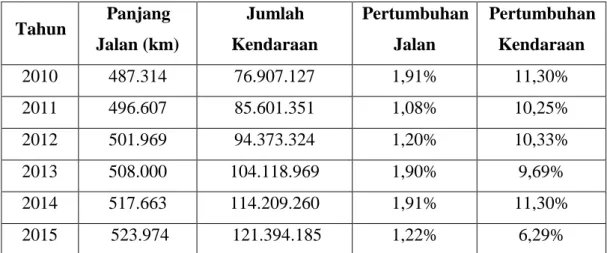
Tabel 1.1 Pertumbuhan Panjang Jalan dan Jumlah Kendaraan
Bebas
10
0
0
Teks penuh
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
(10)
Gambar
Dokumen terkait
bahwa dengan telah ditetapkannya Peraturan Bupati Badung Nomor 64 Tahun 2014 tentang Perubahan Kedua Atas Peraturan Bupati Badung Nomor 1 Tahun 2012 tentang Indikator
Paragraf campuran atau deduktif-induktif dimulai dengan inti uraian (pikiran utama), diikuti penjelasan (pikiran penjelas), dan diakhiri dengan penegasan atau pengulangan inti
sebelum kita masuk lebih dalam mengenai php dan mysql, hal pertama yang harus anda kuasai atau paling tidak mengerti tentang syntax- syntax yang ada di HTML
Lalu rumuskan dan ajukan beberapa pertanyaan tentang hal-hal yang belum kalian ketahui dari hasil pengamatan tersebut Lakukan meditasi dengan posisi seperti pada gambar.
Percobaan lapangan perlakuan mulsa sisa tanaman (batang jagung) dan strip penguat teras telah dilakukan pada usaha tani lahan kering di Sub DAS Solo Hulu dan
(d) Undangan Seminar (rangkap 5);.. Seminar proposal dianggap sah jika dihadiri sekurang-kurangnya 10 peserta seminar, selain moderator, dan notulen sidang. Pelaksanaan
Nilai keragaman ini nantinya akan digunakan untuk menyusun strategi pemuliaan sesuai pernyataan dari Langga (2012) yang menyatakan bahwa Keragaman genetik merupakan
pisang buah domestik yang memiliki kekerabatan paling dekat adalah kultivar Kayu dengan Susu dan Kepok dengan Kluthuk pada indeks kemiripan 0.80, sedangkan
