i
PENGELOMPOKAN PERAN PEMAIN DOTA 2 DALAM
PERTANDINGAN PROFESIONAL DENGAN METODE
AGGLOMERATIVE HIERARCHICAL CLUSTERING
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh
Gelar Sarjana Komputer
Program Studi Teknik Informatika.
DISUSUN OLEH :
Bondan Yudha Pratomo
125314137
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
CLUSTERING ROLE PLAYER DOTA 2 IN A PROFESSIONAL MATCH
WITH AGGLOMERATIVE HIERARCHICAL CLUSTERING
METHODE
A Thesis
Presented as Partial Fulfillment of The Requirements
To Obtain the Sarjana Komputer Degree
In Informatics Engineering Study Program
By :
Bondan Yudha Pratomo
125314137
INFORMATICS ENGINEERING STUDY PROGRAM
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
v
HALAMAN PERSEMBAHAN
“Tetaplah bersyukur dengan apa yang sudah kita miliki , mengeluh hanya
akan menambah beban dari masalah itu sendiri “
Karya ini saya persembahkan kepada : Tuhan Yesus Kristus
Keluarga tercinta, Pacar tercinta, Dosen serta para sahabat dan teman-teman
viii
ABSTRAK
DOTA 2 adalah permainan strategi dimana kita harus bekerja sama dengan pemain yang ada dalam satu tim untuk mengalahkan tim lawan. DOTA 2 merupakan versi terbaru dari DOTA yang dulunya merupakan satu kesatuan dengan WARCRAFT III.Dalam pertandingan DOTA 2 akan menghasilkan sebuah data dimana data ini akan dikelompokan dengan menggunakan Agglomerative Hierarchical Clustering dengan menggunakan 3 Metode yaitu single-linkage,complete-linkage dan average-linkage .
Transformasi Min-Max menjadi yang tertinggi dalam menentukan akurasi dengan 93% karena metode ini mampu melakukan normalisasi hanya pada atribut tertentu tidak semua atribut dimana data pertandingan DOTA 2 ini memiliki 1 atribut yaitu DAMAGE yang harus dinormalisasikan terlebih dahulu karena dapat merusak hasil akurasi,sedangkan menggunakan data asli dan Zscore akurasi yang dihasilkan belum tinggi karena terganggu oleh atribut DAMAGE.Penggunaan PCA(Principal Component Analysis) juga belum mampu menghasilkan akurasi tinggi dikarenakan ada atribut penting yang terpotong.
Dari 3 metode single-linkage,complete-linkage dan average-linkage ,
complete-linkage dan average-linkage menjadi metode dengan rata-rata akurasi tertinggi dan single-linkage menghasilkan rata-rata terendah.
ix
ABSTRACT
DOTA 2 is a strategy game in which we must work closely with the existing players in the team to defeat the opposing team. DOTA 2 is the latest version of DOTA which used to be an integral part of the game Warcraft III. The outcome of the match DOTA 2 will produce a data on which this data will be grouped by using Agglomerative Hierarchical Clustering by using three methods, namely single-linkage, complete linkage and average-linkage ,
Transformation Min-Max to be the highest in determining the accuracy by 93% because this method is able to normalize only on certain attributes are not all attributes where data matches DOTA 2 has one attribute that is DAMAGE that should be normalized in advance because it can decrease the accuracy results, while using Zscore and original data the resulting accuracy is not high because the attributes DAMAGE.Using data reduction by PCA (Principal Component Analysis) also has not been able to produce a high accuracy because there are important attributes are truncated.
Of the three methods of single-linkage, complete linkage and average-linkage, complete linkage and average linkage being a method to the average of the highest accuracy and single-linkage produces the lowest average.
x
KATA PENGANTAR
Puji dan syukur penulis panjatkan kepada Tuhan Yesus Kristus atas segala rahmat dan berkat yang telah diberikan sehingga penulis dapat menyelesaikan
tugas akhir yang berjudul “ Pengelompokan Peran Pemain DOTA 2 Pertandingan International dengan Pendekatan Agglomerative Clustering” sebagai salah satu
syarat memperoleh gelar sarjana pada program studi Teknik Informatika Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta
Dalam penulisan karya ilmiah ini penulis juga tidak lupa mengucapkan terima kasih kepada pihak-pihak yang telah membantu dan juga memberi semangat dalam pengerjaan karya ini.Ucapan terima kasih penulis ucapkan kepada :
1. Tuhan Yesus Kristus yang selalu memberikan berkat serta karunia-Nya yang melimpah dalam mengerjakan karya ini. 2. Keluarga, Bapak Yohanes Basuki , Ibu Mimin Purwanti , dan
adik Yos Rio Puraga ,Kornael Damar Kusuma yang telah memberikan semangat yang sangat membantu penulis dalam pengerjaan,doa ,dan dukungan berupa material dan non-material.
3. Romo Dr.Cyprianus Kuntoro Adi, S.J. M.A., M.Sc. selaku dosen pembimbing yang dengan sabar memberikan bimbingan dan pengarahan yang terbaik dalam pengerjaan tugas akhir ini. 4. Vita Deovita Karlina yang selalu memberikan waktunya untuk
menyemangati ,memberikan motivasi,semangat ,bantuan dan menjadi penghibur dikala pengerjaan tugas akhir ini menemui masalah.
xi
6. Seluruh teman-teman semua yang banyak membantu dalam memberikan motivasi ,ilmu,semangat dan juga penghibur dalam pengerjaan tugas akhir ini.
Penulis menyadari masih banyak kekurangan dalam penulisan tugas akhir ini .Kritik dan saran akan yang membangun diharapkan akan memperbaiki penelitian ini di masa yang akan mendatang.semoga informasi pada penulisan tugas akhir ini bermanfaat bagi pembaca.
Yogyakarta, Februari 2017
xii
DAFTAR ISI
HALAMAN JUDUL ... i
HALAMAN JUDUL (INGGRIS) ... ii
HALAMAN PERSETUJUAN SKRIPSI ... iii
HALAMAN PENGESAHAN SKRIPSI ... iv
HALAMAN PERSEMBAHAN ... v
PERNYATAAN KEASLIAN KARYA ... vi
LEMBAR PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS ... vii
ABSTRAK ... viii
ABSTRACT ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR GAMBAR ... xv
DAFTAR TABEL ... xvii
BAB I PENDAHULUAN ... 1
1.1. Latar Belakang ... 1
1.2. Rumusan Masalah ... 3
1.3. Batasan Masalah ... 3
1.4. Tujuan Penelitian ... 3
1.5. Manfaat Penelitian ... 4
BAB II LANDASAN TEORI ... 5
2.1. Knowledge Discovery in Database ... 5
2.2. Pengertian Clustering ... 8
2.2.1. Tipe Clustering ... 8
xiii
2.2.3. Konsep Agglomerative Hierarchical Clustering ... 10
2.3. Dimensionality Reduction ... 22
2.4. Permainan DOTA 2 ... 23
2.5. Pengujian Keakuratan Metodel ... 25
BAB III METODOLOGI PENELITIAN ... 27
3.1. Gambaran Umum ... 27
3.2. Desain Penelitian ... 28
3.2.1. Studi Literatur ... 28
3.2.2. Pengumpulan Data ... 28
3.2.3. Perancangan Alat Uji ... 30
3.3. Analisa Kebutuhan Proses ... 32
3.4. Implementasi Perancangan ... 34
3.4.1. Diagram Konteks ... 34
3.4.2. Data Flow Diagram Level 1 ... 36
3.4.3. Data Flow Diagram Level 2 ... 37
3.5. Penjelasan Proses ... 39
3.5.1. Baca Data ... 39
3.5.2. Pre-processing ... 39
3.5.3. Pengukuran Jarak ... 41
3.5.4. Clustering ... 41
3.5.5. Perhitungan Akurasi Confusion Matrix ... 44
3.6. Perancangan Antar Muka Alat Uji ... 45
3.7. Spesifikasi Hardware dan Software ... 47
BAB IV IMPLEMENTASI HASIL DAN ANALISIS ... 48
4.1. Hasil Penelitian dan Analisis ... 48
xiv
BAB V KESIMPULAN DAN SARAN ... 76
5.1. Kesimpulan ... 76
5.2. Saran ... 77
DAFTAR PUSTAKA ... 78
LAMPIRAN ... 79
A. Tabel Data Pertandingan ... 119
xv
DAFTAR GAMBAR
Gambar Keterangan Halaman
2.1 Proses pengolahan data 5
2.2 Pengelompokan cluster dendrogram dan kedekatan data
10
2.3 Perbedaan perhitungan jarak 11
2.4 Hasil dendrogram untuk cluster single-linkage 16 2.5 Hasil dendrogram untuk cluster single-linkage 18 2.6 Hasil dendrogram untuk cluster average-linkage 20
2.7 Hero-hero pada DOTA 2 23
3.1 Diagram Blok 27
3.2 Hasil pertandingan DOTA 2 29
3.3 Diagram blok proses clustering 34
3.4 Diagram blok proses perhitungan akurasi 34
3.5 Diagram konteks proses clustering 35
3.6 Diagram DFD level 1 36
3.7 Diagram DFD level 2 untuk preprocesing 37 3.8 Diagram DFD level 2 untuk clustering data 38
3.9 contoh dendrogram single-linkage 42
3.10 contoh dendrogram complete-linkage 43
3.11 contoh dendrogram average-linkage 44
3.12 User interface alat uji 45
4.1 grafik akurasi tanpa PCA 51
4.2 grafik akurasi dengan menggunakan PCA 54 4.3 Grafik hasil akurasi dari normalisasi 55
4.4 1 Grafik hasil akurasi dari metode 56
4.5 Grafik hasil akurasi dari PCA 57
4.6 Dendrogram single-linkage data asli 58
4.7 dendrogramaverage-linkage data asli 59
4.8 Dendrogram complete-linkage data asli 60 4.9 Dendrogram single-linkage data Z-score 61 4.10 Dendrogram complete-linkage data Z-score 62 4.11 Dendrogram average-likage data Z-score 62 4.12 Dendrogram single-linkage data MinMax 64 4.13 Dendrogram complete-linkage data MinMax 65 4.14 Dendrogram average-linkage data MinMax 66 4.15 Dendrogram single-linkage data asli + PCA 67 4.16 Dendrogram compelte-linakge data asli + PCA 68 4.17 Dendrogram average-linakge data asli + PCA 69 4.18 Dendrogram single-linakge data Z-score + PCA 70 4.19 Dendrogram complet-linkage data Z-score +
PCA
71
4.20 Dendrogram average-linkage data Z-score + PCA
xvi
4.22 Dendrogram complete-linkage data MinMax + PCA
74 4.23 Dendrogram average-linkage data MinMax +
PCA
74
DAFTAR TABEL
Tabel Keterangan Halaman
2.1 Contoh data 13
2.2 Hasil Euclidean disteance dari contoh data 13 2.3 pencarian jarak terdekat single iterasi 1 13 2.4 Hasil pencarian jarak terdekat single iterasi 1 14 2.5 Pencarian jarak terdekat single iterasi 2 14 2.6 Hasil pencarian jarak terdekat single iterasi 2 15 2.7 1 Pencarian jarak terdekat single iterasi 3 15
2.8 Hasil cluster single-linkage 15
2.9 Pencarian jarak terdekat complete iterasi 1 16 2.10 Hasil pencarian jarak terdekat complete iterasi 1 17 2.11 Pencarian jarak terdekat complete iterasi 17 2.12 Pencarian jarak terdekat complete iterasi 3 17 2.13 Hasil pencarian jarak terdekat complete iterasi 3 18
2.14 Hasil cluster complete-linkage 18
2.15 Hasil pencarian jarak terdekat average iterasi 1 19 2.16 Pencarian jarak terdekat average iterasi 2 20 2.17 Hasil pencarian jarak terdekat average iterasi 2 20 2.18 Pencarian jarak terdekat average iterasi 3 20
2.19 Hasil cluster average-linkage 20
2.20 Tabel kebenaran 26
3.1 Penjelasan atribut data 29
3.2 contoh matrix data 41
3.3 Tabel evaluasi confusion matrix 44
3.4 Penjelasan fungsi user interface alat uji 45
4.1 Deskripsi masing-masing peran 48
4.2 Contoh perbedaan damage hero berdasarkan peran
49
4.3 perbandingan akurasi tanpa PCA 50
4.4 perbandingan akurasi dengan menggunakan PCA 53
4.5 Hasil akurasi dari normalisasi 54
4.6 Hasil akurasi dari metode 55
4.7 Hasil akurasu dari PCA 56
xvii
4.13 Confusion matrix single-linkage Z-score 61 4.14 Confusion matrix Complete-linkage data asli 62 4.15 Confusion matrix Average-linkage data asli 63 4.16 hasil akurasi dengan normalisasi MinMax 63 4.17 Confusion matrix single-linkage MinMax 64 4.18 Confusion matrix Complete-linkage MinMax 65 4.19 Confusion matrix Average-linkage MinMax 66 4.20 data asli tanpa normalisasi dan PCA 67 4.21 Confusion matrix single-linkage data asli + PCA 67 4.22 Confusion matrix Complete-linkage data asli +
PCA
68 4.23 Confusion matrix Average-linkage data asli +
PCA
69 4.24 hasil akurasi normalisasi Z-score dan PCA 70 4.25 Confusion matrix single-linkage Z-score + PCA 70 4.26 Confusion matrix Complete-linkage Z-score +
PCA
71 4.27 Confusion matrix Average-linkage Z-score +
PCA
72 4.28 hasil akurasi dengan normalisasi MinMax dan
PCA
73 4.29 Confusion matrix single-linkage MinMax + PCA 73 4.30 Confusion matrix Complete-linkage MinMax +
PCA
74 4.31 Confusion matrix Average-linkage MinMax +
PCA
1
BAB 1
PENDAHULUAN
Pada Bab ini akan dijelaskan mengenai latar belakang yang akan dijadikan acuan dalam pembuatan penelitian,rumusan masalah yang akan penulisa selesaikan dalam penelitian ini ,tujuan penelitian ,manfaat penelitian dan juga metodologi penelitian dalam pengambilan data.
1.1.Latar Belakang
Pada perkembangan teknologi yang sangat pesat pada jaman ini memiliki dampak buruk serta juga baiknya,salah satunya adalah Game Online.Game online di Indonesia masih dipandang sebagai sesuatu yang buruk oleh masyarakat karena banyaknya anak-anak mereka kecanduan dalam game online.Tidak semua game buruk ,ada beberapa game yang menghasilkan uang jika kita menekuni game tersebut dalam arti menekuni jangan sampai kencanduan .Salah satu cabang game yang sedang ramai dalam pertandingan-pertandingan lokal bahkan sudah mencapai seluruh dunia adalah E-Sport.
E-sports juga dikenal sebagai Electronic sports - Professional gaming. Ini adalah jenis olahraga dimana semua aspek utama dari olahraga sesungguhnya difasilitasi oleh sistem elektronik (Houston,Senz 2016). Ini berarti input dari team dan player maupun output dari "actual esports sistem" dimediasi oleh interface yang terdiri dari manusia dan komputer.Penjelasan paling sederhana, eSports adalah kompetisi-kompetisi yang sudah terorganisasi untuk multiplayer video games antara player-player yang telah menjadikan gaming sebagai profesi mereka sesungguhnya. Genre yang paling sering ditemui di eSports adalah MOBA (multiplayer online battle arena), FPS (First Person Shooter), Fighting (street fighter) dan real time strategy games.Kompetisi-kompetisi ini menyediakan live
broadcast dengan produksi yang sangat luar biasa, disertai dengan uang hadiah dan fasilitas yang sangat menjanjikan untuk para juara dan peserta.
2
banyakan kompetisi-kompetisi eSports yang mulai dilirik oleh channel TV seperti ESPN, TURNER, bahkan ASTRO Malaysia mempunyai channel Egg Network yang mana merupakan channel eSports pertama di Asia Tenggara.
Salah satu pilihan atau kesempatan adalah eSports. Dengan proyeksi perkembangan yang ada saat ini, bisa dipastikan kalau esports adalah "thing of the future", sebagian besar dari kita menghabiskan sebagian besar waktu kita di depan
gadget atau PC atau device kita oleh karena itu diadakan e-sports untuk menghasilkan uang juga.
Game E-Sports yang sedang digeluti salah satunya adalah DOTA 2 , DOTA 2 adalah permainan strategi dimana kita harus bekerja sama dengan pemain yang ada dalam satu tim untuk menjatuhkan markas tim lawan. DOTA 2 merupakan versi terbaru dari DOTA yang dulunya merupakan satu kesatuan dengan WARCRAFT III. DOTA dan DOTA 2 tidak jauh berbeda dari segi HERO (sebutan karakter atau unit pada game yang bisa kita kendalikan) yang dapat kita pilih dan item yang dapat kita beli. Namun pada DOTA 2 visual yang ditampilkan jauh lebih bagus dan sistem pembelian item yang lebih mudah . Dalam permainan DOTA 2 juga terdapat pembagian peran yaitu Carry,Support,dan juga Hard-support , peran Carry sangat penting dalam tim karena bertugas dalam membawa
3
pemain dalam pertandingan yang dia mainkan dimana dari hasil yang sudah dicluster akan digunakan untuk menempatkan pemain baru diposisi yang tepat.
1.2.Rumusan Masalah
Apakah penggunaan metode Agglomerative Hierarchical Clustering mampu mengelompokan peran pemain dalam pertandingan professional DOTA 2 dengan dataset pemain profesional untuk menempatkan pemain baru diposisi yang tepat?
1.3.Batasan Masalah
Agar dalam pembahasan nantinya tidak panjang lebar, maka penulis membatasi beberapa masalah yang akan dibahas, diantaranya:
1. Menggunakan data pertandingan Turnamen DOTA 2 profesional pada tahun 2016
2. Metode yang digunakan Algoritma Agglomerative Hierarchical Clustering meliputi Single-linkage, Complete-linkage dan Avarage-Linkage.
3. Hanya membagi kedalam 3 peran yaitu Carry,Support,Hard-support. 4. Data pertandingan hanya diambil dengan durasi 40 menit sampai 50 menit.
1.4.Tujuan Penelitian
4
1.5. Manfaat Penelitian
1. Manfaat Praktis
Bagi penulis, manfaat praktis yang di harapakan adalah dengan adanya penelitian yang penulis teliti diharapkan dapat memperluas wawasan dan memperoleh pengetahuan baru tentang mengelompokan data pertandingan DOTA 2 ,dimana game belum terlalu banyak dalam sebuah penelitian.
2. Manfaat Akademis
5
BAB 2
LANDASAN TEORI
Pada bab ini akan dijelaskan bagaimana cara penulis mendapatkan informasi dalam pengerjaan karya ini ,dan agar tentunya landasan teori ini dapat
mempertanggung jawabkan hasil akhir dari penelitian ini.
2.1 Knowledge Discovery in Database
Knowledge Discovery and Data Mining(KDD) adalah proses yang dibantu
oleh komputer untuk menggali dan menganalisis sejumlah besar himpunan data dan mengekstrak informasi dan pengetahuan yang berguna. Data mining tools memperkirakan perilaku dan tren masa depan, memungkinkan bisnis untuk
membuat keputusan yang proaktif dan berdasarkan pengetahuan. Data mining tools mampu menjawab permasalahan bisnis yang secara tradisional terlalu lama
untuk diselesaikan. Data mining tools menjelajah database untuk mencari pola tersembunyi, menemukan infomasi yang prediktif yang mungkin dilewatkan para pakar karena berada di luar ekspektasi mereka.Proses KDD terdiri dari 5 proses seperti terlihat pada gambar di bawah.Akan tetapi , dalam proses KDD yang sesungguhnya ,dapat saja terjadi iterasi atau pengulangan pada tahap tertentu.Pada setiap tahap dalam proses KDD,bisa saja dapat kembali ke tahap sebelumnya.Sebagai contoh pada saat coding atau data mining,ada proses cleaning yang belum dilakukan dengan sempurna, kemudian menemukan informasi baru
untuk memperkaya data yang sudah ada.
6 1. Data Selection
Menciptakan himpunan data target , pemilihan himpunan data, atau memfokuskan pada subset variabel atau sampel data, dimana penemuan (discovery) akan dilakukan.Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari basis data operasional.
2. Pre-processingatau Cleaning
Pemprosesan pendahuluan dan pembersihan data merupakan operasi dasar seperti penghapusan noise dilakukan.Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi fokus KDD.Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak
(tipografi).Dilakukan proses enrichment, yaitu proses “memperkaya” data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
3. Transformation
Pencarian fitur-fitur yang berguna untuk mempresentasikan data bergantung kepada goal yang ingin dicapai.Merupakan proses transformasi pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses ini merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data .Dalam penelitian ini menggunakan 2 normalisasi yaitu Z-score dan MinMax
a. Normalisasi Z-score
Disebut juga zero-mean normalization, dimana value dari sebuah atribut A dinormalisasi berdasarkan nilai rata-rata dan standar deviasi dari atribut A. Sebuah value v dari atribut A dinormalisasi menjadi v' dengan rumus:
7
(2.1) Keterangan : - ̅ = adalah rata-rata dari nilai
-
σ
A = adalah standar deviasi dari atribut A- v = adalah nilai yang ingin diubah - v’ = adalah hasil Z-score
b. Normalisasi MinMax
MinMax normalization memetakan sebuah value v dari atribut A
menjadi v' ke dalam range [new_minA, new_maxA] berdasarkan rumus:
(2.2) Keterangan :
- v = adalah nilai yang akan dinormalisasi - v’=adalah nilai hasil normalisasi
- min = adalah nilai minimal lama dari nilai v - max = adalah nilai maksimal lama dari nilai v
- new_min = adalah nilai minimal baru sesuai kebutuhan - new_max = adalah nilai maksimal baru sesuai kebutuhan
4. Data mining
8
metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
5. Interpretationatau Evaluation
Penerjemahan pola-pola yang dihasilkan dari data mining.Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah mimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDD yang mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesa yang ada sebelumnya.
2.2 Pengertian Clustering
Menurut Han dan Kamber (2011), Clustering adalah proses pengelompokkan kumpulan data menjadi beberapa kelompok sehingga objek di dalam satu kelompok memiliki banyak kesamaan dan memiliki banyak perbedaan dengan objek dikelompok lain. Perbedaan dan persamaannya biasanya berdasarkan nilai atribut dari objek tersebut dan dapat juga berupa perhitungan jarak. Clustering sendiri juga disebut Unsupervised Classification, karena clustering lebih bersifat untuk dipelajari dan diperhatikan. Cluster analysis
merupakan proses partisi satu set objek data ke dalam himpunan bagian. Setiap himpunan bagian adalah cluster, sehingga objek yang di dalam cluster mirip satu sama dengan yang lainnya, dan mempunyai perbedaan dengan objek dari cluster yang lain. Partisi tidak dilakukan dengan manual tetapi dengan algoritma clustering. Oleh karena itu,clustering sangat berguna dan bisa menemukan group
yang tidak dikenal dalam data.
2.2.1 Tipe Clustering
9 1. Partitional vs Hierarchical
Partitional clustering adalah pembagian objek data kedalam sub himpunan(cluster) yang tidak overlap sedemikian hingga tiap objek data berada dalam tepat satu sub-himpunan.Hierarchical clustering merupakan sebuah himpunan cluster bersarang yang diatur sebagai suatu pohon hirarki.Tiap simpul(cluster) dalam pohon(kecuali simpul daun) merupakan gabungan dari anaknya(subcluster) dan simpul akar berisi semua objek
2. Exclusive vs non-exclusive
Semua bentuk clustering merupakan exclusive clustering ,karena setiap objek berada tepat pada satu cluster.sebaliknya dalam overlapping atau non-exclusive clustering ,sebuah objek dapat berada di lebih dari satu
cluster secara bersamaan.
3. Fuzzy vs non-Fuzzy
Dalam fuzzy clustering ,sebuah titik termasuk dalam setiap cluster
dengan suatu nilai bobot antara 0 dan 1.jumlah dari bobot-bobot tersebut sama dengan 1.clustering probabilitas mempunyai karakteristik yang sama.
4. Partial vs Complete
Dalam complete clustering ,setiap objek ditempatkan dalam sebuah
cluster.Tetapi dalam partial clustering,tidak semua objek ditempatkan dalam sebuah cluster.kemungkinan ada objek yang tidak tepat untuk ditempatkan di salah satu cluster,misalkan berupa outlier atau noise.
2.2.2 Pengertian Hierarchical Clustering
10
pohon yang berfungsi sebagai diagram yang mencatat urutan dari penggabungan atau pemisahan seperti pada gambar berikut :
Ada dua tipe utama hierarchical clustering , yaitu divisive dan agglomerative (Tan,Steinbach,dkk 2004) :
Agglomerative:
1. Mulai dengan titik-titik sebagai individual clusters.
2. Pada tiap langkah,gabungkan pasangan cluster terdekat sampai hanya
terdapat satu cluster (atau k cluster) yang tersisa
Divisive :
1. Mulai dengan satu,semua inclusive cluster.
2. Pada tiap langkah,pisahkan sebuah cluster sampai tiap cluster terdiri dari
sebuah titik(atau ada k cluster).
Tradisional algoritma hirarikal menggunakan sebuah matriks similaritas atau matriks jarak dengan menggabungkan atau memisahkan satu cluster dalam tiap langkahnya.
2.2.3 Konsep AgglomerativeHierarchical Clustering
11
halnya dengan partition-based clustering, bisa juga memilih jenis jarak yang digunakan untuk menghitung tingkat kemiripan antar data.
Salah satu cara untuk mempermudah pengembangan dendogram untuk hierarchical clustering ini adalah dengan membuat similarity matrix yang memuat tingkat kemiripan antar data yang dikelompokkan. Tingkat kemiripan bisa dihitung dengan berbagai macam cara seperti dengan Euclidean distance. Berawal dari similarity matrix ini, dapat menggunakan lingkage jenis mana yang akan digunakan untuk mengelompokkan data yang dianalisa.Berikut adalah langkah dalam pengelompokan dengan agglomerative clutering :
1) Hitung matrix jarak,jika diperlukan 2) Ulangi langkah 3 dan 4,
3) Gabungkan 2 cluster terdekat
4) Kemudian perbarui matrix jarak antara 2 cluster terdekat pada langkah 3 kemudian bentuk cluster baru
5) Sampai hanya tersisa sati cluster(Tan,Steinbach,dkk 2004)
Untuk perhitungan jarak Single-linkage, Complete-linkage dan
Average-linkageseprti pada rumus berikut :
a. Single-linkage merupakan merupakan jarak minimum antara setiap data terdekat. Metode ini akan mengelompokkan dua objek yang mempunyai jarak terdekat terlebih dahulu, dapat didefinisikan sebagai berikut :
d
(
i
,
j
)
k
= min(
dik
,
djk
)
12
(2.3)
Keterangan : - Jarak terkecil antar kelompok (I,j) dengan k
b. Complete-linkage merupakan merupakan jarak maximum antara setiap data terdekat, Metode ini akan mengelompokkan dua objek yang mempunyai jarak terjauh terlebih dahulu, dapat didefinisikan sebagai berikut :
d
(
i
,
j
)
k
= Max(
dik
,
djk
)
(2.4) Keterangan :
- Jarak terbesar antar kelompok (I,j) dengan k
c. Average-linkage merupakan merupakan rata-rata jarak antara setiap data terdekat. Metode ini mengelompokkan objek berdasarkan jarak rata-rata yang didapat dengan melakukan rata-rata-rata-rata semua jarak objek terlebih dahulu. dapat didefinisikan sebagai berikut :
d
(
i
,
j
)
k
= Average(
dik
,
djk
)
(2.5) Keterangan :
- Jarak rata-rata antar kelompok (I,j) dengan k
Pada sistem ini menggunakan Single-linkage,Complete-linkage dan
Avarage-Linkage ,dibawah ini adalah contoh data yang belum dihitung jarak kedekatanya . Dalam penelitian ini menghitung jarak kedekatan dengan Euclidean distance
13
(2.6) Keterangan :
- n adalah jumlah atribut atau dimensi
- Pk dan Qk adalah data yang akan dihitung jaraknya
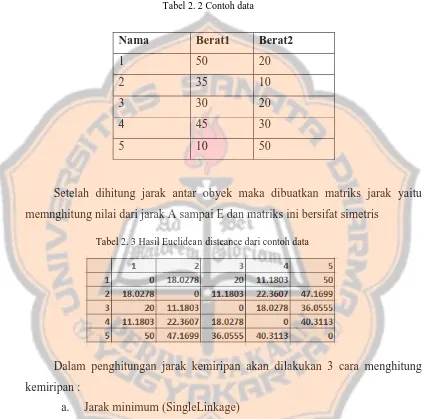
Tabel 2. 2 Contoh data
Setelah dihitung jarak antar obyek maka dibuatkan matriks jarak yaitu memnghitung nilai dari jarak A sampai E dan matriks ini bersifat simetris
Dalam penghitungan jarak kemiripan akan dilakukan 3 cara menghitung kemiripan :
a. Jarak minimum (SingleLinkage)
Pada Single-linkage kemiripan data dicari dari nilai jarak yang paling minimum yaitu 11.1803 pada titik 1,4
Nama Berat1 Berat2
1 50 20
2 35 10
3 30 20
4 45 30
5 10 50
Tabel 2. 3 Hasil Euclidean disteance dari contoh data
14
Pertama adalah mencari nilai minimum pada matrix kedekatan yang sudah dihitung menggunakan Euclidean distance ,yaitu 1 dan 4 memiliki nilai minimum kemudian kedua objek tersebut digabungkan menjadi cluster (14) ,dan objek lain yang tersisa adalah 2,3 dan 5 .dengan jarak :
Min {2,1 dan 2,4} = 18,0278 Min {3,1 dan 3,4} = 18,0278 Min {5,1 dan 5,4} = 40.3113
Setelah mendapatkan nilai minimalnya hapus objek 1 atau 4 untuk membentuk 1 cluster baru yaitu (14).maka akan menjadi table seperti di bawah dengan cluster baru yaitu (14).
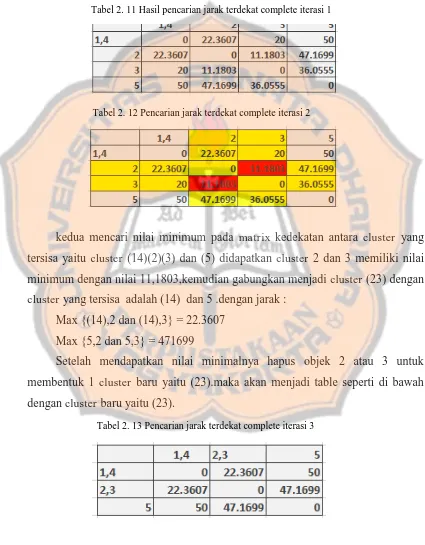
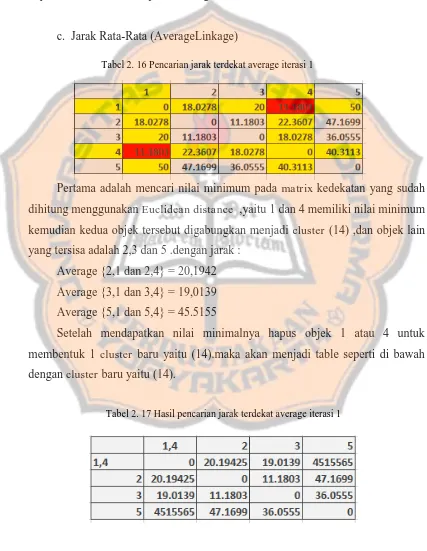
kedua mencari nilai minimum pada matrix kedekatan antara cluster yang tersisa yaitu cluster (14)(2)(3) dan (5) didapatkan cluster 2 dan 3 memiliki nilai minimum dengan nilai 11,1803,kemudian gabungkan menjadi cluster (23) dengan
cluster yang tersisa adalah (14) dan 5 .dengan jarak : Min {(14),2 dan (14),3} = 18,0278
Min {5,2 dan 5,3} = 36.0555
Setelah mendapatkan nilai minimalnya hapus objek 2 atau 3 untuk membentuk 1 cluster baru yaitu (23).maka akan menjadi table seperti di bawah dengan cluster baru yaitu (23).
Tabel 2. 5 Hasil pencarian jarak terdekat single iterasi 1
15
ketiga mencari nilai minimum pada matrix kedekatan antara cluster yang tersisa yaitu cluster (14)(23) dan (5) didapatkan cluster (14) dan (23) memiliki nilai minimum dengan nilai 18,0278,kemudian gabungkan menjadi cluster (1423) dengan cluster yang tersisa adalah 5 .dengan jarak :
Min {(1423),5 dan (1423),5} = 36.0555
Setelah mendapatkan nilai minimalnya hapus objek 14 atau 23 untuk membentuk 1 cluster baru yaitu (1423).maka akan menjadi table seperti di bawah dengan cluster baru yaitu (1423).
Setelah terbentuk menjadi 2 cluster kita dapat menggambarkan dendogramnya sebagai berikut :
Tabel 2. 8 Pencarian jarak terdekat single iterasi 3
16
Cluster 1 dan 4 adalah cluster yang terbentuk pertama , kemudian pada 2 dan 3 adalah pembentukan cluster ke 2 , kemudian pada pembentukan cluster
ketiga cluster 14 dan 23 bergabung menjadi cluster 1423 , kemudian tersisa
cluster 5 yang otomatis menjadi cluster terakhir dan bergabung bersama cluster
1423 menjadi 1 cluster utuh yaitu 14235, untuk melihat pembagian cluster kita
dapat melakukan cut-off pada dendogram.
b. Jarak Maximum (CompleteLinkage)
Pertama adalah mencari nilai minimum pada matrix kedekatan yang sudah dihitung menggunakan Euclidean distance ,yaitu 1 dan 4 memiliki nilai minimum kemudian kedua objek tersebut digabungkan menjadi cluster (14) ,dan objek lain yang tersisa adalah 2,3 dan 5 .dengan jarak :
Max {2,1 dan 2,4} = 22.3607 Max {3,1 dan 3,4} = 20
Gambar 2. 4 Hasil dendrogram untuk cluster single-linkage
17 Max {5,1 dan 5,4} = 50
Setelah mendapatkan nilai minimalnya hapus objek 1 atau 4 untuk membentuk 1 cluster baru yaitu (14).maka akan menjadi table seperti di bawah dengan cluster baru yaitu (14).
kedua mencari nilai minimum pada matrix kedekatan antara cluster yang tersisa yaitu cluster (14)(2)(3) dan (5) didapatkan cluster 2 dan 3 memiliki nilai
minimum dengan nilai 11,1803,kemudian gabungkan menjadi cluster (23) dengan
cluster yang tersisa adalah (14) dan 5 .dengan jarak : Max {(14),2 dan (14),3} = 22.3607
Max {5,2 dan 5,3} = 471699
Setelah mendapatkan nilai minimalnya hapus objek 2 atau 3 untuk membentuk 1 cluster baru yaitu (23).maka akan menjadi table seperti di bawah dengan cluster baru yaitu (23).
Tabel 2. 11 Hasil pencarian jarak terdekat complete iterasi 1
Tabel 2. 12 Pencarian jarak terdekat complete iterasi 2
18
ketiga mencari nilai minimum pada matrix kedekatan antara cluster yang tersisa yaitu cluster (14)(23) dan (5) didapatkan cluster (14) dan (23) memiliki nilai minimum dengan nilai 18,0278,kemudian gabungkan menjadi cluster (1423)
dengan cluster yang tersisa adalah 5 .dengan jarak : Max {(1423),5 dan (1423),5} = 50
Setelah mendapatkan nilai minimalnya hapus objek 14 atau 23 untuk membentuk 1 cluster baru yaitu (1423).maka akan menjadi table seperti di bawah dengan cluster baru yaitu (1423).
Setelah terbentuk menjadi 2 cluster kita dapat menggambarkan dendogramnya sebagai berikut :
Tabel 2. 14 Hasil pencarian jarak terdekat complete iterasi 3
Tabel 2. 15 Hasil cluster complete-linkage
19
Cluster 1 dan 4 adalah cluster yang terbentuk pertama , kemudian pada 2 dan 3 adalah pembentukan cluster ke 2 , kemudian pada pembentukan cluster
ketiga cluster 14 dan 23 bergabung menjadi cluster 1423 , kemudian tersisa
cluster 5 yang otomatis menjadi cluster terakhir dan bergabung bersama cluster
1423 menjadi 1 cluster utuh yaitu 14235, untuk melihat pembagian cluster kita dapat melakukan cut-off pada dendogram.
c. Jarak Rata-Rata (AverageLinkage)
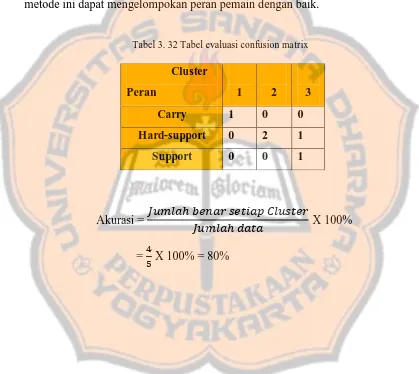
Pertama adalah mencari nilai minimum pada matrix kedekatan yang sudah dihitung menggunakan Euclidean distance ,yaitu 1 dan 4 memiliki nilai minimum kemudian kedua objek tersebut digabungkan menjadi cluster (14) ,dan objek lain yang tersisa adalah 2,3 dan 5 .dengan jarak :
Average {2,1 dan 2,4} = 20,1942 Average {3,1 dan 3,4} = 19,0139 Average {5,1 dan 5,4} = 45.5155
Setelah mendapatkan nilai minimalnya hapus objek 1 atau 4 untuk membentuk 1 cluster baru yaitu (14).maka akan menjadi table seperti di bawah dengan cluster baru yaitu (14).
Tabel 2. 16 Pencarian jarak terdekat average iterasi 1
20
kedua mencari nilai minimum pada matrix kedekatan antara cluster yang
tersisa yaitu cluster (14)(2)(3) dan (5) didapatkan cluster 2 dan 3 memiliki nilai minimum dengan nilai 11,1803,kemudian gabungkan menjadi cluster (23) dengan
cluster yang tersisa adalah (14) dan 5 .dengan jarak : Average {(14),2 dan (14),3} = 19,604
Average {5,2 dan 5,3} = 41.6127
Setelah mendapatkan nilai minimalnya hapus objek 2 atau 3 untuk membentuk 1 cluster baru yaitu (23).maka akan menjadi table seperti di bawah dengan cluster baru yaitu (23).
ketiga mencari nilai minimum pada matrix kedekatan antara cluster yang tersisa yaitu cluster (14)(23) dan (5) didapatkan cluster (14) dan (23) memiliki nilai minimum dengan nilai 18,0278,kemudian gabungkan menjadi cluster (1423) dengan cluster yang tersisa adalah 5 .dengan jarak :
Average {(1423),5 dan (1423),5} = 43.384
Tabel 2. 19 Hasil pencarian jarak terdekat average iterasi 2
21
Setelah mendapatkan nilai minimalnya hapus objek 14 atau 23 untuk membentuk 1 cluster baru yaitu (1423).maka akan menjadi table seperti di bawah dengan cluster baru yaitu (1423).
Setelah terbentuk menjadi 2 cluster kita dapat menggambarkan dendogramnya sebagai berikut :
Cluster 1 dan 4 adalah cluster yang terbentuk pertama , kemudian pada 2 dan 3 adalah pembentukan cluster ke 2 , kemudian pada pembentukan cluster
ketiga cluster 14 dan 23 bergabung menjadi cluster 1423 , kemudian tersisa
cluster 5 yang otomatis menjadi cluster terakhir dan bergabung bersama cluster
1423 menjadi 1 cluster utuh yaitu 14235, untuk melihat pembagian cluster kita dapat melakukan cut-off pada dendogram.
Tabel 2. 21 Hasil cluster average-linkage
22 2.3 Dimensionality Reduction
Dimensionality Reduction adalah sebuah proses untuk mengurangi dimensi daa dari data yang berdimensi besar menjadi data yang berdimensi kecil.Ada dua teknik dalam Dimensionality Reduction ini,yaitu feature selection dan feature extraction .Feature selection adalah memilih feature yang berpengaruh untuk data tersebut yang diambil dari sekumpulan data asli. Dalam Feature extraction
membentuk sebuah feature baru berdasarkan feature yang lama dengan dimensi lebih sedikit dibandingkan dengan sebelumnya.
Metode yang digunakan adalah PCA(principal component analysis).Tujuan dari principal component analysis adalah suatu teknik statistik untuk mengubah dari sebagian besar variabel asli yang digunakan dan saling berkorelasi satu dengan yang lainnya menjadi satu set variabel baru yang lebih kecil dan tidak berkorelasi (Web 1). Setiap 4 pengukuran multivariat (atau observasi), komponen utama merupakan kombinasi linier dari variabel p awal. Tujuan utama analisis komponen utama ialah untuk mengurangi dimensi peubah-peubah yang saling berhubungan dan cukup banyak variabelnya sehingga lebih mudah untuk menginterpretasikan data-data tersebut (Johnson dan Wichern, 2002). Metode yang digunakan yaitu menentukan komponen utama dengan melakukan alih ragam orthogonal atau membentuk kombinasi linier Y A' X (Sumarga, 1996). Dari sini akan dipilih beberapa komponen utama yang dapat memberikan sebagian besar keragaman total data semula.Berikut adalah cara kerja principal component analysis :
1. Hitung rata-rata setiap data (scaling)
2. Hitung covariance matrix dari kumpulan data matrix. 3. Hitung eigenvector dan eigenvalue dari covariance matrix.
4. Pilih component dan bentuk vector feature dan ambil principal component
dari eigenvector yang memiliki eigenvalue paling besar 5. Menurunkan data set yang baru.(Smith,2002).
23 2.4 Permainan DOTA 2
DOTA 2 adalah game yang sudah dimodifikasi yang awalnya bernama World of Warcraft yang dibuat oleh Blizzard (Kurniawan,Iqbal dkk 2016). DOTA atau defense of the ancient diciptakan pertama kali sebagai mod di Warcraft 3. Kebanyakan hero di DOTA pun sebenarnya terinspirasi dari hero-hero di game warcraft. Lalu munculah ide dari icefrog untuk membangun game DOTA sendiri, dan akhirnya dibuat dengan kerjasama valve menjadi game dengan engine source bernama DOTA2.
Jadi sebenarnya DOTA 2 dengan DOTA tidak jauh berbeda, hero-hero di DOTA 2 pun berasal dari DOTA. DOTA 2 adalah permainan real time strategy, dan harus memilih suatu karakter atau hero dari banyak hero. Perlu diketahui di DOTA 2 hanya akan mengontrol satu hero atau unit, namun beberapa hero bisa membuat beberapa unit juga, tapi umumnya hanya mengontrol satu hero dan tidak perlu mengontrol unit lebih dari 10 (Newell,Gabe dkk). Tujuan utama di DOTA 2 sebenarnya adalah menghancurkan ancient musuh, apabila ancient musuh hancur maka tim akan menang. Di DOTA 2 ada banyak hal yang harus cepat untuk dicapai, misalnya level dan item, semakin tinggi level atau semakin bagus item maka hero yang anda gunakan akan semakin kuat. Terdapat 108 hero dari game ini dengan pembagian kasta yaitu strength,agility dan intelligence seperti gamber berikut :
24
Sebagian besar Support berada pada intelligence tapi tidak semua bisa dijadikan Support tergantung pada situasi saat pertandingan oleh karena itu penelitian ini akan mencoba memisahkan antara Support ,Carry dan Hard-support dari hasil pertandingan tersebut .
Permainan ini sangat menarik jika dijadikan penelitian karena selain game online favorit , game ini juga dapat menghasilkan penghasilan yang tidak main-main untuk Turnamen International yang diadakan Agustus 2016 yang lalu mencapai 20.000.000 dollar.Untuk penelitian tentang DOTA 2 ini belum pernah dilakukan sebelumnya karena saya menggunakan data pertandingan ,yang sudah melakukan penelitian tentang DOTA 2 adalah hanya menganalisa jenis hero.Sedangkan yang akan dijadikan dalam penelitian ini adalah hasil pertandingan yang mana terdapat atribut level,GMP(Gold Per Minute),XPM(Experience Per Minute),Networth,dll.Dalam Penelitian ini hanya
terbatas pada meneliti jenis peran yang ter cluster yaitu Carry,Support, atau Hard-support.Berikut ini beberapa penjelasan tentang ketiga peran yang akan diteliti
dalam penelitian ini :
a. Carry
Peran yang satu ini memang cukup sulit, apalagi jika anda bukan tipe yang
bisa melakukan banyak last hit pada laning phase.Karena Carry
membutuhkan banyak gold untuk bisa berguna di mid late game. Carry
seperti namanya memang mampu membawa tim menuju kemenangan, dan
ini akan membuat tim musuh mengincar Carry terlebih dahulu. Dalam game
DOTA 2 tim lawan akan mencari counter yang mencegah seorang Carry
memiliki uang banyak.
b. Support
25
Support bergantian dengan Hard-support untuk membeli item-item Support
seperti ward, dust, dan lain-lain. Selain itu Hero Posisi peran ini juga biasanya dapat farming di hutan, atau juga bisa membantu Carry untuk creep stacking.
c. Hard-support
Kebanyakan player baru sering meremehkan role ini karena mereka
beranggapan bahwa Hard-support hanya bertugas membantu tim saja.
Padahal itu adalah anggapan yang salah. Seorang Hard-support tidak
membutuhan uang sebanyak Carry dan dia mampu melakukan early kill dan
bahkan mengganggu Carry tim lawan. Biasanya seorang Hard-support yang
baik mampu membuat Carry mendapatkan uang yang banyak dengan
mengamankannya saat laning phase dan mencegah Carry agar tetap aman
dari tim lawan.
2.5 Pengujian Keakuratan Metode
Untuk menguji apakah metode ini memiliki hasil yang valid maka diperlukan pengujian untuk mengetahui keakuratan metode.Pada clustering
sendiri pengujian keakuratan dapat dibagi menjadi 3 cara pendekatan untuk melihat keakuratannya yaitu external test,internal test dan relative test.
d. External test
26 Keterangan :
a dan d = jumlah benar setiap cluster
b dan c = cluster yang salah
a,b,c dan d = jumlah data keseluruhan
Akurasi = (Jumlah benar setiap clusteratauJumlah data )*100%
e. Internal test
adalah pengujian tanpa informasi dari luar cluster yang digunakan untuk melihat kualitas dari cluster tersebut .Dalam penggunaanya pada internal test yaitu cluster separation dan cluster cohesion(jain dan dubes dkk1988).
a) Cluster cohesion adalah jumlah dari lebar semua link yang ada di
dalam cluster.Cohesion adalah pengukuran di dalam cluster dengan sum of square(SSE)
b) Cluster separation adalah pengukuran antara cluster dengan sum of
square
f. Relative test
pada metode ini digunakan pengukuran internal index dan external index dengan SSE atau entropy , penyelesaian cluster yang berbeda dengan algoritma yang sama dengan parameter berbeda pula.
Dalam mencari keakuratan metode penelitian , penulis menggunakan
external test dengan menggunakan clustering yang sudah ada kemudian dibandingkan dengan hasil cluster dari metode Agglomerative Hiearchical
clustering,kemudian dapat melihat tingkat akurasi yang didapat dengan label yang sudah tersedia .Setelah itu dapat dilihat manakah clustering yang terbaik akurasinya.
27
BAB 3
METODOLOGI PENELITIAN
Pada bab ini akan dijelaskan bagaimana metode pengelompokan bekerja pada sistem serta dijelaskan pula desain penelitian ,analisa kebutuhan proses,implementasi perancangan ,penjelasan proses dan desain antar muka (user interface)
3.1 Gambaran Umum
Pembuatan sistem pengelompokan pemain dengan metode Agglomerative Hiearchical Clustering (AHC) untuk menguji apakah metode ini bagus untuk data pertandingan DOTA 2 , berikut sistem yang akan dibangun oleh penulis dalam bentuk diagram blok
Data pada penelitian ini adalah data pertandingan international DOTA 2 yang didapatkan dari setiap akhir pertandingannya , kemudian membuatnya menjadi data numeric dan akan dicluster menggunakan agglomerative hierarchical clustering dengan 3 cara yaitu single(minimal), complete(maximal) ,average(mean) setelah mendapatkan hasil akan menampilkan cluster dan akurasi.
28
3.2 Desain Penelitian
Dalam penelitian ini terdapat 3 tahapan yang penulis buat yaitu studi literatur untuk informasi data,pengumpulan data, dan juga merancang alat uji . Berikut adalah penjelasan tentang ketiganya :
3.2.1 Studi Literatur
Studi literatur dilakukan untuk mendapatkan informasi tentang data yang digunakan dalam penelitian seperti mengamati pertandingan dalam turnamen DOTA 2 setiap eventnya yang berjalan pada tahun 2016.
3.2.2 Pengumpulan Data
Dalam mengumpulkan data pertandingan DOTA 2 penulis melihat hasil pertandingan dalam event yang diadakan pada tahun 2016 .Dalam pengumpulan data terdapat 3 tahap dalam mendapatkan data sehingga dapat diolah sebagai berikut :
Tahap 1 Mengumpulkan Data Pertandingan
29
kedalam bentuk excel secara manual dari data gambar yang sudah di dapatkan.Data terkumpul sebanyak 300 data dengan 14 atribut , dimana atribut tambahan terdapat 4 atribut yaitu CARRY_ITEM, SUPPORT_ITEM, HARD_SUPPORT_ITEM dan NORMAL_ITEM.Atribut ini menjelaskan seorang pemain ap[akah dia memiliki item sebagaimana peran yang ia bawa atau tidak.Dalam pengisian di dalam excel dilihat dari gambar apakah ada item-item tersebut atau tidak, jika ada di beri nilai 1 dan jika tidak ada diberi nilai 0.
Tabel 3. 1 Penjelasan atribut data
No Atribut Penjelasan
1 KILL adalah jumlah dimana hero mampu
menghabisi hero lawan sampai jumlah HP hero musuh menjadi 0.
2 DEATH Adalah jumlah dimana jumlah HP hero
menjadi 0 atau mati dikarenakan hero musuh menghabisi hero kita.
3 ASSIST Adalah jumlah hero dalam kontribusi
30
membunuh hero lawan sebelum hero lawan jumlah HP nya menjadi 0 atau mati.
4 NETWORTH Adalah jumlah gold yang mampu
dikumpulkan seorang pemain dalam satu pertandingan
5 LEVEL Adalah sebuah pencapaian setiap level
naik maka setiap hero memiliki kemampuan khusus untuk menaikan skillnya
6 LAST HIT Adalah jumlah seorang pemain melakukan last hit atau sentuhan terakhir sebelum creep(monster hutan atau monster yang muncul 30 detik sekali ) digunakan untuk mendapatkan gold lebih ketika melakukan last hit .
7 DENIED Adalah jumlah seorang membunuh creep
(monster hutan atau monster yang muncul 30 detik sekali ) sendiri agar musuh tidak melakukan last hit dan menghambat musuh mendapatkan gold.
8 GOLD PER MINUTE Adalah jumlah rata-rata pendapatan gold setiap hero sampai akhir pertandingan
9 EXPERIENCE PER
MINUTE
Adalah jumlah rata-rata experience setiap hero sampai akhir pertandingan
,experience digunakan untuk menaikan level.
10 DAMAGE Dalah jumlah serangan yang masuk
kepada hero musuh.
11 CARRY ITEM Adalah jumlah item yang biasa digunakan oleh hero Carry
31
13 HARD-SUPPORT ITEM Adalah jumlah item yang biasa digunakan oleh hero Hard-support
14 NORMAL ITEM Adalah jumlah item standar yang biasa digunakan oleh hero
Dalam setiap tim professional yang bertanding peran setiap pemain sudah ditentukan , dalam setiap tim pada pertandingan DOTA 2 minimal memiliki 2 orang pemain dengan peran Carry ,2 orang pemain dengan peran Support dan 1 orang sebagai Hard-support.Pada data yang diambil adalah data pertandingan profesional DOTA 2 yang berlangsung pada tahun 2016 ,tidak hanya pada satu event saja dalam pengambilan data akan tetapi seluruh event internationl khususnya pemain profesional pada tahun 2016.
Tahap 2 Import data ke Excel
Setelah mendapatkan data dalam game DOTA 2 kemudian memasukan data numerik yang ada di gambar dengan cara manual kedalam excel ,serta memasukan juga slot item apakah item yang dibeli dalam record pertandingan itu adalah item Support,Carry atau Hard-support .
Tahap 3 Pelabelan Cluster Data
Dalam membuat label class dalam penelitian ini penulis mencari label dengan tingkat akurasi tertinggi yang akan dijadikan label , dalam contoh pada normalisasi Z-score peran Carry ada di label 1 atau cluster 1 , ketika normalisasi MinMax peran Carry dengan akurasi tinggi terdapat dilabel 2 atau cluster 2 .Jadi
32
3.2.3 Perancangan Alat Uji
Dalam penelitian ini penulis menggunakan metodologi waterfall dimana metode waterfall adalah suatu proses pengembangan perangkat lunak berurutan, di mana kemajuan dipandang sebagai terus mengalir ke bawah seperti air terjun melewati fase-fase perencanaan, pemodelan, implementasi(konstruksi), dan pengujian.
a. Analisa Kebutuhan Pengguna (User Requierment)
Tahap pertama ini adalah sebuah tahap yang dibutuhkan oleh pengguna untuk menyelesaikan masalah dengan adanya alat uji yang sudah dibuat dalam penelitian ini,dengan kata lain tahap ini kebutuhan pengguna untuk menyelesaikan masalah dengan adanya alat uji . Berikut adalah kebutuhan pengguna dalam menyelesaikan masalah :
- Melihat hasil pengelompokan (cluster) - Melihat hasil akurasi confusion matrix
b. Analisa Kebutuhan Sistem (Sistem Requierment)
Tahap requirement atau spesifikasi kebutuhan sistem adalah analisa kebutuhan sistem yang dibuat dalam bentuk yang dapat dimengerti oleh user. Dalam tahap ini klien atau pengguna menjelaskan segala kendala dan tujuan serta mendefinisikan apa yang diinginkan dari sistem.
c. Desain (Design)
33
d. Pengkodean (Coding)
Pengkodean adalah tahap dimana perancangan diterjemahkan kedalam sebuah bahasa mesin pada komputer,kemudian menghasilkan sebuah alat uji yang digunakan untuk melihat apakah metode memiliki akurasi yang bagus atau tidak.
e. Pengujian (Testing)
Pada tahap terakhir adalah tahap pengujian untuk menguji apakah sistem uji ini sudah mampu memenuhi kebutuhan pengguna .
3.3 Analisa Kebutuhan Proses
34
Gambar 3. 2 Diagram blok proses clustering
35
3.4 Implementasi Perancangan
3.4.1 Diagram Konteks
Pada Gambar 3.6 di atas merupakan gambar diagram konteks atau bisa disebut juga sebagai data flow diagram level 0.Diagram ini merupakan level tertinggi dari data flow diagram .Diagram ini menjelaskan ruang linkgup dari sebuah alat uji yang akan dibangun.Terdapat salah satu proses besar pada diagram konteks tersebut yaitu proses clustering data pertandingan DOTA 2 dengan menggunakan Hierarchical Agglomerative Clustering.Pada diagram konteks terdepat seorang pengguna(User) sebagai pemberi input saat memilih sebuah normalisasi dan metode clustering ,yang kemudian sistem akan menampilkan hasil cluster beserta dengan hasil akurasinya.
36
3.4.2 Data Flow Diagram Level 1
Gambar 3. 6 Diagram DFD level 1
Pada Gambar 3.7 di atas merupakan gambar data flow diagram level 1,diagram ini merupakan pecahan dari diagram konteks.terddepat user sebegai external entity,300 data peran pemain dari pertandingan DOTA 2.
Proses pertama user memberikan pilihan dalam proses preprocesing yaitu akan menggunakan data asli ,normalisasi zscore atau normalisasi minmax setelah melakukan pilihan tersebut user juga akan memilih jenis metode cluster single-linkage,complete-linkage atau average-linkage.
37
3.4.3 Data Flow Diagram level 2
DFD Level 2 no 1 Preprocessing
Pada Gambar 3.8 di atas merupakan data flow diagram level 2 untuk proses preprocesing.Pada diagram di atas terdapat 3 proses yaitu proses pertama adalah menghitung normalisasi untuk zscore , kemudian yang kedua adalah menghitung normalisasi untuk minmax dan proses terakhir adalah data reduksi dengan menggunakan PCA.Setelah semua data melewati proses tersebut data disimpan dalam bentuk excel kemudian akan diproses pengelompokan dengan Hierarchical Agglomerative Clustering.
38
DFD Level 2 no 2 Clustering dan Akurasi data pertandingan
Pada Gambar 3.9 adalah proses akhir dari sebuah clustering dimana akan menampilkan hasil akurasi serta dendrogram.Terdapat 4 proses dalam data flow diagram level 2 untuk clustering dan akurasi.Yang pertama setelah melewati proses preprocesing kemudian data akan dihitung jarak antara data dengan metode perhitungan jarak euclidean distance .Proses kedua adalah menghitung cluster single-linkage dengan menggunakan matriks jarak yang sudah didapatkan . Proses ketiga adalah menghitung cluster complete-linkage dengan menggunakan matriks jarak yang sudah didapatkan. Proses ketiga adalah menghitung cluster
39
linkage dengan menggunakan matriks jarak yang sudah didapatkan.kemudian proses terakhir atau proses keempat adalah proses perhitungan akurasi dengan berdasarkan cluster yang terbentuk dan dendrogram yang terbentuk.
3.5 Penjelasan Proses
3.5.1 Baca Data
Setelah data dimasukan kedalam excel dan melewati tahap knowledge discovery in database data siap digunakan dalam proses selanjutnya yaitu
pre-processing .Dalam sebuah pertandingan seorang Carry diwajibkan memiliki
Gold-Per-Minute (GPM) yang tinggi karena dibutuhkan untuk membeli item atau
barang yang menunjang kemenangan tim tersebut.
3.5.2 Pre-processing
Setelah data siap maka proses selanjutnya adalah melakukan preprocessing pada data.terdapat 2 tahap Pre-processing sebelum data digunakan yaitu transformasi data dengan Z-score dan MinMax terhadap 300 data pertandingan.Selain transformasi data juga akan diuji menggunakan PCA(Principal component analysis) untuk menguji apakah akurasi dapat lebih besar atau sebaliknya.Bagi yang memilkiki peran Carry NETWORTH menjadi sangat penting karena dalam tim Carry diwajibkan memiliki item progres yang cepat , kemudian seroang Carry juga harus memiliki LAST_HIT yang banyak dan juga KILL yang banyak. Sangat berbeda dengan yang berperan sebagai Support dan Hard-support dalam peran ini harus merelekan item mereka demi seorang Carry agar Carry menjadi kuat dengan kata lain Carry menjadi prioritas
40
dalam permainan.sedangkan NETWORTH ,GOLD_PER_MINUTE dan EXPERIENCE_PER_MINUTE menggunakan normalisasi [0-471] karena dari ketiga atribut itu sangat tergantung pada LAS_HIT .Berikut adalah tahap-tahap normalisasi :
a) Langkah-langkah function MinMax
1. Proses cut data pada data pertandingan DOTA 2 profesional 2016 pemotongan hanya pada atribut 4,8,9 dan 10.
2. Simpan data cut menjadi satu dalam bentuk excel dengan nama DATA_CUT_NORMALISASI.xlsx.
3. Kemudian membuat data yang tidak di-cut dalam proses di atas menjadi 1 dengan nama DATA_CUT_SISA_NORMALISASI.xlsx 4. Mengambil nilai dari data cut minmax ,kemudian menentukan nilai
minimal dan maksimal yang baru untuk dipakai dalam perhitungan. 5. Menghitung rumus minmax yaitu
minmax=(dataAwalcut-nilai_max_baru)*( nilai_max_baru - nilai_min_baru)/( nilai_max- nilai_min)+ nilai_max
6. Kemudian data hasil perhitungan dengan rumus tersebut digabungkan dengan data sisa hasil cut kemudian dijadikan menjadi satu file excel untuk diolah dengan nama
DATA_FINAL_HASIL_NORMALISASI.xlsx
b) Zscore menggunkan fungsi pada matlab
%data zscore
zscoredata=zscore(dataAwal);
c) Langkah-Langkah Perhitungan PCA
1. membuat matriks x dengan cara mengurangi rata2 setiap dimensi pada matriks
41
3. menghitung eigenvector dan eigenvalue dari covariance matrix.
4. Pilih komponen dan bentuk vector feature dan principal component dari eigenvector yang memiliki eigenvalue paling besar diambil (decreasing order).
5. menurunkan satu set data baru
6. kemudian memasukan jumlah PCA yang digunakan dalam pemotongan data.
3.5.3 Pengukuran Jarak
Setelah proses Pre-processing selesai dilakukan langkah selanjutnya adalah pengukuran jarak dengan menggunakan salah satu metode yang ada.Seperti yang sudah dijelaskan sebelumnya dalam penelitian ini menggunakan Euclidean distance.
3.5.4 Clustering
Ssetelah mendapatkan data matriks dari hasil pengukuran jarak kemudian akan masuk kedalam tahap clustering atau pengelompokan untuk mengelompokan peran-peran berdasarkan data pertandingan yang sudah diproses.Data pertandingan akan diukur kemiripannya dengan agglomerative hierarchical clustering dengan metode single-linkage(jarak minimum),Complete-linkage(jarak maximum),Average-linkage(jarak rata-rata).Dari hasil clustering yang telah
42
terbentuk kemudian menggambarkan sebuah dendrogram agar sebuah cluster dapat terlihat dengan mudah akan masuk dalam kelompok mana saja.
a. Single-linkage
Pengukuran jarak menggunakan single-linkage adalah mengukur jarak minimal antara setiap elemen data.Dari matriks jarak di atas 3 dan 4 adalah jarak terdekat kemudian pasangkan objek 3 dan 4 menjadi 1 cluster dengan data minimal.Hasil jarak baru membentuk matriks jarak baru dan kemudian dilanjutkan hingga tersisa 1 cluster.hasil dendrogramnya sebagai berikut :
b. Complete-linkage
Pengukuran jarak menggunakan complete-linkage adalah mengukur jarak minimal antara setiap elemen data.Dari matriks jarak di atas 3 dan 4 adalah jarak terdekat kemudian pasangkan objek 3 dan 4 menjadi 1 cluster dengan data minimal.Hasil jarak baru membentuk matriks jarak baru dan kemudian dilanjutkan hingga tersisa 1 cluster.hasil dendrogramnya sebagai berikut :
43 c. Average-linkage
Pengukuran jarak menggunakan complete-linkage adalah mengukur jarak rata-rata antara setiap elemen data.Dari matriks jarak di atas 3 dan 4 adalah jarak terdekat kemudian pasangkan objek 3 dan 4 menjadi 1 cluster dengan data minimal.Hasil jarak baru membentuk matriks jarak baru dan kemudian dilanjutkan hingga tersisa 1 cluster.hasil dendrogramnya sebagai berikut :
Gambar 3. 50 contoh dendrogram complete-linkage
44
3.5.5 Perhitungan Akurasi Confusion Matrix
Setelah dendrogram ditampilkan selanjutnya adalah menguji apakah hasil clustering tersebut mendapatkan akurasi yang diinginkan atau tidak.Tabel
perhitungan akurasi adalah sebuah tabel evaluasi cluster untuk mengetahui keakuratan agglomerative hierarchical clustering untuk mengelompokan peran pemain DOTA 2.Perhitungan ini membandingkan hasil pengelompokan denagn data asli , perlunya menghitung akurasi adalah untuk mengetahui seberapa bagus metode ini dapat mengelompokan peran pemain dengan baik.
Tabel 3. 32 Tabel evaluasi confusion matrix
Akurasi =
X 100%
= X 100% = 80%
Cluster
Peran 1 2 3
Carry 1 0 0
Hard-support 0 2 1
45
3.6 Perancangan Antar Muka Alat Uji
Gambar 3. 14 User interface alat uji
Dalam sebuah perancangan sistem atau membuat alat uji user interface
sangat penting karena menghubungkan suatu sistem dengan pengguna ,dimana dalam sistem ditanamkan sebuah metode clustering agglomerative untuk menguji apakah metode ini baik dalam menemukan akurasi dengan data pertandingan DOTA 2 .Pada antar muka diatas terdapat 2 proses penting akan tetapi dijadikan menjadi 1 tombol dimana tombol cluster akan memproses cluster sekaligus mencari tingkat akurasi cluster Single-linkage,Complete-linkage dan juga Average-linkage .Berikut penjelasan check box dan tombol yang tersedia pada
antar muka di atas :
Tabel 3. 4 Penjelasan fungsi user interface alat uji
No Nama Fungsi
1 Checkbox data asli Untuk menampilkan data asli dari data pertandingan DOTA 2 profesional 2016
46
pertandingan DOTA 2 profesional 2016
3 Checkbox MinMax Untuk menampilkan data hasil normalisasi MinMax dari data pertandingan DOTA 2 profesional 2016
4 Checkbox Complete-linkage
Untuk memilih jenis clustering dengan metode Complete-linkage
5 Checkbox Average-linkage Untuk memilih jenis clustering dengan metode Average-linkage
6 Checkbox single linkage Untuk memilih jenis clustering dengan metode single linkage
7 Checkbox PCA Untuk memilih akan menggunakan PCA atau tidak
8 Textfield PCA Memasukan jumlah pemotongan feature yang diingankan
9 Tabel data Menampilkan data agar dapat dilihat user
10 Graph hasil cluster Menampilkan dendrogram hasil dari clustering yang telah dipilih
11 Tabel confusion matrix Menampilkan hasil confusion matrix dari clustering
12 Tabel jumlah cluster Menampilkan jumlah setiap cluster 13 Kolom akurasi Menampilkan hasil akurasi dari sebuah
cluster dengan menghitung hasil benar
dibagi jumlah data 14 Graph perbandingan
cluster
Menampilkan hasil perbandingan cluster 1, 2 dan 3
47 16 Submenu file
17 Submenu help
3.7 Spesifikasi Hardware dan Software
Pada tahap implementasi spesifikasi hardware dan software yang digunakan adalah sebagai berikut :
1. Software
a. Sistem Operasi : Microsoft Windows 7 Ultimate 32-bit b. Software : Matlab versi 8.0.0.783(R2012b) 2. Hardware
a. Processor : Intel® Celeron® CPU 877 @1.40GHz b. RAM : 2GB
48
BAB 4
IMPLEMENTASI HASIL DAN ANALISA
Pada bab ini membahas mengenai hasil dari pengelompokan data pertandingan DOTA 2 dengan agglomerative hierarchical clustering . Selain itu juga hasil keakuratan dari metode dijelaskan pada bab ini.
4.1 Hasil Penelitian dan Analisis
Pada tahap pengujian dan implementasi data yang telah dilakukan terhadap 300 data pertandingan DOTA 2 profesional dengan pembagian peran Carry,Support dan Hard-support.Dalam data pertandingan atribut NETWORTH ,
GPM(gold per minute) dan XPM (experience per minute) menjadi sangat penting dalam melihat peran apa yang di lakukan oleh pemain tersebut .
Tabel 4. 1 Deskripsi masing-masing peran
No Peran Keterangan
1 Carry Memiliki NETWORH ,Last hit , GPM(gold per minute) dan XPM (experience per minute) yang
tinggi untuk cepat mendapatkan item.Dan angka DEATH yang rendah.
2 Hard-support Memiliki DENIED dan ASSIST yang tinggi untuk menghambat Carry lawan berkembang,serta memiliki angka DEATH tinggi karena selalu yang pertama diincar lawan.
3 Support Memiliki DENIED ,ASSIST , GPM(gold per minute) dan XPM (experience per minute) yang
49
Dalam sebuah pertandingan seorang pemain dapat berubah peran tergantung pada situasi musuh dan kendala waktu.Dalam data terdapat atribut DAMAGE ,atribut ini mengindikasikan berpa jumlah serangan yang masuk kedalam hero lawan .Atribut DAMAGE menjadi sangat tidak berpengaruh dalam pengelompokan karena bisa saja Support dan Hard-support memiliki nilai DAMAGE yang besar .
Tabel 4. 2 Contoh perbedaan damage hero berdasarkan peran
No kemampuan Peran Keterangan
1
Finger of Death (Lion) Damage level max : 850
Hard- Support Hero seperti ini sangat memiliki damage besar dalam skill akan tetapi dia berperan sebagai Support karena memiliki sekill pendukung lainya berupa stun dan disable.
2
Ravage (Tidehunter) Damage level max : 380
Support Hero Support serperti tidehunter sangat penting dalam sebuah tim karena memiliki skill stun yang sangat luas jangkauannya
dan mampu dalam
membuka sebuah war. 3
Chemical rage (Alchemist) Tidak ada damage
50
berkutik.
1. Perbandingan akurasi tanpa Principal Component Analysis(PCA)
Dari seluruh percobaan tanpa menggunakan PCA hanya normalisasi MinMax dengan Complete-linkage mendapat akurasi paling besar yiatu 93% walaupun tidak mencapai 100% akurasi ini terbilang sudah sangat bagus.Kemudian akurasi paling buruk adalah MinMax dengan single-linkage dengan akurasi 50% akurasi ini terlbilang buruk karena belum mencapai target yang diinginkan.Akurasi terbaik kedua adalah 82% masih dalam normalisasi MinMax dengan Average-linkage.
Tabel 4.3 perbandingan akurasi tanpa PCA
Metode normalisasi MinMax menjadi sangat optimal dalam normalisasi dikarenakan metode ini mampu mentransformasi beberapa atribut saja dibandingkan normalisasi Z-score.Dalam MinMax transformasi dilkakukan terhadap 4 atribut dimana digai lagi menjadi 2 yaitu atribut DAMAGE normalisasi MinMax dengan nilai minimal 0 dan nilai maksimal 1 dan atribut NETWORTH,GPM(gold per minute) dan XPM(experience per minute) nilai minimal dengan 0 dan nilai maksimal 471 .Atribut DAMAGE
Metode Normalisasi Akurasi
Single-linkage Tidak 51% Complete-linkage Tidak 62% Average-linkage Tidak 51% Single-linkage Z-score 54% Complete-linkage Z-score 55% Average-linkage Z-score 51% Single-linkage MinMax 50%
Complete-linkage MinMax 93%
51
menggunakan [0,1] dikarenakan atribut ini tidak memiliki sesuatu yang berpengaruh dan cenderung dapat mengganggu pengelompokan data serta nilai datanya sangat besar dan memiliki jarak yang sangat jauh dengan data lain ,oleh karena itu perlu dilakukan normalisasi agar data dapat dikelompokan dengan baik tanpa adanya masalah.Kemudian untuk ketiga atribut NETWORTH,GPM(gold per minute) dan XPM(experience per minute) menggunakan normalisasi [0,471] nilai maksimal dan minimal diambil dari atribut LAST_HIT karena atribut ini berpengaruh terhadap 3 atribut di atas .Karena jarak data yang terlalu besar pada atribut NETWORTH maka normalisasi ini juga sekaligus membuat jarak data menjadi tidak terlalu jauh dan data dapat diolah dengan baik.Atribut yang paling berpengaruh dalam pengelompokan peran pemain DOTA 2 sebenarnya adalah atribut NETWORTH jika bernilai rendah berperan sebagai Hard-support ,sedang Support dan tinggi adalah seorang Carry.Normalisasi MinMax dalam pengelompokan data pemain menjadi
sangat baik karena normalisasi ini mampu melakukan transformasi terhadapa beberapa atribut data saja yang penting tanpa harus membuang sebuah atribut.Berikut grafik perhitungan akurasi tanpa menggunakan PCA :
Gambar grafik di atas menjelaskan perbandingan 2 normalisasi dan 1 dengan data asli dimana data asli diwakilkan oleh warna merah ,normalisasi
52
Z-score diwakilkan dengan warna biru dan normalisasi MinMax diwakilkan
dengan warna kuning.Terlihat dari gambar bahwa normalisasi MinMax dengan nilai akurasi tertinggi dengan 93% untuk Complete-linkage dan 82% untuk Average-linkage.Normalisasi MinMax juga terdapat pengelompokan yang buruk yaitu pada linkage dikarenakan pada metode Single-linkage pengambilan nilai adalah yang terdekat atau minimal mengakibatkan data pengelompokan yang seharusnya saling memisahkan menjadi beberapa cluster akan bergabung menjadi satu seperti terlihat pada gambar 4.7 dendrogram MinMax single-linkage.Karena untuk data pertandingan DOTA 2 pencarian jarak dengan mengambil nilai terendah belum memenuhi harapan.Tidak hanya pada normalisasi MinMax saja metode single-linkage sterlihat buruk dalam menghasilkan akurasi, dalam gambar diatas hanya pada normalisasi Z-score saja single-linkage terlihat m