Fakultas Ilmu Komputer
825
Identifikasi Diagnosis Gangguan Autisme Pada Anak Menggunakan
Metode Modified K-Nearest Neighbor (MKNN)
Jojor Jennifer Sianipar1, M.Tanzil Furqon2, Putra Pandu Adikara3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email:
:
1[email protected], 2[email protected], 3[email protected]Abstrak
Autisme adalah suatu gangguan neurologis yang secara signifikan mengakibatkan kurangnya kemampuan membentuk hubungan sosial, komunikasi yang normal, dan juga perilaku pada anak. Gejala autisme ini pada umumnya timbul sebelum anak mencapai usia 3 tahun. Autisme bukan penyakit kejiwaan karena autisme adalah suatu gangguan yang terjadi pada otak sehingga menyebabkan otak anak tersebut tidak dapat berfungsi normal dan hal tersebut termanifestasi pada perilaku anak autisme. Ada beberapa penelitian yang mengatakan bahwa penyebab autisme yaitu gangguan saraf pusat yang menyebabkan pada kelainan struktur otak anak. Ahli yang berbeda menyebutkan bahwa autisme salah satu penyebabnya adalah jenis makanan yang dikonsumsi salah atau dikarenakan berada dalam lingkungan yang banyak zat-zat berbahaya yang menyebabkan masalah dalam sikap ataupun tingkah laku anak. Untuk menangani gangguan autisme maka dibuat sistem untuk identifikasi gangguan autisme pada anak menggunakan metode Modified K-Nearest Neighbor (MKNN). Metode ini adalah salah satu metode klasifikasi berdasarkan kemunculan kelas terbanyak pada nilai data latih. Terdapat 14 gejala dari 4 aspek yang digunakan sebagai parameter dalam pengembangan sistem. Keluaran yang dihasilkan sistem merupakan mengalami gangguan autisme atau tidak pada anak. Berdasarkan pengujian yang telah dilakukan sistem yang menggunakan metode Modified K-Nearest Neighbor (MKNN) memperoleh hasil akurasi maksimum 100% serta akurasi minimum 92%. Berdasarkan hasil tersebut, sistem yang menggunakan metode Modified K-Nearest Neighbor (MKNN) dapat diimplementasikan dalam kehidupan sehari-hari.
Kata kunci: autisme, klasifikasi, Modified K-Nearest Neighbor (MKNN).
Abstract
Autism is a neurological disorder that shows significant result as a lack of ability to form social relationships, normal communication, and behavior in children. This symptoms generally appear before children reach the age of 3 years. It is not classified as a psychiatric disease because autism is a disorder that occurs malfunction of children’s brain and it is manifested on children’s behaviour. Some research states that autism causes as the neurodevelopmental disorder that causes abnormalities in children’s brain structure. Different experts mentioned that autism in children caused by the kind of food they consumed or they living environment that contain many harmful substances that shows in children’s behaviour. Therefore, the system for the identification of autism disorders in children will be create to help identifies autism disorder by using the method of Modified K-Nearest Neighbor (MKNN). It is one of classification method based on the appearance of largest classes in data training. There are 14 symptoms from 4 aspects that are used as parameters in the development of the system. The output of the system is showing whether a child is autistic individuals or not. Based on the testing that has been done on the system that using Modified K-Nearest Neighbor (MKNN), maximum accuracy shows 100% accuracy while minimum accuracy is 92%. Based on those results, the uses of Modified K-Nearest Neighbor (MKNN) method can be implemented in our daily life.
1. PENDAHULUAN
Autisme merupakan salah satu jenis gangguan tumbuh kembang, yang serupa dengan kumpulan gejala yang mengakibatkan adanya kelainan saraf tertentu yang menyebabkan fungsi otak tidak bekerja secara normal sehingga mempengaruhi tumbuh kembang, kemampuan komunikasi, dan kemampuan interaksi sosial seseorang. Gejala-gejala autisme dapat diketahui dari adanya penyimpangan dari ciri-ciri tumbuh kembang anak secara normal (Sunu,2012).
Semakin banyak jumlah anak yang menderita autisme dengan banyak gejala yang berbeda-beda patut diwaspadai terlebih dengan peningkatan jumlah penderitanya setiap tahunnya. Hal inilah seharusnya orang tua mengetahui untuk penanganan pada anak yang mengalami gangguan autisme. Dengan kekurangan pengetahuan orang tua mengenai autisme juga menyebabkan keterlambatan orang tua untuk segera memeriksa anaknya pada psikolog anak. Selain dari faktor orang tua, psikolog anak jarang ditemukan di kota-kota kecil sehingga untuk mendukung faktor ini dibangun suatu sistem yang dapat mengidentifikasi autisme sejak dini (Kusumadewi 2003).
Penelitian lain yang pernah dilakukan dengan metode Modified K-Nearest Neighbor (MKNN) oleh Andhina (2016) membahas bagaimana menerapkan metode Modified K-Nearest Neighbor dalam mendiagnosis penyakit pada tanaman jagung. Penelitian ini menggunakan 5 jenis penyakit dengan 16 gejala penyakit tanaman jagung. Pengujian dengan nilai yang berbeda maka diperoleh nilai rata-rata akurasi yang berbeda juga pada masing-masing data latih. Data latih yang digunakan dalam pengujian adalah data latih 346 data data uji 90 data. Nilai akurasi terbesar terdapat pada nilai k=1 dengan rata rata akurasi sebesar 98,89%. Sedangkan dengan jumlah data latih berbeda dan jumlah data uji tetap menghasilkan nilai akurasi 97,5% pada jumlah data latih sebanyak 125 data dengan data uji 80 data (Andhina, 2016).
Berdasarkan penelitian-penelitian tersebut maka pada penelitian ini digunakan metode
Modified K-Nearest Neighbor (MKNN) untuk diterapkan ke dalam sistem yang akan dibangun. Kemudian, dibangunlah sebuah
sistem identifikasi untuk mendiagnosis gangguan autisme pada anak dengan judul
“Identifikasi Diagnosis Gangguan Autisme Pada Anak Menggunakan Metode Modified
K-Nearest Neighbor (MKNN)”. Sistem ini menggunakan data gejala Childhood Autism Rating Scale (CARS) yang menjadi acuan psikolog dalam mendiagnosis autisme pada anak. Demikian dengan adanya penelitian ini diharapkan dapat membantu dalam menyelesaikan permasalahan diagnosis gangguan autisme pada anak.
2. LANDASAN KEPUSTAKAAN
2.1 Autisme
Autisme berasal dari kata ‘auto’ yang
artinya sendiri. Istilah tersebut dipakai karena mereka yang mengidap gejala autisme seringkali memang kelihatan seperti seorang yang memiliki hidup sendiri. Mereka seolah-olah hidup di dunianya sendiri dan terlepas dari kontak sosial yang ada di sekitarnya (Sunu, 2012).
Anak autisme juga memiliki perilaku-perilaku yang khas dalam kesehariaannya. Berikut bentuk perilaku yang unik dan sering terlihat pada anak-anak autis yaitu (Sunu, 2012):
1. Kurangnya motivasi, anak autis biasanya terlihat menarik diri dari lingkungan sosial dan sibuk dengan dunianya sendiri. Beberapa anak autis biasanya tidak memiliki keinginan untuk ingin tahu dunia yang ada di sekitarnya. Mereka tidak memiliki keinginan untuk memberitahu lingkungan dan memperluas ruang lingkup mereka.
2.Selektif terhadap stimulasi rangsang dari lingkungan sekitarnya, sehingga seringkali kesulitan menangkap informasi secara maksimal dan sekitarnya. Sikap ini sering membuat anak autis menjadi kurang peka jika ada bahaya di sekelilingnya. Misalnya saat anak tersebut berada di kolam renang atau di jalan raya.
4. Merespon imbalan secara langsung. Hal ini akhirnya menjadi salah satu cara yang dipakai dalam terapi perilaku, seperti dengan memanfaatkan respon langsung anak autis pada imbalan sebagai sarana untuk mengetahui perilaku baru yang diinginkan.
2.2 Data Mining
Data mining adalah sebuah proses eksplorasi dan analisis secara otomatis atau semi-otomatis dengan kuantitas data cukup besar untuk menemukan pola dan aturan (rule).
Data mining melibatkan proses komputasi degan data set besar. Tujuan dari analisis ini adalah proses ekstraksi informasi dari kumpulan data dan mentransformasikan data tersebut menjadi struktur data yang mudah untuk dipahami serta dapat digunakan lebih lanjut. Data mining merupakan sebuah cara untuk memecahkan masalah dengan menganalisis data yang sudah ada dalam
database. Terdapat 5 elemen utama data mining, yaitu (Nikita, 2013):
1. Extract, transform (mengubah) dan transaksi data ke sistem data warehouse.
2. Menyimpan dan mengola data dalam multidimensi sistem database.
3. Memberikan akses data analisis bisnis dan professional teknologi informasi.
4. Menganalisis data dengan aplikasi perangkat lunak.
5. Menyajikan data dalam format yang berguna seperti grafik.
Data mining menjadi popular di bidang kesehatan karena mengefesiensikan kebutuhan dalam menganalisis untuk mendeteksi informasi yang tidak diketahui dan berharga dalam data kesehatan. Data mining memberikan solusi bagi para peneliti kesehatan untuk membuat kebijakan kesehatan yang efisien, membangun sistem sistem yang lain (Divya, 2013).
2.3 K-Nearest Neighbor
K-Nearest Neighbor (KNN) adalah suatu metode yang biasa digunakan untuk klasifikasi data. Algoritme KNN adalah sebuah metode untuk mengklasifikasikan objek berdasarkan data pembelajaran yang jaraknya paling dekat dengan objek tertentu. KNN merupakan suatu metode yang menggunakan algoritma
supervised. Supervised learning bertujuan
untuk menemukan pola baru dalam data dengan menghubungkan pola data yang sudah ada dengan data yang baru. Tujuan dari algoritme ini adalah mengklasifikasikan objek baru berdasarkan atribut dan training sample
(Aktivia, 2012).
2.3.1 Algoritme K-Nearest Neighbor
Proses algoritme K-Nearest Neighbor untuk mengklasifikasikan data adalah (Chen, 2010):
1. Tentukan parameter K
2. Hitung jarak antara data yang akan dievaluasi dengan semua data latih.
3. Urutkan jarak yang terbentuk dan tentukan k
tetangga terdekat berdasarkan nilai k
terdekat.
4. Pasang kelas yang bersesuaian.
5. Tentukan kategori berdasarkan kelas yang mayoritas dari kelas tetangga terdekat sebagai nilai prediksi data baru.
2.3.2 Euclidean Distance
Interval scarled variabel adalah ukuran-ukuran continue dari skala linier. Ukuran-ukuran tersebut berupa Ukuran-ukuran jarak, yang biasanya digunakan adalah jarak Euclidean.
Persamaan perhitungan untuk mencari
Euclidean dengan d adalah jarak dan p adalah dimensi data dengan rumus sebagai berikut:
𝒅(𝒙,𝒚)= √∑ (𝒙𝒊− 𝒚𝒊)𝟐 𝒑
𝒊=𝟏 (𝟏)
dengan 𝑥𝑖 sampel data latih, 𝑦𝑖 data uji, 𝑑(𝑥,𝑦) jarak antara titik pada data latih x dan titik data uji y dan 𝑝 adalah dimensi data
2.4 Modified K-Nearest Neighbor
Metode MKNN adalah memasukkan label kelas dari data berdasarkan data poin pada data data latih yang sudah divalidasi dengan nilai k. Pertama yang dilakukan adalah perhitungan validitas untuk semua data yang terdapat pada data latih, selanjutnya dilakukan perhitungan
weight voting untuk semua data ini menggunakan validatas data (Parvin,et all., 2010). Berikut langkah-langkah pada metode
Modified K-Nearest Neighbor adalah:
1. menentukan nilai k
2. Menghitung jarak antar data latih menggunakan rumus Euclidean Distance
3. Validitas data latih
Validitas dari tiap data dihitung berdasarkan tetangganya. Validitas data hanya dilakukan sekali pada semua data latih. Kemudian dilakukan validasi data, berikutnya data tersebut digunakan sebagai informasi tambahan (Parvin,et all., 2010).
Cara menghitung validitas data pada data
training, tetangga terdekat harus
dipertimbangkan. Di antara tetangga terdekat dengan data, validitas digunakan untuk menghitung jumlah titik dengan label yang sama untuk data. Persamaan yang digunakan untuk menghitung validitas pada data training
pada Persamaan 2 (Parvin,et all., 2010).
𝑽𝒂𝒍𝒊𝒅𝒊𝒕𝒂𝒔(𝒙) =𝟏𝒌 ∑ 𝑺 (𝒍𝒃𝒍(𝒙), 𝒍𝒃𝒍(𝑵𝒊(𝒙))) (𝟐)
Ni(x) : label kelas titik terdekat x Fungsi S digunakan untuk menghitung kesamaan antara titik 𝒂 dan data ke-𝒃 tetangga terdekat. Persamaan untuk mendefinisikan fungsi S terdapat dalam Persamaan dibawah ini:
𝑺(𝒂, 𝒃) = {𝟏𝟎𝒂 = 𝒃𝒂 ≠ 𝒃 (𝟑) menggunakan Persamaan 1. Perhitungan dilakukan untuk seluruh data latih.
5. Weight Voting (pembobotan)
Weight voting KNN merupakan salah satu jenis metode KNN yang menggunakan tetangga terdekat, terlepas dari kelas data, tetapi menggunakan weight voting dari tiap-tiap data pada data training. Setiap masing-masing data diberikan weight voting yang biasanya sama dengan beberapa fungsi jarak dari data yang diketahui. Pada metode MKNN ini weight voting tiap tetangga dihitung menggunakan Persamaan 4 (Parvin,et all., 2010).
𝑾(𝒙) = 𝑽𝒂𝒍𝒊𝒅𝒊𝒕𝒂𝒔 (𝒙) × 𝒅𝟏
𝒆+𝜶 (𝟒)
dengan:
W(i): perhitungan weight voting
Validitas (x): nilai validasi
𝒅𝒆: jarak Euclidean
6. Menentukan kelas dari data uji yang memiliki bobot terbesar sesuai dengan nilai k.
3. PENGUMPULAN DATA
Lokasi peneitian ini adalah klinik House of Fatima Jl. Sumbing Malang. Kasus ini dianalisis melalui pengumpulan data dengan cara wawancara secara langsung. Variabel penelitan ini adalah gejala-gejala pada anak yang memiliki gangguan autisme berdasarkan perhitungan metode Modified K-Nearest Neighbor. Pengumpulan data pada penelitian ini menggunakan metode data sekunder dengan gejala-gejala gangguan autisme adalah:
1. Pergaulan dengan orang lain 2. Peniruan
3. Tanggapan emosi
4. Koordinasi keselarasan tubuh 5. Perhatian dan penggunaan benda 6. Penyesuaian diri pada perubahan 7. Tanggapan penglihatan
8. Tanggapan pendengaran
9. Tanggapan penggunaan rasa,cium dan raba 10.Takut dan cemas
11.Komunikasi verbal 12.Komunikasi non-verbal 13.Derajat aktivitas
14.Derajat dan stabilitas fungsi intelektual Dari 14 gejala yang ada, masing masing gejala memiliki 4 aspek tertentu yaitu: 1. Komunikasi Sosial
2. Perilaku 3. Indera
4. Proses Informasi
Masukkan dalam sistem ini memiliki 14 pertanyaan gejala-gejala gangguan. Dari masukkan ini akan diklasifikasikan menggunakan metode Modified K-Nearest Neighbor. Data yang digunakan dalam penelitan ini 155 data.
4. PENGUJIAN
Pada pengujian ini dilakukan untuk mengetahui hasil akurasi yang didapatkan dari implementasi sistem yang sudah dilakukan. Ada beberapa skenario pengujian yang dilakukan, yaitu pengujian pengaruh nilai k,
pengujian pengaruh jumlah data latih, pengujian pengaruh jumlah data uji, pengujian
4.1 Pengujian Pengaruh Nilai K
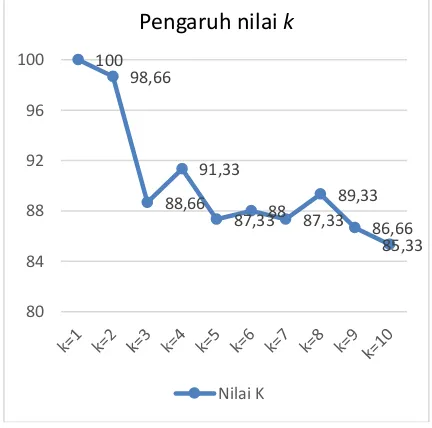
Pengujian menggunakan nilai k dari k=1 sampai k=10 dengan 70 data latih dan 30 data uji. Kemudian masing-masing nilai k dicoba pada kombinasi data uji dan data latih dengan total 100 dengan pengambilan data secara acak. Hasil pengujian ditujukan pada Gambar 1.
Dari Gambar 1 dapat dilihat bahwa grafik mengalami penurunan pada rentang nilai k=1 sampai k=2 dan mengalami kenaikan di k=3 kemudian mengalami penurunan hingga k=7 dan mengalami kenaikan di k=8 dan mengalami penurunan di k=9 hingga k=10. Penurunan rata-rata akurasi dikarenakan semakin banyaknya nilai k maka semakin banyak juga kemungkinan tetangga dengan pola yang berbeda dalam proses klasifikasi. Ketidakstabilan tingkat akurasi yang dihasilkan disebabkan adanya pola dari data latih yang sangat berdekatan dengan tetangga terdekatnya, sehingga nilai validitas menjadi besar dan memperbesar nilai weight voting yang menjadi dasar prediksi. Hasil akurasi tidak hanya dipengaruhi oleh besarnya atau kecilnya nilai k tetapi juga dipengaruhi oleh sebaran data dari masing-masing kelas dan jumlah data latih yang digunakan.
Gambar 1. Pengujian Pengaruh Nilai K
4.2 Pengujian Pengaruh Jumlah Data Latih
Proses pengujian pada penambahan data latih dengan data uji tetap dilakukan dengan mengubah jumlah data latih sebanyak 5 kali dengan cara menghitung nilai akurasi pada data
latih yang digunakan dimulai dari 20 hingga 60 dalam rentang data latih adalah 20. Jumlah data uji yang digunakan tetap yaitu 30 dan nilai k yang digunakan dari pengujian sebelumnya
k=1. Proses pengujian adalah melakukan perhitungan terhadap jumlah data latih berbeda dengan jumlah data uji sama sehingga menghasilkan nilai akurasi untuk melihat pengaruh dari perubahan jumlah data latih. Hasil pengujian ditujukan pada Gambar 2.
Gambar 2 Jumlah Data Latih
Pada Gambar 2 dapat dilihat pengujian yang dilakukan terlihat bahwa jumlah data latih sangat mempengaruhi nilai akurasi karena akurasi memiliki peningkatan saat penambahan jumlah data latih. Pengaruh penambahan jumlah data latih juga memiliki pengaruh terhadap jarak, semakin banyak jumlah data latih maka semakin banyak juga jumlah jarak yang mendekati kelas data uji yang akan diklasifikasikan. Kemudian dihasilkan jumlah data latih 60 memiliki akurasi 100% dengan nilai k=1. Hal ini dikarenakan semakin banyak data latih yang digunakan pada proses perhitungan maka proses perhitungan yang digunakan semakin baik.
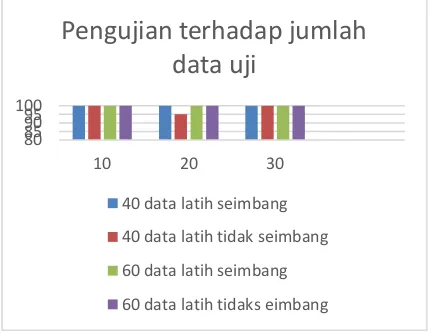
4.3 Pengujian Jumlah Data Uji
Proses pengujian pada jumlah data uji ini menggunakan jumlah data uji sebanyak tiga kali uji coba pada masing masing jumlah data latih yang berbeda. Nilai k yang digunakan dihasilkan dari pengujian sebelumnya yaitu
k=1. Jumlah data uji yang digunakan adalah 10 hingga 30 dengan rentang jumlah data uji 10. Untuk data latih yang digunakan adalah data
latih dengan akurasi yaitu 40 dan 60 data latih menggunakan sebaran data dengan kelas yang seimbang dan tidak seimbang. Berikut ini hasil pengujian ditujukan pada Gambar 3.
Gambar 3 Pengujian Jumlah Data Uji
Dari Gambar 3 hasil dari perhitungan pengujian jumlah data uji dengan sebaran data latih seimbang dan tidak seimbang memiliki akurasi 100%. Dari pengujian data latih seimbang dan tidak seimbang terhadap akurasi. Pada jenis data latih seimbang terlihat bahwa grafik tetap di 100% seiring bertambahnya jumlah data latih. Hal ini dikarenakan pada data seimbang menggunakan jumlah gangguan yang sama pada masing-masing data latih yang digunakan. Sedangkan pada jenis data latih tidak seimbang kurang stabil dikarenakan data latih tidak seimbang ini terdapat dominasi gangguan tertentu yang menyebabkan hasil tidak akurat dalam proses klasifikasi karena dipengaruhi oleh gangguan dominasi.
4.4 Pengujian Confusion Matrix
Pada pengujian ini menggunakan jumlah data latih dan data uji terbaik dari pengujian sebelumnya yaitu 60 data latih seimbang dan 30 data uji. Pada pengujian ini menggunakan nilai
k=2. Pengujian ini melakukan uji coba sebanyak 3 kali dimana akan menghasilkan rata rata nilai sensitivity dan specificity. Berikut ini hasil pengujian ditunjukkan pada persamaan dibawah ini dan Tabel 1.
𝑠𝑒𝑛𝑠𝑖𝑡𝑖𝑣𝑖𝑡𝑦 = 17 + 0 × 100% = 100%17
𝑠𝑝𝑒𝑐𝑖𝑓𝑖𝑐𝑖𝑡𝑦 = 13
0 + 13 × 100% = 100%
Tabel 1 Pengujian Confusion Matric
Truth
Test Result
Autisme Non Autisme
Autisme 17 0
Non Autisme 0 13
Sensitivity(%) 100
Specificity(%) 100
Dari uji coba yang sudah dilakukan dengan menggunakan parameter terbaik dan jumlah data latih dan data uji yang menghasilkan akurasi terbaik, makan nilai didapatkan untuk
sensitivity dan specificity yang tinggi.
5. KESIMPULAN
Metode Modified K-Nearest Neighbor
untuk mengidentifikasi gangguan autisme yang diimplementasikan dengan menggunakan 14 parameter yaitu gejala-gejala gangguan autisme yang dialami oleh anak. Penelitian ini dapat mengklasifikasikan apakah anak tersebut mengalami gangguan autisme atau tidak dengan cara menghitung jarak antar data latih, menghitung nilai validitas data latih, menghitung jarak antar data latih dan data uji, dan menghitung weight voting.
Dari hasil pengujian yang telah dilakukan didapatkan akurasi terbaik sebesar 100%. Adapun parameter yang diperoleh melalui proses percobaan dengan berbagai macam kombinasi nilai. Nilai terbaik untuk nilai k adalah 1 jumlah data latih sebanyak 60 data dan 30 data uji.
6. DAFTAR PUSTAKA
Andhina, K. 2016. Pemodelan Sistem Pakar Untuk Diagnosa Penyakit Tanaman Jagung Menggunakan Metode Modified K-Nearest Neighbor (MKNN). S1. Universitas Brawijaya.
Aktivia, R. 2012. Pengenalan Iris Mata Menggunakan Algoritma K-Nearest Neighbor Berbasis Histogram. S1. Institut Pertanian Bogor.
Chen, Yu. 2010. How KNN works ?. Indiana University. USA.
80 85 90 95 100
10 20 30
Pengujian terhadap jumlah
data uji
40 data latih seimbang
40 data latih tidak seimbang
60 data latih seimbang
Divya T., Sonali. 2013. A Survey on Data Mining Approcahers for Healthcare.
International Journal of Bio-Bcience and Bio – Technology.
Kusumadewi S. 2003. Artifical Intelligence (teknik dan Aplikasi). Yogyakarta: Graha Ilmu.
Nikita J., Vishal S. 2013. Data Mining Techinique. A Survey Paper International Journal of Research in engineering and Technology.
Parvin H., Hoseinali., & Behrouz M. 2010. Modification on K-Nearest Neighbor Classification. Global Journal of Computer Science and Technology Vol.10 Issue 14 (Ver.1.0).
Sunu, Christopher. 2012. Panduan Memecahkan Masalah Autisme: