BAB 3
ANALISIS DAN PERANCANGAN SISTEM
Bab ini secara garis besar membahas analisis metode Web Scrapping dan Naïve Bayes Classifier pada sistem dan tahap-tahap yang dilakukan dalam perancangan sistem yang akan dibangun.
3.1 Data Yang Digunakan
Data yang digunakan dalam penelitian ini adalah data yang bersumber dari website aqicn.org. Website ini merupakan sebuah website monitoring kualitas udara yang memberikan gambaran bagaimana kualitas dengan menampilkan nilai-nilai konsentrasi polutan dari beberapa daerah yang ikut serta mengumpukan data secara crowdsourcing.
Pada sistem yang akan dibangun, data yang akan digunakan merupakan data kota Beijing. Penggunaan data kota ini dikarenakan nilai seluruh parameter polutan yang dibutuhkan untuk klasifikasi tersedia lengkap dan memiliki nilai yang beragam. Pengumpulan data dilakukan dengan menggunakan metode web scraping yang dikerjakan secara periodik. Setelah data terkumpul kemudian dilakukan analisa data yang sesuai dengan kebutuhan sistem ini. Oleh karena itu, untuk menghasilkan kesimpulan berdasarkan rule pada analisis data, diperlukan data nilai variabel-variabel polutan udara di kota Beijing. Analisis data tersebut dilakukan berdasarkan klasifikasi menggunakan algoritma Naïve Bayes Classifier.
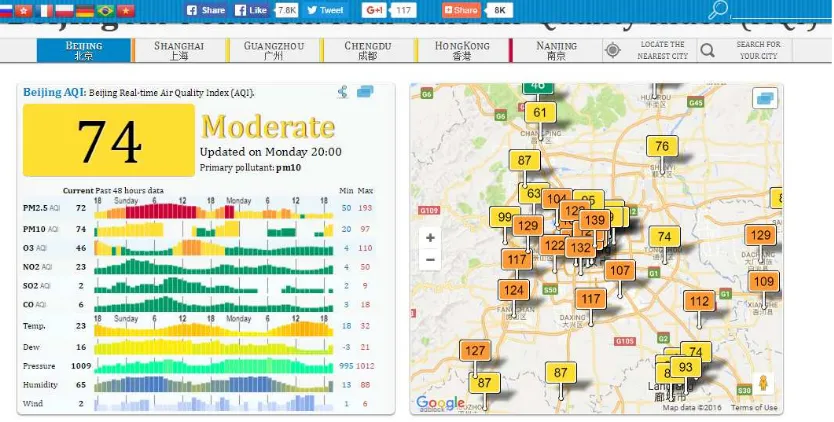
Website aqicn.org merupakan website yang menyediakan informasi kualitas udara. Data pada website ini yang akan diambil adalah :
6. Temperatur
7. Titik EmbunTekanan Udara 8. Kelembapan, dan
9. Kecepatan Angin
Keseluruhan data yang disebutkan dapat dilihat pada halaman website seperti yang terdapat pada gambar 3.1.
3.2 Arsitektur Umum
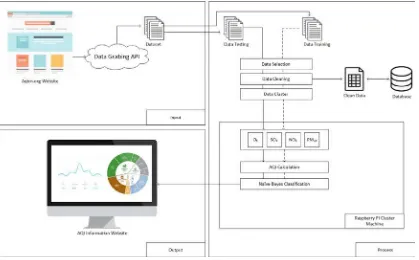
Proses analisis dilakukan sebelum melakukan perancangan. Dilakukan analisis unuk mendapatkan kebutuhan dari sistem yang akan dikembangkan. Sistem ini bertujuan menyediakan informasi mengenai kualitas udara dengan pengolahan data dan klasifikasi menggunakan API yang diimplementasikan pada raspberry pi server cluster grid. Untuk dapat membangun sistem ini, diperlukan beberapa metode yang akan diimplementasikan, yaitu metode web scraping dan naïve bayes classifier. Secara umum metode yang diajukan digambarkan pada arsitektur umum pada Gambar 3.2.
Gambar 3. 2 Arsitektur Umum
Arsitektur umum pada gambar 3.2 memiliki beberapa tahapan dalam menjalankan seluruh proses yang ada baik dari input, proses utama hingga menghasilkan output. Proses-proses tersebut dijabarkan pada poin-poin berikut ini :
3.2.1 Web Scraping
Langkah langkah pada pseudocode dapat dijelaskan sebagai berikut : 1. Melakukan pengecekan url yang valid
URL dari halaman websit pemrograman untuk membuat web scraping melakukan pengecekan apakah website tersebut valid atau tidak.
2. Melakukan render struktur data semantik
Pada tahap ini halaman website yang telah ditentukan kemudian diubah menjadi kode kode program yang masih memiliki spesial karakter yang belum terstruktur. Halaman website kemudian diubah menjadi rangkaian string array dalam plain teks, lalu dilakukan pemilahan dan pengenalan tag, selector dan beberapa atribut lain penyusun kode sebuah halaman website menjadi menjadi objek objek dokumen (DOM).
3. Melakukan parse halaman website
Pada tahap ini hasil objek dokumen pada keluaran yang telah didapatkan melalui tahapan sebelumnya kemudian dipilih field mana yang akan diambil datanya. Hasil parse data pada langkah ini kemudian akan diekstraksi. Field yang akan diekstraksi datanya dapat dilihat pada gambar 3.2.
Function scraping(url)
check_is_valid_url(url) urlpage = this -> url data = parse(urlpage)
for each parseData in data : getSpecialWrapperClass()
4. Ekstraksi class elemen spesial dan value dari polutan
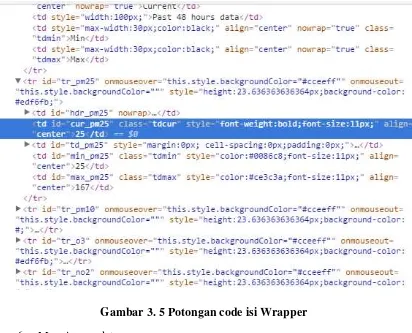
Bagian website yang akan diambil datanya ditandai dengan class elemen spesial yaitu : aqiwgt-table-aqiinfo. Di dalam class tersebut terdapat beberapa field yang menyimpan nilai nilai yang dibutuhkan, field tersebut ditandai dengan field : pm25, pm10, o3, no2, so2, co, t, d,p, h dan w. Gambar 3.3 merupakan potongan source code dari halaman website aqicn yang menyimpan informasi nilai yang akan diambil datanya dengan menggunakan web scraping.
Data tersebut masih terdapat dalam tag, langkah selanjutnya adalah normalisasi dengan menghilangkan tag-tag yang tidak diperlukan lalu mengekstrasksi teks informasi yang diinginkan ke dalam sebuah array.
Gambar 3. 4 Data yang akan diambil (sumber: http://aqicn.org/beijing) 5. Pengecekan data
Gambar 3. 5 Potongan code isi Wrapper 6. Menyimpan data
Nilai yang telah dimasukkan ke dalam array pada langkah ke 5 kemudian disusun ke dalam sebuah string yang nantinya akan dikonstruksi menjadi sintaks query untuk dapat disimpan ke dalam database.
3.2.2 Data Cleaning
Proses pemutakhiran data merupakan proses yang diperlukan untuk mendapatkan data yang terbaik dengan beberapa cara. Untuk mendapatkan data yang baik dan memiliki sedikit noise, penulis menggunakan metode data cleaning digunakan untuk deteksi dan menghapus error serta inkonsistensi dari bongkahan data untuk meningkatkan kualitas data yang akan diolah (Rahm & do, 2000). Pada penelitian ini, data yang telah didapat akan dibersihkan dengan mengubah nilai dari field – field yang tidak sesuai menjadi string value yang sebenarnya.
Gambar 3. 6 Raw data yang tidak valid 3.2.3 Data Selection
Pada tahap ini dilakukan proses seleksi pada data untuk melihat kecenderungan data dikarenakan data yang terdapat pada tabel hasil scraping memiliki tingkat kepentingan yang berbeda. Hasil dari proses ini adalah menghasilkan beberapa parameter atribut dalam penentuan kualitas udara yaitu NO, SO2, CO, O3, dan Curah Hujan.
3.3 Perancangan Server Cluster Raspberry Pi
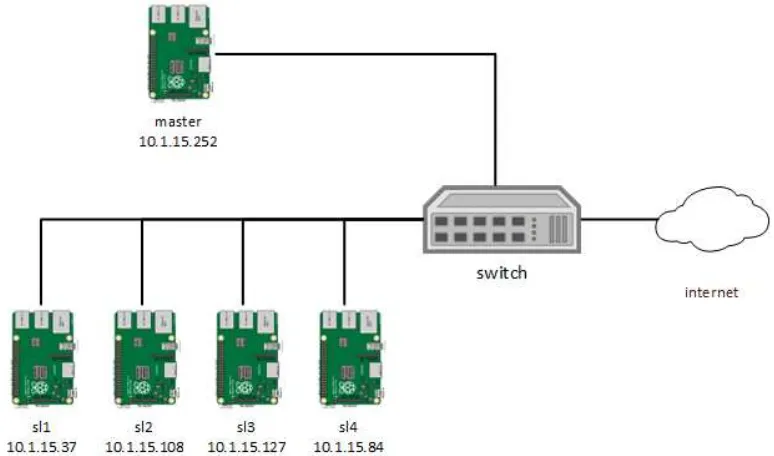
Pada penelitian ini sistem yang dibangun akan diterapkan pada sebuah cluster server grid berbasis raspberry pi yang terdiri dari satu buah node master dan empat buah node slave seperti pada gambar 3.6. Raspberry pi yang dipakai pada sistem ini adalah lima buah raspberry pi 2.
Raspberry pi yang telah diinstall sistem operasi raspbian kemudian dihubungkan pada jaringan. Penggunaan jaringan bertujuan agar setiap node raspberry dapat berkomunikasi dalam melakukan eksekusi proses secara terdistribusi. Masing masing raspberry pi telah membutuhkan beberapa aplikasi dan library tambahan yang wajib diinstall yaitu :
a. Nfs-kernel-server dan nfs-client b. Portmapper
c. Passwordless ssh, dan d. Mpich 2
e. Python 2.7.12 dan python 3.5
Gambar 3. 7 Arsitektur Raspberry Pi Server Grid
3.4 Naïve Bayes Classifier
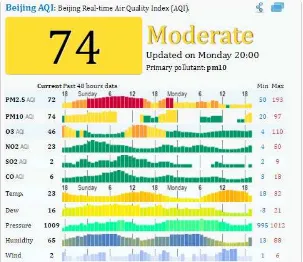
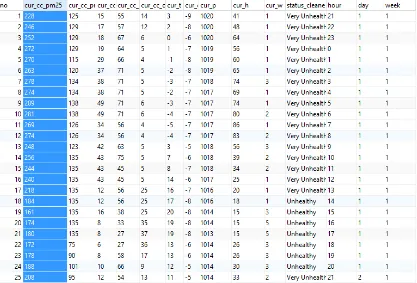
Pada tahapan ini, data hasil web scraping yang telah diproses menjadi dataset untuk training dan testing kemudian diolah untuk dapat diklasifikasikan menggunakan algoritma naïve bayes classifire. Algoritma ini akan menghitung nilai probabilitas dari range data per minggu, lalu mengklasifikasikannya berdasarkan 6 tingkatan nilai AQI. Dalam melakukan implementasi algoritma Naïve Bayes perlu diperhatikan rasio pembagian data training dan data testing serta tingkat akurasi prediksi hasil klasifikasi. Sebagai contoh untuk melakukan klasifikasi data dalam 1 hari dengan data seperti pada gambar 3.6
Dengan menggunakan teorema Bayes, kita dapat melakukan kalkulasi nilai rata-rata tertinggi dari beberapa parameter. Pada gambar 3.6 terlihat secara jelas bahwa data untuk parameter PM2.5 memiliki nilai yang sangat tinggi dibandingkan dengan yang lain.
Berdasarkan rumus, langkah selanjutnya yang dilakukan adalah :
1. Melakukan konversi data polutan PM2.5 pada gambar 3.6 menjadi tabel 3.1 : Tabel 3. 1Tabel Frekuensi AQI Level selama 24 Jam
Level Frekuensi
Very Unhealthy 17
Hazardous 0
Total Data 24
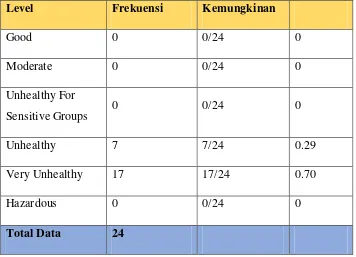
2. Buat Tabel kemungkinan berdasarkan tabel frekuensi 3.1 menjadi tabel 3.2 Tabel 3. 2 Tabel Kemungkinan Berdasarkan tabel frekuensi
Level Frekuensi Kemungkinan
3. Gunakan Rumus Bayessian (rumus 2.2) untuk melakukan kalkulasi probabilitas akhir dari setiap kelas. Kelas dengan probabilitas akhir tertinggi kemungkinan merupakan hasil prediksi klasifikasi. Dalam hal ini ada 2 kelas yang memiliki nilai probabilitas lebih tinggi dari kelas lainnya yaitu :
�����(��ℎ����ℎ�) = 7
24 = 0.29
�����(������ℎ����ℎ�) = 17
24 = 0.70
Berdasarkan contoh Prior Probabilitas di atas, diasumsikan untuk objek baru yang akan diklasifikasikan akan berada diantara dua kelas tersebut. Kemudian kita dapat menghitung kemungkinan dengan perbandingan 1 : 3 dimana dalam sebuah himpunan terdapat 1 objek dengan kemungkinan Unhealthy dan 3 objek dengan kemungkinan Very Unhealthy.
����ℎ���(�|��ℎ����ℎ�) = 1
7 = 0.14
����ℎ���(�|������ℎ����ℎ�) = 3
17 = 0.17
Maka kemungkinan akhir objek X untuk berada dalam kategori Unhealthy adalah: ���������(�|��ℎ����ℎ�) = 7
24 × 1
7 = 0.04
Sementara kemungkinan akhir objek X untuk berada dalam kategori Very Unhealthy adalah :
���������(�|������ℎ����ℎ�) = 17 24 ×
3
17 = 0.303
Maka, objek X dapat diklasifikasikan sebagai Very Unhealthy dikarenakan kelas tersebut memiliki kemungkinan posterior yang terbesar.
3.5 Perancangan Antarmuka Sistem
Perancangan antarmuka merupakan tahap dimana melakukan perancangan tampilan yang menghubungkan pengguna dengan aplikasi. Perancangan antar muka sendiri dilakukan sebelum melakukan implementasi agar mendapatkan gambaran umum setiap tampilan yang terdapat pada aplikasi yang dibangun. Hal ini dilakukan agar memudahkan dalam pengembangan sistem. Dalam melakukan perancangan antarmuka diusahakan membuat tampilan dan layout yang bersifat mudah digunakan, sehingga pengguna dapat mengguna aplikasi dengan tepat dan benar.
3.5.1 Perancangan Halaman Utama Hasil Klasifikasi
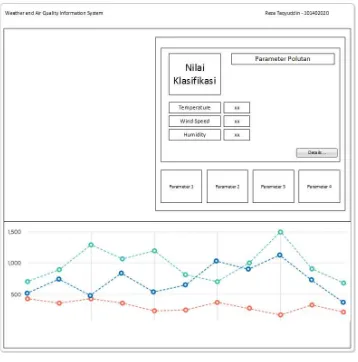
Halaman utama pada sistem ini merupakan halaman depan yang menampilkan data hasil klasifikasi kualitas udara yang telah diproses secara background pada server. Ketika halaman ini dibuka, akan terdapat beberapa elemen penyusun halaman seperti kotak nilai dari masing masing parameter polutan, kotak nilai polutan utama hasil klasifikasi dan kotak yang menampilkan grafik kualitas udara selama beberapa minggu.
Gambar 3. 9 Rancangan tampilan halaman utama 3.5.2 Perancangan Halaman Informasi Health Concern
Pada halaman ini user dapat mengetahui informasi terkait masalah kesehatan yang mungkin terjadi diakibatkan nilai polutan yang mencapai ambang batas tertentu. Ketika halaman ini dibuka, terdapat kotak berisi combobox untuk user dapat memilih jenis polutan dan ambang batasnya dan sebuah tombol untuk memproses pilihan user.
BAB 4
IMPLEMENTASI DAN PENGUJIAN
Setelah melakukan analisis dan perancangan sistem selanjutnya dilakukan implementasi. Pada bab ini akan membahas tentang hasil yang diperoleh setelah melakukan implementasi.
4.1 Implementasi Sistem
Dalam penelitian ini, penerapan metode Web Scraping dilakukan dengan menggunakan bahasa pemograman PHP, metode Naïve Bayes menggunakan bahasa pemrograman Python, sedangkan untuk antarmuka menggunakan HTML beserta Javascript.
4.1.1 Konfigurasi Perangkat Keras
Spesifikasi perangkat keras yang digunakan untuk membangun sistem ini dan agar pengujian dapat berjalan dengan baik, penelitian ini menggunakan lima unit mini komputer raspberry pi 2 dengan spesifikasi perangkat keras yang dapat dilihat pada tabel 4.1.
Tabel 4. 1 Konfigurasi perangkat keras yang digunakan No. Jenis Komponen Komponen yang digunakan
1. SoC Broadcom BCM2836
2. CPU 900 MHz quad-core ARM Cortex A7 (ARMv7)
3. Kartu Grafis
4.1.2 Konfigurasi Perangkat Lunak
Konfigurasi Perangkat Lunak yang digunakan pada penelitian ini, baik saat proses implementasi maupun pengujian dapat dilihat pada tabel 4.2.
Tabel 4. 2Konfigurasi perangkat lunak yang digunakan
No. Jenis Software Software yang digunakan
1. Sistem Operasi Microsoft® Windows 10 Pro 64bit
2. Sistem Operasi Server Raspbian Jessie
3. Browser Min. Chrome v42
4. IDE Sublime Text Editor
5. Library SciPy dan NumPy
6. Python Version Python 2.7.12 atau 3.5.1
4.2 Implementasi Perancangan Antar Muka
Berikut akan dijelaskan tampilan dari aplikasi yang dibangun. Pada aplikasi ini, hanya memiliki dua buah tampilan, yaitu tampilan informasi kualitas udara dan halaman informasi mengenai kesehatan terkait pencemaran udara.. Kedua tampilan tersebut dibangun dengan menggunakan bahasa pemograman HTML dan didukung dengan Javascript. Berikut merupakan hasil implementasi dari perancangan yang telah dilakukan :
4.2.1 Tampilan Halaman Informasi Kualitas Udara
Gambar 4. 1 Tampilan halaman utama Kualitas Udara
Pada tampilan halaman Informasi kualitas udara, terdapat kotak panel informasi nilai AQI (Air Quality Index) yang berisi kondisi udara pada saat sekarang didalam kotak yang akan berubah warna sesuai dengan kualitas udara pada saat tersebut. Di dalam panel terdapat kondisi cuaca, suhu, waktu terakhir ketika sistem melakukan update data dan sebuah tombol berwarna biru yang akan menampilkan sebuah dialog untuk menjelaskan indikator warna kualitas udara seperti pada gambar 4.2.
menggambarkan beberapa nilai polutan dan perubahan yang terjadi setiap jam selama proses monitoring.
Gambar 4. 2 Tampilan dialog indikator kualitas udara
4.2.2 Tampilan Halaman Informasi Health Concern
Selain untuk memberikan gambaran umum tentang nilai kualitas udara pada saat sekarang, user juga membutuhkan informasi yang dapat memberikan pemahaman mengenai bahaya dan dampak dari pencemaran udara pada kesehatan tubuh seperti terdapat pada gambar 4.3.
Gambar 4. 4 Form Untuk memilih Jenis Polutan dan Level Batas
Lalu terdapat sebuah tombol untuk memproses request dari user sehingga ditampilkan informasi mengenai polusi dan dampaknya bagi kesehatan. Ketika tombol di klik, maka tabel disebelah form akan terisi informasi seperti pada gambar 4.5.
4.3 Pengujian Sistem
Tahapan pengujian sistem adalah tahapan dimana dilakukan serangkaian langkah- langkah untuk menguji apakah sistem yang dibangun sudah berjalan dengan baik ataupun respon sistem terhadap kesalahan yang dilakukan oleh pengguna dapat ditanggulangi dengan baik atau tidak. Pada pengujian kali ini, dilakukan beberapa tahapan berikut :
4.3.1 Pengujian Cluster Server
Sistem yang dibangun menggunakan server terdistribusi secara cluster pada perangkat raspberry pi2. Server yang dibangun menggunakan Simple Cluster Machine dengan memanfaatkan penggunaan Shared NFS (Network File System) dan teknik Message Passing untuk dapat berkomunikasi antar node seperti pada gambar 4.6.
Gambar 4. 6 Raspberry Pi Cluster Server
Untuk menguji apakah semua node telah saling terkoneksi dan dapat berkomunikasi satu dengan yang lain diperlukan beberapa tes yaitu dengan :
a. Pengecekan koneksi ssh pada tiap node.
Proses ini membutuhkan mekanisme login menggunakan ssh tanpa password. Penggunaan ssh tanpa password dapat dibuat dengan mengenalkan tiap-tiap hostname node pada Master.
b. Pada Master node, direktori /var/www/html/skripsi/ dijadikan shared directory. Lalu master node melakukan binding nfs dengan menggunakan portmapper pada port 2049 seperti pada gambar 4.7
d. Setelah memastikan seluruh slave node telah melakukan mounting, selanjutnya dilakukan dengan membuat sebuah file text pada shared directory di salah satu node lalu melakukan cek pada direktori yang sama di node lainnya seperti pada tabel 4.8.
Gambar 4. 8 Status mounting Network File System pada Slave Node
4.3.2 Pengujian Web Scraping Data Polusi
Gambar 4. 9 Tampilan Halaman sebelum dilakukan scraping (jam 13.50)
Web scraping dijalankan dengan mengakses file ./grab/grab.php pada web server lokal. Pada sistem operasi windows otomatisasi akses file tersebut dilakukan dengan menggunakan windows task scheduler yang akan terus dikerjakan secara berulang pada menit ke 30 di setiap jam. Sementara pada server raspberry pi, akses pada file grab.php menggunakan perintah curl yang dijalankan secara otomatis dengan bantuan cronjob yang akan melakukan eksekusi pada menit ke 59 di setiap jam. Perintah curl juga dapat dieksekusi secara manual seperti pada gambar 4.10
Gambar 4. 11 Tampilan Halaman setelah dilakukan scraping (jam 14.05)
Proses pengambilan data dilakukan secara background process pada sisi server, dimana aplikasi hanya sebagai aplikasi antarmuka yang tidak melakukan proses logika. Sehingga terlihat pada gambar 4.10 eksekusi telah berhasil dilakukan dan tidak mengembalikan pesan apapun. Namun, perubahan data dapat diperhatikan pada gambar 4.11.
Pada gambar 4.11, kotak Current Air Quality berubah nilainya dari 38 ke 25 yang mengindikasikan pada jam sebelumya kualitas udara berada pada index 38 dan ketika pada jam selanjutnya, indeks berubah menjadi 25. Hal ini menandai bahwa proses web scraping yang telah dilakukan berhasil dieksekusi. Perubahan ini juga dapat dilihat dengan mengakses langsung ke database MySQL.
Gambar 4. 12 Hasil Log web scraping 4.3.3 Pengujian Pengambilan Data Cuaca
Data cuaca yang digunakan pada penelitian ini merupakan data yang dihasilkan dari API Wunderground. Pemanggilan API ini menggunakan method GET atau akses langsung melalui url. API mengirimkan respon ke server berupa data dengan format JSON. Data udara wunderground dipebaharui setiap saat, oleh karena itu pada sistem ini pengambilan data cuaca dikerjakan secara otomatis dengan melakukan eksekusi url melalui cronjob secara berkala setiap 5 menit sekali. File tersebut akan dipindahkan ke server lokal dengan nama file current-tanggal.json.
Karena hasil response yang diberikan oleh server berupa dalam format JSON seperti pada gambar 4.13, maka perlu dilakukan perantaraan oleh aplikasi untuk melakukan pembacaan hasil response dan menjadikannya Human-Readable dengan mengambil obyek dari JSON dan melakukan parsing informasi untuk digunakan dalam tampilan antarmuka. Objek yang diambil pada json ini adalah :
• latitude
• longitude
• weather
• temp_c
4.3.4 Pengujian Klasifikasi Kualitas Udara
Data yang telah dibersihkan dan diseleksi lalu ditraining dengan menggunakan algoritma naïve bayes. Algoritma ini dijalankan sebagai background process pada server dan didistribusikan serta dieksekusi secara paralel di setiap node. Dikarenakan proses berjalan secara background, hasil klasifikasi kemudian dimasukkan ke dalam mysql database. Pada tampilan antarmuka, data hasil klasifikasi ditampilkan seperti pada gambar 4.14. gambar 4.14 menampilkan kondisi udara pada saat itu dan juga hasil klasifikasi kualitas udara pada hari terakhir dari data yang telah terkumpul. Screenshot menampilkan data klasifikasi pada hari ke-197 pengambilan data.
BAB 5
KESIMPULAN DAN SARAN 5.1 Kesimpulan
Setelah melakukan penelitian dan pembangunan aplikasi ini, dapat diambil kesimpulan dengan melakukan implementasi Web Scraping dapat membentuk sebuah model pengumpulan data udara yang termonitoring dengan baik. Dan dengan penerapan Distributed Naïve Bayes Classifier, hasil pengelolaan data yang telah didapatkan melalui model sebelumnya dapat memberikan hasil klasifikasi mengenai kualitas udara secara harian dengan akurasi 98% dan dengan sumber daya minimal pada perangkat Raspberry Pi. .
5.2 Saran
Beberapa saran yang dapat menjadi pertimbangan dalam penelitian selanjutnya ialah: 1. Melakukan pengumpulan data menggunakan data hasil sensor udara.
2. Dapat menggunakan pengecekan berkala dalam monitoring pengumpulan data untuk dapat mengurangi adanya data yang hilang.
3. Menggunakan Penjadwalan Pengerjaan (Job Schedulling) secara paralel untuk pengelolaan data yang lebih baik pada sistem terdistribusi.