PENERAPAN ALGORITMA K-NEAREST NEIGHBOR (K-NN) UNTUK PREDIKSI WAKTU KELULUSAN MAHASISWA
Andi Gita Novianti1, Dian Prasetyo2
1,2Program Studi Teknik Informatika, Fakultas Ilmu Komputer dan Manajemen, Universitas Sains dan Teknologi Jayapura, Jl. Raya Sentani Padang Bulan Abepura - Jayapura
1[email protected], 2 [email protected]
Abstrak
Angka kelulusan yang tinggi dapat dianggap sebagai salah satu indikator keberhasilan dalam proses penyelenggaraan pendidikan di Perguruan Tinggi. Secara spesifik, Ketua Program Studi maupun Dosen Wali di Fakultas Ilmu Komputer dan Manajemen (FIKOM) Universitas Sains dan Teknologi Jayapura (USTJ) belum pernah melakukan prediksi tentang waktu kelulusan mahasiswa, yang ada adalah proses mendata mahasiswa lulus dan lama studinya. Penelitian ini bertujuan untuk menerapkan Algoritma K-Nearest Neighbor (K-NN) dan Fungsi Similarity untuk menghitung kemiripan data dalam sebuah perangkat lunak yang dapat memberikan prediksi waktu kelulusan mahasiswa. Hasil pengujian menggunakan aplikasi prediksi waktu kelulusan dengan 7 (tujuh) kriteria yaitu IPS1-IPS4, jumlah SKS lulus sampai semester 4, jurusan SLTA, program studi, asal suku, penghasilan orang tua dan jenis kelamin di dapat akurasi untuk Program Studi Teknik Informatika S1 sebesar 84% sedangkan Program Studi Sistem Informasi S1 sebesar 87%.
.
Kata kunci :
Algoritma K-Nearest Neighbor (K-NN), Fungsi Similarity, Prediksi Kelulusan, FIKOM-USTJ1. Pendahuluan
Angka kelulusan menjadi salah satu indikator atau tolak ukur tingkat keberhasilan Perguruan Tinggi dalam melaksanakan proses belajar mengajar (PBM). Prosentase naik turunnya kemampuan mahasiswa untuk menyelesaikan studi tepat waktu merupakan salah satu elemen penilaian akreditasi Universitas, untuk itu perlu adanya pemantauan maupun evaluasi terhadap kecenderungan mahasiswa lulus tepat waktu atau tidak.
Algoritma K-Nearest Neighbor (K-NN) adalah pendekatan untuk mencari kasus dengan menghitung kedekatan antara kasus baru dengan kasus lama, berdasarkan pada pencocokan bobot dari sejumlah fitur yang ada. Dengan memanfaatkan Algoritma K- NN akan dapat membantu Ketua Program Studi Teknik Informatika S-1 dan Sistem Informasi S-1 pada Fakultas Ilmu Komputer dan Manajemen (FIKOM) USTJ dalam memprediksi waktu kelulusan mahasiswa.
2. Dasar Teori
2.1 Algoritma K-Nearest Neighbor (K-NN) Menurut Kusrini dan Emha Taufiq Luthfi dalam buku Algoritma Data Mining (2009; 93) menyatakan Nearest Neighbor adalah pendekatan untuk mencari kasus dengan menghitung kedekatan antara kasus baru dengan kasus lama, yaitu berdasarkan pada pencocokan bobot dari sejumlah fitur yang ada.
Misalkan diinginkan untuk mencari solusi terhadap seorang pasien baru dengan menggunakan solusi dari pasien terdahulu.
Untuk mencari kasus pasien mana yang akan digunakan, maka dihitung kedekatan kasus pasien baru dengan semua kasus pasien lama kasus pasien lama dengan kedekatan terbesarlah yang akan diambil solusinya untuk digunakan pada kasus pasien baru.
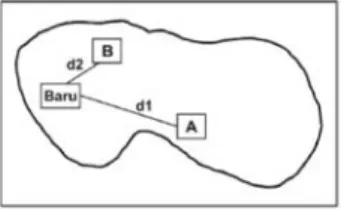
Gambar 1. Ilustrasi Kedekatan Kasus (Sumber Kusrini dan Emha Taufiq Luthfi 2009; 94)
Seperti tampak pada Gambar 1 ada dua pasien lama: A dan B. ketika ada pasien baru, maka solusi yang akan diambil adalah solusi dari pasien terdekat dari pasien baru. Seandainya d1 adalah kedekatan antara 8 pasien baru dan pasien A, sedangkan d2 adalah kedekatan antara pasien baru dan pasien B, karena d2 lebih dekat dari d1, maka solusi dari pasien B-lah yang akan digunakan untuk memberikan solusi pasien baru.
Adapun rumus untuk melakukan perhitungan kedekatan antara dua kasus adalah sebagai berikut:
108
Similarity (T,S) = ∑ , ∗ Keterangan :
T : kasus baru
S : kasus yang ada dalam penyimpanan N : jumlah atribut dalam setiap kasus I : atribut individu antara 1 s.d n
f : fungsi similarity i antara kasus T dan S wi : bobot yang diberikan pada atribut ke-i
Menurut Eko Prasetyo dalam buku Data Mining Konsep dan Aplikasi menggunakan Matlab (2012;
23) menyatakan kemiripan (similarity) adalah ukuran derajat numerik dimana dua objeknya mirip, nilai 0 jika tidak mirip dan 1 jika mirip penuh.
Formula kemiripan dua data dengan satu atribut adalah sebagai berikut:
s =
{
Adapun rumus untuk pemberian bobot pada setiap atribut (I Wayan, 2012) adalah sebagai berikut:
1. Input nilai kriteria masing-masing model 2. Input bobot masing-masing kriteria 3. Hitung normalisasi dari bobot
NK = ∑ %
Nilai Akhir = ∑
Dimana : SBK : Kriteria
BBT : Bobot Kriteria
NK : Nilai Kriteria
Menurut M. Reza Faisal dalam buku Seri Belajar Data Science Klasifikasi dengan Bahasa Pemograman R (2016; 69) secara umum, pengukuran kinerja algoritma dilakukan dengan cara membandingkan antara hasil prediksi algoritma klasifikasi dengan nilai target variabel data testing sebagai data sebenarnya. Maka secaralogika sederhana dapat disimpulkan kinerja algoritma adalah sebagai berikut:
Kinerja = x100%
2.2 Data Mining
Turban, dkk (2005) dalam buku karangan Kusrini dan Emha Taufiq Luthfi dengan judul Algoritma Data Mining (2009; 5) menyatakan data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database. Data mining adalah proses yang menguraikan teknik statistik, matematika, kecerdasan buatan dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar.
3. Pembahasan
3.1 Menentukan data training
Untuk melakukan prediksi waktu kelulusan mahasiswa dibutuhkan data mahasiswa Fakultas Ilmu Komputer dan Manajemen Program Studi Teknik Informatika S-1 dan Sistem Informasi S-1 angkatan 2010 dan 2011 yang telah lulus sebagai data training, sedangkan angkatan 2012, 2013 dan 2014 yang masih aktif sebagai data testing. Kriteria pada mahasiswa yang digunakan yaitu Indeks Prestasi Semester (IPS) 1 - IPS 4, program studi, asal suku, jenis kelamin, jurusan SLTA, penghasilan orang tua, jumlah satuan kredit semester (SKS) capai hingga semester 4.
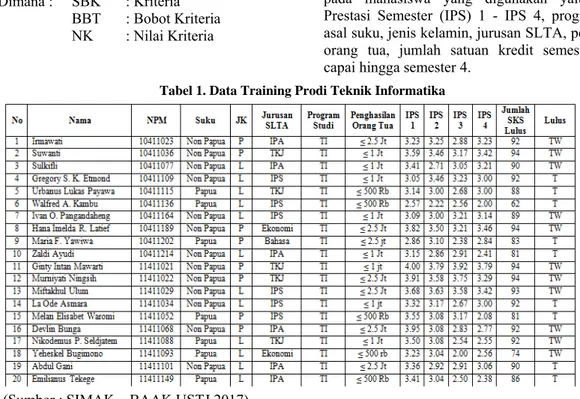
Tabel 1. Data Training Prodi Teknik Informatika
(Sumber : SIMAK – BAAK USTJ 2017) (1)
(3)
(4) 1 jika x = y
0 jika x ≠ y (2)
(5)
109
Tabel 2. Data Training Prodi Sistem Informasi
(Sumber : SIMAK – BAAK USTJ 2017) 3.2 Pemberian Nilai bobot Untuk Tiap Kriteria
Pemberian bobot kriteria, dimana bobot antara satu kriteria dengan kriteria yang lain dapat didefinisikan dengan nilai yang berbeda. Berikut ini adalah contoh pemberian bobot pada kriteria indeks prestasi sementara (IPS) dimana nilai bobot digunakan untuk menghitung nilai kriteria. Rumus perhitungan nilai bobot mengacu pada persamaan (2) dan (3).
Tabel 3. Nilai Indeks Prestasi Sementara (IPS)
No Kriteria Nilai Bobot
1 IPS ≥ 3.5 100 = 1
30% = 0.3 2 IPS ≥ 3 dan < 3.5 80 = 0.8
3 IPS ≥ 2 dan < 3 60 = 0.6 4 IPS < 2 40 = 0.4 Nilai Kriteria IPS adalah:
Nilai Kriteria = ∑ , , , , Nilai Kriteria =
Nilai Kriteria = Nilai Kriteria = 21
Perhitungan yang sama seperti di atas, berlaku untuk semua kriteria dalam menentukan Nilai dari kriteria-kriteria. Tabel 4 menunjukkan bobot untuk tiap kriteria yang digunakan.
Tabel 4. Tabel Bobot Kriteria
No Kriteria Bobot
1 Nilai IPS 0.3
2 Jumlah SKS Tempuh 0.2
3 Jurusan SLTA 0.15
4 Program Studi 0.1
5 Asal Suku 0.1
6 Penghasilan Orang Tua 0.1
7 Jenis Kelamin 0.05
3.3 Menghitung Nilai Kedekatan Antar Kriteria Setelah menghitung nilai bobot kriteria, selanjutnya menentukan Nilai Kedekatan untuk semua kriteria, dimana nilai kedekatan adalah nilai yang berada pada rentang nilai antara 0 s.d 1. Nilai 0 berarti kedua kasus mutlak tidak mirip, sebaliknya untuk nilai 1 artinya kasus mirip secara mutlak. Nilai kedekatan akan digunakan untuk menghitung jarak terdekat antara data training dan data testing.
Contoh berikut ini adalah tabel Nilai kedekatan untuk Kriteria IPS:
Tabel 5. Nilai Kedekatan Kriteria IPS
≥3.5 ≥3 dan
<3,5
≥2 dan
<3
<2
≥3.5 1 0.8 0.6 0.4
≥3 dan <3,5 0.8 1 0.75 0.5
≥2 dan <3 0.6 0.75 1 0.667
<2 0.4 0.5 0.667 1
3.4 Perhitungan fungsi Similarity
Selanjutnya dilakukan perbandingan antara Data Testing dan Data Training yang telah dipersiapkan sebelumnya dengan menggunakan rumus pada persamaan (5), dimana data testing ke-1 dibandingkan dengan kasus yang telah terjadi sebelumnya (DataTraining).
3.4.1 Prodi Teknik Informatika
Data testing ke-1 (Hanoch N. Yaristouw), dihitung nilainya berdasarkan langkah-langkah yang telah dijabarkan sebelumnya. Berikut adalah contoh perhitungan dari tabel hasil perhitungan dengan kasus yang baru yaitu:
1.
Menghitung Kasus 1a. Kedekatan nilai IPS 1 = 0.75 110
b. Kedekatan nilai IPS 2 = 0.75 c. Kedekatan nilai IPS 3 = 1 d. Kedekatan nilai IPS 4 = 0.5 e. Bobot kedekatan nilai IPS = 0.3 f. Kedekatan jumlah SKS = 0.25 g. Bobot jumlah SKS = 0.2
h. Kedekatan jurusan SLTA = 0.833 i. Bobot kedekatan jurusan SLTA = 0.15 j. Kedetakan program studi = 1
k. Bobot kedekatan program studi = 0.1 l. Kedekatan asal suku = 0
m. Bobot kedekatan asal suku = 0.1
n. Kedekatan penghasilan orang tua = 0.333 o. Bobot kedekatan penghasilan orang tua =
0.1
p. Kedekatan jenis kelamin = 0
q. Bobot kedekatan jenis kelamin = 0.05
Menghitung (Kasus 1) :
∗ ∗ ∗ ∗ ∗ ∗ ∗ ∗ ∗ ∗
∗
. ∗ . . ∗ . ∗ . . ∗ . . ∗ . . ∗ . ∗ . ∗ . . ∗ . ∗ .
∗ . . . . . . .
1.208 1.9 0.636
Tabel 6. Hasil Perhitungan Jarak Data Testing Ke-1
Proses perhitungan diatas dilakukan hingga data training ke-20 dengan menggunakan persamaan yang sama yaitu rumus (5). Berdasarkan hasil perhitungan dari 20 kasus yang dilakukan sebelumnya, maka terlihat nilai tertinggi terdapat pada kasus ke 6 yaitu mahasiswa lulus terlambat.
Prediksi waktu kelulusan untuk kasus 1 (Hanoch N.
Yarisetouw) kemungkinan akan lulus Terlambat.
3.4.2 Prodi Sistem Informasi
Berikut adalah contoh perhitungan dari tabel hasil perhitungan dengan kasus yang baru yaitu Data Testing ke-2 (Rismawaty Tikulembang) sebagai berikut:
Menghitung Kasus 2:
a. Kedekatan nilai IPS 1 = 0.8 b. Kedekatan nilai IPS 2 = 0.8 c. Kedekatan nilai IPS 3 = 0.6 d. Kedekatan nilai IPS 4 = 1 e. Bobot kedekatan nilai IPS = 0.3 f. Kedekatan jumlah SKS = 1 g. Bobot jumlah SKS = 0.2 h. Kedekatan jurusan SLTA = 0.5 i. Bobot kedekaran jurusan SLTA = 0.15 j. Kedetakan program studi = 1
k. Bobot kedekatan program studi = 0.1 111
l. Kedekatan asal suku = 1 m. Bobot kedekatan asal suku = 0.1 n. Kedekatan penghasilan orang tua = 1
o. Bobot kedekatan penghasilan orang tua = 0.1 p. Kedekatan jenis kelamin = 1
q. Bobot kedekatan jenis kelamin = 0.05 Menghitung (Kasus 2) :
∗ ∗ ∗ ∗ ∗ ∗ ∗ ∗ ∗ ∗
∗
. ∗ . . ∗ . . ∗ . ∗ . ∗ . . ∗ . ∗ . ∗ . ∗ . ∗ .
∗ . . . . . . .
1.585 1.9 0.834
Tabel 7. Hasil Perhitungan Jarak Data Testing ke-2
Proses perhitungan diatas dilakukan hingga data training ke-20 dengan menggunakan persamaan yang sama yaitu rumus (5).
Berdasarkan hasil perhitungan dari 20 kasus yang dilakukan sebelumnya, maka terlihat nilai tertinggi terdapat pada kasus ke 1 yaitu mahasiswa lulustepat waktu. Prediksi waktu kelulusan untuk kasus 1 (Rismawaty Tikulembang) kemungkinan akan lulus Tepat Waktu.
3.5 Implementasi
Berdasarkan analisis perhitungan yang telah dilakukan, kemudian diimplementasikan ke dalam sebuah aplikasi.
Berdasarkan analisis perhitungan yang telah dilakukan, kemudian diimplementasikan ke dalam sebuah aplikasi. Form Prediksi Kelulusan, adalah form yang digunakan untuk memprediksi waktu kelulusan mahasiswa menggunakan algoritma K- Nearest Neighbor (K-NN) dan fungsi similarity, dimana aplikasidapat mengetahui waktu kelulusan mahasiswa (lulus Tepat Waktu dan Terlambat).
Dapat dilihat pada Gambar 2, hasil prediksi yang dihasilkan oleh aplikasi sudah sesuai dengan
analisis perhitungan manual yang dilakukan sebelumnya.
Gambar 2. Form Prediksi Kelulusan
112
4. Penutup 4.1 Kesimpulan
Berdasarkan penelitian yang telah dilakukan yaitu penerapan algoritma k-nearest neighbor (K- NN) untuk prediksi waktu kelulusan mahasiswa, dapat diambil kesimpulan sebagai berikut:
1. Hasil pengujian pada Program Studi Teknik Informatika S-1 dengan jumlah data training sebanyak 151 mahasiswa dan data testing sebanyak 50 mahasiswa di dapat nilai akurasi sebesar 84%.
2. Hasil pengujian pada Program Studi Sistem Informasi S-1 dengan jumlah data training sebanyak 55 mahasiswa dan data testing sebanyak 15 mahasiswa di dapat nilai akurasi sebesar 87%.
3. Penyajian laporan prediksi hanya dapat mencetak laporan masing-masing mahasiwa.
4. Aplikasi prediksi waktu kelulusan dapat membantu Dosen Wali maupun Ketua Program Studi dalam mengetahui waktu kelulusan mahasiswa.
5. Hasil prediksi dapat dijadikan acuan bagi Program Studi untukmengurangi tingkat drop out (DO) mahasiswa.
4.2 Saran
Saran yang dapat ditambahkan untuk pengembangan dan penelitian selanjutnya adalah sebagai berikut:
1. Menggunakan algoritma klasifikasi lain seperti Algoritma ID3, Algoritma C4.5, Algoritma C5.0 dan Algoritma Mean Vektor agar terlihat perbandingannya.
2. Dapat dikembangkan dalam bentuk web agar mahasiswa dapat menggunakan aplikasi untuk mengetahui prediksi waktu kelulusan mereka.
3. Aplikasi prediksi waktu kelulusan agar lebih akurat atau optimal, dibutuhkan data training lebih banyak dan menambahkan jumlah kriteria untuk prediksi kelulusan.
5. Daftar Pustaka
[1] Fathansyah, 2012, Basis Data, Informatika, Bandung.
[2] Kadir A., 2013, Pengenalan Algoritma – Pendekatan Secara Visual dan Interaktif menggunakan Raptor, Andi, Yogyakarta.
[3] Kusrini., Luthfi E. T., 2009, Algoritma Data Mining, Andi, Yogyakarta.
[4] Leidiyana H., 2013, Penerapan Algoritma K- Nearest Neighbor Untuk Penentuan Resiko Kredit Kepemilikan Kendaraan Bermotor, STMIK Nusa Mandiri, Sukabumi.
[5] Ndaumanu R. I., Kusrini, Arief M. R., 2014, Analisis Prediksi Tingkat Pengunduran Diri Mahasiswa Dengan Metode K-Nearest Neighbor, STMIK AMIKOM Yogyakarta, Yogyakarta.
[6] Prasetyo E., 2012, Data Mining – Konsep dan Aplikasi menggunakan MATLAB,
Andi, Yogyakarta.
[7] Pressman R. S., 2012, Rekayasa Perangkat Lunak, Andi, Yogyakarta
[8] Rohman A., 2015, Model Algoritma K-Nearest Neighbor (K-NN) Untuk Prediksi Kelulusan Mahasiswa, Universitas Pandanaran Semarang, Semarang.
[9] Silluta C. Y., 2016, Implementasi Data Mining Untuk Memprediksi Kelulusan Mahasiswa Dengan Menggunakan Metode Klasifikasi Dan Algoritma K-Nearest Neighbor Berbasis Desktop (Studi Kasus: Fakultas Teknologi Informasi, Program Studi Teknik Informatika), Universitas Budi Luhur, Jakarta.
[10] Sumarlin, 2015, Implementasi Algoritma K- Nearest Neighbor Sebagai Pendukung Keputusan Klasifikasi Penerima Beasiswa PPA dan BBM, STIKOM
Uyelindo Kupang, Kupang.
[11] Supriana I. W., 2012, Sistem Pendukung Keputusan Dalam Pemilihan Tempat Kost Dengan Metode Pembobotan (Studi Kasus:
Sleman Yogyakarta), Universitas Gajah Mada, Yogyakarta.
113