A. Waktu dan Tempat Penelitian
Waktu penelitian yang digunakan oleh peneliti adalah selama bulan September 2016 hingga bulan Juni 2017. Penelitian ini dilakukan terhadap nilai perusahaan pada perusahaan industri logam dan sejenisnya yang terdaftar di Bursa Efek Indonesia (BEI) atau Indonesia Stock Exchange (IDX) dengan periode
2013-2015 sebagai objek dalam penelitian ini.
Dalam menyusun penelitian ini, peneliti mengadakan penelitian di Jakarta. Lokasi penelitian merupakan sebuah obyek penelitian yang diambil oleh peneliti dengan data sekunder di Bursa Efek Indonesia. Untuk pengumpulan data sekunder yang dibutuhkan oleh peneliti diperoleh dari Website Bursa Efek Indonesia yaitu www.idx.co.id yang mana untuk mendapatkan data laporan keuangan, ringkasan kinerja tercatat dan factbook perusahaan industri logamdansejenisnya dari tahun
2013 – 2015.
B. Desain Penelitian
Dalam penelitian ini desain penelitian yang digunakan adalah asosiatif kausal, yaitu tipe hubungan yang menjelaskan hubungan sebab akibat atau pengaruh variable dependen (Sekaran, 2006). Penelitian kausal adalah penelitian
terhadap variabel tertentu (dependent variabel). Dalam penelitian ini yang diteliti
adalah pengaruh DER, ROE, dan Size (independent variabel) terhadap nilai
perusahaan (dependent variabel).
C. Definisi dan Operasional Variable a. Identifikasi Variabel
Menurut Sugiyono (2014), mendefinisikan bahwa variabel penelitian adalah suatu atribut atau sifat nilai dari orang, objek atau kegiatan yang mempunyai variasi tertentu yang ditetapkan oleh peneliti untuk dipelajari dan kemudian ditarik kesimpulannya.
Dalam penelitian ini variabel yang diamati terdapat dua variabel, yaitu variabel independent dan variabel dependent.
a. Variabel Independent
Menurut Sugiyono (2014), pengertian variabel independent adalah variabel
yang mempengaruhi atau yang menjadi sebab perubahannya atau timbulnya variabel dependent (terikat). Variabel bebas merupakan variabel stimulus atau
variabel yang dapat mempengaruhi variabel lain. Variabel bebas merupakan variabel yang diukur, dimanipulasi, atau dipilih oleh peneliti untuk menentukan hubungannya dengan suatu gejala yang diobservasi.
b. Variabel Dependent
Menurut Sugiyono (2014), pengertian variabel dependent adalah variabel
Dalam penelitian ini yang menjadi variabel independent adalah Debt to Equity Ratio (DER), Return on Equity (ROE), dan Size sedangkan yang menjadi
variabel dependent ialah Nilai Perusahaan.
b. Definisi Operasional Variabel a. Debt to Equity Ratio (X1)
Syafri (2013) menyatakan bahwa DER merupakan rasio hutang modal menggambarkan sampai sejauh mana modal pemilik yang dapat menutupi hutang – hutang kepada pihak luar dan merupakan rasio yang mengukur hingga sejauh mana perusahaan dibiayai dari hutang. Rasio ini disebut juga leverage ratio.
b. Return on Equity (X2)
ROE adalah rasio untuk mengukur laba bersih sesudah pajak dengan modal sendiri. Rasio ini menunjukkan efisiensi penggunaan modal sendiri. Semakin tinggi rasio ini, maka semakin baik. Artinya posisi pemilik perusahaan semakin kuat, demikian pula sebaliknya (Martono dan Harjito, 2010).
c. Ukuran Perusahaan / Size (X3)
Ukuran perusahaan dilihat dari total asset yang dimiliki oleh perusahaan yang dapat dipergunakan untuk kegiatan operasi perusahaan (Prasetya et al.,
2016).Ukuran perusahaan (Size) diukur dengan log natural dari total aktiva.
d. Nilai Perusahaan (Y)
Nilai perusahaan diukur dengan melihat rasio Price to Book Value (PBV),
2015, yang dinyatakan sebagai berikut (dalam satuan rasio) : PBV = Nilai Pasar Ekuitas / Nilai Buku Ekuitas.
Memaksimumkan nilai perusahaan disebut sebagai memaksimumkan kemakmuran pemegang saham (stakeholder wealth maximation) yang dapat
diartikan juga sebagai memaksimumkan harga saham biasa dari perusahaan. Adapun pengukuran operasionalisasi dari masing-masing variabel yang terdapat dalam tabel berikut
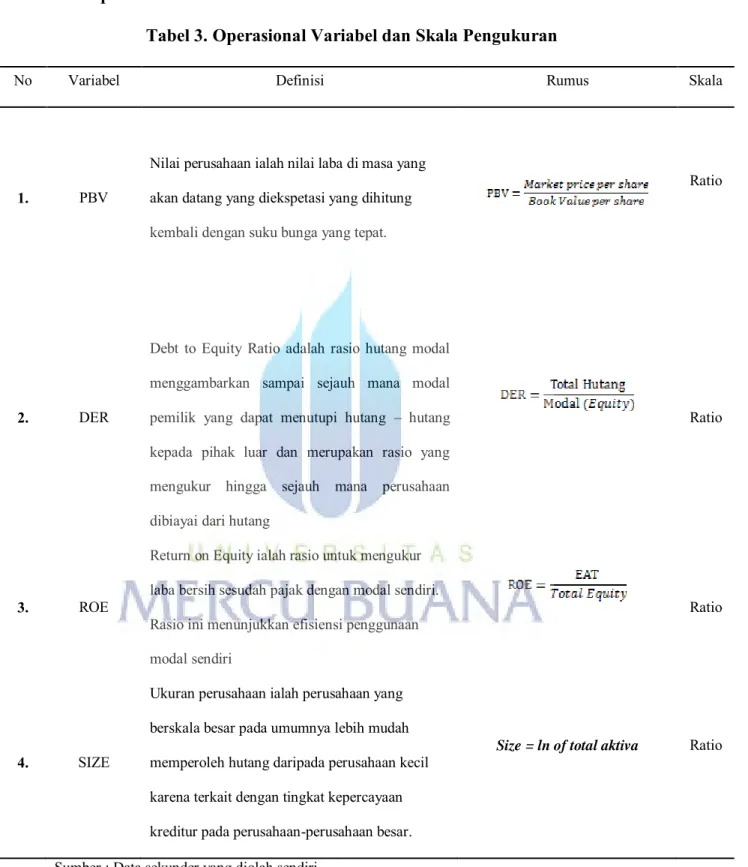
e. Operasional Variabel
Tabel 3. Operasional Variabel dan Skala Pengukuran
No Variabel Definisi Rumus Skala
1. PBV
Nilai perusahaan ialah nilai laba di masa yang akan datang yang diekspetasi yang dihitung kembali dengan suku bunga yang tepat.
Ratio
2. DER
Debt to Equity Ratio adalah rasio hutang modal menggambarkan sampai sejauh mana modal pemilik yang dapat menutupi hutang – hutang kepada pihak luar dan merupakan rasio yang mengukur hingga sejauh mana perusahaan dibiayai dari hutang
Ratio
3. ROE
Return on Equity ialah rasio untuk mengukur laba bersih sesudah pajak dengan modal sendiri. Rasio ini menunjukkan efisiensi penggunaan modal sendiri
Ratio
4. SIZE
Ukuran perusahaan ialah perusahaan yang berskala besar pada umumnya lebih mudah memperoleh hutang daripada perusahaan kecil karena terkait dengan tingkat kepercayaan kreditur pada perusahaan-perusahaan besar.
Size = ln of total aktiva Ratio
D. Populasi dan Sampel Penelitian 1. Populasi Penelitian
Menurut Sugiyono (2014), pengertian populasi adalah wilayah generalisasi yang terdiri atas proyek / subyek yang mempunyai kualitas dan karakteristik tertentu yang ditetapkan oleh penelitian untuk dipelajari dan kemudian ditarik kesimpulan.
Populasi yang diteliti dalam penelitian ini adalah perusahaan industry logam dan sejenisnya yang terdaftar di Bursa EfekIndonesia (BEI) padatahun 2013– 2015. Dengan populasi sebanyak 16 perusahaan.
2. Sampel Penelitian
Menurut Sugiyono (2014), pengertian sampel adalah bagian dari jumlah dan karakteristik yang dimiliki oleh populasi tersebut. Teknik pengambilan sampel dilakukan dengan metode purposive sampling. Purposive Sampling adalah
teknik penentuan sampel dengan pertimbangan tertentu. Teknik ini paling cocok digunakan dalam penelitian kualitatif yang tidak melakukan generalisasi (Sugiyono, 2011). Dalam penelitian ini sampel harus memenuhi kriteria sebagai berikut :
a. Perusahaan tersebut terdaftar di BEI setidaknya tahun 2013-2015 atau selama periode pengamatan.
b. Perusahaan tersebut secara periodik mengeluarkan laporan keuangan tiap tahunnya dan memiliki kelengkapan data selama periode pengamatan.
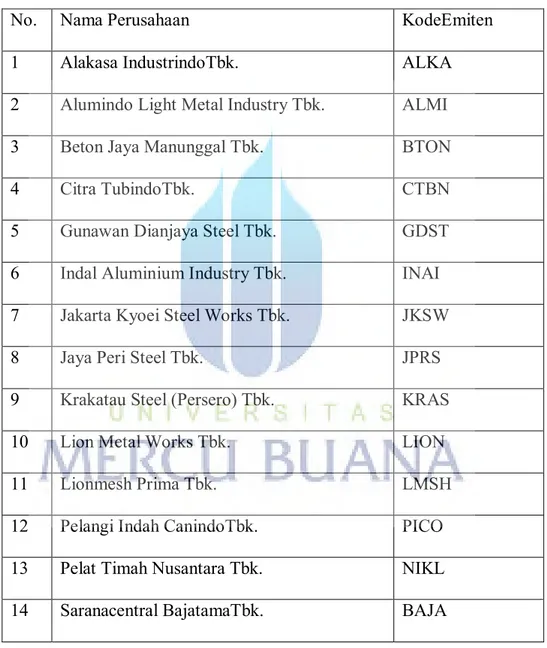
Dari populasi yang berjumlah 16 Perusahaan, sebanyak 14 Perusahaan yang memenuhi syarat menjadi sampel dalam penelitian ini. Berikut ini tabel 4 perusahaan yang menjadi sampel Penelitian :
Table 4. Daftar Nama Perusahaan yang Menjadi Sample
No. Nama Perusahaan KodeEmiten
1 Alakasa IndustrindoTbk. ALKA
2 Alumindo Light Metal Industry Tbk. ALMI
3 Beton Jaya Manunggal Tbk. BTON
4 Citra TubindoTbk. CTBN
5 Gunawan Dianjaya Steel Tbk. GDST
6 Indal Aluminium Industry Tbk. INAI
7 Jakarta Kyoei Steel Works Tbk. JKSW
8 Jaya Peri Steel Tbk. JPRS
9 Krakatau Steel (Persero) Tbk. KRAS
10 Lion Metal Works Tbk. LION
11 Lionmesh Prima Tbk. LMSH
12 Pelangi Indah CanindoTbk. PICO
13 Pelat Timah Nusantara Tbk. NIKL
E. Teknik Pengumpulan Data
Jenis data yang digunakan dalam penelitian ini adalah data sekunder berupa data laporan keuangan, ringkasan kinerja tercatat, dan factbook perusahaan
industry logam dan sejenisnya yang tercatat di Bursa Efek Indonesia pada tahun 2013-2015. Data sekunder menurut Sugiyono (2012) adalah sumber data yang diperoleh dengan cara membaca, mempelajari dan memahami melalui media yang bersumber dari literatur, buku-buku, serta dokumen perusahaan atau sumber data sekunder adalah data yang tidak langsung diberikan kepada pengumpul data.
Adapun sumber data yang diperlukan untuk penelitian ini adalah Laporan keuangan, ringkasan kinerja perusahaan tercatat dan factbook perusahaan sub
sektor Logam dan Sejenisnya yang terdaftar di BEI. Laporan keuangan, ringkasan kinerja perusahaan tercatat dan factbook diambil dari tahun 2013-2015 melalui
situs www.idx.co.id
F. Metode Analisis Data
Menurut Sugiyono (2014) yang dimaksud dengan analisis data ialah kegiatan setelah data dari seluruh responden terkumpul. Kegiatan dalam analisis data adalah mengelompokkan data berdasarkan variabel dan jenis responden, mentabulasi data berdasarkan variabel dari seluruh responden, menyajikan data tiap variabel yang diteliti, melakukan perhitungan untuk menjawab masalah, dan melakukan perhitungan untuk menguji hipotesis yang telah diajukan.
1. Analisis Statitik Deskriptif
Menurut Sugiyono (2014) statistik deskriptif adalah statistik yang digunakan untuk menganalisa data dengan cara mendeskripsikan atau menggambarkan data yang telah terkumpul sebagaimana adanya tanpa bermaksud membuat kesimpulan yang berlaku untuk umum atau generalisasi.
Analisis statistik deskriptif dalam penelitian ini mencakup karakteristik perusahaan pertambangan batubara yang menjadi sampel penelitian ini. Selain itu juga dilakukan penggambaran variabel yang mencakup rata-rata, maksimum, minimum, dan deviasi standar dari masing-masing variabel yang digunakan dalam analisis.
2. Analisis Kelayakan Data
Dalam penelitian ini, data yang digunakan adalah data panel (Panel Pooled Data), karena kelebihan dari pengguna data panel, salah satunya adalah dapat
memberikan data yang lebih informatif, dan lebih baik dalam mendeteksi dan mengukur efek yang tidak dapat diamati dalam data cross section dan time series
(Agus, 2007).
a. Uji Stasioner Data
Uji stasioner data dilakukan untuk melihat apakah data stasioner atau tidak. Data yang tidak stasioner bila diregresikan akan mudah menyebabkan referensi lancung. Data dikatakan stationer bila memenuhi syarat sebagai berikut : 1. Rata-rata dan variannya konstan sepanjang waktu.
2. Kovarian antara dua data runtut waktu tergantung pada kelambanan antara dua periode tersebut. Oleh karenanya data yang tidak stasioner harus dijadikan stasioner terlebih dahulu.
Untuk menjadikan data tidak stasioner menjadi data stasioner biasanya data cukup di difrensi saja. Pada tingkat difrensi pertama, biasanya data sudah menjadi stasioner, kalau ternyata belum, kemungkinan besar pada diferensi kedua sudah stasioner (Gujarati, 2012).
3. Analisis Regresi Data Panel
Dalam analisis regresi data panel ada beberapa keunggulan Wibisono (2015), antara lain :
1. Panel data mampu memperhitungkan heterogenitas individu secara eksplisit dengan mengijinkan variabel spesifik individu.
2. Kemampuan mengontrol heterogenitas ini selanjutnya menjadikan data panel data digunakan untuk menguji dan membangun model perilaku lebih komplek. 3. Data panel mendasarkan diri pada Observasi Cross-Section yang
berulang-ulang (Time Series), sehingga metode data panel cocok digunakan sebagai study of dynamic adjustman.
4. Tingginya jumlah observasi memiliki implikasi pada data yang lebih informatif, lebih variatif, dan kolinearitas (multiko) antara data semakin berkurang, dan derajat kebebasan (Degree of freedom / DF) lebih tinggi
sehingga dapat diperoleh hasil estimasi yang lebih efisien.
5. Data panel dapat digunakan untuk mempelajari model-model perilaku yang kompleks.
6. Data panel dapat digunakan untuk meminimalkan bias yang mungkin ditimbulkan oleh agregasi data individu.
Kemudian dalam permodelan dengan menggunakan teknik Regresi data panel dapat dilakukan dengan 3 Pendekatan Alternatif metode pengolahannya, yaitu :
a. Metode Common Effect (Pooled Least Square)
Model ini merupakan model paling sederhana dibandingkan dengan kedua model lainnya. Model ini tidak dapat membedakan varians antara silangtempat dan titik waktu karena memiliki intercept yang tetap, dan bukanbervariasi secara random (Kuncoro, 2014).
Persamaan untuk common effect ditulis dengan persamaan sebagai berikut :
Yit = α+βXit + εit untuk i = 1,2,...,N dan t = 1,2,....,T
Dimana N adalah jumlah unit cross section (individu) dan T adalah jumlah periode waktunya. Dengan mengasumsi komponen eror dalam pengolahan kuadrat terkecilbiasa dapat melakukan proses estimasi secara terpisah untuk setiap unit cross section.
b. Metode Fixed Effect (FE)
Pengertian model Fixed Effect adalah model dengan intercept
berbeda-beda untuk setiap subjek (cross section), tetapi slope setiap subjek tidak berubah
seiring waktu (Gujarati, 2012). Model ini mengasumsikan bahwa intercept adalah berbeda setiap subjek sedangkan slope tetap sama antarsubjek. Dalam
(Kuncoro, 2014). Model ini sering disebut dengan model Least Square Dummy Variables (LSDV).
Secara matematis model panel data yang menggunakan fixed effect adalah
sebagai berikut :
Yit = α+βXit +γ2W2t + γ3W3t +....+ γnWnt + σ2Zit+ σ3Zi3....+ σtZit+ εit
Dimana :
Yit = variabel terikat untuk individu ke-i dan waktu ke-t
Xit = variabel bebas untuk individu ke-i dan waktu ke-t
Wit = merupakan variabel boneka (dummy) dimana Wit = 1 untuk individu i, i= 1,2,...N dan bernilai 0 untuk lainnya.
Zit = merupakan variabel boneka (dummy) dimana Zit = 1 untuk periode t, t =1,2,...T dan bernilai 0 untuk lainnya.
Pada Fixed Effects Approach terdapat beberapa kemungkinan persamaan regresi yang tergantung pada asumsi yang digunakan :
1. Intercept dan slope dari koefisien tetap atau konstan sepanjang waktu dan error term menangkap perbedaan – perbedaan sepanjang waktu dan individu.
2. Slope dari koefisien konstan tetapi intersep individual bervariasi
3. Slope dari koefisien konstan tetapi intersep bervariasi berdasarkan individu maupun pada waktu.
4. Seluruh koefisien bervariasi pada individual
5. Intersep dan juga slope dari koefisien berbeda pada individu maupun waktu. Model fixed effect memiliki beberapa kelemahan yaitu:
1. Terlalu banyak variabel boneka (dummy)
2. Terlalu banyak variabel didalam model sehingga ada kemungkinan terjadi multikoliniaritas.
3. Tidak mampu mengidentifikasi dampak variabel – variabel time invariant seperti jenis kelamin, warna dan etnik.
4. Harus berhati-hati dalam memikirkan error term Uit
c. Metode Random Effect (RE)
Random effect disebabkan variasi dalam nilai dan arah hubungan antar subjek diasumsikan random yang dispesifikasikan dalam bentuk residual (Kuncoro, 2012). Model ini mengestimasi data panel yang variabel residual diduga memiliki hubungan antar waktu dan antar subjek.
Menurut Widarjono (2007) model random effect digunakan untuk mengatasi kelemahan model fixed effect yang menggunakan variabel dummy. Metode analisis data panel dengan model random effect harus memenuhi persyaratan yaitu jumlah cross section harus lebih besar daripada jumlah variabel penelitian. Berikut ini persamaan random effect :
Yit = α+βXit + εit ; εit = ut + vt + wit
Dimana :
ut = komponen cross section error vt = komponen time series error wit = komponen error kombinasi
Untuk menguji permodelan Regresi data panel ketiga estimasi model regresi dengan melakukan uji Chow dan uji Hausman yang ditujukan untukmenentukan apakah model data panel dapat diregresi dengan metode
Common Effect , metode Fixed Effect atau metode Random Effect (Widarjono,
2007).
4. Pemilihan Model Regresi Data Panel
Pertama yang harus dilakukan adalah melakukan uji F untuk memilih model mana yang terbaik diantara ketiga model tersebut adalah dengan melakukan uji chow dan uji hausman.
a. Uji Chow
Uji Chow merupakan uji untuk membandingkan model common effect
dengan fixed effect (Widarjono, 2007). Chow test dalam penelitian ini
menggunakan Eviews 8. Hipotesis yang dibentuk dalam Chow Test ini adalah sebagai berikut :
Ho = Model Common Effect
Ha = Model Fixed Effect
Uji Chow digunakan untuk menentukan apakah model data panel diregresi dengan metode Common Effect atau dengan metode Fixed Effect apabila
dari hasil uji tersebut ditentukan bahwa metode Common Effect yang digunakan,
maka tidak perlu diuji kembali dengan Uji Hausman. Namun apabila dari hasil Uji Chow tersebut ditentukan bahwa metode Fixed Effect yang digunakan, maka
atau metode Random Effect yang digunakan untuk mengestimasi regresi data
panel. Pertimbangan pemilihan pendekatan yang digunakan ini didekati dnegan menggunakan statistik F yang berusaha memperbandingkan antara nilai jumlah kuadrat dari error dari proses pendugaan dengan metode kuadrat terkecil dan efek tetap adalah :
Dimana :
RRSS = Restricted Residual Sum Square
URSS = Unrestricted Residual Sum Square
N = Jumlah data Cross Section
T = Jumlah data Time Series
K = Jumlah variabel penjelas
Hipotesis :
H0 = Model menggunakan pendekatan Common Effect
Ha = Model menggunakan pendekatan Fixed Effect
Pengujian yang dilakukan dengan menggunakan Chow Test atau
Likelihood Ratio Test dengan asumsi :
Ho ditolak jika ρ-value lebih kecil dari α.
Ha diterima jika ρ-value lebih besar dari α. Nilai α yang digunakan sebesar 0,05 atau 5%.
b. Uji Hausman
Pengujian ini membandingkan model fixed effect dengan metode random effect dalam menentukan model yang terbaik untuk digunakan sebagai model
regresi data panel (Gujarati, 2012). Hausman Test menggunakan program yang serupa dengan Chow Test yaitu program Eviews. Hipotesis yang dibentuk dalam Hausman test adalah sebagai berikut :
Ho = Model Random Effect
Ha = Model Fixed Effect
Model Uji Hausman yang digunakan adalah sebagai berikut :
W = X2 [k-1] = [b – 𝛃] [b – 𝛃]
Sementara itu hipotesis yang digunakan dalam pengujian ini adalah : Ho = W memiliki distribusi chi-square yang terbatas dengan derajat kebebasan
(k-1)
Ha = W memiliki distribusi chi-square yang tidak terbatas dengan derajat
kebebasan (k-1)
Uji menggunakan chi-square dimana jika probabilitas dari hausman lebih
kecil dari α (hasil hausman test signifikan) maka Ho ditolak dan model fixed effect
digunakan.
1. Ho diterima dan Ha ditolak apabila ρ value > 0,05 atau bila signifikansi >α = 0,05 berarti model regresi dalam penelitian ini tidak layak atau fit untuk
2. Ho ditolak dan Ha diterima apabila ρ value < 0,05 atau bila signifikansi <α = 0,05 berarti model regresi dalam penelitian ini layak atau fit untuk digunakan
dalam penelitian.
c. Uji Lagrange Multiplier – Test (LM Test)
Lagrange Multiplier (LM) adalah uji untuk mengetahui apakah model Random Effect atau model Common Effect (OLS) yang paling tepat digunakan
(Widarjono,2007). Uji signifikasi Random Effect ini dikembangkan oleh Breusch
Pagan. Metode Breusch Pagan untuk uji signifikasi Random Effect didasarkan
pada nilai residual dari metode OLS.
Hipotesis yang dibentuk dalam Uji LM ini adalah sebagai berikut : Ho = Model Common Effect
Ha = Model Random Effect
Dimana,
Uji LM ini didasarkan pada distribusi chi-squares dengan degree of freedom
sebesar jumlah variabel independen. Sehingga kriterianya adalah sebagai berikut : H0 ditolak jika probabilitas lebih kecil dari α. Sebaliknya H0 diterima jika probabilitasnya lebih besar dari α. Nilai α yang digunakan adalah 5% atau 0,05.
5. Pengujian Model Regresi Data Panel a. Uji Model Regresi Data Panel (Uji F)
Uji F dapat dilakukan dengan membandingkan Fhitung dengan Ftabel, jika Fhitung> dari Ftabel, (Ho ditolak dan Ha diterima) maka model signifikan atau bisa
Uji Regresi dengan metode Enter / Full Model). Model signifikan selama kolom signifikansi <α dan sebaliknya jika Fhitung< Ftabel, maka model tidak signifikan, hal ini juga ditandai dengan nilai kolom signifikansi akan lebih besar dari alpha. Rumus yang dapat digunakan untuk dapat melakukan pengujian ini adalah :
Dimana :
k = jumlah variabel independen n = jumlah anggota sampel
Kriteria pengambilan keputusan yang digunakan adalah sebagai berikut : Ho diterima atau Ha ditolak jika probabilitas tingkat signifikansi Fhitung>α = 0,05 Ho ditolak atau Ha diterima jika probabilitas tingkat signifikansi Fhitung<α = 0,05
Apabila Ho diterima, maka hal ini menunjukkan bahwa variabel independen tidak mempunyai hubungan yang signifikan dengan variabel dependen dan sebaliknya. Apabila Ho ditolak, maka hal ini menunjukkan bahwa variabel independen mempunyai hubungan yang signifikan dengan variabel dependen.
b. Uji Koefisien Regresi Data Panel (Uji t)
Uji t digunakan untuk menguji secara parsial masing-masing variabel. Hasil
Uji t dapat dilihat pada tabel coefficients pada kolom sig (significance). Jika
probabilitas nilai t atau signifikansi < 0,05, maka dapat dikatakan bahwa terdapat
Namun jika probabilitas nilai t atau signifikansi > 0,05, maka dapat
dikatakan bahwa tidak terdapat pengaruh yang signifikan antara masing-masing variabel bebas terhadap variabel terikat.
Hipotesis Uji t :
Ho : diterima jika Sig >α Ha : diterima jika Sig <α
Rumus yang digunakan dalam menguji hipotesis (Uji t) penelitian ini adalah
:
Dimana :
t = nilai uji t
b = koefisien regresi
Sb = standard error dari variabel independen
Apabila Ho diterima, maka hal ini menunjukkan bahwa variabel independen tidak mempunyai hubungan yang signifikan dengan variabel dependen dan sebaliknya. Apabila Ho ditolak, maka hal ini menunjukkan bahwa variabel independen mempunyai hubungan yang signifikan dengan variabel dependen. Dalam memudahkan dan mempercepat proses pengolahan data, penulis menggunakan komputerisasi dengan menggunakan program Eviews 9.