakukan adalah proses clustering terhadap data anggota baru
Paduan Suara Mahasiswa Cantus Firmus dengan menggunakan metode Agglomerative Hierarchical Clustering. Terdapat seorang User sebagai pemberi input saat memasukkan data dan memilih metode clustering yang kemudian akan menghasilkan hasil cluster dan akurasi hasil pengujian.
3.6.2. Data Flow Diagram Level 1
Gambar 3. 8 Data Flow Diagram level 1
Gambar 3.8 adalah data flow diagram level 1 yang merupakan pecahan dari diagram konteks atau diagram data flow level 0. Pada diagram ini terdapat User sebagai external entity, 150 data vokal anggota baru Paduan Suara Mahasiswa Cantus Firmus.
Proses pertama yang dilakukan adalah User memasukkan data asli kedalam proses preprocessing kemudian data tersebut akan ditransformasi untuk menjadi data yang siap untuk diolah dalam proses berikutnya yaitu proses clustering, lalu User memilih
jenis metode clustering yang akan digunakan, diantaranya metode single-linkage, average-linkage, dan complete-linkage.
Proses kedua, User menekan tombol cluster maka sistem akan memproses clustering terhadap data yang sudah di preprocessing, kemudian akan ditampilkan hasil cluster dan akurasi dari pengujian cluster tersebut.
3.6.3. Data Flow Diagram Level 2
Gambar 3. 9 Diagram Data Flow level 2 clustering
Gambar 3.9 merupakan diagram flow data level 2 proses kedua. dimana akan ditampilkan hasil clustering dalam bentuk dendogram, dan persentasi dari hasil pengujian akurasi pada proses
ini. Terdapat 4 proses dalam diagram data flow level 2 ini. Yang pertama adalah data yang sudah di preprocessing kemudian akan dihitung matrik jaraknya menggunakan metode Euclidean Distance. Proses kedua adalah menghitung cluster single-linkage menggunakan matrik jarak yang sudah diperoleh. Proses ketiga adalah menghitung cluster average-linkage menggunakan matrik jarak yang sudah diperoleh. Proses keempat adalah menghitung cluster complete-linkage menggunakan matrik jarak yang sudah diperoleh. Proses kelima kemudian memproses perhitungan akurasi dengan berdasarkan cluster yang telah terbentuk dan menampilkan hasil perhitungan akurasi beserta dendogram kepada User.
3.7. Penjelasan Proses 3.7.1. Input Data
Data yang telah disiapkan dalam bentuk dokumen Excel akan diinputkan ke dalam sistem untuk kemudian dibaca oleh sistem untuk dilanjutkan pada proses berikutnya yaitu tahap pre-processing.
3.7.2. Pre-processing
Dalam tahap pre-processing ini, peneliti akan mengolah data mentah menjadi data yang siap untuk kemudian dapat diinputkan kedalam sistem. Data mentah pada tahap ini akan di preprocessing secara manual oleh peneliti. Pertama peneliti akan melakukan proses cleaning terhadap data mentah tersebut dengan membersihkan variabel-variabel pada data mentah yang tidak diperlukan seperti program studi, angkatan, nilai notasi, nilai ketukan, nilai solfegio, penguji, dan nilai final. Kemudian juga mengisi nilai variabelnya jika terdapat missing value pada data mentah tersebut dan membuang outlier (data yang sekiranya terlalu banyak noise). Dari proses cleaning, dihasilkan variabel untuk data
siap olah seperti nama, jenis kelamin, jenis suara, range nada, karakter suara, noise, ketebalan suara, dan nada tinggi. Setiap variabel tersebut memiliki attributnya masing-masing seperti berikut :
Tabel 3. 2 Variabel Jenis Kelamin
Jenis Kelamin Pria
Wanita
Tabel 3. 3 Variabel Jenis Suara Jenis Suara
Sopran Alto Tenor Bass
Tabel 3. 4 Variabel Range Nada Range Suara
C4-A6 E3-G5 C3-E5 E2-B4
Tabel 3. 5 Variabel Karakter Suara Karakter Suara
Pop
Tabel 3. 6 Variabel Noise Noise
Tidak Sedang Banyak
Tabel 3. 7 Variabel Ketebalan Suara Ketebalan Suara
Tipis Sedang Tebal
Tabel 3. 8 Variabel Nada Tinggi Nada Tinggi
Tidak Goyang Stabil
Proses berikutnya yaitu transformasi data, pada proses ini, data diolah agar lebih efisien dalam proses data mining serta mempermudah pola yang dihasilkan dengan memberi bobot terhadap beberapa atribut seperti range nada, karakter suara, noise, ketebalan suara, dan nada tinggi sebagai berikut :
Tabel 3. 9 Pembobotan Variabel Jenis Kelamin Jenis Kelamin Bobot
Pria 1
Tabel 3. 10 Pembobotan Variabel Jenis Suara Jenis Suara Bobot
Sopran 1
Alto 2
Tenor 3
Bass 4
Tabel 3. 11 Pembobotan Variabel Range Nada Range Suara Bobot
C4-A6 1
E3-G5 2
C3-E5 3
E2-B4 4
Tabel 3. 12 Pembobotan Variabel Karakter Suara Karakter Suara Bobot
Pop 1
Semi Klassik 2
Tabel 3. 13 Pembobotan Variabel Noise
Noise Bobot
Tidak 1
Sedang 2
Tabel 3. 14 Pembobotan Variabel Ketebalan Suara Ketebalan Suara Bobot
Tipis 1
Sedang 2
Tebal 3
Tabel 3. 15 Pembobotan Variabel Nada Tinggi Nada Tinggi Bobot
Tidak 1
Goyang 2
Stabil 3
3.7.3. Pengukuran jarak
Setelah proses pre-processing selesai, tahap berikutnya adalah menghitung matriks jarak dengan menggunakan metode perhitungan yang ada. Dalam penelitian ini, peneliti akan menggunakan Euclidean Distance.
Berikut adalah data yang belum dihitung jarak kedekatannya yang berjumlah 5 data.
Tabel 3. 16 Contoh 5 data atribut Jenis Kelamin Ra- nge Karakter Suara No-ise Ketebalan Suara Nada Tinggi Jenis Suara data data 1 2 1 1 2 1 2 1 data 2 2 2 1 2 2 1 2 data 3 1 3 1 1 2 2 3 data 4 1 3 1 3 2 3 3 data 5 2 1 1 1 2 2 1
Setelah dihitung jarak kedekatan antar objek menggunakan Euclidean Distance, dihasilkan matriks jarak seperti berikut :
Tabel 3. 17 Contoh matrik jarak 1 2 3 4 5 1 0,00 1,73 2,65 2,83 1,41 2 1,73 0,00 2,00 2,65 1,73 3 2,65 2,00 0,00 2,24 2,24 4 2,83 2,65 2,24 0,00 3,16 5 1,41 1,73 2,24 3,16 0,00 3.7.4. Clustering
Pada tahap ini, setelah pengukuran jarak berhasil mendapatkan matrik jarak untuk data yang dimasukkan, proses clustering atau proses pengelompokan untuk mengelompokkan data seleksi penyanyi paduan suara akan dilakukan. Proses clustering kemudian akan menghasilkan cluster-cluster jenis suara dari data yang sudah diproses. Dalam proses mengelompokkan tiap data tersebut, digunakan metode-metode yang ada didalam Agglomerative Hierarchical Clustering untuk mengukur nilai jarak kedekatannya satu sama lain, yaitu metode Single-linkage yang mengambil nilai jarak paling minimum, metode Average-linkage yang mengambil nilai jarak rata-rata, dan metode Complete-linkage yang mengambil nilai jarak paling maksimum. Ketika proses pengelompokan atau clustering selesai diproses, akan ditampilkan sebuah dendogram yang mempermudah untuk melihat jalan pengelompokan yang telah berlangsung.
Berikut adalah contoh proses clustering terhadap 5 data yang berlangsung :
1. Single-linkage
Tabel 3. 18 Pencarian objek terdekat single iterasi 1
1 2 3 4 5 1 0 1,73 2,65 2,83 1,41 2 1,73 0 2,00 2,65 1,73 3 2,65 2,00 0 3,87 3,32 4 2,83 2,65 3,87 0 2,83 5 1,41 1,73 3,32 2,83 0
Pada matrik jarak yang sudah dihitung menggunakan Euclidean Distance, dicari obyek yang memiliki jarak paling minimum. 1 dan 5 memiliki jarak yang paling dekat, yaitu 1,41. Maka kedua objek tersebut akan digabungkan menjadi satu cluster. Maka cluster saat ini adalah (15), (2), (3), (4). Jarak cluster (15) dengan cluster lainnya sebagai berikut :
D(1 5)2 = min {D1 2, D5 2} = 1,73 D(1 5)3 = min {D1 3, D5 3} = 2,65 D(1 5)4 = min {D1 4, D5 4} = 2,83
Setelah mengetahui jarak cluster yang baru terbentuk (15) dengan cluster lainnya, maka tabel akan berubah sebagai berikut :
Tabel 3. 19 Hasil pencarian objek terdekat single iterasi 1
1,5 2 3 4
1 0 1,73 2,65 2,83
2 1,73 0 2,00 2,65
3 2,65 2,00 0 3,87
Tabel 3. 20 Pencarian objek terdekat single iterasi 2 1,5 2 3 4 1 0 1,73 2,65 2,83 2 1,73 0 2,00 2,65 3 2,65 2,00 0 3,87 4 2,83 2,65 3,87 0
Dari hasil pencarian objek terdekat iterasi 1, kemudian dicari objek yang memiliki jarak minimum. Cluster (15) dan (2) memiliki nilai paling minimum yakni 1,73. Oleh karena itu, kedua cluster tersebut akan digabungkan sehingga cluster saat ini menjadi : (152), (3), (4). Jarak cluster (152) dengan cluster lainnya sebagai berikut :
D(152)3 = min {D15 3, D2 3} = 2,00 D(152)4 = min {D15 4, D2 4} = 2,65
Setelah mengetahui jarak cluster yang baru terbentuk (152) dengan cluster lainnya, maka tabel akan berubah sebagai berikut :
Tabel 3. 21 Hasil pencarian objek terdekat single iterasi 2
1,5,2 3 4
1,5,2 0 2,00 2,65
3 2,00 0 3,87
4 2,65 3,87 0
Tabel 3. 22 Pencarian objek terdekat single iterasi 3
1,5,2 3 4
1,5,2 0 2,00 2,65
3 2,00 0 3,87
4 2,65 3,87 0
Dari hasil pencarian objek terdekat iterasi 2, kemudian dicari objek yang memiliki jarak minimum. Cluster (152)
dan (3) memiliki nilai paling minimum yakni 2,00. Oleh karena itu, kedua cluster tersebut akan digabungkan sehingga cluster saat ini menjadi : (1523) dan (4). Jarak cluster (1523) dengan cluster lainnya sebagai berikut :
D(1523) 4 = min {D152 4, D3 4} = 2,65
Setelah mengetahui jarak cluster yang baru terbentuk (1523) dengan cluster lainnya, maka tabel akan berubah sebagai berikut :
Tabel 3. 23 Hasil cluster Single-linkage
1,5,2,3 4
1,5,2,3 0 2,65
4 2,65 0
Setelah memperoleh 2 cluster, pada langkah terakhir cluster (1523) akan digabung dengan cluster (4) sehingga terbentuk cluster tunggal. Maka dapat digambarkan dendogram dari proses clustering yang sudah dilakukan sebagai berikut :
Pada iterasi pertama, terbentuk cluster dari 1 dan 5, lalu pada iterasi ke-2 cluster 15 bergabung dengan 2 sehingga membentuk cluster 152, kemudian iterasi ke-3 cluster 152 bergabung dengan 3 sehingga membentuk cluster 1523. Pada iterasi ke-3, cluster 1523 dan 4 bergabung sehingga membentuk cluster tunggal. Garis merah pada gambar 3.10 adalah cut-off yang berfungsi unuk melihat pembagian jumlah cluster.
2. Average-linkage
Tabel 3. 24 Pencarian objek terdekat average iterasi 1
1 2 3 4 5 1 0 1,73 2,65 2,83 1,41 2 1,73 0 2,00 2,65 1,73 3 2,65 2,00 0 3,87 3,32 4 2,83 2,65 3,87 0 2,83 5 1,41 1,73 3,32 2,83 0
Pada matrik jarak yang sudah dihitung menggunakan Euclidean Distance, dicari obyek yang memiliki jarak paling minimum. 1 dan 5 memiliki jarak yang paling dekat, yaitu 1,41. Maka kedua objek tersebut akan digabungkan menjadi satu cluster. Maka cluster saat ini adalah (15), (2), (3), (4). Jarak cluster (15) dengan cluster lainnya sebagai berikut :
D(1 5)2 = average {D1 2, D5 2} = 1,73 D(1 5)3 = average {D1 3, D5 3} = 2,99 D(1 5)4 = average {D1 4, D5 4} = 2,83
Setelah mengetahui jarak cluster yang baru terbentuk (15) dengan cluster lainnya, maka tabel akan berubah sebagai berikut :
Tabel 3. 25 Hasil pencarian objek terdekat average iterasi 1 1,5 2 3 4 1 0 1,73 2,99 2,83 2 1,73 0 2,00 2,65 3 2,99 2,00 0 3,87 4 2,83 2,65 3,87 0
Tabel 3. 26 Pencarian objek terdekat average iterasi 2
1,5 2 3 4
1 0 1,73 2,99 2,83
2 1,73 0 2,00 2,65
3 2,99 2,00 0 3,87
4 2,83 2,65 3,87 0
Dari hasil pencarian objek terdekat iterasi 1, kemudian dicari objek yang memiliki jarak minimum. Cluster (15) dan (2) memiliki nilai paling minimum yakni 1,73. Oleh karena itu, kedua cluster tersebut akan digabungkan sehingga cluster saat ini menjadi : (152), (3), (4). Jarak cluster (152) dengan cluster lainnya sebagai berikut :
D(152)3 = average {D15 3, D2 3} = 2,49 D(152)4 = average {D15 4, D2 4} = 2,74
Setelah mengetahui jarak cluster yang baru terbentuk (152) dengan cluster lainnya, maka tabel akan berubah sebagai berikut :
Tabel 3. 27 Hasil pencarian objek terdekat average iterasi 2
1,5,2 3 4
1,5,2 0 2,49 2,74
3 2,49 0 3,87
4 2,74 3,87 0
Tabel 3. 28 Pencarian objek terdekat average iterasi 3
1,5,2 3 4
1,5,2 0 2,49 2,74
3 2,49 0 3,87
4 2,74 3,87 0
Dari hasil pencarian objek terdekat iterasi 2, kemudian dicari objek yang memiliki jarak minimum. Cluster (152) dan (3) memiliki nilai paling minimum yakni 2,49. Oleh karena itu, kedua cluster tersebut akan digabungkan sehingga cluster saat ini menjadi : (1523) dan (4). Jarak cluster (1523) dengan cluster lainnya sebagai berikut :
D(1523) 4 = average {D152 4, D3 4} = 3,31
Setelah mengetahui jarak cluster yang baru terbentuk (1523) dengan cluster lainnya, maka tabel akan berubah sebagai berikut :
Tabel 3. 29 Hasil cluster average-linkage
1,5,2,3 4
1,5,2,3 0 3,31
4 3,31 0
Setelah memperoleh 2 cluster, pada langkah terakhir cluster (1523) akan digabung dengan cluster (4) sehingga terbentuk cluster tunggal. Maka dapat digambarkan dendogram dari proses clustering yang sudah dilakukan sebagai berikut :
Gambar 3. 11 Dendogram cluster average-linkage
Pada iterasi pertama, terbentuk cluster dari 1 dan 5, lalu pada iterasi ke-2 cluster 15 bergabung dengan 2 sehingga membentuk cluser 152, kemudian iterasi ke-3 cluster 152 bergabung dengan 3 sehingga membentuk cluster 1523. Pada iterasi ke-3, cluster 1523 dan 4 bergabung sehingga membentuk cluster tunggal. Garis merah pada gambar 3.11 adalah cut-off yang berfungsi unuk melihat pembagian jumlah cluster.
3. Complete-linkage
Tabel 3. 30 Pencarian objek terdekat complete iterasi 1
1 2 3 4 5 1 0 1,73 2,65 2,83 1,41 2 1,73 0 2,00 2,65 1,73 3 2,65 2,00 0 3,87 3,32 4 2,83 2,65 3,87 0 2,83 5 1,41 1,73 3,32 2,83 0
Pada matrik jarak yang sudah dihitung menggunakan Euclidean Distance, dicari obyek yang memiliki jarak paling minimum. 1 dan 5 memiliki jarak yang paling dekat, yaitu 1,41. Maka kedua objek tersebut akan digabungkan menjadi satu cluster. Maka cluster saat ini adalah (15), (2), (3), (4). Jarak cluster (15) dengan cluster lainnya sebagai berikut :
D(1 5)2 = max {D1 2, D5 2} = 1,73 D(1 5)3 = max {D1 3, D5 3} = 3,32 D(1 5)4 = max {D1 4, D5 4} = 2,83
Setelah mengetahui jarak cluster yang baru terbentuk (15) dengan cluster lainnya, maka tabel akan berubah sebagai berikut :
Tabel 3. 31 Hasil pencarian objek terdekat complete iterasi 1
1,5 2 3 4
1 0 1,73 3,32 2,83
2 1,73 0 2,00 2,65
3 3,32 2,00 0 3,87
4 2,83 2,65 3,87 0
Tabel 3. 32 Pencarian objek terdekat complete iterasi 2
1,5 2 3 4
1 0 1,73 3,32 2,83
2 1,73 0 2,00 2,65
3 3,32 2,00 0 3,87
4 2,83 2,65 3,87 0
Dari hasil pencarian objek terdekat iterasi 1, kemudian dicari objek yang memiliki jarak minimum. Cluster (15) dan (2) memiliki nilai paling minimum yakni 1,73. Oleh karena itu, kedua cluster tersebut akan digabungkan