KLASIFIKASI VARIETAS KOPI ARABIKA MENGGUNAKAN
METODE SUPPORT VECTOR MACHINE (SVM)
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Informatika
Oleh :
Anastasia Novia Windrawati 165314090
PROGRAM STUDI INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
CLASSIFICATION OF ARABICA COFFEE VARIETY USING
SUPPORT VECTOR MACHINE (SVM) METHOD
A THESIS
Submitted in Partial Fulfillment of The Requirements For The Degree of Sarjana Komputer
In Informatics Study Program
By :
Anastasia Novia Windrawati 165314090
INFORMATICS STUDY PROGRAM FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY YOGYAKARTA
v
HALAMAN PERSEMBAHAN
“Serahkanlah segala kekuatiranmu kepada-Nya, sebab Ia yang memelihara kamu.”
1 Petrus 5:7
Skripsi ini didedikasikan kepada : Ibu, Kakak, dan Adik
viii
ABSTRAK
Pengendalian mutu kopi merupakan salah satu hal yang memiliki pengaruh dalam pendistribusian kopi. Kopi dengan hasil mutu yang baik tentunya dapat meningkatkan daya jual sehingga sangat penting untuk mengetahui varietas kopi dengan kualitas mutu baik sehingga nantinya dapat meningkatkan pendistribusian varietas kopi di masing-masing daerah. Pengukuran kualitas kopi sendiri dapat dilakukan melalui pengujian fisik maupun melalui pengujian cita rasa kopi. Pengujian dengan menggunakan cita rasa kopi diukur melalui tingkat aroma, keasaman, manis, dll. Pengelompokkan varietas kopi berdasarkan pengujian cita rasa kopi dapat dilakukan dengan menggunakan penambangan data. Penambangan data yang dilakukan dalam uji cita rasa kopi untuk mengelompokkan kopi kedalam varietas tertentu diharapkan dapat menghasilkan akurasi yang baik dengan menggunakan metode Support Vector Machine (SVM). Penelitian dilakukan dengan menggunakan 689 data uji dan menggunakan pemodelan klasifikasi one against one. Teknik pengujian yang digunakan yaitu 3-Fold Cross Validation. Berdasarkan pengujian tersebut akurasi yang dihasilkan oleh sistem memiliki akurasi optimal sebesar 48.33% dengan menggunakan Polynomial Kernel dan normalisasi min-max.
Kata kunci : varietas kopi arabika, Data Mining, Polynomial Kernel, Support Vector Machine (SVM).
ix
ABSTRACT
Coffee quality control is one thing that has advantages in the distribution of coffee. Coffee with good quality can increase selling power, so it is very important to know the varieties of coffee with good quality so as to increase the distribution of coffee varieties in each region. The measurement of the quality of coffee itself can be done through physical testing through testing the taste of coffee. Test by using the taste of coffee, processing aroma, acidity, sweetness, etc. The grouping of coffee varieties based on the assessment of the taste of coffee can be done using data mining. Data mining which is done in a coffee flavor test to classify coffee into certain varieties is expected to produce good classification using the Support Vector Machine (SVM) method. The study was conducted using 689 dataset and using one to one classification modeling. The testing technique used is 3-Fold Cross Validation. Based on these tests, generated by a system that has an optimal accuracy of 48.33% using Polynomial Kernel and min-max normalization.
Keywords: Arabica coffee varieties, Data Mining, Linear Kernel, Support Vector Machine (SVM).
xii
DAFTAR ISI
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ... iii
HALAMAN PERSEMBAHAN ... iv
PERNYATAAN KEASLIAN KARYA ... vi
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS ... vii
ABSTRAK ... vii
ABSTRACT ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR TABEL ... xv BAB IPENDAHULUAN ... 1 1.1 Latar belakang ... 1 1.2 Rumusan Masalah ... 3 1.3 Tujuan ... 3 1.4 Manfaat ... 4 1.5 Batasan Masalah ... 4 1.6 Metodologi Penelitian ... 4 1.7 Sistematika Penulisan ... 5
BAB IITINJAUAN PUSTAKA ... 6
2.1 KDD (Knowledge Discovery in Databases)... 6
2.2 Penambangan Data ... 6
2.3 Klasifikasi ... 7
xiii
2.5 Multi Class SVM ... 15
2.5.1 One-against-all ... 15
2.5.2 One-against-one ... 17
2.6 Information Gain ... 18
2.7 K-Fold Cross Validation ... 20
2.8 Confusion Matrix ... 21
2.9 Normalisasi ... 22
2.9.1 Normalisasi Min-Max... 23
2.9.2 Normalisasi Z-Score ... 24
2.10 Varietas Kopi Arabika ... 26
2.11 Pengujian Mutu Kopi ... 27
2.12 Pengujian Mutu Cita Rasa Kopi SCAA ... 28
BAB IIIMETODOLOGI PENELITIAN... 31
3.1 Data ... 31
3.2 Desain Alat Uji ... 37
3.3 Cara Mengolah Data ... 38
3.3.1 Tahap Preprocessing ... 38
3.3.2 K-Fold Cross Validation ... 42
3.3.3 Tahap Klasifikasi ... 43
3.4 Desain Pengujian ... 46
3.5 Kebutuhan Sistem ... 47
3.5.1 Perangkat Keras (Hardware) ... 47
3.5.2 Perangkat Lunak (Software) ... 47
3.6 Perancangan Antar Muka Sistem ... 48
xiv 4.1 Distribusi Data ... 49 4.2 Preprocessing ... 50 4.2.1 Data Selection ... 50 4.2.2 Transformasi Data ... 53 4.3 Klasifikasi ... 55
4.4 Pelatihan dan Pengujian ... 58
4.4.1 Uji Performa Fungsi Kernel ... 58
4.4.2 Uji Performa dengan Normalisasi ... 59
4.5 Analisis Hasil ... 66
BAB VPENUTUP ... 70
5.1 Kesimpulan ... 70
5.2 Saran ... 70
xv
DAFTAR TABEL
Tabel 2.1 Contoh data sampel ... 11
Tabel 2.2 Plot hyperplane ... 13
Tabel 2.3 Hasil Klasifikasi ... 14
Tabel 2.4 Contoh kombinasi biner 4 kelas dengan metode one-against-all ... 16
Tabel 2.5 Contoh kombinasi biner dengan metode one-against-one ... 17
Tabel 2.6 Ukuran evaluasi model klasifikasi ... 21
Tabel 2.7 Confusion Matrix ... 22
Tabel 2.8 Sampel data sebelum dinormalisasi ... 24
Tabel 2.9 Sampel data setelah dinormalisasi min-max ... 24
Tabel 2.10 Sampel data setelah dinormalisasi zscore ... 26
Tabel 2.11 Skala Kualitas ... 30
Tabel 2.12 Skala Skor Total ... 30
Tabel 3.1 Contoh sampel data ... 31
Tabel 3.2 Penjelasan Atribut ... 34
Tabel 3.3 Jumlah Seleksi Kelas ... 39
Tabel 3.4 Atribut hasil Information Gain ... 41
Tabel 3.5 Simulasi pembagian data training dan data testing ... 43
Tabel 3.6 Tabel Pengujian... 47
Tabel 3.7 Spesifikasi PC ... 47
Tabel 4.1 Atribut Masukkan ... 49
Tabel 4.2 Atribut Keluaran ... 50
Tabel 4.3 Akurasi perangkingan atribut ... 51
Tabel 4.4 Transformasi atribut variety ... 53
Tabel 4.5 Sampel data sebelum dinormalisasi ... 54
Tabel 4.6 Sampel data setelah dinormalisasi min-max ... 54
Tabel 4.7 Sampel data setelah dinormalisasi z-score ... 55
Tabel 4.8 Implementasi fungsi SVM ... 56
xvi
Tabel 4.10 Hasil akurasi dengan normalisasi min-max ... 60
Tabel 4.11 Hasil akurasi dengan normalisasi z-score ... 63
Tabel 4.12 Confusion matrix Polynomial Kernel data uji ke-1 ... 66
Tabel 4.13 Confusion matrix Polynomial Kernel data uji ke-2 ... 67
xvii
DAFTAR GAMBAR
Gambar 2.1 Hyperplane yang mungkin untuk set data ... 9
Gambar 2.2 Margin Hyperplane ... 9
Gambar 2.3 Visualisasi hyperplane data uji ... 13
Gambar 2.4 Pemetaan data ke ruang vektor berdimensi lebih tinggi ... 14
Gambar 2.5 Skema klasifikasi dengan metode one-against-all ... 16
Gambar 2.6 Skema klasifikasi menggunakan metode one-against-one ... 18
Gambar 2.7 Skema pembagian data 3-Fold Cross Validation ... 20
Gambar 2.8 Cupping Form ... 29
Gambar 3.1 Tahapan Penambangan Data ... 37
Gambar 3.2 Sampel data berbagai macam label kelas ... 39
Gambar 3.3 Sampel data tiga macam label kelas ... 40
Gambar 3.4 Hasil perangkingan atribut ... 41
Gambar 3.5 Klasifikasi dengan tiga kelas ... 44
Gambar 3.6 Kelas 1 dan kelas 2 ... 44
Gambar 3.7 Kelas 1 dan kelas 3 ... 45
Gambar 3.8 Kelas 2 dan kelas 3 ... 45
Gambar 3.9 Hasil voting ... 46
Gambar 3.10 Prototype GUI Program ... 48
Gambar 4.1 Hasil variabel voting ... 57
Gambar 4.2 Hasil variabel voting ... 57
Gambar 4.3 Grafik Akurasi Fungsi Kernel ... 59
Gambar 4.4 Grafik Perbandingan Akurasi min-max ... 61
Gambar 4.5 Grafik akurasi dengan min-max dan Polynomial Kernel ... 61
Gambar 4.6 Grafik akurasi dengan min-max dan RBF Kernel ... 62
Gambar 4.7 Grafik akurasi dengan min-max dan Linear Kernel ... 62
Gambar 4.8 Grafik Perbandingan Akurasi Z-Score ... 64
xviii
Gambar 4.10 Grafik akurasi dengan z-score dan Polynomial Kernel ... 65 Gambar 4.11 Grafik akurasi dengan z-score dan RBF Kernel... 65 Gambar 4.12 Pengujian Data ... 68
1
BAB I
PENDAHULUAN
1.1 Latar belakangTanaman kopi yang memiliki nama latin perpugenus coffea dari familia Rubiaceae merupakan salah satu komoditas yang banyak diminati dan telah memiliki segmen pasar yang cukup luas. Tanaman kopi ini bukan merupakan tanaman homogen, kopi memiliki beragam varietas yang tersebar diseluruh dunia dan tentunya beragam pula cara pengolahannya. Terdapat empat kelompok besar dari 4500 jenis kopi diseluruh dunia yaitu Coffea Canephora (Robusta), Coffea Arabica (Arabika), Coffea Excelsa (Excelsa), dan Coffea Liberica (Liberica) (Spillane, 1990).
Arabika menjadi pemenang dalam pemasaran karena menyumbang sekitar 70% dari produksi dunia, dibandingkan dengan robusta yang menghasilkan 24%, sedangkan Liberica dan Excelsa memproduksi sebanyak 3%. Hal ini tak lepas dari kualitas dan kuantitas kopi arabika yang memiliki rasa lebih enak serta jumlah kafein yang lebih rendah dibanding robusta. Oleh sebab itu biasanya harga kopi arabika akan lebih mahal daripada kopi robusta (Spillane, 1990).
Pengendalian mutu kopi merupakan salah satu hal yang penting dalam pendistribusian kopi. Kopi yang bermutu tinggi akan meningkatkan daya jual sehingga sangat penting untuk mengetahui varietas kopi dengan kualitas mutu baik. Ukuran kualitas kopi sendiri dapat diukur melalui tingkat aroma, keasaman, manis, dll. Pengelompokkan varietas kopi dapat dilakukan dengan menggunakan pengujian mutu pada biji kopi. Pengujian ini terdiri dari dua jenis yaitu pengujian secara mutu fisik dan pengujian secara mutu cita rasa. Pengelompokkan ini kemudian dapat dilakukan dengan menggunakan penambangan data.
Pada penelitian ini, akan digunakan metode Support Vector Machine(SVM) dalam melakukan klasifikasi biji kopi varietas arabika. Penggunaan karakteristik uji cita rasa kopi dapat membantu pengelompokkan
biji kopi ke dalam varietas kopi arabika tertentu. Penggunaan metode klasifikasi ini mempunyai kemampuan generalisasi data yang tinggi serta mampu menghasilkan model klasifikasi yang baik meskipun dilatih dengan himpunan data yang relatif sedikit(dibanding ruang masalah yang harus diselesaikan) hanya dengan pengaturan parameter yang sederhana. SVM memiliki konsep dan parameter yang harus diatur sehingga relatif mudah diimplementasikan karena penentuan support vector dapat dirumuskan dalam masalah QP (Quadratic Programming) (Suyanto, 2019).
Penelitian yang berkaitan dengan klasifikasi varietas kopi arabika sebelumnya telah banyak dilakukan dengan metode pengenalan citra. Seperti pada penelitian yang dilakukan oleh (Sebatubun & Nugroho, 2017) dengan menggunakan ekstraksi fitur bentuk circularity dan klasifikasi MultiLayer Perceptron. Varietas kopi arabika yang digunakan yaitu Sigarar Utang dan Lini S-795, dan hasil akurasi yang didapatkan yaitu sebesar 80%. Selain itu (Nugroho & Sebatubun, 2020) melakukan klasifikasi kopi arabika menggunakan metode Deep Learning yang diimplementasikan pada dataset varietas kopi arabika Ciwangi Redbourbon, Ciwangi Catimor dan Rasuna Sigararutang. Dengan menggunakan google autoML, penelitian tersebut mendeteksi varietas Ciwangi Redbourbon sebesar 71.4%, Ciwangi Catimor sebesar 85.7%, dan Rasuna sigararutang 80%. Penelitian lain yang berkaitan dengan metode SVM sebelumnya dilakukan oleh (Condori, et al., 2014) yang melakukan pengenalan biji kopi dengan menggunakan ekstraksi fitur CGLCM dan metode klasifikasi SVM. Hasil akurasi yang didapatkan yaitu sebesar 86% dengan menggunakan 3367 dataset gambar serta 12 kategori cacat fisik. Selain itu penelitian SVM dengan kasus lain dilakukan oleh (Sianturi, 2019) yang mengimplementasikan SVM pada aksara Batak Toba dengan judul “Alih Aksara Batak Toba Tulisan Tangan Menggunakan Metode Ekstraksi Ciri Freeman Chain Code (FCC) dan Metode Klasifikasi Support Vector Machine(SVM)”. Dalam penelitian tersebut aksara Batak Toba dapat dikenali dengan tingkat akurasi sebesar 87.7607%. Selain itu, (Octaviani, et al., 2014) telah menerapkan metode SVM dengan judul
“Penerapan Metode Klasifikasi Support Vector Machine(SVM) pada Data Akreditasi Sekolah Dasar (SD) di Kabupaten Magelang”. Penelitian ini menghasilkan akurasi klasifikasi terbaik dengan menggunakan fungsi kernel Gaussian Radial Basic Function (RBF) yang menghasilkan akurasi sebesar 100% dengan data training sebesar 337 data, sedangkan jika menggunakan fungsi kernel Polynomial menghasilkan akurasi klasifikasi sebesar 98.810%.
Pada penelitian yang akan penulis lakukan, klasifikasi varietas biji kopi arabika dilakukan dengan menggunakan metode Support Vector Machine (SVM) dan varietas yang digunakan yaitu Bourbon, Caturra, dan Typica. Proses klasifikasi dilakukan berdasarkan pengujian cita rasa kopi yang menggunakan 689 dataset varietas kopi arabika.
1.2 Rumusan Masalah
• Bagaimana menggunakan dan membangun algoritma Support Vector Machine (SVM) untuk melakukan klasifikasi varietas kopi ?
• Berapa akurasi yang diperoleh dalam mengelompokkan varietas kopi arabika dengan menggunakan metode klasifikasi Support Vector Machine (SVM) berdasarkan pengujian cita rasa kopi ?
• Bagaimana pengujian yang didapatkan dengan menggunakan 3-Fold Cross Validation ?
1.3 Tujuan
• Membangun sistem klasifikasi varietas kopi Arabika menggunakan metode Support Vector Machine (SVM).
• Analisis hasil akurasi yang berhasil didapatkan dalam mengelompokkan varietas kopi Arabika dengan menggunakan metode Support Vector Machine (SVM) berdasarkan pengujian cita rasa kopi.
• Mengetahui tingkat keberhasilan klasifikasi dengan menggunakan pengujian 3-Fold Cross Validation.
1.4 Manfaat
Manfaat dari penelitian ini adalah :
1. Menambah wawasan, pengetahuan dan pemahaman mengenai algoritma Support Vector Machine (SVM) dan klasifikasi penambangan data menggunakan algoritma Support Vector Machine (SVM).
2. Membantu pihak-pihak yang berkaitan seperti lembaga penguji kualitas kopi maupun para pengelola kopi untuk mengklasifikasikan biji kopi berdasarkan uji cita rasa kopi.
1.5 Batasan Masalah
a. Atribut yang digunakan untuk menentukan varietas kopi arabika yaitu berdasarkan pengujian mutu kopi dengan menggunakan pengujian cita rasa kopi.
b. Data yang digunakan adalah data Coffee Beans Reviews by Coffee Quality Institute yang berasal dari https://www.kaggle.com/ankurchavda/coffee-beans-reviews-by-coffee-quality-institute.
1.6 Metodologi Penelitian 1. Studi literatur
Pada tahap ini peneliti mempelajari teori – teori melalu buku dan jurnal yang berkaitan dengan Support Vector Machine (SVM).
2. Pembuatan alat uji
Tahap ini peneliti melakukan perancangan sistem dengan menggunakan metode yang ada yang kemudian diterapkan dalam aplikasi berbasis Matlab.
3. Analisis Hasil
Pada tahap ini peneliti melakukan penarikan kesimpulan dari alat uji dengan menguji ketepatan dan tingkat akurasi dari algoritma yang ada.
1.7 Sistematika Penulisan BAB I PENDAHULUAN
Bab ini berisi tentang latar belakang masalah, rumusan masalah, tujuan penelitian, batasan masalah, metodologi penelitian serta sistematika penulisan dari sistem yang akan diteliti.
BAB II TINJAUAN PUSTAKA
Bab ini berisi tentang teori-teori dasar yang berkaitan dengan penelitian dalam penerapan sistem yang dibuat.
BAB III METODOLOGI PENELITIAN
Bab ini memuat langkah-langkah dalam penelitian yang bertujuan untuk menjawab dan menyelesaikan rumusan masalah yang dimiliki yang terdiri dari data, perangkat lunak dan perangkat keras, algoritma yang dipakai, serta desain alat uji.
BAB IV IMPLEMENTASI DAN ANALISIS HASIL
Bab ini berisi hasil dari implementasi sistem yang telah dibuat dan pembahasan yang mencakup analisis hasil dari penelitian yang telah dilakukan.
BAB V PENUTUP
Bab ini berisi kesimpulan yang terdiri dari rangkuman keseluruhan isi yang telah dibahas dan saran yang berisi saran penelitian untuk pengembangan penelitian.
DAFTAR PUSTAKA
Bab ini berisi semua sumber kepustakaan yang digunakan dalam penelitian baik berupa buku, jurnal, internet, dan sebagainya.
6
BAB II
TINJAUAN PUSTAKA
2.1 KDD (Knowledge Discovery in Databases)
Penambangan data atau Data Mining merupakan langkah analisis terhadap proses penemuan pengetahuan di dalam basis data atau knowledge discovery in databases yang disingkat KDD. Tahapan yang terdapat dalam KDD yaitu :
1. Pembersihan data (data cleaning), untuk menghilangkan noise dan data yang tidak konsisten.
2. Integrasi data (data integration), keadaan dimana terdapat sumber data yang dikombinasikan.
3. Seleksi data (data selection), dimana data relevan dengan tugas analisis yang diambil dari basis data.
4. Transformasi data (data transformation), data ditransformasikan dan dikonsolidasikan ke dalam bentuk yang sesuai dengan penambangan data dengan melakukan operasi penyederhanaan maupun agregasi.
5. Penambangan data (data mining), proses mendasar yang perlu dilakukan dimana metode cerdas diterapkan dalam menghasilkan sebuah pola data. 6. Evaluasi pola (pattern evaluation), dilakukan untuk mengidentifikasi pola
yang benar-benar menarik yang mewakili pengetahuan.
7. Presentasi pengetahuan, dimana visualisasi dan teknik representasi pengetahuan digunakan untuk menyajikan pengetahuan kepada pengguna. (Han, et al., 2011)
2.2 Penambangan Data
Penambangan data merupakan teknik yang relatif cepat dan mudah dalam menemukan pengetahuan, pola atau relasi antar data secara otomatis. Penggabungan empat disiplin ilmu komputer ini menghantarkan pengetahuan
dapat ditemukan dalam lima proses berurutan yaitu seleksi, prapemrosesan, transformasi, data mining, dan interpretasi/evaluasi. (Fayyad, et al., 1996).
Penambangan data memiliki tujuan untuk mengekstrak pengetahuan dari sekumpulan data sehingga didapat struktur yang dapat dipahami oleh manusia. Penemuan struktur dari data ini memiliki masalah dari berbagai segi yang termasuk dalam komponen basisdata dan manajemen data, prapemrosesan data, pertimbangan data dan inferensi, ukuran ketertarikan, pertimbangan kompleksitas algoritma, pascapemrosesan terhadap struktur yang ditemukan, visualisasi, dan online updating (Chakrabarti, et al., 2006).
Penggunaan teknik data mining dapat dibagi menjadi dua yaitu deskriptif dan prediktif. Deskriptif berarti data mining digunakan untuk mencari pola-pola yang dapat dipahami manusia yang menjelaskan karakteristik data. Sedangkan prediktif berarti data mining digunakan untuk membentuk sebuah model pengetahuan yang akan digunakan untuk melakukan prediksi (Suyanto, 2019). Tugas data mining dapat dikelompokkan menjadi enam bagian berdasarkan fungsionalitasnya seperti klasifikasi, klasterisasi, regresi, deteksi anomali, pembelajaran aturan asosiasi serta perangkuman (Fayyad, et al., 1996).
2.3 Klasifikasi
Klasifikasi merupakan bagian penting dalam data mining yang digunakan untuk memprediksi label atau kelas dari model yang telah dipelajari sebelumnya (Zaki & Jr., 2013). Melalui pendekatan teknik klasifikasi ini data-data yang telah dipelajari kemudian akan menghasilkan suatu pola atau aturan. Selanjutnya dari pola yang didapat, data baru yang belum pernah dipelajari sebelumnya dapat diklasifikasi berdasarkan pola tersebut.
Model klasifikasi dapat dibangun berdasarkan pengetahuan seorang pakar(ahli). Namun, mengingat himpunan data yang relatif besar, model klasifikasi lebih sering dibangun menggunakan teknik pembelajaran dalam
bidang machine learning. Proses pembelajaran secara otomatis terhadap suatu himpunan data mampu menghasilkan model klasifikasi (fungsi target) yang memetakan objek data x (input) ke salah satu kelas y yang telah didefinisikan sebelumnya. Jadi, proses pembelajaran memerlukan masukan (input) berupa himpunan data latih (training set) yang berlabel (memiliki atribut kelas) dan mengeluarkan output yang berupa model klasifikasi (Suyanto, 2019). Terdapat banyak model klasifikasi yang dapat digunakan seperti decision tree, probabilistic classifiers, support vector machines, dan sebagainya (Zaki & Jr., 2013).
2.4 Support Vector Machine
Support vector machine merupakan metode klasifikasi berdasarkan pada diskriminan linear margin maksimum, tujuannya adalah untuk mencari hyperplane dengan memaksimalkan jarak atau margin antar kelas. Kita dapat menggunakan kernel trick untuk mencari batas keputusan nonlinear yang optimal antar kelas yang berhubungan dengan hyperplane dalam beberapa ruang dimensi “nonlinear” (Zaki & Jr., 2013).
Vapnik memperkenalkan SVM pada tahun 1992 sebagai suatu teknik klasifikasi yang efisien untuk masalah nonlinier. SVM hanya menemukan satu hyperplane yang posisinya tepat di tengah-tengah antara dua kelas. Jadi, hyperplane tersebut membelah himpunan data menjadi dua kelas secara sama. Artinya, jarak antara hyperplane dengan objek-objek data berbeda kelas yang berdekatan (terluar). Mengapa harus memaksimalkan margin ? Tujuannya yaitu agar memiliki kemampuan generalisasi yang tinggi terhadap data-data yang akan datang (Suyanto, 2019).
(a) (b)
Gambar 2.1 Hyperplane yang mungkin untuk set data (Nugroho, et al., 2003)
Konsep dasar dari proses pelatihan pada SVM yaitu untuk mencari lokasi hyperplane. Pilihan untuk menemukan hyperplane yang mungkin untuk suatu set data dapat terlihat seperti pada gambar 2.1(a), sedangkan hyperplane dengan margin paling maksimal terdapat pada gambar 2.1(b). Hyperplane terbaik antara kedua kelas dapat ditemukan dengan mengukur margin hyperplane dan kemudian mencari titik maksimalnya. Margin adalah jarak antara hyperplane tersebut dengan data terdekat dari masing-masing kelas. Data yang paling dekat ini disebut sebagai support vector (Prasetyo, 2014).
Seperti yang terlihat pada Gambar 2.2, SVM bekerja untuk menemukan hyperplane dengan margin yang maksimal. Hyperplane klasifikasi linier memisahkan kedua kelas dengan persamaan :
𝑤. 𝑥𝑖+ 𝑏 = 0 (2.1)
Keterangan : w = vector bobot
x = nilai masukan atribut b = bias
Sehingga didapatkan persamaan untuk kelas positif dan kelas negatif. Pada kelas positif (+1), sehingga suatu data 𝑥𝑖 dapat diklasifikasikan sebagai kelas +1 jika
𝑤. 𝑥𝑖+ 𝑏 > 1 (2.2)
dan dapat diklasifikasikan sebagai kelas -1 jika
𝑤. 𝑥𝑖+ 𝑏 ≤ −1 (2.3)
Margin hyperplane terbaik dapat ditemukan dengan memaksimalkan nilai jarak antara hyperplane dengan titik terdekatnya menggunakan rumus
1
‖𝑤‖. Selanjutnya dapat dirumuskan sebagai Quadratic Programming (QP)
problem untuk mencari titik minimal persamaan 𝑚𝑖𝑛 𝑤 → 𝜏(𝑤) =1 2‖𝑤‖ 2 (2.4) 𝑦𝑖(𝑥𝑖 ∙ 𝑤 + 𝑏) − 1 ≥ 0 (2.5)
Permasalahan ini dapat diselesaikan dengan menggunakan berbagai cara, salah satunya menggunakan Lagrange Multiplier.
𝐿(𝑤, 𝑏, 𝛼) = 1 2‖𝑤‖ 2− ∑ 𝛼 𝑖(𝑦𝑖(𝑥𝑖 ∙ 𝑤 + 𝑏) − 1), 𝑖 = 1,2, … , 𝑙 𝑙 𝑖=1 (2.6)
Dengan 𝑎𝑖 ≥ 0 adalah Lagrange multipliers, nilai optimal dari persamaan tersebut dapat dihitung dengan meminimalkan L terhadap w dan b sekaligus memaksimalkan L terhadap 𝑎𝑖. Dengan diketahui titik optimal gradient L = 0, maka persamaan (2.6) dapat dimodifikasi dengan memaksimalkan ∑𝑙𝑖=1𝑎𝑖 −1 2∑ 𝑎𝑖𝑎𝑗𝑦𝑖𝑦𝑗𝑥𝑖𝑥𝑗 𝑙 𝑖,𝑖=1 (2.7) 𝑎𝑖 ≥ 0(𝑖 = 1,2, … 𝑙) ∑𝑙𝑖=1𝑎𝑖𝑦𝑖 = 0 (2.8)
Maksimalisasi ini menghasilkan sejumlah 𝑎𝑖 yang bernilai positif.
Data-data yang berhubungan dengan 𝑎𝑖 positif inilah yang disebut sebagai
support vector. Fungsi pemisah dapat didefinisikan sebagai berikut.
g(x) := sgn(f(x)) (2.9)
Dengan f(x) = wTx + b (2.10)
(Santosa, n.d.)
Berikut illustrasi cara kerja Support Vector Machine dengan data seperti pada Tabel 2.1.
Tabel 2.1 Contoh data sampel
x1 x2 yi
4 4 1
6 4 -1
4 6 -1
4 8 1
Terdapat dua atribut x1 dan x2 yang akan menghasilkan dua bobot yaitu w1
dan w2. Kemudian margin diminimalkan menggunakan rumus pada
persamaan 2.4 dengan syarat sebagai berikut.
yi(w1 . xi + w1 . xi +b) ≥ 1 (2.12)
Sehingga diperoleh persamaan sebagai berikut.
(1) 1 ( 4w1 + 4w2 + b ) ≥ 1 → ( 4w1 + 4w2 + b ) ≥ 1
(2) -1 ( 6w1 + 4w2 + b ) ≥ 1 → ( -6w1 -4w2 - b ) ≥ 1
(3) -1 ( 4w1 + 6w2 + b ) ≥ 1 → ( -4w1 -6w2 - b ) ≥ 1
(4) 1 ( 4w1 + 8w2 + b ) ≥ 1 → ( 4w1 + 8w2 + b ) ≥ 1
Selanjutnya yaitu mencari nilai w dan b dari persamaan (1) dan (2) sebagai berikut. + (-6𝑤1-4𝑤2- b ) ≥ 1 ( 4𝑤1+ 4𝑤2+ b ) ≥ 1 𝑤 −2𝑤1 = 2 1 = −1
Kemudian mencari nilai w dan b dari persamaan (3) dan (4) sebagai berikut. +
( 4𝑤1 + 8𝑤2 + b ) ≥ 1
( −4𝑤1 −6𝑤2 − b ) ≥ 1 2𝑤2= 2 𝑤2 = 1
Sehingga nilai b yang didapat dari persamaan (1) dan (4) yaitu : + (4𝑤1 + 8𝑤2 + b ) ≥ 1 ( 4𝑤1+ 4𝑤2+ b ) ≥ 1 8𝑤1+ 12𝑤2+ 2𝑏 = 2 8(−1) + 12(1) + 2𝑏 = 2 −8 + 12 + 2𝑏 = 2 2𝑏 = 2 − 4 2𝑏 = −2 𝑏 = −1 Persamaan hyperplane menjadi :
𝑤1𝑥1+ 𝑤2𝑥2+ 𝑏 = 0 −1𝑥1+ 1𝑥2− 1 = 0
𝑥2− 1 = 𝑥1
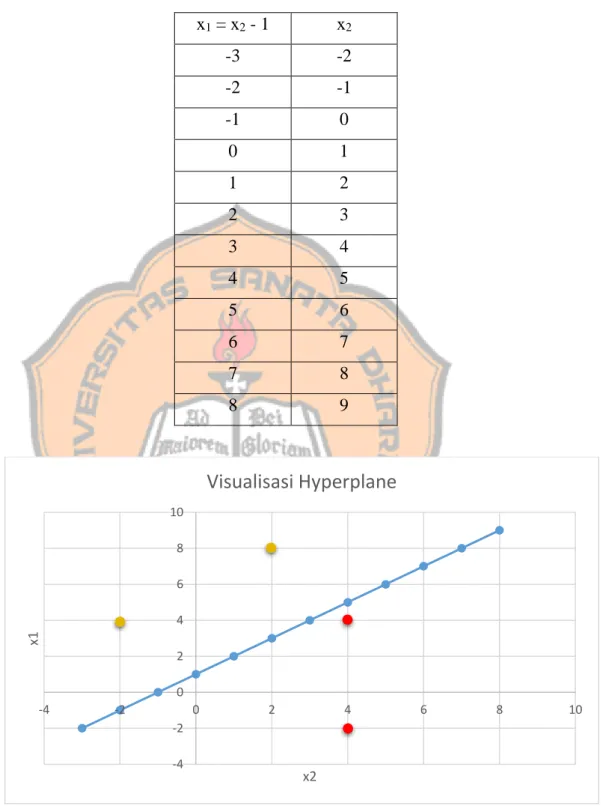
Selanjutnya dibuat plot hyperplane dengan fungsi -x1 + x2 – 1 menggunakan
Tabel 2.2 Plot hyperplane x1 = x2 - 1 x2 -3 -2 -2 -1 -1 0 0 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9
Gambar 2.3 Visualisasi hyperplane data uji
Setelah ditentukan garis hyperplane seperti pada Gambar 2.3, maka langkah selanjutnya yaitu mengklasifikasikan data uji melalui hyperplane
-4 -2 0 2 4 6 8 10 -4 -2 0 2 4 6 8 10 x1 x2
Visualisasi Hyperplane
dengan menggunakan fungsi f(x) = -x1 + x2 – 1 dengan g(x) := sgn(f(x)).
Gambar 2.3 menunjukkan garis hyperplane yang memisahkan hasil data uji yang terdapat pada Tabel 2.3 dengan label kelas positif disimbolkan dengan warna kuning dan kelas negatif dengan warna merah.
Tabel 2.3 Hasil Klasifikasi
No X1 X2 Hasil Klasifikasi ( Kelas = sgn(f(x)) ) 1 4 4 Sgn(-4 + 4 -1) = -1
2 2 8 Sgn(-2 + 8 -1) = 1 3 -2 4 Sgn(-(-2) + 4 -1) = 1 4 4 -2 Sgn(-4 + (-2) -1) = -1
Pada pembelajaran SVM, mudah untuk menyelesaikan masalah secara linier. Tetapi pada kenyataannya masalah yang dihadapi dalam kondisi nyata adalah masalah non-linier. Sehingga SVM dimodifikasi sedemikian rupa dengan memasukkan fungsi kernel. Dalam fungsi non-linier, SVM pertama-tama akan memetakan data 𝑥 menggunakan fungsi Φ(𝑥⃑) ke ruang vektor yang berdimensi lebih tinggi. Seperti terlihat pada Gambar 2.4 menunjukkan terdapat data berdimensi dua yang tidak dapat dipisahkan secara linier. Selanjutnya fungsi Φ akan memetakan setiap data tersebut ke ruang vektor baru yang berdimensi lebih tinggi atau berdimensi tiga. Sehingga kedua kelas dapat terpisah secara linier oleh sebuah hyperplane.
Pada umumnya terdapat empat fungsi kernel yang dapat digunakan yaitu : 1. Kernel Linier 𝐾(𝑥, 𝑥𝑖) = 𝑥𝑘𝑇𝑥 (2.13) 2. Kernel Polynomial 𝐾(𝑥, 𝑥𝑘) = (𝑥𝑘𝑇𝑥 + 1)𝑑 (2.14)
3. Kernel Gaussian (Radial Basis Function, RBF)
𝐾(𝑥, 𝑥𝑘) = exp {−‖𝑥 − 𝑥𝑘‖22/𝜎2} (2.15)
4. Kernel Sigmoid
𝐾(𝑥, 𝑥𝑘) = tanh [𝜅𝑥𝑘𝑇𝑥 + 𝜃] (2.16) Fungsi kernel dapat memberi kemudahan karena hanya perlu untuk
mengetahui fungsi kernel yang dipakai untuk menentukan support vector. Kemudian SVM akan melakukan proses klasifikasi sebuah objek data x yang
diformulasikan dengan persamaan :
𝑓(𝑥) = ∑𝑛𝑖=1,𝑥𝑖 𝜖 𝑆𝑉𝑎𝑖𝑦𝑖𝐾(𝑥, 𝑥𝑖) + 𝑏 (2.17) SV merupakan objek-objek data pada himpunan data latih yang terpilih sebagai support vector (Suyanto, 2019).
2.5 Multi Class SVM
SVM hanya dapat mengklasifikasikan data ke dalam dua kelas pada saat pertama kali diperkenalkan oleh Vapnik pada tahun 1992. Setelah berkembangnya riset dan penelitian, SVM dapat berkembang menjadi multi kelas (multi class) yang artinya teknik ini dapat mengklasifikasikan lebih dari dua kelas. Dalam mengimplementasikan SVM multi kelas dapat menggunakan dua pendekatan, yaitu dengan menggabungkan beberapa SVM biner dan yang kedua yaitu menggabungkan semua data dari semua kelas ke dalam sebuah bentuk permasalahan optimasi (Suyanto, 2019). Metode dengan pendekatan pertama yaitu :
2.5.1 One-against-all
Metode ini menggunakan prinsip satu lawan semua dengan membandingkan satu kelas dengan semua kelas lainnya. Ketika akan
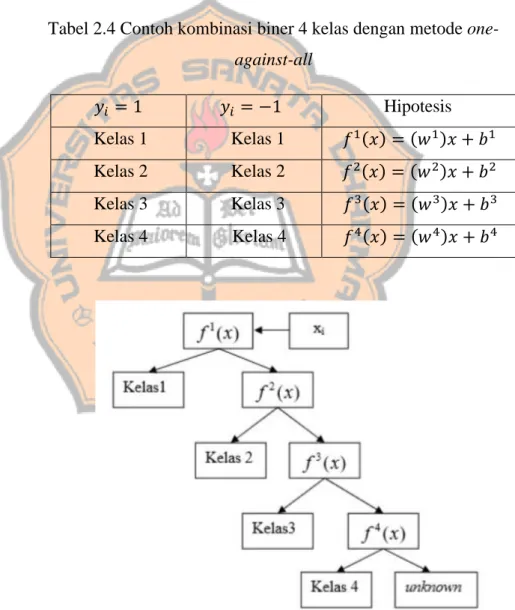
melakukan klasifikasi data ke dalam k kelas, maka harus dibangun pula sejumlah k model SVM biner. Setiap model biner SVM ke-i akan dilatih dengan menggunakan keseluruhan data agar ditemukan apakah merupakan bagian dari kelas ke-i atau bukan ketika diklasifikasikan. Sebagai contoh, ketika akan mengklasifikasikan ke dalam 4 kelas maka perlu dibangun pula 4 buah SVM biner seperti terlihat pada Tabel 2.4 dan Gambar 2.5. Kemudian SVM biner yang pertama dilatih dengan dengan menggunakan semua data latih.
Tabel 2.4 Contoh kombinasi biner 4 kelas dengan metode one-against-all 𝑦𝑖 = 1 𝑦𝑖 = −1 Hipotesis Kelas 1 Kelas 1 𝑓1(𝑥) = (𝑤1)𝑥 + 𝑏1 Kelas 2 Kelas 2 𝑓2(𝑥) = (𝑤2)𝑥 + 𝑏2 Kelas 3 Kelas 3 𝑓3(𝑥) = (𝑤3)𝑥 + 𝑏3 Kelas 4 Kelas 4 𝑓4(𝑥) = (𝑤4)𝑥 + 𝑏4
Gambar 2.5 Skema klasifikasi dengan metode one-against-all (Wicaksono, 2017)
2.5.2 One-against-one
Metode one against one atau satu lawan satu ini akan membandingkan satu kelas dengan kelas lainnya dalam membangun sejumlah model SVM. Ketika akan melakukan klasifikasi data ke dalam k kelas, maka diharuskan untuk membangun sejumlah model dengan rumus sebagai berikut.
𝑘(𝑘−1)
2 (2.18)
Keterangan : k = jumlah kelas (Suyanto, 2019)
Sehingga jika akan membangun sejumlah SVM biner dengan 4 kelas maka yang harus dibuat yaitu 4(4−1)
2 = 6 buah biner SVM.
Sehingga setiap kelas harus dibandingkan dengan kelas lainnya seperti pada Tabel 2.5. Voting dapat dilakukan untuk mendapatkan kelas keputusan. Berikut ilustrasi klasifikasi dengan 4 buah jumlah kelas.
Tabel 2.5 Contoh kombinasi biner dengan metode one-against-one 𝑦𝑖 = 1 𝑦𝑖 = −1 Hipotesis Kelas 1 Kelas 2 𝑓12(𝑥) = (𝑤12)𝑥 + 𝑤12 Kelas 1 Kelas 3 𝑓13(𝑥) = (𝑤13)𝑥 + 𝑤13 Kelas 1 Kelas 4 𝑓14(𝑥) = (𝑤14)𝑥 + 𝑤14 Kelas 2 Kelas 3 𝑓23(𝑥) = (𝑤23)𝑥 + 𝑤23 Kelas 2 Kelas 4 𝑓24(𝑥) = (𝑤24)𝑥 + 𝑤24 Kelas 3 Kelas 4 𝑓34(𝑥) = (𝑤34)𝑥 + 𝑤34
Setelah kombinasi kelas biner terbentuk, selanjutnya dilakukan perbandingan tiap kelas. Pada Gambar 2.6 kelas f12(x) ditentukan masuk ke dalam kelas 1 atau 2, diasumsikan pada contoh ditentukan
masuk pada kelas 1. Hal yang sama dilakukan pula pada kelas biner yang lainnya. Sehingga setelah semua kelas biner mendapat kelas keputusan kemudian dilakukan voting dengan kelas mana yang mendapat hasil terbanyak. Pada contoh Gambar 2.6 kelas 1 mendapat voting terbanyak, sehingga hasil klasifikasi yang didapatkan yaitu pada kelas 1.
Gambar 2.6 Skema klasifikasi menggunakan metode one-against-one (Wicaksono, 2017)
2.6 Information Gain
Information gain merupakan salah satu metode seleksi fitur yang banyak dipakai oleh peneliti untuk menentukan batas dari kepentingan sebuah atribut. Nilai information gain diperoleh dari nilai entropi sebelum pemisahan dikurangi dengan nilai entropi setelah pemisahan. Pengukuran nilai ini hanya digunakan sebagai tahap awal untuk penentuan atribut yang nantinya akan digunakan atau dibuang. Atribut yang memenuhi kriteria pembobotan yang nantinya akan digunakan dalam proses klasifikasi sebuah algoritma (Maulana & Al Karomi, 2016). Pemilihan fitur dengan information gain dilakukan dalam 3 tahapan, yaitu:
1. Menghitung nilai information gain untuk setiap atribut dalam dataset original.
2. Tentukan batas (treshold) yang diinginkan. Hal ini akan memungkinkan atribut yang berbobot sama dengan batas atau lebih besar akan dipertahankan serta membuang atribut yang berada dibawah batas. 3. Dataset diperbaiki dengan pengurangan atribut.
Berikut rumus untuk menghitung Information Gain :
Gain(A) = I (D) – I (A) (2.19) Keterangan :
A : atribut
D : jumlah seluruh sampel data Gain (A) : information atribut A I (D) : total entropi
I (A) : entropi A
Untuk mendapatkan nilai total entropi A, digunakan rumus :
info(D) = ∑𝑚𝑖=1𝑝𝑖 log2(𝑝𝑖) (2.20) Keterangan :
m : jumlah kelas klasifikasi
i : maksimal nilai pada atribut target pi : jumlah sampel untuk kelas i
Untuk mendapatkan nilai entropi A, digunakan rumus : infoA(D) = ∑ |𝐷𝑗|
𝐷 𝑥 𝑖𝑛𝑓𝑜(𝐷𝑖) 𝑣
𝑗=1 (2.21)
Keterangan :
v : suatu nilai yang mungkin untuk atribut A j : nilai maksimal yang mungkin untuk atribut A |Dj| : jumlah sampel untuk nilai j
D : jumlah seluruh sampel data Di : jumlah sampel untuk kelas i
2.7 K-Fold Cross Validation
Model klasifikasi yang dibangun dengan menggunakan teknik pembelajaran dapat digunakan metode k-fold cross-validation untuk mempartisi data. Himpunan data D dipartisi secara acak menjadi k fold (sub himpunan) yang saling bebas: f1, f2, … fk, sehingga masing-masing fold berisi 1/k bagian data. Selanjutnya dapat dibangun k himpunan data: D1, D2, … Dk yang masing-masing berisi (k-1) fold untuk data latih dan 1 fold untuk data uji. Misalnya, dengan menggunakan k=5 maka akan didapatkan himpunan data D1 berisi empat fold: f2, f3, f4, dan f5 untuk data latih serta satu fold f1 untuk data uji. Himpunan data D2 berisi fold f1, f3, f4 dan f5 sebagai data latih sementara f2 digunakan sebagai data uji. Begitu pula seterusnya untuk himpunan data D3, D4, dan D5. Tidak hanya sebatas dua himpunan saja, k fold dapat dibangun menjadi tiga himpunan yang terdiri dari data latih, data validasi dan data uji. Sehingga masing-masing berisi (k-2) fold untuk data latih, 1 fold untuk data validasi dan 1 fold untuk data uji. Pada umumnya, penggunaan k=10 lebih banyak digunakan karena akan mendapatkan akurasi dengan bias dan variansi yang lebih relatif rendah. Dengan menggunakan metode k-fold cross-validation, dapat digunakan untuk mengukur kualitas dari model klasifikasi yang dibangun (Suyanto, 2019). Berikut diilustrasikan pembagian data menggunakan 3-Fold Cross Validation yang membagi data menjadi 1
3 data testing dan 2
3 data training.
Gambar 2.7 Skema pembagian data 3-Fold Cross Validation Keterangan :
Testing set Training set
Dataset Fold 1 Fold 2 Fold 3 Dataset Fold 1 Fold 2 Fold 3 Dataset Fold 1 Fold 2 Fold 3
2.8 Confusion Matrix
Confusion matrix merupakan ukuran evaluasi untuk menilai kualitas classifier. Confusion matrix menyatakan jumlah data uji yang benar diklasifikasikan dan jumlah data uji yang salah diklasifikasikan. Terdapat beberapa ukuran yang dapat digunakan dalam menilai atau mengevaluasi model klasifikasi seperti accuracy atau tingkat pengenalan, error rate atau tingkat kesalahan, recall atau sensitivity atau true positive rate, specificity atau true negative rate, precision, F-measure atau F1 atau F-score atau
rata-rata harmonik dari precision dan recall, serta Fβ (Han, et al., 2012).
Tabel 2.6 Ukuran evaluasi model klasifikasi
No Ukuran Rumus
1 Accuracy atau tingkat pengenalan 𝑇𝑃 + 𝑇𝑁
𝑃 + 𝑁
2 Error rate atau tingkat kesalahan 𝐹𝑃 + 𝐹𝑁
𝑃 + 𝑁
3 Recall atau true positive rate 𝑇𝑃
𝑃
4 Specificity atau true negative 𝑇𝑁
𝑁
5 Precision 𝑇𝑃
𝑇𝑃 + 𝐹𝑃
6 F atau F1 2 𝑥 𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 𝑥 𝑟𝑒𝑐𝑎𝑙𝑙
𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 + 𝑟𝑒𝑐𝑎𝑙𝑙 7 Fβ, di mana β adalah sebuah bilangan
riil non-negatif
(1 + 𝛽2) 𝑥 𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 𝑥 𝑟𝑒𝑐𝑎𝑙𝑙 𝛽2 𝑥 𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 + 𝑟𝑒𝑐𝑎𝑙𝑙
Terdapat beberapa istilah penting dalam memahami ukuran evaluasi di atas yaitu :
• TP atau True Positives adalah jumlah tuple positif yang dilabeli dengan benar oleh classifier.
• TN atau True Negative adalah jumlah tuple negatif yang dilabeli dengan benar oleh classifier.
• FP atau False Positives adalah jumlah tuple negatif yang salah dilabeli oleh classifier.
• FN atau False Negative adalah jumlah tuple positif yang salah dilabeli oleh classifier.
Istilah-istilah tersebut dapat digambarkan sebagai confusion matrix seperti gambar berikut ini.
Tabel 2.7 Confusion Matrix Kelas hasil Prediksi
Ya Tidak Jumlah
Kelas aktual Ya TP FN P
Tidak FP TN N
Jumlah P’ N’ P + N
TP dan TN menyatakan bahwa classifier mengenali tuple dengan benar, yang berarti tuple positif dikenali sebagai positif dan tuple negatif dikenali sebagai negatif. Sebaliknya, FP dan FN menyatakan bahwa classifier salah dalam mengenali tuple, tuple negatif dikenali sebagai positif dan tuple negatif dikenali sebagai posititf. P’ adalah jumlah tuple yang diberi label positif(TP + FP) sedangkan N’ adalah jumlah tuple yang diberi label negatif (TN + FN). Sementara itu, jumlah keseluruhan tuple dapat dinyatakan sebagai (TP + TN + FP + FN) atau (P + N) atau (P’ + N’) (Suyanto, 2019).
2.9 Normalisasi
Keberagaman nilai atribut dalam suatu dataset seringkali membuat suatu atribut dapat mendominasi seluruh dataset. Sehingga diperlukan adanya normalisasi agar setiap atribut dalam dataset memiliki bobot yang sama. Normalisasi adalah proses transformasi dimana sebuah atribut numerik diskalakan dalam range yang lebih kecil seperti -1.0 sampai 1.0, atau 0.0
sampai 1.0 (Junaedi, et al., 2011). Terdapat beberapa metode yang dapat diterapakan untuk menormalisasi data, salah satunya yaitu min-max dan z-score.
2.9.1 Normalisasi Min-Max
Metode min-max merupakan metode yang sering dipergunakan dalam menormalisasi data. Metode normalisasi ini merupakan metode yang paling sederhana dengan melakukan transformasi linier terhadap data asli dan memiliki kelebihan yaitu terdapat keseimbangan nilai perbandingan antara nilai data sebelum dinormalisasi dengan nilai data yang telah dinormaliasi (Rofiqoh, et al., 2017). Berikut rumus yang digunakan dalam normalisasi min-max :
𝑣′= 𝑣−𝑚𝑖𝑛𝐴
𝑚𝑎𝑥𝐴−𝑚𝑖𝑛𝐴(𝑛𝑒𝑤_𝑚𝑎𝑥𝐴 − 𝑛𝑒𝑤_𝑚𝑖𝑛𝐴) + 𝑛𝑒𝑤_𝑚𝑖𝑛𝐴 (2.22) Keterangan :
v : value (data asli) v’ : nilai value baru A : atribut
maxA, minA : nilai value maksimum dan minimum dalam data asli new_maxA, new_minA : rentang nilai value maximum dan minimum yang sudah dinormalisasi, contoh [1,0]
Implementasi dari perhitungan normalisasi min-max dapat dijabarkan seperti dalam contoh berikut ini yang menggunakan contoh data sampel pada Tabel 2.8.
Normalisasi atribut X1 data ke-1 8.4 − 7
Normalisasi atribut X2 data ke-1 3 − 0
4 − 0(1 − 0) + 0 = 0.75
Tabel 2.8 Sampel data sebelum dinormalisasi
Dat a X1 X2 1 8.4 3 2 8.3 2 3 8 1 4 7 0 5 8 4
Setelah dilakukan normalisasi min-max, hasil transformasi data tampil seperti pada Tabel 2.9.
Tabel 2.9 Sampel data setelah dinormalisasi min-max
Data X1 X2 1 1 0.75 2 0.93 0.50 3 0.71 0.25 4 0 0 5 0.71 1 2.9.2 Normalisasi Z-Score
Normalisasi z-score atau disebut juga zero-mean normalization merupakan normalisasi yang dimana nilai dari sebuah atribut A dinormalisasi berdasarkan nilai rata-rata dan standar deviasi dari atribut A (Hardiani, et al., n.d.). Berikut rumus yang digunakan dalam normalisasi z-score :
𝑣′= 𝑣−𝐴̅
Keterangan :
v : value (data asli) v’ : nilai value baru
𝐴̅ : nilai rata-rata atribut A 𝜎𝐴 : standar deviasi atribut A
Implementasi dari perhitungan normalisasi z-score dapat dijabarkan seperti dalam contoh berikut ini yang menggunakan contoh data sampel pada Tabel 2.8.
Hitung nilai rata-rata atribut X1 𝑋1
̅̅̅̅ = 8.4+8.3+8+7+8
5 = 7.94
Hitung nilai standar deviasi atribut X1
Data X1 X12 1 8.4 70.56 2 8.3 68.89 3 8 64 4 7 49 5 8 64 Jumlah 39.7 316.45 𝜎𝑋1 = √∑ 𝑋1 2−(∑ 𝑋1)2 𝑛 𝑛 − 1 = √316.45 −(39.7) 2 5 5 − 1 = √316.45 − 315.218 4 = √0.308 = 0.55
Keterangan :
n : jumlah data
Normalisasi atribut X1 data ke-1 menggunakan rumus 2.23
𝑣′= 8.4 − 7.94
0.55 = 0.83
Setelah dilakukan normalisasi z-score, hasil transformasi data tampil seperti pada Tabel 2.10.
Tabel 2.10 Sampel data setelah dinormalisasi z-score
Data X1 X2 1 0.83 0.63 2 0.65 0.00 3 0.11 -0.63 4 -1.69 -1.26 5 0.11 1.26
2.10 Varietas Kopi Arabika
Persebaran kopi arabika di dunia saat ini telah berkembang varietasnya dan sangat variatif. Proses penanaman dan lokasi tanam yang berbeda mengakibatkan mutu cita rasa kopi arabika berbeda pula. Ukuran cita rasa kopi yang biasa digunakan meliputi aroma, flavor, aftertaste, acidity, body, sweetness, cniformity, clean cup, balance, defect, serta overall (Team, 2007). Beragam varietas kopi yang telah dikenal di seluruh dunia dikelompokkan menjadi 4 jenis utama :
• Bourbon-Typica Group • Ethiopian Landrace • Introgressed
• F1 Hybrids (Research, 2018)
Seperti terlihat pada keempat kelompok varietas kopi diatas, pada penelitian ini akan digunakan kelompok varietas turunan dari kelompok Bourbon-Typica Group. Dalam Bourbon Typica Group sendiri terdapat 23 turunan yang terdiri dari 3 kategori yaitu Bourbon (Bourbon, Bourbon Mayaguez, Caturra, Jackson, K7, KP423, Pacas, SL28, Tekisic, Venecia, Villa Sarchi), Typica (Harrar Rwanda, Maragogipe, Mibirizi, Nyasaland, Pache, Pp3303/21, SL14, SL34, Typica) dan Bourbon and Typica (Catuai, Mundo Novo, Pacamara) (Research, 2018). Dalam penelitian ini akan digunakan 3 turunan dari kategori Bourbon dan Typica, ketiga turunan tersebut yaitu :
• Bourbon
Kopi ini dikenal sebagai kopi yang berkualitas tinggi. Bourbon memiliki ciri seperti relatif rendahnya tingkat produksi, mudah terpengaruh oleh penyakit, dan kualitas cangkir yang sangat baik. • Caturra
Caturra merupakan tanaman dengan potensi hasil yang tinggi dari standar di bagian Amerika Tengah. Kopi ini sangat rentan terhadap karat daun kopi.
• Typica
Typica merupakan salah satu kopi arabika yang penting secara budaya dan genetis dengan kualitas tinggi di bagian Amerika Tengah. Kopi ini memiliki kerentanan yang sangat tinggi terhadap karat daun, tetapi dapat beradaptasi dengan baik pada kondisi terdingin.
(Research, 2019) 2.11 Pengujian Mutu Kopi
Standar umum pengujian mutu pada biji kopi dapat dilakukan dua acara yaitu mutu fisik dan mutu cita rasa. Pengujian berdasarkan mutu fisik merupakan suatu sistem yang digunakan untuk menilai kualitas dari biji kopi berdasarkan fisiknya, baik menggunakan alat bantu atau menggunakan indra manusia sesuai dengan standar yang berlaku. Standar yang digunakan dapat
berdasarkan Standar Nasional Indonesia(SNI) atau Specialty Coffee Association of America (SCAA) untuk specialty coffee. Sedangkan pengujian berdasarkan mutu cita rasa ditentukan berdasar uji organoleptik (analisis sensorial) oleh panelis (Team, 2007)
2.12 Pengujian Mutu Cita Rasa Kopi SCAA
Standar pengujian mutu cita rasa yang dianjurkan oleh SCAA bertujuan sebagai pedoman yang memastikan kemampuan untuk menilai kualitas kopi secara akurat. Proses pengujian ini menggunakan gelas cupping sebagai alat bantu. Ketentuan gelas cupping yang digunakan untuk menilai berdasarkan rekomendasi SCAA yaitu memiliki bahan kaca atau keramik. Harus diantara 7-9 ons cairan (207ml hingga 266ml), dengan diameter atas antara 3 sampai 3.5 inci (76mm-89mm). Semua cangkir yang digunakan harus memiliki volume, dimensi dan bahan pembuatan yang identik serta memiliki tutup. Selain itu konsentrasi air yang digunakan kurang lebih 125-175 ppm (SCAA, 2015). Ketentuan persiapan pengujian yang telah dijabarkan merupakan hanya sebagian kecil dari protokol yang terdapat dalam cupping protocol SCAA.
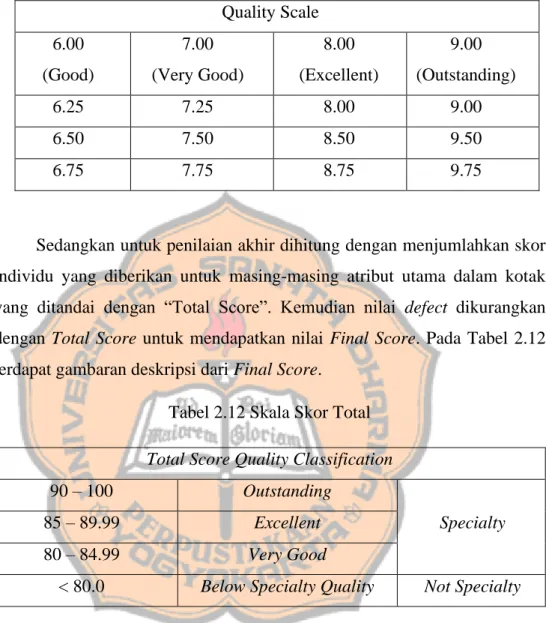
Prosedur penilaian dilakukan dengan menggunakan SCAA Cupping Form yang tampak pada Gambar 2.8 pada form ini diisikan dengan skala kualitas seperti yang tertera pada Tabel 2.11. Skor penilaian berupa nilai numerik dengan skala 6 sampai 9.
Tabel 2.11 Skala Kualitas Quality Scale 6.00 (Good) 7.00 (Very Good) 8.00 (Excellent) 9.00 (Outstanding) 6.25 7.25 8.00 9.00 6.50 7.50 8.50 9.50 6.75 7.75 8.75 9.75
Sedangkan untuk penilaian akhir dihitung dengan menjumlahkan skor individu yang diberikan untuk masing-masing atribut utama dalam kotak yang ditandai dengan “Total Score”. Kemudian nilai defect dikurangkan dengan Total Score untuk mendapatkan nilai Final Score. Pada Tabel 2.12 terdapat gambaran deskripsi dari Final Score.
Tabel 2.12 Skala Skor Total Total Score Quality Classification
90 – 100 Outstanding
Specialty
85 – 89.99 Excellent
80 – 84.99 Very Good
31
BAB III
METODOLOGI PENELITIAN 3.1 Data
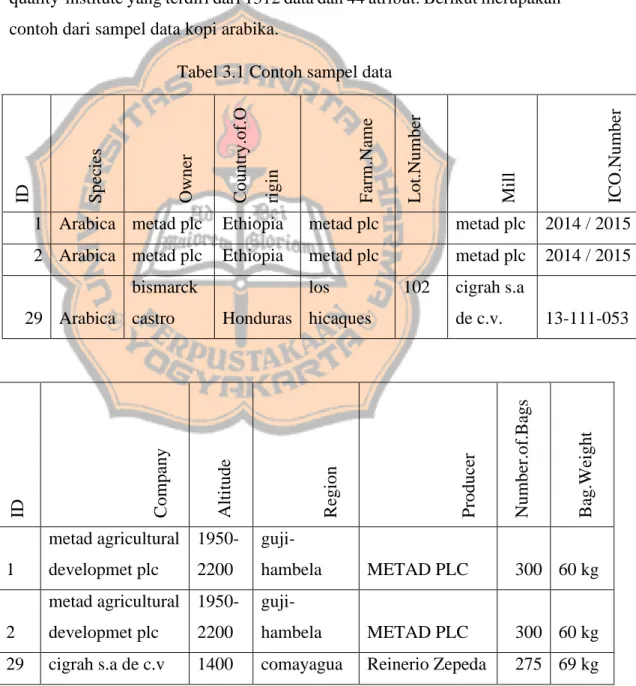
Pada penelitian ini digunakan data Coffee Bean Review yang diperoleh dari Coffee Quality Institute dan dapat diakses di : https://www.kaggle.com/ankurchavda/coffee-beans-reviews-by-coffee-quality-institute yang terdiri dari 1312 data dan 44 atribut. Berikut merupakan contoh dari sampel data kopi arabika.
Tabel 3.1 Contoh sampel data
ID Company Alti tude R egion P roduc er Numbe r.of .B ags B ag.W eight 1 metad agricultural developmet plc 1950-2200 guji-hambela METAD PLC 300 60 kg 2 metad agricultural developmet plc 1950-2200 guji-hambela METAD PLC 300 60 kg
29 cigrah s.a de c.v 1400 comayagua Reinerio Zepeda 275 69 kg
ID Spe cies Ow ne r C ountry.of .O rigin Farm.N ame Lot.Numbe r Mil l ICO.N umber
1 Arabica metad plc Ethiopia metad plc metad plc 2014 / 2015 2 Arabica metad plc Ethiopia metad plc metad plc 2014 / 2015
29 Arabica bismarck castro Honduras los hicaques 102 cigrah s.a de c.v. 13-111-053
ID In.Country.Par tner Ha rve st.Y ea r Gr ading.Da te Ow ne r.1 Va rie ty P roc essi ng.Me thod 1 METAD Agricultural Development plc 2014 April 4th, 2015 metad plc Washed / Wet 2 METAD Agricultural Development plc 2014 April 4th, 2015 metad plc Other Washed / Wet 29 Instituto Hondureño del Café 2016 May 18th, 2017 Bismarck Castro Caturra ID Ar oma F lavor Af ter taste Ac idi ty B ody B alanc e Unifo rmity C lea n.C up S we etness C uppe r.Poi n ts Tota l.C up.P oint s 1 8.67 8.83 8.67 8.75 8.5 8.42 10 10 10 8.75 90.58 2 8.75 8.67 8.5 8.58 8.42 8.42 10 10 10 8.58 89.92 29 8.17 8.08 8.08 8 8.08 8 10 10 10 8.25 86.67
ID Mois ture C ategor y.One .D ef ec ts Qua ke rs C olor C ategor y.Tw o.D efe cts Expira ti on C ertific ati on.B ody 1 0.12 0 0 Green 0 April 3rd, 2016 METAD Agricultural Development plc 2 0.12 0 0 Green 1 April 3rd, 2016 METAD Agricultural Development plc 29 0.1 0 0 Green 3 May 18th, 2018
Instituto Hondureño del Café ID Certific ati on.Addr ess C er ti fic ati on.C ontac t unit _of_me asure men t alt it ude _low_mete rs alt it ude _high_m eter s alt it ude _mea n_mete r s 1 309fcf77415a3661ae83 e027f7e5f05dad786e44 19fef5a731de2db57d16 da10287413f5f99bc2dd m 1950 2200 2075 2 309fcf77415a3661ae83 e027f7e5f05dad786e44 19fef5a731de2db57d16 da10287413f5f99bc2dd m 1950 2200 2075 29 b4660a57e9f8cc613ae5 b8f02bfce8634c763ab4 7f521ca403540f81ec99 daec7da19c2788393880 m 1400 1400 1400
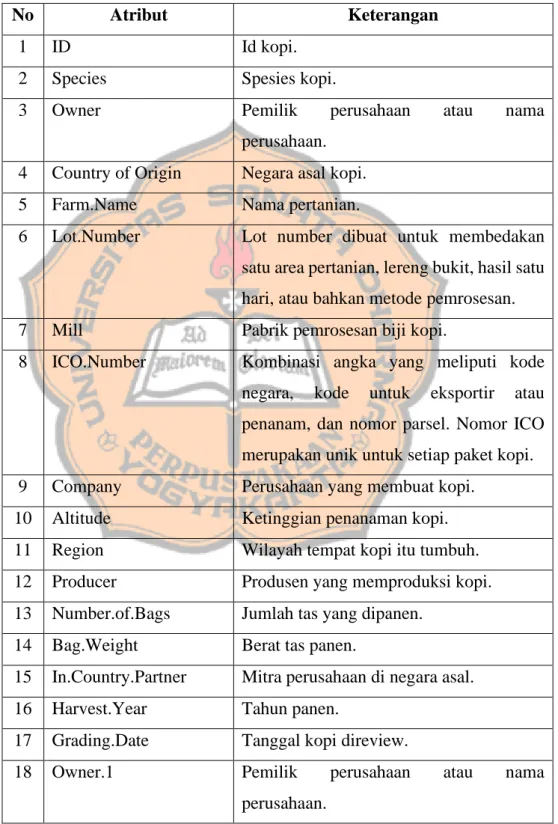
Berikut merupakan penjelasan dari setiap atribut pada sampel dataset Tabel 3.1.
Tabel 3.2 Penjelasan Atribut
No Atribut Keterangan
1 ID Id kopi.
2 Species Spesies kopi.
3 Owner Pemilik perusahaan atau nama
perusahaan. 4 Country of Origin Negara asal kopi.
5 Farm.Name Nama pertanian.
6 Lot.Number Lot number dibuat untuk membedakan satu area pertanian, lereng bukit, hasil satu hari, atau bahkan metode pemrosesan.
7 Mill Pabrik pemrosesan biji kopi.
8 ICO.Number Kombinasi angka yang meliputi kode negara, kode untuk eksportir atau penanam, dan nomor parsel. Nomor ICO merupakan unik untuk setiap paket kopi.
9 Company Perusahaan yang membuat kopi.
10 Altitude Ketinggian penanaman kopi.
11 Region Wilayah tempat kopi itu tumbuh.
12 Producer Produsen yang memproduksi kopi.
13 Number.of.Bags Jumlah tas yang dipanen.
14 Bag.Weight Berat tas panen.
15 In.Country.Partner Mitra perusahaan di negara asal.
16 Harvest.Year Tahun panen.
17 Grading.Date Tanggal kopi direview.
18 Owner.1 Pemilik perusahaan atau nama
No Atribut Keterangan
19 Variety Jenis kopi.
20 Processing.Method Metode pemrosesan yang digunakan untuk mengolah biji kopi.
21 Aroma Bau kopi setelah ditambahkan air panas.
22 Flavor Karakteristik rasa dari kopi.
23 Aftertaste Lama bertahannya suatu flavor positif (rasa dan aroma) yang berasal dari langit-langit belakang mulut dan bertahan setelah kopi ditelan.
24 Acidity Ketajaman dan keaktifan keasaman pada kopi.
25 Body Perasaan sentuhan kopi di mulut
khususnya antara lidah dan langit-langit mulut.
26 Balance Semua aspek flavor, aftertaste, acidity dan body seimbang, tidak ada satu rasa mendominasi yang lain. Jika terdapat salah satu aspek kurang atau berlebihan maka nilai balance dapat berkurang.
27 Uniformity Keseragaman yang mengacu pada
konsistensi rasa dari sampel cangkir yang berbeda.
28 Clean.Cup Kurangnya gangguan negatif dari
konsumsi pertama hingga akhir aftertaste (tidak adanya cacat rasa).
29 Sweetness Rasa manis yang mengacu pada
kepenuhan rasa yang enak serta rasa manis yang jelas. Hasil persepsi ini merupakan hasil dari adanya karbohidrat tertentu.
No Atribut Keterangan
30 Cupper.Points Aspek penilaian “keseluruhan” yang dirasakan oleh panelis.
31 Total.Cup.Points Poin yang didapatkan dengan
menjumlahkan skor individu yang kemudian dikurangi dengan jumlah cacat. 32 Moisture Jumlah cairan yang tersebar dalam jumlah kecil di dalam biji kopi hijau, jika kelembabannya stabil, biji kopi akan mempertahankan kelembabannya sampai ketika dipanggang.
33 Category.One.Defects Cacat utama pada biji kopi.
34 Quakers Biji kopi mentah, seringkali dengan
permukaan yang keriput dan tidak menjadi gelap ketika di panggang.
35 Color Warna biji kopi.
36 Category.Two.Defects Cacat minor pada biji.
37 Expiration Waktu kadaluwarsa sertifikat biji kopi. 38 Certification.Body Badan sertifikasi.
39 Certification.Address Alamat sertifikasi. 40 Certification.Contact Kontak sertifikasi.
41 unit_of_measurement Unit pengukuran ketinggian pertanian. 42 altitude_low_meters Ketinggian pertanian yang terendah. 43 altitude_high_meters Ketinggian pertanian yang tertinggi. 44 altitude_mean_meters Ketinggian pertanian rata-rata.
3.2 Desain Alat Uji
Sub bab ini berisikan tentang perancangan sistem yang akan dibangun. Proses yang terjadi dimulai dari tahap preprocessing data, training dan testing data hingga proses klasifikasi. Berikut merupakan gambaran umum dari tahapan penelitian yang dilakukan penulis.
Gambar 3.1 Tahapan Penambangan Data
Pada Gambar 3.1 menunjukkan sistem akan melakukan input dataset kopi yang kemudian dilakukan tahap preprocessing data untuk mengolah data ke dalam bentuk yang siap diproses oleh sistem. Pada tahap preprocessing dilakukan beberapa tahapan seperti seleksi data dan transformasi data, seleksi data akan menyeleksi data berdasarkan kelas dan atribut sedangkan transformasi data mengubah data kelas kedalam bentuk numerik dan kemudian dilakukan normalisasi data menggunakan normalisasi
min-max dan z-score. Setelah didapatkan dataset hasil preprocessing selanjutnya terdapat dua tahapan proses yaitu proses training dan testing.
Pada tahapan training dilakukan pemberian label pada data, yaitu 1 untuk Bourbon, 2 untuk Caturra, dan 3 untuk Typica sebagai data latih yang akan terbagi berdasarkan 3-Fold Cross Validation dengan 2/3 data akan digunakan sebagai data training. Selanjutnya data dilatih untuk menghasilkan model SVM. Model SVM yang dibangun menggunakan metode multiclass one against one dan terdapat 3 fungsi kernel yang digunakan yaitu kernel Linear, RBF dan Polynomial.
Pada tahapan testing yang menggunakan 1/3 dataset akan dilakukan klasifikasi berdasarkan model SVM yang telah dibuat pada proses training. Kemudian dilakukan perhitungan akurasi dengan menggunakan confusion matrix yang akan membagi jumlah hasil prediksi benar dengan jumlah seluruh data.
3.3 Cara Mengolah Data 3.3.1 Tahap Preprocessing
Tahapan dalam preprocessing data adalah seleksi data, transformasi data, pembersihan data, integrasi data dan normalisasi.
a. Seleksi data
Tahapan ini dilakukan untuk menyeleksi data dan menentukan atribut-atribut yang akan digunakan. Seleksi data yang dilakukan pada penelitian ini menggunakan tools Microsoft Excel dengan memilih data dengan label kelas Bourbon, Caturra dan Typica. Pada data yang tersedia terdapat 29 label kelas yang terdiri dari Arusha, Blue Mountain, Bourbon, Catuai, Caturra, Ethiopian Heirlooms, Ethiopian Yirgacheffe, Gesha, Hawaiian Kona, Java, Mandheling, Marigojipe, Moka Peaberry, Mundo Novo, Pacamara, Pacas, Pache Comun, Peaberry, Ruiru 11, SL14, SL28, SL34, Sulawesi, Sumatra, Sumatra Lintong, Typica, dan Yellow Bourbon. Dari 29 kelas yang tersedia,
pada penelitian ini hanya akan digunakan 3 kelas untuk dilakukan pengelompokkan varietas. Ketiga kelas tersebut yaitu Bourbon, Caturra dan Typica. Pemilihan ketiga kelas ini dilakukan dengan pertimbangan jumlah dataset Bourbon, Caturra dan Typica yang lebih seimbang dibandingkan dengan jumlah dataset pada kelas lain. Jumlah data ketiga kelas tersebut tampak seperti pada Tabel 3.3.
Tabel 3.3 Jumlah Seleksi Kelas
Kelas Jumlah
Bourbon 225
Caturra 256
Typica 208
Total 689
Berikut ditampilkan sampel data dengan beragam label kelas pada Gambar 3.2.
Gambar 3.2 Sampel data berbagai macam label kelas
Setelah ditentukan data dengan label kelas hanya Bourbon, Caturra dan Typica maka data akan menjadi seperti pada Gambar 3.3.
Gambar 3.3 Sampel data tiga macam label kelas
Seleksi data yang dilakukan dengan menggunakan label kelas Bourbon, Caturra, dan Typica menghasilkan sebanyak 689 data yang akan digunakan dalam penelitian dari 1312 data yang tersedia.
Seleksi data yang selanjutnya dilakukan yaitu dengan menentukan atribut yang akan digunakan, penentuan atribut dilakukan dengan menggunakan ketentuan cupping form seperti yang terdapat pada Gambar 2.8 dan menggunakan perangkingan atribut dengan bantuan Weka tools versi 3.8. Metode yang diterapkan yaitu dengan menggunakan Information Gain yang akan melakukan evaluasi atribut pada data training untuk mendapatkan perangkingan atribut.
Seleksi atribut dengan menggunakan cupping form menghasilkan sejumlah 12 atribut dari 44 atribut. Sehingga hasil dari seleksi atribut tersebut yaitu Aroma, Flavor, Aftertaste, Acidity, Body, Balance, Uniformity, Clean.Cup, Sweetness, Cupper.Points, Category.One.Defects, dan Category.Two.Defects. Selanjutnya dilakukan perangkingan atribut untuk melihat atribut-atribut yang relevan dalam penelitian.
Hasil perangkingan atribut dengan menggunakan information gain terlihat dalam Gambar 3.4 yang menempatkan atribut Balance sebagai atribut yang memiliki nilai rangking tertinggi.
Gambar 3.4 Hasil perangkingan atribut
Setelah didapat hasil perangkingan atribut dari data uji 12 atribut, terdapat informasi dengan 3 atribut yang mendapatkan nilai terendah yaitu Sweetness, Category.One.Defects, dan Clean.Cup. Selanjutnya dilakukan seleksi atribut dengan menggunakan akurasi yang terdapat pada WEKA seperti yang terdapat pada Tabel 4.3. Sehingga atribut yang akan digunakan dalam penelitian ini hanya akan menggunakan 11 atribut saja seperti tampak pada Tabel 3.4.
Tabel 3.4 Atribut hasil Information Gain No. Nama Atribut
1. Aroma 2. Flavor 3. Aftertaste 4. Acidity 5. Body 6. Balance 7. Uniformity 8. Sweetness 9. Cupper.Points 10. Category.One.Defects 11. Category.Two.Defects
b. Transformasi data
Transformasi data pada penelitian ini dilakukan dengan dua cara. Pertama, dilakukan transformasi data pada label kelas dengan mengubah tipe data kolom Variety menjadi numerik agar dapat diproses pada saat klasifikasi. Sehingga transformasi pada label kelas akan menjadi seperti berikut.
• Bourbon : 1 • Caturra : 2 • Typica : 3
Selanjutnya transformasi data dilakukan dengan menormalisasi data agar setiap atribut dalam dataset memiliki bobot yang sama sehingga tidak ada salah satu atribut yang mendominasi. Hal ini dilakukan karena jika terdapat atribut yang berbeda-beda seringkali pemrosesan data menjadi bias. Normalisasi yang akan dilakukan yaitu menggunakan normalisasi max dan z-score. Normalisasi min-max akan mentransformasi nilai data berdasarkan nilai minimum dan maksimum pada dataset, sedangkan normalisasi z-score mentransformasi nilai data berdasarkan nilai rata-rata dan standar deviasi.
3.3.2 K-Fold Cross Validation
Pada penelitian ini digunakan data sebanyak 689 data records yang akan dibagi menjadi dua bagian untuk melakukan pengujian yaitu data training dan data testing. Masing-masing kelompok data dibagi berdasarkan pengujian 3-Fold Cross Validation yang ditentukan 2/3 data training dan 1/3 data testing. Berikut ini ilustrasi pembagian data yang dilakukan pada Tabel 3.5.
Tabel 3.5 Simulasi pembagian data training dan data testing
Keterangan :
Testing set Training set
3.3.3 Tahap Klasifikasi
Tahap klasifikasi ini menggunakan Support Vector Machine (SVM). Support Vector Machine akan menggunakan tools pada Matlab menggunakan fungsi biner yang akan ditambahkan fungsi multi kelas. Berikut ilustrasi tahapan klasifikasi SVM menggunakan metode one-against-one dengan tiga label kelas pada Gambar 3.5 sampai dengan Gambar 3.9. SVM hanya dapat mengklasifikasikan 2 kelas saja, tetapi dengan adanya konsep multiclass maka metode SVM memungkinkan untuk melakukan klasifikasi lebih dari dua kelas. Pada Gambar 3.5 memperlihatkan terdapat 3 kelas data yang diperlihatkan dengan warna hitam sebagai kelas 1, merah sebagai kelas 2, dan biru sebagai kelas 3. Dengan menggunakan konsep multiclass dan metode one-against-one maka akan dibangun 3 kelas biner. Tiga kelas biner ini diperoleh dengan menggunakan rumus pada persamaan 2.18 sehingga model biner SVM yang dibangun yaitu sejumlah 3(3-1)/2=3. Model biner SVM ini terdiri dari kelas 1 lawan 2, 1 lawan 3, dan 2 lawan 3.
Data ke : 1 - 229 Data ke : 230 – 459 Data ke : 460 - 689 Data ke : 1 – 229 Data ke : 230 – 459 Data ke : 460 - 689 Data ke : 1 – 229 Data ke : 230 – 459 Data ke : 460 - 689
Gambar 3.5 Klasifikasi dengan tiga kelas (W, 2017)
Pada model kelas biner yang pertama seperti yang terlihat pada Gambar 3.6, objek baru diklasifikasikan dengan menggunakan data training dari kelas 1 dan 2. Diasumsikan objek data tersebut lebih dekat ke kelas 2, maka kelas 2 akan dipilih untuk dilakukan voting.
Gambar 3.6 Kelas 1 dan kelas 2
Pada model kelas biner yang kedua seperti yang terlihat pada Gambar 3.7, objek baru diklasifikasikan dengan menggunakan data training dari kelas 1 dan 3. Diasumsikan objek data tersebut lebih dekat ke kelas 3, maka kelas 3 akan dipilih untuk dilakukan voting.
Gambar 3.7 Kelas 1 dan kelas 3
Pada model kelas biner yang ketiga seperti yang terlihat pada Gambar 3.10, objek baru diklasifikasikan dengan menggunakan data training dari kelas 2 dan 3. Diasumsikan objek data tersebut lebih dekat ke kelas 2, maka kelas 2 akan dipilih untuk dilakukan voting.
Gambar 3.8 Kelas 2 dan kelas 3
Selanjutnya dilakukan voting untuk menentukan kelas klasifikasi. Hasil voting dari kelas biner pertama hingga ketiga, kelas 2 memiliki voting terbanyak, sehingga hasil klasifikasi dari data objek baru akan dikategorikan sebagai kelas 2 seperti yang terlihat pada Gambar 3.9.
Gambar 3.9 Hasil voting 3.4 Desain Pengujian
Pada penelitian ini digunakan pengujian menggunakan metode 3-Fold Cross Validation yang akan membagi 689 data menjadi 3 bagian. Selanjutnya dilakukan pengujian sebanyak 3 kali dengan menggunakan kelompok-kelompok data yang telah terbagi. Illustrasi pembagian kelompok-kelompok data tampak seperti pada Table 3.5.
Setelah dilakukan pembagian kelompok data kemudian dilakukan pengujian data. Pengujian data dilakukan sebanyak 3 kali karena menggunakan 3-Fold Cross Validation. Tampak pengujian seperti pada Tabel 3.6. Hasil dari pengujian ini yaitu sebuah confusion matrix yang merepresentasikan jumlah prediksi dalam klasifikasi baik itu prediksi yang benar maupun yang salah. Setelah didapatkan jumlah hasil prediksi, langkah selanjutnya menghitung akurasi berdasarkan confusion matrix yang diperoleh. Rumus perhitungan akurasi ini tampak seperti pada rumus 3.1.
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = 𝑇𝑢𝑝𝑙𝑒 𝑏𝑒𝑛𝑎𝑟
Tabel 3.6 Tabel Pengujian
Percobaan Data Training Data Testing
1 2, 3 1
2 1, 3 2
3 1, 2 3
3.5 Kebutuhan Sistem
3.5.1 Perangkat Keras (Hardware)
Laptop diperlukan dalam menunjang pembuatan sistem, adapun spesifikasi yang digunakan dalam pembuatan sistem ini yaitu :
Tabel 3.7 Spesifikasi PC
Model ASUS X45C
Platform Notebook-PC
Hard Disk Drive 500 Gigabyte
Graphic Processing Unit Intel® HD Graphics 3000
Operating System Microsoft Windows 10 Professional
Memory 4 Gigabyte
3.5.2 Perangkat Lunak (Software)
Perangkat lunak yang diperlukan adalah menggunakan software Microsoft Excel 2013, Weka versi 3.8 dan Matlab versi R2016b untuk membuat serta menjalankan sistem yang dibuat.
3.6 Perancangan Antar Muka Sistem
Gambar 3.10 Prototype GUI Program
Gambar 3.10 merupakan desain dari user interface yang akan digunakan. Terdapat dua panel utama yang digunakan yaitu panel proses data dan panel uji data tunggal. Pada panel proses data terdapat tombol Upload File untuk memasukkan data tabel yang telah dilakukan preprocessing dan kemudian muncul pada tabel Data Uji Cita Rasa Kopi. Selanjutnya proses training data dilakukan pada tombol Train yang akan memberikan output confusion matrix pada tabel Confusion Matrix Data Uji 1, 2, dan 3. Kemudian hasil akurasi tampil pada field Akurasi dan Total Akurasi. Panel yang kedua yaitu panel Uji Data Tunggal, panel ini digunakan untuk pengguna melakukan klasifikasi terhadap data baru yang dimasukkan oleh user pada masing-masing field yang dimana ketika telah dimasukkan keseluruhan data dan diklik tombol Klasifikasi, sistem akan memberikan output varietas kopi pada panel Hasil Klasifikasi. Tombol Reset digunakan untuk mengosongkon field isian dan menjadi default seperti semula.