Foreword by
Craig Mundie,
Chief Research and Strategy Officer, MicrosoftT
�
T
Concurrent
Programming
on Windows
Development
Series
Praise for Concurrent Programming on Windows
"I have been fascinated with concurrency ever since I added threading support to the Common Language Runtime a decade ago. That's also where I met Joe, who is a world expert on this topic. These days, concurrency is a first-order concern for practically all developers. Thank goodness for Joe's book. It is a tour de force and I shall rely on it for many years to come."
-Chris Brumme, Distinguished Engineer, Microsoft
"I first met Joe when we were both working with the Microsoft CLR team. At that time, we had several discussions about threading and it was apparent that he was as passionate about this subject as I was. Later, Joe transitioned to Microsoft's Parallel Computing Platform team where a lot of his good ideas about threading could come to fruition. Most threading and concurrency books that I have come across contain information that is incorrect and explains how to solve contrived problems that good architecture would never get you into in the first place. Joe's book is one of the very few books that I respect on the matter, and this respect comes from knowing Joe's knowledge, experience, and his ability to explain concepts."
-Jeffrey Richter, Wintellect "There are few areas in computing that are as important, or shrouded in mystery, as concurrency. It's not simple, and Duffy doesn't claim to make it so-but armed with the right information and excellent advice, creating correct and highly scalable systems is at least possible. Every self-respecting Windows developer should read this book."
-Jonathan Skeet, Software Engineer, Clearswift
"What I love about this book is that it is both comprehensive in its coverage of concurrency on the Windows platform, as well as very practical in its presen tation of techniques immediately applicable to real-world software devel opment. Joe's book is a 'must have' resource for anyone building native or managed code Windows applications that leverage concurrency!"
"This book is a fabulous compendium of both theoretical knowledge and practical guidance on writing effective concurrent applications. Joe Duffy is not only a preeminent expert in the art of developing parallel applications for Windows, he's also a true student of the art of writing. For this book, he has combined those two skill sets to create what deserves and is destined to be a
long-standing classic in developers' hands everywhere. II
-Stephen Toub, Program Manager Lead, Parallel Computing Platform, Microsoft
II
As chip designers run out of ways to make the individual chip faster, they have moved towards adding parallel compute capacity instead. Consumer PCs with multiple cores are now commonplace. We are at an inflection point where improved performance will no longer come from faster chips but rather from our ability as software developers to exploit concurrency. Understanding the concepts of concurrent programming and how to write concurrent code has therefore become a crucial part of writing successful software. With Concurrent Programming on Windows, Joe Duffy has done a great job explaining concurrent concepts from the fundamentals through advanced techniques. The detailed descriptions of algorithms and their interaction with the underlying hardware turn a complicated subject into something very approachable. This book is the perfect companion to have at your side while writing concurrent software for Windows."
Microsoft .NET Development Series John Montgomery, Series Advisor
Don Box, Series Advisor
Brad Abrams, Series Advisor
The award-winning Microsoft .NET Development Series was established in 2002 to provide professional developers with the most comprehensive and practical coverage of the latest .NET technologies. It is supported and developed by the leaders and experts of Microsoft development technologies, including Microsoft architects, MVPs, and leading industry luminaries. Books in this series provide a core resource of information and understanding every developer needs to write effective applications.
Titles in the Series
Brad Abrams, .NET Framework Standard Library Annotated Reference Volume 1: Base Class Library and Extended Numerics Library, 978-0-321-15489-7
Brad Abrams and Tamara Abrams, .NET Framework Standard Library Annotated Reference, Volume 2:
Networking Library, Reflection Library, and XML Library,
978-0-321-19445-9
Chris Anderson, Essential Windows Presentation Foundation (WPF), 978-0-321-37447-9
Bob Beauchemin and Dan Sullivan, A Developer's Guide to SQL Server 2005, 978-0-321-38218-4
Adam Calderon, Joel Rumerman, Advanced ASP.NET AJAX Server Controls: For .NET Framework 3.5, 978-0-321-51444-8
Eric Carter and Eric Lippert, Visual Studio Tools for Office:
Using C# with Excel, Word, Outlook, and InfoPath,
978-0-321-33488-6
Eric Carter and Eric Lippert, Visual Studio Tools for Office: Using Visual Basic 2005 with Excel, Word, Outlook, and InfoPath, 978-0-321-41175-4
Steve Cook, Gareth Jones, Stuart Kent, Alan Cameron Wills, Domain-Specific Development with Visual Studio DSL Tools, 978-0-321-39820-8
Krzysztof Cwalina and Brad Abrams, Framework Design Guidelines: Conventions, Idioms, and Patterns for Reusable NET Libraries, Second Edition, 978-0-321-54561-9 Joe Duffy, Concurrent Programming on Windows, 978-0-321-43482-1
Sam Guckenheimer and Juan J. Perez, Software Engineering with Microsoft Visual Studio Team System,
978-0-321-27872-2
Anders Hejlsberg, Mads Torgersen, Scott Wiltamuth, Peter Golde, T he C# Programming Language, Third Edition,
978-0-321-56299-9
Alex Homer and Dave Sussman, ASPNET 2.0 Illustrated,
978-0-321-41834-0
Joe Kaplan and Ryan Dunn, T he .NET Developer's Guide to Directory Services Programming, 978-0-321-35017-6
Mark Michaelis, Essential C# 3.0: For .NET Framework 3.5, 978-0-321-53392-0
James S. Miller and Susann Ragsdale,
T he Common Language Infrastructure Annotated Standard, 978-0-321-15493-4
Christian Nagel, Enterprise Services with the .NET Framework: Developing Distributed Business Solutions with .NET Enterprise Services, 978-0-321-24673-8 Brian Noyes, Data Binding with Windows Forms 2.0: Programming Smart Client Data Applications with .NET, 978-0-321-26892-1
Brian Noyes, Smart Client Deployment with ClickOnce: Deploying Windows Forms Applications with ClickOnce, 978-0-321-19769-6
Fritz Onion with Keith Brown, Essential ASPNET 2.0, 978-0-321-23770-5
Steve Resnick, Richard Crane, Chris Bowen, Essential Windows Communication Foundation: For .NET Framework 3.5,978-0-321-44006-8
Scott Roberts and Hagen Green, Designing Forms for Microsoft Office InfoPath and Forms Services 2007, 978-0-321-41059-7
Neil Roodyn, eXtreme .NET: Introducing eXtreme Programming Techniques to .NET Developers, 978-0-321-30363-9
Chris Sells and Michael Weinhardt, Windows Forms 2.0 Programming, 978-0-321-26796-2
Dharma Shukla and Bob Schmidt, Essential Windows Workflow Foundation, 978-0-321-39983-0
Guy Smith-Ferrier, .NET Internationalization: T he Developer's Guide to Building Global Windows and Web Applications, 978-0-321-34138-9
Will Stott and James Newkirk, Visual Studio Team System: Better Software Development for Agile Teams, 978-0-321-41850-0
Paul Yao and David Durant, .NET Compact Framework Programming with C#, 978-0-321-17403-1
Concurrent
Programming
on Windows
•
Joe Duffy
�.� Addison-Wesley
Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trademark claim, the designations have been printed with initial capital letters or in all capitals.
The .NET logo is either a registered trademark or trademark of Microsoft Corporation in the United States and/ or other countries and is used under license from Microsoft.
The author and publisher have taken care in the preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or conse quential damages in connection with or arising out of the use of the information or programs contained herein. The publisher offers excellent discounts on this book when ordered in quantity for bulk purchases or special sales, which may include electronic versions and/or custom covers and content particular to your business, training goals, marketing focus, and branding interests. For more information, please contact:
U.s. Corporate and Government Sales (800) 382-3419
For sales outside the United States please contact: International Sales
[email protected] Visit us on the Web: informit.com/ aw Library o/Congress Cataloging-in-Publication Data Duffy, Joe,
1980-Concurrent programming on Windows / Joe Duffy. p. cm.
Includes bibliographical references and index.
ISBN 978-0-321-43482-1 (pbk. : alk. paper) 1. Parallel programming (Computer science) 2. Electronic data processing-Distributed processing. 3. Multitasking (Computer science) 4. Microsoft Windows (Computer file) I. Title.
QA76.642D84 2008 005.2'75-<1c22
Copyright © 2009 Pearson Education, Inc.
2008033911
All rights reserved. Printed in the United States of America. This publication is protected by copyright, and permission must be obtained from the publisher prior to any prohibited reproduction, storage in a retrieval system, or transmission in any form or by any means, electronic, mechanical, photocopying, recording, or like wise. For information regarding permissions, write to:
Pearson Education, Inc
Rights and Contracts Department 501 Boylston Street, Suite 900 Boston, MA 02116
Fax (617) 671-3447 ISBN-13: 978-0-321-43482-1 ISBN-lO: 0-321-43482-X
Contents at a Glance
Con ten ts Xl
Foreword xix Preface xxiii
Acknowledgmen ts XXVll
About the Au thor xxix
PART I Concepts 1
1 Introduction 3
2 Synchronization and Time 13
PART II Mechanisms 77
3 Threads 79
4 Advanced Threads 127
5 Windows Kernel Synchronization 183 6 Data and Control Synchronization 253
7 Thread Pools 315
8 Asynchronous Programming Models 399
9 Fibers 429
PART III Techniques 475
10 Memory Models and Lock Freedom 477
x C o n t e n t s a t a G l a n ce
12 Parallel Containers 613
13 Data and Task Parallelism 657 14 Performance and Scalability 735
PART IV Systems 783 15 Input and Output 785
16 Graphical User Interfaces 829
PART V Appendices 863
A Designing Reusable Libraries for Concurrent .NET Programs 865
B Parallel Extensions to .NET 887
Contents
Foreword xix Preface xxiii
Acknowledgments xxvii About the Au thor XXIX
PART I Concepts 1
1 Introduction 3
Why Concurrency? 3
Program Architecture and Concurrency 6
Layers of Parallelism 8
Why Not Concurrency? 1 0
Where Are We? 1 1
2 Synchronization and Time 13
Managing Program State 1 4
Identifying Shared vs. Private S tate 1 5 State Machines and Time 1 9
Isolation 3 1 Immutability 34
Synchronization: Kinds and Techniques 38
Data Synchronization 40
Coordination and Control Synchronization 60
xii C o n t e n t s
PART II Mechanisms 77
3 Threads 79
Threading from 1 0,001 Feet 80
What Is a Windows Thread? 81 What Is a CLR Thread? 85
Explicit Threading and Alternatives 87
The Life and Death of Threads 89
Thread Creation 89 Thread Termination 1 01 DlIMain 1 1 5
Thread Local S torage 1 1 7
Where Are We? 1 24
4 Advanced Threads 127
5
Thread State 1 27
User-Mode Thread S tacks 1 2 7
Internal Data Structures (KTHREAD, ETHREAD, TEB) 1 45 Contexts 1 51
Inside Thread Creation and Termination 1 52
Thread Creation Details 1 52 Thread Termination Details 1 53
Thread Scheduling 1 54
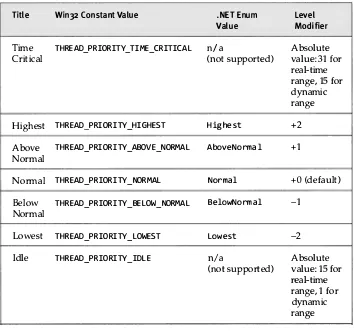
Thread S tates 1 55 Priorities 1 59 Quantums 1 63
Priority and Quantum Adjustmen ts 1 64 Sleeping and Yielding 1 67
S uspension 1 68
Affin ity: Preference for Running on a Particular CPU 1 70
Where Are We? 1 80
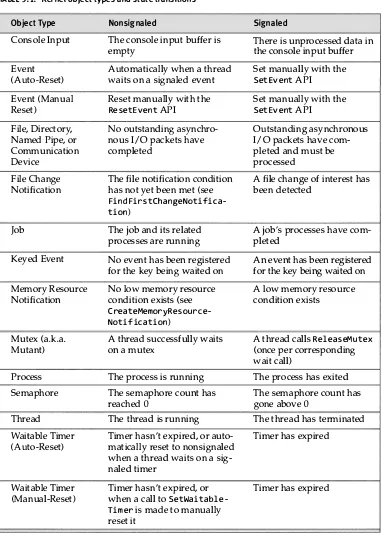
Windows Kernel Synchronization 183 The Basics: Signaling and Waiting 1 84
Why Use Kernel Objects? 1 86 Waiting in Native Code 1 89 Managed Code 204
Using the Kernel Objects 2 1 1
Mutex 2 1 1 Semaphore 2 1 9
Co n t e n t s xiii
A Mutex/Semaphore Example: Blocking/Bounded Queue 224 Auto- and Man ual-Reset Events 226
Waitable Timers 234
Signaling an Object and Waiting A tomically 241 Debugging Kernel Objects 250
Where Are We? 251
6 Data and Control Synchronization 253 Mutual Exclusion 255
Win32 Critical Sections 256 CLR Locks 272
Reader I Writer Locks (RWLs) 287
Windows Vista Slim Reader/Writer Lock 289 .NET Framework Slim Reader/Writer Lock (3.5) 293 .NET Framework Legacy Reader/Writer Lock 300
Condition Variables 304
Windows Vista Condition Variables 304 .NET Framework Monitors 309 Guarded Regions 3 1 1
Where Are We? 3 1 2
7 Thread Pools 315
Thread Pools 1 01 3 1 6
Three Ways: Windows Vista, Windows Legacy, a n d CLR 3 1 7 Common Features 3 1 9
Windows Thread Pools 323
Windows Vista Thread Pool 323 Legacy Win32 Thread Pool 353
CLR Thread Pool 364
Work Items 364
I/O Completion Ports 368 Timers 371
Registered Waits 374
xiv Contents
Thread Pool Thread Managemen t 377 Debugging 386
A Case Study: Layering Priorities and Isolation on Top of the Thread Pool 387
Performance When Using the Thread Pools 391 Where Are We? 398
8 Asynchronous Programming Models 399
Asynchronous Programming Model (APM) 400
Rendezvousing: Four Ways 403 Implementing IAsyncResult 4 1 3
Where the APM Is Used i n the .NET Framework 4 1 8 ASP.NET Asynchronous Pages 420
Event-Based Asynchronous Pattern 421
The Basics 42 1
Supporting Cancellation 425
Supporting Progress Reporting and Incremental Results 425 Where the EAP Is Used in the .NET Framework 426
Where Are We? 427
9 Fibers 429
An Overview of Fibers 430
Upsides and Downsides 43 1
Using Fibers 435
Creating New Fibers 435
Converting a Thread in to a Fiber 438 Determining Whether a Thread Is a Fiber 439 Switching Between Fibers 440
Deleting Fibers 441
An Example of Switching the Curren t Thread 442
Additional Fiber-Related Topics 445
Fiber Local S torage (FLS) 445 Thread Affinity 447
A Case Study: Fibers and the CLR 449
Building a User-Mode Scheduler 453
The Implemen tation 455
A Word on S tack vs. S tackless Blocking 472
PART III Techniques 475
10 Memory Models and Lock Freedom 477 Memory Load and Store Reordering 478
What Runs Isn 't Always What You Wrote 481 Critical Regions as Fences 484
Data Dependence and Its Impact on Reordering 485
Hardware Atomicity 486
The Atomicity of Ordinary Loads and S tores 487 Interlocked Operations 492
Memory Consistency Models 506
Hardware Memory Models 509 Memory Fences 511
.NET Memory Models 51 6 Lock Free Programming 5 1 8
Examples of Low-Lock Code 520
Lazy Initialization and Double-Checked Locking 520 A Nonblocking S tack and the ABA Problem 534 Dekker 's Algorithm Revisited 540
Where Are We? 541
11 Concurrency Hazards 545 Correctness Hazards 546
Data Races 546
Recursion and Reentrancy 555 Locks and Process Shutdown 561
Liveness Hazards 572
Deadlock 572
Missed Wake- Ups (a.k.a. Missed Pulses) 597 Livelocks 601
Lock Convoys 603 Stampeding 605 Two-Step Dance 606
Priority Inversion and S tarvation 608
Where Are We? 609
xvi C o n t e n t s
12 Parallel Containers 613 Fine-Grained Locking 6 1 6
A rrays 6 1 6 FIFO Queue 61 7 Linked Lists 621
Dictionary (Hash table) 626
Lock Free 632
General-Purpose Lock Free FIFO Queue 632 Work S tealing Queue 636
Coordination Containers 640
Producer/Consumer Data Structures 641 Phased Computations with Barriers 650
Where Are We? 654
13 Data and Task Parallelism 657 Data Parallelism 659
Loops and Iteration 660
Task Parallelism 684
Fork/Join Parallelism 685
Dataflow Parallelism (Futures and Promises) 689 Recursion 702
Pipelines 709 Search 71 8
Message-Based Parallelism 71 9
Cross-Cutting Concerns 720
Concurrent Exceptions 72 1 Cancellation 729
Where Are We? 732
14 Performance and Scalability 735
Parallel Hardware Architecture 736
SMP, CMF, and HT 736 Superscalar Execution 738 The Memory Hierarchy 739
A Brief Word on Profiling in Visual Studio 754
Measuring Improvements Due to Parallelism 758 A mdahl's Law 762
Critical Paths and Load Imbalance 764 Garbage Collection and Scalability 766
Spin Waiting 767
How to Properly Spin on Windows 769 A Spin-Only Lock 772
Mellor-Crummey-Scott (MCS) Locks 778
Where Are We? 781
PART IV Systems 783 15 Input and Output 785
Overlapped I / O 786
Overlapped Objects 788 Win32 Asynchronous I/O 792
.NET Framework Asynchronous I/O 81 7
I / O Cancellation 822
Asynchronous I/O Cancellation for the Current Thread 823 Synchronous I/O Cancellation for Another Thread 824 Asynchronous I/O Cancellation for Any Thread 825
Where Are We? 826
16 Graphical User Interfaces 829 CUI Threading Models 830
Single Threaded Apartments (STAs) 833 Responsiveness: What Is It, Anyway? 836
.NET Asynchronous CUI Features 837
.NET GUI Frameworks 837 Synchronization Contexts 847 Asynchronous Operations 855
A Convenient Package: BackgroundWorker 856
Where Are We? 860
PART V Appendices 863
C o n t e n t s xvii
A Designing Reusable libraries for Concurrent .NET Programs 865
xviii Conte n t s
The Details 867
Locking Models 867 Using Locks 870 Reliability 875
Scheduling and Threads 879 Scalability and Performance 881 Blocking 884
B Parallel Extensions to .NET 887
Task Parallel Library 888
Unhandled Exceptions 893 Paren ts and Children 895 Cancellation 897
Futures 898 Contin uations 900 Task Managers 902
Putting it All Together: A Helpful Parallel Class 904 Self-Replicating Tasks 909
Parallel LINQ 9 1 0
Buffering and Merging 912 Order Preservation 9 1 4
Synchronization Primitives 915
ISupportsCancelation 915 Coun tdownEven t 915 Lazylnit<T> 91 7
Man ualResetEven tSlim 91 9 SemaphoreSlim 920 Spin Lock 92 1 Spin Wait 923
Concurrent Collections 924
BlockingCollection<T> 925 Concurren tQueue<T> 928 Concurren tStack<T> 929
Foreword
THE COMPUTER INDUSTRY
is once again at a crossroads. Hardware concurrency, in the form of new manycore processors, together with growing soft ware complexity, will require that the technology industry fundamentally rethink both the architecture of modern computers and the resulting soft ware development paradigms.
For the past few decades, the computer has progressed comfortably along the path of exponential performance and capacity growth without any fundamental changes in the underlying computation model. Hardware followed Moore's Law, clock rates increased, and software was written to exploit this relentless growth in performance, often ahead of the hardware curve. That symbiotic hardware-software relationship continued unabated until very recently. Moore's Law is still in effect, but gone is the unnamed law that said clock rates would continue to increase commensurately.
The reasons for this change in hardware direction can be summarized by a simple equation, formulated by David Patterson of the University of California at Berkeley:
xx Foreword
increase in clock speed without heroic (and expensive) cooling (or materi als technology breakthroughs) is not possible. This is the "Power Wall" part of the equation. Improvements in memory performance increasingly lag behind gains in processor performance, causing the number of CPU cycles required to access main memory to grow continuously. This is the "Mem ory Wall." Finally, hardware engineers have improved the performance of sequential software by speculatively executing instructions before the results of current instructions are known, a technique called instruction level parallelism (ILP). ILP improvements are difficult to forecast, and their com plexity raises power consumption. As a result, ILP improvements have also stalled, resulting in the "ILP Wall."
We have, therefore, arrived at an inflection point. The software ecosys tem must evolve to better support manycore systems, and this evolution will take time. To benefit from rapidly improving computer performance and to retain the "write once, run faster on new hardware" paradigm, the programming community must learn to construct concurrent applications. Broader adoption of concurrency will also enable Software + Services
through asynchrony and loose-coupling, client-side parallelism, and server-side cloud computing.
The Windows and .NET Framework platforms offer rich support for concurrency. This support has evolved over more than a decade, since the introduction of multiprocessor support in Windows NT. Continued improvements in thread scheduling performance, synchronization APIs, and memory hierarchy awareness-particularly those added in Windows Vista-make Windows the operating system of choice for maximizing the use of hardware concurrency. This book covers all of these areas. When you begin using multithreading throughout an application, the importance of clean architecture and design is critical to reducing software complexity and improving maintainability. This places an emphasis on understanding not only the platform's capabilities but also emerging best practices. Joe does a great job interspersing best practice alongside mechanism through out this book.
Foreword xxi
continued increase in compute power will qualitatively change the applications that we can create in ways that make them a lot more inte resting and helpful to people, and able to do new things that have never been possible in the past. Through this evolution, software will enable more personalized and humanistic ways for us to interact with computers. So enjoy this book. It offers a lot of great information that will guide you as you take your first steps toward writing concurrent, many core aware soft ware on the Windows platform.
Craig Mundie
Chief Research and Strategy Officer Microsoft Corporation
Preface
I BEGAN WRITING
this book toward the end of 2005. At the time, dual-core processors were becoming standard on the mainstream PCs that ordinary (nonprogrammer) consumers were buying, and a small number of people in industry had begun to make noise about the impending concurrency problem. (Herb Sutter's, The Free Lunch is Over, paper immediately comes to mind.) The problem people were worried about, of course, was that the software of the past was not written in a way that would allow it to natu rally exploit that additional compute power. Contrast that with the never ending increase in clock speeds. No more free lunch, indeed.It seemed to me that concurrency was going to eventually be an impor tant part of every software developer's job and that a book such as this one would be important and useful. Just two years later, the impact is beginning to ripple up from the OS, through the libraries, and on up to applications themselves.
xxiv P reface
entrenched in all topics concurrency. What better way to get entrenched even further than to write a book on the subject?
As I worked on all of these projects, and eventually PLINQ grew into the Parallel Extensions to the .NET Framework technology, I was amazed at how few good books on Windows concurrency were available. I remember time and time again being astonished or amazed at some intricate and eso teric bit of concurrency-related information, jotting it down, and earmark ing it for inclusion in this book. I only wished somebody had written it down before me, so that I didn't need to scour it from numerous sources: hallway conversations, long nights of pouring over Windows and CLR source code, and reading and rereading countless Microsoft employee blogs. But the best books on the topic dated back to the early '90s and, while still really good, focused too much on the mechanics and not enough on how to structure parallel programs, implement parallel algorithms, deal with concurrency hazards, and all those important concepts. Everything else targeted academics and researchers, rather than application, system, and library developers.
I set out to write a book that I'd have found fascinating and a useful way to shortcut all of the random bits of information I had to learn throughout. Although it took me a surprisingly long two-and-a-half years to finish this book, the state of the art has evolved slowly, and the state of good books on the topic hasn't changed much either. The result of my efforts, I hope, is a new book that is down to earth and useful, but still full of very deep tech nical information. It is for any Windows or .NET developer who believes that concurrency is going to be a fundamental requirement of all software somewhere down the road, as all industry trends seem to imply.
I look forward to kicking back and enjoying this book. And I sincerely hope you do too.
Book Structure
P reface xxv
section describes common patterns, best practices, algorithms, and data structures that emerge while writing concurrent software. The fourth sec tion, Systems, covers many of the system-wide architectural and process concerns that frequently arise. There is a progression here. Concepts is first because it develops a basic understanding of concurrency in general. Under standing the content in Techniques would be difficult without a solid under standing of the Mechanisms, and similarly, building real Systems would be impossible without understanding the rest. There are also two appendices at the end.
Code Requirements
To run code found in this book, you'll need to download some free pieces of software.
• Microsoft Windows SDK. This includes the Microsoft C++ compiler and relevant platform headers and libraries. The latest versions as of this writing are the Windows Vista and Server 2008 SDKs.
• Microsoft .NET Framework SDK. This includes the Microsoft C# and Visual Basic compilers, and relevant framework libraries. The latest version as of this writing is the .NET Framework 3.5 SDK.
Both can be found on MSDN: http: / /msdn.microsoft.com.
In addition, it's highly recommended that you consider using Visual Studio. This is not required-and in fact, much of the code in this book was written in emacs-but provides for a more seamless development and debugging experience. Visual Studio 2008 Express Edition can be down loaded for free, although it lacks many useful capabilities such as perform ance profiling.
xxvi Preface
A companion website is available at:
http://www.bluebytesoftware.comlbooks
Joe Duffy June 2008
Acknowledgments
MANY PEOPLE HAVE
helped with the creation of this book, both directlyand indirectly.
First, I have to sincerely thank Chris Brumme and Jan Gray for inspiring me to get the concurrency bug several years ago. You've both been incredi bly supportive and have helped me at every turn in the road . This has led to not only this book but a never-ending stream of career, technical, and per sonal growth opportunities. I'm still not sure how I'll ever repay you guys.
Also, thanks to Herb Sutter, who was instrumental in getting this book's contract in the first place. And also to Craig Mundie for writing a terrific Foreword and, of course, leading Microsoft and the industry as a whole into our manycore future.
Vance Morrison deserves special thanks for not only being a great men tor along the way, but also for being the toughest technical reviewer I've ever had. His feedback pushed me really hard to keep things concise and relevant. I haven't even come close to attaining his vision of what this book could have been, but I hope I'm not too far afield from it.
xxviii Ac k n owled,m e n t s
Joel Pobar, Jeff Richter, Paul Ringseth, Burton Smith, Stephen Toub, Roger Wolff, and Keith Yedlin. For those reviewers who were constantly prom ised drafts of chapters that never actually materialized on time, well, I sin cerely appreciate the patience.
About the Author
1
Introduction
C
ONCURRENCY IS EVERYWHERE.
No matter whether you're doing server-side programming for the web or cloud computing, building a responsive graphical user interface, or creating a new interactive client appli cation that uses parallelism to attain better performance, concurrency is ever present. Learning how to deal with concurrency when it surfaces and how to exploit it to deliver more capable and scalable software is necessary for a large category of software developers and is the main focus of this book.Before jumping straight into the technical details of how to use concur rency when developing software, we'll begin with a conceptual overview of concurrency, some of the reasons it can be important to particular kinds of software, the role it plays in software architecture, and how concurrency will fit progressively into layers of software in the future.
Everything in this chapter, and indeed most of the content in this book, applies equally to programs written in native C++ as it does to programs written in the .NET Framework.
Why Concurrency?
There are many reasons why concurrency may be interesting to you.
• You are programming in an environment where concurrency
4 C h a pter 1 : I n t rod u c t i o n
OS programming, and server-side programming. It is the reason, for example, that most database programmers must become deeply familiar with the notion of a transaction before they can truly be effective at their jobs.
• You need to maintain a responsive user interface (UI) while
performing some compute- or I /O-intensive activity in response to some user input. In such cases, running this work on the UI thread will lead to poor responsiveness and frustrated end users. Instead, concurrency can be used to move work elsewhere, dramatically improving the responsiveness and user experience.
• You'd like to exploit the asynchrony that already exists in the
relationship between the CPU running your program and other hardware devices. (They are, after all, separately operating and independent pieces of hardware.) Windows and many device drivers cooperate to ensure that large I / O latencies do not severely impact program performance. Using these capabilities requires that you rewrite code to deal with concurrent orchestration of events.
• Some problems are more naturally modeled using concurrency.
Games, AI, and scientific simulations often need to model interac tions among many agents that operate mostly independently of one another, much like objects in the real world. These interactions are inherently concurrent. Stream processing of real-time data feeds, where the data is being generated in the physical world, typically requires the use of concurrency. Telephony switches are inherently massively concurrent, leading to special purpose languages, such as Erlang, that deal specifically with concurrency as a first class concept.
• You'd like to utilize the processing power made available by
multiprocessor architectures, such as multicore, which requires a form of concurrency called parallelism to be used. This requires individual operations to be decomposed into independent parts that can run on separate processors.
Why C o n c u rre n cy 5
may arrive concurrently via the network and must be dealt with simultaneously. If you're writing a Web request handler and need to access shared state, concurrency is suddenly thrust to the forefront.
While it's true that concurrency can sometimes help express problems more naturally, this is rare in practice. Human beings tend to have a diffi cult time reasoning about large amounts of asynchrony due to the combi natorial explosion of possible interactions. Nevertheless, it is becoming increasingly more common to use concurrency in instances where it feels unnatural. The reason for this is that microprocessor architecture has fun damentally changed; parallel processors are now widespread on all sorts of mainstream computers. Multicore has already pervaded the PC and mobile markets, and highly parallel graphics processing units (CPUs) are every where and sometimes used for general purpose computing. In order to fully maximize use of these newer generation processors, programs must
be written in a naturally scalable manner. That means applications must
contain sufficient laten t concurrency so that, as newer machines are adopted, program performance automatically improves alongside by realizing that latent concurrency as actual concurrency.
In fact, although many of us program in a mostly sequential manner, our code often has a lot of inherent latent concurrency already by virtue of the way operations have been described in our language of choice. Data and control dependence among loops, if-branches, and memory moves can constrain this, but, in a surprisingly large number of cases, these are artifi cial constraints that are placed on code out of stylistic habit common to C-style programming.
This shift is a change from the past, particularly for client-side pro
grams. Parallelism is the use of concurrency to decompose an operation
6 C h a pter 1 : I n t ro d u c t i o n
Program Architecture and Concurrency
Concurrency begins with architecture. It is also possible to retrofit concurrency into an existing application, but the number of common pitfalls is vastly decreased with careful planning. The following taxonomy is a use ful way to think about the structure of concurrent programs, which will help during the initial planning and architecture phases of your project:
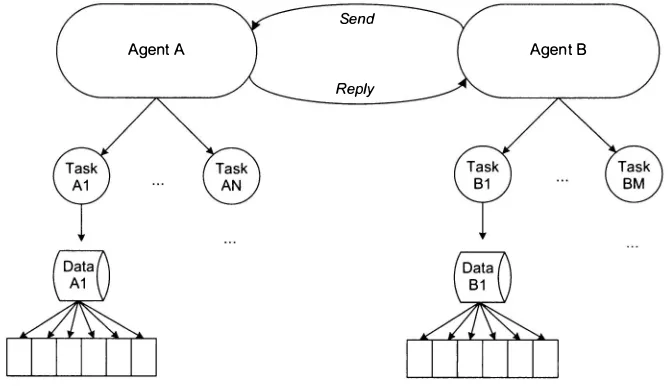
• Agents. Most programs are already coarsely decomposed into independent agents. An agent in this context is a very abstract term, but the key attributes are: ( 1 ) state is mostly isolated within it from the outset, (2) its interactions with the world around it are
asynchronous, and (3) it is generally loosely coupled with respect to peer agents. There are many manifestations of agents in real-world systems, ranging from individual Web requests, a Windows Communication Foundation (WCF) service request, COM component call, some asynchronous activity a program has farmed off onto another thread, and so forth. Moreover, some programs have just one agent: the program's entry point.
• Tasks. Individual agents often need to perform a set of operations at once. We'll call these tasks. Although a task shares many ideas with agents-such as being asynchronous and somewhat independent tasks are unique in that they typically share state intimately. Many sequential client-side programs fail to recognize tasks are first class concepts, but doing so will become increasingly important as fine grained parallelism is necessary for multicore. Many server-side programs also do not have a concept of tasks, because they already use large numbers of agents in order to expose enough latent concurrency to utilize the hardware. This is OK so long as the number of active agents exceeds the number of available processors; as processor counts and the workloads a single agent is responsible for grow, this can become increasingly difficult to ensure.
• Data. Operations on data are often naturally parallel, so long as they are programmed such that the system is made available of latent
Progra m Arch ite c t u re a n d Co n c u rre n cy 7
include transformations of data in one format into another, business intelligence analysis, encryption, compression, sorting, searching data for elements with certain characteristics, summarizing data for reporting purposes, rendering images, etc. The more data there is, the more compute- and time-intensive these operations are. They are typically leaf level, very fine grained, and, if expressed properly, help to ensure future scaling. Many programs spend a large portion of their execution time working with data; thus, these operations are likely to grow in size and complexity as a program's requirements and data input evolves over time.
This taxonomy forms a nice hierarchy of concurrency, shown in Figure 1 . 1 . While it's true that the clean hierarchy must be strictly broken in some cases (e.g., a data parallel task may need to communicate with an agent), a clean separation is a worthy goal.
State isolation also is crucial to think about while architecting concurrent programs. For example, it is imperative to strive for designs that lead to agents having state entirely isolated from one another such that they can remain loosely coupled and to ease the synchronization burden. As finer grained concurrency is used, state is often shared, but functional concepts
Send
Agent A Agent B
Reply
8 C h a pter 1 : I n t rod u c t i o n
such as immutability and purity become important: these disciplines help to eliminate concurrency bugs that can be extraordinarily difficult to track down and fix later. The topics of state and synchronization are discussed at length in Chapter 2, Synchronization and Time.
What you'll find as you read the subsequent chapters in this book is that these terms and concepts are merely guidelines on how to create structured architecture in your program, rather than being concrete technologies that you will find in Windows and the .NET Framework. Several examples of agents were already given, and both task and data parallelism may take one of many forms today. These ideas often map to work items executed in ded icated threads or a thread pool (see Chapter 7, Thread Pools), but this varies from one program to the next.
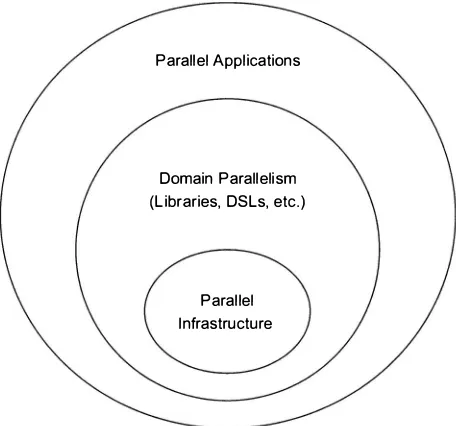
Layers of Parallelism
It is not the case that all programs can be highly parallel, nor is it the case that this should be a goal of most software developers. At least over the next half decade, much of multicore's success will undoubtedly be in the realm of
Parallel Applications
Domain Parallelism (Libraries, DSLs, etc.)
Parallel Infrastructure
FIG U R E 1.2: A taxonomy of concurrent program structure
Layers of P a r a l l e l i s m 9
free, particularly if a large portion of time is spent executing that library code. This is attractive because the parallelism is reusable in a variety of contexts.
The resulting landscape of parallelism is visualized in Figure 1 .2. If you stop to think about it, this picture is not very different from what we are accustomed to seeing for sequential software. Software developers creating libraries focus on ensuring that their performance meets customer expec tations, and they spend a fair bit of time on optimization and enabling future scalability. Parallelism is similar; the techniques used are different, but the primary motivating factor-that of improving performance-is shared among them.
10 C h a pter s: I n t rod u c t i o n
pro filers (such as the one in Visual Studio) to identify CPU-bound hotspots in programs to identify opportunities for fine-grained parallelism.
Why Not Concurrency?
Concurrency is not for everyone. The fact that a whole book has been written about concurrency alone should tell you that it's a somewhat dense topic. It is relatively easy to get started with concurrency-thanks to the fact that creating threads, queuing work to thread pools, and the like, are all very simple (and indeed automated by some commonly used program ming models such as ASP.NET)-but there are many subtle consequences.
Concurrency is a fundamental cross-cutting property of software. Once you've got many threads actively calling into a shared data structure that you've written, for example, the number of concerns you must have con sidered and proactively safeguarded yourself against when writing that data structure is often daunting. Indeed it will often only be evident after you've been programming with concurrency for a while or until you've read a book about it.
Here is a quick list of some examples of such problems. Chapter 2, Synchronization and Time, and later, Chapter 1 1 , Concurrency Hazards, will provide more detail on each.
• State management decisions, as noted above, often lead to synchro
nization. Most often this means some form of locking. Locking is
difficult to get right and can have a negative impact on performance. Verifying that you've implemented some locking policy correctly tends to be vastly more difficult than typical unit-test-style verifica tion. And getting it wrong will lead to race conditions, which are bugs that depend on intricate timing and machine architecture and are very difficult to reproduce.
W h e re Are We ? 1 1
critical event in time). When optimistic concurrency is used, a
similar phenomenon, livelock, can occur.
• Data structure invariants are significantly more important to reason
about and solidify when concurrency is involved. Reentrancy can
break them and so, too, can incorrect synchronization granularity. A common source of the latter problem is releasing a lock before invariants have been restored . Yet at the same time, our current languages and tools do not encourage any kind of invariant capture or verification, complicating the task of ensuring correctness.
• The current generation of tools-including Visual Studio 2008 and
Debugging Tools for Windows-do not tailor the debugging experi ence to concurrency. Thus debugging all of the above mentioned problems tends to be more of a black art than a science and requires deep knowledge of OS and threading internals.
Concurrency is a double-edged sword . It can be used to do amazing new things and to enable new compute-intensive experiences that will only become possible with the amount of computing power available in the next generation of microprocessor architecture. And in some situations concur rency is unavoidable. But it must also be used responsibly so as not to neg atively impact software robustness and reliability. This book's aim is to help you decide when it is appropriate, in what ways it is appropriate, and, once you've answered those questions for your situation, to aid you in develop ing, testing, and maintaining concurrent software.
Where Are We?
12 C h a pter 1 : I n t rod u c t i o n
FU RTHER READI NG
K. Asanovic, R. Bodik, B. C. Catanzaro, J. J. Gebis, P. Husbands, K. Keutzer, D. A. Patterson, W. L. Plishker, J. Shalf, S. W. Williams, K. A. Yelick. The Landscape of Parallel Computing Research: A View from Berkeley, EECS Technical Report EECS-2006-1 83 (University of California, 2006).
J. Larus, H. Sutter. Software and the Concurrency Revolution. ACM Queue, Vol. 3, No. 7 (2005).
J. Larus. Spending Moore's Dividend. Microsoft Technical Report, MSR-TR-2008-69 (May 2008).
2
Synchronization and Time
S
T A TE IS A N
important part of any computer system. This point seems so obvious that it sounds silly to say it explicitly. But state within even a sin gle computer program is seldom a simple thing, and, in fact, is often scattered throughout the program, involving complex interrelationships and different components responsible for managing state transitions, persistence, and so on. Some of this state may reside inside a process's memory-whether that means memory allocated dynamically in the heap (e.g., objects) or on thread stacks-as well as files on-disk, data stored remotely in database systems, spread across one or more remote systems accessed over a network, and so on. The relationships between related parts may be protected by transactions, handcrafted semi transactional systems, or nothing at all.The broad problems associated with state management, such as keeping all sources of state in-synch, and architecting consistency and recoverabil ity plans all grow in complexity as the system itself grows and are all traditionally very tricky problems. If one part of the system fails, either state must have been protected so as to avoid corruption entirely (which is generally not possible) or some means of recovering from a known safe point must be put into place.
While state management is primarily outside of the scope of this book, state "in-the-small" is fundamental to building concurrent programs. Most
Windows systems are built with a strong dependency on shared memory due
14 C h a pter 2 : Syn c h ro n i za t i o n a n d T i m e
virtual memory address space. The introduction o f concurrent access to such state introduces some tough challenges. With concurrency, many parts of the program may simultaneously try to read or write to the same shared memory locations, which, if left uncontrolled, will quickly wreak havoc. This is due to a fundamental concurrency problem called a data race or often just race condition. Because such things manifest only during certain inter actions between concurrent parts of the system, it's all too easy to be given a false sense of security-that the possibility of havoc does not exist.
In this chapter, we'll take a look at state and synchronization at a fairly high level. We'll review the three general approaches to managing state in a concurrent system:
1 . Isolation, ensuring each concurrent part of the system has its own copy of state.
2. Immutability, meaning that shared state is read-only and never modified, and
3. Synchronization, which ensures multiple concurrent parts that wish to access the same shared state simultaneously cooperate to do so in a safe way.
We won't explore the real mechanisms offered by Windows and the .NET Framework yet. The aim is to understand the fundamental principles first, leaving many important details for subsequent chapters, though pseudo-code will be used often for illustration.
We also will look at the relationship between state, control flow, and the impact on coordination among concurrent threads in this chapter. This brings about a different kind of synchronization that helps to coordinate state dependencies between threads. This usually requires some form of
waiting and notification. We use the term control synchronization to dif
ferentiate this from the kind of synchronization described above, which we
will term data synchronization.
Managing Program State
Before discussing the three techniques mentioned above, let's first be very
M a n ag i n g Progra m State 1 5
state that is accessible by more than one thread at a time. It's surprisingly difficult to pin down more precisely, and the programming languages commonly in use on the platform are not of help.
Identifying Shared vs. Private State
In object oriented systems, state in the system is primarily instance and static (a.k.a. class) fields. In procedural systems, or in languages like C++ that support a mixture of object oriented and procedural constructs, state is also held in global variables. In thread based programming systems, state may also take the form of local variables and arguments on thread stacks used during the execution and invocation of functions. There are also sev eral other subtle sources of state distributed throughout many layers in the overall infrastructure: code, DLLs, thread local storage (TLS), runtime and OS resources, and even state that spans multiple processes (such as mem ory mapped files and even many OS resources).
Now the question is "What constitutes 'shared state' versus 'private state?'" The answer depends on the precise mechanisms you are using to introduce concurrency into the system. Stated generally, shared state is any state that may, at any point in time, be accessed by multiple threads con currently. In the systems we care about, that means:
• All state pointed to by a global or static field is shared.
• Any state passed during thread creation (from creator to createe) is
shared.
• Any state reachable through references in said state is also shared,
transitively.
16 C h a pter 2: Syn c h ro n i za t i o n a n d T i m e
respectively. Certain programming patterns such a s producer/consumer use consistent sharing and transfer of ownership patterns, making the points of publication and privatization more apparent. Even then it's easy to trip up and make a mistake, such as treating something private although it is still shared, causing race conditions.
It's also important to note that the above definitions depend to some degree on modern type safety. In the .NET Framework this is generally not negotiable, whereas in systems like C++ it is highly encouraged but can be circumvented. When any part of the program can manufacture a pointer to any arbitrary address in the process's address space, all data in the entire address space is shared state. We will ignore this loophole. But when pointer arithmetic is involved in your system, know that many of the same problems we'll look at in this chapter can manifest. They can be even more nondeterministic and hard to debug, however.
To illustrate some of the challenges in identifying shared state, here's a class definition in C++. It has one simple method, f, and two fields, one static ( s_f ) and the other instance ( m_f ) . Despite the use of C++ here, the same principles clearly apply to managed code too.
c l a s s C {
int m_f j public :
} j
void f ( int * Py ) {
}
int X j
X++ j I I loc a l variable s_f++ j II static c l a s s member m_f++ j II c l a s s member
( * PY ) ++j II pointer to something
The method contains four read /increment/write operations (via C++'s ++ unary operator). In a concurrent system, it is possible that multiple
threads could be invoking f on the same instance of c concurrently with
M a n a l l n l Prolra m S t a te 17
put, any increments of shared data are problematic. This is not strictly true because higher level programming conventions and constructs may actu ally prevent problematic shared interactions, but given the information above, we have no choice but to assume the worst.
By simply looking at the class definition above, how do we determine what state is shared? Unfortunately we can't. We need more information.
The answer to this question depends on how instances of C are used in
addition to where the py pointer came from.
We can quickly label the operations that do not act on shared state because there are so few (just one). The only memory location not shared with other threads is the x variable, so the x++ statement doesn't modify shared state. (Similar to the statement above about type safety, we are relying on the fact that we haven't previously shared the address of x on the thread's stack with another thread. Of course, another thread might have found an address to the stack through some other means and could perform address arithmetic to access x indirectly, but this is a remote possibility. Again, we will assume some reasonable degree of type safety.) Though it doesn't appear in this example, if there was a statement to increment the value of py, i.e., py++, it would not affect shared state because py is passed by value.
The s_f++ statement affects shared state because, by the definition of static variables, the class's static memory is visible to multiple threads run ning at once. Had we used a static local variable in f in the above example, it would fall into this category too.
Here's where it becomes complicated. The m_f++ line might, at first glance, appear to act on private memory, but we don't have enough infor mation to know. Whether it modifies shared state or not depends on if the caller has shared the instance of C across multiple threads (or itself received the pointer from a caller that has shared the instance). Remember, m_f++ is a pointer dereference internally, ( t h i s - >m_f ) ++. The t h i s pointer might refer to an object allocated on the current thread's stack or allocated dynam ically on the heap and may or may not be shared among threads in either case.
c l a s s D {
18 C h a pter 2: Syn c h ro n i za t i o n a n d T i m e
}
void g O {
}
int x = B j
C c l ( ) j II stac k - alloc c 1 . f ( & x ) j
C c 2 = new C ( ) j I I heap - alloc c 2 . f ( &x ) j
s_c . f ( &x ) j m_c . f ( &x ) j
In the case of the c 1 . f ( &x ) function call, the object is private because it was allocated on the stack. Similarly, with c 2 . f ( &x ) the object is probably private because, although allocated on the heap, the instance is not shared with other threads. (Neither case is simple: ('S constructor could publish a reference to itself to a shared location, making the object shared before the call to f happens.) When called through 5_C, clearly the object is shared because it is stored in a shared static variable. And the answer for the call through m_c is "it depends." What does it depend on? It depends on the allo cation of the instance of D through which g has being invoked. Is it referred to by a static variable elsewhere, another shared object, and so forth? This illustrates how quickly the process of identifying shared state is transitive and often depends on complex, dynamically composed object graphs.
Because the member variable and explicit pointer dereference are simi lar in nature, you can probably guess why "it depends" for ( * py ) ++ too.
The caller of f might be passing a pointer to a private or shared piece of
memory. We really have no way of telling.
M a n a g i n g Progra m State 19
too naIve. An object can also become shared at thread creation time by passing a pointer to it as an argument to thread creation routines. The same goes for thread pool APIs, among others. Some objects are special, such as
the one global shared OutOfMemo ry Exception object that the CLR throws
when memory is very low. Some degree of compiler analysis could help. A technique called escape analysis determines when private memory "escapes" into the shared memory space, but its application is limited mostly to academic papers (see Further Reading, Choi, Gupta, Serrano, Sreedhar, Midkiff). In practice, complications, such as late bound method calls, pointer aliasing, and hidden sources of cross-thread sharing, make static analysis generally infeasible and subject to false negatives without restrictions in the programming model. There is research exploring such ideas, such as ownership types, but it is probably years from mainstream use (see Further Reading, Boyapati, Liskov, Shrira).
In the end, logically separating memory that is shared from memory that is private is of utmost importance. This is perhaps the most funda mental and crucial skill to develop when building concurrent systems in modern programming environments: accurately identifying and properly managing shared state. And, more often than not, shared state must be managed carefully and with a great eye for detail. This is also why under standing and debugging concurrent code that someone else wrote is often very difficult.
State Machines and Time
20 C h a pter 2 : Syn c h ro n i z a t i o n a n d T i m e
When state i s shared, multiple concurrent threads, each o f which may have been constructed with a set of sequential execution assumptions, may end up overlapping in time. And when they overlap in time, their opera tions become interleaved. If these operations access common memory locations, they may possibly violate the legal set of state transitions that the program's state machine was planned and written to accommodate. Once this happens, the program may veer wildly off course, doing strange and inexplicable things that the author never intended, including performing bogus operations, corrupting memory, or crashing.
Broken Invariants and Invalid States
As an illustration, let's say on your first day at a new programming job you were assigned the task of implementing a reusable, dynamically resizing queue data structure. You'd probably start out with a sketch of the algo rithms and outline some storage alternatives. You'd end up with some fields and methods and some basic decisions having been made, perhaps such as using an array to store elements versus a linked list. If you're really method ical, you might write down the state invariants and transitions and write them down as asserts in the code or even use a formal specification system to capture (and later verify) them. But even if you didn't go to these lengths, those invariants still exist. Break any one of them during development, or worse after code has been embedded into a system, and you've got a bug. Let's consider a really simple invariant. The count of the queue must be less than or equal to the length of the array used to store the individual ele ments. (There are of course several others: the head and tail indices must be within the legal range, and so on.) If this queue was meant only to be used by sequential programs, then preserving the invariant at the entrance and exit of all public methods would be sufficient as a correctness condition. It would be trivial: only those methods that modify the fields need to be writ ten to carefully respect the invariant. The most difficult aspect of attaining this would be dealing with failures, such as an inability to allocate mem ory when needed.
M a n a li n l Prolra m S t a te 21
even that might not be sufficient if some lines of code (in whatever higher level language you are programming in) were compiled into multiple instructions in the machine language. Moreover, this task becomes impos sible when there are multiple variables involved in the operation (as is probably the case with our queue), leading to the requirement of some extra form of state management: i.e., isolation, immutability, or synchronization. The fact is that it's very easy to accidentally expose invalid program states as a result of subtle interactions between threads. These states might not exist on any legal state machine diagram we would have drawn for our data structure, but interleaving can cause them. Such problems frequently differ in symptom from one execution of your code to the next-causing new exceptions, data corruption, and so forth and depend on timing in order to manifest. The constant change in symptom and dependence on timing makes it difficult to anticipate the types of failures you will experi ence when more concurrency is added to the system and makes such failures incredibly hard to debug and fix.
The various solutions hinted at above can solve this problem. The sim plest solutions are to avoid sharing data or to avoid updating data completely. Unfortunately, taking such an approach does not completely eliminate the need to synchronize. For instance, you must keep intermedi ate state changes confined within one thread until they are all complete and then, once the changes are suitable to become visible, you must use some mechanism to publish state updates to the globally visible set of memory as a single, indivisible operation (i.e., atomic operation). All other threads must cooperate by reading such state from the global memory space as a single, indivisible atomic operation.
This is not simple to achieve. Because reading and writing an arbitrary number of memory locations atomically at once are not supported by cur rent hardware, software must simulate this effect using critical regions.
22 C h a pter 2 : Syn c h ro n i za t i o n a n d T i m e
A Simple Dlltll Rllee
Consider this deceivingly simple program statement.
int * a = ( * a ) ++ j
(Forgive the C++-isms for those managed programmers reading this. ( * a ) ++ is used instead of a++, just to make it obvious that a points to some shared memory location.)
When translated into machine code by the compiler this seemingly simple, high-level, single-line statement involves multiple machine instructions:
MOV EAX , [ a ] INC EAX MOV [ a ] , EAX
Notice that, as a first step, the machine code dereferences a to get some virtual memory address and copies 4 bytes' worth of memory starting at that address into the processor local EAX register. The code then incre ments the value of its private copy in EAX, and, lastly, makes yet another copy of the value, this time to copy the incremented value held in its private register back to the shared memory location referred to by a .
The multiple steps and copies involved i n the + + operator weren't apparent in the source file at all. If you were manipulating multiple vari ables explicitly, the fact that there are multiple steps would be a little more apparent. In fact, it's as though we had written:
int * a = • • • j int tmp = * a j tmp++ j *a = tmp j
M a n a ll n l P rolra m State 23
Conversely, reading or writing data with a size larger than the addressable unit of memory on your CPU is nonatomic. For instance, if you wrote a 64-bit value on a 32-bit machine, it will entail two move instructions from processor private to shared memory, each to copy a 4-byte segment. Similarly, reading from or writing to unaligned addresses (Le., address ranges that span an addressable unit of memory) also require multiple memory operations in addition to some bit masking and shifting, even if the size of the value is less than or equal to the machine's addressable memory size. Alignment is a tricky subject and is discussed in much more detail in Chapter 1 0, Memory Models and Lock Freedom.
So why is all of this a problem?
An increment statement is meant to monotonically increase the value held in some memory location by a delta of 1 . If three increments were made to a counter with an original value 0, you'd expect the final result to be 3. It should never be possible (overflow aside) for the value of the counter to decrease from one read to the next; therefore, if a thread executes two ( * a ) ++ operations, one after the other, you would expect that the sec ond update always yields a higher value than the first. These are some very basic correctness conditions for our simple ( * a ) ++ program. (Note: You shouldn't be expecting that the two values will differ by precisely 1 , how ever, since another thread might have snuck in and run between them.)
There's a problem. While the actual loads and stores execute atomically by themselves, the three operation sequence of load, increment, and store is nonatomic, as we've already established. Imagine three threads, tl , t2, and t3, are running the compiled program instructions simultaneously.
t 1
24 C h a pter 2: Syn c h ro n i za t i o n a n d T i m e
simultaneously, there i s only one central, shared memory system with a cache coherency system that ensures a globally consistent view of memory. We can therefore describe the execution history of our program in terms of a simple, sequential time scale.
In the following time scale, the y-axis (labeled T) represents time, and the abscissa, in addition to a label of the form thread (sequence#) and the instruction itself, depicts a value in the form #n, where n is the value in the memory target of the move after the instruction has been executed.
T t1 t 2
o t 1 ( 0 ) : MOV EAX, [ a ] #0 1 t 1 ( 1 ) : INC, EAX #1 2 t 1 ( 2 ) : MOV [ a ] , EAX #1 3
4 5 6 7 8
t 2 ( 0 ) : MOV EAX , [ a ] #1 t 2 ( 1 ) : INC , EAX #2 t 2 ( 2 ) : MOV [ a ] , EAX #2
t 3
t 3 ( 0 ) : MOV EAX, [ a ] #2 t3 ( 1 ) : INC, EAX #3 t3 ( 2 ) : MOV [ a ] , EAX #3
If a is an integer that begins with a value of ° at time step 0, then after three ( * a ) ++ operations have executed, we expect the value to be 0 + 3 = 3. Indeed, we see that this is true for this particular history: t1 runs to com pletion, leaving value 1 in * a, and then t2, leaving value 2, and finally, after executing the instruction at time 8 in our timeline, t3 has finished and * a contains the expected value 3 .
We can compress program histories into more concise representations so that they fit on one line instead of needing a table like this. Because only one instruction executes at any time step, this is simple to accomplish. We'll write each event in sequence, each with a thread (sequence#) label, using the notation a ....,. b to denote that event a happens before b. A sequence of operations is written from left to right, with the time advancing as we move from one operation to the next. Using this scheme, the above history could be written instead as follows.
t 1 ( 0 ) - >t 1 ( 1 ) - >t 1 ( 2 ) - >t 2 ( 0 ) - >t2 ( 1 ) - >t 2 ( 2 ) - >t 3 ( 0 ) - >t3 ( 1 ) - >t3 ( 2 )
M a n a g i n g Progra lll State 25
often clearer to illustrate specific values and is better at visualizing subtle timing issues, particularly for larger numbers of threads.
No matter the notation, examining timing like this is a great way of reasoning about the execution of concurrent programs. Programmers are accustomed to thinking about programs as a sequence of individual steps. As you develop your own algorithms, writing out the concurrent threads and exploring various legal interleavings and what they mean to the state of your program, it is imperative to understanding the behavior of your concurrent programs. When you think you might have a problematic tim ing issue, going to the whiteboard and trying to devise some problematic history, perhaps in front of a colleague, is often an effective way to uncover concurrency hazards (or determine their absence).
Simple, noninterleaved histories pose no problems for our example. The following histories are also safe with our algorithm as written.
t 1 ( 0 ) - >t1 ( 1 ) - >t 1 ( 2 ) - >t3 ( 0 ) - >t3 ( 1 ) - >t 3 ( 2 ) - >t 2 ( 0 ) - >t2 ( 1 ) - >t 2 ( 2 ) t 2 ( 0 ) - >t2 ( 1 ) - >t 2 ( 2 ) - >t1 ( 0 ) - >t1 ( 1 ) - >t 1 ( 2 ) - >t 3 ( 0 ) - >t3 ( 1 ) - >t3 ( 2 ) t 2 ( 0 ) - >t2 ( 1 ) - >t2 ( 2 ) - >t 3 ( 0 ) - >t 3 ( 1 ) - >t 3 ( 2 ) - >t 1 ( 0 ) - >t 1 ( 1 ) - >t 1 ( 2 ) t 3 ( 0 ) - >t3 ( 1 ) - >t 3 ( 2 ) - >t1 ( 0 ) - >t 1 ( 1 ) - >t 1 ( 2 ) - >t 2 ( 0 ) - >t 2 ( 1 ) - >t 2 ( 2 ) t 3 ( 0 ) - >t3 ( 1 ) - >t 3 ( 2 ) - >t 2 ( 0 ) - >t 2 ( 1 ) - >t2 ( 2 ) - >t 1 ( 0 ) - >t 1 ( 1 ) - >t 1 ( 2 )
These histories yield correct results because none results i n one thread's statements interleaving amongst another's. In each scenario, the first thread runs to completion, then another, and then the last one. In these histories, the threads are serialized with respect to one another (or the history is
serializable) .
But this example is working properly by virtue of sheer luck. There is nothing to prevent the other interleaved histories from occurring at run time, where two (or more) threads overlap in time, leading to an inter leaved timing and resulting race conditions. Omitting t3 from the example for a moment, consider this simple timing, written out longhand so we can emphasize the state transitions from one time step to the next.
T t l t2
o t l ( 0 ) : MOV EAX , [ a j #0
1 t 2 ( 0 ) : MOV EAX , [ a j #0
2 t 2 ( 1 ) : INC, EAX #1
3 t 2 ( 2 ) : MOV [ a j , EAX #1