Lirik merupakan salah satu media komunikasi yang sering digunakan untuk
menyampaikan perasaan dari seseorang. Salah satunya yaitu melalui lirik lagu yang dapat
dijumpai oleh seluruh masyarakat melalui media online, buku dan lainnya. Lirik lagu ini
digunakan sebagai data yang diperoleh melalui beberapa situs website, lirik lagu yang telah
disalin akan disimpan dengan format ekstensi *.txt agar mampu diolah oleh sistem.
Agar mempermudah dalam pemerolehan informasi data lirik lagu yang dicari, maka
dilakukan pengklasifikasian data teks. Penelitian ini bertujuan untuk memudahkan pemilihan
lagu yang baik dan tidak baik terhadap anak. Fungsi klasifikasi pada penelitian ini dibagi dalam
dua klasifikasi yaitu baik dan tidak baik. Proses yang akan dilalui oleh data diantaranya
membaca data, tokenizing, normalization, stop word, stemming, sorting dan grouping. Sistem
ini akan menggunakan vektor ciri berupa TF (
Term Frequency
) yang merupakan jumlah
kemunculan suatu kata dalam sebuah dokumen.
A song is one of the media that is often used to express feelings for a person. Song texts
amongst other can be found by all people online, in books and in other media. The songs used
in this research were obtained from various online media and were transcribed and saved with
*.txt extension so that it can be processed through the system.
To facilitate the collection of information on songs that were searched, the text was
classified. The purpose of this research is to facilitate the selection of songs that are appropriate
and inappropriate for children. The classification function in this research was divided into two
groups; appropriate and inappropriate songs for children. The data processing includes reading
of the data, tokenizing, normalization, stop word, stemming, calculation of data frekuensi,
sorting and grouping. This system uses vector feature Term Frequency, meaning the number
of times a certain word appears in certain data.
The classification process of song texts used a Multinominal Naïve Bayes algorithm. The
expectation is that the grouping based on this classification will specify which song is
i
HALAMAN JUDULANALISIS SENTIMEN PADA LIRIK LAGU
MENGGUNAKAN METODE MULTINOMIAL NAÏVE BAYES
Skripsi
Diajukan Untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh
Elsa Rika Octaviana
115314079
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
HALAMAN JUDULANALYSIS SENTIMENT FOR SONG LYRICS
BY USING MULTINOMIAL NAÏVE BAYES METHOD
A Final Project
Presented as Partial Fulfillment of The Requirements
To Obtain
Sarjana Komputer
Degree
In Informatics Engineering Study Program
By
Elsa Rika Octaviana
115314079
INFORMATICS ENGINEERING STUDY PROGRAM
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
iii
iv
v
HALAMAN PERSEMBAHAN
Tugas akhir ini saya persembahkan kepada:
Tuhan Yesus yang telah memberikan berkat, rahmat, perlindungan serta
arahan yang terbaik dalam hidupku.
vi
vii
viii
KATA PENGANTAR
Puji dan syukur penulis panjatkan atas kehadirat Tuhan Yang Maha Esa atas
berkat, rahmat serta kasih-Nya sehingga penulis dapat menyelesaikan skripsi yang
berjudul “
Analisis Sentimen pada Lirik Lagu Menggunakan Metode
Multinomial Naive Bayes
”.
Penulisan skripsi ini bertujuan untuk memenuhi sebagian syarat memperoleh
gelar sarjana komputer program studi S1 jurusan Teknik Informatika Universitas
Sanata Dharma. Penulis menyadari bahwa skripsi ini masih jauh dari sempurna oleh
sebab itu penulis mengharapkan kritik dan saran yang bersifat membangun dari
semua pihak demi kesempurnaan skripsi ini.
Selesainya skripsi ini tidak lepas dari peran penting berbagai pihak, sehingga
pada kesempatan ini penulis dengan segala kerendahan hati serta rasa hormat
mengucapkan terima kasih yang sebesar
–
besarnya kepada semua pihak yang telah
memberikan dukungan baik secara langsung maupun tidak langsung kepada
penulis dalam penyusunan skripsi ini hingga selesai, terutama kepada yang saya
hormati:
1.
Ibu Sri Hartati Wijono, S.Si., M.Kom. selaku pembimbing yang sabar
memberikan pengarahan serta solusi dalam pengerjaan skripsi ini hingga
selesai.
2.
Yang tersayang orang tua penulis yaitu Marlan Rikeh, S.Pd., M.Pd. dan
Frederica Ujiana, S.Pd yang selalu rela berkorban, mendoakan serta
memberikan motivasi baik dari segi moril maupun material kepada penulis
sehingga dapat terselesaikan skripsi ini dengan baik.
3.
Yang terkasih saudara dan saudari yaitu Frederikus Rinaldo dan Cyintia
Septiana Rini yang telah mendoakan.
4.
Yang terkasih Gersom Jalaq yang telah meluangkan waktu serta membantu
dalam penyelesaian skripsi ini dengan baik.
5.
Seluruh keluarga besar yang yang telah memberikan dukungan serta motivasi
x
ABSTRAK
Lirik merupakan salah satu media komunikasi yang sering digunakan untuk
menyampaikan perasaan dari seseorang. Salah satunya yaitu melalui lirik lagu yang
dapat dijumpai oleh seluruh masyarakat melalui media online, buku dan lainnya.
Lirik lagu ini digunakan sebagai data yang diperoleh melalui beberapa situs
website, lirik lagu yang telah disalin akan disimpan dengan format ekstensi *.txt
agar mampu diolah oleh sistem.
Agar mempermudah dalam pemerolehan informasi data lirik lagu yang
dicari, maka dilakukan pengklasifikasian data teks. Penelitian ini bertujuan untuk
memudahkan pemilihan lagu yang baik dan tidak baik terhadap anak. Fungsi
klasifikasi pada penelitian ini dibagi dalam dua klasifikasi yaitu baik dan tidak baik.
Proses yang akan dilalui oleh data diantaranya membaca data, tokenizing,
normalization, stop word, stemming, sorting dan grouping. Sistem ini akan
menggunakan vektor ciri berupa TF (
Term Frequency
) yang merupakan jumlah
kemunculan suatu kata dalam sebuah dokumen.
xi
ABSTRACT
A song is one of the media that is often used to express feelings for a person.
Song texts amongst other can be found by all people online, in books and in other
media. The songs used in this research were obtained from various online media
and were transcribed and saved with *.txt extension so that it can be processed
through the system.
To facilitate the collection of information on songs that were searched, the
text was classified. The purpose of this research is to facilitate the selection of songs
that are appropriate and inappropriate for children. The classification function in
this research was divided into two groups; appropriate and inappropriate songs for
children. The data processing includes reading of the data, tokenizing,
normalization, stop word, stemming, calculation of data frekuensi, sorting and
grouping. This system uses vector feature Term Frequency, meaning the number of
times a certain word appears in certain data.
xii
DAFTAR ISI
HALAMAN JUDUL
... i
HALAMAN JUDUL
... ii
HALAMAN PERSETUJUAN
... iii
HALAMAN PENGESAHAN
...iv
HALAMAN PERSEMBAHAN
...iv
PERNYATAAN KEASLIAN KARYA
...vi
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI
... vii
KATA PENGANTAR
... viii
ABSTRAK
... x
ABSTRACT
... xi
DAFTAR ISI
... xii
DAFTAR TABEL
... xiv
DAFTAR GAMBAR
... xv
BAB I PENDAHULUAN
... 1
1.1
Latar Belakang ... 1
1.2
Rumusan Masalah ... 2
1.3
Batasan Masalah ... 3
1.4
Tujuan Penelitian ... 3
1.5
Metodologi Penelitian ... 3
BAB II LANDASAN TEORI
... 5
2.1
Analisis Sentimen ... 5
2.2
Pemerolehan Informasi ... 5
2.3
Indexing ... 7
2.4
Porter Stemmer ... 9
2.4.1
Tentang Porter Stemmer
... 9
2.4.2
Porter Stemmer Bahasa Indonesia
... 9
2.5
Klasifikasi Teks ... 13
2.6
Naive Bayes ... 14
2.7
Multinomial Naive Bayes... 14
2.8
Penerapan Multinomial Naive Bayes Pada Klasifikasi Teks ... 16
2.9.1
Data Training
... 16
xiii
BAB III PERANCANGAN SISTEM
... 36
3.1
Gambaran Umum Sistem ... 36
3.2
Teknik Analisis Data ... 37
3.2.1
Metode Pengumpulan Data
... 37
3.2.1
Pengolahan Data
... 38
3.2.2
Preprocessing Data
... 39
3.2.3
Klasifikasi Data
... 40
3.3
Akurasi Data ... 41
BAB IV IMPLEMENTASI
... 43
4.1
Antarmuka Menu ... 43
4.2
Antarmuka Training ... 43
4.3
Antarmuka Testing ... 44
BAB V PENGUJIAN
... 48
5.1
Pengujian Data ... 48
5.1.1
Pengujian Akurasi
... 51
5.2
Analisis Pengujian ... 52
BAB VI KESIMPULAN DAN SARAN
... 60
6.1
Kesimpulan ... 60
6.2
Saran ... 60
DAFTAR PUSTAKA
... 62
xiv
DAFTAR TABEL
Tabel 2.1 Aturan 1 Inflection Particle.
... 10
Tabel 2.2 Aturan 2 Inflection Possessive Pronouns.
... 11
Tabel 2.3 Aturan 3 Fisrt Order of Derivational Prefixs.
... 11
Tabel 2.4 Aturan 4 Second Order of Derivational Prefixs.
... 12
Tabel 2.5 Aturan 5 Derivational Suffixes.
... 12
Tabel 2.6 Aturan 6 Suku Kata dalam Bahasa Indonesia
... 13
Tabel 2.7 Tokenizing Training
... 17
Tabel 2.8
Normalization Training
... 18
Tabel 2.9 Stop Word Training
... 19
Tabel 2.10 Stemming Training
... 20
Tabel 2.11 Daftar Kata beserta Frekuensi Kata Training
... 21
Tabel 2.12 Hasil Sorting secara Ascending Training
... 22
Tabel 2.13 Hasil Grouping dengan Kata yang Sama Training
... 23
Tabel 2.14 Prior Probabilitas Training
... 24
Tabel 2.15 Conditional Probabilitas Training
... 24
Tabel 2.16 Tokenizing Testing
... 26
Tabel 2.17 Normalization Testing
... 27
Tabel 2.18 Stop Word Testing
... 28
Tabel 2.19 Stemming Testing
... 29
Tabel 2.20 Daftar Kata beserta Frekuensi Kata Testing
... 30
Tabel 2.21 Hasil Sorting secara Ascending Testing
... 31
Tabel 2.22 Hasil Grouping dengan Kata yang Sama Testing
... 32
Tabel 2.23 Prior Probabilitas Testing
... 33
Tabel 2.24 Hasil Proses Matching antara Model dengan Data Testing
... 33
Tabel 2.25 Hasil Matching beserta dengan Nilai Conditional Probabilitas Testing
. 34
Tabel 2.26 Hasil Perkalian Nilai Conditional Probabilitas dengan Frekuensi Kata
Testing
... 35
Tabel 2.27 Hitung Probabilitas Testing
... 35
Tabel 3.1 Tabel Data Training dan Testing
... 38
Tabel 3.2 Tabel
Confusion Matrix
... 41
Tabel 5.1 Sebelum Diolah Sistem
... 48
Tabel 5.2 Setelah Diolah Sistem
... 49
Tabel 5.3 Tabel
Confusion Matrix
... 51
Tabel 5.4
Perbandingan Data Testing Terhadap Model
... 54
Tabel 5.5 Batasan Frekuensi Kata
... 55
xv
DAFTAR GAMBAR
Gambar 2.1 Model Pemerolehan Informasi (Bates, 1989).
... 5
Gambar 2.2 Proses Porter Stemmer untuk Bahasa Indonesia (Tala, 2003).
... 10
Gambar 3.1 Diagram Block Proses Klasifikasi
... 36
Gambar 4.1 Menu
... 43
Gambar 4.2 Input Data
... 43
Gambar 4.3 Hasil Stemming
... 44
Gambar 4.4 Ambil File
... 44
Gambar 4.5 Hasil Klasifikasi
... 45
Gambar 4.6 Penentu Kategori Lagu
... 45
Gambar 4.7 Akurasi Sistem
... 45
Gambar 4.8 Nomor Lagu
... 46
Gambar 4.9 Progres Sistem dan Reset
... 46
Gambar 4.10 Isi Teks Lagu
... 47
Gambar 5.1 Jumlah Kata
... 52
1
1.
BAB I
PENDAHULUAN
1.1
Latar Belakang
Perkembangan teknologi yang semakin pesat membuat manusia melakukan
berbagai macam karya cipta yang baru dan inovatif. Pada dunia industri musik,
terutama pada lirik lagu yang dapat mempengaruhi terhadap perkembangan anak.
Pengawasan yang kurang dari orang tua membuat anak bebas melakukan banyak
hal baik itu bersifat hal positif maupun negatif. Tanpa disadari musik telah
mempengaruhi kehidupan sosial masyarakat khususnya untuk anak. Musik dapat
dikatakan sebagai sebuah media dalam menyampaikan pesan oleh penulis.
Dalam penelitian ini penggunaan lirik lagu sebagai acuan untuk
mengklasifikasikan lagu dalam dua kelas yaitu lagu yang baik atau tidak baik untuk
anak. Pemilihan lirik lagu sebagai acuan klasifikasi dikarenakan pada lirik lagu
terdapat kata yang mengandung suatu ungkapan perasaan atau makna tertentu yang
disampaikan oleh pembicara atau penulis untuk pendengar. Sehingga lirik lagu
dapat dijadikan sebagai salah satu acuan untuk menggali data dalam mengetahui
ketepatan akurasi dari penggunaan algoritma Naive Bayes
dalam klasifikasi data
teks.
Sebelumnya pernah dilakukan penelitian mengenai
oponion mining
pada lirik
lagu (Shu, 2010). Penelitian tersebut adalah mengklasifikasikan lagu dengan lirik
berdasarkan kepopuleran lagu pada tahun tertentu. Pada penelitian ini
menggunakan teori
Natural Language Processing
. Hal berbeda pada penelitian ini,
2
anak dengan menggunakan analisis sentimen terhadap hasil klasifikasi lagu yang
baik dan tidak baik. Analisis sentimen (Go & Bhayani, 2009) adalah proses
memahami, mengekstrak dan mengolah data tekstual secara otomatis untuk
mendapatkan informasi. Analisis sentimen merupakan salah satu bagian dari
opinion mining
.
Berkenaan dengan penggalian data dengan menggunakan analisis sentimen
maka digunakan metode Multinomial Naive Bayes. Klasifikasi yang akan
dilakukan dengan mengklasifikasikan data berdasarkan jumlah kemunculan kata
dalam teks lirik lagu. Kegiatan klasifikasi data pada lirik lagu ini dapat
menggunakan metode Multinomial Naive Bayes untuk mengklasifikasikan data
sehingga dapat diperoleh hasil analisis sentimen terhadap klasifikasi lagu yang baik
atau tidak baik untuk anak.
1.2
Rumusan Masalah
Berdasarkan pada latar belakang yang telah dipaparkan, perumusan masalah
akan dijabarkan sebagai berikut:
1.
Bagaimana mengklasifikasikan lagu untuk analisis sentimen lagu yang baik
atau tidak baik untuk anak.
2.
Bagaimana ketepatan akurasi klasifikasi data lirik lagu untuk menentukan
analisis sentimen lagu baik atau tidak untuk anak dengan menggunakan metode
3
1.3
Batasan Masalah
Dalam penulisan ini batasan
–
batasan permasalahan yang akan dibahas yaitu:
1.
Bahasa yang digunakan dalam data berupa bahasa Indonesia.
2.
Klasifikasi lagu ditujukan pada anak usia 5
–
10 tahun.
1.4
Tujuan Penelitian
Tujuan penulisan ini adalah memperoleh hasil analisis sentimen
terhadap klasifikasi lagu baik atau tidak baik untuk anak dengan
menggunakan Multinomial Naive Bayes.
1.5
Metodologi Penelitian
Langkah
–
langkah yang digunakan untuk melakukan penelitian ini adalah
sebagai berikut:
1.
Studi Pustaka
Penggunaan studi pustaka pada penelitian ini adalah untuk mencari sumber
–
sumber mengenai metode Multinomial Naive Bayes untuk mengklasifikasikan
data teks.
2.
Observasi
Penggunaan observasi pada penelitian adalah untuk melakukan pencarian data
4
3.
Antarmuka
Penggunaan antarmuka pada penelitian adalah mempermudah melakukan
analisis sentimen terhadap klasifikasi lagu yang baik dan tidak baik untuk anak.
4.
Pengujian
Penggunaan pengujian pada penelitian berikut adalah untuk mengukur
ketepatan akurasi klasifikasi data teks dengan menggunakan metode
5
2.
BAB II
LANDASAN TEORI
2.1
Analisis Sentimen
Analisis sentimen atau
opinion mining
merupakan proses memahami,
mengekstrak dan mengolah data tekstual secara otomatis untuk mendapatkan
informasi sentimen yang terkandung dalam suatu kalimat opini. Analisis sentimen
dilakukan untuk melihat pendapat atau kecenderungan opini terhadap sebuah
masalah atau objek oleh seseorang, apakah cenderung beropini negatif atau positif.
2.2
Pemerolehan Informasi
Pemerolehan informasi atau biasa dikenal dengan
Information Retrieval
mengacu pada pengambilan data terstruktur yang berisi bahasa teks alami. Data
yang dapat diolah dalam pemerolehan informasi diantaranya teks, gambar, video,
audio dan lainnya. Pemerolehan informasi fokus pada pengambilan data teks alami,
karena terdapat tekanan penting dan banyaknya data tekstual dalam internet dan
data pribadi.
Document
Document
Representation
Query
Information
Need
Matching
6
1.
Document
Document merupakan kumpulan informasi yang dibutuhkan oleh pengguna.
Pada penelitian ini data yang dimaksud adalah data teks pada lirik lagu yang
akan diklasifikasikan berdasarkan kata.
2.
Document Representastion
Document representation merupakan kumpulan informasi yang telah
direpresentasikan atau diolah sesuai dengan kebutuhan yang diinginkan oleh
pengguna. Pada penelitian ini proses yang dilakukan untuk mendapatkan
document representation tersebut yaitu melalui proses
indexing
.
3.
Query
Query merupakan proses merepresentasikan informasi yang dibutuhkan oleh
pengguna sehingga menghasilkan sebuah
query
. Pengertian secara umum
query merupakan interaksi antara pengguna dan komputer, sehingga
menghasilkan suatu pemahaman terhadap informasi yang dibutuhkan oleh
pengguna.
4.
Information Need
Informastion need merupakan kebutuhan pengguna mengenai suatu informasi
yang belum jelas atau belum dipahami.
5.
Matching
Matching merupakan sebuah proses untuk membandingkan query dengan
indexed document
yang diperoleh melalui proses pencocokan. Tujuan dalam
proses matching tersebut berguna dalam menemukan data teks yang sesuai.
Hasil proses matching tersebut berupa daftar peringkat
(rangking)
dalam data.
7
informasi yang dibutuhkan. Pada penelitian ini yang diharapkan adalah
perbandingan mengenai lagu yang akan diklasifikasikan menggunakan model
berdasarkan hasil training dengan menggunakan Multinomial Naive Bayes
sehingga hasil yang didapatkan sesuai.
2.3
Indexing
Langkah
–
langkah untuk membangun sebuah indeks dalam data teks menurut
Christopher dan Raghavan:
1.
Tokenizing
Tokenizing merupakan proses pemisahan karakter yang muncul dalam suatu
teks
Input: Andi, mari kita berangkat sekarang Juga !
Output:
Andi
mari
kita
berangkat
sekarang
juga
!
Tokenizing:
Titik (.)
Kurung siku ([])
Kurung kurawal ({})
Petik (“)
Sign (@ _ )
Operator matematika (+ - * / = <>)
Titik dua (:)
Kurung ( ( ) )
Karakter special ( | & ~)
Koma (,)
Titik koma (;)
2.
Normalization
Normalization merupakan proses menyamakan ejaan dalam sebuah teks yang
8
tlah, atau Telah; pada tiga kata tersebut terdapat penulisan kata yang berbeda tetapi
memiliki makna atau arti yang sama sehingga diganti menjadi telah.
3.
Stop Word
Stop word merupakan proses menghilangkan kata pada data yang tidak
memiliki arti atau makna yang mempengaruhi proses klasifikasi sehingga
mendapatkan hasil akurasi yang lebih tepat. Stop word didapat dari hasil tokenizing
dan normalization.
stop word:
abang ada adalah adik agar ah akan aku alih anak andaikan antara apabila apalagi
asalkan atas atau ayah bagai bahkan bahwa bak biar biarpun bibi cicit cucu dan
daripada demi demikian dengan di dia du engkau hanya ho hoo ialah ibarat ibu ini
ipar itu jika jikalau kakak kakek kalau kami kamu kanda karena ke kemudian
kendati kendatipun keponakan ketika la lagi lagipula laksana maka manakala
maupun melainkan menantu menjadi mereka mertua meskipun namun nenek oh
oleh om ooo pada padahal paman pun sambil sampai seakan seandainya sebab
sebagai sebagaimana sebelum sedangkan sedari sehingga sehubungan sejak sekali
sekalipun sekiranya selagi selain selama selesai semenjak sementara seolah seperti
sepupu seraya serta sesudah setelah setelah seusai sewaktu sungguh sungguhpun
supaya tanpa tante tatkala tetapi tidak umpamanya untuk walau walaupun yaitu
yakni yang
4.
Stemming
Stemming merupakan proses menghilangkan kata imbuhan pada setiap kata
seperti awalan, akhiran, dan sisipan sehingga diperoleh kata dasar. Dalam proses
9
5.
Sorting dan Grouping
Proses sorting dan grouping akan dilakukan setelah stemming dilakukan.
Data yang diperoleh akan diurutkan mulai dari abjad a sampai dengan z.
2.4
Porter Stemmer
2.4.1
Tentang Porter Stemmer
Porter Stemmer (Porter, 2006) merupakan sebuah algoritma yang digunakan
untuk melakukan proses menghapus akhiran infeksional dan morfologi yang umum
pada kata dalam Bahasa Inggris. Terutama, penggunaan porter stemmer sebagai
proses normalisasi pada kata yang biasa digunakan pada saat membangun sebuah
pemerolehan informasi
(Information retrieval)
.
Algoritma porter stemmer didasarkan pada ide akhiran dalam Bahasa Inggris,
secara umum terdiri dari kombinasi akhiran yang sederhana. Proses pada algoritma
porter stemmer akan melalui beberapa tahapan, simulasi proses infleksional dan
derivasional pada sebuah kata.
Pada tahapan tersebut, sebuah akhiran dihapus melalui aturan subsitusi, aturan
subsitusi menerapkan pada suatu kondisi harus terpenuhi secara keseluruhan.
Dalam suatu kondisi kata dasar yang diakhiri dengan huruf mati maupun huruf
hidup, maka panjang pada kata dasar yang telah dihasilkan disebut dengan
measure
.
2.4.2
Porter Stemmer Bahasa Indonesia
Dalam Bahasa Indonesia terdapat sebuah kombinasi pada struktur yaitu
infleksional dan derivasional yang sederhana. Tahap
–
tahap dalam porter stemmer
adalah simulasi proses pada infleksional dan derivasional dalam Bahasa Inggris
10
Penggunaan bahasa yang berbeda tersebut adalah sangat berbeda sehingga
terdapat aturan tersendiri pada penggunaan algoritma porter stemmer untuk Bahasa
Indonesia. Aturan untuk Bahasa Indonesia diantaranya, menghilangkan awalan,
konflik, dan peneyesuaian ejaan pada kasus, dimana pada karakter awal pada
sebuah kata dasar dapat berubah pada saat penambahan awalan dilakukan.
Remove Particle
Remove Possessive
Remove First Order Prefix
Remove Second Order Prefix Remove Suffix
Remove Suffix Remove Second Order Prefix Word
Stem
Gambar 2.2 Proses Porter Stemmer untuk Bahasa Indonesia (Tala, 2003).
Tabel 2.1 Aturan 1 Inflection Particle.
Akhiran
Replacement Measure
Conditional
Additional
Conditional
-kah
NULL
2
NULL
pensilkah pensil
-lah
NULL
2
NULL
janganlah jangan
11
Tabel 2.2 Aturan 2 Inflection Possessive Pronouns.
Akhiran
Replacement Measure
Conditional
Additional
Conditional
-ku
NULL
2
NULL
pensilku pensil
-mu
NULL
2
NULL
bukumu buku
-nya
NULL
2
NULL
pensilnya pensil
Tabel 2.3 Aturan 3 Fisrt Order of Derivational Prefixs.
Awalan
Replacement Measure
Conditional
Additional
Conditional
meng-
NULL
2
NULL
menggali gali
meny-
NULL
2
NULL
menyapa apa
men-
NULL
2
NULL
mencuri curi
mem-
NULL
2
NULL
membaca baca
me-
NULL
2
NULL
menulis tulis
peng-
NULL
2
NULL
penggali gali
peny-
NULL
2
NULL
penyayang sayang
pen-
NULL
2
NULL
pencuri curi
pem-
NULL
2
NULL
pembawa bawa
di-
NULL
2
NULL
dicuri curi
ter-
NULL
2
NULL
tercuri curi
12
Tabel 2.4 Aturan 4 Second Order of Derivational Prefixs.
Awalan
Replacement Measure
Conditional
Additional
Conditional
ber-
NULL
2
NULL
berlutut lutut
Bel
NULL
2
NULL
belajar ajar
Be
NULL
2
NULL
bekerja kerja
Per
NULL
2
NULL
perjelas jelas
pel-
NULL
2
NULL
pelajar ajar
pe-
NULL
2
NULL
penulis tulis
Tabel 2.5 Aturan 5 Derivational Suffixes.
Akhiran
Replacement Measure
Conditional
Additional
Conditional
-kan
NULL
2
Awalan
ϵ
{ke, peng}
tuliskan tulis
carikan cari
-an
NULL
2
Awalan
ϵ
{di, meng,
ter}
(per)janjian janji
minuman minum
-i
NULL
2
V|K…
,
≠
s,
≠ i
,
dan awalan
ϵ
curangi curang
13
{ber,
ke,
[image:30.595.109.517.205.574.2]peng}
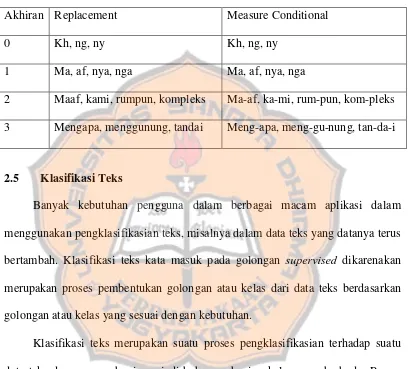
Tabel 2.6 Aturan 6 Suku Kata dalam Bahasa Indonesia
Akhiran Replacement
Measure Conditional
0
Kh, ng, ny
Kh, ng, ny
1
Ma, af, nya, nga
Ma, af, nya, nga
2
Maaf, kami, rumpun, kompleks
Ma-af, ka-mi, rum-pun, kom-pleks
3
Mengapa, menggunung, tandai
Meng-apa, meng-gu-nung, tan-da-i
2.5
Klasifikasi Teks
Banyak kebutuhan pengguna dalam berbagai macam aplikasi dalam
menggunakan pengklasifikasian teks, misalnya dalam data teks yang datanya terus
bertambah. Klasifikasi teks kata masuk pada golongan
supervised
dikarenakan
merupakan proses pembentukan golongan atau kelas dari data teks berdasarkan
golongan atau kelas yang sesuai dengan kebutuhan.
Klasifikasi teks merupakan suatu proses pengklasifikasian terhadap suatu
data teks dengan membagi menjadi beberapa bagian kelas yang berbeda. Proses
klasifikasi tersebut akan melalui beberapa tahapan reprocessing untuk mendapatkan
data yang dibutuhkan oleh pengguna sehingga proses klasifikasi memiliki tingkat
akurasi yang tinggi. Penggunaan klasifikasi pada teks biasanya dapat digunakan
14
2.6
Naive Bayes
Naïve bayes (Tan & Kumar, 2006) merupakan salah satu metode yang
digunakan untuk pengklasifikasian sebuah data dengan berdasarkan teorema bayes
dengan mengasumsikan bahwa suatu data memiliki sifat tidak saling terkait antar
satu dengan yang lain atau disebut independen. Teknik penggunaan Naive Bayes
sangat sederhana dan cepat dengan penggunaan probabilistik. Untuk
memaksimalkan penggunaan dari metode
Naive Bayes
maka digunakan metode
Multinomial Naive Bayes.
2.7
Multinomial Naive Bayes
Multinomial Naive Bayes merupakan proses pengambilan jumlah kata yang
muncul dalam setiap dokumen, dengan mengasumsikan dokumen memiliki
beberapa kejadian dalam kata dengan panjang yang tidak tergantung dari kelasnya
dalam dokumen. Menurut (Manning, Raghavan, & Schutze, 2008), probabilitas
sebuah dokumen d berada dikelas c, kondisi berikut dapat dinyatakan dengan
rumus:
� | ∝ �
∏
≤�≤�� �
�|
(1)
P(t
k|c) merupakan conditional probabilitas dari kata
�
�yang terdapat dalam sebuah
dokumen dari kelas c.
P(c) merupakan prior probabilitas dari sebuah dokumen yang terdapat dalam kelas
c.
(t
1,t
2,…
, t
nd) merupakan token dalam dokumen d yang merupakan bagian dari
15
Untuk memperkirakan prior probability
�
̂
dinyatakan dengan rumus:
�
=
��(2)
�
�= jumlah dokumen training dalam kelas c.
�
= jumlah keseluruhan dokumen training dari seluruh kelas.
Untuk perkiraan conditional probability
�
̂ �|
dinyatakan dengan rumus:
� �| =
��∑ �′∈� ��
(3)
�
��= jumlah kemunculan kata t dalam sebuah dokumen training pada kelas c.
��
∑ �′∈� ��
= jumlah total keseluruhan kata dalam dokumen training pada kelas c.
�
′= jumlah total kata dalam dokumen training
Untuk menghilangkan nilai nol pada sebuah dokumen, digunakan
laplace
smoothing
sebagai proses penambahan nilai 1 pada setiap nilai T
ctpada perhitungan
conditional probabilities
dan dinyatakan dengan rumus:
� ��
��| =
∑ �′∈� ���+� + �′(4)
�
′= total kata unik pada keseluruhan kelas dalam dokumen training
Untuk memperoleh nilai probabilitas yang tinggi dari setiap kata digunakan laplace
smoothing atau
add-one
, laplace smoothing digunakan agar nilai dari probabilitas
masing
–
masing kata dapat memenuhi syarat yaitu tidak sama dengan 0. Jika nilai
dari probabilitas kata adalah 0 maka data baik training maupun testing tidak akan
16
2.8
Penerapan Multinomial Naive Bayes Pada Klasifikasi Teks
2.9.1
Data Training
Data training merupakan kumpulan dokumen yang dijadikan sebuah data
percobaan untuk menghasilkan sebuah model, data yang diuji sebagai berikut:
Aku adalah anak gembala Selalu riang serta gembira Karena aku senang bekerja Tak pernah malas ataupun lengah
Tralala la la la la Tralala la la la la la la Setiap hari ku bawa ternak Ke padang rumput, di kaki bukit
Rumputnya hijau subur dan banyak Ternakku makan tak pernah
sdikit Tralala la la la la Tralala la la la la la la
Aku seorang Kapiten mempunyai pedang panjang Kalau berjalan prok-prok-prok
Aku seorang Kapiten Akan kuingat selalu
Ade irma suryani Waktu dipeluk dipangku ibu
Dengan segala kasih Kini ia terbaring dipangkuan
tuhan Senang dan bahagia hatinya Kini ia terlena tertidur terbaring
Nyenyak dipelukan tuhannya Baik
Isi Dokumen Kategori
Aku ini anak manja kusendiri di rumah saja
tiap hari kubernyanyi lagunya sesuka hati
Ayah ibu kaya raya apa saja yang kuminta
semuanya tersedia
Aku makan tiga kali maksakannya enak sekali
pakaianku tiga almari serba mewah, warna warni Tidak Baik
Akankah kau melihatku Saat ku jauh Akankah kau merasakan
Kehilanganku
Jiwaku yang telah mati Bukan cintaku Janjiku s'lalu abadi
Hanya milikmu
Aku pergi dan takkan kembali Akhir dari cinta yang abadi
Akankah kau melihatku Di akhir nanti Jiwaku yang telah mati
Bukan cintaku Janjiku s'lalu abadi
Hanya untukmu
Aku pergi dan takkan kembali Air mata untuk yang abadi Aku pergi ke alam yang suci
Akhir dari abadi cintaku
Aku pergi ke alam yang abadi Akhir dari cinta yang abadi
Ada yang bergerak di dalam dadaku ini Seperti ku kenal pernah
kurasakan Waktu aku jatuh cinta Waktu hatiku tertarik Rasanya pun begini
Jatuh cinta
Apakah ini sama seperti yang itu Hatiku bergerak
Aku jatuh cinta Dinding hatiku berlagu Harmoni cinta menyentuh
Pipiku pun merona Jatuh cinta
Harmoni cintaku kini datang Nyanyikan suara hatiku
17
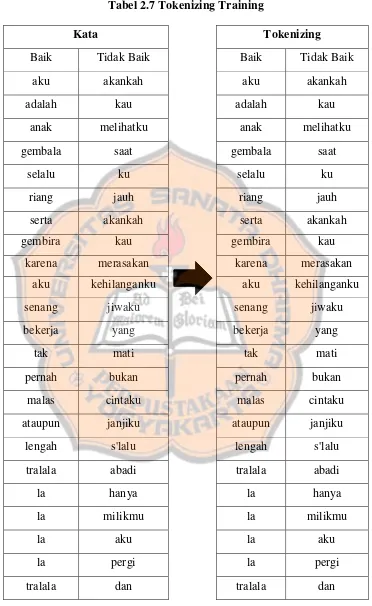
1)
Tokenizing
Tabel 2.7 Tokenizing Training
Kata
Tokenizing
Baik
Tidak Baik
Baik
Tidak Baik
aku
akankah
aku
akankah
adalah
kau
adalah
kau
anak
melihatku
anak
melihatku
gembala
saat
gembala
saat
selalu
ku
selalu
ku
riang
jauh
riang
jauh
serta
akankah
serta
akankah
gembira
kau
gembira
kau
karena
merasakan
karena
merasakan
aku
kehilanganku
aku
kehilanganku
senang
jiwaku
senang
jiwaku
bekerja
yang
bekerja
yang
tak
mati
tak
mati
pernah
bukan
pernah
bukan
malas
cintaku
malas
cintaku
ataupun
janjiku
ataupun
janjiku
lengah
s'lalu
lengah
s'lalu
tralala
abadi
tralala
abadi
la
hanya
la
hanya
la
milikmu
la
milikmu
la
aku
la
aku
la
pergi
la
pergi
18
2)
Normalization
Tabel 2.8
Normalization Training
Tokenizing
Normalization
Baik
Tidak Baik
Baik
Tidak Baik
aku
akankah
aku
akankah
adalah
kau
adalah
kau
anak
melihatku
anak
melihatku
gembala
saat
gembala
saat
selalu
ku
selalu
ku
riang
jauh
riang
jauh
serta
akankah
serta
akankah
gembira
kau
gembira
kau
karena
merasakan
karena
merasakan
aku
kehilanganku
aku
kehilanganku
senang
jiwaku
senang
jiwaku
bekerja
yang
bekerja
yang
tak
mati
tak
mati
pernah
bukan
pernah
bukan
malas
cintaku
malas
cintaku
ataupun
janjiku
ataupun
janjiku
lengah
s'lalu
lengah
s'lalu
tralala
abadi
tralala
abadi
la
hanya
la
hanya
la
milikmu
la
milikmu
19
3)
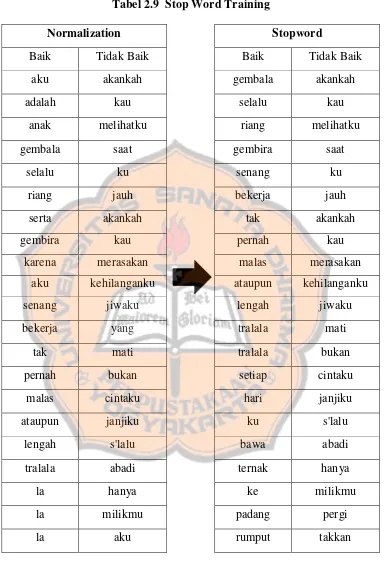
Stop Word
Tabel 2.9 Stop Word Training
Normalization
Stopword
Baik
Tidak Baik
Baik
Tidak Baik
aku
akankah
gembala
akankah
adalah
kau
selalu
kau
anak
melihatku
riang
melihatku
gembala
saat
gembira
saat
selalu
ku
senang
ku
riang
jauh
bekerja
jauh
serta
akankah
tak
akankah
gembira
kau
pernah
kau
karena
merasakan
malas
merasakan
aku
kehilanganku
ataupun
kehilanganku
senang
jiwaku
lengah
jiwaku
bekerja
yang
tralala
mati
tak
mati
tralala
bukan
pernah
bukan
setiap
cintaku
malas
cintaku
hari
janjiku
ataupun
janjiku
ku
s'lalu
lengah
s'lalu
bawa
abadi
tralala
abadi
ternak
hanya
la
hanya
ke
milikmu
la
milikmu
padang
pergi
20
4)
Stemming
Tabel 2.10 Stemming Training
Stopword
Stemming
Baik
Tidak Baik
Baik
Tidak Baik
gembala
akankah
gembala
akan
selalu
kau
selalu
kau
riang
melihatku
riang
saat
gembira
saat
gembira
ku
senang
ku
senang
jauh
bekerja
jauh
kerja
akan
tak
akankah
tak
kau
pernah
kau
pernah
rasa
malas
merasakan
malas
jiwa
ataupun
kehilanganku
atau
mati
lengah
jiwaku
lengah
bukan
tralala
mati
hari
cinta
tralala
bukan
ku
janji
setiap
cintaku
bawa
lalu
hari
janjiku
ternak
abadi
ku
s'lalu
ke
hanya
bawa
abadi
padang
milik
ternak
hanya
rumput
pergi
ke
milikmu
kaki
tak
padang
pergi
bukit
kembali
21
5)
Daftar Kata beserta Frekuensi Kata
Kumpulan kata pada tabel 2.10 kemudian disusun kedalam satu kolom dan
dihitung frekuensi kata kemunculan masing
–
masing dokumen.
Tabel 2.11 Daftar Kata beserta Frekuensi Kata Training
Stemming
Daftar Kata Beserta Frekuensi Kata
Baik
Tidak Baik
gembala
akan
Kata
Frekuensi Kata
selalu
kau
Baik
Tidak Baik
riang
saat
gembala
1
0
gembira
ku
selalu
1
0
senang
jauh
riang
1
0
kerja
akan
gembira
1
0
tak
kau
senang
1
0
pernah
rasa
kerja
1
0
malas
jiwa
tak
1
0
atau
mati
pernah
1
0
lengah
bukan
malas
1
0
hari
cinta
atau
1
0
ku
janji
lengah
1
0
bawa
lalu
hari
1
0
ternak
abadi
ku
1
0
ke
hanya
bawa
1
0
padang
milik
ternak
1
0
rumput
pergi
ke
1
0
kaki
tak
padang
1
0
bukit
kembali
rumput
1
0
rumput
akhir
kaki
1
0
22
6)
Hasil Sorting secara Ascending
Tabel 2.12 Hasil Sorting secara Ascending Training
Daftar Kata Beserta
Frekuensi Kata
Hasil Sorting Secara
Ascending
Kata
Frekuensi Kata
Kata
Frekuensi Kata
Baik Tidak Baik
Baik Tidak Baik
gembala
1
0
abadi
0
1
selalu
1
0
abadi
0
1
riang
1
0
abadi
0
1
gembira
1
0
abadi
0
1
senang
1
0
abadi
0
1
kerja
1
0
abadi
0
1
tak
1
0
abadi
0
1
pernah
1
0
ade
1
0
malas
1
0
air
0
1
atau
1
0
akan
0
1
lengah
1
0
akan
0
1
hari
1
0
akan
0
1
ku
1
0
akhir
0
1
bawa
1
0
akhir
0
1
ternak
1
0
akhir
0
1
ke
1
0
akhir
0
1
padang
1
0
alam
0
1
rumput
1
0
apa
0
1
kaki
1
0
apakah
0
1
23
7)
Hasil Grouping dengan Kata yang Sama
Setelah proses sorting pada tabel 2.12, dapat dilihat kata yang sama sehingga
kata yang sama dapat digabungkan seperti pada tabel berikut:
Tabel 2.13 Hasil Grouping dengan Kata yang Sama Training
Hasil sorting secara
ascending
Hasil Grouping berdasarkan
kata yang sama
Kata
Frekuensi kata
Kata
Frekuensi kata
Baik Tidak Baik
Baik
Tidak Baik
abadi
0
1
abadi
0
7
abadi
0
1
ade
1
0
abadi
0
1
air
0
1
abadi
0
1
akan
0
3
abadi
0
1
akhir
0
4
abadi
0
1
alam
0
1
abadi
0
1
apa
0
1
ade
1
0
apakah
0
1
air
0
1
atau
1
0
akan
0
1
bahagia
1
0
akan
0
1
banyak
1
0
akan
0
1
baring
2
0
akhir
0
1
bawa
1
0
akhir
0
1
begini
0
1
akhir
0
1
bukan
0
2
akhir
0
1
bukit
1
0
alam
0
1
cinta
0
12
apa
0
1
dada
0
1
apakah
0
1
dalam
0
1
24
8)
Prior Probabilitas
Tabel 2.14 Prior Probabilitas Training
Atribut kelas
P(class)
Lagu Baik
3/6
Lagu Tidak Baik
3/6
[image:41.595.112.550.257.714.2]9)
Conditional Probabilitas
Tabel 2.15 Conditional Probabilitas Training
Conditional probabilitas (P(t|c)
Laplace Smoothing
Kata
Baik
Tidak Baik
Kata
Baik
Tidak Baik
abadi
0
0.039106145
abadi
8.474576271 44.69273743
ade
0.008
0
ade
16.94915254 5.586592179
air
0
0.005586592
air
8.474576271 11.17318436
akan
0
0.016759777
akan
8.474576271 22.34636872
akhir
0
0.022346369
akhir
8.474576271 27.93296089
alam
0
0.005586592
alam
8.474576271 11.17318436
apa
0
0.005586592
apa
8.474576271 11.17318436
apakah
0
0.005586592
apakah
8.474576271 11.17318436
atau
0.008
0
atau
16.94915254 5.586592179
bahagia
0.008
0
bahagia
16.94915254 5.586592179
banyak
0.008
0
banyak
16.94915254 5.586592179
baring
0.017
0
baring
25.42372881 5.586592179
bawa
0.008
0
bawa
16.94915254 5.586592179
begini
0
0.005586592
begini
8.474576271 11.17318436
bukan
0
0.011173184
bukan
8.474576271 16.75977654
25
2.9.2
Data Testing
Data testing merupakan data yang digunakan sebagai uji coba terhadap
model yang terbentuk dari data training dengan data sebagai berikut:
Hati hati dengan hatiku Karna hatiku mudah layu Jangan kamu bermain-main
Karna kutak’ main-main
Sungguh aku bersungguh-sungguh Cintaku ini cinta mati
Mati-matian aku Pertahankan cintaku
Aku takkan rela...bila kau tinggalkan Aku kan berbuat...apa saja Untuk mendapatkan kamu lagi
Rupa rupa alasan kamu Untuk tetap tinggalkan aku
Rupanya kamu memang Sudah tak cinta aku
Cintamu yang berbisa Bisa racuni aku
Bisa-bisanya kamu mau tinggalkan aku ?
26
1)
Tokenizing
Tabel 2.16 Tokenizing Testing
Kata
Tokenizing
Hati
Hati
hati
hati
dengan
dengan
hatiku
hatiku
Karna
Karna
hatiku
hatiku
mudah
mudah
layu
layu
Jangan
Jangan
kamu
kamu
bermain
bermain
-
main
main
Karna
Karna
kutak’
kutak’
main
main
main
-
Sungguh
main
aku
Sungguh
bersungguh
aku
sungguh
bersungguh
Cintaku
-
ini
sungguh
cinta
Cintaku
mati
27
2)
Normalization
Tabel 2.17 Normalization Testing
Tokenizing
Normalization
Hati
hati
hati
hati
dengan
dengan
hatiku
hatiku
Karna
karna
hatiku
hatiku
mudah
mudah
layu
layu
Jangan
jangan
kamu
kamu
bermain
bermain
main
main
Karna
karna
kutak’
kutak’
main
main
main
main
Sungguh
sungguh
aku
aku
bersungguh
bersungguh
sungguh
sungguh
Cintaku
cintaku
ini
ini
cinta
cinta
mati
mati
28
3)
Stop Word
Tabel 2.18 Stop Word Testing
Normalization
Stopword
hati
hati
hati
hati
dengan
hatiku
hatiku
karna
karna
hatiku
hatiku
mudah
mudah
layu
layu
jangan
jangan
bermain
kamu
main
bermain
karna
main
kutak’
karna
main
kutak’
main
main
bersungguh
main
sungguh
sungguh
cintaku
aku
cinta
bersungguh
mati
sungguh
mati
cintaku
matian
ini
pertahankan
cinta
cintaku
29
4)
Stemming
Tabel 2.19 Stemming Testing
Stopword
Stemming
hati
hati
hati
hati
hatiku
hati
karna
hati
hatiku
mudah
mudah
layu
layu
jangan
jangan
main
bermain
main
main
main
karna
main
kutak’
sungguh
main
sungguh
main
cinta
bersungguh
cinta
sungguh
mati
cintaku
mati
cinta
tahan
mati
cinta
mati
tak
matian
rela
pertahankan
bila
cintaku
kau
takkan
tinggal
30
5)
Daftar Kata Beserta Frekuensi Kata
Tabel 2.20 Daftar Kata beserta Frekuensi Kata Testing
Stemming
Daftar Kata Beserta Frekuensi
Kata
Hati
Kata
Frekuensi Kata
hati
apa
1
hati
bila
1
hati
bisa
1
mudah
bisa
1
layu
bisa
1
jangan
bisa
1
main
buat
1
main
cinta
1
main
cinta
1
main
cinta
1
sungguh
cinta
1
sungguh
cinta
1
cinta
dapat
1
cinta
hati
1
mati
hati
1
mati
hati
1
tahan
hati
1
cinta
jangan
1
tak
kan
1
rela
kau
1
bila
layu
1
kau
main
1
tinggal
main
1
kan
main
1
31
6)
Hasil Sorting secara Ascending
Tabel 2.21 Hasil Sorting secara Ascending Testing
Daftar kata beserta frekuensi
katanya
Hasil sorting secara ascending
Kata
Frekuensi kata
Kata
Frekuensi kata
apa
1
apa
1
bila
1
bila
1
bisa
1
bisa
4
bisa
1
buat
1
bisa
1
cinta
5
bisa
1
dapat
1
buat
1
hati
4
cinta
1
jangan
1
cinta
1
kan
1
cinta
1
kau
1
cinta
1
layu
1
cinta
1
main
4
dapat
1
mati
3
hati
1
mau
1
hati
1
memang
1
hati
1
mudah
1
hati
1
rela
1
jangan
1
rupa
3
kan
1
saja
1
kau
1
sungguh
2
layu
1
tahan
1
main
1
tak
2
32
7)
Hasil Grouping dengan Kata yang Sama
Tabel 2.22 Hasil Grouping dengan Kata yang Sama Testing
Hasil Sorting Secara Ascending
Hasil Grouping Berdasarkan Kata
Yang Sama
Kata
Frekuensi Kata
Kata
Frekuensi Kata
apa
1
apa
1
bila
1
bila
1
bisa
4
bisa
4
buat
1
buat
1
cinta
5
cinta
5
dapat
1
dapat
1
hati
4
hati
4
jangan
1
jangan
1
kan
1
kan
1
kau
1
kau
1
layu
1
layu
1
main
4
main
4
mati
3
mati
3
mau
1
mau
1
memang
1
memang
1
mudah
1
mudah
1
rela
1
rela
1
rupa
3
rupa
3
saja
1
saja
1
sungguh
2
sungguh
2
tahan
1
tahan
1
tak
2
tak
2
tetap
1
tetap
1
33
8)
Prior Probabilitas
Tabel 2.23 Prior Probabilitas Testing
Prior Porbabilitas
Atribut Kelas
P(Class)
Baik
1/2
Tidak Baik
1/2
9)
Hasil Proses Matching antara Model dengan Data Testing
Tabel 2.24 Hasil Proses Matching antara Model dengan Data Testing
Hasil Proses Matching
antara Model dengan Data
Testing
Kata
Frekuensi Kata
apa
1
cinta
5
hati
4
kau
1
mati
3
saja
1
tak
2
34
10)
Hasil Matching beserta dengan Nilai Conditional Probabilitas
Setelah proses hasil matching antara model beserta dengan nilai conditional
probabilitas-nya, frekuensi kata akan digabungkan dengan nilai conditional
[image:51.595.131.493.281.575.2]probabilitas-nya.
Tabel 2.25 Hasil Matching beserta dengan Nilai Conditional Probabilitas
Testing
Hasil Matching beserta dengan Nilai Conditional Probabilitas-nya
kata
Frekuensi kata
Baik
Tidak Baik
apa
1
8.474576271
11.17318436
cinta
5
8.474576271
72.62569832
hati
4
16.94915254
27.93296089
kau
1
8.474576271
22.34636872
mati
3
8.474576271
16.75977654
saja
1
8.474576271
16.75977654
35
11)
Hasil Perkalian Nilai Conditional Probabilitas dengan Frekuensi Kata
Tabel 2.26 Hasil Perkalian Nilai Conditional Probabilitas dengan Frekuensi
Kata Testing
Hasil Perkalian Nilai Conditional Probabilitas Dengan Frekuensi Kata
Kata
Baik
Tidak Baik
apa
8.474576271
11.17318436
cinta
43710.92162
2020466279
hati
82526.22002
608790.5374
kau
8.474576271
22.34636872
mati
608.6308727
4707.655467
saja
8.474576271
16.75977654
tak
646.3659868
280.8901095
Total
8.63711E+17
6.80633E+24
12)
Hitung Probabilitas
Untuk menghitung nilai probabilitas dari data testing diperlukan perkalian
antara nilai prior probabilitas dengan hasil perkalian antara nilai contiditional
[image:52.595.113.513.196.588.2]probabilitas dengan frekuensi kata sehingga didapat hasil sebagai berikut:
Tabel 2.27 Hitung Probabilitas Testing
Hitung probabilitas
P(Baikllagu7)
4.31855E+17
P(Tidak Baikllagu7)
3.40316E+24
Dari hasil perhitungan diatas dapat disimpulkan bahwa lagu7 kata masuk
pada klasifikasi lagu yang tidak baik untuk anak dengan nilai
3.40316E+24
yang
36
3.
BAB III
PERANCANGAN SISTEM
3.1
Gambaran Umum Sistem
Sistem yang dibangun dalam penelitian ini adalah sistem pengujian akurasi
dari penggunaan metode Multinomial Naïve Bayes pada klasifikasi data teks lirik
lagu. Lirik lagu yang digunakan adalah lirik lagu dari beberapa situs website salah
satunya adalah lirik.kapanlagi.com dan liriklaguanak.com. Proses klasifikasi yang
akan dilakukan pada sistem ini menggunakan metode Multinomial Naïve Bayes
sebagai klasifikasi.
User dalam sistem ini adalah pihak yang menggunakan sistem. Data yang
digunakan dalam penelitian adalah data dengan format ekstensi *.txt yang diimport
dari direktori kemudian hasil teks akan dieksekusi kedalam proses indexing. Proses
klasifikasi tersebut dapat dilihat pada Gambar 3.1.
Data Training Tentukan Kategori Tokenazing Normalization Stop Word Stemming Sorting dan Grouping
Indexing
Hitung Prior Porbabilitas
Hitung Conditional
Probabilites Laplace Smoothing
Training
Data Testing Tokenazing Normalization Stop Word Stemming Sorting dan Grouping Indexing Matching
Pangkatkan Nilai Conditional Probabilites
Hitung Probabilitas Tiap Kelas
Testing Hasil Klasifikasi
Model
Index
Index
Classification
[image:53.595.115.512.282.729.2]Modelling
37
Pada Gambar 3.1 proses indexing menghasilkan kumpulan kata beserta nilai
frekuensi kata dari masing - masing yang telah diseleksi. Kumpulan kata ini akan
diolah menggunakan metode Multinomial Naïve Bayes sehingga menghasilkan
model yang digunakan untuk proses klasifikasi.
Proses klasifikasi, akan melalui proses indexing yang sama pada proses
training tanpa diketahui kelas atau kategorinya yang menghasilkan kumpulan kata.
Hasil kumpulan kata digunakan untuk proses matching agar mendapatkan daftar
kata yang sama pada kumpulan kata dan data model. Hasil proses matching
digunakan untuk melakukan klasifikasi menggunakan metode Multinomial Naïve
Bayes.
3.2
Teknik Analisis Data
3.2.1
Metode Pengumpulan Data
Data yang diperoleh merupakan data yang melalui beberapa tahapan.
Adapaun tahapan yang dilalui untuk melakukan pengumpulan data dalam penelitian
ini sebagai berikut:
1.
Studi Pustaka
Penggunaan studi pustaka pada penelitian ini adalah untuk mencari sumber
–
sumber mengenai metode Multinomia Naive Bayes untuk mengklasifikasikan
data teks.
2.
Observasi
Penggunaan observasi pada penelitian adalah untuk melakukan pencarian
38
3.
Wawancara
Metode wawancara digunakan untuk pengelompokan data sebagai acuan
pemberian label terhadap data dari seorang ahli. Dalam kasus penelitian ahli
dipilih dari dosen psikologi untuk menentukan klasifikasi data yang baik dan
tidak baik untuk anak.
3.2.1
Pengolahan Data
Dalam penelitian data yang digunakan sebanyak 500. Data yang digunakan
diperoleh melalui beberapa situs website. Pembagian data dapat dilihat pada tabel
[image:55.595.117.489.285.552.2]3.1 berikut:
Tabel 3.1 Tabel Data Training dan Testing
Jumlah Data
Data Training Data Testing
Klasifikasi
Lagu Baik
200
50
Lagu Tidak Baik
200
50
Total
400
100
Sebanyak 400 data sebagai data training akan melalui tahap preprocessing
untuk mendapatkan sebuah model dan 100 data sebagai data testing akan melalui
tahap preprocessing untuk mencocokan data testing dengan model untuk
mengetahui hasil klasifikasi. Sampai pada akhirnya perhitungan akurasi dengan
39
3.2.2
Preprocessing Data
Preprocessing akan dilalui oleh data sebelum proses klasifikasi. Proses ini
dilakukan untuk meminimalisir permasalahan yang timbul dalam data diantaranya
mengurangi jumlah kata yang tidak berarti atau tidak memiliki makna dalam data
dalam dokumen. Proses yang berlangsung pada setiap data dilakukan melalui
tahapan sebagai berikut :
1)
Tokenizing
Tahapan ini, menghilangkan karakter yang tidak memiliki arti pada kumpulan
kata.
2)
Normalization
Tahapan ini, mengembalikan bentuk kata dari huruf besar menjadi huruf kecil.
3)
Stop Word
Tahapan ini, menghilangkan kata yang tidak memiliki arti atau tidak
mempengaruhi pemerolehan informasi.
4)
Stemming
Tahapan ini, mengembalikan bentuk kata menjadi bentuk kata dasar
5)
Sorting dan Grouping
Tahapan ini, mengurutkan kata dari abjad a sampai z serta menggabungkan kata
40
3.2.3
Klasifikasi Data
Proses klasifikasi data yang telah melalui tahapan menghitung frekuensi kata
yang akan diklasifikasikan berdasarkan klasifikasi yang telah ditentukan.
Klasifikasi data ini menggunakan metode Multinomial Naïve Bayes, adapun
tahapan dalam proses klasifikasi data adalah sebagai berikut :
1.
Menghitung Prior Probabilitas
Pada proses ini , hitung prior probabilitas pada data training dalam kelas
dengan menggunakan rumus:
� � =
�
�
�2.
Menghitung Conditional Probabilitas
Pada proses ini , hitung nilai conditional probabilitas pada setiap data baik data
training atau testing dengan menggunakan rumus berikut:
� |� =
∑
′�
∈ � �
��
Untuk menghilangkan nilai nol pada sebuah dokumen, digunakan
laplace
smoothing
sebagai proses penambahan nilai 1 pada setiap nilai T
ctpada
perhitungan
conditional probabilities
dan dinyatakan dengan rumus:
� �
�|� =
∑
′∈ � �
�
�+
41
3.
Hasil proses matching antara model dan data testing
Pada proses ini, untuk data testing akan dicari hasil matching melalui
pengecekan ada atau tidak kata yang dicari pada model.
4.
Hasil matching beserta dengan nilai conditional probabilitas-nya
Pada proses ini, setelah proses matching antara model dan data testing maka
nilai dari kata yang sama pada data testing dan model, maka nilai dari kata
pada model akan diambil dan dimasukkan dalam data testing.
5.
Hasil perkalian conditional probabilitas dengan frekuensi kata
Pada proses ini, nilai yang diperoleh dari masing
–
masing kata pada data
testing akan dipangkatkan sesuai dengan jumlah frekuensi kata yang dicari.
3.3
Akurasi Data
Confusion matrix
(Paskianti, 2011) adalah sebuah tabel yang menyatakan
jumlah data uji yang benar diklasifikasikan dan jumlah data uji yang salah
[image:58.595.112.511.212.614.2]diklasifikasikan. Confusion matrix ditunjukan pada tabel berikut:
Tabel 3.2 Tabel
Confusion Matrix
Kelas Prediksi
1
0
Kelas
sebenarnya
1
TP
FN
0
FP
TN
tp (
True positive
) : jumlah dokumen dari kelas 1 yang benar diklasifikasikan sebagai
kelas 1
Gambar






Dokumen terkait
Pengujian akurasi klasifikasi tweets dilakukan untuk mengetahui tingkat akurasi klasifikasi tweets yang dilakukan secara manual dengan klasifikasi tweets yang
Sistem analisis sentimen pada ulasan produk online menggunakan metode Naive Bayes ini dapat menggunakan metode lain untuk memperoleh hasil prediksi yang lebih baik. Sistem
yaitu data yang dikumpulkan menggunakan teknik scraping lebih cepat dibandingkan dengan cara manual, klasifikasi sentimen komentar opini para pelanggan digital printing
Berdasarkan uraian di atas, peneliti mengusulkan penelitian dengan menggunakan Naive Bayes untuk klasifikasi opini film dan untuk menangani masalah kata yang tidak
Klasifikasi sentimen dengan Lexicon Based adalah klasifikasi berdasarkan kata positif, kata negatif ataupun netral yang ada pada tweets yang telah dibersihkan pada
Untuk menerapkan sistem digunakan lirik lagu berbahasa Indonesia, sehingga dalam proses stemming dapat dengan mudah sistem mengabaikan penggunaan bahasa Indonesia
Struktur Stilistik Pada dasarnya elemen dengan bagaimana pemilihan kata yang dipakai tidak semata hanya karena kebetulan, tetapi bisa untuk menunjukan bagaimana pemaknaan lagu
Dataset yang digunakan diambil dari teks tweets yang bersumber dari media sosial Twitter dengan kata kunci sebelum Tragedi Kanjuruhan yaitu ‘PSSI’ pada periode 01 Januari 2022 hingga 31
