Modelling the dynamics of visual classification learning
* ¨
Alexander Unzicker , Martin Juttner, Ingo Rentschler
¨ ¨ ¨ ¨
Institut f ur Medizinische Psychologie, Universitat Munchen, Munchen FRG, Goethestrasse 31, D-80336 Munich, Germany
Accepted 1 March 1998
Abstract
Classification learning of grey-level images is severely degraded in extrafoveal relative to foveal vision. Using a probabilistic virtual prototype (PVP) model we have recently demonstrated that this deficit is related to a reduced perceptual dimensionality of extrafoveally acquired class
¨
concepts relative to that of foveally developed representations [Juttner, M., Rentschler, I., 1996. Reduced perceptual dimensionality in extrafoveal vision. Vision Research 36, 1007–1021]. Here we show how the PVP technique can be extended to capture the dynamics of classification learning. Unlike former attempts at such a description our approach does not primarily aim at modelling a learning curve, i.e., the gradual change of a global error measure. Rather it provides a means to trace the learning status of the observer by visualizing the changing pattern of classification errors. This allows one to assess the cognitive strategies observers employ during concept learning. 1999 Elsevier Science B.V. All rights reserved.
Keywords: Classification learning; Dynamics; Virtual prototype; Cognitive stereotypes
1. Introduction
Psychophysical approaches to human vision have been endeavouring, over a long time, to characterize visual performance in terms of acuity measures, visual field and contrast sensitivity. From a paradigmatic viewpoint, such a notion of visual processing can be related to tasks of detection or discrimination which are intrinsically character-ized by a one-dimensional processing of stimulus information. Even in psychophysical models of spatial vision (Thomas, 1985; Olzack and Thomas, 1986) which inherently involve multidimensional representations in terms of multiple channel outputs, these
*Corresponding author. Tel.:149-89-5996-202; fax:149-89-5996-615. E-mail address: [email protected] (A. Unzicker)
representations are typically reduced by some form of vector normalization to a single response variable, which then provides an index of visibility or discriminability. By contrast, cognitive psychologists have traditionally preferred to define pattern recogni-tion as the ability to assign perceived objects to previously acquired categorical concepts (Bruner, 1957; Rosch, 1978). Such classifications in general require a simultaneous consideration of stimulus information along multiple stimulus dimensions (Watanabe, 1985).
The distinction between the tasks of discrimination or detection on the one side and classification on the other seems to be more than a mere epistemological differentiation. This has become evident in recent psychophysical studies on perceptual learning across
¨
the visual field (Juttner and Rentschler, in preparation). Here for a common set of grey-level patterns (compound-sinewave gratings, cf. Fig. 1) classification and discrimi-nation performance were compared in foveal and extrafoveal (2.58 eccentric) viewing. Whereas for a foveal presentation of the stimuli learning speed for the two types of tasks was found to be equal, there was a clear dissociation in case of an extrafoveal presentation. Learning duration for pattern classification now increased by a factor of five relative to the foveal condition, while it remained unaffected for pattern discrimina-tion. Such a divergence suggests that internal representations underlying pattern classification and discrimination arise at distinct cortical levels in the brain, and that the former are normally developed within an extremely narrow visual field delimited to the fovea.
To some extent these results bolster earlier psychophysical findings concerning foveal and extrafoveal character recognition (Strasburger and Harvey Jr., 1991; Strasburger and Rentschler, 1996). However, their novel contribution lies in that they provide an approach to pattern recognition from the perspective of concept learning, where subjects are trained to assign hitherto unfamiliar patterns into predefined classes. Methodo-logically, this paradigm raises two major issues, namely: (1) how the internal class concepts acquired during the training period can be related to physical stimulus properties; and (2) how the evolution of such mental concepts, i.e. the dynamics of learning, can be adequately described.
The PVP approach provides a parsimonious description of classification behaviour based on a similarity concept which, on the one hand, is based on a stimulus-dependent physical signal description, and on the other hand includes observer-dependent cognitive biases. As an important property it allows inferences about the dimensionality or the degrees of freedom characterizing internal class concepts. In particular, it was shown that the perceptual dimensionality of extrafoveally acquired class concepts is
distinctive-¨
ly reduced relative to foveally developed representations (Juttner and Rentschler, 1996). The adequateness of the PVP model within the domain of psychophysical classification also has been demonstrated by Unzicker et al. (1998) in a comparative evaluation of various standard models in the classification literature, including prototype approaches, exemplar-based models, General Recognition Theory and HyperBf-Networks.
In all non-trivial cases, the learning of class concepts does not occur instantaneously. A certain limitation of the current version of the PVP approach can be seen in that so far it has been mainly applied to experimental classification data cumulated across the entire training procedure. Consequently, the data base only provides some sort of average error profile an observer reveals during the learning process. In the concrete case of extrafoveal classification the training often extends over several hours, and learning often proceeds in a seemingly non-continuous and irregular manner. Such a behaviour makes it desirable to find ways for analyzing classification data beyond the standard method of visualization in form of a learning curve. What is needed is a method to track the evolution of class concepts as they emerge during the training.
In this article we propose how such a description concerning the dynamics of learning can be obtained. The primary scope of the paper is to achieve this goal within the framework of the PVP model. However, it should be clear that the basic issue of modelling learning processes also arises in the context of other standard models in the classification literature although this problem so far has been largely ignored. In the following, we will first restate the basic assumptions of the PVP approach. On this basis we show how such an analysis can be extended to capture the dynamics of learning. The method will be illustrated by applying it to samples of psychophysical classification data. Finally, the results will be discussed in the context of alternative approaches to perceptual classification and learning.
2. The probabilistic virtual prototype approach
2.1. The signal representation assumption
A given physical stimulus x in the external world is uniquely specified by a feature vector in an appropriate physical feature space of dimensionality d and gives rise to a specific perceptual realization. In other words, perception is regarded as some sort of measurement process which acts on the physical signal vector and results into another signal vector z, corresponding to the internal representation of the external stimulus. As to the relationships between physical and internal signal representations, we model them in terms of an additive error vector w, i.e.,
z;x1w. (1)
This approach is standard in applied optimal estimation (Gelb, 1974) and multi-dimensional extensions of signal detection theory (Ashby, 1992). It dates back to methodologies developed by Gauss (1963). The error vector w in Eq. (1) incorporates the additional degrees of freedom of both bias and variance introduced by the perceptual process of internal feature measurement. Following the parametric approach, we assume this error signal to be normally distributed, i.e.,
9 9
Heremj denotes the d-component expectation or mean vector of the jth classvj, Cj
21
9 9 9
is the corresponding d3d covariance matrix, Cj is the inverse of C , andj uCju its determinant. The superscript T denotes transposition.
2.2. The class representation assumption
Signal vectors of stimuli belonging to the same stimulus class are assumed to be parametrically distributed. This means that the signal vectors in their feature space representation form clusters whose spread can be described by parametric distribution functions.
If we further assume x to be normally distributed with mean valuemj and covariance
C and add statistical independence of x and w, then we have as a resulting distributionj
of z
9 9
p(zuvj)5N(z;mj1mj, Cj1C ),j (4)
9 9
which is also normal with the parameters mj1mj and Cj1C . The assumption ofj
2.3. The classification assumption
Given the stochastic nature of the internal representation of individual signals and signal classes, the probability that a given signal is assigned to a particular class is then provided by the Bayes theorem. Accordingly, p(vjuz) is given by
p(zuvj)P(vj)
]]]]]
p(vjuz)5
O
, (5)p(zuvk)P(vk)
k
where P(vj) is the a priori probability of classvjand the summation in the denominator is over the number of classes. Note that Eq. (5) restates the basic assumption of the PVP approach, namely that the characteristics of human classification behaviour do not directly depend on the physical input signal, but on its corresponding internal representation.
2.4. Parameter estimation
The above assumptions form the basis of a probabilistic virtual prototype
classifica-1
9
tion model with four parameters , namely the mean value vectors (mj,mj) as well as the
9
covariance matrices (C , C ) of the distributions of the physical input signals and of thej j
perceptual error vectors, respectively. Themj and C are already completely specified byj
the distributions of the signals in physical feature space. However, the mean and the
9 9
covariance of the error vector distribution,mj and C , are free parameters of the model:j
They capture the additional degrees of bias, or distortion, and that of covariance, or fuzziness, of the internal representation for a particular class. The class means of the input signal distributions can be interpreted as class prototypes in physical feature space.
9
Their counterparts in the internal representation, mj1mj, may then be regarded as prototypes in a virtual sense. Although physically not existing, the virtual prototypes allow one to account for the observed classification behaviour of human observers by a Bayesian classifier operating on the corresponding biased density functions.
Within the PVP approach, the mean and the covariance of the perceptual error distributions, specified by d1d (d11) / 2 components per class, are the essential parameters capturing the internal representations of the signal classes underlying the classification judgment. For the following, we will consider a restricted form of this
9
general model, by further assuming that the covariances C are identical for all classes,j
9
i.e. Cj5C9, for j51, . . . , n , and that the elements of Cc 9are small compared to those of the C . They can then be set arbitrarily to zero. In other words, we assume that thej
class conditional probability densities in physical and internal feature space have the same covariances and differ only in their mean values, or in their class specific bias (bias model). This restriction leads to a substantial reduction of free parameters of the model
1
(d per class) and allows for a more robust parameter estimation even with a relatively
2
small data sets.
For a given classification experiment, let n denote the number of classes, n thec s
*
number of signals per class and let Pij be the observed relative frequency for classifying signal i into classvj. We further assume equal a priori probabilities for all classes, i.e.
p(vi)51 /nc for i51, . . . , n . If we identify the model predicted classificationc
probability p with the a posteriori probability given in Eq. (5), i.e.ij
pij;p(vjuz ),i (6a)
the parameters of the model can be estimated by minimizing the mean-squared error
2 21 2
*
e 5(n nc s 21)
O
( pij 2 p ) .ij (6b)i, j
In practical applications, we have solved this optimization problem by using a downhill simplex algorithm (Nelder and Mead, 1965).
2.5. Example
We will now illustrate the use of the PVP approach in a psychophysical classification experiment. Observers were trained to classify a set of 15 grey-level images specified by compound Gabor signals (Fig. 1). Such signals consist of a fundamental cosine waveform and its third harmonic modulated by an isotropic Gaussian aperture. The intensity profile was defined by
1 2 2
]
G(x, y)5L01exp
H
2 2(x 1y )J
sa cos(2pf x)0 1b cos(2p3f x0 1f) ,d (7)a
where L determines the mean luminance,0 a the space constant of the Gaussian aperture,
a the amplitude of the fundamental, b that of the third harmonic, andf the phase angle of the latter. Signal variation was restricted to b andf. This allowed the use of a metric feature space with the Cartesian coordinates j 5b cos f (’evenness’) andh 5b sinf
(’oddness’). The signal set was grouped into three clusters defining three classes in feature space, each containing five samples. The training procedure employed a supervised learning schedule consisting of a variable number of learning units. One learning unit included three subsequent presentations of the learning set, in random
2
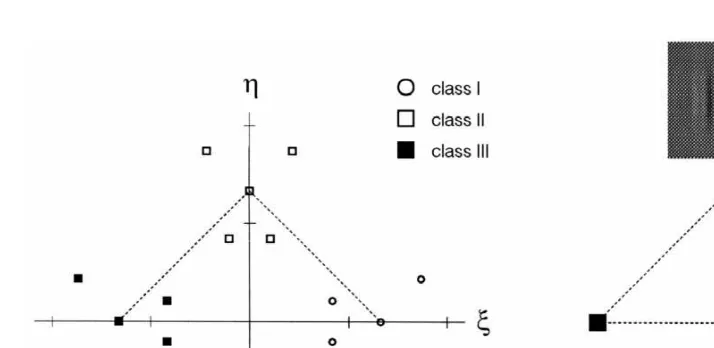
Fig. 1. Feature space representations of the signal set used for classification learning. The learning set consists of 15 compound Gabor patches, defined in a two-dimensional metric feature space. Within this feature space, the patterns of the learning set formed three clusters of five samples each thus defining three pattern classes
2 2
(left). Scale: 1 unit corresponds to 15 cd / m . Mean luminance was kept at 70 cd / m . Right: The grey-level images corresponding to the three prototype signals (mean pattern vector).
order, with 200 ms exposure duration for each pattern. Following each presentation, a number specifying the class to which the pattern belonged was displayed for 1 s. The interval between the learning signal and the number was 500 ms. Each learning unit ended with a test of how well the subject was able to classify the fifteen patterns. Only one exposure per sample was used here. The learning procedure was repeated for each observer until he or she had either achieved the learning criterion of an error-free classification (100% correct), or the limit of 40 learning units had been reached.
Fig. 2 shows, for extrafoveal and foveal viewing, the virtual prototype configurations representing the acquired class concepts as they were reconstructed by means of the PVP technique. The estimates are based on the classification data cumulated across the entire learning procedure. The internal class concepts acquired in foveal (Fig. 2A) and extrafoveal (Fig. 2B) viewing appear to be topologically distinct. In the former case, the virtual prototype configuration proves to be veridical to the configuration of the physical prototypes, indicated by the vertices of the dashed triangle. However, for extrafoveal learning the physical and internal class representations clearly diverge. Whereas the former extends in two feature dimensions, the virtual prototype formation degenerates to a nearly collinear configuration. Hence, extrafoveally obtained pattern representations are characterized by a lower perceptual dimensionality in feature space relative to the
2
3. Assessing the dynamics of learning
The topological differences between foveally and extrafoveally acquired class configurations are reflected in the duration of learning which takes much longer in case of extrafoveal viewing. In the example for foveal learning presented in Fig. 2A, the observer reached the learning criterion after two learning units. For extrafoveal learning (Fig. 2B) the subject failed to reach it even after 40 learning units. Global learning performance however, as measured by the average rate of a correct classification across the entire learning set, increased in the latter case from about 35% in the beginning of the training procedure to a final level of approximately 65%. This asymptotic level of nearly 66% directly relates to the prototype configuration depicted in Fig. 2B, according to which the observer correctly differentiates between two classes (I and III) while continuing to confound the third one (class II). The general observation, that extrafoveal learning does occur even if the learning criterion of 100% correct is not met, raises the question as to the evolution of internal class concepts.
k
For the following, lethR ; iij 51, . . . , n , js 51, . . . , ncjdesignate the elements of the
ns3n response matrix in learning unit k, with n denoting the number of signals, and nc s c k
the number of classes. Note that since each signal is presented once in such a test, Rikis 1 if, in learning unit k, the observer assigns signal i to class j, and 0 otherwise. The adequate description of the dynamics of classification learning is a non-trivial problem for two main reasons: First, the PVP approach is based on probability values. Probability, however, is a timeless concept assuming stationarity, whereas learning per definition is time-dependent. Hence it is necessary to take apart the learning process into successive intervals of assumed quasi-stationarity, i.e. intervals, where the parameters of the response generating process can be approximated by constant values. Within each sampling interval, the response data matrices are combined to yield relative frequencies as (temporally) local estimates of probability values. This procedure inevitably involves some form of uncertainty principle: The more local the temporal estimate, i.e., the smaller the sampling interval, the more it is affected by noise – and vice-versa: the larger the sampling interval, i.e., the more precise the estimate, the less localized this estimate becomes in time. Formally, the tracking of the evolution of a matrix containing classification frequencies appears to be related both to the field of time series analysis and that of probability estimation theory, with neither field to our knowledge offering a convenient way to solve the issue.
estimates. An adequate interpretation of learning tomograms in the context of theories of learning therefore requires a criterion to differentiate between these two possibilities.
3.1. Learning tomograms and cognitive stereotypes
Our proposed solution to the aforementioned problems involves the following five steps:
k
˜
1. The generation of a series of local estimateshp , kij 51, . . . , nljfor the classification probability across the sequence of the n learning unitsl
k
2. The computation of the corresponding series of learning tomogramshP , k,51, . . . ,
nlj
3. The detection of non-continuous transitions within the sequence of learning tomog-rams
4. The construction of a list of so-called stereotypes, which can be considered as the basic configurations that compose the tomograms series
5. A temporal scale-space analysis to discriminate cognitive from accidental stereotypes.
k
˜
Step 1. Local estimates pij for the probabilities at learning unit k are obtained by
k
where C is a normalization constant given byk
min(k1h, n )l
Due to the centering of the kernel, the pij at trial k primarily depend on the responses given in that learning unit. However, they are also affected by both the preceding and successive responses within a certain temporal window, which we have truncated at6h.
The fact that both past and future responses contribute to the estimate in a symmetrical way provides continuity and coherence between consecutive estimates. Being a post-hoc analysis applied to the complete sequence of response data, the reference to future responses does not contradict the principle of causality. For stationary systems, kernel smoothing is a well-known technique in probability estimation theory and the value of h can be optimally specified (Thompson and Tapia, 1990). In the present context, where h determines both the sampling interval (for which stationarity of the response data is assumed) and the degree of temporal resolution, nothing can be said a priori about the
k
˜
optimal choice of h. Thus the pij implicitly depend on this resolution parameter.
Step 2. Next, the local probability estimates are used to compute the corresponding configurations of virtual prototypes. The estimation procedure outlined in Section 2,
k k
each consisting of the feature space coordinates of the n virtual prototypes. Note thatc
the resulting series of prototype configurations, or learning tomograms, again depends on the resolution parameter h.
Step 3. The detection of discontinuities between successive prototype configurations requires a measure of pairwise dissimilarity concerning these configurations. We define
2
such a measure on the basis of the L (or Euclidean) norm of the difference vector
i j
between two configurations. Accordingly, for two prototype configurations P and P
i j
their dissimilarity s(P ,P ) is given by
n dc 1 / 2
i j i j i j 2
s(P , P )5iP 2P i5
F
O
(Pk2P )kG
(9)k51
This dissimilarity function is applied to pairs of successive configurations in the series
i j
of learning tomograms. Non-continuous transitions are detected by comparing s(P ,P ) to a continuity threshold dc. In the present version of the model, dc is chosen heuristically, since in all cases studied so far the dissimilarity values for continuous and abrupt transitions clearly diverge from each other, so that the particular choice of dc
seems less critical.
Step4. Each time a discontinuity is detected, the corresponding prototype configura-tion becomes a candidate for the list of so-called stereotype configuraconfigura-tions. Here the underlying idea is to consider all continuous configural transitions between two discontinuities as variations of some basic configuration, or stereotype. As a conse-quence, non-continuous transitions are interpreted as transitions between different stereotype patterns. The discontinuity detection in step (3) is used to generate, for a given series of learning tomograms, a list L containing all stereotypes occurring in thats
series. Initially L is empty, i.e. Ls s5 [. The list is updated while moving through the
k k
are simultaneously satisfied. Condition (10b) ensures that Ls will only contain stereotypes which are categorized as pairwise dissimilar according to the continuity criteriondc.
Step5. Note that so far all prototype configurations depend implicitly on the temporal resolution parameter h determining the probability estimates in step (1) of the algorithm. To that extent the detection of abrupt transitions in the tomogram series and therefore the list of stereotypes is also affected by the particular choice of h. This means, L mays
contain accidental stereotypes, i.e. configurations which only occur for certain values of
h and therefore may be regarded as artifacts, and ’true’ stereotypes occurring across a
less robust probability estimates, the number of stereotypes sharply declines with increasing sampling interval h, eventually leading to a plateau made up by cognitive stereotypes only.
More specifically, the emergence of such a plateau can be described as follows. With
k k11
˜ ˜
increasing h the difference dk,k11 (h) between successive local estimates pij and pij , defined by the Euclidean measure
declines monotonly (Eq. 8a, 8b), leading to an increased probability for the associated
k k11
prototype configurations P and P to be assigned to the same stereotype (Eq. 10). Therefore, the number of stereotypes will decline with increasing h in general, although this decline may not be monotone. However, the rate of that decline will depend on the type of prototype: For cognitive prototypes which correspond to certain response patterns observed over a range of successive learning units it will be more shallow than for accidental stereotypes that occur on a short time scale. Furthermore, for a fixed value
*
will also decrease monotonly as h increases. Again this leads to an increase of the
k k
probability that the associated prototype configurations P (h) and P (h11) will be associated to the same stereotype according to criteriondc and the metrics given in Eq. (9). Together these considerations predict that the above-mentioned plateau will consist of a set of cognitive stereotypes which is stable across a range of h values. Such stability considerations within a temporal scale space can be seen in analogy to similar approaches proposed in the context of spatial vision for the detection of contour information in images (Marr and Hildreth, 1980).
3.2. Example
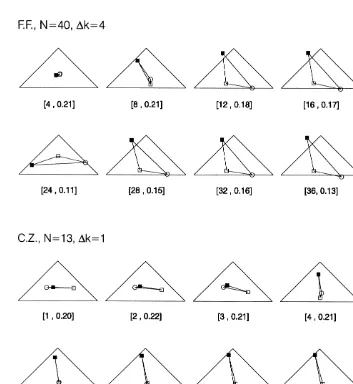
The proposed scheme for the analysis of learning processes is illustrated for the learning data of two observers performing the psychophysical classification task introduced in Fig. 1. The learning data comprised 40 learning units in case of subject F.F., and 13 in case of subject C.Z., both obtained in extrafoveal viewing.
Fig. 3. Learning-tomogram series for two observers. These estimates were obtained using a Gaussian Kernel with spread parameter h set to four learning units. The values in brackets refer to the center position k of the kernel (cf. Eq. 8a, 8b) and to the root of the mean squared error (Eq. 6b), emin, qualifying the goodness of the data fit. For subject F.F., the tomogram series is depicted with a step widthDk of 4 for sake of brevity, i.e., only every fourth configuration is depicted.
Occasionally, these stereotype configurations also reappear at a later stage of training (cf. the configuration in trial 20 and trial 28 for subject F.F.).
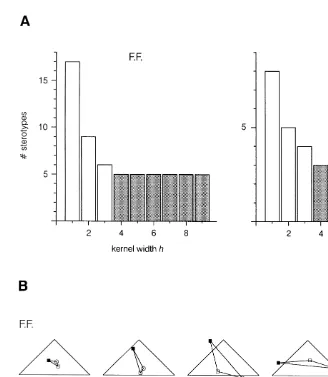
Fig. 4. (A) Histogram plot of the number of stereotypes obtained for a range of temporal resolutions defined by the Kernel width parameter h. Note that the number of stereotypes drops rapidly with increasing sampling interval to a plateau (shaded bars) which consists of the cognitive stereotypes expressing the learning status of the observer. The plateau consists of five stereotypes in case of subject F.F., and of three stereotypes in case of subject C.Z. They are depicted in part (B) of the figure.
learning may be described in fact by successive regimes of these stereotype configura-tions (for observer F.F.: I–II–III–IV–III–V; for observer C.Z.: I–II–III).
4. Discussion
As a matter of fact classification learning does not occur instantaneously, in any but trivially easy cases. Instead proportions of correct responses per trial block typically follow an irregular course from an initial chance level to some asymptotic value. While there exists a great variety of approaches to model classification (see e.g. Ashby, 1992), attempts to model the dynamics of category learning are relatively rare. Most efforts in learning models have been devoted to elementary tasks such as paired-associate learning, T-maze learning and avoidance learning, i.e. tasks that aim at the development of a rigid stimulus-response pattern. For such tasks, that typically avoid the cognitive processes of concept formation, learning processes has been successfully assessed within the framework of Markov chains (for reviews see (Norman, 1972; Wickens, 1982)). Among the few attempts that explicitly model classification learning, most have been undertaken in the context of exemplar-based models (Medin and Schaffer, 1978; Estes, 1986a). Here learning has been formalized in terms of probabilistic memory processes concerning the storage of individual class instances (see also (Estes, 1986b; Estes, 1989)).
More recent approaches endeavour to embed the problem of learning within connectionist classification schemes (McClelland and Rumelhart, 1985; Gluck and Bower, 1988; Kruschke, 1992). Basically, these models learn in a memorization-like fashion by encoding individual stimuli and modifying their weights in response to each stimulus to process that stimulus better. In the form originally presented by Gluck and Bower (1988), the model is based on a network of nodes and connecting paths. A node is defined for each feature from which the category exemplars are generated. Each feature node is connected to a set of output nodes, which correspond to the categories available for choice. The path from any feature node f to a category node C has ani j
associated adjustable weight w whose value measures the degree to which input fromij
the feature node tends to activate the category node. In later versions these simple adaptive networks have been augmented by memory nodes representing class instances, rendering this approach similar to the standard exemplar-based model (Kruschke, 1992; Nosofsky et al., 1992; Estes, 1994).
Such connectionist approaches allow one to account for the learning difficulty measured in terms of the inter-class similarities. They model category learning in terms of a gradual adaptation, leaving aside the problem of simulating particular patterns of confusion errors as they occur during that process. By contrast, the present approach aims at tracing the dynamic changes of these error patterns. The learning status is reflected in the current configuration of the virtual prototypes which are assumed to determine human classification according to a Bayesian classification scheme.
3
configurations are quasi-stationary and phases of abrupt configural transitions . Accord-ing to our analysis the latter do in fact correspond to non-continuous changes in the cognitive status of the observer. We propose that these transitions reflect a switching between different working hypotheses the subject puts forward to solve the classification task. Each hypothesis is mirrored in a particular prototype configuration, which we referred to as cognitive stereotype. The fact that observers seem to reuse certain hypotheses (cf. in Fig. 3 the re-occurrence of stereotype III (Fig. 4) in trial 20 and trial 28 for observer F.F.) manifest in the reappearance of a certain configuration, seems to support such an interpretation. Furthermore, the data of subject F.F. in Fig. 3 suggest that transitions between stereotypes tend to occur more often in the early phase of training whereas the response pattern becomes more stable in latter phase. This observation corresponds to a similar finding of Ashby and Todd (1992) who describe it in terms of General Recognition Theory as the tendency of experienced observers to respond more deterministically than novices.
What does the occurrence of a particular cognitive stereotype say about the actual processing of the stimulus pattern by the observer? Being a psychometric classification model the PVP approach per se provides no direct answer to that question. However, there have been recent attempts towards a bottom-up modelling of human pattern
¨
classification. Juttner et al. (1997) propose such an approach adopted from evidenced-based schemes for object recognition in computer vision (see Caelli and Pennington, 1993; Caelli and Dreier, 1994). This model assumes that observers generate a structure-oriented pattern description in terms of individual parts and their relations. On that basis, rules are formed concerning the occurrence of unary specific) and binary (part-relational) combinations of attributes. The activation pattern of such rules provides partial evidence for the class alternatives. Hence, the approach assumes two things are learned: (1) the selection of appropriate image attributes and an appropriate partitioning of the attribute spaces into evidence regions, and (2) the determination of evidence weights for the response alternatives, or classes. It is intriguing to relate these two aspects of what has been learned to the dichotomy evident in the dynamics of learning, as established in the PVP analysis. Each hypothesis may then be identified with a set of unary or binary attributes the observer employs to form his / her classification rules. Changes of attributes, on the one hand, should yield quite different classification behaviours as they become manifest in the abrupt transitions between various stereotypes. Adjustment of evidence weights, on the other hand, should affect classifica-tion behaviour only mildly, leading to smooth variaclassifica-tions of a given prototype configuration.
3
As outlined in Section 2.4 we have decided to consider the PVP approach in the form of a pure bias model. This means, in order to fit the model to the data we only chose the mean vectors of observer specific biases as parameters of variation while the covariances of the bias vector distributions are kept constant. In principle, it would be also feasible to follow the inverse strategy, by varying the covariances and keeping the error means constant. Since the a priori probability p(zuvj) depends, according to Eqs. (3) and (4), on the Euclidean
9 9
distance between z andmj1mj, normalized by the covariance Cj1C (the so-called Mahalanobis-distance)j
There has been, with respect to the content of acquired knowledge in the context of human learning, a distinction between instance learning and rule learning (for a review, see Shanks and John, 1994). Rule learning models have been proposed in form of prototype concepts (Posner and Keele, 1968; Posner and Keele, 1970; Reed, 1972) and assume that categories are represented by prototypes the closest of which determines classification behaviour. By contrast, instance learning assumes that observers do not form classification rules but simply rely on fragmentary knowledge in the form of stored class instances, the similarity of which with respect to a new item determines the classification. Exemplar-based models for classification are typical representatives of such a notion (Brooks, 1978; Medin and Schaffer, 1978; Nosofsky, 1986).
Connectionist approaches to learning processes do not allow an easy distinction between these two possibilities. Neural nets, in principle, are capable of learning both types of knowledge simultaneously and in the same set of weights. Studies focusing on the rule / instance issue therefore have involved non-dynamic paradigms, where subjects were tested for their ability to classify test items of varying similarity to a previously learned training set (Allen and Brooks, 1991; Regehr and Brooks, 1993). These experiments generally showed that humans can adopt both types of knowledge and that the particular choice is determined by the type of stimulus used and the precise nature of the task. Interestingly, it was shown that rule learning is more likely for stimuli composed of interchangeable features – a condition which also holds in the context of our psychophysical classification paradigm. To consider stereotypes as working hypoth-esis with respect to certain classification rules appears, from that perspective, to be a natural interpretation.
In conclusion, learning-tomogram analysis may provide a way to disentangle rule-based from instance-rule-based learning mechanisms merely on the basis of learning dynamics. In that sense it would seem that our proposed extension of the PVP concept exceeds traditional methods that focus on learning curves which only give an estimate of learning speed. Instead our method could provide a general technique for assessing, within the domain of parameterized stimulus material, the cognitive strategies observers are employing during learning processes.
Acknowledgements
This study was supported by the Deutsche Forschungsgemeinschaft Grant Re 337 / 10-2 to I.R. The authors are grateful to Bernhard Treutwein for helpful discussions on the manuscript.
References
Ahmed, N., Rao, K.R., 1975. Orthogonal Transforms For Digital Signal Processing, Springer, Berlin. Allen, S.W., Brooks, L.R., 1991. Specializing the operation of an explicit rule. Journal of Experimental
Ashby, F.G., 1992. Multidimensional models of categorization. In: Ashby, F.G. (Ed.), Multidimensional Models of Perception and Cognition, Erlbaum, Hillsdale, NJ, pp. 449–483.
Ashby, F.G., Maddox, W.T., 1992. Complex decision rules in categorization: contrasting novice and experienced performance. Journal of Experimental Psychology: Human Perception and Performance 18, 50–71.
Brooks, L., 1978. Nonanalytic concept formation and memory for instances. In: Rosch, E., Lloyd, B.B. (Eds.), Cognition and Categorization, Erlbaum, Hillsdale, NJ, pp. 170–211.
Bruner, J., 1957. On perceptual readiness. Psychological Review 64, 123–157.
Caelli, T., Dreier, A., 1994. Variations on the evidence-based object recognition theme. Pattern Recognition 27, 185–204.
Caelli, T., Pennington, A., 1993. An improved rule generation method for evidence-based classification systems. Pattern Recognition 26, 733–740.
Duda, R.O., Hart, P.E., 1973. Pattern Classification and Scene Analysis, Wiley, New York. Estes, W.K., 1986a. Array models for category learning. Cognitive Psychology 18, 500–549.
Estes, W.K., 1986b. Storage and retrieval processes in category learning. Journal of Experimental Psychology: General 115, 155–174.
Estes, W.K., 1989. Early and late memory processing in models for category learning. In: Izawa, C. (Ed.), Current Issues in Cognitive Processes: the Tulane Flowerree Symposium On Cognition, Erlbaum, Hillsdale, NJ, pp. 11–24.
Estes, W.K., 1994. Classification and Cognition, Oxford University Press, New York.
Flannagan, M.J., Fried, L.S., Holyoak, K.J., 1986. Distributed expectations and the induction of category structure. Journal of Experimental Psychology: Learning, Memory and Cognition 12, 241–256. Fried, L.S., Holyoak, K.J., 1984. Induction of category distributions: A framework for classification learning.
Journal of Experimental Psychology: Learning, Memory and Cognition 10, 234–257.
Gauss, C.F., 1963. Theoria motus (1809), English translation: Theory of the Motion of the heavenly bodies about the sun in the conic sections, Dover, New York.
Gelb, A., 1974. Applied Optimal Estimation, MIT Press, Cambridge, MA.
Gluck, M.A., Bower, G.H., 1988. From conditioning to category learning: An adaptive network model. Journal of Experimental Psychology: General 117, 225–244.
¨
Juttner, M., Rentschler, I., 1996. Reduced perceptual dimensionality in extrafoveal vision. Vision Research 36, 1007–1021.
¨
Juttner, M., Caelli, T., Rentschler, I., 1997. Evidence-based pattern classification: A structural approach to human perceptual learning and generalization. Journal of Mathematical Psychology 41, 244–259. Kruschke, J.K., 1992. ALCOVE: An exemplar-based connectionist model of category learning. Psychological
Review 99, 22–44.
Marr, D., Hildreth, E., 1980. Theory of edge detection. Proceedings Royal Society of London Series B 207, 187–216.
McClelland, J.L., Rumelhart, D.E., 1985. Distributed memory and the representation of general and specific information. Journal of Experimental Psychology: General 114, 159–188.
Medin, D.L., Schaffer, M.N., 1978. Context theory of classification learning. Psychological Review 85, 207–238.
Nelder, J., Mead, R., 1965. A simplex method for function minimization. Computer Journal 7, 308–313. Norman, M.F., 1972. Markov Processes and Learning Models, Academic Press, New York.
Nosofsky, R.M., 1986. Attention, similarity, and the identification-categorization relationship. Journal of Experimental Psychology: General 115, 39–57.
Nosofsky, R.N., Kruschke, J.K., McKinley, S., 1992. Combining exemplar-based category representations and connectionist learning rules. Journal of Experimental Psychology: Learning, Memory and Cognition 18, 211–233.
Olzack, L.A., Thomas, J.P., 1986. Seeing spatial patterns. In: Boff, K.R., Kauffman, L., Thomas, J.P. (Eds.), Handbook of Perception and Human Performance, Sensory processes and perception (Chap. 7, Vol. 1, Wiley, New York.
Posner, M.I., Keele, S.W., 1968. On the genesis of abstract ideas. Journal of Experimental Psychology 77, 353–363.
Reed, S.K., 1972. Pattern recognition and categorization. Cognitive Psychology 3, 382–407.
Regehr, G., Brooks, L.R., 1993. Perceptual manifestations of an analytic structure: The priority of holistic individuation. Journal of Experimental Psychology: General 122, 92–114.
¨
Rentschler, I., Juttner, M., Caelli, T., 1993. Ideal observers for supervised learning and classification. In: Steyer, R., Wender, K.F., Widamann, K.F. (Eds.), Psychometric Methodology, Fischer, Stuttgart, pp. 40–45.
¨
Rentschler, I., Juttner, M., Caelli, T., 1994. Probabilistic analysis of human supervised learning and classification. Vision Research 34, 669–687.
Rosch, E., 1978. Principles of categorization. In: Rosch, E., Lloyd, B.B. (Eds.), Cognition and Categorization, Erlbaum, Hillsdale, NJ.
Shanks, D.R., John, M.F., 1994. Characteristics of dissociable human learning systems. Behavioral and Brain Sciences 17, 367–447.
Strasburger, H., Harvey, Jr L.O., 1991., I. Rentschler, Contrast thresholds for identification of numeric characters in direct and eccentric view. Perception and Psychophysics 49, 495–508.
Strasburger, H., Rentschler, I., 1996. Contrast-dependent dissociation of visual recognition and detection fields. European Journal of Neuroscience 8, 1787–1791.
Thomas, J.P., 1985. Detection and identification: How are they related? Journal of the Optical Society of America A2, 1457–1467.
Thompson, J.R., Tapia, R.A., 1990. Nonparametric Function Estimation, Modelling, and Simulation, SIAM, Philadelphia.
¨
Unzicker, A., Juttner, M., Rentschler, I., 1998. Similarity-based models of visual classification. Vision Research. 38, 2289–2305.