III-1
BAB III
ANALISIS PENYELESAIAN MASALAH
Pada bab ini akan dipaparkan analisis yang dilakukan dalam pengerjaan Tugas Akhir ini. Analisis diawali dengan analisis terhadap konsep Bayesian network yang diperlukan berdasarkan teori yang telah dijabarkan pada Bab II. Setelah itu, dilakukan analisis terhadap bidang kajian web mining yang menjadi fokus dalam Tugas Akhir ini. Dan terakhir, dianalisis studi kasus dari bidang kajian web mining yang dipilih.
III.1 Analisis Konsep Bayesian network
Seperti telah dijelaskan sebelumnya, BN dapat digunakan pada permasalahan deskriptif maupun permasalahan prediktif (dalam bentuk permasalahan klasifikasi). Pada permasalahan deskriptif, dibutuhkan konsep d-separation untuk mendapatkan solusi. Ketika sebuah evidence diberikan pada variabel dalam causal network, informasi ini akan dialirkan kepada variabel-variabel lain. Untuk menggambarkan aliran informasi yang terjadi diantara variabel dalam causal network, digunakan ketiga aturan yang telah dijelaskan pada bagian II.1.3, yaitu serial connection, diverging connection, dan converging connection. Dengan menggunakan ketiga aturan tersebut, dapat dianalisis variabel mana saja yang akan mempengaruhi atau tidak mempengaruhi variabel lainnya jika sebuah variabel diberikan evidence tertentu. Pada permasalahan deskriptif, pengetahuan mengenai kombinasi variabel yang memiliki dependensi satu sama lain digunakan untuk memperoleh deskripsi mengenai permasalahan tersebut. Sementara pada permasalahan prediktif, klasifikasi dilakukan dengan memperhitungkan markov boundary dan markov blanket dari DAG yang dimiliki. Uraian lebih mendalam mengenai markov bounday dan markov blanket dapat dilihat pada Lampiran B. Setelah mengetahui markov boundary dan markov
blanket dari DAG tersebut, klasifikasi dilakukan dengan menggunakan kumpulan conditional probability pada CPT.
Berdasarkan uraian tersebut, studi kasus yang dipilih dapat memodelkan kedua bentuk permasalahan tersebut. Namun, sesuai dengan batasan masalah yang terdapat pada bab I.4, studi kasus akan difokuskan kepada bentuk permasalahan deskriptif. Pada studi kasus tersebut, akan dilihat dependensi antara kata dengan direktori pada dokumen e-mail.
III.2 Analisis Bidang Kajian Web mining yang Menjadi
Fokus
Dari ketiga bidang kajian web mining yang telah dijelaskan pada subbab II.2, berikut ini dianalisis bidang kajian web mining yang memiliki bentuk permasalahan yang sesuai dengan karakteristik BN seperti telah dijelaskan pada bagian sebelumnya. Untuk itu, perlu diperhatikan data mentah yang digunakan, bentuk permasalahan yang dapat diselesaikan, dan data mining task yang umum ditemui pada setiap bidang kajian. Mengacu kepada subbab III.1, BN dapat menyelesaikan permasalahan deskriptif dan prediktif. Untuk penjelasan lebih lanjut mengenai data mining task dapat dilihat pada Lampiran A. Selain itu, untuk setiap bidang kajian juga dijelaskan contoh permasalahan yang dapat diselesaikan dengan BN.
Seperti telah dijelaskan pada bagian II.6, pada web content mining, data mentah yang digunakan adalah content/isi dari sebuah halaman web. Content yang diproses umumnya berupa teks. Tujuan dari web content mining dapat berbentuk deskriptif maupun prediktif. Untuk permasalahan prediktif, data mining task yang umum ditemukan pada webcontentmining adalah klasifikasi dan clustering.
Pada web content mining, classification task umumnya berupa pengelompokkan komponen web (misalnya e-mail atau halaman web) berdasarkan kedekatannya dengan sebuah keyword. Pada Tugas Akhir ini, sampel data yang diperoleh untuk web content mining adalah content e-mail. Sampel data ini melibatkan lebih dari 20.000 email yang dikategorisasi menjadi 20 kategori. Disini data yang diperoleh belum terstruktur sehingga harus melalui proses preprocessing terlebih dahulu.
Berbeda dengan web content mining, pada web structure mining, data mentah yang digunakan adalah topologi sebuah web yang mencakup link-link diantara halaman-halaman web. Topologi ini sering disebut dengan struktur web, seperti yang telah dijelaskan pada bagian II.2.2. Struktur ini menggambarkan sebuah halaman web akan menjadi reference maupun referent dari halaman web mana.
Web structure mining umumnya dilakukan dengan tujuan menyelesaikan permasalahan-permasalahan deskriptif. Contoh penggunaan BN pada web structuremining adalah webstructureanalysis. Disini dapat dianalisis pola akses pengguna pada website tertentu dengan menggunakan BN. Dari pola yang didapat, dinilai efektivitas dari sebuah struktur web. Untuk melakukan hal ini, struktur web akan direpresentasikan sebagai sebuah graf bayesian network. Setiap halaman akan direpresentasikan sebagai sebuah variabel. Kemudian hubungan link diantara setiap halaman direpresentasikan sebagai sebuah arc berarah diantara variabel. Seluruh struktur ini kemudian akan membentuk sebuah directed graph.
Sampel data yang diperoleh untuk web structure mining adalah kumpulan file HTML dari sebuah website. Seperti halnya pada web content mining, data ini belum terstruktur sehingga harus melalui proses preprocessing terlebih dahulu. Permasalahan yang timbul dengan data mentah berupa struktur sebuah web dengan menggunakan teknik BN adalah bahwa graf yang dihasilkan dapat merupakan sebuah cyclic graph. Hal ini disebabkan karena setiap web site dapat memiliki link ke dirinya sendiri. Oleh karena itu, bila BN akan diterapkan pada data mentah berbentuk struktur web, maka harus dilakukan penanganan terhadap
kondisi cyclic ini. Hal ini dilakukan dengan melakukan pembuangan link yang berasal dari halaman website tersebut dan mengacu ke dirinya sendiri.
Bidang kajian terakhir yang akan dianalisis adalah web usage mining. Data mentah yang akan digunakan pada web usage mining adalah perilaku dari pengguna. Web usage mining dapat digunakan untuk tujuan deskriptif dan prediktif. Untuk keperluan prediktif, data miningtask yang umum ditemui pada webusage mining ini sangat bervariasi, mencakup seluruh data mining task yang ada. Salah satu contoh aplikasi klasifikasi pada web usage mining adalah untuk melakukan analisis perilaku pengunjung. Disini sampel data yang diperoleh berupa data perilaku pengunjung website piala dunia. Sebagai contoh, dari data dapat dianalisa apakah seorang pengunjung web yang membeli tiket piala dunia umumnya perempuan atau laki-laki. Data yang digunakan adalah data pengunjung website yang berasal dari web access log.
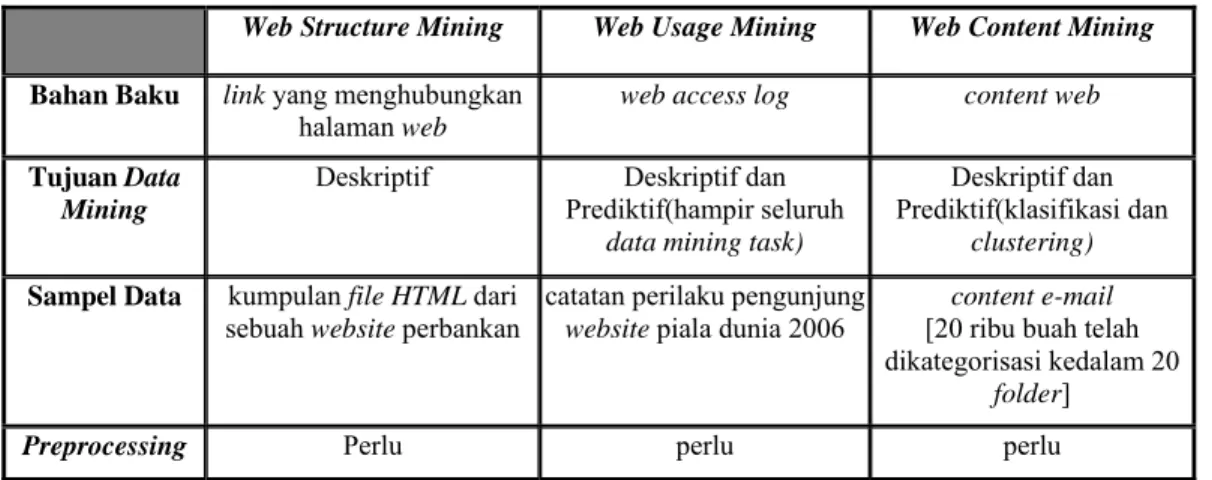
Tabel 4. Rangkuman analisis terhadap bidang kajian web mining
Web Structure Mining Web Usage Mining Web Content Mining Bahan Baku link yang menghubungkan
halaman web
web access log content web Tujuan Data
Mining
Deskriptif Deskriptif dan Prediktif(hampir seluruh
data mining task)
Deskriptif dan Prediktif(klasifikasi dan
clustering) Sampel Data kumpulan file HTML dari
sebuah website perbankan
catatan perilaku pengunjung website piala dunia 2006
content e-mail [20 ribu buah telah dikategorisasi kedalam 20
folder]
Preprocessing Perlu perlu perlu
Dari hasil analisis terhadap ketiga bidang kajian web mining tersebut dapat dilihat bahwa BN dapat digunakan pada web content mining, web usage mining, maupun web structure mining. Namun demikian, dengan mempertimbangkan kesulitan proses preprocessing yang dilakukan, pada Tugas Akhir ini dipilih bidang kajian web content mining dengan sampel data content e-mail. Hasil analisis terhadap seluruh bidang kajian web mining telah dirangkum dalam Tabel 4.
III.3 Analisis Studi Kasus
III.3.1 Deskripsi Umum
Studi kasus yang diambil dalam pengerjaan Tugas Akhir ini adalah permasalahan deskriptif dalam bentuk pengelompokan dokumen e-mail. Pengelompokan dokumen e-mail adalah salah satu contoh aplikasi web content mining. Dengan menggunakan aplikasi web mining yang akan dikembangkan, dapat dilihat kumpulan kata yang memiliki pengaruh terhadap proses pengelompokan email serta depedensi antara kata.
III.3.2 Deskripsi Data Masukan
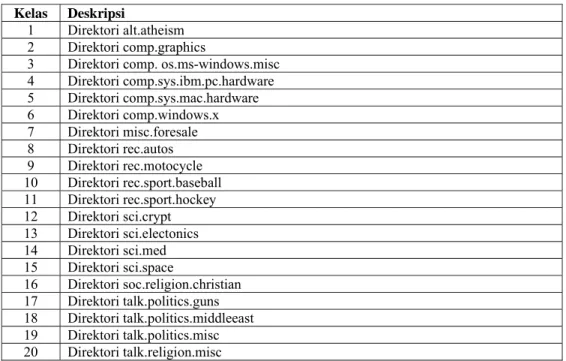
Data awal yang dimiliki berupa file arsip yang berisi 19,998 buah file e-mail mentah (raw) dalam bahasa Inggris. E-mail-e-mail ini berasal dari arsip kelompok diskusi (discussion group) / berita (newsgroup) – sejenis milis yang membahas topik-topik tertentu (misalnya talk.politics.guns yang membahas tentang masalah senjata api, umumnya di Amerika Serikat), atau melayani kepentingan tertentu (misalnya, misc.forsale yang berfungsi sebagai bursa informasi jual beli). File-file e-mail mentah ini dinamai dengan sebuah nomor identifikasi urut tanpa ekstensi file, dan diorganisasi menurut topik yang dibahas oleh kelompok diskusi tersebut ke dalam direktori-direktori yang bersesuaian, di mana terdapat 20 direktori untuk 20 kelompok diskusi. Informasi detail mengenai klasifikasi direktori tersebut dapat dilihat pada Tabel 5. Contoh content dokumen e-mail yang diterima dapat dilihat pada Lampiran C.
Tabel 5. Klasifikasi kelas Kelas Deskripsi
1 Direktori alt.atheism 2 Direktori comp.graphics 3 Direktori comp. os.ms-windows.misc 4 Direktori comp.sys.ibm.pc.hardware 5 Direktori comp.sys.mac.hardware 6 Direktori comp.windows.x 7 Direktori misc.foresale 8 Direktori rec.autos 9 Direktori rec.motocycle 10 Direktori rec.sport.baseball 11 Direktori rec.sport.hockey 12 Direktori sci.crypt 13 Direktori sci.electonics 14 Direktori sci.med 15 Direktori sci.space 16 Direktori soc.religion.christian 17 Direktori talk.politics.guns 18 Direktori talk.politics.middleeast 19 Direktori talk.politics.misc 20 Direktori talk.religion.misc
Data yang dimiliki masih berupa file teks yang belum terstruktur. Bentuk seperti ini akan mengakibatkan proses mining memakan waktu dan resource yang lebih banyak karena data yang tidak diperlukan (misalnya stopword seperti ‘and’ atau ‘or’) juga akan ikut dipertimbangkan. Oleh karena itu, harus dilakukan preprocessing terlebih dahulu terhadap data masukan yang dimiliki.
III.3.3 Analisis Preprocessing
Sesuai dengan uraian mengenai data preprocessing pada bagian II.5.3, dalam melakukan pemrosesan terhadap content email terdapat beberapa tahapan yang harus diperhatikan, yaitu :
1. Data Cleaning
Pada data content email yang dimiliki, ditemukan adanya tiga bentuk data yang tidak diperlukan : stopword (kata-kata umum yang tidak memberi diferensiasi, biasanya diabaikan oleh mesin pencari – seperti misalnya I, they, we, you, are, is, dan seterusnya), karakter non-alfabetis (seperti tanda baca dan angka), dan
header email. Header dihilangkan dari proses pembelajaran karena informasi-informasi di dalamnya potensial mengganggu proses. Misalnya nama server e-mail yang dilalui (yang kurang lebih tidak bermakna) atau bahkan nama newsgroup secara langsung, yang kemungkinan membuat program mengkorelasikan variabel nama newsgroup dengan klasifikasi yang diminta, menghambat proses pembelajaran dan menjadikan fungsi target yang dihasilkan tidak sesuai dengan yang diharapkan.
2. Data Integration and Transformation
Pada tahap ini, data yang telah bersih dari data yang tidak diperlukan akan diindeks ke dalam suatu binary search tree untuk mempercepat indexing dan penghitungan frekuensi kata. Setiap kata yang disimpan pada binary search tree ini disusun secara terurut berdasarkan abjad untuk mempermudah pencarian kata tertentu dalam pohon yang sedang dibangun. Setelah seluruh kata telah masuk ke dalam binary search tree, pohon kata tersebut akan ditransformasi ke dalam bentuk list kata yang telah terurut berdasarkan frekuensi kemunculan setiap kata.
3. Data Reduction
Akhirnya, list kata tersebut akan dipangkas sesuai n jumlah kata dengan frekuensi kemunculan terbanyak. Jumlah kata yang dilibatkan ke dalam pembelajaran, atau pemangkasan atribut dapat divariasikan. Pada Tugas Akhir ini, diasumsikan frekuensi kemunculan istilah dianggap mampu mewakili signifikansi dari kata yang diminta.
Setelah melalui seluruh tahap pada data preprocessing tersebut, content e-mail yang akan menjadi data mentah bagi aplikasi web mining yang dikembangkan telah siap digunakan.
III.3.4 Analisis Aplikasi Web Mining
Berdasarkan deskripsi permasalahan yang telah dijelaskan pada bagian sebelumnya, ditawarkan sebuah aplikasi web mining yang diharapkan dapat
membantu melakukan klasifikasi terhadap kumpulan dokumen e-mail yang dimiliki. Aplikasi web mining tersebut meliputi :
1. Sebuah perangkat lunak yang dapat membantu melakukan preprocessing
Dikarenakan perangkat lunak yang dibutuhkan untuk melakukan preprocessing belum tersedia, perangkat lunak ini akan dikembangkan terlebih dahulu. Input dari perangkat lunak ini berupa kumpulan dokumen e-mail yang telah dideskripsikan sebelumnya. Sedangkan ouput pada perangkat lunak ini akan disesuaikan dengan input yang diperlukan perangkat lunak pembangun struktur BN.
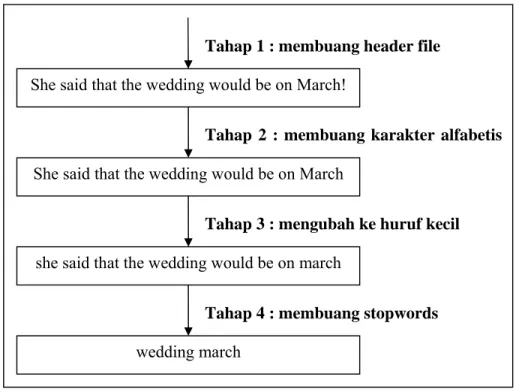
Preprocessing dilakukan dalam beberapa tahap. Tahap pertama preprocessing ialah pendaftaran kata pada seluruh file yang berada dalam direktori-direktori beserta kategorinya. Hal ini dilakukan untuk menjamin keseragaman format standar data dan proses terhadap seluruh data, serta kecepatan pemrosesan. Setiap file dibaca dan dibersihkan dari header e-mail. Isi e-mail kemudian di-filter dari karakter non alfabetis, untuk mempermudah proses indexing. Kata-kata yang telah dibersihkan dan distandarkan menjadi huruf kecil dicocokkan terhadap sebuah daftar stop words. Kata-kata yang tidak ditemukan dalam daftar stopword, yang berpotensi memiliki makna, akan dianggap sebagai kata yang valid. Daftar seluruh stopword dapat dilihat pada Lampiran D. Untuk lebih memahami skema kerja dari proses pembersihan data ini dapat dilihat pada Gambar 12.
Gambar 12. Skema kerja data cleaning dari aplikasi preprocessing
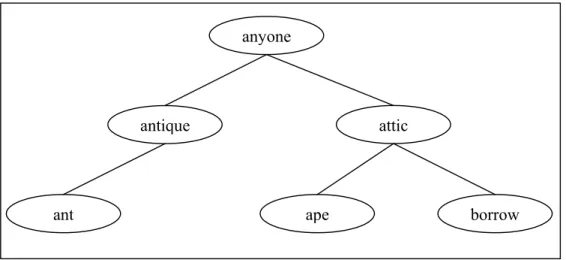
Kata yang telah dianggap valid kemudian dimasukkan oleh aplikasi ke dalam binary search tree seperti yang telah dijelaskan pada bagian III.3.3. Kemudian aplikasi preprocessing akan mengubah pohon kata tersebut menjadi list kata yang terurut berdasarkan frekuensi kemunculan kata. Terakhir, list kata tersebut akan dipangkas sesuai dengan data masukan yang diberikan pengguna. Contoh dari binary search tree yang dibangun dapat dilihat pada Gambar 13.
She said that the wedding would be on March!
Tahap 1 : membuang header file
She said that the wedding would be on March
Tahap 2 : membuang karakter alfabetis
she said that the wedding would be on march
Tahap 3 : mengubah ke huruf kecil
wedding march
Gambar 13. Contoh Binary Search Tree yang dibangun
Disini perlu diperhatikan bahwa aplikasi processing yang dikembangkan membutuhkan intervensi pengguna untuk memilih format file keluaran yang diminta, jumlah partisi data, jumlah kata yang akan dilibatkan dalam proses pembelajaran, serta jumlah dokumen untuk setiap partisi. Partisi data yang digunakan untuk memastikan akurasi hasil perhitungan algoritma, dilakukan secara random. Setiap file dalam daftar file dimasukkan ke dalam partisi ke-n, di mana n merupakan bilangan acak antara 0 dengan jumlah partisi. Hasilnya kemudian disimpan ke dalam suatu file internal dengan format sesuai kebutuhan.
Secara umum, langkah kerja dari proses preprocessing ini adalah sebagai berikut :
1. Seluruh dokumen akan di-scan secara rekursif untuk setiap direktori di dalam direktori untuk mendapatkan list dokumen dan list kategori.
2. Untuk setiap dokumen pada list dokumen, akan di-scan setiap kata. Kata akan di-filter apakah merupakan kata yang valid atau tidak. Setiap kata yang valid akan dimasukkan ke dalam sebuah pohon kata dan ke dalam list kata yang dimiliki setiap dokumen (list of contained word). anyone attic antique borrow ape ant
3. Setelah seluruh kata yang valid masuk ke dalam pohon kata, akan dibangun sebuah list kata berdasarkan pohon kata tersebut. Kemudian, sesuai masukan n jumlah kata dari pengguna, list kata tersebut akan dipotong hingga tersisa n kata dengan frekuensi terbanyak.
4. Pilih dokumen secara acak kemudian dibandingkan antara list kata yang dimiliki setiap dokumen dengan list kata keseluruhan. Jika terdapat kata yang sama, maka status kata tersebut pada dokumen itu akan diberi nilai 1. Sebaliknya, akan diberi nilai 0.
2. Sebuah perangkat lunak yang dapat mengolah data hasil preprocessing menjadi struktur BN berdasarkan data yang diterimanya.
Untuk perangkat lunak ini, akan digunakan perangkat lunak yang dikembangkan oleh Laboratorium Basis Data, Institut Teknologi Bandung. Untuk analisis lebih lanjut mengenai perangkat lunak yang akan digunakan ini, akan dibahas pada bagian III.4.
Secara umum, skema solusi yang ditawarkan dapat dilihat pada Gambar 14.