KOMPUTAKI Vol.3, No.1 Februari 2017
1
ALGORITMA
K-NEAREST NEIGHBOR
BERBASIS
FORWARD
SELECTION
UNTUK MENDIAGNOSIS PENYAKIT JANTUNG
KORONER
Achmad Nuruddin Safriandono
email : [email protected]
Abstrak
K-Nearest Neighbor merupakan salah satu algoritma yang diusulkan oleh para peneliti data mining di bidang kesehatan seperti penyakit jantung koroner. Penyakit jantung koroner adalah penyakit berbahaya dan salah satu penyebab kematian di seluruh dunia. Maka dari itu, penyakit jantung koroner perlu didiagnosis. Algoritma yang digunakan dalam penelitian ini adalah K-Nearest Neighbor (K-NN) berbasis Forward Selection untuk meningkatkan akurasi dalam diagnosis penyakit jantung koroner. Penelitian ini menggunakan dataset jantung koroner yang diperoleh dari UCI Dataset Machine Learning Repository. Hasil penelitian menunjukkan bahwa algoritma Forward Selection-KNN memiliki akurasi yang lebih baik dari pada KNN.
Kata kunci: Data mining, penyakit jantung koroner, K-Nearest Neighbor, Forward Selection
PENDAHULUAN
Penyakit jantung Koroner adalah salah satu penyakit yang menyebabkan kematian di Amerika [1]. Lebih dari 600.000 orang-orang Amerika meninggal setiap tahun disebabkan penyakit jantung. Istilah “penyakit jantung” menjelaskan beberapa tipe kondisi jantung [1]. Salah satu tipe penyakit jantung adalah coronary artery disease, yang menyebabkan serangan jantung. Jenis penyakit jantung yang lain termasuk katup jantung atau jantung yang tidak terpompa dengan baik dan menyebabkan gangguan jantung. Beberapa orang meninggal karena penyakit jantung [1]. Maka dari itu penyakit jantung perlu didiagnosis. Para dokter menguji melakukan tes untuk mendiagnosis penyakit jantung, termasuk X-rays pada dada, coronary angiograms,
electrocardiograms (ECG or EKG), dan tes-tes untuk menghilangkan stress.
Data mining dapat diaplikasikan di
bidang kesehatan misalnya mendiagnosis
penyakit kanker payudara, penyakit jantung,
penyakit diabetes dan lain-lain [2]. Terdapat
beberapa metode dalam mendiagnosis
penyakit kanker payudara misalnya K-Nearest Neighbor (KNN) [3], Naïve Bayes [4] , Neural Network [5], C4.5 [5] dan lain-lain.
2 jarak antara record baru dan record yang
tersedia dalam dataset training. Hal ini menyebabkan proses klasifikasi yang tidak baik dan menurunkan akurasi algoritma klasifikasi. Pendekatan utama untuk menangani masalah ini adalah untuk atribut-atribut bobot yang berbeda ketika menghitung jarak antara dua record. Dalam pembahasan ini, menggunakan aturan-aturan asosiasi untuk atribut-atribut bobot dan menyarankan algoritma klasifikasi baru K-Nearest Neighbor Based Association (KNNBA) yang dapat meningkatkan akurasi algoritma KNN. Pengujian ini menggunakan 15 UCI data set, dan dibandingkan dengan yang algoritma klasifikasi lain Naïve Bayes (NB), Neural Network (NN), J4.8, NBTREE, VFI, LWL dan IBK. Algoritma Naïve Bayes (NB) menggunakan dataset heart disease menghasilkan akurasi sebesar 83.707%. Algoritma Neural Network (NN) menggunakan dataset jantung menghasilkan akurasi sebesar 78.15%. Algoritma J48 menggunakan dataset jantung menghasilkan akurasi sebesar 76.67%. Algoritma Naïve Bayes Tree (NBTree) menggunakan dataset jantung menghasilkan akurasi sebesar 80.37%. Algoritma VFI menggunakan dataset jantung menghasilkan akurasi sebesar 80%. Algoritma LWL menggunakan dataset jantung menghasilkan akurasi sebesar 71.85%. Algoritma IBK menggunakan dataset jantung menghasilkan akurasi sebesar 81.48%. Algoritma KNNBA menggunakan dataset jantung menghasilkan akurasi sebesar
81.48% [3].
Penelitian yang dilakukan oleh Jia WU dan Zhihua CAI telah mengusulkan banyak metode efektif untuk meningkatkan kinerja Naïve Bayes dengan menggabungkan metode-metode seperti backwards sequential elimination, lazy elimination dan lain-lain [4]. Mengujikan algoritma baru menggunakan 36 data set dari UCI Repository diseleksi dengan perangkat lunak Weka dan dibandingkan dengan algoritma Differential Evolution Weighted Naïve Bayes (DE-WNB), Naïve Bayes (NB), Gain Ratio-Weighted Naïve Bayes (GR-WNB), MI-WNB, Correlation-based Feature Selection-Weighted Naïve Bayes (CFS-WNB) dan Tree-Weighted Naïve Bayes (Tree-WNB). Algoritma Differential Evolution Weighted Naïve Bayes (DE-WNB) menggunakan dataset jantung menghasilkan keakuratan sebesar 83.44±5.51%. Algoritma Naïve Bayes (NB) menggunakan dataset jantung menghasilkan keakuratan sebesar 83.78±5.41%. Algoritma Gain Ratio-Weighted Naïve Bayes (GR-WNB) menggunakan dataset jantung menghasilkan keakuratan sebesar 81.63±6.23%. Algoritma Correlation-based Feature Selection-Weighted Naïve Bayes (CFS-WNB) menggunakan dataset jantung menghasilkan keakuratan sebesar 84.22±5.99%. Algoritma Mutual Information-Weighted Naïve Bayes (MI-WNB) menggunakan dataset jantung menghasilkan keakuratan sebesar 82.93±6.14%. Algoritma Tree-Weighted Naïve Bayes (Tree-WNB) menggunakan dataset jantung menghasilkan keakuratan sebesar 84.04±5.90% [4].
KOMPUTAKI Vol.3, No.1 Februari 2017
3 akurasinya belum tinggi. Kelebihan-kelebihan
spesifik model algoritma K-Nearest Neighbor berbasis Forward Selection pada penyakit jantung yang akan diteliti dibanding teknik-teknik diagnosis lain yaitu Forward Selection digunakan untuk mereduksi ukuran data set [5] sehingga dapat meningkatkan akurasi pada K-Nearest Neighbor. Maka dari itu, penelitian ini menggunakan algoritma K-Nearest Neighbor berbasis Forward Selection untuk mendiagnosis penyakit jantung yang dapat meningkatkan akurasi dibandingkan dengan penelitian-penelitian sebelumnya.
METODOLOGI PENELITIAN
Penelitian ini menggunakan proses Cross-Standard Industry-Data Mining (CRISP-DM) dengan tahap-tahap penelitian meliputi pemahaman bisnis, pemahaman data, pengolahan data, pemodelan dan evaluasi [2].
Tahap Pemahaman Bisnis
Penelitian ini dilakukan untuk menerapkan algoritma K-Nearest Neighbor berbasis Forward Selection untuk meningkatkan akurasi dalam mendiagnosis penyakit jantung.
Tahap Pemahaman Data
Penelitian ini mengambil dataset jantung dari UCI Machine Learning [10].
Tahap Pengolahan Data
Teknik-teknik pengolahan data awal (data
pre-processing) yang digunakan pada penelitian
ini adalah [5] :
1. Data cleaning dapat digunakan untuk data yang missing value [5]. Karena ditemukan
adanya data yang terlewat tidak terisi
(missing value) pada data. Pengolahan data
awal dilakukan untuk mengisi nilai yang
missing value dengan pekerjaan replace
missing value dilakukan.
2. Data reduction digunakan untuk menghasilkan data set yang volumenya
lebih kecil [5]. Salah satu strategi data
reduction yang digunakan pada penelitian
ini adalah attribute subset selection [5].
Attribute subset selection digunakan untuk
mereduksi ukuran data set dengan
menghilangkan atribut-atribut yang tidak
relevan atau redudant [5]. Salah satu teknik
attribute subset selection yang digunakan
pada penelitian ini adalah Forward
Selection [5].
Tahap Pemodelan
Model yang digunakan dalam tahap ini menggunakan algoritma K-Nearest Neighbor berbasis Forward Selection.
Tahap Pemodelan pada Algoritma K-Nearest Neighbor (KNN) dengan Dataset
Jantung Koroner
4 Dataset jantung koroner sebanyak 10 data
Ag telah didapatkan dihitung dengan metode KNN untuk mendapatkan hasil berupa Sex “Male (M) atau “Female (F)”.
Langkah-langkah penghitungan algoritma K-Nearest Neighbor :
1. Menentukan parameter k, misal k = 5.
2. Menghitung jarak (similarity) di antara semua training records dan objek baru
dapat dilihat pada tabel 3.2.
6 = (25 + 1 + 2500 + 0 + 0 + 0 + 400 +
1 + 1 + 4 + 0 + 9 + 1)1/2
0
Tabel 4.2 Perhitungan dengan melibatkan sampel data set jantung
3. Pengurutan data berdasarkan nilai jarak dari nilai yang terkecil sampai terbesar dapat
dilihat pada Tabel 4.3.
Tabel 4.3. Hasil pengurutan dataset jantung berdasarkan nilai jarak
4. Pengambilan data sejumlah nilai K (misal K=5), dapat dilihat pada tabel 4.4.
Tabel 4.4. Pengambilan dataset jantung
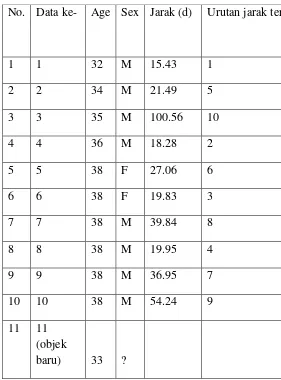
sejumlah nilai K=5 No. Data ke- Age Sex Jarak (d)
1 1 32 M 15.43
2 2 34 M 21.49
3 3 35 M 100.56
4 4 36 M 18.28
5 5 38 F 27.06
6 6 38 F 19.83
7 7 38 M 39.84
8 8 38 M 19.95
9 9 38 M 36.95
10 10 38 M 54.24
11 11 (objek
baru) 33 ?
No. Data ke- Age Sex Jarak (d) Urutan jarak terke
1 1 32 M 15.43 1
2 2 34 M 21.49 5
3 3 35 M 100.56 10
4 4 36 M 18.28 2
5 5 38 F 27.06 6
6 6 38 F 19.83 3
7 7 38 M 39.84 8
8 8 38 M 19.95 4
9 9 38 M 36.95 7
10 10 38 M 54.24 9
11 11 (objek
8 5. Menentukan label yang frekuensinya paling
sering di antara k training records yang
paling dekat dengan objek.
Pada tabel 4.4, hasil pengambilan data sejumlah nilai K, yaitu 5 data, maka didapatkan hasil “sex” sebagai berikut:
Male (M) = 4
Female (F) = 1
Dengan menggunakan label yang frekuensinya paling sering, maka didapatkan nilai atribut class adalah ”Male (M)”.
Jadi objek baru pada dataset jantung adalah age = 33; sex = M; trestbpd = 100; chol = 0; fbs = 0; restecg = 0; thalach = 140; exang = 0; oldpeak = 1; slope = 2; ca= 0; thal = 6 dan num =2.
Tahap Pemodelan pada Algoritma Forward Selection dengan Dataset Jantung
Langkah-langkah Forward Selection yang digunakan untuk dataset jantung :
1. Mulai dengan tidak ada variabel-variabel dalam model.
2. Variabel yang paling berkorelasi dengan Cp sebagai variabel dependen dipilih dan jika
signifikan dimasukkan ke dalam model. 3. Menentukan prediktor-prediktor yang
dimasukkan ke dalam model. Variabel
Exang yang memiliki nilai koefisien
korelasi (r = 0.269). F-statistic sekuensial
yang berhubungan dengan Restecg menjadi
variabel kedua yang dimasukkan ke dalam
model. F-statistic sekuensial yang
berhubungan dengan Num menjadi variabel
ketiga yang dimasukkan ke dalam model.
Data ke- Urutan jarak terkecil
Age Sex Jarak (d)
1 32 M 15.43 1
4 36 M 18.28 2
6 38 F 19.83 3
8 38 M 19.95 4
2 34 M 21.49 5
11 (objek
KOMPUTAKI Vol.3, No.1 Februari 2017
9 4. Prosedur yang variabel-variabelnya tidak
signifikan maka masuk ke dalam model dan model regresi berganda (multiple regression) untuk Cp sebagai variabel
dependen:
y = β0 + β1(Exang) + β2(Restecg) + β3(Num) + ε
5. Menghitung F-statistik sekuensial pada
variabel-variabel dapat dilihat pada Tabel
4.6. Tabel 4.6 berisi tabel ANOVA untuk
model-model dipilih oleh prosedur forward
selection. Model 1 menunjukkan model
dengan single epithelial cell size hanya
sebagai prediktor. Model 2 menunjukkan
model dengan single epithelial cell size dan
normal nucleoli yang dimasukkan sebagai
prediktor. Model 3 menunjukkan model
dengan Exang, Rectecg dan Num yang
dimasukkan sebagai prediktor.
SSextra = SSfull − SSreduced
SSRestecg|Exang = SSExang,Restecg,– SSExang
Tabel ANOVA dan model summary dari prosedur Forward Selection dengan dataset jantung dibuat menggunakan software SPSS 16.0.
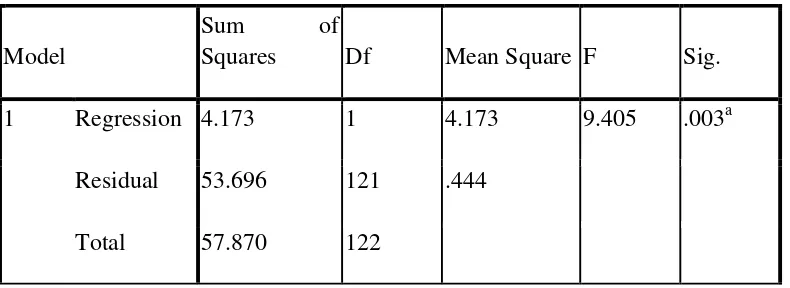
Dari Tabel 4.6 kami memiliki SSRestecg,Exang= 6.653 dan SSExang = 4.173,
memberikan
SSRestecg|Exang = SSExang,Restecg,– SSExang = 6.653
− 4.173 = 2.48
Statistik uji untuk F-test parsial (atau sekuensial) pada dataset jantung adalah :
F(Exang|Resteg) = SSExang,Restecg : MSERestecg,Exang
Dari tabel 4.6 memiliki MSERestecg,Exang =
0.427, memeberikan
F(Exang|Resteg) = SSExang,Restecg : MSERestecg,Exang= 6.653 : 0.427 = 15.58.
Statistik uji untuk F-test parsial (atau sekuensial) pada dataset jantung adalah 15.58.
Model summary dari prosedur Forward
10 Mod
el R R Square
Adjuste d R Square
Std. Error of the Estimate
Change Statistics
R Squar e Chang e
F Chang
e df1 df2
Sig. F Change
1 .269a .072 .064 .66616 .072 9.405 1 121 .003
2 .339b .115 .100 .65330 .043 5.810 1 120 .017
3 .401c .161 .140 .63871 .046 6.548 1 119 .012
a. Predictors: (Constant), Exang
b. Predictors: (Constant), Exang, Restecg
c. Predictors: (Constant), Exang, Restecg, Num
Tabel 4.6 Tabel ANOVA untuk model-model yang dipilih prosedur Forward Selection dengan dataset jantung
ANOVAd
Model
Sum of
Squares Df Mean Square F Sig.
1 Regression 4.173 1 4.173 9.405 .003a
Residual 53.696 121 .444
KOMPUTAKI Vol.3, No.1 Februari 2017
11 2 Regression 6.653 2 3.327 7.794 .001b
Residual 51.217 120 .427
Total 57.870 122
3 Regression 9.324 3 3.108 7.619 .000c
Residual 48.546 119 .408
Total 57.870 122
a. Predictors: (Constant), Exang
b. Predictors: (Constant), Exang, Restecg
c. Predictors: (Constant), Exang, Restecg, Num
d. Dependent Variable: Cp
Tahap Pengukuran dan Evaluasi
Pengukuran dan evaluasi pada penelitian ini
menggunakan confusion matrix (accuracy)
dan ROC Curve.
HASIL DAN PEMBAHASAN
Hasil Eksperimen dan Pengujian Model Penelitian ini menggunakan dataset jantung koroner yang diambil dari UCI parameter-parameter yaitu age, sex, chest pain type (Cp), tresbpd (resting blood pressure), Chol (serum cholestoral in mg/dl), fbs (fasting blood sugar), Restecg (Resting electrocardiographic results), Thalach (maximum heart rate achieved), Exang : exercise induced angina, oldpeak, slope, Ca (number of major vessels
(0-3) colored by flourosopy), thal, dan Num (diagnosis of heart disease). Jumlah data set jantung sebanyak 123 record [10].
Salah satu teknik untuk menilai akurasi adalah cross validation [5]. Pengujian pada penelitian ini menggunakan ten fold cross validation. Pengujian pada diagnosis jantung koroner dengan menggunakan algoritma K-Nearest Neighbor, setelah itupengujian pada algoritma Forward Selection-KNN.
12 1. Pengujian 1 : record 1-12 termasuk data
testing, record 13-123 termasuk data
training.
2. Pengujian 2 : record 13-24 termasuk data testing, record 25-123 termasuk data
training.
3. Pengujian 3 : record 25-36 termasuk data testing, record 37-123 termasuk data
training.
4. Pengujian 4 : record 37-48 termasuk data testing, record 49-123 termasuk data
training.
5. Pengujian 5 : record 49-60 termasuk data
testing, record 61-123 termasuk data
training.
6. Pengujian 6 : record 61-72 termasuk data
testing, record 73-123 termasuk data
training.
7. Pengujian 7 : record 73-84 termasuk data
testing, record 85-123 termasuk data
training.
8. Pengujian 8 : record 85-96 termasuk data testing, record 97-123 termasuk data
training.
9. Pengujian 9 : record 97-108 termasuk data testing, record 109-123 termasuk
data training.
10. Pengujian 10 : record 108-123 termasuk data testing.
Pengukuran dan Evaluasi
Evaluasi dan validasi pada penelitian ini menggunakan confusion matrix (accuracy) dan ROC Curve.
Pengukuran dan Evaluasi pada K-Nearest Neighbor dengan Dataset Jantung
Dataset jantung pada k=1 yang memiliki nilai akurasi 86.79% +/- 7.73%. Tabel confusion matrix dan kurva Area Under Curve (AUC) pada algoritma K-Nearest Neighbor dengan dataset jantung dapat dilihat pada tabel 5.1 dan gambar 5.1.
Tabel 5.1 Confusion matrix pada algoritma
K-Nearest Neighbor dengan dataset
jantung
true Male true Female class precision
pred. Male 105 8 92.92%
pred. Female 8 2 20.00%
0
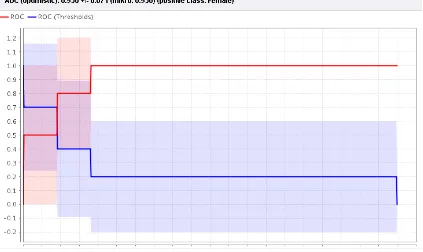
Gambar 5.1 Area Under Curve (AUC) pada algoritma K-Nearest Neighbor dengan dataset jantung
Pada tabel 5.1 dihasilkan nilai TP (true positive) 105, nilai TN (true negative) 2, nilai FP (false positive) 8, nilai FN (false negative) 8 dan nilai AUC (Area Under Curve) 0,936+/-0.071 yang termasuk dalam kategori “klasifikasi sangat baik (excellent classification)”. Jika akurasinya adalah:
Diketahui:
TP = 105 FN = 8
FP = 8 TN = 2
Akurasi =
TP+TN
TP+TN+FP+FN
=
105+2
105+2+8+8
= 107 : 123 = 86.79%
14 Pengukuran dan Evaluasi pada Forward
Selection - K-Nearest Neighbor (KNN)
dengan Dataset Jantung
Dataset jantung pada k=1 yang memiliki nilai akurasi 91.86% +/- 0.29%. Tabel confusion matrix dan kurva Area Under Curve (AUC)
pada algoritma Forward Selection – KNN dengan dataset jantung dapat dilihat pada tabel 5.2 dan gambar 5.2.
Tabel 5.2 Confusion matrix pada algoritma
Forward Selection– KNN dengan dataset jantung
true Male true Female class precision
pred. Male 113 10 91.87%
pred. Female 0 0 0.00%
class recall 100.00% 0.00%
Gambar 5.2 Area Under Curve (AUC) pada algoritma Forward Selection– KNN dengan dataset jantung
Pada tabel 5.2 dihasilkan nilai TP (true positive) 113, nilai TN (true negative) 0, nilai FP (false positive) 0, nilai FN (false negative)
KOMPUTAKI Vol.3, No.1 Februari 2017
Dari penelitian-penelitian yang pernah dilakukan tentang diagnosis penyakit jantung koroner terutama yang menggunakan algoritma K-Nearest Neighbor, akurasinya belum tinggi.
Pada dataset jantung koroner, algoritma KNN (k=1) memiliki nilai akurasi 86.79% +/- 7.73% dan nilai AUC (Area Under Curve) 0,936+/-0.071 yang termasuk dalam kategori klasifikasi sangat baik (excellent classification).
Pada dataset jantung koroner, algoritma Forward Selection-KNN (k=1) memiliki nilai akurasi 91.86% +/- 0.29% dan nilai AUC (Area Under Curve) 0.777+/-0.134 yang termasuk dalam kategori klasifikasi sama (fair classification).
Pada penelitian ini, algoritma Forward Selection berbasis K-Nearest Neighbor (KNN) tingkat akurasinya lebih tinggi dari pada algoritma K-Nearest Neighbor (KNN) dalam mendiagnosis penyakit jantung koroner.
DAFTAR PUSTAKA
[1] N. C. for C. D. P. and H. Promotion, “Heart Disease,” National Center for Chronic Disease Prevention and Health Promotion, pp. 1–2, 2009.
[2] D. T. Larose, Discovering Knowledge in Data: An Introduction to Data Mining. United States of America: John Wiley & Sons, Inc, 2005.
[3] M. Moradian and A. Baraani, “KNNBA: K-Nearest-Neighbor Based Association Algorithm,” Journal of Theoretical and Applied Information Technology, 2009.
[4] J. Wu and Z. Cai, “Attribute Weighting via Differential Evolution Algorithm for Attribute Weighted Naive Bayes ( WNB ),” vol. 5, pp. 1672–1679, 2011.
[5] J. Han and M. Kamber, Data Mining Concept dan Techniques, 2nd ed. United States of America: Diane Cerra, 2006.
[6] I. H. Witten, E. Frank, and M. A.Hall, Data mining: Practical Machine Learning Tools and Techniques, 3rd ed. USA: Kauffmann, Morgan, p. 2011.
[7] F. Gorunesco, Data Mining Concept Model Technique. Romania: Springer, 2011.
16 Journal of Hydrology, vol. 401, no. 3–
4, pp. 177–189, 2011.
[9] D. T. Larose, Data Mining Methods and Models. New Jersey, Canada: John Wiley & Sons, Inc, 2007.
[10] Frank, A. & Asuncion, A, “UCI
Machine Learning Repository”