i
SISTEM PEMEROLEHAN INFORMASI DATA GAMBAR
PADA DOKUMEN FOTOGRAFI
MENGGUNAKAN STRUKTUR DATA INVERTED INDEX
DAN PEMBOBOTAN TF-IDF
Skripsi
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Teknik Informatika(S.Kom)
Program Studi Teknik Informatika Universitas Sanata Dharma
Oleh:
A
DRIAN
A
DENDENDRATA
NIM : 09 5314 054
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
ii
INFORMATION RETRIEVAL OF IMAGE ON
PHOTOGRAPHY DOCUMENTS
USING INVERTED INDEX DATA STRUCTURE AND
WEIGHTING TF-IDF
Thesis:
Presented as Partial Fullfilment of the Requirements To Obtain the Computer Bachelor Degree
In Informatics Engineering Universitas Sanata Dharma
By:
A
DRIAN
A
DENDENDRATA
NIM : 09 5314 054
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
vi
HALAMAN MOTO
“About the money,
vii
HALAMAN PERSEMBAHAN
viii
ABSTRAKSI
Ketersediaan dokumen fotografi yang terus berkembang dan meningkat menyebabkan sulitnya menemukan dokumen fotografi yang sesuai. Berdasarkan hal tersebut maka dibutuhkan suatu sistem Pemerolehan Informasi. Pada sistem Pemerolehan Informasi, hasil pencarian dokumen diurutkan berdasarkan bobot dengan menggunakan algoritma tertentu, algoritma yang digunakan adalah pembobotan tf-idf, sehingga adanya sistem tersebut dapat melakukan pencarian dokumen dengan cepat. Umumnya sistem Pemerolehan Informasi mencari dokumen berdasarkan data teks pada setiap dokumen maka penulis ingin meneliti apakah data gambar pada dokumen fotografi dapat membantu pengguna dalam menentukan dokumen fotografi yang sesuai.
Penelitian ini menggunakan beberapa tahap metode dalam pengembangannya, tahap-tahap tersebut adalah pengumpulan contoh data, pembuatan sistem, pengumpulan data dan evaluasi. Pengumpulan contoh data dokumen fotografi digunakan agar mempercepat proses pengembangan sistem. Evaluasi penelitian ini menggunakan recall dan precision yang dibantu oleh responden.
ix
ABSTRACT
Now availability of photographic document are constantly evolving and increasing cause difficulty finding appropriate photographic document. Based on this case, we need a Information Retrieval system. On Information Retrieval system document search results sorted by weight using a particular algorithm, the algorithm used is the tf-idf weighting. So with such a system can create documents quickly search. Commonly, On Information Retrieval system search for documents based on data text owned by each document. The authors wanted to examine whether the image data on photographic document may help users to determine the photographic document that fit their needs. This research measured performance based on the value of the average precision of the results of sorting system based on text data and image data.
In this research, the development of several stages, there are, collecting examples of data, systems development, data collection and evaluation. Where sample data of photographic document is used in order to speed up the process of system development. This evaluation on this research using recall and precision are assisted by respondents.
xi
KATA PENGANTAR
Puji dan Syukur saya panjatkan kepada Tuhan Yesus Kristus YME, atas berkat dan kuasa-Nya yang diberikan sehingga saya dapat menyelesaikan Tugas Akhir ini. Tugas Akhir ini adalah salah syarat memperolah gelar Sarjana Teknik Informatika (S.Kom) Program Studi Teknik Informatika, Universitas Sanata Dharma.
Dalam penyelesaian skripsi ini ada begitu banyak pihak atau pribadi yang selalu membantu saya sampai dengan akhir pengerjaan. Oleh kerena itu saya ingin mengucapkan rasa terima kasih atas bantuan yang telah diberikan.
1. Ibu Paulina Heruningsih Prima Rosa, S.Si., M.Sc. selaku dekan Fakultas Sains dan Teknologi Universitas Sanata Dharma.
2. Ibu Ridowati Gunawan, S.kom., M.T. selaku ketua jurusan Teknik Informatika Universitas Sanata Dharma.
3. Bapak JB. Budi Darmawan, S.T., M.Sc. selaku dosen pembimbing skripsi. Beliau dengan sabar selalu membimbing dan memberikan banyak kontribusi dalam pengerjaan.
4. Ibu Sri Hartati Wijono, S.Si., M.Kom. dan Bapak Puspaningtyas Sanjoyo Adi, S.T., M.T.sebagai dosen penguji.
5. Keluarga, FA Adihendro (Ayah), Sri Nurwidayatun (Ibu) dan Denis Darujati (Kakak) yang terus memberi dukungan moral.
xiii
DAFTAR ISI
HALAMAN JUDUL INDONESIA ... i
HALAMAN JUDUL INGGRIS ... ii
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ... iv
PERNYATAAN KEASLIAN ILMIAH ... v
HALAMAN MOTO ... vi
HALAMAN PERSEMBAHAN ... vii
ABSTRAKSI ... viii
ABSTRACT ... ix
PUBLIKASI KARYA ILMIAH UNTUK KEPERLUAN AKADEMIS ... x
KATA PENGANTAR ... xi
1.5 Metodelogi Penelitian ... 3
1.6 Sistematika Penulisan ... 5
BAB 2 ... 7
LANDASAN TEORI ... 7
2.1 Pemerolehan Informasi ... 6
2.2 Teks Operasi ... 9
2.2.1 Pemisahan Kata ( Tokenization ) ... 9
2.2.2 Penghapusan Kata Umum (Stop Words) ... 10
2.2.3 Stemming ... 11
xiv
2.3.1 Inverted Index... 17
2.3.2 Tabel Hash (HashTable) ... 18
2.3.3 Kelas ArrayList ... 18
2.4 Searching ... 20
2.6.1 Pembobotan tf-idf ... 20
BAB 3 ... 23
ANALISIS DAN PERANCANGAN ... 23
3.1 Kasus Diskripsi ... 23
3.2 Cara Penyelesaian Masalah ... 23
3.3 Perancangan Peta Sistem ... 23
3.4 Model Use Case ... 25
3.4.1 Skenario Login ... 27
3.4.2 Skenario Menambah Dokumen ... 27
3.4.3 Skenario Mencari Dokumen ... 28
3.4.4 Skenario Mengunduh Dokumen ... 29
3.4.5 Skenario Logout ... 29
3.5 Perancangan Diagram Aktifitas ... 30
3.5.1 Diagram Aktifitas Login ... 30
3.5.2 Diagram Aktifitas Menambah Dokumen ... 31
3.5.3 Diagram Aktifitas Mencari Dokumen ... 32
3.5.4 Diagram Aktifitas Mengunduh Dokumen ... 33
3.5.5 Diagram Aktifitas Logout ... 34
3.6 Perancangan Diagram Kolaborasi ... 35
3.6.1 Diagram Kolaborasi Login ... 35
xv
3.6.3 Diagram Kolaborasi Mencari Dokumen ... 37
3.6.4 Diagram Kolaborasi Mengunduh Dokumen ... 38
3.6.4 Diagram Kolaborasi Logout ... 38
3.7 Perancangan Diagram Sekuensial ... 39
3.7.1 Diagram Sekuensial Login ... 39
3.7.2 Diagram Sekuensial Menambah Dokumen ... 40
3.7.3 Diagram Sekuensial Mencari Dokumen ... 41
3.7.4 Diagram Sekuensial Mengunduh Dokumen ... 42
3.7.4 Diagram Sekuensial Logout ... 43
3.8 Perancangan Basis Data ... 43
3.8.1 Entity Rationalship Diagram ... 44
3.8.2 Rational Model Design Database ... 44
3.8.3 Physical Design Database ... 45
3.9 Perancangan Inverted Index ... 48
3.10 Perancangan Antar Muka ... 49
3.10.1 Perancangan Antar Muka Halaman Pencarian ... 50
3.10.2 Perancangan Antar Muka Halaman Upload Dokumen ... 51
3.11 Peracangan Diagram Kelas... 51
3.11.1 Aplikasi Searching ... 51
3.11.2 Aplikasi Indexing ... 54
BAB 4 ... 58
IMPLEMENTASI ... 58
4.1 Implemtasi sql pada Basis Data ... 58
4.2 Implemtasi Parsing Data Teks dan data Gambar ... 59
xvi
4.3.1 Pemisahan Kata ... 63
4.3.2 Penghapusan Kata Umum ... 64
4.3.3 Stemming ... 64
4.4 Implementasi Indexing ... 68
4.5 Implementasi Inverted Index ... 69
4.6 Implementasi Searching ... 70
4.6.1 Persamaan AND ... 71
4.7 Implemtasi Antar Muka ... 72
4.7.1 Halaman Login ... 72
4.7.2 Halaman Pencarian... 72
4.7.3 Halaman Unggah ... 74
BAB 5 ... 75
ANALISA HASIL ... 75
5.1 Analisa Hasil Sistem ... 75
5.1.1 Analisa Uji Coba Pengguna ... 75
5.2 Kelebihan dan Kekurangan Sistem ... 99
5.2.1 Kelebihan Sistem ... 99
5.2.2 Kelemahan Sistem ... 100
BAB 6 ... 101
KESIMPULAN DAN SARAN ... 101
6.1 Kesimpulan ... 101
6.2 Saran ... 101
DAFTAR PUSTAKA ... 103
xvii
DAFTAR GAMBAR
Gambar 2.1 Proses Menuju Pengindeksan (Baeza, 1999) ... 8
Gambar 2.2 Konsep Sistem Pemerolehan Informasi (Beaza, 1999) ... 9
Gambar 2.3 Proses Pemotongan Kata ... 10
Gambar 2.4 Proses Penghapusan Kata Umum ... 10
Gambar 2.5 Proses Pengindeksan ... 17
Gambar 2.6Inverted Indexx ... 18
Gambar 3.1 Peta Sistem Keseluruhan ... 25
Gambar 3.2 Use Case Diagram ... 26
Gambar 3.3 Diagram Aktifitas Login ... 30
Gambar 3.4 Diagram Menambah Dokumen... 31
Gambar 3.5 Diagram Aktifitas Mencari Dokumen ... 32
Gambar 3.6 Diagram Aktifitas Unduh Dokumen ... 33
Gambar 3.7 Diagram Aktifitas Logout ... 34
Gambar 3.8 Diagram Kolaborasi Login ... 35
Gambar 3.8 Diagram Kolaborasi Menambah Dokumen ... 36
Gambar 3.10 Diagram Kolaborasi Mencari Dokumen ... 37
Gambar 3.11 Diagram Kolaborasi Mengunduh Dokumen ... 38
Gambar 3.12 Diagram Kolaborasi Logout ... 39
Gambar 3.13 Diagram Skuensial Login ... 39
Gambar 3.14 Diagram Skuensial Menambah Dokumen ... 40
Gambar 3.15 Diagram Skuensial Mencari Dokumen ... 41
Gambar 3.16 Diagram Skuensial Mengunduh Dokumen ... 42
Gambar 3.17 Diagram Skuensial Logout ... 43
Gambar 3.18Entity Rationalship Diagram ... 44
Gambar 3.19RationalModelDesignDatabase ... 45
Gambar 3.20 Perancangan struktur data Inverted Index dalam bentuk HashTable ... 49
Gambar 3.21 Halaman Pencarian. Sebelum dilakukan pencarian ... 50
xviii
Gambar 3.22 Halaman Menambah Dokumen ... 51
Gambar 3.25 Diagram UML: Aplikasi - Searching: IR ... 52
Gambar 3.26 Diagram UML: Aplikasi - Searching: database ... 52
Gambar 3.27 Diagram UML: Aplikasi - Searching: entitites ... 53
Gambar 3.28 Diagram UML: Aplikasi - Searching: textoperation ... 53
Gambar 3.29 Diagram UML: Aplikasi - Searching: tools ... 53
Gambar 3.30 Diagram UML: Aplikasi - Indexing: IR ... 54
Gambar 3.31 Diagram UML: Aplikasi - Indexing: database... 54
Gambar 3.32 Diagram UML: Aplikasi - Indexing: entities ... 55
Gambar 3.33 Diagram UML: Aplikasi - Indexing: textoperation ... 55
Gambar 3.34 Diagram UML: Aplikasi - Indexing: tools... 56
Gambar 3.35 Diagram UML: Aplikasi - Indexing: thread ... 56
Gambar 4.1 Rangkaian Proses Text Operations ... 61
Gambar 4.2 GUI: Halaman Login ... 72
Gambar 4.3 GUI: Halaman Pencarian 1 ... 73
Gambar 4.4 GUI: Halaman Pencarian 2 ... 73
Gambar 4.4 GUI: Halaman Unggah ... 74
Gambar 5.1 Hasil Pencarian: Responden Pertama ... 76
Gambar 5.2 Interpolasi: Responden Pertama ... 79
Gambar 5.3 Hasil Pencarian: Responden Kedua ... 81
Gambar 5.4 Interpolasi: Responden Kedua ... 84
Gambar 5.5 Hasil Pencarian: Responden Ketiga... 86
Gambar 5.6 Interpolasi: Responden Ketiga ... 89
Gambar 5.7 Interpolasi: Responden Ketiga ... 91
Gambar 5.8 Interpolasi: Responden Keempat ... 94
Gambar 5.9 Hasil Pencarian: Responden Kelima ... 95
xix
DAFTAR TABEL
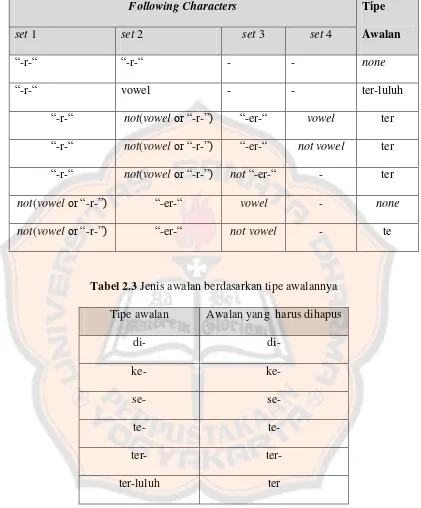
Tabel 2.1 Kombinasi awalan akhiran yang tidak diijinkan ... 13
Tabel 2.2 Cara menemukan tipe awalan untuk kata diawali de “te-“ ... 14
Tabel 2.3 Jenis awalan berdasarkan tipe awalannya ... 14
Tabel 3.1 Skenario Use Case Login ... 27
Tabel 3.2 Skenario Use Case Menambah Dokumen ... 28
Tabel 3.3 Skenario Use Case Mencari Dokumen ... 28
Tabel 3.4 Skenario Use Case Mengunduh Dokumen ... 29
Tabel 3.5 Skenario Use Case Logout ... 29
Tabel 3.6 Tabel Documents ... 45
Tabel 3.7 Tabel Images ... 46
Table 3.8 Tabel Terms ... 46
Table 3.9 Tabel Indeks ... 47
Table 3.10 Tabel Dictionary ... 48
Table 3.11 Tabel Stopword ... 48
Tabel 5.1PrecisionTable:Responden Pertama... 76
Tabel 5.2aRecallandPrecision Pengurutan Sistem: Responden Pertama ... 77
Tabel 5.2aRecallandPrecision Pengurutan Menggunakan Data Gambar oleh Responden: Responden Pertama ... 77
Tabel 5.3a Sebelas Titik Interpolasi Pengurutan Sistem: Responden Pertama .... 78
Tabel 5.3b Sebelas Titik Interpolasi Pengurutan Menggunakan Data Gambar oleh Responden: Responden Pertama ... 78
Tabel 5.4PrecisionTable Responden Kedua ... 82
Tabel 5.5aRecallandPrecision Pengurutan Sistem: Responden Kedua ... 82
Tabel 5.5bRecallandPrecision Pengurutan Menggunakan Data Gambar oleh Responden: Responden Kedua ... 83
Tabel 5.6a Sebelas Titik Interpolasi Pengurutan Sistem: Responden Kedua ... 83
Tabel 5.6b Sebelas Titik Interpolasi Pengurutan Menggunakan Data Gambar oleh Responden: Responden Kedua ... 84
xx
Tabel 5.8aRecallandPrecision Pengurutan Sistem: Responden Ketiga ... 87
Tabel 5.8bRecallandPrecision Pengurutan Menggunakan Data Gambar
oleh Responden: Responden Ketiga... 88
Tabel 5.9a Sebelas Titik Interpolasi Pengurutan Sistem: Responden Ketiga ... 88
Tabel 5.9b Sebelas Titik Interpolasi Pengurutan Menggunakan Data Gambar oleh Responden: Responden Ketiga... 89
Tabel 5.10PrecisionTable Responden Keempat ... 92
Tabel 5.11aRecallandPrecision Pengurutan Sistem: Responden Keempat ... 92
Tabel 5.11bRecallandPrecision Pengurutan Menggunakan Data Gambar oleh Responden: Responden Keempat ... 92
Tabel 5.12a Sebelas Titik Interpolasi Pengurutan Sistem: Responden Keempat 93
Tabel 5.12b Sebelas Titik Interpolasi Pengurutan Menggunakan Data Gambar oleh Responden: Responden Keempat ... 93
Tabel 5.13PrecisionTable Responden Kelima ... 96
Tabel 5.14aRecallandPrecision Pengurutan Sistem: Responden Kelima ... 96
Tabel 5.14bRecallandPrecision Pengurutan Menggunakan Data Gambar oleh Responden: Responden Kelima ... 96
Tabel 5.15a Sebelas Titik Interpolasi Pengurutan Sistem: Responden Kelima ... 97
xxi
DAFTAR SOURCE CODE
Code 4.1 Implementasi Table untuk Dokumen ... 59
Code 4.2. Implementasi Parsing Data Teks dan Data Gambar ... 60
Code 4.3 Implementasi table STOPWORDS dan DICTIONARY ... 60
Code 4.4 Text Operations ... 61
Code 4.5 Implementasi Teks Operations, Pemisahan Kata ... 63
Code 4.6 Implementasi Teks Operations, Penghapusan Kata Umum ... 64
Code 4.7 Implementasi Teks Operations, Stemming ... 65
Code 4.8 Implementasi Indexing ... 68
Code 4.9 Implementasi InvertedIndex ... 69
Code 4.10 Implementasi Searching ... 70
1
BAB 1
PENDAHULUAN
Bagian ini akan menjelaskan tentang permasalahan yang sedang terjadi dan harapan yang diperoleh dari hasil penelitian.
1.1 Latar Belakang
Fotografi dalam bidang informasi dewasa ini sudah sangat berkembang seturut dengan meningkatnya jumlah pencinta fotografi yang ingin belajar melalui media dokumen digital. Didukungnya dengan sistem yang sudah ada dokumen fotografi sangat mudah untuk ditemukan atau diperoleh. Setiap tahun perubahan dan penambahan informasi mengenai fotografi terus berkembang. Hal tersebut mengakibatkan ketersediaan dokumen fotografi menjadi sangat banyak sehingga sulit untuk mencari dokumen yang sesuai dengan kebutuhan yang diinginkan. Beberapa mesin pencari yang sudah dikembangkan sebelumnya belum khusus membahas tentang topik fotografi sehingga memungkinkan untuk mengembalikan informasi yang tidak sesuai dengan fotografi.
Dokumen fotografi umumnya memiliki dua elemen, yaitu data gambar dan data teks. Data teks adalah presentasi isi dokumen dalam bentuk teks pada suatu dokumen. Sementara itu, data gambar umumnya memberikan ilustrasi atau pencitraan kembali yang sesuai dengan keterangan pada data teks. Namun, terpadat beberapa dokumen yang mungkin tidak menggunakan data gambar sebagai ilustrasi pada data teks.
informasi (Hasibuan, 2001). Pemerolehan Informasi (Information Retrieval) adalah sistem yang bertujuan untuk menemukan dokumen dengan cepat. Dalam Pemerolehan Informasi hasil pencarian dokumen diurutkan berdasarkan besar bobot yang dimiliki setiap dokumen. Sedangkan teknik pembobotannya adalah teknik pembobotan berdasarkan frekuensi dan teknik pembobotan menurut rumus Savoy.
Umumnya sistem Pemerolehan Informasi hanya menggunakan data teks untuk mencari dokumen. Untuk dokumen fotografi memiliki data teks dan beberapa data gambar maka penulis ingin meneliti apakah data gambar pada sistem Pemerolehan Informasi dengan dokumen fotografi juga dapat membantu pengguna dalam memilih dokumen yang sesuai dengan kebutuhannya. Diharapkan dengan adanya penelitian ini dapat membantu fotografer pemula untuk menentukan dokumen yang sesuai dengan kebutuhannya.
1.2 Rumusan Masalah
Sejauh mana data gambar pada sistem Pemerolehan Informasi dengan dokumen fotografi dapat membantu pengguna dalam memilih dokumen yang sesuai dengan kebutuhannya.
1.3 Tujuan
1.4 Batasan Masalah
Batasan masalah penelitian ini adalah:
1. Sistem tidak melakukan crawling pada file dokumen. 2. Algoritma pembobotan menggunakan pembobotan tf-idf.
3. Relevansi dihitung menggunakan recall and precision dan rata-rata precision. 4. Sistem Pemerolehan Informasi ini hanya digunakan untuk mencari dokumen
fotografi berbahasa Indonesia.
1.5 Metodologi Penelitian
Metode yang digunakan pada penelitian ini adalah sebagai berikut; 1. Metode Literatur
Mengumpul dan mempelajari berbagai literatur atau penelitian sebelumnya yang relevan dengan Pemerolehan Informasi dan algoritma tf-idf. Sebagai sumber data akan dikumpulkan dokumen fotografi yang juga mengandung data gambar dan teks pada dokumen tersebut.
2. Metode Pengembangan Sistem
a. Requirements Analysis and Definition: Layanan sistem, batasan dan tujuan untuk menetapkan hasil konsultasi dari pengguna sistem. Mereka kemudian didefinisikan secara rinci dan sebagai kebutuhan sistem.
b. System and Software Design: Desain proses yang menjelaskan suatu kebutuhan baik perangkat keras ataupun perangkat lunak, sebagai pembentukan arsitektur sistem secara keseluruhan.
c. Implementation and Unit Testing: Perangkat lunak dirancang lebih matang sebagai perancangan beberapa program atau unit program. Unit testing mencakup verifikasi di mana setiap unitnya memenuhi dengan kebutuhannya.
d. Integration and System Testing: Unit yang berdiri sendiri atau program yang saling berintegrasi diujikan sebagai kelengkapan sistem untuk meyakinkan kebutuhan dari perangkat lunak sudah sesuai. Setelah pengujian, sistem perangkat lunak dikirimkan kepada pengguna.
1.6 Sistematika Penulisan
BAB I PENDAHULUAN
Memberikan gambaran secara umum tentang isi penelitian yang meliputi: Latar belakang, rumusan masalah, batasan masalah, tujuan dan manfaat, metode penelitian dan sistematika penulisan. BAB II LANDASAN TEORI
Berisi konsep dasar sistem temu kembali informasi (information retrieval system), bagian- bagian dari sistem temu kembali informasi, teknik- teknik temu- kembali informasi, dan evaluasi sistem temu kembali informasi.
BAB III ANALISIS DAN PERANCANGAN SISTEM
Berisi analisis kebutuhan, metode pengumpulan data, diagram arus data,kamus data, E-R diagram sistem, perancangan proses, perancangan basis data, perancangan modul, perancangan tampilan masukan dan keluaran untuk pengguna, dan perancangan teknologi.
BAB IV IMPLEMENTASI
Berisi penjelasan dan fungsi program bantu pencarian sebagai alat bantu pencarian data lirik dan lagu.
BAB V ANALISIS HASIL
Berisi evaluasi program sistem temu- kembali informasi, kelebihan dan kekurangan program.
Berisi kesimpulan dan saran dari pembuatan program mesin pencari dokumen fotografi
7
BAB 2
LANDASAN TEORI
Bagian ini menjelaskan mengenai studi literatur yang berhubungan guna menunjang dalam penelitian.
2.1 Pemerolehan Informasi
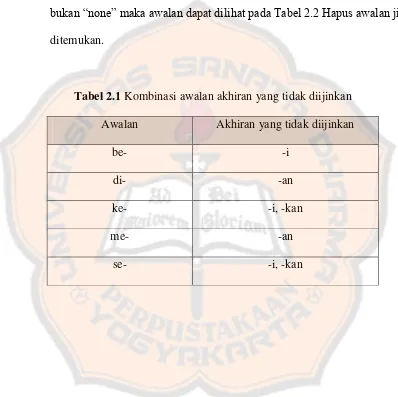
Pemerolehan Informasi (Information Retrieval) adalah menemukan bahan (umumnya dokumen) dari sesuatu tidak terstruktur (biasanya teks) yang memenuhi kebutuhan informasi dari kumpulan berskala besar (biasanya disimpan pada komputer) (Manning, 2009). Beberapa keuntungan yang didapatkan menggunakan Pemerolehan Informasi adalah sebagai berikut.
1. Untuk memproses kumpulan dokumen berskala besar.
2. Mengizinkan untuk melakukan pencocokan yang lebih fleksibel. 3. Mengizinkan pengembalian secara terurut.
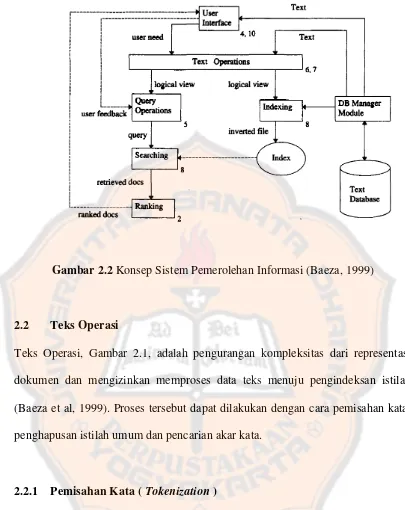
Gambar 2.1 Proses Menuju Pengindeksan (Baeza, 1999)
Gambar 2.2 Konsep Sistem Pemerolehan Informasi (Baeza, 1999)
2.2 Teks Operasi
Teks Operasi, Gambar 2.1, adalah pengurangan kompleksitas dari representasi dokumen dan mengizinkan memproses data teks menuju pengindeksan istilah (Baeza et al, 1999). Proses tersebut dapat dilakukan dengan cara pemisahan kata, penghapusan istilah umum dan pencarian akar kata.
2.2.1 Pemisahan Kata ( Tokenization )
Input Friend, Romans, Countrymen, Lend me your ears
Output Friends Romans Country Lend me your ears
Gambar 2.3 Proses Pemotongan Kata
2.2.2 Penghapusan Kata Umum (StopWords)
Beberapa kata yang umum untuk digunakan akan mengakibatkan membuat suatu nilai menjadi kecil dalam membantu memilih dokumen yang sesuai dengan kebutuhan pengguna. Kata yang umum tersebut adalah stopwords. Terdapat beberapa cara untuk menentukan kata umum tersebut adalah stopwords atau bukan, Salah satunya adalah dengan cara mengurutkan collection frequency
(jumlah setiap kemunculan kata dari koleksi dokumen) dan kemudian mengambil frekuensi yang tertinggi untuk mengkategorikan kata stopwords. Atau sering kali digunakan cara dengan menyaring kata/ stopwords berdasarkan daftar yang sudah ditentukan sebelumnya, kemudian stopwords akan dihapus selama dilakukannya pengindeksan (Manning et al. 2009).
Dalam bahasa Inggris, contoh kata umum yang digunakan adalah am, is, are, be, to, this, that, dan lain lain. Namun dalam bahasa Indonesia sendiri juga mengenal kata umum seperti yang, dan, ini, itu. Berikut adalah contoh penghapusan kata umum dalam bahasa indonesia, Gambar 2.4.
Input Sesuai dengan perjanjian ini saya umumkan
Output Sesuai perjanjian saya umumkan
2.2.3 Stemming
Stemming atau dalam konteks Pemerolehan Informasi adalah salah satu proses yang terdapat dalam Teks Operasi. Stemming memiliki fungsi untuk mentransformasi kata-kata yang terdapat dalam suatu dokumen ke kata akarnya (root word) dengan menggunakan aturan-aturan tertentu. Sebagai contoh, kata
bersama, kebersamaan, menyamai, akan distem ke root wordnya yaitu “sama”.
Proses stemming pada teks berBahasa Indonesia berbeda dengan stemming pada teks berbahasa Inggris. Pada teks berbahasa Inggris, proses yang diperlukan hanya proses menghilangkan sufiks. Sedangkan pada teks berbahasa Indonesia, selain sufiks, prefiks, dan konfiks juga dihilangkan. Pada umumnya kata dasar pada bahasa Indonesia terdiri dari kombinasi: Prefiks 1 + Prefiks 2 + Kata asar + Sufiks 3 + Sufiks 2 + Sufiks 1 2.
Algoritma yang dibuat oleh Bobby Nazief dan Mirna Adriani ini memiliki tahap-tahap sebagai berikut: diulangi lagi untuk menghapus Possesive Pronouns (“-ku”, “-mu”, atau “
3. Hapus Derivation Suffixes (“-i”, “-an” atau “-kan”). Jika kata ditemukan di kamus, maka algoritma berhenti. Jika tidak maka ke langkah 3a
a. Jika “-an” telah dihapus dan huruf terakhir dari kata tersebut adalah “
-k”, maka “-k” juga ikut dihapus. Jika kata tersebut ditemukan dalam kamus maka algoritma berhenti. Jika tidak ditemukan maka lakukan langkah 3b.
b. Akhiran yang dihapus (“-i”, “-an” atau “-kan”) dikembalikan, lanjut ke langkah 4.
4. Hapus Derivation Prefix. Jika pada langkah 3 ada sufiks yang dihapus maka pergi ke langkah 4a, jika tidak pergi ke langkah 4b.
a. Periksa tabel kombinasi awalan-akhiran yang tidak diijinkan. Jika ditemukan maka algoritma berhenti, jika tidak pergi ke langkah 4b. b. For i = 1 to 3, tentukan tipe awalan kemudian hapus awalan. Jika root
word belum juga ditemukan lakukan langkah 5, jika sudah maka algoritma berhenti. Catatan: jika awalan kedua sama dengan awalan pertama algoritma berhenti.
5. Melakukan Recoding.
6. Jika semua langkah telah selesai tetapi tidak juga berhasil maka kata awal diasumsikan sebagai root word. Proses selesai.
Tipe awalan ditentukan melalui langkah-langkah berikut:
2. Jika awalannya adalah “te-”, “me-”, “be-”, atau “pe-” maka dibutuhkan sebuah proses tambahan untuk menentukan tipe awalannya.
3. Jika dua karakter pertama bukan “di-”, “ke-”, “se-”, “te-”, “be-”, “me-”,
atau “pe-” maka berhenti.
4. Jika tipe awalan adalah “none” maka berhenti. Jika tipe awalan adalah
bukan “none” maka awalan dapat dilihat pada Tabel 2.2 Hapus awalan jika
ditemukan.
Tabel 2.1 Kombinasi awalan akhiran yang tidak diijinkan Awalan Akhiran yang tidak diijinkan
be- -i
di- -an
ke- -i, -kan
me- -an
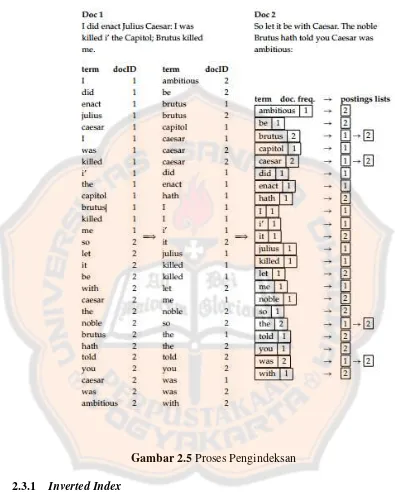
Tabel 2.2Cara menemukan tipe awalan untuk kata diawali de “te-”
Following Characters Tipe
Awalan set 1 set 2 set 3 set 4
“-r-“ “-r-“ - - none
“-r-“ vowel - - ter-luluh
“-r-“ not(vowelor “-r-”) “-er-“ vowel ter
“-r-“ not(vowelor “-r-”) “-er-“ notvowel ter
“-r-“ not(vowelor “-r-”) not“-er-“ - ter
not(vowelor “-r-”) “-er-“ vowel - none not(vowelor “-r-”) “-er-“ notvowel - te
Tabel 2.3 Jenis awalan berdasarkan tipe awalannya Tipe awalan Awalan yang harus dihapus
di- di-
ke- ke-
se- se-
te- te-
ter- ter-
Untuk mengatasi keterbatasan pada algoritma di atas, maka ditambahkan aturan-aturan di bawah ini:
1. Aturan untuk reduplikasi.
Jika kedua kata yang dihubungkan oleh kata penghubung adalah kata yang sama maka root word adalah bentuk tunggalnya, contoh : “buku
-buku” root word-nya adalah “buku”.
Kata lain, misalnya “bolak-balik”, “berbalas-balasan, dan ”seolah-olah”. Untuk mendapatkan root word-nya, kedua kata diartikan secara terpisah. Jika keduanya memiliki root word yang sama maka diubah menjadi
bentuk tunggal, contoh: kata “berbalas-balasan”, “berbalas” dan
“balasan” memiliki root word yang sama yaitu “balas”, maka root word “berbalas-balasan” adalah “balas”. Sebaliknya, pada kata “bolak-balik”,
“bolak” dan “balik” memiliki root word yang berbeda, maka root word
-nya adalah “bolak-balik”.
2. Tambahan bentuk awalan dan akhiran serta aturannya.
Untuk tipe awalan “mem-“, kata yang diawali dengan awalan “memp-”
memiliki tipe awalan “mem-”.
Tipe awalan “meng-“, kata yang diawali dengan awalan “mengk-”
2.3 Pengindeksan (Indexing)
Pengindeksan adalah proses penyimpanan kembali dokumen secara urut dengan aturan tertentu. Proses penyimpanan tersebut ditujukan guna mempercepat proses pencarian suatu dokumen yang sesuai dengan kebutuhan pengguna. Sebagai cara untuk dapatkan keuntungan dalam percepatan dalam melakukan proses pengindeksan, dapat membangun indeks terlebih dahulu. Untuk langkah proses tersebut adalah sebagai berikut (Manning et al. 2009) :
1. Kumpulkan dokumen terlebih dahulu yang akan di indeks.
2. Lakukan proses pemisahan kata guna mendapatkan daftar token.
3. Dapat dilakukan aturan tertentu untuk mendapat daftar token yang sudah dinormalisasikan sebelum dilakukan pengindeksan.
4. Indeks dokumen untuk masing-masing istilah yang dimilikinya dengan membuat InvertedIndex.
yang muncul beberapa kali dan menuliskan kembali jumlah kemunculan istilah tersebut dengan menunjuk kumpulan dokumen yang memiliki istilah tersebut.
Gambar 2.5 Proses Pengindeksan
2.3.1 Inverted Index
dapat dilihat pada Gambar 2.5. Pada Gambar 2.6 dapat dilihat bahwa konsep
InvertedIndex memiliki dua bagian, bagian pertama adalah Dictionary dan bagian kedua adalah Posting. Dictionary adalah istilah yang kemudian menunjuk pada
Posting. Posting adalah kumpulan dokumen dengan suatu istilah terdapat.
Gambar 2.6Inverted Index
2.3.2 Tabel Hash (HashTable)
Tabel Hash adalah struktur data yang sangat cepat dalam melakukan penyisipan dan pencarian. Tidak tergantung berapa data yang terdapat, penyisipan dan pencarian (dan terkadang penghapusan) dapat memakan waktu yang hampir sama yaitu O(1) dalam notasi O (Sommerville, 2011).
2.3.3 Kelas ArrayList
Objek ArrayList dapat juga dianggap sebagai perkembangan dari larik(array) satu dimensi. Sama seperti larik, objek ArrayList juga mendukung untuk melakukan
yang konstan. Tetapi tidak seperti larik yang ukuran dari objek ArrayList dapat secara otomatis dapat dikelola saat program sedang berjalan (Sommerville et al, 2009).
Di sini akan menjelaskan sifat pada ArrayList itu sendiri:
1. Posisi relatif pada setiap elemen dalam objek ArrayList diberikan oleh indeks yang dari bilangan bulat dengan rentang dari 0 sampai n-1, dimana n
mewakili jumlah dari elemen dalam objek ArrayList.
2. Elemen pada indeks dalam objek ArrayList dapat diakses dalam waktu yang konstan.
3. Untuk menghapus elemen pada indeks yang sudah diberikan, worstTime(n) adalah O(n). Untuk lebih spesifik, worstTime(n, indeks) adalah O(n - indeks), sehingga penghapusan di sekitar awal dari ArrayList memakan waktu lebih lama dibandingkan penghapusan di sekitar pertengahan, dan keduanya memakan waktu lebih lama dibandingkan penghapusan di sekitar akhir. 4. Untuk penyisipan di sekitar akhir dari objek ArrayList yaitu, pada indeks n,
avarageTime(n) adalah konstan. Tetapi jika elemen dari objek ArrayList sudah menempati seluruh alokasi ruang untuk objek ArrayList dan penyisipan pada indeks n akan tetap diusahakan, alokasi ruang akan secara otomatis menambahkan ukurannya dan penyisipan akan dilakukan. Sejauh ini penambahan ruang yang disertai penyisipan, worstTime(n) adalah O(n), tetapi untuk n pada akhir penyisipan, worstTime(n) tetap sama dengan O(n).
spesifik, worstTime(n, indeks) sama dengan O(n - indeks). Dengan kata lain, penyisipan di sekitar awal objek ArrayList lebih lama dibandingkan penyisipan di sekitar tengah dan keduanya memakan waktu lebih lama daripada penyisipan sekitar akhir.
Melihat bahwa larik memiliki seluruh sifat yang sama, kecuali bagian keempat: penambahan ruang untuk larik yang penuh tidak akan bertambah secara otomatis. Maka dari itu larik sudah dibuat dengan ruang cukup untuk menampung sejumlah
n elemen. Jika elemen n telah tersimpan pada indeks 0 sampai dengan n – 1 dan berusaha untuk menyisipkan elemen baru pada indeks n, maka akan menimbulkan ArrayIndexOutOfBound. Untuk menghindari pengecualian tersebut, jelas pengubah ukuran dibutuhkan.
2.4 Searching
2.6.1 Pembobotan tf-idf
Sekarang akan menggabungkan definisi dari frekuensi istilah ( tf ) dan invers frekuensi dokumen ( idf ) untuk dapat menghasilkan penggabungan bobot pada setiap istilah dari setiap dokumen(Manning et al, 2009). Skema pembobotan
tf-idf yang menunjukkan bahwa bobot istilah t pada dokumen d, sebagai berikut (2.1)
berbeda diperlukan tahap normalisasi. Berikut adalah skema normalisasi pembobotan tf-idf menurut Savoy (1993).
2.2
dimana aturan ntf dan nidf adalah sebagai berikut:
2.3
2.4
Keterangan:
Wik adalah bobot istilah k pada dokumen i.
tfik merupakan frekuensi dari istilah k dalam dokumen i.
n adalah jumlah dokumen dalam kumpulan dokumen.
dfk adalah jumlah dokumen yang mengandung istilah k.
Maxj tfij adalah frekuensi istilah terbesar pada satu dokumen.
23
BAB 3
ANALISIS DAN PERANCANGAN
Bab ini menjelaskan mengenai analisis dan perancangan dalam pembuatan sistem yang akan dibuat.
3.1 Kasus Deskripsi
Kasus yang diambil adalah penelitian mengenai pencarian dengan data gambar yang terdapat pada dokumen fotografi. Pencarian dokumen menggunakan data teks pada dokumen fotografi. Berdasarkan hasil pencarian ingin meneliti apakah dengan adanya data gambar dapat membantu pengguna dalam menentukan dokumen.
3.2 Cara Penyelesaian Masalah
Agar pencarian dokumen dapat dilakukan dengan cepat, maka dibutuhkan sistem Pemerolehan Informasi yang hasil pencarian dokumennya diurutkan berdasarkan bobot yang dimiliki. Perhitungan bobot dihitung menggunakan rumus
tf-idf menurut Savoy.
Pengujian ini akan melihat dua grafik interpolasi yang berbeda. Kedua grafik tersebut adalah hasil perhitungan recall & precision dari pengurutan oleh sistem dan pengurutan data gambar yang dilakukan oleh responden. Responden dalam pengujian ini membantu dalam menentukan dokumen yang sesuai dan mengurutkan hasil pencarian berdasarkan data gambar.
3.3 Perancangan Peta Sistem
Aplikasi Searching dan Aplikasi Indexing. Aplikasi Searching adalah aplikasi yang bertugas untuk mencari dokumen dari kumpulan koleksi dokumen pada basis data. Sementara itu, Aplikasi indexing adalah aplikasi yang bertugas mengindeks dokumen baru yang belum terindeks. Kedua aplikasi tersebut menggunakan proses TextOperation yang sama.
Aktor yang menggunakan Aplikasi Searching adalah Pengguna. Pengguna dapat memasukan kata kunci sebelum dapat melakukan pencarian. Kata kunci tersebut sebaiknya berhubungan dengan fotografi. Pencarian hanya akan menggunakan dokumen yang sudah diindeks oleh Aplikasi Indexing. Hasil pencarian dokumen diurutkan berdasarkan bobotnya sebelum dikembalikan kepada Pengguna.
Gambar 3.1 Peta Sistem Keseluruhan
3.4 Model UseCase
cara logout. Pengguna adalah aktor yang ingin mencari dokumen fotografi. Selain Pengguna dapat mencari dokumen fotografi, Pengguna juga dapat mengunduh dokumen yang diinginkan. Berikut adalah Diagram Use Case untuk kedua aktor, Gambar 3.2.
3.4.1 Skenario Login
Berikut adalah penjelasan langkah dasar dan kondisi-kondisi yang terjadi saat administrator menjalankan operasi Login.
Tabel 2.3 Jenis awalan berdasarkan tipe awalannya
Aktor Administrator
Kondisi awal -
Kondisi akhir Administrator berhasil melakukan verifikasi identitas
Aksi Aktor Reaksi Sistem Skenario Utama
Langkah 1:
Administrator memasukan username
dan password.
Langkah 2:
Username dan password akan dikelola untuk dilakukan validasi.
*Jika tidak ada kesesuaian antara
username dan password, lanjutkan ke Skenario Alternatif.
username/ password yang dimasukkan tidak sesuai.
3.4.2 Skenario Menambah Dokumen
Tabel 3.2 Skenario UseCase Menambah Dokumen
Aktor Administrator
Kondisi awal Administrator sudah melakukan Login
Kondisi akhir Dokumen baru berhasil tertambahkan ke dalam basis data
Aksi Aktor Reaksi Sistem Skenario Utama
Langkah 1:
Administrator memasukan judul dan memilih dokumen .pdf yang akan diunggah.
Langkah 2:
Sistem menambah dokumen baru ke dalam basis data.
Langkah 3:
Dokumen baru berhasil ditambah pada basis data.
3.4.3 Skenario Mencari Dokumen
Berikut adalah penjelasan langkah dasar dan kondisi-kondisi yang terjadi saat Pengguna menjalankan operasi Mencari Dokumen.
Tabel 3.3 Skenario UseCase Mencari Dokumen
Aktor Pengguna,
Kondisi awal
Kondisi akhir Dokumen yang relevan tertampil pada laman pengguna.
Aksi Aktor Reaksi Sistem Skenario Utama
Langkah 1:
Pengguna mamasukan kata kunci
Langkah 2:
Sistem malakukan Teks Operasi untuk kata kunci
Langkah 3:
Langkah 3:
Sejumlah hasil pencari ditampilkan.
Skenario Alternatif
Langkah 3.1:
Hasil pencarian tidak ditemukan.
3.4.3 Skenario Mengunduh Dokumen
Berikut adalah penjelasan langkah dasar dan kondisi-kondisi yang terjadi saat pengguna menjalankan operasi Unduh Dokumen.
Tabel 3.4 Skenario UseCase Mengunduh Dokumen
Aktor Pengguna.
Kondisi awal Hasil pencarian telah ditemukan.
Kondisi akhir Dokumen berformat .pdf berhasil diunduh.
Aksi Aktor Reaksi Sistem Skenario Utama
Langkah 1:
Pengguna memilih dokumen.
Langkah 2:
Sistem menggunakan parameter id_doc sebagai pemanggilan file. Langkah 3:
Pengguna mendapatkan dokumen yang sudah dipilih.
3.4.5 Skenario Logout
Berikut adalah penjelasan langkah dasar dan kondisi-kondisi yang terjadi saat administrator menjalankan operasi Logout.
Tabel 3.5 Skenario UseCaseLogout
Aktor Administrator
Kondisi awal Administrator sudah melakukan Login.
Skenario Utama
Langkah 1:
Menekan tombol untuk keluar.
Langkah 2:
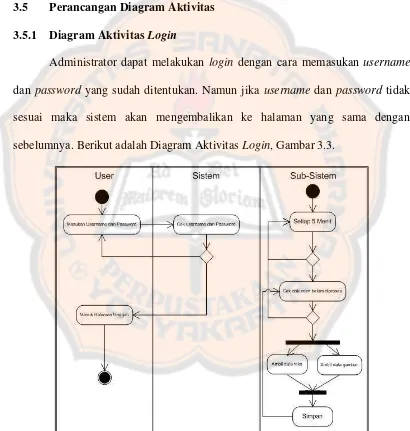
Sistem menghapus sesi identitas. Langkah 3:
Administrator kembali pada halaman Login.
3.5 Perancangan Diagram Aktivitas
3.5.1 Diagram Aktivitas Login
Administrator dapat melakukan login dengan cara memasukan username
dan password yang sudah ditentukan. Namun jika username dan password tidak sesuai maka sistem akan mengembalikan ke halaman yang sama dengan sebelumnya. Berikut adalah Diagram Aktivitas Login, Gambar 3.3.
3.5.2 Diagram Aktivitas Menambah Dokumen
Setelah Login, administrator dapat menambah dokumen fotografi dengan cara memasukan judul dan lokasi file dokumen fotografi. Berikut adalah Diagram Menambah Dokumen, Gambar 3.4.
3.5.3 Diagram Aktivitas Mencari Dokumen
Pengguna dapat mencari dokumen dengan cara memasukan kata kunci yang diinginkan. Berikut adalah Diagram Aktivitas Mencari Dokumen, Gambar 3.5.
3.5.4 Diagram Aktivitas Mengunduh Dokumen
Pengguna dapat menekan tombol „download’ untuk mendapat dokumen yang butuhkan. Berikut adalah Diagram Aktivitas Mengunduh Dokumen, Gambar 3.6.
3.5.5 Diagram Aktivitas Logout
Administrator dapat menghentikan tugasnya menambah dokumen dengan
cara menekan tombol „logout’, Gambar 3.7.
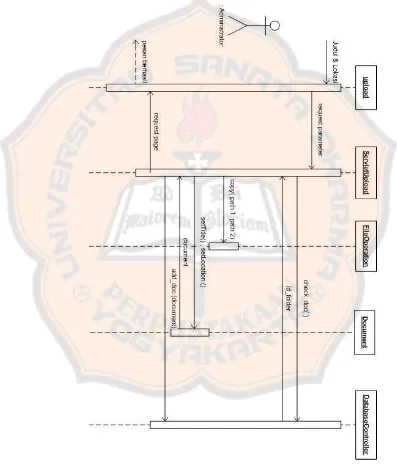
3.6 Perancangan Diagram Kolaborasi
Diagram Kolaborasi adalah diagram yang menjelaskan bagaimana suatu operasi dijalankan dengan melihat model, view , controller.
3.6.1 Diagram Kolaborasi Login
Pada Gambar 3.8 menunjukkan bahwa valid atau tidaknya username dan
password akan divalidasi pada controller LoginServlet.
3.6.2 Diagram Kolaborasi Menambah Dokumen
Pada Gambar 3.9 menunjukkan bahwa administrator menambah dokumen baru ke dalam basis data.
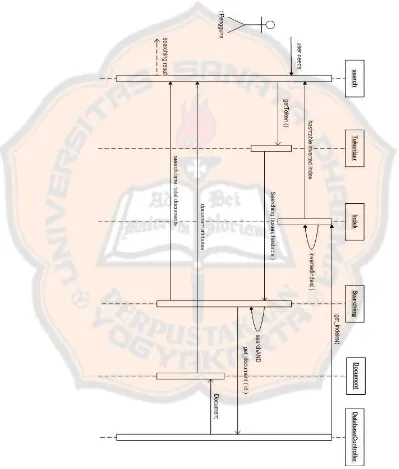
3.6.3 Diagram Kolaborasi Mencari Dokumen
Pada Gambar 3.10 menunjukkan bahwa proses pencarian menggunakan struktur data inverted index berdasarkan kata kunci pengguna.
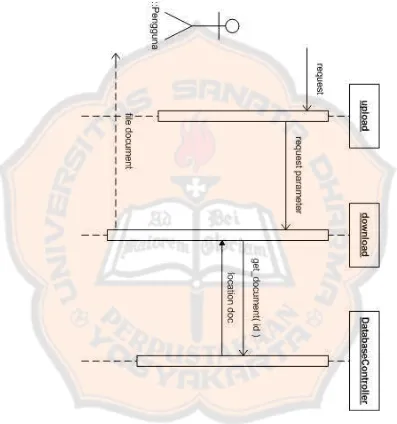
3.6.4 Diagram Kolaborasi Mengunduh Dokumen
Pada Gambar 3.11 pengguna menentukan dokumen yang ingin dia dapatkan.
Gambar 3.11 Diagram Kolaborasi Mengunduh Dokumen
3.6.5 Diagram Kolaborasi Logout
Gambar 3.12 Diagram Kolaborasi Logout
3.7 Perancangan Diagram Sekuensial
Diagram Sekuensial adalah diagram yang menjelaskan bagaimana suatu operasi dijalankan secara tahap demi tahap.
3.7.1 Diagram Sekuensial Login
Username dan password yang sudah dilakukan akan divalidasi oleh sistem, jika sesuai maka administrator akan dihadapkan pada halaman upload. Berikut adalah tahapan proses Login, Gambar 3.13.
3.7.2 Diagram Sekuensial Menambah Dokumen
Administrator menambahkan dokumen dengan cara memasukan judul dan lokasi dokumen. Sebelum dokumen baru dimasukkan dalam basis data, dokumen tersebut disalin kembali ke lokasi baru dengan folder yang sesuai dengan ID Dokumen. Berikut adalah tahapan proses Menambah Dokumen, Gambar 3.14.
3.7.3 Diagram Sekuensial Mencari Dokumen
Pengguna dapat mencari dokumen dengan memasukan kata kunci. Pencarian dilakukan berdasarkan kata kunci dengan menggunakan struktur data
InvertedIndex. Berikut adalah tahapan proses Mencari Dokumen, Gambar 3.15.
3.7.4 Diagram Sekuensial Mengunduh Dokumen
Pengguna akan mendapatkan dokumen yang dipilih saat menekan tombol
„download’. Berikut adalah tahapan proses Mengunduh Dokumen, Gambar 3.16.
3.7.6 Diagram Sekuensial Logout
Sistem akan memindahkan administrator ke halaman Login saat menekan tombol Logout. Berikut adalah tahapan proses Logout 3.17.
Gambar 3.17 Diagram Sekuensial Logout
3.8 Perancangan Basis Data
3.8.1 Entity Rationalship Diagram
Terdapat tiga entitas yang saling berhubungan, yaitu documents memiliki
images dan documents berindekskan terms. Hubungan documents dengan images
adalah satu documents memiliki beberapa images. Hubungan documents dengan
terms adalah banyak documents mengandung banyak terms. Berikut adalah Entity RationalshipDiagram, Gambar 3.18.
Gambar 3.18Entity Rationalship Diagram
3.8.2 Rational Model Design Database
Rational Model Design Database adalah bentuk Entity Rationalship Diagram yang sudah melalui tahap normalisasi. Entitas dictionary dan stopword
adalah entitas yang digunakan untuk mendukung proses Text Operations. Entitas
Gambar 3.19RationalModelDesignDatabase
3.8.3 Physical Design Database
3.8.3.1 Tabel Documents
Berikut adalah tabel perancangan implementasi untuk tabel documents
beserta tipe data dan ukuran field yang dimiliki, Table 3.6:
Tabel 3.6 Tabel Documents
No Nama Field Tipe Data Ukuran Keterangan
1 ID_DOC VARCHAR 20 Primay Key untuk
tabel documents
2 TITLE_DOC VARCHAR 200 Judul documents
3 LOCATION_DOC VARCHAR 1000 Lokasi file dokumen disimpan.
4 STATUS_DOC NUMBER - Status dokumen
5 UPLOAD_DOC VARCHAR 20 Tanggal dilakukan penambahan record
3.8.3.2 Tabel Images
Berikut adalah tabel perancangan implementasi untuk tabel images beserta tipe data dan ukuran field yang dimiliki, Table 3.7:
Tabel 3.7 Tabel Images
No Nama Field Tipe Data Ukuran Keterangan
Berikut adalah tabel perancangan implementasi untuk tabel terms beserta tipe data dan ukuran field yang dimiliki, Table 3.3:
Tabel 3.8 Tabel Images
4 IDF NUMBER - inverse document
Berikut adalah tabel perancangan implementasi untuk tabel Indeks beserta tipe data dan ukuran field yang dimiliki, Table 3.4:
Table 3.9 Tabel Indeks
3.8.3.5 Tabel Dictionary
Berikut adalah tabel perancangan implementasi untuk tabel Dictionary beserta tipe data dan ukuran field yang dimiliki, Table 3.5:
Table 3.10 Tabel Dictionary
No Nama Field Tipe Data Ukuran Keterangan
ID_DICTIONARY NUMBER - Primay key untuk
tabel dictionary
ROOT_WORD VARCHAR 20 Kata dasar
3.8.3.6 Tabel Stopword
Berikut adalah tabel perancangan implementasi untuk tabel Stopword beserta tipe data dan ukuran field yang dimiliki, Table 3.6:
Table 3.6 Tabel Stopword
Nama Field Tipe Data Ukuran Keterangan
1 ID_STOPWORD NUMBER - Primay key untuk
3.9 Perancangan Inverted Index
pencarian dengan waktu yang relatif konstan O(n), sehingga sangat cocok sebagai penerapan inverted index. Sebagai gambaran dari perancangan pada dilihat pada Gambar 3.20
Gambar 3.20 Perancangan struktur data InvertedIndex dalam bentuk HashTable
3.10 Perancangan Antar Muka
3.10.1 Perancangan Antar Muka Halaman Pencarian
Halaman Pencarian ini difokuskan pada sesuatu yang harus dimasukkan pengguna sebelum pencarian dapat dilakukan, yaitu pengguna harus memasukan kata kunci/keyword. Pada perancangan halaman ini akan dibuat ukuran field yang lebih besar, diharapkan pengguna dapat mengerti secara langsung tugas yang harus dikerjakan terlebih dahulu. Berikut adalah Gambar 3.21 sebagai ilustrasi sebelum dilakukan pencarian.
Gambar 3.21 Halaman Pencarian. Sebelum dilakukan pencarian
Setelah kata kunci sudah dimasukkan oleh pengguna maka hasil pencarian dapat ditampilkan. Hasil pencarian tersebut akan menampilkan data gambar, judul dan deskripsi singkat serta fitur mengunduhdokumen, Gambar 3.22.
3.10.1 Perancangan Antar Muka Halaman Upload Dokumen
Pada halaman ini, administrator diminta untuk memasukan judul dan lokasi file dokumen. Administrator dapat menggunakan file explorer untuk mendapatkan path dari file dokumen.
Gambar 3.22 Halaman Menambah Dokumen
3.11 Perancangan Diagram Kelas
Perancangan diagram kelas ini adalah sebagai bentuk gambaran untuk melihat keterhubungan antar kelas pada suat aplikasi. Dalam sistem yang akan dibangun terdapat dua aplikasi yaitu Aplikasi Searching dan Aplikasi Indexing.
3.11.1 Aplikasi Searching
3.11.1.1 Package IR
Gambar 3.25 Diagram UML: Aplikasi Searching: IR
3.11.1.2 Package database
3.11.1.3 Package entities
Gambar 3.27 Diagram UML: Aplikasi Searching: entities
3.11.1.4 Package textoperation
Gambar 3.28 Diagram UML: Aplikasi Searching: textoperation
3.11.1.5 Package tools
3.11.2 Aplikasi Indexing
AplikasiIndexing adalah sistem yang digunakan sebagai pengindeksan. 3.11.2.1 Package IR
Gambar 3.30 Diagram UML: AplikasiIndexing: IR
3.11.2.2 Package database
Gambar 3.31 Diagram UML: AplikasiIndexing: database
3.11.2.3 Package entities
Gambar 3.32 Diagram UML: AplikasiIndexing: entities
3.11.2.4 Package textoperation
3.11.2.5 Package tools
Gambar 3.34 Diagram UML: AplikasiIndexing: tools
3.11.2.6 Package theard
58
BAB 4
IMPLEMENTASI
Pada bagian ini membahas mengenai implementasi pada Sistem Pencarian Data Gambar dengan menggunakan metode if-idf.
4.1 Implementasi sql pada basis data
Pada sistem yang akan dibuat dibutuhkan basis data yang mampu menyimpan informasi yang butuhkan. Implementasi basis data ini dibuat berdasarkan dari rancangan rational model. Berikut adalah implementasi basis data dengan pada Oracle XE10g, Code 4.1.
CREATE TABLE "IR"."DOCUMENTS" (
"ID_DOC" VARCHAR2(20 BYTE) NOT NULL ENABLE, "TITLE_DOC" VARCHAR2(200 BYTE),
"LOCATION_DOC" VARCHAR2(1000 BYTE), "STATUS_DOC" NUMBER DEFAULT 0, "UPLOAD_DATE" VARCHAR2(20 BYTE),
CONSTRAINT "DOCUMENT_PK" PRIMARY KEY ("ID_DOC") USING INDEX PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT) TABLESPACE "USERS" ENABLE
)
CREATE TABLE "IR"."IMAGES" (
"ID_IMAGE" VARCHAR2(20 BYTE) NOT NULL ENABLE, "LOCATION_IMAGE" VARCHAR2(1000 BYTE),
"ID_DOC" VARCHAR2(20 BYTE),
CONSTRAINT "IMAGES_PK" PRIMARY KEY ("ID_IMAGE") USING INDEX PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT) TABLESPACE "USERS" ENABLE PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT )
CREATE TABLE "IR"."INDEKS" (
"ID_DOC" VARCHAR2(20 BYTE), "ID_TERMS" VARCHAR2(20 BYTE), "TF" NUMBER,
"ID_TERMS" VARCHAR2(20 BYTE) NOT NULL ENABLE, "TERMS" VARCHAR2(30 BYTE),
"DF" NUMBER DEFAULT 0, "IDF" NUMBER DEFAULT 0, "NIDF" NUMBER DEFAULT 0,
CONSTRAINT "TERMS_PK" PRIMARY KEY ("ID_TERMS") USING INDEX PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT) TABLESPACE "USERS" ENABLE
)
Code 4.1 Implementasi Table untuk Dokumen
4.2 Implementasi Parsing Data Teks dan Data Gambar
Dokumen fotografi memiliki dua elemen, yaitu data gambar dan data teks. Kedua elemen tersebut harus dapat dipisahkan untuk melengkapi proses indexing.
Parsing pada kedua data tersebut menggunakan source code yang sudah dipublikasikan oleh www.itext.com. Hasil dari parsing data gambar akan menjadi .jpg untuk setiap gambarnya dan data teks akan menjadi .txt , Code 4.2.
public void extractImages(String filename, String result, Images images) throws IOException, DocumentException {
PdfReader reader = new PdfReader(filename);
PdfReaderContentParser parser = new PdfReaderContentParser(reader);
MyImageRenderListener listener = new MyImageRenderListener(result, images); for (int i = 1; i <= reader.getNumberOfPages(); i++) {
parser.processContent(i, listener); }
reader.close(); }
PdfReaderContentParser parser = new PdfReaderContentParser(reader); PrintWriter out = new PrintWriter(new FileOutputStream(c_pdf)); // result TextExtractionStrategy strategy;
for (int i = 1; i <= reader.getNumberOfPages(); i++) {
strategy = parser.processContent(i, new SimpleTextExtractionStrategy()); out.println(strategy.getResultantText());
Code 4.2. Implementasi Parsing Data Teks dan Data Gambar
4.3 Implementasi TextOperations
Sistem ini menggunakan proses Text Operations yang didukung oleh kamus untuk mencari akar kata dan kata umum. Dalam sistem ini akar kata disimpan pada basis data dengan tabel dictionary dan daftar kata umum disimpan pada tabel stopword. Berikut adalah implementasi kamus untuk tabel stopwords
dan dictionary, Code 4.3.
CREATE TABLE "IR"."DICTIONARY" (
"ID_DICTIONARY" NUMBER(*,0), "ROOT_WORD" VARCHAR2(20 BYTE) )
CREATE TABLE "IR"."STOPWORDS" (
"ID_STOPWORD" NUMBER(*,0), "STOPWORD" VARCHAR2(20 BYTE) )
Code 4.3 Implementasi table STOPWORDS dan DICTIONARY
Text Operations memiliki tiga tahap yaitu tokenizing, penghapusan
bagaimana proses Text Operations dilakukan. Seluruh rangkaian proses Text Operations ini akan diimplementasikan pada classTokenizer, Code 4.4.
→ → →
Gambar 4.1 Rangkain Proses Text Operations
public class Tokenizer {
private List<String> token; private String fileLocation; private List<String> daftarKata;
public Tokenizer(String fileLocation) { this.fileLocation = fileLocation; }
public Tokenizer() { }
public List<String> getToken() throws FileNotFoundException, IOException, SQLException {
String words = null; String line;
BufferedReader bufferedReader = new BufferedReader(new FileReader(fileLocation));
while ((line = bufferedReader.readLine()) != null) { words = words + line + "\n";
}
StringTokenizer stringTokenizer = new StringTokenizer(words);
token = new ArrayList<String>();
RemoveStopword removeStopword = new RemoveStopword(); IndonesianStemmer indonesianStemmer = new IndonesianStemmer(); removeStopword.setListWord(token);
token = removeStopword.getRemovedList();
indonesianStemmer.setWord(token.get(i).replaceAll("[.�,]",
public List<String> getToken(String keyword) throws SQLException { String words = keyword;
StringTokenizer stringTokenizer = new StringTokenizer(words);
token = new ArrayList<String>();
RemoveStopword removeStopword = new RemoveStopword(); IndonesianStemmer indonesianStemmer = new IndonesianStemmer(); removeStopword.setListWord(token);
token = removeStopword.getRemovedList();
List<String> listToRemove = new ArrayList<String>(); for (int i = 0; i < token.size(); i++) {
this.token = token; }
public String getFileLocation() { return fileLocation;
}
public void setFileLocation(String fileLocation) { this.fileLocation = fileLocation;
}
public List getResultToken() throws SQLException, FileNotFoundException, IOException { sementara dalam bentuk List<String>. Proses ini juga menghapus karakter khusus dan mentransformasikan setiap istilah ke dalam huruf kecil, Code 4.5
BufferedReader bufferedReader = new BufferedReader(new FileReader(fileLocation));
while ((line = bufferedReader.readLine()) != null) { words = words + line + "\n";
}
StringTokenizer stringTokenizer = new StringTokenizer(words);
token = new ArrayList<String>();
4.3.2 Penghapusan Kata Umum
Proses penghapusan kata umum adalah proses yang melengkapi proses pemisahan kata sebelumnya. Proses ini memeriksa apakah pada daftar istilah sebelumnya terdapat kata umum atau tidak, jika terdapat maka akan dihapus. Hasil dari penghapusan kata ini disimpan sementara dalam bentuk List<String> Code 4.6.
public class RemoveStopword {
private List<String> listWord; private List<Stopword> stopwords;
public RemoveStopword() throws SQLException {
stopwords = DatabaseController.getDatabaseController().get_stopwords(); }
public List<String> getRemovedList() throws SQLException {
List<String> helpers = new ArrayList<String>(); for (int i = 0; i < stopwords.size(); i++) {
public void setListWord(List<String> removedList) throws SQLException { this.listWord = removedList;
}
}
Code 4.6 Implementasi Text Operations, Penghapusan Kata Umum
4.3.3 Stemming
public class IndonesianStemmer {
private String word;
private List<String> dictionaries;
public IndonesianStemmer() throws SQLException {
}
Code 4.7 Implementasi Teks Operations, Stemming
4.4 Implementasi Indexing
Proses indexing pada sistem ini menggunakan daftar istilah yang didapat dari proses Text Operations. Setiap istilah akan ditambahkan pada basis data, Code 4.8.
public class Indexing {
DatabaseController databaseController = DatabaseController.getDatabaseController();
public void indek_term(Tokenizer tokenizer, String id_doc) throws SQLException, FileNotFoundException, IOException {
Indek indek = new Indek(tokenizer.getToken()); Terms terms = new Terms();
Terms bantu = terms.seacrh_byID(list.get(i));
databaseController.updateAllTerm(); databaseController.updateAllIndeks(); }
}
Code 4.8 Implementasi Indexing
4.5 Implementasi InvertedIndex
Sebelum proses pencarian dapat dilakukan, maka diperlukan struktur data
Inverted Index untuk mempercepat proses pencarian tersebut, Code 4.9. Inverted Index pada sistem ini menggunakan struktur Hastable karena struktur tersebut dapat mencari elemen dengan cepat.
public Hashtable invertedIndex() throws SQLException { double satu = System.nanoTime();
DatabaseController databaseController = DatabaseController.getDatabaseController();
List<Indek> invertedIndexs = databaseController.get_indeks();
Hashtable invertedIndexHashtable = new Hashtable(); for (int i = 0; i < invertedIndexs.size(); i++) {
(invertedIndexHashtable.containsKey(invertedIndexs.get(i).getTerms())) {
invertedIndexHashtable.put(invertedIndexs.get(i).getTerms(), postinglist); } else {
invertedIndexHashtable.put(invertedIndexs.get(i).getTerms(), postinglist); }
}
double dua = System.nanoTime();
System.out.println("Waktu konversi kedalam HashTable dgn metode 2 adalah: " + (dua - satu));
return invertedIndexHashtable; }
Code 4.9 Implementasi InvertedIndex
4.6 Implementasi Searching
Pencarian dokumen fotografi dicari berdasarkan kata kunci yang sudah dimasukkan. Pencari menggunakan struktur data Inverted Index untuk mendapatkan keuntungan dalam percepatan, Code 4.9. Sebagai keluaran untuk hasil pencarian adalah List<Posting> yang sudah diurutkan, List<Posting> dimana sudah menampung segala informasi seperti id_doc dan w (bobot), Code 4.10.
public List<Posting> search() throws SQLException { List<Posting> searchList = new ArrayList<Posting>();
List<Posting> postingLists = (ArrayList<Posting>) hashtable.get(query.get(i));
Collections.sort(searchList, new ComparatorPosting()); for (int i = 0; i < searchList.size(); i++) {
Code 4.10 Implementasi Searching
4.6.1 Persamaan AND
Tidak cukup sampai dengan metode search(), Code 4.10. Hasil pencarian akan disaring terlebih dahulu untuk mendapat persamaan AND sesuai dengan masukan kata kunci yang diberikan, Code 4.11.
List<Posting> searchANDList = new ArrayList<Posting>();
Collections.sort(searchANDList, new ComparatorPosting()); return searchANDList;
}
Code 4.11 Implementasi Searching, Persamaan AND
4.7 Implemtasi Antar Muka
Sebagai media yang dapat mempermudah pengguna dalam berinteraksi dalam menggunakan sistem maka GUI(Graphical User Interface) dibuat bersadarkan perancangan yang sebelumnya ditentukan.
4.7.1 Halaman Login
Pengguna dapat akses sebagai administrator dengan cara memasukan
username dan password yang sudah ditentukan, Gambar 4.2.
Gambar 4.2 GUI: Halaman Login
4.7.2 Halaman Pencarian
Gambar 4.3 GUI: Halaman Pencarian 1
Saat pengguna sudah memasukan kata kunci, sistem akan memberikan
feedback berupa hasil pencarian. Hasil pencarian tersebut adalah pencarian hanya memiliki persamaan AND pada kata kunci dalam proses pencarian yang dilakukan, Gambar 4.4.
4.7.3 Halaman Unggah
Agar mudah untuk menambah koleksi dokumen, maka pada Halaman Unggah ini administrator cukup memasukan judul pada dokumen dan destinasi lokasi dokumen, Gambar 4.5
75
BAB 5
ANALISA HASIL
Bagian ini menjelaskan mengenai sistematika dan hasil dari pengujian.
5.1 Analisa Hasil Sistem
Pengujian ini akan dilakukan kepada 5(lima) responden yang sudah memiliki pengetahuan seputar fotografi. Pengujian dilakukan dengan cara menjalankan fitur pencarian. Responden juga mengisikan kuesioner untuk menentukan dokumen yang sesuai dengan kebutuhannya, baik pada hasil pencarian maupun pada seluruh dokumen yang terdapat pada koleksi. Tujuan dari pengujian ini adalah selain mencoba fungsi sistem, pengujian ini juga ingin mencari kedua nilai precision dengan adanya data gambar dan tidak. Diharapkan hasil keluaran dari penelitian ini dapat membantu pengguna dalam memilih dokumen fotografi yang dibutuhkan dengan bantuan data gambar.
5.1.1 Analisa Uji Coba Pengguna